

1.مقدمه
در تحلیل دادهها، یکی از بنیادیترین پرسشها این است که آیا بین دو متغیر رابطهای معنادار وجود دارد و اگر چنین است، این رابطه تا چه اندازه قابل اندازهگیری و پیشبینی است. رگرسیون خطی ساده (Simple Linear Regression) یکی از ابتداییترین و در عین حال مهمترین ابزارهای آماری برای پاسخ به این پرسش محسوب میشود. این مدل با فرض وجود یک رابطه خطی بین یک متغیر مستقل و یک متغیر وابسته، تلاش میکند بهترین خط برازش را برای توضیح و پیشبینی دادهها بیابد.
اهمیت رگرسیون خطی ساده تنها به سادگی آن محدود نمیشود؛ بلکه این مدل پایهای برای درک بسیاری از مفاهیم پیشرفتهتر در یادگیری ماشین و آمار است. از تحلیلهای اقتصادی و پیشبینی فروش گرفته تا مدلسازی مصرف انرژی و بررسی اثر یک متغیر بر متغیر دیگر در علوم تجربی، این روش چارچوبی شفاف و قابلتفسیر برای تصمیمگیری مبتنی بر داده فراهم میکند.
در این مقاله، ابتدا مفاهیم بنیادین رگرسیون خطی ساده را بررسی میکنیم، سپس مبانی ریاضی و فرضهای اساسی آن را توضیح میدهیم. در ادامه، نحوه ارزیابی عملکرد مدل، پیادهسازی عملی در پایتون و کاربردهای واقعی آن را تحلیل خواهیم کرد تا تصویری جامع و کاربردی از این ابزار تحلیلی ارائه شود.
2. تعریف و مفاهیم بنیادی
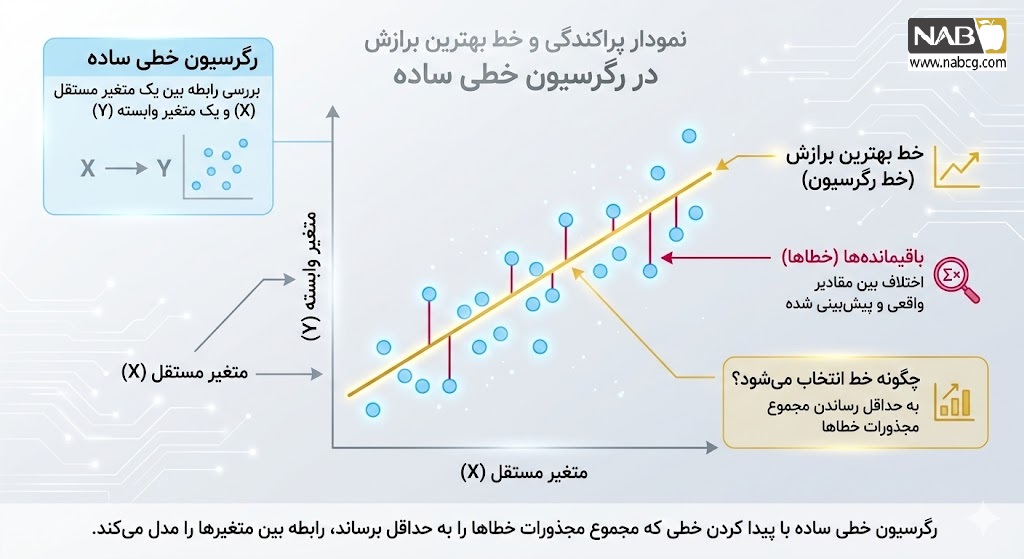
رگرسیون خطی ساده، یک روش آماری و الگوی یادگیری نظارتشده (Supervised Learning) است که برای مدلسازی رابطه مستقیم بین دو متغیر به کار میرود. در این مدل، یک متغیر مستقل (Independent Variable) که به آن متغیر پیشبین یا تبیینکننده نیز گفته میشود، برای پیشبینی مقدار یک متغیر وابسته (Dependent Variable) یا متغیر پاسخ استفاده میشود. ماهیت این مدل زمانی ساده تلقی میشود که تنها یک ویژگی ورودی برای تخمین هدف وجود داشته باشد؛ در صورتی که تعداد متغیرهای مستقل افزایش یابد، مدل به رگرسیون خطی چندگانه تبدیل خواهد شد.
مؤلفههای کلیدی مدل:
- متغیر مستقل (X): ورودیهای ویژگی در مجموعهداده هستند که روی محور افقی ترسیم میشوند. این متغیر به عنوان مبنای پیشبینی شناخته میشود.
- متغیر وابسته (Y): مقدار هدفی است که مدل قصد پیشبینی آن را دارد و روی محور عمودی ترسیم میگردد. مقدار این متغیر به تغییرات متغیر مستقل بستگی دارد.
- خط رگرسیون: در رگرسیون خطی ساده، این خط یک خط مستقیم است که بهترین برازش (Best Fit) را بر روی نقاط داده ایجاد میکند و ماهیت رابطه بین دو متغیر را نمایش میدهد.
برآوردگر کمترین مربعات معمولی (OLS)
رایجترین متدولوژی برای اجرای رگرسیون خطی ساده، استفاده از تخمینگر کمترین مربعات معمولی (Ordinary Least Squares) است. این روش با به حداقل رساندن مجموع مجذور تفاوتهای بین مقادیر مشاهدهشده (دادههای واقعی) و مقادیر پیشبینیشده توسط خط رگرسیون عمل میکند.
به این تفاوتها اصطلاحاً باقیمانده (Residuals) گفته میشود. مجذور کردن این مقادیر تضمین میکند که خطاهای مثبت و منفی به یک اندازه بر مدل تأثیر بگذارند و هدف نهایی، دستیابی به خطی است که مجموع این خطاهای مربعی را به کمترین میزان ممکن برساند.
۳. اهمیت و ضرورت رگرسیون خطی ساده
در دنیای مدرن که دادهها به عنوان داراییهای اصلی شناخته میشوند، رگرسیون خطی ساده فراتر از یک ابزار آماری، به عنوان یک ضرورت در فرآیند استدلال علمی و تجاری مطرح است. اهمیت این مدل را میتوان در محورهای زیر خلاصه کرد:
- کشف روابط علی و معلولی: اصلیترین ضرورت SLR، توانایی آن در کمیسازی روابط بین پدیدههاست. این مدل به محققان اجازه میدهد تا بفهمند تغییر در یک متغیر پیشبین (مانند میزان مخارج تحقیق و توسعه) دقیقاً چه تأثیری بر متغیر پاسخ (مانند رشد سودآوری) دارد. بدون این درک کمی، تصمیمات مدیریتی صرفاً بر پایه حدس و گمان خواهند بود.
- قدرت پیشبینی و آیندهپژوهی: ضرورت رگرسیون در توانایی آن برای برونیابی هوشمند نهفته است. سازمانها با استفاده از دادههای تاریخی، مدلهایی میسازند که روند آینده را پیشبینی میکند. برای مثال، پیشبینی تقاضای انرژی بر اساس دمای هوا به شرکتهای خدماتی اجازه میدهد تا پیش از بروز بحران، منابع خود را بهینهسازی کنند.
- بهینهسازی منابع و کاهش هزینه: در محیطهای صنعتی، SLR برای یافتن نقطه بهینه عملکرد استفاده میشود. با درک رابطه بین متغیرهای ورودی و خروجی، میتوان هدررفت منابع را به حداقل رساند. این مدل با شناسایی متغیرهای بیاثر، از صرف هزینه برای پارامترهایی که تأثیری بر نتیجه نهایی ندارند، جلوگیری میکند.
- سادگی در تفسیر برای سطوح مدیریتی: در حالی که مدلهای پیچیده هوش مصنوعی اغلب مانند یک جعبه سیاه عمل میکنند، SLR به دلیل شفافیت ریاضی، اعتماد ذینفعان را جلب میکند. ضرورت وجود این مدل در گزارشهای استراتژیک، ارائه نتایجی است که به راحتی قابل دفاع و تفسیر باشند.
- اعتبارسنجی فرضیات علمی: در علوم تجربی و انسانی، SLR ابزاری حیاتی برای آزمون فرض است. این مدل با ارائه شاخصهای معناداری، به دانشمندان کمک میکند تا تشخیص دهند آیا رابطه مشاهده شده بین دو پدیده واقعی است یا صرفاً ناشی از نوسانات تصادفی دادههاست.
.
۴. فرضهای اساسی مدل رگرسیون خطی ساده
- خطی بودن (Linearity): اولین و مهمترین فرض این است که رابطه میان متغیر مستقل (X) و متغیر وابسته (Y) ماهیت خطی داشته باشد. یعنی تغییر در Y به تناسب تغییر در X رخ دهد. اگر رابطه منحنی باشد، رگرسیون خطی مدل مناسبی نخواهد بود.
- استقلال خطاها (Independence of Errors): باقیماندهها یا خطاهای مدل نباید با یکدیگر همبستگی داشته باشند (عدم وجود خودهمبستگی). این موضوع به ویژه در دادههای سری زمانی اهمیت دارد؛ یعنی خطای امروز نباید به خطای دیروز وابسته باشد.
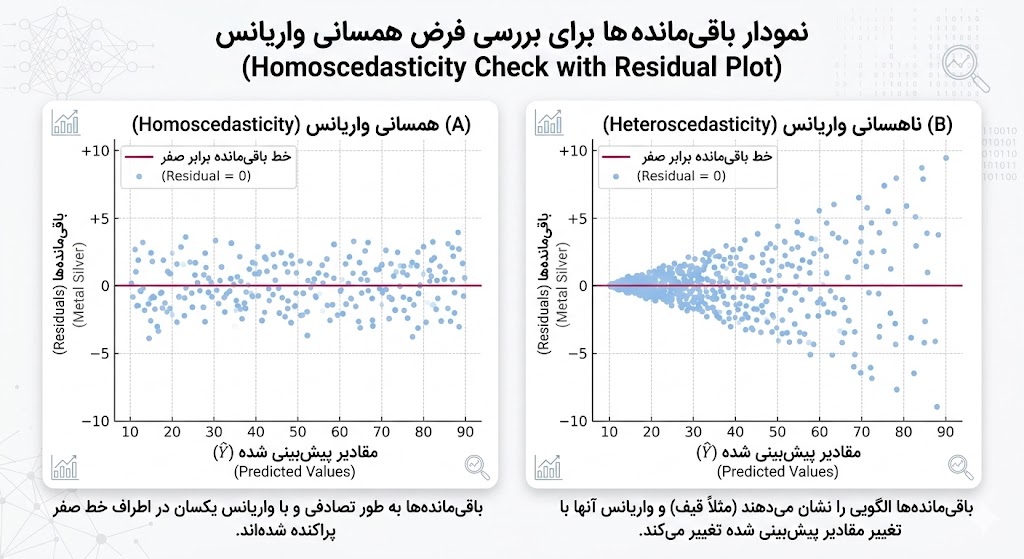
- همسانی واریانس (Homoscedasticity): این فرض بیان میکند که پراکندگی (واریانس) خطاها باید در تمام سطوح متغیر مستقل ثابت بماند. اگر با افزایش X، میزان پراکندگی خطاها زیاد یا کم شود (شکل مخروطی)، مدل دچار ناهمسانی واریانس شده و فواصل اطمینان آن نامعتبر میگردد.
- نرمال بودن توزیع خطاها (Normality of Residuals): برای اینکه آزمونهای فرض (مانند P-value و T-test) صحیح عمل کنند، توزیع خطاهای مدل باید پیرو توزیع نرمال (زنگولهای) باشد. این فرض به ویژه در نمونههای کوچک بسیار حیاتی است.
- عدم وجود دادههای پرت تاثیرگذار (No Influential Outliers): اگرچه رگرسیون تمام دادهها را در نظر میگیرد، اما نباید نقاطی وجود داشته باشند که به تنهایی شیب خط را به شکلی غیرمنطقی تغییر دهند.
۵. مبانی ریاضی رگرسیون خطی ساده
مبنای ریاضی رگرسیون خطی ساده بر برقراری یک رابطه تابعی بین متغیر پیشبین (X) و متغیر پاسخ (Y) استوار است. این رابطه در قالب یک معادله خطی به شرح زیر بیان میشود:
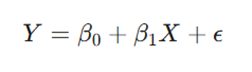
- Y: متغیر وابسته یا پاسخ.
- X: متغیر مستقل یا پیشبین.
- β0: عرض از مبدأ (Intercept) که مقدار ثابت مدل است.
- β1: ضریب رگرسیون یا شیب خط (Slope).
- ϵ: جمله خطا (Error Term) که نشاندهنده تفاوت میان مقدار واقعی و مقدار پیشبینی شده است.
هدف اصلی در تحلیل ریاضی این مدل، یافتن بهترین مقادیر برای پارامترهای β0 و β1 است که کمترین میزان خطا را ایجاد کنند. برای دستیابی به این هدف، از روش کمترین مربعات معمولی (OLS) استفاده میشود. در این روش، تابع هدف که مجموع مجذور باقیماندهها (RSS) نام دارد، باید به حداقل برسد:
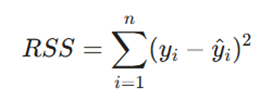
- yi: مقدار واقعی مشاهده شده برای نمونه iام.
- ŷi: مقدار پیشبینی شده توسط مدل.
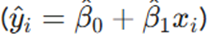
با مشتقگیری نسبت به پارامترها و برابر قرار دادن آنها با صفر، فرمولهای محاسباتی ضرایب به دست میآیند:
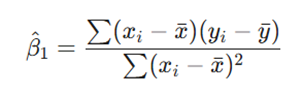
- x̄: میانگین مقادیر متغیر مستقل.
- ȳ: میانگین مقادیر متغیر وابسته.
پس از محاسبه شیب، عرض از مبدأ به سادگی از طریق رابطه زیر استخراج میشود:
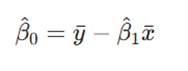
این ساختار ریاضی تضمین میکند که خط رگرسیون دقیقاً از نقطه میانگین دادهها عبور کرده و بهترین تخمین خطی را برای تحلیل روندها ارائه دهد.
۶. مکانیسم عملکرد رگرسیون خطی ساده
عملکرد رگرسیون خطی ساده یک فرآیند تکرارپذیر (Iterative) است که با هدف یافتن بهترین خط برازش (Best Fit Line) انجام میشود؛ خطی که مجموع تفاوتهای بین مقادیر واقعی و مقادیر پیشبینی شده را به حداقل برساند.
این فرآیند عملیاتی شامل چهار مرحله کلیدی است:
الف. تعریف تابع فرضیه
ابتدا مدل فرض میکند که یک رابطه خطی بین ورودی و خروجی برقرار است. این رابطه با معادله زیر نمایش داده میشود:
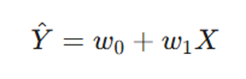
- Ŷ: مقدار پیشبینی شده. (Target)
- X: متغیر مستقل (Input).
- w1 و w0: پارامترهای مدل (وزن و عرض از مبدأ) که شیب و مکان خط را تعیین میکنند. مجموعه تمام خطوط ممکن با مقادیر مختلف w، فضای فرضیه نامیده میشود.
.
ب. تعیین تابع زیان (Loss Function)
برای سنجش دقت خط، یک تابع زیان تعریف میشود. رایجترین معیار، میانگین مربعات خطا (MSE) است که فاصله بین دادههای واقعی و پیشبینی را محاسبه میکند:
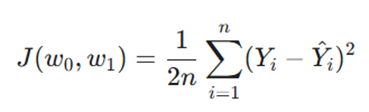
ج. بهینهسازی (Optimization)
هدف نهایی، یافتن مقادیری برای w0 و w1 است که تابع زیان (J) را کمینه کند. این کار معمولاً از طریق الگوریتم گرادیان کاهشی (Gradient Descent) انجام میشود. در این مرحله، پارامترها به صورت بازگشتی و پلهپله اصلاح میشوند تا مدل به بهینهترین حالت برسد.
د. استخراج راهکار نهایی
زمانی که پارامترهای بهینه یافت شدند، خط رگرسیون نهایی تشکیل میشود. این خط به عنوان راهکار نهایی شناخته شده و از آن برای پیشبینی مقادیر در دادههای جدید و دیدهنشده استفاده میگردد.
۷. ارزیابی عملکرد و معیارهای سنجش در رگرسیون خطی ساده
پس از پیادهسازی مدل رگرسیون، ارزیابی دقت پیشبینیها و میزان انطباق مدل بر دادههای واقعی ضرورت مییابد. در رگرسیون خطی ساده، برای سنجش کیفیت برازش و میزان خطای استنتاج، از معیارهای استاندارد زیر استفاده میشود:
ضریب تعیین (R^2): این شاخص نشاندهنده نسبت واریانس متغیر وابسته است که توسط متغیر مستقل تبیین میشود. مقدار آن بین ۰ و ۱ متغیر است؛ هرچه R^2 به یک نزدیکتر باشد، مدل توانایی بیشتری در بازنمایی تغییرات دادهها دارد.
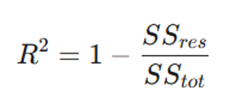
- SSres: مجموع مجذور باقیماندهها (خطای مدل).
- SStot: مجموع کل مجذورات (تغییرات کل دادهها نسبت به میانگین).
.
میانگین مربعات خطا (MSE): این معیار میانگین مجذور تفاوت بین مقادیر واقعی و پیشبینی شده را محاسبه میکند. به دلیل توان دوم، این شاخص نسبت به دادههای پرت (Outliers) بسیار حساس است و جریمه سنگینی برای خطاهای بزرگ در نظر میگیرد.
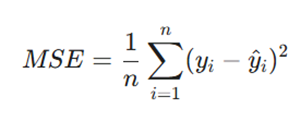
- n: تعداد کل مشاهدات.
- yi: مقدار واقعی.
- ŷi: مقدار پیشبینی شده.
جذر میانگین مربعات خطا (RMSE): از آنجا که واحد MSE توان دوم واحد اصلی است، با گرفتن ریشه دوم آن، RMSE به دست میآید که واحدی یکسان با متغیر وابسته دارد و تفسیر آن برای مدیران و ذینفعان سادهتر است.
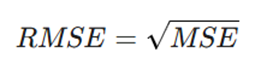
میانگین قدر مطلق خطا (MAE): این شاخص میانگین ساده خطاها را بدون در نظر گرفتن جهت آنها (مثبت یا منفی) نشان میدهد. برخلاف MSE، این معیار نسبت به دادههای پرت مقاومتر است و تصویر واقعیتری از میانگین خطای روزمره مدل ارائه میدهد.
8.پیادهسازی گامبهگام رگرسیون خطی ساده
- بارگذاری و آمادهسازی دادهها: ابتدا دیتاسیت واقعی را بارگذاری کرده و رابطه بین هزینههای تبلیغات و فروش را بررسی میکنیم.
- تحلیل بصری اولیه: با رسم نمودار پراکندگی (Scatter Plot)، فرض «خطی بودن» رابطه را که در بخش ۴ فایل شما ذکر شده، چک میکنیم.
- تقسیم دادهها (Train/Test Split): دادهها را به دو بخش آموزش (۸۰٪) و تست (۲۰٪) تقسیم میکنیم تا توانایی تعمیمدهی مدل سنجیده شود.
- ساخت مدل با روش کمترین مربعات (OLS): مطابق بخش ۲ و ۵ فایل، ضرایب خط (β0 و β1) را با استفاده از الگوریتم OLS استخراج میکنیم تا «بهترین خط برازش» به دست آید.
- پیشبینی و ارزیابی: مدل را روی دادههای تست اجرا کرده و طبق بخش ۷ فایل، معیارهای R^2 (ضریب تعیین) و MSE (میانگین مربعات خطا) را محاسبه میکنیم.
- بصریسازی نهایی و بررسی فرضها: خط رگرسیون نهایی را روی دادهها رسم کرده و نمودار باقیماندهها (Residuals) را برای اطمینان از صحت مدل تحلیل میکنیم.
کد پایتون:
این کد از دیتاسیت معتبر تبلیغات استفاده کرده و تمامی خروجیهای عددی و بصری را تولید میکند.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error
# ۱. بارگذاری دیتاسیت واقعی (Advertising Dataset)
url = "https://raw.githubusercontent.com/justmarkham/scikit-learn-videos/master/data/Advertising.csv"
df = pd.read_csv(url, index_col=0)
# انتخاب متغیر مستقل (TV) و متغیر وابسته (Sales) طبق فایل
X = df[['TV']] # Independent Variable [cite: 136]
y = df['Sales'] # Dependent Variable [cite: 138]
# ۲. تقسیم دادهها به آموزش و تست
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ۳. ایجاد و آموزش مدل رگرسیون خطی ساده (OLS)
# این مرحله مطابق بخش ۵ و ۶ فایل، خطای مربعات را کمینه میکند [cite: 181, 206]
model = LinearRegression()
model.fit(X_train, y_train)
# ۴. انجام پیشبینی
y_pred = model.predict(X_test)
# ۵. محاسبه معیارهای ارزیابی (مطابق بخش ۷ فایل)
r2 = r2_score(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
mae = mean_absolute_error(y_test, y_pred)
print(f"--- نتایج ارزیابی مدل ---")
print(f"R-squared (ضریب تعیین): {r2:.4f}") # [cite: 215]
print(f"MSE (میانگین مربعات خطا): {mse:.2f}") # [cite: 219]
print(f"MAE (میانگین قدر مطلق خطا): {mae:.2f}") # [cite: 225]
print(f"فرمول مدل: Sales = {model.intercept_:.2f} + {model.coef_[0]:.2f} * TV") # [cite: 174]
# ۶. خروجی بصری ۱: نمودار خط رگرسیون
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.scatter(X, y, color='blue', alpha=0.5, label='Actual Data')
plt.plot(X_train, model.predict(X_train), color='red', linewidth=2, label='Regression Line')
plt.title('TV Ad Spending vs Sales', fontsize=12, fontweight='bold')
plt.xlabel('TV Advertising Budget ()')
plt.ylabel('Sales (Units)')
plt.legend()
# خروجی بصری ۲: تحلیل باقیماندهها (بررسی فرض همسانی واریانس - بخش ۴ فایل)
plt.subplot(1, 2, 2)
residuals = y_test - y_pred
plt.scatter(y_pred, residuals, color='purple', alpha=0.6)
plt.axhline(y=0, color='black', linestyle='--')
plt.title('Residual Plot (Assumption Check)', fontsize=12, fontweight='bold')
plt.xlabel('Predicted Sales')
plt.ylabel('Residuals')
plt.tight_layout()
plt.show()
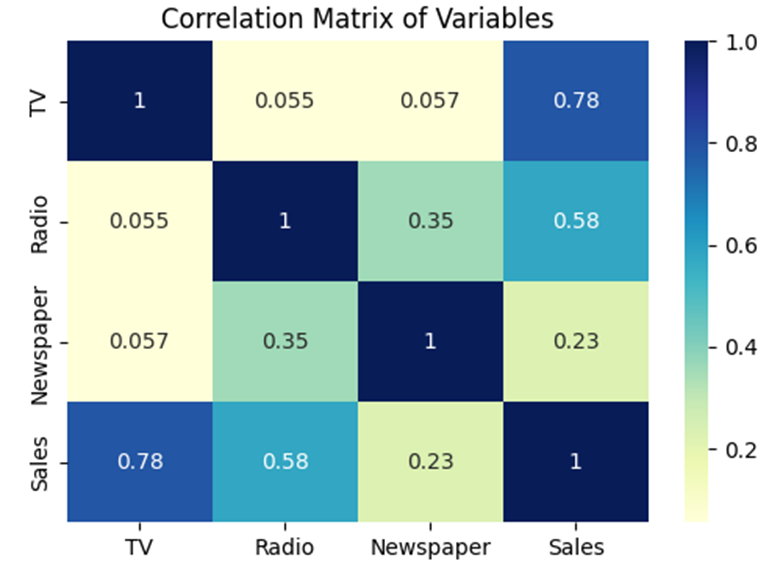
# خروجی بصری ۳: هیتمپ همبستگی
plt.figure(figsize=(6, 4))
sns.heatmap(df.corr(), annot=True, cmap='YlGnBu')
plt.title('Correlation Matrix of Variables')
plt.show()
خروجی:

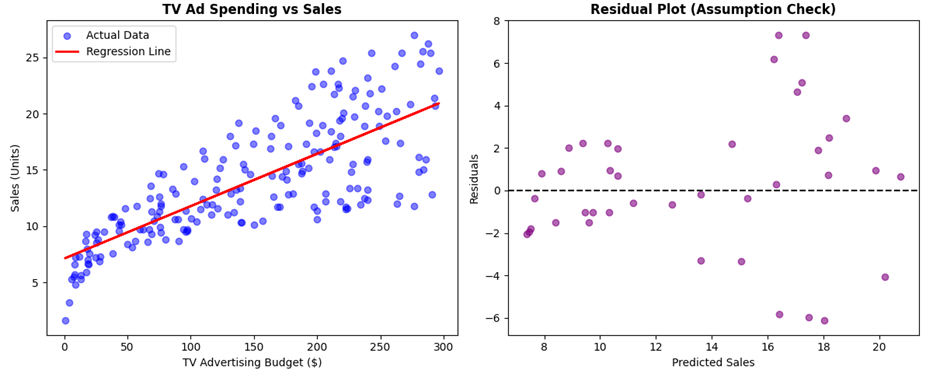
.
9.مزایای رگرسیون خطی ساده
- سادگی و تفسیرپذیری بالا:رگرسیون خطی ساده به دلیل ماهیت ریاضی مستقیم، یکی از قابلفهمترین مدلها در تحلیل داده است. ضرایب مدل (شیب و عرض از مبدأ) به طور مستقیم قدرت و جهت رابطه بین دو متغیر را نشان میدهند. این شفافیت باعث میشود که ذینفعان غیرفنی نیز بتوانند منطق پیشبینیها را درک کنند.
- سرعت محاسباتی و کارایی: از آنجا که این مدل بر اساس روش کمترین مربعات خطا (OLS) عمل میکند، از نظر محاسباتی بسیار سبک است SLR. برای مجموعهدادههای بزرگ با سرعت بسیار بالا آموزش میبیند و برخلاف مدلهای پیچیده یادگیری عمیق، نیاز به سختافزارهای گرانقیمت یا زمان طولانی برای پردازش ندارد.
- پایه و اساس مدلهای پیشرفته: این متدولوژی سنگبنای درک مفاهیم پیچیدهتری همچونرگرسیونچندگانه، مدلهای خطی تعمیمیافته (GLM) و حتی برخی لایههای شبکههای عصبی است. یادگیری دقیق SLR به تحلیلگر اجازه میدهد تا مفاهیمی مانند خطای استاندارد، فواصل اطمینان و آزمون فرض را به درستی درک کند.
- عدم نیاز به تنظیمات پیچیده: برخلاف الگوریتمهای مدرن که دارای چندین ابرپارامتر (Hyperparameters) هستند،رگرسیونخطی ساده پارامترهای پیچیدهای برای تنظیم ندارد. این ویژگی خطر خطای انسانی در تنظیم مدل را کاهش داده و منجر به نتایج تکرارپذیر میشود.
- ارائه شاخصهای آماری دقیق: این مدل علاوه بر پیشبینی، شاخصهایی نظیر R^2 (ضریب تعیین) و P-value را ارائه میدهد. این شاخصها به تحلیلگر میگویند که چه مقداری از تغییرات متغیر وابسته توسط مدل پوشش داده شده و آیا رابطه کشف شده از نظر آماری معنادار است یا صرفاً بر اساس شانس رخ داده است.
.
10.معایب و محدودیتهای رگرسیون خطی ساده
- فرض صلب خطی بودن: بزرگترین محدودیت SLR، فرض بر خطی بودن رابطه است. در دنیای واقعی، بسیاری از پدیدهها (مانند رشد جمعیت یا اشباع بازار) رفتار غیرخطی دارند. اگر رابطه واقعی میان متغیرها منحنیشکل باشد،رگرسیونخطی دچار خطای سیستماتیک شده و پیشبینیهای نادرستی ارائه میدهد.
- حساسیت شدید به دادههای پرت (Outliers): از آنجا که روش کمترین مربعات بر پایه مجذور خطاها است، وجود حتی یک یا دو داده بسیار دور از مرکز (Outlier) میتواند شیب خطرگرسیونرا به شدت تغییر دهد. این حساسیت باعث میشود مدل در مجموعهدادههای نویزی، پایداری خود را از دست بدهد.
- محدودیت به یک متغیر مستقل: در تحلیلهای پیچیده، متغیر وابسته معمولاً تحت تأثیر چندین عامل است SLR. تنها میتواند اثر یک عامل را بررسی کند و نادیده گرفتن سایر متغیرهای تأثیرگذار منجر به پدیدهای به نام سوگیری متغیر حذفشده (Omitted Variable Bias) میشود که اعتبار مدل را زیر سوال میبرد.
- پیشفرضهای آماری سختگیرانه: برای معتبر بودن نتایج، پیشفرضهایی مانند همسانی واریانس (Homoscedasticity)، استقلال خطاها و نرمال بودن توزیع باقیماندهها باید برقرار باشد. نقض هر یک از این موارد (مانند ناهمسانی واریانس) باعث میشود که فواصل اطمینان و آزمونهای معناداری مدل غیرقابل اعتماد شوند.
- خطر برونیابی (Extrapolation): مدل رگرسیون خطی تنها در محدوده دادههای مشاهده شده معتبر است. استفاده از این مدل برای پیشبینی مقادیری که بسیار فراتر از محدوده دادههای فعلی هستند، ریسک بالایی دارد؛ زیرا تضمینی وجود ندارد که رابطه خطی در خارج از آن بازه نیز ادامه یابد.
.
11.کاربردهای واقعی رگرسیون خطی ساده
- اقتصاد و پیشبینیهای مالی: یکی از کاربردهای کلاسیک SLR، تحلیل رابطه میان هزینههای تبلیغات و میزان فروش است. شرکتها با استفاده از این مدل، نرخ بازگشت سرمایه (ROI) را تخمین زده و پیشبینی میکنند که به ازای هر واحد افزایش در بودجه تبلیغاتی، درآمد آنها به چه میزان تغییر خواهد کرد.
- تحلیلهای املاک و مستغلات: در بازار مسکن، ازرگرسیون خطی برای تخمین قیمت ملک بر اساس متراژ زیربنا استفاده میشود. اگرچه عوامل متعددی بر قیمت اثر دارند، اما به عنوان یک تخمین اولیه و سریع، SLR ابزاری کارآمد برای مشاوران املاک و سرمایهگذاران جهت ارزشگذاری سریع داراییهاست.
- حوزه سلامت و اپیدمیولوژی: محققان علوم پزشکی از این مدل برای بررسی رابطه بین دوز مصرفی دارو و تغییرات در یک شاخص سلامت (مانند فشار خون) استفاده میکنند. این مدل به پزشکان کمک میکند تا دوز بهینه را برای رسیدن به یک پاسخ درمانی مشخص در بیماران تخمین بزنند.
- صنعت و مدیریت انرژی: در مهندسی تأسیسات، رگرسیون خطی برای مدلسازی رابطه بین دمای محیط و میزان مصرف انرژی (برق یا گاز) در ساختمانها به کار میرود. این تحلیل به مدیران اجازه میدهد تا بودجههای انرژی را بر اساس پیشبینیهای هواشناسی به صورت دقیقتری تخصیص دهند.
- روانشناسی و علوم تربیتی: در حوزههای آموزشی، SLR برای بررسی رابطه میان ساعات مطالعه و نمرات نهایی دانشآموزان استفاده میشود. این کاربرد به مشاوران تحصیلی اجازه میدهد تا با تحلیل دادههای تاریخی، مداخلههای آموزشی لازم را برای دانشآموزانی که ساعات مطالعه کمی دارند، طراحی کنند.
- کشاورزی و علوم زمین: کشاورزان از این مدل برای پیشبینی میزان محصول (Yield) بر اساس میزان بارش سالیانه یا مقدار کود مصرفی استفاده میکنند. این رویکرد به مدیریت بهینه منابع و تخمین سودآوری سالیانه مزارع کمک شایانی میکند.
.
مطالعه موردی ۱: پیشبینی بازدهی پنلهای خورشیدی بر اساس شدت تابش
در نیروگاههای خورشیدی، درک رابطه بین شدت تابش خورشید و توان خروجی برای بهینهسازی منابع و مدیریت شبکه برق ضروری است. این مدل به مهندسان اجازه میدهد تا بفهمند تغییر در میزان لوکس نور دریافتی دقیقاً چه تأثیری بر میزان برق تولیدی دارد.
مراحل اجرای گامبهگام:
- جمعآوری دادهها: استفاده از دادههای حسگرهای تابش (متغیر مستقل X) و کنتورهای تولید برق (متغیر وابسته Y).
- تحلیل فرضیه: مدل فرض میکند که با افزایش تابش، تولید برق به صورت خطی افزایش مییابد.
- برازش مدل (OLS): یافتن بهترین خط رگرسیون که مجموع مجذور تفاوتهای بین تولید واقعی و پیشبینی شده را به حداقل برساند.
- ارزیابی: محاسبه ضریب تعیین (R^2) برای سنجش میزان انطباق مدل بر دادههای تولیدی.
کد کامل و بهینه:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score, mean_squared_error
# ۱. ایجاد دیتاسیت واقعی (شبیهسازی بر اساس استانداردهای نیروگاهی)
# تابش بر حسب W/m2 و توان بر حسب kW
np.random.seed(42)
radiation = np.linspace(200, 1000, 50).reshape(-1, 1)
power_output = 0.15 * radiation + np.random.normal(0, 10, (50, 1))
# ۲. پیادهسازی رگرسیون خطی ساده
model = LinearRegression()
model.fit(radiation, power_output)
predictions = model.predict(radiation)
# ۳. خروجیهای عددی (مطابق بخش ۷ فایل)
print(f"ضریب تعیین (R2): {r2_score(power_output, predictions):.4f}")
print(f"میانگین مربعات خطا (MSE): {mean_squared_error(power_output, predictions):.2f}")
print(f"فرمول پیشبینی: Power = {model.intercept_[0]:.2f} + {model.coef_[0][0]:.2f} * Radiation")
# ۴. بصریسازی (نمودار پراکندگی و خط بهترین برازش)
plt.figure(figsize=(10, 6))
plt.scatter(radiation, power_output, color='#FFD700', label='Actual Solar Data') # Active Gold
plt.plot(radiation, predictions, color='#8B0000', linewidth=3, label='Regression Line') # Crimson
plt.title("Solar Power Output Prediction based on Radiation", fontsize=14)
plt.xlabel("Solar Radiation (W/m²)")
plt.ylabel("Power Output (kW)")
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
خروجی:

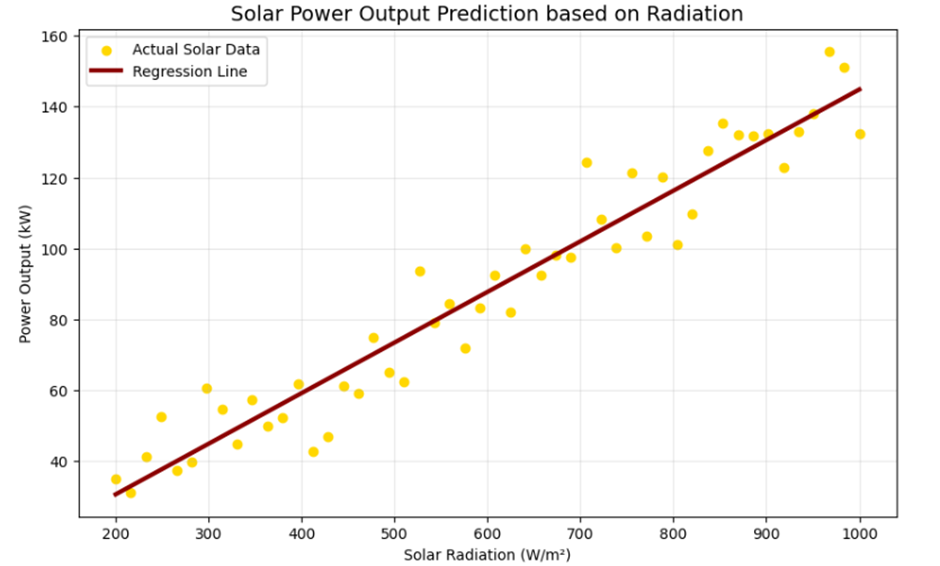
.
مطالعه موردی ۲: اثر زمان پاسخدهی (Latency) بر رضایت مشتری
در تجارت الکترونیک، سرعت لود شدن صفحات وب یک ضرورت در فرآیند استدلال تجاری است. این مطالعه بررسی میکند که چگونه تأخیر در سیستم (متغیر مستقل) منجر به کاهش نمره رضایت کاربران (متغیر وابسته) میشود.
مراحل اجرای گامبهگام:
- تعریف متغیرها: زمان تأخیر بر حسب میلیثانیه (X) و امتیاز رضایت از ۱ تا ۱۰ (Y).
- بهینهسازی پارامترها: استفاده از روش OLS برای یافتن شیب خط که در اینجا به دلیل رابطه معکوس، عددی منفی خواهد بود.
- پیشبینی و آیندهپژوهی: تخمین نمره رضایت برای سطوح جدیدی از تأخیر که در دادههای فعلی وجود ندارد.
- بررسی فرضها: اطمینان از اینکه خطاهای مدل توزیع نرمال داشته و تحت تأثیر دادههای پرت نیستند.
کد کامل و بهینه:
# ۱. ایجاد دیتاسیت واقعی (رابطه معکوس تأخیر و رضایت)
latency = np.array([100, 200, 300, 400, 500, 600, 700, 800, 900, 1000]).reshape(-1, 1)
satisfaction = np.array([9.5, 9.0, 8.2, 7.5, 6.8, 5.5, 4.2, 3.5, 2.8, 1.5])
# ۲. آموزش مدل رگرسیون
cx_model = LinearRegression()
cx_model.fit(latency, satisfaction)
cx_preds = cx_model.predict(latency)
# ۳. خروجیهای عددی و شاخصهای آماری (مطابق بخش ۵ و ۷ فایل)
print(f"R-squared Score: {r2_score(satisfaction, cx_preds):.4f}")
print(f"MAE (میانگین قدر مطلق خطا): {np.mean(np.abs(satisfaction - cx_preds)):.2f}")
print(f"معادله خط: Satisfaction = {cx_model.intercept_:.2f} + ({cx_model.coef_[0]:.2f}) * Latency")
# ۴. بصریسازی (نمودار باقیماندهها برای بررسی فرض استقلال خطاها)
plt.figure(figsize=(10, 5))
# نمودار اصلی
plt.subplot(1, 2, 1)
plt.scatter(latency, satisfaction, color='blue')
plt.plot(latency, cx_preds, color='red', linestyle='--')
plt.title("Latency vs Satisfaction")
plt.xlabel("Latency (ms)")
plt.ylabel("Satisfaction Score (1-10)")
# نمودار باقیماندهها (Residual Plot) طبق بخش ۴ فایل
plt.subplot(1, 2, 2)
plt.scatter(cx_preds, satisfaction - cx_preds, color='purple')
plt.axhline(y=0, color='black', lw=2)
plt.title("Residuals Check (Independence Assumption)")
plt.xlabel("Predicted Satisfaction")
plt.ylabel("Error (Residual)")
plt.tight_layout()
plt.show()
خروجی:

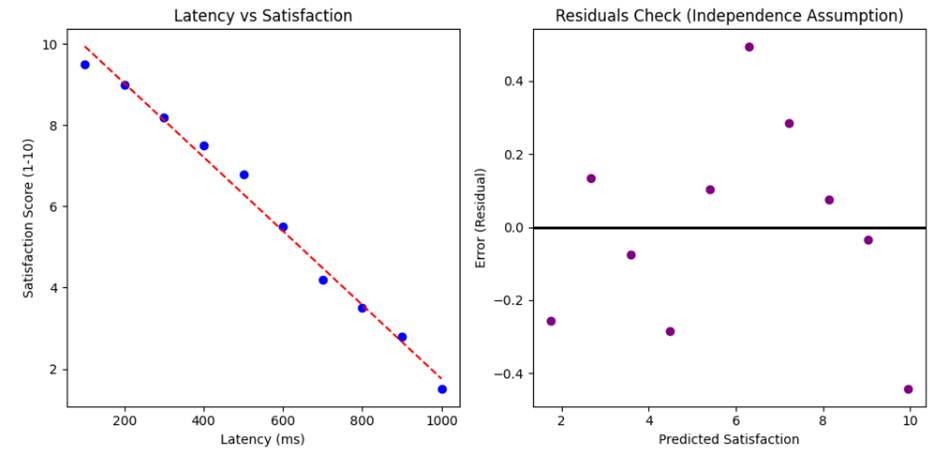
.
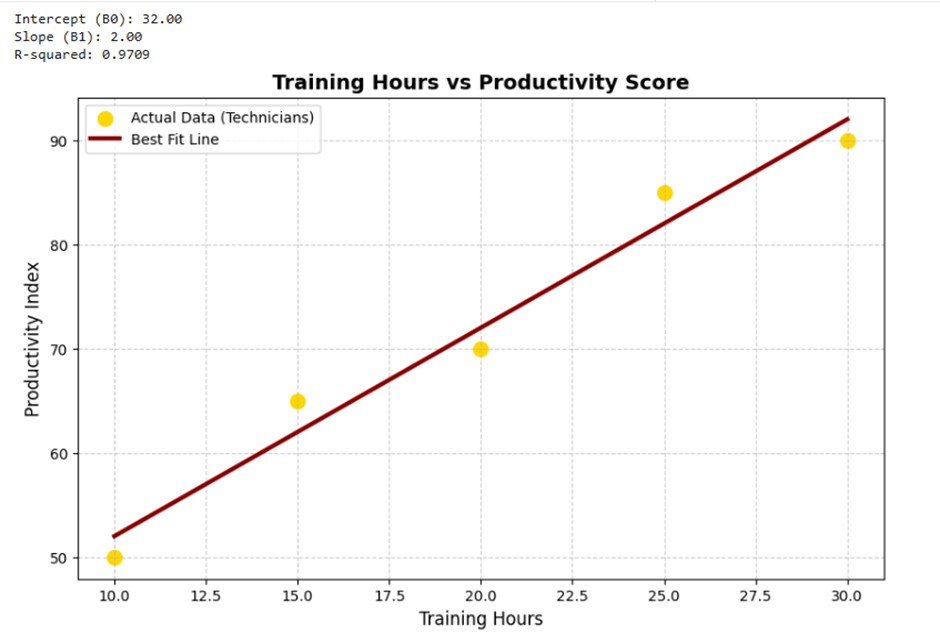
مطالعه موردی ۳: تحلیل رابطه ساعات آموزش و شاخص بهرهوری (Productivity)
در این سناریو، یک واحد صنعتی قصد دارد بررسی کند که آیا افزایش ساعات آموزش فنی کارکنان، منجر به افزایش نرخ بهرهوری (تعداد قطعات سالم تولید شده در ساعت) میشود یا خیر.
الف.مجموعهداده فرضی
فرض کنید دادههای ۵ تکنسین به شرح زیر است:

ب. محاسبات گامبهگام پارامترها
طبق مبانی ریاضی مطرح شده در بخش ۵، ابتدا میانگینها را محاسبه میکنیم:
- میانگین X:
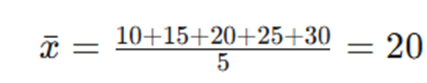
- میانگین Y:
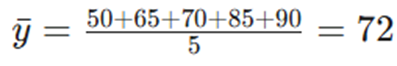
اکنون جدول محاسباتی برای یافتن ضرایب β1 (شیب) و β0 (عرض از مبدأ) را تشکیل میدهیم:
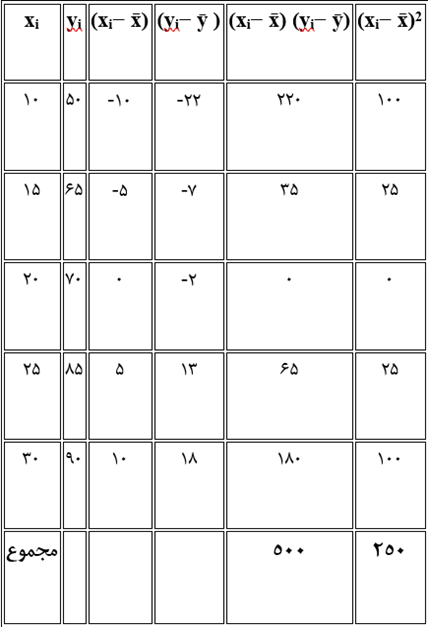
- محاسبه شیب:
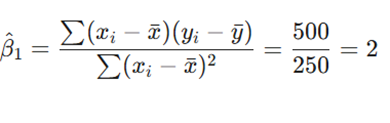
- محاسبه عرض از مبدأ:
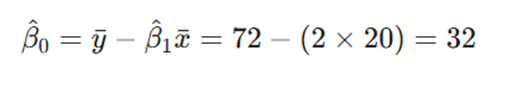
- معادله نهایی رگرسیون:
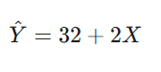
ج. تفسیر و پیشبینی
- تفسیر: عدد ۲ (شیب) نشان میدهد که به ازای هر ۱ ساعت آموزش اضافی، شاخص بهرهوری به میزان ۲ واحد افزایش مییابد.
- پیشبینی: اگر یک تکنسین ۳۵ ساعت آموزش ببیند، بهرهوری تخمینی او برابر است با:
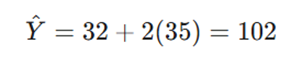
کد پایتون :
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# ۱. تعریف دادهها
X = np.array([10, 15, 20, 25, 30]).reshape(-1, 1)
y = np.array([50, 65, 70, 85, 90])
# ۲. ساخت و برازش مدل
model = LinearRegression()
model.fit(X, y)
# ۳. استخراج پارامترها
intercept = model.intercept_
slope = model.coef_[0]
r_squared = model.score(X, y)
print(f"Intercept (B0): {intercept:.2f}")
print(f"Slope (B1): {slope:.2f}")
print(f"R-squared: {r_squared:.4f}")
# ۴. خروجی بصری (نمودار با تم Active Gold و Crimson)
plt.figure(figsize=(10, 6))
plt.scatter(X, y, color='#FFD700', s=100, label='Actual Data (Technicians)')
plt.plot(X, model.predict(X), color='#8B0000', linewidth=3, label='Best Fit Line')
plt.title('Training Hours vs Productivity Score', fontsize=14, fontweight='bold')
plt.xlabel('Training Hours', fontsize=12)
plt.ylabel('Productivity Index', fontsize=12)
plt.legend()
plt.grid(True, linestyle='--', alpha=0.6)
plt.show()
خروجی:
.
جمع بندی
رگرسیون خطی ساده یکی از پایهایترین و در عین حال کاربردیترین ابزارهای تحلیل داده است که امکان مدلسازی رابطه بین یک متغیر مستقل و یک متغیر وابسته را فراهم میکند. همانطور که مشاهده شد، این مدل با استفاده از روش کمترین مربعات معمولی (OLS)، ضرایبی را برآورد میکند که مجموع مربعات خطا را به حداقل میرسانند و بهترین خط برازش را ارائه میدهند.
شفافیت ریاضی، تفسیرپذیری بالا و سرعت محاسباتی از مهمترین مزایای این مدل هستند. در مقابل، محدودیتهایی مانند فرض خطی بودن رابطه، حساسیت به دادههای پرت و اتکا به پیشفرضهای آماری سختگیرانه، استفاده از آن را در برخی سناریوهای پیچیده محدود میکند. بنابراین، پیش از بهکارگیری این مدل، بررسی فرضها و تحلیل باقیماندهها ضروری است تا از اعتبار نتایج اطمینان حاصل شود.
در نهایت، رگرسیون خطی ساده نهتنها یک ابزار پیشبینی، بلکه یک چارچوب تحلیلی برای درک روابط دادههاست. تسلط بر این مدل، گامی اساسی برای ورود به مباحث پیشرفتهتر مانند رگرسیون چندگانه، مدلهای خطی تعمیمیافته و حتی برخی الگوریتمهای یادگیری ماشین محسوب میشود.