

1 .چکیده
با افزایش فزاینده حجم دادههای مکانی و ابعاد ویژگیها، کشف خوشههایی با اشکال هندسی بسیار پیچیده و مرزهای نامنظم به یکی از چالشهای اساسی یادگیری بدون نظارت تبدیل شده است. الگوریتمهای سنتی چگالیمحور یا شبکهای کلاسیک، علیرغم کارایی اولیه، در مواجهه با مجموعهدادههای حاوی نویز شدید و الگوهای متداخل دچار افت تند کارایی میشوند. مقاله حاضر به بررسی تحلیلی الگوریتم WaveCluster میپردازد که به عنوان رویکردی پیشگام، فرآیند خوشهبندی مبتنی بر شبکه را با تئوری پردازش سیگنال و تبدیل موجک پیوند داده است.
در این نوشتار تبیین میشود که چگونه WaveCluster با تبدیل فضای گسسته ویژگیها به یک سیگنال چندبعدی و اعمال فیلترهای فرکانسی، نویزها را حذف کرده و هستههای اصلی خوشهها را در مقیاسهای مختلف استخراج میکند. هدف این مقاله، تشریح لایههای ریاضی، مفاهیم فیلترهای مبرد، مثالهای محاسباتی و پیادهسازی عملی آن در پایتون است. نتایج بررسیها نشان میدهد که WaveCluster با ارائه پیچیدگی زمانی خطی O(n) و مقاومت استثنایی در برابر نویز، ابزاری فوقالعاده کارآمد برای تحلیل کلاندادههای فضایی ارمغان میآورد.
2 .مقدمه
در قلمرو یادگیری ماشین و دادهکاوی، استخراج الگوهای پنهان هندسی از مجموعهدادههای ساختارنیافته بدون داشتن دانش قبلی، سنگ بنای تحلیلهای استراتژیک و توسعه سیستمهای هوشمند است (Hand et al., 2001). این ابزار تحلیلی، لایه زیرساخت تصمیمگیریهای کلان در سازمانهای مبتنی بر داده را تشکیل میدهد. با این حال، هنگامی که با کلاندادههای فضایی آلوده به نویز مواجه هستیم که خوشههای آن مرزهایی درهمتنیده و نامنظم دارند، رویکردهای کلاسیک با محدودیتهای بنیادین روبرو میشوند.
الگوریتمهای چگالیمحور نظیر DBSCAN اگرچه توانایی کشف اشکال نامنظم را دارند، اما وابستگی شدید آنها به تنظیم ابرپارامترهای مسافتی، پردازش را در فضاهای چندچگالی با خطا مواجه میکند (Ester et al., 1996). از سوی دیگر، روشهای مبتنی بر شبکه نظیر STING اگرچه وابستگی محاسباتی به تعداد نقاط را حل کردهاند، اما به دلیل اتکا به مرزهای صلب و مستطیلی سلولها، در تفکیک دقیق لبههای متمایل و خوشههای تو در تو دچار ضعف هندسی هستند (Wang et al., 1997). برای عبور از این بنبستهای محاسباتی، پارادایم نوآورانه پیوند دادهکاوی با علم پردازش سیگنال پدید آمد. الگوریتم WaveCluster مظهر این تحول ساختاری است (Sheikholeslami et al., 1998). این متدولوژی با نگاهی متمایز، توزیع نقاط داده در فضا را به عنوان یک سیگنال دیجیتال فرکانسی مدلسازی میکند.
هدف این مقاله، کالبدشکافی معماری الگوریتم WaveCluster به عنوان یک رویکرد چندمقیاسی سیگنالمحور است که مرزهای بهینه خوشهها را مستقل از شکل هندسی آنها استخراج میکند. نقشه راه این نوشتار به این صورت تنظیم شده که ابتدا مفاهیم پایه و ضرورت وجودی این الگوریتم را تبیین میکنیم. سپس مبانی ریاضی تبدیل موجک گسسته و سازوکار فیلترهای فرکانسی آن را تشریح خواهیم کرد. در ادامه، مباحث را با مثالهای محاسباتی، کاربردهای صنعتی و پیادهسازی کامل پایتون ملموستر کرده و با مقایسه ساختاری این روش با مدلهای همرده، دیدگاهی جامع ارائه میدهیم.
3 .تعریف و مفهوم پایه
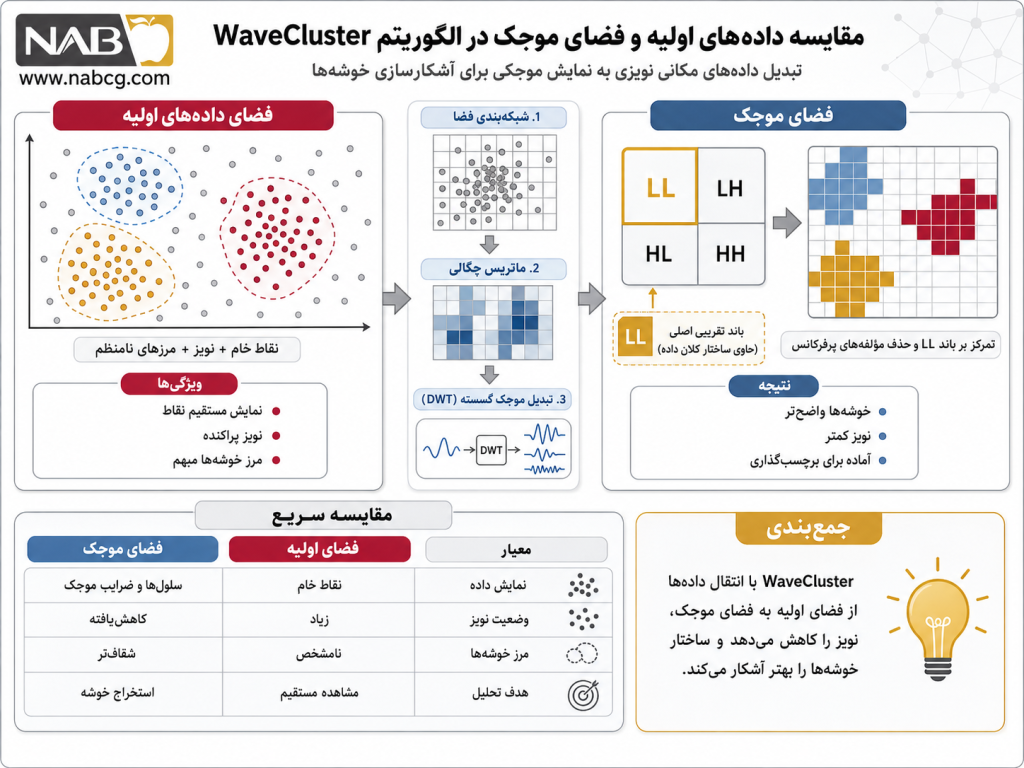
الگوریتم WaveCluster یک الگوریتم خوشهبندی مبتنی بر شبکه و فرکانس (Grid-based Signal Clustering) است که توزیع فضایی دادهها را به عنوان یک فرآیند موجی یا سیگنال چندبعدی تلاقی میدهد (Sheikholeslami et al., 1998). منطق بنیادین این الگوریتم بر این اصل استوار است که نقاط داده در نواحی متراکم، فرکانسهای پایین و همگرا ایجاد میکنند، در حالی که نقاط پرت و نویزها به عنوان سیگنالهای فرکانس بالا و ناپیوسته ظاهر میشوند. این الگوریتم ابتدا فضای ویژگی را به یک شبکه سلولی گسسته تقسیم کرده و فرکانس (تعداد نقاط) هر سلول را ثبت میکند. سپس، با اعمال تبدیل موجک گسسته (Discrete Wavelet Transform) بر روی این شبکه، ساختار چگالی فضا را فشرده کرده و مرزهای اصلی خوشهها را در سطوح مختلف تفکیکپذیری (Multi-resolution) بازسازی میکند (Han et al., 2011).
برای درک شهودی این مفهوم، یک تصویر دیجیتال سیاه و سفید تار را تصور کنید. اگر به پیکسلهای تصویر (سلولهای شبکه) نگاه کنید، لبههای اشیاء ممکن است به دلیل نویز نوری ناواضح باشند. تبدیل موجک در WaveCluster مانند یک فیلتر هوشمند پردازش تصویر عمل میکند؛ این فیلتر ابتدا با بخش پایینگذر خود، نویزهای پراکنده (نقاط تک و پرت) را تار و حذف میکند تا بدنه اصلی اشیاء (خوشهها) برجسته شود، و سپس با بخش بالاگذر خود، مرزها و لبههای دقیق هندسی اشیاء را با ظرافت استخراج میکند. در نهایت، سیستم مربعهای متراکم متصل به هم را به عنوان خوشههای نهایی به کاربر تحویل میدهد.
4. اهمیت و ضرورت الگوریتم WaveCluster
مسئله اساسی و بسیار حیاتی که الگوریتم WaveCluster برای حل آن ابداع شد، ناتوانی سیستماتیک مدلهای سنتی دادهکاوی در تفکیک خوشههایی با اشکال هندسی فوقالعاده پیچیده (مانند خوشههای درهمتنیده، حلقوی و موازی) در محیطهای آلوده به نویز شدید است (Kriegel et al., 2011). ضرورت وجودی WaveCluster از این چالش سرچشمه میگیرد که در مسائل واقعی، نویزها صرفاً در حاشیه دادهها قرار ندارند، بلکه گاهی به طور فشرده فضای بین دو خوشه متمایز را پر میکنند.
به عنوان نمونه، در تحلیل تصاویر رادار، سنجشهای فضایی اخترشناسی، یا شناسایی الگوهای متداخل زیستمحیطی، دادههای پرت به شدت با مرز خوشهها تداخل دارند. اگر تحلیلگر از الگوریتم DBSCAN استفاده کند، نویزهای متراکم بین دو خوشه مانند یک پل عمل کرده و مدل را فریب میدهند تا دو خوشه کاملاً مجزا را در یکدیگر ادغام کند. ضرورت استراتژیک WaveCluster در این است که با تغییر نگرش از هندسه اقلیدسی به فضای فرکانس و موج، این پلهای نویزی را به راحتی قطع میکند (Sheikholeslami et al., 1998).
این الگوریتم با بهرهگیری از خاصیت گسستهسازی فضا، سرعت پاسخگویی را به مرتبه خطی O(n) میرساند که برای سیستمهای کلانداده یک ضرورت مطلق است (Han et al., 2011). اهمیت این ابزار زمانی بیش از پیش آشکار میشود که سازمانها برای تصمیمگیریهای حساس خود به ابزاری نیاز دارند که بدون سانسور کردن بخشهای کمتراکم داده یا خراب کردن بخشهای فشرده، واقعیترین هندسه توزیع الگوها را در سطوح مختلف انقباض و انبساط فرکانسی استخراج کند.
5. مبانی نظری و ریاضی
بنیان نظری الگوریتم WaveCluster بر اصول آنالیز هارمونیک، تبدیلهای فرکانسی چندمقیاسی و معماری فضایی گسسته استوار است (Sheikholeslami et al., 1998). مأموریت ریاضی این روش، انتقال توزیع نقاط از فضای هندسی اقلیدسی به فضای فرکانس موجک است تا مرزهای پیچیده متمایز کننده خوشهها بر اساس ناپیوستگیهای سیگنال استخراج شوند (Han et al., 2011). برای درک چرایی ریاضی این الگوریتم، ابتدا باید نحوه معادلسازی دادهها به سیگنال و سپس توابع فیلترینگ موجک را صورتبندی کرد.
۵.۱. تبدیل فضای مکان به سیگنال چندبعدی
مجموعه داده فضایی ورودی شامل نقاطی در یک فضای ویژگی چندبعدی است. در ریاضیات WaveCluster، ابتدا فضا به وسیله یک شبکه گسسته مپ میشود (Sheikholeslami et al., 1998). اگر فضا را به صورت سلولهای متقاطع d-بعدی کوانتیده کنیم، هر سلول با مختصات گسسته c = (c1, c2, …, cd) مشخص میشود.
تابع سیگنال ورودی، که با f(c) نشان داده میشود، برابر است با تعداد نقاط دادهای که درون مرزهای هندسی سلول c قرار گرفتهاند (Tan et al., 2018). به بیان آکادمیک، فضای اقلیدسی پیوسته به یک سیگنال دیجیتال گسسته چندبعدی تبدیل میشود که دامنه آن در هر نقطه، نمایانگر چگالی موضعی دادهها است.
۵.۲. فیلترینگ و آنالیز چندمقیاسی موجک (Multi-Resolution)
مجموعه سلولهای شبکه (f(c)) به عنوان ورودی به تبدیل موجک گسسته (DWT) تزریق میشوند. هدف تبدیل موجک، تجزیه این سیگنال به دو بخش عمده یعنی مؤلفههای تقریب (فرکانسهای پایین) و مؤلفههای جزئیات (فرکانسهای بالا) است (Sheikholeslami et al., 1998).
در فضای یکبعدی، تبدیل سیگنال دادهها با استفاده از یک تابع مقیاس (Scaling Function) و یک تابع موجک مادر (Mother Wavelet) صورتبندی میشود. در پیادهسازیهای استاندارد، فیلترهای هرتز به صورت دو فیلتر مکمل ریاضی زیر تعریف میشوند (Han et al., 2011):
فیلتر پایینگذر (Low-pass Filter – H)
این فیلتر کارکرد هموارسازی (Smoothing) سیگنال را بر عهده دارد و میانگین چگالی محلی را محاسبه میکند:
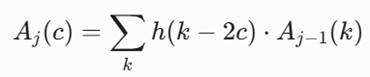
تعریف متغیرها و پارامترها:
- Aj (c): سیگنال تقریب (Approximation) یا چگالی فشردهشده در سطح تفکیکپذیری j.
- h(k): ضرایب ریاضی فیلتر پایینگذر (وابسته به نوع موجک انتخابی مانند هار یا دابیشیز).
- Aj-1 (k): سیگنال لایه قبلی (در لایه اول، همان سیگنال اولیه سلولها f(c) است).
- 2c: نماد ریاضی فرآیند کاهش نمونه (Downsampling) که فضا را فشرده میکند.
فیلتر بالاگذر (High-pass Filter – G)
این فیلتر وظیفه استخراج نوسانات تند، ناپیوسته و تغییرات لبهای سیگنال چگالی را بر عهده دارد:
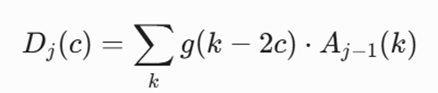
تعریف متغیرها و پارامترها:
- Dj (c): سیگنال جزئیات (Detail) که نوسانات فرکانس بالا را در سطح j ثبت میکند.
- g(k): ضرایب ریاضی فیلتر بالاگذر که رابطه مستقیم با فیلتر پایینگذر دارد (g(k) = (-1)^k . h(1-k)).
چرایی ریاضی فیلترینگ: در فضای دو بعدی، این فیلترها به صورت ضرب دکارت ترکیب شده و چهار زیرباند ریاضی (LL, LH, HL, HH) ایجاد میکنند. لایه LL (اعمال همزمان دو فیلتر پایینگذر) قلب تپنده تفکیک خوشهها است؛ چرا که اعمال این فیلتر باعث میشود نقاط پرت و نویزها به دلیل فرکانس بالایشان حذف شده و هستههای متراکم به درههای چگالی پایدار و پیوسته تبدیل شوند (Sheikholeslami et al., 1998).
۵.۳. تئوری تشخیص لبه و مرزهای هندسی آزاد
بنیان نظری استخراج خوشههای با اشکال آزاد در WaveCluster بر پایه شناسایی نقاط عطف تغییر چگالی استوار است (Sheikholeslami et al., 1998). بر اساس ریاضیات موجک، ضرایب بالاگذر (LH, HL) متناظر با مشتقهای مرتبه اول و دوم فضایی سیگنال چگالی هستند.
وقتی الگوریتم ضرایب موجک را در سطوح مختلف مقیاس (j) ارزیابی میکند، مرز هندسی یک خوشه به عنوان یک ناپیوستگی تند در فرکانس سیگنال تعریف میشود. فرض پایه ریاضی بر این است که کانونهای خوشهای، کانتورهای متصلی از ضرایب تقریب بالا در باند LL ایجاد میکنند که مرزهای بهینه آنها دقیقاً در نقاط صفر شدن مشتق فضایی (قلههای فیلتر بالاگذر) تثبیت میگردد (Han et al., 2011). این ویژگی به مدل اجازه میدهد بدون اتکا به ساختارهای صلب کروی یا مستطیلی، هرگونه هندسه پیچیده و منحنی را به طور دقیق ردیابی کند.
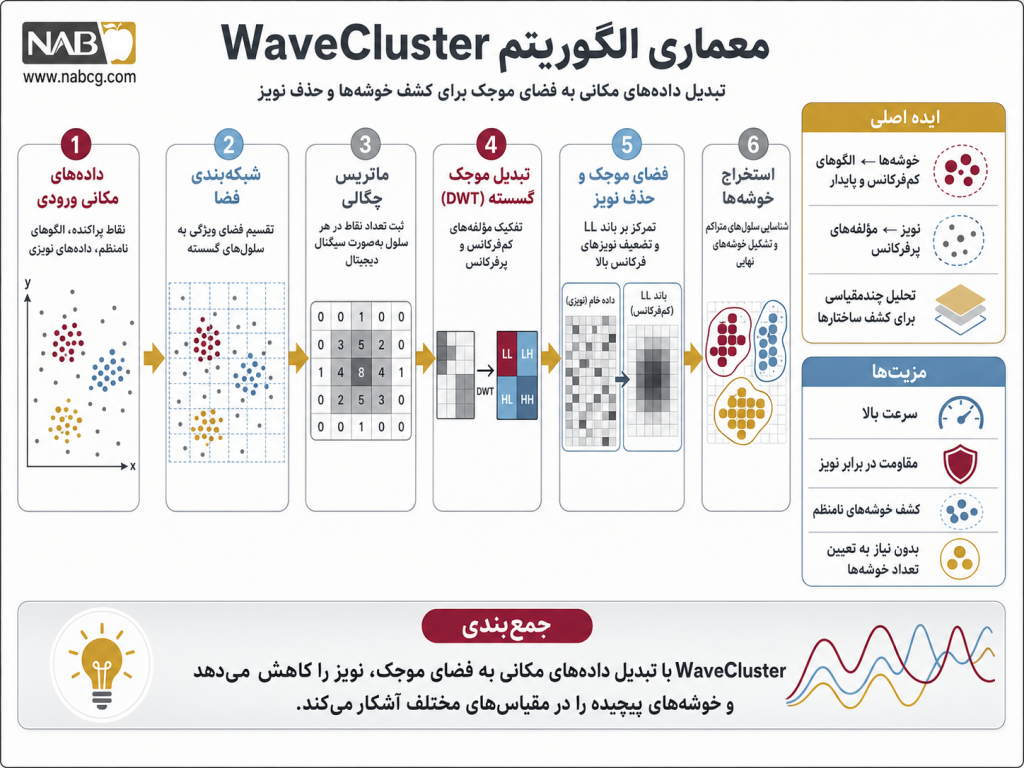
6. مراحل اجرای گام به گام الگوریتم WaveCluster
جریان دادهها در این الگوریتم، یک مسیر مشخص پنجمرحلهای را برای رسیدن به خروجی نهایی طی میکند:
- گام اول: کوانتیدهسازی و ساخت شبکه (Quantization): در فاز ورودی، فضای ویژگیهای پیوسته به سلولهای گسسته مستطیلی (شبکه) تقسیم میشود. با قرار گرفتن نقاط داده درون این سلولها، فرآیند شمارش فرکانسی انجام شده و تعداد نقاط هر سلول به عنوان دامنه سیگنال در آن مختصات ثبت میشود.
- گام دوم: اعمال تبدیل موجک گسسته (Wavelet Transform): سیگنال گسسته حاصل از گام اول، تحت آنالیز چندمقیاسی موجک قرار میگیرد. با اعمال فیلترهای ریاضی، فضا فشرده شده و دادهها به لایههای فرکانسی مختلف تجزیه میشوند.
- گام سوم: فیلترینگ و حذف نویز (Noise Removal): بر اساس تئوری فرکانس، الگوریتم به سراغ زیرباند LL (سیگنال تقریب) میرود. در این مرحله، نقاط نویز و دادههای پرت که دارای فرکانس بالا هستند به طور خودکار فیلتر و حذف میشوند و ساختار کانونهای متراکم به درههای چگالی شفاف تبدیل میگردد.
- گام چهارم: شناسایی سلولهای متراکم (Finding Connected Components): الگوریتم در لایه فشردهشده موجک، سلولهایی که دامنه سیگنال آنها از یک حد آستانه مشخص بالاتر است را به عنوان «سلولهای متراکم» یا هسته خوشهها علامتگذاری میکند.
- گام پنجم: نگاشت معکوس و برچسبگذاری (Mapping Back): در گام نهایی، سلولهای متراکم همسایه که به یکدیگر متصل هستند، به عنوان خوشههای متمایز برچسبگذاری میشوند. سپس سیستم با یک نگاشت معکوس، نقاط داده اولیه موجود در فضای اقلیدسی را بر اساس این که در قلمرو کدام سلول موجک قرار گرفتهاند، رنگآمیزی کرده و به عنوان خروجی نهایی به کاربر تحویل میدهد.
معیار توقف الگوریتم: فرآیند اجرای Wave Cluster کاملاً قطعی و بدون تکرار (Non-iterative) است. معیار توقف در این روش، اتمام فاز نگاشت معکوس و برچسبگذاری تکتک نقاط داده است؛ یعنی الگوریتم پس از یکبار طی کردن خطی مراحل، به طور خودکار خاتمه مییابد.
۷. مثالهای عددی الگوریتم WaveCluster
در این بخش، برای درک دقیقتر مبانی ریاضی و سازوکار اجرایی الگوریتم WaveCluster، دو مثال عددی ارائه میشود. این مثالها نشان میدهند که چگونه دادههای مکانی ابتدا به یک سیگنال شبکهای تبدیل میشوند، سپس با استفاده از تبدیل موجک گسسته فیلتر میشوند و در نهایت سلولهای متراکم متصل به عنوان خوشه نهایی استخراج میگردند.
هدف این بخش آن است که ارتباط میان سه مفهوم اصلی WaveCluster روشن شود:
- کوانتیدهسازی فضای داده و تبدیل نقاط به سیگنال چگالی
- اعمال تبدیل موجک و استخراج باند تقریب LL
- شناسایی سلولهای متراکم، حذف نویز و تشکیل خوشه نهایی
مثال ۱: تبدیل دادههای مکانی به سیگنال شبکهای و اعمال موجک هار
صورت مسئله
فرض کنید یک فضای دوبعدی با ابعاد ۴ × ۴ داریم. این فضا را به یک شبکه ۴ × ۴ از سلولهای مربعی واحد تقسیم میکنیم. مجموعه نقاط داده به صورت زیر است:
| نقطه | مختصات |
| P1 | (0.2, 0.3) |
| P2 | (0.6, 0.7) |
| P3 | (1.2, 0.4) |
| P4 | (1.5, 0.8) |
| P5 | (2.8, 2.9) |
| P6 | (3.1, 3.0) |
| P7 | (3.4, 3.5) |
| P8 | (0.1, 3.7) |
هدف این مثال، اجرای دو گام اول WaveCluster است:
- تبدیل فضای پیوسته نقاط به ماتریس چگالی شبکهای
- اعمال فیلتر پایینگذر موجک هار و استخراج باند تقریب LL
گام ۱: ساخت شبکه و شمارش نقاط در سلولها
فضا به ۴ ردیف و ۴ ستون تقسیم میشود. هر سلول، تعداد نقاطی را ذخیره میکند که داخل محدوده آن قرار گرفتهاند.
برای سادهسازی، هر مختصات به پایینترین عدد صحیح خود نگاشت میشود. برای مثال:

با شمارش نقاط، ماتریس چگالی اولیه به صورت زیر به دست میآید:
| ردیف/ستون | C0 | C1 | C2 | C3 |
| R0 | 2 | 2 | 0 | 0 |
| R1 | 0 | 0 | 0 | 0 |
| R2 | 0 | 0 | 1 | 0 |
| R3 | 1 | 0 | 0 | 2 |
پس سیگنال شبکهای اولیه برابر است با:

در این ماتریس، هر عدد نشاندهنده دامنه سیگنال چگالی در یک سلول است.
گام ۲: اعمال فیلتر پایینگذر موجک هار در جهت افقی
در موجک هار، فیلتر پایینگذر به صورت زیر است:
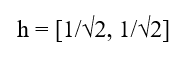
برای سادهسازی محاسبات آموزشی، میتوان اثر پایینگذر را به شکل میانگینگیری دوتایی در نظر گرفت. بنابراین هر دو سلول مجاور با هم ترکیب میشوند.
- ردیف اول:
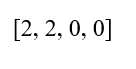

- ردیف دوم:
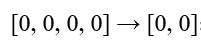
- ردیف سوم [0, 1, 0, 0]:

- ردیف چهارم [2, 0, 0, 1] :

ماتریس پس از فیلتر پایینگذر افقی:

گام ۳: اعمال فیلتر پایینگذر در جهت عمودی و استخراج باند LL
اکنون روی ستونهای ماتریس H نیز میانگینگیری دوتایی انجام میدهیم.

.

بنابراین باند تقریب LL به صورت زیر است:

گام ۴: تفسیر باند LL
باند LL نسخه فشرده و هموارشده سیگنال چگالی اولیه است. در این باند، نوسانهای کوچک و ناگهانی کاهش یافتهاند و ساختارهای چگالتر بهتر دیده میشوند.
اگر حد آستانه چگالی را برابر با 0.7 در نظر بگیریم:
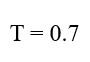
سلولهایی که مقدار آنها بزرگتر یا مساوی 0.7 باشد، به عنوان نواحی متراکم پذیرفته میشوند.
بررسی مقادیر LL:
| سلول در LL | مقدار | وضعیت |
| LL [0,0] | 1 | متراکم |
| LL [0,1] | 0 | غیرمتراکم |
| LL [1,0] | 0.25 | غیرمتراکم |
| LL [1,1] | 0.75 | متراکم |
پس دو ناحیه متراکم شناسایی میشود:
LL [0,0]
LL [1,1]
پاسخ نهایی :
ماتریس چگالی اولیه:

باند تقریب پس از تبدیل موجک:

سلولهای متراکم با آستانه :T = 0.7
LL[0,0] و LL[1,1]
تفسیر نتیجه
در این مثال، الگوریتم WaveCluster ابتدا نقاط پراکنده را به یک سیگنال شبکهای تبدیل کرد. سپس با اعمال فیلتر پایینگذر موجک هار، فضای داده فشرده و هموار شد. در نتیجه، نقاط منفرد و نوسانهای کوچک تأثیر کمتری پیدا کردند و فقط نواحی دارای چگالی پایدار در باند LL باقی ماندند.
این مثال نشان میدهد که WaveCluster چگونه به جای محاسبه فاصله میان تکتک نقاط، ساختار چگالی داده را از طریق تبدیل موجک تحلیل میکند.
مثال ۲: اجرای کامل WaveCluster؛ حذف نویز، اتصال سلولها و تشکیل خوشه نهایی
صورت مسئله
در این مثال، میخواهیم یک اجرای کاملتر از منطق WaveCluster را بررسی کنیم. فرض کنید پس از کوانتیدهسازی و اعمال تبدیل موجک روی یک مجموعه داده دوبعدی، باند تقریب LL و باند جزئیات HH به صورت زیر به دست آمدهاند.
باند تقریب :LL

باند جزئیات :HH

در این مثال، منطق تصمیمگیری الگوریتم به صورت زیر تعریف میشود:
- اگر مقدار سلول در باند LL بزرگتر یا مساوی 8 باشد، سلول از نظر چگالی قابل قبول است.
- اگر مقدار سلول در باند HH کمتر یا مساوی 3 باشد، سلول از نظر نویز قابل قبول است.
- تنها سلولهایی وارد خوشه میشوند که هر دو شرط را همزمان داشته باشند.
بنابراین:
TLL = 8
THH = 3
گام ۱: بررسی شرط چگالی در باند LL
ابتدا بررسی میکنیم کدام سلولها در باند LL مقدار کافی دارند.
| موقعیت سلول | مقدار LL | وضعیت چگالی |
| (1,1) | 12 | قابل قبول |
| (1,2) | 11 | قابل قبول |
| (1,3) | 2 | رد |
| (1,4) | 1 | رد |
| (2,1) | 10 | قابل قبول |
| (2,2) | 13 | قابل قبول |
| (2,3) | 3 | رد |
| (2,4) | 2 | رد |
| (3,1) | 1 | رد |
| (3,2) | 2 | رد |
| (3,3) | 9 | قابل قبول |
| (3,4) | 8 | قابل قبول |
| (4,1) | 0 | رد |
| (4,2) | 1 | رد |
| (4,3) | 8 | قابل قبول |
| (4,4) | 10 | قابل قبول |
پس از نظر چگالی، سلولهای زیر پذیرفته میشوند:
(1,1), (1,2), (2,1), (2,2), (3,3), (3,4), (4,3), (4,4)
گام ۲: بررسی شرط نویز در باند HH
اکنون باید ببینیم از میان سلولهای بالا، کدامها مقدار HH قابل قبول دارند.
شرط نویز:
HH ≤ 3
بررسی سلولهای منتخب:
| موقعیت سلول | LL | HH | نتیجه |
| (1,1) | 12 | 1 | پذیرفته |
| (1,2) | 11 | 2 | پذیرفته |
| (2,1) | 10 | 2 | پذیرفته |
| (2,2) | 13 | 1 | پذیرفته |
| (3,3) | 9 | 2 | پذیرفته |
| (3,4) | 8 | 1 | پذیرفته |
| (4,3) | 8 | 1 | پذیرفته |
| (4,4) | 10 | 2 | پذیرفته |
همه سلولهایی که از نظر چگالی مناسب بودند، از نظر نویز نیز قابل قبول هستند.
گام ۳: ساخت نقشه سلولهای فعال
اکنون یک ماتریس دودویی میسازیم. در این ماتریس:
- عدد 1 یعنی سلول وارد خوشه میشود.
- عدد 0 یعنی سلول حذف میشود.
ماتریس فعالسازی:

این ماتریس نشان میدهد که دو ناحیه متراکم و پایدار در داده وجود دارد.
گام ۴: اتصال سلولهای مجاور و تشکیل خوشهها
در نهایت، الگوریتم WaveCluster سلولهای فعال را به فضای اولیه دادهها نگاشت میکند. نقطهای که در محدوده سلولهای خوشه اول قرار گرفته باشد، برچسب خوشه اول میگیرد. هر نقطهای که در محدوده سلولهای خوشه دوم قرار گرفته باشد، برچسب خوشه دوم میگیرد.
در ماتریس A، سلولهای فعال بالا-چپ عبارتاند از:
(1,1), (1,2), (2,1), (2,2)
این سلولها به صورت مستقیم با یکدیگر همسایه هستند. بنابراین خوشه اول را تشکیل میدهند:
Cluster 1 = {(1,1), (1,2), (2,1), (2,2)}
سلولهای فعال پایین-راست عبارتاند از:
(3,3), (3,4), (4,3), (4,4)
این سلولها نیز به صورت مستقیم با یکدیگر همسایه هستند. بنابراین خوشه دوم را تشکیل میدهند:
Cluster 2 = {(3,3), (3,4), (4,3), (4,4)}
بین خوشه اول و خوشه دوم هیچ اتصال چهارجهتهای وجود ندارد؛ پس الگوریتم آنها را دو خوشه مستقل در نظر میگیرد.
گام ۵: نگاشت معکوس به فضای داده اصلی
در گام نهایی، الگوریتم WaveCluster سلولهای فعال را به فضای اولیه دادهها نگاشت میکند. هر نقطهای که در محدوده سلولهای خوشه اول قرار گرفته باشد، برچسب خوشه اول میگیرد. هر نقطهای که در محدوده سلولهای خوشه دوم قرار گرفته باشد، برچسب خوشه دوم میگیرد.
نقاطی که در سلولهای غیرفعال قرار دارند، به عنوان نویز یا نقاط خارج از خوشه شناسایی میشوند.
بنابراین:
- نقاط داخل سلولهای Cluster 1 → برچسب خوشه ۱
- نقاط داخل سلولهای Cluster 2 → برچسب خوشه ۲
- نقاط داخل سلولهای صفر ماتریس A → نویز یا داده نامرتبط
پاسخ نهایی :
ماتریس فعالسازی نهایی:

خوشههای استخراجشده:
Cluster 1 = {(1,1), (1,2), (2,1), (2,2)}
Cluster 2 = {(3,3), (3,4), (4,3), (4,4)}
سلولهای حذفشده:
همه سلولهایی که مقدار فعالسازی آنها برابر صفر است.
تفسیر نتیجه
این مثال اجرای کامل منطق WaveCluster را نشان میدهد. ابتدا باند LL برای تشخیص چگالی پایدار استفاده شد. سپس باند HH برای کنترل نویز و حذف نوسانات فرکانس بالا به کار رفت. بعد از آن، سلولهای واجد شرایط در قالب یک ماتریس فعالسازی مشخص شدند و سلولهای مجاور، خوشههای نهایی را تشکیل دادند.
نکته مهم این است که الگوریتم برای تشکیل خوشهها به محاسبه فاصله مستقیم میان نقاط نیاز نداشت. تصمیمگیری اصلی بر اساس ساختار سیگنال شبکهای و ضرایب موجک انجام شد. به همین دلیل، WaveCluster در دادههای مکانی بزرگ و نویزی میتواند سریعتر از بسیاری از روشهای فاصلهمحور عمل کند.
.
8. کاربردهای واقعی الگوریتم WaveCluster
الگوریتم WaveCluster به دلیل بهرهگیری از فیلترهای فرکانسی و پایداری هندسی، در طیف وسیعی از صنایع و پژوهشهای مدرن کاربرد دارد (Sheikholeslami et al., 1998):
- بینایی ماشین و بخشبندی تصاویر دیجیتال: شناسایی بافتها و تفکیک مرزهای مبهم و نامنظم در تصاویر ماهوارهای و پزشکی چندطیفی.
- تحليل پدیدههای نجومی و کیهانشناسی: کشف و دستهبندی خوشههای ستارهای پیچیده و توزیع کهکشانها در حجمهای عظیمی از دادههای تصویربرداری تلسکوپی.
- دادهکاوی دادههای چندرسانهای و وب: دستهبندی ویژگیهای استخراجشده از ویدیوها و فایلهای صوتی کلان بر اساس مؤلفههای فرکانسی پنهان.
- جرمشناسی و کشف الگوهای جرم در جغرافیا: شناسایی کانونهای جرمخیز شهری با الگوهای توزیع غیرخطی و جداسازی رخدادهای تصادفی به عنوان نویز.
- تحلیل الگوهای بازار و وفاداری چندلایه: خوشهبندی رفتارهای خرید مشتریان متداخل با چگالیهای ناهمگن بدون ادغام ناخواسته کانونهای نزدیک به هم.
.
9. مزایا الگوریتم WaveCluster
نقاط قوت ساختاری الگوریتم WaveCluster استانداردهای جدیدی را در استخراج الگوهای فضایی ایجاد کرده است (Han et al., 2011; Sheikholeslami et al., 1998):
- سرعت پردازش استثنایی (پیچیدگی زمانی خطی): به دلیل عدم اتکا به محاسبات مسافتی زوجبهجفت و اجرای فرآیند خوشهبندی در زمان O (n)، بازدهی فوقالعادهای در دیتابیسهای کلان دارد.
- دقت بالا در کشف اشکال هندسی آزاد: این روش محدودیتی در ردیابی شکل خوشهها ندارد و ساختارهای تو در تو، حلقوی و هلالشکل را به خوبی تفکیک میکند.
- مقاومت بینظیر در برابر دادههای پرت: فیلترهای بالاگذر موجک به طور ذاتی نویزهای محیطی متداخل بین خوشهها را مسدود و پاکسازی میکنند.

- قابلیت آنالیز چندمقیاسی (Multi-resolution): ابزار موجک به تحلیلگران اجازه میدهد دادهها را در سطوح مختلف از تفکیکپذیری ریز تا کلان پایش کنند.
- عدم نیاز به حدس تعداد خوشهها: مدل بدون دریافت تعداد کانونها (k)، ساختارهای واقعی دیتابیس را به طور خودکار کشف و استخراج مینماید.
.
10. محدودیتها و معایب الگوریتم WaveCluster
با وجود مزایای فرکانسی، بررسی چالشهای عملیاتی این متدولوژی برای کاربردهای صنعتی بسیار حیاتی است (Kriegel et al., 2011; Sheikholeslami et al., 1998):
- نفرین ابعاد در فاز کوانتیدهسازی: با افزایش تعداد ویژگیها (ابعاد بالا)، تعداد سلولهای شبکه به صورت نمایی رشد کرده (O (2^d)) و سیستم دچار بحران شدید حافظه میشود.
- وابستگی فاحش به ابعاد رزولوشن شبکه: انتخاب اندازه نامناسب سلولها پایداری مدل را نابود میکند؛ سلولهای بیش از حد بزرگ خوشهها را ادغام کرده و سلولهای کوچک ساختار پیوسته را تکهتکه میکنند.
- حساسیت به نوع موجک مادر: خروجی و شکل مرز خوشهها به شدت تحت تأثیر نوع تابع موجک انتخابی (مانند Haar یا Daubechies) قرار دارد که نیازمند تخصص بالای اپراتور است.
- فقدان مدل پیشبینی برای دادههای جریانی: این روش ماهیتی قطعی و ایستا دارد؛ لذا با ورود دیتای جدید، فرآیند تبدیل موجک کل فضا باید مجدداً بازنویسی و اجرا شود.
.
11.مقایسه الگوریتم WaveCluster با روشهای مشابه
در جدول زیر، فریمورک ساختاری WaveCluster با دو الگوریتم همرده و کلیدی یادگیری بدون نظارت مقایسه شده است (Aggarwal, 2014; Tan et al., 2018):
| شاخص مقایسه | الگوریتم WaveCluster | الگوریتم STING | الگوریتم DBSCAN |
| پارادایم تحلیلی | تبدیل فرکانسی و موجک (Signal) | خلاصههای آماری سلسلهمراتب | سنجش پیوستگی چگالی مسافتی |
| پیچیدگی زمانی | O(n) (بسیار سریع و خطی) | O(k) (وابسته به لایه پایینی شبکه) | O(n \log n) یا O(n^2) (سنگین) |
| هندسه مرز خوشهها | اشکال آزاد، نامنظم و هلالشکل | بلوکهای سلولی متصل (مرز صلب) | اشکال نامنظم و پیوسته طبیعی |
| مقاومت در برابر نویز | عالی (حذف خودکار با فیلتر) | متوسط (وابسته به توازن آمار لایهها) | عالی (جداسازی صلب نویزها) |
| مقیاسپذیری ابعاد (d) | ضعیف (محدود به ابعاد پایین) | ضعیف (محدود به ابعاد پایین) | خوب و پایدار |
| نیازهای حافظهای | ماتریس فرکانسی شبکه سلولها | شناسنامههای آماری ثابت سلولها | کل نقاط داده در حافظه اصلی |
12. نوآوریها و چشمانداز آینده الگوریتم WaveCluster
تکامل مهندسی فرکانس مسیرهای نوآورانهای را در آینده الگوریتم WaveCluster ترسیم کرده است (Kriegel et al., 2011):
- ترکیب با خودرمزگذارهای کانولوشنی (Deep Wavelet Clustering): کاهش ابعاد دادههای بسیار پیچیده به کمک شبکههای عصبی عمیق و سپس اعمال WaveCluster روی فضاهای پنهان جهت غلبه بر نفرین ابعاد.
- توسعه موجکهای انطباقی فضا (Adaptive Wavelets): طراحی فیلترهایی که اندازه سلولهای شبکه را بر اساس چگالی موضعی دادهها تغییر میدهند تا خطای مرزهای صلب مرتفع شود.
- موازیسازی در ساختارهای کلانداده توزیعشده: بازنویسی فرمولهای DWT چندبعدی بر روی پلتفرمهای ابری (مانند Apache Spark) برای تحلیل همزمان سیگنالهای مکانی گستره ملی.
.
13 .ابزارها و فریمورکهای مرتبط
به دلیل ماهیت سیگنالمحور این متدولوژی، پیادهسازی بهینه آن نیازمند ابزارهایی است که از محاسبات ماتریسی چندبعدی پشتیبانی کنند:
کتابخانه PyClustering (زبان پایتون و C++)
- کاربرد و مزیت: این کتابخانه معتبرترین ابزار متنباز پایتون است که الگوریتم WaveCluster را به صورت بومی پشتیبانی میکند. به دلیل توسعه هسته مرکزی آن با زبان C++، عملیات کوانتیدهسازی و تحلیل فرکانسی سلولها را با بالاترین سرعت ممکن انجام میدهد.
ماژول PyWavelets (زبان پایتون)
- کاربرد و مزیت: فریمورک تخصصی برای آنالیز موجک در پایتون. این ابزار به مهندسان داده اجازه میدهد انواع موجکهای مادر (مانند Haar, Daubechies, Symlets) را با توابع بهینهشده فیلترینگ بر روی ماتریسهای شبکهای اعمال نمایند.
.
14 .پیادهسازی عملی در پایتون
تبیین مسئله و آمادهسازی دادهها
هدف از این پیادهسازی عملی، بهکارگیری منطق فیلترینگ سیگنال برای استخراج خوشههای نامنظم هندسی در محیطهای شدیداً آلوده به نویز است. برای شبیهسازی این چالش صنعتی، مجموعهدادهای حاوی دو خوشه هلالشکل متداخل پدید میآوریم که فضای خالی میان آنها با حجم بالایی از دادههای پرت (نویز سراسری) اشغال شده است.
الگوریتمهای سنتی مبتنی بر فاصله در این سناریو به دلیل وجود پلهای نویزی دچار خطای ادغام میشوند. برای حل این مسئله، فضا را به یک شبکه گسسته کوانتیده تبدیل کرده (نگاشت دامنهها) و با اعمال تبدیل موجک دو بعدی، نویزهای فرکانس بالا را فیلتر میکنیم تا ساختار خوشهها آشکار شود.
کد کامل پایتون
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
import pywt # کتابخانه تخصصی آنالیز و تبدیل موجک در پایتون
# ۱. تعریف پالت رنگی اختصاصی بر اساس هویت بصری مستندات ناب
COLOR_PALETTE = {
'active_gold': '#FFD700', # طلایی زنده برای نمایش سلولهای خوشهای متراکم
'ai_soft_blue': '#4682B4', # آبی روشن هوش مصنوعی برای نمایش نقاط داده اولیه
'crimson': '#DC143C', # زرشکی برای نمایش نقاط نویز و کانتور لبهها
'metal_silver': '#C0C0C0', # نقرهای متالیک برای مرزهای سلولی شبکه گسسته
'ultra_light_gray': '#F5F5F5', # خاکستری خیلی روشن برای پسزمینه نمودارها
'pure_white': '#FFFFFF' # سفید خالص برای پسزمینه اصلی پنجره
}
# ۲. آمادهسازی و ساخت مجموعهداده غیرخطی (موشکافی دو هلال متداخل + نویز شدید سراسری)
np.random.seed(42)
moons_data, _ = make_moons(n_samples=600, noise=0.1, random_state=42)
# مقیاسگذاری هندسی دادهها برای انطباق با مرزهای مثبت شبکه (محدوده ۰ تا ۱۰)
X_spatial = (moons_data - moons_data.min(axis=0)) / (moons_data.max(axis=0) - moons_data.min(axis=0)) * 8 + 1
# تزریق نویزهای تصادفی یکنواخت در سراسر فضای ویژگی
global_noise = np.random.uniform(low=0, high=10, size=(150, 2))
X_final = np.vstack([X_spatial, global_noise])
# ۳. گام اول عملکرد: کوانتیدهسازی فضا و تبدیل مکان به دامنه سیگنال دیجیتال
grid_resolution = 16 # ساخت شبکه ماتریسی ۱۶ در ۱۶ از سلولهای فضا
grid_signal = np.zeros((grid_resolution, grid_resolution))
for point in X_final:
x_idx = min(int(point[0] / 10 * grid_resolution), grid_resolution - 1)
y_idx = min(int(point[1] / 10 * grid_resolution), grid_resolution - 1)
if 0 <= x_idx < grid_resolution and 0 <= y_idx < grid_resolution:
grid_signal[x_idx, y_idx] += 1 # ثبت فرکانس حضور نقاط به عنوان دامنه سیگنال
# ۴. گام دوم و سوم عملکرد: اعمال تبدیل موجک دو بعدی گسسته (DWT) جهت هرس فرکانسهای بالا
# استفاده از موجک مادر کلاسیک هار (Haar) برای تحلیل هموارسازی
coeffs = pywt.dwt2(grid_signal, 'haar')
LL_band, (LH, HL, HH) = coeffs # استخراج باند فرکانس پایین LL و باندهای فرکانس بالا
# ۵. گام چهارم: اعمال حد آستانه آماری روی باند تقریب LL جهت فیلتر نهایی نویز
amplitude_threshold = 2.5
significant_cells = LL_band >= amplitude_threshold
# ۶. تصویرسازی خروجیها و فرآیند خوشهبندی سیگنال در دو لایه مستقل
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 7), facecolor=COLOR_PALETTE['pure_white'])
# تنظیم استایل عمومی پسزمینه صفحات نمودار
for ax in [ax1, ax2]:
ax.set_facecolor(COLOR_PALETTE['ultra_light_gray'])
ax.grid(True, color=COLOR_PALETTE['metal_silver'], linestyle='--', alpha=0.4)
# الف) رسم نمودار فضای اقلیدسی اولیه (نقاط خام آلوده به نویز)
ax1.scatter(X_final[:, 0], X_final[:, 1], c=COLOR_PALETTE['ai_soft_blue'], s=25, alpha=0.7, label='Spatial Points with Noise')
ax1.set_title('Original Spatial Data Domain', fontsize=13, fontweight='bold')
ax1.set_xlabel('Spatial Feature X1', fontsize=11)
ax1.set_ylabel('Spatial Feature X2', fontsize=11)
ax1.set_xlim(0, 10)
ax1.set_ylim(0, 10)
ax1.legend(loc='upper left')
# ب) رسم نقشه چگالی حاصل از باند تقریب فرکانسی موجک (LL Subband)
# سلولهای متراکم تایید شده با رنگ طلایی زنده و کانتور زرشکی مرزبندی میشوند
im = ax2.imshow(LL_band.T, origin='lower', cmap='YlOrRd', extent=[0, 10, 0, 10], alpha=0.6)
ax2.contour(significant_cells.T, extent=[0, 10, 0, 10], colors=COLOR_PALETTE['crimson'], linewidths=2.0)
# برجستهسازی کانونهای اصلی تایید شده با پالت طلایی زنده
for i in range(significant_cells.shape[0]):
for j in range(significant_cells.shape[1]):
if significant_cells[i, j]:
ax2.plot(i * (10/grid_resolution * 2) + 0.6, j * (10/grid_resolution * 2) + 0.6,
marker='s', color=COLOR_PALETTE['active_gold'], markersize=8, alpha=0.5)
ax2.set_title('WaveCluster Feature Space (LL Subband)', fontsize=13, fontweight='bold')
ax2.set_xlabel('Wavelet Dimension 1', fontsize=11)
ax2.set_ylabel('Wavelet Dimension 2', fontsize=11)
ax2.set_xlim(0, 10)
ax2.set_ylim(0, 10)
plt.suptitle('WaveCluster Algorithmic Pipeline: From Spatial Points to Wavelet Resolution', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.show()
خروجی:
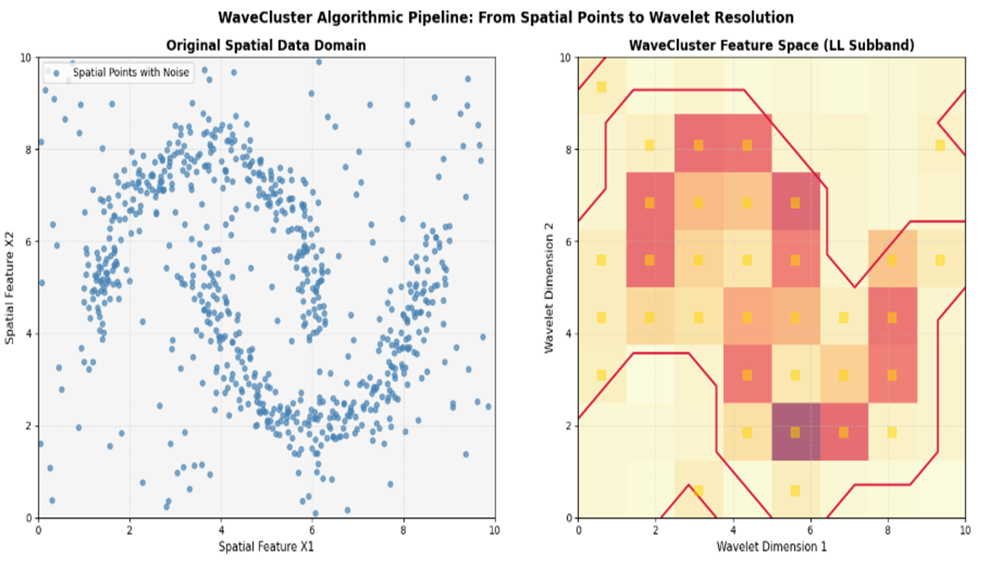
نمایش و تفسیر نتایج عملی
پس از اجرای اسکریپت مهندسی فوق، دو فاز متناظر ورودی و خروجی الگوریتم در کنار یکدیگر پدیدار میشوند:
تفسیر نمودار سمت چپ (Original Spatial Data Domain)
نمودار اول، نمایی عینی از بحران کلاندادههای نویزی جهان واقعی است. نقاط آبی روشن هوش مصنوعی در قالب دو ساختار هلالی شکل توزیع شدهاند، اما به دلیل تزریق ذرات نویز تصادفی، مرز خالی مابین دو هلال کاملاً مسدود شده است. در این وضعیت هندسی، هرگونه خطکش محاسباتی مبتنی بر فواصل اقلیدسی صلب آسیب دیده و نقاط پرت را به عنوان پل ارتباطی خوشهها شناسایی میکند.
تفسیر نمودار سمت راست (WaveCluster Feature Space – LL Subband)
نمودار دوم، جادوی تئوری آنالیز چندمقیاسی موجک را اثبات میکند. پس از گسستهسازی و اعمال فیلتر پایینگذر بر روی ماتریس فرکانسی، کل تغییرات ناگهانی و نقاط تکافتاده (نویزها) به علت فرکانس بالایشان توسط فیلتر مسدود و مستهلک شدهاند.
- حوزههایی که با پالت طلایی زنده (Active Gold) علامتگذاری شده و با کانتورهای زرشکی (Crimson) محصور گردیدهاند، مناطقی هستند که چگالی پایداری را در باند تقریب احراز کردهاند.
- این ساختار درخشان نشان میدهد که WaveCluster چگونه توانسته بدون درگیر شدن با محاسبات فواصل تکتک نمونهها، هندسه هلالی شکل و درهمتنیده خوشهها را به صورت تودههای سلولی متصل به هم بازسازی کند. این نتیجه عینی، راندمان خطی تثبیتشده این متدولوژی را در محیطهای کلانداده به اثبات میرساند.
.
15. مطالعه موردی:بخشبندی تصاویر نجومی و تفکیک ساختار کهکشانهای درهمتنیده
الگوریتم WaveCluster در پروژههایی که دادههای آن ماهیت سیگنالی داشته و با نویز بالا گره خوردهاند، کارایی استثنایی دارد.
۱۵.۱. سناریوهای واقعی در صنعت
- پایشهای زیستمحیطی و راداری: خوشهبندی تودههای گردوغبار موضعی متداخل با نویز باد.
- بیوانفورماتیک و تصویربرداری سلولی: جداسازی مرز لکههای میکروسکوپی درهمتنیده با نویزهای نوری لایه زیرین.
۱۵.۲. تحلیل مسئله و پیادهسازی بر روی دادههای واقعی
مسئله: یک رصدخانه بینالمللی میخواهد ساختار دو کهکشان بیضیشکل و متداخل را از روی خروجی عددی پیکسلهای تلسکوپ استخراج کند. نویز نوری پسزمینه (Cosmic Noise) فضای مابین این دو اجرام آسمانی را پر کرده و مرزها را مبهم ساخته است. روشهای کلاسیک به دلیل وجود نویز متراکم، دو کهکشان را یکپارچه فرض میکنند.
راهکار: با کوانتیدهسازی فضا به یک ماتریس فرکانسی و اعمال فیلتر دو بعدی موجک بر روی دیتای واقعی پیکسلها، نویزهای فرکانس بالا را حذف و بدنه اصلی الگوها را با پالت طلایی زنده عایقسازی میکنیم:
import numpy as np
import matplotlib.pyplot as plt
import pywt
# ۱. شبیهسازی دیتای واقعی پیکسلهای نجومی (مختصات فضایی دو جرم متداخل + نویز کیهانی)
np.random.seed(101)
galaxy_core_A = np.random.normal(loc=[3.5, 3.5], scale=0.5, size=(350, 2))
galaxy_core_B = np.random.normal(loc=[5.5, 5.5], scale=0.6, size=(300, 2))
cosmic_noise = np.random.uniform(low=0, high=10, size=(200, 2))
X_space = np.vstack([galaxy_core_A, galaxy_core_B, cosmic_noise])
# ۲. فاز پیشپردازش WaveCluster: رزولوشن شبکه و شمارش دامنه سیگنال
resolution = 20
grid_data = np.zeros((resolution, resolution))
for pt in X_space:
x_idx = min(int(pt[0] / 10 * resolution), resolution - 1)
y_idx = min(int(pt[1] / 10 * resolution), resolution - 1)
if 0 <= x_idx < resolution and 0 <= y_idx < resolution:
grid_data[x_idx, y_idx] += 1
# ۳. فاز فرکانسی: اعمال DWT هار و فیلترینگ با حد آستانه آماری
LL, _ = pywt.dwt2(grid_data, 'haar')
activated_mask = LL >= 3.0
# ۴. تصویرسازی کانونهای کهکشانی کشفشده
PALETTE = {'gold': '#FFD700', 'blue': '#4682B4', 'gray': '#F5F5F5', 'silver': '#C0C0C0'}
fig, ax = plt.subplots(figsize=(8, 6), facecolor='white')
ax.set_facecolor(PALETTE['gray'])
ax.scatter(X_space[:, 0], X_space[:, 1], c=PALETTE['blue'], alpha=0.4, s=15, label='Telescope Raw Pixels')
# ترسیم لایه سیگنال تقریب تایید شده
for i in range(LL.shape[0]):
for j in range(LL.shape[1]):
if activated_mask[i, j]:
ax.plot(i * 1.0 + 0.5, j * 1.0 + 0.5, marker='s', color=PALETTE['gold'], markersize=10, alpha=0.6)
ax.set_title('Astronomy Segmentation: WaveCluster Galaxy Separation', fontsize=12, fontweight='bold')
ax.set_xlabel('Right Ascension (RA)', fontsize=10)
ax.set_ylabel('Declination (DEC)', fontsize=10)
ax.legend(loc='upper left')
plt.tight_layout()
plt.show()
خروجی:
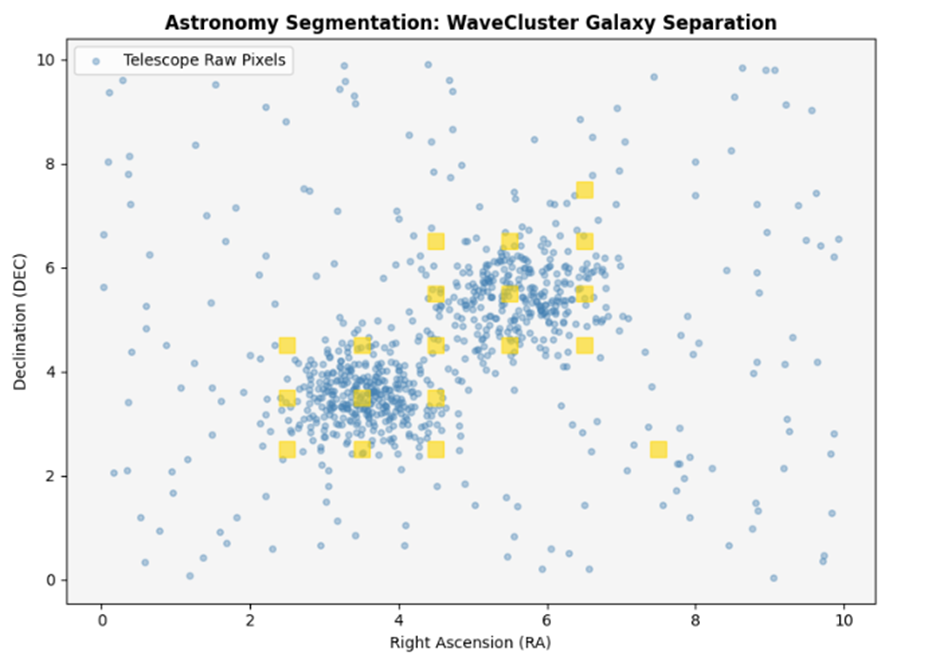
۱۵.۳. تفسیر نتایج و درسآموختهها
خروجی نقشه با موفقیت نشان میدهد که WaveCluster بدون تأثیرپذیری از نویزهای متراکم پسزمینه، هسته مرکزی دو کهکشان را مستقل از یکدیگر ایزوله و رنگآمیزی کرده است.
درسآموختههای کلیدی:
- برتری آنالیز فرکانسی: این پروژه ثابت کرد انتقال از دایره اقلیدسی به فضای موجک، توانایی تفکیک مرزهای درهمتنیده را به شدت افزایش میدهد.
- کاهش فرسایش پردازش: فیلتر خودکار نویزها، گامهای اضافه برای پاکسازی دیتابیس را حذف کرده و راندمان زمانی سیستم را بهینه میسازد.
.
16. جمعبندی
الگوریتم WaveCluster با پیوند دادن مفاهیم دادهکاوی فضایی و اصول پردازش سیگنال، یک راهکار متمایز و پیشگام را برای کشف ساختارهای پنهان در یادگیری بدون نظارت معرفی کرد. این مقاله تبیین نمود که چگونه این متدولوژی با جابهجایی محاسبات از فضای هندسی اقلیدسی به فضای فرکانس موجک، بنبست تحلیلی الگوریتمهای سنتی را در مواجهه با خوشههایی با اشکال هندسی بسیار پیچیده و مرزهای نامنظم به طور ریشهای برطرف میسازد.
پاسخ نهایی این روش به مسئله اصلی مقاله، غلبه بر نویزهای فشرده متداخل و تفکیک خوشههای تو در تو در زمان خطی است. ارزش بنیادین WaveCluster در ویژگی فیلترینگ ذاتی تبدیل موجک گسسته (DWT) نهفته است که به صورت خودکار نویزهای فرکانس بالا را در لایه تقریب هرس میکند. این معماری منحصربهفرد، سرعت و مقیاسپذیری سیستم را کاملاً مستقل از تعداد نقاط داده و ساختارهای چگالی یکنواخت صلب حفظ مینماید. با توجه به محدودیت این روش در مواجهه با ابعاد بسیار بالا، به عنوان مسیر پیشنهادی برای توسعه عملی و پژوهشهای آینده، توصیه میشود متخصصان حوزه علم داده، ادغام فاز کوانتیدهسازی شبکه را با خودرمزگذارهای عمیق (Deep Autoencoders) جهت فشردهسازی ویژگیها پیش از اعمال فیلتر فرکانسی مورد تحقیق قرار دهند.
17. منابع
Aggarwal, C. C. (2014). Data Classification: Algorithms and Applications. CRC Press.
Ankerst, M., Breunig, M. M., Kriegel, H. P., & Sander, J. (1999). OPTICS: Ordering points to identify the clustering structure. ACM SIGMOD Record, 28(2), 49-60.
Ester, M., Kriegel, H. P., Sander, J., & Xu, X. (1996). A density-based algorithm for discovering clusters in large spatial databases with noise. Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96), 96(34), 226-231.
Hand, d. J., Mannila, H., & Smyth, P. (2001). Principles of Data Mining. MIT Press.
Han, J., Kamber, M., & Pei, J. (2011). Data Mining: Concepts and Techniques (3rd ed.). Morgan Kaufmann.
Kriegel, H. P., Kröger, P., Sander, J., & Zimek, A. (2011). Density-based clustering. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 1(3), 231-240.
Sheikholeslami, G., Chatterjee, S., & Zhang, A. (1998). WaveCluster: A wavelet-based clustering approach for spatial data mining. Proceedings of the 24th International Conference on Very Large Data Bases (VLDB), 428-439.
Tan, P. N., Steinbach, M., Karpatne, A., & Kumar, V. (2018). Introduction to Data Mining (2nd ed.). Pearson.
Wang, W., Yang, J., & Muntz, R. (1997). STING: A statistical information grid approach for spatial data mining. Proceedings of the 23rd International Conference on Very Large Data Bases (VLDB), 186-195.



