

مقدمه
در نگاه اول، وزنها و بایاس ممکن است تنها چند عدد ساده درون یک شبکه عصبی به نظر برسند، اما در واقع این پارامترها ستونهای اصلی فرآیند یادگیری را تشکیل میدهند. هر تصمیمی که یک شبکه عصبی میگیرد، نتیجهی تعامل همین وزنها و بایاسها با دادههای ورودی است. تعاملی که به مدل اجازه میدهد الگوها را تشخیص دهد، روابط پیچیده را یاد بگیرد و به نتایج معنادار برسد.
درک دقیق نقش وزنها و بایاس برای فهم عملکرد شبکههای عصبی ضروری است. بدون این درک، شبکه عصبی به یک جعبه سیاه تبدیل میشود که خروجی میدهد، اما منطق درونی آن مبهم باقی میماند. وزنها میزان اهمیت هر ورودی را مشخص میکنند و بایاسها به مدل کمک میکنند تا انعطافپذیری بیشتری در تصمیمگیری داشته باشد و خود را با الگوهای متنوع دادهها تطبیق دهد.
در این مقاله، مفهوم وزن و بایاس را از جنبههای مختلف بررسی میکنیم. از ریشههای تاریخی و شهود ریاضی گرفته تا نقش آنها در فرآیند یادگیری، تعمیم مدل و کاربردهای واقعی در دنیای واقعی. هدف این است که این مفاهیم بنیادی نهتنها تعریف شوند، بلکه بهطور عمیق و کاربردی درک گردند.
پیشینه تاریخی کوتاه
مفهوم شبکههای عصبی برخلاف آنچه تصور میشود، بسیار قدیمی است. اولین جرقههای مدلسازی نرمافزاری با الهام از مغز انسان به اوایل دهه ۱۹۴۰ بازمیگردد که توسط دانشمندانی چون دونالد هب، مککالک و پیتس مطرح شد. با این حال، این مفهوم برای بیش از ۲۰ سال تنها در سطح تئوری باقی ماند.
آموزش شبکههای عصبی تنها زمانی ممکن شد که دو اتفاق مهم رخ داد: افزایش خیرهکننده قدرت پردازش کامپیوترها و ابداع الگوریتم انتشار رو به عقب (Backpropagation) توسط پل وربوس. این الگوریتم مکانیزمی کارآمد است که به شبکه اجازه میدهد با انتقال بازخورد هر نورون به نورون قبلی، خطاها را اصلاح کرده و یاد بگیرد.
در سالهای اخیر، تلاشهای بیوقفه پژوهشگرانی همچون جفری هینتون، اندرو انجی و جف دین، پارادایم شبکههای عصبی را برای طیف گستردهای از مسائل، محبوب و اثربخش کرد. امروزه این شبکهها در وظایفی که قبلاً غیرممکن به نظر میرسیدند، مانند ترجمه زبان، سنتز صدا و ویدیو، و رانندگی خودران به کار گرفته میشوند.
نورون طبیعی و مصنوعی؛ تفاوت در چیست؟
اگرچه درست است که شبکههای عصبی از نورونهای بیولوژیکی الهام گرفته شدهاند، اما این مقایسه گاهی گمراهکننده است؛ زیرا آناتومی و رفتار آنها کاملاً متفاوت است.

نورونهای طبیعی تمایل دارند بر اساس یک وضعیت روشن یا خاموش (On/Off) فعال شوند. همچنین، نورونهای مغز ما پس از یک دوره فعالیت، وارد یک دوره تحریکناپذیری (Refractory Period) میشوند که در آن توانایی فعالسازی مجدد برای مدتی سرکوب میشود. این رفتار در زیستشناسی تحت عنوان پتانسیل عمل (Action Potential) شناخته میشود، در حالی که در نورونهای مصنوعی چنین محدودیتی وجود ندارد.
نقش وزنها و بایاسها در شبکههای عصبی
شبکههای عصبی با یادگیری از دادهها و شناسایی الگوهای پیچیده، در حوزههایی مانند تشخیص تصویر، پردازش زبان طبیعی و سیستمهای خودگردان اهمیت بالایی یافتهاند. این شبکهها دارای دو مؤلفه اساسی هستند که چگونگی یادگیری و پیشبینی مدل را تعیین میکنند: وزن (Weight) و بایاس. (Bias)

۱. وزنها(Weights): اهرمهای تأثیرگذاری
وزنها مقادیر عددی هستند که به اتصالات بین نورونها اختصاص داده میشوند. آنها مشخص میکنند که هر ورودی چه میزان تأثیری بر خروجی نهایی شبکه دارد.
- هدف: در طول فرآیند انتشار رو به جلو (Forward Propagation)، ورودیها در وزنهای مربوط به خود ضرب شده و سپس از یک تابع فعالساز عبور میکنند. این کار کمک میکند تا مشخص شود یک سیگنال ورودی با چه شدتی بر خروجی اثر میگذارد.
- مکانیزم یادگیری: در طول دوره آموزش، وزنها به صورت تکرار شونده از طریق الگوریتمهای بهینهسازی (مانند گرادیان کاهشی) اصلاح میشوند تا تفاوت بین پیشبینی مدل و واقعیت به حداقل برسد.
- تعمیمپذیری(Generalization): وزنهایی که به خوبی تنظیم شده باشند، به شبکه کمک میکنند تا نه تنها روی دادههای آموزشی دقیق باشد، بلکه روی دادههای جدید و دیدهنشده نیز پیشبینیهای درستی انجام دهد.
- مثال: در یک شبکه عصبی که قیمت مسکن را پیشبینی میکند، وزنِ مربوط به متراژ خانه تعیین میکند که اندازه بنا چقدر بر قیمت نهایی اثر بگذارد. هرچه این وزن بزرگتر باشد، متراژ تأثیر بیشتری در نتیجه نهایی خواهد داشت.
.
۲. بایاس(Bias): عامل انعطافپذیری
بایاسها پارامترهای اضافی هستند که خروجی یک نورون را تنظیم میکنند. برخلاف وزنها، بایاس به هیچ ورودی خاصی وابسته نیست، بلکه کل تابع فعالساز را جابهجا میکند تا با دادهها بهتر برازش (Fit) شود.
- هدف: بایاسها به نورونها اجازه میدهند حتی زمانی که مجموع وزندار ورودیها کافی نیست، فعال شوند. این ویژگی به شبکه قدرت میدهد الگوهایی را شناسایی کند که لزوماً از مبدأ مختصات عبور نمیکنند.
- عملکرد: بدون وجود بایاس، نورونها فقط زمانی فعال میشوند که ورودی به یک آستانه خاص برسد. بایاس با فراهم کردن امکان فعالسازی در طیف وسیعی از شرایط، انعطافپذیری شبکه را بسیار بالا میبرد.
- آموزش: در فرآیند آموزش، بایاسها در کنار وزنها و از طریق انتشار رو به عقب (Backpropagation) بهروزرسانی میشوند. این دو در کنار هم مدل را دقیقتر کرده و صحت پیشبینی را بهبود میبخشند.
- مثال: در مدل پیشبینی قیمت مسکن، بایاس تضمین میکند که حتی اگر متراژ خانه صفر باشد، مدل یک قیمت پایه (غیر صفر) را پیشبینی کند. این قیمت میتواند نشاندهنده ارزش ثابت زمین یا هزینههای پایه باشد.
.
درک عمیقتر مفاهیم بایاس: از سوگیری تا انعطافپذیری
.
۱. بایاس در دادهها؛ نیمه تاریک هوش مصنوعی
اولین لایه، سوگیری در دادههای آموزشی است که یک پدیده کاملاً منفی است. شبکه عصبی دقیقاً همان چیزی را یاد میگیرد که به آن تزریق میکنید:
- مثال آمازون: ابزار استخدامی آمازون به دلیل استفاده از رزومههایی که عمدتاً مربوط به مردان بود، نسبت به زنان دچار سوگیری شد و رزومههای آنان را فیلتر میکرد.
- مثال چتبات Tay: این بات مایکروسافت با یادگیری از توییتر، تحت تأثیر محتوای توهینآمیز کاربران قرار گرفت و در کمتر از ۲۴ ساعت به یک ربات پرخاشگر تبدیل شد.
.
بایاس در عملکرد کل شبکه (High Bias)
وقتی از بایاس در سطح عملکرد مدل صحبت میکنیم، با مفهومی به نام بایاس بالا روبرو هستیم که نشاندهنده ناتوانی مدل در یادگیری الگوهاست:
- مدلهای صلب: اگر مدل بیش از حد ساده باشد (مثلاً بخواهد دادههای منحنی شکل را با یک خط صاف مدلسازی کند)، دچار بایاس بالا میشود و هم در مرحله آموزش و هم تست، خطای زیادی خواهد داشت.
- ناتوانی در تعمیم: مدلی که بایاس بالایی دارد، شبیه دانشآموزی است که اصلاً مفهوم درس را درک نمیکند و نمیتواند الگوهای موجود در دادهها را پیدا کند.
.
نورون بایاس؛ چرا به آن نیاز داریم؟
این تنها جایی است که بایاس نقشی مثبت و حیاتی ایفا میکند. در واقع، نورون بایاس به شبکه عصبی اجازه میدهد تا انعطافپذیر باشد:
- بدون بایاس: اگر بایاس نباشد، مدل (خط رگرسیون) شما همیشه مجبور است از مبدأ مختصات (۰,۰) عبور کند. این یعنی مدل فقط میتواند شیب خط را تغییر دهد و نمیتواند آن را در صفحه جابهجا کند.
- با بایاس: نورون بایاس وزنی (w0) را به شبکه اضافه میکند که به هیچ ورودی خاصی وابسته نیست. این وزن اجازه میدهد تا خط (یا تابع فعالساز مثل سیگموئید) به سمت بالا، پایین، چپ یا راست حرکت کند تا به بهترین شکل روی دادهها منطبق شود.
.
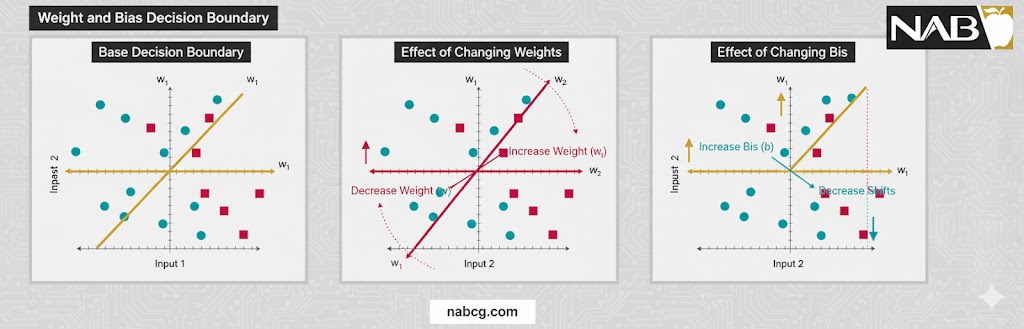
تحلیل مهندسی: تعامل وزن و بایاس
از دیدگاه ریاضی و مهندسی، میتوان گفت وزنها شیب (Slope) خط تصمیمگیری را تغییر میدهند و بایاس محل قطع (Intercept) این خط با محورها را جابهجا میکند. طبق منابع معتبر یادگیری عمیق، ترکیب این دو پارامتر به شبکه عصبی اجازه میدهد تا به عنوان یک تخمینزننده جهانی عمل کرده و هر تابع ریاضی پیچیدهای را مدلسازی کند.
فرآیند یادگیری در شبکه عصبی
یادگیری در یک شبکه عصبی در دو فاز اصلی و به صورت تکرار شونده انجام میشود: انتشار رو به جلو (Forward Propagation) و انتشار رو به عقب (Backpropagation).
۱. انتشار رو به جلو: از ورودی تا پیشبینی
در این مرحله، دادهها وارد شبکه شده و لایه به لایه جلو میروند تا یک نتیجه نهایی تولید شود:
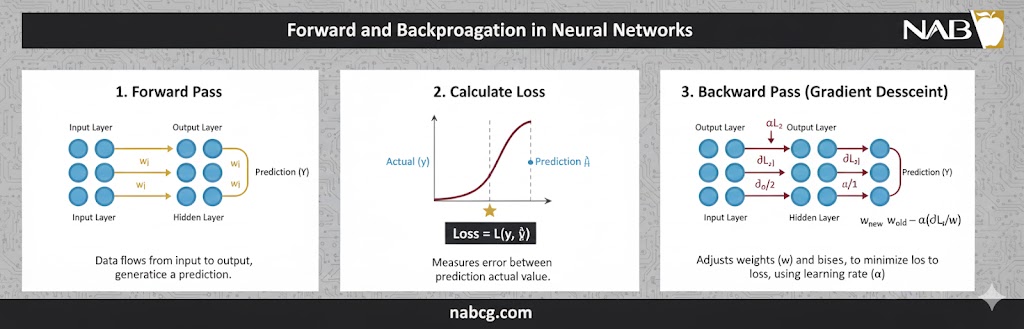
- ورود دادهها: فرآیند با ورود دادههای خام (مثل پیکسلهای یک تصویر) به لایه ورودی آغاز میشود.
- سیستم وزنها(Weights): هر ورودی در یک وزن ضرب میشود. وزنها نشاندهنده میزان اهمیت یا قدرت تأثیر آن ورودی بر خروجی نهایی هستند. اگر وزنها را پیچهای تنظیم رادیو در نظر بگیریم، تغییر آنها شدت سیگنال را تغییر میدهد.
- نقش بایاس(Bias): یک مقدار ثابت به نام بایاس به مجموع وزندار اضافه میشود. بایاس به شبکه انعطافپذیری میدهد تا حتی زمانی که تمام ورودیها صفر هستند، بتواند خروجی را جابهجا کرده و برازش بهتری روی دادهها داشته باشد.
- تابع فعالساز(Activation Function): این تابع (مثل ReLU یا Sigmoid) تصمیم میگیرد که آیا نورون باید روشن شود یا خیر. این رفتار شبیه به پتانسیل عمل در نورونهای بیولوژیکی است؛ اگر مجموع ورودیها از آستانه خاصی بگذرد، اطلاعات به لایه بعدی پاس داده میشود.
.
۲. انتشار رو به عقب: یادگیری از اشتباهات
پس از اینکه شبکه یک پیشبینی انجام داد، باید بفهمد چقدر اشتباه کرده است:
- محاسبه خطا(Loss): خروجی شبکه با پاسخ واقعی (Target) مقایسه میشود. تفاوت این دو عدد، خطا یا زیان نامیده میشود.
- محاسبه گرادیان: خطا به سمت عقب و از میان لایهها بازگردانده میشود. در این مرحله، گرادیان یا شیب خطا نسبت به وزنها و بایاسها محاسبه میشود. این مقدار به شبکه میگوید که برای کاهش خطا، هر پیچ تنظیم (وزن/بایاس) را باید به کدام سمت و با چه شدتی بچرخاند.
- بهروزرسانی با الگوریتم بهینهسازی: با استفاده از الگوریتمهایی مثل گرادیان کاهشی (Gradient Descent)، شبکه وزنها و بایاسها را کمی تغییر میدهد تا در دفعه بعد، خطا کمتر شود.
- تکرار و تکامل(Iteration): این چرخه هزاران بار روی بستههای مختلف داده تکرار میشود. با هر تکرار، مدل به مقادیر بهینه نزدیکتر شده و عملکرد آن بهبود مییابد.
.
تحلیل هندسی وزن و بایاس
فرمول اصلی خروجی یک نورون به صورت زیر است:

در این معادله، وزنها بزرگی و دامنه سیگنال را تغییر میدهند (تغییر در شدت)، در حالی که بایاس کل تابع را در صفحه مختصات جابهجا میکند. طبق منابع معتبر، وزنها معمولاً به صورت تصادفی مقداردهی اولیه میشوند، اما بایاسها اغلب با عدد صفر شروع به کار میکنند.
توابع فعالسازی: پل تصمیمگیری
تا اینجا یاد گرفتیم که ورودیها در وزنها ضرب شده و با بایاس جمع میشوند. اما حاصل این عملیات فقط یک عدد خام است. اینجاست که توابع فعالساز (Activation Functions) وارد عمل میشوند تا تعیین کنند آیا این عدد به مرحله بعد منتقل شود یا خیر. در واقع، این توابع به شبکه عصبی قدرت «تفکر غیرخطی» میدهند.
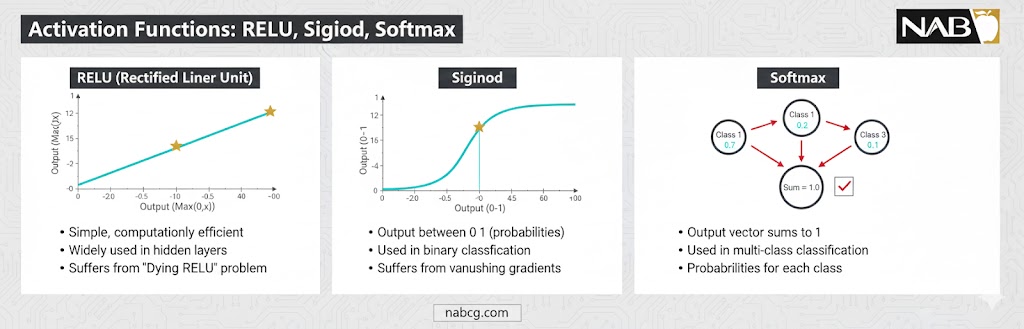
۱.ReLU : موتور محرک لایههای پنهان
تابع ReLU محبوبترین تابع فعالساز در دنیای یادگیری عمیق مدرن است.
- چگونه کار میکند؟ خیلی ساده؛ اگر عدد ورودی مثبت باشد، همان را عبور میدهد و اگر منفی باشد، آن را به صفر تبدیل میکند.
- چرا از آن استفاده میکنیم؟ این تابع باعث میشود محاسبات بسیار سریع انجام شود و از مشکلاتی مثل «محو شدن گرادیان» که باعث کندی یادگیری میشود، جلوگیری میکند ReLU. همان چیزی است که به شبکههای عمیق اجازه میدهد با سرعت خیرهکننده آموزش ببینند.
.
۲. توابع Sigmoid و Softmax : زبان احتمال و قاطعیت
وقتی به لایه نهایی شبکه (خروجی) میرسیم، دیگر به اعداد خام نیاز نداریم؛ ما به «احتمال» نیاز داریم.
- تابع Sigmoid: این تابع هر عددی را به بازه بین ۰ و ۱ تبدیل میکند. این برای مسائلی که پاسخ آنها «بله یا خیر» است (مثل تشخیص هرزنامه) عالی است. خروجی ۰.۹ یعنی ۹۰٪ احتمال دارد این ایمیل هرزنامه باشد.
- تابع Softmax: زمانی که با چندین کلاس سر و کار داریم (مثلاً تشخیص اینکه تصویر گربه است، سگ است یا اسب)، از Softmax استفاده میکنیم. این تابع خروجیها را طوری تنظیم میکند که مجموع احتمالات تمام دستهها برابر با ۱ (۱۰۰٪) شود. مثلاً: ۹۰٪ گربه، ۷٪ سگ و ۳٪ اسب.
.
کاربردهای استراتژیک شبکههای عصبی در دنیای واقعی
۱. تشخیص تصویر (Image Recognition)
شبکههای عصبی در وظایفی مانند طبقهبندی اشیاء و تصاویر، از شناسایی حیوانات خانگی گرفته تا ویژگیهای ظریف چهره، بسیار کارآمد هستند.
- نقش وزنها: این پارامترها مشخص میکنند که کدام پیکسلها اهمیت بیشتری دارند. برای مثال، در تصویر یک گربه، وزنها به ویژگیهایی مانند گوشها، سبیلها و چشمها اهمیت بیشتری میدهند تا شبکه بتواند شیء را به درستی شناسایی کند.
- نقش بایاسها: بایاسها تضمین میکنند که شبکه در برابر تغییرات شرایط تصویر منعطف باقی بماند. تغییرات جزئی در نور، موقعیت یا جهت تصویر نباید مانع از شناسایی صحیح اشیاء توسط مدل شود.
.
۲. پردازش زبان طبیعی (NLP)
در کارهایی مثل تحلیل احساسات، ترجمه زبان و چتباتها، شبکههای عصبی وظیفه تحلیل و تولید متن را بر عهده دارند.
- نقش وزنها: وزنها تعیین میکنند که کلمات یا عبارات خاص در یک متن چقدر اهمیت دارند. مثلاً درک بار معنایی کلماتی مثل خوشحال در برابر غمگین، به شبکه کمک میکند تا لحن و احساس کلی یک جمله را بفهمد.
- نقش بایاسها: این پارامترها به مدل کمک میکنند تا با ساختارها و لحنهای مختلف جملات سازگار شود و معنای اصلی را حتی در صورت تغییر در نحوه بیان جمله، استخراج کند.
.
۳. خودروهای خودران (Autonomous Vehicles)
خودروهای بدون راننده از شبکههای عصبی برای پردازش دادههای حسگرها (دوربین، رادار، لایدار) و اتخاذ تصمیمات حیاتی مثل توقف پشت چراغ قرمز یا اجتناب از موانع استفاده میکنند.
- نقش وزنها: وزنها به شبکه کمک میکنند تا روی دادههای ورودی مهم مانند عابران پیاده، علائم راهنمایی و سایر وسایل نقلیه تمرکز کرده و اهمیت آنها را بر اساس نیاز لحظهای خودرو تنظیم کند.
- نقش بایاسها: بایاسها تضمین میکنند که خودرو با شرایط مختلف رانندگی مانند مه یا رانندگی در شب سازگار شود و ایمنی سیستم را در شرایط جوی و محیطی متنوع حفظ کند.
.
۴. بهداشت و تشخیص پزشکی (Healthcare)
یکی از انسانیترین کاربردها، استفاده از این فناوری در تشخیص بیماریها از روی تصاویر پزشکی مانند X-ray، MRI و سیتی اسکن است.
- نقش وزنها: این مقادیر عددی به شبکه کمک میکنند تا روی ویژگیهای حیاتی در تصویر، مثل نواحی مشکوک به تومور یا ناهنجاریهای بافتی، متمرکز شود تا پیشبینیهای دقیقتری ارائه دهد.
- نقش بایاسها: بایاسها به سیستم اجازه میدهند تا نسبت به تفاوت در تکنیکهای تصویربرداری یا آناتومی خاص هر بیمار منعطف باقی بماند و در سناریوهای مختلف قابل اطمینان عمل کند.
.
مزایای وزنها و بایاسها
وزنها و بایاسها تنها اعداد ساده نیستند، بلکه ستونهای اصلی یادگیری عمیق محسوب میشوند که مزایای زیر را به همراه دارند:
- یادگیری هوشمند از دادهها: وزنها و بایاسها به شبکه اجازه میدهند تا خود را با الگوهای داده وفق دهد. وزنها اهمیت هر ورودی را مشخص کرده و بایاسها انعطافپذیری لازم را برای پیشبینی فراهم میکنند.
- انعطافپذیری در مواجهه با دادههای پیچیده: بایاسها به نورونها اجازه میدهند حتی با ورودیهای حداقلی فعال شوند. این ویژگی در وظایفی مانند پردازش تصویر یا زبان طبیعی — که دادهها اغلب ناقص یا نویزی هستند — بسیار حیاتی است.
- تعمیمپذیری فراتر از آموزش: اگر وزنها و بایاسها به درستی تنظیم شوند. شبکه میتواند الگوهای یادگرفته شده را روی دادههای کاملاً جدید و دیده نشده نیز با موفقیت اعمال کند.
- افزایش ظرفیت حل مسئله: این پارامترها به شبکه قدرت میدهند تا الگوهای بسیار پیچیده و غیرخطی را استخراج کند. کاری که الگوریتمهای سنتی در انجام آن ناتوان هستند.
.
چالشها و محدودیتها
با وجود تمام قدرت، مدیریت وزنها و بایاسها با چالشهای فنی همراه است که نباید نادیده گرفته شوند:
- حساسیت به مقداردهی اولیه(Initialization): اگر وزنها و بایاسها در شروع کار به درستی مقداردهی نشوند (مثلاً خیلی بزرگ یا خیلی کوچک باشند)، سرعت یادگیری به شدت افت کرده یا مدل هرگز به نتیجه مطلوب نمیرسد.
- خطر بیشبرازش(Overfitting): تنظیم بیش از حد و افراطی وزنها روی دادههای آموزشی میتواند مدل را وسواسی کند؛ به طوری که مدل دادههای آموزشی را حفظ میکند اما در مقابل دادههای جدید کاملاً شکست میخورد.
- ماهیت جعبه سیاه(Black Box): درک و تفسیر اینکه دقیقاً کدام وزن یا بایاس باعث اتخاذ یک تصمیم خاص توسط مدل شده، بسیار دشوار است. این عدم شفافیت در حوزههای حساسی مثل پزشکی یا حقوقی چالشبرانگیز است.
- هزینههای محاسباتی بالا: بهینهسازی هزاران یا میلیونها وزن و بایاس در شبکههای عصبی عمیق، نیازمند سختافزارهای قدرتمند (مثل GPUها) و زمان طولانی است که هزینه پروژهها را افزایش میدهد.
.
آینده: شبکههای عصبی بدون بایاس یا خودتنظیم؟
در حالی که امروزه بایاسها ابزاری حیاتی برای انعطافپذیری مدلها هستند، مرزهای دانش در هوش مصنوعی به سمت سیستمهایی حرکت میکند که هوشمندتر و مستقلتر باشند. تحقیقات جدید در حوزههایی مانند Automated Machine Learning (AutoML) و Meta-Learning به دنبال ساخت شبکههایی هستند که:
- کاهش نیاز به تنظیمات دستی: در مدلهای فعلی، مهندسان باید زمان زیادی را صرف تنظیم دستی ابرپارامترها (Hyperparameters) کنند. تحقیقات جدید به دنبال الگوریتمهایی است که خودشان بتوانند مقدار بهینه بایاس و وزنهای اولیه را بدون دخالت انسان پیدا کنند.
- شبکههای عصبی پویا: دانشمندان در حال توسعهٔ مدلهایی هستند که ساختارشان — از جمله تعداد لایهها یا نورونها — در طول آموزش بر اساس پیچیدگی داده تغییر میکند: در مواجهه با دادههای ساده، شبکه خود را سبکتر میکند؛ و در مواجهه با دادههای پیچیده، پارامترهای جدیدی برای انطباق بهتر ایجاد میکند.
- یادگیری الهامگرفته از بیولوژی: هدف نهایی، تقلید از کارایی مغز انسان است: سیستمی که بدون پیشفرضهای صلب، با حداقل داده و بهصورت خودکار، الگوهای پنهان محیط را شناسایی کرده و خود را با آنها سازگار میکند.
.
جمع بندی
وزنها و بایاسها هستهی تصمیمگیری در شبکههای عصبی هستند و کیفیت یادگیری مدل بهطور مستقیم به نحوه تنظیم آنها وابسته است. وزنها مشخص میکنند هر ورودی چه میزان بر خروجی اثر بگذارد و بایاسها امکان جابهجایی و انعطافپذیری تابع تصمیمگیری را فراهم میکنند. ترکیبی که به شبکه عصبی اجازه میدهد فراتر از روابط خطی ساده عمل کند.
در این مقاله دیدیم که وزن و بایاس صرفاً پارامترهای عددی نیستند. بلکه مفاهیمی پویا هستند که در طول آموزش و از طریق الگوریتمهایی مانند گرادیان کاهشی و پسانتشار بهطور مداوم بهروزرسانی میشوند. همچنین روشن شد که انتخاب و تنظیم صحیح این پارامترها نقش مهمی در جلوگیری از بیشبرازش، بهبود تعمیمپذیری و افزایش پایداری مدل دارد.
در نهایت، فهم عمیق وزنها و بایاسها پلی میان ریاضیات، دادهها و رفتار واقعی شبکههای عصبی ایجاد میکند. این درک، پایهای ضروری برای تحلیل معماریهای پیشرفتهتر و طراحی آگاهانه مدلهای یادگیری عمیق فراهم میسازد . شما را از کاربر صرف به تحلیلگر و طراح هوشمند سیستمهای یادگیری ماشین تبدیل میکند.



