

مقدمه
در فرآیند آموزش مدلهای یادگیری عمیق، یکی از چالشهای اصلی گرادیان کاهشی، نوسان مسیر بهینهسازی و کندی همگرایی در نواحی خاص از فضای پارامترهاست. بهویژه در مسائل دارای سطح خطای ناهموار یا گرادیانهای نویزی، گرادیان کاهشی ساده ممکن است بهصورت زیگزاگی حرکت کند و زمان زیادی را صرف رسیدن به ناحیهی مناسب بهینه نماید.
روش Momentum با الهام از مفاهیم دینامیکی، سازوکاری برای کاهش این نوسانات و تسریع همگرایی ارائه میدهد. این روش با ترکیب گرادیان فعلی و جهت حرکت گذشته، نوعی اینرسی در فرآیند بهروزرسانی پارامترها ایجاد میکند که باعث هموارتر شدن مسیر بهینهسازی میشود Momentum . یکی از نخستین گامها در مسیر توسعهی بهینهسازهای پیشرفتهتر بوده و نقش مهمی در تکامل الگوریتمهای آموزش شبکههای عصبی ایفا کرده است.
هدف این مطلب ارائهی یک بررسی جامع از Momentum است؛ از شهود و فرمولبندی ریاضی گرفته تا مثالهای عددی، پیادهسازی عملی و مقایسه با گرادیان کاهشی ساده و روشهای پیشرفتهتر. تمرکز اصلی بر این است که روشن شود Momentum چگونه عمل میکند، چه مشکلی را حل میکند و در چه شرایطی استفاده از آن منطقیتر است.
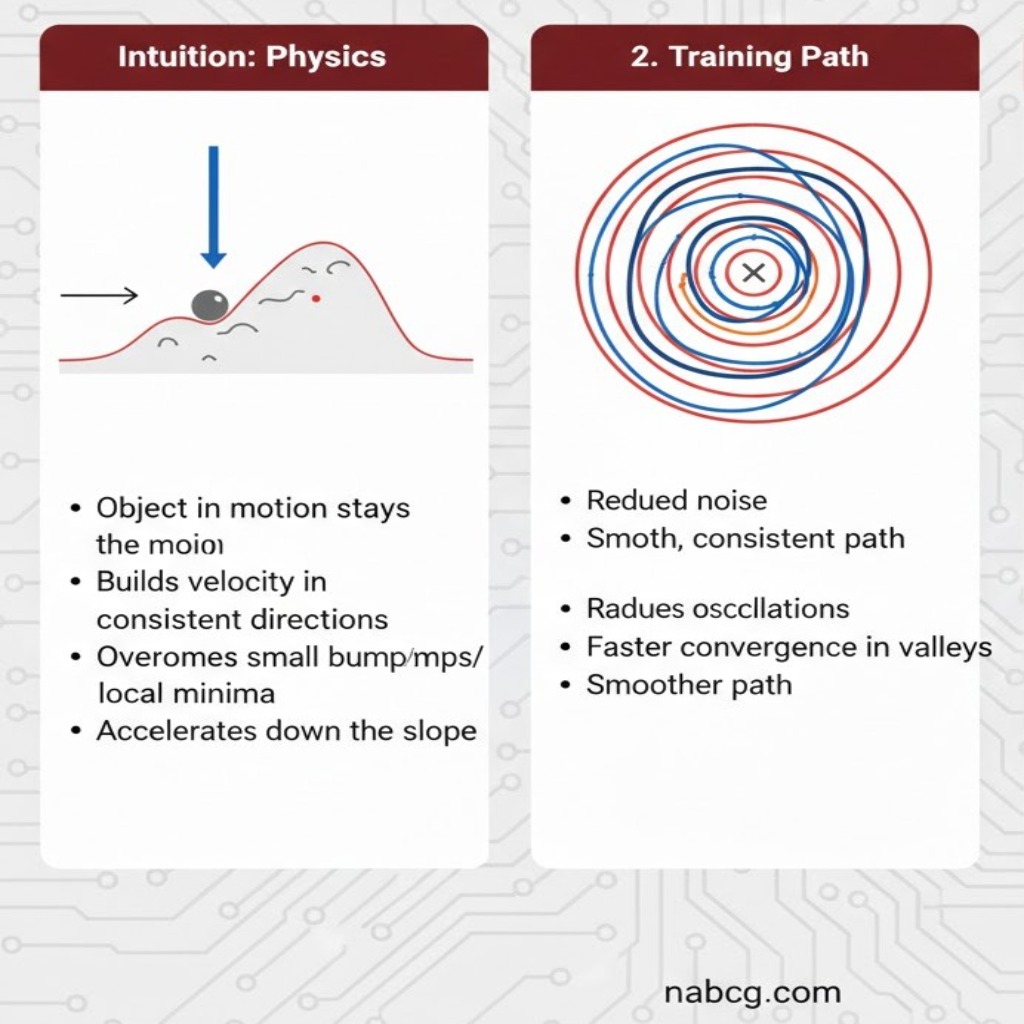
ممنتوم(Momentum) چیست؟
در دنیای هوش مصنوعی ممنتوم دقیقاً مانند مفهوم تکانه در فیزیک عمل میکند. تصور کنید یک توپ سنگین را از بالای یک تپهی ناهموار به پایین رها میکنید. این توپ در حین پایین آمدن، سرعت و جرم خود را حفظ کرده و تکانه (Momentum) میگیرد.
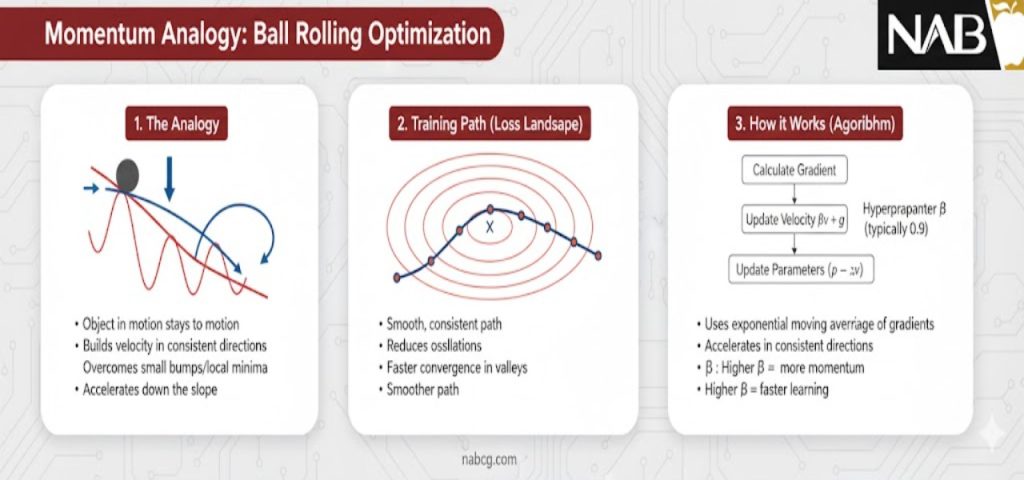
- غلبه بر موانع: به دلیل سنگینی و سرعتی که توپ پیدا کرده، دستاندازهای کوچک یا چالههای کمعمق مسیر نمیتوانند آن را متوقف کنند؛ توپ از روی آنها میپرد و به سمت پایینترین نقطه دره حرکت میکند.
- حرکت روان: ممنتوم باعث میشود که توپ به جای لرزشهای بیهوده به چپ و راست، مسیری مستقیم و روان را به سمت هدف طی کند.
- خلاصه: در آموزش مدل، ممنتوم یعنی حافظه داشتن؛ یعنی مدل گامهای قبلی خود را به یاد میآورد و از آنها برای شتاب گرفتن در جهت درست استفاده میکند.
تعریف تخصصی
در محاسبات پیشرفته، ممنتوم یک متد بهینهسازی مرتبه اول است که با انباشت (Accumulation) میانگین متحرک نمایی گرادیانهای گذشته، یک بردار سرعت (Velocity) ایجاد کرده و از آن برای بهروزرسانی پارامترها استفاده میکند. هدف اصلی این تکنیک، تعدیل نرخ یادگیری در جهتهایی است که دارای انحنای بالا (High Curvature) هستند
.
ممنتوم(Momentum) چگونه کار میکند؟
در روش گرادیان کاهشی سنتی (Vanilla SGD)، بهینهساز مانند فردی است که در هر گام فقط به زیر پای خود نگاه میکند و هیچ حافظهای از گامهای قبلی ندارد. این موضوع باعث میشود در مسیرهای پرپیچوهوا، مدل دچار نوسانات فرساینده شود. ممنتوم(Momentum) برای حل این بحران، مفهوم اینرسی (Inertia) یا همان لختی را وارد معادلات کرد.
ممنتوم با اضافه کردن بخشی از بردار بهروزرسانی قبلی به بردار فعلی، به مدل اجازه میدهد تا سرعت بگیرد. اثر ترکیبی این فرآیند جادویی است:
- در جهت درست شتاب میگیرد: اگر گرادیانها در چندین گام متوالی همجهت باشند، ممنتوم باعث میشود اندازه گامها به صورت تصاعدی بزرگتر شود تا مدل سریعتر به مقصد برسد.
- نوسانات را خنثی میکند: در مواجهه با نوسانات (Oscillations) ناخواسته (مثلاً در درههای باریکی که دیوارههای تند دارند)، ممنتوم به عنوان یک فیلتر عمل کرده و با خنثی کردن بردارهای مخالف، مسیر حرکت را صاف و پایدار میکند.
.
مبانی ریاضی ممنتوم(Momentum)
برای درک عمیق این فرآیند، باید ریاضیات آن را به عنوان یک سیستم بازخوردی ببینیم. بهروزرسانیهای مبتنی بر ممنتوم در دو گام حیاتی و زنجیرهای تعریف میشوند:
گام اول: بهروزرسانی و انباشت سرعت
در این مرحله، بردار سرعت (vt+1) که قلب تپنده ممنتوم است، محاسبه میشود. این بردار در واقع یک میانگین متحرک نمایی (Exponentially Weighted Moving Average) از تمام گرادیانهای گذشته است:
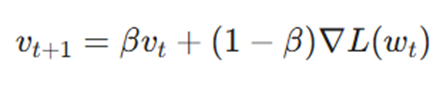
تحلیل متغیرها:
- vt+1 (بردار سرعت): این متغیر نشاندهنده جهت و قدرت حرکت انباشته شده است. ممنتوم به جای اینکه مستقیماً از گرادیان استفاده کند، آن را در این مخزن سرعت ذخیره میکند.
- β (فاکتور ممنتوم): این پارامتر که معمولاً روی ۰.۹ تنظیم میشود، نقش اصطکاک یا حافظه را دارد. اگر β نزدیک به ۱ باشد، یعنی مدل حافظه بسیار طولانی دارد و سرعت قبلی را به شدت حفظ میکند. اگر نزدیک به ۰ باشد، یعنی مدل به سرعت قبلی بیتوجه است و شبیه SGD معمولی عمل میکند.
- L(wt)∇: این همان نیروی لحظهای است که از سمت تابع هزینه به پارامترها وارد میشود تا آنها را تغییر دهد.
.
گام دوم: بهروزرسانی پارامترهای مدل
پس از اینکه سرعت جدید مشخص شد، وزنهای مدل (wt+1) بر اساس این سرعتِ اصلاحشده تغییر مییابند:
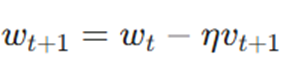
تحلیل متغیرها:
- wt+1: وزنها یا بایاسهای جدید مدل که یک گام به بهینه شدن نزدیکتر شدهاند.
- η (نرخ یادگیری): تعیینکنندهی ابعاد گامی است که در جهت بردار سرعت برداشته میشود. در واقع η کنترل میکند که این سرعت انباشته شده، با چه شدتی روی وزنها اعمال شود.
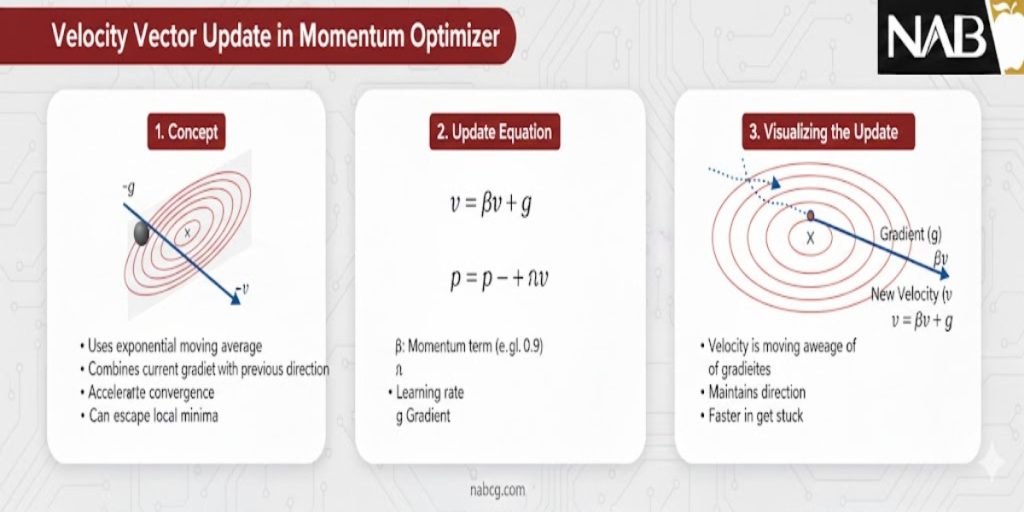
مدیریت استراتژیک هایپرپارامترهای کلیدی
درک تعامل میان این دو پارامتر، مرز بین یک مدل پایدار و یک مدل واگرا را تعیین میکند:
الف) نرخ یادگیری (η – Learning Rate)
این پارامتر حساسترین ولوم در دستگاه یادگیری عمیق است. در ممنتوم، نقش آن دوچندان میشود:
- تعامل با ممنتوم: نرخ یادگیری تعیین میکند که مدل با چه جسارتی در جهت سرعت حرکت کند.
- خطر واگرایی: اگر η بیش از حد بزرگ باشد، ترکیب آن با سرعت انباشته شده باعث میشود مدل مانند یک ماشین مسابقهای که ترمز ندارد، از پیچها به بیرون پرتاب شود (Overshooting).
- پایداری همگرایی: انتخاب دقیق آن تضمین میکند که مدل در فاز نهایی آموزش، به آرامی در کف درهی تابع هزینه مستقر شود.
.
ب) فاکتور ممنتوم (β – Momentum Factor)
این ضریب کنترل میکند که مدل چقدر به تجربیات گذشته خود وفادار بماند:
- اینرسی بالا (β ≈ 0.99): مدل به سختی تغییر جهت میدهد. این برای عبور از نواحی بسیار تخت عالی است اما ممکن است در پیچهای تند باعث شود مدل از مسیر اصلی منحرف شود.
- اینرسی پایین (β ≈ 0.5): مدل به شدت تحت تأثیر گرادیان لحظهای است و نوسانات را به خوبی فیلتر نمیکند.
- تعادل طلایی: عدد ۰.۹ به این دلیل استاندارد شده است که توازنی عالی میان سرعت در مسیرهای مستقیم و قابلیت مانور در پیچها ایجاد میکند.
.
برای اینکه تفاوت حرکت یکنواخت و حرکت شتابدار را درک کنیم، سناریوی زیر را در نظر میگیریم:
تنظیمات آزمایش (Setup)
- هدف: بهینهسازی پارامتر (وزن).w
- هایپرپارامترها: نرخ یادگیری برابر با 0.1 و ضریب ممنتوم (β) برابر با 0.9.
- شرایط اولیه: وزن شروع w0 = 10.0 و سرعت اولیه v0 = 0.
- فرض محیطی: فرض میکنیم در یک درهی شیبدار با گرادیان ثابت به صورت زیر قرار داریم (یعنی مدل باید وزن را کاهش دهد).
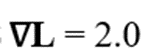
.
محاسبات گامبهگام: ممنتوم در برابر SGD
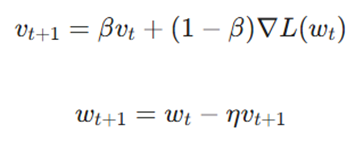
(t=1): شروع حرکت
- ممنتوم:
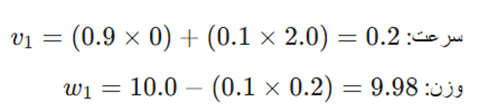
- SGD معمولی:
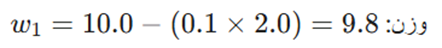
- تحلیل: در گام اول، SGD سریعتر است چون ممنتوم هنوز در حال گرم کردن موتور (انباشت سرعت) است.
(t=2): انباشت اینرسی
- ممنتوم:
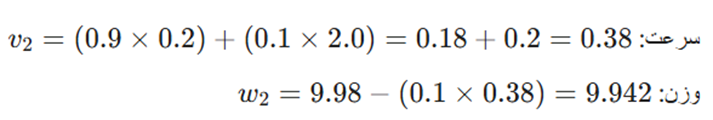
- SGD معمولی:
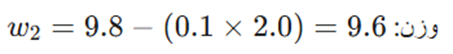
(t=10): شلیک به سمت هدف
اگر محاسبات را ادامه دهیم، در گام دهم اتفاق شگفتانگیزی میافتد:
- ممنتوم: سرعت به حدود1.3 رسیده است. وزن در هر مرحله با گامهای بزرگتری (حدود 0.13) کاهش مییابد.
- SGD معمولی: همچنان با همان گام ثابت 0.2 پیش میرود.
- تحلیل: ممنتوم حالا از SGD سبقت گرفته و با تکانه انباشته شده، مسیر را در مینوردد.
جدول مقایسهای نهایی:
| تکرار (Iteration) | سرعت ممنتوم (vt) | گام ممنتوم (ηvt) | گام SGD معمولی (η∇L) | نتیجهگیری |
| ۱ | 0.20 | 0.020 | 0.20 | SGD در ابتدا جسورتر است. |
| ۲ | 0.38 | 0.038 | 0.20 | ممنتوم شروع به شتابگیری میکند. |
| ۵ | 0.82 | 0.082 | 0.20 | ممنتوم قدرت خود را دو برابر کرده است. |
| ۱۰ | 1.30 | 0.130 | 0.20 | ممنتوم با سرعت خیرهکننده پیش میرود. |
تحلیل :
این مثال عددی به ما میآموزد که ممنتوم یک بهینهساز صبور اما قدرتمند است. در حالی که SGD معمولی مانند کسی است که با قدمهای یکنواخت راه میرود، ممنتوم مانند کسی است که سوار بر اسکی در حال پایین آمدن از کوه است؛ هر چه زمان بیشتری میگذرد، سرعت او به دلیل انباشت تاریخچهی حرکت (بردار v) بیشتر میشود. این دقیقاً همان دلیلی است که باعث میشود مدلهای عمیق بتوانند از نواحی تخت و بیروح تابع هزینه عبور کنند.
پیادهسازی ممنتوم
برای ساخت این «آزمایشگاه بهینهسازی»، ۶ گام اصلی را دنبال میکنیم:
- تعریف تابع هزینه مشترک: یک تابع هدف واحد (مانند w^2) را به عنوان زمین بازی انتخاب میکنیم.
- تنظیم هایپرپارامترهای استاندارد: نرخ یادگیری ، ضرایب ممنتوم و مقادیر پایداری عددی را برای تمامی متدها تعریف میکنیم.
- پیادهسازی متدهای پایه: الگوریتمهای SGD و Momentum را به عنوان پایه شبیهسازی میکنیم.
- پیادهسازی متدهای تطبیقی: الگوریتمهای Ada Grad، RMSProp و Adam را که نرخ یادگیری را برای هر پارامتر جداگانه تنظیم میکنند، وارد مدار میکنیم.
- محاسبه گامهای آیندهنگر: ممنتوم Nesterov (NAG) را برای پیشبینی حرکتهای بعدی پیادهسازی میکنیم.
- تجسمسازی نهایی: تمامی مسیرهای حرکت را ثبت کرده و در یک نمودار رسم میکنیم.
کد پایتون:
import numpy as np
import matplotlib.pyplot as plt
# 1. Define Loss Function and its Gradient
def loss_function(w): return w**2
def gradient(w): return 2*w
# 2. Global Hyperparameters
w_start, lr, iterations = 10.0, 0.1, 50
beta, beta2, eps = 0.9, 0.999, 1e-8
# 3. Optimizers Logic
optimizers = ['SGD', 'Momentum', 'Nesterov', 'AdaGrad', 'RMSProp', 'Adam']
history = {opt: [w_start] for opt in optimizers}
# Initialization for buffers
v_mom, v_nag, cache_ada, cache_rms, m_adam, v_adam = 0, 0, 0, 0, 0, 0
for t in range(1, iterations + 1):
# SGD
history['SGD'].append(history['SGD'][-1] - lr * gradient(history['SGD'][-1]))
# Momentum (Classical)
v_mom = beta * v_mom + (1 - beta) * gradient(history['Momentum'][-1])
history['Momentum'].append(history['Momentum'][-1] - lr * v_mom)
# Nesterov (NAG)
w_lookahead = history['Nesterov'][-1] - lr * beta * v_nag
v_nag = beta * v_nag + (1 - beta) * gradient(w_lookahead)
history['Nesterov'].append(history['Nesterov'][-1] - lr * v_nag)
# AdaGrad
g = gradient(history['AdaGrad'][-1])
cache_ada += g**2
history['AdaGrad'].append(history['AdaGrad'][-1] - lr * g / (np.sqrt(cache_ada) + eps))
# RMSProp
g = gradient(history['RMSProp'][-1])
cache_rms = beta * cache_rms + (1 - beta) * g**2
history['RMSProp'].append(history['RMSProp'][-1] - lr * g / (np.sqrt(cache_rms) + eps))
# Adam
g = gradient(history['Adam'][-1])
m_adam = beta * m_adam + (1 - beta) * g
v_adam = beta2 * v_adam + (1 - beta2) * g**2
m_hat = m_adam / (1 - beta**t)
v_hat = v_adam / (1 - beta2**t)
history['Adam'].append(history['Adam'][-1] - lr * m_hat / (np.sqrt(v_hat) + eps))
# 4. Numerical Table Output
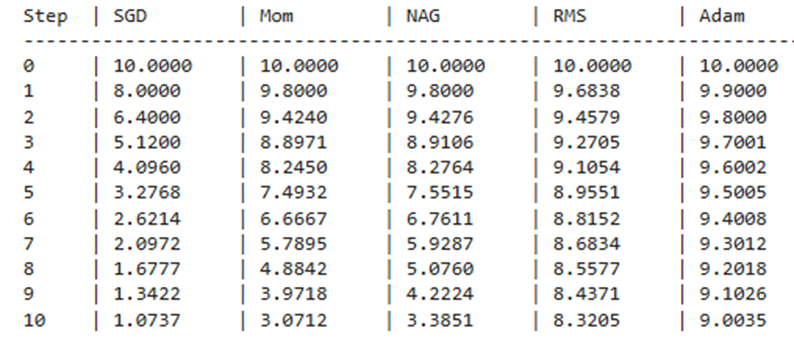
print(f"{'Step':<5} | {'SGD':<10} | {'Mom':<10} | {'NAG':<10} | {'RMS':<10} | {'Adam':<10}")
print("-" * 70)
for i in range(11):
print(f"{i:<5} | {history['SGD'][i]:<10.4f} | {history['Momentum'][i]:<10.4f} | "
f"{history['Nesterov'][i]:<10.4f} | {history['RMSProp'][i]:<10.4f} | {history['Adam'][i]:<10.4f}")
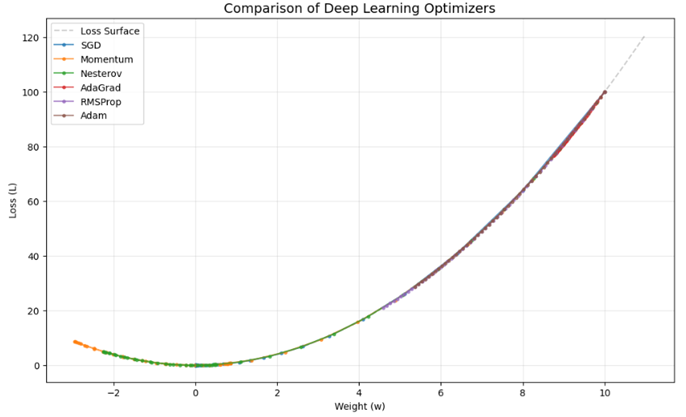
# 5. Professional Visualization with English Labels
plt.figure(figsize=(12, 7))
x = np.linspace(-2, 11, 100)
plt.plot(x, loss_function(x), 'k--', alpha=0.2, label='Loss Surface')
for opt in optimizers:
plt.plot(history[opt], [loss_function(w) for w in history[opt]], 'o-', label=opt, alpha=0.7, markersize=3)
plt.title('Comparison of Deep Learning Optimizers', fontsize=14)
plt.xlabel('Weight (w)'); plt.ylabel('Loss (L)'); plt.legend(); plt.grid(True, alpha=0.3)
plt.savefig('optimizers_comparison_final.png')
خروجی:
.
انواع بهینهسازهای مبتنی بر ممنتوم
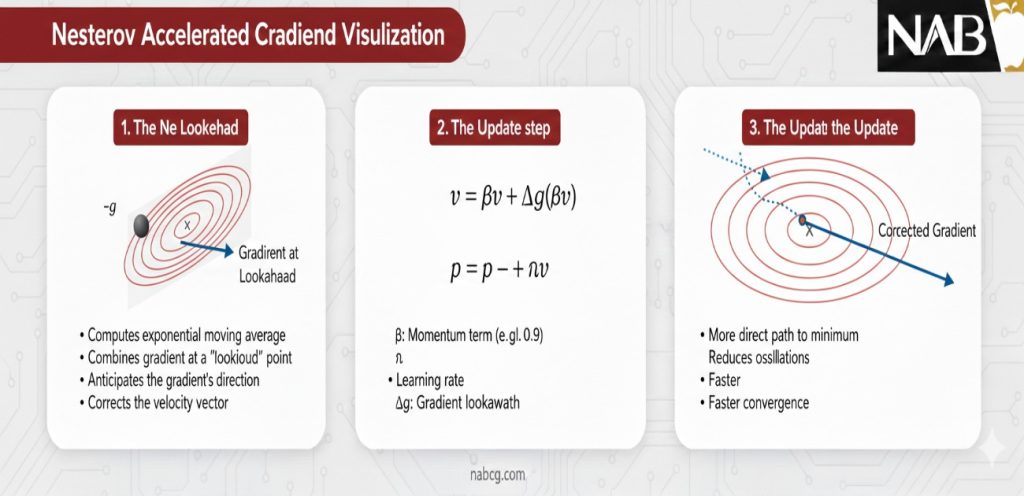
۱. ممنتوم شتابیافتهی نستروف (Nesterov Accelerated Gradient – NAG)
ممنتوم نستروف یک فرم پیشرفته و آیندهنگر از بهینهسازی مبتنی بر ممنتوم است. تفاوت بنیادین این روش با ممنتوم کلاسیک (CM) در زمان محاسبهی گرادیان نهفته است؛ نستروف ابتدا یک گام پیشبینانه برمیدارد و سپس گرادیان را در آن نقطهی جدید محاسبه میکند.
فرمول ریاضی و تحلیل متغیرها
بر اساس منابع علمی، بهروزرسانی نستروف به شکل زیر تعریف میشود:
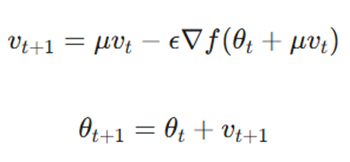
- vt+1: بردار سرعت (Velocity) جدید که جهت و قدرت حرکت بعدی را تعیین میکند.
- μ (ضریب ممنتوم): پارامتری بین ۰ و ۱ که نشاندهنده میزان حفظ سرعت قبلی است.
- ε (نرخ یادگیری): طول گام برداشته شده در هر تکرار.
- f(θt + μvt)∇: گرادیان در موقعیت تقریبیِ آینده. این یعنی مدل ابتدا با سرعت فعلی کمی به جلو میرود و سپس وضعیت را میسنجد.
.
چرا نستروف بهتر عمل میکند؟
- اصلاح به موقع: اگر گام ممنتوم (μvt) باعث شود مدل به ناحیهای نامناسب برود، گرادیان در آن نقطهی جدید (∇f(θt + μvt)) با قدرت بیشتری مدل را به عقب میکشد و سرعت را اصلاح میکند.
- کاهش نوسانات: NAG در مقایسه با ممنتوم کلاسیک، نوسانات را در جهتهایی با انحنای بالا (High Curvature) به شدت کاهش میدهد.
- پایداری در نرخهای بالا: این روش اجازه میدهد از ضرایب ممنتوم بزرگتر (مثل ۰.۹۹) استفاده کنیم بدون اینکه مدل دچار بیثباتی شود.
.
۲. آدا-ممنتوم (Ada Momentum)
این بهینهساز پیوندی استراتژیک میان نرخ یادگیری تطبیقی و ممنتوم ایجاد میکند. هدف اصلی آن، هوشمند کردنِ خودِ پارامتر ممنتوم بر اساس هندسهی تابع هزینه است.
ساختار و عملکرد
در حالی که در ممنتوم معمولی ضریب β ثابت است، در Ada Momentum این ضریب بر اساس تغییرات اخیر گرادیانها بهروزرسانی میشود:
- حساسیت به محیط: این بهینهساز نسبت به پستیوبلندیهای تابع هزینه بسیار حساستر است و در نواحی که گرادیانها به سرعت تغییر میکنند، ممنتوم را تعدیل میکند.
- تنظیم دقیق: این ویژگی به مدل کمک میکند تا در مراحل نهایی همگرایی، با دقت بسیار بالاتری به سمت کمینه مطلق حرکت کند.
کاربرد اصلی
- استفاده در مدلهایی که دادههای آنها دارای ویژگیهای بسیار متنوعی هستند و نیاز است که برای هر بخش از فضا، رفتار ممنتوم متفاوت باشد.
.
۳. آر-ام-اس-پراپ (RMS Prop)
هرچند RMS Prop در دستهبندی سنتی ممنتوم قرار نمیگیرد، اما نوع خاصی از ممنتوم را از طریق تطبیق نرخ یادگیری پیادهسازی میکند. این الگوریتم به جای تمرکز بر جهت حرکت، بر ابعاد گام در هر جهت تمرکز دارد.
مکانیسم و فرمول
RMS Prop نرخ یادگیری را برای هر پارامتر به صورت جداگانه و بر اساس میانگین متحرک مجذور گرادیانها تقسیم میکند:
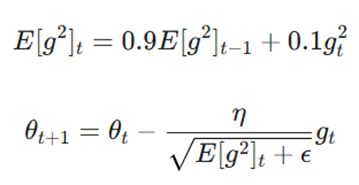
- تعدیل نرخ یادگیری: این روش باعث میشود پارامترهایی که گرادیانهای بزرگی دارند، نرخ یادگیری کوچکتری دریافت کنند و برعکس.
- پایداری در اهداف غیرایستا: RMS Prop در مدیریت مسائلی که هدف آنها مدام تغییر میکند (مانند آموزش RNNها) فوقالعاده عمل میکند.
.
کاربردهای واقعی
۱. آموزش شبکههای عصبی بسیار عمیق (DNNs)
بدون ممنتوم، آموزش مدلهایی با لایههای بسیار زیاد (مثل ۱۰ لایه یا بیشتر) به دلیل مشکلاتی مثل انحنای شدید تابع هزینه، عملاً با شکست مواجه میشد.
- عبور از نواحی تخت: ممنتوم به مدل اجازه میدهد در لایههای ابتدایی که گرادیانها ضعیف میشوند، متوقف نشود و به مسیر خود ادامه دهد.
- جایگزین روشهای سنگین: ممنتوم (بهویژه نوع نستروف) نتایجی را ارائه میدهد که پیش از این فقط با محاسبات بسیار سنگین مرتبه دوم (Hessian-Free) قابل دستیابی بود.
.
۲. یادگیری وابستگیهای بلندمدت در شبکههای بازگشتی (RNNs)
یکی از سختترین چالشهای هوش مصنوعی، یادگیری الگوهایی است که فاصلهی زمانی زیادی با هم دارند (مثل درک معنای کل یک پاراگراف طولانی).
- حل مشکل محوشدگی گرادیان: ممنتوم با انباشت سرعت، اثر گرادیانهای کوچک را تقویت کرده و اجازه میدهد اطلاعات از زمانهای دور به زمان حال منتقل شوند.
- پایداری در دادههای سری زمانی: در پردازش سیگنال و متن، ممنتوم از نوسانات شدید ناشی از نویزهای لحظهای جلوگیری میکند.
.
۳. فشردهسازی و بازسازی دادهها (Deep Autoencoders)
در پروژههایی که هدف آنها کاهش ابعاد داده یا بازسازی تصاویر نویزی است (مثل حذف نویز از عکسهای پزشکی)، ممنتوم نقش کلیدی دارد.
- دقت در بازسازی: ممنتوم با فیلتر کردن نوسانات، به مدل کمک میکند تا جزئیات دقیقتری را در لایه تنگنا (Bottleneck) ذخیره و مجدداً بازیابی کند.
- سرعت در همگرایی: در دیتاستهای بزرگی مثل MNIST یا Curve، ممنتوم زمان آموزش را به شدت کاهش داده و مدل را سریعتر به کمینه مطلق میرساند.
.
مزایا
- همگرایی سریعتر (Faster Convergence): ممنتوم با در نظر گرفتن گرادیانهای قبلی، به فرآیند آموزش شتاب میدهد. این ویژگی به مدل کمک میکند تا با کارایی بسیار بیشتری از نواحی تخت (که در آنها گرادیان نزدیک به صفر است و مدلهای معمولی متوقف میشوند) عبور کند.
- کاهش نوسانات (Reduces Oscillation): در گرادیان کاهشی سنتی، اگر در برخی جهتها شیب تند و در برخی دیگر شیب ملایم باشد، مدل دچار حرکت زیگزاگی یا نوسان میشود. ممنتوم با حفظ جهت آپدیتهای قبلی، این نوسانات آزاردهنده را خنثی کرده و حرکت را در جهت اصلی متمرکز میکند.
- بهبود قدرت تعمیم (Improved Generalization): با نرم کردن فرآیند بهینهسازی، روشهای مبتنی بر ممنتوم معمولاً منجر به عملکرد بهتر روی دادههای نادیده (تست) میشوند. این کار مانع از آن میشود که مدل بیش از حد بر روی نویزهای کوچک دادههای آموزشی حساس شود (جلوگیری ازOverfitting).
.
محدودیتها
- تنظیم حساس هایپرپارامترها: انتخاب مقدار مناسب برای نرخ یادگیری (α) و ضریب ممنتوم (β) میتواند چالشبرانگیز باشد. اگرچه مقدار ۰.۹ برای ضریب ممنتوم بسیار رایج است، اما بسته به نوع داده و پیچیدگی مسئله، ممکن است نیاز به تغییر داشته باشد.
- خطر انباشت بیش از حد (Over-Accumulation): اگر مقدار ممنتوم خیلی بزرگ شود، ممکن است مدل دچار بیشپرشی (Overshooting) شود. یعنی مدل با سرعت زیادی حرکت میکند و از روی نقطهی کمینه اصلی رد میشود، بهویژه زمانی که گرادیانها نویزی باشند.
- حساسیت به مقداردهی اولیه: شروع حرکت ممنتوم تأثیر زیادی بر نرخ همگرایی دارد. یک مقداردهی اولیه نامناسب میتواند منجر به رفتار نوسانی یا بسیار کند در ابتدای فرآیند بهینهسازی شود.
.
مطالعه موردی: نبرد با ابرهای مزاحم؛ پیشبینی هوشمند انرژی خورشیدی با ممنتوم
در دنیای انرژیهای پاک، نیروگاههای خورشیدی با یک چالش بزرگ روبرو هستند: بیثباتی. عبور یک تکه ابر از روی پنلها کافی است تا تولید برق در چند ثانیه به شدت افت کند. برای مدیریت شبکه برق ملی، ما به پیشبینیهایی نیاز داریم که فریب این «نویزهای لحظهای» را نخورند.
تعریف چالش
سنسورهای نیروگاه مدام دادههای تابش را ارسال میکنند. در یک روز ابری، این دادهها سرشار از نوسانات شدید (Jitter) هستند.
- مشکل SGD معمولی: بهینهسازهای بدون حافظه، به هر نوسان کوچک واکنش سریع نشان میدهند. این کار باعث میشود پیشبینی مدل مدام زیگزاگ بزند و پایداری شبکه را به خطر بیندازد.
- راهکار ممنتوم: ممنتوم با ایجاد یک «اینرسی محاسباتی»، اجازه نمیدهد مدل با هر سایه ابر جهت خود را عوض کند. ممنتوم بر روی روند کلی (Trend) تمرکز میکند.
.
تحلیل عددی:
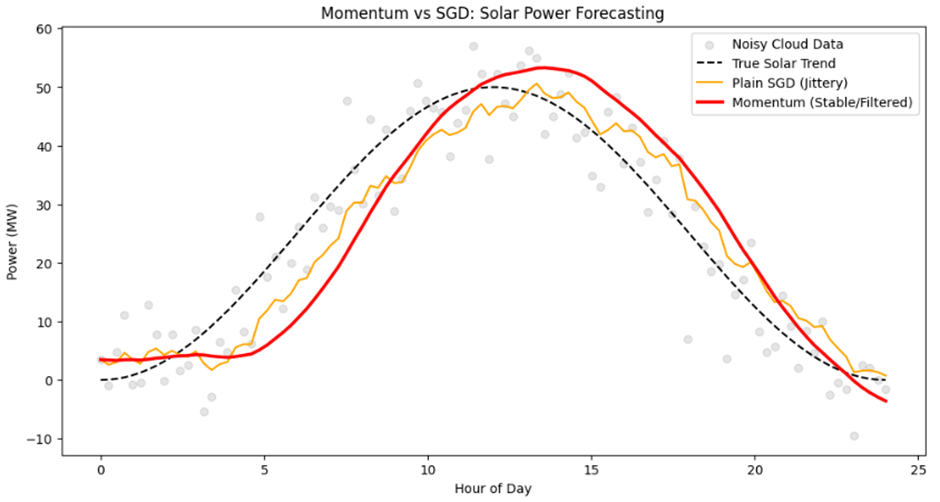
در جدول زیر، تفاوت واکنش دو الگوریتم را در ۱۰ گام اول یک روز ابری مشاهده میکنید. توجه کنید که چگونه ممنتوم (Momentum Pred) بسیار نرمتر از SGD عمل کرده است:
| زمان (ساعت) | خروجی سنسور (نویزی) | پیشبینی SGD (عصبی) | پیشبینی ممنتوم (پایدار) |
| ۰.۰۰ | ۳.۴۸ | ۳.۴۸ | ۳.۴۸ |
| ۰.۷۳ | ۱۱.۱۱ | ۴.۶۴ | ۳.۴۵ |
| ۱.۴۵ | ۱۲.۸۵ | ۴.۷۸ | ۳.۵۲ |
| ۲.۱۸ | ۷.۷۷ | ۴.۹۸ | ۴.۰۰ |
کد پایتون :
import numpy as np
import matplotlib.pyplot as plt
# شبیهسازی دادههای نیروگاه خورشیدی
np.random.seed(42)
time = np.linspace(0, 24, 100)
true_trend = 50 * np.sin(np.pi * time / 24)**2 # روند واقعی خورشید
noise = np.random.normal(0, 7, 100) # نویز ناشی از ابرها
sensor_data = true_trend + noise
# تنظیمات بهینهسازها
lr, beta = 0.2, 0.9
sgd_pred, mom_pred, v = [sensor_data[0]], [sensor_data[0]], 0
for i in range(1, len(sensor_data)):
# SGD ساده: واکنش آنی
sgd_pred.append(sgd_pred[-1] + lr * (sensor_data[i] - sgd_pred[-1]))
# ممنتوم: استفاده از اینرسی (سرعت)
v = beta * v + (1 - beta) * (sensor_data[i] - mom_pred[-1])
mom_pred.append(mom_pred[-1] + lr * v)
# رسم نمودار نهایی
plt.figure(figsize=(12, 6))
plt.scatter(time, sensor_data, color='gray', alpha=0.2, label='Noisy Cloud Data')
plt.plot(time, true_trend, 'k--', label='True Solar Trend')
plt.plot(time, sgd_pred, 'orange', label='Plain SGD (Jittery)')
plt.plot(time, mom_pred, 'red', linewidth=2.5, label='Momentum (Stable/Filtered)')
plt.title('Momentum vs SGD: Solar Power Forecasting')
plt.xlabel('Hour of Day'); plt.ylabel('Power (MW)'); plt.legend(); plt.show()
خروجی:
.
نتیجهگیری استراتژیک
این مطالعه موردی ثابت میکند که ممنتوم صرفاً یک مبحث ریاضی نیست، بلکه یک فیلتر هوشمند است. در سیستمهای حساس مثل نیروگاهها یا بازارهای مالی، ممنتوم با نادیده گرفتن «نویزهای گذرا» و تمرکز بر «روندهای واقعی»، دقت و پایداری مدل را تضمین میکند.
جمع بندی
Momentum یکی از سادهترین و در عین حال مؤثرترین بهبودهای گرادیان کاهشی محسوب میشود. این روش با کاهش نوسانات گرادیان و تقویت جهتهای سازگار، امکان حرکت پایدارتر و سریعتر به سمت نواحی مناسب بهینه را فراهم میکند. در این مطلب دیدیم که Momentum چگونه از اطلاعات گذشته برای اصلاح بهروزرسانیهای فعلی استفاده میکند و چرا در بسیاری از مسائل، نسبت به گرادیان کاهشی ساده عملکرد بهتری دارد.
بررسی مثالهای عددی و پیادهسازی عملی نشان داد که انتخاب پارامتر Momentum (β) نقش مهمی در رفتار الگوریتم دارد و باید متناسب با مسئله و داده تنظیم شود. همچنین مشخص شد که Momentum بهتنهایی یک راهحل نهایی نیست، بلکه پایهای مفهومی برای توسعهی بهینهسازهای پیشرفتهتری مانند Nesterov Accelerated Gradient، RMSprop و Adam به شمار میآید.
در عمل، Momentum اغلب بهعنوان اولین ارتقا نسبت به SGD در نظر گرفته میشود؛ روشی که با هزینهی محاسباتی اندک، بهبود قابلتوجهی در پایداری و سرعت آموزش ایجاد میکند. درک دقیق Momentum به مهندس یادگیری ماشین کمک میکند تا منطق درونی بهینهسازهای مدرن را بهتر بفهمد و در انتخاب و تنظیم آنها، تصمیمهایی آگاهانهتر و مبتنی بر اصول مهندسی اتخاذ کند.



