

1.مقدمه
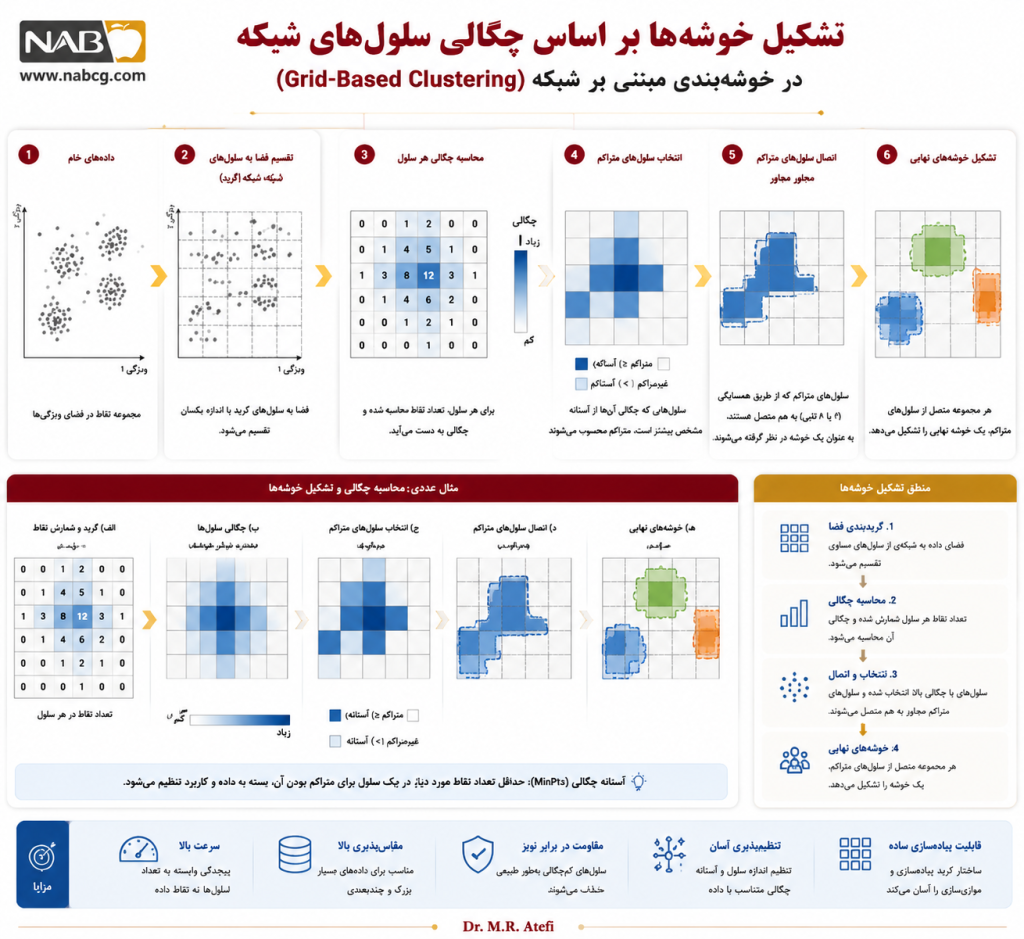
خوشهبندی مبتنی بر شبکه یا Grid-Based Clustering یکی از رویکردهای مهم در یادگیری بدونناظر است که با هدف افزایش سرعت پردازش، کاهش پیچیدگی محاسباتی و مدیریت دادههای حجیم و چندبعدی توسعه یافته است. در این رویکرد، برخلاف بسیاری از روشهای کلاسیک خوشهبندی که مستقیماً با تکتک نقاط داده سروکار دارند، فضای داده ابتدا به مجموعهای از سلولهای منظم یا نیمهمنظم تقسیم میشود. سپس عملیات خوشهبندی بهجای سطح نقاط، در سطح سلولهای شبکه انجام میگیرد.
ایده اصلی این روش آن است که نقاطی که در یک سلول گرید قرار میگیرند، از نظر آماری یا هندسی بهعنوان یک واحد محلی در نظر گرفته شوند. بنابراین، الگوریتم بهجای محاسبه مکرر فاصله میان همه نقاط، اطلاعات خلاصهشده هر سلول مانند تعداد نقاط، چگالی، میانگین، واریانس یا سایر شاخصهای آماری را ذخیره و تحلیل میکند.
این ویژگی باعث میشود که در بسیاری از الگوریتمهای شبکهمحور، پیچیدگی زمانی خوشهبندی بیش از آنکه به تعداد کل نقاط داده n وابسته باشد، به تعداد سلولهای شبکه وابسته شود. به همین دلیل، خوشهبندی مبتنی بر شبکه یکی از گزینههای بسیار مناسب برای تحلیل کلاندادهها، دادههای مکانی، دادههای چندبعدی، دادههای تصویری، دادههای جغرافیایی و پایگاههای داده بسیار بزرگ محسوب میشود.
در این رویکرد، فضای ویژگیها به شکل زیر به سلولهایی گسسته تقسیم میشود:
G={g1,g2,…,gm}
که در آن:
- G: کل ساختار شبکه یا گرید
- gi: یک سلول مشخص از شبکه
- m: تعداد کل سلولهای ایجادشده در فضای داده
سپس برای هر سلول، میتوان چگالی را بهصورت ساده زیر تعریف کرد:
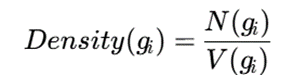
که در آن:
- (gi) N: تعداد نقاط داده در سلول gi
- (gi)V : حجم یا اندازه هندسی سلول
- (gi) Density: چگالی محلی سلول
در ادامه، سلولهایی که چگالی آنها از یک آستانه مشخص بیشتر باشد، بهعنوان سلولهای متراکم شناخته میشوند و اتصال میان سلولهای متراکم مجاور، خوشههای نهایی را شکل میدهد.

2. الگوریتمهای خوشهبندی مبتنی بر شبکه
در ادبیات دادهکاوی، الگوریتمهای متعددی برای خوشهبندی مبتنی بر شبکه معرفی شدهاند. برخی از آنها مستقیماً مبتنی بر گرید هستند، برخی با خوشهبندی چگالیمحور ترکیب شدهاند و برخی دیگر برای دادههای پُربُعد، زیرفضایی یا جریانی توسعه یافتهاند.
در ادامه، مهمترین الگوریتمهای این خانواده معرفی میشوند.
فلسفه محاسباتی و مکانیزم عملکرد
این استراتژی با یک ایده انقلابی برای مهار پدیده محاسباتی سنگین نفرین ابعاد (Curse of Dimensionality) در فضاهای بزرگ خلق شد. در این دیدگاه، فضا به جای اسکن نقطه به نقطه، به مجموعهای متناهی از سلولها شبیه به یک جدول یا شبکه (Grid) خرد میشود. تمام دادههای درون یک سلول گرید، عضو یک واحد آماری فرضی یکپارچه هستند؛ در نتیجه، پیچیدگی زمانی فرآیند کاملاً مستقل از تعداد نقاط داده (n) شده و صرفاً به تعداد سلولهای گرید وابسته است که سرعت پردازش را به شدت بالا میبرد.
2.۱. الگوریتم (Statistical Information Grid) STING
الگوریتم STING یکی از نخستین و شناختهشدهترین الگوریتمهای خوشهبندی و تحلیل داده مبتنی بر شبکه است. این روش فضای داده را به سلولهای مستطیلی در چند سطح سلسلهمراتبی تقسیم میکند و برای هر سلول، اطلاعات آماری مانند تعداد نقاط، میانگین، واریانس، کمینه، بیشینه و نوع توزیع را ذخیره مینماید.
STING بیشتر برای دادههای مکانی و پاسخ سریع به کوئریهای ناحیهای طراحی شده است. مزیت اصلی آن سرعت بسیار بالا در پردازش دادههای بزرگ است، زیرا بهجای بررسی مستقیم همه نقاط، از خلاصههای آماری سلولها استفاده میکند.
این الگوریتم فضای ویژگیها را به ساختاری چندلایه و سلولی تبدیل میکند تا فرآیند کلاسترینگ و پاسخ به کوئریها به صورت آنی (Real-time) انجام شود. این متد روابط دادهها را در سطوح مختلف رزولوشن استخراج میکند.

گامهای اجرایی
- ساخت گرید سلسلهمراتب: فضای کل ویژگیها به سلولهای مستطیلی شکل سلسلهمراتب در چندین سطح رزولوشن (از کلان به خُرد) تقسیم میشود. هر سلول در سطح بالاتر، به چندین سلول فرزند در سطح پایینتر تفکیک میشود.
- محاسبه پارامترهای پیشپردازش: پارامترهای آماری پایهای هر سلول (مانند میانگین، انحراف معیار، تعداد نقاط و نوع توزیع) در گام پیشپردازش به صورت موازی محاسبه و ذخیره میشوند.
- فیلترینگ بالا به پایین (Query Processing): در زمان پردازش، یک کوئری از بالاترین سطح شبکه شروع شده و با استفاده از آزمونهای آماری، سلولهای مرتبط و پر چگال فیلتر میشوند.
- شکلدهی کلاستر نهایی: سلولهای متراکم مجاور در پایینترین سطح رزولوشن به یکدیگر متصل شده و تودههای کلاستر را شکل میدهند.
تابع هدف ریاضی
ارزیابی احتمال مرتبط بودن هر سلول شبکه با استفاده از بازههای اطمینان آماری و واریانس درونسلولی:
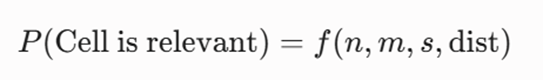
معرفی متغیرها
- n: تعداد نقاط داده واقع در یک سلول خاص.
- m: میانگین عددی ویژگیهای نقاط درون آن سلول گرید.
- s: انحراف معیار دادههای موجود در سلول.
مزایا و نقاط قوت
- مستقل بودن فاز اصلی کلاسترینگ از تعداد کل نقاط داده دیتابیس.
- سازگاری فوقالعاده عالی با معماری پردازشهای موازی و توزیعشده.
معایب و محدودیتها
- مرزهای خوشهها همواره موازی با محورهای عمودی یا افقی شبکه گرید هستند و جزئیات هندسی مورب فدا میشوند.
- کیفیت نهایی مدل به شدت به اندازه سلولها در پایینترین سطح رزولوشن وابسته است.
کاربردهای واقعی
- تحلیل و مدیریت دادههای مکانی مگا-سایز جغرافیایی و تصاویر ماهوارهای.
- کلاسترینگ دیتابیسهای چندبعدی در سیستمهای الگوخوانی آنلاین و موتورهای جستجوی مکانی.
2.۲. الگوریتم WaveCluster
یک الگوریتم خوشهبندی مبتنی بر شبکه (Grid-Based) و چگالیمحور بسیار پیشرفته است که از تئوری ریاضی تبدیل موجک (Wavelet Transformation) برای پردازش فضا استفاده میکند. در این روش، فضای داده ابتدا به شبکهای از سلولها تبدیل میشود و سپس تعداد نقاط هر سلول بهعنوان مقدار یک سیگنال چندبعدی در نظر گرفته میشود.
این متد با تبدیل مجموعهداده به یک سیگنال چندبعدی، نویزها را فیلتر کرده و مرز کلاسترهای متراکم را در سطوح مختلف رزولوشن استخراج مینماید. با اعمال تبدیل موجک، نویزها و نوسانات محلی حذف شده و نواحی متراکم تقویت میشوند. این روش برای کشف خوشههای با شکل پیچیده، حذف نویز و تحلیل چندرزولوشنی بسیار مناسب است.

گامهای اجرایی
- کوانتومسازی فضا (گریدبندی): تقسیم فضای ویژگیها به سلولهای یک شبکه گرید متمایز و تخصیص نقاط داده به این سلولها.
- شکلدهی سیگنال داده: شمارش تعداد نقاط درون هر سلول گرید؛ به طوری که کل ساختار شبکه به عنوان یک سیگنال دیجیتال چندبعدی با دامنههای متغیر تعریف میشود.
- اعمال تبدیل موجک: عبور دادن سیگنال حاصله از فیلترهای ریاضی تبدیل موجک (مانند فیلترهای بالاگذر و پایینگذر دابیشی یا کلاه مکزیکی). فیلتر پایینگذر بخشهای متراکم (فرکانسهای پایین/بدنه کلاستر) را تقویت و فیلتر بالاگذر نویزها و نقاط پرت (فرکانسهای بالا) را به طور کامل حذف میکند.
- تشخیص جاذبها و خوشهبندی: اتصال سلولهای متراکم همجوار که در فضای موجک جدید دارای پتانسیل چگالی بالایی هستند جهت شکلدهی کلاسترهای نهایی.
تابع هدف ریاضی
نگاشت سیگنال شبکه فضا (x) به فضای فرکانسی-مکانی با استفاده از دگرگونی و فیلترینگ توابع موجک گسسته (DWT)
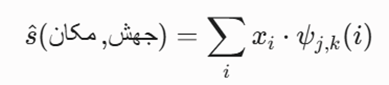
مزایا و نقاط قوت
- توانایی مطلق در حذف نویزها و دادههای پرت به دلیل ماهیت فرکانسی فیلترهای بالاگذر موجک.
- کشف دقیق خوشههایی با اشکال هندسی بسیار پیچیده، مایل، توخالی و تودرتو بدون محدود شدن به مرزهای موازی شبکه.
- عدم نیاز به تعیین پیشفرض تعداد خوشهها توسط کاربر.
معایب و محدودیتها
- افت شدید کارایی و خطای محاسباتی در فضاهای بسیار چندبعدی (بیش از ۵ یا ۶ بعد) به دلیل افزایش تصاعدی تعداد سلولهای گرید خالی.
- حساسیت خروجی به تنظیم اندازه اولیه سلولهای شبکه گرید و نوع تابع موجک انتخابی.
کاربردهای واقعی
- پردازش تصاویر راداری و دادههای حجیم عارضهنگاری ماهوارهای.
- کلاسترینگ دادههای نجومی کلان و الگوهای چندبعدی اینترنت اشیاء (IoT).
.
2.۳. الگوریتم CLIQUE
یک الگوریتم خوشهبندی مبتنی بر شبکه (Grid-Based) و چگالیمحور پیشرفته است که منحصراً برای کشف خوشهها در زیرفضاهای (Subspaces) مجموعهدادههای بسیار چندبعدی (High-Dimensional Data) طراحی شده است. این الگوریتم با ترکیب ایده شبکهبندی فضا و تئوری قوانین انجمنی (Apriori)، مشکل پدیده محاسباتی سنگین بختک ابعاد را حل میکند.
CLIQUE از اصل Apriori استفاده میکند؛ یعنی اگر یک ناحیه در فضای k-بعدی متراکم باشد، تصویر آن در زیرفضاهای (k-1) −بعدی نیز باید متراکم باشد. این خاصیت باعث کاهش قابل توجه فضای جستوجو میشود.
گامهای اجرایی
- شبکهبندی یکبعدی (فاز مبنا): ابتدا هر بعد یا ویژگی فضای مسئله به طور مستقل به تعداد مشخصی از فواصل مساوی (سلول) تقسیم شده و سلولهای متراکم یکبعدی شناسایی میشوند.
- کاهش ابعاد و صعود لایهای (Apriori-like): بر اساس تئوری آپریوری، کلاسترهای متراکم k-بعدی تنها در صورتی میتوانند وجود داشته باشند که زیرفضاهای (k-1)-بعدی آنها نیز متراکم باشند. الگوریتم با این استراتژی، گامبهگام فضای سلولهای متراکم را به ابعاد بالاتر توسعه میدهد.
- شناسایی کلاسترهای زیرفضا: سلولهای متراکم به هم چسبیده و همجوار در زیرفضاهای نهایی شناسایی شده و به عنوان کلاسترهای فرعی علامتگذاری میشوند.
- تولید عبارات منطقی (Minimal Cover): الگوریتم در نهایت برای هر خوشه کشفشده، یک برچسب یا فرمول منطقی خلاصه شده تولید میکند تا مرزهای دقیق آن را در زیرفضاهای مختلف توصیف کند.

تابع هدف ریاضی
شناسایی لایهای سلولهای متراکم چندبعدی (Dk) بر پایه تقاطع سلولهای متراکم ابعاد پایینتر بر اساس تئوری مونوتونیک (Monotonicity property)
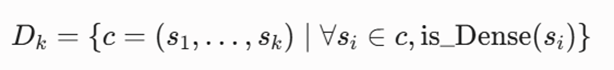
مزایا و نقاط قوت
- توانایی فوقالعاده و بیرقیب در کشف خوشههای پنهان در زیرفضاهای مختلف دیتابیس، بدون وابستگی به کل ابعاد فضا.
- تولید خودکار توصیف منطقی و متنی ساده برای مرزهای هر خوشه که تفسیر خروجی را بسیار آسان میکند.
- مقیاسپذیری خطی نسبت به حجم دادهها (O(n)).
معایب و محدودیتها
- افزایش تصاعدی و سنگین بار محاسباتی و زمانی با افزایش تعداد ابعاد مبنایی فضا در صورت پایین بودن آستانه چگالی .
- کیفیت و دقت کلاسترینگ به شدت به تنظیم همزمان دو هایپرپارامتر حساس xi و tau وابسته است.
کاربردهای واقعی
- دادهکاوی دیتابیسهای بسیار چندبعدی پزشکی (مانند ابعاد بیوانفورماتیک و ژنتیک).
- تحلیل رفتارهای چندبعدی مشتریان در بازارهای کلان مالی و کشف کلاسترهای پنهان تراکنشی.
.
2.۴. الگوریتم OptiGrid
یک الگوریتم خوشهبندی پیشرفته مبتنی بر شبکه (Grid-Based) است که برای حل ضعف ساختاری روشهای سنتی (مانند STING و CLIQUE) در مواجهه با دادههای چندبعدی ناشی از برشهای صلب و یکنواخت فضا مهندسی شده است. این متد با ترکیب مفاهیم شبکه و تکنیکهای پیشرفته کاهش ابعاد، صفحات برش خود را دقیقاً بر روی نواحی با کمترین چگالی (درهها) در فضای چندبعدی قرار میدهد تا کلاسترها را با کمترین خطا تفکیک کند.
گامهای اجرایی
- تصویرسازی هندسی (Projection): انتقال و نگاشت نقاط داده بر روی مجموعهای از محورها یا زیرفضاهای بهینه با استفاده از تکنیکهای ریاضی(مانند تحلیل مؤلفههای اصلی PCA –).
- محاسبه توابع چگالی زیرفضا: محاسبه توابع تخمین چگالی برای تکتک محورهای تصویرشده جهت استخراج توزیع آماری قلهها و درهها.
- تعیین صفحات برش بهینه (Optimal Cuts): شناسایی درهها (نواحی با چگالی نزدیک به صفر) بر روی هر محور. صفحاتی که از این درهها میگذرند به عنوان خطوط جداکننده بهینه انتخاب میشوند.
- افرازبندی چندبعدی فضا: خرد کردن فضای بزرگ ویژگیها به سلولهای ناهمگون شبکه بر اساس صفحات برش بهینه انتخابشده.
- شکلدهی و اتصال کلاسترها: شناسایی سلولهای متراکم مجاور و ترکیب آنها برای تولید خوشههای نهایی و تفکیک دادههای پرت به عنوان نویز.
تابع هدف ریاضی
بیشینهسازی امتیاز کیفیت صفحات برش (P) از طریق یافتن نقاط کمترین چگالی محلی (درهها) بر روی محورهای تصویرشده فضا:
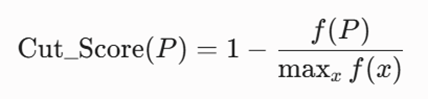
مزایا و نقاط قوت
- مقاومت عالی در برابر دادههای پرت و نویزها به دلیل عدم تأثیرگذاری آنها بر مکان صفحات برش بهینه.
- سرعت و کارایی محاسباتی بسیار بالا در ابعاد بزرگ.
معایب و محدودیتها
- کیفیت نهایی کلاسترینگ به شدت وابسته به فاز اول یعنی کیفیت تصویرسازی هندسی و یافتن محورهای بهینه زیرفضا است.
- در صورت عدم وجود درههای چگالی واضح در توزیع آماری دادهها، الگوریتم در یافتن صفحات برش دچار خطا میشود.
کاربردهای واقعی
- دادهکاوی دیتابیسهای چندبعدی تصویربرداریهای پزشکی و سیگنالهای حیاتی پیچیده.
- بخشبندی بازارهای مالی و خوشهبندی سبد داراییها با ویژگیهای چندگانه ساختارنیافته.
.
3.کاربردهای خوشهبندی مبتنی بر شبکه
خوشهبندی مبتنی بر شبکه به دلیل سرعت بالا، قابلیت خلاصهسازی دادهها و سازگاری با دادههای بزرگ، در حوزههای متنوعی کاربرد دارد. مهمترین کاربردهای این نوع خوشهبندی عبارتاند از:

3.1. تحلیل دادههای مکانی و جغرافیایی
یکی از مهمترین کاربردهای Grid-Based Clustering در تحلیل دادههای مکانی است. دادههای مکانی معمولاً شامل حجم عظیمی از مختصات جغرافیایی، نقاط GPS، دادههای سنجش از دور، تصاویر ماهوارهای و دادههای سیستمهای اطلاعات جغرافیایی هستند.
در چنین مسائلی، تقسیم فضا به سلولهای شبکهای باعث میشود بتوان نواحی پرتراکم، مناطق داغ، الگوهای فضایی و خوشههای جغرافیایی را با سرعت بالا شناسایی کرد.
نمونه کاربردها:
- شناسایی مناطق پرتردد شهری
- تحلیل تراکم جمعیت
- کشف نقاط داغ تصادفات جادهای
- تحلیل پراکندگی بیماریها در جغرافیای شهری
- خوشهبندی دادههای GPS خودروها و کاربران موبایل
.
3.2. پردازش تصاویر و دادههای ماهوارهای
در پردازش تصویر، هر تصویر را میتوان به شبکهای از پیکسلها یا بلوکهای مکانی تقسیم کرد. روشهای مبتنی بر شبکه میتوانند برای بخشبندی تصویر، تشخیص الگو، حذف نویز و استخراج نواحی مشابه به کار روند.
بهویژه الگوریتمهایی مانند WaveCluster که از تبدیل موجک استفاده میکنند، در تحلیل تصاویر ماهوارهای، راداری و پزشکی بسیار کاربردی هستند.
نمونه کاربردها:
- بخشبندی تصاویر پزشکی
- تحلیل تصاویر راداری
- خوشهبندی بافتهای تصویری
- تشخیص نواحی غیرعادی در تصاویر ماهوارهای
- تحلیل دادههای سنجش از دور
.
3.3 خوشهبندی دادههای چندبعدی و زیرفضایی
در دادههای بسیار چندبعدی، بسیاری از خوشهها ممکن است فقط در برخی از ابعاد قابل مشاهده باشند، نه در کل فضای ویژگیها. الگوریتمهایی مانند CLIQUE برای همین مسئله طراحی شدهاند و میتوانند خوشههای پنهان را در زیرفضاهای مختلف کشف کنند.
نمونه کاربردها:
- دادههای ژنتیکی و بیوانفورماتیک
- تحلیل رفتار مشتریان با ویژگیهای متعدد
- دادههای پزشکی چندمتغیره
- دادههای مالی چندبعدی
.
3.4. دادهکاوی در پایگاههای داده بسیار بزرگ
در پایگاههای داده عظیم، محاسبه فاصله میان همه نقاط یا اجرای الگوریتمهای تکراری سنگین ممکن است بسیار پرهزینه باشد. روشهای مبتنی بر شبکه با خلاصهسازی دادهها در سطح سلولها، امکان پردازش سریع و مقیاسپذیر را فراهم میکنند.
نمونه کاربردها:
- تحلیل تراکنشهای بانکی
- خوشهبندی لاگهای وب
- تحلیل دادههای فروشگاههای آنلاین
- کشف الگوهای رفتاری کاربران
- تحلیل دادههای عملیاتی سازمانی
.
3.5. تحلیل دادههای جریانی و اینترنت اشیا
در دادههای جریانی، دادهها بهصورت پیوسته وارد سیستم میشوند و ذخیرهسازی یا پردازش کامل آنها دشوار است. برخی روشهای شبکهمحور مانند D-Stream برای خوشهبندی دادههای جریانی طراحی شدهاند و با بهروزرسانی چگالی سلولها در طول زمان، تغییرات ساختار داده را دنبال میکنند.
نمونه کاربردها:
- پایش حسگرهای صنعتی
- تحلیل دادههای اینترنت اشیا
- تشخیص ناهنجاری در شبکهها
- تحلیل ترافیک شهری بهصورت بلادرنگ
- پایش سامانههای حملونقل هوشمند
.
3.6. تشخیص ناهنجاری و نقاط پرت
در روشهای Grid-Based، سلولهایی که تراکم بسیار کمی دارند یا در همسایگی نواحی پرتراکم قرار ندارند، میتوانند بهعنوان نواحی مشکوک یا نویزی شناسایی شوند. این ویژگی برای تشخیص دادههای پرت بسیار مفید است.
نمونه کاربردها:
- تشخیص تقلب مالی
- شناسایی رخدادهای غیرعادی در شبکه
- تشخیص رفتارهای غیرمعمول کاربران
- پایش خطا در حسگرها
- کنترل کیفیت صنعتی
.
4.مزایای خوشهبندی مبتنی بر شبکه
خوشهبندی مبتنی بر شبکه دارای مجموعهای از مزایای مهم است که آن را برای بسیاری از مسائل دادهکاوی و یادگیری ماشین کاربردی میسازد.
4.1. سرعت پردازش بسیار بالا
مهمترین مزیت این رویکرد، کاهش وابستگی مستقیم الگوریتم به تعداد نقاط داده است. پس از تبدیل دادهها به سلولهای شبکه، پردازش اصلی روی سلولها انجام میشود، نه روی تکتک نمونهها.
در حالت کلی، اگر تعداد سلولها برابر با m و تعداد نقاط برابر با n باشد، بسیاری از عملیاتها میتوانند بهجای وابستگی شدید به n، به ساختار شبکه وابسته شوند:
Complexity≈O(m)
البته در مرحله تخصیص نقاط به سلولها معمولاً هزینهای متناسب با O(n) وجود دارد، اما پس از آن، تحلیل ساختاری روی فضای خلاصهشده انجام میشود.
4.2. مناسب برای کلاندادهها
از آنجا که دادهها در سطح سلولهای گرید خلاصه میشوند، این روشها برای مجموعهدادههای بسیار بزرگ بسیار مناسب هستند. ذخیره اطلاعاتی مانند تعداد نقاط، میانگین، واریانس یا چگالی هر سلول میتواند حجم محاسبات را بهشدت کاهش دهد.
4.3. قابلیت اجرای موازی و توزیعشده
تقسیم فضا به سلولهای مستقل، امکان پردازش موازی را بهصورت طبیعی فراهم میکند. هر سلول یا مجموعهای از سلولها میتواند بهصورت مستقل روی پردازندههای مختلف، گرههای محاسباتی یا محیطهای توزیعشده پردازش شود.
این ویژگی باعث میشود Grid-Based Clustering برای چارچوبهایی مانند:
- MapReduce
- Apache Spark
- پردازش GPU
- سامانههای توزیعشده مکانی
بسیار مناسب باشد.
4.4.عدم نیاز به محاسبه کامل ماتریس فاصله
در بسیاری از روشهای خوشهبندی، محاسبه فاصله میان همه نقاط یکی از پرهزینهترین مراحل است. در مقابل، روشهای شبکهمحور معمولاً به محاسبه کامل ماتریس فاصله نیاز ندارند و بیشتر بر موقعیت نقاط در سلولها، چگالی سلولها و مجاورت شبکهای تکیه میکنند.
4.5.توانایی شناسایی خوشههای با شکل دلخواه
برخی الگوریتمهای شبکهمحور، بهویژه روشهایی که با چگالی یا موجک ترکیب میشوند، میتوانند خوشههایی با شکلهای غیرکروی، نامنظم، توخالی یا پیچیده را شناسایی کنند. برای مثال، WaveCluster در شناسایی ساختارهای هندسی پیچیده عملکرد مطلوبی دارد.
4.6.مناسب برای تحلیل چندرزولوشنی
در الگوریتمهایی مانند STING و WaveCluster، امکان بررسی دادهها در چند سطح رزولوشن وجود دارد. این قابلیت اجازه میدهد ساختارهای کلی در سطح درشت و جزئیات محلی در سطح ریزتر تحلیل شوند.
4.7. قابلیت خلاصهسازی آماری دادهها
در این روش، هر سلول میتواند مجموعهای از شاخصهای آماری را نگهداری کند؛ مانند:
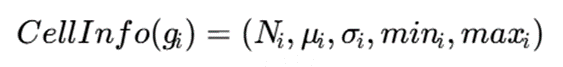
که در آن:
- Ni: تعداد نقاط سلول
- μi : میانگین نقاط در سلول
- σi : انحراف معیار
- mini: کمینه مقدار
- maxi: بیشینه مقدار
این خلاصهسازی آماری برای پاسخ به کوئریها، تحلیل سریع و پردازش بلادرنگ بسیار سودمند است.
.
5.معایب و محدودیتهای خوشهبندی مبتنی بر شبکه
با وجود مزایای قابل توجه، خوشهبندی مبتنی بر شبکه محدودیتهایی نیز دارد که باید در طراحی و استفاده از آن مورد توجه قرار گیرد.
5.1. حساسیت به اندازه سلولها
یکی از مهمترین چالشهای این روش، انتخاب اندازه مناسب سلولها یا تعداد تقسیمات در هر بعد است. اگر سلولها بیش از حد بزرگ باشند، جزئیات محلی داده از بین میرود و چند خوشه متمایز ممکن است در یک سلول ادغام شوند. اگر سلولها بیش از حد کوچک باشند، تعداد سلولهای خالی یا کمتراکم افزایش مییابد و هزینه محاسباتی بالا میرود.
به بیان ساده:
- سلول بزرگ: کاهش دقت، ادغام خوشهها
- سلول کوچک: افزایش هزینه، پراکندگی بیش از حد، حساسیت به نویز
5.2.مشکل رشد نمایی تعداد سلولها در ابعاد بالا
اگر هر بعد به q بازه تقسیم شود و تعداد ابعاد برابر با d باشد، تعداد کل سلولهای بالقوه برابر است با:
m = q^d
این رابطه نشان میدهد که با افزایش تعداد ابعاد، تعداد سلولها بهصورت نمایی رشد میکند. بنابراین، اگرچه روشهای Grid-Based برای دادههای بزرگ مناسباند، اما در فضاهای بسیار پُربُعد ممکن است با مشکل انفجار تعداد سلولها مواجه شوند.
5.3.وابستگی به ساختار محورهای مختصات
در بسیاری از روشهای شبکهمحور کلاسیک، مرزهای سلولها موازی محورهای مختصات هستند. این مسئله ممکن است باعث شود خوشههایی که جهتگیری مورب، منحنی یا غیرهمراستا با محورها دارند، بهخوبی نمایش داده نشوند.
5.4. کاهش دقت در مرز خوشهها
از آنجا که دادهها در سطح سلول خلاصه میشوند، اطلاعات دقیق مربوط به موقعیت تکتک نقاط ممکن است از بین برود. این موضوع بهویژه در مرز میان خوشهها اهمیت دارد، زیرا نقاط نزدیک به مرز ممکن است بهاشتباه در یک سلول مشترک قرار گیرند یا به خوشه نامناسب نسبت داده شوند.
5.5. نیاز به تنظیم هایپرپارامترها
بسیاری از الگوریتمهای این خانواده به پارامترهایی مانند موارد زیر وابستهاند:
- تعداد تقسیمات هر بعد
- اندازه سلول
- آستانه چگالی
- سطح رزولوشن
- نوع تابع موجک
- مقدار آستانه تراکم
- تعداد سطوح سلسلهمراتبی
انتخاب نامناسب این پارامترها میتواند کیفیت خوشهبندی را بهشدت تحت تأثیر قرار دهد.
5.6. دشواری در دادههای با توزیع بسیار نامتوازن
اگر دادهها دارای چگالیهای بسیار متفاوت باشند، یک گرید یکنواخت ممکن است برای همه نواحی مناسب نباشد. در چنین شرایطی، برخی نواحی بیش از حد فشرده و برخی بیش از حد پراکنده نمایش داده میشوند. روشهایی مانند OptiGrid یا گریدهای تطبیقی برای کاهش این مشکل طراحی شدهاند.
.
6.نوآوریهای جدید در خوشهبندی مبتنی بر شبکه(Grid-Based Clustering)
خوشهبندی مبتنی بر شبکه یا Grid-Based Clustering یکی از رویکردهای مهم در دادهکاوی و یادگیری بدونناظر است که بهجای تحلیل مستقیم تکتک نقاط داده، فضای ویژگی را به مجموعهای از سلولها یا نواحی گسسته تقسیم میکند. سپس خوشهها بر اساس ویژگیهایی مانند چگالی، پیوستگی، آمار محلی یا شباهت میان سلولها شناسایی میشوند. این رویکرد از ابتدا با هدف افزایش سرعت و مقیاسپذیری طراحی شد و در الگوریتمهایی مانند STING، WaveCluster، CLIQUE، OptiGrid، MAFIA، ENCLUS و D-Stream توسعه یافت.
با رشد دادههای عظیم، دادههای جریانی، دادههای مکانی ـ زمانی، دادههای چندمنبعی و دادههای دارای ابعاد بالا، خوشهبندی مبتنی بر شبکه نیز از یک روش ساده تقسیم فضا به سلولهای ثابت، به چارچوبی انعطافپذیر برای تحلیل دادههای پیچیده تبدیل شده است. نوآوریهای جدید این حوزه عمدتاً بر شبکههای تطبیقی، پردازش جریانی، مقیاسپذیری، یادگیری عمیق، کاهش اثر ابعاد بالا، مدلسازی عدم قطعیت، حفظ حریم خصوصی و تفسیرپذیری متمرکز هستند.
.
6.1. شبکههای تطبیقی و چندرزولوشنی(Adaptive and Multi-Resolution Grids)
در روشهای کلاسیک، فضای داده معمولاً به سلولهایی با اندازه ثابت تقسیم میشود. این کار ساده و سریع است، اما برای دادههایی با چگالی نامتوازن مناسب نیست. در بسیاری از مسائل واقعی، بخشی از فضا بسیار پرتراکم و بخشی دیگر بسیار خلوت است. اگر اندازه سلولها بزرگ باشد، ساختارهای محلی از بین میروند؛ و اگر اندازه سلولها بسیار کوچک باشد، تعداد زیادی سلول خالی یا کماهمیت ایجاد میشود.
در نوآوریهای جدید، از شبکههای تطبیقی استفاده میشود. در این روشها، سلولها در نواحی پرتراکم کوچکتر و در نواحی کمچگال بزرگتر انتخاب میشوند. این ایده باعث میشود الگوریتم هم دقت محلی بالاتری داشته باشد و هم از افزایش غیرضروری تعداد سلولها جلوگیری کند.
بهصورت مفهومی، اگر چگالی یک سلول از آستانه مشخصی بیشتر شود، آن سلول به زیرسلولهای کوچکتر تقسیم میشود:
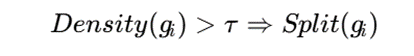
و اگر چگالی چند سلول مجاور پایین باشد، میتوان آنها را ادغام کرد:
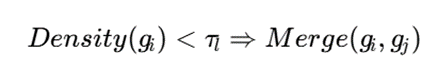
در اینجا gi یک سلول شبکه، τ آستانه تقسیم و Ƞ آستانه ادغام است.
این نوآوری برای دادههای مکانی، تصاویر پزشکی، دادههای ماهوارهای، تحلیل ترافیک شهری و خوشهبندی نقاط GPS بسیار ارزشمند است؛ زیرا در این مسائل، تراکم دادهها معمولاً در بخشهای مختلف فضا یکسان نیست.
.
6.2.خوشهبندی شبکهمحور برای دادههای جریانی(Grid-Based Clustering for Data Streams)
یکی از مهمترین جهتگیریهای جدید در این حوزه، استفاده از گرید برای تحلیل دادههای جریانی است. در بسیاری از سامانههای مدرن، دادهها بهصورت پیوسته تولید میشوند؛ مانند دادههای حسگرهای اینترنت اشیا، تراکنشهای مالی، لاگهای شبکه، موقعیت مکانی خودروها و رفتار کاربران در وب.
در چنین شرایطی، الگوریتم خوشهبندی نمیتواند همه دادهها را ذخیره و چندین بار پردازش کند. بنابراین، روشهای جدید تلاش میکنند با ذخیره خلاصه آماری سلولها، خوشهها را بهصورت برخط بهروزرسانی کنند.
در این روشها، چگالی هر سلول معمولاً وابسته به زمان تعریف میشود:
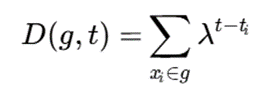
که در آن D(g,t) چگالی سلول g در زمان t، ti زمان ورود داده xi، و λ ضریب کاهش زمانی است. مقدار λ بین صفر و یک قرار دارد و باعث میشود اثر دادههای قدیمی بهتدریج کاهش یابد.
این ایده امکان تشخیص خوشههای در حال ظهور، خوشههای منقرضشده، تغییر مفهوم یا Concept Drift و الگوهای زمانی را فراهم میکند. الگوریتمهایی مانند D-Stream نمونهای مهم از این جهتگیری هستند.
.
6.3. گریدهای پراکنده برای دادههای پُربُعد(Sparse Grids for High-Dimensional Data)
یکی از چالشهای اصلی خوشهبندی مبتنی بر شبکه، رشد نمایی تعداد سلولها با افزایش ابعاد است. اگر هر بعد به q بازه تقسیم شود و تعداد ابعاد برابر d باشد، تعداد سلولهای بالقوه برابر خواهد بود با:
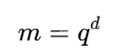
این مسئله باعث میشود استفاده مستقیم از گرید در دادههای پُربُعد بسیار پرهزینه شود.
نوآوریهای جدید برای حل این مشکل از گریدهای پراکنده استفاده میکنند. در این روش، بهجای ذخیره همه سلولهای ممکن، فقط سلولهایی نگهداری میشوند که واقعاً حاوی داده یا دارای چگالی معنادار هستند:
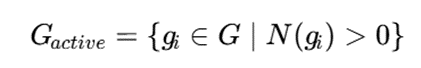
که در آن Gactive مجموعه سلولهای فعال و (gi) N تعداد نقاط داخل سلول است.
این ایده در کنار روشهایی مانند انتخاب ویژگی، کاهش بُعد، projection تصادفی، PCA، UMAP و autoencoderها میتواند خوشهبندی شبکهمحور را برای دادههای ژنتیکی، متنی، مالی، رفتاری و embeddingهای مدلهای یادگیری عمیق مناسبتر کند.
.
6.4.ترکیب با یادگیری عمیق(Deep Grid-Based Clustering)
در دادههایی مانند تصویر، متن، صوت و دادههای زیستی، فضای خام ویژگیها معمولاً برای گریدبندی مناسب نیست. برای مثال، فاصله اقلیدسی میان پیکسلهای خام تصویر لزوماً نشاندهنده شباهت معنایی تصاویر نیست. به همین دلیل، یکی از نوآوریهای جدید، ترکیب Grid-Based Clustering با یادگیری عمیق است.
در این رویکرد، ابتدا یک مدل عصبی مانند autoencoder، شبکه کانولوشنی، Transformer یا مدل embedding، داده خام را به فضای نهفته منتقل میکند:
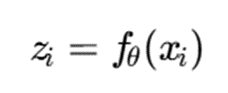
که در آن xi داده خام، fθ مدل یادگیری عمیق و zi نمایش نهفته داده است. سپس گریدبندی و خوشهبندی در فضای z انجام میشود، نه در فضای خام x.
این کار چند مزیت مهم دارد:
- کاهش اثر نویز و ابعاد بالا؛
- افزایش معنایی بودن فاصلهها؛
- بهبود کیفیت خوشهها؛
- امکان تحلیل دادههای پیچیده مانند تصویر و متن؛
- ترکیب با یادگیری خودنظارتی و contrastive learning.
این رویکرد بهویژه در خوشهبندی تصاویر پزشکی، گروهبندی اسناد، تحلیل کاربران، دادههای چندرسانهای و دادههای زیستی اهمیت دارد.
.
6.5.خوشهبندی شبکهمحور خودنظارتی و تقابلی(Self-Supervised and Contrastive Grid Clustering)
در بسیاری از مسائل واقعی، داده برچسبدار کافی وجود ندارد. یادگیری خودنظارتی این امکان را فراهم میکند که مدل بدون برچسب انسانی، نمایشهای مفید و ساختارمند از داده یاد بگیرد. سپس میتوان گرید را در این فضای آموختهشده ساخت.
در یادگیری تقابلی، نمونههای مشابه به هم نزدیک و نمونههای نامشابه از هم دور میشوند. تابع هدف رایج در این حوزه بهصورت زیر قابل نمایش است:
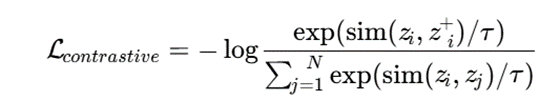
در این رابطه، zi نمایش نمونه اصلی، +^zi نمایش مثبت از همان نمونه، sim تابع شباهت و τ پارامتر دما است.
پس از یادگیری نمایش، خوشهبندی مبتنی بر شبکه در فضای embedding انجام میشود. در نتیجه، سلولهای گرید نهتنها نواحی هندسی، بلکه نواحی معنایی را نمایش میدهند. این ایده برای دادههای عظیم بدون برچسب، مانند تصاویر، متنهای وب، سیگنالها و دادههای کاربران بسیار کاربردی است.
.
6.6.خوشهبندی شبکهمحور مکانی ـ زمانی(Spatio-Temporal Grid-Based Clustering)
بخش مهمی از دادههای مدرن دارای دو جنبه همزمان مکان و زمان هستند. دادههای GPS، ترافیک شهری، رخدادهای شبکه، دادههای هواشناسی، انتشار بیماریها و رویدادهای اجتماعی نمونههایی از این نوع دادهاند.
در خوشهبندی شبکهمحور مکانی ـ زمانی، سلولها فقط در فضای مکانی تعریف نمیشوند، بلکه زمان نیز بهعنوان یک بعد مهم وارد مدل میشود:
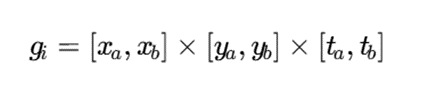
در این حالت، هر سلول یک ناحیه مکانی و یک بازه زمانی مشخص را نمایش میدهد. چگالی سلول نیز میتواند بهصورت زیر تعریف شود:
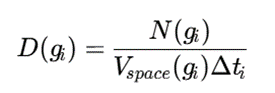
که در آن (gi) Nتعداد رخدادها، (gi) Vspaceحجم یا مساحت مکانی و Δti طول بازه زمانی است.
این رویکرد برای کشف نقاط داغ پویا، تحلیل ترافیک، پایش بیماریها، تحلیل زلزله، ردیابی جمعیت و پیشبینی الگوهای مکانی ـ زمانی بسیار مفید است.
.
6.7.ترکیب گرید با گراف و شبکههای همسایگی(Graph-Enhanced Grid-Based Clustering)
در روشهای کلاسیک، همسایگی سلولها معمولاً بر اساس مجاورت هندسی تعریف میشود. اما در بسیاری از مسائل واقعی، ارتباط میان نواحی صرفاً بر اساس فاصله مکانی نیست. برای مثال، در یک شهر، دو منطقه ممکن است از نظر جغرافیایی نزدیک باشند، اما به دلیل ساختار خیابانها یا موانع طبیعی ارتباط کمی داشته باشند.
در نوآوریهای جدید، سلولهای گرید بهعنوان گرههای یک گراف در نظر گرفته میشوند:
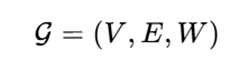
که در آن V مجموعه سلولهای فعال، E یالهای میان سلولها و W وزن ارتباطات است. وزن یالها میتواند بر اساس فاصله، جریان، شباهت، همرخدادی یا شدت تعامل تعریف شود.
چگالی گرافی یک سلول را میتوان بهصورت زیر بیان کرد:
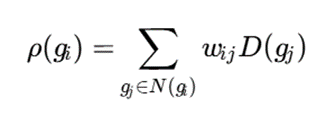
این ترکیب باعث میشود خوشهبندی شبکهمحور بتواند ساختارهای پیچیدهتر را مدل کند. کاربردهای مهم آن شامل تحلیل ترافیک شهری، شبکههای اجتماعی مکانی، شبکههای حسگر، گرافهای دانش مکانی و سامانههای حملونقل است.
.
6.8. خوشهبندی شبکهمحور مقاوم به نویز و داده پرت(Robust Grid-Based Clustering)
اگرچه Grid-Based Clustering به دلیل خلاصهسازی دادهها تا حدی نسبت به نویز مقاوم است، اما در دادههای واقعی، نویز میتواند باعث ایجاد سلولهای پرتراکم کاذب یا اختلال در مرز خوشهها شود. بنابراین، یکی از نوآوریهای مهم، طراحی روشهای مقاومتر برای محاسبه چگالی و تشخیص سلولهای معتبر است.
در روشهای جدید، بهجای شمارش ساده نقاط، میتوان از چگالی وزندار استفاده کرد:
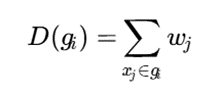
که در آن wj وزن اطمینان یا اعتبار نقطه xj است. نقاط مشکوک به نویز وزن کمتری میگیرند و تأثیر آنها در تشکیل خوشه کاهش مییابد.
همچنین میتوان از روشهایی مانند فیلتر موجک، تحلیل پایداری چندرزولوشنی، تشخیص ناهنجاری، حذف سلولهای کمپایداری و تخمین چگالی مقاوم استفاده کرد.
این نوآوری برای دادههای GPS نویزی، حسگرهای صنعتی، دادههای پزشکی، امنیت سایبری و تشخیص تقلب کاربرد دارد.
.
6.9.خوشهبندی شبکهمحور مبتنی بر عدم قطعیت(Uncertainty-Aware Grid-Based Clustering)
در بسیاری از سامانهها، مقدار یا موقعیت دادهها قطعی نیست. برای مثال، موقعیت GPS دارای خطای اندازهگیری است، دادههای حسگرها نویزیاند و برخی دادههای پزشکی با عدم قطعیت همراه هستند. در این شرایط، اختصاص سخت هر نقطه به یک سلول ممکن است باعث خطا شود.
در روشهای جدید، هر داده میتواند بهجای یک نقطه قطعی، بهصورت یک توزیع احتمالی مدل شود. بنابراین، احتمال تعلق داده به سلولهای مختلف محاسبه میشود:
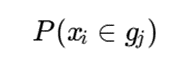
و چگالی احتمالی سلول بهصورت زیر تعریف میشود:
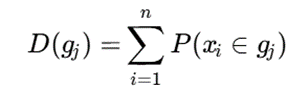
این رویکرد باعث میشود نتایج خوشهبندی پایدارتر، واقعبینانهتر و همراه با سطح اطمینان باشند. کاربردهای آن در رباتیک، مکانیابی موبایل، نقشهبرداری، دادههای سنسوری، پزشکی و تحلیل رویدادهای جغرافیایی بسیار قابل توجه است.
.
6.10.خوشهبندی شبکهمحور چندنمایی و چندمنبعی(Multi-View and Multi-Source Grid-Based Clustering)
دادههای واقعی اغلب از چند منبع یا چند نوع ویژگی تشکیل میشوند. برای مثال، در تحلیل بیماران ممکن است دادههای آزمایشگاهی، تصویربرداری، سوابق متنی و دادههای ژنتیکی همزمان وجود داشته باشند. در تحلیل کاربران نیز ممکن است دادههای رفتاری، مکانی، اجتماعی و تراکنشی در کنار هم بررسی شوند.
در روشهای جدید، بهجای ساخت یک گرید واحد روی همه ویژگیها، برای هر نما یا منبع داده یک ساختار شبکهای جداگانه ساخته میشود. سپس اطلاعات این گریدها در سطح چگالی، شباهت یا خوشهها ترکیب میشود:
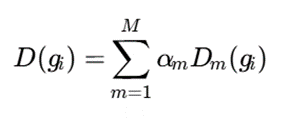
که در آن M تعداد نماها، (gi) Dm چگالی سلول در نمای m، و αm وزن اهمیت آن نما است.
این نوآوری امکان کشف خوشههای پایدارتر، کاهش اثر نویز در یک منبع خاص، و ترکیب هوشمند اطلاعات ناهمگون را فراهم میکند.
.
6.11.اجرای موازی، توزیعشده و GPU-محور(Parallel, Distributed and GPU-Based Grid Clustering)
یکی از دلایل محبوبیت خوشهبندی شبکهمحور، قابلیت بالای آن برای موازیسازی است. محاسبه چگالی سلولها، تخصیص نقاط به سلولها و اتصال سلولهای متراکم را میتوان روی چند پردازنده، چند گره محاسباتی یا GPU انجام داد.
در نسخههای جدید، از چارچوبهایی مانند Spark، MapReduce، CUDA و پردازش ابری برای اجرای مقیاسپذیر استفاده میشود. راهبردهای رایج شامل:
- تقسیم داده میان گرههای پردازشی؛
- محاسبه موازی چگالی سلولها؛
- استفاده از hashing برای نگاشت سریع نقاط به سلولها؛
- ذخیره فقط سلولهای فعال؛
- ادغام خوشههای مرزی میان پارتیشنها؛
- اجرای موازی عملیات اتصال سلولی.
این نوآوری باعث شده است Grid-Based Clustering برای دادههای بسیار بزرگ، تحلیل بلادرنگ و سامانههای صنعتی در مقیاس وسیع قابل استفاده باشد.
.
6.12.خوشهبندی شبکهمحور فدرال و حریمخصوصیمحور(Federated and Privacy-Preserving Grid-Based Clustering)
در کاربردهایی مانند پزشکی، بانکداری، اینترنت اشیا و شهر هوشمند، دادهها معمولاً میان چند سازمان یا دستگاه توزیع شدهاند و امکان انتقال داده خام به یک مرکز مشترک وجود ندارد. خوشهبندی فدرال و حریمخصوصیمحور اهمیت پیدا میکند.
در این رویکرد، هر نهاد محلی فقط خلاصه آماری سلولهای خود را محاسبه و ارسال میکند:
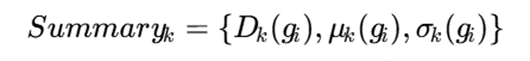
سپس سرور مرکزی خلاصهها را ادغام میکند:
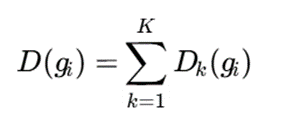
در این روش، داده خام منتقل نمیشود و خطر افشای اطلاعات کاهش مییابد. همچنین میتوان از روشهایی مانند Differential Privacy، Secure Aggregation و رمزنگاری برای افزایش امنیت استفاده کرد.
.
6.13.خودکارسازی انتخاب پارامترهای گرید(Automated Grid Parameter Selection)
یکی از چالشهای مهم در خوشهبندی شبکهمحور، انتخاب اندازه سلول، تعداد تقسیمات، سطح رزولوشن و آستانه چگالی است. انتخاب دستی این پارامترها میتواند نتیجه خوشهبندی را بهشدت تحت تأثیر قرار دهد.
در نوآوریهای جدید، تلاش میشود این پارامترها بهصورت خودکار و دادهمحور تعیین شوند. برخی معیارهای مورد استفاده عبارتاند از:
- پایداری خوشهها در رزولوشنهای مختلف؛
- معیارهای اعتبارسنجی داخلی مانند Silhouette یا Davies-Bouldin؛
- جستوجوی بیزی؛
- الگوریتمهای تکاملی؛
- یادگیری متا؛
- تحلیل خطای بازسازی چگالی؛
- مقایسه ساختار خوشهها در چند سطح گرید.
برای مثال، پایداری خوشهها در چند رزولوشن را میتوان چنین محاسبه کرد:
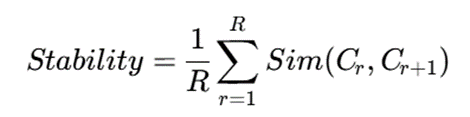
که در آن Cr نتیجه خوشهبندی در رزولوشن r و Sim معیار شباهت میان دو خوشهبندی است.
.
6.14.خوشهبندی شبکهمحور قابل تفسیر((Interpretable Grid-Based Clustering
یکی از مزایای ذاتی روشهای Grid-Based، تفسیرپذیری نسبی آنهاست. زیرا هر خوشه از مجموعهای از سلولهای مشخص تشکیل میشود و هر سلول نیز با بازههایی روی ویژگیها تعریف شده است.
در نسخههای جدید، این ویژگی برای تولید توضیحهای قابل فهم استفاده میشود. یک خوشه را میتوان بهصورت اجتماع سلولها نمایش داد:
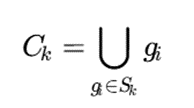
و سپس آن را با قواعد بازهای توضیح داد:
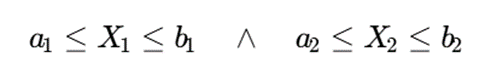
این قابلیت در کاربردهایی مانند پزشکی، مالی، کنترل کیفیت، دادهکاوی آموزشی و تحلیل مشتریان اهمیت زیادی دارد؛ زیرا در این حوزهها صرفاً دانستن خوشهها کافی نیست، بلکه باید دلیل شکلگیری آنها نیز قابل توضیح باشد.
.
جمعبندی
نوآوریهای جدید در حوزه خوشهبندی مبتنی بر شبکه نشان میدهند که این رویکرد از یک روش کلاسیک و سریع برای تقسیم فضای داده به سلولهای ثابت، به یک چارچوب پیشرفته و انعطافپذیر برای تحلیل دادههای مدرن تبدیل شده است. امروزه Grid-Based Clustering با حوزههایی مانند یادگیری عمیق، یادگیری خودنظارتی، دادههای جریانی، تحلیل مکانی ـ زمانی، گراف، پردازش توزیعشده، حفظ حریم خصوصی، عدم قطعیت و تفسیرپذیری پیوند خورده است.
بهطور خلاصه، مهمترین مسیرهای نوآوری در این حوزه عبارتاند از:
- شبکههای تطبیقی و چندرزولوشنی؛
- خوشهبندی برخط برای دادههای جریانی؛
- ترکیب با یادگیری عمیق و embeddingها؛
- خوشهبندی خودنظارتی و تقابلی؛
- تحلیل مکانی ـ زمانی؛
- ترکیب گرید با گراف؛
- مقاومت در برابر نویز و داده پرت؛
- مدلسازی عدم قطعیت؛
- خوشهبندی چندنمایی و چندمنبعی؛
- اجرای موازی، توزیعشده و GPU-محور؛
- خوشهبندی فدرال و حریمخصوصیمحور؛
- انتخاب خودکار پارامترهای گرید؛
- و افزایش تفسیرپذیری خوشهها.
بنابراین، آینده خوشهبندی مبتنی بر شبکه در جهت تبدیل شدن به یک چارچوب سریع، مقیاسپذیر، قابل تفسیر، مقاوم، تطبیقی و مناسب برای دادههای پیچیده و پویا حرکت میکند.



