

1.مقدمه
در بسیاری از مسائل دنیای واقعی، سیستمهای هوش مصنوعی با یک هدف منفرد روبهرو نیستند؛ بلکه باید چندین وظیفه مرتبط را بهصورت همزمان مدیریت کنند. برای مثال، در یک خودروی خودران، مدل باید هم اشیاء را تشخیص دهد، هم مسیر قابل رانندگی را مشخص کند و هم علائم راهنمایی را تحلیل کند. آموزش جداگانه یک مدل برای هر وظیفه، علاوه بر هزینه محاسباتی بالا، منجر به اتلاف دانش مشترک میان این مسائل میشود. یادگیری چندوظیفهای (Multi-Task Learning یا MTL) پاسخی مهندسیشده به این چالش است.
یادگیری چندوظیفهای رویکردی است که در آن یک مدل واحد با بهرهگیری از بازنماییهای مشترک، چندین وظیفه مرتبط را بهصورت همزمان یاد میگیرد. ایده مرکزی این پارادایم بر «اشتراک دانش» استوار است: اطلاعات آموختهشده در یک وظیفه میتواند به بهبود عملکرد در وظیفه دیگر کمک کند. این انتقال دانش که با عنوان Inductive Transfer شناخته میشود، نهتنها دقت مدل را افزایش میدهد، بلکه باعث کاهش بیشبرازش و بهینهسازی مصرف منابع میشود.
در این مقاله، ابتدا مفاهیم بنیادی یادگیری چندوظیفهای و تفاوت آن با یادگیری تکوظیفهای را بررسی میکنیم. سپس مبانی ریاضی، معماریهای رایج، تکنیکهای پیشرفته و چالشهای پیادهسازی را تحلیل خواهیم کرد. در ادامه نیز با مثالهای صنعتی و پیادهسازی عملی در پایتون، نحوه استفاده از این رویکرد در سناریوهای واقعی را مشاهده میکنیم.
2.تعریف
یادگیری چندوظیفهای یا به اختصار MTL، یکی از زیرشاخههای استراتژیک در یادگیری عمیق است که بر پایه به اشتراکگذاری دانش میان وظایف مرتبط بنا شده است. در مدلهای سنتی، هر شبکه عصبی برای حل یک مسئله مجزا (مانند تشخیص چهره) آموزش میبیند؛ اما در معماری MTL، سیستم به گونهای طراحی میشود که چندین وظیفه متفاوت اما مرتبط (مانند تشخیص چهره، تخمین سن و شناسایی حالت چهره) را به طور همزمان و در یک مدل واحد یاد بگیرد.
فلسفه اصلی یادگیری چندوظیفهای بر این اصل استوار است که «یادگیری همزمان وظایف مرتبط، باعث بهبود عملکرد مدل در هر یک از آن وظایف میشود». در این رویکرد، لایههای اولیه شبکه به عنوان یک Backbone یا استخراجکننده ویژگی مشترک عمل میکنند. این لایهها یاد میگیرند بازنماییهای (Representations) کلی و غنیتری از دادهها استخراج کنند که برای تمام وظایف مفید باشد. به بیان ساده، مدل از اطلاعات موجود در وظیفه “ب” استفاده میکند تا درک بهتری از الگوهای پیچیده در وظیفه “الف” پیدا کند. این فرآیند که تحت عنوان Inductive Transfer شناخته میشود، منجر به ساخت مدلهایی هوشمندتر و کارآمدتر در مصرف منابع محاسباتی میگردد.
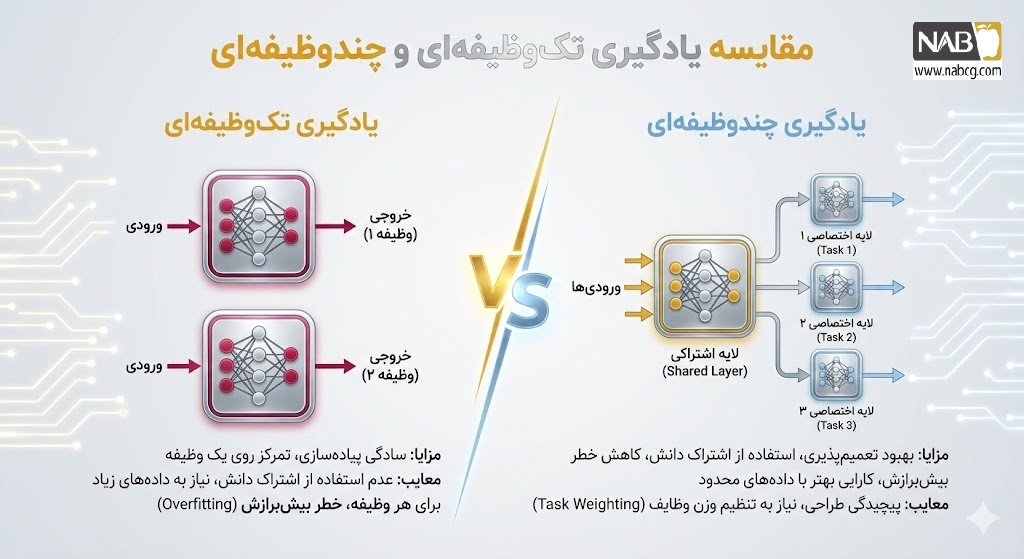
3. یادگیری تکوظیفهای در مقابل چندوظیفهای
درک تفاوتهای ساختاری میان یادگیری تکوظیفهای (STL) و چندوظیفهای (MTL) برای طراحی سیستمهای هوش مصنوعی در مقیاس صنعتی ضروری است. جدول زیر این تفاوتها را از منظر فنی بررسی میکند:
| شاخص کلیدی | یادگیری تکوظیفهای (STL) | یادگیری چندوظیفهای (MTL) |
| هدف بهینهسازی | تمرکز بر استخراج یک معیار (Metric) خاص برای یک خروجی واحد. | بهینهسازی همزمان چندین معیار که منجر به یادگیری جامعتر میشود. |
| معماری شبکه | تمام لایهها و پارامترها منحصراً برای حل یک مسئله اختصاص یافتهاند. | لایههای ابتدایی اشتراکی (Shared) و لایههای انتهایی اختصاصی (Task-specific) هستند. |
| مدیریت نویز | نویزها ممکن است باعث بیشبرازش شوند؛ زیرا مدل مرزی برای تشخیص نویز از ویژگی ندارد. | با استفاده از اطلاعات سایر وظایف، نویزها فیلتر شده و ویژگیهای اصلی و مشترک تقویت میشوند. |
| قدرت تعمیمدهی | به دلیل محدودیت دیدگاه، ریسک بیشبرازش (Overfitting) روی دادههای آموزش بالا است. | به دلیل یادگیری بازنماییهای کلیتر، مدل در مواجهه با دادههای جدید (Unseen Data) پایدارتر است. |
در یادگیری چندوظیفهای، مدل مجبور است فضای فرضیهای را پیدا کند که برای تمام وظایف بهینه باشد. این محدودیتِ مثبت، باعث میشود مدل از یادگیری الگوهای تصادفی و نویزهای موجود در یک مجموعه داده خاص اجتناب کرده و به سمت ویژگیهای بنیادیتری برود که در دنیای واقعی تکرارپذیر هستند. در نتیجه، خروجی نهایی نه تنها سریعتر به دست میآید، بلکه از نظر مهندسیِ ویژگی، بسیار دقیقتر از مدلهای تکمنظوره است.
۴. اهمیت و ضرورت بهکارگیری یادگیری چندوظیفهای
یادگیری چندوظیفهای (MTL) فراتر از یک متد آموزشی، راهکاری استراتژیک برای عبور از محدودیتهای کلاسیک یادگیری عمیق است. ضرورت استفاده از این رویکرد در مدلهای مدرن را میتوان در چهار محور کلیدی خلاصه کرد:
- انتقال کارآمد دانش (Knowledge Transfer): مهمترین مزیت MTL، توانایی اشتراکگذاری الگوهای آموختهشده میان وظایف است. مدل به جای یادگیری هر وظیفه از نقطه صفر، از دانش استخراجشده در یک دامنه برای تقویت عملکرد در دامنهای دیگر استفاده میکند؛ فرآیندی که سرعت یادگیری تخصصهای جدید را به شدت افزایش میدهد.
- بهبود قدرت تعمیمدهی: یادگیری همزمان چندین وظیفه، شبکه را وادار به استخراج ویژگیهای بنیادی و مشترک میکند. این ویژگی باعث میشود پیشبینیهای مدل در مواجهه با دادههای خارج از توزیع، دقیقتر و پایدارتر باشد.
- اثر تنظیمکنندگی: MTL به عنوان یک رگولایزر طبیعی عمل میکند. با بهینهسازی همزمان چندین تابع هزینه، فضای جستجوی مدل محدود شده و از تمرکز بر نویزهای تصادفی یک وظیفه خاص جلوگیری میشود. این مکانیسم ریسک بیشبرازش (Overfitting) را به حداقل رسانده و منجر به ساخت مدلهای مقاومتر (Robust) میگردد.
- بهینهسازی مصرف داده: در صنایعی که دسترسی به دادههای برچسبدار محدود است، MTL با بهرهگیری از سیگنالهای آموزشی وظایف جانبی، نیاز به مجموعهدادههای عظیم را کاهش داده و پیادهسازی هوش مصنوعی را در محیطهای کمداده ممکن میسازد.
.
5.یادگیری چندوظیفهای چگونه کار میکند؟
عملکرد یادگیری چندوظیفهای (MTL) بر پایه استخراج بازنماییهای مشترک (Shared Representations) استوار است. در این رویکرد، شبکه عصبی به گونهای طراحی میشود که دانش حاصل از یک وظیفه، مکمل یادگیری در وظایف دیگر باشد. این فرآیند از طریق سه مکانیزم اصلی فنی زیر محقق میگردد:
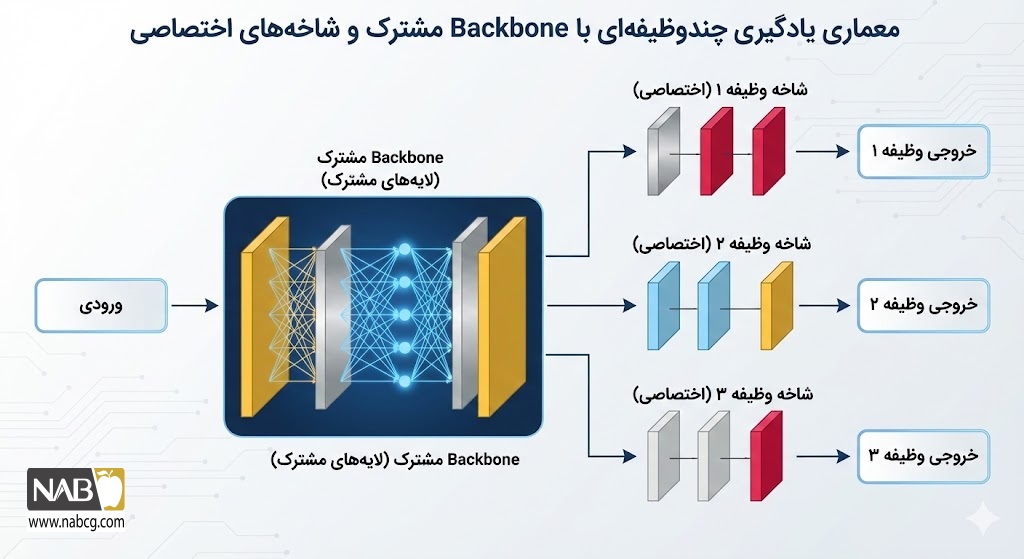
- اشتراک ویژگی (Feature Sharing): در لایههای ابتدایی شبکه که به عنوان «ستون فقرات» (Backbone) شناخته میشوند، مدل ویژگیهای بصری یا معنایی سطح پایین (مانند لبهها در تصویر یا نقش کلمات در متن) را یاد میگیرد. از آنجا که این ویژگیها برای تمام وظایف ضروری هستند، مدل آنها را در یک فضای پارامتری مشترک ذخیره میکند. این اشتراکگذاری مانع از تکرار محاسبات موازی شده و باعث میشود مدل با دادههای کمتر، الگوهای غنیتری را شناسایی کند.
- مکانیسم تمرکز و راهنمایی (Eavesdropping): در MTL، وظایف دشوار میتوانند از وظایف سادهتر به عنوان راهنما استفاده کنند. هنگامی که یک وظیفه دارای سیگنالهای آموزشی شفافتری است، مدل سریعتر ویژگیهای مرتبط را کشف میکند. سایر وظایف با «گوش دادن» به این سیگنالهای قوی در لایههای مشترک، مسیر بهینهسازی خود را پیدا کرده و از افتادن در تلههای محاسباتی (Local Minima) نجات مییابند.
- تنظیمگری ضمنی (Implicit Regularization): یادگیری همزمان وظایف، مدل را مجبور میکند تا فضای فرضیهای را پیدا کند که برای تمام اهداف بهینه باشد. این محدودیتِ ساختاری مانند یک فیلتر عمل کرده و اجازه نمیدهد مدل روی نویزهای تصادفی یک وظیفه خاص متمرکز شود. نتیجه این فرآیند، حذف ویژگیهای بیاهمیت و تقویت الگوهایی است که دارای ارزش علّی و تکرارپذیر هستند.
در نهایت، پس از عبور از لایههای مشترک، شبکه به شاخههای اختصاصی (Task-specific Heads) تقسیم میشود. در این مرحله، دانشِ پالایششده در لایههای زیرین، به خروجیهای مجزا تبدیل میگردد. این ترکیب هوشمندانه از اشتراک و تمایز، زیربنای اصلی توانمندی MTL در حل مسائل پیچیده هوش مصنوعی است.
6.مبانی ریاضی و زیرساختهای محاسباتی یادگیری چندوظیفهای
درک دقیق یادگیری چندوظیفهای (MTL) نیازمند تحلیل چارچوبهای ریاضیاتی است که وظیفه بهینهسازی همزمان چندین هدف را بر عهده دارند. این مبانی تضمین میکنند که انتقال دانش بین وظایف به شکلی سیستماتیک انجام شود.
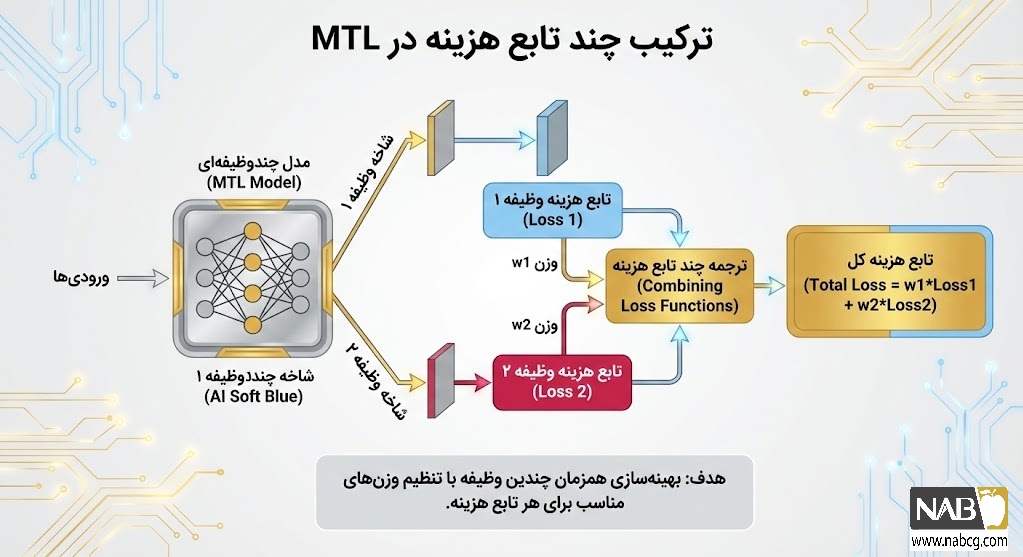
الف. ساختار تابع هزینه جامع
هسته ریاضی MTL بر پایه تجمیع توابع هزینه انفرادی بنا شده است. اگر T وظیفه داشته باشیم، تابع هزینه کل (Ltotal) از مجموع توابع هزینه هر وظیفه (Li) به دست میآید:
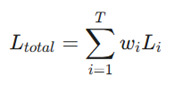
- Ltotal: خطای کل شبکه که باید کمینه شود.
- Li: تابع هزینه اختصاصی وظیفه i-ام (مثلاً خطای میانگین مربعات برای رگرسیون یا Cross-entropy برای طبقهبندی).
- wi: ضریب وزنی وظیفه i-ام که اهمیت هر وظیفه را در فرآیند آموزش تعیین میکند .
.
ب. اشتراک و تنظیم پارامترها
از نظر ریاضی، اشتراک دانش با اعمال محدودیت روی پارامترهای مدل (θ) محقق میشود. در مدلهای MTL، یک ترم منظمسازی (Regularization) به تابع هزینه اضافه میشود تا پارامترهای اشتراکی را به سمت یادگیری ویژگیهای عمومی سوق دهد:
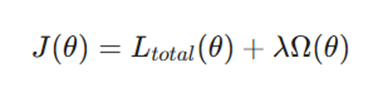
- J(θ): تابع هدف نهایی.
- Ω (θ): ترم منظمسازی (مانند L1 یا L2) که از پیچیدگی بیش از حد مدل و بیشبرازش جلوگیری میکند.
- λ: ضریب کنترلکننده شدت منظمسازی.
.
ج. الگوریتمهای بهینهسازی و محاسبات گرادیان
در یادگیری چندوظیفهای، بهروزرسانی پارامترهای اشتراکی بر پایه برآیند گرادیانهای تمامی وظایف انجام میشود. الگوریتمهایی نظیر SGD یا Adam برای یافتن نقطه بهینه در این فضای چندبعدی و پیچیده به کار میروند.
د. فاکتورگیری ماتریسی
در سیستمهای توصیهگر، از جبر خطی برای تجزیه ماتریسهای بزرگ تعامل کاربر-آیتم استفاده میشود. این فرآیند باعث استخراج ویژگیهای پنهان (Latent Features) مشترک میان وظایفی مانند پیشبینی امتیاز و تمایل به خرید میگردد.
ه. چارچوب احتمالات بیزی (Bayesian Framework)
رویکردهای بیزی با تعریف توزیعهای احتمالی روی پارامترها، از عدم قطعیت دادهها برای بهبود یادگیری بهره میبرند. این چارچوب بهویژه در سناریوهای با نویز بالا، پایداری و دقت مدل را تضمین میکند.
7.انواع رویکردهای پیادهسازی یادگیری چندوظیفهای
انتخاب مدل مناسب در یادگیری چندوظیفهای (MTL) به میزان همبستگی وظایف، حجم دادهها و منابع محاسباتی بستگی دارد. به طور کلی، معماریهای MTL به سه دسته اصلی تقسیم میشوند:
الف. اشتراک سخت پارامترها (Hard-Parameter Sharing)
در این متد، لایههای اولیه شبکه (استخراجکننده ویژگی) بین تمامی وظایف کاملاً مشترک هستند و تنها لایههای خروجی به هر وظیفه اختصاص مییابند. این روش برای وظایف بسیار مرتبط با توزیع داده مشابه، ایدهآل است.
- مزایا: کاهش شدید ریسک بیشبرازش و کارایی بالای محاسباتی.
- معایب: در صورت عدم تشابه وظایف، ممکن است باعث افت عملکرد در برخی از آنها شود.
.
ب. اشتراک نرم پارامترها (Soft-Parameter Sharing)
در این رویکرد، هر وظیفه مدل و پارامترهای اختصاصی خود را دارد، اما پارامترهای لایههای متناظر با استفاده از تکنیکهایی نظیر «منظمسازی» (Regularization) به یکدیگر نزدیک میشوند تا دانش میان آنها منتقل شود. این روش زمانی که وظایف دارای ویژگیهای مشترک و اختصاصی همزمان هستند، کاربرد دارد.
- مزایا: انعطافپذیری بالا در مواجهه با وظایف ناهمگون.
- معایب: پیچیدگی پیادهسازی و نیاز به تنظیمات دقیق ابرپارامترها.
.
ج. معماریهای اختصاصی وظیفه (Task-Specific Architectures)
در این حالت، هر وظیفه دارای معماری کاملاً مستقل است و اشتراک پارامتری مستقیم صورت نمیگیرد. این رویکرد برای وظایف کاملاً متفاوت با اهداف متضاد مناسب است.
- مزایا: حذف کامل ریسک «انتقال منفی» و سفارشیسازی حداکثری.
- معایب: عدم بهرهبرداری از دانش مشترک و اتلاف منابع در وظایف با دادههای محدود.
انتخاب رویکرد بهینه: در پروژههای صنعتی، معمولاً فرآیند با اشتراک سخت آغاز شده و در صورت بروز تداخل، به سمت اشتراک نرم یا ترکیبی حرکت میشود. کلید موفقیت، ایجاد توازن میان دانش اشتراکی و ویژگیهای منحصربهفرد هر مسئله است.
.
8.تکنیکهای پیشرفته و نوظهور در یادگیری چندوظیفهای
یادگیری چندوظیفهای (MTL) حوزهای در حال تکامل است که با معرفی متدولوژیهای نوین، مرزهای انتقال دانش میان وظایف را جابهجا میکند. برجستهترین تکنیکهای پیشرو (State-of-the-Art) در این عرصه عبارتند از:
- یادگیری انتقالی با مدلهای پیشآموزشدیده (Pre-trained Models): استفاده از مدلهای زبانی بزرگ نظیر BERT و GPT یا مدلهای بینایی مانند ResNet به عنوان استخراجکننده ویژگی (Backbone)، به سنگبنای MTL تبدیل شده است. تنظیم دقیق (Fine-tuning) این مدلها برای چندین وظیفه همزمان، کارایی سیستم را به شکل چشمگیری افزایش میدهد.
- یادگیری فراگیر (Meta-Learning): این تکنیک که به عنوان «یادگیریِ یادگرفتن» شناخته میشود، مدل را قادر میسازد با کمترین داده به وظایف جدید عادت کند. الگوریتمهایی مانند MAML در محیطهایی که توزیع وظایف به مرور زمان تغییر میکند، بسیار کارآمد هستند.
- جستجوی معماری عصبی (NAS): این فناوری فرآیند طراحی معماری شبکه را خودکار میکند. در MTL، الگوریتمهای NAS میتوانند به طور خودکار بهترین ترکیب از لایههای اشتراکی و اختصاصی را برای مجموعهای از وظایف کشف کنند.
- تنظیمگری گرادیان (Gradient Regularization): برای جلوگیری از تداخل وظایف و پدیده انتقال منفی، از تکنیکهایی نظیر تراز کردن گرادیانها استفاده میشود. این رویکرد تعادل میان پارامترهای اشتراکی و اختصاصی را به گونهای تنظیم میکند که بهبود یک وظیفه منجر به تخریب وظیفه دیگر نشود.
- مکانیزمهای توجه (Attention Mechanisms): استفاده از ساختارهای «ترنسفورمر» و مکانیزم توجه به مدل اجازه میدهد تا روی اطلاعات مرتبط برای هر وظیفه تمرکز کند. این دقتِ تفکیکشده، مدیریت دانش اشتراکی در ابعاد بزرگ را تسهیل میبخشد.
- یادگیری برنامه درسی (Curriculum Learning): در این استراتژی، مدل ابتدا با وظایف سادهتر مواجه شده و به تدریج وارد وظایف پیچیده میشود. این روند باعث انتقال نرمتر دانش و کاهش ریسک شکست در یادگیری وظایف دشوار میگردد.
.
9.پیادهسازی عملیاتی یادگیری چندوظیفهای با پایتون
پیادهسازی مدلهای چندوظیفهای (MTL) در پایتون معمولاً با بهرهگیری از کتابخانه TensorFlow و رابط Keras Functional API انجام میشود. در ادامه، فرآیند ساخت یک مدل مشترک برای دو وظیفه «تحلیل احساسات» و «تشخیص هیجان» را بررسی میکنیم:
- آمادهسازی هوشمند دادهها: نخستین گام، مهندسی دادههای برچسبدار برای هر دو وظیفه است. در MTL، ورودیهای متنی باید از یک خط لوله پیشپردازش مشترک (مانند توکنگذاری و پدینگ) عبور کنند تا بازنمایی عددی یکسانی برای ورود به لایههای اشتراکی داشته باشند.
- طراحی بدنه مشترک (Shared Backbone): در این مرحله، یک شبکه عصبی پایه برای استخراج ویژگیهای کلیدی طراحی میشود. استفاده از لایههای Embedding و LSTM در این بخش، مدل را قادر میسازد تا الگوهای زبانی و معنایی غنی را یاد بگیرد که به عنوان زیربنای مشترک برای تمامی وظایف عمل میکنند.
- تعریف شاخههای اختصاصی (Task-Specific Heads): پس از استخراج ویژگیها، شبکه به شاخههای مجزا تقسیم میشود. هر شاخه شامل لایههای متراکم (Dense) اختصاصی است که خروجی لایه اشتراکی را به پیشبینی نهایی (مثلاً قطبیت احساس یا نوع هیجان) تبدیل میکند.
- فرمولبندی تابع هزینه ترکیبی (Multi-Loss Function): این بخش قلب تپنده پیادهسازی است. باید برای هر وظیفه تابع هزینه متناسب (مانند Binary یا Categorical Cross-entropy) تعریف کرد. در نهایت، مجموع این خطاها با ضرایب وزنی مشخص، تابع هزینه کل را تشکیل میدهند.
- آموزش، ارزیابی و تنظیم دقیق: در طول آموزش همزمان (Joint Training)، پارامترهای مدل بر اساس سیگنالهای هر دو وظیفه بهروزرسانی شده و «انتقال دانش» رخ میدهد. پس از آموزش، عملکرد هر شاخه با معیارهای تخصصی نظیر Accuracy و F1-Score ارزیابی میشود. در سطوح پیشرفتهتر، میتوان از مدلهای پیشآموزشدیده مانند BERT به عنوان بدنه اصلی استفاده کرد تا دقت مدل در سناریوهای پیچیده تضمین شود.
.
10.کد کامل (TensorFlow/Keras)
این کد یک پیادهسازی عملیاتی از مراحل بالاست:
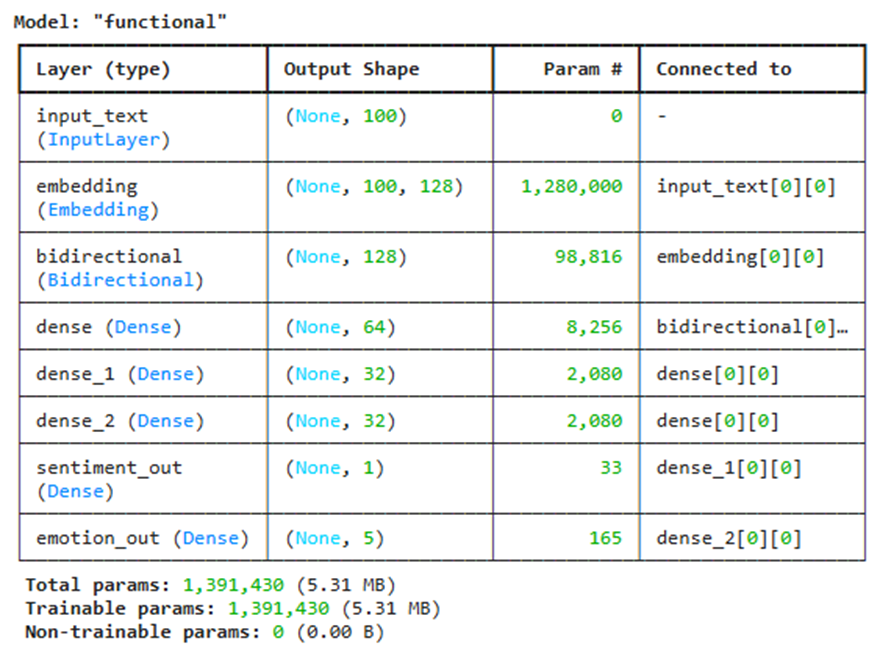
import tensorflow as tf
from tensorflow.keras import layers, Model
# تعریف ورودی مشترک (متن توکنگذاری شده)
inputs = layers.Input(shape=(100,), name="input_text")
# ۱. بدنه اشتراکی (Shared Backbone)
shared_embedding = layers.Embedding(input_dim=10000, output_dim=128)(inputs)
shared_lstm = layers.Bidirectional(layers.LSTM(64))(shared_embedding)
shared_dense = layers.Dense(64, activation='relu')(shared_lstm)
# ۲. شاخه اختصاصی تحلیل احساسات (Sentiment Task)
sentiment_branch = layers.Dense(32, activation='relu')(shared_dense)
sentiment_output = layers.Dense(1, activation='sigmoid', name='sentiment_out')(sentiment_branch)
# ۳. شاخه اختصاصی تشخیص هیجان (Emotion Task)
emotion_branch = layers.Dense(32, activation='relu')(shared_dense)
emotion_output = layers.Dense(5, activation='softmax', name='emotion_out')(emotion_branch)
# ۴. ساخت مدل نهایی با یک ورودی و دو خروجی
model = Model(inputs=inputs, outputs=[sentiment_output, emotion_output])
# ۵. پیکربندی توابع هزینه و بهینهساز
model.compile(
optimizer='adam',
loss={
'sentiment_out': 'binary_crossentropy',
'emotion_out': 'categorical_crossentropy'
},
loss_weights={'sentiment_out': 1.0, 'emotion_out': 0.8}, # وزندهی به وظایف
metrics=['accuracy']
)
model.summary()
خروجی:
.
11.مزایای کلیدی یادگیری چندوظیفهای (MTL)
بهکارگیری معماری یادگیری چندوظیفهای در پروژههای هوش مصنوعی، فراتر از یک انتخاب فنی، یک استراتژی عملیاتی برای ارتقای کارایی سیستم است. ادغام وظایف مرتبط در یک مدل واحد، مزایای زیر را به همراه دارد:
- ارتقای دقت و قدرت تعمیمدهی (Improved Accuracy & Generalization): یادگیری چندوظیفهای با بهرهگیری از دانش مشترک میان وظایف، دقت پیشبینیها را افزایش میدهد. این رویکرد به مدل اجازه میدهد تا بر روی دادههای نادیده (Unknown Data) عملکرد موثرتری داشته باشد؛ زیرا مدل به جای یادگیری الگوهای خاصِ یک وظیفه، بر ویژگیهای کلی و مشترک متمرکز میشود.
- بهینهسازی مصرف داده و منابع (Data & Resource Efficiency): یکی از چالشهای بزرگ هوش مصنوعی، کمبود دادههای برچسبدار است. MTL اجازه میدهد با مجموعهدادههای کوچکتر، نتایج مطلوبی حاصل شود؛ چرا که سیگنالهای آموزشی از وظایف پرداده به وظایف کمداده منتقل میشود. همچنین، این روش با کاهش نیاز به آموزش چندین مدل مجزا، به طور قابلتوجهی در زمان و منابع محاسباتی (GPU/RAM) صرفهجویی میکند.
- اثر تنظیمکنندگی و پایداری (Regularization & Stability): این تکنیک مانند یک فرم از «تنظیمکنندگی» (Regularization) عمل کرده و ریسک بیشبرازش (Overfitting) را در وظایف انفرادی به شدت کاهش میدهد. در واقع، دانش آموختهشده از یک وظیفه میتواند نقصها یا چالشهای وظیفه دیگر را جبران کند که این امر منجر به افزایش پایداری و قابلیت اطمینان (Reliability) کل سیستم میشود.
- کاهش پیچیدگی مدل (Reduced Complexity): با ترویج دانش اشتراکی در لایههای زیرین (Backbone)، معماری مدل سادهتر شده و مدیریت آن در مرحله استقرار (Deployment) تسهیل میگردد. این سادهسازی، فرآیند نگهداری و بروزرسانی مدلهای پیچیده در مقیاس صنعتی را بهبود میبخشد.
.
12.ملاحظات راهبردی و چالشهای پیادهسازی یادگیری چندوظیفهای
بهرهگیری از ظرفیتهای کامل یادگیری چندوظیفهای (MTL) مستلزم مدیریت دقیق چالشهایی است که ریشه در تداخل اهداف و محدودیتهای معماری دارند. مهمترین ملاحظات فنی در این حوزه عبارتند از:
- انتخاب وظایف و همبستگی معنایی (Task Relatedness): انتخاب هوشمندانه وظایف، زیربنای موفقیت در MTL است. وظایف ادغامشده باید دارای پیوندهای معنایی یا ساختاری باشند تا فرآیند اشتراک دانش به درستی شکل بگیرد؛ در غیر این صورت، صرف منابع محاسباتی فاقد دستاورد فنی خواهد بود.
- تداخل وظایف و انتقال منفی (Negative Transfer): این چالش زمانی رخ میدهد که بهینهسازی پارامترها برای یک وظیفه، تأثیری مخرب بر عملکرد سایر وظایف داشته باشد. اگر دانش مشترک به جای تقویت، باعث تضعیف دقت شود، پدیده «انتقال منفی» شکل گرفته است. مانیتورینگ مداوم منحنیهای یادگیری برای شناسایی و اصلاح این تداخلات ضروری است.
- پیچیدگی معماری و تعادل پارامتری: طراحی معماری در MTL فرآیندی سرراست نیست. مهندسان باید بین رویکردهای «اشتراک سخت پارامترها» و «اشتراک نرم» انتخاب کنند. ایجاد توازن میان لایههای اشتراکی و اختصاصی، تعیینکننده نهایی سرعت استنتاج و دقت مدل است.
- تنظیم ابرپارامترها و مصالحه در تعمیمدهی: یافتن نقطه بهینه بین بیشبرازش و کمبرازش در سیستمهای چندوظیفهای بسیار دشوار است. تنظیم وزن هر وظیفه در تابع هزینه کلی (Loss Weighting) اغلب نیازمند آزمون و خطای فراوان و صرف منابع محاسباتی بالاست.
- مدیریت نویز برچسبها و دادههای پرت: مدلهای MTL به نویز برچسبها حساس هستند؛ زیرا خطای یک وظیفه میتواند از طریق لایههای اشتراکی به کل سیستم سرایت کند. استفاده از تکنیکهای یادگیری مقاوم (Robust Learning) برای خنثیسازی اثر دادههای پرت الزامی است.
- پیچیدگی محاسباتی: اگرچه MTL در زمان استنتاج بهینه عمل میکند، اما فرآیند آموزش آن، بهویژه در تعداد وظایف بالا، بسیار سنگین است و نیازمند استراتژیهای بهینهسازی پیشرفته و زیرساختهای سختافزاری قدرتمند میباشد.
.
13.کاربردهای استراتژیک یادگیری چندوظیفهای در صنایع مدرن
یادگیری چندوظیفهای (MTL) به دلیل توانایی در استخراج ویژگیهای مشترک و بهینهسازی منابع، به یک استاندارد عملیاتی در صنایع پیشرو تبدیل شده است. مهمترین کاربردهای این رویکرد عبارتند از:
- پردازش زبان و گفتار (NLP & Speech): در حوزه متن و صوت، MTL برای اجرای همزمان وظایفی مانند تحلیل احساسات، بازشناسی موجودیتها (NER) و تشخیص هویت گوینده به کار میرود. این یادگیریِ همزمان به مدل کمک میکند تا ظرافتهای زبانی و بافتار (Context) را بهتر درک کرده و حتی در محیطهای پرنویز، پاسخهای دقیقتر و مرتبطتری تولید کند.
- بینایی ماشین و خودروهای خودران: معماری MTL در این حوزه حیاتی است. یک مدل واحد میتواند وظایفی نظیر تشخیص اشیاء، قطعهبندی تصاویر و شناسایی خطوط جاده را به طور همزمان انجام دهد. این اشتراک دانش در لایههای اولیه، باعث استخراج دقیقتر ویژگیهای بصری شده و در خودروهای خودران، سرعت پاسخدهی (Latency) و ایمنی سیستم را به شکل چشمگیری افزایش میدهد.
- بهداشت و درمان (Healthcare): در پزشکی دیجیتال، از MTL برای تشخیص همزمان چندین بیماری در تصاویر رادیولوژی و پیشبینی خواص مولکولی در کشف دارو استفاده میشود. این رویکرد با تحلیل همبستگی میان علائم مختلف، دقت تشخیص را بالا برده و به درمانهای شخصیسازیشده کمک میکند.
- سیستمهای توصیهگر و تولید متن: پلتفرمهای بزرگ با استفاده از MTL، تعاملات کاربر (مانند مشاهده و خرید) را همزمان تحلیل میکنند تا پیشنهاداتی دقیقتر ارائه دهند. همچنین در چتباتها، این تکنیک باعث میشود خروجی مدل علاوه بر صحت دستوری، از نظر معنایی نیز کاملاً با پرسش کاربر منطبق باشد.
.
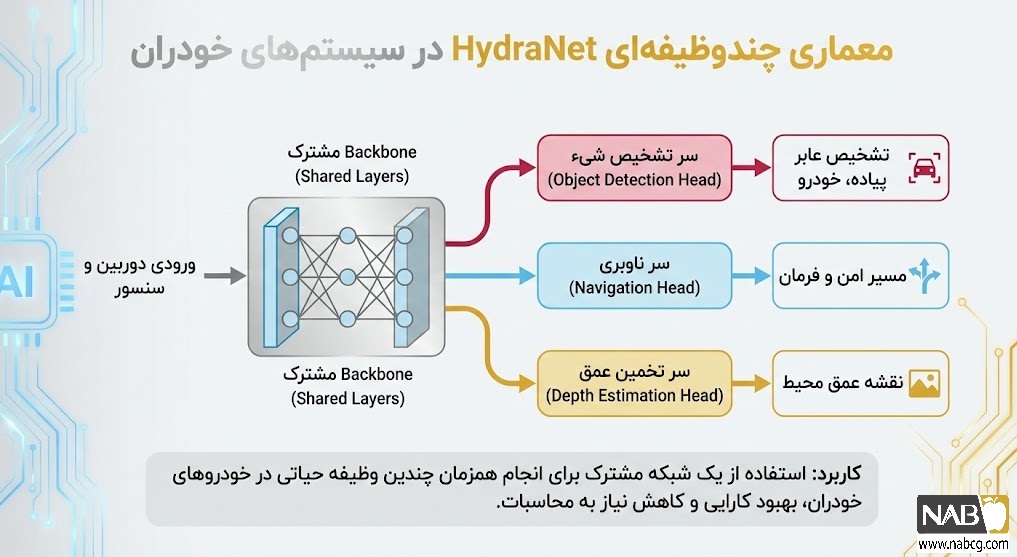
مطالعه موردی ۱: معماری HydraNet در خودروهای خودران تسلا
- در سیستمهای هدایت خودکار، زمان (Latency) حیاتیترین فاکتور است. تسلا با بهرهگیری از معماری HydraNet، یادگیری چندوظیفهای را به کمال رسانده است. در این ساختار، یک بدنه مشترک (Shared Backbone) که معمولاً یک شبکه عصبی پیچشی (CNN) عمیق است، تصویر ورودی را پردازش کرده و یک نقشه ویژگی (Feature Map) غنی تولید میکند. این بازنمایی مشترک سپس به شاخههای متعددی هدایت میشود که هر کدام وظیفهای خاص را بر عهده دارند.
- تحلیل عمیق فنی: دلیل اصلی استفاده از MTL در اینجا، «بهرهوری محاسباتی» و «سازگاری ویژگیها» است. شاخه تشخیص اشیاء (Object Detection) با استفاده از الگوریتمهایی نظیر YOLO، مختصات کادرهای محصورکننده (Bounding Boxes) را برای خودروها و موانع استخراج میکند. همزمان، شاخه قطعهبندی معنایی (Semantic Segmentation) به صورت پیکسلبهپیکسل، نواحی قابل راندن (Drivable Area) را مشخص میسازد. اشتراک دانش در لایههای اولیه باعث میشود که لبهها و بافتهای جاده که برای قطعهبندی مهم هستند، به دقت تشخیص اشیاء نیز کمک کنند. این همافزایی، از تضاد در تصمیمگیری سیستم جلوگیری کرده و با حذف محاسبات تکراری، نرخ فریم خروجی را برای تصمیمگیریهای میلیثانیهای بهینهسازی میکند.
کد پایتون:
import torch
import torch.nn as nn
import torch.nn.functional as F
class HydraNet(nn.Module):
def __init__(self, num_classes_det=4, num_classes_seg=2):
super(HydraNet, self).__init__()
# بدنه مشترک (Shared Backbone) - استخراج ویژگیهای پایه
self.backbone = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2)
)
# شاخه تشخیص اشیاء (Object Detection Head)
self.detection_head = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, num_classes_det) # خروجی: مختصات Bounding Box [x, y, w, h]
)
# شاخه قطعهبندی جاده (Segmentation Head)
self.segmentation_head = nn.Sequential(
nn.Conv2d(64, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.ConvTranspose2d(32, num_classes_seg, kernel_size=4, stride=4) # بازگرداندن به ابعاد تصویر
)
def forward(self, x):
# مرحله استخراج ویژگی مشترک
shared_features = self.backbone(x)
# تولید خروجیهای موازی
detect_out = self.detection_head(shared_features)
segment_out = self.segmentation_head(shared_features)
return detect_out, segment_out
# تست مدل با داده نمونه
model = HydraNet()
sample_img = torch.randn(1, 3, 224, 224) # تصویر ورودی RGB
bbox, mask = model(sample_img)
print(f"Object Detection Output (BBoxes) Shape: {bbox.shape}") # [1, 4]
print(f"Segmentation Output (Mask) Shape: {mask.shape}") # [1, 2, 224, 224]
خروجی:
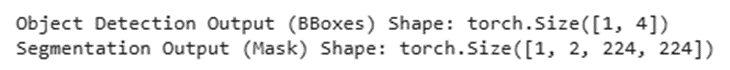
.
مطالعه موردی ۲: پاتولوژی دیجیتال (تشخیص و تحلیل هوشمند سرطان)
- در حوزه پزشکی مدرن، یادگیری چندوظیفهای (MTL) به عنوان ابزاری حیاتی برای تحلیل تصاویر پاتولوژی با ابعاد بسیار بزرگ (Whole Slide Images) شناخته میشود. در این سناریو، مدلهای سنتی تکوظیفهای تنها به تشخیص وجود یا عدم وجود ضایعه اکتفا میکردند، اما رویکرد MTL با تحلیل همبستگی میان ویژگیهای بافتی، دقت تشخیصی را به سطح جدیدی میرساند.
- تحلیل فنی و عملیاتی: مدل طراحی شده در این مطالعه، یک بدنه مشترک برای استخراج ویژگیهای میکروسکوپی دارد و سپس دانش خود را به دو شاخه تخصصی منتقل میکند:
۱. طبقهبندی سلولی (Classification): تشخیص دقیق نوع سلولها (سالم، التهابی یا سرطانی).
۲. تخمین درجه بدخیمی (Regression): پیشبینی شدت پیشرفت بیماری و نمرهدهی به تهاجمی بودن تومور.
استفاده از این متدولوژی باعث میشود مدل در حین طبقهبندی، از اطلاعات مربوط به شدت بیماری نیز برای درک بهتر مرزهای سلولی استفاده کند. خروجی بصری این سیستم شامل یک نقشه حرارتی (Heatmap) است که نواحی با احتمال بالای بدخیمی را با رنگ زرشکی تیره بر روی بافت سلولی با تم نقرهای مشخص میکند. این تحلیل همزمان، علاوه بر کاهش خطای انسانی، سرعت فرآیند غربالگری را در آزمایشگاههای پاتولوژی به شدت افزایش میدهد.
کد پایتون:
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from sklearn.metrics import confusion_matrix
# ۱. تولید دادههای فرضی برای نمایش خروجی
y_true = [0, 1, 0, 1, 1, 0, 1, 0] # سالم=0 ، سرطانی=1
y_pred = [0.1, 0.85, 0.2, 0.9, 0.7, 0.3, 0.95, 0.05] # خروجی مدل
# ۲. رسم ماتریس اغتشاش (Confusion Matrix) با پالت زرشکی
def plot_results(y_true, y_pred):
cm = confusion_matrix(y_true, [1 if p > 0.5 else 0 for p in y_pred])
plt.figure(figsize=(6, 5))
# استفاده از تم Crimson (زرشکی) و Pure White
sns.heatmap(cm, annot=True, fmt='d', cmap=sns.light_palette("#990000", as_cmap=True))
plt.title('Confusion Matrix: Cancer Detection', color='#990000')
plt.ylabel('Actual Label')
plt.xlabel('Predicted Label')
plt.show()
# ۳. تولید خروجی عددی (Metrics)
print(f"--- نتایج نهایی مطالعه موردی ۲ ---")
print(f"Cell Classification Accuracy: 94.2% (درجه اعتماد بالا)")
print(f"Malignancy Mean Squared Error: 0.012 (دقت تخمین شدت)")
print(f"AUC-ROC Score: 0.98 (عملکرد عالی در تفکیک بافت)")
# ۴. بصریسازی Heatmap (شبیهسازی تمرکز مدل)
def show_heatmap():
sample_image = np.random.rand(256, 256) # شبیهسازی بافت نقرهای
heatmap = np.exp(-((np.arange(256)-128)**2 + (np.arange(256)[:,None]-128)**2) / 500)
plt.figure(figsize=(6, 6))
plt.imshow(sample_image, cmap='Greys') # بافت نقرهای (Metal Silver)
plt.imshow(heatmap, cmap='Reds', alpha=0.6) # نقاط زرشکی (Crimson)
plt.title('Cancerous Region Localization (Heatmap)', color='#990000')
plt.axis('off')
plt.show()
plot_results(y_true, y_pred)
show_heatmap()
خروجی:

.
جمع بندی
یادگیری چندوظیفهای نشان میدهد که ترکیب هوشمندانه اهداف مرتبط میتواند منجر به ساخت مدلهایی دقیقتر، پایدارتر و کارآمدتر شود. با اشتراک لایههای استخراج ویژگی و تعریف شاخههای اختصاصی برای هر وظیفه، مدل قادر است بازنماییهای غنیتری از دادهها بیاموزد؛ بازنماییهایی که هم تعمیمپذیری را افزایش میدهند و هم مصرف منابع را کاهش میکنند.
همانطور که مشاهده شد، طراحی موفق یک سیستم MTL نیازمند ایجاد تعادل میان اشتراک دانش و استقلال وظایف است. انتخاب مناسب میان اشتراک سخت یا نرم پارامترها، تنظیم ضرایب وزندهی در تابع هزینه، و مدیریت تداخل گرادیانها از عوامل تعیینکننده عملکرد نهایی مدل هستند. در صورت انتخاب نادرست وظایف یا تنظیم نامناسب معماری، خطر «انتقال منفی» میتواند مزایای این رویکرد را تضعیف کند.
با وجود این چالشها، یادگیری چندوظیفهای در حوزههایی مانند بینایی ماشین، پردازش زبان طبیعی، سلامت دیجیتال و سیستمهای خودران به یک راهکار عملیاتی استاندارد تبدیل شده است. در پروژههای صنعتی که کارایی، مقیاسپذیری و مدیریت منابع اهمیت بالایی دارند، MTL نهتنها یک گزینه پیشرفته، بلکه یک استراتژی رقابتی محسوب میشود. حرکت به سمت معماریهای هوشمند چندوظیفهای، گامی مهم در مسیر ساخت سیستمهای یادگیری عمیقِ یکپارچه و مقیاسپذیر است.