

مقدمه
یادگیری عمیق به عنوان یکی از تحولآفرینترین فناوریهای قرن بیست و یکم ظهور کرده و حوزههای مختلفی، از بینایی ماشین و پردازش زبان طبیعی گرفته تا مراقبتهای بهداشتی و سیستمهای خودران را دگرگون ساخته است. در هستهی اصلی این فناوری، شبکههای عصبی مصنوعی با لایههای متعدد قرار دارند که بازنماییهای سلسلهمراتبی از دادهها را میآموزند؛ این توانمندی به ماشینها اجازه میدهد تا وظایف پیچیدهای را که پیش از این تصور میشد تنها از عهدهی هوش انسانی برمیآید، انجام دهند.
اهمیت یادگیری عمیق در زمینههای گوناگون، ناشی از توانایی آن در نفوذ به لایههای پیچیدهی روابط موجود در دادههاست. با این حال، یکی از حیاتیترین عوامل در آموزش مدلهای یادگیری عمیق، چالش بیشبرازش (Overfitting) و کمبرازش (Underfitting) است. این پدیدهها در واقع دو روی یک سکه هستند و بزرگترین مانع برای رسیدن به عملکرد بهینه در تعمیمدهی مدل محسوب میشوند.
این مقاله، مفاهیم بیشبرازش و کمبرازش را از هر دو دیدگاه نظری و عملی بررسی میکند در اینجا مبانی ریاضی، مثالهای عددی، پیادهسازیهای پایتون و مطالعات موردی واقعی را ارائه میدهیم تا درکی کامل از این مفاهیم کلیدی حاصل شود. شواهد تجربی نشان میدهند که تکنیکهای منظمسازی (Regularization) در بهبود عملکرد مدل بر روی مجموعهدادههای استاندارد بسیار مؤثر هستند. با این حال، باید توجه داشت که برخی تکنیکها ممکن است برای معماریهای خاصی از مدل یا مجموعهدادههای مشخصی مناسبتر باشند؛ بنابراین، متخصصان باید رویکردهای مختلف را آزمایش کرده و انتخابهای خود را از طریق تستهای دقیق اعتبارسنجی کنند.
مبانی ریاضی بیش برازش و کم برازش
.
توابع ضرر و بهینهسازی
در یادگیری عمیق، فرآیند آموزش شامل کمینه کردن یک تابع ضرر (Loss Function) است که تفاوت بین مقادیر پیشبینیشده و مقادیر واقعی را اندازهگیری میکند. درک توابع ضرر برای فهم ریشهای بیشبرازش و کمبرازش ضروری است.
توابع ضرر رایج:
- میانگین توان دوم خطا(MSE): این تابع که برای وظایف رگرسیون استفاده میشود، میانگین مجذور تفاوت بین پیشبینیها و مقادیر هدف را محاسبه میکند.
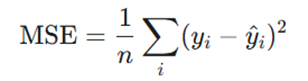
- ضرر آنتروپی متقاطع(Cross-Entropy Loss): این تابع برای وظایف طبقهبندی (Classification) استفاده میشود و میزان واگرایی بین احتمالات پیشبینیشده و برچسبهای واقعی را اندازهگیری میکند.
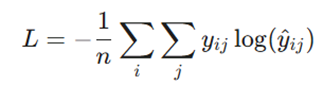
گرادیان کاهشی و انتشار بازگشتی
گرادیان کاهشی (Gradient Descent)، الگوریتم بهینهسازی بنیادینی است که برای کمینه کردن تابع ضرر به کار میرود. در این روش، وزنها در جهت مخالف گرادیانِ تابع ضرر نسبت به وزنها، بهروزرسانی میشوند.
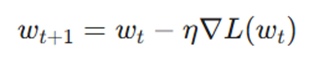
انتشار بازگشتی (Backpropagation) نیز الگوریتمی است که برای محاسبهی کارآمد این گرادیانها با استفاده از قاعده زنجیرهای در حساب دیفرانسیل، از میان لایههای شبکه استفاده میشود.
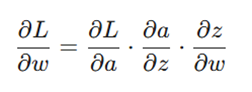
تجزیه بایاس-واریانس (Bias-Variance Decomposition)
تجزیه بایاس-واریانس یک چارچوب ریاضی برای درک منابع خطای پیشبینی در مدلهای یادگیری ماشین فراهم میکند. برای یک مدل داده شده (f (x)) که بر روی مجموعهداده D آموزش دیده است، انتظار خطای پیشبینی در نقطه x را میتوان به صورت زیر تجزیه کرد:
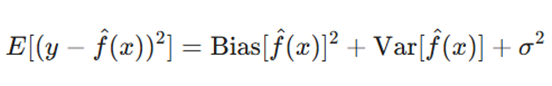
معرفی متغیرها:
- Bias [f(x)]: بایاس؛ خطای سیستماتیک ناشی از فرضهای نادرست مدل (عامل کمبرازش).
- Var[f(x)]: واریانس؛ میزان حساسیت مدل به نوسانات کوچک در دادههای آموزشی (عامل بیشبرازش).
- σ^2: نویز کاهشناپذیر موجود در خودِ دادهها.
درک بیشبرازش (Overfitting)
بیشبرازش زمانی رخ میدهد که یک مدل یادگیری ماشین، دادههای آموزشی را بیش از حدِ نیاز و با جزئیاتِ افراطی یاد میگیرد؛ به طوری که به جای استخراج الگوها یا توزیعهای زیربنایی، حتی نویزها و نوسانات تصادفی موجود در دادهها را نیز به عنوان الگو ثبت میکند.
در واقع، یک مدل بیشبرازش شده به جای یادگیریِ الگوهای قابل تعمیم، دادههای آموزشی را حفظ میکند. نتیجهی این اتفاق، عملکردی خیرهکننده بر روی دادههای آموزشی و در مقابل، عملکردی بسیار ضعیف بر روی دادههای جدید و دیدهنشده (خارج از مجموعهی آموزش) است.
فرمول ریاضی
از دیدگاه ریاضی، بیشبرازش با شکاف بزرگ بین ریسک تجربی (خطای آموزش) و ریسک مورد انتظار (خطای تعمیم) شناخته میشود:
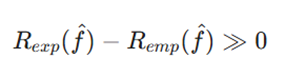
معرفی متغیرها:
- Rexp(f): ریسک مورد انتظار (Expected Risk) یا همان خطای واقعی مدل روی کل توزیع دادههای دنیای واقعی.
- Remp(f): ریسک تجربی (Empirical Risk) یا همان خطای مدل روی دادههای آموزشی موجود.
.
علل و عوامل کلیدی ریسک در بیش برازش
شناخت ریشههای بیشبرازش اولین قدم برای مهار آن است. به طور کلی، عوامل زیر اصلیترین محرکهای این پدیده هستند:
- پیچیدگی مدل (Model Complexity): استفاده از مدلی با پارامترهای بسیار زیاد نسبت به حجم دادههای آموزشی در دسترس.
- کمبود دادههای آموزشی (Insufficient Training Data): محدود بودن تعداد نمونهها، حفظ کردن الگوهای خاص را برای مدل آسانتر از تعمیم دادن آنها میکند.
- آموزش بیش از حد (Training for Too Long): تعداد اپوکهای (Epochs) بسیار زیاد میتواند منجر به یادگیری نویزهای موجود در دادههای آموزشی توسط مدل شود.
- ویژگیهای با واریانس بالا (High Variance Features): وجود ویژگیهایی که در نمونههای مختلف تغییرات شدیدی دارند، میتواند مدل را به سمت بیشبرازش سوق دهد.
- نبود منظمسازی (Lack of Regularization): استفاده نکردن از تکنیکهایی که پیچیدگی مدل را محدود و مهار میکنند.
.
روشهای تشخیص بیشبرازش و معیارهای ارزیابی
شناسایی بهموقع بیشبرازش (Overfitting) کلید موفقیت در آموزش یک مدل پایدار است. این کار مستلزم پایش دقیق و مستمر عملکرد مدل در تمام مراحل فرآیند آموزش است.
رایجترین و معتبرترین نشانهی این پدیده، ایجاد یک شکاف (Gap) معنادار بین دقت مدل روی دادههای آموزشی و دادههای اعتبارسنجی است. در واقع، وقتی مدل شروع به حفظ کردن میکند، ارتباطش با واقعیتِ دادههای جدید قطع میشود.
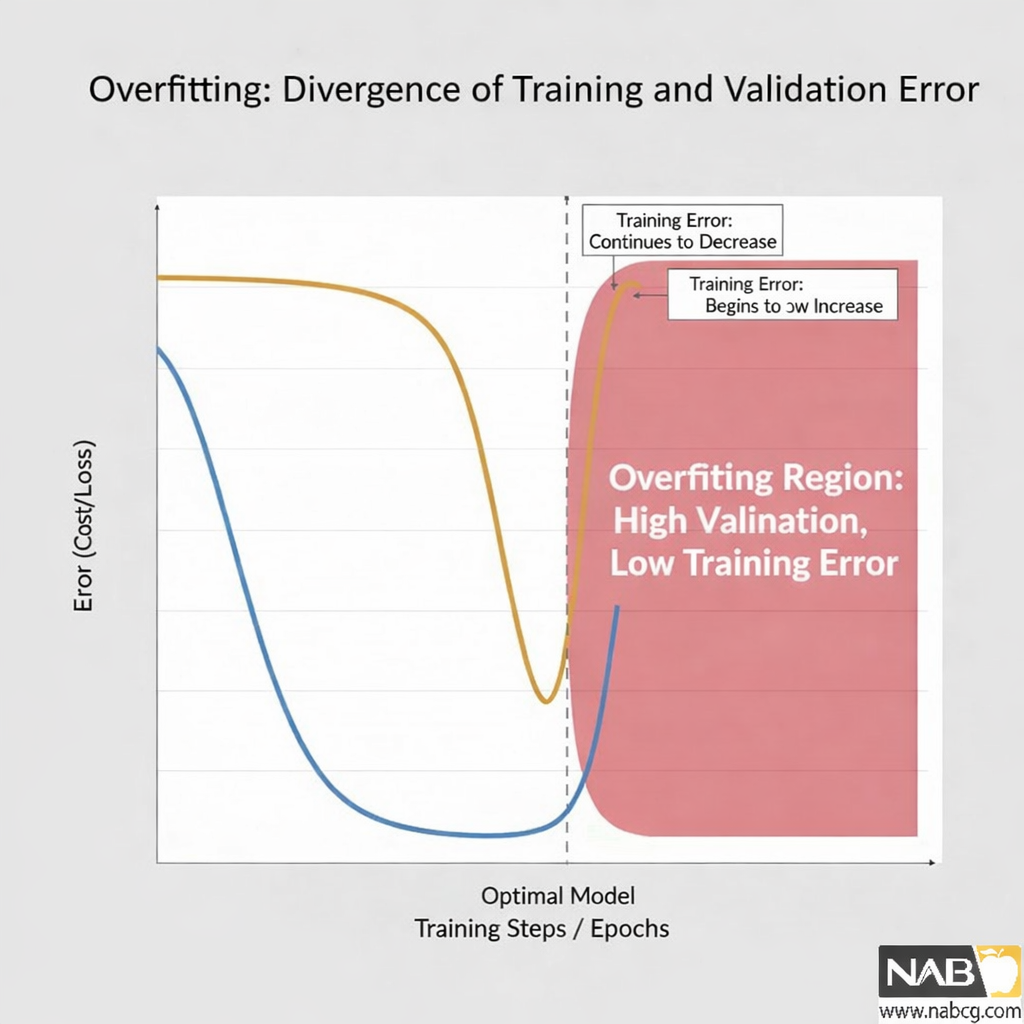
علائم و نشانههای رایج
- اختلاف فاحش در دقت: دقت روی دادههای آموزشی به شکل قابلتوجهی بالاتر از دقت روی دادههای اعتبارسنجی یا تست قرار میگیرد.
- واگرایی در نمودار ضرر (Loss): یکی از نشانههای قطعی این است که در حین آموزش، در حالی که ضرر آموزش همچنان رو به کاهش است، ضرر اعتبارسنجی متوقف شده یا شروع به افزایش میکند.
- عملکرد ضعیف در مواجهه با ناشناختهها: مدل در برابر دادههای جدید و دیدهنشده که از همان حوزهی مسئله هستند، عملکرد بسیار ضعیفی از خود نشان میدهد.
- حساسیت افراطی به تغییرات: مدل نسبت به تغییرات بسیار جزئی یا نویزهای موجود در دادههای آموزشی، واکنشهای شدید و غیرمنطقی نشان میدهد.
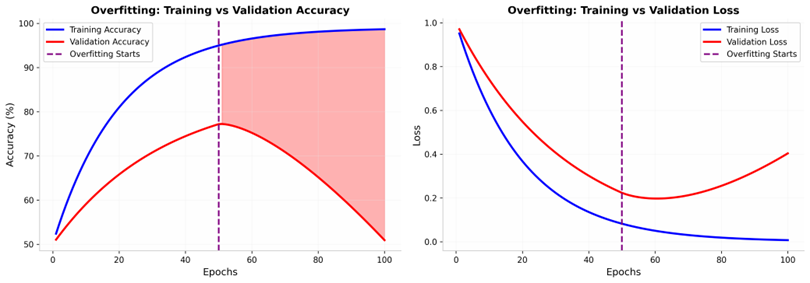
این نمودار به خوبی الگوهای کلاسیک بیشبرازش (Overfitting) را به تصویر میکشد: در حالی که دقت آموزش (Training Accuracy) به طور مداوم در حال بهبود است، دقت اعتبارسنجی (Validation Accuracy) پس از یک نقطه مشخص (حدود اپوک ۵۰) ثابت مانده یا حتی شروع به کاهش میکند.
مثال: بیشبرازش در رگرسیون چندجملهای
برای درک بهتر این موضوع، یک مسئله رگرسیون چندجملهای را در نظر بگیرید. هدف ما این است که مدلی را بر روی دادههای نویزی (همراه با اختلال) که از یک تابع درجه دوم تولید شدهاند، برازش دهیم.
فرض کنید تابع اصلی تولیدکنندهی دادهها به صورت زیر است:
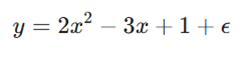
در این آزمایش، ۲۰ نقطه داده از بازهی x ∈ [-2, 2]نمونهبرداری شده و مدلهایی با درجات مختلف d بررسی شدهاند.
تحلیل نتایج بر اساس پیچیدگی مدل:
| درجه چندجملهای (d) | وضعیت مدل | میانگین مجذور خطای آموزش (Train MSE) | میانگین مجذور خطای تست (Test MSE) |
| d=2 (صحیح) | برازش بهینه | 0.48 | 0.52 |
| d=5 | شروع بیشبرازش | 0.35 | 0.89 |
| d=15 | بیشبرازش شدید | 0.12 | 3.45 |
نتیجهگیری:
همانطور که مشاهده میکنید، مدل با درجه ۱۵ به خطای آموزشی خیرهکنندهای (نزدیک به صفر) دست یافته است، اما در زمان مواجهه با دادههای تست، عملکردی فاجعهبار دارد.
این مثال به وضوح نشان میدهد که افزایش پیچیدگی مدل (بالا بردن درجه چندجملهای) بدون استفاده از تکنیکهای منظمسازی (Regularization)، مدل را به سمتی میبرد که به جای یادگیری الگو، نویزهای دادههای آموزشی را حفظ کند. نتیجهی این اتفاق، چیزی جز شکست در تعمیمدهی (Generalization) نخواهد بود.
درک کمبرازش (Underfitting)
کمبرازش زمانی رخ میدهد که مدل انتخابی بیش از حد ساده باشد و نتواند ساختار زیربنایی و الگوهای اصلی دادهها را استخراج کند. یک مدل کمبرازش نه تنها در مرحله آموزش ضعیف عمل میکند، بلکه در مواجهه با دادههای اعتبارسنجی نیز ناتوان است. این وضعیت نشاندهنده وجود بایاس بالا (High Bias) در مدل است.
از دیدگاه ریاضی، کمبرازش با بایاس بالا تعریف میشود؛ جایی که میانگین پیشبینیهای مدل تفاوت فاحشی با تابع واقعی تولیدکنندهی دادهها دارد:
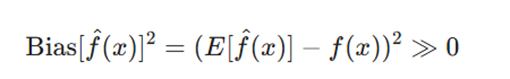
معرفی متغیرها:
- E[f(x)]: مقدار مورد انتظار یا میانگین پیشبینیهای مدل بر روی مجموعهدادههای مختلف
- f(x): مقدار واقعی و هدف که مدل سعی در تخمین آن دارد.
- Bias: بایاس؛ خطای سیستماتیک ناشی از فرضهای سادهانگارانه مدل.
در واقع، کمبرازش زمانی اتفاق میافتد که فضای فرضیه (Hypothesis Space) مدل بیش از حد محدود باشد و تابع اصلی تولیدکننده دادهها در آن فضا نگنجد.
.
علل و عوامل ریسک کم برازش
مهمترین عواملی که مدل را به سمت کمبرازش سوق میدهند عبارتند از:
- سادگی بیش از حد مدل: استفاده از مدلی که ظرفیت یا پارامترهای کافی برای درک پیچیدگی مسئله را ندارد (مثلاً استفاده از خط صاف برای دادههای منحنی).
- آموزش ناکافی: متوقف کردن فرآیند آموزش پیش از آنکه مدل فرصت کافی برای کشف الگوها را داشته باشد (تعداد اپوکهای کم).
- منظمسازی افراطی: استفاده بیش از حد از جریمههای وزن یا دراپاوت که باعث محدود شدن بیش از حد ظرفیت یادگیری مدل میشود.
- انتخاب ویژگی ضعیف: وارد نکردن متغیرهای کلیدی و مرتبطی که ساختار اصلی دادهها را توصیف میکنند.
- الگوریتمهای با بایاس ذاتی: برخی الگوریتمها اساساً برای مسائل پیچیده طراحی نشدهاند و به طور طبیعی دچار کمبرازش میشوند.
.
روشهای تشخیص و معیارها
تشخیص کمبرازش معمولاً بسیار سادهتر از بیشبرازش است؛ زیرا مدل در تمامی جبههها عملکرد ضعیفی از خود نشان میدهد. شاخص اصلی این وضعیت، پایین بودن مداوم دقت (یا بالا بودن خطا) در هر دو مجموعهی آموزش و اعتبارسنجی است.
علائم رایج کمبرازش:
- پایین بودن دقت در هر دو مجموعهی دادهی آموزش و اعتبارسنجی.
- خطای آموزشی بالا که حتی با افزایش زمان آموزش، کاهش معناداری پیدا نمیکند.
- ناتوانی مدل در درک و بازسازی الگوهای بدیهی و آشکار موجود در دادهها.
- عملکرد ضعیف و یکنواخت در تمامی زیرمجموعههای داده.
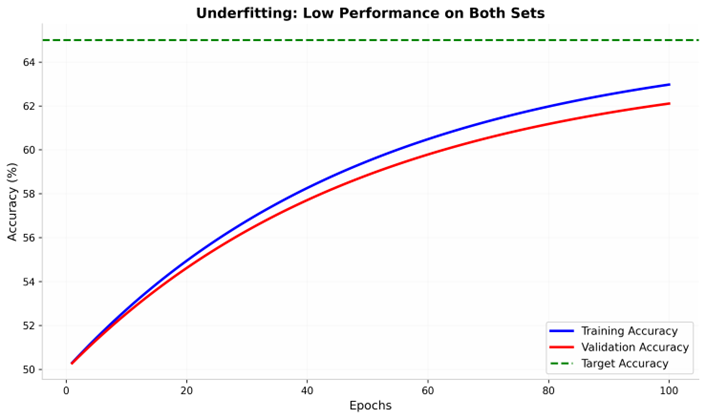
این تصویر به خوبی الگوهای کلاسیک و رایج مربوط به کمبرازش (Underfitting) را به نمایش میگذارد. همانطور که در روند نمودار مشهود است، دقت مدل در هر دو مجموعهی دادهی آموزش و اعتبارسنجی در تمام طول فرآیند یادگیری در سطح پایینی درجا میزند و مدل عملاً موفق نشده است به سطح عملکرد مطلوب و استانداردهای تعیین شده برسد.
در این نمودار، متغیرها و المانهای زیر وضعیت مدل را توصیف میکنند:
- دقت آموزش(Training Accuracy): با منحنی آبی ملایم (AI Soft Blue) نشان داده شده و بازگوکنندهی میزان درک مدل از دادههای تمرینی است.
- دقت اعتبارسنجی(Validation Accuracy): با منحنی زرشکی (Crimson) مشخص شده و نشان میدهد که مدل روی دادههای جدید نیز به همان اندازه ضعیف عمل میکند.
- دقت هدف(Target Accuracy): با خطچین طلایی (Active Gold) در بالای نمودار مشخص شده است که هدف نهایی ماست و مدل از رسیدن به آن بازمانده است.
.
مثال عددی: شکست مدل خطی در برابر دایرهها
در این مثال، مسئلهی طبقهبندی دادههایی را بررسی میکنیم که به شکل دایرههای متحدالمرکز چیده شدهاند. استفاده از یک طبقهبند خطی (Linear Classifier) در این سناریو منجر به یک کمبرازش شدید میشود.
- مسئله: طبقهبندی دوتایی (Binary) با مرز تصمیمگیری دایرهای.
- دادهها: نقاطی از دو دایره متحدالمرکز با شعاعهای ۲ و ۴.
مقایسه عملکرد مدلها
در جدول زیر میبینید که چطور با پیچیدهتر شدن مدل، مشکل کمبرازش حل میشود:
| مدل (Model) | دقت آموزش (Train Acc) | دقت تست (Test Acc) | وضعیت |
| طبقهبند خطی | ۵۲٪ | ۵۱٪ | کمبرازش شدید |
| چندجملهای (درجه ۲) | ۷۸٪ | ۷۶٪ | عملکرد متوسط |
| شبکه عصبی (۲ لایه) | ۹۸٪ | ۹۷٪ | برازش ایدهآل |
چرا مدل خطی شکست خورد؟
مدل خطی به سادگی توانایی درک الگوی دایرهای را ندارد! این مثال به وضوح نشان میدهد که وقتی از یک مدل بیش از حد ساده (خطی) برای یک مسئله پیچیده (مرز تصمیمگیری غیرخطی) استفاده میکنیم، ظرفیت (Capacity) مدل برای استخراج الگوهای نهفته در دادهها کافی نیست و در نتیجه با شکست مواجه میشویم.
.
جدول مقایسهای جامع: بیشبرازش در برابر کمبرازش
| مقایسه | بیشبرازش (Overfitting) | کمبرازش (Underfitting) |
| تعریف | حالتی که در آن مدل به جای یادگیری منطق حاکم بر پدیدهها، دادههای آموزشی را با تمام جزئیات و نویزها حفظ میکند. این پدیده باعث میشود مدل در برابر مثالهای تکراری عالی اما در برابر دادههای جدید ناتوان باشد. | وضعیتی که در آن مدل بیش از حد سادهانگار است و نمیتواند ساختار پایه و روابط اصلی موجود در دادهها را کشف کند. مدل حتی بر روی مجموعهی آموزش هم عملکرد قابل قبولی ندارد. |
| علت ریاضی | واریانس بالا و حساسیت شدید به نوسانات کوچک در دادههای آموزشی که منجر به انحراف مدل از الگوهای کلی میشود. | بایاس بالا ناشی از فرضهای بسیار ساده درباره ماهیت دادهها که باعث میشود مدل الگوهای کلیدی را نادیده بگیرد. |
| (Loss) | خطای آموزشی بسیار پایین و نزدیک به صفر، اما خطای اعتبارسنجی و تست بسیار بالا و رو به صعود. | خطا در هر دو مجموعهی آموزش و اعتبارسنجی به طور یکسان بالا است و با افزایش زمان آموزش بهبود نمییابد. |
| پیچیدگی مدل | پیچیدگی مدل نسبت به حجم و تنوع دادهها بسیار زیاد است (تعداد پارامترهای آزاد بیش از حد ظرفیت مسئله است). | مدل بسیار ساده است و ظرفیت کافی برای پردازش و بازنمایی پیچیدگیهای موجود در فضای ویژگی را ندارد. |
| استراتژی درمان | کاهش ظرفیت مدل، استفاده از لایههای دراپاوت، اعمال جریمههای L1/L2، افزایش چشمگیر دادههای آموزشی و متوقف کردن زودهنگام فرآیند یادگیری پیش از شروع صعود خطا. | افزایش عمق و عرض شبکه عصبی، اضافه کردن ویژگیهای مهندسیشده جدید، بهبود کیفیت برچسبها، افزایش زمان آموزش و کاهش شدت محدودیتهای منظمسازی لایهها. |
| آنالوژی (مثال ساده) | دانشآموزی که تمام سوالات کتاب را با جوابهایشان حفظ کرده اما در امتحان با تغییر جزئی اعداد، از حل مسئله باز میماند. | دانشآموزی که حتی مفاهیم پایهای درس را یاد نگرفته و در حل سادهترین تمرینات کتاب هم با مشکل روبرو میشود. |
روش های جلوگیری از بیش برازش در یادگیری عمیق
منظمسازی مجموعهای از روشهاست که با اعمال محدودیت بر روی مدل در طول فرآیند آموزش، مانع از بیشبرازش (Overfitting) میشوند. این تکنیکها به طور مستقیم ظرفیت مدل را کنترل کرده و به آن کمک میکنند تا روی دادههای جدید و دیدهنشده، تعمیمپذیری بسیار بهتری داشته باشد.
1. منظمسازی L1 و L2
2. دراپاوت (Dropout)
3. افزونگی دادهها (Data Augmentation)
4. توقف زودهنگام (Early Stopping)
5. نرمالسازی دستهای (Batch Normalization)
6. سایر روشهای منظمسازی
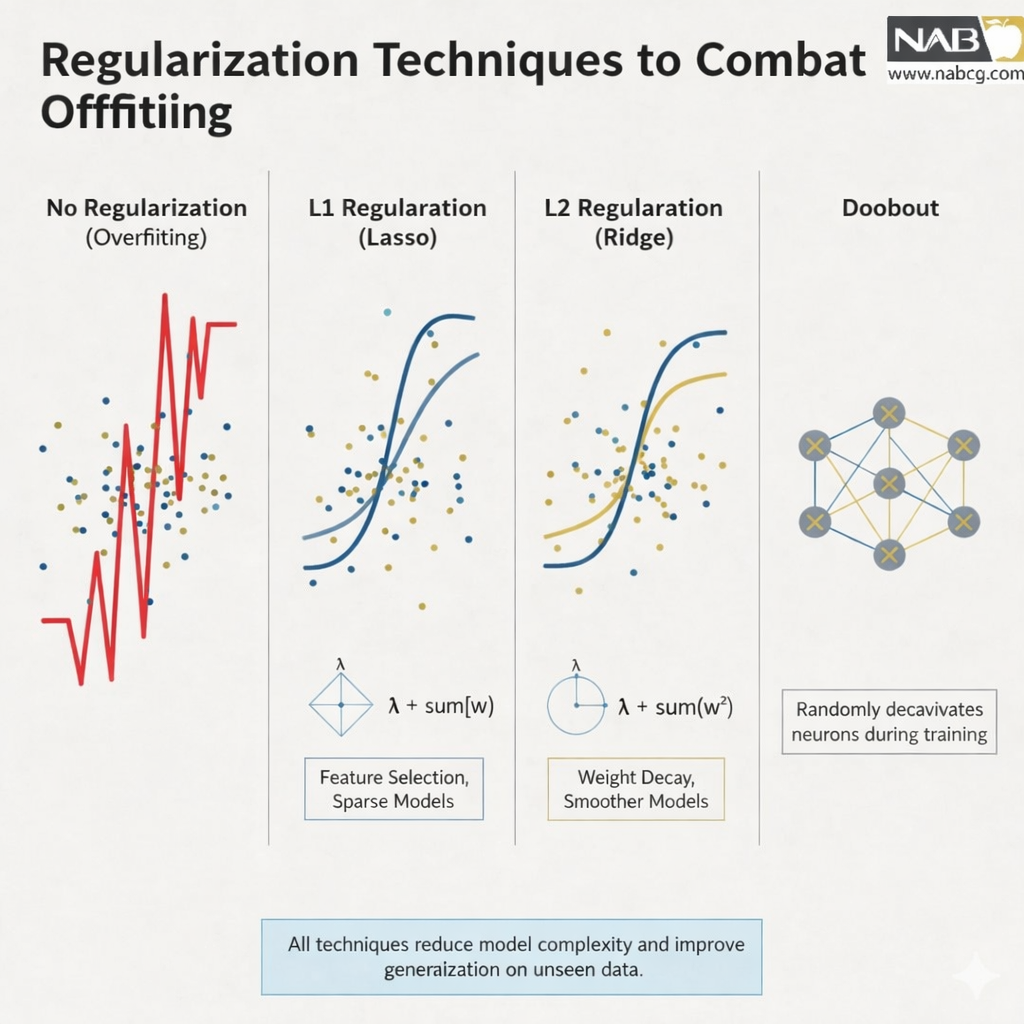
.
منظمسازی L1 و L2
- منظمسازی L2 (Ridge): این روش جریمهای متناسب با توان دوم بزرگی ضرایب به تابع ضرر اضافه میکند. این کار باعث میشود وزنها به سمت مقادیر کوچکتر میل کنند، اما معمولاً صفر نمیشوند؛ نتیجه این است که مدل سادهتر شده و نویزها را کمتر جدی میگیرد.
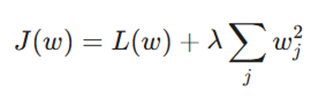
معرفی متغیرها:
- J(w): تابع هزینه کل (ترکیب ضرر اصلی و جریمه منظمسازی).
- L(w): تابع ضرر اصلی(مانند MSE یا Cross-Entropy) که میزان اختلاف پیشبینی با واقعیت را میسنجد.
- λ (لاندا): پارامتر منظمسازی که شدت جریمه را تعیین میکند. مقادیر بزرگتر، مدل را سادهتر میکنند.
- wj: وزنهای شبکه که باید بهینهسازی شوند.
گرادیان تابع ضرر در L2 شامل ترمی است که باعث میشود در هر مرحله از بهروزرسانی، وزنها به سمت صفر کشیده شوند (Weight Decay):
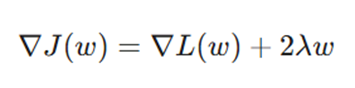
معرفی متغیرها:
- ∇J(w): گرادیان (مشتق) تابع هزینه کل نسبت به وزنها.
- L(w)∇: گرادیان تابع ضرر اصلی.
- 2λw: ترم جریمه که باعث کوچک شدن تدریجی وزنها در هر تکرار میشود.
- منظمسازی L1 (Lasso): این روش جریمهای متناسب با قدر مطلق بزرگی ضرایب اضافه میکند. یکی از ویژگیهای جذاب L1 این است که میتواند برخی از وزنها را دقیقاً به صفر برساند؛ این یعنی مدل به طور خودکار ویژگیهای بیاهمیت را حذف کرده و نوعی انتخاب ویژگی انجام میدهد.
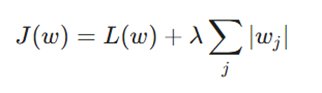
معرفی متغیرها:
- |wj|: قدر مطلق وزنها.
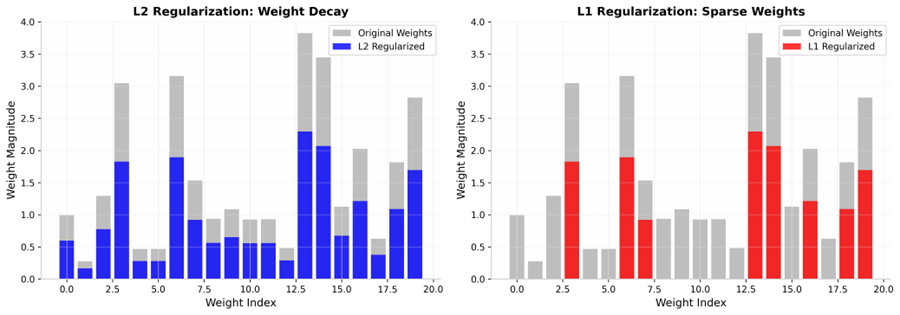
این تصویر به شکلی گویا نشان میدهد که چگونه هر یک از این دو تکنیک، ساختار مدل را تحت تأثیر قرار میدهند: در حالی که منظمسازی L2 تمام وزنها را به صورت متناسب کوچک میکند (بدون آنکه لزوماً آنها را حذف کند)، منظمسازی L1 با صفر کردن دقیق برخی از وزنها، منجر به ایجاد بردارهای وزن تنک (Sparse) میشود. این ویژگی منحصربهفرد L1 در واقع نوعی انتخاب ویژگی هوشمندانه است که باعث میشود مدل فقط بر روی مهمترین متغیرها تمرکز کند.
دراپاوت (Dropout): تقویت تابآوری شبکه
دراپاوت یک تکنیک منظمسازی هوشمندانه است که اختصاصاً برای لایههای شبکههای عصبی طراحی شده است. اگر بخواهیم ساده بگوییم، این روش مانند این است که در یک تیم فوتبال، در هر تمرین چند بازیکن را به صورت تصادفی از زمین خارج کنیم؛ این کار باعث میشود بقیه بازیکنان یاد بگیرند که به جای تکیه بر یک ستاره، خودشان مسئولیت بیشتری بپذیرند و مهارتهایشان را تقویت کنند.
در طول فرآیند آموزش، نورونهایی که به صورت تصادفی انتخاب شدهاند با احتمال مشخصی (p) حذف (مقدار صفر) میشوند. این مکانیزم از هموابستگی (Co-adaptation) بیش از حد نورونها به یکدیگر جلوگیری کرده و شبکه را مجبور میکند تا ویژگیهای مقاومتر و مستقلتری را یاد بگیرد.
مبانی ریاضی دراپاوت
.
الف) در طول آموزش (Training Phase)
خروجی هر نورون در یک متغیر تصادفی برنولی (r) ضرب میشود:
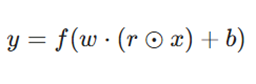
معرفی متغیرها:
- y: خروجی نهایی لایه.
- f: تابع فعالساز (Activation Function).
- w: وزنهای لایه.
- r: متغیر تصادفی برنولی که برای هر نورون مقدار ۰ یا ۱ میگیرد.
- ⊙: ضرب نقطهای (Hadamard product).
- x: ورودی لایه.
- b: بایاس (Bias).
.
ب) در طول استنتاج (Inference Phase)
در زمان تست یا استفاده واقعی، تمام نورونها فعال هستند، اما برای حفظ تعادل انرژی و خروجیها، مقادیر آنها بر اساس احتمال دراپاوت مقیاسبندی میشود:
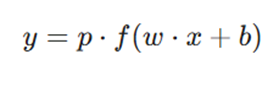
ویژگیهای کلیدی
- نرخهای رایج: این تکنیک معمولاً با نرخهای دراپاوت بین ۰.۲ تا ۰.۵ اعمال میشود.
- فقط زمان تمرین: دراپاوت صرفاً در مرحله آموزش فعال است و در زمان ارزیابی یا تست (Inference) غیرفعال میگردد.
- انعطاف در لایهها: این متد را میتوان بر روی لایههای ورودی، لایههای پنهان یا هر دو اعمال کرد.
- اثر تجمیعی (Ensemble): دراپاوت مانند این است که شما تعداد زیادی زیرشبکه مختلف را به صورت همزمان آموزش میدهید و در نهایت نتایج آنها را با هم ترکیب میکنید.
.
افزونگی دادهها (Data Augmentation)
یک تکنیک قدرتمند است که با اعمال دگرگونیهای مختلف روی دادههای موجود، اندازه مجموعهداده آموزشی را به صورت مصنوعی افزایش میدهد. این روش با قرار دادن مدل در معرض تغییرات و تنوعهای بیشتری از دادههای ورودی، به تعمیمپذیری بهتر آن کمک میکند. در واقع، ما به مدل یاد میدهیم که ویژگیهای اصلی را فدای جزئیات تصادفی (مثل زاویه یا نور تصویر) نکند.
فرمول ریاضی:
از دیدگاه ریاضی، افزونگی دادهها نمونههای آموزشی جدیدی را از طریق اعمال توابع تبدیل T بر روی دادههای اصلی ایجاد میکند:
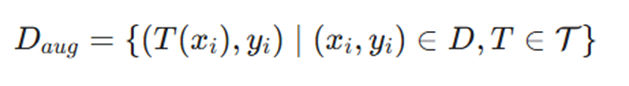
معرفی متغیرها:
- Daug: مجموعهداده نهایی حاصل از افزونگی.
- T: تابع تبدیل (Transformation) اعمال شده روی ورودی.
- xi: داده ورودی اصلی (مانند یک تصویر یا متن).
- yi: برچسب یا کلاس مربوط به داده ورودی.
- D: مجموعهداده آموزشی اولیه.
.
تکنیکهای رایج افزونگی:
- تصویر: چرخش، معکوس کردن (Flipping)، تغییر مقیاس، برش تصادفی، تنظیم روشنایی و تزریق نویز.
- متن: جایگزینی کلمات با مترادفها، ترجمه بازگشتی (Back-translation) و حذف یا درج تصادفی کلمات.
- صدا: کشش زمانی (Time stretching)، تغییر گام صدا (Pitch shifting) و افزودن نویز پسزمینه.
- دادههای جدولی: استفاده از روش SMOTE، افزودن نویز گاوسی و جابجایی ویژگیها.
.
توقف زودهنگام (Early Stopping)
نوعی از منظمسازی است که بر پایش عملکرد مدل روی مجموعهی اعتبارسنجی تمرکز دارد. ایده ساده است: بهمحض اینکه مدل شروع به بیشبرازش کرد و عملکردش روی دادههای جدید متوقف شد، آموزش را قطع میکنیم. این کار با محدود کردن زمان آموزش، از غرق شدن مدل در نویزهای دادههای تمرینی جلوگیری میکند.
معیار توقف:
الگوریتم، میزان ضرر اعتبارسنجی (Lval) را در هر اپوک زیر نظر میگیرد و زمانی متوقف میشود که:
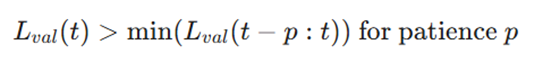
معرفی متغیرها:
- Lval (t): مقدار تابع ضرر روی دادههای اعتبارسنجی در اپوک فعلی (t).
- min(Lval(t-p:t)): کمترین مقدار ضرر ثبت شده در بازهی زمانی (Patience) تعیین شده.
.
نرمالسازی دستهای (Batch Normalization)
بچ نرمالیزیشن تکنیکی است که ورودیهای هر لایه را نرمالسازی میکند. این کار به کاهش پدیدهای به نام تغییر کوواریانس داخلی (Internal Covariate Shift) کمک کرده و در عین حال به عنوان یک منظمساز (Regularizer) عمل میکند. اگرچه هدف اصلی آن شتابدهی به آموزش است، اما به دلیل تزریق نویز در دستههای کوچک، اثرات منظمسازی قابل توجهی دارد.
برای یک دستهی کوچک (Mini-batch) شامل B = x1, …, xm، این الگوریتم محاسبات زیر را انجام میدهد:
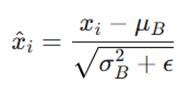
سپس برای حفظ ظرفیت یادگیری شبکه، عملیات مقیاس و انتقال (Scale and Shift) اعمال میشود:
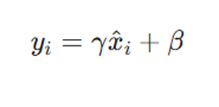
معرفی متغیرها:
- μB: میانگین دستهی کوچک.
- σB ^2: واریانس دستهی کوچک.
- ε: مقدار بسیار کوچکی برای جلوگیری از تقسیم بر صفر.
- γ و β: پارامترهای قابل یادگیری که به شبکه اجازه میدهند دادهها را در صورت نیاز دوباره مقیاسدهی کند.
.
مزایای کلیدی:
- کاهش حساسیت به مقداردهی اولیه وزنها: دیگر لازم نیست نگران تنظیمات بسیار دقیق اولیه باشید.
- اجازه استفاده از نرخ یادگیری (Learning Rate) بالاتر: فرآیند همگرایی را بسیار سریعتر میکند.
- منظمسازی ملایم: از طریق تزریق نویز تصادفی در هر دسته، از بیشبرازش جلوگیری میکند.
- کاهش نیاز به سایر تکنیکها: استفاده از این روش معمولاً نیاز به دراپاوت (Dropout) شدید را کم میکند.
.
سایر روشهای منظمسازی
علاوه بر موارد اصلی، چندین تکنیک دیگر نیز وجود دارند که در سناریوهای خاص معجزه میکنند:
- کاهش وزن (Weight Decay): که در اکثر بهینهسازها معادل همان منظمسازی L2 است.
- نرمسازی برچسب (Label Smoothing): به جای استفاده از برچسبهای سخت (۰ و ۱)، از مقادیر نرم (مثلاً ۰.۱ و ۰.۹) استفاده میکند تا از اعتماد به نفس کاذب مدل جلوگیری شود.
- Mixup: با ترکیب جفتهایی از ورودیها و برچسبها، نمونههای آموزشی مجازی و جدیدی خلق میکند.
- Cutout/Maskout: بخشهایی از تصویر ورودی را به صورت تصادفی حذف میکند تا مدل یاد بگیرد به تمام اجزای تصویر دقت کند.
- روشهای گروهی (Ensemble Methods): پیشبینیهای چندین مدل مختلف را با هم ترکیب میکند تا خطا و واریانس کاهش یابد.
و…………….
پیاده سازی در پایتون
1.پیادهسازی منظمسازی L1 و L2
برای استفاده از این تکنیک، باید در زمان تعریف لایهها، جریمهی مورد نظر را به «هسته» (Kernel) هر لایه اضافه کنیم.
الف) با استفاده از TensorFlow/Keras
در کراس، این کار به سادگی با استفاده از آرگومان kernel_regularizer انجام میشود:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, regularizers
# تعریف مدل با منظمسازی L2
model = keras.Sequential([
# لایه اول با جریمه L2
layers.Dense(128, activation='relu',
kernel_regularizer=regularizers.l2(0.001),
input_shape=(784,)),
# لایه دوم با جریمه L1
layers.Dense(64, activation='relu',
kernel_regularizer=regularizers.l1(0.001)),
# لایه خروجی
layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
ب) با استفاده از PyTorch
در پایتورچ، این فرآیند معمولاً با اضافه کردن مجموع مجذور وزنها به تابع ضرر نهایی انجام میشود:
import torch
import torch.nn as nn
import torch.optim as optim
class RegularizedNet(nn.Module):
def __init__(self, l2_lambda=0.001):
super(RegularizedNet, self).__init__()
self.fc1 = nn.Linear(784, 128)
self.l2_lambda = l2_lambda
def forward(self, x):
return torch.relu(self.fc1(x))
def l2_regularization_loss(self):
l2_loss = sum(torch.sum(param ** 2) for param in self.parameters())
return self.l2_lambda * l2_loss
# در حلقه آموزش:
# loss = criterion(outputs, labels) + model.l2_regularization_loss()
2.پیادهسازی دراپاوت (Dropout)
دراپاوت یکی از موثرترین روشهاست که در آن نورونها در هر مرحله به صورت تصادفی «خاموش» میشوند تا بقیه مجبور به یادگیری بهتر شوند.
# در TensorFlow/Keras
model = keras.Sequential([
layers.Dense(256, activation='relu', input_shape=(784,)),
layers.Dropout(0.5), # حذف تصادفی 50% نورونها در هر اپوک
layers.Dense(10, activation='softmax')
])
۳ .خط لوله کامل آموزش (Complete Training Pipeline)
در نهایت، یک مدل حرفهای ترکیبی از تمام این ابزارهاست. در کد زیر، یک شبکهی عصبی پیچشی (CNN) را میبینید که همزمان از Data Augmentation، Batch Normalization، Dropout و L2 استفاده میکند تا به بالاترین سطح تعمیمپذیری برسد:
import tensorflow as tf
from tensorflow.keras import layers, models, callbacks, regularizers
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
# ۱. بارگذاری و پیشپردازش دادهها (برای تولید خروجی واقعی)
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
X_train, X_test = X_train / 255.0, X_test / 255.0 # نرمالسازی پیکسلها
y_train, y_test = to_categorical(y_train), to_categorical(y_test)
# ۲. تعریف افزونگی دادهها (Data Augmentation)
datagen = ImageDataGenerator(
rotation_range=20,
width_shift_range=0.2,
horizontal_flip=True,
zoom_range=0.2
)
# ۳. معماری مدل (بر اساس فایل پیادهسازی شما)
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu',
kernel_regularizer=regularizers.l2(0.001),
input_shape=(32, 32, 3)),
layers.BatchNormalization(), # افزایش سرعت و پایداری
layers.MaxPooling2D((2, 2)),
layers.Dropout(0.25), # ترمز اول برای جلوگیری از بیشبرازش
layers.Flatten(),
layers.Dense(128, activation='relu',
kernel_regularizer=regularizers.l2(0.001)),
layers.Dropout(0.5), # ترمز دوم
layers.Dense(10, activation='softmax')
])
# ۴. تنظیمات توقف زودهنگام (Early Stopping)
early_stopping = callbacks.EarlyStopping(
monitor='val_loss',
patience=5,
restore_best_weights=True
)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# ۵. اجرای آموزش (خارج کردن از حالت کامنت)
print("--- شروع فرآیند آموزش ---")
history = model.fit(
datagen.flow(X_train, y_train, batch_size=64),
epochs=10, # برای تست سریع روی 10 تنظیم شده
validation_data=(X_test, y_test),
callbacks=[early_stopping]
)
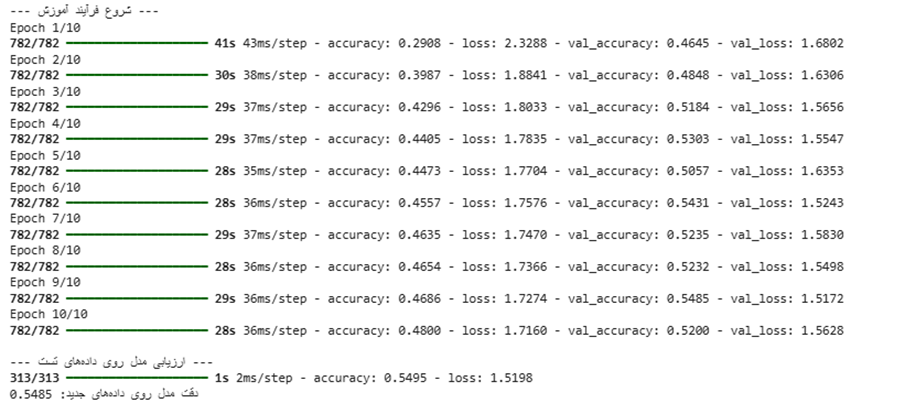
# ۶. نمایش خروجی نهایی و نمودارها
print("\n--- ارزیابی مدل روی دادههای تست ---")
test_loss, test_acc = model.evaluate(X_test, y_test)
print(f"دقت مدل روی دادههای جدید: {test_acc:.4f}")
خروجی:
.
مطالعه موردی ۱: طبقهبندی تصاویر (CIFAR-10)
مسئله: طبقهبندی تصاویر در مجموعهداده CIFAR-10 که شامل ۶۰,۰۰۰ تصویر رنگی در ۱۰ کلاس مختلف است. چالش اصلی، ساخت یک شبکه عصبی پیچشی (CNN) است که بتواند فراتر از عکسهای آموزشی، تصاویر جدید را هم به درستی تشخیص دهد.
- مدل پایه (بدون منظمسازی):
- معماری: ۳ لایه Conv + ۲ لایه Dense با حدود ۵۰۰,۰۰۰ پارامتر.
- عملکرد: دقت آموزش ۹۸.۵٪ اما دقت تست فقط ۷۰.۱٪.
- تحلیل: بیشبرازش شدید؛ مدل دادهها را حفظ کرده و شکاف (Gap) عملکردی بیش از ۲۵٪ است.
- مدل منظمشده (Regularized Model):
- تغییرات: اضافه شدن L2، دراپاوت (۰.۲۵ تا ۰.۵)، BatchNorm و افزونگی دادهها.
- عملکرد: دقت آموزش ۹۲.۱٪ و دقت تست ۸۴.۹٪.
- نتیجه: شکاف به حدود ۷٪ کاهش یافت که نشاندهنده بهبود خیرهکننده در تعمیمدهی است.
import tensorflow as tf
from tensorflow.keras import layers, models, regularizers
import matplotlib.pyplot as plt
COLORS = {'gold': '#FFD700', 'crimson': '#DC143C', 'blue': '#87CEEB', 'silver': '#A9A9A9'}
# ۱. آمادهسازی دادهها
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# ۲. تعریف مدل با منظمسازی کامل (Dropout + L2 + BatchNorm)
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', kernel_regularizer=regularizers.l2(0.001), input_shape=(32, 32, 3)),
layers.BatchNormalization(),
layers.MaxPooling2D((2, 2)),
layers.Dropout(0.25), # ترمز اول
layers.Flatten(),
layers.Dense(128, activation='relu', kernel_regularizer=regularizers.l2(0.001)),
layers.Dropout(0.5), # ترمز دوم
layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# ۳. آموزش مدل
history = model.fit(x_train[:10000], y_train[:10000], epochs=15,
validation_data=(x_test[:2000], y_test[:2000]), verbose=1)
# ۴. خروجی بصری
plt.figure(figsize=(10, 5))
plt.plot(history.history['accuracy'], label='Train Accuracy', color=COLORS['blue'], linewidth=3)
plt.plot(history.history['val_accuracy'], label='Val Accuracy', color=COLORS['crimson'], linewidth=3)
plt.title('Case Study 1: Image Classification Performance', fontsize=14)
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
خروجی:
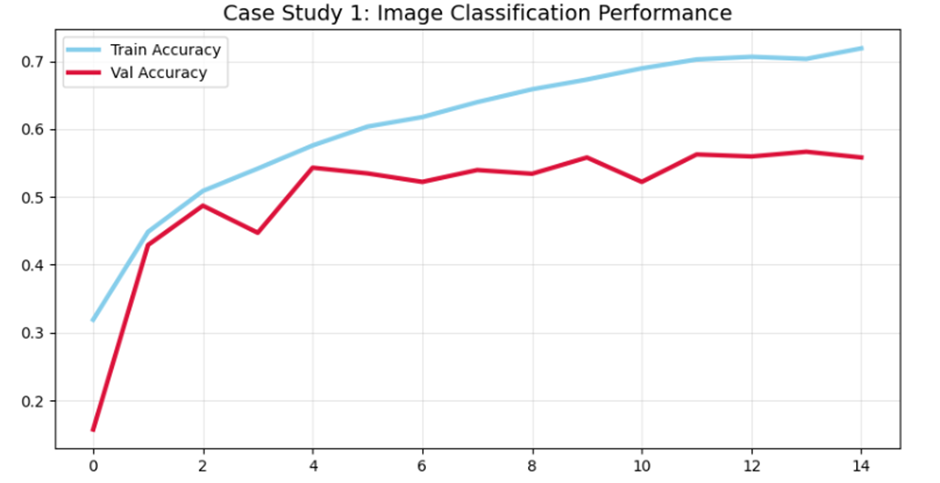
.
مطالعه موردی ۲: پیشبینی سریهای زمانی (قیمت سهام)
مسئله: پیشبینی قیمتهای آینده بر اساس دادههای تاریخی که به دلیل ماهیت نویزی و غیرایستا، بسیار دشوار است. مدلها معمولاً الگوهای تصادفی گذشته را که تکرار نمیشوند، حفظ میکنند.
مقایسه عملکرد مدلهای LSTM:
| مدل | خطای آموزش (RMSE) | خطای تست (RMSE) | شکاف (Gap) |
| LSTM ساده | ۲.۳۴ | ۸.۹۲ | ۶.۵۸ |
| +LSTM دراپاوت | ۳.۸۷ | ۵.۲۳ | ۱.۳۶ |
| +LSTM تمام تکنیکها | ۴.۱۲ | ۴.۴۵ | ۰.۳۳ |
- یافتههای کلیدی: بدون منظمسازی، مدل فقط حافظهی تاریخی دارد. ترکیب L2، دراپاوت و توقف زودهنگام (Early Stopping) منجر به شکاف ناچیز (۰.۳۳) و پیشبینیهای واقعگرایانه شده است.
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
from sklearn.metrics import mean_squared_error
# ۱. تولید دادههای نویزی مشابه بازار سهام
np.random.seed(42)
data = np.sin(np.linspace(0, 100, 1000)) + np.random.normal(0, 0.1, 1000)
# ایجاد پنجرههای زمانی (Sliding Window)
X = np.array([data[i:i+10] for i in range(len(data)-10)]).reshape(-1, 10, 1)
y = data[10:]
# جداسازی دادهها (80% آموزش، 20% تست)
split = int(0.8 * len(X))
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]
# ۲. تعریف مدل LSTM با مکانیزمهای منظمسازی
model_ts = Sequential([
LSTM(50, activation='relu', input_shape=(10, 1), recurrent_dropout=0.2),
Dropout(0.3),
Dense(1)
])
model_ts.compile(optimizer='adam', loss='mse')
# ۳. اجرای آموزش (بدون نمایش لاگهای طولانی)
history = model_ts.fit(X_train, y_train, epochs=20, batch_size=32,
validation_data=(X_test, y_test), verbose=0)
# ۴. محاسبه خروجیهای عددی
test_preds = model_ts.predict(X_test)
test_rmse = np.sqrt(mean_squared_error(y_test, test_preds))
# ۵. خروجی بصری (Visualization)
plt.figure(figsize=(12, 6), facecolor='white')
ax = plt.gca()
ax.set_facecolor('#F5F5F5') # Ultra Light Gray
# رسم دادههای واقعی نویزی
plt.plot(y_test, color='#A9A9A9', label='Actual Values (Noisy)', linewidth=1.5, alpha=0.7)
# رسم پیشبینیهای مدل
plt.plot(test_preds, color='#DC143C', label='LSTM Predictions', linewidth=2.5)
plt.title('Time Series Case Study: Generalization Performance', fontsize=16, fontweight='bold')
plt.xlabel('Time Steps', fontsize=12)
plt.ylabel('Normalized Value', fontsize=12)
plt.legend(facecolor='white', framealpha=1)
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()
print(f"Test RMSE: {test_rmse:.4f}")
خروجی:
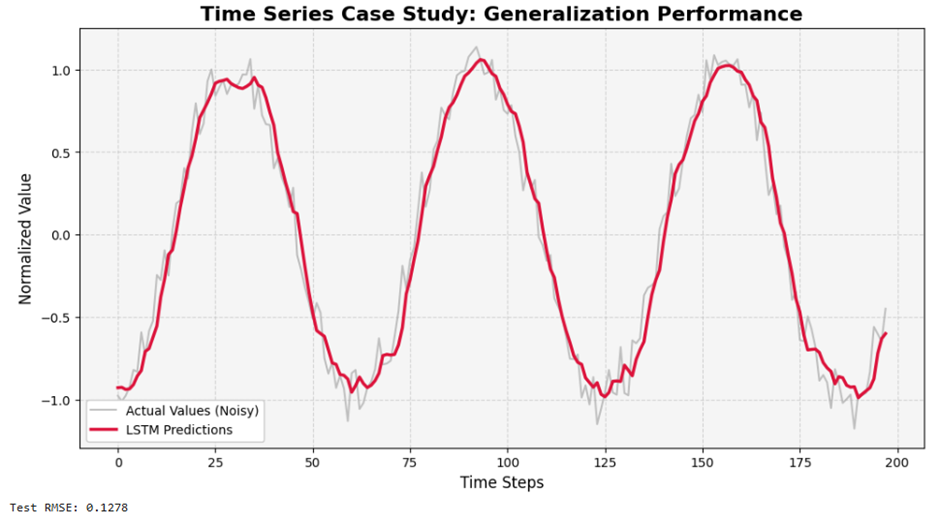
.
جمع بندی
بیشبرازش (Overfitting) و کمبرازش (Underfitting) دو شکست کلاسیک در فرایند تعمیم مدلهای یادگیری ماشین و بهویژه یادگیری عمیق هستند. کمبرازش زمانی رخ میدهد که مدل ظرفیت بازنمایی کافی برای استخراج الگوهای اصلی داده را ندارد و در نتیجه با Bias بالا مواجه است. در مقابل، بیشبرازش نتیجهی ظرفیت بیشازحد یا انعطافپذیری بالا است که منجر به Variance زیاد و حساسیت شدید به نویز دادههای آموزش میشود.
در چارچوب تحلیلی، این پدیدهها را میتوان با تجزیهی خطای مورد انتظار به سه مؤلفهی Bias²، Variance و Noise توضیح داد. هدف طراحی مدل، یافتن نقطهی تعادل در Bias–Variance Tradeoff است؛ جایی که خطای تعمیم (Generalization Error) حداقل میشود، نه صرفاً خطای آموزش.
در یادگیری عمیق، به دلیل تعداد پارامترهای زیاد و ظرفیت مدلهای عصبی، خطر بیشبرازش جدیتر است. بنابراین استفاده از راهکارهایی مانند Regularization (L1/L2)، Dropout، Early Stopping، افزایش داده (Data Augmentation) و تنظیم مناسب معماری شبکه، بخشی جداییناپذیر از طراحی سیستمهای یادگیری عمیق محسوب میشود.
در نهایت، معیار اصلی موفقیت یک مدل نه کاهش صرف Loss روی دادههای آموزش، بلکه توانایی تعمیم پایدار روی دادههای دیدهنشده است. هر تصمیم معماری یا بهینهسازی باید با این هدف ارزیابی شود: کاهش خطای تعمیم و رسیدن به تعادل پایدار میان پیچیدگی مدل و ساختار واقعی داده.



