

1.مقدمه
در بسیاری از مسائل تحلیلی و تصمیمگیری، هدف صرفاً پیشبینی یک مقدار نیست، بلکه اندازهگیری دقیق اثر متغیرها بر یکدیگر است. زمانی که میخواهیم بدانیم یک عامل مشخص تا چه حد بر یک خروجی تأثیر گذاشته و این تأثیر تا چه اندازه قابل اتکا و قابل دفاع است، نیاز به روشی داریم که هم از نظر آماری معتبر باشد و هم تفسیرپذیری روشنی ارائه دهد.
روش حداقل مربعات معمولی (Ordinary Least Squares یا OLS) یکی از بنیادیترین و پرکاربردترین ابزارها برای پاسخ به این نیاز است. این روش با کمینهسازی مجموع مربعات خطاها، ضرایبی را برآورد میکند که بهترین تقریب خطی از رابطهی میان متغیرهای مستقل و متغیر هدف را فراهم میسازند. اهمیت OLS تنها به سادگی محاسباتی آن محدود نمیشود؛ بلکه بهدلیل ویژگیهای آماری شناختهشده، پایهی بسیاری از تحلیلهای کلاسیک اقتصادسنجی، علوم اجتماعی، پزشکی و یادگیری ماشین محسوب میشود.
هدف این مطلب ارائهی یک بررسی جامع و ساختیافته از OLS است؛ از تعریف و شهود اولیه گرفته تا فرمبندی ریاضی، فرضیات اساسی، پیادهسازی عملی و محدودیتها. تمرکز اصلی بر این است که روشن شود OLS در چه شرایطی انتخابی مناسب و قابل دفاع است و در چه موقعیتهایی باید با احتیاط یا همراه با روشهای تکمیلی از آن استفاده کرد.
2.تعریف
حداقل مربعات معمولی (OLS) یک تکنیک بهینهسازی ریاضی و برآورد آماری است که به عنوان سنگبنای تحلیلهای رگرسیون خطی شناخته میشود. این متد با هدف مدلسازی رابطه بین یک متغیر وابسته (هدف) و یک یا چند متغیر مستقل (پیشبین) طراحی شده است.
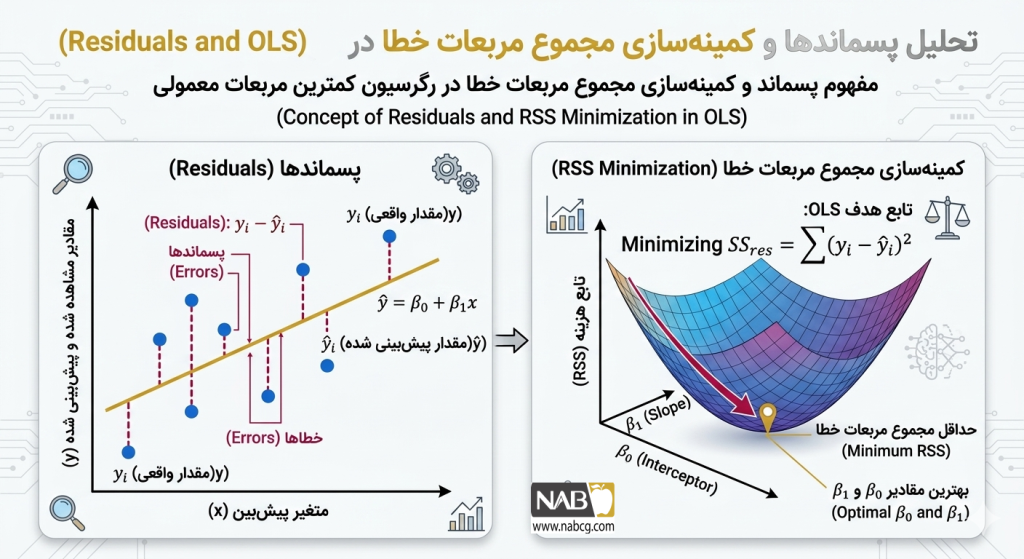
در یک تعریف دقیقتر، OLS فرآیندی است که در آن ضرایب مدل خطی بهگونهای تخمین زده میشوند که مجموع مربعات باقیماندهها (Sum of Squared Residuals) به حداقل برسد. باقیمانده یا پسماند، در واقع اختلاف عمودی بین مقدار واقعی مشاهده شده و مقدار پیشبینی شده توسط مدل است.
3. حداقل مربعات معمولی (OLS)چگونه کار میکند؟
فرض بنیادین در حداقل مربعات معمولی (OLS)این است که جهان از یک منطق خطی پیروی میکند. یعنی تغییر در ورودی، با یک نسبت ثابت باعث جابجایی در خروجی میشود.
فرمول:
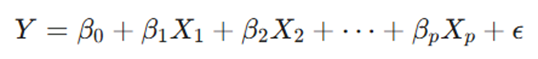
- y (متغیر وابسته): مقصدی که به دنبال پیشبینی آن هستیم (مثلاً نرخ تورم).
- β0 (عرض از مبدأ): مقدار پایه؛ زمانی که تمام متغیرهای ورودی صفر باشند، مدل چه عددی را نشان میدهد؟
- βj (ضرایب رگرسیون): نشاندهنده وزن و جهت اثر هر ویژگی. اگر β1 مثبت باشد، رابطه مستقیم و اگر منفی باشد، رابطه معکوس است.
- ε (جمله خطا): نویزهای دنیای واقعی. این بخش شامل تمام فاکتورهای ناشناختهای است که در مدل ما حضور ندارند.
.
هدف: مینیمم کردن مجموع مربعات باقیمانده (RSS)
حداقل مربعات معمولی (OLS) به دنبال مقادیری برای β میگردد که کمترین فاصله را بین «واقعیت» و «پیشبینی» ایجاد کند.
استفاده از توان ۲ باعث میشود:
- خطاهای مثبت و منفی همدیگر را خنثی نکنند.
- خطاهای بزرگ به صورت نمایی جریمه شوند، که مدل را مجبور میکند تا حد ممکن به تمام نقاط داده نزدیک بماند.
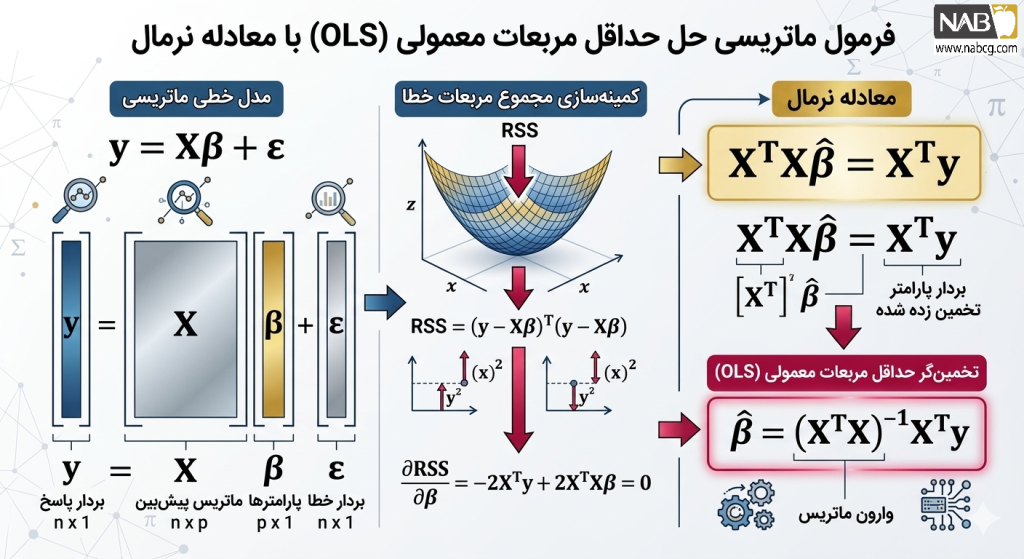
4.رویکرد ماتریسی؛ قدرت جبر خطی در کلانداده
در پروژههای واقعی با صدها ویژگی، محاسبات دستی غیرممکن است. اینجا جبر ماتریسی وارد عمل میشود تا با یک حرکت، تمام ضرایب را پیدا کند.
فرمول :
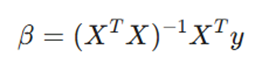
- ماتریس X: ماتریسی شامل تمام ویژگیها (همراه با یک ستون عدد ۱ برای محاسبه عرض از مبدأ).
- ترانهاده X^T: با ضرب ماتریس در ترانهادهاش، یک ماتریس مربعی ایجاد میشود که قابلیت وارونسازی پیدا میکند.
- پاسخ یگانه: بزرگترین برتری OLS نسبت به مدلهای تکرارشونده (مانند))، این است که مستقیماً به یک جواب دقیق و قطعی میرسد و نیازی به حدس و خطا ندارد.
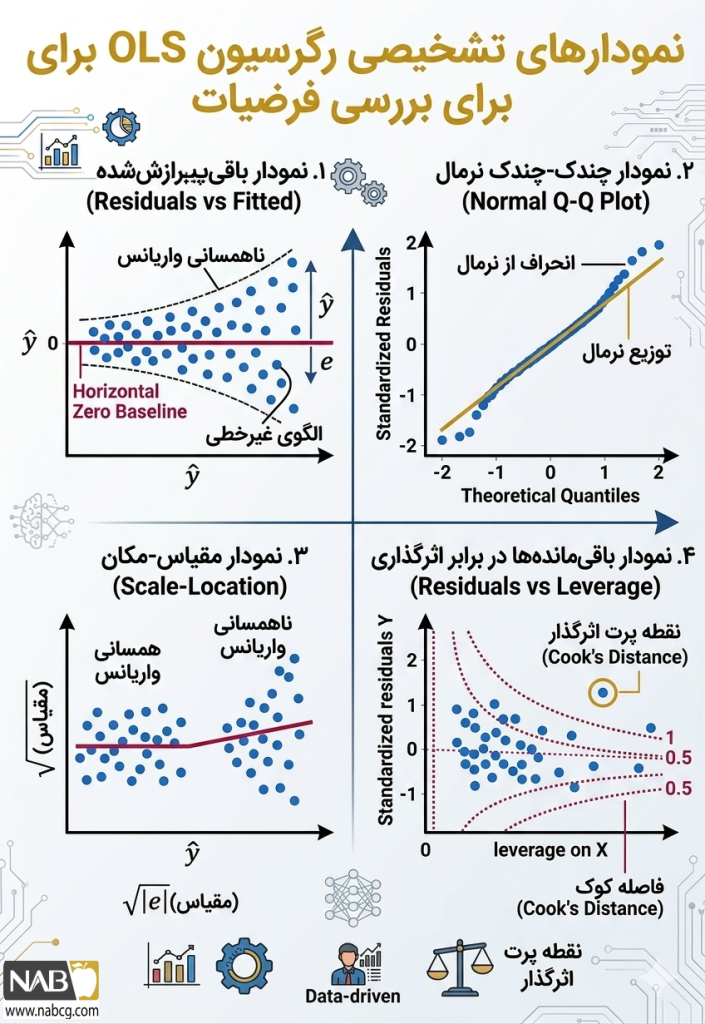
5.فرضیات اساسی (تستهای سلامت مدل)
برای اینکه خروجی حداقل مربعات معمولی (OLS)داستانی واقعی تعریف کند، باید ۵ شرط اساسی برقرار باشد:
- خطی بودن(Linearity): مدل فرض میکند رابطه متغیرها یک خط راست است. اگر دادهها منحنی باشند، OLS دچار کمبرازش (Underfitting) شدید میشود.
- استقلال مشاهدات(Independence): دادهها نباید از هم تاثیر بگیرند (نباید خودهمبستگی داشته باشند).
- همسانی واریانس(Homoscedasticity): پراکندگی خطاها باید در تمام طول خط ثابت باشد. اگر خطاها در بخشی از نمودار فشرده و در بخشی دیگر پهن شوند (Heteroscedasticity)، فواصل اطمینان مدل دیگر معتبر نخواهند بود.
- نرمال بودن توزیع خطاها: برای اینکه آزمونهای فرض (مثل تست T) درست کار کنند، باقیماندهها باید توزیع نرمال داشته باشند.
- عدم همخطی(No Multicollinearity): ویژگیها نباید با هم همبستگی شدیدی داشته باشند. اگر دو متغیر همزاد باشند، مدل نمیتواند سهم هر کدام را در پیشبینی تشخیص دهد.
6.ارزیابی عملکرد
پس از ساخت مدل، باید آن را با خطکشهای آماری بسنجیم:
- ضریب تعیین(R^2): این شاخص بین ۰ تا ۱ است. مثلاً R^2 = 0.85 یعنی ۸۵٪ از تغییرات هدف توسط مدل ما توضیح داده شده است.
- R^2 تعدیلشده(Adjusted R-squared): برخلاف R^2 معمولی، این شاخص جریمهای برای اضافه کردن متغیرهای بیاهمیت در نظر میگیرد و معیار دقیقتری برای مدلهای پیچیده است.
- مقادیر P (P-values): سطح معناداری هر ضریب را نشان میدهد. اگر P < 0.05 باشد، یعنی آن ویژگی واقعاً روی هدف اثر دارد و وجودش در مدل تصادفی نیست.
- آماره F (F-statistic): نشان میدهد که آیا کل مدل به صورت کلی معنادار است یا خیر. یک F-statistic بالا یعنی مدل شما بهتر از حدس زدن میانگین عمل میکند.
- خطای استاندارد: میزان نوسان و عدم قطعیت در تخمین ضرایب را نشان میدهد. هرچه کمتر باشد، تخمین ما دقیقتر است.
.
7.حداقل مربعات معمولی (OLS)چه زمانی انتخاب مناسبی است؟
اگر به دنبال مدلسازی سریع، تفسیرپذیر و علمی بر روی دادههای با حجم متوسط هستید، OLS بیرقیب است. اما اگر با نویز زیاد، دادههای پرت یا ویژگیهای بسیار زیاد روبرو هستید، باید آماده باشید تا در مقاله بعدی با رگرسیون ریج (Ridge) آشنا شوید که برای مهار ضعفهای حداقل مربعات معمولی (OLS) طراحی شده است.
.
8.پیاده سازی اجرای رگرسیون OLS با Statsmodels
a: آمادهسازی محیط و تولید دادههای هوشمند
در این مرحله، ابتدا کتابخانههای مورد نیاز را فراخوانی میکنیم. سپس برای اینکه بتوانیم عملکرد مدل را در شرایط ایدهآل بسنجیم، مجموعهدادهای فرضی میسازیم که رابطه بین متغیرها در آن کاملاً خطی باشد. با استفاده از تابع np.random.normal و قرار دادن مقدار انحراف معیار روی ۰.۵، میزان نویز (فاصله نقاط از خط) را به حداقل رساندیم تا نقاط کاملاً به خط رگرسیون نزدیک باشند.
b: ساختاربندی دادهها
دادههای تولید شده را در قالب یک جدول (Dataframe) مرتب میکنیم. این کار به ما کمک میکند تا متغیر مستقل (X) و متغیر وابسته یا هدف (Y) را به وضوح از یکدیگر تفکیک کنیم.
c: تزریق مقدار ثابت
این مرحله یکی از حیاتیترین بخشها در استفاده از کتابخانه statsmodels است. به طور پیشفرض، این کتابخانه فرض میکند خط رگرسیون باید حتماً از نقطه صفر (مبدأ) عبور کند. با استفاده از تابع sm.add_constant ما به صورت دستی یک ستون مقدار ثابت به دادهها اضافه میکنیم تا مدل اجازه داشته باشد عرض از مبدأ (Intercept) را به درستی محاسبه کند و خط از نقطه واقعی خود شروع شود.
d: اجرای موتور OLS و آموزش مدل
در این مرحله، تابع sm.OLS را فراخوانی کرده و متغیرهای هدف و ورودی را به آن معرفی میکنیم. متد .fit() در واقع همان مرحله “آموزش” است که در آن ماشین با استفاده از محاسبات ماتریسی، ضرایبی را پیدا میکند که مجموع مربعات خطا را به حداقل برساند.
e: استخراج و تحلیل گزارش آماری
با دستور print(results.summary()) مدل یک گزارش کامل از سلامت خود ارائه میدهد. در اینجا انتظار داریم عدد R-squared بسیار نزدیک به ۱ باشد که نشاندهنده دقت فوقالعاده مدل و فاصله بسیار ناچیز نقاط آبی از خط قرمز است. همچنین مقادیر P-value نشان میدهند که آیا متغیرهای ما از نظر آماری معنادار هستند یا خیر.
کد پایتون
import statsmodels.api as sm
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# ۱. تولید دادههای هوشمند با نویز بسیار کم
np.random.seed(42)
x = np.linspace(0, 10, 100)
# کاهش پارامتر دوم در np.random.normal باعث میشود نقاط به خط چسبیده باشند
# در اینجا نویز را از 2 به 0.5 کاهش دادیم
noise = np.random.normal(0, 0.5, 100)
y = 2 * x + 5 + noise
# ۲. تبدیل به دیتافریم
data = pd.DataFrame({'X': x, 'Y': y})
# ۳. اضافه کردن مقدار ثابت (Constant) - حیاتی برای محاسبه Intercept
# این گام اجازه میدهد خط از جایی غیر از صفر شروع شود
X_with_constant = sm.add_constant(data['X'])
# ۴. اجرای رگرسیون OLS
# مدل OLS مجموع مربعات اختلافات را مینیمم میکند
model = sm.OLS(data['Y'], X_with_constant)
results = model.fit()
# ۵. چاپ خلاصه نتایج (R-squared در اینجا باید بسیار نزدیک به 1 باشد)
print(results.summary())
# ۶. تصویرسازی برای مشاهده چسبندگی نقاط به خط
plt.figure(figsize=(10, 6))
plt.scatter(data['X'], data['Y'], color='blue', alpha=0.6, label='Actual Observations')
plt.plot(data['X'], results.predict(X_with_constant), color='red', linewidth=3, label='OLS Perfect Fit')
plt.title('OLS Regression with Minimal Residuals', fontsize=14)
plt.xlabel('Independent Variable (X)', fontsize=12)
plt.ylabel('Dependent Variable (Y)', fontsize=12)
plt.legend()
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()
خروجی:


9.مطالعه موردی: مهندسی فروش در شرکت “تکنو-پلاس”
الف. صورت مسئله
شرکت “تکنو-پلاس” که در حوزه فروش لپتاپهای گیمینگ فعالیت میکند، با یک چالش بزرگ روبروست: هزینههای بازاریابی در حال افزایش است اما نرخ رشد فروش نوسانی دارد. مدیرعامل از تیم داده میخواهد رابطهی بین “بودجه تبلیغات در اینستاگرام” و “میزان فروش نهایی” را پیدا کنند تا بودجهبندی سال آینده را بهینه کنند.
ب. دادههای جمعآوری شده
تیم داده، اطلاعات ۶ ماه گذشته را استخراج میکند:
| ماه | بودجه تبلیغات (میلیون تومان) x – | میزان فروش (تعداد دستگاه) y- |
| فروردین | ۱۰ | ۵۵ |
| اردیبهشت | ۲۰ | ۱۰۵ |
| خرداد | ۳۰ | ۱۵۸ |
| تیر | ۴۰ | ۲۰۲ |
| مرداد | ۵۰ | ۲۴۵ |
ج. پیادهسازی مدل حداقل مربعات معمولی (OLS)
هدف ما پیدا کردن بهترین خطی است که از بین این نقاط عبور کند :y = β0 + β1 x +ε
گامهای محاسباتی ماشین:
- محاسبه میانگینها: ماشین ابتدا میانگین بودجه (30) و میانگین فروش (153) را به دست میآورد.
- یافتن شیب(β1): با استفاده از فرمول OLS، نسبت تغییرات y به x محاسبه میشود. فرض کنیم ماشین به عدد ۴.۸ میرسد.
- یافتن عرض از مبدأ(β0): ماشین محاسبه میکند که اگر بودجه صفر باشد، فروش پایه چقدر است. فرض کنیم عدد ۸ به دست میآید.
فرمول نهایی مدل:
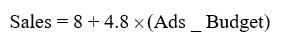
د. تفسیر استراتژیک
حالا وقت آن است که به این اعداد “جان” بدهیم:
- عرض از مبدأ (۸): این عدد به ما میگوید که حتی اگر شرکت یک ریال هم برای تبلیغات اینستاگرام خرج نکند، به طور میانگین ۸ دستگاه در ماه به خاطر “اعتبار برند” یا “مراجعه مستقیم” میفروشد.
- ضریب تبلیغات (۴.۸): این حیاتیترین عدد است! یعنی به ازای هر ۱ میلیون تومان اضافه در بودجه تبلیغات، فروش شرکت به طور متوسط ۴.۸ دستگاه افزایش مییابد.
- نوع رابطه: ضریب مثبت است، پس رابطه مستقیم و صعودی است.
.
ه. ارزیابی مدل
قبل از ارائه به مدیرعامل، باید مطمئن شویم مدل چقدر معتبر است:
- بررسی R^2: فرض کنید مقدار آن ۰.۹۸ به دست آمده است. این یعنی ۹۸٪ تغییرات فروش مستقیماً به بودجه تبلیغات ربط دارد و مدل فوقالعاده دقیق است.
- بررسی پسماندها(Residuals): تیم داده نمودار خطاها را چک میکند. اگر خطاها به صورت تصادفی پخش شده باشند (Homoscedasticity)، یعنی مدل ما “سالم” است.
.
و. تصمیمگیری بیزینسی
مدیرعامل با دیدن این گزارش دو تصمیم کلیدی میگیرد:
- پیشبینی آینده: اگر ماه آینده بودجه را به ۶۰ میلیون تومان برسانیم، انتظار داریم فروش به حدود ۲۹۶ دستگاه برسد (8 + 4.8 ✕ 60).
- محاسبه بازگشت سرمایه(ROI): اگر سود هر دستگاه ۱ میلیون تومان باشد، و هزینه تبلیغات برای فروش هر دستگاه (۱ تقسیم بر ۴.۸) حدود ۲۰۰ هزار تومان باشد، پس تبلیغات به شدت سودآور است.
.
ز. محدودیتهایی که در این مطالعه دیده شد
- دادههای پرت: اگر در تیرماه یک یوتیوبر معروف به صورت رایگان لپتاپ را تبلیغ میکرد و فروش به جای ۲۰۰ به ۴۰۰ میرسید، این “نقطه پرت” کل خط OLS را جابجا میکرد و محاسبات ما را به هم میزد.
- رابطه غیرخطی: اگر با افزایش بودجه به ۱۰۰ میلیون، بازار اشباع شود و فروش دیگر رشد نکند، مدل OLS دیگر جواب نمیدهد و باید سراغ مدلهای پیچیدهتر رفت.
.
پیاده سازی
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# ۱. آمادهسازی دادهها (بودجه و فروش)
X = np.array([10, 20, 30, 40, 50]).reshape(-1, 1) # بودجه تبلیغات
y = np.array([55, 105, 158, 202, 245]) # تعداد فروش
# ۲. ساخت و آموزش مدل OLS
model = LinearRegression()
model.fit(X, y)
# ۳. استخراج ضرایب
intercept = model.intercept_
coefficient = model.coef_[0]
print(f"Intercept (w0): {intercept:.2f}")
print(f"Coefficient (w1): {coefficient:.2f}")
# ۴. پیشبینی برای بودجه ۶۰ میلیونی
budget_new = np.array([[60]])
prediction = model.predict(budget_new)
print(f"Prediction for 60M budget: {prediction[0]:.2f} units")
# ۵. تصویرسازی نتایج
plt.scatter(X, y, color='blue', label='Actual Data')
plt.plot(X, model.predict(X), color='red', label='OLS Line')
plt.xlabel('Ads Budget (M Toman)')
plt.ylabel('Sales (Units)')
plt.legend()
plt.show()
خروجی:

10.مزایا
- تفسیرپذیری بیرقیب(Interpretability): در دنیای مدلهای جعبه سیاه، حداقل مربعات معمولی یک جعبه شیشهای است. ضرایب آن به مستقیمترین شکل ممکن معنای بیزنسی دارند. شما میتوانید به مدیران خود بگویید: به ازای هر ۱ واحد تغییر در متغیر مستقل، خروجی ما دقیقاً w مقدار تغییر میکند.
- بهینگی طبق فرضیه BLUE: بر اساس قضیه گاوس-مارکوف (Gauss-Markov Theorem)، اگر فرضیات کلاسیک رگرسیون برقرار باشد، حداقل مربعات معمولی بهترین برآوردکننده خطی بدون سوگیری است. این یعنی هیچ مدل خطی دیگری نمیتواند ضرایبی با واریانس کمتر از حداقل مربعات معمولی پیدا کند.
- سرعت محاسباتی در مقیاس بزرگ: برخلاف الگوریتمهای یادگیری عمیق که به تکرارهای فراوان نیاز دارند، حداقل مربعات معمولی با یک فرمول ریاضی مستقیم (موسوم به معادله نرمال) حل میشود. این یعنی پردازش میلیونها داده در کسری از ثانیه.
- پایداری آماری: نتایج حداقل مربعات معمولی به دلیل پایه ریاضی قوی، در جوامع علمی و حقوقی (مثل دادگاهها یا مقالات پزشکی) به عنوان یک مدرک معتبر و استاندارد شناخته میشود.
- سادگی در درک و پیادهسازی: حداقل مربعات معمولی به دلیل شفافیت در ساختار، به راحتی قابل فهم است. ضرایب آن به مستقیمترین شکل ممکن معنای فیزیکی و بیزنسی دارند.
.
11.معایب
- آسیبپذیری در برابر نقاط پرت(Outliers): از آنجایی که حداقل مربعات معمولی تلاش میکند مجموع مربعات خطا را مینیمم کند، خطاهای بزرگ (دادههای غلط) به توان دو میرسند و وزن عجیبی پیدا میکنند. یک دادهی پرت میتواند کل خط رگرسیون را منحرف کند.
- چالش همخطی(Multicollinearity): اگر ویژگیهای ورودی شما (مثلاً قد و طول پا) همبستگی شدیدی داشته باشند، مدل در تفکیک اثر هر کدام فلج میشود. این موضوع باعث میشود ضرایب مدل اعداد بسیار بزرگی شوند که هیچ معنای منطقی ندارند.
- اسارت در دنیای خطوط(Linearity Bias): دنیای واقعی همیشه خطی نیست. اگر رابطه واقعی دادهها منحنی باشد، OLS دچار کمبرازش (Underfitting) شده و الگوهای اصلی را از دست میدهد.
- بحران دادههای پُربعد: زمانی که تعداد ویژگیهای شما بیشتر از تعداد نمونهها باشد (p > n)، از نظر ریاضی ماتریسهای حداقل مربعات معمولی غیرقابل معکوس میشوند و مدل عملاً متلاشی میشود. در این شرایط باید به سراغ رگرسیون Ridge یا Lasso رفت.
.
12.کاربردها در دنیای واقعی
مدل OLS فراتر از تئوری، در حال حل سختترین مسائل صنعتی و اجتماعی است:
الف) امور مالی و مدیریت ریسک
- قیمتگذاری داراییها(CAPM): سرمایهگذاران از حداقل مربعات معمولی (OLS) استفاده میکنند تا بفهمند بازدهی یک سهم چقدر تحت تاثیر نوسانات کل بازار است.
- پیشبینی نرخ تورم: تحلیل رابطه بین نرخ بهره بانکی و شاخصهای قیمت مصرفکننده.
ب) اقتصاد و سیاستگذاری کلان
- تخمین نرخ بیکاری: بررسی اینکه هر ۱ درصد رشد در تولید ناخالص داخلی (GDP)، دقیقاً چقدر از نرخ بیکاری میکاهد (قانون اوکان).
- الگوهای مصرف خانوار: تحلیل تاثیر تغییرات مالیاتی بر قدرت خرید و سبد مصرفی مردم.
ج) بهداشت، درمان و بیولوژی
- آنالیز بیومتریک: بررسی رابطه بین شاخص توده بدنی (BMI) و پارامترهای سلامت مثل فشار خون یا سطح قند خون.
- مدیریت بیمارستانی: پیشبینی زمان ترخیص یا نرخ بازگشت بیماران بر اساس سوابق درمانی و سن.
د) مهندسی بازاریابی و فروش
- سنجش اثربخشی تبلیغات: محاسبه دقیق نرخ بازگشت سرمایه (ROI) به ازای هر ریال هزینه در کمپینهای دیجیتال.
- کشش قیمتی تقاضا: تحلیل اینکه با چه میزان تغییر در قیمت، مشتریان به صورت خطی واکنش نشان داده و تقاضا تغییر میکند.
.
جمع بندی
روش حداقل مربعات معمولی یکی از ستونهای اصلی تحلیل رگرسیونی است و همچنان نقش مهمی در مدلسازی، تبیین و تصمیمگیری مبتنی بر داده ایفا میکند. در این مطلب دیدیم که OLS چگونه با کمینهسازی خطا، ضرایب مدل را برآورد میکند و تحت چه فرضیاتی میتوان به نتایج آن اعتماد کرد.
بررسی فرم ماتریسی، فرضیات کلاسیک و مثالهای عملی نشان داد که قدرت OLS تنها در سادگی آن نیست، بلکه در شفافیت تفسیر، قابلیت آزمون فرضیات و چارچوب نظری مستحکم آن نهفته است. در عین حال، محدودیتهایی مانند حساسیت به همخطی، نقاط پرت و نقض فروض آماری یادآور این نکتهاند که استفادهی صحیح از OLS نیازمند شناخت دقیق داده و مسئله است.
در عمل، OLS اغلب بهعنوان نقطهی شروع تحلیل بهکار میرود؛ مدلی که میتواند بینش اولیهای از ساختار داده ارائه دهد و مبنایی برای انتخاب روشهای پیشرفتهتر مانند Ridge، Lasso یا مدلهای غیرخطی باشد. تسلط بر OLS به تحلیلگر یا مهندس داده این امکان را میدهد که فراتر از اجرای صرف کد، نتایج را بهصورت انتقادی ارزیابی کند و تصمیمهای آماری و مهندسی آگاهانهتری اتخاذ کند.