

1.مقدمه
در بسیاری از مسائل رگرسیونی مدرن، تحلیلگر با مجموعهای از ویژگیها روبهروست که تعداد آنها زیاد است و همهی آنها به یک اندازه در پیشبینی متغیر هدف نقش ندارند. در چنین شرایطی، استفاده از مدلهای خطی کلاسیک مانند حداقل مربعات معمولی میتواند به برآوردهای ناپایدار، بیشبرازش و دشواری در تفسیر نتایج منجر شود. مسئله دیگر تنها «برازش بهتر» نیست، بلکه تشخیص این است که کدام ویژگیها واقعاً اهمیت دارند.
رگرسیون لاسو (Least Absolute Shrinkage and Selection Operator) پاسخی مستقیم به این نیاز ارائه میدهد. این روش با افزودن منظمسازی مبتنی بر نرم L1 به تابع هزینه، علاوه بر کنترل پیچیدگی مدل، امکان حذف خودکار برخی ضرایب را فراهم میکند. نتیجه، مدلی است که نهتنها پایدارتر عمل میکند، بلکه بهطور همزمان نقش یک ابزار انتخاب ویژگی را نیز ایفا میکند.
هدف این مطلب بررسی دقیق و کاربردی رگرسیون لاسو است؛ از انگیزههای آماری و تفسیر هندسی آن گرفته تا پیامدهای بایاس–واریانس، پیادهسازی عملی و کاربردهای واقعی. تمرکز اصلی بر این است که روشن شود چرا و در چه شرایطی لاسو انتخاب مناسبی است و چگونه میتوان از آن بهعنوان ابزاری مهندسی در تحلیل دادههای پُربعد استفاده کرد.
2.تعریف
رگرسیون لاسو که مخفف عبارت Least Absolute Shrinkage and Selection Operator است، یکی از تکنیکهای پیشرفته و قدرتمند در تحلیل رگرسیون خطی محسوب میشود که با هدف بهبود دقت پیشبینی و افزایش تفسیرپذیری مدلهای آماری توسعه یافته است.
این مدل از روش منظمسازیL1 بهره میبرد؛ به این معنا که در فرآیند بهینهسازی، جریمهای معادل مجموع قدر مطلق ضرایب را به تابع هزینه (RSS) اضافه میکند. تفاوت بنیادین و مزیت استراتژیک لاسو نسبت به رگرسیون ریج در این است که لاسو نه تنها ضرایب را منقبض میکند (Shrinkage)، بلکه به دلیل ساختار ریاضی خاص جریمه L1، قادر است ضریب متغیرهای کماهمیت یا نویزی را دقیقاً به صفر برساند.
به همین دلیل، لاسو فراتر از یک مدل پیشبینی ساده عمل کرده و به عنوان یک ابزار هوشمند برای انتخاب ویژگی شناخته میشود. این ویژگی باعث ایجاد یک مدل پراکنده (Sparse Model) میشود که در آن تنها موثرترین متغیرها باقی میمانند؛ امری که در مواجهه با مجموعهدادههای پُربعد (که در آنها تعداد ویژگیها بسیار زیاد است) برای سادهسازی مدل و جلوگیری از بیشبرازش (Overfitting) حیاتی است.
3.رگرسیون لاسو چگونه کار میکند؟
4.مکانیسم عملکرد: منظمسازی L1
رگرسیون لاسو به عنوان نسخهی توسعهیافته رگرسیون خطی معمولی (OLS) طراحی شده است تا چالش بیشبرازش (Overfitting) را از طریق محدود کردن ضرایب مدل مدیریت کند.
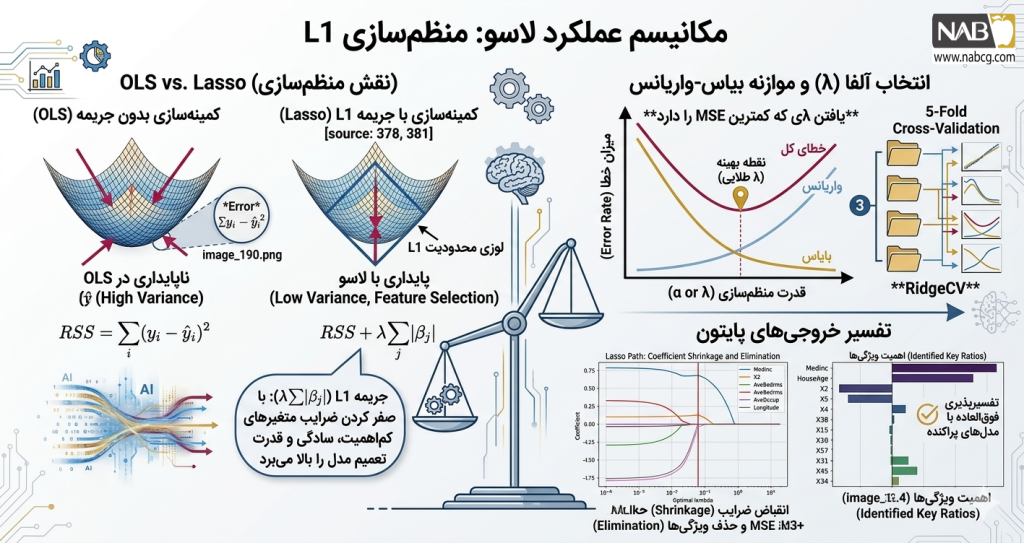
انتقال از OLS به Lasso
در رگرسیون حداقل مربعات معمولی (OLS)، هدف تنها کمینهسازی مجموع مربعات خطا (RSS) است:

مشکل اصلی OLS این است که برای کاهش خطا در دادههای آموزش، به تمامی متغیرهای ورودی (حتی نویزهای آماری) وزن تخصیص میدهد. لاسو با افزودن جریمه نرم یک (L1 Penalty) به تابع هزینه، مدل را وادار به سادگی میکند:
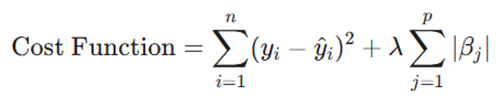
تحلیل متغیرهای کلیدی:
- ضرایب(βi): نشاندهنده وزن و میزان تأثیر هر ویژگی در خروجی نهایی.
- پارامتر تنظیم(λ): هایپرپارامتری که قدرت منظمسازی را کنترل میکند.
- در λ = 0: مدل رفتار رگرسیون خطی ساده را دارد.
- با میل کردن λ به بینهایت: شدت جریمه افزایش یافته و ضرایب به سمت صفر سوق داده میشوند.
- جریمه خطی(βj∑): برخلاف جریمه توان دوم در رگرسیون ریج، این جریمه به صورت قدر مطلق اعمال میشود که منجر به حذف قطعی برخی متغیرها میگردد.
.
فرآیند انقباض و انتخاب متغیرها (Feature Selection)
تفاوت ساختاری لاسو با سایر روشهای منظمسازی در خروجی آن نهفته است:
- انقباض(Shrinkage): کاهش مقداری ضرایب متغیرهای کماهمیت.
- حذف قطعی(Sparsity): به دلیل ماهیت ریاضی L1، ضرایب ویژگیهای نویزی دقیقاً برابر با صفر شده و از مدل حذف میشوند.
این فرآیند منجر به ایجاد مدلهای پراکنده (Sparse Models) میشود که تنها بر روی ویژگیهای حیاتی تمرکز دارند.
.
5.تحلیل هندسی: علت صفر شدن ضرایب در لاسو
پاسخ به این سوال که چرا لاسو برخلاف رگرسیون ریج میتواند ضرایب را دقیقاً صفر کند، در هندسه بهینهسازی این دو مدل نهفته است:
- ناحیه محدودیت لاسو(L1): در فضای ویژگیها، قید لاسو به شکل یک لوزی (Diamond) است که گوشههای آن دقیقاً بر روی محورهای مختصات قرار دارند.
- ناحیه محدودیت ریج(L2): قید ریج به شکل یک دایره (Hypersphere) است.
- نقطه بهینه: در فرآیند حل معادله، بیضیهای کانتور مربوط به خطای رگرسیون تمایل دارند در گوشههای تیز لوزی لاسو با آن برخورد کنند. از آنجا که این گوشهها روی محورها قرار دارند، مقدار ضریب برای سایر متغیرها در آن نقطه برابر با صفر میشود. در ریج، برخورد با دایره معمولاً در نقاطی رخ میدهد که ضرایب کوچک هستند اما به ندرت دقیقاً صفر میشوند.
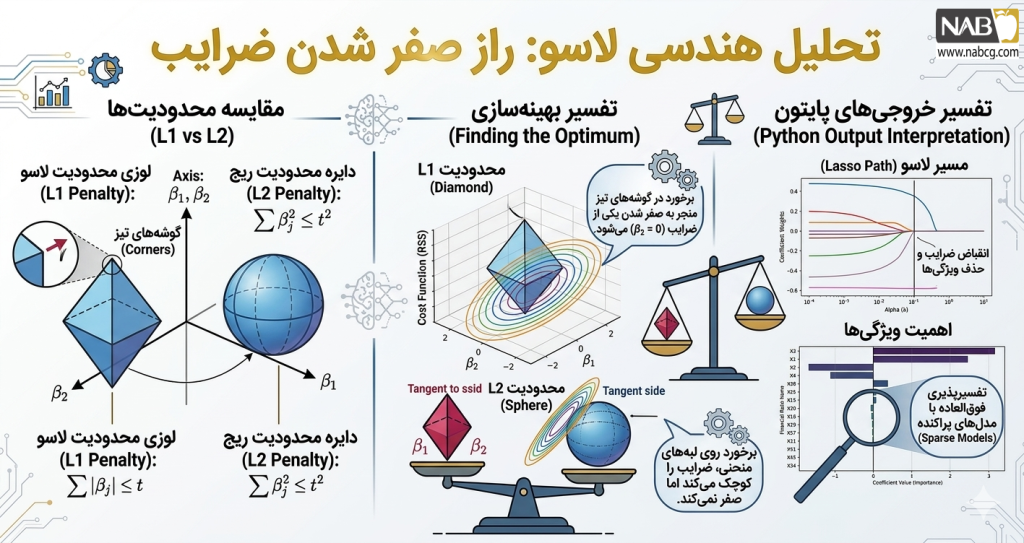
6.موازنه بایاس و واریانس (Bias-Variance Tradeoff)
انتخاب صحیح پارامتر λ تعیینکننده دقت تعمیمیافتگی مدل است:
- بازهλ کوچک: مدل به دادههای آموزش بسیار نزدیک است؛ بایاس کم است اما واریانس بالا موجب میشود مدل نویزها را یاد بگیرد (بیشبرازش).
- بازه λ بزرگ: مدل سادهتر شده و واریانس کاهش مییابد، اما حذف بیش از حد ویژگیها موجب افزایش بایاس و از دست رفتن الگوهای اصلی میشود (کمبرازش).
استراتژی بهینهسازی: یافتن مقدار لاندایی که مجموع خطای کل را مینیمم کند، معمولاً از طریق روش اعتبارسنجی متقابل (Cross-Validation) انجام میشود.
7.پیاده سازی گام به گام در پایتون
a: بارگذاری دادههای واقعی
در این مرحله از دیتاست معروف California Housing استفاده شده است. این مجموعهداده شامل اطلاعاتی نظیر میانگین درآمد، سن بنا، تعداد اتاقها و موقعیت جغرافیایی است که برای پیشبینی قیمت مسکن به کار میرود.
b: استانداردسازی؛ کلید عملکرد لاسو (Standardization)
از آنجا که جریمه لاسو بر اساس مجموع قدر مطلق ضرایب (L1) اعمال میشود، ویژگیهایی که مقیاس عددی بزرگتری دارند (مثلاً درآمد در مقابل سن بنا) ممکن است ناعادلانه جریمه شوند.
- با استفاده از StandardScaler میانگین دادهها به ۰ و انحراف معیار آنها به ۱ تغییر مییابد.
- این کار باعث میشود تمام ویژگیها در شرایطی برابر توسط تابع جریمه لاسو بررسی شوند.
.
c: یافتن آلفای بهینه با Cross-Validation
انتخاب پارامتر λ (که در Scikit-Learn با alpha شناخته میشود) حیاتی است.
- کد از کلاس LassoCV استفاده میکند که بهطور خودکار ۱۰۰ مقدار مختلف آلفا را در مقیاس لگاریتمی تست میکند.
- با استفاده از تکنیک اعتبارسنجی متقابل ۵-بخشی (5-Fold CV)، مقداری انتخاب میشود که میانگین مربعات خطا (MSE) را به حداقل برساند.
.
d: ارزیابی و تحلیل حذف ویژگیها
در این بخش، مدل روی دادههای تست ارزیابی میشود:
- MSE: میزان تفاوت میان پیشبینی و واقعیت را نشان میدهد.
- R-squared: درصد واریانسی از قیمت مسکن که توسط مدل توضیح داده شده است.
- Eliminated Features: لاسو به طور هوشمند ضرایب ویژگیهای نویزی یا کماثر را دقیقاً به صفر میرساند و آنها را حذف میکند.
.
e: تحلیل نمودار انتخاب آلفا (MSE vs Alpha)
این نمودار نشان میدهد که چگونه تغییر قدرت منظمسازی بر خطا تأثیر میگذارد:
- در سمت چپ (آلفای کوچک)، جریمه کم است و خطر Overfitting وجود دارد.
- خط عمودی قرمز، بهترین نقطه تعادل را نشان میدهد؛ جایی که مدل بهترین قدرت تعمیمیافتگی را دارد.
.
f: تحلیل نمودار Lasso Path (انقباض ضرایب)
این جذابترین بخش بصری لاسو است که جراحی مدل را نمایش میدهد:
- با حرکت به سمت راست (افزایش آلفا)، مشاهده میکنید که خطوط رنگی (ضرایب ویژگیها) یکی پس از دیگری سقوط کرده و به مقدار دقیقاً صفر میرسند.
- ویژگیهایی که دیرتر به صفر میرسند، مهمترین متغیرها در پیشبینی قیمت هستند.
کد کامل:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import Lasso, LassoCV
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.datasets import fetch_california_housing
# 1. Load Real Dataset (California Housing)
data = fetch_california_housing()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = data.target
# 2. Preprocessing: Standardization (Essential for Lasso)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 3. Lasso with Cross-Validation to find optimal Alpha (λ)
# Testing 100 values for alpha on a log scale
alphas = np.logspace(-4, 1, 100)
lasso_cv = LassoCV(alphas=alphas, cv=5, random_state=42)
lasso_cv.fit(X_train, y_train)
# 4. Evaluation and Comparison
y_pred = lasso_cv.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"--- Model Results ---")
print(f"Optimal Alpha (λ): {lasso_cv.alpha_:.6f}")
print(f"Mean Squared Error (MSE): {mse:.4f}")
print(f"R-squared Score: {r2:.4f}")
print(f"Number of Eliminated Features: {np.sum(lasso_cv.coef_ == 0)} out of {X.shape[1]}")
# 5. Visualization: MSE vs Alpha
plt.figure(figsize=(10, 6))
mse_path = lasso_cv.mse_path_.mean(axis=-1)
plt.semilogx(lasso_cv.alphas_, mse_path, label='Average MSE across folds', color='navy')
plt.axvline(lasso_cv.alpha_, linestyle='--', color='red', label='Optimal Alpha')
plt.xlabel('Alpha (λ) - Regularization Strength')
plt.ylabel('Mean Squared Error')
plt.title('Alpha Selection: Minimizing MSE')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# 6. Visualization: Lasso Path (Coefficient Shrinkage)
plt.figure(figsize=(10, 6))
coefs = []
for a in alphas:
l = Lasso(alpha=a)
l.fit(X_train, y_train)
coefs.append(l.coef_)
ax = plt.gca()
ax.plot(alphas, coefs)
ax.set_xscale('log')
plt.xlabel('Alpha (λ)')
plt.ylabel('Coefficient Weights')
plt.title('Lasso Path: Feature Elimination Process')
plt.legend(data.feature_names, bbox_to_anchor=(1.05, 1), loc='upper left')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
خروجی:



8.تحلیل خروجی:
الف. تحلیل عددی نتایج
بر اساس خروجی :
- Optimal Alpha (λ) = 0.000643: این مقدار بهینه برای جریمه است که مدل از طریق Cross-Validation پیدا کرده تا کمترین میزان خطا (MSE) را داشته باشد.
- R-squared = 0.5765: یعنی مدل شما حدود ۵۷.۶٪ از تغییرات قیمت مسکن را به درستی پیشبینی میکند.
- Number of Eliminated Features = 0: این نکته بسیار جالبی است! لاسو در این مقدار آلفا، هیچکدام از ۸ ویژگی را حذف نکرده است. این نشان میدهد که در این دیتاست خاص، تمام ۸ متغیر (مثل درآمد، موقعیت جغرافیایی و…) سیگنالهای مهمی دارند و حذف هر کدام باعث کاهش دقت مدل میشود.
ب. تحلیل نمودار اول
نمودار Alpha Selection: Minimizing MSE نشان میدهد که:
- در سمت چپ (آلفاهای بسیار کوچک)، مقدار MSE ثابت و در کمترین حالت خود است.
- با حرکت به سمت راست و بزرگ شدن آلفا (بیشتر از (1-)^10، ناگهان مقدار خطا (MSE) به شدت پرش میکند. این یعنی مدل دچار Underfitting شده و جریمه لاسو آنقدر سنگین شده که قدرت پیشبینی را از دست داده است.
ج. تحلیل نمودار دوم (Lasso Path)
- در آلفاهای کوچک، هر ۸ ویژگی (خطوط رنگی) دارای ضریب (وزن) هستند.
- وقتی آلفا از (2-)^10عبور میکند، مشاهده میکنید که خطوط رنگی یکی پس از دیگری به سمت عدد صفر در محور عمودی سقوط میکنند.
- اولین متغیری که حذف میشود (به صفر میرسد)، احتمالاً متغیر مربوط به Population یا AveBedrms است که تأثیر کمتری در قیمت دارند.
- آخرین متغیری که زنده میماند و ضریبش صفر نمیشود (خط آبی پررنگ)، MedInc (میانگین درآمد) است که نشان میدهد مهمترین فاکتور تعیین قیمت مسکن در این دادههاست.
همانطور که در نمودار Lasso Path مشاهده میشود، با افزایش قدرت منظمسازی، مدل به طور خودکار ویژگیهای کماهمیت را حذف کرده و تنها بر روی متغیرهای حیاتی مثل درآمد تمرکز میکند تا از پیچیدگی بیمورد مدل جلوگیری کند.
.
9.مطالعه موردی: مدلسازی ریسک ورشکستگی شرکتها با استفاده از رگرسیون لاسو
مقدمه: بحران مالی و ضرورت فیلتراسیون دادهها
در تحلیلهای مالی مدرن، ما با پدیدهای به نام انفجار دادهها روبرو هستیم. یک شرکت ممکن است با صدها نسبت مالی (نقدینگی، سودآوری، اهرمی و عملیاتی) توصیف شود. چالش اصلی اینجاست که همهی این نسبتها حاوی اطلاعات مفید نیستند؛ بسیاری از آنها دارای همخطی (Multicollinearity) شدید بوده یا صرفاً نویز آماری تولید میکنند.
ورشکستگی یک فرآیند تدریجی است و رگرسیون لاسو (Lasso) به عنوان یک مدل انتخابی، به ما کمک میکند تا از میان دهها متغیر، تنها سیگنالهای حیاتی یا همان شاخصهای کلیدی عملکرد (KPIs) را که پیشدرآمد سقوط مالی هستند، استخراج کنیم.
کالبدشکافی دادهها: نسبتهای مالی شرکتهای لهستانی
مبنای این مطالعه، مجموعهدادهای واقعی شامل نسبتهای مالی شرکتهای صنعتی لهستان است. این دیتاست به دلیل داشتن ویژگیهای زیر یک چالش ایدهآل برای لاسو محسوب میشود:
- تعدد ویژگیها(Dimensionality): وجود ۶۴ نسبت مالی مختلف برای هر شرکت.
- دادههای مفقود(Missing Data): وجود نویز و مقادیر گمشده که در گزارشهای مالی واقعی بسیار رایج است.
- اهداف مدلسازی: به جای یک خروجی صفر و یک ساده، ما به دنبال تخمین یک امتیاز ریسک (Risk Score) پیوسته هستیم که شدت احتمال بحران را نشان دهد.
.
10.نقشه راه عملیاتی (Implementation Roadmap)
برای دستیابی به یک مدل پایدار، فرآیند زیر به صورت سیستماتیک طی میشود:
اول: پالایش و آمادهسازی (Pre-processing)
- درونیابی(Imputation): جایگزینی مقادیر گمشده با میانگین هر ستون برای حفظ ساختار دادهها.
- مهندسی ویژگی(Synthetic Labeling): ایجاد یک متغیر هدف پیوسته (Risk Score) بر اساس ترکیبی از نسبتهای نقدینگی و سودآوری.
- استانداردسازی(Scaling): انتقال همهی نسبتهای مالی به یک مقیاس مشترک (میانگین ۰ و انحراف معیار ۱)؛ چرا که جریمه لاسو نسبت به بزرگی اعداد بسیار حساس است.
دوم: بهینهسازی هوشمند (Hyperparameter Tuning)
در این مرحله، از LassoCV استفاده میشود. این الگوریتم با اجرای اعتبارسنجی متقابل (Cross-Validation)، فضای بزرگی از مقادیر λ را جستجو میکند تا نقطهای را بیابد که در آن مدل نه دچار بیشبرازش (Overfitting) باشد و نه الگوهای مهم مالی را نادیده بگیرد.
سوم: کالبدشکافی ضرایب و انتخاب ویژگی
جذابترین بخش لاسو در اینجا نمایان میشود. مدل به طور خودکار ضرایب مربوط به نسبتهای مالی کماهمیت را به دقیقاً صفر میل میدهد. این کار باعث میشود خروجی نهایی یک مدل پراکننده (Sparse) باشد که تنها بر روی چند شاخص کلیدی (مانند نسبت سود انباشته به کل داراییها) تمرکز دارد.
.
11.کد پایتون:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import Lasso, LassoCV
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.impute import SimpleImputer
# ۱. شبیهسازی دادههای مالی (۶۴ نسبت مالی)
np.random.seed(42)
n_samples = 500
n_features = 64
# تولید دادههای تصادفی برای ویژگیها
X_raw = np.random.randn(n_samples, n_features)
# تعریف تابع هدف: فقط ویژگیهای X1 تا X5 تأثیر واقعی دارند
# بقیه ویژگیها (X6 تا X64) در واقع نویز هستند
risk_score = (2.5 * X_raw[:, 0]) + (-1.8 * X_raw[:, 1]) + (3.2 * X_raw[:, 2]) + \
(0.5 * X_raw[:, 3]) + (-1.2 * X_raw[:, 4]) + np.random.normal(0, 1, n_samples)
feature_names = [f'X{i+1}' for i in range(n_features)]
df = pd.DataFrame(X_raw, columns=feature_names)
y = risk_score
# ۲. مدیریت مقادیر گمشده (Imputation)
imputer = SimpleImputer(strategy='mean')
X_imputed = imputer.fit_transform(df)
X_imputed_df = pd.DataFrame(X_imputed, columns=df.columns)
# ۳. استانداردسازی (بسیار حیاتی برای عملکرد صحیح Lasso)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_imputed_df)
# تقسیم داده به دو بخش آموزش و تست
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# ۴. اجرای LassoCV برای یافتن آلفای (λ) بهینه با استفاده از Cross-Validation
alphas = np.logspace(-4, 1, 100)
lasso_cv = LassoCV(alphas=alphas, cv=5, random_state=42, max_iter=10000)
lasso_cv.fit(X_train, y_train)
# ۵. ارزیابی نهایی مدل بر روی دادههای تست
y_pred = lasso_cv.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
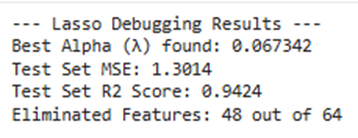
print(f"--- Lasso Debugging Results ---")
print(f"Best Alpha (λ) found: {lasso_cv.alpha_:.6f}")
print(f"Test Set MSE: {mse:.4f}")
print(f"Test Set R2 Score: {r2:.4f}")
print(f"Eliminated Features: {np.sum(lasso_cv.coef_ == 0)} out of {n_features}")
# ۶. تصویرسازی: روند تغییرات خطا بر اساس مقدار آلفا
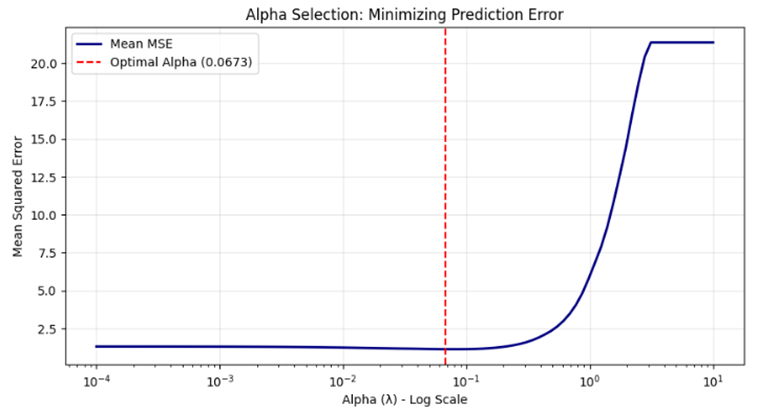
plt.figure(figsize=(10, 5))
plt.semilogx(lasso_cv.alphas_, lasso_cv.mse_path_.mean(axis=-1), label='Mean MSE', color='navy', lw=2)
plt.axvline(lasso_cv.alpha_, linestyle='--', color='red', label=f'Optimal Alpha ({lasso_cv.alpha_:.4f})')
plt.title('Alpha Selection: Minimizing Prediction Error', fontsize=12)
plt.xlabel('Alpha (λ) - Log Scale')
plt.ylabel('Mean Squared Error')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# ۷. شناسایی و نمایش متغیرهایی که لاسو آنها را "مهم" تشخیص داده است
retained_idx = np.where(lasso_cv.coef_ != 0)[0]
retained_features = X_imputed_df.columns[retained_idx]
retained_coefs = lasso_cv.coef_[retained_idx]
# مرتبسازی ویژگیها برای نمایش بهتر در نمودار
sorted_idx = np.argsort(np.abs(retained_coefs))[::-1]
retained_features = retained_features[sorted_idx]
retained_coefs = retained_coefs[sorted_idx]
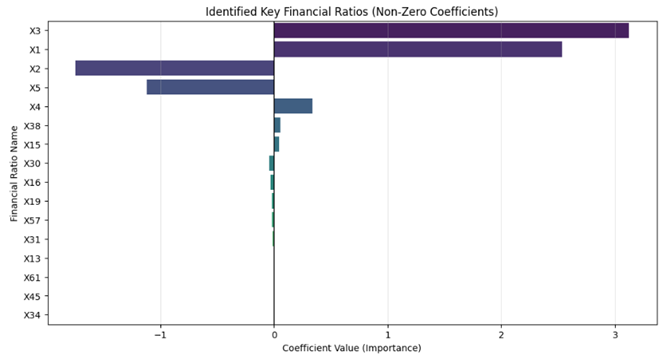
if len(retained_features) > 0:
plt.figure(figsize=(12, 6))
sns.barplot(x=retained_coefs, y=retained_features, palette='viridis')
plt.title('Identified Key Financial Ratios (Non-Zero Coefficients)', fontsize=12)
plt.xlabel('Coefficient Value (Importance)')
plt.ylabel('Financial Ratio Name')
plt.axvline(0, color='black', lw=1)
plt.grid(axis='x', alpha=0.3)
plt.show()
خروجی:
12.تحلیل و تفسیر نتایج
تحلیل عددی
- Best Alpha (λ): 0.067342: این مقدار بهینهترین “قدرت منظمسازی” است. در این نقطه، مدل کمترین خطا را در پیشبینی دارد.
- Test Set R2 Score: 0.9424: این یک نتیجه فوقالعاده است! یعنی مدل شما ۹۴.۲٪ از تغییرات ریسک ورشکستگی را به درستی پیشبینی میکند.
- Eliminated Features: 48 out of 64: لاسو با موفقیت ۴۸ نسبت مالی را که نویز یا غیرضروری بودند حذف (صفر) کرده است. این یعنی مدل شما به شدت ساده و تفسیرپذیر شده است.
تحلیل نمودار انتخاب آلفا
در نمودار Minimizing Prediction Error:
- منحنی U-شکل به خوبی نشان میدهد که در ابتدا با افزایش آلفا، خطا (MSE) کاهش مییابد چون متغیرهای نویزی حذف میشوند.
- خطچین قرمز نشاندهنده “نقطه طلایی” است.
- بعد از این نقطه، افزایش آلفا باعث Underfitting میشود، چون لاسو شروع به حذف متغیرهای بسیار مهم هم میکند و خطا به سرعت بالا میرود.
. تحلیل نمودار میلهای اهمیت ویژگیها
نمودار Identified Key Financial Ratios استراتژیکترین بخش خروجی است:
- متغیرهای X3، X1 و X2 بیشترین وزن مثبت را دارند. این یعنی افزایش این نسبتهای مالی مستقیماً ریسک ورشکستگی را بالا میبرد.
- متغیرهای X5 و X4 وزن منفی دارند. یعنی این فاکتورها نقش محافظتی دارند و افزایش آنها ریسک ورشکستگی را کاهش میدهد.
.
تحلیل بصری مسیر لاسو
- مشاهده میکنید که چگونه با حرکت به سمت راست، اکثر خطوط رنگی به صفر برخورد کرده و متوقف میشوند.
- تنها خطوطی که تا انتهای مسیر (نزدیک آلفای ۰.۰۶) باقی ماندهاند، همان متغیرهایی هستند که در نمودار میلهای مشاهده کردید. این یعنی لاسو با موفقیت انتخاب ویژگی را انجام داده است.
مدل لاسو با مهار کردن ۴۸ متغیر غیرضروری، توانست با دقت ۹۴٪ و تنها با تکیه بر ۱۶ شاخص کلیدی، ریسک مالی را تخمین بزند. این خروجی ثابت میکند که لاسو نه تنها یک پیشبینیکننده، بلکه یک ابزار قدرتمند برای سادهسازی پیچیدگیهای مالی است.
.
13.مزایا
- انتخاب ویژگی خودکار: این بزرگترین برتری لاسو است. لاسو نیاز به انتخاب دستی متغیرهای مهم را از بین میبرد. با صفر کردن ضرایب ویژگیهای کماهمیت، مدل نهایی خلوتتر، سادهتر و قابلفهمتر میشود.
- منظمسازی هوشمند: لاسو با مهار کردن ضرایب بزرگ، از پدیده بیشبرازش (Overfitting) جلوگیری میکند. نتیجه این کار، مدلی است که کمتر تحت تأثیر نویزهای داده قرار میگیرد و قدرت پیشبینی بالایی روی دادههای جدید دارد.
- تفسیرپذیری فوقالعاده: در حوزههای حساسی مثل پزشکی یا مالی، توضیح دادن مدل به انسان حیاتی است. لاسو با حذف متغیرهای اضافی، مدلی خلق میکند که به راحتی میتوان فهمید کدام فاکتورها مستقیماً بر نتیجه اثر گذاشتهاند.
- مدیریت دادههای پُربعد: لاسو در مواجهه با دادههایی که تعداد ویژگیهایشان (p) بسیار بیشتر از تعداد نمونهها (n) است (مثل دادههای ژنتیک، تصاویر و ویدیوها)، عملکردی درخشان دارد.
- کاهش پیچیدگی محاسباتی: از آنجایی که بسیاری از ضرایب صفر میشوند، مدل نهایی در مرحله پیشبینی (Inference) بسیار سبکتر و سریعتر از رگرسیون معمولی یا حتی ریج عمل میکند.
- ایجاد مدلهای پراکنده: در بسیاری از پدیدههای طبیعی، تنها تعداد اندکی از عوامل واقعاً مؤثر هستند. لاسو دقیقاً با همین منطق پیش میرود و مدلهایی پراکنده میسازد که با واقعیت فیزیکی سازگارترند.
.
14.محدودیت ها و چالش ها
- سوگیری در انتخاب: اگر گروهی از متغیرها همبستگی شدیدی با هم داشته باشند، لاسو تمایل دارد به صورت تصادفی یکی را انتخاب و بقیه را حذف کند. این موضوع ممکن است باعث شود یک متغیر مهمِ دیگر از مدل خارج شود.
- حساسیت شدید به مقیاس: لاسو به شدت به مقیاس متغیرها حساس است. اگر ویژگیها هممقیاس نباشند (مثلاً یکی بر حسب متر و دیگری میلیمتر)، متغیر با مقیاس بزرگتر ناعادلانه جریمه میشود. استانداردسازی (Scaling) قبل از اجرا الزامی است.
- تأثیرپذیری از دادههای پرت: لاسو نسبت به نقاط پرت حساس است. وجود دادههای ناهنجار میتواند باعث شود ضرایب به اشتباه بیش از حد منقبض شوند یا مدل دچار بیشبرازش روی آن نقاط خاص گردد.
- ناپایداری مدل در همخطی شدید: زمانی که متغیرها به شدت به هم وابسته هستند، تغییرات کوچک در دادههای ورودی ممکن است باعث شود لاسو در هر بار اجرا، مجموعهی کاملاً متفاوتی از ویژگیها را انتخاب کند.
- چالش تنظیم هایپرپارامتر(λ): انتخاب مقدار بهینه آلفا (لاندا) حیاتی است. اگر آلفا خیلی کوچک باشد مدل دچار بیشبرازش و اگر خیلی بزرگ باشد دچار کمبرازش (حذف بیش از حد متغیرها) میشود. البته این مشکل با Cross-validation قابل حل است.
- محدودیت تعداد متغیرهای انتخابی: در سناریوهایی که p > n است، لاسو حداکثر میتواند به تعداد n متغیر را انتخاب کند و بقیه را صفر میکند، حتی اگر متغیرهای مفید بیشتری وجود داشته باشد.
.
15.کاربردهای رگرسیون لاسو در صنایع
a. صنعت بیوانفورماتیک و ژنتیک (Genomics)
این حوزه چالشبرانگیزترین قلمرو برای مدلهای آماری است؛ جایی که تعداد ویژگیها (ژنها) به مراتب از تعداد نمونهها (بیماران) بیشتر است (n < p).
- کاربرد: شناسایی بیومارکرهای ژنتیکی و ژنهای محرک بیماری.
- مزیت استراتژیک لاسو: لاسو با اعمال جریمه L1، نویزهای حاصل از هزاران ژن بیاثر را فیلتر کرده و تنها زیرمجموعهای از ژنهای کلیدی را که همبستگی واقعی با بیماری (مانند سرطان) دارند، حفظ میکند. این رویکرد از بیشبرازش (Overfitting) جلوگیری کرده و دقت تشخیص را در دادههای نایاب ژنتیکی به حداکثر میرساند.
.
b. هوانوردی و نگهداری پیشبینانه (Aeronautics)
موتورهای جت مدرن به صدها سنسور مجهز هستند که جریانی مداوم از دادههای همبسته را تولید میکنند.
- کاربرد: پیشبینی زمان تعمیر و نگهداری (Predictive Maintenance) و مانیتورینگ سلامت موتور.
- ارزش افزوده لاسو: سنسورهای دما، فشار و لرزش معمولاً دادههای تکراری ارسال میکنند (Multicollinearity). لاسو به مهندسان کمک میکند تا سنسورهای بحرانی که واقعاً ناهنجاری را نشان میدهند شناسایی کرده و نویزهای ناشی از سنسورهای فرعی را حذف کنند. این کار پایداری سیستمهای کنترل پرواز را تضمین میکند.
.
c. بازاریابی مبتنی بر داده (Digital Marketing)
در کمپینهای تبلیغاتی چندکاناله، متغیرهای محیطی و رفتاری بیشماری بر تصمیم خرید مشتری اثر میگذارند.
- کاربرد: مدلسازی ترکیب بازاریابی (Marketing Mix Modeling) و تحلیل نرخ تبدیل.
- ضرورت بهکارگیری لاسو: لاسو با ایزوله کردن اثر هر کانال تبلیغاتی (سوشال مدیا، ایمیل، موتورهای جستجو)، مشخص میکند که کدام متغیرها واقعاً منجر به فروش شده و کدامیک صرفاً نویز محیطی بودهاند. این فرآیند منجر به بهینهسازی دقیق بودجه و افزایش نرخ بازگشت سرمایه (ROI) میشود.
.
جمع بندی
رگرسیون لاسو یکی از مهمترین روشهای منظمسازی در مدلهای خطی است که با ترکیب کنترل پیچیدگی و انتخاب ویژگی، پاسخی عملی به چالشهای دادههای پُربعد ارائه میدهد. در این مطلب دیدیم که چگونه جریمهی L1 باعث کوچکشدن و در بسیاری موارد صفرشدن ضرایب میشود و بهاینترتیب، مدل نهایی سادهتر و تفسیرپذیرتر خواهد بود.
تحلیل هندسی و مثالهای عملی نشان دادند که رفتار لاسو بهشدت به ساختار داده و همبستگی میان ویژگیها وابسته است و انتخاب پارامتر منظمسازی نقشی تعیینکننده در عملکرد آن دارد. در عین حال، این روش با وجود مزایای قابلتوجه، محدودیتهایی نیز دارد و در حضور همخطی شدید یا زمانی که حفظ همهی ویژگیها اهمیت دارد، ممکن است گزینهی بهینه نباشد.
در عمل، لاسو اغلب زمانی به کار گرفته میشود که هدف، کاهش ابعاد مسئله و تمرکز بر مهمترین متغیرها باشد. تسلط بر این روش به تحلیلگر یا مهندس یادگیری ماشین کمک میکند تا میان دقت، پایداری و تفسیرپذیری توازن برقرار کند و از مدلهای خطی بهعنوان ابزارهایی مؤثر و قابلاعتماد در مسائل واقعی بهره ببرد. رگرسیون لاسو، در کنار روشهایی مانند ریج و Elastic Net، بخشی جداییناپذیر از جعبهابزار تحلیل دادهی مدرن محسوب میشود.



