

مقدمه
با پیشرفت هوش مصنوعی، اصطلاحات یادگیری ماشین و یادگیری عمیق بیشتر از قبل شنیده میشوند. اما تفاوت واقعی میان آنها چیست؟ و کدامیک برای یک مسئلهٔ مشخص گزینهٔ بهتری است؟
بسیاری این دو مفهوم را اشتباه بهجای یکدیگر بهکار میبرند، در حالی که یادگیری عمیق زیرمجموعهای از یادگیری ماشین است — با ویژگیها و الزامات خاص خود.
یادگیری ماشین سالهاست بهعنوان ابزاری قدرتمند برای تحلیل دادهها، پیشبینی و تصمیمگیری استفاده میشود، در حالی که یادگیری عمیق با تکیه بر شبکههای عصبی چندلایه، امکان پردازش دادههای حجیم و خام مانند تصویر، صدا و متن را فراهم کرده است. هرکدام از این رویکردها نقاط قوت، محدودیتها و کاربردهای متفاوتی دارند که شناخت آنها برای انتخاب درست ضروری است.
در این مقاله، یادگیری ماشین و یادگیری عمیق را از جنبههای کلیدی — از ساختار و نیازهای دادهای تا هزینهٔ محاسباتی، تفسیرپذیری و کاربردهای عملی — مقایسه میکنیم. هدف این است که خواننده بتواند با دیدی آگاهانه و مهندسیشده، رویکرد مناسب را برای مسئلۀ خود انتخاب کند.
هوش مصنوعی (AI) چیست؟
هوش مصنوعی شاخهای از علوم کامپیوتر است که هدف آن خلق سیستمهای هوشمندی است که میتوانند وظایفی را که به طور معمول به سطح هوش انسانی نیاز دارد، انجام دهند.
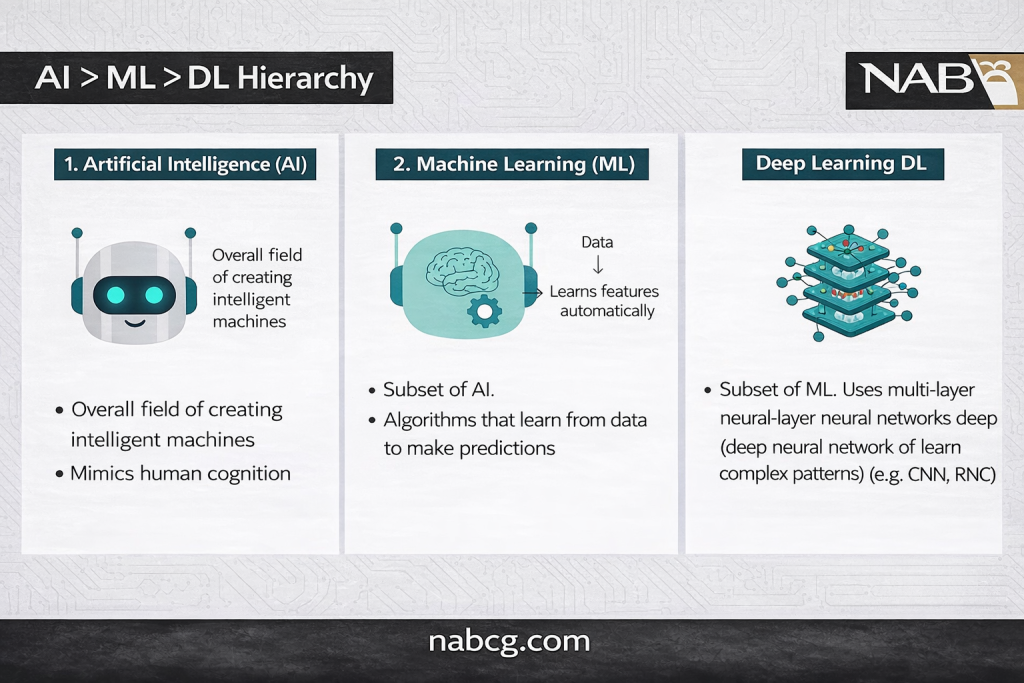
- ابزاری برای هوشمندسازی: AI مجموعهای از ابزارهاست که باعث میشود کامپیوترها رفتار هوشمندانهای داشته باشند و وظایف را خودکار کنند.
- کاربردها: از خودروهای خودران و سیستمهای پیشنهاددهنده تا دستیارهای صوتی، همگی از کاربردهای AI هستند.
.
یادگیری ماشین؛ از الگوریتم تا تصمیمگیری هوشمند
ML شاخهای از هوش مصنوعی است که بر پایهٔ مدلهای آماری و الگوریتمها است و به سیستمها اجازه میدهد تا پیشبینی و تصمیمگیری کنند. الگوریتمهای یادگیری ماشین با شناسایی الگوهای دادههای آموزشی، در طول زمان بهبود مییابند، خود را تطبیق میدهند و قابلیتهایشان را غنیتر میکنند.
برای عملکرد دقیق، یادگیری ماشین به مهندسی ویژگی توسط انسان وابسته است: دادههای مرتبط باید با دقت پیشپردازش و تهیه شوند. در عوض، ML با این ورودیِ باکیفیت، در شناسایی الگوهای پنهان و استخراج بینشهای قابلتفسیر از مسائل پیچیده، عملکردی بسیار ماهرانه از خود نشان میدهد.
چرخه استاندارد عملکرد یک مدل ML
- دریافت اطلاعات جدید از طریق پرسوجوی کاربر.
- تجزیه و تحلیل دادهها.
- یافتن الگو در دادههای ورودی.
- پیشبینی بر اساس الگوهای کشف شده.
- ارسال پاسخ نهایی به کاربر.
.
انواع سهگانه یادگیری در مدلهای ML
اصلیترین تفاوت بین مدلهای یادگیری ماشین در نحوه آموزش آنهاست. سه نوع متداول یادگیری عبارتند از:
- یادگیری نظارتشده (Supervised Learning): در این روش، الگوریتم با دادههای آموزشی برچسبدار تغذیه میشود و مدل یاد میگیرد چگونه به دادههای جدید پاسخ دهد.
- یادگیری نظارتنشده(Unsupervised Learning): ابزارهای هوش مصنوعی با دادههای بدون برچسب تغذیه میشوند و بدون دخالت انسان، الگوها را شناسایی میکنند.
- یادگیری تقویتی(Reinforcement Learning): مدلها با دادههای آموزشی تغذیه شده و از طریق آزمون و خطا و دریافت بازخورد (پاداش یا جریمه) یاد میگیرند.
نکته کلیدی: انتخاب بهترین نوع یادگیری کاملاً به نیازها و انتظارات کاربر بستگی دارد، به ویژه اگر قرار باشد مدل از اتوماسیون هوشمند پشتیبانی کند.
مثال: سیستم هوشمند پیشنهاد فیلم (نتفلیکس)
تصور کنید قصد دارید مدلی طراحی کنید که حدس بزند یک کاربر به فیلم جدید میانستارهای (Interstellar) چه امتیازی میدهد.
- دادههای ورودی (ویژگیها): شما مجموعهای از دادههای ۱۰۰۰ کاربر قبلی را دارید که شامل مواردی مثل: ژانرهای مورد علاقه (مثلاً علمی-تخیلی)، مدت زمان تماشای فیلمهای مشابه، و امتیازاتی که به فیلمهای کارگردانان خاص دادهاند میشود.
- فرآیند یادگیری: شما این ویژگیها را به الگوریتمی مثل جنگل تصادفی (Random Forest) میدهید. مدل با تحلیل این دادهها، رابطه بین علاقه به فضا و امتیاز بالا به کریستوفر نولان را کشف میکند.
- پیشبینی نهایی: کاربر جدیدی وارد میشود که به فیلمهای فضایی علاقه نشان داده است. مدل — بدون نیاز به برنامهریزی از پیش — پیشبینی میکند که این کاربر با احتمال ۹۵٪ به فیلم امتیاز ۵ ستاره دهد و آن را در لیست «پیشنهاد برای شما» قرار میدهد.
.
یادگیری عمیق (Deep Learning)
زیرمجموعهای از یادگیری ماشین است که بر ساختاردهی به فرآیند یادگیری کامپیوترها (مشابه انسان) تمرکز دارد. تمایز اصلی آن در استفاده از شبکههای عصبی با سه لایه یا بیشتر است.
- ساختار شبکههای عصبی: این شبکهها شامل یک لایه ورودی ، لایههای پنهان (که پارامترها یا همان وزنها در آن یاد گرفته میشوند) و یک لایه خروجی برای پیشبینی نهایی هستند.
- تابع تخمینگر: شبکه سعی میکند پارامترها (وزنها) را در لایههای پنهان یاد بگیرد تا وقتی در ورودی ضرب میشوند، خروجی پیشبینی شده به خروجی مطلوب نزدیک باشد.
.
ساختار و انواع شبکههای عصبی در یادگیری عمیق
برنامههای یادگیری عمیق از ساختاری لایهبندیشده از الگوریتمها — شبکههای عصبی — برای دریافت دادههای بدون برچسب (ورودی)، شناسایی الگوهای پیچیده و تولید خروجی استفاده میکنند. مهمترین انواع آنها عبارتند از:
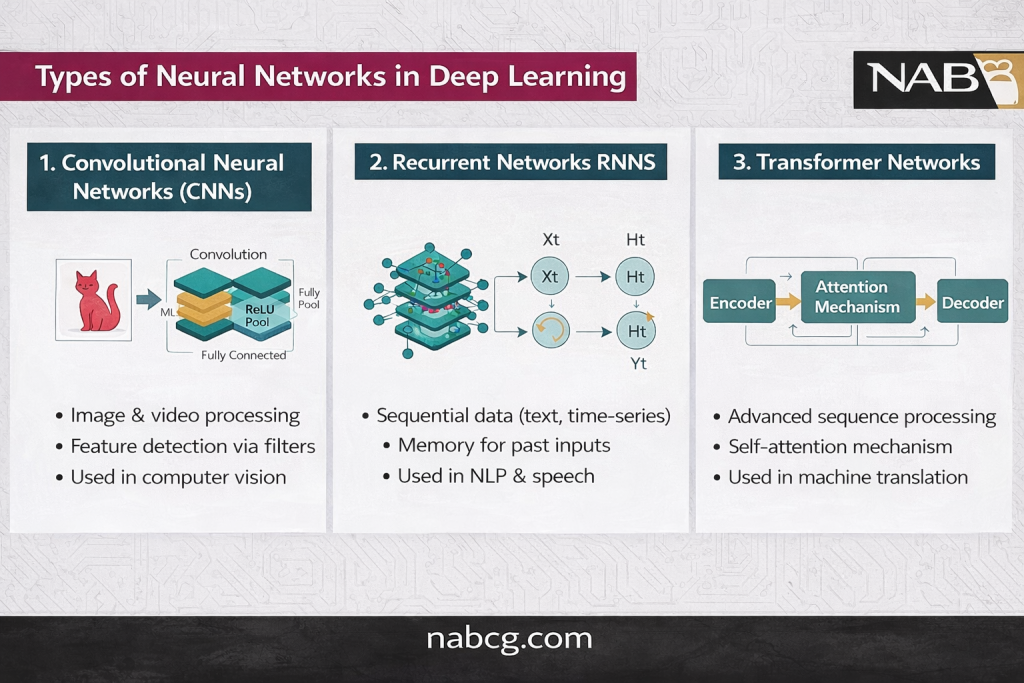
- شبکههای عصبی پیشخور: سادهترین شکل یادگیری عمیق که در آن اطلاعات فقط در یک جهت (از ورودی به خروجی) جریان مییابد و هیچ حلقه یا چرخهای ندارد.
- پرسپترونهای چندلایه: نوعی شبکه پیشخور متشکل از چندین لایه پرسپترون که قادر به یادگیری الگوهای پیچیده و حل مسائل غیرخطی در حوزههای مختلف است.
- شبکههای عصبی بازگشتی (RNN): الگوریتمهایی با حلقههای بازخورد داخلی که ورودیهای قبلی را بهخاطر میسپارند و از این حافظه برای درک رویدادهای کنونی یا پیشبینی آینده استفاده میکنند.
- LSTM : نوعی شبکهٔ بازگشتی تخصصی که برای یادگیری و بهخاطرسپاری وابستگیهای طولانیمدت در دادههای متوالی طراحی شده است. این معماری در وظایفی که زمینه و توالی ورودیهای قبلی تعیینکننده است — مانند پردازش متن — بسیار مؤثر عمل میکند.
- شبکههای عصبی پیچشی: الگوریتمهایی که موتور محرک بینایی ماشین و تشخیص تصویر هستند و با ارزیابی الگوها، بافتها، اشکال و رنگها، محرکهای بصری را فیلتر میکنند.
- شبکههای مولد رقابتی: معماری شامل دو شبکه (مولد برای ساخت دادههای مصنوعی و متمایزکننده برای تشخیص دادههای واقعی از جعلی) که در مقابل هم فعالیت میکنند.
.
مطالعه موردی
سفر به اعماق ۱۰,۰۰۰ تکرار: در طول آموزش شبکه عصبی چه میگذرد؟
بسیاری از ما آموزش یک مدل را مثل یک جعبه سیاه میبینیم؛ دکمه شروع را میزنیم و منتظر نتیجه میمانیم. اما اگر مانند این مطالعه موردی، هر ۵ گام یکبار زیر میکروسکوپ به شبکه نگاه کنیم، شاهد یک سفر تکاملی خواهیم بود:
۱. مرحله آشوب و نویز (گام ۱ تا ۵۰۰)
در لحظات اول، وزنها و بایاسها کاملاً تصادفی هستند. شبکه مانند نوزادی است که فقط نور و سایه را میبیند. نمودار خطا (Loss) به شدت نوسان میکند چون شبکه مدام حدسهای اشتباه میزند و سعی میکند جهت درست را پیدا کند.
۲. مرحله کشف الگو (گام ۵۰۰ تا ۲۰۰۰)
اینجاست که انتشار رو به عقب رخ میدهد. شبکه ناگهان الگوهای کلی را میبیند. اگر تصویر باشد، یاد میگیرد لبهها و خطوط را تشخیص دهد. خطا با شیب تندی سقوط میکند؛ یعنی مدل قواعد بازی را یاد گرفته است.
۳. مرحله صبوری و اصلاحات ظریف (گام ۲۰۰۰ تا ۸۰۰۰)
در این بازه طولانی، تغییرات در وزنها بسیار کوچک و مینیاتوری میشوند. شبکه دیگر کلیات را میداند و حالا روی جزئیات تمرکز میکند . دقت با شیبی بسیار ملایم بالا میرود و بایاسها جابهجا میشوند تا مدل را با توزیع واقعی دادهها تراز کنند.
۴. مرحله اشباع و وسواس (گام ۸۰۰۰ تا ۱۰,۰۰۰)
در اواخر مسیر، خطر بیشبرازش (Overfitting) ظاهر میشود. شبکه به جای یادگیری، شروع به حفظ کردن نویزهای دادههای آموزشی میکند. اینجا همان نقطهای است که یک مهندس هوشمند با تکنیکهایی مثل Dropout یا توقف زودهنگام، آموزش را متوقف میکند تا مدل برای دادههای جدید منعطف باقی بماند.
کد پایتون: شبیهسازی این سفر آموزشی
این یک کد ساده با استفاده از کتابخانه PyTorch است که دقیقاً همین فرآیند را پیادهسازی میکند و به شما اجازه میدهد خطا را در طول تکرارها رصد ببینید:
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import numpy as np
# ۱. آمادهسازی دادههای فرضی (Learning y = 2x1 - 3x2 + 0.5)
torch.manual_seed(42)
X = torch.randn(100, 2)
true_params = torch.tensor([[2.0], [-3.0]])
true_bias = 0.5
y = X @ true_params + true_bias + torch.randn(100, 1) * 0.1 # افزودن کمی نویز برای واقعگرایی
# ۲. تعریف ساختار شبکه عصبی
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.linear = nn.Linear(2, 1) # یک لایه با وزنها و بایاس
def forward(self, x):
return self.linear(x)
model = SimpleNet()
criterion = nn.MSELoss() # تابع خطا
optimizer = optim.SGD(model.parameters(), lr=0.01) # بهینهساز
# ۳. حلقه آموزش ۱۰,۰۰۰ تکراری با ثبت جزئیات
iterations = 10000
history = {'loss': [], 'weight': [], 'bias': [], 'step': []}
print("--- شروع فرآیند آموزش ---")
for i in range(iterations + 1):
outputs = model(X)
loss = criterion(outputs, y)
optimizer.zero_grad()
loss.backward() # انتشار رو به عقب
optimizer.step() # بهروزرسانی وزنها و بایاس
# ثبت دادهها در هر ۵ گام (مطابق مطالعه موردی)
if i % 5 == 0:
history['loss'].append(loss.item())
history['weight'].append(model.linear.weight[0][0].item())
history['bias'].append(model.linear.bias.item())
history['step'].append(i)
# خروجی عددی در فواصل ۲۰۰۰ تایی
if i % 2000 == 0:
print(f"گام {i:5d} | خطا: {loss.item():.6f} | وزن اول: {model.linear.weight[0][0].item():.4f} | بایاس: {model.linear.bias.item():.4f}")
# ۴. تصویرسازی نتایج
plt.figure(figsize=(12, 5))
# نمودار کاهش خطا (مقیاس لگاریتمی برای دیدن جزئیات ریز)
plt.subplot(1, 2, 1)
plt.plot(history['step'], history['loss'], color='#FF6F61', label='Loss')
plt.yscale('log')
plt.title('کاهش خطا در طول ۱۰,۰۰۰ تکرار')
plt.xlabel('تعداد تکرار')
plt.ylabel('مقدار خطا (مقیاس لگاریتمی)')
plt.grid(True, alpha=0.3)
plt.legend()
# نمودار همگرایی پارامترها (وزن و بایاس)
plt.subplot(1, 2, 2)
plt.plot(history['step'], history['weight'], color='#00CED1', label='Weight 1')
plt.plot(history['step'], history['bias'], color='#FFA500', label='Bias')
plt.axhline(y=2.0, color='gray', linestyle='--', alpha=0.5, label='Target Weight')
plt.title('تکامل و ثبات وزنها و بایاس')
plt.xlabel('تعداد تکرار')
plt.ylabel('مقدار پارامتر')
plt.legend()
plt.tight_layout()
plt.savefig('training_analysis.png') # ذخیره خروجی مصور
print("\n--- آموزش پایان یافت. فایل نمودار ذخیره شد. ---")
خروجی:

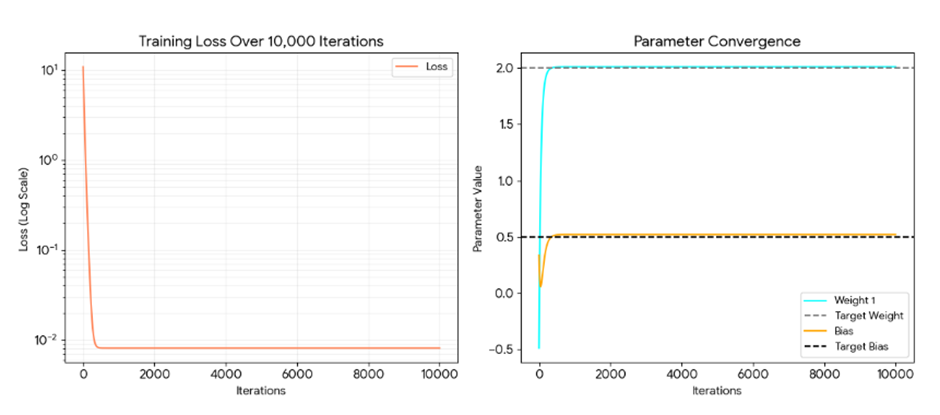
.
شباهتهای کلیدی: ریشههای مشترک ML و Deep Learning
برخی از مهمترین شباهتهای آنها عبارتند از:
- تکنیکهای هوش مصنوعی: یادگیری عمیق و یادگیری ماشین زیرمجموعهای از علوم داده و هوش مصنوعی (AI) هستند. آنها وظایف محاسباتی پیچیدهای را انجام میدهند که انجام آنها از طریق برنامهنویسی سنتی نیازمند زمان و منابع بسیار زیادی است.
- پایه آماری: هر دو از روشهای آماری مانند تحلیل رگرسیون، درختهای تصمیم، جبر خطی و حساب دیفرانسیل برای آموزش الگوریتمها استفاده میکنند. به همین دلیل، متخصصان هر دو حوزه باید تسلط بالایی بر آمار داشته باشند.
- نیاز به مجموعهدادههای بزرگ: هر دو برای انجام پیشبینیهای دقیق به دادههای آموزشی باکیفیت و حجیم نیاز دارند.
- فرآیند یادگیری خودکار: فرآیند یادگیری در هر دو سیستم به صورت خودکار و با حداقل مداخله انسانی انجام میشود. در طول آموزش، الگوریتمها همبستگی بین ورودیها و خروجیهای شناخته شده را پیدا میکنند تا بتوانند برای ورودیهای ناشناخته، خروجی پیشبینی کنند.
- بهبود تدریجی: هرچه این سیستمها دادههای بیشتری جذب کنند، در شناسایی الگوها دقیقتر میشوند. هر ورودی جدید به سیستم به عنوان یک نقطه داده برای آموزش عمل کرده و باعث ارتقای مدل میشود.
.
جدول خلاصه شباهتها
| ویژگی | یادگیری ماشین (ML) | یادگیری عمیق (DL) |
| هدف اصلی | شناسایی الگو و پیشبینی خروجی | شناسایی الگو و پیشبینی خروجی |
| مبنای علمی | آمار، جبر خطی و ریاضیات | آمار، جبر خطی و ریاضیات |
| نوع یادگیری | خودکار با دادههای آموزشی | خودکار با دادههای آموزشی |
| مقیاسپذیری | با ورود دادههای جدید بهبود مییابد | با ورود دادههای جدید بهبود مییابد |
.
تفاوتهای بنیادین: یادگیری ماشین در مقابل یادگیری عمیق
در حالی که یادگیری عمیق زیرمجموعهای از یادگیری ماشین است، رویکرد آنها در مواجهه با چالشها کاملاً متفاوت است:

وابستگی به داده و عملکرد
- یادگیری ماشین: با مجموعهدادههای کوچک و ساختاریافته به خوبی کار میکند. در واقع، الگوریتمهای کلاسیک ML میتوانند با دادههای محدود هم نتایج رضایتبخشی ارائه دهند.
- یادگیری عمیق: تشنه دادههای بزرگ (Big Data) است. عملکرد مدلهای DL با افزایش حجم داده به طور چشمگیری بهبود مییابد، در حالی که عملکرد یادگیری ماشین سنتی پس از مدتی به اشباع میرسد.
.
استخراج ویژگی
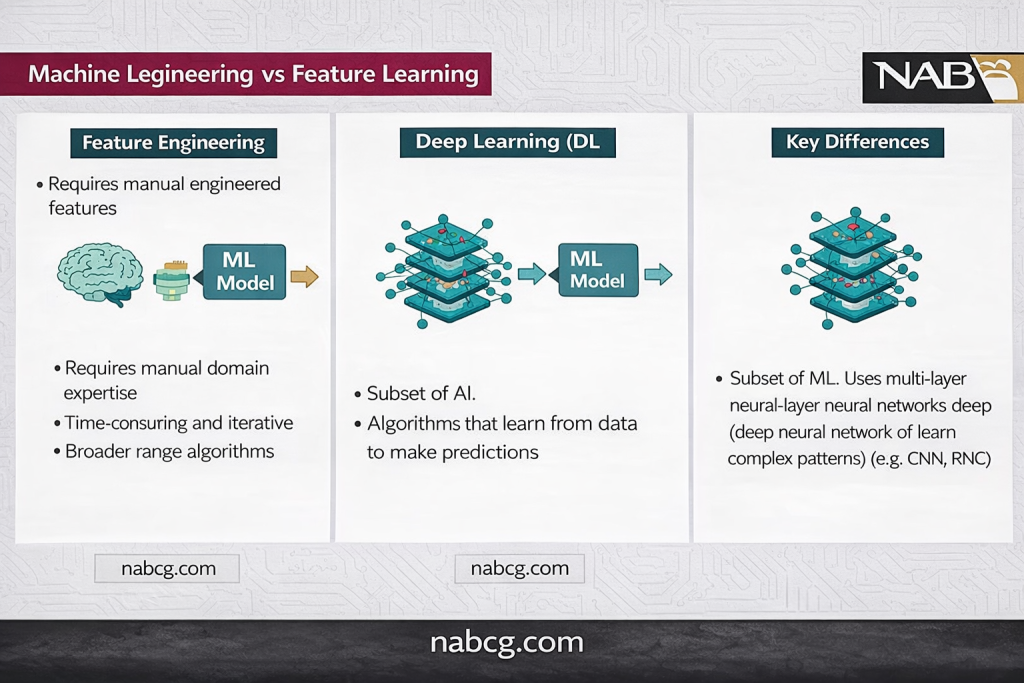
- یادگیری ماشین: به شدت به مهندسی ویژگی توسط انسان وابسته است. متخصصان باید ویژگیهای مهم داده را شناسایی و به صورت دستی استخراج کنند تا مدل بهینه عمل کند.
- یادگیری عمیق: این فرآیند را به صورت خودکار انجام میدهد. مدل یاد میگیرد که از دادههای خام (مثل پیکسلهای تصویر)، خودش ویژگیهای معنادار را استخراج کند.
.
قدرت محاسباتی و منابع
- یادگیری ماشین: تقاضای کمتری دارد و بسیاری از الگوریتمهای آن روی پردازندههای معمولی (CPU) اجرا میشوند.
- یادگیری عمیق: به سختافزارهای قدرتمند، به ویژه GPU (واحد پردازش گرافیکی) نیاز دارد تا محاسبات سنگین لایههای عصبی را با سرعت بالا انجام دهد.
.
زمان آموزش و اجرا
- یادگیری ماشین: آموزش مدلها نسبتاً سریع است و از چند دقیقه تا چند ساعت زمان میبرد.
- یادگیری عمیق: فرآیند آموزش میتواند بسیار زمانبر باشد — تا حدی که در مدلهای پیچیده، از چند هفته تا چند ماه طول بکشد. همچنین، زمان استنتاج (Inference) به دلیل عمق و پیچیدگی لایهها، معمولاً بیشتر است.
.
شفافیت و تفسیرپذیری
- یادگیری ماشین: مدلهای ML اغلب شفافتر هستند و مسیر تبدیل ورودی به خروجی بهراحتی قابل تفسیر است — ویژگیای حیاتی در صنایع حساس مانند سلامت و مالی.
- یادگیری عمیق: به عنوان یک جعبه سیاه (Black Box) شناخته میشود؛ به این معنی که درک فرآیند تصمیمگیری در لایههای تو در توی آن برای انسان بسیار دشوار است.
.
جدول مقایسهای
| معیار | یادگیری ماشین (ML) | یادگیری عمیق (DL) |
| داده | عملکرد خوب با دادههای محدود | نیازمند دادههای انبوه برای عملکرد عالی |
| استخراج ویژگی | وابسته به تخصص انسان (دستی) | خودکار و یادگیری مستقیم از دادههای خام |
| سختافزار | قابل اجرا روی CPUهای استاندارد | نیازمند GPUهای قدرتمند |
| حل مسئله | شکستن مسئله به بخشهای کوچک | حل مسئله به صورت یکپارچه و کلنگر (End-to-End) |
| نوع خروجی | معمولاً اعداد، امتیازها یا طبقهبندی | خروجیهای متنوع شامل متن، تصویر و گفتار |
.
زیستبوم ابزارها (Tools & Libraries): از تئوری تا کدنویسی
دانستن تئوری، تنها نیمی از راه است؛ نیمه دیگر، تسلط بر ابزارهایی است که این مفاهیم را به واقعیت تبدیل میکنند. امروزه استاندارد صنعت بر پایه کتابخانههای قدرتمند پایتون بنا شده است:
- کتابخانه Scikit-learn (برای یادگیری ماشین): این کتابخانه انتخاب اول برای پیادهسازی الگوریتمهای کلاسیک ML مانند درختهای تصمیم، رگرسیون و خوشهبندی است. سادگی و کارایی باعث شده تا برای پروژههایی با دادههای ساختاریافته و عددی ایدهآل باشد.
- فریمورکهای یادگیری عمیق (PyTorch و TensorFlow): این دو پلتفرم پیشرو برای ساخت شبکههای عصبی پیچیده و عمیق مورد استفاده قرار میگیرند.
- کتابخانههای کمکی (Pandas و NumPy): این ابزارها برای مدیریت، پاکسازی و انجام محاسبات ریاضی روی دادهها قبل از ورود به مدل ضروری هستند.
.
کاربردهای عملی و هوشمندانه
.
حوزه سلامت و تشخیص پزشکی
- کاربرد: تشخیص سلولهای سرطانی، بازسازی تصاویر MRI و تجزیه و تحلیل سوابق بیماران.
- انتخاب: هر دو.
- علت: یادگیری ماشین برای تحلیل دادههای ساختاریافته (مثل پروندههای عددی بیمار) عالی است، اما یادگیری عمیق در تفسیر تصاویر پزشکی و الگوهای گفتاری برای ارزیابیهای عصبی بیرقیب عمل میکند.
بخش بانکی و مالی
- کاربرد: پیشبینی بازار سهام، تصمیمگیریهای مالی و تشخیص کلاهبرداری.
- انتخاب: یادگیری ماشین.
- علت: مدلهایی مثل رگرسیون و درخت تصمیم در تحلیل دادههای عددی و ساختاریافته بسیار موثر هستند. همچنین در تشخیص کلاهبرداری، ML میتواند الگوهای تراکنش را تحلیل کرده و فعالیتهای مشکوک را شناسایی کند.
پردازش زبان طبیعی (NLP) و پیشنهاددهندهها
- کاربرد: سیستمهای پیشنهاد فیلم (مثل نتفلیکس)، تحلیل احساسات و چتباتها.
- انتخاب: هر دو.
- علت: یادگیری ماشین برای تحلیل رفتار کاربر در سیستمهای پیشنهادی عالی است. در مقابل، یادگیری عمیق در درک و تولید زبان انسانی (مثل ترجمه و تحلیل لحن) قدرت فوقالعادهای دارد.
.
جمع بندی
هردو (یادگیری ماشین و یادگیری عمیق) ابزارهای قدرتمندی در اکوسیستم هوش مصنوعی هستند، اما برای اهداف و شرایط متفاوتی طراحی شدهاند:
- یادگیری عمیق در مواجهه با دادههای حجیم و پیچیده، میتواند الگوهایی را کشف کند که روشهای کلاسیک از دستیابی به آنها عاجزند.
- یادگیری ماشین در مسائل با دادههای ساختاریافته و حجم متوسط، عملکردی سریع، قابلتفسیر و مقرونبهصرفه ارائه میدهد.
در این مقاله دیدیم: انتخاب بین این دو رویکرد نباید بر اساس محبوبیت یا پیچیدگی ظاهری باشد. حجم و نوع داده، منابع محاسباتی، نیاز به تفسیرپذیری و هدف پروژه، عوامل تعیینکنندهٔ این تصمیم هستند. در بسیاری از سناریوهای واقعی، یادگیری ماشین سادهتر و کارآمدتر است؛ اما یادگیری عمیق تنها زمانی گزینهای منطقی میشود که پردازش دادههای خام و پیچیده ضروری باشد.
در نهایت، یادگیری عمیق جایگزین کامل یادگیری ماشین نیست، بلکه تکامل طبیعی آن در مواجهه با مسائل پیچیدهتر است. درک تفاوتها و نقاط قوت هر دو رویکرد به شما کمک میکند بهجای انتخابهای هیجانی، تصمیمهایی دقیق، هدفمند و مبتنی بر مسئله بگیرید؛ تصمیمهایی که موفقیت پروژههای هوش مصنوعی را تضمین میکنند.



