

مقدمه: استخراج معنا از ابهام
در عصر دادههای بزرگ ، بسیاری از اطلاعات ارزشمند سازمانها بهصورت بدون برچسب (Unlabeled) و خام باقی میمانند. در حالی که یادگیری نظارتشده نیازمند راهنمایی دقیق انسانی است، یادگیری بدون نظارت (Unsupervised Learning) قدرتی شگفتانگیز برای استخراج دانش از دادههایی دارد که هیچ توضیحی برای آنها وجود ندارد.
در دنیایی که بیش از 99% دادههای تولیدشده برچسبگذارینشده هستند (منبع: MIT Technology Review, 2023 )، یادگیری نظارتشده تنها بخش کوچکی از پتانسیل هوش مصنوعی را پوشش میدهد. اینجاست که یادگیری بدون نظارت (Unsupervised Learning) وارد میدان میشود: حوزهای که در آن ماشینها بدون راهنمایی انسان، ساختارهای پنهان را در دادههای خام کشف میکنند.
اما سؤال اصلی این است: یادگیری بدون نظارت واقعاً چیست؟ آیا فقط «خوشهبندی» است؟ چه کاربردهایی در دنیای واقعی دارد؟ و چرا امروزه بهعنوان یکی از کلیدهای اصلی هوش مصنوعی عمومی (AGI) محسوب میشود؟
یادگیری بدون نظارت، هنری است که به ماشینها اجازه میدهد تا بدون معلم، خودآموزی کنند؛ الگوهای مخفی، ساختارهای درونی و روابط نهفته در دادهها را که ممکن است از چشم انسان پنهان بمانند، کشف کنند.
این مقاله برای دانشجویان و متخصصانی طراحی شده است که میخواهند بدانند چگونه مدلها میتوانند بدون داشتن پاسخ صحیح، به درک عمیق دادهها برسند و این قابلیت چه انقلابی را در صنایع مختلف، از بازاریابی گرفته تا ژنتیک، به پا کرده است. ما با اتکا به تحقیقات دانشگاهی مؤسسه فناوری ماساچوست (MIT)، اصول آماری هاروارد و گزارشهای تحلیلی مککنزی و دلویت، به رمزگشایی از این حوزه خواهیم پرداخت.
تعریف یادگیری بدون نظارت
یادگیری بدون نظارت، یکی از روشهای یادگیری ماشین است که در آن دادهها تنها شامل ورودی هستند و خروجی یا برچسبی برای یادگیری وجود ندارد. یادگیری بدون نظارت به مجموعهای از روشها اطلاق میشود که در آن، مدل یادگیری ماشین سعی میکند الگوها، ساختارها یا توزیعهای احتمالی underlying را در دادههای ورودی، بدون هیچ گونه راهنمایی خارجی (برچسب) کشف کند. به بیان ساده، سیستم “خودش” باید دادهها را کاوش کرده و به یک دروننگاشت (Insight) برسد.
در این رویکرد:
- الگوریتم تلاش میکند ساختار پنهان دادهها را کشف کند.
- هدف اصلی، کاهش پیچیدگی دادهها و یافتن الگوهای مشترک میان آنهاست.
مقایسه یادگیری نظارتشده و بدون نظارت
- یادگیری با نظارت: مدل از دادههای برچسبدار برای پیشبینی استفاده میکند .مانند دانشآموزی است که با جوابهای صحیح تمرین میکند. (ورودی: داده، خروجی: برچسب)
- یادگیری بدون نظارت: الگوریتم هیچ برچسبی ندارد و بهطور مستقل الگوها را شناسایی میکند .مانند دانشمندی است که برای اولین بار در حال بررسی یک پدیده ناشناخته است. (فقط ورودی: داده)
چرا یادگیری بدون نظارت مهم است؟
دلایل اهمیت این حوزه را میتوان در چند نکته کلیدی خلاصه کرد:
کاهش هزینه و افزایش مقیاس پذیری :
برچسبزنی دادهها در مقیاس بزرگ، بسیار پرهزینه و زمانبر است. یادگیری بدون نظارت امکان بهرهبرداری از انبوه دادههای بدون برچسب را فراهم میآورد.
کشف روابط پنهان و نوآوری در داده ها:
این روشها میتوانند الگوها و روابط غیرمنتظرهای را کشف کنند که انسان حتی به آنها فکر نکرده بود و از سوگیریهای پیشفرض انسانی جلوگیری میکنند.
بهبود مدل های یادگیری با نظارت:
خروجی یادگیری بدون نظارت (مانند کاهش ابعاد) میتواند به عنوان ورودی کارآمدتری برای مدلهای یادگیری با نظارت استفاده شود.
مبانی نظری و هدف یادگیری بدون نظارت
یادگیری بدون نظارت، درک ماشینی را از “پیشبینی پاسخ برچسبدار” فراتر برده و به “توصیف ساختار درونی داده” میرساند.
هدف و مکانیسم اصلی
هدف اصلی یادگیری بدون نظارت، استنتاج توزیع احتمال (Probability Distribution) دادههای ورودی (X) است. به عبارت سادهتر، مدل به دنبال تابعی نیست که X را به Y نگاشت کند (چون Y وجود ندارد)، بلکه به دنبال تابعی است که ساختار داده را بازنمایی کند:
f:X→X′
نقش زیستشناسی و شبیه سازی یادگیری انسانی:
این رویکرد، شبیهتر به نحوه یادگیری نوزادان است؛ آنها دنیا را مشاهده میکنند و بدون راهنمایی مستقیم، اشیاء و مفاهیم را بر اساس شباهتهایشان در گروههای ذهنی طبقهبندی میکنند.
مزیت در داده های کلان :
در عصری که هزینههای برچسبگذاری دادهها سرسامآور است، یادگیری بدون نظارت اجازه میدهد تا از حجم عظیم دادههای ارزان و خام (مانند تصاویر بدون توضیح یا متون بدون خلاصه) برای آموزش مدلهای پیشرفته استفاده شود.
اجزای کلیدی یادگیری بدون نظارت
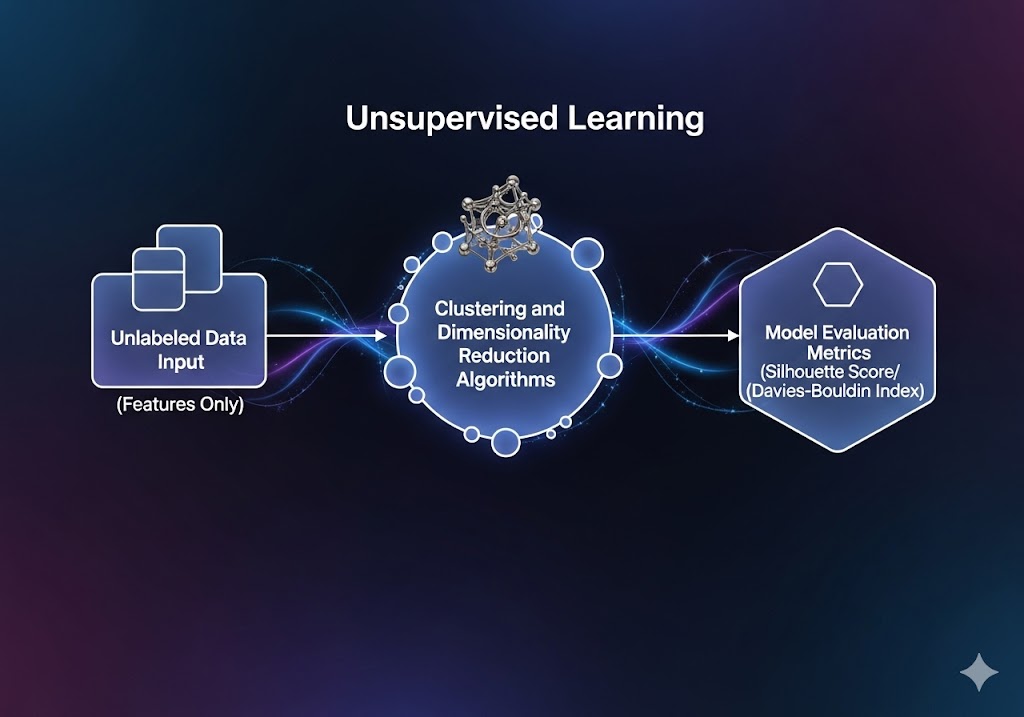
دادههای بدون برچسب (Unlabeled Data)
ورودیها فقط ویژگیها را شامل میشوند (مثلاً قد و وزن افراد) اما هیچ خروجی مشخصی وجود ندارد.
الگوریتمهای خوشهبندی و کاهش ابعاد
ابزارهای اصلی برای شناسایی گروهها یا الگوهای پنهان.
معیارهای ارزیابی کیفیت مدل
سنجش کیفیت نتایج بدون برچسب دشوار است. معمولاً از معیارهایی مانند Silhouette Score یا Davies-Bouldin Index استفاده میشود.
الگوریتمهای پرکاربرد در یادگیری بدون نظارت
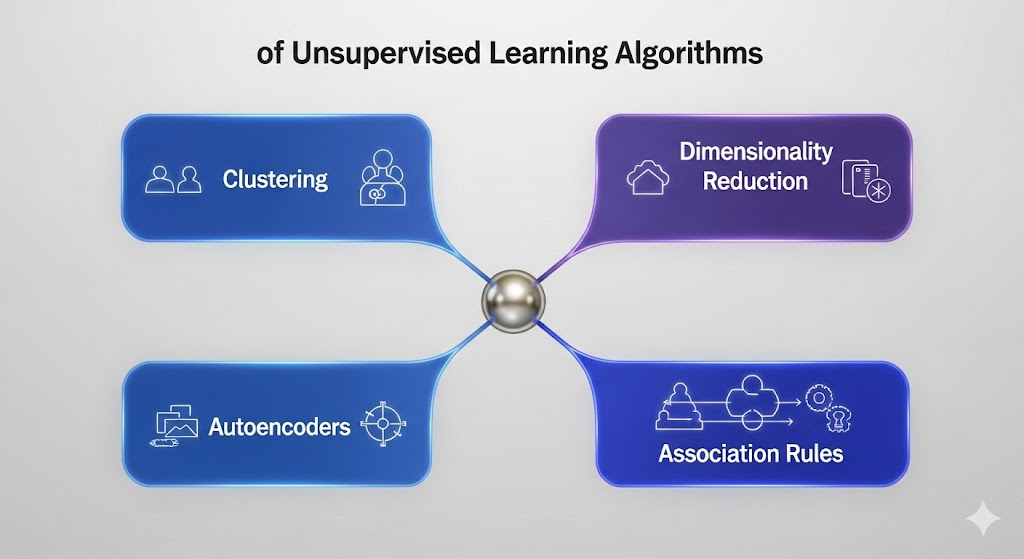
خوشهبندی (Clustering) :
هدف از خوشهبندی، تقسیم دادهها به گروههایی (خوشهها) است که در هر خوشه، اشیاء به یکدیگر شبیهتر و به اشیاء در خوشههای دیگر نامشابه هستند. این کار شبیه پیدا کردن دستههای طبیعی در دادههاست.
الگوریتمهای معروف خوشهبندی:
K-Means :
سادهترین و پرکاربردترین الگوریتم.
- مکانیزم: تعداد خوشههای مورد نظر (K) توسط کاربر تعیین میشود. الگوریتم به صورت تکراری، مرکز خوشهها (Centroids) را به روز میکند تا فاصله دادهها از مرکز خوشه مربوطه کمینه شود.
- مزایا : ساده، سریع و مقیاسپذیر برای دادههای حجیم.
معایب : نیاز به تعیین K از قبل، حساسیت به مقیاس داده و مراکز اولیه، عملکرد ضعیف در شناسایی خوشههای غیرکروی.
خوشهبندی سلسله مراتبی (Hierarchical Clustering):
- مکانیزم: این الگوریتم یک درخت خوشهای (دندروگرام) میسازد که روابط سلسله مراتبی بین دادهها را نشان میدهد. میتوان از پایین به بالا (تجمعی) یا از بالا به پایین (تقسیمی) عمل کرد.
- مزایا: نیازی به تعیین تعداد خوشه از قبل نیست، خروجی بصری و تفسیرپذیر است.
- معایب: برای دادههای حجیم محاسباتی سنگین است.
DBSCAN:
- مکانیزم: بر اساس تراکم نقاط عمل میکند. خوشهها را به عنوان مناطق پرتراکم داده تعریف کرده و نقاطی که در مناطق کمتراکم قرار دارند را به عنوان “نویز” شناسایی میکند.
- مزایا: توانایی کشف خوشههایی با اشکال دلخواه، شناسایی خودکار نقاط پرت.
- معایب: عملکرد ضعیف هنگامی که تراکم خوشهها بسیار متفاوت است.
کاربرد واقعی:
در بانکداری، برای شناسایی گروههای رفتاری مشتریان بدون داشتن برچسب «وفادار» یا «غیروفادار». طبق گزارش دیلویت (2024)، این روش به بانکها کمک کرده تا 22% از مشتریان پرخطر را زودتر شناسایی کنند.
الگوریتمهای کاهش ابعاد (Dimensionality Reduction): فشردهسازی و تجسم
زمانی که دادهها دارای صدها یا هزاران ویژگی (بعد) باشند، “نفرین ابعاد بالا” (Curse of Dimensionality) رخ میدهد که باعث کاهش کارایی بسیاری از الگوریتمها میشود. کاهش ابعاد به دنبال نگاشت دادهها به یک فضای با ابعاد کمتر، با حفظ حداکثر اطلاعات ممکن است.
نمایش داده در فضایی با ابعاد کمتر، بدون از دست دادن اطلاعات کلیدی.
الگوریتمهای معروف کاهش ابعاد:
(Principal Component Analysis) PCA:
- مکانیزم: یک روش خطی که جهتهای (مولفههای اصلی) که بیشترین واریانس داده را در بر میگیرند، پیدا میکند. دادهها بر روی این مولفههای جدید که orthogonal هستند، افراز میشوند.
- کاربرد: حذف نویز، فشردهسازی داده، تجسم دادههای چندبعدی در ۲ یا ۳ بعد.
(t-Distributed Stochastic Neighbor Embedding) t-SNE :
- مکانیزم: یک الگوریتم غیرخطی که برای تجسم دادههای با ابعاد بالا در فضای ۲ یا ۳ بعدی طراحی شده است. این الگوریتم سعی میکند ساختارهای محلی و فاصلههای بین خوشهها را در فضای با ابعاد پایین حفظ کند.
- کاربرد: تجسم خوشهها و بررسی کیفیت خوشهبندی. (توجه: از t-SNE برای کاهش ابعاد به منظور استفاده در مدلهای دیگر نباید استفاده کرد).
- t-SNE و UMAP : این الگوریتمها برای بصریسازی دادههای با ابعاد بسیار بالا (مانند ژنومیک یا دادههای متنی) به فضای دو یا سهبعدی عالی هستند و اغلب در محیطهای تحقیقاتی هاروارد و MIT استفاده میشوند
- کاربرد واقعی:
در ژنتیک، برای کاهش 20,000 ژن به 50 ویژگی کلیدی که بتوانند انواع سرطان را تمایز دهند
الگوریتمهای شبکههای عصبی خودرمزگذار(Autoencoders):
مکانیزم: از یک معماری شبکه عصبی استفاده میکند که یک بخش کدگذار (Encoder) داده را به یک نمایش فشرده (کد) تبدیل میکند و یک بخش کدگشا (Decoder) سعی میکند از روی این کد، داده اصلی را بازسازی کند. لایه میانی (کد)، نمایش کاهشبعدیافته داده است.
کاربرد: کاهش ابعاد غیرخطی پیچیده، حذف نویز از دادهها.
مطالعات منتشرشده در MIT Technology Review نشان میدهند که استفاده از Autoencoderها در تشخیص تقلب بانکی، توانسته دقت کشف الگوهای غیرمعمول را تا ۴۵٪ افزایش دهد.
این شاخه، پایهی مدلهای زبانی بزرگ (LLM) است. همانطور که هاروارد بیزینس ریویو (2023) تأکید میکند:
بدون یادگیری بدون نظارت، مدلهایی مانند ChatGPT هرگز نمیتوانستند از متن خام، معنا را استخراج کنند.
قوانین انجمنی (Association Rule Mining)
هدف این تکنیک، کشف روابط “اگر-آنگاه” یا وابستگیهای رایج بین اقلام در مجموعههای بزرگ تراکنش است.
- مکانیسم: یافتن قوانین به صورت A→B (اگر A رخ دهد، آنگاه B نیز رخ خواهد داد). این قوانین با سه معیار ارزیابی میشوند:
- پشتیبانی (Support) : چند درصد از کل دادهها حاوی هر دو قلم A و B هستند.
- اطمینان (Confidence) : اگر A رخ دهد، احتمال رخ دادن B چقدر است.
- بلند کردن (Lift) : نسبت احتمال وقوع B در حضور A به احتمال وقوع B به طور مستقل. (این معیار نشان میدهد که آیا رابطه تصادفی است یا واقعی.)
- کاربرد تجاری (Deloitte) : تحلیل سبد خرید (Market Basket Analysis) در خردهفروشی برای بهینهسازی چینش قفسهها، ایجاد تخفیفهای ترکیبی یا سیستمهای توصیهگر.
مراحل اجرای یک پروژه یادگیری بدون نظارت
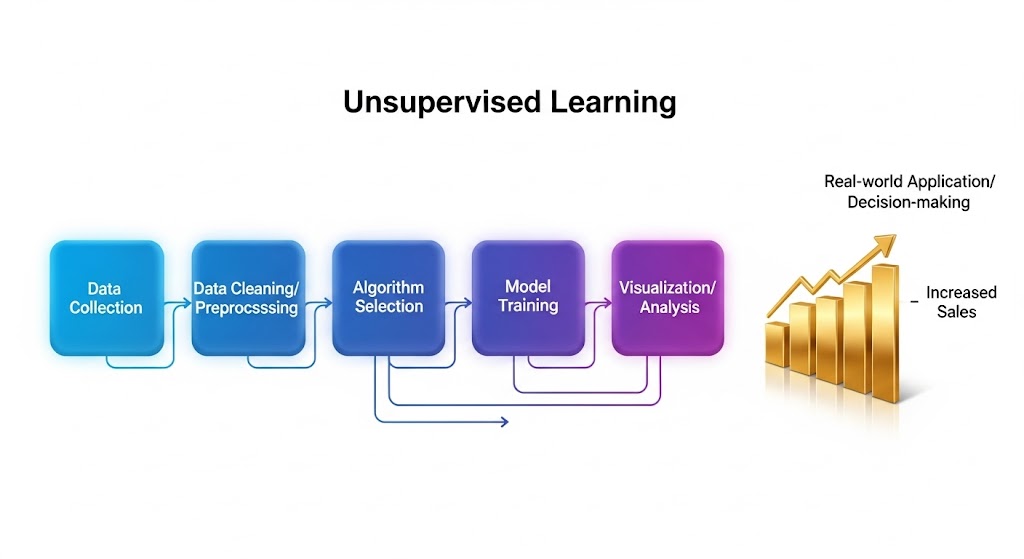
- جمعآوری دادهها (از منابع سازمانی یا عمومی)
- پاکسازی دادهها (رفع دادههای پرت، نرمالسازی مقادیر)
- انتخاب الگوریتم مناسب بر اساس هدف پروژه (خوشهبندی یا کاهش ابعاد)
- آموزش مدل روی دادههای بدون برچسب
- تجسم و تحلیل نتایج
- کاربرد در تصمیمگیری واقعی
گزارش McKinsey (2023) نشان میدهد که شرکتهای پیشرو در صنایع خردهفروشی، با بهرهگیری از خوشهبندی مشتریان توانستهاند تا ۲۰٪ فروش خود را افزایش دهند.
کاربردهای یادگیری بدون نظارت در صنایع
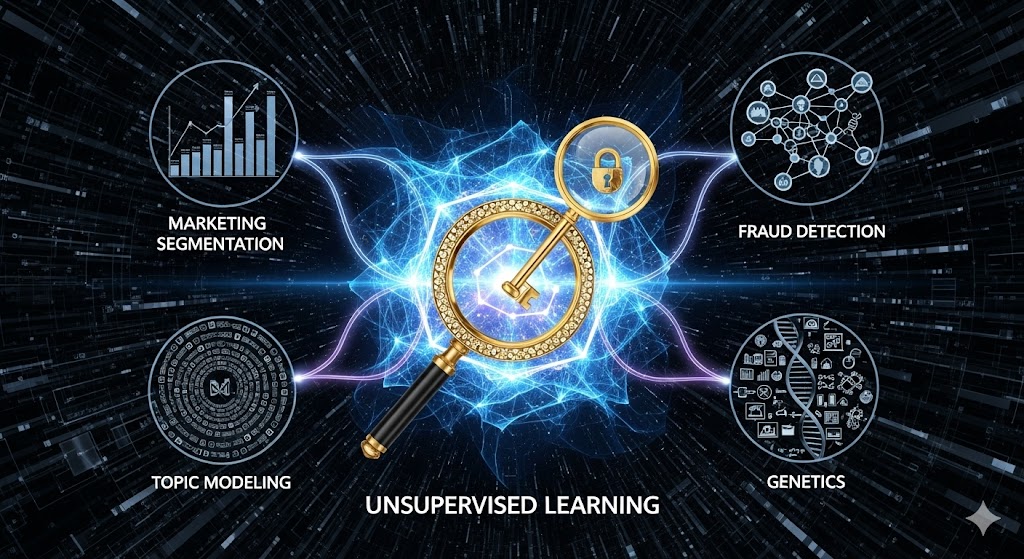
این تکنیکها در صنایع پیشرو به طور گسترده مورد استفاده قرار میگیرند. گزارشهای شرکتهایی مانند مک کینزی بر نقش این فناوری در بخشبندی بازار و شخصیسازی خدمات تأکید دارند.
بخشبندی مشتریان در بازاریابی
شرکتهایی مانند Amazon و Netflix از الگوریتمهای خوشهبندی برای گروهبندی مشتریان بر اساس رفتار خرید یا تماشا استفاده میکنند. این بخشبندی به آنها امکان میدهد کمپینهای بازاریابی بسیار هدفمند و شخصیسازیشدهای را اجرا کنند.
تشخیص ناهنجاری (Anomaly Detection) در امنیت سایبری و مالی
الگوریتمهایی مانند خوشهبندی میتوانند الگوهای “عادی” تراکنشهای شبکه یا مالی را یاد بگیرند. هرگونه رفتاری که خارج از این خوشههای عادی قرار گیرد، به عنوان یک ناهنجاری (مانند حمله سایبری یا کلاهبرداری مالی) پرچمگذاری میشود.
مدلسازی موضوعی (Topic Modeling) در پردازش زبان طبیعی
الگوریتمهایی مانند LDA (Latent Dirichlet Allocation) که نوعی یادگیری بدون نظارت است، میتوانند موضوعات پنهان در یک مجموعهای بزرگ از اسناد متنی (مانند مقالات خبری یا نظرات مشتریان) را کشف کنند. این کار برای خلاصهسازی و درک روندها حیاتی است.
ژنتیک و زیستشناسی
از خوشهبندی برای گروهبندی ژنهایی که الگوی بیان مشابهی دارند استفاده میشود. این کار به شناسایی ژنهای involved در یک بیماری خاص کمک میکند.
مزایا و محدودیتهای یادگیری بدون نظارت
مزایا
- عدم نیاز به دادههای برچسبدار (صرفهجویی در زمان و هزینه).
- کشف روابط پنهان و پیچیده.
- کاربرد گسترده در دادههای کلان.
محدودیتها
- دشواری ارزیابی دقت مدل.
- حساسیت به انتخاب تعداد خوشهها یا ابعاد.
- احتمال ایجاد خوشههای غیرمعنیدار.
طبق گزارش PwC، بیش از ۵۰٪ پروژههای مبتنی بر یادگیری بدون نظارت، در مرحله تحلیل نیازمند بازنگری انسانی هستند تا از صحت نتایج اطمینان حاصل شود.
چرا یادگیری بدون نظارت برای آینده هوش مصنوعی حیاتی است؟
کمبود دادههای برچسبگذاریشده
برچسبگذاری داده نیاز به زمان، هزینه و تخصص انسانی دارد. در حوزههایی مانند رادیولوژی یا ژنتیک، این کار اغلب غیرعملی است.
کشف دانش جدید
در پژوهشهای علمی، ما اغلب نمیدانیم چه چیزی را باید بیابیم. یادگیری بدون نظارت به دانشمندان کمک میکند تا الگوهای غیرمنتظره را کشف کنند — مانند شناسایی یک زیرگروه جدید از بیماری آلزایمر.
پایهی هوش مصنوعی عمومی (AGI)
طبق نظر Yoshua Bengio (برندگان جایزه تورینگ)، هوش انسانی بیشتر از طریق یادگیری خودکار از جهان شکل میگیرد — نه از طریق نظارت. بنابراین، یادگیری بدون نظارت کلید اصلی برای ساخت سیستمهایی با درک عمیقتر از جهان است.
چالشهای بنیادین یادگیری بدون نظارت
با وجود پتانسیل بالا، این حوزه با چالشهای جدی مواجه است:
اعتبار سنجی خوشه (Cluster Validation)
در یادگیری نظارتشده، دقت (Accuracy) معیار شفافی است. اما در یادگیری بدون نظارت، چگونه بفهمیم مدل «خوب» کار کرده است؟
راهحلهای پیشنهادی:
- Silhouette Score برای خوشهبندی که نشان دهنده میزان انسجام یک نقطعه درون خوشه خود و فاصله آن از خوشههای دیگر است.
- Reconstruction Error برای Autoencoders
- تحلیل کیفی توسط انسان
حساسیت به پارامترهای اولیه
الگوریتمهایی مانند K-Means بهشدت به مقداردهی اولیه وابستهاند.
تفسیرپذیری پایین
تفسیر نهایی به دانش کسبوکار یا دانش دامنه (Domain Expertise) وابسته است. یک مدل ممکن است خوشههایی را پیدا کند، اما این فقط متخصصان هستند که میتوانند تعیین کنند آیا این خوشهها از نظر تجاری یا علمی، منطقی و قابل استفاده هستند یا خیر. حتی اگر مدل ساختاری را کشف کند، درک معنای آن ساختار نیاز به تخصص دامنهای دارد.
شرکت آیبیام در گزارش «Unsupervised Learning in Enterprise» (2024) پیشنهاد میکند که هر پروژه یادگیری بدون نظارت باید همکاری نزدیکی بین دانشمند داده و متخصص دامنه داشته باشد.
کاربردهای نوین در صنعت و پژوهش
تشخیص ناهنجاری (Anomaly Detection)
- در صنعت: شناسایی قطعات معیوب در خط تولید.
- در امنیت: کشف فعالیتهای غیرعادی در شبکه.
تولید داده (Generative Modeling)
- شبکههای مولد تخاصمی (GANs):تولید تصاویر واقعگرایانه.
- مدلهای زبانی: تولید متن بر اساس توزیع احتمالی کلمات.
یادگیری خودنظارتی (Self-Supervised Learning)
رویکردی نوین که از داده خام، وظایف مصنوعی ایجاد میکند (مثلاً پیشبینی کلمه بعدی). این روش، پلی بین یادگیری بدون نظارت و نظارتشده است.
طبق گزارش مک کنزی (2023)، شرکتهایی که از یادگیری خودنظارتی استفاده میکنند، تا 40% کمتر به دادههای برچسبگذاریشده وابستهاند.
آینده یادگیری بدون نظارت
یادگیری بدون نظارت در ترکیب با روشهای دیگر، مسیر آینده هوش مصنوعی را شکل میدهد:
- یادگیری نیمهنظارتی (Semi-Supervised Learning) :استفاده از تعداد کمی داده برچسبدار در کنار حجم زیادی داده بدون برچسب.
- یادگیری خودنظارتی(Self-Supervised Learning) :روشی که امروزه در آموزش مدلهای زبانی بزرگ (مانند ChatGPT و BERT) استفاده میشود.
- هوش مصنوعی مولد (Generative AI) :استفاده از شبکههای مولد (GANs) برای تولید دادههای مشابه دادههای واقعی.
شرکت Accenture در گزارش سال ۲۰۲۴ پیشبینی کرده است که ترکیب یادگیری بدون نظارت و خودنظارتی میتواند تا سال ۲۰۳۰ ارزش اقتصادی هوش مصنوعی را تا ۷ تریلیون دلار افزایش دهد.
جمعبندی
یادگیری بدون نظارت، ابزاری کلیدی برای تحلیل دادههای بدون برچسب و کشف الگوهای پنهان در آنهاست. این رویکرد به صنایع مختلف از بازاریابی و مالی گرفته تا سلامت و حملونقل کمک میکند تا تصمیمهای هوشمندانهتری بگیرند.
هرچند چالشهایی مانند دشواری ارزیابی نتایج یا حساسیت به انتخاب الگوریتم وجود دارد، اما آینده این حوزه روشن است. بهویژه با ترکیب آن با یادگیری نیمهنظارتی و خودنظارتی، میتوان انتظار داشت که در سالهای آینده یادگیری بدون نظارت، نقشی محوری در توسعه هوش مصنوعی ایفا کند.