

1.مقدمه
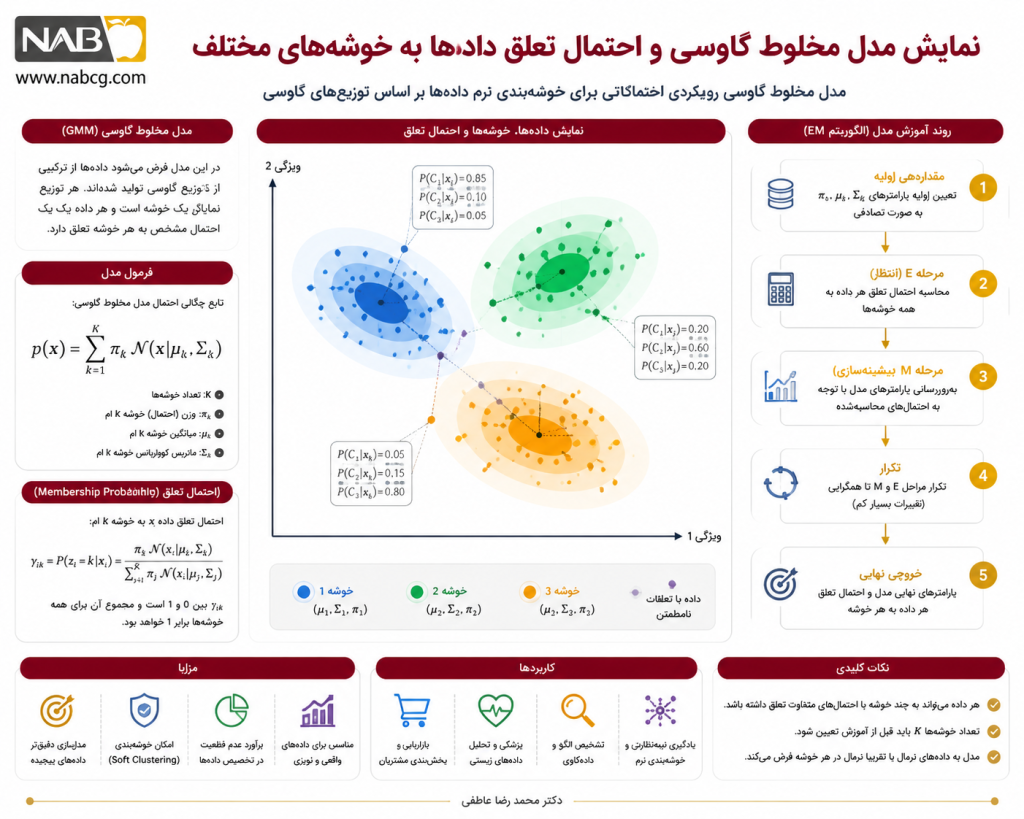
خوشهبندی مدلمحور رویکردی در یادگیری بدونناظر است که برخلاف روشهای فاصلهمحور، خوشهها را گروههایی از نقاط نزدیک نمیداند، بلکه فرض میکند دادهها توسط مدلهای آماری، احتمالاتی یا محاسباتی پنهان تولید شدهاند. هر خوشه نماینده یک توزیع آماری، مدل مولد یا مؤلفه احتمالاتی است. هدف، یافتن بهترین مدلها برای توضیح ساختار پنهان دادههاست. دادهها حاصل ترکیب چند فرایند پنهان هستند؛ هر فرایند بخشی از دادهها را تولید کرده و آن بخش یک خوشه است. در مدل مخلوط گاوسی (GMM)، دادهها از ترکیب چند توزیع گاوسی تولید میشوند و هر توزیع نماینده یک خوشه است. از نظر ریاضی، اگر مجموعه داده شامل n نمونه باشد:
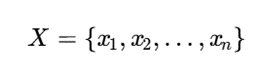
در مدل مخلوط، احتمال مشاهده هر داده بهصورت ترکیبی از چند توزیع بیان میشود:
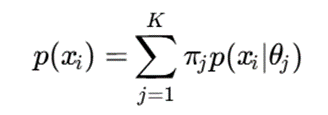
که در آن:
- K: تعداد مؤلفهها یا خوشهها؛
- πj : وزن یا احتمال پیشین خوشه j؛
- θj : پارامترهای مدل مربوط به خوشه j؛
- p(xi∣θj): احتمال تولید داده xi توسط خوشه j.
در این نوع خوشهبندی، عضویت دادهها بهصورت نرم یا احتمالاتی تعیین میشود؛ یعنی یک داده میتواند همزمان با درجات مختلفی به چند خوشه تعلق داشته باشد (مثلاً با احتمال ۰.۷۵ به خوشه اول، ۰.۲۰ به خوشه دوم و ۰.۰۵ به خوشه سوم). این ویژگی برای دادههای همپوشان، مرزی و نامطمئن بسیار مناسب است. خوشهبندی مدلمحور پلی میان آمار، یادگیری ماشین، مدلسازی احتمالاتی، شبکههای عصبی و یادگیری مفهومی است. الگوریتمهایی مانند EM، GMM، COBWEB، CLASSIT و SOM هر یک با منطق متفاوتی تلاش میکنند ساختار پنهان دادهها را از طریق یک مدل قابل یادگیری استخراج کنند.
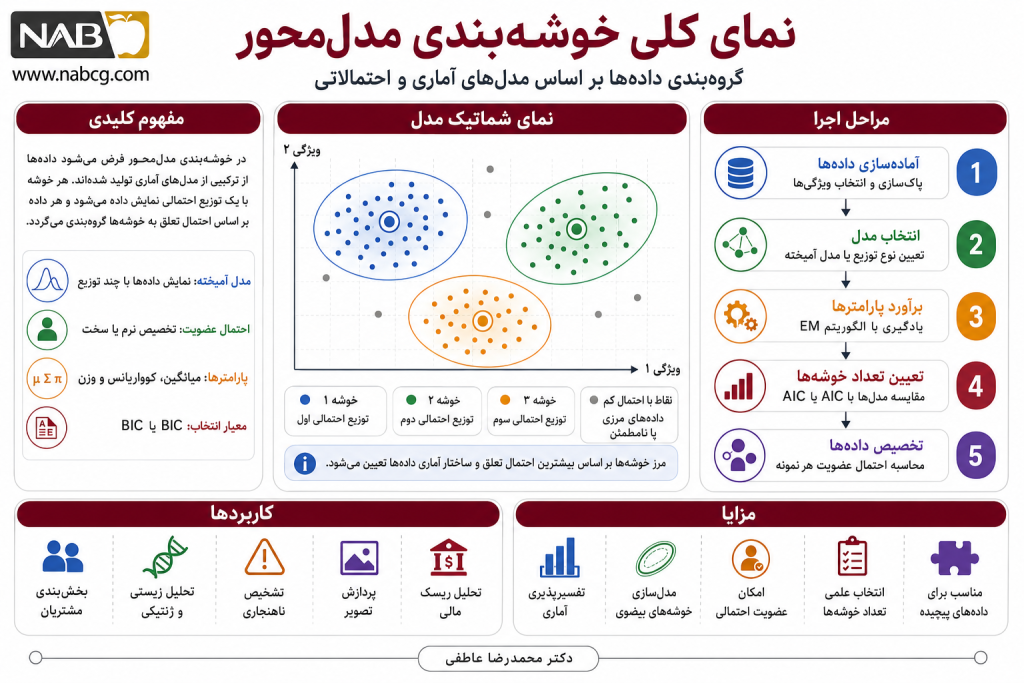
2. الگوریتمهای خوشهبندی مدلمحور
خوشهبندی مدلمحور شامل طیف متنوعی از الگوریتمهاست که برخی بر پایه آمار و مدلهای احتمالاتی، برخی بر پایه مفاهیم سلسلهمراتبی، و برخی بر پایه شبکههای عصبی عمل میکنند. در ادامه، مهمترین الگوریتمهای این خانواده معرفی میشوند.
فلسفه محاسباتی و مکانیزم عملکرد
این رویکرد فرض میکند که دادههای موجود در جهان واقعی، خروجیهای تصادفیِ ترکیبی از چندین مدل ریاضی یا توزیع آماری پنهان هستند. هدف این رویکرد، بهینهسازی پارامترهای این مدلها به گونهای است که بیشترین تطابق احتمالی (Likelihood) را با دیتابیس پیدا کنند. این لایه ذاتاً ساختار خوشهبندی نرم (Soft Clustering) را پوشش میدهد.
2.۱. الگوریتم (Expectation-Maximization) EM
الگوریتم EM یکی از بنیادیترین روشهای بهینهسازی در خوشهبندی مدلمحور است. این الگوریتم برای تخمین پارامترهای مدلهایی به کار میرود که دارای متغیرهای پنهان هستند. در خوشهبندی، متغیر پنهان همان عضویت واقعی هر داده در خوشههاست.
هسته محاسباتی و موتور بهینهسازی خوشهبندیهای توزیعمحور (مانند مدل مخلوط گاوسیGMM -) است که با دو فاز تکرارشونده، پارامترهای آماری مدلهای پنهان را بهینه میکند. این الگوریتم تعمیمی فراتر از K -Means است که به جای خوشهبندی صلب، ساختار احتمالی چندبعدی فضا را کشف مینماید.
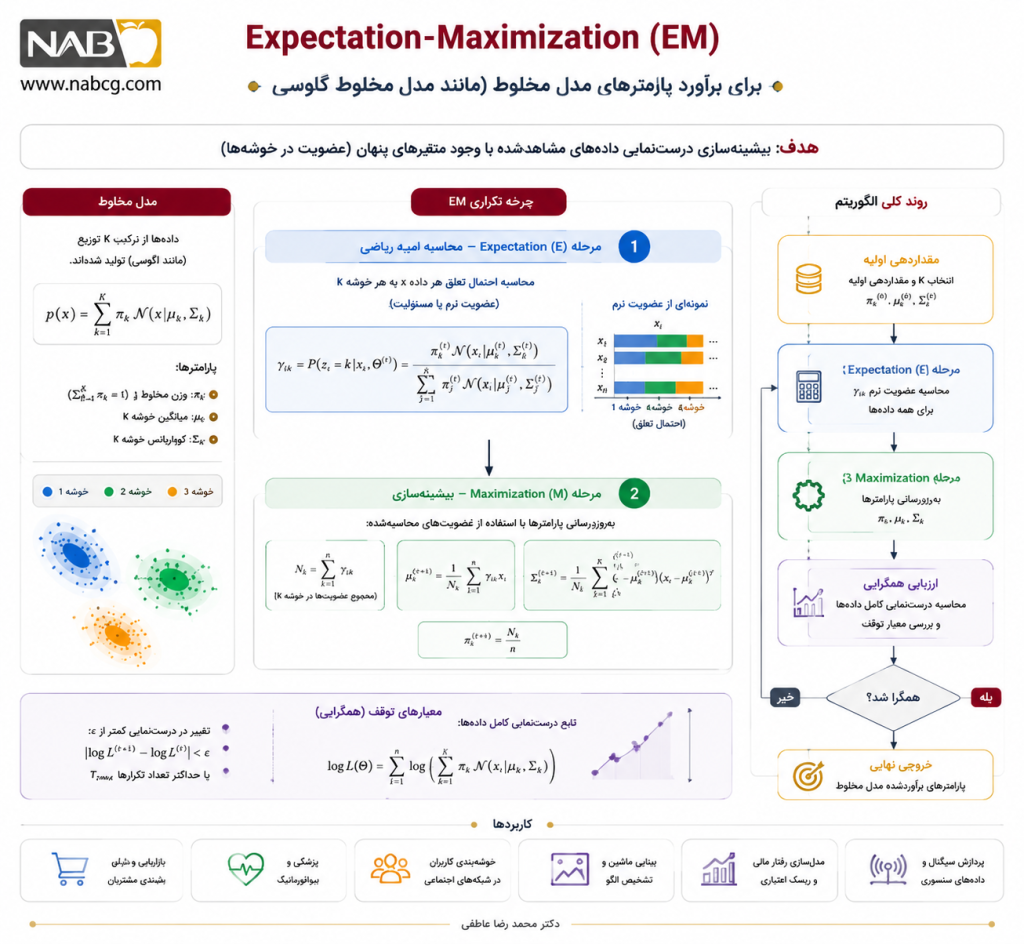
گامهای اجرایی
- مقداردهی اولیه: تخصیص مقادیر تصادفی یا مبتنی بر K-Means به پارامترهای توزیعها (میانگین، کوواریانس و وزن کلاسترها).
- گام E (Expectation): محاسبه احتمال تعلق هر داده به هر خوشه؛
- گام M (Maximization): بهروزرسانی پارامترهای مدل آماری (میانگینها، کوواریانسها و وزن پیشین) بر اساس این احتمالات، و بیشینهسازی تابع بیشینه احتمال (Likelihood).
- شرط توقف: تکرار متوالی گامهای E و M تا زما نی که تغییرات تابع لگاریتم احتمال به زیر آستانه همگرایی مشخصی برسد.
تابع هدف ریاضی
فرمول تابع چگالی احتمال یک مدل مخلوط گاوسی (GMM) برای یک نقطه داده 😡
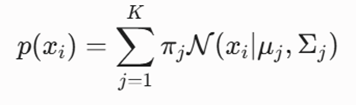
- معرفی متغیرها: πj وزن یا احتمال پیشین کلاستر؛ μj بردار میانگین (مرکز بیضی)؛ σj ماتریس کوواریانس که زاویه، هندسه و پهنای بیضی کلاستر را تعیین میکند.
مزایا و نقاط قوت
- مرزهای کلاستر بیضوی فوقالعاده منعطف با قابلیت تنظیم زاویه، حجم و جهت.
- ارائه خروجیهای احتمالی و پیوسته دقیق برای دیتای واقع در مناطق مرزی و کلاسترهای همپوشان.
- فنداسیون آماری بسیار قدرتمند و قابلیت همگرایی ریاضی اثباتشده.
معایب و محدودیتها
- حساسیت شدید به مقداردهی اولیه تصادفی پارامترها و ریسک بالای سقوط در بهینههای محلی.
- احتمال مواجهه با مسئله تکینگی (Singularity) در صورت کاهش شدید نقاط درون یک کلاستر.
کاربردهای واقعی
- بازشناسی گفتار (Speech Recognition) و مدلسازی ویژگیهای صوتی فرکانسی.
- پردازش تصویر، تفکیک پسزمینه از اشیاء متحرک (Background Subtraction) و کلاسترینگ بافتهای نرم پزشکی.
.
2.۲. الگوریتم COBWEB
یک الگوریتم خوشهبندی مدلمحور، سلسلهمراتب، مفهومی و تدریجی (Incremental) است که منحصراً برای پردازش و کلاسترینگ دادههای کیفی و اسمی (Categorical) طراحی شده است. هر گره در این درخت نماینده یک مفهوم آماری است و الگوریتم با معیار Category Utility تصمیم میگیرد که داده جدید به کدام گره افزوده شود، گره جدیدی ایجاد شود، دو گره ادغام شوند یا یک گره تقسیم شود.
ویژگی متمایز کننده این الگوریتم توانایی آن در یادگیری آنلاین و پویا بدون نیاز به بارگذاری همزمان کل دیتابیس است. COBWEB برای یادگیری آنلاین مفاهیم، سیستمهای خبره، رباتیک و دادههای کیفی مناسب است.
گامهای اجرایی
- پویش جریانی: ورود تکتک دادههای کیفی به صورت متوالی و تدریجی به ساختار مدل.
- ارزیابی درختی: عبور نقطه داده جدید از ریشه درخت به سمت پایین و ارزیابی آن در تمام گرههای موجود در لایه جاری بر اساس شاخص «مفید بودن طبقه».
- عملگرهای چهارگانه پویا: سیستم برای قرار دادن نقطه داده جدید در بهترین لایه، یکی از چهار سناریوی زیر را به صورت حریصانه انتخاب میکند:
- تخصیص: الحاق نقطه داده جدید به یکی از کلاسترهای (گرههای) موجود.
- تولد (Create): ایجاد یک گره یا کلاستر کاملاً جدید برای نقطه داده.
- ادغام (Merge): ترکیب دو گره موجود که به دلیل ورود نقطه جدید شباهت بالایی یافتهاند.
- تقسیم (Split): خرد کردن یک گره بزرگ به زیرگرههای کوچکتر جهت حفظ همگنی مفهومی.
- بهروزرسانی احتمالات: اصلاح آمارههای فراوانی و احتمالات شرطی ویژگیها در تمام گرههای مسیر.
تابع هدف ریاضی
بیشینهسازی معیار «مفید بودن طبقه» (Category Utility – CU) که تعادلی آماری میان شباهت درونخوشهای (Predictability) و تمایز بینخوشهای (Predictiveness) ایجاد میکند:
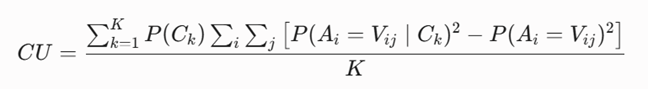
مزایا و نقاط قوت
- توانایی ذاتی در خوشهبندی تدریجی و آنلاین (Online Learning) بدون نیاز به ذخیرهسازی کل دادهها.
- استخراج خودکار تعداد بهینه خوشهها و عمق درخت سلسلهمراتب بر اساس هندسه مفهومی دادهها.
- عملکرد بسیار دقیق و بومی روی متغیرهای کیفی و اسمی بدون نیاز به فرمولهای فاصله غیراقلیدسی.
معایب و محدودیتها
- ناتوانی ساختاری در پردازش مستقیم متغیرهای عددی و پیوسته (مگر در نسخه توسعهیافته CLASSIT).
- وابستگی بسیار شدید شکل نهایی درخت و کیفیت کلاسترینگ به ترتیب ورود دادهها به مدل.
- بار محاسباتی و سنگینی فرآیند بهینهسازی عملگرهای چهارگانه در صورت بالا بودن تنوع ویژگیهای اسمی.
کاربردهای واقعی
- سیستمهای بازشناسی الگو و یادگیری ماشین هوشمند در رباتیک برای دستهبندی مفاهیم محیطی.
- تحلیل و خوشهبندی سلسلهمراتب اسناد متنی و سیستمهای خبره پزشکی مبتنی بر علائم کیفی بیماری.
.
2.۳. الگوریتم CLASSIT
یک الگوریتم خوشهبندی مدلمحور، مفهومی، سلسلهمراتبی و تدریجی (Incremental) است که به عنوان توسعه مستقیم الگوریتم COBWEB برای مدیریت و پردازش مجموعهدادههایی با متغیرهای عددی و پیوسته (Continuous Features) طراحی شده است. این متد با حذف محدودیتهای دادههای اسمی، کلاسترها را به عنوان مفاهیمی آماری در قالب توابع توزیع نرمال (گاوسی) مدلسازی کرده و دندروگرام احتمالی فضا را به صورت آنلاین و جریانی بازسازی میکند.
گامهای اجرایی
- پذیرش جریانی داده: ورود تکتک نمونههای عددی به صورت پیوسته و بدون نیاز به ذخیرهسازی یا دسترسی همزمان به کل دیتابیس.
- ریزش و ارزیابی درختی: هدایت نقطه داده جدید از ریشه درخت به سمت برگها و محاسبه معیار «مفید بودن طبقه» برای لایه جاری بر اساس پارامترهای پیوسته.
- اعمال عملگرهای ساختاری حریصانه: مدل بر اساس بیشینهسازی تابع هدف، یکی از سناریوهای زیر را انتخاب میکند:
- تخصیص: ادغام نقطه داده جدید در یکی از خوشههای عددی موجود و بهروزرسانی میانگین و انحراف معیار آن.
- خوشهزایی (Create): ایجاد یک گره یا کلاستر مستقل جدید برای این نقطه.
- ادغام پویای گرهها (Merge): ترکیب دو کلاستر همجوار در صورت افزایش همگنی کل لایه.
- تقسیم گره (Split): خرد کردن یک کلاستر پیوسته به زیرمجموعههای مستقل.
- اصلاح پارامترهای آماری: نوسازی بردار میانگین و انحراف معیار تمام گرههای مسیر طیشده.
تابع هدف ریاضی
بیشینهسازی شاخص «مفید بودن طبقه برای دادههای پیوسته» (CUcontinuous) بر پایه ادغام انحراف معیار ویژگیها در لایههای مختلف:
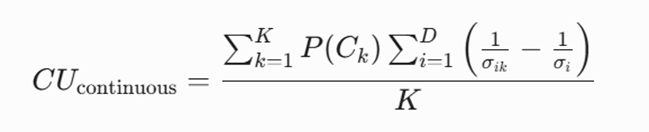
مزایا و نقاط قوت
- انعطافپذیری هندسی بالا به دلیل مدلسازی خوشهها بر پایه ساختار توزیع نرمال و انحراف معیار.
- استخراج خودکار تعداد کلاسترها و عمق بهینه درخت بدون نیاز به تنظیم پارامتر صلب K.
معایب و محدودیتها
- وابستگی شدید ساختار درخت مفهوم به ترتیب ورود دادههای عددی به مدل (امکان تغییر کامل خروجی با جابهجایی دیتای ورودی).
- عدم کارایی در مجموعهدادههای ترکیبی حاوی ویژگیهای اسمی (تکبعدی بودن روی دیتای پیوسته).
کاربردهای واقعی
- سیستمهای پردازش آنلاین جریان دادهها (Data Streams) در اینترنت اشیاء و تجهیزات حسگر صنعتی.
- دستهبندی سلسلهمراتب و تدریجی الگوهای سیگنالی و فرکانسی در سیستمهای هوشمند تعاملی.
.
2.۴. الگوریتم SOMs (نگاشتهای خودسازمانده Kohonen Networks/)
SOM یا نگاشت خودسازمانده کوهونن، یک روش شبکه عصبی بدونناظر است که دادههای پُربُعد را روی یک گرید معمولاً دوبعدی از نورونها نگاشت میکند. هدف SOM حفظ روابط توپولوژیک میان دادههاست؛ یعنی دادههای مشابه روی نورونهای نزدیک به هم قرار میگیرند.
این متد با الهام از قشر حرکتی و حسی مغز انسان، فضاهای چندبعدی و بسیار پیچیده دادهها را به یک شبکه دوعددی فشرده و منظم (معمولاً یک گرید دوبعدی از نورونها) نگاشت میکند، به طوری که روابط توپولوژیک و همسایگی هندسی میان دادهها کاملاً حفظ میشود. این الگوریتم هم برای خوشهبندی و هم برای تصویرسازی دادههای پیچیده استفاده میشود. این الگوریتم در تحلیل دادههای صنعتی، مالی، زیستی، تصویری و سیگنالی کاربرد گسترده دارد.

گامهای اجرایی
- مقداردهی اولیه شبکه: ایجاد یک گرید دوبعدی از نورونها و تخصیص یک بردار وزن تصادفی همبعد با دادههای ورودی به هر نورون.
- رقابت نورونی (Competition): انتخاب یک نقطه داده از دیتابیس و محاسبه فاصله اقلیدسی آن با بردار وزن تمام نورونهای شبکه؛ نورونی که کمترین فاصله (بیشترین شباهت) را دارد به عنوان «نورون برنده» یا BMU (Best Matching Unit) برگزیده میشود.
- همکاری موضعی (Cooperation): تعیین یک محدوده همسایگی شعاعی پیرامون نورون برنده (BMU)؛ نورونهای واقع در این همسایگی شناسایی میشوند.
- سازگاری پویای وزنها (Adaptation): بهروزرسانی و اصلاح بردارهای وزن نورون برنده و همسایگانش، به گونهای که بردار وزن آنها به مختصات نقطه داده ورودی نزدیکتر شود (میزان تغییر با افزایش فاصله از BMU کاهش مییابد).
- انقباض شعاعی و توقف: کاهش تدریجی شعاع همسایگی و نرخ یادگیری در طول تکرارها (Epochs) تا زمان تثبیت کامل وزنها و همگرایی شبکه.
تابع هدف ریاضی
بهروزرسانی بازگشتی بردار وزن نورونها (wj) در گام یادگیری (t) بر پایه تابع توپولوژیک همسایگی :(hji)
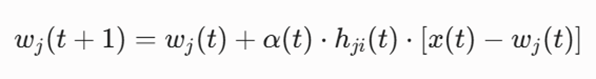
مزایا و نقاط قوت
- توانایی فوقالعاده در کاهش ابعاد (Dimensionality Reduction) و تصویرسازی همزمان فضاهای چندبعدی پیچیده.
- عدم وابستگی به فرضیات صلب توزیعهای احتمالی (یک روش کاملاً ناپارامتری آماری).
- مقاومت بالا در برابر نویزها به دلیل توزیع یکپارچه وزنها در شبکه.
معایب و محدودیتها
- نیاز به تعیین پیشفرض هندسه و تعداد نورونهای شبکه گرید (مثلاً شبکه 10 در 10).
- بار محاسباتی سنگین و زمان آموزش طولانی به دلیل فازهای تکرارشونده رقابت و بهروزرسانی وزنها برای تکتک دادهها.
- وابستگی کیفیت نهایی نقشه به نحوه مقداردهی اولیه وزن نورونها.

2.5.مدل مخلوط گاوسی(Gaussian Mixture Model – GMM)
GMM یکی از شناختهشدهترین مدلهای خوشهبندی مدلمحور است. در این روش فرض میشود دادهها از ترکیب چند توزیع گاوسی تولید شدهاند. هر توزیع گاوسی یک خوشه را نشان میدهد.
تابع چگالی کلی GMM بهصورت زیر است:
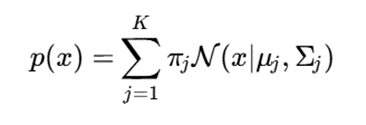
که در آن:
- πj : وزن مؤلفه j؛
- μj : میانگین مؤلفه؛
- Σj : ماتریس کوواریانس؛
- N: توزیع نرمال چندمتغیره.
GMM برای خوشههای بیضوی، همپوشان و دارای عدم قطعیت بسیار مناسب است.
2.6. مدل مخلوط چندجملهای(Multinomial Mixture Model)
این مدل برای دادههای شمارشی و گسسته، بهویژه دادههای متنی، مناسب است. در این روش، هر خوشه میتواند با یک توزیع چندجملهای روی واژگان یا ویژگیهای گسسته توصیف شود.
کاربردهای مهم آن شامل:
- خوشهبندی اسناد؛
- تحلیل موضوعی؛
- مدلسازی دادههای شمارشی؛
- دستهبندی متون بدون برچسب.
.
2.7.مدل مخلوط برنولی(Bernoulli Mixture Model)
در مدل مخلوط برنولی، ویژگیها معمولاً دودویی هستند؛ مانند وجود یا عدم وجود یک واژه در سند، فعال یا غیرفعال بودن یک ویژگی، یا پاسخ بله/خیر به یک سؤال.
این مدل برای دادههای دودویی و اسمی ساده مناسب است و میتواند در تحلیل پرسشنامهها، دادههای پزشکی دودویی و دادههای متنی دودویی استفاده شود.
.
2.8.مدلهای مخلوط بیزی(Bayesian Mixture Models)
در مدلهای بیزی، پارامترهای مدل خود بهعنوان متغیرهای تصادفی در نظر گرفته میشوند و برای آنها توزیع پیشین تعریف میشود. این رویکرد میتواند عدم قطعیت پارامترها را بهتر مدل کند و در برخی نسخهها حتی به تعیین خودکار تعداد خوشهها کمک کند.
نمونه مهم این خانواده، مدلهای مبتنی بر Dirichlet Process Mixture Model است که در آن تعداد خوشهها میتواند بهصورت انعطافپذیر و دادهمحور رشد کند.
.
2.9. Latent Class Analysis – LCA
تحلیل طبقات پنهان یا LCA یکی از روشهای مدلمحور برای دادههای اسمی و ردهای است. در این روش فرض میشود پاسخها یا ویژگیهای مشاهدهشده تحت تأثیر یک متغیر پنهان طبقهای قرار دارند.
کاربردهای آن در علوم اجتماعی، روانسنجی، بازاریابی، پزشکی و تحلیل پرسشنامهها بسیار رایج است.
.
2.10.Hidden Markov Model Clustering
در دادههای ترتیبی و زمانی، میتوان هر خوشه را با یک مدل مارکوف پنهان یا HMM توصیف کرد. در این حالت، هر خوشه نماینده یک الگوی زمانی یا توالی پنهان است.
این رویکرد برای موارد زیر مفید است:
- خوشهبندی توالیهای زیستی؛
- تحلیل گفتار؛
- تشخیص فعالیت انسانی؛
- تحلیل سریهای زمانی؛
- مدلسازی رفتار کاربران.
جمعبندی بخش الگوریتم ها
خوشهبندی مدلمحور یکی از غنیترین و انعطافپذیرترین خانوادههای خوشهبندی است. این رویکرد بهجای اتکا به فاصله ساده یا چگالی محلی، تلاش میکند مدلی آماری، احتمالاتی، مفهومی یا عصبی برای تولید دادهها بیابد. به همین دلیل، برای دادههای همپوشان، نویزی، پیچیده و دارای عدم قطعیت بسیار مناسب است.
در این رویکرد، خوشهها میتوانند بهصورت توزیعهای گاوسی، مفاهیم آماری، ساختارهای سلسلهمراتبی، مدلهای بیزی یا نورونهای یک شبکه خودسازمانده نمایش داده شوند. مهمترین الگوریتمهای آن شامل EM، GMM، COBWEB، CLASSIT و SOM هستند و در کنار آنها مدلهایی مانند Bernoulli Mixture، Multinomial Mixture، Bayesian Mixture Models، LCA و HMM-based Clustering نیز نقش مهمی در توسعه این خانواده دارند.
بهطور کلی، اگر هدف تحلیلگر فقط جداسازی ساده دادهها نباشد، بلکه بخواهد احتمال عضویت، ساختار پنهان، عدم قطعیت، مدل تولید داده و تفسیر آماری خوشهها را نیز بررسی کند، خوشهبندی مدلمحور یکی از بهترین انتخابها خواهد بود.
.
3.کاربردهای خوشهبندی مدلمحور
خوشهبندی مدلمحور به دلیل برخورداری از پایه آماری، خروجی احتمالاتی و توانایی مدلسازی ساختارهای پیچیده، در بسیاری از حوزههای علمی و صنعتی کاربرد دارد. این روش بهویژه زمانی مفید است که هدف تنها تقسیم دادهها به چند گروه نباشد، بلکه بخواهیم سازوکار تولید دادهها، احتمال تعلق نمونهها و ساختار پنهان جمعیت آماری را نیز تحلیل کنیم.

3.1. پردازش تصویر و بینایی ماشین
در پردازش تصویر، بسیاری از مسائل را میتوان بهصورت ترکیبی از چند الگوی آماری مدلسازی کرد. برای مثال، در تفکیک پسزمینه از اشیای متحرک، هر پیکسل یا ناحیه تصویری میتواند توسط یک مدل آماری مانند GMM توصیف شود. این کار باعث میشود سیستم بتواند تغییرات نور، حرکت، سایه و نویز را بهتر مدیریت کند.
کاربردهای رایج در این حوزه عبارتاند از:
- تفکیک پسزمینه و پیشزمینه؛
- قطعهبندی تصویر؛
- تشخیص اشیای متحرک؛
- خوشهبندی بافتهای تصویری؛
- تحلیل تصاویر پزشکی؛
- کاهش نویز و تشخیص الگوهای بصری.
.
3.2. بازشناسی گفتار و پردازش صوت
در بازشناسی گفتار، سیگنال صوتی معمولاً دارای الگوهای آماری پیچیده است. ویژگیهایی مانند MFCCها، انرژی فرکانسی و ضرایب طیفی را میتوان با مدلهای احتمالاتی مانند GMM یا مدلهای ترکیبی دیگر توصیف کرد.
خوشهبندی مدلمحور در این حوزه برای موارد زیر استفاده میشود:
- مدلسازی آواها و واجها؛
- خوشهبندی ویژگیهای صوتی؛
- تشخیص گوینده؛
- جداسازی منابع صوتی؛
- شناسایی الگوهای گفتاری؛
- تحلیل سیگنالهای فرکانسی.
.
3.3. پزشکی، زیستداده و بیوانفورماتیک
در علوم پزشکی و زیستی، دادهها معمولاً ناهمگن، نویزی و دارای همپوشانی هستند. خوشهبندی مدلمحور به دلیل توانایی در ارائه عضویت احتمالاتی، برای تحلیل این نوع دادهها بسیار مناسب است.
نمونه کاربردها:
- خوشهبندی بیماران بر اساس علائم، آزمایشها یا دادههای تصویربرداری؛
- کشف زیرگروههای بیماری؛
- تحلیل دادههای ژنبیان؛
- بخشبندی تصاویر MRI، CT و سونوگرافی؛
- مدلسازی دادههای زیستی دارای عدم قطعیت؛
- تشخیص الگوهای پنهان در دادههای پزشکی.
برای نمونه، در یک مسئله پزشکی، ممکن است بیماریها مرز کاملاً صلبی نداشته باشند. یک بیمار میتواند ویژگیهایی از چند زیرگروه بیماری را همزمان نشان دهد. در چنین حالتی، خروجی احتمالاتی مدلمحور بسیار ارزشمند است.
.
3.4. تحلیل بازار، مشتریان و سیستمهای توصیهگر
در بازاریابی و تحلیل مشتریان، افراد معمولاً رفتارهای ترکیبی دارند. یک مشتری ممکن است همزمان بخشی از رفتار مشتریان اقتصادی، بخشی از رفتار مشتریان وفادار و بخشی از رفتار مشتریان تنوعطلب را نشان دهد. خوشهبندی مدلمحور میتواند این همپوشانیها را بهتر از روشهای سخت مدل کند.
کاربردها شامل:
- بخشبندی مشتریان؛
- تحلیل رفتار خرید؛
- مدلسازی ترجیحات کاربران؛
- خوشهبندی کاربران در سیستمهای توصیهگر؛
- تشخیص الگوهای پنهان مصرف؛
- تحلیل احتمال تعلق مشتری به چند بخش بازار.
.
3.5. تحلیل دادههای متنی و اسنادی
الگوریتمهای مفهومی مانند COBWEB و نسخههای توسعهیافته آن میتوانند برای سازماندهی تدریجی اسناد، مفاهیم و ویژگیهای اسمی استفاده شوند. در دادههای متنی، هر سند میتواند از ترکیب چند موضوع یا مفهوم پنهان تشکیل شده باشد.
کاربردهای رایج:
- خوشهبندی اسناد؛
- دستهبندی مفهومی متون؛
- سازماندهی سلسلهمراتبی مفاهیم؛
- تحلیل موضوعی؛
- ساختاردهی پایگاههای دانش؛
- سیستمهای خبره و پرسشوپاسخ.
.
3.6.رباتیک و یادگیری مفهومی
در رباتیک، سیستم هوشمند باید بتواند مفاهیم محیطی را بهتدریج یاد بگیرد. الگوریتمهایی مانند COBWEB و CLASSIT به دلیل ماهیت تدریجی و آنلاین، برای یادگیری مفاهیم از دادههای پیوسته و جریانی مناسباند.
کاربردها:
- یادگیری مفاهیم محیطی؛
- دستهبندی اشیاء؛
- تشخیص موقعیتها؛
- خوشهبندی رویدادهای حسی؛
- یادگیری تدریجی از تعامل با محیط؛
- ساخت مدلهای مفهومی قابل بهروزرسانی.
.
3.7. دادههای جریانی، اینترنت اشیا و حسگرها
در دادههای جریانی، نمونهها بهصورت پیوسته وارد سیستم میشوند. برخی الگوریتمهای مدلمحور مانند COBWEB و CLASSIT میتوانند بدون نیاز به ذخیره کل دادهها، ساختار خوشهها را بهتدریج بهروزرسانی کنند.
کاربردها:
- پایش صنعتی؛
- تحلیل دادههای حسگر؛
- اینترنت اشیا؛
- تحلیل سیگنالهای پیوسته؛
- خوشهبندی آنلاین رفتار سامانهها.
.
3.8. تصویرسازی دادههای پُربُعد
الگوریتم SOM یا نگاشت خودسازمانده، یکی از ابزارهای شناختهشده برای نگاشت دادههای پُربُعد به یک صفحه دوبعدی است. این ویژگی باعث شده است SOM هم برای خوشهبندی و هم برای تصویرسازی دادهها بسیار کاربردی باشد.
کاربردها:
- کشف ساختار توپولوژیک دادهها؛
- تحلیل نقشههای ویژگی؛
- خوشهبندی دادههای صنعتی؛
- تحلیل دادههای مالی؛
- نمایش دوبعدی دادههای چندبعدی.
.
4.مزایای خوشهبندی مدلمحور
خوشهبندی مدلمحور نسبت به بسیاری از رویکردهای کلاسیک، مزایای نظری و عملی قابل توجهی دارد. مهمترین مزیت آن، برخورداری از یک چارچوب آماری یا محاسباتی مشخص برای توضیح ساختار دادههاست.
4.1.برخورداری از مبنای آماری و احتمالاتی قوی
در بسیاری از الگوریتمهای مدلمحور، خوشهها بر اساس توزیعهای آماری یا مدلهای مولد تعریف میشوند. این موضوع باعث میشود نتایج خوشهبندی فقط بر پایه فاصله هندسی نباشند، بلکه تفسیر آماری نیز داشته باشند.
برای مثال، در GMM هر خوشه با پارامترهایی مانند میانگین، کوواریانس و وزن پیشین توصیف میشود. این پارامترها تصویری روشن از شکل، اندازه، جهت و سهم هر خوشه در دادهها ارائه میدهند.
4.2. پشتیبانی از خوشهبندی نرم
در روشهایی مانند K-Means، هر داده فقط به یک خوشه تعلق دارد. اما در خوشهبندی مدلمحور، هر داده میتواند با احتمالهای متفاوت به چند خوشه تعلق داشته باشد:
P(Cj∣xi)
این ویژگی برای دادههایی که مرزهای خوشهای مبهم دارند، بسیار مهم است. برای مثال، در پزشکی، بازاریابی یا پردازش گفتار، نمونهها اغلب بهصورت کامل و قطعی به یک گروه تعلق ندارند.
4.3. توانایی مدلسازی خوشههای بیضوی و همپوشان
مدلهایی مانند GMM با استفاده از ماتریس کوواریانس میتوانند خوشههایی با شکلهای بیضوی، جهتدار و دارای حجمهای مختلف را مدل کنند. این قابلیت نسبت به روشهایی مانند K-Means که معمولاً خوشههای کروی و هماندازه را بهتر مدل میکنند، انعطافپذیری بیشتری ایجاد میکند.
4.4. امکان تفسیر پارامترهای مدل
در خوشهبندی مدلمحور، پارامترهای مدل معمولاً معنا دارند. برای مثال:
- میانگین نشاندهنده مرکز آماری خوشه است؛
- کوواریانس نشاندهنده پراکندگی و جهت خوشه است؛
- وزن پیشین نشاندهنده سهم خوشه در کل داده است؛
- احتمال عضویت نشاندهنده میزان اطمینان مدل به تخصیص نمونه است.
این ویژگی باعث میشود مدلمحور بودن در تحلیلهای علمی و تصمیمگیریهای حساس مفید باشد.
4.5. قابلیت انتخاب تعداد خوشهها با معیارهای آماری
در برخی روشهای مدلمحور، میتوان تعداد مناسب خوشهها را با معیارهایی مانند AIC، BIC، ICL یا اعتبارسنجی احتمال انتخاب کرد. این مزیت، وابستگی به انتخاب کاملاً دستی تعداد خوشهها را کاهش میدهد.
برای نمونه، معیار BIC بهصورت کلی چنین تعریف میشود:
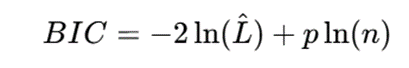
که در آن:
- ^L: بیشینه درستنمایی مدل؛
- p: تعداد پارامترهای مدل؛
- n: تعداد نمونهها.
مدلی مناسبتر است که هم برازش خوبی داشته باشد و هم پیچیدگی بیش از حد ایجاد نکند.
4.6. قابلیت یادگیری تدریجی و آنلاین در برخی الگوریتمها
الگوریتمهایی مانند COBWEB و CLASSIT میتوانند دادهها را بهصورت تدریجی دریافت کنند و ساختار خوشهها را بهروزرسانی نمایند. این مزیت برای دادههای جریانی، رباتیک، حسگرها و محیطهای پویا بسیار مهم است.
4.7. مناسب برای دادههای مفهومی، اسمی و عددی
خوشهبندی مدلمحور فقط محدود به دادههای عددی نیست. الگوریتم COBWEB برای دادههای اسمی و کیفی طراحی شده است، در حالی که CLASSIT نسخهای برای دادههای عددی و پیوسته محسوب میشود. این تنوع باعث میشود این خانواده از روشها در مسائل مختلف قابل استفاده باشد.
4.8. قابلیت کاهش بُعد و تصویرسازی در SOM
SOM علاوه بر خوشهبندی، میتواند دادههای پُربُعد را روی یک گرید دوبعدی نگاشت کند. در نتیجه، برای تحلیل اکتشافی، تصویرسازی و درک توپولوژی دادهها ابزار مفیدی است.
5.معایب و محدودیتهای خوشهبندی مدلمحور
با وجود مزایای زیاد، خوشهبندی مدلمحور محدودیتهایی نیز دارد. آگاهی از این محدودیتها برای انتخاب صحیح این رویکرد ضروری است.
.
5.1. وابستگی به فرضیات مدل
در بسیاری از روشهای مدلمحور، باید فرض کنیم دادهها از توزیع یا مدل خاصی تولید شدهاند. برای مثال، در GMM فرض میشود هر خوشه ماهیتی گاوسی دارد. اگر دادهها با این فرض سازگار نباشند، کیفیت خوشهبندی کاهش مییابد.
به همین دلیل، این رویکرد زمانی بهترین عملکرد را دارد که مدل انتخابشده با ماهیت واقعی دادهها تا حد قابل قبولی همخوانی داشته باشد.
5.2. حساسیت به مقداردهی اولیه
الگوریتمهایی مانند EM و SOM به مقداردهی اولیه حساساند. اگر پارامترهای اولیه یا وزنهای اولیه بهخوبی انتخاب نشوند، الگوریتم ممکن است به پاسخ ضعیف یا بهینه محلی همگرا شود.
برای کاهش این مشکل معمولاً از روشهایی مانند:
- مقداردهی اولیه با K-Means؛
- چندبار اجرای مدل با شروعهای مختلف؛
- انتخاب بهترین مدل بر اساس likelihood یا BIC؛
- منظمسازی پارامترها؛
- کنترل مقدار کوواریانسها؛
استفاده میشود.
5.3. احتمال گرفتار شدن در بهینه محلی
تابع درستنمایی در مدلهای مخلوط معمولاً غیرمحدب است. بنابراین الگوریتمهایی مانند EM تضمین نمیکنند که به بهترین پاسخ جهانی برسند. آنها معمولاً به یک نقطه بهینه محلی همگرا میشوند.
5.4. هزینه محاسباتی بالا در دادههای بزرگ و پُربُعد
مدلهای مدلمحور، بهویژه زمانی که شامل تخمین کوواریانس کامل، محاسبه احتمال عضویت برای همه نمونهها و چندین تکرار بهینهسازی باشند، میتوانند از نظر زمانی و حافظهای پرهزینه شوند.
در GMM با کوواریانس کامل، تعداد پارامترها با افزایش ابعاد بهسرعت زیاد میشود و ممکن است مدل دچار بیشبرازش یا ناپایداری عددی شود.
5.5. مسئله تکینگی در مدلهای گاوسی
در مدل مخلوط گاوسی، اگر یک مؤلفه گاوسی روی تعداد بسیار کمی از نقاط متمرکز شود، ممکن است ماتریس کوواریانس آن به سمت تکینگی حرکت کند. در این حالت، مقدار درستنمایی میتواند بهصورت غیرواقعی افزایش یابد و مدل ناپایدار شود.
برای کنترل این مشکل از regularization، حداقل مقدار واریانس، حذف مؤلفههای کوچک یا محدود کردن ساختار کوواریانس استفاده میشود.
5.6. نیاز به انتخاب تعداد مؤلفهها یا ساختار مدل
در بسیاری از مدلها باید تعداد خوشهها، تعداد مؤلفهها، ساختار کوواریانس یا اندازه شبکه از قبل تعیین شود. برای مثال:
- در GMM معمولاً باید K مشخص شود؛
- در SOM باید اندازه و توپولوژی شبکه تعیین شود؛
- در برخی مدلهای سلسلهمراتبی باید معیار توقف و رشد درخت مشخص باشد.
اگر این انتخابها مناسب نباشند، نتیجه خوشهبندی ضعیف خواهد شد.
5.7. وابستگی به ترتیب ورود دادهها در الگوریتمهای تدریجی
در الگوریتمهایی مانند COBWEB و CLASSIT، ترتیب ورود دادهها میتواند بر ساختار نهایی درخت تأثیر قابل توجهی داشته باشد. ورود متفاوت نمونهها ممکن است منجر به درختهای مفهومی متفاوت شود.
6.نوآوریهای جدید در خوشهبندی مدلمحور(Recent Innovations in Model-Based Clustering)
خوشهبندی مدلمحور در سالهای اخیر از چارچوبهای کلاسیک آماری مانند مدلهای مخلوط گاوسی، الگوریتم EM، COBWEB، CLASSIT و SOM فراتر رفته و به حوزههایی مانند یادگیری عمیق، مدلهای بیزی ناپارامتری، مدلهای مولد، دادههای جریانی، عدم قطعیت، یادگیری خودنظارتی، خوشهبندی فدرال، تفسیرپذیری و مدلسازی دادههای چندوجهی متصل شده است.
در گذشته، خوشهبندی مدلمحور عمدتاً بر این فرض استوار بود که دادهها از ترکیب چند توزیع آماری مشخص، مانند توزیعهای گاوسی، تولید شدهاند. اما در نسخههای جدیدتر، مدل تولید داده میتواند بسیار پیچیدهتر باشد؛ برای مثال، ممکن است دادهها ابتدا توسط یک شبکه عصبی به فضای نهفته منتقل شوند، سپس در آن فضا با یک مدل مخلوط احتمالاتی خوشهبندی شوند، یا ممکن است تعداد خوشهها بهصورت خودکار توسط یک مدل بیزی ناپارامتری تعیین شود.
در ادامه، مهمترین نوآوریهای جدید در حوزه Model-Based Clustering معرفی میشوند.
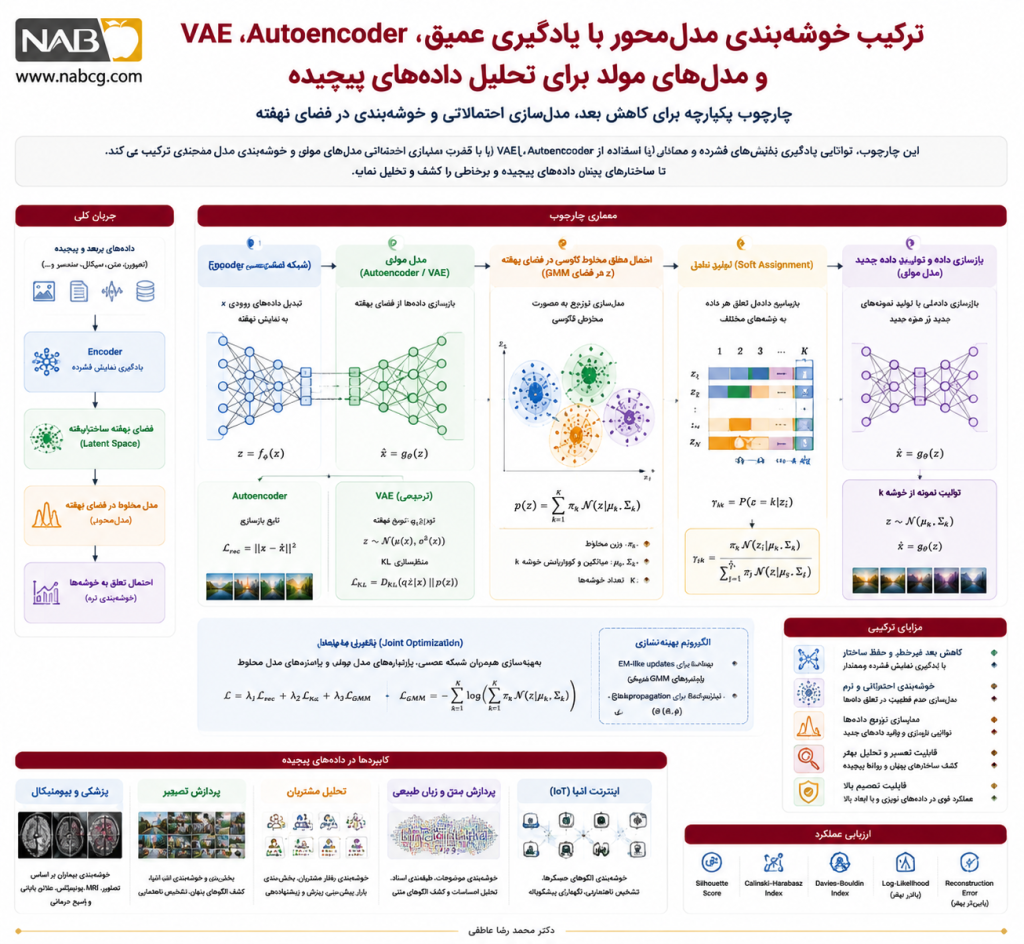
6.1. خوشهبندی مدلمحور عمیق(Deep Model-Based Clustering)
یکی از مهمترین تحولات جدید، ترکیب خوشهبندی مدلمحور با یادگیری عمیق است. در این رویکرد، بهجای اجرای مستقیم مدلهای آماری روی داده خام، ابتدا یک شبکه عصبی نمایش فشردهتر و معنادارتری از داده تولید میکند.
اگر داده خام xi باشد، شبکه عصبی آن را به بردار نهفته تبدیل میکند:
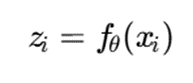
سپس خوشهبندی مدلمحور روی فضای نهفته انجام میشود:
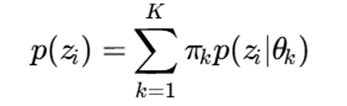
برای مثال، در یک چارچوب ترکیبی، میتوان از autoencoder برای کاهش بُعد و استخراج ویژگی استفاده کرد و سپس روی بردارهای نهفته، یک Gaussian Mixture Model اجرا نمود.
در این حالت، هدف مدل فقط بازسازی داده نیست، بلکه یادگیری فضای نهفتهای است که در آن خوشهها از نظر آماری بهتر از هم جدا شوند.
تابع هدف میتواند ترکیبی از خطای بازسازی و درستنمایی مدل مخلوط باشد:
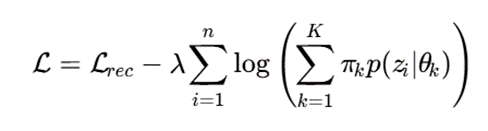
که در آن:
- Lrec: خطای بازسازی autoencoder؛
- λ: ضریب تعادل میان بازسازی و خوشهبندی؛
- (θk∣zi) p: احتمال تولید نمایش نهفته توسط خوشه k.
این نوآوری باعث شده خوشهبندی مدلمحور برای دادههای پیچیدهای مانند تصویر، صوت، متن، دادههای زیستی و دادههای حسگری عملکرد بسیار بهتری داشته باشد.
.
6.2.مدلهای مخلوط عمیق(Deep Mixture Models)
در مدلهای مخلوط کلاسیک، هر خوشه معمولاً با یک توزیع ساده مانند گاوسی مدل میشود. اما در مدلهای مخلوط عمیق، هر مؤلفه میتواند یک مدل پیچیده، مانند شبکه عصبی یا مدل مولد عمیق باشد.
در حالت کلاسیک داریم:
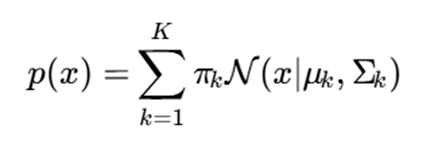
اما در مدل مخلوط عمیق، توزیع شرطی هر خوشه میتواند توسط شبکه عصبی پارامتری شود:
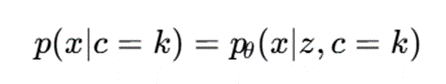
یا:
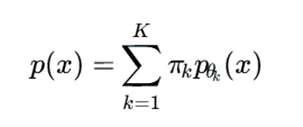
در اینجا (x)pθk میتواند یک مدل مولد عمیق باشد که دادههای متعلق به خوشه k را توصیف میکند.
این ایده بهویژه در مسائلی مفید است که هر خوشه ساختار غیرخطی و پیچیدهای دارد. برای مثال، در خوشهبندی تصاویر، هر خوشه ممکن است شامل تنوع زیادی از شکل، زاویه، نور و بافت باشد که با یک گاوسی ساده قابل مدلسازی نیست.
.
6.3.ترکیب مدلهای مخلوط با Autoencoder و VAE
یکی از مسیرهای مهم نوآوری، ترکیب مدلهای مخلوط با Autoencoder و Variational Autoencoder (VAE) است.
در autoencoder معمولی، داده به فضای نهفته فشرده میشود و سپس بازسازی میگردد:
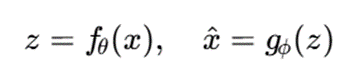
اما در نسخههای مدلمحور، فضای نهفته بهگونهای طراحی میشود که از یک مدل مخلوط پیروی کند:
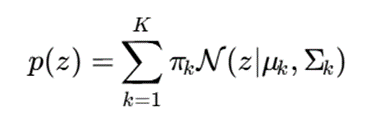
در مدلهای مبتنی بر VAE، بهجای یک prior ساده مانند نرمال استاندارد، از prior مخلوط استفاده میشود:
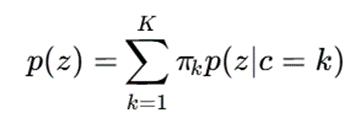
این ساختار باعث میشود فضای نهفته بهصورت طبیعی به چند ناحیه خوشهای تقسیم شود. در نتیجه، مدل هم توانایی تولید دادههای جدید دارد و هم ساختار خوشهای دادهها را کشف میکند.
مزیت مهم این رویکرد آن است که خوشهبندی و یادگیری نمایش بهصورت همزمان انجام میشوند، نه در دو مرحله جداگانه.
.
6.4.خوشهبندی مدلمحور بیزی ناپارامتری(Bayesian Nonparametric Model-Based Clustering)
یکی از چالشهای اصلی در خوشهبندی مدلمحور، تعیین تعداد خوشههاست. در مدلهای کلاسیک مانند GMM معمولاً باید تعداد خوشهها K از قبل مشخص شود. اما در روشهای جدید بیزی ناپارامتری، تعداد خوشهها میتواند بهصورت خودکار و دادهمحور تعیین شود.
یکی از مهمترین چارچوبها در این زمینه، Dirichlet Process Mixture Model (DPMM) است.
در این روش، فرض میشود:
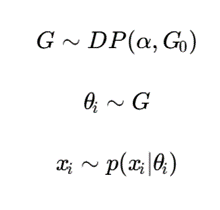
که در آن:
- DP: فرایند ؛
- α: پارامتر تمرکز؛
- G0: توزیع پایه؛
- θi : پارامتر خوشه مربوط به نمونه i.
در این چارچوب، مدل میتواند با ورود دادههای جدید، خوشههای تازه ایجاد کند. بنابراین بهجای تعیین دستی KKK، پیچیدگی مدل با ساختار داده تنظیم میشود.
این رویکرد برای دادههای پویا، دادههای ناشناخته، دادههای پزشکی، زیستی و کاربردهایی که تعداد گروههای پنهان از قبل معلوم نیست بسیار ارزشمند است.
.
6.5.خوشهبندی مدلمحور با فرایند رستوران چینی(Chinese Restaurant Process Clustering)
یکی از تفسیرهای مشهور فرایند دیریکله، فرایند رستوران چینی یا CRP است. هر داده جدید یا به یکی از خوشههای موجود میپیوندد یا یک خوشه جدید ایجاد میکند.
احتمال پیوستن نمونه جدید به خوشه موجود k برابر است با:
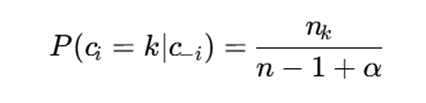
و احتمال ایجاد خوشه جدید:
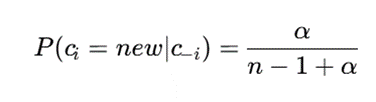
که در آن:
- nk: تعداد نمونههای خوشه k؛
- n: تعداد کل نمونهها؛
- α: پارامتر کنترلکننده تمایل مدل به ایجاد خوشههای جدید.
این ایده در خوشهبندی آنلاین و مدلسازی جمعیتهایی که تعداد زیرگروههای آنها نامعلوم است، کاربرد زیادی دارد.
.
6.6.مدلهای مخلوط مقاوم در برابر دادههای پرت((Robust Mixture Models
مدلهای کلاسیک مانند GMM به دادههای پرت حساساند، زیرا توزیع گاوسی دنبالههای نسبتاً سبکی دارد. وجود چند داده پرت میتواند میانگین و کوواریانس مؤلفهها را بهشدت تغییر دهد.
برای حل این مشکل، یکی از نوآوریهای مهم استفاده از توزیعهای مقاومتر مانند Student-t Mixture Model است:
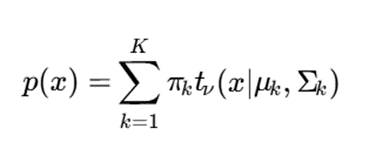
که در آن tν توزیع t با درجه آزادی ν است.
توزیع t دنبالههای سنگینتری نسبت به گاوسی دارد و بنابراین در برابر دادههای پرت مقاومتر است.
همچنین در روشهای جدید، از مدلهای مخلوط آلوده یا contaminated mixture models استفاده میشود که در آن هر خوشه شامل دو بخش است:
- بخش اصلی یا دادههای تمیز؛
- بخش آلوده یا دادههای نویزی.
بهصورت کلی:
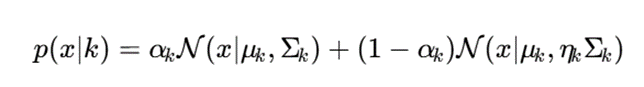
که در آن:
- αk : نسبت دادههای تمیز؛
- ηk>1: ضریب افزایش پراکندگی برای دادههای آلوده.
این مدلها برای دادههای واقعی که دارای خطا، نویز اندازهگیری، نمونههای مشکوک یا رفتارهای غیرعادی هستند، بسیار مناسباند.
.
6.7.مدلهای مخلوط برای دادههای پُربُعد و تنک(High-Dimensional and Sparse Model-Based Clustering)
در دادههای پُربُعد، مدلهای مخلوط کلاسیک با مشکلاتی مانند افزایش شدید تعداد پارامترها، تکینگی کوواریانس و بیشبرازش مواجه میشوند. به همین دلیل، نوآوریهای جدید بر کاهش پیچیدگی مدل و انتخاب ویژگی تمرکز کردهاند.
یکی از راهکارها، استفاده از کوواریانسهای محدودشده است:
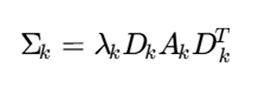
که در آن:
- λk: حجم خوشه؛
- Ak: شکل خوشه؛
- Dk: جهتگیری خوشه.
همچنین روشهای جدید از regularization استفاده میکنند:
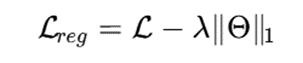
عبارت 1L باعث تنک شدن پارامترها و حذف ویژگیهای کماهمیت میشود.
در برخی روشها، خوشهبندی و انتخاب ویژگی بهصورت همزمان انجام میشود. یعنی مدل هم خوشهها را پیدا میکند و هم مشخص میکند کدام ویژگیها برای جداسازی خوشهها اهمیت بیشتری دارند.
این نوآوریها برای دادههای ژنبیان، متن، شبکههای اجتماعی، دادههای مالی و دادههای تصویری پُربُعد بسیار مهم هستند.
.
6.8.خوشهبندی مدلمحور چندنمایی و چندوجهی(Multi-View and Multi-Modal Model-Based Clustering)
در بسیاری از مسائل واقعی، دادهها از چند منبع یا چند نما تشکیل شدهاند. برای مثال، درباره یک بیمار ممکن است هم داده تصویربرداری، هم داده آزمایشگاهی و هم داده ژنتیکی وجود داشته باشد. در تحلیل کاربران نیز ممکن است داده رفتاری، متنی، مکانی و تراکنشی همزمان در دسترس باشد.
در خوشهبندی مدلمحور چندنمایی، احتمال داده بهصورت ترکیبی از چند نما مدل میشود:
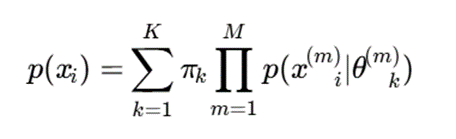
که در آن:
- M: تعداد نماها یا منابع داده؛
- در نسخههای پیشرفتهتر، برای هر نما وزن یادگرفتنی تعریف میشود:
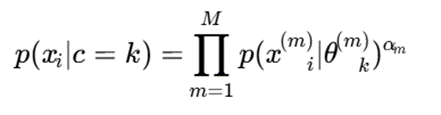
که در آن αm اهمیت نمای m را مشخص میکند.
این رویکرد برای پزشکی دقیق، تحلیل شبکههای اجتماعی، سیستمهای توصیهگر، تحلیل چندرسانهای و دادههای علمی چندمنبعی بسیار کاربردی است.
.
6.9.خوشهبندی مدلمحور برای دادههای جریانی و آنلاین(Online and Streaming Model-Based Clustering)
دادههای مدرن اغلب بهصورت پیوسته و زمانمند تولید میشوند؛ مانند دادههای حسگر، تراکنشهای مالی، لاگهای وب، دادههای اینترنت اشیا و دادههای صنعتی. در چنین شرایطی، الگوریتمهای کلاسیک batch مناسب نیستند، زیرا نیاز دارند کل دادهها از ابتدا در حافظه موجود باشد.
در نسخههای آنلاین، پارامترهای مدل بهصورت تدریجی بهروزرسانی میشوند. برای مثال، اگر θt پارامتر مدل در زمانt باشد:
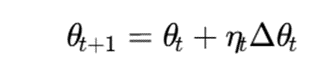
که در آن:
- ηt : نرخ یادگیری؛
- Δθt تغییرات ناشی از داده جدید.
در مدلهای مخلوط آنلاین، وزن خوشهها، میانگینها و کوواریانسها با ورود نمونههای جدید بهروزرسانی میشوند. همچنین برای مدیریت تغییر مفهوم یا concept drift، از عامل فراموشی استفاده میشود:
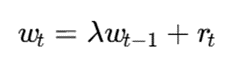
که در آن:
- λ: عامل فراموشی؛
- rt: مسئولیت یا احتمال تعلق نمونه جدید به خوشه.
.
6.10.خوشهبندی مدلمحور با یادگیری خودنظارتی(Self-Supervised Model-Based Clustering)
یادگیری خودنظارتی یکی از مهمترین روندهای اخیر در یادگیری ماشین است. در این رویکرد، مدل بدون نیاز به برچسب انسانی، از خود دادهها سیگنال آموزشی استخراج میکند.
در خوشهبندی مدلمحور جدید، ابتدا نمایشهای نهفته با استفاده از اهداف خودنظارتی یاد گرفته میشوند، سپس یک مدل مخلوط روی این نمایشها اعمال میشود.
برای مثال، در یادگیری تقابلی، دو نمای تغییریافته از یک داده باید به هم نزدیک شوند، در حالی که دادههای متفاوت از هم دور شوند:
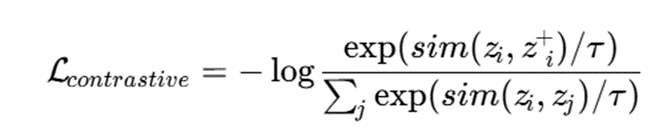
سپس خوشهبندی مدلمحور روی zi انجام میشود:
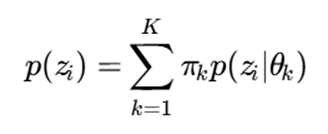
مزیت اصلی این رویکرد آن است که فضای ویژگی قبل از خوشهبندی، ساختاری معنادار و خوشهپذیر پیدا میکند.
.
6.11.خوشهبندی مدلمحور مبتنی بر عدم قطعیت(Uncertainty-Aware Model-Based Clustering)
یکی از ویژگیهای طبیعی خوشهبندی مدلمحور، توانایی تولید احتمال عضویت است. در نوآوریهای جدید، این ایده توسعه یافته و عدم قطعیت در چند سطح مدلسازی میشود:
- عدم قطعیت در عضویت نمونهها؛
- عدم قطعیت در پارامترهای مدل؛
- عدم قطعیت در تعداد خوشهها؛
- عدم قطعیت ناشی از نویز داده؛
- عدم قطعیت پیشبینی در دادههای جدید.
احتمال عضویت نمونه xi در خوشه k معمولاً بهصورت زیر تعریف میشود:
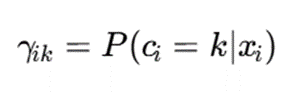
برای اندازهگیری ابهام عضویت میتوان از آنتروپی استفاده کرد:
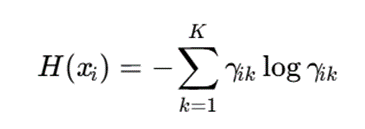
اگر آنتروپی بالا باشد، یعنی نمونه در مرز میان چند خوشه قرار دارد و مدل نسبت به تخصیص آن مطمئن نیست.
در کاربردهایی مانند پزشکی، امنیت، تشخیص ناهنجاری و تصمیمگیری پرریسک، دانستن این عدم قطعیت بهاندازه خود خوشهبندی اهمیت دارد.
.
6.12.خوشهبندی مدلمحور فدرال و حریمخصوصیمحور(Federated and Privacy-Preserving Model-Based Clustering)
در بسیاری از حوزهها مانند سلامت، بانکداری، آموزش و دولت الکترونیک، دادهها میان چند سازمان توزیع شدهاند و به دلایل حریم خصوصی نمیتوان آنها را در یک مرکز واحد تجمیع کرد.
در خوشهبندی فدرال، هر مرکز محلی مدل خود را روی دادههای داخلی آموزش میدهد و فقط پارامترها یا خلاصههای آماری را به سرور مرکزی ارسال میکند.
برای مثال، هر مرکز میتواند خلاصههایی مانند موارد زیر ارسال کند:
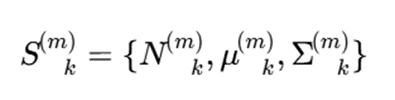
که در آن:
- m: شماره مرکز یا کلاینت؛
- Nmk : تعداد نمونههای خوشه k در مرکز m؛
سرور مرکزی سپس پارامترهای کلی را تجمیع میکند:
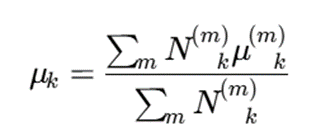
در نسخههای پیشرفتهتر، از روشهایی مانند differential privacy، secure aggregation و رمزنگاری همریخت برای افزایش حریم خصوصی استفاده میشود.
.
6.13.خوشهبندی مدلمحور با مدلهای گرافی احتمالاتی(Probabilistic Graphical Model-Based Clustering)
مدلهای گرافی احتمالاتی مانند Bayesian Networks، Markov Random Fields و Latent Variable Graphical Models امکان مدلسازی وابستگیهای پیچیده میان ویژگیها، نمونهها و متغیرهای پنهان را فراهم میکنند.
در بسیاری از مسائل، فرض استقلال ویژگیها یا ساختار کوواریانس ساده کافی نیست. در این حالت میتوان هر خوشه را با یک ساختار گرافی مدل کرد:
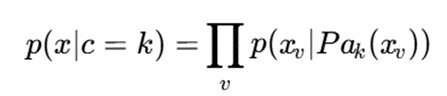
که در آن:
- xv: ویژگی یا متغیر v؛
- Pak(xv): والدهای متغیر در ساختار گرافی مربوط به خوشه k.
این رویکرد برای دادههایی با وابستگیهای ساختاری، مانند دادههای زیستی، شبکههای ژنی، دادههای اجتماعی، دادههای مالی و سیستمهای پیچیده بسیار مناسب است.
.
6.14.خوشهبندی مدلمحور برای سریهای زمانی و دادههای ترتیبی
دادههای زمانی، ترتیبی و دنبالهای در بسیاری از کاربردها دیده میشوند؛ از جمله گفتار، حرکت انسان، دادههای مالی، سیگنالهای صنعتی، رفتار کاربران و دادههای پزشکی زمانمند.
در مدلمحورهای جدید، هر خوشه میتواند با یک مدل زمانی خاص توصیف شود. برای مثال، هر خوشه میتواند یک Hidden Markov Model، یک مدل state-space، یک مدل ARMA/ARIMA یا یک شبکه عصبی بازگشتی احتمالاتی باشد.
بهصورت کلی:
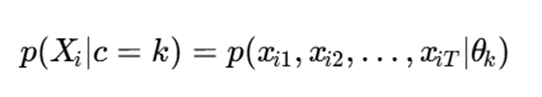
که در آن θk پارامترهای مدل زمانی خوشه k است.
در نسخههای جدیدتر، از مدلهای عمیق مانند RNN، LSTM، Transformer و Neural State Space Models برای تعریف p(Xi|c=k) استفاده میشود.
این رویکرد امکان کشف الگوهای زمانی پنهان را فراهم میکند؛ برای مثال:
- گروههای مختلف بیماران بر اساس مسیر پیشرفت بیماری؛
- الگوهای رفتاری کاربران در طول زمان؛
- رژیمهای مختلف بازار مالی؛
- حالتهای عملیاتی مختلف ماشینآلات صنعتی.
.
6.15.خوشهبندی مدلمحور تفسیرپذیر(Interpretable Model-Based Clustering)
با افزایش استفاده از خوشهبندی در تصمیمگیریهای حساس، تفسیرپذیری به یکی از محورهای مهم پژوهش تبدیل شده است. در خوشهبندی مدلمحور، چون هر خوشه معمولاً با پارامترهای آماری توصیف میشود، امکان تفسیر ذاتی تا حدی وجود دارد؛ اما مدلهای پیچیدهتر نیازمند روشهای توضیحپذیری پیشرفته هستند.
رویکردهای جدید، برای هر خوشه پروفایل قابلفهم ساخته میشود:
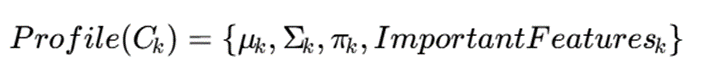
همچنین میتوان ویژگیهای مهم هر خوشه را بر اساس تفاوت پارامترهای آن با سایر خوشهها استخراج کرد:
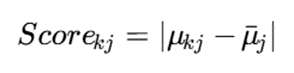
که در آن Scorekj اهمیت ویژگی j در خوشه k را نشان میدهد.
در کاربردهای پزشکی، بازاریابی، علوم اجتماعی و سیاستگذاری دادهمحور، این نوع تفسیرپذیری برای اعتمادپذیری نتایج ضروری است.
.
6.16.انتخاب خودکار مدل و تعداد خوشهها
یکی از مسائل مهم در خوشهبندی مدلمحور انتخاب تعداد خوشهها، نوع توزیع، ساختار کوواریانس و پیچیدگی مدل است. نوآوریهای جدید بر خودکارسازی این انتخابها تمرکز دارند.
روشهای رایج شامل:
- معیار اطلاعات آکائیک یا AIC؛
- معیار اطلاعات بیزی یا BIC؛
- Integrated Completed Likelihood یا ICL؛
- اعتبارسنجی متقابل؛
- پایداری خوشهها؛
- جستوجوی بیزی؛
- روشهای AutoML؛
- مدلهای بیزی ناپارامتری.
برای مثال، معیار BIC بهصورت زیر استفاده میشود:
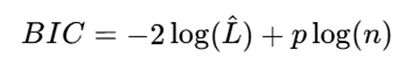
مدلی انتخاب میشود که تعادل مناسبی میان برازش و پیچیدگی برقرار کند.
در رویکردهای جدیدتر، انتخاب مدل بهصورت همزمان با یادگیری نمایش و خوشهبندی انجام میشود؛ یعنی سیستم میتواند بهصورت خودکار تعیین کند که چه نوع ساختار نهفتهای برای داده مناسبتر است.
.
6.17.خوشهبندی مدلمحور مبتنی بر انرژی و جریانهای نرمالساز(Energy-Based and Normalizing Flow Mixture Models)
مدلهای مخلوط کلاسیک معمولاً به توزیعهای سادهای مانند گاوسی وابستهاند. اما در نوآوریهای جدید، از مدلهای انعطافپذیرتری مانند Energy-Based Models و Normalizing Flows استفاده میشود.
در مدلهای جریان نرمالساز، یک متغیر ساده z از توزیع پایه به داده پیچیده x تبدیل میشود:
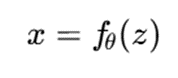
و چگالی داده با تغییر متغیر محاسبه میشود:
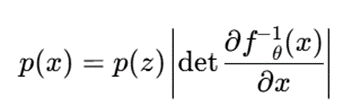
در خوشهبندی مدلمحور، میتوان از مخلوطی از جریانها استفاده کرد:
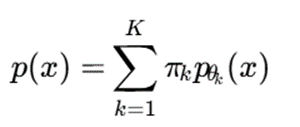
هر مؤلفه میتواند یک جریان نرمالساز باشد و بنابراین شکلهای بسیار پیچیدهتری از خوشهها را مدل کند.
این رویکرد برای دادههای تصویری، دادههای علمی پیچیده و دادههایی با توزیعهای غیرگاوسی بسیار قدرتمند است.
.
6.18.خوشهبندی مدلمحور برای دادههای ناقص(Model-Based Clustering with Missing Data)
در دادههای واقعی، مقادیر گمشده بسیار رایجاند. یکی از مزایای مدلمحور بودن این است که میتوان دادههای ناقص را در چارچوب احتمالاتی مدیریت کرد
اگر داده xi شامل بخش مشاهدهشده xobs و بخش گمشده x mis باشد، مدل بهجای حذف نمونه، احتمال مشاهده را بر اساس بخش موجود محاسبه میکند:
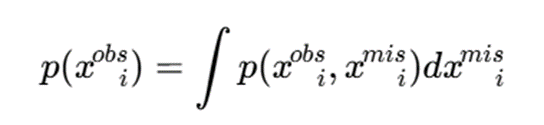
در نسخههای جدید، تخمین دادههای گمشده و خوشهبندی بهصورت همزمان انجام میشود. این رویکرد در پزشکی، پیمایشهای اجتماعی، دادههای حسگری و سامانههای صنعتی بسیار کاربردی است.
.
6.19.ترکیب خوشهبندی مدلمحور با تشخیص ناهنجاری
چون مدلهای مدلمحور احتمال تولید هر نمونه را تخمین میزنند، بهصورت طبیعی برای تشخیص ناهنجاری نیز مناسباند. اگر احتمال یک نمونه تحت مدل بسیار کم باشد، میتوان آن را ناهنجار دانست:
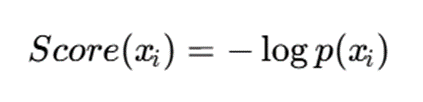
هرچه این امتیاز بزرگتر باشد، نمونه غیرعادیتر است.
در روشهای جدید، خوشهبندی و تشخیص ناهنجاری بهصورت همزمان انجام میشوند؛ یعنی مدل هم ساختار خوشههای عادی را یاد میگیرد و هم نمونههایی را که با هیچ خوشهای سازگار نیستند شناسایی میکند.
کاربردها:
- امنیت سایبری؛
- پایش صنعتی؛
- تشخیص تقلب؛
- سلامت دیجیتال؛
- تحلیل لاگها؛
- سیستمهای هشدار زودهنگام.
.
6.20.خوشهبندی مدلمحور در چارچوب AutoML
یکی دیگر از نوآوریهای مهم، استفاده از AutoML برای انتخاب خودکار مدلهای خوشهبندی مدلمحور است. در این رویکرد، سیستم بهصورت خودکار موارد زیر را جستوجو و تنظیم میکند:
- تعداد خوشهها؛
- نوع توزیع هر خوشه؛
- ساختار کوواریانس؛
- نوع regularization؛
- معماری autoencoder یا VAE؛
- معیار انتخاب مدل؛
- پارامترهای بهینهسازی.
هدف این است که خوشهبندی مدلمحور از یک فرایند کاملاً دستی و وابسته به تجربه کاربر، به یک فرایند نیمهخودکار یا خودکار تبدیل شود.
جمعبندی
نوآوریهای جدید در خوشهبندی مدلمحور نشان میدهند که این خانواده از روشها از مدلهای کلاسیک آماری به سمت چارچوبهای بسیار پیشرفتهتر حرکت کرده است. در گذشته، تمرکز اصلی بر مدلهایی مانند GMM، EM، COBWEB، CLASSIT و SOM بود؛ اما امروزه این حوزه با مفاهیمی مانند یادگیری عمیق، VAE، مدلهای مولد، مدلهای بیزی ناپارامتری، دادههای جریانی، یادگیری خودنظارتی، تحلیل چندنمایی، عدم قطعیت، حریم خصوصی، تفسیرپذیری و AutoML ترکیب شده است.
بهطور خلاصه، مهمترین مسیرهای نوآوری در این حوزه عبارتاند از:
- ترکیب مدلهای مخلوط با شبکههای عصبی عمیق؛
- استفاده از autoencoder و VAE برای خوشهبندی در فضای نهفته؛
- تعیین خودکار تعداد خوشهها با مدلهای بیزی ناپارامتری؛
- مقاومسازی مدلها در برابر نویز و دادههای پرت؛
- توسعه روشها برای دادههای پُربُعد، تنک و چندنمایی؛
- خوشهبندی آنلاین و جریانی؛
- استفاده از یادگیری خودنظارتی و تقابلی؛
- مدلسازی عدم قطعیت در عضویت، پارامترها و تعداد خوشهها؛
- خوشهبندی فدرال و حریمخصوصیمحور؛
- استفاده از مدلهای گرافی احتمالاتی، سریهای زمانی و مدلهای مولد پیشرفته؛
- افزایش تفسیرپذیری و خودکارسازی انتخاب مدل.
در نتیجه، خوشهبندی مدلمحور امروزی دیگر فقط یک روش آماری برای برازش چند توزیع ساده نیست، بلکه به یک چارچوب قدرتمند برای کشف ساختارهای پنهان، مدلسازی فرایند تولید داده، تحلیل عدم قطعیت و خوشهبندی دادههای پیچیده و چندمنبعی تبدیل شده است.



