

مقدمه
در آموزش شبکههای عصبی عمیق، انتخاب بهینهساز نقشی تعیینکننده در سرعت همگرایی، پایداری آموزش و کیفیت راهحل نهایی ایفا میکند. گرادیان کاهشی ساده، اگرچه مبنای نظری بسیاری از روشهاست، در عمل با چالشهایی مانند نوسان گرادیان، حساسیت به نرخ یادگیری و مقیاس متفاوت پارامترها مواجه میشود. این چالشها بهویژه در مدلهای عمیق و دادههای پُربعد، آموزش پایدار را دشوار میکنند.
بهینهساز آدام (Adaptive Moment Estimation یا Adam) با ترکیب ایدههای گرادیان کاهشی تطبیقی و مومنتوم، راهکاری عملی برای رفع بخشی از این مشکلات ارائه میدهد. این روش با نگهداشتن تخمینهایی از گشتاور اول و دوم گرادیانها و اعمال تصحیح بایاس، امکان تنظیم خودکار نرخ یادگیری برای هر پارامتر را فراهم میکند. نتیجه، الگوریتمی است که در بسیاری از مسائل، آموزش سریعتر و پایدارتر را ممکن میسازد.
هدف این مطلب ارائهی یک بررسی دقیق و متعادل از Adam است؛ از شهود و فرمولبندی ریاضی گرفته تا پیادهسازی عملی، مزایا، محدودیتها و مقایسه با روشهای دیگر. تمرکز اصلی بر این است که روشن شود Adam در چه شرایطی انتخاب مناسبی است و کجا باید با احتیاط یا همراه با گزینههای جایگزین از آن استفاده کرد.
تعریف
الگوریتم Adam که مخفف Adaptive Moment Estimation (تخمین گشتاور تطبیقی) است، یکی از پیشرفتهترین و پرکاربردترین بهینهسازهای (Optimizers) مرتبه اول در یادگیری عمیق مدرن به شمار میرود که توازنی استراتژیک میان سرعت محاسباتی و پایداری همگرایی ایجاد میکند. این بهینهساز با ترکیب هوشمندانه مزایای دو تکنیک Momentum و RMSProp، نرخ یادگیری را برای هر پارامتر به صورت انفرادی و تطبیقی تنظیم میکند.
Adam چگونه کار میکند؟
الگوریتم Adam با بازنگری در روش گرادیان کاهشی سنتی، به جای استفاده از یک نرخ یادگیری ثابت برای تمام پارامترها، رویکردی تطبیقی (Adaptive) را اتخاذ کرده است. این هوشمندی از طریق محاسبه مستمر میانگین متحرک گشتاورهای اول (میانگین) و دوم (واریانس) گرادیانها حاصل میشود.
در واقع، Adam به گونهای مهندسی شده است که معماری داخلی خود را با توپولوژی دادهها وفق دهد. این الگوریتم برای هر پارامتر در مدل شما، یک نرخ یادگیری انحصاری در نظر میگیرد. این نرخها نه به صورت ایستا، بلکه در طول فرآیند آموزش و بر اساس ماهیت دادههایی که مدل با آنها مواجه میشود، به طور مداوم اصلاح و بهینهسازی میشوند.

استعارهای برای درک بهتر: رانندگی در زمینهای ناهموار
تصور کنید در حال رانندگی در جادهای ناشناخته با پستی و بلندیهای فراوان هستید. در مسیرهای صاف، کفی و مستقیم، شما با اطمینان پدال گاز را فشار میدهید (در اینجا Adam نرخ یادگیری را برای عبور سریع از نواحی هموار افزایش میدهد). اما به محض رسیدن به پیچهای تند، مسیرهای سنگلاخی یا مه غلیظ، سرعت خود را کم کرده و با احتیاط ترمز میکنید (در اینجا Adam سرعت بهروزرسانی یا همان نرخ یادگیری را بر اساس ماهیت نوسانی گرادیان کاهش میدهد).
الگوریتم Adam دارای یک سیستم حافظه پویا است. این الگوریتم اقدامات و جهتگیریهای قبلی (گرادیانهای گذشته) را در حافظه خود ثبت کرده و گامهای جدید را با الهام از تجربیات قبلی برمیدارد. این حافظه صرفاً یک میانگینگیری ساده ریاضی نیست؛ بلکه ترکیبی هوشمندانه از اطلاعات گرادیانهای دور و نزدیک است که با اختصاص وزن بیشتر به مشاهدات اخیر، مدل را نسبت به تغییرات ناگهانی حساس نگه میدارد.
الگوریتم Adam (گامبهگام با ریاضیات)
هسته اصلی کارایی Adam در تلفیق استراتژیک دو مفهوم Momentum (برای سرعت و جهت) و RMSprop (برای پایداری و ابعاد گام) نهفته است.
گام ۱: مقداردهی اولیه (Initialization)
در شروع کار، Adam دو بردار حالت به نامهای m و v ایجاد میکند که ابعادی دقیقاً برابر با پارامترهای مدل (θ) دارند:
- بردار m (گشتاور اول): وظیفه ذخیره میانگین متحرک گرادیانها را بر عهده دارد تا جهت کلی حرکت مشخص شود.
- بردار v (گشتاور دوم): وظیفه رهگیری میانگین متحرک مجذور گرادیانها را دارد که در واقع نشاندهنده واریانس یا میزان تغییرات هر پارامتر است.
- شمارنده زمان t: برای رهگیری دقیق تعداد دفعات بهروزرسانی و استفاده در اصلاح سوگیری کاربرد دارد.
وضعیت اولیه:
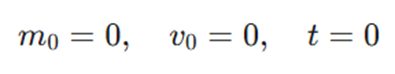
.
گام ۲: محاسبه گرادیانهای لحظهای (Compute Gradients)
در هر مرحله از آموزش (t)، بردار گرادیان gt محاسبه میشود. این بردار در واقع مشتق تابع هزینه نسبت به پارامترهای فعلی است:
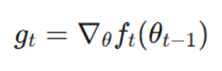
- gt: بردار گرادیان در تکرار فعلی. t
- θ∇: عملگر گرادیان (مشتقگیر) نسبت به پارامترهای θ.
- ft(θt−1): تابع هدف (Loss Function) که بر اساس مقادیر پارامترها در تکرار قبلی سنجیده میشود.
.
گام ۳: بهروزرسانی گشتاور اول (Update m – Momentum)
این بخش از فرمول، مسئول ایجادتکانه یا اینرسی در حرکت است. با استفاده از میانگین وزنی گرادیانهای قبلی، نوسانات اضافی (Oscillations) حذف میشوند:
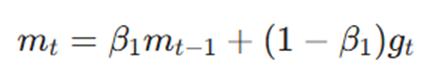
- mt: بردار گشتاور اول در زمان t (تخمین میانگین گرادیان).
- β1: نرخ کاهش نمایی برای گشتاور اول که معمولاً روی ۰.۹ تنظیم میشود.
- gt: گرادیان لحظهای محاسبه شده در گام فعلی.
.
گام ۴: بهروزرسانی گشتاور دوم (Update v – RMSprop)
این گام با محاسبه میانگین متحرک مجذور گرادیانها، میزانتغییرپذیری یا ناپایداری هر پارامتر را تخمین میزند:
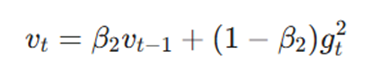
- vt: بردار گشتاور دوم در زمان t (تخمین واریانس یا انرژی گرادیان).
- β2: نرخ کاهش نمایی برای گشتاور دوم که معمولاً روی ۰.۹۹۹ تنظیم میشود.
- gt^2: مربع گرادیان لحظهای که باعث میشود جهت اهمیت خود را از دست داده و فقط شدت تغییرات ثبت شود.
.
گام ۵: اصلاح سوگیری (Correct the Bias)
از آنجایی که بردارهای m و v با مقدار صفر شروع میشوند، در مراحل ابتدایی آموزش به شدت به سمت عدد صفر متمایل هستند Adam. با انجام محاسبات زیر، این سوگیری را در گامهای آغازین خنثی میکند:
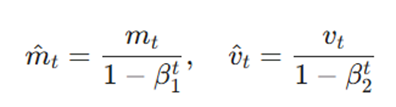
- m^t و v^t: مقادیر گشتاورهای اول و دوم که برای اثرات شروع سرد (Cold Start) اصلاح شدهاند.
- t: شماره تکرار فعلی که به عنوان توان در مخرج ظاهر میشود.
.
گام ۶: بهروزرسانی نهایی و تطبیقی پارامترها (Update Parameters)
در مرحله نهایی، پارامترهای مدل بر اساس اطلاعات جمعآوری شده از گشتاورها بهروزرسانی میشوند:
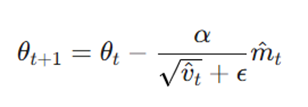
- θt+1 : مقادیر جدید پارامترها (وزنها و بایاسها) پس از بهروزرسانی.
- α: نرخ یادگیری پایه (Initial Learning Rate) یا اندازه گام اصلی.
- v^t√: مخرج کسر که باعث میشود پارامترهای با تغییرات زیاد، نرخ یادگیری کوچکتر و پارامترهای با تغییرات کم، نرخ یادگیری بزرگتری دریافت کنند.
- ϵ: یک ثابت بسیار کوچک (معمولاً ( 10^(-8) که صرفاً برای جلوگیری از خطای ریاضی تقسیم بر صفر در فرمول گنجانده شده است.
.
چرا نرخ یادگیری تطبیقی Adam تا این حد کارآمد است؟
ویژگی منحصربهفرد Adam در این است که ابعاد گامها را به صورت انفرادی برای هر پارامتر مقیاسبندی میکند. این تنظیمات بر اساس دو فاکتور حیاتی انجام میشود: Momentum (که جهت حرکت را تثبیت میکند) و Variability (که میزان غیرقابلپیشبینی بودن گرادیان را بازتاب میدهد).
- در نواحی پرشیب و ناپایدار: جایی که گرادیان به سرعت و به صورت غیرمنتظره تغییر میکند، Adam گامهای محتاطانه و کوچکی برمیدارد تا از نقطه کمینه مطلوب عبور نکند.
- در نواحی کمشیب و پیشبینیپذیر: جایی که گرادیان تغییرات ملایمی دارد، الگوریتم با اعتماد به نفس بیشتری گامهای بزرگتری برمیدارد تا سرعت آموزش و همگرایی را به حداکثر برساند.
این انعطافپذیری فوقالعاده باعث میشود Adam در بهینهسازی مدلهای پیچیده با دادههای نویزی یا تابع هزینههای دارای سطوح پرنوسان، بسیار هوشمندتر از الگوریتمهایی با نرخ یادگیری ثابت عمل کند.
راهنمای گامبهگام پیادهسازی Adam در پایتون
برای تبدیل فرمولهای ریاضی به کد برنامه نویسی، باید دقیقاً همان مراحلی را که در فایل بررسی کردیم، در یک حلقه تکرار (Training Loop) پیاده کنیم:
- مقداردهی اولیه: ابتدا باید بردارهای m (گشتاور اول) و v (گشتاور دوم) را با مقادیر صفر و به اندازه پارامترهای مدل ایجاد کنیم.
- محاسبه گرادیان: در هر تکرار، مشتق تابع هزینه نسبت به وزنها را محاسبه میکنیم. (gt)
- بهروزرسانی گشتاورها: با استفاده از ضرایب β1 و β2 (معمولاً ۰.۹ و ۰.۹۹۹)، میانگین متحرک گرادیان و مجذور آن را آپدیت میکنیم. اینجاست که حافظه مدل شکل میگیرد.
- اصلاح سوگیری (Bias Correction): چون m و v با صفر شروع شدهاند، در گامهای اول باید آنها را اصلاح کنیم تا مدل دچارشروع سرد نشود.
- تغییر پارامترها: در نهایت، وزنهای جدید را با تقسیم گشتاور اول اصلاح شده بر ریشه دوم گشتاور دوم اصلاح شده (به اضافه یک عدد بسیار کوچک ϵ) محاسبه میکنیم.
کد پایتون:
این کد یک کلاس Custom Adam را از صفر پیادهسازی کرده و عملکرد آن را با بهینهساز SGD روی یک مسئله طبقهبندی مقایسه میکند.
import numpy as np
import matplotlib.pyplot as plt
# 1. Custom Adam Optimizer Implementation (From Scratch)
class CustomAdam:
def __init__(self, learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-8):
self.lr = learning_rate
self.beta1 = beta1
self.beta2 = beta2
self.epsilon = epsilon
self.m = None
self.v = None
self.t = 0 # Time step counter
def update(self, params, grads):
if self.m is None:
self.m = [np.zeros_like(p) for p in params]
self.v = [np.zeros_like(p) for p in params]
self.t += 1
new_params = []
for i in range(len(params)):
# [cite_start]Update first moment (m_t)
self.m[i] = self.beta1 * self.m[i] + (1 - self.beta1) * grads[i]
# [cite_start]Update second moment (v_t)
self.v[i] = self.beta2 * self.v[i] + (1 - self.beta2) * (grads[i]**2)
# [cite_start]Bias correction
m_hat = self.m[i] / (1 - self.beta1**self.t)
v_hat = self.v[i] / (1 - self.beta2**self.t)
# [cite_start]Final parameter update
p_new = params[i] - self.lr * m_hat / (np.sqrt(v_hat) + self.epsilon)
new_params.append(p_new)
return new_params
# 2. Synthetic Data and Simple Model for Testing
np.random.seed(42)
X = np.random.randn(100, 2)
y = (X[:, 0] + X[:, 1] > 0).astype(float).reshape(-1, 1) # Simple linear boundary
def sigmoid(x): return 1 / (1 + np.exp(-x))
def train_model(optimizer_type='adam'):
weights = np.random.randn(2, 1)
bias = np.zeros((1, 1))
params = [weights, bias]
loss_history = []
opt = CustomAdam(learning_rate=0.1) if optimizer_type == 'adam' else None
for epoch in range(100):
# Forward pass
z = np.dot(X, params[0]) + params[1]
a = sigmoid(z)
# Loss (Binary Cross-Entropy)
loss = -np.mean(y * np.log(a) + (1 - y) * np.log(1 - a))
loss_history.append(loss)
# Backward pass (Gradients)
dz = a - y
dw = np.dot(X.T, dz) / len(y)
db = np.sum(dz) / len(y)
grads = [dw, db]
if optimizer_type == 'adam':
params = opt.update(params, grads)
else: # Basic SGD update
params[0] -= 0.1 * dw
params[1] -= 0.1 * db
return loss_history
# 3. Running Comparison
adam_loss = train_model('adam')
sgd_loss = train_model('sgd')
# 4. Visualization with English Labels
plt.figure(figsize=(10, 6))
plt.plot(adam_loss, label='Adam Optimizer', linewidth=2, color='navy')
plt.plot(sgd_loss, label='SGD Optimizer', linewidth=2, color='orange', linestyle='--')
plt.title('Optimization Comparison: Adam vs SGD')
plt.xlabel('Epochs')
plt.ylabel('Loss Value')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
خروجی:
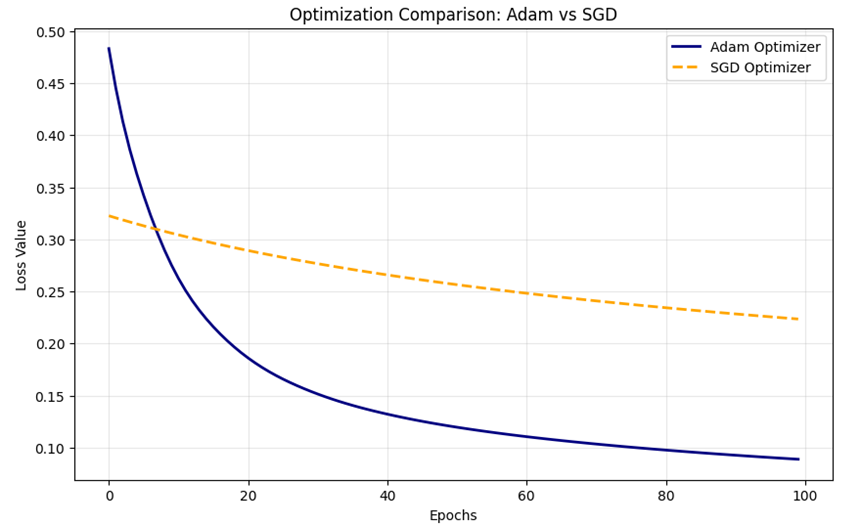
تحلیل تجربی خروجی: Adam در برابر SGD
نمودار حاصل از اجرای کد، تفاوت عملکرد این دو بهینهساز را در ۱۰۰ اپوک آموزشی نشان میدهد:
- همگرایی سریعتر در بسیاری از مسائل: همانطور که در نمودار مشهود است، منحنی سرمهای رنگ مربوط به Adam با شیبی بسیار تندتر از SGD سقوط کرده است. این یعنی Adam توانسته در کمتر از ۲۰ اپوک به سطحی از خطا (Loss) برسد که SGD حتی پس از ۱۰۰ اپوک نیز به آن دست نیافته است.
- تنظیم تطبیقی نرخ یادگیری: دلیل این تفاوت، هماننرخ یادگیری انفرادی برای هر پارامتر است که در فایل به آن اشاره شد. در حالی که SGD با یک سرعت ثابت و سنتی حرکت میکند، Adam با تحلیل گشتاورهای گرادیان، در مسیرهای هموار شتاب میگیرد.
- پایداری در نقطه بهینه: منحنی Adam پس از طی مراحل اولیه، به شکلی نرم و پایدار در سطوح پایین خطا تثبیت شده است. این پایداری نتیجه مستقیم استفاده از ترکیب Momentum و RMS Prop برای مهار نوسانات ناخواسته است.
.
مزایا
انتخاب Adam فراتر از یک عادت در برنامهنویسی، یک تصمیم استراتژیک برای افزایش کارایی مدل است.
- همگرایی سریع در سطوح پیچیده: Adam به لطف نرخ یادگیری تطبیقی، بسیار سریعتر از متدهای سنتی مانند SGD به نقطه بهینه میرسد؛ بهویژه در توابع هزینهای که دارای سطوح ناهموار و پیچیده هستند.
- نرخ یادگیری تطبیقی برای هر پارامتر: Adam برای هر وزن در شبکه عصبی، یک نرخ یادگیری مجزا تنظیم میکند. این ویژگی آن را برای طیف وسیعی از وظایف از جمله بینایی ماشین، NLP و یادگیری تقویتشده ایدهآل میسازد.
- پایداری و مقاوم (Robustness):Adam نسبت به انتخاب اولیه هایپرپارامترها چندان حساس نیست؛ این موضوع باعث میشود حتی بدون تنظیمات دستی طاقتفرسا، نتایج قابلقبولی ارائه دهد.
- تنوع در شیوههای آموزش: این الگوریتم هم در سناریوهای یادگیری آنلاین (بهروزرسانی مداوم با ورود داده جدید) و هم در یادگیری دستهای (Batch) با قدرت عمل میکند.
- مصرف بهینه حافظه: برخلاف تصورات، Adam در مقایسه با بسیاری از بهینهسازهای پیشرفته، نیاز به حافظه کمی دارد که اجازه میدهد شبکههای بزرگ را بدون محدودیتهای شدید سختافزاری آموزش دهید.
.
محدودیت ها
علیرغم قدرت بالا، Adam ابزاری بدون نقص نیست و در پیادهسازیهای حرفهای باید به این موارد دقت کرد:

- اهمیت نرخ یادگیری اولیه: اگرچه Adam منعطف است، اما انتخاب نرخ یادگیری اولیه (Initial Learning Rate) همچنان حیاتی است. مقدار بیش از حد بالا منجر به ناپایداری و مقدار بسیار پایین باعث کندی روند آموزش میشود.
- نیاز به حافظه اضافی برای گشتاورها: Adam باید میانگین متحرک (گشتاور اول و دوم) را برای تکتک پارامترها ذخیره کند. این موضوع در مدلهای فوقسنگین (مانند مدلهای زبانی بزرگ) باید از نظر منابع سختافزاری مدیریت شود.
- حساسیت به نویز و دادههای پرت (Outliers): دادههای بسیار نویزی یا نقاط پرت شدید میتوانند بر دقت تخمین گرادیان در Adam تأثیر منفی بگذارند؛ بنابراین پیشپردازش دادهها اهمیت بالایی دارد.
.
کاربردهای واقعی
۱. پیشرفت قابلتوجه در درک زبان انسان (NLP & LLMs)
- آموزش مدلهای غولآسا (مانندGPT): برای آموزش مدلهایی با میلیاردها پارامتر، Adam با مدیریت هوشمندانه حافظه و سرعت همگرایی بالا، یکی از گزینههای رایجای است که اجازه میدهد این مدلها در زمانی معقول آموزش ببینند.
- دستیارهای هوشمند و ترجمه: در سیستمهای ترجمه همزمان، Adam نرخ یادگیری را برای هرتوکن یا کلمه به صورت جداگانه تنظیم میکند. این یعنی مدل میتواند تفاوتهای ظریف معنایی را در جملات طولانی به درستی درک کند.
.
2 .پردازش صدا؛ گوشهای هوشمند مصنوعی
صدا یک سیگنال نویزی و متغیر است که Adam در مدیریت آن تخصص دارد.
- دستیارهای صوتی (Siri و Alexa): این سیستمها باید بتوانند احساسات شما را از تُن صدایتان تشخیص دهند. Adam با یادگیری الگوهای منحصربهفرد هر کاربر، این شخصیسازی را ممکن میکند.
- حذف نویز در لحظه: فیلترهای صوتی که صدای محیط را حذف میکنند، مدیون سرعت بالای Adam در مواجهه با سیگنالهای نویزی هستند تا بتوانند در کسری از ثانیه صدای شفاف را استخراج کنند.
.
3. سیستمهای توصیهگر؛ تطبیق خودکار پارامترها
تا به حال فکر کردهاید که یوتیوب یا نتفلیکس چطور دقیقاً چیزی را پیشنهاد میدهند که دوست دارید؟
- شخصیسازی لحظهای Adam: اجازه میدهد مدلها بر اساسرفتار آنلاین شما در همان لحظه بهروزرسانی شوند. یعنی به محض اینکه یک ویدیو را لایک میکنید، سیستم با سرعت Adam خود را برای پیشنهاد بعدی آماده میکند.
- تجارت الکترونیک: در فروشگاههای بزرگی مثل آمازون، بهرهوری حافظه در Adam اجازه میدهد تا علایق میلیونها کاربر به میلیونها کالا، بدون منفجر شدن سرورها پردازش شود.
.
مطالعه موردی ۱: بقا دردرهی توابع هزینهی پیچیده (Landscape Optimization)
هدف: نمایش هوش استراتژیک Adam در پیمایش سطوح ریاضی غیرمنظم و یافتن مسیر بهینه در کمترین زمان.
- چالش فنی: در دنیای واقعی یادگیری عمیق، تابع هزینه (Loss Function) همیشه یک سطح صاف و ساده نیست. تابع Beale که در این آزمایش استفاده شد، دارای نواحی وسیع تخت و گودالهای عمیقی است که الگوریتمهای سنتی مثل SGD را در خود حبس میکند.
- مکانیسم Adam در مواجهه با چالش:
- عبور از سطوح تخت: وقتی گرادیانها بسیار کوچک میشوند (در نواحی صاف)، Adam با تکیه برگشتاور اول (Momentum) از توقف مدل جلوگیری کرده و به آن شتاب میدهد تا از بنبست خارج شود.
- ترمز هوشمند در پیچها: به محض نزدیک شدن به درهی اصلی،گشتاور دوم (RMSProp) با تحلیل واریانس گرادیانها، نرخ یادگیری را به صورت انفرادی برای هر پارامتر کاهش میدهد تا مدل از نقطه بهینه جهش نکند.
کد پایتون:
import numpy as np
import matplotlib.pyplot as plt
# Beale Function: A famous non-convex function for testing optimizers
def beale(x, y):
return (1.5 - x + x*y)**2 + (2.25 - x + x*y**2)**2 + (2.625 - x + x*y**3)**2
def gradients(x, y):
dx = 2*(1.5 - x + x*y)*(y - 1) + 2*(2.25 - x + x*y**2)*(y**2 - 1) + 2*(2.625 - x + x*y**3)*(y**3 - 1)
dy = 2*(1.5 - x + x*y)*(x) + 2*(2.25 - x + x*y**2)*(2*x*y) + 2*(2.625 - x + x*y**3)*(3*x*y**2)
return dx, dy
# Adam Implementation
def optimize_adam(start_x, start_y, lr=0.02, epochs=1000):
x, y = start_x, start_y
m_x, m_y, v_x, v_y = 0, 0, 0, 0
path = [(x, y)]
for t in range(1, epochs + 1):
gx, gy = gradients(x, y)
m_x = 0.9 * m_x + 0.1 * gx
m_y = 0.9 * m_y + 0.1 * gy
v_x = 0.999 * v_x + 0.001 * (gx**2)
v_y = 0.999 * v_y + 0.001 * (gy**2)
m_hat_x, m_hat_y = m_x / (1 - 0.9**t), m_y / (1 - 0.9**t)
v_hat_x, v_hat_y = v_x / (1 - 0.999**t), v_y / (1 - 0.999**t)
x -= lr * m_hat_x / (np.sqrt(v_hat_x) + 1e-8)
y -= lr * m_hat_y / (np.sqrt(v_hat_y) + 1e-8)
path.append((x, y))
return np.array(path)
# Visualization
x_range = np.linspace(-4.5, 4.5, 100)
y_range = np.linspace(-4.5, 4.5, 100)
X, Y = np.meshgrid(x_range, y_range)
Z = beale(X, Y)
path = optimize_adam(-3.0, -3.0)
plt.figure(figsize=(10, 7))
plt.contour(X, Y, Z, levels=np.logspace(0, 5, 35), cmap='jet', alpha=0.4)
plt.plot(path[:, 0], path[:, 1], color='navy', linewidth=2, label='Adam Path')
plt.plot(3, 0.5, 'r*', markersize=15, label='Global Minimum')
plt.title('Adam Optimizer on Beale Function Landscape')
plt.xlabel('x'); plt.ylabel('y'); plt.legend(); plt.show()
خروجی:
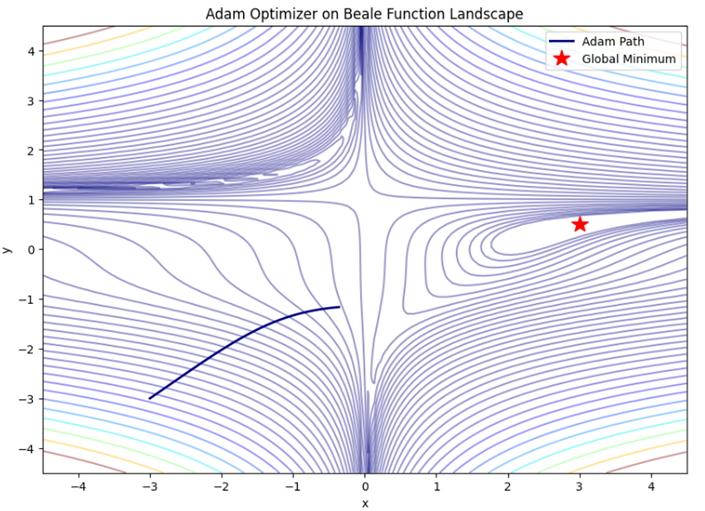
- تحلیل خروجی : در نمودار خروجی، مسیر حرکت Adam (خط سرمهای) به جای زیگزاگ زدنهای بیهوده، با یک منحنی نرم و هدفمند مستقیماً به سمت مرکز هدف (ستاره قرمز) حرکت میکند.
.
مطالعه موردی ۲: نبرد بانویزهای تصادفی در پیشبینی بازار مالی
هدف: اثبات پایداری و قدرت فیلترینگ Adam در مواجهه با دادههای پرنوسان و غیرقابلپیشبینی.
- چالش فنی: دادههای مالی (مثل قیمت سهام یا رمزارز) پر از نویزهای لحظهای هستند. یک بهینهساز ضعیف ممکن است با هر نوسان کوچک، جهت کل مدل را تغییر دهد که منجر به خطای فاحش در پیشبینی نهایی میشود.
- مکانیسم Adam در مواجهه با چالش:
- فیلترینگ نوسانات: Adam ازسیستم حافظه پویا خود استفاده میکند تا به جای واکنش آنی به هر دادهی نویزی، میانگین متحرکی از جهتهای قبلی را در نظر بگیرد.
- تعدیل وزن نویزها: با اختصاص وزن بیشتر به مشاهدات اخیر و اصلاح سوگیری ، Adam میتواند اثر دادههای پرت (Outliers) را خنثی کرده و تمرکز مدل را بر روی روند واقعی حفظ کند.
کد پایتون:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
# Data Loading
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
train_set = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True)
def get_model():
return nn.Sequential(nn.Flatten(), nn.Linear(784, 128), nn.ReLU(), nn.Linear(128, 10))
def train(optimizer_name):
model = get_model()
criterion = nn.CrossEntropyLoss()
if optimizer_name == 'Adam':
optimizer = optim.Adam(model.parameters(), lr=0.001)
else:
optimizer = optim.SGD(model.parameters(), lr=0.01)
losses = []
for batch_idx, (data, target) in enumerate(train_loader):
if batch_idx > 100: break # Small subset for quick demo
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
losses.append(loss.item())
return losses
adam_losses = train('Adam')
sgd_losses = train('SGD')
plt.figure(figsize=(10, 6))
plt.plot(adam_losses, label='Adam (Learning Rate 0.001)', color='navy')
plt.plot(sgd_losses, label='SGD (Learning Rate 0.01)', color='orange')
plt.title('Deep Learning Speed: Adam vs SGD on MNIST Images')
plt.xlabel('Iterations'); plt.ylabel('Training Loss')
plt.legend(); plt.grid(True); plt.show()
خروجی:
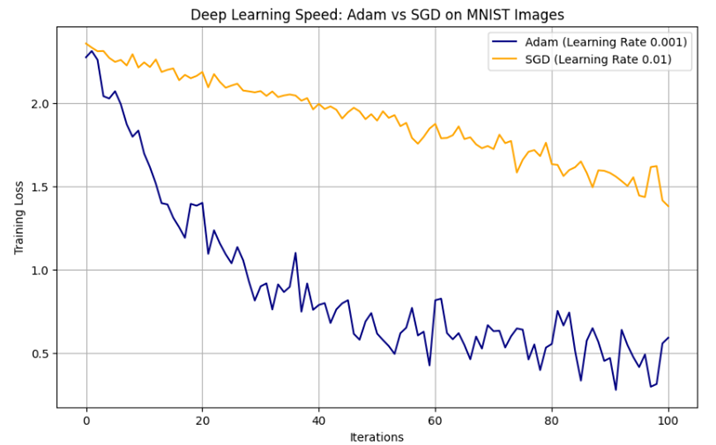
.
جمع بندی
Adam یکی از پرکاربردترین بهینهسازهای یادگیری عمیق است و بهدلیل پایداری نسبی و نیاز کمتر به تنظیم دستی نرخ یادگیری، به انتخاب پیشفرض بسیاری از فریمورکها تبدیل شده است. در این مطلب دیدیم که چگونه ترکیب مومنتوم و تنظیم تطبیقی نرخ یادگیری، Adam را به ابزاری مؤثر برای آموزش مدلهای پیچیده و پُربعد تبدیل میکند.
، بررسی دقیقتر نشان میدهد که Adam یک راهحل همهمنظوره نیست. در برخی مسائل، بهویژه زمانی که تعمیم نهایی مدل اهمیت بیشتری از سرعت همگرایی دارد، روشهایی مانند SGD بههمراه Momentum میتوانند عملکرد بهتری ارائه دهند. همچنین تفاوت میان پیادهسازیهای مختلف Adam و نسخههای اصلاحشدهای مانند AdamW یادآور این نکته است که انتخاب بهینهساز باید آگاهانه و متناسب با مسئله انجام شود.
در عمل، Adam اغلب نقطهی شروع مناسبی برای آموزش مدلهای عمیق محسوب میشود، اما تصمیم نهایی نباید صرفاً بر اساس محبوبیت آن باشد. تسلط بر سازوکار Adam و درک مزایا و محدودیتهای آن به مهندس یادگیری ماشین کمک میکند تا بهینهساز مناسب را با توجه به داده، معماری مدل و هدف نهایی انتخاب کند و فرآیند آموزش را بهصورت مهندسی و قابلدفاع بهینهسازی نماید.



