

مقدمه
پرسپترون تکلایه سادهترین و در عین حال بنیادیترین شکل یک شبکه عصبی مصنوعی است که درک آن، نقطه شروع فهم عمیقتر یادگیری ماشین و شبکههای عصبی محسوب میشود. بسیاری از مفاهیم کلیدی مانند وزن، بایاس، تابع فعالسازی و مرز تصمیمگیری، نخستینبار در قالب همین مدل ساده معنا پیدا کردهاند.
با وجود سادگی ساختار، پیادهسازی عملی پرسپترون نقش مهمی در درک نحوه یادگیری مدلها از دادهها دارد. استفاده از فریمورکهایی مانند TensorFlow این امکان را فراهم میکند که مفاهیم تئوریک بهصورت عملی و در مقیاس واقعی پیادهسازی شوند و رفتار مدل در فرآیند آموزش بهطور ملموس مشاهده شود.
در این مطلب، ابتدا مفهوم پرسپترون تکلایه بهصورت شهودی و فنی مرور میشود و سپس نحوه پیادهسازی آن با TensorFlow بررسی خواهد شد. هدف این است که خواننده پس از مطالعه این مقاله، بتواند ارتباط میان نظریه شبکههای عصبی و پیادهسازی عملی آنها را بهدرستی درک کند.
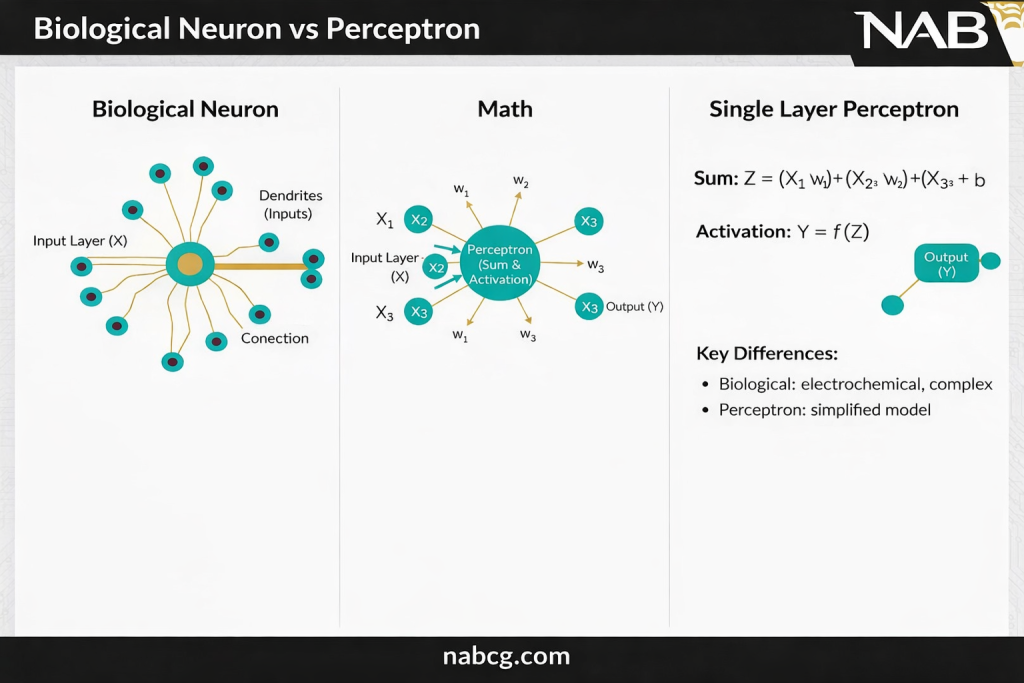
پرسپترون؛ سنگبنای هوش مصنوعی
پرسپترون (Perceptron) سادهترین شکل یک شبکه عصبی است که با ترکیب ورودیها و وزنها و اعمال یک تابع فعالساز، تصمیمگیری میکند. این مدل عمدتاً برای حل مسائل طبقهبندی دوتایی (Binary Classification) استفاده میشود و واحد سازنده اصلی بسیاری از مدلهای پیشرفته یادگیری عمیق است.
ویژگیهای کلیدی:
- ورودیهای متعددی را دریافت کرده و به هر کدام وزنی اختصاص میدهد.
- مجموع وزندار ورودیها را محاسبه کرده و یک مقدار آستانه (Threshold) بر آن اعمال میکند.
- خروجی آن همیشه یک مقدار دوتایی (۰ یا ۱) است.
- فونداسیون و زیربنای شبکههای عصبی بزرگتر را تشکیل میدهد.
.
اجزای اصلی یک پرسپترون

۱. ورودیها (x1, x2, …, xn)
اینها ویژگیها یا صفات قابل اندازهگیری از یک داده هستند که پرسپترون برای تصمیمگیری از آنها استفاده میکند. هر ورودی سیگنالی را ارسال میکند که در نتیجه نهایی نقش دارد.
- مثال: در یک گیت منطقی OR، ورودیها دوتایی هستند x1, x2 ∈ {0, 1}:
- ورودیها به تنهایی هیچ نفوذی ندارند، مگر اینکه در وزنها ضرب شوند.
۲. وزنها (w1, w2, …, wn)
وزنها تعیین میکنند که هر ورودی چقدر در پیشبینی نهایی سهم دارد. وزن بزرگتر به معنای تأثیرگذاری بیشتر آن ورودی خاص است.
- وزنها در طول فرآیند آموزش و بر اساس خطاها اصلاح میشوند و یاد میگیرند.
- آنها در واقع «امتیاز اهمیت» برای هر ویژگی هستند.
۳. بایاس (Bias)
بایاس یک مقدار ثابت است که به مجموع وزندار اضافه میشود تا مرز تصمیمگیری را جابهجا کند.
- بایاس به پرسپترون اجازه میدهد حتی زمانی که تمام ورودیها صفر هستند، طبقهبندی درستی انجام دهد.
- بدون بایاس، مدل مجبور است همیشه مرز تصمیمگیری را از مبدأ مختصات عبور دهد که باعث کاهش دقت میشود.
تفاوت وزن و بایاس: وزنها کنترل میکنند که هر ورودی چقدر بر خروجی اثر بگذارد (شیب خط را تغییر میدهند)، اما بایاس زمان فعال شدن پرسپترون را مستقل از ورودیها کنترل میکند (خط را بالا/پایین یا چپ/راست میبرد).
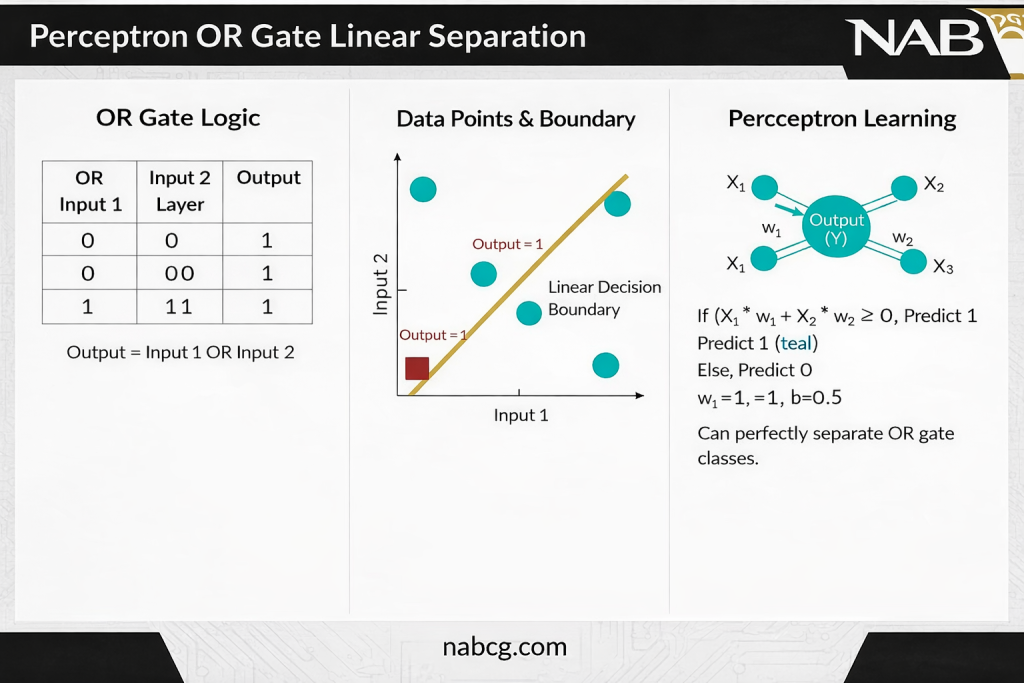
۴. ورودی خالص (Weighted Sum)
این مقدار نشاندهنده اثر ترکیبی تمام ورودیها و وزنهای آنهاست:
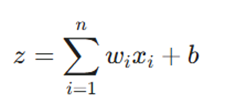
این عدد قدرت فعالسازی را قبل از عبور از تابع فعالساز نشان میدهد.
۵. تابع فعالساز (Step Function)
این تابع، ورودی عددی را به یک خروجی دوتایی تبدیل میکند:
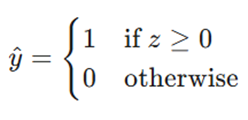
اگرچه مرز تصمیمگیری خطی باقی میماند، اما این تابع مفهوم غیرخطی بودن را به تصمیمگیری وارد میکند.
مبانی شبکه عصبی (تعمیم پرسپترون)
یک شبکه عصبی، با اتصال تعداد زیادی پرسپترون در چندین لایه، قدرت پرسپترون را گسترش میدهد.
۱. لایه ورودی (Input Layer)
این لایه بردار ویژگیهای خام را دریافت میکند. هیچ محاسباتی در اینجا انجام نمیشود و فقط مقادیر را به لایه بعدی پاس میدهد.
۲. لایههای پنهان (Hidden Layers)
این لایهها شامل چندین نورون هستند که نمایشهای میانی دادهها را یاد میگیرند.
محاسبات لایه پنهان:
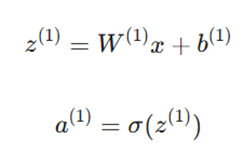
در اینجا W ماتریس وزنها، b بردار بایاس و σ تابع فعالساز غیرخطی(مانند ReLU یا Sigmoid) است. لایههای پنهان الگوهای پیچیدهای را شناسایی میکنند که از ورودی خام به تنهایی قابل رویت نیستند.
۳. لایه خروجی (Output Layer)
این لایه پیشبینی نهایی را تولید میکند که بسته به مسئله میتواند دوتایی، چندکلاسه یا یک عدد پیوسته باشد.
- Sigmoid: برای طبقهبندی دوتایی.
- Softmax: برای طبقهبندی چندکلاسه.
- Linear: برای مسائل رگرسیون.
نکته نهایی: به دلیل وجود لایههای متعدد و توابع فعالساز غیرخطی، شبکههای عصبی میتوانند مرزهای تصمیمگیری پیچیده و غیرخطی را مدلسازی کنند، در حالی که یک تکپرسپترون فقط قادر به رسم یک خط راست است.
پرسپترون چگونه کار میکند؟ از ساختار اولیه تا یادگیری هوشمند
پرسپترون در سادهترین تعریف، یک طبقهبندیکننده خطی (Linear Classifier) است. این الگوریتم تلاش میکند با ترسیم یک خط مستقیم (در فضاهای دوبعدی) یا یک ابرصفحه (در فضاهای چندبعدی)، دادهها را به دو دسته مجزا تقسیم کند.
۱. فرآیند پردازش داده (انتشار رو به جلو)
یک پرسپترون برای تولید خروجی، مراحل زیر را طی میکند:
- محاسبه مجموع وزندار: ابتدا هر ویژگی ورودی (xi) در وزن مخصوص به خود (wi) ضرب شده و در نهایت با یک مقدار بایاس (b) جمع میشود.
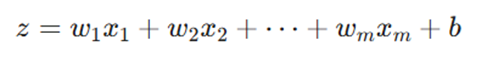
- اعمال تابع فعالساز: این مقدار عددی (z) وارد یک تابع تصمیمگیرنده به نام تابع فعالساز (Activation Function) میشود. در پرسپترونهای اولیه، از تابع پلهای واحد (Heaviside Step Function) استفاده میشود که خروجی را به صورت دوتایی (۰ و ۱) یا (۱- و ۱) صادر میکند.
۲. فرآیند آموزش (قانون یادگیری پرسپترون)
آموزش پرسپترون به معنای یافتن وزنها و بایاس مناسب برای طبقهبندی درست اکثر دادهها است. این فرآیند به صورت تکرار شونده (Iterative) انجام میشود:
- پیشبینی و مقایسه: مدل برای هر داده یک خروجی پیشبینی کرده و آن را با برچسب واقعی (y) مقایسه میکند تا خطا مشخص شود:
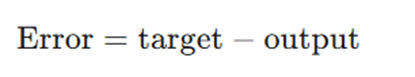
2.بهروزرسانی وزنها: اگر پیشبینی اشتباه باشد، وزنها متناسب با نرخ یادگیری (η) و مقدار خطا اصلاح میشوند:

- اصلاح بایاس: بایاس نیز به همین ترتیب برای جابهجایی مرز تصمیمگیری به چپ یا راست آپدیت میشود.
- تکرار در اپوکها: این چرخه چندین بار روی کل مجموعهداده (Epoch) تکرار میشود تا وزنها به ثبات برسند.
نکته کلیدی: همگرایی پرسپترون تنها زمانی تضمین میشود که دادهها به صورت خطی تفکیکپذیر باشند.
گذار از پرسپترون ساده به شبکههای عمیق (توابع فعالساز)
پرسپترونهای تکلایه به دلیل استفاده از تابع پلهای که مشتقناپذیر است، نمیتوانند الگوهای غیرخطی را یاد بگیرند و در الگوریتم انتشار رو به عقب (Backpropagation) شکست میخورند. برای حل این مشکل، توابع فعالساز غیرخطی و مشتقپذیر معرفی شدند:
جدول مقایسهای توابع فعالساز مدرن
| تابع فعالساز | بازه خروجی | ویژگی اصلی | چالش بزرگ |
| Sigmoid | (۰ تا ۱) | مناسب برای پیشبینی احتمال | اشباع شدن و از بین رفتن گرادیان |
| Tanh | (۱- تا ۱) | خروجی صفر-مرکز (Zero-centered) | مشابه سیگموئید دچار اشباع میشود |
| ReLU | ]۰ تا ∞) | سرعت بسیار بالا در همگرایی (SGD) | مشکل “نورونهای مرده” (Dying ReLU) |
| Leaky ReLU | (∞- تا ∞+) | حل مشکل نورونهای مرده با شیب کم در ناحیه منفی | نیاز به تنظیم هایپرپارامتر اضافی |
در حالی که پرسپترونهای اولیه فقط قادر به حل مسائل ساده و خطی بودند، شبکههای عصبی مدرن با جایگزینی تابع پلهای با توابعی مثل ReLU و استفاده از لایههای پنهان، به تخمینزنندههای جهانی (Universal Approximators) تبدیل شدهاند که میتوانند پیچیدهترین روابط غیرخطی را درک کنند.
پیاده سازی پرسپترون از صفر با پایتون
.
گام ۱: فراخوانی کتابخانهها و ایجاد مجموعهداده
در اولین قدم از پیادهسازی، ما دو ابزار حیاتی را وارد پروژه میکنیم: کتابخانه NumPy که ستون فقرات محاسبات عددی و ماتریسی در پایتون است، و کتابخانه Matplotlib که به ما کمک میکند روند یادگیری را به صورت بصری دنبال کنیم.
برای این آموزش، ما از مجموعهداده گیت منطقی OR استفاده میکنیم. انتخاب این گیت هوشمندانه است؛ زیرا دادههای آن به صورت خطی تفکیکپذیر هستند، به این معنی که میتوان با یک خط مستقیم آنها را از هم جدا کرد و این دقیقاً همان کاری است که یک پرسپترون در آن مهارت کامل دارد.
import numpy as np
import matplotlib.pyplot as plt
X_or = np.array([
[0, 0],
[0, 1],
[1, 0],
[1, 1]
])
y_or = np.array([0, 1, 1, 1])
گام ۲: تعریف کلاس پرسپترون
در این مرحله، ما کل بدنه مدل خود را در قالب یک کلاس (Class) در پایتون تعریف میکنیم. این کلاس شامل سه بخش حیاتی است که موتور محرک هوش مصنوعی ما محسوب میشوند:
- سازنده: در این بخش، تنظیمات اولیه مدل مانند نرخ یادگیری و تعداد دفعات تکرار (Epochs) مشخص میشوند.
- متد پیشبینی: این تابع وظیفه دارد با استفاده از وزنهای فعلی، ورودیهای جدید را تحلیل کرده و برچسب خروجی (۰ یا ۱) را حدس بزند.
- متد آموزش: این بخش قلب تپنده مدل است. تابع ().fit با مرور مجموعهداده، هر زمان که با یک تشخیص اشتباه (Misclassification) مواجه شود، وزنها و بایاس را اصلاح میکند. همچنین، این متد میزان خطاهای رخداده در هر اپوک را ردیابی و ذخیره میکند تا بتوانیم روند پیشرفت مدل را مانیتور کنیم.
class Perceptron:
def __init__(self, learning_rate=0.1, epochs=20):
self.lr = learning_rate
self.epochs = epochs
self.weights = None
self.bias = None
self.errors_per_epoch = []
def predict(self, X):
linear_output = np.dot(X, self.weights) + self.bias
return np.where(linear_output >= 0, 1, 0)
def fit(self, X, y):
n_samples, n_features = X.shape
self.weights = np.zeros(n_features)
self.bias = 0.0
for _ in range(self.epochs):
errors = 0
for xi, target in zip(X, y):
linear_output = np.dot(xi, self.weights) + self.bias
y_pred = 1 if linear_output >= 0 else 0
update = self.lr * (target - y_pred)
self.weights += update * xi
self.bias += update
errors += int(update != 0)
self.errors_per_epoch.append(errors)
گام ۳: آموزش پرسپترون روی دادههای گیت OR
در این مرحله، یک نمونه از کلاس پرسپترون خود میسازیم و آن را با استفاده از مجموعهداده گیت منطقی OR آموزش میدهیم. گیت OR یکی از بهترین مثالها برای تست پرسپترون است، زیرا دادههای آن بهطور خطی تفکیکپذیر هستند.
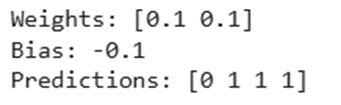
پس از اتمام فرآیند آموزش، موارد زیر را بررسی خواهیم کرد:
- وزنهای یادگرفته شده (Learned Weights): مقادیری که مدل برای تشخیص اهمیت هر ورودی به دست آورده است.
- مقدار بایاس (Bias): عددی که مرز تصمیمگیری را برای بهترین برازش جابهجا کرده است.
- پیشبینیهای نهایی: خروجی مدل که برای گیت OR باید دقیقاً به صورت [0 1 1 1] باشد.
این خروجی به ما ثابت میکند که پرسپترون ساده توانسته است منطق گیت OR را بهطور کامل درک و مدلسازی کند.
p_or = Perceptron(learning_rate=0.1, epochs=20)
p_or.fit(X_or, y_or)
print("Weights:", p_or.weights)
print("Bias:", p_or.bias)
print("Predictions:", p_or.predict(X_or))
خروجی:
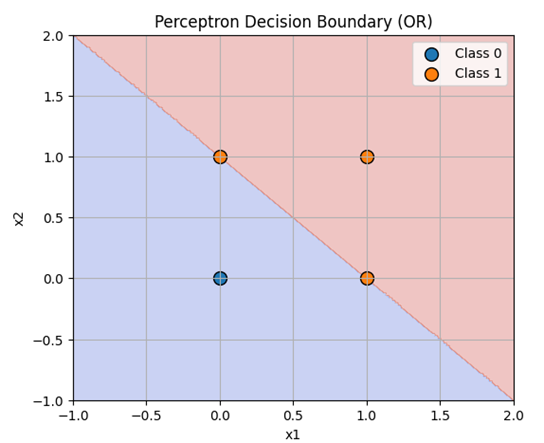
گام4:ترسیم مرز تصمیمگیری (Decision Boundary Plot)
برای اینکه درک کنیم پرسپترون دقیقاً چه منطقی را یاد گرفته است، مراحل زیر را انجام میدهیم:
- ایجاد شبکه نقاط (Dense Grid): ما ابتدا یک شبکه متراکم از نقاط را روی کل فضای ورودی ایجاد میکنیم.
- پیشبینی منطقهای: سپس مدل برای تکتک این نقاط، کلاس (۰ یا ۱) را پیشبینی میکند و بر اساس این پیشبینی، هر ناحیه را با رنگ خاصی مشخص میکنیم.
- انطباق با دادههای واقعی: در نهایت، نقاط واقعی دادههای مربوط به گیت OR را روی این نواحی رنگی قرار میدهیم .
def plot_decision_boundary(X, y, model, title):
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(
np.linspace(x_min, x_max, 300),
np.linspace(y_min, y_max, 300)
)
grid = np.c_[xx.ravel(), yy.ravel()]
Z = model.predict(grid)
Z = Z.reshape(xx.shape)
plt.figure(figsize=(6, 5))
plt.contourf(xx, yy, Z, alpha=0.3, cmap="coolwarm")
for label in np.unique(y):
pts = X[y == label]
plt.scatter(pts[:, 0], pts[:, 1],
s=100, edgecolor='black',
label=f"Class {label}")
plt.title(title)
plt.xlabel("x1")
plt.ylabel("x2")
plt.legend()
plt.grid(True)
plt.show()
plot_decision_boundary(X_or, y_or, p_or, "Perceptron Decision Boundary (OR)")
خروجی:
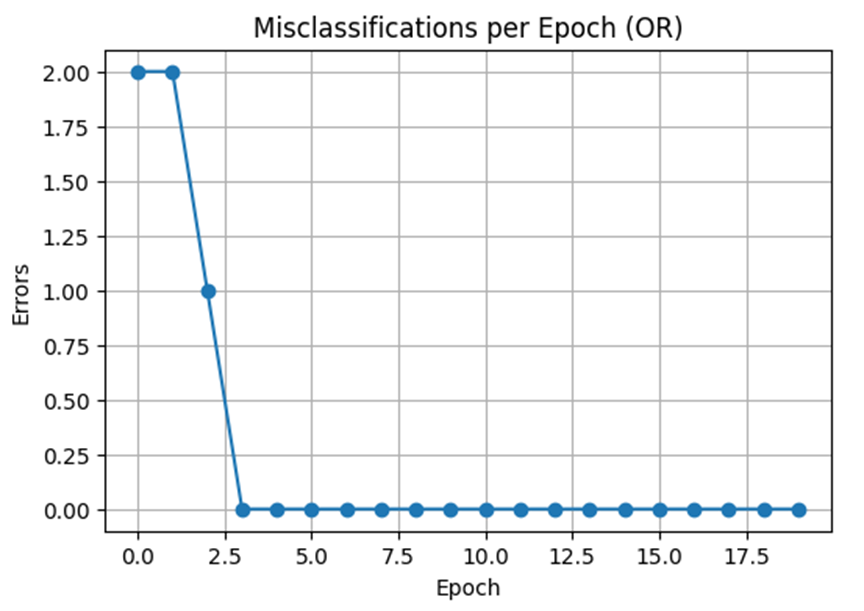
گام5:ترسیم نمودار خطاهای طبقهبندی در هر اپوک (Misclassifications per Epoch)
این نمودار به شکلی بصری نشان میدهد که میزان خطای مدل در طول دورههای آموزشی (Epochs) چگونه تغییر میکند.
- رهگیری فرآیند آموزش: در هر اپوک، تعداد دادههایی که مدل به اشتباه طبقهبندی کرده است شمارش و ترسیم میشود.
- تشخیص همگرایی: برای مسائلی که به صورت خطی تفکیکپذیر هستند (مانند گیت منطقی OR)، تعداد اشتباهات باید به سرعت کاهش یافته و به عدد صفر برسد. رسیدن به خطای صفر به این معناست که مدل «همگرا» شده و وزنهای بهینه را پیدا کرده است.
- تحلیل رفتار مدل: اگر نمودار پس از چندین اپوک به صفر نرسد یا نوسان زیادی داشته باشد، نشاندهنده این است که یا دادهها به صورت خطی تفکیکپذیر نیستند و یا نرخ یادگیری نیاز به تنظیم مجدد دارد.
plt.figure(figsize=(6, 4))
plt.plot(p_or.errors_per_epoch, marker='o')
plt.title("Misclassifications per Epoch (OR)")
plt.xlabel("Epoch")
plt.ylabel("Errors")
plt.grid(True)
plt.show()
خروجی:
مقایسه پرسپترون (Perceptron) و پرسپترون چندلایه (MLP)
در جدول زیر، تفاوتهای بنیادین این دو مدل را از زوایای مختلف بررسی کردهایم:
| جنبه مقایسه | پرسپترون ساده (Single-Layer) | پرسپترون چندلایه (MLP) |
| عمق مدل | تکلایه و فاقد نورونهای پنهان | دارای چندین لایه (یک یا چند لایه پنهان) |
| نوع الگوهای یادگیری | فقط روابط خطی و جداسازی با خط مستقیم | الگوهای پیچیده، غیرخطی و مرزهای منحنی |
| توانایی حل مسئله | ناتوان در حل مسئله XOR یا دادههای غیرخطی | به راحتی XOR و سایر وظایف پیچیده را حل میکند |
| توابع فعالساز | استفاده از تابع پلهای ساده (خروجی ۰/۱) | استفاده از ReLU، Sigmoid و Tanh برای یادگیری غنیتر |
| روش یادگیری | آموزش با قانون بهروزرسانی ساده پرسپترون | آموزش با استفاده از انتشار رو به عقب (Backpropagation) |
| کاربرد در دنیای واقعی | محدود به دموهای ساده و طبقهبندیهای پایه | استفاده در سیستمهای پیشرفته بینایی ماشین و NLP |
مزایا
- معماری ساده: درک، پیادهسازی و تجسم آن به عنوان یک مدل پایه بسیار آسان است.
- آموزش سریع: محاسبات سبک باعث میشود یادگیری حتی در دستگاههای ضعیف بسیار سریع باشد.
- عملکرد عالی در دادههای خطی: اگر مرز خطی وجود داشته باشد، به عملکرد کامل (Perfect) میرسد.
- نیاز به منابع کم: حافظه و توان پردازشی حداقلی میطلبد و برای مجموعهدادههای کوچک مناسب است.
- زیربنای یادگیری عمیق: پایه مفهومی برای ساخت مدلهای MLP و شبکههای پیچیده را فراهم میکند.
.
محدودیتها
- عدم یادگیری غیرخطی: در مسائلی مثل XOR که به مرزهای منحنی نیاز دارند، شکست میخورد.1
- خروجی صرفاً دوتایی: بدون تغییرات اضافی، نمیتواند خروجیهای چندکلاسه یا احتمالی تولید کند.
- فقدان لایه پنهان: به دلیل نداشتن عمق، قادر به یادگیری الگوهای سلسلهمراتبی یا انتزاعی نیست.
- حساسیت به مقیاس دادهها: اگر ویژگیها نرمالسازی یا مقیاسبندی نشوند، عملکرد به شدت افت میکند.
- نامناسب برای ML مدرن: برای وظایف امروزی مانند بینایی ماشین یا مدلسازی توالیها بسیار ساده است.
.
کاربردهای استراتژیک پرسپترون
پرسپترون با وجود سادگی، در پنج حوزه کلیدی نقشآفرینی میکند که آن را به فراتر از یک مدل تئوری تبدیل کرده است:
- ۱. طبقهبندی دوتایی (Binary Classification): این مدل در تصمیمگیریهای حساس “صفر و یک” بسیار کارآمد است. برای مثال، در تشخیص هرزنامه (Spam Detection)، پرسپترون با بررسی وجود کلمات کلیدی خاص، ایمیلها را به دو دسته سالم یا هرزنامه طبقهبندی میکند.
- ۲. مدلسازی گیتهای منطقی (Logic Gate Modelling): پرسپترون قادر است گیتهای منطقی پایه مانند AND، OR و NAND را با دقت ۱۰۰٪ پیادهسازی کند. این ویژگی ثابت میکند که یک نورون واحد میتواند منطقهای شرطی پایه را در سختافزارها یا نرمافزارها شبیهسازی کند.
- ۳. مبانی تشخیص الگو (Pattern Recognition Basics): در سناریوهایی که کلاسهای داده با یک خط مستقیم (Linear) از هم جدا میشوند، پرسپترون سریعترین ابزار است. این مدل به عنوان سنگبنای سیستمهای تشخیص الگو عمل کرده و به شناسایی اشکال یا روندهای ساده در دادههای خطی کمک میکند.
- ۴. تحلیل اهمیت ویژگیها (Feature Importance Insight): در مهندسی داده، مقادیر وزنها (Weights) در یک پرسپترون مانند یک قطبنما عمل میکنند. وزنهای بالاتر نشان میدهند که کدام ویژگی (مثلاً قیمت یا سن بنا) تأثیر حیاتیتری بر نتیجه نهایی دارد؛ این موضوع به متخصصان اجازه میدهد روی دادههای مهمتر تمرکز کنند.
- ۵. استاندارد آموزشی (The Educational Standard): پرسپترون محبوبترین ابزار آموزشی برای معرفی مفاهیم انتشار رو به جلو و قانون یادگیری به دانشجویان است. درک این مدل، مسیر را برای یادگیری شبکههای عصبی پیچیده و معماریهای عمیق (Deep Learning) هموار میکند.
.
پیادهسازی پرسپترون در تنسورفلو
بیایید با استفاده از کتابخانه قدرتمند TensorFlow، یک پرسپترون تکلایه ساده بسازیم. این مدل به شما کمک میکند تا درک کنید که شبکههای عصبی در بنیادیترین سطح خود چگونه عمل میکنند.
گام اول: فراخوانی کتابخانهها
برای شروع، به دو ابزار کلیدی در اکوسیستم پایتون نیاز داریم:
- Scikit-learn: این کتابخانه ابزارهای بسیار کارآمد و سادهای را برای دادهکاوی و یادگیری ماشین فراهم میکند. اسکیلِرن به ما اجازه میدهد تا الگوریتمهای طبقهبندی، رگرسیون و خوشهبندی را با سرعت بسیار بالا پیادهسازی کنیم.
- TensorFlow: تنسورفلو یک کتابخانه متنباز و پیشرو در حوزه هوش مصنوعی است که توسط گوگل توسعه یافته. این کتابخانه مجموعهای از توابع حرفهای را در اختیار ما قرار میدهد که به کمک آنها میتوانیم پیچیدهترین معماریهای عصبی را تنها با چند خط کد کوتاه پیادهسازی کنیم.
import tensorflow as tf
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
گام ۲: ایجاد و تقسیمبندی مجموعه داده مصنوعی
ما یک مجموعه داده ساده برای طبقهبندی دوتایی (Binary Classification) ایجاد میکنیم که دارای ۲ ویژگی (Feature) است. استفاده از دادههای مصنوعی به ما این امکان را میدهد که کنترل کاملی روی متغیرها داشته باشیم و مفاهیم آموزشی را دقیقتر لمس کنیم.
پس از تولید دادهها، آنها را به دو بخش آموزش (Training) و تست (Testing) تقسیم میکنیم. این کار برای این است که مطمئن شویم مدل ما واقعاً یاد گرفته است و صرفاً دادهها را حفظ نکرده است )جلوگیری از (Overfitting
X, y = make_classification(
n_samples=1000,
n_features=2,
n_informative=2,
n_redundant=0,
n_repeated=0,
n_classes=2,
random_state=42
)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
گام ۳: استانداردسازی مجموعهداده (Standardization)
اکنون زمان آن رسیده است که مجموعهداده خود را استانداردسازی کنیم تا امکان محاسبات سریعتر و دقیقتر فراهم شود.
اما چرا این کار را انجام میدهیم؟
- سرعت در همگرایی: استانداردسازی به مدل کمک میکند تا بسیار سریعتر به نقطه بهینه (همگرایی) برسد.
- افزایش دقت: این تکنیک اغلب باعث بهبود چشمگیر دقت نهایی مدل میشود؛ چرا که از غلبه عددی برخی ویژگیها بر ویژگیهای دیگر جلوگیری میکند.
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
گام ۴: ساخت شبکه عصبی (تولد اولین مدل)
در این مرحله، ما با استفاده از معماری Sequential (ترتیبی)، یک مدل تکلایه میسازیم که شامل یک لایه Dense (متراکم) است. عبارت Dense(1) به این معناست که این لایه تنها دارای یک نورون است.
برای خروجی این نورون، ما از تابع فعالساز Sigmoid استفاده میکنیم. این تابع، خروجی را به عددی بین ۰ و ۱ تبدیل میکند که برای مسائل طبقهبندی دوتایی (Binary Classification) ایدهآل است.
چرا به جای مدلهای قدیمی از سیگموئید استفاده میکنیم؟ پرسپترونهای اولیه از تابع پلهای (Step Function) استفاده میکردند که خروجی آن فقط ۰ یا ۱ مطلق بود و روش آموزش متفاوتی داشت. اما مدلهای مدرن از Sigmoid استفاده میکنند؛ زیرا این تابع نرم و پیوسته است. این ویژگی به مدل کمک میکند تا با استفاده از روشهای مبتنی بر گرادیان، فرآیند یادگیری را بسیار بهتر و دقیقتر انجام دهد.
در نهایت، پارامتر input_shape=(2,) مشخص میکند که هر نمونه ورودی ما شامل دو ویژگی (Feature) مجزا است که وارد شبکه میشود.
model = tf.keras.Sequential([
tf.keras.layers.Dense(1, activation='sigmoid', input_shape=(2,))
])
گام ۵: کامپایل کردن مدل (تنظیم موتور محرک)
حالا که ساختار شبکه را طراحی کردیم، نوبت به «کامپایل کردن» آن میرسد. در این مرحله، ما استراتژی یادگیری مدل را مشخص میکنیم:
- بهینهساز: ما از بهینهساز Adam استفاده میکنیم. این الگوریتم به دلیل کارایی بالا و سرعت مناسب در بهروزرسانی وزنها، یکی از محبوبترین انتخابها در دنیای هوش مصنوعی برای بهینهسازی شبکههای عصبی است.
- تابع زیان: از آنجایی که هدف ما یک مسئله طبقهبندی دوتایی (Binary Classification) با تابع فعالساز سیگموئید است، تابع زیان Binary Cross-Entropy را برمیگزینیم. این تابع به بهترین شکل تفاوت بین پیشبینیهای مدل و واقعیت را محاسبه میکند.
- معیار ارزیابی: برای اینکه بفهمیم مدل چقدر خوب عمل میکند، معیار Accuracy (دقت) را در طول مراحل آموزش و تست رصد میکنیم.
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
گام ۶: آموزش مدل (Training the Model)
حالا زمان آن رسیده است که مدل خود را آموزش دهیم. این کار با تکرار فرآیند یادگیری روی تمام دادههای آموزشی انجام میشود. هر بار که مدل تمام مجموعه داده را یک دور کامل مرور میکند، یک اپوک (Epoch) نامیده میشود.
در طول فرآیند آموزش، دادهها به دستههای کوچکتری به نام Batch Size تقسیم میشوند. اندازه این دستهها تعیین میکند که پیش از بهروزرسانی وزنهای مدل، چه تعداد نمونه باید توسط شبکه پردازش شود.
علاوه بر این، ما بخشی از دادههای آموزشی را به عنوان دادههای اعتبارسنجی (Validation Data) کنار میگذاریم. این کار به ما کمک میکند تا عملکرد مدل را روی دادههایی که قبلاً ندیده است، به صورت لحظهای رصد کنیم و مطمئن شویم که مدل صرفاً دادهها را حفظ نمیکند، بلکه در حال یادگیری مفاهیم است.
history = model.fit(X_train, y_train,
epochs=50,
batch_size=16,
validation_split=0.1,
verbose=0)
گام ۷: ارزیابی مدل (Model Evaluation)
پس از پایان فرآیند آموزش، نوبت به سنجش عیار مدل میرسد. در این مرحله، ما عملکرد شبکه عصبی را روی دادههای دیده نشده (Unseen Data) یا همان مجموعه داده تست، آزمایش میکنیم. هدف اصلی این است که بفهمیم آیا مدل ما واقعاً یاد گرفته است که الگوها را تشخیص دهد یا صرفاً دادههای آموزشی را حفظ کرده است .
loss, accuracy = model.evaluate(X_test, y_test, verbose=0)
print(f"Test Accuracy: {accuracy:.2f}")
خروجی:

حتی با استفاده از چنین مدل سادهای، ما موفق شدیم به دقتی نزدیک به ۸۸ درصد دست پیدا کنیم. این عدد برای یک شبکه عصبی که تنها از یک لایه تشکیل شده است، واقعاً تحسینبرانگیز و فراتر از انتظار است.
با این حال، مسیر یادگیری در اینجا متوقف نمیشود. برای دستیابی به نتایجی درخشانتر و دقتهای بالاتر، میتوانیم از استراتژیهای زیر استفاده کنیم:
- افزایش لایههای پنهان: با عمیقتر کردن شبکه، قدرت مدل در درک الگوهای پیچیدهتر به طرز چشمگیری افزایش مییابد.
- استفاده از معماریهای پیشرفته: مهاجرت به سمت ساختارهای تخصصیتر مانند شبکههای عصبی کانولوشنی (CNNs) که پادشاه پردازش تصویر و دادههای پیچیده هستند.
این نتایج به ما ثابت میکند که پرسپترونها، علیرغم ساختار سادهشان، هنوز هم زیربنای مستحکم هوش مصنوعی مدرن هستند.
جمع بندی
پرسپترون تکلایه اگرچه از نظر ساختار بسیار ساده است، اما نقش مهمی در شکلگیری و فهم شبکههای عصبی مدرن دارد. این مدل نشان میدهد که چگونه یک سیستم میتواند با تنظیم وزنها و بایاسها، از دادهها یاد بگیرد و یک مرز تصمیمگیری خطی ایجاد کند.
در این فایل دیدیم که پیادهسازی پرسپترون با TensorFlow نهتنها فرآیند آموزش را سادهتر میکند، بلکه امکان مشاهده رفتار مدل، همگرایی و دقت پیشبینیها را نیز فراهم میآورد. همچنین مشخص شد که با وجود کارایی پرسپترون در مسائل خطی ساده، این مدل در مواجهه با دادههای غیرخطی و مسائل پیچیده محدودیتهای جدی دارد.
در نهایت، پرسپترون تکلایه را میتوان سکوی پرتابی برای ورود به شبکههای عصبی پیشرفتهتر دانست. تسلط بر این مدل، درک مفاهیم بنیادینی را فراهم میکند که برای یادگیری شبکههای چندلایه (MLP) و معماریهای عمیقتر ضروری هستند و مسیر یادگیری عمیق را هموارتر میسازند.



