

دادههای نویزی یکی از رایجترین چالشها در فرآیند دادهکاوی هستند. این جزوه تلاش میکند با ارائه مثالهای واقعی، روشهای حذف نویز، فیلترها و الگوریتمهای robust، تصویری جامع از مدیریت دادههای نویزی ارائه دهد.
تعریف
داده نویزی (Noisy Data) به دادههایی اطلاق میشود که حاوی خطا یا ناهنجاریهای تصادفی هستند. در اصل، نویز یک “مؤلفه تصادفی از خطای اندازهگیری“ است.
تصور کنید یک سیگنال یا داده واقعی و «تمیز» در اختیار دارید — مثلاً دمای واقعی هوا. نویز، یک مؤلفه ناخواسته است که خطاهای سنسور یا تداخلهای محیطی آن را تولید کرده و با داده مطلوب ترکیب میکنند. در نتیجه، آنچه شما ثبت میکنید، حاصل جمع داده واقعی و نویز است.
- داده ثبت شده = داده واقعی + نویز
این نویز باعث میشود مقادیر داده، نوسانات بالا و پایین ناخواستهای داشته باشند.
مثال بصری: سیگنال تمیز در برابر سیگنال نویزی
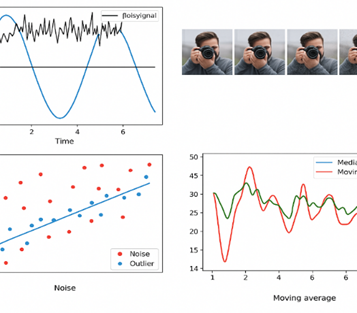
در سمت چپ یک سیگنال تمیز و یکنواخت دیده میشود. در سمت راست همان سیگنال پس از اضافه شدن نویز نمایش داده شده است که نوسانات تصادفی باعث غیرقابلتشخیص شدن شکل اصلی شدهاند.
انواع نویز در دادهها
همه نویزها شبیه هم نیستند. در عمل، مدلهای مختلفی از نویز استفاده میشود که هرکدام رفتار خاص خود را دارند:
نویز گاوسی (Gaussian Noise)
رایجترین مدل نویز پیوسته است. مقدار نویز از یک توزیع نرمال با میانگین صفر و واریانس مشخص پیروی میکند. در بسیاری از سنسورهای فیزیکی، فرض میشود خطای اندازهگیری از این نوع است.
نویز نمک و فلفل (Salt-and-Pepper Noise)
در این حالت، بعضی نقاط داده بهصورت ناگهانی به مقادیر خیلی بزرگ یا خیلی کوچک (مثلاً ۰ یا ۲۵۵ در تصویر) جهش میکنند. این نوع نویز در تصاویر دیجیتال خراب یا انتقال ناقص داده زیاد دیده میشود.
نویز یکنواخت (Uniform Noise)
مقدار نویز در یک بازه مشخص بهطور یکنواخت توزیع شده است. همه مقادیر در آن بازه احتمال یکسان دارند.
نویز پواسون (Poisson Noise)
در سیستمهایی که با شمارش رویدادها سروکار دارند (مثل تعداد فوتونهای ثبتشده در دوربینهای حساس)، نویز اغلب از نوع پواسون است.
شناخت نوع نویز کمک میکند روش مناسبتری برای حذف یا کاهش آن انتخاب کنیم.
چرا دادهها نویزی میشوند؟ (علل رایج)
نویز میتواند در هر مرحله از جمعآوری و انتقال داده رخ دهد:
خطای دستگاه اندازهگیری:
- سنسورها یا دستگاههای جمعآوری داده دقیق نیستند.
- مثال : یک دستگاه سنجش آلودگی هوا، علاوه بر آلودگی واقعی، ممکن است نوسانات تصادفی (بالا و پایین شدن) را به دلیل خطای دستگاه ثبت کند.
تداخل محیطی:
- عوامل خارجی میتوانند روی سیگنال اصلی تأثیر بگذارند.
- مثال : یک میکروفون که صدای فردی را ضبط میکند، همزمان نویز محیط (صدای باد، همهمه) را نیز به عنوان یک مؤلفه ناخواسته ضبط میکند.
خطای ورود داده:
- خطاهای انسانی هنگام وارد کردن دستی دادهها.
- مثال: اپراتور به جای وارد کردن سن “25”، به اشتباه “255” را تایپ میکند.
خطای انتقال داده:
خراب شدن بیتهای داده در حین انتقال در شبکه.
مثال بصری: نویز در تصاویر

در این تصویر چهار مرحلهی افزایش نویز را مشاهده میکنید. تصویر اول کاملاً واضح است، اما با افزایش سطح نویز، پیکسلها تغییرات تصادفی پیدا میکنند و جزئیات چهره بهتدریج محو میشود. این نمونه نشان میدهد که چگونه نویز میتواند کیفیت دادههای تصویری را کاهش دهد.
نویز در انواع دادهها چگونه ظارهر میشود؟
نحوه ظاهر شدن نویز در دادهها به نوع داده بستگی دارد:
دادههای عددی (جدولی / سنسوری)
نویز معمولاً به صورت نوسانات کوچک یا گهگاه جهشهای بزرگ در مقادیر دیده میشود؛ مثل دمای ۲۵ درجه که بهطور تصادفی به ۲۷ یا ۲۳ ثبت میشود.
دادههای تصویری
نویز میتواند به شکل پیکسلهای خیلی روشن یا خیلی تیره (Salt-and-Pepper)، لکههای رنگی یا بافتهای دانهدانه روی تصویر ظاهر شود. هرچه نویز بیشتر باشد، جزئیات تصویر سختتر دیده میشود.
دادههای صوتی
در سیگنال صوتی، نویز شبیه خشخش، نویز پسزمینه یا صدای همهمه است که روی سیگنال اصلی (مثلاً صدای گوینده) سوار میشود.
به همین دلیل، روشهای حذف نویز برای هر نوع داده کمی متفاوت طراحی میشوند.
تفاوت نویز (Noise) با داده پرت (Outlier)
اغلب این دو مفهوم با هم اشتباه گرفته میشوند، اما تفاوت ظریفی دارند.
داده پرت (Outlier) :
- یک مشاهده یا یک نقطه داده است که ویژگیهای آن به طور قابل توجهی با اکثریت دادههای دیگر متفاوت است. این یک نقطه داده کامل است که “عجیب” به نظر میرسد.
- مثال: در دادههای مشتریان یک فروشگاه، فردی با “سن: ۱۲۰ سال” یا “تعداد خرید: ۵۰۰۰ عدد در روز”.
نویز (Noise) :
- یک خطای تصادفی است که مقدار یک ویژگی را تغییر میدهد. نویز به خودی خود یک نقطه داده مجزا نیست، بلکه خرابی در یک نقطه داده موجود است.
- مثال: سن واقعی فرد ۴۵ سال بوده اما به دلیل نویز (لرزش سنسور یا خطای ثبت) ۴۸.۵ ثبت شده است.
نکته مهم: گاهی اوقات نویز شدید میتواند باعث ایجاد داده پرت شود. در مثال اپراتور، مقدار “255” برای سن، هم نویز (ناشی از خطای ورود داده) و هم یک داده پرت (چون با بقیه دادههای سن بسیار متفاوت است) محسوب میشود.
نمودار تفاوت نویز و داده پرت
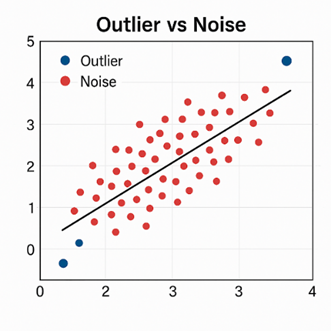
در نقاط آبی، دادهها از بقیه گروه بهطور واضح فاصله دارند (داده پرت). نقاط قرمز نوسانات تصادفی هستند که حول یک الگوی اصلی پخش شدهاند (نویز). این تصویر تفاوت بنیادی نویز و Outlier را نشان میدهد.
اثر نویز بر مدلهای یادگیری ماشین
وجود نویز، اگر مدیریت نشود، میتواند مشکلات جدی برای مدلهای یادگیری ماشین ایجاد کند:
افزایش Variance و Overfitting :
مدل تلاش میکند نوسانات تصادفی را هم یاد بگیرد و در نتیجه روی داده آموزش بیشازحد خوب و روی داده جدید ضعیف عمل میکند.
کاهش دقت پیشبینی:
برآورد پارامترها (مثل ضرایب رگرسیون) بههم میریزد و خطای کلی افزایش پیدا میکند.
ناپایداری مرز تصمیمگیری:
در مسائل طبقهبندی، نویز میتواند باعث شود مرز بین کلاسها کج و پیچیده شود.
به همین دلیل، یا باید دادهها را تا حد امکان از نویز پاک کنیم، یا از الگوریتمهایی استفاده کنیم که ذاتاً در برابر نویز مقاومتر باشند.
استراتژیهای برخورد با دادههای نویزی
همانطور که در جزوه اشاره شده، دو رویکرد اصلی برای مدیریت دادههای بیکیفیت (شامل نویز) وجود دارد:
پیشپردازش (Denoising):
تلاش برای تمیز کردن داده و حذف نویز قبل از دادن آن به الگوریتم. این فرآیند Data Cleaning نامیده میشود.
الگوریتمهای مقاوم (Robust Algorithms):
طراحی الگوریتمهایی (مانند درخت تصمیم یا استفاده از میانه) که ذاتاً در برابر نویز و دادههای پرت مقاوم هستند و میتوانند کیفیت پایین داده را “تحمل” کنند.
در این بخش، ما بر رویکرد اول (Denoising) تمرکز میکنیم.
الگوریتمها و روشهای مقاوم به نویز
برخی الگوریتمها بهطور طبیعی در برابر نویز و دادههای پرت مقاومترند:
درخت تصمیم و Random Forest
بهدلیل تقسیم داده بر اساس آستانهها و استفاده از تجمیع در جنگل تصادفی، معمولاً نسبت به چند نقطه نویزی حساسیت کمتری دارند.
K-medians و K-medoids
در خوشهبندی، اگر بهجای میانگین از میانه یا نقاط نماینده (Medoid) استفاده کنیم، خوشهها نسبت به Outlierها پایدارتر میشوند.
Isolation Forest و روشهای Outlier Detection
این روشها بهطور خاص برای شناسایی و ایزوله کردن دادههای پرت طراحی شدهاند و میتوانند قبل از آموزش مدل اصلی اجرا شوند.
ترکیب یک مرحله Denoising با انتخاب الگوریتمهای مقاوم، معمولاً بهترین نتیجه را میدهد.
مثال: تکنیکهای حذف نویز (Denoising)
هدف در اینجا “هموارسازی” (Smoothing) دادهها برای کاهش نوسانات تصادفی و بازیابی سیگنال اصلی است.
سناریو:
فرض کنید دادههای دمای یک سنسور را در ۷ ثانیه متوالی داریم که حاوی نویز لحظهای (Impulse Noise) است.
داده نویزی اولیه:
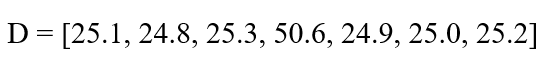
مقدار 50.6 به وضوح یک نویز شدید (و همچنین یک داده پرت) است که دمای واقعی محیط (حدود ۲۵ درجه) را منعکس نمیکند.
تکنیک اول: فیلتر میانگین متحرک (Moving Average)
توضیح :
این تکنیک برای دادههای ترتیبی (مثل سری زمانی) مناسب است. هر نقطه با میانگین همسایگان خود (در یک “پنجره” مشخص) جایگزین میشود.
مثال (با پنجره = ۳):
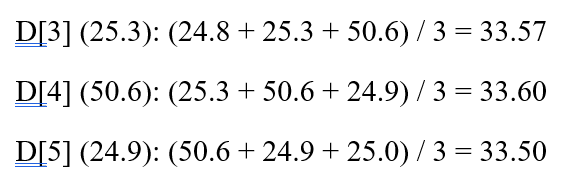
داده هموار شده :
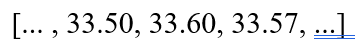
تحلیل :
این روش داده را هموار کرد، اما نویز 50.6 به همسایگان خود “نشت” کرد و آنها را نیز خراب کرد. میانگین به داده پرت حساس است.
تکنیک دوم: فیلتر میانه (Median Filter)
توضیح:
این تکنیک (مخصوصاً برای نویز “salt-and-pepper” در تصاویر) بسیار مؤثر است. هر نقطه با میانه همسایگان خود جایگزین میشود.
مثال (با پنجره = ۳):

داده هموار شده :
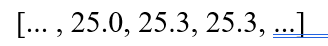
تحلیل:
میانه به داده پرت حساس نیست. این فیلتر توانست نویز 50.6 را به طور کامل حذف کند و مقدار 25.3 (که بسیار منطقیتر است) را جایگزین آن کند، بدون اینکه بر مقادیر همسایه تأثیر مخرب بگذارد.
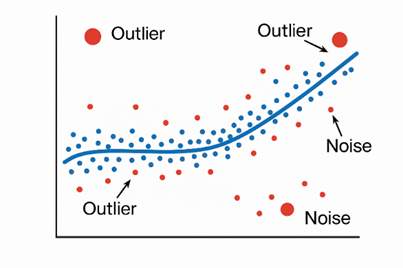
در این نمودار مشاهده میکنید که فیلتر میانگین متحرک (خط قرمز) نویز شدید را به نقاط مجاور منتقل میکند، در حالی که فیلتر میانه (خط آبی) نویز را حذف کرده و شکل اصلی سیگنال را بهتر بازیابی میکند.
تکنیک سوم: هموارسازی با گسستهسازی (Binning)
توضیح:
دادهها را مرتب کرده، در “سطل” (Bin) هایی با اندازه مساوی قرار میدهیم، و سپس مقادیر هر سطل را با یک مقدار مشترک (مثل میانگین یا میانه سطل) جایگزین میکنیم.
مثال (با ۳ سطل و استفاده از میانگین):
- ۱. مرتبسازی S = [24.8, 24.9, 25.0, 25.1, 25.2, 25.3, 50.6] :
- ۲. تقسیمبندی: (Binning) (مثلاً بر اساس فرکانس مساوی، ۳ داده در هر سطل، سطل آخر ۱ دانه)
- Bin 1: [24.8, 24.9, 25.0]
- Bin 2: [25.1, 25.2, 25.3]
- Bin 3: [50.6]
- ۳. محاسبه میانگین سطل:
- Mean(Bin 1) = 24.9
- Mean(Bin 2) = 25.2
- Mean(Bin 3) = 50.6
- ۴. جایگزینی (مقادیر اصلی با میانگین سطل خود جایگزین میشوند):
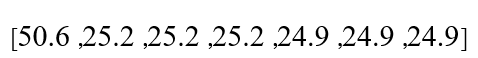
تحلیل:
روش Bucket Median Smoothing (هموارسازی با میانه سطل) واقعاً یک راهکار هوشمندانه برای مواجهه با دادههای پرت در Binning است — بهویژه در دادههای نامتقارن (مثل درآمد مشتریان یا مبالغ تراکنشهای بانکی که دنباله بلند راست دارند). پس ذکر دقیق نام روش (حتی به انگلیسی در پرانتز) در متن علمی توصیه میشود.
آمار مقاوم در برابر نویز (Robust Statistics)
یکی از ایدههای مهم در برخورد با نویز این است که بهجای استفاده از مقادیری که به شدت تحت تأثیر دادههای پرت قرار میگیرند (مثل میانگین)، از معیارهای مقاوم استفاده کنیم.
میانه (Median)
اگر چند مقدار خیلی بزرگ یا خیلی کوچک در داده وجود داشته باشد، روی میانه تأثیر زیادی نمیگذارند. به همین دلیل، فیلتر میانه برای حذف نویزهای ناگهانی انتخاب بسیار خوبی است.
MAD (Median Absolute Deviation)
بهجای استفاده از انحراف معیار (که به Outlierها حساس است)، میتوان از میانه انحرافهای مطلق نسبت به میانه استفاده کرد تا پراکندگی دادهها را مقاومتر تخمین بزنیم.
این دیدگاه «آمار مقاوم» پشت بسیاری از روشهای Denoising مدرن قرار دارد.
جدول خلاصه
| کاربرد مناسب | معایب | مزایا | روش |
|---|---|---|---|
| هموارسازی نوسانهای ملایم در سریهای زمانی | به Outlier حساس است، نویز شدید را به همسایهها منتقل میکند | ساده، شهودی، پیادهسازی سریع | فیلتر میانگین متحرک (Moving Average) |
| نویز ضربهای (Impulse Noise) و نمکوفلفل در دادههای عددی و تصویری | کمی سنگینتر محاسباتی، ممکن است جزئیات ریز سیگنال را صاف کند | مقاوم در برابر دادههای پرت، بسیار مناسب برای نویزهای ناگهانی | فیلتر میانه (Median Filter) |
| دادههای ترتیبی، زمانی که هدف، کاهش جزئیات و سادهسازی است | اگر درست تنظیم نشود، ممکن است Outlier را حفظ کند یا ساختار ظریف داده را از بین ببرد | ساده، مناسب برای خلاصهسازی دادههای زیاد | Binning |
نکات و اشتباهات رایج در برخورد با دادههای نویزی
اشتباه ۱: حذف نکردن دادههای پرتِ واضح
وقتی یک مقدار مثل 50.6 وسط دماهای حدود 25 قرار میگیرد، اگر آن را بدون بررسی در محاسبه میانگین وارد کنیم، هم سیگنال و هم فیلترهای ساده را خراب میکند.
اشتباه ۲: استفاده بیفکر از میانگین
میانگین به دادههای پرت بسیار حساس است. در حضور نویز شدید یا Outlier، اغلب میانه انتخاب بهتری است.
اشتباه ۳: هموارسازیِ بیش از حد
اگر فیلتر را بیش از حد قوی تنظیم کنیم، علاوه بر نویز، خود سیگنال اصلی هم صاف میشود و جزئیات مهم از بین میرود.
اشتباه ۴: یکسان فرض کردن همه نویزها
چون نویزهای نمکوفلفل، گاوسی و نویزهای دادههای تصویری یا صوتی رفتار متفاوتی دارند، یک فیلتر ثابت همیشه مؤثر نخواهد بود.
اشتباه ۵: نادیدهگرفتن تأثیر نویز بر مدل
حتی اگر نمودار ظاهراً فقط «کمی شلوغ» به نظر برسد، همین شلوغی میتواند مرز تصمیمگیری مدل را کاملاً کج و نامطمئن کند.
این نکات کمک میکنند هنگام کار عملی با دادههای نویزی، دچار تصمیمهای سادهانگارانه نشویم.
جمعبندی نهایی
- نویز یک خطای تصادفی است و اگر مدیریت نشود، میتواند منجر به Overfitting، کاهش دقت مدل و ایجاد مرزهای تصمیمگیری نامناسب شود.
- هیچ روش واحدی برای همه شرایط بهترین نیست؛ شما باید نوع داده، نوع نویز و هدف تحلیل را در نظر بگیرید.
- بهترین راهکار معمولاً این است:کاهش نویز → استفاده از معیارهای مقاوم → انتخاب الگوریتم مقاوم
مدیریت اصولی نویز، پیشنیاز اصلی ساخت مدلهای قابل اعتماد در یادگیری ماشین است.