

1.مقدمه
در بسیاری از دادههای واقعی، خوشهها ساختار ساده و هندسی منظم ندارند. برای مثال، در دادههای مکانی ممکن است نقاط مربوط به یک پدیده شهری بهصورت ناحیهای کشیده، خمیده یا چندشاخه ظاهر شوند. در تصاویر پزشکی، سلولها یا بافتها ممکن است مرزهای پیچیده و نامنظم داشته باشند و در دادههای شبکهای نیز اجتماعات کاربران ممکن است بر اساس روابط غیرخطی و الگوهای اتصال شکل بگیرند.
در چنین شرایطی، الگوریتمهایی که به مرکز خوشه، میانگین فاصله یا فرض کرویبودن خوشهها وابستهاند، معمولاً دچار خطا میشوند. خوشهبندی چگالیمحور برای حل همین مسئله طراحی شده است. این خانواده از الگوریتمها به جای پرسیدن این سؤال که:
«هر نقطه به کدام مرکز خوشه نزدیکتر است؟»
میپرسند:
«آیا این نقطه در ناحیهای پرتراکم از دادهها قرار دارد و آیا میتواند به زنجیرهای از نقاط چگال متصل شود؟»
این تغییر نگاه، بنیاد فلسفی خوشهبندی چگالیمحور را میسازد.
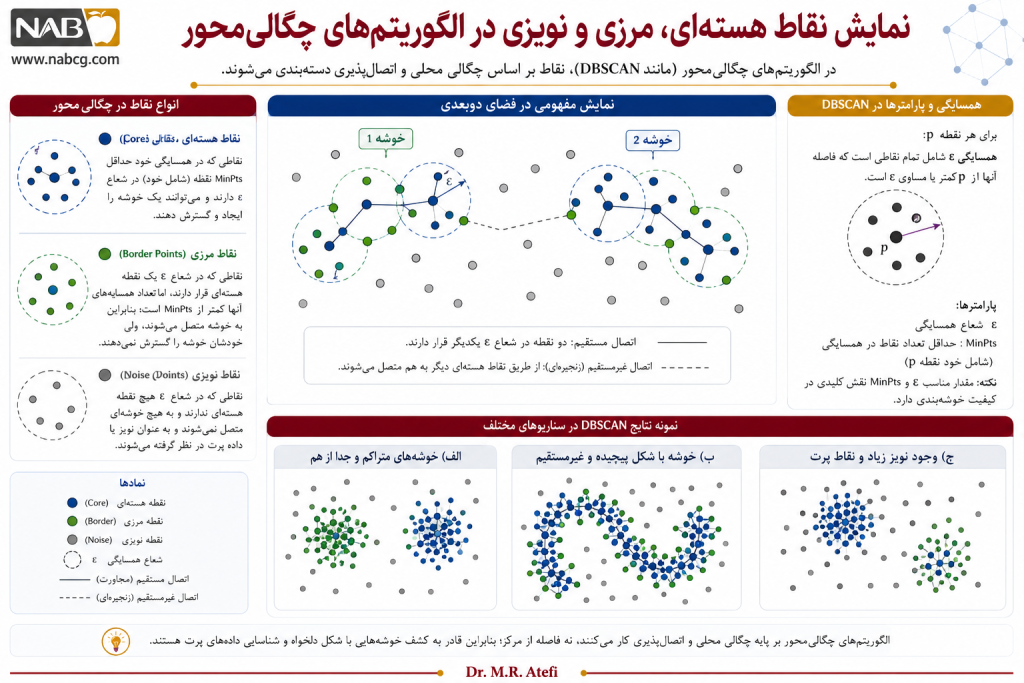
در این رویکرد، نقاط معمولاً به سه گروه اصلی تقسیم میشوند:
- نقاط هستهای یا مرکزی ـ Core Points
یعنی نقاطی که در همسایگی خود تعداد کافی از نمونهها را دارند و میتوانند یک ناحیه چگال را شکل دهند.
- نقاط مرزی ـ Border Points
بدین معنی نقاطی که خودشان تراکم کافی برای تشکیل خوشه ندارند، اما در مجاورت یک نقطه هستهای قرار گرفتهاند و به خوشه متصل میشوند.
- نقاط نویزی یا پرت ـ Noise/Outliers
نقاطی که نه چگالی کافی دارند و نه به یک ناحیه چگال متصلاند؛ بنابراین از ساختار اصلی خوشهها حذف یا جدا میشوند.
به همین دلیل، خوشهبندی چگالیمحور نهتنها یک ابزار خوشهبندی، بلکه روشی قدرتمند برای تشخیص دادههای پرت، کشف الگوهای غیرخطی و تحلیل ساختارهای فضایی پیچیده نیز محسوب میشود.
.
2. مهمترین الگوریتمهای خوشهبندی چگالیمحور( (Density-Based Clustering
خانواده خوشهبندی چگالیمحور شامل الگوریتمهای متنوعی است که هرکدام برای نوع خاصی از داده، چگالی، ساختار هندسی یا کاربرد طراحی شدهاند. در این بخش، مهمترین الگوریتمهایی که در ادامه مقاله بررسی میشوند، معرفی شدهاند.
نکته علمی: برخی از الگوریتمهای این فهرست، مانند Spectral Clustering، از نظر طبقهبندی کلاسیک بیشتر در خانواده روشهای گرافمحور قرار میگیرند؛ اما به دلیل توانایی در کشف ساختارهای غیرخطی، خوشههای نامنظم و ارتباط نزدیک با مفهوم اتصال، چگالی و توپولوژی داده، میتوانند در کنار رویکردهای چگالیمحور و ساختاری نیز بررسی شوند.

فلسفه محاسباتی و مکانیزم عملکرد
در این تفکر استراتژیک، فواصل خطی و معیارهای هندسی سنتی کاملاً بیمعنی هستند. این رویکرد، خوشهها را به عنوان تودههای فشرده و متراکم در فضا میبیند که توسط نواحی خالی یا کمتراکم (نویز) از یکدیگر جدا شدهاند. تا زمانی که زنجیرهای از دادههای همچوار تراکم بالایی تشکیل دهند، بدنه کلاستر جلو میرود و هر نقطهای که توانایی اتصال به این چگالی را نداشته باشد، به عنوان نویز ذوب و حذف میشود.
.
2.۱. الگوریتم DBSCAN
DBSCAN یکی از معروفترین و پرکاربردترین الگوریتمهای چگالیمحور است. این الگوریتم بر اساس دو پارامتر اصلی، یعنی شعاع همسایگی 𝜀 و حداقل تعداد نقاط 𝑀𝑖𝑛𝑃𝑡𝑠، نقاط داده را به سه دسته هستهای، مرزی و نویزی تقسیم میکند.
مهمترین ویژگی DBSCAN این است که بدون نیاز به تعیین تعداد خوشهها، میتواند خوشههایی با شکلهای کاملاً نامنظم را شناسایی کند و همزمان دادههای پرت را نیز جدا نماید و بر اساس سنجش تراکم موضعی نقاط، اشکالی با هندسه کاملاً پیچیده را کشف و دادههای پرت را فیلتر میکند.
گامهای اجرایی
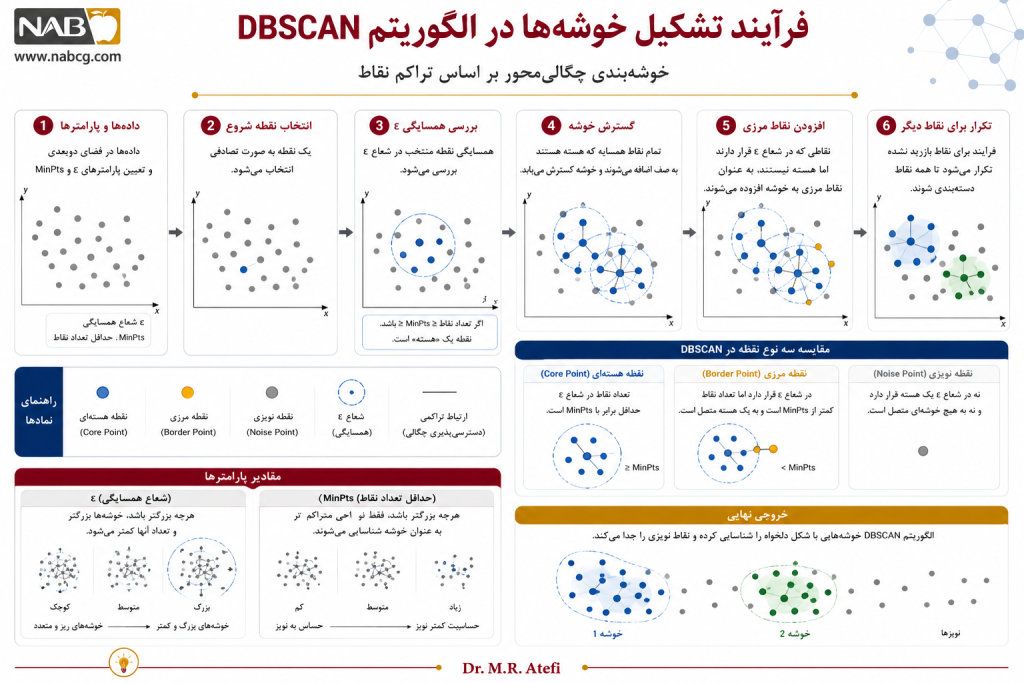
- اسکن شعاعی: انتخاب یک نقطه تصادفی و محاسبه تعداد نقاط موجود در شعاع 𝜀 آن.
- معرفی و برچسبگذاری نقاط: نقاط هسته (Core Points): اگر تعداد نقاط همسایه از MinPoints بیشتر باشد، نقطه به عنوان هسته علامتگذاری شده و یک کلاستر جدید متولد میشود.
- نقاط مرزی (Border Points): نقاطی که تراکم کافی ندارند اما در همسایگی یک نقطه هسته قرار گرفتهاند.
- نویز (Noise): نقاطی که نه هستهاند و نه مرزی.
- توسعه زنجیرهای (Density-Reachability): اتصال زنجیرهای نقاط هسته همجوار به یکدیگر جهت پیشروی و گسترش مرزهای کلاستر.
- پایان پویش: تکرار مراحل برای تمام نقاط اسکننشده تا زمان تعیین تکلیف کل فضای مسئله.
تابع هدف ریاضی
این الگوریتم فاقد یک تابع هدف بهینهسازی سراسری (Global) متعارف است و بر پایه معیارهای توپولوژیکِ تراکم موضعی و دسترسی چگالی (D) عمل میکند:
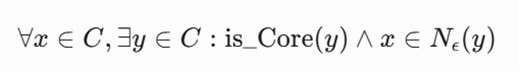
معرفی متغیرها
- ε (Epsilon): حداکثر شعاع همسایگی برای کاوش تراکم یک نقطه.
- MinPoints: حداقل تعداد نقاط مجاز در شعاع εبرای تشکیل یک هسته چگال.
- Nε (y): مجموعه نقاط واقع در همسایگی شعاعی نقطه y.
مزایا و نقاط قوت
- حذف خودکار و مقتدرانه نویزها و دادههای پرت.
- عدم نیاز به حدس زدن یا تعیین پارامتر تعداد کلاستر (K).
معایب و محدودیتها
- افت شدید عملکرد و خطا در مواجهه با دیتاستهایی با چگالیهای متنوع و نامتوازن.
- حساسیت بسیار بالا به تنظیم دقیق دو هایپرپارامتر مبنایی ε و MinPoints.
کاربردهای واقعی
- شناسایی نقاط داغ جرم و جنایت در نقشههای شهری و سیستمهای اطلاعات جغرافیایی (GIS).
- فیلترینگ نویز و بازشناسی الگوهای نجومی در دادههای ساختارنیافته ماهوارهای.

2.۲. الگوریتم OPTICS
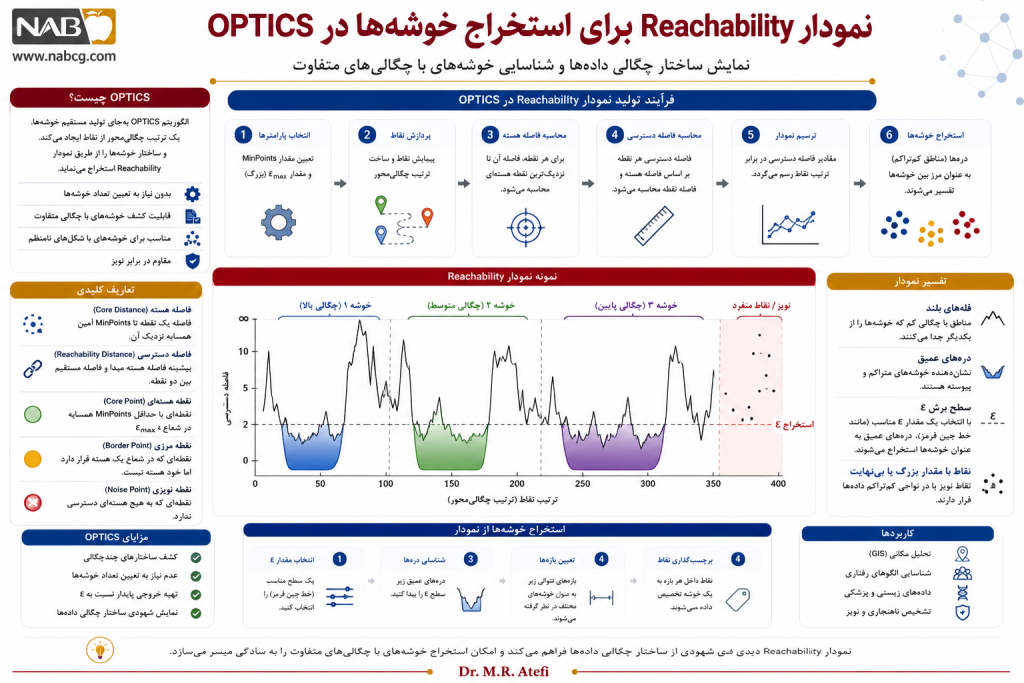
یک الگوریتم خوشهبندی چگالیمحور پیشرفته است که منحصراً برای پوشش ضعف بزرگ DBSCAN یعنی ناتوانی در مدیریت دیتای چندچگالی مهندسی و متولد شد. این الگوریتم بهجای تولید مستقیم خوشهها، یک ترتیب چگالیمحور از نقاط ایجاد میکند و سپس ساختار خوشهها را از طریق نمودار دسترسی یا Reachability Plot نمایش میدهد.
مزیت اصلی OPTICS این است که وابستگی کمتری به یک مقدار ثابت برای شعاع همسایگی دارد و میتواند ساختارهای چندچگالی را بهتر آشکار کند. این روش به جای محدود کردن فضا به یک شعاع صلب، ساختار چگالیهای متغیر را استخراج میکند.
گامهای اجرایی
- اولویتدهی ترتیبی: الگوریتم خوشهها را مستقیماً تشکیل نمیدهد؛ بلکه با محاسبه فواصل هسته و دسترسی، یک ساختار خطی و اولویتدار از وضعیت دسترسی نقاط ایجاد میکند.
- بروزرسانی لیست کاندیدها: با انتخاب یک نقطه، فواصل نقاط همسایه اسکنشده بروزرسانی شده و در یک صف اولویتدار بر اساس کمترین فاصله دسترسی مرتب میشوند.
- ترسیم نقشه چگالی: خروجی این فرآیند ترتیبی به صورت یک نمودار دره و قله (Reachability Plot) ترسیم میشود.
- استخراج کلاسترها: گودیها و درههای موجود در این نمودار، نشاندهنده کلاسترهای متراکم با چگالیهای مختلف در فضا هستند.
تابع هدف ریاضی
این متد ساختار ترتیبی فضا را با بهینهسازی و ثبت مداوم کمترین میزان فاصله دسترسی به ازای هر گام پویش هندسی استخراج میکند:
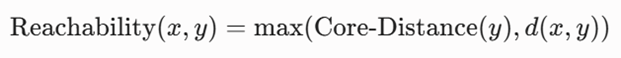
معرفی متغیرها
- فاصله هسته (Core Distance): کمترین شعاعی که یک نقطه را با توجه به MinPoints تبدیل به یک Core Point میکند.
- فاصله دسترسی (Reachability Distance): حداکثر مقدار بین فاصله واقعی دو نقطه و فاصله هسته نقطه مبدا.
- εmax: حداکثر شعاع اولیه برای محدود کردن سقف محاسبات (اختیاری).
- MinPoints: حداقل تعداد نقاط همسایه برای ارزیابی چگالی موضعی.
مزایا و نقاط قوت
- عدم وابستگی شدید به یک هایپرپارامتر شعاعی صلب و واحد.
- نمایش بصری بسیار قدرتمند از ساختار و عمق کلاسترهای دیتابیس.
معایب و محدودیتها
- پیچیدگی زمانی O (n log n) که در ابعاد بزرگ سنگین ارزیابی میشود.
- نیاز به الگوریتمهای جانبی ثانویه برای استخراج مرزهای قطعی کلاسترها از روی نمودار.
کاربردهای واقعی
- تحلیل امواج و سیگنالهای مغزی پیچیده که حاوی نویز زیاد و تراکمهای فرکانسی متغیر هستند.
- دستهبندی دادههای مکانی جغرافیایی تراکممتغیر مانند نقاط توزیع جمعیت شهری و روستایی.
.
2.۳. الگوریتم DBCLASD
DBCLASD یک الگوریتم مبتنی بر توزیع آماری است که تلاش میکند بهجای استفاده از پارامترهای صلب هندسی، ساختار خوشهها را بر اساس آزمونهای آماری و الگوی توزیع نقاط شناسایی کند. یک الگوریتم خوشهبندی چگالیمحور توزیعشده، احتمالی و پویا است که با جایگزینی معیارهای ثابت هندسی با آزمونهای ریاضی، کاربر را از چالش تنظیم پارامترهای صلب نجات میدهد.
در این روش، فرض میشود نقاط درون یک خوشه از نظر فاصله نزدیکترین همسایگان، رفتار آماری مشخصی دارند. بنابراین، توسعه خوشهها با آزمونهای نیکویی برازش و ارزیابی همگنی آماری انجام میشود.
گامهای اجرایی
- تعریف فرضیه توزیع یکنواخت: فرضیه مبنایی این متد این است که نقاط درون یک کلاستر متراکم، باید پیرو یک توزیع یکنواخت احتمالی (Uniform Distribution) از فواصل نزدیکترین همسایگان خود باشند.
- رشد و توسعه خودکار: الگوریتم به صورت خودکار از یک نقطه مبدا شروع به توسعه مرزهای کلاستر میکند.
- ارزیابی با آزمون فرضیه: در هر گام با آزمونهای فرضیه آماری (مانند Chi-Square Test) بررسی میشود که آیا افزودن نقطه جدید، توزیع یکنواخت کلاستر را خراب میکند یا خیر.
- پذیرش یا تخصیص نویز: اگر نقطه جدید توزیع را حفظ کند پذیرفته میشود، در غیر این صورت به عنوان نویز موقت کنار گذاشته میشود.
تابع هدف ریاضی
تایید همگنی توزیع فواصل نزدیکترین همسایگی بر اساس انطباق آزمون نیکویی برازش خیدو (χ²) در سطح اطمینان مشخص (α):
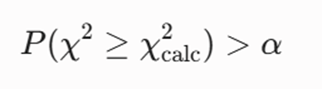
مزایا و نقاط قوت
- خوشهبندی کاملاً خودکار و بدون نیاز به تنظیم حساس هایپرپارامترهای فرضی مانند ε.
- توانایی بالا در استخراج خوشههایی با اشکال هندسی کاملاً دلخواه و پیچیده.
- فیلترینگ قدرتمند دادههای پرت بر اساس انحراف آماری.
معایب و محدودیتها
- حساسیت شدید به تغییرات، نویزهای اولیه و نوسانات آماری ناگهانی دیتابیس.
- وابستگی شدید به فرض توزیع یکنواخت دادهها که ممکن است در دیتای واقعی برقرار نباشد.
- بار محاسباتی سنگین به دلیل اجرای مکرر آزمونهای آماری برای تکتک کاندیداها.
کاربردهای واقعی
- دستهبندی دادههای مکانی کلان با ویژگیهای توزیع آماری مشخص.
- معدنکاوی دادههای ترافیکی و مخابراتی جهت کشف مناطق داغ و پایدار جفتی.
.
2.۴. الگوریتم (DENsity-based CLUsterEst) DENCLUE
رویکردی فوقالعاده پیشرفته و کاملاً ریاضیاتی است که چگالی فضا را به صورت یک میدان فیزیکی مدلسازی میکند. این الگوریتم به جای شمارش ساده نقاط درون یک شعاع صلب، از توابع هموار ریاضی برای محاسبه پیوسته میزان جرم و تراکم در سراسر فضای چندبعدی استفاده مینماید.
در این الگوریتم، نقاط داده به سمت قلههای چگالی حرکت میکنند و نقاطی که به یک قله مشترک همگرا میشوند، یک خوشه را تشکیل میدهند. این روش از نظر مفهومی با تخمین چگالی هستهای و صعود گرادیان ارتباط نزدیکی دارد.
گامهای اجرایی
- نقشهبرداری از چگالی فضا: چگالی کل فضای دادهها با استفاده از توابع ریاضی هموارساز (تابع هسته) به صورت یکپارچه تخمین زده میشود.
- محاسبه شیب چگالی: بر اساس فرمولهای ریاضی، نقشه شیب چگالی فضا (Density Gradient) محاسبه میشود.
- صعود گرادیان: تکتک نقاط داده بر اساس تکنیک صعود گرادیان (Gradient Ascent) به سمت قلههای متراکم که «جاذبهای چگالی هندسی» (Density Attractors) نام دارند حرکت میکنند.
- تولد کلاسترها: نقاطی که به یک قله مشترک ختم میشوند، یک کلاستر را شکل میدهند. نقاط منزوی واقع در درههای بسیار کمتراکم نیز به عنوان نویز حذف میگردند.
فرمول ریاضی تخمین چگالی هسته (KDE):
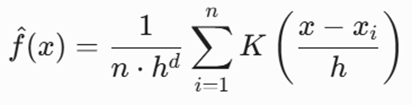
- معرفی متغیرها: n تعداد کل نقاط؛ h پهنای باند پنجره چگالی (Bandwidth)؛ d ابعاد فضا؛ K تابع هسته (معمولاً گاوسی).
مزایا و نقاط قوت
- پایه ریاضی فوقالعاده مستحکم و رفتار هموار هندسی.
- عملکرد عالی در دیتابیسهای ابعاد بالا (High-Dimensional Data) در مقایسه با سایر روشهای چگالیمحور.
- مدیریت بینقص نویز و استخراج دقیق خوشههایی با اشکال بسیار نامنظم و متغیر.
معایب و محدودیتها
- تنظیم هایپرپارامتر پهنای باند (h) به شدت حساس است؛ اگر اشتباه انتخاب شود، خوشهها بیش از حد خرد یا کاملاً ادغام میشوند.
- بار محاسباتی سنگین به دلیل محاسبه مشتقات توابع و اجرای فرآیند تکراری صعود گرادیان برای تکتک دادهها.
کاربردهای واقعی
- پیشبینی و دستهبندی جریانهای نوری و الگوهای حرکتی اشیاء در بینایی ماشین.
- کلاسترینگ دادههای بیان ژن در بیوانفورماتیک که دارای ابعاد بالا و نویز زیاد هستند.
.
2.۵. الگوریتم خوشهبندی طیفی (Spectral Clustering)
این الگوریتم یک روش قدرتمند مبتنی بر تئوری گراف و جبر خطی برای حل گرههای هندسی غیرخطیِ به شدت در هم تنیده است. در این الگوریتم، دادهها ابتدا بهصورت یک گراف شباهت مدلسازی میشوند. سپس با استفاده از ماتریس لاپلاسی گراف و تجزیه مقادیر ویژه، دادهها به فضایی جدید نگاشت میشوند که در آن خوشهها بهتر از یکدیگر جدا میشوند. این الگوریتم به جای اتکا به فواصل خطی مستقیم، با نگاشت دادهها به یک فضای برداری جدید، پیچیدهترین الگوهای توپولوژیک و تودرتو را به کلاسترهایی کاملاً تفکیکپذیر تبدیل میکند.
اگرچه خوشهبندی طیفی بهطور مستقیم یک الگوریتم چگالیمحور کلاسیک نیست، اما به دلیل توانایی بالا در کشف ساختارهای غیرخطی، حلقوی، تودرتو و پیچیده، در تحلیلهای ساختاری و توپولوژیک دادهها بسیار مهم است.
گامهای اجرایی
- ساخت گراف شباهت: دادهها به عنوان گرههای یک گراف مدلسازی شده و وزن یالها (W) بر اساس شباهت جفتی نقاط تعیین میشود.
- محاسبه ماتریس لاپلاسی: ماتریس درجه گرهها (D) استخراج شده و سپس ماتریس لاپلاسی گراف (L) تشکیل میشود.
- تجزیه طیفی (Spectral Decomposition): مقادیر ویژه و بردارهای ویژه (Eigenvectors) ماتریس لاپلاسی استخراج میشوند.
- کاهش ابعاد و نگاشت: این بردارها فضا را به زیرفضایی با ابعاد پایینتر منتقل میکنند که در آن، دادههای پیچیده قدیمی تبدیل به ساختارهایی کاملاً جداپذیر شدهاند.
- خوشهبندی نهایی: الگوریتم K-Means بر روی این فضای خطی و کاهشبعدیافته جدید اجرا میشود تا مرزهای قطعی کلاسترها را تعیین کند.
تابع هدف ریاضی
استخراج بردار خطی زیرفضا با کمینهسازی معیار برش نرمالشده گراف (Normalized Cut) از طریق ماتریس لاپلاسی:
L = D – W
معرفی متغیرها و پارامترها
- W (Similarity Matrix): ماتریس متقارن همبستگی و شباهت جفتی نقاط (معمولاً بر پایه هسته RBF).
- D (Degree Matrix): ماتریس قطری که نشاندهنده درجه و مجموع وزن یالهای متصل به هر گره است.
- L (Laplacian Matrix): ماتریس لاپلاسی غیرافتراقی (یا نسخههای نرمالشده آن Lsym که ساختار توپولوژیک گراف را فشرده میکند.
مزایا و نقاط قوت
- قدرت مطلق و بیرقیب در تفکیک ساختارهای هندسی مارپیچ، حلقوی و به شدت در هم تنیده.
- فنداسیون ریاضی بسیار مستحکم بر پایه تئوری گراف و جبر خطی مدرن.
معایب و محدودیتها
- سربار محاسباتی بسیار سنگین به صورت O (n^3) ناشی از فرآیند تجزیه مقادیر ویژه که آن را برای دیتای کلان کند و غیرممکن میکند.
- حساسیت بالا به هایپرپارامترهای ساخت گراف اولیه (مانند پهنای باند هسته گاوسی \sigma).
کاربردهای واقعی
- تفکیک و بخشبندی اشیاء در تصاویر پیچیده دیجیتال (Image Segmentation) و بینایی ماشین.
- کلاسترینگ شبکههای اجتماعی بزرگ و کشف اجتماعات (Community Detection) بر پایه یالهای ارتباطی.
.
2.۶. الگوریتم Substractive Method
این الگوریتم روشی سریع برای تخمین تعداد خوشهها و یافتن مراکز اولیه بدون نیاز به حدس زدن تعداد خوشهها است. در این روش، هر نقطه داده بهعنوان یک کاندیدای بالقوه برای مرکز خوشه در نظر گرفته میشود و بر اساس میزان تراکم اطراف خود، یک مقدار پتانسیل دریافت میکند.
نقطهای که بیشترین پتانسیل را دارد بهعنوان مرکز خوشه انتخاب میشود و سپس پتانسیل نقاط اطراف آن کاهش مییابد تا از انتخاب مراکز بسیار نزدیک جلوگیری شود. این روش در طراحی سیستمهای فازی و مدلهای عصبی ـ فازی کاربرد زیادی دارد.
گامهای اجرایی
- محاسبه پتانسیل اولیه: پتانسیل چگالی تمام نقاط فضا بر اساس میزان همسایگی و نزدیکی به سایر دادهها محاسبه میشود.
- انتخاب اولین مرکز: نقطهای که بالاترین امتیاز پتانسیل چگالی را در کل فضا دارد، به عنوان مرکز کلاستر اول انتخاب میشود.
- سرکوب چگالی (Destruction): پتانسیل تمام نقاط اطراف این مرکز بر اساس یک تابع کاهشی منهای مقدار مشخصی میشود تا شانس مرکز شدن از نواحی همسایگی سلب شود (پتانسیل آنها کسر میشود).
- تکرار فرآیند: مجدداً نقطهای با بیشترین پتانسیل باقیمانده به عنوان مرکز بعدی انتخاب و فاز سرکوب تکرار میشود؛ این چرخه تا زمان افت پتانسیلها به زیر آستانه توقف ادامه مییابد.
تابع هدف ریاضی
فرمول ارزیابی و استخراج میزان پتانسیل چگالی (Pi) برای نقطه داده xi نسبت به سایر نقاط فضا:
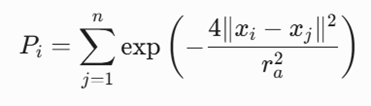
مزایا و نقاط قوت
- پیچیدگی محاسباتی خطی نسبت به تعداد دادهها که سرعت آن را افزایش میدهد.
- عدم وابستگی به موقعیت و فرضیات صلب مراکز اولیه.
معایب و محدودیتها
- وابستگی مستقیم کیفیت کل مدل به شعاع تاثیر (ra) تعریفشده از سوی کاربر؛ تنظیم اشتباه آن تعداد خوشهها را مخدوش میکند.
- حساسیت محاسباتی بالا در فضاهای دادهای غیراقلیدسی ساختارنیافته.
کاربردهای واقعی
- تولید خودکار سیستمهای استنتاج فازی (Fuzzy Inference Systems) و فنداسیون شبکههای عصبی فازی متکی بر داده.
- پردازش سیگنال، عیبیابی هوشمند سیستمهای صنعتی و پردازش اولیه الگوهای صوتی.
.
2.۷. الگوریتم Mean Shift (انتقال میانگین)
Mean Shift یک الگوریتم ناپارامتری و چگالیمحور است که به دنبال یافتن قلههای چگالی در فضای داده میگردد. این الگوریتم با قرار دادن یک پنجره جستجو روی نقاط داده و انتقال تدریجی آن به سمت میانگین نقاط همسایه، نقاط را به سمت نواحی پرتراکم هدایت میکند.
این الگوریتم فضای دادهها را به عنوان یک تابع توزیع احتمال پیوسته میبیند. این متد برخلاف K-Meansنیازی به تعیین تعداد خوشهها ندارد و با اتکا به مفهوم صعود گرادیان، به دنبال یافتن قلههای متراکم (نقاط بیشینه محلی چگالی) در فضای داده میگردد. در پایان، نقاطی که به یک قله چگالی مشترک همگرا شدهاند، در یک خوشه قرار میگیرند. Mean Shift در پردازش تصویر، ردیابی اشیا و بخشبندی دادههای تصویری کاربرد گسترده دارد.
گامهای اجرایی
- پنجرههای مَکنده: قرار دادن یک پنجره یا هسته (Kernel) با پهنای باند مشخص به عنوان پنجره جستجو بر روی تکتک نقاط داده.
- محاسبه بردار انتقال (Mean Shift Vector): محاسبه میانگین ریاضی مختصات تمام نقاطی که درون این پنجره قرار گرفتهاند.
- انتقال به سمت چگالی: جابهجا کردن مرکز پنجره به سمت میانگین محاسباتی جدید (حرکت در جهت صعود گرادیان چگالی فضا).
- تکرار و همگرایی: تکرار مداوم گامهای ۲ و ۳ برای تمام پنجرهها تا زمانی که مرکز پنجرهها کاملاً ثابت شده و به قلههای متراکم (Mode) برسند.
- ادغام قلهها: نقاطی که به یک قله چگالی مشترک ختم شدهاند، برچسب کلاستر یکسانی دریافت میکنند.
تابع هدف ریاضی
محاسبه و بیشینهسازی تابع هسته چگالی از طریق بردار انتقال میانگین (Mh) جهت سوق دادن مراکز به سمت قلهها:
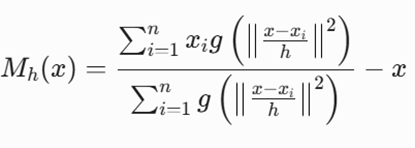
معرفی متغیرها و پارامترها
- x: موقعیت یا مختصات فعلی مرکز پنجره جستجو.
- Mh(x): بردار انتقال میانگین که جهت و مقدار جابهجایی بعدی مرکز را تعیین میکند.
- h (Bandwidth): هایپرپارامتر پهنای باند پنجره که اندازه شعاع کاوش چگالی را مشخص میکند.
- g(s): مشتق منفی تابع هسته فرعی (معمولاً مشتق هسته گاوسی یا تخت).
- xi: نقاط داده واقع در محدوده پنجره جستجوی هسته.
مزایا و نقاط قوت
- توانایی کشف خوشههایی با اشکال هندسی کاملاً نامنظم و آزاد.
- مقاومت بالا در برابر دادههای پرت و نویزها به دلیل جذب شدن به قلههای اصلی.
- داشتن تنها یک هایپرپارامتر کلیدی برای تنظیم (پهنای باند h).
معایب و محدودیتها
- سربار محاسباتی بسیار سنگین و زمانبر به صورت O (T . n^2) که کارایی آن را در کلاندادهها به شدت کاهش میدهد.
- وابستگی شدید خروجی مدل به تنظیم دقیق پهنای باند (h)؛ مقادیر اشتباه خوشهها را کاملاً ادغام یا بیش از حد خرد میکند.
کاربردهای واقعی
- تعقیب و ردیابی خودکار اشیاء در حال حرکت در کادرهای ویدئویی (Object Tracking).
- بخشبندی تصاویر دیجیتال و فیلترینگ ناپیوستگیهای رنگی در بینایی ماشین.
.
3.کاربردهای خوشهبندی چگالیمحور
روشهای چگالیمحور به دلیل توانایی در شناسایی خوشههای نامنظم و حذف نویز، در حوزههای متنوع علمی، صنعتی و تجاری کاربرد گستردهای دارند. مهمترین کاربردهای این خانواده از الگوریتمها عبارتاند از:
تحلیل دادههای مکانی و جغرافیایی GIS
یکی از مهمترین کاربردهای خوشهبندی چگالیمحور، تحلیل دادههای مکانی است. در سامانههای اطلاعات جغرافیایی، بسیاری از پدیدهها بهصورت نواحی پرتراکم در نقشه ظاهر میشوند؛ مانند تراکم جرم، تصادفات، بیماریها، فروشگاهها یا نقاط ترافیکی.
برای مثال، با استفاده از الگوریتم DBSCAN میتوان نقاط داغ جرم و جنایت را در یک شهر شناسایی کرد. در این حالت، ناحیههایی که تعداد زیادی رخداد جنایی در نزدیکی یکدیگر دارند بهعنوان خوشه شناسایی میشوند و رخدادهای منفرد یا پراکنده بهعنوان نویز کنار گذاشته میشوند.
تشخیص دادههای پرت و ناهنجاریها
از آنجا که الگوریتمهای چگالیمحور بهصورت طبیعی نقاط کمتراکم را از خوشهها جدا میکنند، برای تشخیص ناهنجاری بسیار مناسب هستند.
نمونههای کاربردی شامل موارد زیر است:
- تشخیص تراکنشهای مشکوک بانکی
- شناسایی رفتار غیرعادی کاربران در سامانههای آنلاین
- کشف حملات سایبری در دادههای شبکه
- شناسایی خرابیهای غیرعادی در تجهیزات صنعتی
- کشف نمونههای غیرعادی در دادههای پزشکی
در این مسائل، دادههایی که به هیچ خوشه پرتراکمی تعلق ندارند میتوانند بهعنوان موارد مشکوک یا غیرعادی بررسی شوند.
پردازش تصویر و بینایی ماشین
در پردازش تصویر، بسیاری از ساختارها دارای مرزهای پیچیده و غیرخطی هستند. روشهای چگالیمحور میتوانند برای بخشبندی تصویر، تشخیص اشیا، تفکیک نواحی رنگی، ردیابی اشیاء و حذف نویز تصویری به کار روند.
برای مثال، الگوریتم Mean Shift در ردیابی اشیاء و بخشبندی تصویر کاربرد گسترده دارد. این الگوریتم با یافتن قلههای چگالی در فضای ویژگیهای تصویر، مانند رنگ، مکان یا بافت، میتواند نواحی همگن را از یکدیگر جدا کند.
تحلیل دادههای زیستی و پزشکی
دادههای زیستی معمولاً دارای ابعاد بالا، نویز زیاد و ساختارهای پیچیده هستند. برای نمونه، دادههای بیان ژن، دادههای سلولی، دادههای پروتئومی و تصاویر پزشکی اغلب فاقد خوشههای ساده و کرویاند.
در چنین شرایطی، الگوریتمهایی مانند DENCLUE، DBSCAN و OPTICS میتوانند برای شناسایی زیرگروههای بیماران، کشف الگوهای ژنتیکی، دستهبندی سلولها یا تحلیل دادههای پزشکی چندبعدی استفاده شوند.
بهعنوان مثال، در تحلیل بیان ژن، ژنهایی که الگوی بیان مشابه و پرتراکمی دارند میتوانند در یک خوشه قرار گیرند و ژنهایی که رفتار غیرمعمول دارند بهعنوان نویز یا داده پرت بررسی شوند.
تحلیل شبکههای اجتماعی و کشف اجتماعات
در شبکههای اجتماعی، هدف معمولاً شناسایی گروههایی از کاربران است که ارتباطات بیشتری با یکدیگر دارند. این گروهها ممکن است از نظر هندسی در فضای ویژگیها شکل سادهای نداشته باشند، اما از نظر چگالی ارتباطی یا شباهت رفتاری، ساختار معناداری ایجاد کنند.
روشهایی مانند خوشهبندی طیفی و الگوریتمهای مبتنی بر گراف میتوانند برای کشف اجتماعات در شبکههای اجتماعی، شبکههای همکاری علمی، شبکههای خرید مشتریان و شبکههای ارتباطی استفاده شوند.
نجوم و دادههای ماهوارهای
در دادههای نجومی و ماهوارهای، حجم دادهها بسیار زیاد و نویز قابل توجه است. بسیاری از پدیدههای نجومی مانند خوشههای ستارهای، کهکشانها، الگوهای تابشی یا نواحی پرتراکم فضایی را میتوان با روشهای چگالیمحور استخراج کرد.
برای مثال، DBSCAN میتواند در دادههای آسمانی برای شناسایی نواحی پرتراکم ستارهای یا حذف نویزهای ناشی از اندازهگیری مورد استفاده قرار گیرد.
تحلیل ترافیک، حملونقل و شهرهای هوشمند
در شهرهای هوشمند، دادههای مکانی ـ زمانی از حسگرها، GPS، دوربینها و سامانههای حملونقل جمعآوری میشوند. خوشهبندی چگالیمحور میتواند برای کشف نواحی پرترافیک، شناسایی الگوهای سفر، تحلیل تجمع خودروها یا تشخیص رفتارهای غیرعادی در شبکه حملونقل به کار رود.
برای مثال، الگوریتم OPTICS برای دادههایی که تراکم آنها در مناطق شهری و روستایی متفاوت است، گزینه مناسبی محسوب میشود؛ زیرا برخلاف DBSCAN به یک مقدار ثابت برای شعاع چگالی وابسته نیست.
سیستمهای صنعتی و نگهداشت پیشبینانه
در سامانههای صنعتی، دادههای حسگرها معمولاً دارای نویز، نوسان و تغییرات غیرخطی هستند. خوشهبندی چگالیمحور میتواند وضعیتهای عادی عملکرد ماشینآلات را از وضعیتهای غیرعادی جدا کند.
کاربردهای رایج در این حوزه عبارتاند از:
- تشخیص خرابی زودهنگام تجهیزات
- تحلیل الگوهای ارتعاشی
- دستهبندی شرایط عملیاتی ماشینآلات
- کشف وضعیتهای ناپایدار یا خطرناک
- عیبیابی هوشمند در خطوط تولید
4.مزایا خوشهبندی چگالیمحور
خوشهبندی چگالیمحور نسبت به بسیاری از روشهای کلاسیک خوشهبندی، مزایای مهمی دارد. این مزایا باعث شدهاند این رویکرد در مسائل واقعی، بهویژه مسائل دارای نویز و ساختار غیرخطی، بسیار محبوب باشد.
عدم نیاز به تعیین تعداد خوشهها در بسیاری از الگوریتمها
در روشهایی مانند K-Means، کاربر باید تعداد خوشهها یعنی K را از قبل مشخص کند. اما در بسیاری از الگوریتمهای چگالیمحور مانند DBSCAN، OPTICS، Mean Shift و DENCLUE، تعداد خوشهها بهطور مستقیم از ساختار چگالی دادهها استخراج میشود.
این ویژگی در تحلیل اکتشافی دادهها بسیار مهم است؛ زیرا در بسیاری از مسائل واقعی، تعداد خوشهها از قبل مشخص نیست.
توانایی کشف خوشههایی با شکلهای نامنظم
یکی از بزرگترین مزایای این روشها، توانایی شناسایی خوشههایی با شکلهای پیچیده، خمیده، کشیده، مارپیچ، حلقوی یا چندشاخه است.
در حالی که K-Means معمولاً خوشههای کروی یا محدب را بهتر شناسایی میکند، DBSCAN و روشهای مشابه میتوانند خوشههایی با مرزهای بسیار نامنظم را نیز تشخیص دهند.
شناسایی و حذف طبیعی نویز
در بسیاری از الگوریتمهای چگالیمحور، نقاطی که در نواحی کمتراکم قرار دارند و به هیچ خوشهای متصل نیستند، بهصورت خودکار بهعنوان نویز تشخیص داده میشوند. این ویژگی برای دادههای واقعی که معمولاً دارای خطا، نویز و نمونههای پرت هستند، اهمیت زیادی دارد.
مناسب برای تحلیل دادههای مکانی و فضایی
خوشهبندی چگالیمحور در دادههای مکانی عملکرد بسیار خوبی دارد؛ زیرا پدیدههای مکانی اغلب بهصورت نواحی پرتراکم ظاهر میشوند. ازاینرو، این روشها در GIS، تحلیل شهری، اپیدمیولوژی، جرمشناسی، حملونقل و سنجش از دور بسیار کاربردی هستند.
سازگاری با ساختارهای غیرخطی
روشهای چگالیمحور معمولاً به مرزهای خطی وابسته نیستند. آنها میتوانند ساختارهای غیرخطی را بر اساس اتصال چگالی یا قلههای تراکم شناسایی کنند. این ویژگی برای دادههای پیچیده تصویری، زیستی و رفتاری بسیار ارزشمند است.
قابلیت ترکیب با روشهای گرافی، طیفی و هستهای
بسیاری از ایدههای چگالیمحور را میتوان با روشهای گرافی، کرنلی، طیفی و یادگیری عمیق ترکیب کرد. برای مثال، میتوان ابتدا فضای ویژگی را با یک شبکه عصبی یا روش کاهش بُعد بازنمایی کرد و سپس خوشهبندی چگالیمحور را روی فضای جدید اجرا نمود.
5.معایب و محدودیتهای خوشهبندی چگالیمحور
با وجود مزایای قابل توجه، خوشهبندی چگالیمحور محدودیتهایی نیز دارد که باید در انتخاب الگوریتم و تفسیر نتایج به آنها توجه کرد.
حساسیت به هایپرپارامترها
بسیاری از الگوریتمهای چگالیمحور به پارامترهایی مانند شعاع همسایگی، حداقل تعداد نقاط، پهنای باند هسته یا آستانه چگالی وابستهاند. برای مثال، در DBSCAN دو پارامتر مهم وجود دارد: ε و MinPts
اگر مقدار ε\varepsilonε بسیار کوچک انتخاب شود، بسیاری از نقاط بهعنوان نویز شناسایی میشوند. اگر بسیار بزرگ انتخاب شود، خوشههای جداگانه ممکن است بهاشتباه با یکدیگر ادغام شوند.
دشواری در دادههایی با چگالیهای متفاوت
یکی از محدودیتهای مهم DBSCAN و برخی روشهای مشابه این است که در دادههایی با چگالیهای بسیار متفاوت عملکرد ضعیفی دارند. اگر یک خوشه بسیار متراکم و خوشه دیگر کمتراکم باشد، انتخاب یک مقدار ثابت برای شعاع همسایگی میتواند باعث خطا شود.
الگوریتمهایی مانند OPTICS برای حل این مشکل طراحی شدهاند، اما همچنان استخراج مرزهای نهایی خوشهها ممکن است به تصمیمگیری اضافی نیاز داشته باشد.
کاهش کارایی در ابعاد بالا
در فضاهای با بُعد بالا، مفهوم فاصله و چگالی دچار مشکل میشود. این پدیده که با عنوان نفرین بُعدپذیری شناخته میشود، باعث میشود فاصله میان نقاط کمتر متمایز باشد و برآورد چگالی دشوارتر شود.
در نتیجه، برخی الگوریتمهای چگالیمحور در دادههای بسیار پُربُعد ممکن است نیازمند کاهش بُعد، انتخاب ویژگی یا یادگیری بازنمایی باشند.
هزینه محاسباتی بالا در برخی الگوریتمها
برخی الگوریتمهای چگالیمحور مانند Mean Shift، DENCLUE یا روشهای مبتنی بر تخمین چگالی هستهای، ممکن است از نظر محاسباتی سنگین باشند؛ بهویژه زمانی که تعداد نمونهها زیاد یا ابعاد داده بالا باشد.
برای مثال، Mean Shift در حالت ساده میتواند پیچیدگی بالایی در حد زیر داشته باشد: O(Tn^2)که در آن T تعداد تکرارها و n تعداد نمونههاست.
وابستگی به معیار فاصله یا شباهت
اگرچه خوشهبندی چگالیمحور نسبت به روشهای مرکزگرا انعطافپذیرتر است، اما همچنان کیفیت آن به معیار فاصله یا شباهت بستگی دارد. انتخاب نامناسب معیار فاصله میتواند باعث شناسایی خوشههای نادرست شود؛ بهویژه در دادههای متنی، گرافی، ترتیبی یا چندرسانهای.
دشواری تفسیر در برخی روشهای پیشرفته
در الگوریتمهایی مانند خوشهبندی طیفی یا روشهای مبتنی بر تخمین چگالی پیوسته، تفسیر مستقیم خروجی ممکن است دشوارتر از روشهای سادهتر باشد. برای مثال، فهم اینکه چرا یک نمونه در فضای ویژهبردارها به یک خوشه خاص تعلق گرفته است، همیشه ساده نیست.
.
6.نوآوریهای جدید در حوزه خوشهبندی چگالیمحور
خوشهبندی چگالیمحور در سالهای اخیر از یک خانواده کلاسیک متکی بر پارامترهایی مانند شعاع همسایگی ε، حداقل تعداد نقاط MinPts و تخمین چگالی موضعی، به مجموعهای از رویکردهای پیشرفته، مقیاسپذیر، عمیق، گرافمحور و سازگار با دادههای پیچیده تبدیل شده است. اگرچه الگوریتمهایی مانند DBSCAN، OPTICS، DENCLUE و Mean Shift همچنان نقش بنیادین دارند، اما دادههای مدرن از نظر حجم، بُعد، نویز، ناهمگنی، پویایی و چندمنبعیبودن، چالشهایی ایجاد کردهاند که نسخههای کلاسیک این الگوریتمها بهتنهایی قادر به پاسخگویی کامل به آنها نیستند.
نوآوریهای جدید در این حوزه عمدتاً بر چند هدف متمرکز هستند:
- کاهش حساسیت به پارامترهای دستی
- مدیریت دادههایی با چگالیهای متغیر
- افزایش مقیاسپذیری برای کلاندادهها
- بهبود عملکرد در دادههای پُربُعد
- ترکیب با یادگیری عمیق و یادگیری خودنظارتی
- افزایش مقاومت در برابر نویز و دادههای پرت
- توسعه روشهای قابل تفسیر و قابل اعتماد
- سازگاری با دادههای گرافی، جریانی، مکانی ـ زمانی و چندنمایی
در ادامه، مهمترین نوآوریهای جدید در حوزه Density-Based Clustering معرفی میشوند.
.
6.1.خوشهبندی چگالیمحور با چگالی تطبیقی(Adaptive Density-Based Clustering)
یکی از ضعفهای اصلی الگوریتمهایی مانند DBSCAN این است که معمولاً از یک مقدار ثابت برای شعاع همسایگی ε\varepsilonε استفاده میکنند. این فرض در دادههایی که خوشهها دارای چگالیهای متفاوت هستند، مشکلساز میشود. برای مثال، اگر یک خوشه بسیار متراکم و خوشهای دیگر پراکندهتر باشد، انتخاب یک ε\varepsilonε واحد میتواند باعث شود خوشه متراکم بیشازحد خرد شود یا خوشه کمتراکم بهعنوان نویز حذف گردد.
نوآوریهای جدید در خوشهبندی چگالیمحور تطبیقی تلاش میکنند بهجای استفاده از یک آستانه ثابت، چگالی را بهصورت محلی و وابسته به ناحیه داده تخمین بزنند.
ایده اصلی
در این رویکرد، برای هر نقطه یا هر ناحیه از فضای داده، پارامترهای چگالی بهصورت محلی تنظیم میشوند. بهجای تعریف یک شعاع ثابت، میتوان از مفاهیمی مانند فاصله تا k-امین همسایه، چگالی نسبی، یا مقایسه چگالی نقطه با ناحیه اطراف آن استفاده کرد.
برای نمونه، میتوان شعاع محلی نقطه xi را بهصورت زیر در نظر گرفت:
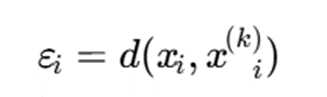
که در آن xik نشاندهنده k-امین نزدیکترین همسایه نقطه xi است.
در این حالت، چگالی موضعی نقطه میتواند به شکل زیر تخمین زده شود:
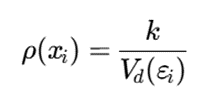
که در آن vd(εi) حجم کرهای با شعاع εi در فضای d-بعدی است.
مزایا
- عملکرد بهتر در دادههای چندچگالی
- کاهش وابستگی به یک مقدار ثابت برای ε
- سازگاری بیشتر با ساختارهای محلی داده
- کاهش نرخ شناسایی اشتباه نویز در خوشههای کمتراکم
کاربردها
این دسته از روشها در تحلیل دادههای شهری، زیستی، سنسوری، جغرافیایی و دادههای مشتریان که معمولاً چگالی یکنواختی ندارند، بسیار مؤثر هستند.
.
6.2. نسخههای مقیاسپذیر و توزیعشده برای کلاندادهها(Scalable and Distributed Density-Based Clustering)
الگوریتمهای چگالیمحور کلاسیک معمولاً برای دادههای کوچک تا متوسط طراحی شدهاند. اما در کاربردهای مدرن مانند شبکههای اجتماعی، اینترنت اشیا، دادههای مکانی بزرگمقیاس، دادههای تراکنشی و تصاویر ماهوارهای، تعداد نمونهها ممکن است به میلیونها یا میلیاردها برسد.
در چنین شرایطی، محاسبه همسایگیها، فاصلههای جفتی و تراکم موضعی بهصورت مستقیم، بسیار پرهزینه است.
جهتگیریهای نوین
برای حل این مسئله، رویکردهای جدید از راهکارهای زیر استفاده میکنند:
- تقسیمبندی دادهها به بلوکهای مکانی یا پارتیشنها
- استفاده از پردازش توزیعشده روی چارچوبهایی مانند Spark و MapReduce
- بهرهگیری از GPU برای محاسبات فاصله و همسایگی
- استفاده از ساختارهای مکانی مانند KD-Tree، Ball-Tree و R-Tree
- استفاده از جستجوی تقریبی نزدیکترین همسایهها
- فشردهسازی دادهها با نمونههای نماینده یا micro-clusters
مزیت علمی و عملی
بهجای اجرای مستقیم الگوریتم روی کل داده، داده ابتدا به بخشهای کوچکتر تقسیم میشود. سپس در هر بخش خوشههای محلی استخراج شده و در مرحله بعد، خوشههای مرزی یا همپوشان ادغام میشوند.
کاربردها
- خوشهبندی میلیاردها نقطه GPS
- تحلیل شبکههای اجتماعی در مقیاس بزرگ
- دادهکاوی لاگهای وب
- پردازش دادههای سنجش از دور
- تحلیل دادههای حسگرهای صنعتی و اینترنت اشیا
.
6.3. خوشهبندی چگالیمحور جریانی و برخط(Online and Streaming Density-Based Clustering)
در بسیاری از سامانههای واقعی، دادهها بهصورت پیوسته وارد میشوند و امکان ذخیره یا پردازش کامل همه دادهها وجود ندارد. برای مثال، جریان تراکنشهای بانکی، دادههای حسگرهای صنعتی، رخدادهای شبکه، رفتار کاربران وب و دادههای ترافیکی شهری همگی ماهیتی جریانی دارند.
در این شرایط، الگوریتم باید بتواند ساختار چگالی را بهصورت پیوسته بهروزرسانی کند.
ایده اصلی
در خوشهبندی چگالیمحور جریانی، بهجای نگهداری همه نقاط، از خلاصهسازیهایی مانند micro-clusters استفاده میشود. هر micro-cluster یک خلاصه آماری از مجموعهای از نقاط نزدیک به هم است و معمولاً شامل موارد زیر است:
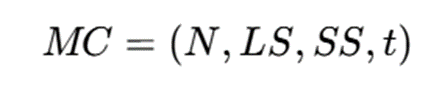
که در آن:
- N: تعداد نقاط موجود در micro-cluster
- LS: مجموع خطی نقاط
- SS: مجموع مربعات نقاط
- t: زمان آخرین بهروزرسانی
با ورود داده جدید، الگوریتم تصمیم میگیرد که آیا نقطه به یکی از micro-clusterهای موجود افزوده شود، micro-cluster جدیدی ایجاد کند یا بهعنوان نویز موقت نگهداری شود.
چالشهای مهم
- مدیریت تغییر مفهوم یا Concept Drift
- حذف یا کماثر کردن دادههای قدیمی
- تشخیص سریع نویز و ناهنجاری
- حفظ تعادل میان دقت و سرعت
- محدودیت حافظه در پردازش بلادرنگ
کاربردها
- تشخیص نفوذ در شبکه بهصورت بلادرنگ
- پایش حسگرهای صنعتی
- تحلیل رفتار آنلاین کاربران
- تشخیص ناهنجاری در تراکنشهای مالی
- تحلیل دادههای ترافیکی و حملونقل هوشمند
.
6.4. ترکیب خوشهبندی چگالیمحور با یادگیری عمیق(Deep Density-Based Clustering)
یکی از مهمترین نوآوریهای جدید، ترکیب خوشهبندی چگالیمحور با یادگیری عمیق است. در دادههایی مانند تصویر، متن، صوت، ویدئو و دادههای زیستی، فضای ویژگی خام معمولاً برای محاسبه چگالی مناسب نیست. فاصله اقلیدسی در فضای خام ممکن است بیانگر شباهت معنایی واقعی نباشد.
در رویکردهای عمیق، ابتدا یک شبکه عصبی، بازنمایی نهفته و فشردهای از دادهها یاد میگیرد. سپس خوشهبندی چگالیمحور در این فضای نهفته اجرا میشود.
چارچوب کلی
- دریافت داده خام
- آموزش شبکه عصبی یا autoencoder
- تولید embeddingهای نهفته
- تخمین چگالی در فضای embedding
- استخراج خوشهها بر اساس قلهها یا نواحی پرتراکم
- بازتنظیم شبکه بر اساس ساختار خوشهها
بهصورت کلی:
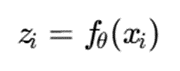
که در آن:
- xi: داده خام
- fθ: شبکه عصبی با پارامترهای θ
- zi: نمایش نهفته داده
سپس خوشهبندی چگالیمحور روی مجموعه زیر انجام میشود:
Z={z1,z2,…,zn}
مزایا
- بهبود عملکرد در دادههای پُربُعد
- یادگیری شباهت معنایی بهتر
- کاهش اثر نویز ویژگیهای خام
- مناسب برای دادههای تصویر، متن و صوت
- امکان یادگیری همزمان بازنمایی و ساختار خوشهها
مثال کاربردی
در خوشهبندی تصاویر پزشکی، شبکه عصبی ابتدا ویژگیهای سطح بالا مانند بافت، شکل و شدت ناحیهها را استخراج میکند. سپس الگوریتمی مانند DBSCAN یا HDBSCAN روی embeddingها اجرا میشود تا زیرگروههای بیماری یا الگوهای بافتی کشف شوند.
.
6.5.خوشهبندی چگالیمحور خودنظارتی و تقابلی(Self-Supervised and Contrastive Density-Based Clustering)
یادگیری خودنظارتی یکی از مهمترین تحولات یادگیری ماشین مدرن است. در این روش، مدل بدون نیاز به برچسب انسانی، از ساختار خود دادهها سیگنال آموزشی استخراج میکند. ترکیب این ایده با خوشهبندی چگالیمحور باعث میشود الگوریتم بتواند چگالی را نه در فضای خام، بلکه در فضایی محاسبه کند که از نظر معنایی غنیتر است.
ایده اصلی
در یادگیری تقابلی، مدل تلاش میکند نمایشهای مختلف از یک نمونه را به یکدیگر نزدیک کند و نمونههای متفاوت را از هم دور سازد. برای مثال، در داده تصویری، دو نسخه تغییریافته از یک تصویر بهعنوان زوج مثبت در نظر گرفته میشوند.
تابع هدف تقابلی رایج میتواند به شکل زیر نوشته شود:
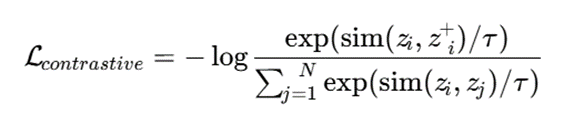
که در آن:
- zi: نمایش نهفته نمونه اصلی
- +^ Zi: نمایش نهفته نمونه مثبت
- sim: تابع شباهت، مانند cosine similarity
- τ: پارامتر دما
- N: تعداد نمونهها یا نمایشهای موجود در batch
پس از آموزش خودنظارتی، الگوریتمهایی مانند DBSCAN، HDBSCAN یا Mean Shift روی فضای embedding اجرا میشوند.
مزایا
- کاهش نیاز به داده برچسبدار
- تولید embeddingهای مناسبتر برای خوشهبندی
- بهبود جداسازی خوشههای غیرخطی
- افزایش پایداری نسبت به نویز
- قابلیت استفاده در دادههای عظیم بدون برچسب
کاربردها
- خوشهبندی تصاویر بدون برچسب
- گروهبندی اسناد و متون علمی
- کشف الگوهای رفتاری کاربران
- تحلیل تصاویر پزشکی
- دستهبندی خودکار دادههای صوتی و ویدئویی
.
6.6. HDBSCAN و خوشهبندی چگالیمحور سلسلهمراتبی(Hierarchical Density-Based Clustering)
یکی از مهمترین نوآوریها در خوشهبندی چگالیمحور، توسعه روشهایی است که ایده چگالی را با ساختار سلسلهمراتبی ترکیب میکنند. HDBSCAN نمونه شاخص این رویکرد است.
HDBSCAN تلاش میکند مشکل اصلی DBSCAN را حل کند؛ یعنی وابستگی زیاد به مقدار ثابت ε\varepsilonε. این الگوریتم بهجای استخراج خوشهها در یک سطح چگالی واحد، ساختاری سلسلهمراتبی از خوشهها در سطوح مختلف چگالی ایجاد میکند و سپس پایدارترین خوشهها را انتخاب میکند.
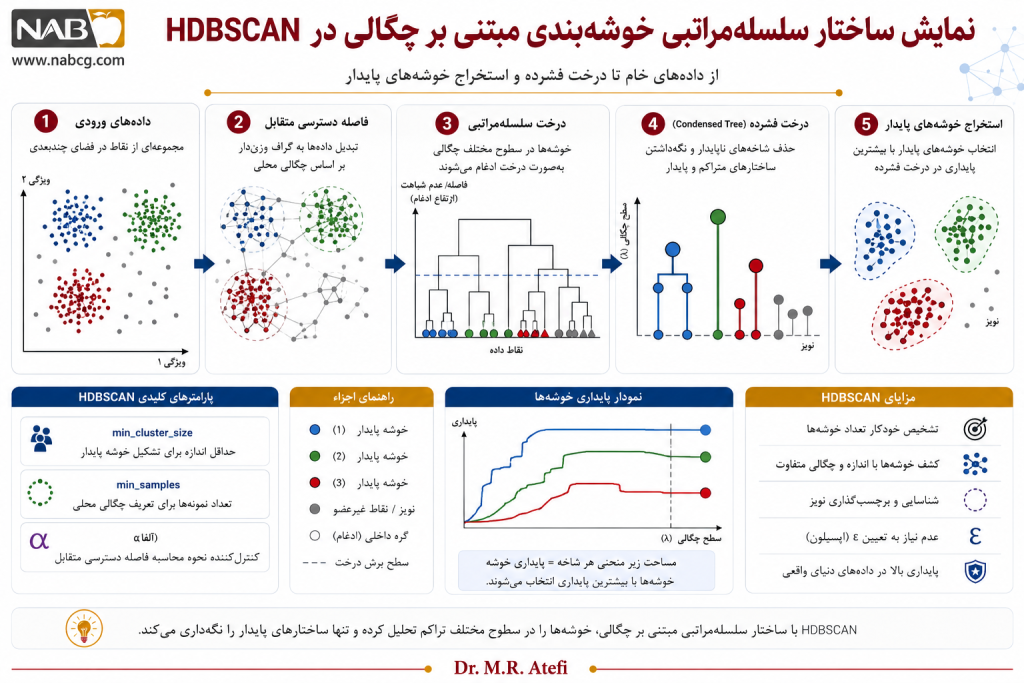
ایده اصلی
در HDBSCAN ابتدا فاصلهای به نام Mutual Reachability Distance تعریف میشود:
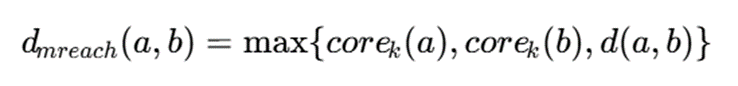
که در آن:
- Corek(a) : فاصله نقطه a تا k-امین همسایه نزدیک خود
- Corek(b) : فاصله نقطه b تا k-امین همسایه نزدیک خود
- d(a,b): فاصله واقعی میان دو نقطه
سپس بر اساس این فاصله، گراف حداقل پوشا یا Minimum Spanning Tree ساخته میشود. با حذف تدریجی یالها، ساختار سلسلهمراتبی چگالی استخراج شده و خوشههای پایدار انتخاب میشوند.
مزایا
- مناسب برای دادههایی با چگالی متغیر
- عدم نیاز به انتخاب دقیق ε\varepsilonε
- تشخیص طبیعی نویز
- امکان تولید خوشههای سلسلهمراتبی
- ارائه معیار پایداری برای خوشهها
کاربردها
- تحلیل دادههای زیستی و ژنومی
- خوشهبندی embeddingهای متنی و تصویری
- تحلیل دادههای مکانی با چگالی متغیر
- کشف اجتماعات پیچیده
- تشخیص ناهنجاری
.
6.7.خوشهبندی چگالیمحور گرافمحور(Graph-Based Density Clustering)
در دادههای مدرن، ساختار روابط میان نمونهها گاهی مهمتر از مختصات عددی آنهاست و در شبکههای اجتماعی، شبکههای زیستی، شبکههای حملونقل، گراف دانش و دادههای ارتباطی، نمونهها بهصورت گره و روابط بهصورت یال مدل میشوند.
در خوشهبندی چگالیمحور گرافی، چگالی تنها بر اساس تعداد نقاط در یک شعاع تعریف نمیشود، بلکه بر اساس تراکم ارتباطات، وزن یالها، تعداد مسیرهای کوتاه و ساختار اجتماعها تعیین میگردد.
ایدههای کلیدی
- تعریف چگالی بر اساس درجه گرهها
- استفاده از k-NN Graph برای تقریب همسایگی
- محاسبه چگالی محلی روی گراف
- تشخیص اجتماعات پرتراکم
- ترکیب با الگوریتمهای انتشار برچسب
- استفاده از embeddingهای گرافی و سپس خوشهبندی چگالیمحور
فرمول نمونه برای چگالی گرافی
برای یک گره v، چگالی محلی میتواند بهصورت زیر تعریف شود:
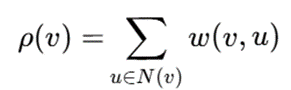
که در آن:
- N(v): مجموعه همسایگان گره v
- w(v,u): وزن یال میان v و u
کاربردها
- کشف اجتماعات در شبکههای اجتماعی
- تحلیل شبکههای پروتئینی
- خوشهبندی گراف دانش
- تحلیل شبکههای حملونقل
- تشخیص گروههای غیرعادی در شبکههای مالی
.
6.8.خوشهبندی چگالیمحور چندنمایی و چندمنبعی(Multi-View Density-Based Clustering)
در بسیاری از مسائل واقعی، دادهها از چند منبع یا چند نوع ویژگی تشکیل شدهاند. برای مثال، در پزشکی ممکن است برای هر بیمار داده تصویری، داده ژنتیکی، داده آزمایشگاهی و داده متنی وجود داشته باشد. در سیستمهای توصیهگر نیز اطلاعات کاربر، ویژگی آیتم و الگوهای تعامل همزمان قابل استفادهاند.
خوشهبندی چگالیمحور چندنمایی تلاش میکند چگالی را با استفاده از چند نمایش مختلف داده تعریف کند.
روشهای رایج
- ادغام ویژگیها در یک فضای مشترک
- ساخت ماتریس شباهت جداگانه برای هر نما
- وزندهی تطبیقی به نماها
- یادگیری embedding مشترک
- تعریف چگالی ترکیبی بر اساس چند منبع
برای نمونه، چگالی کلی یک نقطه میتواند بهصورت ترکیبی از چگالی در نماهای مختلف تعریف شود:
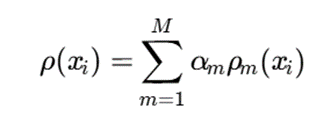
که در آن:
- M: تعداد نماها
- (xi) ρm: چگالی نقطه در نمای m
- αm : وزن نمای m
مزایا
- استفاده از اطلاعات مکمل
- کاهش اثر نویز در یک نمای خاص
- بهبود پایداری خوشهها
- مناسب برای دادههای پزشکی، چندرسانهای و سازمانی
کاربردها
- خوشهبندی بیماران با دادههای چندمنبعی
- تحلیل چندوجهی کاربران
- خوشهبندی تصاویر همراه با متن
- دادهکاوی آموزشی با منابع مختلف
- تحلیل همزمان دادههای سنسوری و مکانی
.
6.9.خوشهبندی چگالیمحور مقاوم در برابر نویز و دادههای پرت(Robust Density-Based Clustering)
اگرچه روشهای چگالیمحور بهطور طبیعی نسبت به نویز مقاومتر از بسیاری روشهای کلاسیک هستند، اما در دادههای بسیار آلوده، نویز ساختاریافته یا نقاط پرت نزدیک به مرز خوشهها، همچنان ممکن است دچار خطا شوند.
نوآوریهای جدید در این حوزه بر ساخت روشهایی تمرکز دارند که بتوانند میان نویز تصادفی، نقاط مرزی واقعی و ساختارهای کمچگال اما معنادار تمایز قائل شوند.
راهبردهای نوین
- استفاده از وزندهی مقاوم به نقاط
- تعریف چگالی نسبی بهجای چگالی مطلق
- استفاده از معیارهای فاصله مقاوم
- ترکیب با تشخیص ناهنجاری
- مدلسازی عدم قطعیت عضویت
- حذف تدریجی نویز با روشهای چندمرحلهای
نمونه تعریف چگالی مقاوم
میتوان چگالی را با وزندهی به همسایگان تعریف کرد:
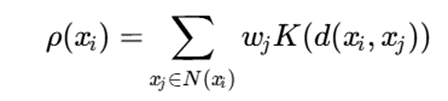
که در آن wj میتواند وزن اطمینان یا اعتبار نقطه xj باشد. نقاط مشکوک یا کماعتماد وزن کمتری در تخمین چگالی دریافت میکنند.
کاربردها
- دادههای امنیت سایبری
- دادههای پزشکی آلوده به خطا
- دادههای حسگرهای صنعتی
- تحلیل تراکنشهای مالی
- دادههای محیطی و اقلیمی
.
6.10.خوشهبندی چگالیمحور در فضاهای پُربُعد(High-Dimensional Density-Based Clustering)
در فضاهای پُربُعد، تعریف چگالی دشوار میشود؛ زیرا فاصلهها به هم نزدیک میشوند و مفهوم همسایگی تضعیف میگردد. این مشکل در متنکاوی، ژنومیک، دادههای تصویری، embeddingهای عمیق و دادههای مالی چندمتغیره بسیار رایج است.
نوآوریهای اصلی
- کاهش بُعد پیش از خوشهبندی
- استفاده از subspace clustering
- تعریف چگالی در زیرفضاهای محلی
- استفاده از embeddingهای عمیق
- انتخاب ویژگی مبتنی بر چگالی
- استفاده از معیارهای شباهت غیر اقلیدسی
ایده چگالی در زیرفضای محلی
بهجای محاسبه چگالی در کل فضای d-بعدی، برای هر نقطه یک زیرفضای مؤثر انتخاب میشود:
Si⊆{1,2,…,d}
سپس چگالی بهصورت زیر تخمین زده میشود:
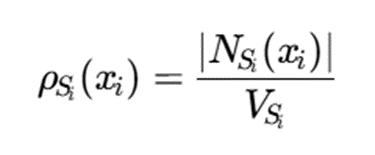
کاربردها
- دادههای بیان ژن
- خوشهبندی اسناد متنی
- embeddingهای مدلهای زبانی
- دادههای تصویری با ویژگیهای عمیق
- تحلیل دادههای مالی چندمتغیره
.
6.11.خوشهبندی چگالیمحور مکانی ـ زمانی(Spatio-Temporal Density-Based Clustering)
در بسیاری از مسائل، دادهها هم مختصات مکانی دارند و هم بُعد زمانی. برای مثال، مسیر حرکت خودروها، دادههای GPS، رخدادهای زلزله، شیوع بیماری، رفتار کاربران موبایل و دادههای اقلیمی همگی دارای ساختار مکانی ـ زمانی هستند.
در این نوع خوشهبندی، چگالی نهتنها در فضا، بلکه در زمان نیز ارزیابی میشود.
ایده اصلی
برای دو نقطه xi و xj فاصله ترکیبی میتواند بهصورت زیر تعریف شود:
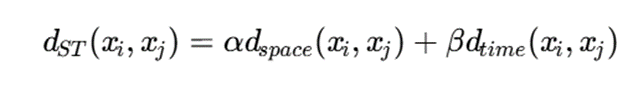
که در آن:
- dspace: فاصله مکانی
- dtime: فاصله زمانی
- α و β : وزنهای کنترلکننده اهمیت مکان و زمان
کاربردها
- تحلیل نقاط داغ ترافیکی
- ردیابی تجمعات شهری
- تحلیل شیوع بیماریها
- کشف رویدادهای غیرعادی در شبکههای حسگر
- تحلیل مسیرهای حرکتی کاربران یا وسایل نقلیه
.
6.12.خوشهبندی چگالیمحور قابل تفسیر(Interpretable Density-Based Clustering)
با افزایش استفاده از خوشهبندی در حوزههای حساس مانند پزشکی، امنیت، مالی و سیاستگذاری شهری، تفسیرپذیری به یک نیاز کلیدی تبدیل شده است. در بسیاری از کاربردها، صرفاً دانستن اینکه نقاط در یک خوشه قرار گرفتهاند کافی نیست؛ بلکه باید بتوان توضیح داد چرا یک ناحیه پرتراکم شکل گرفته، چه ویژگیهایی آن را توصیف میکنند و چه عواملی باعث جدایی آن از سایر خوشهها شدهاند.
راهکارهای تفسیرپذیری
- استخراج قواعد توصیفی برای هر خوشه
- شناسایی ویژگیهای غالب در نواحی پرتراکم
- تولید پروفایل آماری خوشهها
- نمایش مرزهای چگالی بهصورت بصری
- تحلیل حساسیت نسبت به پارامترهای چگالی
- ترکیب با مدلهای قابل تفسیر مانند درخت تصمیم
نمونه خروجی قابل تفسیر
برای یک خوشه مشتریان، میتوان توصیفی مانند زیر تولید کرد:
این خوشه شامل مشتریانی است که تعداد خرید بالا، فاصله زمانی کوتاه میان خریدها، میانگین مبلغ خرید متوسط و تعامل زیاد با کمپینهای تخفیفی دارند.
کاربردها
- پزشکی دقیق
- مدیریت مشتریان
- تحلیل آموزشی
- امنیت سایبری
- تحلیل شهری و سیاستگذاری دادهمحور
.
6.13.خودکارسازی انتخاب پارامترها در خوشهبندی چگالیمحور(Automated Parameter Selection)
یکی از مشکلات اصلی روشهای چگالیمحور، نیاز به انتخاب پارامترهایی مانند ε ، MinPts، پهنای باند h، تعداد همسایهها k یا آستانه چگالی است. انتخاب این پارامترها بهشدت بر نتیجه خوشهبندی اثر میگذارد.
نوآوریهای جدید تلاش میکنند این انتخاب را بهصورت دادهمحور، خودکار و پایدار انجام دهند.
روشهای رایج
- نمودار k-distance
- تشخیص زانو یا elbow detection
- بهینهسازی چندهدفه
- اعتبارسنجی داخلی خوشهها
- تحلیل پایداری در برابر تغییر پارامتر
- جستجوی بیزی برای تنظیم هایپرپارامترها
- روشهای یادگیری متا برای پیشنهاد پارامتر
معیار پایداری
برای ارزیابی پایداری، میتوان خوشهبندی را برای چند مقدار پارامتر اجرا کرد و شباهت نتایج را سنجید:
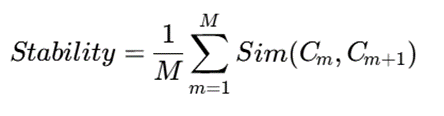
که در آن:
- Cm: نتیجه خوشهبندی در تنظیم پارامتر m
- Sim: معیار شباهت میان دو خوشهبندی، مانند Adjusted Rand Index
- M: تعداد تنظیمات بررسیشده
مزایا
- کاهش وابستگی به تجربه کاربر
- افزایش تکرارپذیری تحلیل
- مناسب برای سامانههای خودکار
- کاهش خطای ناشی از تنظیم دستی
.
6.14.خوشهبندی چگالیمحور مبتنی بر عدم قطعیت(Uncertainty-Aware Density-Based Clustering)
در بسیاری از دادههای واقعی، اندازهگیریها دارای خطا، ابهام یا عدم قطعیت هستند. برای مثال، موقعیت GPS ممکن است خطا داشته باشد، دادههای پزشکی ممکن است از دستگاههای مختلف با دقت متفاوت جمعآوری شوند و دادههای حسگرها ممکن است نویزی باشند.
در خوشهبندی چگالیمحور مبتنی بر عدم قطعیت، هر نقطه بهجای یک مقدار قطعی، بهصورت یک توزیع احتمالی یا ناحیه اطمینان مدل میشود.
ایده اصلی
بهجای محاسبه فاصله قطعی (xi,xj) dفاصله احتمالی یا امید ریاضی فاصله محاسبه میشود:
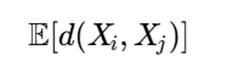
که در آن Xi و Xj متغیرهای تصادفی مربوط به دو نمونه هستند.
همچنین احتمال همسایهبودن دو نقطه میتواند بهصورت زیر تعریف شود:
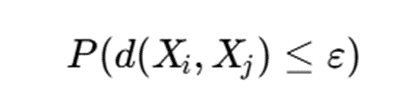
کاربردها
- دادههای GPS با خطای مکانی
- دادههای پزشکی با عدم قطعیت اندازهگیری
- دادههای سنسوری محیطی
- رباتیک و نقشهبرداری
- تحلیل دادههای فضایی ـ زمانی نامطمئن
.
جمعبندی
نوآوریهای جدید در حوزه خوشهبندی چگالیمحور نشان میدهند که این رویکرد همچنان یکی از پویاترین و کاربردیترین شاخههای یادگیری بدونناظر است. روشهای کلاسیک مانند DBSCAN، OPTICS، DENCLUE و Mean Shift بنیان نظری این حوزه را شکل دادهاند، اما مسائل مدرن نیازمند نسخههایی هستند که بتوانند با دادههای حجیم، پُربُعد، نویزی، چندچگالی، جریانی، گرافی، چندمنبعی و نامطمئن سازگار شوند.
امروزه خوشهبندی چگالیمحور با مفاهیمی مانند یادگیری عمیق، یادگیری خودنظارتی، تحلیل گراف، دادههای جریانی، تخمین چگالی تطبیقی، تفسیرپذیری، خودکارسازی پارامترها و مدلسازی عدم قطعیت پیوند خورده است. این تحول باعث شده است که این خانواده از روشها نهتنها برای تحلیل اکتشافی کلاسیک، بلکه برای کاربردهای پیشرفته در پزشکی، امنیت، شهرهای هوشمند، زیستاطلاعات، پردازش تصویر، شبکههای اجتماعی و سامانههای صنعتی نیز بسیار ارزشمند باشد.



