

مقدمه
در مدلهای یادگیری عمیق، افزایش تعداد پارامترها و ظرفیت بازنمایی شبکههای عصبی، توانایی مدلها را در یادگیری الگوهای پیچیده بهطور چشمگیری افزایش داده است. با این حال، همین ظرفیت بالا خطر بیشبرازش (Overfitting) را نیز تشدید میکند؛ وضعیتی که در آن مدل بهجای یادگیری ساختار آماری داده، نویز و نوسانات تصادفی مجموعه آموزش را حفظ میکند و در نتیجه روی دادههای دیدهنشده عملکرد ضعیفی دارد.
منظمسازی (Regularization) مجموعهای از تکنیکهای مهندسیشده برای کنترل ظرفیت مدل و کاهش خطای تعمیم (Generalization Error) است. در سادهترین بیان، منظمسازی با افزودن یک ترم جریمه به تابع هزینه یا با ایجاد محدودیت در فرآیند آموزش، مدل را به سمت راهحلهای پایدارتر و کمپیچیدگیتر هدایت میکند. این کنترل میتواند از طریق محدودسازی مستقیم وزنها (مانند L1 و L2)، ایجاد اختلال تصادفی در ساختار شبکه (مانند Dropout)، اصلاح توزیع دادههای ورودی (Data Augmentation)، یا مدیریت زمان آموزش (Early Stopping) انجام شود.
در این مقاله، منظمسازی را از منظر مهندسی یادگیری عمیق بررسی کردهایم؛ از مبانی ریاضی و تحلیل بایاس–واریانس گرفته تا تکنیکهای عملی و پیشرفتهای که در شبکههای مدرن به کار میروند.
در صورتی که با مفاهیم بیش برازش و کم برازش آشنایی ندارید،پیشنهاد میکنیم ابتدا مقاله بیشبرازش (Overfitting) و کمبرازش (Underfitting) را مطالعه کنید،سپس این مقاله را بخوانید.
تعریف
از دیدگاه مهندسی یادگیری عمیق، منظمسازی را هرگونه تغییری در الگوریتم یادگیری تعریف میکنیم که هدف آن کاهش خطای تعمیم (Generalization Error) است، بدون آنکه لزوماً تأثیری بر کاهش خطای آموزش داشته باشد.
در شبکههای عصبی عمیق که دارای میلیونها پارامتر آزاد هستند، فضای فرضیه (Hypothesis Space) بسیار گسترده است. منظمسازی با اضافه کردن یک ترم جریمه (Penalty Term) مانند Ω (θ) به تابع ضرر اصلی (L)، فرآیند بهینهسازی را اصلاح میکند:

در این فرمول، پارامتر λ (لاندا) شدت جریمه را کنترل میکند. این جریمه ریاضی، مدل را وادار میکند تا وزنهای (Weights) کوچکتر و توزیعشدهتری را انتخاب کند، زیرا وزنهای بزرگ معمولاً نشاندهنده بیشبرازش روی نویزهای مجموعهداده هستند. علاوه بر جریمههای نُرم (مانند L1 و L2)، تکنیکهایی نظیر دراپاوت (Dropout) با ایجاد اختلال تصادفی در ساختار شبکه و توقف زودهنگام (Early Stopping) با محدود کردن زمان آموزش، به طور غیرمستقیم از غرق شدن مدل در پیچیدگیهای فضای تجربی جلوگیری میکنند.
اثر منظمسازی بر بایاس و واریانس (Bias-Variance Tradeoff)
در مهندسی یادگیری عمیق، هدف نهایی ما کاهش خطای تعمیم (Generalization Error) است. منظمسازی ابزاری است که با دستکاری ظرفیت شبکه، توازن بین دو منبع اصلی خطا را برقرار میکند:
- واریانس بالا (بیشبرازش – Overfitting): وقتی مدل بیش از حد پیچیده باشد، نویزهای دادههای آموزشی را حفظ میکند. منظمسازی با اضافه کردن جریمه (λ)، از رشد بیرویه وزنها جلوگیری کرده و واریانس را کاهش میدهد.
- بایاس بالا (کمبرازش-Underfitting): اگر ضریب منظمسازی (λ) را بیش از حد بزرگ انتخاب کنیم، مدل الگوهای اصلی را نادیده گرفته و بیش از حد ساده میشود. در این حالت، واریانس کم است اما بایاس (خطا نسبت به واقعیت) افزایش مییابد.
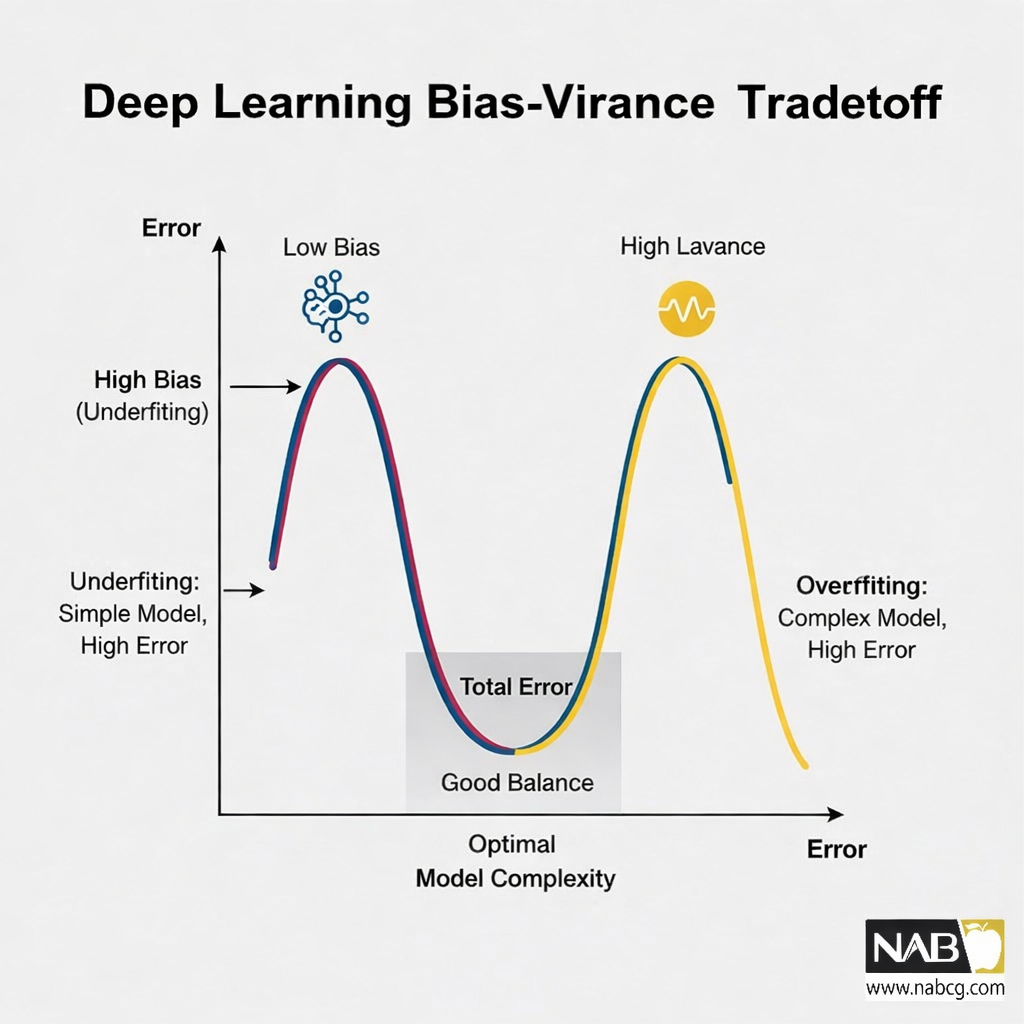
نکته کلیدی: هدف منظمسازی، یافتن نقطهای است که مجموع بایاس و واریانس در آن کمینه باشد تا به مدلی خوشبرازش (Well-fitted) برسیم.
منظمسازی چگونه باعث کاهش بیشبرازش میشود؟
یک شبکهی عصبی را در نظر بگیرید که بر روی دادههای آموزشی دچار بیشبرازش شده است (مطابق تصویر زیر):
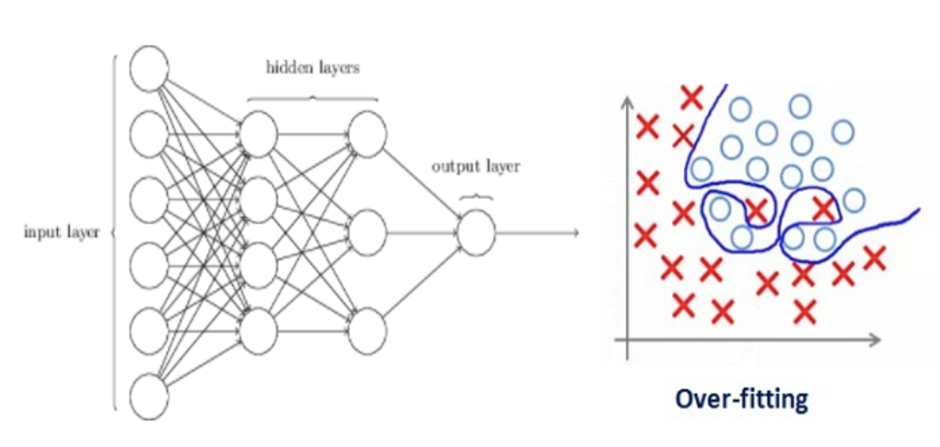
اگر با مفهوم منظمسازی در یادگیری ماشین آشنا باشید، میدانید که این تکنیک ضرایب مدل را جریمه میکند. در یادگیری عمیق، این جریمه مستقیماً بر روی ماتریسهای وزن (Weight Matrices) گرهها اعمال میشود.
مکانیزم اثر: سادهسازی هوشمندانه
فرض کنید ضریب منظمسازی (λ) را به قدری بزرگ انتخاب کنیم که مقدار برخی از ماتریسهای وزن تقریباً با صفر برابر شود:

این اتفاق باعث میشود شبکهی ما به یک مدل خطی بسیار سادهتر تبدیل شده و حتی دچار کمبرازش (Underfitting) جزئی شود.
واضح است که انتخاب چنین مقدار بزرگی برای ضریب منظمسازی چندان کاربردی نیست. هدف اصلی ما این است که مقدار ضریب منظمسازی را به شکلی بهینه تنظیم کنیم تا به یک مدل خوشبرازش (Well-fitted) دست یابیم؛ مدلی که نه نویزها را حفظ کرده و نه الگوهای اصلی را نادیده گرفته است:
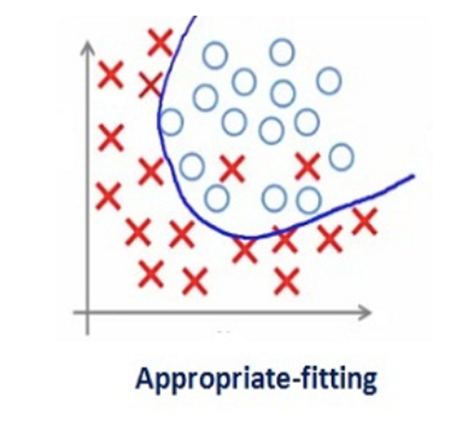
در واقع، منظمسازی با کنترل ابعاد و بزرگی وزنها، ظرفیت شبکه را محدود کرده و آن را وادار میکند تا به جای تمرکز بر جزئیات نویزی، ساختار کلی دادهها را بیاموزد.
تکنیکهای منظمسازی در یادگیری عمیق
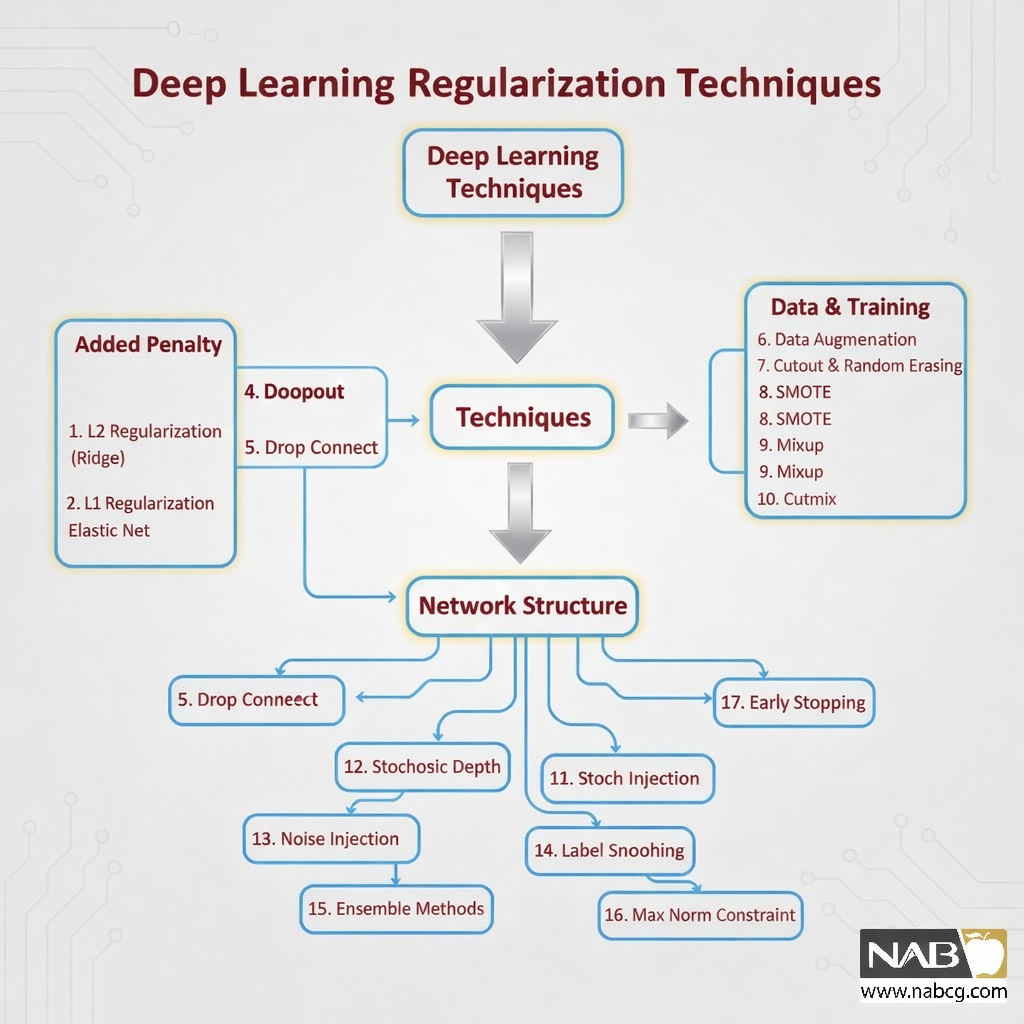
- L2 (Ridge)
- L1 (Lasso)
- Elastic Net
- Dropout
- Drop Connect
- Batch Normalization
- Data Augmentation
- Early Stopping
- Label Smoothing
- Stochastic Depth
- Noise Injection
- Cutout و Random Erasing
- SMOTE
- Mixup
- Cutmix
- Ensemble Methods
- Max Norm Constraint
.
(Ridge)L2
این منظمسازی L2 که به آن منظمسازی Ridge هم گفته میشود، یکی از پرکاربردترین تکنیکها برای مهار شبکههای عصبی است. این روش با اضافه کردن جریمهای متناسب با توان دوم بزرگی وزنها به تابع ضرر، از رشد بیرویهی پارامترها جلوگیری میکند.
فرمول:

متغیرها:
- L: هدفی که بهینهساز سعی در کمینه کردن آن دارد.
- L₀: میزان خطای اصلی
- λ (ضریب منظمسازی): هایپرپارامتری که شدت جریمه را تعیین میکند؛ مقادیر بزرگتر منجر به وزنهای کوچکتر و مدل سادهتر میشوند.
- wᵢ: پارامترهای قابل یادگیری (وزنها) لایههای شبکه
.
| مزایا | معایب |
| جلوگیری از انفجار وزنها: مانع از ایجاد وزنهای بسیار بزرگ میشود که عامل اصلی حساسیت مدل به نویز است. | عدم حذف ویژگیها: برخلاف L1، وزنها را به صفر مطلق نمیرساند، بنابراین مدل همچنان پیچیده باقی میماند. |
| پایداری عددی: با کوچک نگه داشتن وزنها، فرآیند بهینهسازی و همگرایی مدل را پایدارتر میکند. | هزینه محاسباتی: اضافه کردن مشتق ترم جریمه به محاسبات گرادیان، بار محاسباتی اندکی ایجاد میکند. |

(Lasso) L1
منظمسازی L1 که با نام Lasso نیز شناخته میشود، رویکردی متفاوت و تا حدی تهاجمیتر نسبت به L2 دارد. ویژگی منحصربهفرد و متمایزکنندهی این متد، توانایی آن در صفر کردن دقیق برخی از وزنهای شبکه است که منجر به ایجاد یک پاسخ تنک (Sparse Solution) میشود.
فرمول:
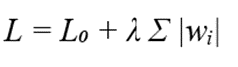
متغیرها:
- L: هدف نهایی برای بهینهسازی.
- L₀: میزان خطای محاسباتی مدل.
- λ: ضریب تنظیم شدت جریمه؛ هرچه لاندا بزرگتر باشد، مدل تمایل بیشتری به حذف ویژگیها (صفر کردن وزنها) پیدا میکند.
- |wᵢ|: قدر مطلق وزنهای مدل که به عنوان جریمه در نظر گرفته میشود.
.
| مزایا | معایب |
| انتخاب ویژگی خودکار: با صفر کردن وزنهای بیاهمیت، به طور خودکار مهمترین ویژگیهای ورودی را شناسایی و بقیه را حذف میکند. | ناپایداری در دادههای همبسته: اگر چند ویژگی به شدت با هم در ارتباط باشند، L1 معمولاً یکی را به صورت تصادفی انتخاب کرده و بقیه را صفر میکند. |
| ایجاد مدلهای ساده و مفسر: به دلیل تنک شدن وزنها، مدل نهایی سبکتر شده و تفسیر نحوهی تصمیمگیری آن آسانتر است. | عدم مشتقپذیری در مبدأ: به دلیل وجود تابع قدر مطلق، در نقطهی صفر مشتقپذیر نیست که میتواند فرآیند بهینهسازی را کمی پیچیده کند. |
| کارایی در ابعاد بالا: برای مجموعهدادههایی با ویژگیهای بسیار زیاد (مانند متن یا دادههای پزشکی) فوقالعاده عمل میکند. | احتمال کمبرازش: اگر ضریب لاندا به درستی تنظیم نشود، ممکن است ویژگیهای کلیدی را هم حذف کرده و باعث کمبرازش شود. |
Elastic Net
اگر L1 را یک جراح سختگیر و L2 را یک مربی ملایم در نظر بگیریم، الاستیکنت (Elastic Net) نقش یک دیپلمات باهوش را ایفا میکند. این تکنیک با ترکیب جریمههای هر دو روش، تعادلی میان تنکسازی (Sparsity) و پایداری ایجاد میکند تا مدلی ساخته شود که نه تنها ساده است، بلکه ویژگیهای کلیدی گروهی را هم به سادگی از دست نمیدهد.
فرمول:
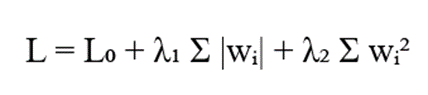
متغیرها:
- λ₁, λ₂: ضرایب منظمسازی که به ترتیب شدت جریمههای L1 و L2 را کنترل میکنند.
- α: هایپرپارامتری که توازن و وزن نسبی بین این دو نوع جریمه را تعیین میکند.
.
| مزایا | معایب |
| اثر گروهی (Grouping Effect): برخلاف L1، اگر گروهی از ویژگیها به هم وابسته باشند، الاستیکنت کل گروه را با هم حفظ یا حذف میکند. | پیچیدگی در تنظیم: به دلیل وجود دو ضریب جریمه ، پیدا کردن ترکیب بهینه هایپرپارامترها زمانبرتر و دشوارتر است. |
| پایداری در ابعاد بالا: وقتی تعداد ویژگیها بسیار بیشتر از تعداد نمونههاست ، این روش از L1 بسیار پایدارتر عمل میکند. | هزینه محاسباتی: نسبت به روشهای تکجریمهای، بار محاسباتی بیشتری در زمان مشتقگیری و بهروزرسانی وزنها به سیستم تحمیل میکند. |
| انعطافپذیری بالا: با تغییر نسبت ترکیب ، میتوان مدل را به هر یک از دو حالت خالص L1 یا L2 نزدیک کرد. | نیاز به دادههای بیشتر: برای بهرهبرداری کامل از پتانسیل ترکیبی این روش، معمولاً به حجم دادههای بیشتری برای اعتبارسنجی دقیق نیاز است. |
Dropout
دراپاوت یکی از انقلابیترین و پرکاربردترین تکنیکهای منظمسازی در شبکههای عصبی عمیق است. اگر بخواهیم ساده بگوییم، این روش مانند تمرین دادن یک تیم فوتبال است که در هر جلسه، چند بازیکن کلیدی را به صورت تصادفی از زمین خارج میکنیم تا بقیهی اعضا یاد بگیرند بدون تکیه بر یک ستاره، مسئولیتپذیرتر و مستقلتر عمل کنند.
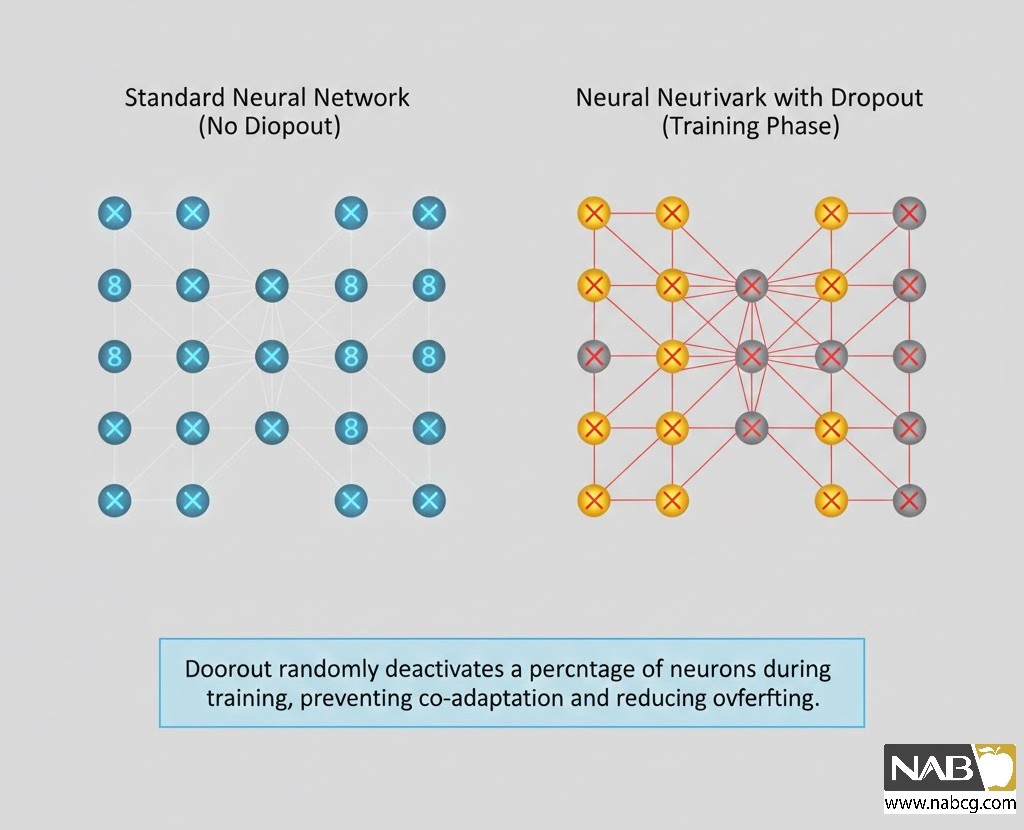
مکانیزم عملکرد و فرمول ریاضی
در طول فرآیند آموزش، در هر تکرار (Iteration)، مجموعهای از نورونها با احتمال p به صورت تصادفی انتخاب شده و خروجی آنها صفر میشود. این کار باعث میشود شبکه مجبور شود بازنماییهای مقاومتر و متنوعتری از دادهها را بیاموزد.
فرمول ریاضی خروجی یک لایه با دراپاوت به صورت زیر است
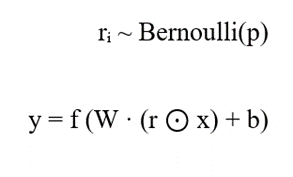
متغیرها:
- p: احتمال حذف یا نگهداشتن نورون که معمولاً عددی بین ۰.۲ تا ۰.۵ انتخاب میشود
- rᵢ: یک متغیر تصادفی که برای هر نورون مقدار ۰ (حذف) یا ۱ (حفظ) را میگیرد
- ⊙: ضرب نقطه ای
.
| مزایا | معایب |
| جلوگیری از هموابستگی (Co-adaptation): مانع از این میشود که نورونها بیش از حد به حضور نورونهای دیگر وابسته شوند و آنها را به استقلال وادار میکند. | افزایش زمان آموزش: به دلیل حذف تصادفی بخشهایی از شبکه، مدل معمولاً به تعداد اپوکهای بیشتری برای همگرایی نیاز دارد. |
| اثر تجمیعی (Ensemble Effect): هر بار که نورونی حذف میشود، گویی در حال آموزش یک زیرشبکه جدید هستیم؛ در نهایت مدل مانند ترکیبی از هزاران شبکه کوچک عمل میکند. | فقط در زمان آموزش: این تکنیک در زمان استنتاج (Inference) غیرفعال میشود و باید خروجیها را به درستی مقیاسبندی کرد. |
| کاهش شدید بیشبرازش: یکی از موثرترین راهها برای کنترل مدلهای بسیار عمیق و پیچیده که پارامترهای زیادی دارند. | ناسازگاری احتمالی: گاهی اوقات استفاده همزمان از Dropout و Batch Normalization میتواند منجر به اختلال در یادگیری شود. |
Drop Connect
اگر دراپاوت را مانند خاموش کردن تصادفی لامپها در یک مدار در نظر بگیریم، دراپکانکت مانند قطع کردن تصادفی سیمهای رابط بین آن لامپهاست. این تکنیک نسخهی کلیتر و دقیقتری از دراپاوت است که به جای حذف کل یک واحد پردازشی (نورون)، مستقیماً به سراغ پیوندها یا همان وزنها میرود.
مکانیزم عملکرد و فرمول ریاضی
در این روش، به جای صفر کردن خروجی نورون، ماتریس وزنها (W) در یک ماسک باینری تصادفی (M) ضرب میشود تا برخی از اتصالات در طول گام آموزش به طور موقت حذف شوند.
فرمولاسیون ریاضی این فرآیند به شرح زیر است:
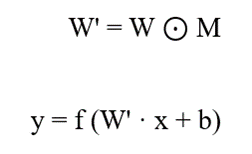
متغیرها:
- W: مجموعهی تمام اتصالات یادگیری شده بین دو لایه.
- M: یک ماتریس باینری که مقادیر آن به صورت تصادفی بر اساس توزیع برنولی تعیین میشوند.
- ⊙: ضرب مولفه به مولفه(نقطه ای)
تفاوت با Dropout:
- Dropout: نورونها را حذف میکند
- Drop Connect: ارتباطات را حذف میکند
.
| مزایا | معایب |
| فضای مدلسازی وسیعتر: به دلیل حذف اتصالات به جای نورونها، تعداد حالتهای ممکن برای زیرشبکهها به مراتب بیشتر از دراپاوت است. | پیچیدگی محاسباتی: پیادهسازی و اجرای دراپکانکت به دلیل نیاز به ماسکگذاری روی تکتک وزنها، از نظر محاسباتی سنگینتر است. |
| جلوگیری دقیقتر از هموابستگی: با هدف قرار دادن وزنها، مدل را وادار میکند تا برای انتقال اطلاعات، وابستگی شدیدی به هیچ اتصال خاصی پیدا نکند. | سختی در بهینهسازی: تنظیم هایپرپارامترها در این روش معمولاً دشوارتر است و ممکن است باعث کند شدن روند همگرایی شود. |
| تعمیمپذیری بالا: نتایج تجربی نشان دادهاند که در برخی معماریها، این روش میتواند رکوردهای دقت بهتری نسبت به دراپاوت ثبت کند. | پشتیبانی محدود در کتابخانهها: برخلاف دراپاوت، دراپکانکت در لایههای استاندارد بسیاری از فریمورکها به صورت پیشفرض وجود ندارد. |
Batch Normalization
نرمالسازی دستهای یا به اختصار بچ نرمالیزیشن، یکی از کلیدیترین پیشرفتها در معماری شبکههای عصبی عمیق است. آموزش شبکههای عمیق به دلیل پدیدهای به نام تغییر کوواریانس داخلی (Internal Covariate Shift) دشوار است؛ جایی که با تغییر وزنهای یک لایه، توزیع ورودیهای لایهی بعدی به شدت تغییر میکند. بچ نرمالیزیشن با ثابت نگه داشتن توزیع ورودیهای هر لایه، این مشکل را حل کرده و پایداری کل شبکه را تضمین میکند.
فرمول ریاضی و متغیرهای کلیدی
برای هر دستهی کوچک (Mini-batch)، محاسبات زیر انجام میشود تا خروجیها نرمالسازی شوند:
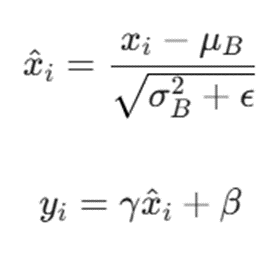
متغیرها:
- μᴮ: میانگین دستهی کوچک (Mini-batch Mean)
- σ²ᴮ: واریانس دستهی کوچک (Mini-batch Variance).
- ε: مقدار بسیار کوچکی که برای جلوگیری از خطای تقسیم بر صفر اضافه میشود.
- γ: پارامتر قابل یادگیری برای مقیاسدهی (Scale)
- β: پارامتر قابل یادگیری برای انتقال یا جابجایی (Shift).
.
| مزایا | معایب |
| تسریع فوقالعاده آموزش: با کاهش وابستگی لایهها به یکدیگر، همگرایی مدل بسیار سریعتر اتفاق میافتد. | وابستگی به اندازه دسته (Batch Size): در دستههای بسیار کوچک (مانند ۲ یا ۴)، تخمین میانگین و واریانس دقیق نیست و عملکرد افت میکند. |
| کاهش حساسیت به مقداردهی اولیه: دیگر نیازی به تنظیمات بسیار دقیق و حساس برای شروع وزنها نیست. | سربار محاسباتی: اضافه کردن این لایهها باعث افزایش زمان محاسبات در هر تکرار و مصرف بیشتر حافظه (GPU) میشود. |
| منظمسازی ملایم: به دلیل تزریق نویز تصادفی در هر دسته، مانند یک منظمساز عمل کرده و نیاز به Dropout را کاهش میدهد. | تفاوت رفتار در آموزش و تست: مدل در زمان استنتاج (Inference) رفتار متفاوتی دارد که باید با دقت مدیریت شود. |
| اجازه استفاده از نرخ یادگیری بالا: میتوان بدون ترس از واگرایی، از نرخهای یادگیری (Learning Rate) بزرگتر استفاده کرد. | نامناسب برای برخی مدلها: در شبکههای بازگشتی (RNN) یا مدلهایی با طول توالی متغیر، پیادهسازی آن چالشبرانگیز است. |
Data Augmentation
افزونگی دادهها یک تکنیک قدرتمند و حیاتی است که با اعمال دگرگونیهای بصری و ساختاری بر روی دادههای موجود، اندازهی مجموعهدادهی آموزشی را به صورت مصنوعی افزایش میدهد. هدف اصلی این روش، آموزش مدل به گونهای است که ویژگیهای کلیدی و اصلی را فدای جزئیات تصادفی و نویزی (مانند زاویه تابش نور یا جهت قرارگیری تصویر) نکند.
مبانی ریاضی و مکانیزم تولید
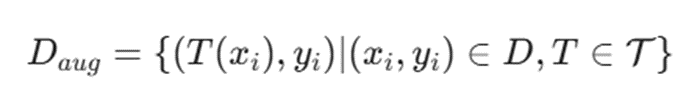
معرفی متغیرها:
- Daug: مجموعهدادهی نهایی و گسترشیافته.
- T: تابع تبدیل (Transformation) اعمال شده.
- xi: دادهی ورودی اصلی (مانند تصویر).
- yi: برچسب یا کلاس مربوط به داده که ثابت میماند.
- D: مجموعهدادهی آموزشی اولیه.
.
تکنیکهای رایج در بینایی ماشین
در پردازش تصویر، روشهای زیر بیشترین کاربرد را برای فریب دادن مثبت مدل و یادگیری بهتر دارند:
- چرخش (Rotation): چرخاندن تصویر به زوایای مختلف برای درک شیء در جهات گوناگون.
- آینه کردن (Flip): معکوس کردن تصویر به صورت افقی یا عمودی.
- تغییر مقیاس (Scale): بزرگنمایی یا کوچکنمایی تصویر.
- برش تصادفی (Crop): جدا کردن بخشهای مختلف تصویر برای تمرکز بر جزئیات.
- تغییر رنگ و نور: تنظیم روشنایی و غلظت رنگها برای شبیهسازی شرایط نوری متفاوت.
.
| مزایا | معایب |
| مهار قدرتمند بیشبرازش: با افزایش تنوع، مانع از حفظ کردن نمونههای تکراری توسط مدل میشود. | افزایش زمان آموزش: حجم بیشتر دادهها به معنای نیاز به توان پردازشی و زمان بیشتر برای یادگیری است. |
| تقویت تابآوری (Robustness): مدل در برابر تغییرات محیطی و نویزهای دنیای واقعی بسیار مقاومتر میشود. | خطر تغییر ماهیت داده: اعمال برخی تبدیلها (مثل چرخش ۱۸۰ درجه برای عدد ۶) ممکن است معنای داده را عوض کند. |
| حل مشکل کمبود داده: بهترین راهکار برای زمانی که دسترسی به دادههای واقعی جدید محدود یا گران است. | پیچیدگی در انتخاب تبدیل: انتخاب نادرست توابع T میتواند مدل را به سمت الگوهای غیرمنطقی سوق دهد. |
Early Stopping
توقف زودهنگام یکی از هوشمندانهترین و در عین حال سادهترین استراتژیهای منظمسازی در یادگیری عمیق است. در فرآیند آموزش، معمولاً خطای مدل روی دادههای آموزشی مدام کاهش مییابد، اما پس از نقطهای مشخص، خطا روی دادههای اعتبارسنجی (Validation) شروع به افزایش میکند که نشانهی بارز شروع بیشبرازش است. توقف زودهنگام دقیقاً در همین نقطه طلایی، عملیات آموزش را متوقف میکند تا مدل از یک حفظکننده به یک تحلیلگر تبدیل شود.
منطق الگوریتم و متغیرها
این تکنیک بر اساس پایش مداوم تابع ضرر مجموعه اعتبارسنجی عمل میکند. منطق شرطی آن را میتوان به زبان ریاضی به شکل زیر بیان کرد:

متغیرها:
- val_lossₜ: میزان تابع ضرر (Loss) در مجموعهی اعتبارسنجی در اپوک فعلی (t)
- p: تعداد اپوکهایی که مدل اجازه دارد علیرغم عدم بهبود در خطای اعتبارسنجی، به آموزش ادامه دهد. این پارامتر به عنوان یک ضربهگیر در برابر نوسانات تصادفی عمل میکند.
.
| مزایا | معایب |
| جلوگیری موثر از بیشبرازش: با توقف در نقطه بهینه، مانع از حفظ کردن نویزهای دادههای آموزشی توسط مدل میشود. | وابستگی شدید به پارامتر Patience: اگر مقدار p خیلی کوچک باشد، ممکن است آموزش در یک مینیمم محلی به اشتباه متوقف شود. |
| صرفهجویی در منابع و زمان: با پایان دادن به آموزشهای بیحاصل، در زمان و هزینههای محاسباتی (GPU) صرفهجویی چشمگیری میکند. | عدم مهار مستقیم پارامترها: برخلاف L1 یا L2، این روش محدودیتی بر بزرگی وزنها اعمال نمیکند و فقط زمان آموزش را مدیریت میکند. |
| ذخیره بهترین نسخه مدل: معمولاً بهترین پارامترهای ثبت شده قبل از شروع واگرایی را به عنوان مدل نهایی ذخیره میکند. | نیاز به مجموعهی اعتبارسنجی: برای عملکرد درست، بخشی از دادههای باارزش باید صرفاً برای مانیتورینگ کنار گذاشته شوند. |
Label Smoothing
در مسائل دستهبندی کلاسیک، ما معمولاً از برچسبهای Hard یا همان One-hot Encoding استفاده میکنیم؛ یعنی احتمال یک کلاس را دقیقاً ۱ و بقیه را ۰ در نظر میگیریم. اما این کار باعث میشود مدل در طول آموزش تلاش کند خروجی لایهی آخر (Logits) را به سمت بینهایت سوق دهد تا احتمال به یک نزدیک شود، که نتیجهی آن اعتمادبهنفس کاذب و بیشبرازش است. هموارسازی برچسبها با توزیع اندکی از احتمال روی سایر کلاسها، برچسبها را به حالت Soft (نرم) درآورده و مدل را وادار به تواضع و تعمیمدهی بهتر میکند.
فرمول:
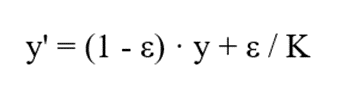
متغیرها:
- ‘y: برچسب هدف جدید
- y: برچسب اصلی (One-hot)
- ε: ضریب هموارسازی (بین 0 و 1)
- K: تعداد کلاسها
| مزایا | معایب |
| جلوگیری از بیشبرازش: مانع از این میشود که مدل بر روی جزئیات نویزی دادههای آموزشی بیش از حد مطمئن شود. | کاهش دقت در دادههای بسیار باکیفیت: اگر دادههای شما هیچ نویزی نداشته باشند، ممکن است هموارسازی باعث کاهش قدرت تشخیص قطعی مدل شود. |
| بهبود عملکرد در پروژههای بزرگ: در مدلهای غولآسایی مثل Inception یا Transformer، این تکنیک باعث پایداری و بهبود دقت نهایی میشود. | چالش در تقطیر دانش (Distillation): در فرآیند Teacher-Student، استفاده از Label Smoothing در مدل معلم میتواند انتقال دانش را سختتر کند. |
| کاهش فاصله بین Logits: با جلوگیری از رشد بیرویهی مقادیر خروجی، فرآیند بهینهسازی را پایدارتر میکند. | نیاز به تنظیم هایپرپارامتر: یافتن مقدار بهینه ε بستگی به شدت نویز در مجموعهداده دارد. |
.
Stochastic Depth
عمق تصادفی (Stochastic Depth) یکی از تکنیکهای منظمسازی در شبکههای عمیق ResNet است که بلوکهای باقیمانده (Residual) را با احتمال تصادفی حذف میکند.
فرمول:

متغیرها:
- bᵢ: متغیر تصادفی برنولی
- pᵢ: احتمال بقای بلوک (Survival Probability)
- F(x, Wᵢ): خروجی بلوک باقیمانده
.
Noise Injection
تزریق نویز یک استراتژی منظمسازی قدرتمند است که با ایجاد اختلالات عمدی در طول فرآیند آموزش، مدل را وادار میکند تا نسبت به تغییرات کوچک و بیاهمیت حساسیت نشان ندهد. این تکنیک را میتوان به نوعی واکسیناسیون تشبیه کرد؛ ما مدل را با مقادیر کمی از نویز مواجه میکنیم تا در آینده و در برابر دادههای ناقص یا نویزی دنیای واقعی، دچار فروپاشی نشود.
انواع تزریق نویز و مکانیزمها
نویز را میتوان در سطوح مختلفی به شبکه تزریق کرد:
۱. نویز در ورودی (Input Noise): رایجترین حالت که در آن دادههای ورودی با مقادیر تصادفی ترکیب میشوند تا مدل یاد بگیرد الگوهای اصلی را فراتر از نوسانات پیکسلها یا اعداد ببیند.
- فرمول

۲. نویز در وزنها (Weight Noise): افزودن نویز به پارامترهای مدل که باعث میشود مدل به جای یافتن یک نقطهی دقیق، در یک ناحیهی امن و پایدار به دنبال کمینه کردن تابع ضرر بگردد.
۳. نویز در برچسبها (Label Noise): که با نام هموارسازی برچسبها نیز شناخته میشود و پیشتر به آن پرداختیم.
| مزایا | معایب |
| تقویت فوقالعادهی تابآوری (Robustness): مدل را در برابر حملات متخاصم و دادههای بیکیفیت بسیار مقاوم میکند. | سختتر شدن همگرایی: تزریق نویز میتواند فرآیند بهینهسازی را نوسانی کرده و زمان رسیدن به کمینه را طولانی کند. |
| جلوگیری از بیشبرازش: با وادار کردن مدل به یادگیری الگوهای کلیتر، از حفظ کردن جزئیات نویزی جلوگیری میکند. | خطر از دست رفتن جزئیات: اگر شدت نویز بیش از حد باشد، ممکن است مدل الگوهای ظریف اما مهم را نیز نادیده بگیرد. |
| آموزش روی دادههای ناقص: به مدل کمک میکند تا در مواجهه با دادههای حذف شده یا ناقص، عملکرد خود را حفظ کند. | نیاز به تنظیم دقیق: تعیین توزیع و شدت نویز مناسب برای هر دیتاسِت، یک چالش تجربی زمانبر است. |
.
Cutout و Random Erasing
در پردازش تصویر، مدلهای یادگیری عمیق گاهی دچار تکبینی میشوند؛ یعنی برای تشخیص یک شیء، بیش از حد به یک جزء خاص (مثلاً فقط گوشهای گربه) تکیه میکنند. تکنیکهای Cutout و Random Erasing با حذف تصادفی بخشهایی از تصویر در طول آموزش، شبکه را مجبور میکنند تا به جای تمرکز بر یک نقطهی خاص، کل ساختار تصویر را برای استخراج ویژگی بررسی کند.
تعاریف و تفاوتهای کلیدی
- Cutout: در این روش، یک مربع با ابعاد تصادفی از تصویر بریده شده و مقدار پیکسلهای آن ناحیه معمولاً با صفر (سیاه) جایگزین میشود.
- Random Erasing: رویکردی منعطفتر است که در آن ناحیهای با ابعاد، نسبت ابعاد و حتی مقادیر رنگی تصادفی (نویز یا میانگین پیکسلها) جایگزین بخشی از تصویر میگردد.
فرمول احتمال:
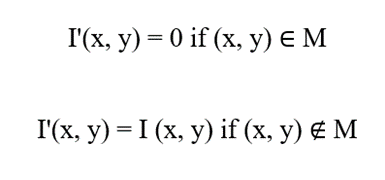
متغیرها:
- M: ناحیهای که قرار است اطلاعات آن حذف شود
- Sᴍ: اندازه ماسک (بین Sᴍᵢₙ و Sᴍₐₓ)
- r: نسبت ابعاد ماسک به تصویر
.
| مزایا | معایب |
| جلوگیری از بیشبرازش: مانع از اتکای مدل به الگوهای محلی و نویزی میشود. | خطر حذف اطلاعات حیاتی: ممکن است ناحیهی حذف شده دقیقاً حاوی تنها بخش نمایانِ شیء هدف باشد که باعث گمراهی مدل میشود. |
| تقویت تشخیص اشیاء ناقص: مدل یاد میگیرد اشیاء را حتی زمانی که بخشی از آنها پشت موانع پنهان شده، شناسایی کند. | افزایش پیچیدگی تنظیمات: یافتن اندازهی بهینهی ماسک (SM) برای دیتاسِتهای مختلف نیاز به آزمون و خطای فراوان دارد. |
| بهبود پایداری (Robustness): مقاومت مدل را در برابر تغییرات ناگهانی در ورودیهای دنیای واقعی افزایش میدهد. | محدودیت کاربرد: این روشها عمدتاً برای دادههای تصویری موثر هستند و در دادههای متنی یا عددی به راحتی قابل اجرا نیستند. |
SMOTE (تکنیک بیشنمونهبرداری مصنوعی)
در بسیاری از پروژههای یادگیری عمیق، با چالش دادههای نامتعادل (Imbalanced Data) روبرو هستیم؛ وضعیتی که در آن تعداد نمونههای یک کلاس (مثلاً تراکنشهای سالم) بسیار بیشتر از کلاس دیگر (مثلاً کلاهبرداری) است. در چنین حالتی، مدل به سادگی به سمت کلاس اکثریت سوگیری پیدا میکند. تکنیک SMOTE به جای کپی کردن تکراری دادههای اقلیت، با استفاده از منطق ریاضی و الگوریتم k-نزدیکترین همسایه (k-NN)، نمونههای مصنوعی اما واقعگرایانه تولید میکند.
مکانیزم عملکرد
SMOTE به جای تکرار ساده، یک نمونه از کلاس اقلیت را انتخاب کرده، نزدیکترین همسایگان آن را مییابد و سپس نقاط جدیدی را در فضای ویژگیها و در امتداد خطوط واصل بین این نقاط خلق میکند. این کار باعث میشود مرز تصمیمگیری مدل (Decision Boundary) به جای حفظ کردن نقاط تکراری، بر اساس ساختار هندسی دادهها گسترش یابد.
| مزایا | معایب |
| جلوگیری از انباشت بیشبرازش: برخلاف Oversampling ساده، باعث نمیشود مدل روی نمونههای تکراری قفل شود و تعمیمدهی را افزایش میدهد. | خطر ایجاد نویز: اگر مرزهای بین دو کلاس تداخل داشته باشند، ممکن است نقاط مصنوعی در محدوده کلاس اکثریت ساخته شوند و باعث گمراهی مدل گردند. |
| حفظ توزیع آماری: با تولید داده در فضای بین نمونههای واقعی، ساختار و همبستگی ویژگیها را بهتر حفظ میکند. | عدم توجه به کلاس اکثریت: این روش فقط روی کلاس اقلیت تمرکز دارد و توزیع کلاس اکثریت را در محاسبات خود لحاظ نمیکند. |
| بهبود دقت در کلاسهای حیاتی: در حوزههایی مثل تشخیص بیماریهای نادر یا کلاهبرداری که شناسایی کلاس اقلیت هدف اصلی است، عملکرد را به شدت ارتقا میدهد. | هزینه محاسباتی: اجرای الگوریتم kNN بر روی مجموعهدادههای بسیار بزرگ و حجیم، زمانبر و مصرفکننده منابع است. |
.
Mixup
- تکنیک Mixup یک رویکرد انقلابی در حوزهی افزونگی دادههاست که فراتر از تغییرات هندسی ساده عمل میکند. در حالی که روشهای سنتی (مانند چرخش یا برش) فقط روی یک تصویر کار میکنند، Mixup با درونیابی (Interpolation) بین دو نمونهی کاملاً متفاوت و برچسبهای آنها، مدل را وادار میکند تا فضاهای خالی بین کلاسها را به صورت منطقی درک کند. این کار باعث میشود مدل به جای یادگیری مرزهای تصمیمگیری ناگهانی و تند، رفتاری نرم و منعطف داشته باشد.
- فرمول:
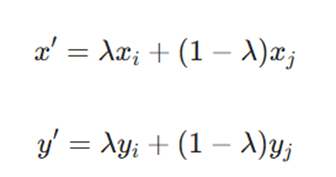
.
| مزایا | معایب |
| تقویت فوقالعاده تعمیمدهی: با پر کردن فضاهای خالی بین خوشههای داده، دقت مدل را روی دادههای جدید به شکل چشمگیری افزایش میدهد. | افزایش ابهام در تصاویر: برای انسان، تصاویر حاصل از Mixup ممکن است کاملاً نامفهوم به نظر برسند، هرچند برای مدل حاوی اطلاعات ساختاری هستند. |
| مقاومت در برابر حملات متخاصم: مدل را در برابر تغییرات کوچک و بدخواهانه در ورودی (Adversarial Attacks) بسیار مقاومتر میکند. | نیاز به تنظیم α: انتخاب پارامتر مناسب برای توزیع بتا جهت تعیین شدت ترکیب، نیاز به آزمون و خطا دارد. |
| کاهش اشتباهات در دادههای نویزی: به دلیل استفاده از برچسبهای نرم، مدل نسبت به برچسبهای اشتباه در مجموعهداده حساسیت کمتری نشان میدهد. | زمانآموزش طولانیتر: به دلیل ایجاد تنوع بینهایت از ترکیبات، همگرایی کامل مدل ممکن است به تکرارهای بیشتری نیاز داشته باشد. |
Cutmix (ترکیب و برش)
اگر Mixup را یک ترکیب شفاف و Cutout را یک حذف ساده بدانیم، CutMix رویکردی میانهرو و هوشمندانه را برگزیده است. در این روش، به جای محو کردن دو تصویر روی هم، یک وصله (Patch) از تصویر اول بریده شده و دقیقاً در همان مختصات روی تصویر دوم چسبانده میشود. نکتهی کلیدی اینجاست که برچسب (Label) خروجی نیز متناسب با مساحت این وصله، ترکیبی از هر دو کلاس خواهد بود.
مکانیزم عملکرد و فلسفه یادگیری
در CutMix، مدل مجبور میشود تا اشیاء را از روی بخشهای کوچک و گاهی غیرمرکزی آنها تشخیص دهد. این کار مانع از آن میشود که شبکه عصبی فقط به یک ویژگی خاص (مثلاً چشمهای یک حیوان) وابسته شود. در واقع، مدل یاد میگیرد که اگر بخشی از یک تصویر شامل دم سگ است، حتی اگر بقیه تصویر بدنه گربه باشد، باید هر دو ویژگی را در تصمیمگیری نهایی لحاظ کند.
| مزایا | معایب |
| بهبود دقت مکانیابی: برخلاف بسیاری از روشها، به مدل کمک میکند تا دقیقاً بفهمد هر شیء در کدام بخش از تصویر قرار دارد. | پیچیدگی در پیادهسازی: محاسبه دقیق مساحت وصله و اصلاح برچسبها نسبت به روشهای سادهتر، به دقت کدنویسی بیشتری نیاز دارد. |
| جلوگیری از اتلاف پیکسل: برخلاف Cutout که بخشی از تصویر را با صفر (سیاه) جایگزین میکرد، در اینجا تمام پیکسلها حاوی اطلاعات مفید هستند. | افزایش زمان آموزش: به دلیل پیچیدگی دادههای ورودی، مدل معمولاً به تعداد تکرار (Iteration) بیشتری برای رسیدن به دقت مطلوب نیاز دارد. |
| تعمیمپذیری خیرهکننده: نتایج تجربی نشان داده که CutMix روی مجموعهدادههای بزرگی مثل ImageNet، عملکردی بهتر از Mixup و Cutout دارد. | حساسیت به اندازه وصله: اگر اندازه ناحیه بریده شده (SM) بیش از حد بزرگ یا کوچک باشد، میتواند باعث سردرگمی مدل در یادگیری الگوها شود. |
Ensemble Methods (روشهای گروهی)
این استراتژی بر پایه شعار دو بار فکر کردن بهتر از یک بار است بنا شده است. روشهای گروهی بر این اصل استوارند که ترکیب پیشبینیهای چندین مدلِ مستقل، معمولاً بسیار دقیقتر و قابلاعتمادتر از پیشبینیِ هر یک از آن مدلها به تنهایی است. در این روش، به جای تکیه بر یک تکمدل، چندین شبکهی عصبی (که ممکن است در معماری، مقداردهی اولیه پارامترها یا دادههای آموزش با هم متفاوت باشند) آموزش داده میشوند.
مکانیزم ترکیب (Aggregation)
خروجی نهایی در این روش از طریق ترکیب نتایج مدلهای مختلف به دست میآید:
- ۱. میانگینگیری: در مسائل رگرسیون، میانگین خروجی تمام مدلها محاسبه میشود.
- ۲. رایگیری: در مسائل طبقهبندی، کلاسی که بیشترین رای را در میان مدلها داشته باشد، به عنوان خروجی نهایی انتخاب میشود.
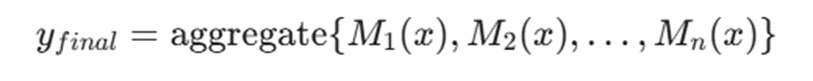
| مزایا | معایب |
| کاهش چشمگیر واریانس: با ترکیب مدلها، خطاهای تصادفی یک مدل توسط مدلهای دیگر خنثی شده و پایداری به شدت بالا میرود. | هزینه محاسباتی سنگین: آموزش و نگهداری چندین مدل به جای یک مدل، به توان پردازشی (GPU) و حافظه بسیار بیشتری نیاز دارد. |
| تضمین تعمیمدهی (Generalization): این روش یکی از بهترین راهکارها برای اطمینان از عملکرد مناسب مدل بر روی دادههای دیدهنشده در دنیای واقعی است. | تاخیر در زمان پاسخدهی (Latency): در زمان استنتاج، باید خروجی تمام مدلها محاسبه شود که این کار زمان پاسخدهی سیستم را افزایش میدهد. |
| مقاومت در برابر بیشبرازش: احتمال اینکه چندین مدل به طور همزمان بر روی یک نویز خاص اورفیت شوند، بسیار کم است. | پیچیدگی در مدیریت: مدیریت نسخههای مختلف مدلها و ترکیب هوشمندانهی آنها چالشهای مهندسی نرمافزاری ایجاد میکند. |
Max Norm Constraint (محدودیت سقف نُرم)
در حالی که تکنیکهایی مثل L2 تلاش میکنند وزنها را با جریمه کردن کوچک نگه دارند، محدودیت سقف نُرم رویکردی مستقیم و تهاجمیتر دارد. این تکنیک یک سقف شیشهای برای بزرگی وزنها تعیین میکند؛ به این معنا که اگر نُرم (طول) بردار وزنهای یک نورون از یک مقدار آستانه (c) فراتر برود، مدل به صورت دستی تمام وزنهای آن نورون را کوچک (Scale) میکند تا طول بردار دقیقاً به مقدار مجاز بازگردد.
| مزایا | معایب |
| جلوگیری قطعی از انفجار گرادیان: با مهار فیزیکی بزرگی وزنها، مانع از خروج مدل از کنترل در تکرارهای طولانی میشود. | نیاز به تنظیم هایپرپارامتر جدید: انتخاب مقدار بهینهی c یک چالش اضافی است که نیاز به آزمون و خطا دارد. |
| آزادی در انتخاب نرخ یادگیری: به شما اجازه میدهد از نرخهای یادگیری (Learning Rate) بسیار بالا استفاده کنید، بدون اینکه نگران ناپایداری مدل باشید. | احتمال محدودسازی بیش از حد: اگر مقدار c خیلی کوچک انتخاب شود، ممکن است مانع از یادگیری الگوهای پیچیده و ضروری توسط شبکه شود. |
| مکمل عالی برای Dropout: ترکیب این دو تکنیک در شبکههای عصبی عمیق، نتایج بسیار درخشانی در کنترل بیشبرازش نشان داده است. | سربار محاسباتی اندک: محاسبات نُرم و مقیاسدهی مجدد در هر لایه، زمان بسیار کمی به فرآیند آموزش اضافه میکند. |

.
جدول مقایسه ای
| تکنیک | کاربرد اصلی | مزیت کلیدی | چالش اصلی |
| L2 (Ridge) | مهار کلی وزنها | جلوگیری از انفجار وزن و پایداری عددی | عدم حذف ویژگیهای بیاهمیت |
| L1 (Lasso) | انتخاب ویژگی | ایجاد مدلهای تنک (Sparse) و ساده | ناپایداری در دادههای دارای همبستگی |
| Elastic Net | تعادل L1 و L2 | مدیریت عالی گروههای ویژگی همبسته | دشواری در تنظیم دو هایپرپارامتر |
| Dropout | لایههای متصل | مهار هموابستگی نورونها | افزایش زمان مورد نیاز برای آموزش |
| Drop Connect | جراحی اتصالات | فضای مدلسازی وسیعتر از Dropout | پیچیدگی محاسباتی و پیادهسازی |
| Batch Norm | پایداری لایهای | تسریع شدید آموزش و کاهش حساسیت | وابستگی شدید به اندازه Batch |
| Data Aug. | تنوع داده | بهبود تعمیمدهی بدون داده جدید | خطر تغییر ماهیت و معنای داده |
| Early Stopping | مدیریت زمان | جلوگیری رایگان و سریع از بیشبرازش | عدم مهار مستقیم بزرگی پارامترها |
| Label Smoothing | تعدیل اطمینان | بهبود پایداری در مدلهای غولآسا | دشواری در فرآیند تقطیر دانش |
| Stochastic Depth | شبکههای ResNet | امکان آموزش مدلهای بسیار عمیق | پیچیدگی در زمان استنتاج (Test) |
| Noise Injection | تابآوری نویزی | واکسیناسیون مدل در برابر نویز محیطی | نوسانی شدن روند همگرایی |
| Cutout/Erasing | بینایی ماشین | یادگیری ویژگیهای توزیع شده | احتمال حذف اطلاعات حیاتی تصویر |
| SMOTE | داده نامتعادل | رفع سوگیری به سمت کلاس اکثریت | خطر ایجاد دادههای مصنوعی نویزی |
| Mixup | مرز تصمیمگیری | ایجاد رفتار خطی و نرم در کلاسها | ابهام بصری برای مفسر انسانی |
| Cutmix | مکانیابی شیء | تشخیص اشیاء از روی بخشهای کوچک | حساسیت به ابعاد ناحیه بریده شده |
| Ensemble | دقت نهایی | کاهش چشمگیر واریانس و خطا | هزینه محاسباتی و حافظه بسیار بالا |
| Max Norm | سقف وزن | مهار قطعی وزنهای افسارگسیخته | نیاز به تنظیم دقیق آستانه c |
.
پیاده سازی در پایتون:
۱. شرح سناریوی عملی
- مدل Baseline (بدون منظمسازی): یک شبکه عصبی ساده که به سرعت دادههای آموزشی را حفظ میکند (حفظکردن به جای یادگیری). در اینجا میبینیم که خطای آموزش صفر میشود اما خطای تست به شدت بالا میرود.
- مدل Regularized (با منظمسازی کامل): در این مدل از ترکیب طلایی Dropout (برای جلوگیری از هموابستگی)، Batch Normalization (برای پایداری) و L2 (Weight Decay) (برای مهار وزنها) استفاده شده است.
۲. کد کامل پایتون
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# ۱. تولید دادههای مصنوعی (۱۰۰ ویژگی و ۵۰۰ نمونه برای ایجاد اورفیتینگ)
X, y = make_classification(n_samples=500, n_features=100, n_informative=10, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# تبدیل به تانسورهای PyTorch
X_train, y_train = torch.FloatTensor(X_train), torch.LongTensor(y_train)
X_test, y_test = torch.FloatTensor(X_test), torch.LongTensor(y_test)
# ۲. مدل بدون منظمسازی (Baseline)
class OverfitNet(nn.Module):
def __init__(self):
super(OverfitNet, self).__init__()
self.net = nn.Sequential(
nn.Linear(100, 256), nn.ReLU(),
nn.Linear(256, 256), nn.ReLU(),
nn.Linear(256, 2)
)
def forward(self, x): return self.net(x)
# ۳. مدل با منظمسازی (L2 + Dropout + Batch Norm)
class RegularizedNet(nn.Module):
def __init__(self):
super(RegularizedNet, self).__init__()
self.net = nn.Sequential(
nn.Linear(100, 256), nn.BatchNorm1d(256), nn.ReLU(),
nn.Dropout(0.5), # مهار هموابستگی نورونها
nn.Linear(256, 256), nn.BatchNorm1d(256), nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(256, 2)
)
def forward(self, x): return self.net(x)
def train(model, optimizer, epochs=100):
criterion = nn.CrossEntropyLoss()
train_loss, test_loss = [], []
for _ in range(epochs):
model.train()
optimizer.zero_grad()
loss = criterion(model(X_train), y_train)
loss.backward(); optimizer.step()
train_loss.append(loss.item())
model.eval()
with torch.no_grad():
test_loss.append(criterion(model(X_test), y_test).item())
return train_loss, test_loss
# آموزش هر دو مدل
model_base = OverfitNet()
opt_base = optim.Adam(model_base.parameters(), lr=0.01)
t_loss_base, v_loss_base = train(model_base, opt_base)
model_reg = RegularizedNet()
# اعمال L2 (Weight Decay) در بهینهساز
opt_reg = optim.Adam(model_reg.parameters(), lr=0.01, weight_decay=1e-3)
t_loss_reg, v_loss_reg = train(model_reg, opt_reg)
# ۴. رسم نمودارهای خروجی
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(t_loss_base, label='Train Loss', color='crimson', linestyle='--')
plt.plot(v_loss_base, label='Test Loss', color='crimson')
plt.title('Baseline (Severe Overfitting)'); plt.legend(); plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(t_loss_reg, label='Train Loss', color='royalblue', linestyle='--')
plt.plot(v_loss_reg, label='Test Loss', color='royalblue')
plt.title('Regularized (L2 + Dropout + BN)'); plt.legend(); plt.grid(True)
plt.show()
خروجی:

تحلیل خروجی
همانطور که در نمودارهای خروجی مشاهده میکنید:
- در نمودار سمت چپ(Baseline): خطای آموزش (خطچین) به سرعت به صفر میرسد، اما خطای تست (خط صاف) به شدت صعودی میشود. این یعنی مدل شما در حال حفظ کردن نویزها است و در دنیای واقعی هیچ کاربردی ندارد.
- در نمودار سمت راست(Regularized): اگرچه خطای آموزش کمی بالاتر مانده است، اما خطای تست همگام با آن کاهش یافته و پایدار میماند. این نشاندهنده تعمیمدهی بالا و موفقیت تکنیکهای منظمسازی در مهار ظرفیت شبکه است.
.
جمع بندی
منظمسازی یکی از ارکان اساسی طراحی سیستمهای یادگیری عمیق است. هرچه ظرفیت مدل افزایش مییابد، نیاز به کنترل دقیقتر پیچیدگی و جلوگیری از بیشبرازش نیز بیشتر میشود. تکنیکهای منظمسازی را میتوان در چند دسته کلی خلاصه کرد:
- جریمه روی پارامترها: مانند L1، L2 و Elastic Net که بزرگی وزنها را کنترل میکنند.
- ایجاد اختلال تصادفی در شبکه: مانند Dropout و DropConnect که از هموابستگی بیشازحد نورونها جلوگیری میکنند.
- نرمالسازی و پایدارسازی آموزش: مانند Batch Normalization.
- دستکاری دادهها: مانند Data Augmentation، Mixup و CutMix برای افزایش تنوع مؤثر دادهها.
- مدیریت فرآیند آموزش: مانند Early Stopping.
- ترکیب مدلها: مانند Ensemble برای کاهش واریانس.
نکته کلیدی این است که هیچ تکنیکی بهتنهایی بهترین راهحل برای همه مسائل نیست. انتخاب روش مناسب منظم سازی به عواملی مانند اندازه داده، پیچیدگی مسئله، معماری مدل و منابع محاسباتی بستگی دارد. در عمل، ترکیبی از چند تکنیک منظمسازی معمولاً بهترین نتیجه را ارائه میدهد.
در نهایت، هدف منظمسازی نه صرفاً کاهش خطای آموزش، بلکه دستیابی به مدلی با تعمیم پایدار، رفتار قابل اعتماد و عملکرد قابل اتکا در دادههای واقعی است.



