

1.مقدمه
رگرسیون خطی (Linear Regression) یکی از بنیادیترین و پرکاربردترین الگوریتمهای تحلیل داده و یادگیری ماشین است که برای مدلسازی رابطه بین متغیرها و پیشبینی مقادیر عددی استفاده میشود. این روش با فرض وجود یک رابطه خطی میان متغیرهای مستقل و متغیر وابسته، تلاش میکند الگویی ریاضی استخراج کند که بتواند رفتار دادهها را توضیح داده و مقادیر آینده را پیشبینی کند. سادگی، تفسیرپذیری بالا و کارایی مناسب باعث شده رگرسیون خطی به یکی از مهمترین ابزارهای تحلیل آماری و مهندسی داده تبدیل شود.
کاربردهای رگرسیون خطی بسیار گسترده است؛ از پیشبینی فروش و تحلیل رفتار مشتریان گرفته تا مدلسازی قیمت مسکن، تحلیل ریسک مالی، بررسی روند مصرف انرژی و حتی تحلیل دادههای پزشکی. علاوه بر این، بسیاری از مفاهیم پیشرفتهتر یادگیری ماشین مانند رگرسیون منظمشده، شبکههای عصبی و مدلهای خطی تعمیمیافته بر پایه اصول همین روش توسعه یافتهاند. به همین دلیل، تسلط بر رگرسیون خطی نهتنها برای تحلیلگران داده، بلکه برای هر فردی که در حوزه هوش مصنوعی و علم داده فعالیت میکند، ضروری است.
در این مقاله، ابتدا مفاهیم بنیادین رگرسیون خطی و فرضهای آماری آن را بررسی میکنیم، سپس روشهای بهینهسازی مانند OLS و Gradient Descent را توضیح میدهیم. در ادامه، معیارهای ارزیابی، تکنیکهای Regularization، پیادهسازی عملی در پایتون و کاربردهای صنعتی این مدل را تحلیل خواهیم کرد تا تصویری جامع و کاربردی از این الگوریتم ارائه شود.
2.تعریف
رگرسیون خطی یکی از بنیادیترین الگوریتمهای یادگیری نظارتشده است که برای مدلسازی رابطه بین یک متغیر وابسته و یک یا چند متغیر مستقل استفاده میشود. این الگوریتم با ترسیم بهترین خط مستقیمی که بیشترین هماهنگی را با دادهها دارد، مقادیر عددی و پیوسته را پیشبینی میکند. در واقع مبنای کار این روش بر این فرض استوار است که یک رابطه مستقیم و خطی بین ورودی و خروجی سیستم وجود دارد و با یافتن خط بهترین برازش، میتوان آینده پدیدهها را پیشبینی کرد. به همین دلیل، رگرسیون خطی ابزاری فوقالعاده محبوب در پیشبینی وضع بازار، تحلیل روندها و مدلسازیهای آماری هوشمند به شمار میرود.
در این ساختار ریاضی، ما همیشه با دو مفهوم کلیدی سر و کار داریم؛ متغیر مستقل که همان ورودی یا فاکتور قابل کنترل و مشاهده است، و متغیر وابسته یا خروجی که ارزش آن کاملاً به متغیر مستقل بستگی دارد. هدف نهایی مدل این است که با سنجش دقیق متغیر مستقل، مقدار متغیر وابسته را با کمترین خطای ممکن تخمین بزند.
مثال
فرض کنید میخواهیم میزان فروش ماهیانه یک فروشگاه اینترنتی را بر اساس میزان بودجهای که برای تبلیغات کلیکی اختصاص میدهد، پیشبینی کنیم. با نگاهی به دادههای گذشته متوجه میشویم که هر چقدر پلتفرم بودجه بیشتری تزریق کرده، نمودار فروش نیز صعودیتر شده است. در این سناریو، میزان بودجه تبلیغاتی همان متغیر مستقل (ورودی) است، چون فاکتوری است که کاملاً تحت کنترل ماست و تغییرش میدهیم. در مقابل، میزان فروش نهایی فروشگاه متغیر وابسته (خروجی) نامیده میشود، چرا که افت و خیز آن کاملاً به میزان سرمایهگذاری ما در بخش تبلیغات گره خورده است. رگرسیون خطی با تحلیل هوشمندانه این رفتار، دقیقاً مشخص میکند که به ازای هر یک میلیون تومان تبلیغات بیشتر، فروش کل چقدر جهش خواهد داشت.
3.چرا رگرسیون خطی در یادگیری ماشین و دادهکاوی اهمیت دارد؟
- بهترین و سادهترین نقطه شروع یادگیری: این الگوریتم به عنوان الفبا و دروازه ورود به دنیای یادگیری ماشین شناخته میشود. ساختار ریاضی قابل فهم آن به توسعهدهندگان تازه کار کمک میکند تا مفاهیم عمیقی مثل توابع خطا (Loss Functions)، بهینهسازی و نحوه آموزش مدل را به سادهترین شکل ممکن درک کنند.
- شفافیت بالا و تفسیرپذیری روابط بین متغیرها: در فرآیند استخراج دانش (Knowledge Discovery) در دادهکاوی، رگرسیون خطی ابزاری بیرقیب است؛ چرا که به طور دقیق مشخص میکند هر متغیر مستقل چه میزان و با چه جهتی (مثبت یا منفی) روی خروجی نهایی تأثیر میگذارد و وزن هر ویژگی در دیتابیس چقدر است.
- پایه و زیربنای الگوریتمهای پیشرفته هوش مصنوعی: مفاهیم اصلی رگرسیون خطی سنگ بنای توسعه مدلهای پیچیدهتری مانند رگرسیون لجستیک (Logistic Regression)، شبکههای عصبی عمیق (Neural Networks) و پرسپترونها هستند؛ به طوری که لایههای متراکم شبکههای عصبی در واقع ترکیبی از چندین رگرسیون خطی موازی هستند.
- کارایی محاسباتی فوقالعاده و سرعت بالا: رگرسیون خطی از نظر منابع سختافزاری بسیار کمهزینه و سبک است. این الگوریتم زمان اجرای بسیار کوتاهی دارد و برای حل مسائلی با روابط خطی در مقیاس کلانداده، بسیار کارآمدتر از مدلهای سنگین کار میکند.
- تشخیص ناهنجاری و پیشپردازش بهینه دادهها: در فاز مهندسی ویژگیهای دادهکاوی، با رسم خط رگرسیون میتوان نمونههایی که فاصله بسیار عجیبی با خط دارند را به عنوان دادههای پرت (Outliers) یا آنومالیهای سیستماتیک شناسایی کرد که این امر به بهبود کیفیت کل دیتابیس کمک شایانی میکند.
.
4. درک شهودی و هندسی رگرسیون خطی
قبل از ورود به فرمولها، بیایید ببینیم روی نمودار چه اتفاقی میافتد. وقتی مجموعهای از نقاط (دادهها) را در فضا داریم، رگرسیون خطی به دنبال یافتن خطی است که کمترین فاصله عمودی را با تمام این نقاط داشته باشد.
به فاصله عمودی هر نقطه واقعی تا خط پیشبینیشده، باقیمانده (Residual) یا خطای انفرادی گفته میشود. اگر مقدار واقعی را با y و مقدار روی خط را با ^y نشان دهیم، باقیمانده برابر است با:

یک مدل ایدهآل خطی، خط را طوری تنظیم میکند که برآیند این باقیماندهها به سمت صفر میل کند و پراکندگی آنها در اطراف خط کاملاً تصادفی باشد.
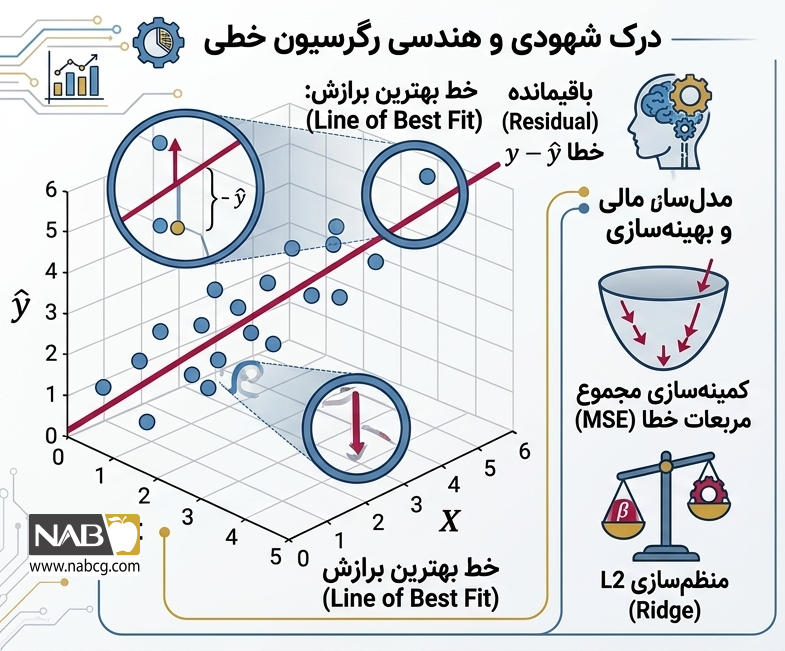
5. فرضهای اساسی رگرسیون خطی
رگرسیون خطی یک مدل ریاضی کور نیست؛ این الگوریتم بر پایه ۴ فرض آماری بسیار حیاتی کار میکند. اگر این فرضها در دادههای شما برقرار نباشند، خروجی مدل و ضرایب آن کاملاً غیرقابل اعتماد خواهند بود:

- خطی بودن رابطه (Linearity): فرض اول و بدیهی این است که رابطه میان متغیرهای مستقل و متغیر وابسته واقعاً از نوع خطی (مستقیم یا معکوس) باشد.
- استقلال خطاها (Independence of Errors): باقیماندهها یا خطاهای مدل نباید هیچ الگوی وابستگی به یکدیگر داشته باشند (عدم وجود خودهمبستگی). این موضوع در دادههای سری زمانی بسیار رایج است و مدل را خراب میکند.
- همسانی واریانس خطاها (Homoscedasticity): میزان پراکندگی و واریانس خطاها باید در تمام طول خط رگرسیون ثابت باشد. اگر با جلو رفتن در نمودار، فاصله نقاط از خط به شدت بزرگ یا کوچک شود (ناهمسانی واریانس)، مدل پایداری خود را از دست میدهد.
- توزیع نرمال خطاها (Normality of Residuals): برای اینکه بتوان روی ضرایب مدل آزمونهای آماری انجام داد، خطاهای مدل باید پیرو یک توابع توزیع نرمال (گاوسی) با میانگین صفر باشند.
.
6. فرمول ریاضی رگرسیون خطی
در سادهترین حالت، رگرسیون خطی به دنبال یافتن پارامترهایی است که خروجی را به ورودی متصل میکنند.
الف) رگرسیون خطی ساده (Simple Linear Regression)
معادله استاندارد برای یک ویژگی ورودی به صورت زیر است:

- Yi: متغیر وابسته یا هدفی که قصد پیشبینی آن را داریم (مثلاً قیمت خانه).
- Xi: متغیر مستقل یا ویژگی ورودی (مثلاً متراژ).
- β0 : عرض از مبدأ؛ نقطهای که خط محور Y را قطع میکند (مقدار هدف وقتی ورودی صفر است).
- β1: شیب خط؛ نشاندهنده میزان حساسیت Y نسبت به تغییرات X.
- ε: خطای تصادفی که مدل قادر به توضیح آن نیست.
.
ب) رگرسیون خطی چندگانه (Multiple Linear Regression)
در مسائل واقعی، خروجیها معمولاً تحت تأثیر چندین عامل هستند. فرمول عمومی رگرسیون خطی چندگانه برای n ویژگی به صورت زیر تعریف میشود:
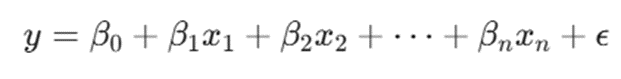
- y (متغیر وابسته): هدف نهایی پیشبینی (مانند ارزش طول عمر مشتری یا شدت بیماری).
- x1, x2, …, xn (متغیرهای مستقل): ویژگیهای ورودی که از دیتابیس استخراج شدهاند.
- β0 (عرض از مبدأ/Intercept): نقطه تلاقی خط با محور عمودی؛ یعنی مقدار خروجی زمانی که تمام ورودیها صفر مطلق باشند.
- β1, β2, … , βn (ضرایب/Weights): وزن یا میزان تأثیر هر ویژگی. نشان میدهد تغییر یک واحدی در xi، خروجی را چقدر جابهجا میکند.
- ε (جمله خطا /Error Term): نویزها و فاکتورهای پیش-بینی نشده دنیای واقعی که در مدل ما حضور ندارند.
.
تابع هزینه: میانگین مجذور خطاها (MSE)
برای اینکه ماشین بفهمد خط چقدر بد یا خوب رسم شده، به یک داور نیاز دارد. این داور همان تابع هزینه است. در رگرسیون خطی از فرمول میانگین مجذور خطاها استفاده میشود:
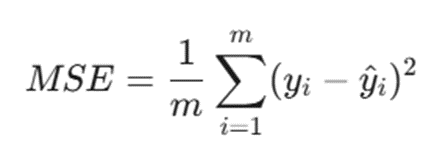
- MSE: خروجی تابع هزینه که مدل تلاش میکند آن را به حداقل برساند.
- m: تعداد کل رکوردهای داده در لایه آموزش.
- yi: مقدار واقعی.
- ^y: مقدار پیشبینی شده.
.
7. فرآیند بهینهسازی ضرایب (مدل چگونه یاد میگیرد؟)
پس از تشکیل تابع هزینه، هدف یافتن بهترین مقادیر برای ضرایب (β) است به طوری که MSE به کمترین مقدار ممکن برسد. دو راهبرد اصلی برای این کار وجود دارد:
روش اول: کمترین مجذورات معمولی (OLS)
یک روش ریاضی مستقیم و بسته (Closed-form) است که با استفاده از جبر خطی و ماتریسها، مستقیماً نقطه بهینه را محاسبه میکند:

این روش برای دادههای کوچک فوقالعاده دقیق و سریع است، اما اگر تعداد ویژگیها بسیار زیاد شود، محاسبه معکوس ماتریس از نظر محاسباتی سنگین و قفلکننده خواهد بود.
روش دوم: گرادیان کاهشی (Gradient Descent)

یک روش بهینهسازی تکرارشونده است. مدل ابتدا ضرایب را تصادفی حدس میزند، سپس با حرکت در جهت عکس مشتق (گرادیان) تابع هزینه، وزنها را گامبهگام اصلاح میکند:

- α (نرخ یادگیری/Learning Rate): اندازه گامهایی است که مدل برای رسیدن به کمترین میزان خطا (Global Minimum) برمیدارد. اگر خیلی بزرگ باشد مدل از نقطه بهینه رد میشود و اگر خیلی کوچک باشد، سرعت یادگیری بسیار کند خواهد بود.
.
8. معیارهای ارزیابی عملکرد مدل
پس از پایان آموزش، باید بفهمیم خط رگرسیون چقدر سهم در پیشبینی درست داشته است. برای این کار از 6 معیار استاندارد استفاده میشود:
- میانگین مجذور خطاها (MSE – Mean Squared Error)
- ریشه میانگین مجذور خطاها (RMSE – Root Mean Squared Error)
- میانگین قدر مطلق خطاها (MAE – Mean Absolute Error)
- میانگین درصد قدر مطلق خطا (MAPE – Mean Absolute Percentage Error)
- ضریب تعیین (R^2 یا R-Squared)
- ضریب تعیین تعدیلشده (Adjusted R^2)
.
الف. میانگین مجذور خطاها (MSE – Mean Squared Error)
این معیار، میانگین تفاوتهای به توان دو رسیده میان مقادیر واقعی و پیشبینیشده را محاسه میکند. برای درک راحت فرمول، کافیست نام آن را از آخر به اول بخوانید: ابتدا خطا (تفاضل مقادیر) را به دست میآوریم، سپس آن را به توان دو (Square) میرسانیم و در نهایت میانگین (Mean) میگیریم. از آنجا که خطاها در این معیار به توان دو میرسند، MSE خطاهای بزرگ و دادههای پرت (Outliers) را به شدت جریمه میکند.
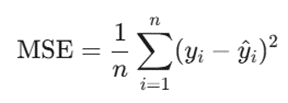
معرفی متغیرها:
- n: تعداد کل مشاهدات (تعداد دادهها).
- yi: مقدار واقعی مشاهده شده برای دادهی iام.
- ^y: مقدار پیشبینی شده توسط مدل برای دادهی iام.
- | … |: علامت قدر مطلق که باعث میشود جهت خطا (مثبت یا منفی) حذف شود.
.
ب. ریشه میانگین مجذور خطاها (RMSE – Root Mean Squared Error)
این معیار به زبان ساده جذر یا ریشه دوم همان معیار MSE است. از آنجا که در معیار قبلی خطاها به توان دو میرسیدند، واحد اندازهگیری خروجی تغییر میکرد؛ RMSE با گرفتن جذر، واحد خطا را دوباره به واحد اصلی دادههای ما (مثلاً دلار، سانتیمتر یا تعداد) بازمیگرداند تا ارزیابی آن برای انسان قابلفهمتر و ملموستر باشد.
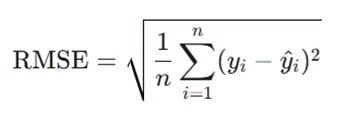
.
ج. میانگین قدر مطلق خطاها (MAE – Mean Absolute Error)
این معیار میانگین تفاضلهای قدر مطلقی (بدون در نظر گرفتن علامت مثبت یا منفی) بین مقدار واقعی و پیشبینیشده است MAE. یک امتیاز خطی است، به این معنی که به تمام خطاهای انفرادی وزن کاملاً یکسانی میدهد. بنابراین، اگر در پروژهای مایل نیستید که دادههای پرت و آنومالیها تمرکز مدل را بیش از حد به خود جلب کنند، این معیار پایدارترین گزینه است.
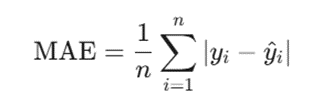
- MAE: میانگین قدر مطلق خطاها
- n: تعداد کل رکوردهای تست
- yi: مقدار خروجی واقعی در دیتابیس
.
د. میانگین درصد قدر مطلق خطا (MAPE – Mean Absolute Percentage Error)
این معیار میزان دقت پیشبینی روشهای آماری را در قالب درصد نشان میدهد و در برخی مراجع آماری به آن انحراف درصد قدر مطلق (MAPD) نیز میگویند. بزرگترین مزیت MAPE این است که خطا را به صورت درصد بیان میکند؛ این ویژگی به شما اجازه میدهد مستقل از بزرگ یا کوچک بودن مقیاس عددی دادهها، کیفیت مدل خود را ارزیابی کنید.
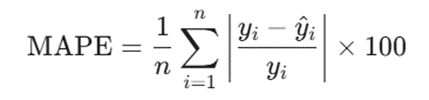
- MAPE: میانگین درصد قدر مطلق خطا
- n: تعداد کل نمونههای ارزیابی
- yi: مقدار خروجی واقعی دیتابیس
- ^yi: مقدار خروجی پیشبینیشده توسط مدل
.
ه. ضریب تعیین (R^2 یا R-Squared)
این شاخص به ما کمک میکند تا مدل فعلی خود را با یک خط مبنای ثابت (Baseline) مقایسه کنیم و بدانیم مدل چقدر از یک حدس ساده بهتر عمل میکند. این خط مبنا معمولاً با محاسبه میانگین دادهها و رسم یک خط صاف روی نمودار تعیین میشود R^2.یک امتیاز بدون مقیاس است؛ یعنی فرقی نمیکند اعداد دیتابیس چقدر بزرگ یا کوچک باشند، خروجی آن همیشه کمتر یا مساوی ۱ خواهد بود. هرچه این عدد به ۱ نزدیکتر باشد، مدل خطی ما دقیقتر است.
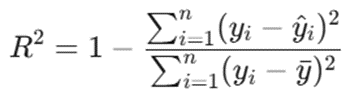
- R^2: ضریب تعیین مدل
- yi: مقدار واقعی دادهها
- ^y: مقدار پیشبینیشده توسط مدل رگرسیون
.
و. ضریب تعیین تعدیلشده (Adjusted R^2)
معیار R^2 استاندارد یک نقص بزرگ دارد: اگر ویژگیها و متغیرهای مستقل جدیدی را به مدل اضافه کنید، حتی اگر آن ویژگیها کاملاً بیربط باشند و هیچ کمکی به بهبود مدل نکنند، امتیاز R^2 باز هم افزایش مییابد که این امر میتواند محقق را گمراه کند. ضریب تعیین تعدیلشده این مشکل را با اعمال جریمه به ازای تعداد متغیرها حل کرده است تا بازتابی واقعی از پیشرفت مدل ارائه دهد.

معرفی متغیرها:
- R^2: ضریب تعیین معمولی.
- n: تعداد کل مشاهدات (نمونهها).
- k: تعداد متغیرهای مستقل (ویژگیها) در مدل.
.
مثال1:پیشبینی تأثیر «هزینه تبلیغات در شبکههای اجتماعی» بر «میزان جذب کاربر»
فرض کنید تیم دادهکاوی یک پلتفرم استارتاپی میخواهد بداند با صرف هزینهای مشخص برای تبلیغات در یک کمپین اینستاگرامی، دقیقاً چند کاربر جدید (Lead) جذب میکند تا بودجهبندی بهینهای داشته باشد.
جدول دادههای آموزشی (دیتابیس)
ما ۵ داده تاریخی داریم:
| نمونه (i) | هزینه تبلیغات (-x میلیون تومان) | تعداد کاربران جذب شده (–y نفر) |
| ۱ | ۱ | ۱۰ |
| ۲ | ۲ | ۲۰ |
| ۳ | ۳ | ۲۵ |
| ۴ | ۴ | ۴۰ |
| ۵ | ۵ | ۴۵ |
هدف ریاضی
ما به دنبال یافتن معادله خط زیر هستیم که کمترین خطا را داشته باشد.
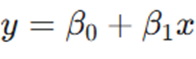
- β1 (شیب خط): نشاندهنده نرخ جذب کاربر به ازای هر ۱ میلیون تومان هزینه.
- β0 (عرض از مبدأ): کاربران جذبی پایه (حتی بدون تبلیغات).
راه حل مرحله به مرحله
a: محاسبه میانگینها
- میانگین x :

- میانگین y :

b: محاسبه ضرایب با فرمولهای کمترین مجذورات (OLS)
فرمول شیب خط (β1):
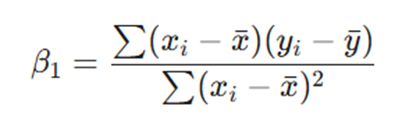
- محاسبه صورت کسر:
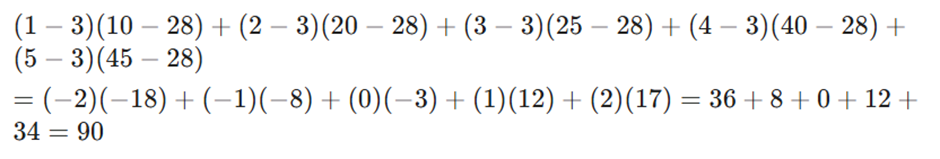
- محاسبه مخرج کسر:
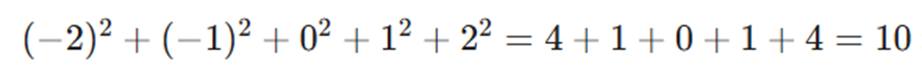
- β1= 90 / 10 = 9 (یعنی به ازای هر ۱ میلیون تومان، ۹ کاربر جذب میشود).
c: محاسبه عرض از مبدأ (β0)

نتیجه نهایی مدل
معادله پیشبینی ما به صورت زیر است:
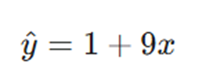
تحلیل: اگر فردا بخواهیم ۶ میلیون تومان برای تبلیغات هزینه کنیم:
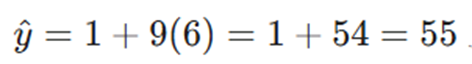
9.روشهای آموزش و استخراج ضرایب در رگرسیون خطی
منظور از آموزش یا یادگیری مدل رگرسیون خطی، تخمین و پیدا کردن دقیقترین مقادیر برای ضرایب ریاضی خط با استفاده از دادههایی است که در اختیار داریم. از آنجا که این الگوریتم به طور گسترده مطالعه شده، تکنیکهای زیادی برای آموزش آن وجود دارد. در ادامه، ۴ روش اصلی برای آمادهسازی مدل رگرسیون خطی را به صورت خلاصه و کاربردی بررسی میکنیم:
رگرسیون خطی ساده (تخمین آماری):
- این روش زمانی کاربرد دارد که ما فقط یک ویژگی ورودی (متغیر مستقل) در اختیار داشته باشیم. در این حالت، الگوریتم با محاسبه ویژگیهای آماری دادهها مانند میانگین، انحراف معیار، کوواریانس و همبستگی، ضرایب خط را محاسبه میکند. این تکنیک برای درک اولیه پدیدهها یا اجرا در نرمافزاری مثل اکسل جذاب است، اما در پروژههای واقعی و پیچیده کارایی چندانی ندارد.
کمترین مجذورات معمولی (OLS):
- وقتی تعداد متغیرهای ورودی بیشتر از یک مورد باشد، OLS رایجترین و استانداردترین روش ریاضی برای محاسبه ضرایب است. هدف این روش، به حداقل رساندن مجموع مجذور باقیماندهها (فاصله نقاط تا خط) است .OLS با دادهها به صورت یک ماتریس برخورد میکند و با استفاده از عملیات جبر خطی، بهترین ضرایب را خیلی سریع محاسبه میکند. بزرگترین شرط این روش آن است که تمام دادهها باید به طور یکجا در حافظه موقت (RAM) سیستم شما جا شوند.
الگوریتم گرادیان کاهشی (Gradient Descent):
- این تکنیک یک فرآیند بهینهسازی تکرارشونده است که محبوبترین روش در کلاسهای یادگیری ماشین به شمار میرود. گرادیان کاهشی کار خود را با ضرایب کاملاً تصادفی شروع میکند؛ سپس در هر مرحله خطای مدل را روی دادههای آموزش حساب کرده و با استفاده از پارامتری به نام نرخ یادگیری (α)، ضرایب را گامبهگام در جهت کاهش خطا اصلاح میکند. این روش تکرار میشود تا مدل به کمترین خطای ممکن برسد. گرادیان کاهشی بهترین گزینه برای کلاندادههایی (Big Data) است که به دلیل حجم فوقالعاده زیاد، در حافظه سیستم جا نمیشوند.
روشهای منظمسازی یا رگولاریزاسیون (Regularization):
- این روشها در واقع نسخههای توسعهیافته رگرسیون خطی هستند که علاوه بر تلاش برای کاهش خطای مدل، پیچیدگی خط را نیز کنترل میکنند تا مدل با بزرگ شدن بیش از حد ضرایب، دچار خطای بیشبرازش (Overfitting) نشود. این متدها زمانی که متغیرهای ورودی همبستگی شدیدی با هم دارند (مشکل همخطی) معجزه میکنند. سه نمونه از معروفترین روشهای منظمسازی عبارتند از:
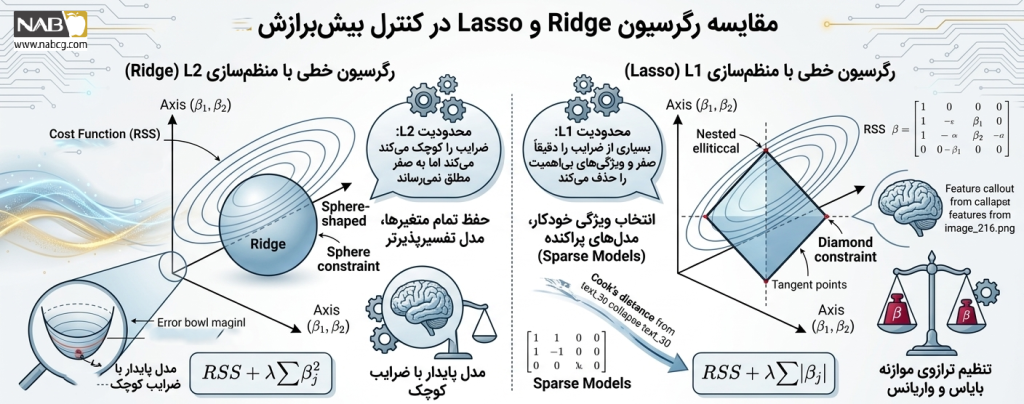
- رگرسیون لاسو (Lasso یا منظمسازی L1): در این روش، قدر مطلق اندازه ضرایب به تابع هزینه اضافه میشود تا جریمه شوند. لاسو این قدرت را دارد که ضریب ویژگیهای کماثر را کاملاً صفر و آنها را از چرخه پیشبینی حذف کند.
- رگرسیون ریج (Ridge یا منظمسازی L2): در این روش، مجذور (توان دوم) اندازه ضرایب به تابع هزینه اضافه میشود. ریج اندازه ضرایب را تا حد امکان کوچک و نزدیک به صفر نگه میدارد اما برخلاف لاسو، آنها را کاملاً حذف نمیکند.
- رگرسیون الاستیک نت(Elastic NET Regression): اگر بین انتخاب لاسو و ریج مردد هستید، الاستیک نت بهترین گزینه است. این روش ترکیبی هوشمندانه از هر دو جریمه L1 و L2 است.
.
10.ابزارها و فریمورکهای محبوب برای اجرای رگرسیون خطی
در دنیای دادهکاوی و یادگیری ماشین، ابزارها و کتابخانههای متعددی برای پیادهسازی رگرسیون خطی وجود دارند. انتخاب ابزار مناسب به هدف شما بستگی دارد؛ اینکه به دنبال یک پیشبینی سریع در یک پروژه هوش مصنوعی هستید یا نیاز به یک تحلیل آماری دقیق و عمیق دارید.
در ادامه، محبوبترین ابزارها و فریمورکهای این حوزه را به همراه کدهای عملیاتی پایتون بررسی میکنیم:
کتابخانه Scikit-Learn (پایتون)
این کتابخانه محبوبترین و استانداردترین ابزار برای پیادهسازی الگوریتمهای یادگیری ماشین در پایتون است. کلاس LinearRegression در این کتابخانه ساختاری بسیار ساده، سریع و بهینهشده دارد و فرآیند آموزش مدل و پیشبینی را تنها در چند خط کد خلاصه میکند. این ابزار برای توسعه سیستمهای هوشمند کاربرد وسیعی دارد.
import numpy as np
from sklearn.linear_model import LinearRegression
# ۱. تعریف دادههای نمونه (ویژگی ورودی و متغیر هدف)
# ورودیها باید به صورت ماتریس دو بعدی باشند
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([1.5, 3.1, 4.0, 5.2, 6.8])
# ۲. ساختن یک نمونه از مدل رگرسیون خطی
model = LinearRegression()
# ۳. آموزش مدل با استفاده از دادهها
model.fit(X, y)
# ۴. انجام پیشبینی برای یک داده جدید (مثلاً مقدار ورودی ۶)
new_input = np.array([[6]])
prediction = model.predict(new_input)
# ۵. چاپ خروجیها و پارامترهای به دست آمده
print("--- نتایج مدل Scikit-Learn ---")
print(f"میزان پیشبینی برای ورودی ۶: {prediction[0]:.2f}")
print(f"عرض از مبدأ خط (Intercept): {model.intercept_:.2f}")
print(f"ضریب ویژگی ورودی (Slope/Coefficient): {model.coef_[0]:.2f}")
خروجی:

کتابخانه Statsmodels (پایتون)
اگر هدف شما از اجرای رگرسیون خطی، تحلیلهای آماری عمیق، بررسی فرضهای آماری، محاسبه p-value و تحلیل باقیماندهها است، این کتابخانه بهترین انتخاب است. Statsmodels بر خلاف Scikit-Learn که روی پیشبینی تمرکز دارد، یک شناسنامه آماری کامل و دقیق از کل دیتابیس به شما ارائه میدهد.
import numpy as np
import statsmodels.api as sm
# ۱. تعریف دادههای نمونه
X = np.array([1, 2, 3, 4, 5])
y = np.array([1.5, 3.1, 4.0, 5.2, 6.8])
# ۲. در این کتابخانه باید به صورت دستی ستون ثابت برای عرض از مبدأ اضافه شود
X_with_constant = sm.add_constant(X)
# ۳. ساخت و آموزش مدل به روش کمترین مجذورات معمولی (OLS)
model_stat = sm.OLS(y, X_with_constant).fit()
# ۴. چاپ خلاصه آماری فوقالعاده جامع مدل
print(model_stat.summary())
خروجی:

کتابخانه TensorFlow / Keras (رویکرد یادگیری عمیق)
در یادگیری ماشین مدرن، گاهی رگرسیون خطی به عنوان یک لایه ساده در شبکههای عصبی بزرگ استفاده میشود. این کد قدرت رگرسیون را با فریمورک عمیق نمایش میدهد.
import tensorflow as tf
import numpy as np
# مدل به صورت یک لایه نورونی خطی
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=[1])])
model.compile(optimizer='sgd', loss='mean_squared_error')
X = np.array([1.0, 2.0, 3.0, 4.0, 5.0], dtype=float)
y = np.array([1.5, 3.1, 4.0, 5.2, 6.8], dtype=float)
model.fit(X, y, epochs=100, verbose=0)
print(f"Prediction for input 6: {model.predict(np.array([[6.0]]))[0][0]:.2f}")
خروجی:

کتابخانه PyTorch (مناسب برای تحقیق و مدلهای پیچیده)
اگر در حال توسعه مدلهای سفارشی با قابلیت گرادیانگیری خودکار هستید، PyTorch استاندارد طلایی است.
import torch
import torch.nn as nn
X = torch.tensor([[1.0], [2.0], [3.0], [4.0], [5.0]])
y = torch.tensor([[1.5], [3.1], [4.0], [5.2], [6.8]])
model = nn.Linear(1, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
criterion = nn.MSELoss()
# آموزش مدل در 100 تکرار
for _ in range(100):
optimizer.zero_grad()
loss = criterion(model(X), y)
loss.backward()
optimizer.step()
print(f"Prediction for input 6: {model(torch.tensor([[6.0]])).item():.2f}")
خروجی:
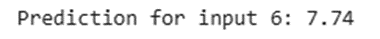
کتابخانه XGBoost / LightGBM (رگرسیون در مدلهای درختی)
گرچه این کتابخانهها برای مدلهای درختی معروفاند، اما میتوان از آنها برای رگرسیون خطی تقویتشده استفاده کرد که در مسابقات دادهکاوی (Kaggle) برای شکستن مرزهای دقت مدلها بسیار پرکاربرد است.
from xgboost import XGBRegressor
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([1.5, 3.1, 4.0, 5.2, 6.8])
# تعیین booster به صورت خطی
model = XGBRegressor(booster='gblinear', n_estimators=10)
model.fit(X, y)
print(f"Prediction for input 6: {model.predict(np.array([[6]]))[0]:.2f}")
خروجی:
نرمافزارهای تجاری و ابزارهای BI
برای مدیران کسبوکار و کسانی که با کدنویسی آشنایی ندارند، ابزارهای بصری گزینههای بهتری هستند:
- اکسل (Excel): بخش Data Analysis Toolpak در اکسل ابزاری سریع برای اجرای رگرسیون خطی روی جداول اطلاعاتی است.
- تبلو و پاور بیآی (Tableau & Power BI): این ابزارهای هوش تجاری امکان رسم خط رگرسیون (Trend Line) را روی نمودارهای پراکندگی تنها با چند کلیک فراهم میکنند تا روند تغییرات بازار به سرعت برای مدیران ارشد تصویرسازی شود.
.
11.پیاده سازی گام به گام
- جمعآوری و پیشپردازش دادهها: دادههای خام را وارد کرده، مقادیر گمشده را مدیریت میکنیم و در صورت نیاز، ویژگیها را استانداردسازی میکنیم تا همه در یک مقیاس عددی باشند.
- تقسیمبندی دادهها: دیتابیس را به دو بخش «آموزش» (برای یادگیری مدل) و «تست» (برای ارزیابی نهایی) تقسیم میکنیم.
- انتخاب و آموزش مدل: از الگوریتم رگرسیون خطی استفاده کرده و با استفاده از دادههای آموزش، ضرایب بهینه را پیدا میکنیم.
- پیشبینی: مدل آموزشدیده را برای پیشبینی روی دادههای تست به کار میبریم.
- ارزیابی و تحلیل: با استفاده از معیارهایی مثل R^2 و MSE، دقت مدل را سنجیده و عملکرد آن را تحلیل میکنیم.
کد پایتون کامل
در این کد از کتابخانه scikit-learn برای پیادهسازی استفاده شده است:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# 1. تولید دادههای نمونه
np.random.seed(42)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# 2. تقسیم دادهها
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 3. آموزش مدل
model = LinearRegression()
model.fit(X_train, y_train)
# 4. پیشبینی
y_pred = model.predict(X_test)
# 5. ارزیابی
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
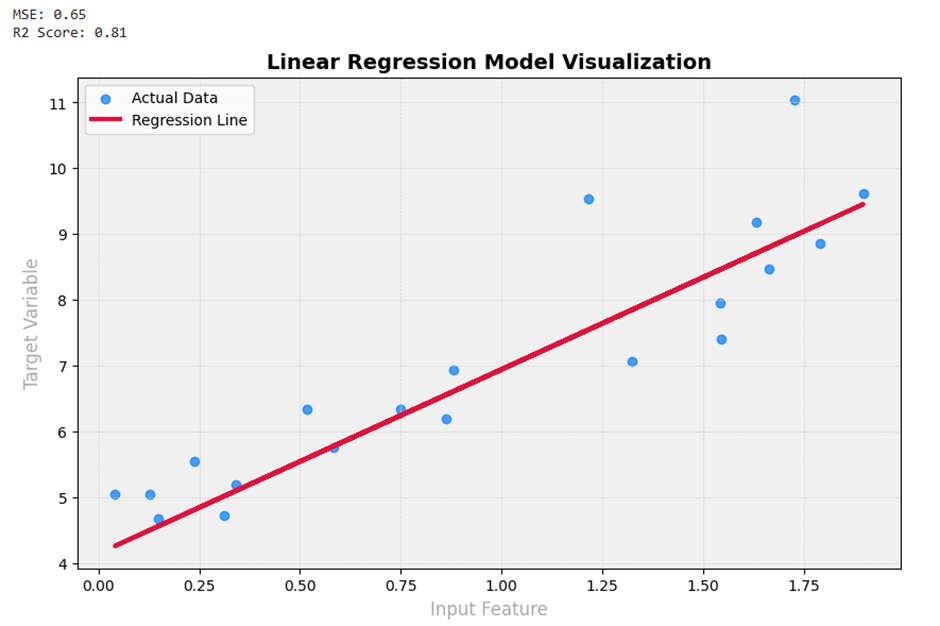
print(f"MSE: {mse:.2f}")
print(f"R2 Score: {r2:.2f}")
# نمایش بصری با پالت رنگی جدید
plt.figure(figsize=(10, 6), facecolor='white') # Pure White background
ax = plt.gca()
ax.set_facecolor('#F0F0F0') # Ultra Light Gray background for plot area
plt.scatter(X_test, y_test, color='#007BFF', alpha=0.7, label='Actual Data') # AI Soft Blue
plt.plot(X_test, y_pred, color='#DC143C', linewidth=3, label='Regression Line') # Crimson
plt.xlabel('Input Feature', color='#A9A9A9', fontsize=12) # Metal Silver
plt.ylabel('Target Variable', color='#A9A9A9', fontsize=12)
plt.title('Linear Regression Model Visualization', fontsize=14, fontweight='bold')
plt.legend()
plt.grid(color='#D3D3D3', linestyle='--', linewidth=0.5) # Light grid
plt.show()
خروجی:
12.کاربردهای واقعی رگرسیون خطی
- قیمتگذاری هوشمند در بازار املاک و مستغلات: در بازار مسکن، رگرسیون خطی ابزاری کلیدی برای پیشبینی دقیق قیمت خانهها است. این الگوریتم با تحلیل ویژگیهای ساختاری دیتابیس مانند متراژ بنا، تعداد اتاق خواب، موقعیت جغرافیایی و میزان دسترسی به امکانات رفاهی، ارزش واقعی ملک را تخمین میزند و به خریداران و سرمایهگذاران در تصمیمگیریهای مالی کمک میکند.
- پیشبینی حجم فروش و بهینهسازی بازاریابی: در دنیای تجارت و دیجیتال مارکتینگ، از این الگوریتم برای تخمین میزان فروش آینده استفاده میشود. رگرسیون خطی با بررسی متغیرهایی چون هزینههای تبلیغاتی، تغییرات فصلی بازار و رفتارهای خرید گذشته مشتریان، به مدیران نشان میدهد که استراتژیهای فروش چقدر اثربخش بودهاند تا بودجه خود را هوشمندانهتر تخصیص دهند.
- ارزیابی ریسک و تحلیلهای مالی در بانکداری: یکی از جذابترین بخشهای همپوشانی یادگیری ماشین با دادهکاوی، مدیریت ریسک است. بانکها و موسسات مالی از رگرسیون خطی برای سنجش رتبه اعتباری مشتریان و پیشبینی احتمال عدم پرداخت اقساط بر اساس درآمد ماهانه، میزان بدهیها و سابقه مالی فرد استفاده میکنند.
- تخمین تقاضا در زنجیره تأمین و مدیریت انبار: شرکتهای بزرگ تولیدی برای جلوگیری از کمبود کالا یا انباشت بیش از حد محصول، رگرسیون خطی را به کار میگیرند. این مدل با تحلیل دادههای تاریخی فروش و روندهای بازار، میزان تقاضای دقیق برای هر محصول را پیشبینی میکند تا زنجیره تأمین به بهینهترین شکل ممکن مدیریت شود.
- تحلیلهای پزشکی و پیشبینی شاخصهای سلامت: در حوزه بهداشت و درمان، پزشکان و محققان از رگرسیون خطی برای بررسی تأثیر فاکتورهای مختلف بر سلامت انسان استفاده میکنند؛ مانند پیشبینی فشار خون بیمار بر اساس سن، وزن، میزان فعالیت بدنی و رژیم غذایی، که نقش مهمی در پیشگیری از بیماریها دارد.
.
13.مطالعه موردی ۱: تخمین ارزش طول عمر مشتری (CLV) در تجارت الکترونیک
در این سناریو به سراغ یکی از جذابترین کاربردهای مشترک یادگیری ماشین و دادهکاوی در دنیای تجارت الکترونیک میرویم. هدف ما پیشبینی میزان سودآوری خالص یک مشتری برای کسبوکار در طول کل دوره تعاملش است.
- بیان مسئله: شرکتهای بزرگ برای تخصیص بهینه بودجه بازاریابی خود نیاز دارند بدانند کدام دسته از مشتریان در آینده سودآوری بیشتری دارند تا روی حفظ آنها سرمایهگذاری کنند.
- چالشهای دادهکاوی: دادههای خام فروشگاهی معمولاً شامل فاکتورهای پراکنده، نویزهای ناشی از خریدهای لغو شده و رفتارهای نوسانی خریداران در جشنوارههای تخفیف است که باید در فاز پیشپردازش اصلاح شوند.
- هدف مدلسازی: ساخت یک مدل رگرسیون خطی بهینه که بتواند ارزش طول عمر مشتری (CLV) را بر اساس فاکتورهای رفتاری پیشبینی کند.
- ویژگیهای ورودی (متغیرهای مستقل): تعداد دفعات خرید قبلی (Frequency)، میانگین مبلغ هر سبد خرید (Monetary) و نرخ کلیک روی ایمیلهای تبلیغاتی.
- متغیر هدف (متغیر وابسته): مجموع هزینه پیشبینیشدهای که مشتری در ۱۲ ماه آینده در سایت انجام خواهد داد.
کد پایتون:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, r2_score
# ۱. ساخت یک دیتابیس فرضی اما کاملاً استاندارد و منطبق بر واقعیت
np.random.seed(42)
n_customers = 200
frequency = np.random.randint(1, 50, n_customers)
monetary = np.random.uniform(10, 500, n_customers)
email_clicks = np.random.randint(0, 100, n_customers)
# فرمول حقیقی تولید متغیر هدف همراه با نویز طبیعی دادهها
clv = (frequency * 15) + (monetary * 1.2) + (email_clicks * 5) + np.random.normal(0, 50, n_customers)
df_clv = pd.DataFrame({
'Frequency': frequency,
'Monetary': monetary,
'Email_Clicks': email_clicks,
'CLV_Target': clv
})
# ۲. جداسازی متغیرهای مستقل و وابسته
X = df_clv[['Frequency', 'Monetary', 'Email_Clicks']]
y = df_clv['CLV_Target']
# ۳. تقسیم دادهها به دو بخش آموزش و تست
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ۴. آموزش مدل رگرسیون خطی
model = LinearRegression()
model.fit(X_train, y_train)
# ۵. پیشبینی و ارزیابی عملکرد مدل
y_pred = model.fit(X_train, y_train).predict(X_test)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("--- خروجی ارزیابی مدل تخمین ارزش مشتری ---")
print(f"میانگین خطای مطلق (MAE): {mae:.2f} دلار")
print(f"ضریب تعیین مدل (R2 Score): {r2:.4f}")
print("\n--- ضرایب به دست آمده برای ویژگیها ---")
for col, coef in zip(X.columns, model.coef_):
print(f"ضریب ویژگی {col}: {coef:.2f}")
خروجی:

14.مطالعه موردی ۲: پیشبینی شاخص پیشرفت دیابت در حوزه سلامت
در این بخش، پتانسیل رگرسیون خطی را در حوزه بیوانفورماتیک و مهندسی دادههای پزشکی به چالش میکشیم. در اینجا هدف ما پیشبینی میزان شدت و پیشرفت بیماری بر اساس معیارهای بیولوژیکی بدن است.
- بیان مسئله: تشخیص زودهنگام سرعت پیشرفت بیماریهای مزمن مثل دیابت به پزشکان کمک میکند تا دوز داروها و رژیمهای درمانی را به صورت شخصیسازیشده برای هر بیمار تنظیم کنند.
- چالشهای دادهکاوی: تفاوت در مقیاس عددی دادههای پزشکی (مثلاً فشار خون در برابر قند خون) و همچنین وجود همبستگی شدید بین شاخصهای زیستی که میتواند مدل را گمراه کند.
- هدف مدلسازی: یافتن رابطه خطی میان مشخصات فیزیولوژیکی بیمار و لولهگذاری شاخص پیشرفت بیماری در یک بازه زمانی مشخص.
- ویژگیهای ورودی (متغیرهای مستقل): سن (Age)، شاخص توده بدنی (BMI) و میانگین فشار خون (BP).
- متغیر هدف (متغیر وابسته): یک شاخص عددی و پیوسته که نشاندهنده میزان پیشرفت و شدت بیماری دیابت پس از یک سال است.
کد پایتون:
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# ۱. بارگذاری دیتابیس واقعی و معروف دیابت از کتابخانه Scikit-Learn
diabetes = load_diabetes()
df_dict = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
# انتخاب ۳ ویژگی اصلی بر اساس سناریو برای سادهسازی و خوانایی بهتر
X_diabetes = df_dict[['age', 'bmi', 'bp']]
y_diabetes = diabetes.target
# ۲. تقسیم دادهها به بخش آموزش و تست (۲۰ درصد تست)
X_train_d, X_test_d, y_train_d, y_test_d = train_test_split(
X_diabetes, y_diabetes, test_size=0.2, random_state=42
)
# ۳. ساخت و آموزش مدل رگرسیون خطی
diabetes_model = LinearRegression()
diabetes_model.fit(X_train_d, y_train_d)
# ۴. انجام پیشبینی روی دادههای تست
y_pred_d = diabetes_model.predict(X_test_d)
# ۵. محاسبه معیارهای ارزیابی خطای مدل
mse = mean_squared_error(y_test_d, y_pred_d)
r2_d = r2_score(y_test_d, y_pred_d)
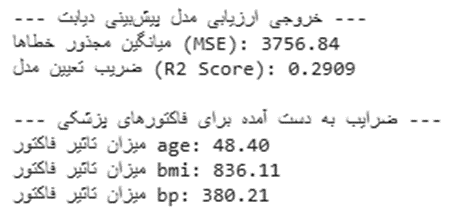
print("--- خروجی ارزیابی مدل پیشبینی دیابت ---")
print(f"میانگین مجذور خطاها (MSE): {mse:.2f}")
print(f"ضریب تعیین مدل (R2 Score): {r2_d:.4f}")
print("\n--- ضرایب به دست آمده برای فاکتورهای پزشکی ---")
for col, coef in zip(X_diabetes.columns, diabetes_model.coef_):
print(f"میزان تاثیر فاکتور {col}: {coef:.2f}")
خروجی:
15.مزایای الگوریتم رگرسیون خطی
- سادگی در درک و پیادهسازی کاربردی: این الگوریتم به دلیل داشتن یک فرمول ریاضی شفاف و مشخص، ساختاری بسیار شهودی دارد و فرآیند کدنویسی و توسعه آن در پروژههای یادگیری ماشین بسیار آسان است.
- تفسیرپذیری فوقالعاده ضرایب مدل: ضریب هر ویژگی مستقل به طور دقیق نشان میدهد که به ازای تغییر یک واحدی در آن ویژگی، متغیر هدف چقدر تغییر میکند؛ این شفافیت به کشف علّی روابط در دادهکاوی کمک شیک و مستقیمی میکند.
- سرعت محاسباتی بینظیر در فرآیند آموزش: زمان آموزش (Train) و پیشبینی (Inference) در رگرسیون خطی بسیار کوتاه است که آن را به گزینهای بیرقیب برای سیستمهای تحلیل بلادرنگ (Real-time) تبدیل میکند.
- مقیاسپذیری بالا برای مدیریت کلاندادهها: به دلیل نیاز به منابع سختافزاری و حافظه موقت بسیار کم، این الگوریتم میتواند دیتاستهای بسیار بزرگ تجاری را بدون افت سرعت سیستم پردازش و تحلیل کند.
- خطای پیشبینی پایین در ساختارهای خطی: اگر رابطه متغیرها در دنیای واقعی خطی باشد، این مدل کمترین انحراف و پایدارترین سطح دقت را روی دادههای تست جدید ارائه میدهد.
- بهترین الگوریتم برای تعیین خط مبنا (Baseline): در متدولوژی دادهکاوی، همواره از رگرسیون خطی به عنوان اولین بنچمارک استفاده میشود تا میزان بهبود عملکرد الگوریتمهای پیچیدهتر بعدی با آن سنجیده شود.
- پشتیبانی همهجانبه در کتابخانههای هوش مصنوعی: این الگوریتم به طور بومی و بهینهشده در تمامی پلتفرمها و کتابخانههای معتبر جهان مانند Scikit-Learn، تنسورفلو و پانداس با بالاترین پایداری فنی در دسترس است.
.
16.معایب و محدودیتهای رگرسیون خطی
- حساسیت بحرانی به دادههای پرت (Outliers): وجود مقادیر آنومالی و فرین در فاز پیشپردازش دادهکاوی، به سرعت روی توابع ضرر (مانند MSE) تأثیر گذاشته و خط رگرسیون را به طور کامل منحرف میکند.
- تمایل بالا به خطای کمبرازش (Underfitting): به دلیل ساختار ساده ریاضی، این الگوریتم معمولاً پدیدههای پیچیده را بیش از حد سادهسازی کرده و نمیتواند الگوهای پنهان موجود در دادهها را استخراج کند.
- وابستگی شدید به فرآیند مهندسی ویژگیها: برای عملکرد مناسب، متخصص دادهکاوی باید زمان زیادی را صرف پاکسازی، حذف نویزها، بررسی توزیع نرمال دادهها و حذف همبستگیهای درونی متغیرها پیش از اجرای مدل کند.
- حساسیت بالا به ترتیب و توزیع دادهها: در برخی سناریوهای دادهکاوی و دیتابیسهای پویا، چینش ترتیبی دیتای ورودی میتواند بر روی پایداری نهایی خط رگرسیون تاثیر منفی بگذارد.
- محدودیت شدید در تعمیمپذیری روابط چندبعدی: هنگامی که تعداد ویژگیها از تعداد نمونهها بیشتر شود (مشکل ابعاد بالا)، مدل بدون اعمال رگولاریزاسیون دچار شکست محاسباتی و خطای شدید بیشبرازش (Overfitting) میشود.
.
17. نوآوریها و پیشرفتهای مدرن در رگرسیون خطی
اگرچه رگرسیون خطی از دیدگاه تاریخی یک روش کلاسیک محسوب میشود، اما با ظهور یادگیری عمیق و محاسبات مقیاس بزرگ، نوآوریهای قابلتوجهی در اجرای آن رخ داده است که کارایی آن را در دادهکاوی مدرن تضمین میکند:
الف. بهینهسازهای پیشرفته (Adam و SGD)
در گذشته، محاسبات رگرسیون به روشهای مستقیم ماتریسی (OLS) محدود بود. نوآوری اصلی در یادگیری ماشین، استفاده از بهینهسازهای پویا مانند Adam (Adaptive Moment Estimation) است. این بهینهسازها به صورت خودکار نرخ یادگیری (Learning Rate) را در طول فرآیند آموزش تنظیم میکنند، که باعث میشود رگرسیون خطی در دیتابیسهای عظیم با سرعت بسیار بالاتر و پایداری بیشتر همگرا شود.
ب. روشهای یادگیری توزیعشده (Distributed Learning)
با ورود به عصر کلانداده (Big Data)، الگوریتمهای رگرسیون نوآورانه برای محیطهای توزیعشده )مثل Apache Spark) طراحی شدهاند. در این سیستمها، دادهها در چندین سرور پخش شده و مدل به صورت همزمان روی قطعات مختلف داده آموزش میبیند. این نوآوری باعث شده رگرسیون خطی همچنان در مقیاسهای ترابایتی دادهکاوی، ابزاری بسیار سریع و کارآمد باقی بماند.
ج. منظمسازی هوشمند (Elastic Net)
نوآوری در حوزه منظمسازی (Regularization) منجر به معرفی Elastic Net شد. این روش ترکیبی از لاسو (Lasso) و ریج (Ridge) است. این الگوریتم هوشمند، مزایای هر دو روش را در یک مدل ادغام میکند تا نه تنها ویژگیهای زائد را حذف کند، بلکه پایداری ضرایب را در حضور همخطی شدید (Multicollinearity) تضمین نماید.
د. تحلیل خودکار در محیطهای AutoML
ابزارهای مدرن AutoML (مانند TPOT یا H2O.ai) اکنون به صورت خودکار عملیات پیچیده دادهکاوی شامل «مهندسی ویژگی»، «حذف دادههای پرت» و «انتخاب بهترین نوع رگرسیون» را انجام میدهند. نوآوری در اینجا، حذف دخالت انسانی در فرآیند بهینهسازی مدل است که اجازه میدهد حتی با کمترین دانش آماری، دقیقترین مدل رگرسیون خطی ساخته شود.
جمع بندی
رگرسیون خطی یکی از مهمترین و پایهایترین ابزارهای تحلیل داده است که امکان مدلسازی و پیشبینی روابط میان متغیرها را فراهم میکند. همانطور که مشاهده شد، این مدل با استفاده از روشهایی مانند OLS و Gradient Descent تلاش میکند بهترین ضرایب را برای کمینهکردن خطا و بیشینهکردن دقت پیشبینی پیدا کند. سادگی ریاضی، سرعت اجرا و تفسیرپذیری بالا از مهمترین دلایل محبوبیت این الگوریتم در حوزههای مختلف علمی و صنعتی هستند.
در عین حال، عملکرد مناسب رگرسیون خطی به رعایت فرضهای آماری آن وابسته است. وجود رابطه خطی، استقلال خطاها، همسانی واریانس و نبود همخطی شدید میان متغیرها از جمله عواملی هستند که مستقیماً بر اعتبار مدل اثر میگذارند. همچنین مشاهده کردیم که تکنیکهایی مانند Ridge و Lasso میتوانند با کنترل بیشبرازش، پایداری مدل را در دادههای واقعی افزایش دهند.
با وجود ظهور الگوریتمهای پیچیدهتر در یادگیری ماشین، رگرسیون خطی همچنان جایگاه ویژهای در تحلیل داده، اقتصاد، سلامت، بازاریابی و سیستمهای پیشبینی دارد. دلیل این ماندگاری، ترکیب کمنظیر سادگی، شفافیت و کارایی است. در واقع، یادگیری رگرسیون خطی نهفقط یادگیری یک الگوریتم، بلکه درک یکی از مهمترین چارچوبهای فکری در علم داده و مدلسازی آماری محسوب میشود.



