

مقدمه
در بسیاری از مسائل واقعی یادگیری ماشین، مسئلهی اصلی کشف الگو از دادههای ناشناخته نیست، بلکه یادگیری یک نگاشت قابلاعتماد بین ورودیها و خروجیهای مشخص است. در چنین شرایطی، دادهها همراه با پاسخ درست در اختیار مدل قرار میگیرند و هدف، آموزش مدلی است که بتواند این رابطه را بهگونهای بیاموزد که روی دادههای جدید نیز عملکرد قابلقبولی داشته باشد.
یادگیری نظارتشده (Supervised Learning) چارچوبی است که دقیقاً برای این دسته از مسائل طراحی شده است. در این رویکرد، مدل با مشاهدهی نمونههای برچسبخورده، تلاش میکند تابعی را بیاموزد که اختلاف میان پیشبینیها و مقادیر واقعی را به حداقل برساند. بخش عمدهای از کاربردهای عملی یادگیری ماشین—از تشخیص بیماری و فیلتر اسپم گرفته تا پیشبینی قیمت و تحلیل متن—در این دسته قرار میگیرند.
هدف این مطلب ارائهی یک نگاه ساختیافته و کاربردی به یادگیری نظارتشده است؛ بهگونهای که علاوه بر تعریف مفاهیم پایه و معرفی الگوریتمها، معیارهای انتخاب روش مناسب و محدودیتهای این رویکرد نیز بهصورت شفاف بررسی شوند.
تعریف
یادگیری نظارتشده (Supervised Learning) را میتوان محبوبترین و در عین حال شهودیترین شاخه یادگیری ماشین دانست. اگر بخواهیم آن را در یک جمله خلاصه کنیم، باید بگوییم: یادگیری از طریق مثالهای حلشده. در این روش، ما با یک مربی روبرو هستیم که پاسخهای صحیح را در اختیار سیستم قرار میدهد تا ماشین بتواند بین ورودیها و خروجیها ارتباط برقرار کند.
ماهیت و قلب تپندهای به نام حقیقت مبنا
در یادگیری نظارتشده، ما از دادههای برچسبدار استفاده میکنیم. هر داده شامل یک سری ویژگی (Input) و یک پاسخ قطعی به نام حقیقت مبنا (Ground Truth) است.
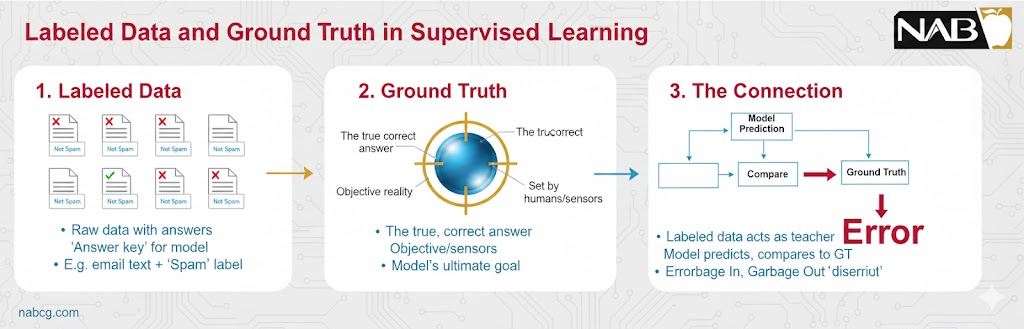
- حقیقت مبنا (Ground Truth) چیست؟ اینها همان پاسخهای صحیحی هستند که توسط انسانهای متخصص یا مشاهدات واقعی تایید شدهاند. در واقع، این دادهها نقش خطکش یا معیار سنجش را دارند تا مدل بفهمد چقدر به واقعیت نزدیک شده است.
- استعاره دانشآموز و مربی: تصور کنید دانشآموزی در حال حل تمرینات ریاضی است. هر تمرین یک سوال (داده ورودی) و انتهای کتاب شامل پاسخنامه (برچسب یا حقیقت مبنا) است. دانشآموز با مقایسه راه حل خود با پاسخنامه، خطاهایش را اصلاح میکند تا در امتحان نهایی (دادههای دیدهنشده) موفق شود.
.
یادگیری نظارتشده چگونه کار میکند؟
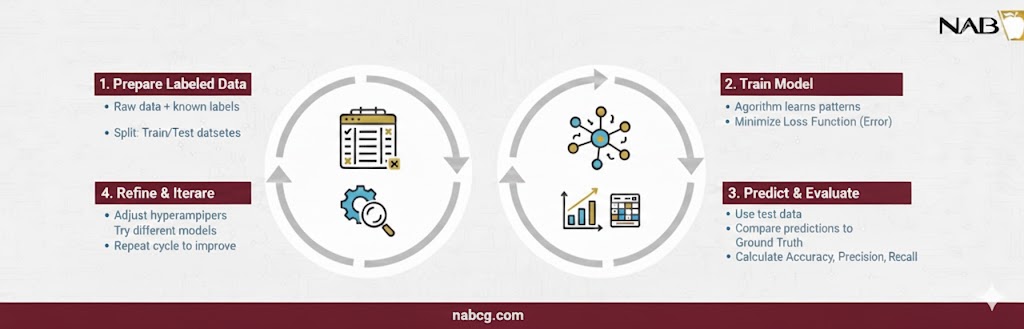
فرآیند آموزش یک چرخه هوشمندانه از خطا و اصلاح است:
- محاسبه خطا (تابع زیان): مدل ابتدا یک پیشبینی انجام میدهد. سپس با استفاده از تابعی به نام تابع زیان، فاصله بین پیشبینی خود و حقیقت مبنا را محاسبه میکند.
- بهینهسازی(SGD): با استفاده از الگوریتمهایی نظیر کاهش گرادیان تصادفی (SGD)، مدل پارامترهای داخلی خود (وزنها) را طوری تغییر میدهد که در تکرار بعدی، میزان خطا کمتر شود.
- کاهش ابعاد: برای اینکه سیستم زیر بار دادههای اضافی و بیاهمیت کمر خم نکند، از تکنیکهای کاهش ابعاد استفاده میکنیم تا فقط ویژگیهای سرنوشتساز و موثر در مدل باقی بمانند.
انواع وظایف در دنیای نظارتشده
الگوریتمهای این حوزه بر اساس خروجی که تولید میکنند، به سه دسته اصلی تقسیم میشوند:
الف) طبقهبندی (Classification)
در اینجا هدف ماشین، قرار دادن دادهها در گروههای مشخص است.
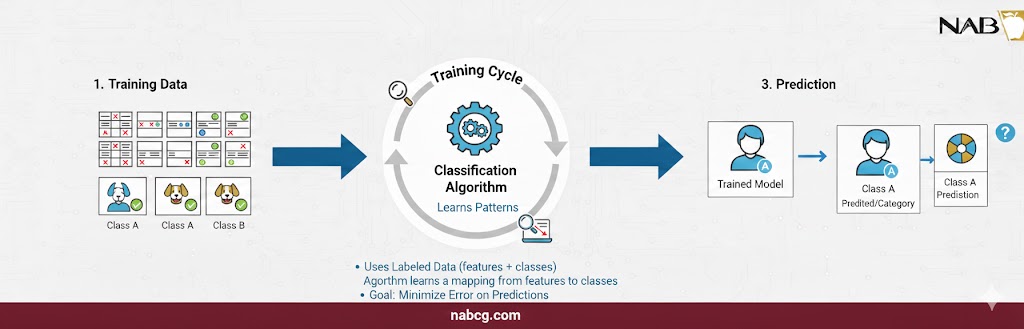
- الگوریتمهای پیشرو: از مدلهای کلاسیک مثل SVM و درخت تصمیم گرفته تا روشهای محبوبی مثل KNN و جنگل تصادفی.
- شبکههای عصبی: ستارههای یادگیری عمیق هستند که با تقلید از ساختار مغز انسان، دادهها را از لایههای مختلف عبور میدهند. هر گره در این شبکه مثل یک کلید عمل میکند؛ اگر دادهها از آستانه مشخصی عبور کنند، گره فعال شده و اطلاعات را به لایه بعد میفرستد.
.
ب) رگرسیون (Regression)؛ پیشبینی اعداد پیوسته
برخلاف طبقهبندی که به دنبال گروه است، رگرسیون به دنبال مقدار میگردد. مثلاً پیشبینی دقیق قیمت یک خانه یا میزان فروش فصل آینده.
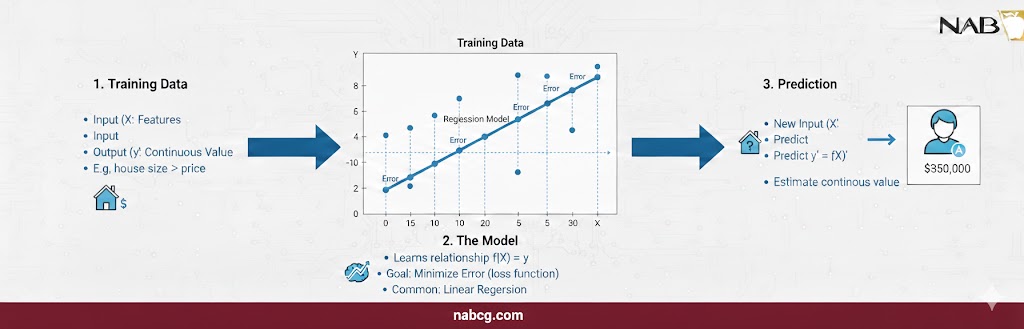
- ابزارهای کلیدی: رگرسیون خطی، Lasso و Ridge که با مدیریت پیچیدگی، دقیقترین تخمین عددی را ارائه میدهند.
.
ج) یادگیری گروهی (Ensemble Learning)؛ قدرتِ اتحاد
گاهی یک مدل به تنهایی کافی نیست. در یادگیری گروهی، ما چندین مدل (یادگیرندههای ضعیف) را با هم ترکیب میکنیم.
- تعادل بایاس و واریانس: جادوی این روش در این است که نقاط ضعف یک مدل (مثلاً خطای زیاد) توسط نقاط قوت مدل دیگر پوشش داده میشود تا در نهایت به یک ابرمدل با کمترین خطای ممکن برسیم.
.
کالبدشکافی نقشه راه یادگیری نظارتشده: کدام الگوریتم برای شما ساخته شده؟
دنیای یادگیری نظارتشده (Supervised Learning) بسیار فراتر از یک پیشبینی ساده است. این حوزه مجموعهای از ابزارهای هوشمند است که هر کدام برای حل گرهای خاص در دنیای دادهها طراحی شدهاند.
- مدلهای خطی
- تحلیل ممیزی خطی و درجه دوم (LDA & QDA)
- رگرسیون ریج هسته (Kernel Ridge Regression)
- ماشینهای بردار پشتیبان (SVM)
- گرادیان کاهشی تصادفی (SGD)
- نزدیکترین همسایگان (Nearest Neighbors)
- فرآیندهای گاوسی (Gaussian Processes)
- تجزیه متقاطع (Cross Decomposition)
- بیز ساده (Naive Bayes)
- درختهای تصمیم (Decision Trees)
- روشهای تجمعی (Ensembles)
- الگوریتمهای چندکلاسه و چندخروجی
- انتخاب ویژگی
- یادگیری نیمهنظارتی (Semi-supervised learning)
- رگرسیون ایزوتونیک (Isotonic regression)
- کالیبراسیون احتمال (Probability calibration)
- مدلهای شبکه عصبی – نظارتشده
.
سه قلمرو اصلی:
۱. ستونهای اصلی: پیشبینی و طبقهبندی
این بخش قلب تپنده یادگیری نظارتشده است؛ جایی که مدلها یاد میگیرند یا یک عدد را حدس بزنند (رگرسیون) یا دادهها را در دستههای مشخص قرار دهند (طبقهبندی).
- مدلهای خطی : این مدلها قهرمانان سرعت و سادگی هستند. اگر فرض کنیم رابطه بین دادهها مثل یک خط راست است، این الگوریتمها بهترین انتخاب برای شروع هستند.
- ماشینهای بردار پشتیبان :وقتی مرز بین دادهها مبهم است، SVM وارد میشود. این مدل با ترسیم دقیقترین مرز ممکن (ابرصفحه)، گروههای مختلف داده را با وسواس زیادی از هم جدا میکند.
- درختهای تصمیم و روشهای تجمعی :این مدلها بر اساس سلسلهمراتبی از سوالات (مثل یک فلوچارت) تصمیم میگیرند. در روشهای پیشرفتهتر مثل جنگل تصادفی، ما لشکری از این درختها را با هم متحد میکنیم تا خطای پیشبینی به حداقل برسد.
- بیز ساده یاNaive Bayes: متخصص احتمالات!. این الگوریتم در تحلیل متن و تشخیص ایمیلهای اسپم، به دلیل سرعت و دقت بالا، رقیب ندارد.
- شبکههای عصبی :پیچیدهترین و جذابترین بخش که با الهام از ساختار مغز انسان ساخته شده است. این لایههای هوشمند، زیربنای اصلی یادگیری عمیق (Deep Learning) را تشکیل میدهند.
.
۲. تکنسینهای پشت صحنه: بهینهسازی و ارتقای مدل
این ابزارها خودشان پیشبینی نمیکنند، بلکه مربیانی هستند که کمک میکنند مدلهای اصلی شما در بالاترین سطح عملکرد قرار بگیرند.
- گرادیان کاهشی تصادفی یاSGD: وقتی با اقیانوسی از دادهها (Big Data) روبرو هستیم، SGD مثل یک موتور توربو عمل میکند تا فرآیند آموزش مدل با سرعتی باورنکردنی انجام شود.
- انتخاب ویژگی یاFeature Selection: ما با حذف دادههای اضافی و نویز، جاده را برای دقت بیشتر مدل صاف میکنیم.
- کالیبراسیون احتمال : این تکنیک تضمین میکند که اگر مدل شما میگوید احتمال بارش باران ۸۰٪ است، این عدد واقعاً با واقعیتِ احتمالات همخوانی داشته باشد، نه اینکه صرفاً یک حدس خوشبینانه باشد.
.
۳. قلمروهای خاص و ترکیبی
گاهی اوقات صورتمسئله ما کمی متفاوت است و نیاز به استراتژیهای خاص دارد:
- یادگیری نیمهنظارتی :راهکار طلایی برای زمانی که برچسبگذاری تمام دادهها گران یا غیرممکن است. در اینجا با داشتن تنها چند پاسخ صحیح، مدل یاد میگیرد از توده عظیمی از دادههای بدون برچسب هم درس بگیرد.
- الگوریتمهای چندخروجی :برای زمانی که یک خروجی کافی نیست! این مدلها میتوانند چندین ویژگی را به صورت همزمان پیشبینی کنند.
انتخاب هوشمندانه الگوریتم، مرز بین شکست و پیروزی است؟
پیدا کردن الگوریتم مناسب در یادگیری نظارتشده بیش از آنکه به «محبوبیت» یک روش وابسته باشد، به ماهیت مسئله، نوع داده و محدودیتهای عملی بستگی دارد. در ادامه، چند معیار کلیدی و توصیهی عملی برای انتخاب الگوریتم ارائه میشود.
1. اندازه و کیفیت داده
- داده کم و ساختیافته:
رگرسیون خطی، Logistic Regression، یا SVM با کرنل ساده اغلب انتخابهای پایدار و قابلتفسیر هستند. - داده زیاد و پیچیده:
در این حالت، مدلهای درختی پیشرفته (Random Forest، Gradient Boosting) یا شبکههای عصبی عملکرد بهتری دارند.
.
2. نوع مسئله (رگرسیون یا طبقهبندی)
- رگرسیون با رابطهی تقریباً خطی:
Linear Regression یا. Ridge/Lasso - طبقهبندی با مرزهای غیرخطی:
SVM، درخت تصمیم، یا شبکههای عصبی.
.
3. تفسیرپذیری مدل
- اگر توضیحپذیری مهم است (مثلاً در پزشکی یا امور مالی):
- رگرسیونها و درخت تصمیم ساده ترجیح داده میشوند.
- اگر دقت نهایی اولویت دارد و تفسیرپذیری ثانویه است:
- Ensembleها یا مدلهای عمیق مناسبترند.
.
4.منابع محاسباتی و زمان
- منابع محدود یا نیاز به آموزش سریع:
- Logistic Regression، Naive Bayes، یا مدلهای خطی.
- منابع کافی و مسئلهی پیچیده:
- Gradient Boosting یا شبکههای عصبی.
.
5. خطر بیشبرازش (Overfitting)
- داده کم + مدل پیچیده → خطر بالا
در این شرایط، استفاده از مدلهای سادهتر یا تنظیم منظمسازی ضروری است.
بهطور خلاصه، انتخاب الگوریتم یک تصمیم مهندسی است، نه یک انتخاب مطلق. شروع با مدلهای ساده و افزایش تدریجی پیچیدگی، در عمل رویکردی مطمئنتر و کمریسکتر محسوب میشود.
.
مقایسه با سایر روشهای یادگیری
یادگیری نظارتشده تنها روش آموزش مدلهای یادگیری ماشین نیست. سایر انواع عبارتند از:
- یادگیری نظارتنشده (Unsupervised)
- یادگیری نیمهنظارتشده (Semi-supervised)
- یادگیری خودنظارتشده (Self-supervised)
- یادگیری تقویتی (Reinforcement Learning)
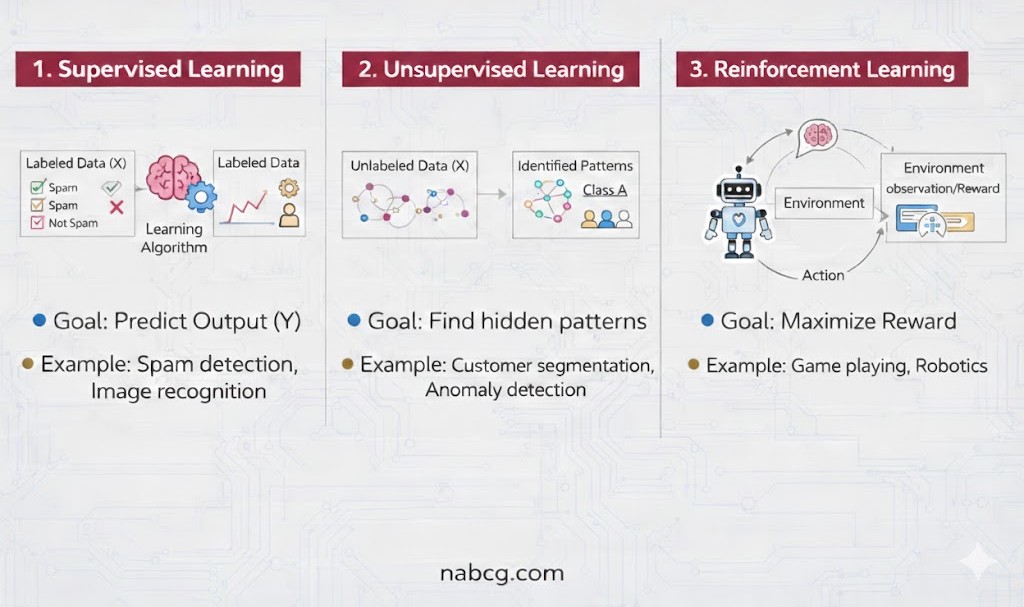
نبرد الگوها: یادگیری نظارتشده در مقابل نظارتنشده
تفاوت کلیدی این دو روش در وجود یا عدم وجود حقیقت مبنا (Ground Truth) نهفته است. در حالی که یادگیری نظارتشده محتاج معلمی است که پاسخهای صحیح را به او دیکته کند، یادگیری نظارتنشده با دادههای بدون برچسب (Unlabeled Data) روبروست و بدون هیچ متر و معیار عینی پیشبرندهای، سفر خود را آغاز میکند.
- اکتشاف خودگردان: در روش نظارتنشده، مدل به حال خود رها میشود تا با جستوجو در دل دادهها، ساختارها، الگوها و روابط پنهانی را که از چشم انسان دور مانده، کشف کند.
- ترکیب برنده در هوش مصنوعی مولد: نکته شگفتانگیز اینجاست که بسیاری از مدلهای پیشرفته هوش مصنوعی مولد (Generative AI)، ابتدا با حجم عظیمی از دادهها به صورت نظارتنشده آموزش میبینند تا الفبای جهان را یاد بگیرند؛ سپس برای رسیدن به تخصص در یک حوزه خاص، تحت نظارت دقیق و یادگیری نظارتشده صیقل داده میشوند.
.
قلمروهای یادگیری نظارتنشده
زمانی که ویژگیهای مشترک در یک دیتاست برای ما نامشخص است، یادگیری نظارتنشده در دو جبهه اصلی به کمک ما میآید:
- خوشهبندی(Clustering): دستهبندی دادههای مشابه در گروههای جداگانه. الگوریتمهای کلاسیکی مثل K-means، مدلهای سلسلهمراتبی و مدلهای مخلوط گاوسی در این بخش حکمرانی میکنند.
- تداعی یا انجمنی(Association): کشف قوانینی که ارتباط بین متغیرها را توضیح میدهند (مثلاً کسانی که محصول الف را میخرند، به احتمال زیاد محصول ب را هم تهیه میکنند)
.
نبرد استراتژیها: یادگیری نظارتشده در برابر یادگیری تقویتی (RL)
در حالی که یادگیری نظارتشده بر پایه الگوبرداری از دادههای گذشته بنا شده، یادگیری تقویتی (Reinforcement Learning) دنیایی متفاوت دارد. در این روش، به جای آموزش مستقیم، ما یک عامل خودگردان (مثل ربات یا خودروی خودران) را در محیطی رها میکنیم تا از طریق تعامل مستمر، تصمیمگیری بهینه را بیاموزد.
- تمایز کلیدی: برخلاف روش نظارتشده، اینجا نیازی به دادههای برچسبدار و پاسخهای از پیش تعیینشده نیست.
- فراتر از الگوها: در مقایسه با یادگیری نظارتنشده، هدف RL فقط کشف ساختارهای پنهان نیست؛ بلکه هدف اصلی، رسیدن به یک هدف خاص است.
- موتور محرک (آزمون و خطا): عامل با هر حرکت خود، یک سیگنال پاداش دریافت میکند؛ او رفتارهای موفق را تقویت و راهبردهای اشتباه را کنار میگذارد تا به بیشترین پاداش ممکن برسد
.
مزایای یادگیری تقویتی
- فتح قلههای پیچیدگی: این روش برای حل چالشهای استراتژیک و پیچیدهای که فرمول مشخصی ندارند، فوقالعاده است.
- یادگیری تجربی (نه تئوری): مدلها به جای تطبیق دادهها، از طریق تجربه واقعی یاد میگیرند.
- هوش خوداصلاحگر: سیستم با هر اشتباه، رفتار خود را دقیقتر و هوشمندتر میکند.
- انعطاف در شرایط متغیر: این مدلها به خوبی میتوانند خود را با اطلاعات جدید و محیطهای پیشبینینشده وفق دهند
.
معایب یادگیری تقویتی
- مستعد نتایج ناپایدار: یادگیری مبتنی بر آزمون و خطا، بهویژه در شروع آموزش، ممکن است تصادفی و غیرقابل پیشبینی به نظر برسد.
- نیاز به دادههای محیطی: یادگیری تقویتی نیازمند این است که مدلها از پیامدهای اقدامات خود درس بگیرند، که این امر مستلزم حجم زیادی از دادههای محیطی است. البته عاملها میتوانند در محیطهای شبیهسازیشده نیز آموزش ببینند.
- هک پاداش: مدلها ممکن است از خلأهای موجود در الگوریتمِ پاداش سوءاستفاده کنند تا بدون انجام صحیح وظایف، پاداش دریافت کنند.
- مختص به وظیفه: یادگیری تقویتی در آموزش مدلها برای یک عملکرد خاص عالی است؛ اما این مدلها ممکن است در انتقال آموختههای خود به وظایف جدید دچار مشکل شوند.
.
یادگیری نظارتشده در برابر یادگیری نیمهنظارتشده
این یادگیری نیمهنظارتشده (Semi-supervised Learning) یک راهکار میانی و بسیار جذاب است. در این روش، مدل با استفاده از یک مجموعه کوچک از دادههای برچسبدار و اقیانوسی از دادههای بدون برچسب آموزش میبیند. این کار مثل این است که به دانشآموز چند مثال حلشده بدهید و سپس از او بخواهید خودش بقیه تمرینها را با الگوبرداری از همان مثالها حل کند.
.
مزایای یادگیری نیمهنظارتشده
- وابستگی کمتر به برچسبگذاری: در مقایسه با روش نظارتشده، به برچسبگذاری کمتری نیاز دارد که موانع ورود برای آموزش مدل را کاهش میدهد.
- کشف الگوهای پنهان: مانند روش نظارتنشده، استفاده از دادههای بدون برچسب در اینجا نیز میتواند منجر به کشف الگوها، روابط و ناهنجاریهایی شود که در غیر این صورت نادیده گرفته میشدند.
- انعطافپذیری بیشتر: این روش با دادههای حقیقت مبنا یک پایه میسازد، سپس آن را با دیتاستهای بدون برچسب تقویت میکند تا مدلها تعمیمپذیرتر شوند.
.
معایب یادگیری نیمهنظارتشده
- · آسیب پذیری در برابر نویز: وجود دادههای بیکیفیت یا نویز در بخش بدون برچسب میتواند عملکرد کل مدل را تضعیف کند.
- · خطر انتقال سوگیری: اگر دادههای اولیه دارای سوگیری باشند، این سوگیری به سرعت به کل مدل سرایت میکند.
- · پیچیدگی محاسباتی: ترکیب دو نوع داده متفاوت در یک فرآیند واحد، به تکنیکهای پردازشی پیشرفته و منابع بیشتری نیاز دارد.
.
یادگیری نظارتشده در برابر یادگیری خودنظارتشده
این یادگیری خودنظارت شده را میتوان انقلابی در هوش مصنوعی دانست که پلی میان یادگیری نظارتشده و نظارتنشده ایجاد کرده است. در این روش، ماشین دیگر منتظر انسان نمیماند تا به او برچسب بدهد؛ بلکه خودش با تحلیل دادههای بدون ساختار، شبهبرچسب تولید کرده و حقیقت را کشف میکند.
چرا یادگیری خودنظارتشده یک تحول است؟
- خودکارسازی برچسبگذاری: به جای صرف زمان توسط متخصصان، خودِ مدل وظیفه ایجاد سیگنالهای نظارتی را بر عهده میگیرد.
- مقیاسپذیری بینهایت: این روش برای کار با استخرهای عظیم دادههای بدون برچسب که در اینترنت وجود دارند، ایدهآل است.
- تطبیقپذیری فوقالعاده: مدلهای SSL ویژگیهای غنی و قابلانتقالی را یاد میگیرند که میتوان آنها را برای وظایف مختلف (Fine-tune) بهینه کرد. این روش به ویژه در بینایی ماشین و پردازش زبان طبیعی (NLP) کاربرد وسیعی دارد.
.
مزایای یادگیری خودنظارتشده
- کارایی: به جای اینکه دانشمندان داده نقاط داده را برچسب بزنند، SSL با محول کردن این وظیفه به مدل، فرآیند برچسبگذاری را خودکار میکند.
- مقیاسپذیری: وابستگی کمتر SSL به برچسبگذاری دستی، آن را برای مقیاسگذاری با استخرهای بزرگترِ دادههای بدون برچسب مناسب میسازد.
- وابستگی کم به برچسبگذاری: در مواردی که دادههای حقیقت مبنای برچسبدار کمیاب هستند، SSL این کمبود را از طریق درکِ تولیدشده توسط خودِ مدل جبران میکند.
- تطبیقپذیری: مدلهای خودنظارتشده ویژگیهای غنی و قابلانتقالی را یاد میگیرند که میتوانند برای بسیاری از وظایف خاصِ دامنه و چندوجهی (Multimodal) تنظیم دقیق (Fine-tune) شوند.
.
معایب یادگیری خودنظارتشده
- محاسبات سنگین: پردازش دیتاستهای بدون برچسب و تولید برچسبها به قدرت محاسباتی زیادی نیاز دارد.
- پیچیدگی: فرآیند ایجاد وظایف پیشتیمار برای یادگیری نظارتشده—که فاز اولیه یادگیری است—نیازمند درجه بالایی از تخصص است.
- احتمال عدم قابلیت اطمینان: همانند سایر روشهای یادگیری ماشین که فاقد نظارت انسانی هستند، خروجیهای این مدلها بهشدت به کیفیت دادهها وابسته است؛ وجود نویز، سوگیری پنهان یا سایر تحریفات در داده میتواند منجر به تصمیمات گمراهکننده یا ناعادلانه شود.
.
موارد کاربرد واقعی یادگیری نظارتشده
یادگیری نظارتشده صرفاً یک مفهوم تئوری نیست؛ بلکه موتوری است که بسیاری از تکنولوژیهای روزمره ما را هدایت میکند. این مدلها با پیشبینیهای دقیق و اتوماسیون تصمیمگیری، نهتنها برنامههای تجاری را طراحی میکنند، بلکه بهطور پویا آنها را ارتقا میدهند.
در ادامه، مهمترین کاربردهای واقعی این فناوری را بررسی میکنیم:
۱. تشخیص تصویر و اشیاء (Image & Object Recognition)
الگوریتمهای یادگیری نظارتشده در مکانیابی، جداسازی و دستهبندی اشیاء در ویدیوها یا تصاویر تخصص دارند. این ویژگی آنها را به ابزاری حیاتی برای وظایف بینایی ماشین و تحلیل تصویر تبدیل کرده است.
۲. تحلیلهای پیشبینیکننده (Predictive Analytics)
سازمانها با استفاده از مدلهای نظارتشده، سیستمهای تحلیلی میسازند که بینشهای عمیقی ارائه میدهند. این امر به مدیران اجازه میدهد نتایج را بر اساس متغیرهای خروجی پیشبینی کرده و تصمیمات دادهمحور بگیرند.
- مثال پزشکی: رگرسیون به پزشکان کمک میکند تا ریسک ابتلا به بیماریها را بر اساس دادههای بیولوژیکی و سبک زندگی بیمار پیشبینی کنند.
۳. تحلیل احساسات مشتری (Sentiment Analysis)
شرکتها میتوانند با حداقل دخالت انسانی، اطلاعات مهمی شامل زمینه، احساس و نیت مشتری را از حجم انبوه دادهها استخراج کنند. این تحلیل باعث درک بهتر تعاملات مشتری و بهبود ارتباط با برند میشود.
۴. بخشبندی هوشمند مشتریان
مدلهای رگرسیون با تحلیل رفتارهای تاریخی و ویژگیهای مختلف، رفتار آینده مشتری را پیشبینی میکنند. کسبوکارها از این مدلها برای ایجاد پرسونای خریدار و بهبود استراتژیهای بازاریابی استفاده میکنند.
۵. تشخیص هرزنامه (Spam Detection)
این یکی از کلاسیکترین کاربردهای یادگیری نظارتشده است. با آموزش الگوریتمهایی مثل Naive Bayes یا Logistic Regression روی دادههای برچسبدار، سیستم یاد میگیرد الگوهای متنی اسپم را شناسایی کرده و ایمیلها را بهطور خودکار دستهبندی کند.
.
چالشهای اصلی یادگیری نظارتشده
مسیر پیادهسازی یادگیری نظارتشده با سنگاندازهایی روبروست که میتواند کارایی پروژه را تحتتأثیر قرار دهد:
- نیاز مبرم به تخصص فنی بالا: طراحی و ساختاردهی صحیح این مدلها فرآیندی پیچیده است. سازمانها برای خروجی گرفتن از این روش، ناچار به استخدام نیروی انسانی متخصص با مهارتهای فنی خاص هستند.
- وابستگی همیشگی به نظارت انسان: این مدلها برخلاف برخی روشهای دیگر، توانایی خودآموزی مستقل ندارند. دانشمندان داده باید به صورت مستمر بر خروجیها نظارت کرده و عملکرد مدل را به صورت دستی اعتبارسنجی کنند.
- پاشنه آشیلی به نام زمان: بزرگترین مانع این روش، نیاز به برچسبگذاری دستی (Manual Labeling) دادههاست. آمادهسازی یک مجموعهداده آموزشی بزرگ و دقیق، فرآیندی بسیار طولانی، خستهکننده و هزینهبر محسوب میشود.
- سختگیری و عدم انعطافپذیری: مدلهای نظارتشده به شدت به چارچوب دادههای آموزشی خود وابستهاند. اگر با دادههایی خارج از آن چارچوب روبرو شوند، برخلاف مدلهای نظارتنشده که سازگارتر هستند، عملاً فلج میشوند.
- بیشبرازش(Overfitting): این یکی از رایجترین مشکلات است؛ جایی که مدل به جای یادگیری الگوها، جزئیات و نویزهای دادههای آموزشی را حفظ میکند. در این شرایط، مدل در مرحله آموزش دقت خیرهکنندهای دارد اما در دنیای واقعی و مواجهه با دادههای جدید شکست میخورد.
.
جمع بندی
یادگیری نظارتشده یکی از بنیادیترین و پرکاربردترین چارچوبهای یادگیری ماشین است و بخش بزرگی از مسائل عملی دنیای واقعی را پوشش میدهد. در این رویکرد، وجود دادههای برچسبخورده امکان تعریف دقیق هدف، ارزیابی عملکرد و بهینهسازی سیستم را فراهم میکند.
در این مطلب دیدیم که یادگیری نظارتشده تنها به انتخاب یک الگوریتم محدود نمیشود، بلکه شامل مجموعهای از تصمیمهای بههمپیوسته است: انتخاب دادهی مناسب، تعیین معیار خطا، کنترل بیشبرازش و در نهایت انتخاب مدلی که با محدودیتهای مسئله همخوانی داشته باشد. همچنین مشخص شد که هیچ الگوریتمی بهطور ذاتی «بهترین» نیست و کیفیت نتیجه، به میزان زیادی به تناسب روش انتخابشده با مسئله بستگی دارد.
با وجود رشد روشهای نوین مانند یادگیری خودنظارتی و تقویتی، یادگیری نظارتشده همچنان ستون اصلی بسیاری از سیستمهای هوشمند باقی مانده است. تسلط بر این رویکرد، پایهای ضروری برای درک روشهای پیشرفتهتر و طراحی سیستمهای یادگیری ماشین قابلاعتماد و قابلاستفاده در مقیاس واقعی بهشمار میآید.



