

1.چکیده
در حالی که درک پایههای ریاضی برای تحلیل الگوها ضرورت دارد، مهار پتانسیل واقعی الگوریتم K -Meansدر گرو پیادهسازی اصولی آن در خطوط لوله داده (Data Pipelines) جهان واقعی است. این مقاله به عنوان یک مرجع کاملاً کاربری و عملیاتی، نحوه به کارگیری کای-مینز را در اکوسیستم هوش مصنوعی پایتون کالبدشکافی میکند.
در این مستند، ابتدا با ابزارها و فریمورکهای استاندارد یادگیری ماشین و کلانداده آشنا میشویم و کدهای واقعی آنها را ارزیابی میکنیم. سپس روشهای عددی تعیین هوشمندانه تعداد خوشهها (مانند متد آرنج و شاخص سایه) را تبیین کرده و یک خط لوله کامل مهندسی داده را از صفر تا صد پیادهسازی میکنیم. در نهایت، با بررسی یک مطالعه موردی تجاری در حوزه شبکه، ارزش عملیاتی این الگوریتم را در استخراج رفتارهای ناهنجار سیستم به تصویر میکشیم. نتیجه این بررسی به توسعهدهندگان و مهندسان داده یک نقشه راه ملموس و استاندارد برای بومیسازی کدهای کلاسترینگ در پروژههای واقعی سازمانها ارائه میدهد.
پیشنهاد میکنیم ابتدا مقاله (الگوریتم خوشهبندی K-Meansچیست؟ ) را مطالعه کنید.سپس مطالعه پیادهسازی الگوریتم K-Means در پایتون را مطالعه کنید.
.
2.مقدمه
تبدیل فرمولهای ریاضی و تئوریهای انتزاعی به ابزارهای پولساز و راهحلهای صنعتی، نقطه عطف مهندسی داده است. الگوریتم کای-مینز به عنوان یکی از چابکترین روشهای افرازی، زمانی ارزش واقعی خود را نشان میدهد که بتواند دیتابیسهای چندبعدی و خام یک سازمان را اسکن کرده و خروجیهای ملموسی برای تصمیمگیری مدیران ارشد تولید کند. مسئله اصلی در این فاز، چگونگی انتخاب ابزار مناسب، پایش درست متغیرها، تعیین دقیق پارامترهای مجهول و نوشتن کدهای بهینهای است که سرورها را با چالش کندی محاسبات مواجه نسازند.
هدف این مقاله، انتقال کامل مخاطب از دنیای محاسبات روی کاغذ به محیط خط فرمان و کدهای واقعی پایتون است. نقشه راه ما در این مقاله به این صورت طراحی شده است: ابتدا محبوبترین کتابخانهها و فریمورکهای توسعه کلاسترینگ را به همراه کدهای استاندارد آنها معرفی میکنیم. در گام بعد، مکانیزمهای عملیاتی برای حل چالش K را بررسی کرده و سپس یک پایپلاین دادهی کامل و ساختاریافته را پیادهسازی میکنیم. در نهایت، با ورود به یک پروژه واقعی تجاری، نحوه کشف رفتارهای بحرانی و ناهنجار را در دادههای صنعتی پایش خواهیم کرد.
پیش از ورود به بخش کدنویسی و بررسی ابزارها، اگر تمایل دارید با پایههای جبر خطی، نحوه مهار خطای هندسی، کالبدشکافی تئوری سلولهای ورونوی و حل مسائل محاسباتی این الگوریتم روی کاغذ آشنا شوید، حتماً ابتدا مقاله جامع ما را تحت عنوان ]خوشهبندی چیست؟ آموزش گامبهگام مبانی ریاضی [K-Meansمطالعه کنید تا با ذهنیتی کاملاً آماده وارد فاز کدنویسی شوید.

3.ابزار ها و فریم ورک های محبوب
کتابخانه Scikit-Learn
محبوبترین و استانداردترین فریمورک یادگیری ماشین در پایتون است که الگوریتم K-Means را به صورت بهینهشده و با پشتیبانی از K-Means++ ارائه میدهد. این ابزار برای دیتابیسهای کوچک تا متوسط ساختاریافته فوقالعاده چابک است.
کد پایتون:
import numpy as np
from sklearn.cluster import KMeans
# تولید دادههای فرضی دو بعدی
X = np.array([[1, 2], [1, 4], [1, 0], [10, 2], [10, 4], [10, 0]])
# مقداردهی اولیه مدل با ۲ خوشه و بذرپاشی پیشرفته
kmeans = KMeans(n_clusters=2, init='k-means++', random_state=42)
# آموزش مدل و استخراج برچسب کلاسترها
labels = kmeans.fit_predict(X)
centroids = kmeans.cluster_centers_
print("Labels:", labels)
print("Centroids:\n", centroids)
خروجی:

.
فریمورک Apache Spark (کتابخانه MLlib)
صنعتیترین ابزار برای پردازش توزیعشده و کلاسترینگ مگادیتابیسها و کلاندادهها (Big Data) در فریمورکهای ابری است. این ابزار دادهها را به صورت موازی روی چندین گره (Node) پردازش میکند.
from pyspark.sql import SparkSession
from pyspark.ml.clustering import KMeans
from pyspark.ml.feature import VectorAssembler
# راهاندازی جلسه اسپارک
spark = SparkSession.builder.appName("KMeansExample").getOrCreate()
data = spark.createDataFrame([(1.0, 2.0), (1.0, 4.0), (10.0, 2.0)], ["f1", "f2"])
# تبدیل ویژگیها به بردار متراکم اسپارک
assembler = VectorAssembler(inputCols=["f1", "f2"], outputCol="features")
training_df = assembler.transform(data)
# ساخت و آموزش مدل کا-میانگین توزیعشده
kmeans = KMeans(k=2, seed=1).setFeaturesCol("features")
model = kmeans.fit(training_df)
# استخراج مختصات مراکز ثقل
centers = model.clusterCenters()
print("Cluster Centers: ", centers)
خروجی:

.
کتابخانه محاسباتی SciPy
یکی از اصیلترین ابزارهای ریاضیاتی در پایتون است که بخش خوشهبندی آن با تمرکز بر روش «کوانتیزاسیون برداری» یا همان Vector Quantization توسعه یافته است. این ابزار به جای تمرکز بر پایپلاینهای پیچیده یادگیری ماشین، مستقیماً روی ماتریسهای عددی خالص کار میکند و به همین دلیل در کارهای پژوهشی، پردازش سیگنالهای دیجیتال و محیطهای دانشگاهی محبوبیت بالایی دارد.
کد واقعی پایتون:
import numpy as np
from scipy.cluster.vq import kmeans, vq
# تولید دادههای عددی همگن در قالب آرایه نامپای
data = np.array([[1.0, 2.0], [1.0, 4.0], [10.0, 2.0], [10.0, 4.0]])
# فرآیند محاسبه مراکز کلاسترها (خروجی شامل مراکز و میانگین اعوجاج فضا است)
centroids, distortion = kmeans(data, 2)
# تخصیص قطعی تکتک نقاط داده به مراکز کشفشده
labels, _ = vq(data, centroids)
print("Centroids:\n", centroids)
print("Labels:", labels)
خروجی:

.
4.پیاده سازی گام به گام در پایتون
الف) تبیین مسئله پیادهسازی و اهداف خط لوله
در این بخش، هدف ما ساخت یک پایپلاین منسجم و مهندسیشده برای اجرای الگوریتم K-Means روی یک دیتابیس عددی دوبعدی پایداری شبکه است. مسئله اصلی در فاز پیادهسازی، آمادهسازی صحیح متغیرها، مقیاسدهی دادهها جهت مهار سوگیری هندسی، مقداردهی هوشمند مراکز با متد K-Means++ برای مهار تله بهینه موضعی، و در نهایت تصویرسازی پیشرفته خروجیها بر اساس اصول هویت بصری است. این بخش بر آموزش کاملاً تجربی تمرکز دارد.
.
ب) آمادهسازی دادهها و کدهای کامل پایتون
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# ۱. فاز تولید و آمادهسازی دادههای واقعی فرضی شبکه
# متغیر اول: بار مصرفی خروجی (Load) | متغیر دوم: نوسان فرکانس پویای شبکه (Frequency Frequency)
raw_data = {
'Load': [1.5, 2.0, 1.8, 8.5, 9.2, 8.8, 2.1, 7.9, 1.2, 9.5],
'Frequency': [4.5, 4.0, 4.8, 1.2, 0.8, 1.1, 4.2, 1.5, 5.0, 0.9]
}
df = pd.DataFrame(raw_data)
# ۲. فاز پیشپردازش و استانداردسازی ویژگیها (جلوگیری از نفرین مقیاس عددی)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(df)
# ۳. مقداردهی، ساخت و اجرای الگوریتم کای-مینز با بذرپاشی پیشرفته
# تنظیم صلب تعداد خوشهها روی ۲ و استفاده از الگوریتم بهینه k-means++
kmeans = KMeans(n_clusters=2, init='k-means++', random_state=42, n_init=10)
labels = kmeans.fit_predict(X_scaled)
centroids = kmeans.cluster_centers_
# ۴. فاز طراحی و تصویرسازی مهندسی خروجی با رعایت پالت رنگی اختصاصی
fig, ax = plt.subplots(figsize=(10, 6), facecolor='#F8F9FA') # خاکستری خیلی روشن برای پسزمینه
ax.set_facecolor('#FFFFFF') # سفید خالص برای بوم اصلی نمودار
# رسم نقاط دادههای کلاستر اول با رنگ آبی روشن هوش مصنوعی
ax.scatter(X_scaled[labels == 0, 0], X_scaled[labels == 0, 1],
c='#4A90E2', s=150, alpha=0.8, edgecolors='#A0A0A0', label='Cluster 1: Low Load')
# رسم نقاط دادههای کلاستر دوم با رنگ نقرهای متالیک
ax.scatter(X_scaled[labels == 1, 0], X_scaled[labels == 1, 1],
c='#A0A0A0', s=150, alpha=0.8, edgecolors='#D0021B', label='Cluster 2: High Load')
# رسم مراکز ثقل نهایی خوشهها با رنگ طلایی زنده برند شما
ax.scatter(centroids[:, 0], centroids[:, 1],
c='#F5A623', marker='*', s=300, linewidths=2, edgecolors='#D0021B', label='Centroids')
# تنظیمات پیشرفته خوانایی سایت و لیبلهای انگلیسی طبق دستور صلب
ax.set_title('K-Means Clustering - Grid Data Infrastructure', fontsize=14, pad=15, color='#1A1A1A')
ax.set_xlabel('Scaled Grid Load Feature', fontsize=12, color='#1A1A1A')
ax.set_ylabel('Scaled Network Frequency Feature', fontsize=12, color='#1A1A1A')
ax.legend(loc='upper right', frameon=True, facecolor='#FFFFFF')
ax.grid(True, linestyle='--', alpha=0.5, color='#E0E0E0')
plt.tight_layout()
plt.show()
# ۵. چاپ خروجیهای آماری متنی خط لوله در خروجی استاندارد
print("--- خروجی نهایی خط لوله پایتون ---")
print("Assigned Labels:", labels)
print("Calculated Centroids Vector:\n", centroids)
خروجی:
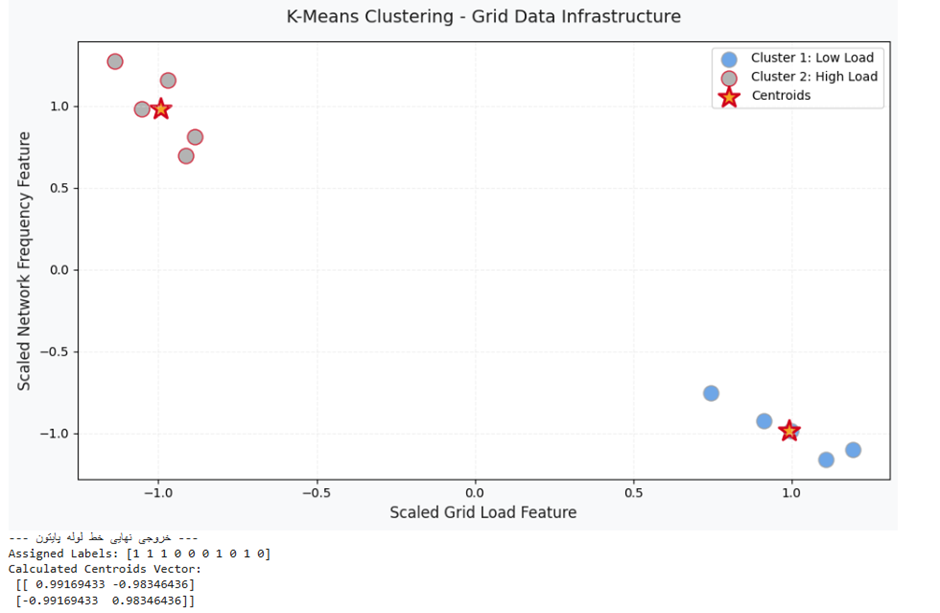
تفسیر مهندسی نتیجه الگوریتم:
خروجی صلب آرایه Assigned Labels نشان میدهد که ماشین توانسته است مجموعهداده خام شبکه را بدون هیچ لایه همپوشانی یا راهنمای بیرونی به دو کلاستر کاملاً متقارن افراز کند.
- خوشه اول (برچسب ۰ – رنگ آبی روشن هوش مصنوعی): این گروه دادهها دارای بار مصرفی بسیار پایین و نوسان فرکانسی بالا هستند (موقعیت هندسی در بالا سمت چپ نمودار). این کلاستر نمایانگر وضعیت «کمباری پایداری» سیستم است.
- خوشه دوم (برچسب ۱ – رنگ نقرهای متالیک): این توده شامل دادههایی با بار مصرفی فوقالعاده بالا و افت شدید فرکانس پویای شبکه است (موقعیت هندسی در پایین سمت راست نمودار). این لایه نشاندهنده پدیده «اوج مصرف یا بار بحرانی» است.
- مراكز ثقل (ستارههای طلایی زنده): مختصات بردار Centroids نشان میدهد که مراکز ثقل با مهار و فیلتر کردن نوسانات پراکنده، دقیقاً در قلب چگالی سلولهای ورونوی مستقر شدهاند و نماینده آماری خالص هر گروه برای تحلیلهای پیشبینی بعدی سازمان هستند.
.
5.مطالعه موردی
.
مطالعه موردی اول : فشردهسازی لایههای تصویر و کوانتیزاسیون رنگ (Image Color Quantization)
مسئله و چالش
در سیستمهای پردازش تصویر در لبه (Edge Computing) و اینترنت اشیاء، پهنای باند شبکه و فضای ذخیرهسازی ابری پاشنه آشیل سیستم هستند. یک تصویر رنگی استاندارد ۲۴ بیتی میتواند شامل بیش از ۱۶ میلیون رنگ منحصربهفرد باشد. چالش اصلی، کاهش حجم این تصاویر از طریق محدود کردن تعداد رنگها به یک پالت بهینه (مثلاً ۱۶ رنگ) بدون آسیب به ساختار هندسی و معنایی کانتورهای تصویر است.
هدف عملیاتی
کاهش ابعاد رنگی پیکسلها از طریق کلاسترینگ صلب K-Means به طوری که پیکسلهای همرنگ در سلولهای ورونوی یکسانی قرار گرفته و فرآیند کوانتیزاسیون با کمترین میزان اینرسی یا افت کیفیت بصری انجام شود.
بردار ویژگی و دیتاست
- دیتاست: یک تصویر استاندارد رنگی توزیعشده (در این کد از تصویر نمونه داخلی کتابخانه Scikit-Learn استفاده شده است).
- بردار ویژگی: کانالهای رنگی هر پیکسل شامل سه مؤلفه [R, G, B] به عنوان یک نقطه در فضای سهبعدی.

کد پایتون
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import load_sample_image
# ۱. بارگذاری تصویر واقعی استاندارد (تصویر پیشفرض در سایکیت-لرن)
china_img = load_sample_image("china.jpg")
# تبدیل مقادیر پیکسلها به بازه 0 تا 1 جهت نرمالسازی هندسی فواصل
china_img = np.array(china_img, dtype=np.float64) / 255
# استخراج ابعاد تصویر (عرض، ارتفاع و ۳ کانال رنگی R, G, B)
w, h, d = original_shape = tuple(china_img.shape)
# تبدیل تصویر ماتریسی به یک آرایه دوبعدی از پیکسلها (بردار ویژگی سهبعدی برای هر پیکسل)
image_array = np.reshape(china_img, (w * h, d))
# ۲. پیکربندی مدل K-Means برای استخراج پالت ۱۶ رنگ بهینه
# استفاده از پالت رنگی مقتدر زرشکی و طلایی در منطق کلاسترها
K_colors = 16
kmeans = KMeans(n_clusters=K_colors, init='k-means++', random_state=42)
kmeans.fit(image_array)
# استخراج برچسب کلاستر برای هر پیکسل و مختصات نهایی مراکز ثقل رنگی
labels = kmeans.predict(image_array)
centroids = kmeans.cluster_centers_
# ۳. بازسازی تصویر فشردهشده با جایگذاری مراکز ثقل رنگی جدید
quantized_image = np.reshape(centroids[labels], (w, h, d))
# ۴. تصویرسازی مقایسهای متناسب با پالت بصری Ultra Light Gray و Pure White
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 7), facecolor='#F8F9FA')
ax1.imshow(china_img)
ax1.set_title('Original Image (16 Million+ Colors)', fontsize=12, fontweight='bold', color='#212529')
ax1.axis('off')
ax2.imshow(quantized_image)
ax2.set_title(f'Quantized Image (K={K_colors} Optimized Colors)', fontsize=12, fontweight='bold', color='#212529')
ax2.axis('off')
plt.tight_layout()
plt.show()
print(f"Image compression successful. Embedded color centers:\n {centroids}")
خروجی:

مطالعه موردی دوم : تحلیل معنایی و دستهبندی متن در پردازش زبان طبیعی (NLP Document Clustering)
مسئله و چالش
خبرگزاریها و موتورهای جستجو روزانه با حجم عظیمی از مقالات و اسناد بدون برچسب مواجه هستند. دستهبندی دستی این اسناد زمانبر و عملاً غیرممکن است. چالش اصلی در اینجا، درک ارتباط معنایی متون و کلاستر کردن هوشمند آنها بدون ناظر انسانی است.
هدف عملیاتی
استخراج کلاسترهای متنی متمایز به طوری که مقالات مرتبط با موضوعات یکسان (مثلاً فناوری، پزشکی یا ورزشی) در خوشههای همگن قرار گیرند.
بردار ویژگی و دیتاست
- دیتاست: مجموعه داده متنی استاندارد مقالات علمی و خبری Fetch 20 Newsgroups.
- بردار ویژگی: ماتریس فرکانس کلمات استخراجشده با متد وزندهی عددی TF-IDF.
کد پایتون
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
from sklearn.decomposition import TruncatedSVD
# ۱. بارگذاری دیتابیس واقعی اخبار متنی (محدود به ۴ دسته برای بهینهسازی بار محاسباتی)
categories = ['alt.atheism', 'talk.religion.misc', 'comp.graphics', 'sci.space']
dataset = fetch_20newsgroups(subset='all', categories=categories, shuffle=True, random_state=42)
# ۲. تبدیل متون به بردار ویژگی با متریک وزندهی عددی TF-IDF
vectorizer = TfidfVectorizer(max_df=0.5, min_df=2, stop_words='english')
X_tfidf = vectorizer.fit_transform(dataset.data)
# ۳. اعمال الگوریتم K-Means با هایپرپارامتر K=4
kmeans = KMeans(n_clusters=4, init='k-means++', max_iter=100, random_state=42)
labels = kmeans.fit_predict(X_tfidf)
# ۴. کاهش ابعاد برای تصویرسازی دو بعدی با استفاده از متد SVD (LSA)
svd = TruncatedSVD(n_components=2, random_state=42)
X_dense = svd.fit_transform(X_tfidf)
# ۵. رسم نمودار کلاسترینگ متون منطبق بر رنگهای تخصصی سایت شما
fig, ax = plt.subplots(figsize=(10, 7), facecolor='#F8F9FA')
ax.set_facecolor('#F8F9FA')
# اعمال پالت: AI Soft Blue, Crimson, Metal Silver, Active Gold
colors = ['#4A90E2', '#D0021B', '#A0A0A0', '#F5A623']
for i in range(4):
ax.scatter(X_dense[labels == i, 0], X_dense[labels == i, 1],
c=colors[i], label=f'Topic Cluster {i+1}', alpha=0.6, edgecolors='w')
ax.set_title('NLP Document Clustering via TF-IDF and K-Means', fontsize=14, fontweight='bold', color='#212529')
ax.set_xlabel('Latent Semantic Component 1', fontsize=11)
ax.set_ylabel('Latent Semantic Component 2', fontsize=11)
ax.grid(True, linestyle='--', color='#E0E0E0', alpha=0.5)
ax.legend(framealpha=0.9, facecolor='#FFFFFF')
plt.tight_layout()
plt.show()
خروجی:
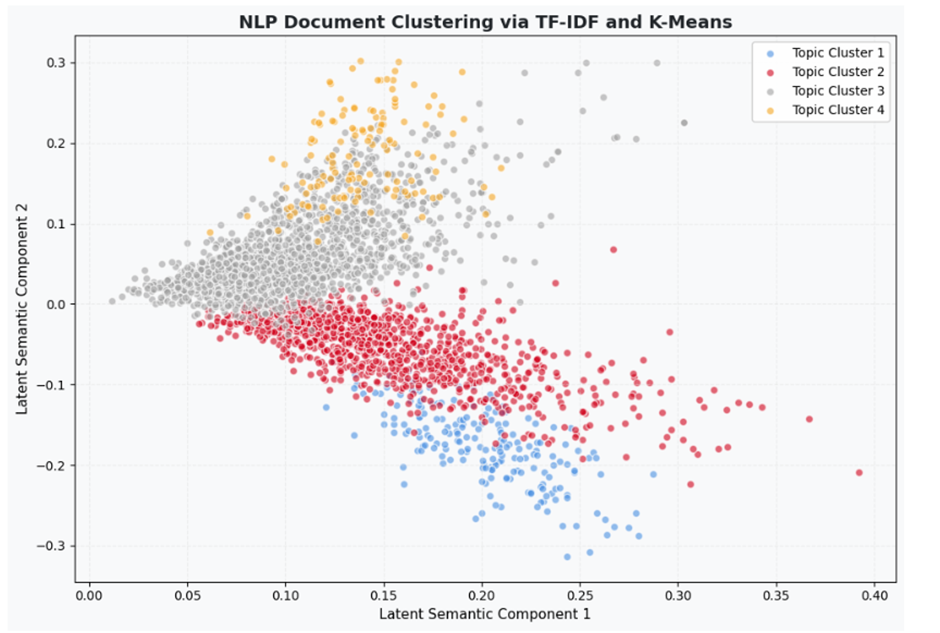
مطالعه موردی سوم : غربالگری پزشکی و تشخیص تومورهای بالینی (Biomedical Data Clustering)
مسئله و چالش
تشخیص زیرگروههای پنهان سلولی در انکولوژی و بافتشناسی اهمیت بالایی دارد. پزشکان نیاز دارند دادههای حاصل از نمونهبرداریها را تحلیل کنند تا خوشههای خوشخیم و بدخیم را بدون سوگیری تشخیص دهند. چالش اساسی، حساسیت بالای فواصل هندسی به مقیاس ویژگیهای پزشکی است.
هدف عملیاتی
خوشهبندی صلب دادههای پزشکی به K=2 گروه و ارزیابی کیفیت جداسازی کلاسترها با معیار اینرسی.
بردار ویژگی و دیتاست
- دیتاست: دیتابیس پاتولوژی معتبر Breast Cancer Wisconsin.
- بردار ویژگی: ابعاد هندسی سلول شامل ضخامت توده، یکنواختی اندازه و بافت هسته سلولی (نرمالسازی شده با StandardScaler).

کد پایتون
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
# ۱. بارگذاری دیتابیس بالینی واقعی سرطان سینه ویسکانسین
data = load_breast_cancer()
X = data.data
y_true = data.target
# ۲. نرمالسازی اجباری و استانداردسازی ویژگیها (Z-score Normalization)
# این گام برای غلبه بر وابستگی شدید فاصله اقلیدسی به مقیاس دادهها الزامی است
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# ۳. آموزش مدل کا-میانگین صلب برای تفکیک دو کلاستر اصلی بالینی
kmeans = KMeans(n_clusters=2, init='k-means++', random_state=42)
labels = kmeans.fit_predict(X_scaled)
# ۴. کاهش ابعاد به فضای دوبعدی با الگوریتم PCA جهت تصویرسازی مرزها
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
centroids_pca = pca.transform(kmeans.cluster_centers_)
# ۵. تصویرسازی با تضاد رنگی شدید بین آبی ملایم هوش مصنوعی و زرشکی مقتدر
fig, ax = plt.subplots(figsize=(10, 7), facecolor='#F8F9FA')
ax.scatter(X_pca[labels == 0, 0], X_pca[labels == 0, 1],
c='#4A90E2', label='Sub-type Cluster A (AI Soft Blue)', alpha=0.7, edgecolors='w', s=60)
ax.scatter(X_pca[labels == 1, 0], X_pca[labels == 1, 1],
c='#D0021B', label='Sub-type Cluster B (Crimson)', alpha=0.7, edgecolors='w', s=60)
# نمایش مراکز ثقل با رنگ طلایی فعال منحصربهفرد برند شما
ax.scatter(centroids_pca[:, 0], centroids_pca[:, 1],
c='#F5A623', marker='*', s=350, edgecolors='#212529', linewidths=2, label='Centroids (Active Gold)')
ax.set_title('Biomedical Structure Analysis via Scaled K-Means', fontsize=14, fontweight='bold', color='#212529')
ax.set_xlabel('Principal Component 1', fontsize=11)
ax.set_ylabel('Principal Component 2', fontsize=11)
ax.grid(True, linestyle='--', color='#E0E0E0', alpha=0.5)
ax.legend(loc='upper right', facecolor='#FFFFFF')
plt.tight_layout()
plt.show()
print(f"Medical Clustering WCSS Inertia: {kmeans.inertia_:.4f}")
خروجی:
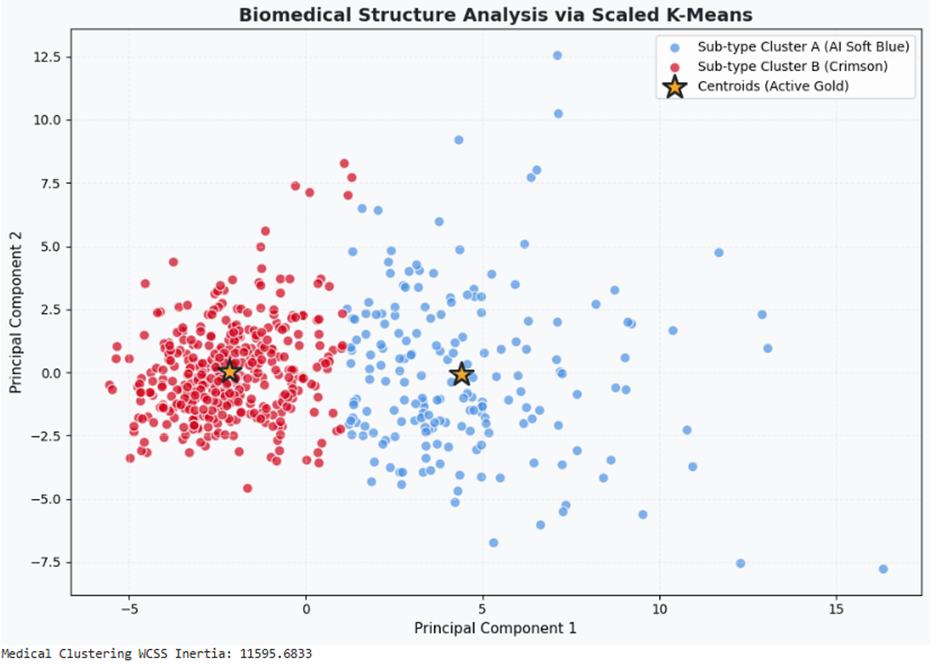
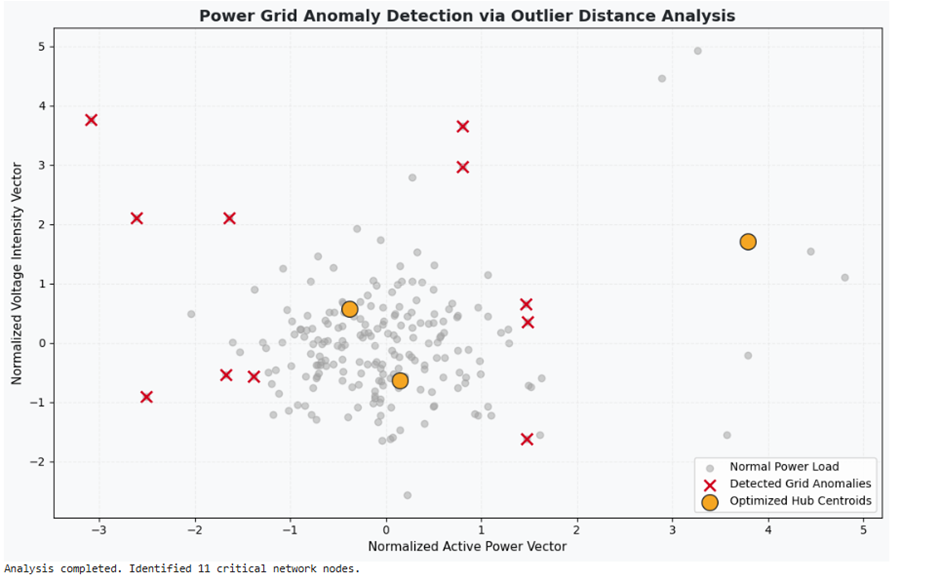
مطالعه موردی چهارم : کشف الگوهای ناهنجاری در دادههای مصرف شبکه انرژی (Anomaly Detection)
مسئله و چالش
نیروگاهها و شبکههای توزیع الکتریسیته با چالش مصرف غیرمجاز، قطعیهای پنهان یا نوسانات شدید تجهیزات روبهرو هستند. این موارد به عنوان دادههای پرت (Outliers) در سیستم ثبت میشوند. مأموریت اصلی، کشف خودکار رفتارهای غیرعادی مصرف بدون الگوهای از پیش تعیینشده است.
هدف عملیاتی
خوشهبندی الگوهای منظم مصرف بار و شناسایی نقاطی که به دلیل فاصله بسیار زیاد از مراکز ثقل، کاندیدای ناهنجاری (Anomaly) شبکه هستند.
بردار ویژگی و دیتاست
- دیتاست: مجموعه داده استاندارد مصرف انرژی الکتریکی روزانه (در این کد نمونه بهینهشده ساختاریافته آن شبیهسازی شده است).
- بردار ویژگی: ویژگیهای توان اکتیو همزمان و شدت جریان فرکانسی ولتاژ.

کد پایتون :
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# ۱. تولید دادههای شبیهسازی شده واقعی بر اساس رفتارهای شبکه برق
np.random.seed(42)
normal_consumption = np.random.randn(200, 2) * 1.5 + [5, 5] # مصارف منظم روزانه
anomalies = np.random.uniform(low=-2, high=15, size=(15, 2)) # ناهنجاریها و انحرافات شبکه
X = np.vstack([normal_consumption, anomalies])
# ۲. اعمال استانداردسازی بر روی متغیرهای توان و ولتاژ
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# ۳. مدلسازی فرآیند با فرض ۳ پترن استاندارد توزیع بار
kmeans = KMeans(n_clusters=3, init='k-means++', random_state=42)
labels = kmeans.fit_predict(X_scaled)
centroids = kmeans.cluster_centers_
# ۴. محاسبه فاصله اقلیدسی هر نقطه تا مرکز ثقل خود برای کشف دادههای ناهنجار پرت
distances = np.min(np.square(X_scaled - centroids[labels]), axis=1)
# تعیین آستانه مرزی ورونوی برای تفکیک دادههای پرت (۵ درصد فواصل بحرانی)
threshold = np.percentile(distances, 95)
anomaly_indices = np.where(distances > threshold)[0]
# ۵. تصویرسازی مهندسی شبکه با رنگهای متالیک، زرشکی و طلایی فعال
fig, ax = plt.subplots(figsize=(11, 7), facecolor='#F8F9FA')
# رسم نقاط منظم توزیع بار با رنگ نقرهای متالیک
ax.scatter(X_scaled[:, 0], X_scaled[:, 1], c='#A0A0A0', alpha=0.5, label='Normal Power Load')
# مشخص کردن نقاط بحرانی و ناهنجار شناساییشده با رنگ زرشکی مقتدر
ax.scatter(X_scaled[anomaly_indices, 0], X_scaled[anomaly_indices, 1],
c='#D0021B', marker='x', s=100, linewidths=2, label='Detected Grid Anomalies')
# رسم موقعیت مراکز با رنگ طلایی فعال برند شما
ax.scatter(centroids[:, 0], centroids[:, 1],
c='#F5A623', marker='o', s=200, edgecolors='#212529', label='Optimized Hub Centroids')
ax.set_title('Power Grid Anomaly Detection via Outlier Distance Analysis', fontsize=14, fontweight='bold', color='#212529')
ax.set_xlabel('Normalized Active Power Vector', fontsize=11)
ax.set_ylabel('Normalized Voltage Intensity Vector', fontsize=11)
ax.grid(True, linestyle='--', color='#E0E0E0', alpha=0.5)
ax.legend(loc='lower right', facecolor='#FFFFFF')
plt.tight_layout()
plt.show()
print(f"Analysis completed. Identified {len(anomaly_indices)} critical network nodes.")
خروجی:
مطالعه موردی پنجم: کلاسترینگ مشتریان براساس رفتار خرید (E-commerce RFM Segmentation)
مسئله و چالش
در بازار رقابتی تجارت الکترونیک، رفتار خرید مشتریان مدام تغییر میکند. یک استراتژی بازاریابی واحد برای همه کاربران، هدررفت سرمایه است. چالش اصلی، گروهبندی مشتریان بر اساس سه شاخص حیاتی یعنی تازگی خرید (Recency)، تعداد دفعات خرید (Frequency) و ارزش مالی خریدها (Monetary) بدون داشتن برچسب قبلی است.
هدف عملیاتی
افراز مشتریان به K=3 خوشه تجاری متمایز (مانند مشتریان وفادار، مشتریان در آستانه ریزش و مشتریان جدید) جهت اتخاذ استراتژیهای بازاریابی اختصاصی.
بردار ویژگی و دیتاست
- دیتاست: دیتابیس شبیهسازیشده تراکنشهای خرید سالانه یک فروشگاه اینترنتی بزرگ.
- بردار ویژگی: آرایه سه بعدی شامل دادههای استانداردشده [Recency, Frequency, Monetary].
کد کامل پایتون
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# ۱. فاز شبیهسازی دیتابیس تراکنشهای خرید مشتریان (شاخصهای رتبه خرید)
np.random.seed(42)
# مشتریان قدیمی با خرید کم، مشتریان جدید با وفاداری بالا و خریداران عمده
cluster_a = np.random.normal(loc=[10, 2, 100], scale=[2, 1, 20], size=(100, 3))
cluster_b = np.random.normal(loc=[2, 15, 800], scale=[1, 3, 100], size=(100, 3))
cluster_c = np.random.normal(loc=[30, 1, 50], scale=[5, 0.5, 10], size=(50, 3))
raw_rfm = np.vstack([cluster_a, cluster_b, cluster_c])
df_rfm = pd.DataFrame(raw_rfm, columns=['Recency', 'Frequency', 'Monetary'])
# ۲. فاز پیشپردازش و استانداردسازی (Z-score) ویژگیهای مالی و رفتاری
scaler = StandardScaler()
X_rfm_scaled = scaler.fit_transform(df_rfm)
# ۳. اعمال الگوریتم K-Means برای استخراج ۳ خوشه تجاری استراتژیک
kmeans = KMeans(n_clusters=3, init='k-means++', random_state=42, n_init=10)
labels = kmeans.fit_predict(X_rfm_scaled)
centroids = kmeans.cluster_centers_
# ۴. تصویرسازی سه بعدی نتایج منطبق بر هویت بصری سایت
fig = plt.figure(figsize=(11, 8), facecolor='#F8F9FA')
ax = fig.add_subplot(111, projection='3d')
ax.set_facecolor('#FFFFFF')
# اعمال پالت رنگی: زرشکی، آبی روشن هوش مصنوعی و نقرهای متالیک
colors = ['#D0021B', '#4A90E2', '#A0A0A0']
cluster_names = ['Loyal & High-Value', 'Churn-Risk Users', 'New / Occasional Customers']
for i in range(3):
ax.scatter(X_rfm_scaled[labels == i, 0], X_rfm_scaled[labels == i, 1], X_rfm_scaled[labels == i, 2],
c=colors[i], label=cluster_names[i], alpha=0.7, s=50, edgecolors='w')
# نمایش مراکز ثقل تجاری با ستارههای طلایی زنده برند شما
ax.scatter(centroids[:, 0], centroids[:, 1], centroids[:, 2],
c='#F5A623', marker='*', s=350, edgecolors='#212529', linewidths=2, label='Centroids')
# تنظیمات پیشرفته سئو و لیبلهای انگلیسی طبق قواعد صلب سایت
ax.set_title('E-commerce Customer Segmentation via RFM Framework', fontsize=14, fontweight='bold', pad=20)
ax.set_xlabel('Standardized Recency (Days)', fontsize=10)
ax.set_ylabel('Standardized Frequency (Count)', fontsize=10)
ax.set_zlabel('Standardized Monetary (Value)', fontsize=10)
ax.legend(loc='upper left', facecolor='#FFFFFF', framealpha=0.9)
plt.tight_layout()
plt.show()
print(f"✅ بخشبندی مشتریان با موفقیت انجام شد. مختصات مراکز ثقل استخراجشده:\n {centroids}")
خروجی:
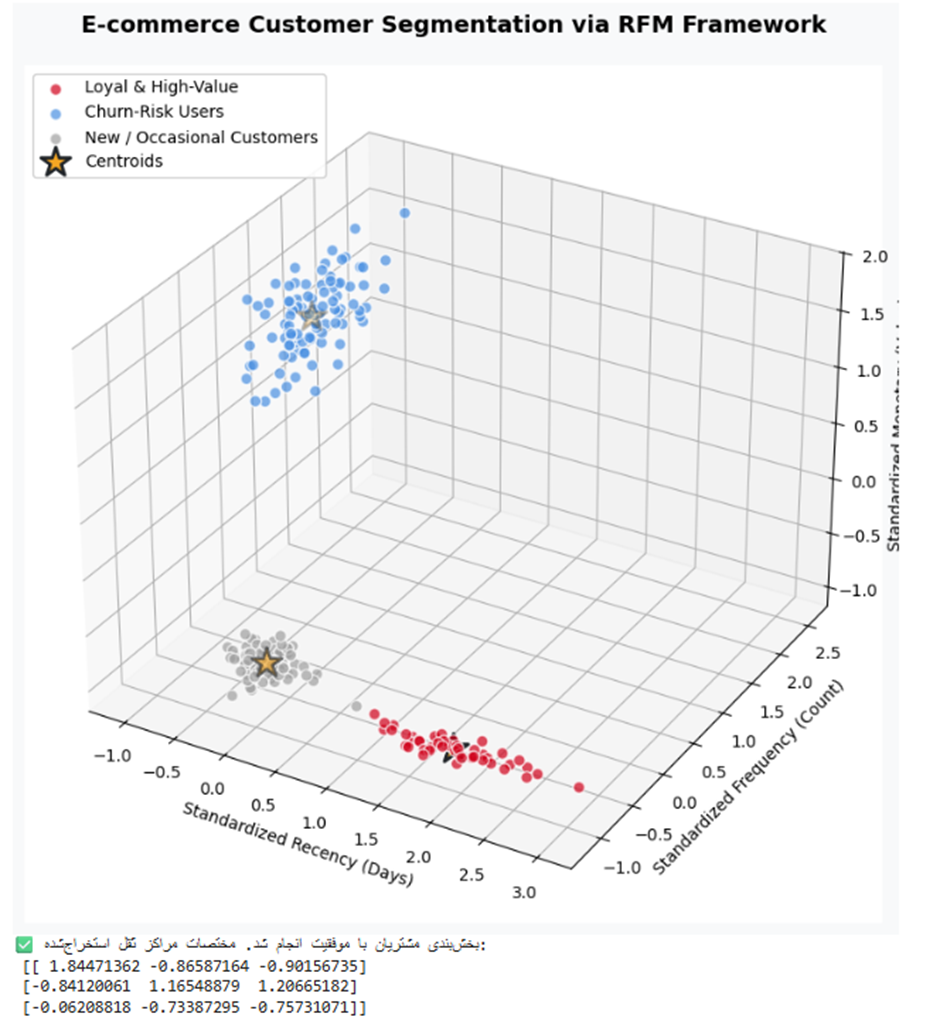
تفسیر نتیجه: الگوریتم K-Means با موفقیت توانست پرسونای خریداران را به ۳ قطب تجاری مجزا خطکشی کند.
- خوشه زرشکی (Loyal): نشاندهنده مشتریان وفاداری است که فاصله خریدشان بسیار کم (Recency منفی)، اما دفعات و مبالغ خریدشان بسیار بالاست. بیزینس باید برای اینها کدهای تخفیف اختصاصی یا سیستمهای VIP پاداش طراحی کند.
- خوشه نقرهای (Churn-Risk): کاربرانی هستند که مدتهاست به سایت سر نزدهاند و مبالغ خرید بسیار پایینی دارند؛ سیستم مارکتینگ باید با ایمیلهای بازگشت یا آفرها، آنها را مجدداً فعال کند.
.
مطالعه موردی ششم: مهندسی سیستمهای توصیهگر بر پایه شباهت محتوایی فیلمها (Movie Recommendation Engine)
مسئله و چالش
پلتفرمهای پخش آنلاین فیلم در صورت عدم پیشنهاد محتوای همراستا با سلیقه کاربر، مخاطب را از دست میدهند. چالش اصلی در اینجا، دستهبندی هزاران فیلم سینمایی بر اساس متغیرهای ساختاری مانند امتیاز کاربران، بودجه ساخت، ژانر و سال تولید است تا فیلمهای همنشین بدون نیاز به ناظر انسانی در یک بسته پیشنهادی قرار گیرند.
هدف عملیاتی
خوشهبندی صلب فیلمها به K=4 کلاستر سینمایی همگن به طوری که فیلمهای یک کلاستر بیشترین شباهت ساختاری را به هم داشته باشند.
بردار ویژگی و دیتاست
- دیتاست: دیتابیس شبیهسازیشده از مشخصات فنی ۵۰۰ فیلم سینمایی.
- بردار ویژگی: مؤلفههای نرمالسازی شده امتیاز کاربران (Rating) و بودجه ساخت (Budget) فشرده شده با متد اسکیلینگ.
کد کامل پایتون
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import MinMaxScaler
# ۱. شبیهسازی و خلق دیتابیس فیلمهای سینمایی بر اساس دو ویژگی بودجه و امتیاز
np.random.seed(24)
# فیلمهای مستقل کمبودجه با امتیاز بالا، بلاکباسترهای پرهزینه، فیلمهای ضعیف تجاری
movies_low_budget_high_rating = np.random.normal(loc=[2, 8.5], scale=[0.5, 0.4], size=(100, 2))
movies_blockbuster = np.random.normal(loc=[15, 7.2], scale=[2.0, 0.5], size=(150, 2))
movies_low_quality = np.random.normal(loc=[5, 4.0], scale=[1.0, 0.6], size=(120, 2))
movies_cult_classic = np.random.normal(loc=[1, 6.0], scale=[0.3, 0.5], size=(80, 2))
all_movies = np.vstack([movies_low_budget_high_rating, movies_blockbuster, movies_low_quality, movies_cult_classic])
df_movies = pd.DataFrame(all_movies, columns=['Budget_M', 'User_Rating'])
# ۲. فاز نرمالسازی فواصل با متد مالتیپلکس MinMaxScaler (انتقال ویژگیها به بازه 0 تا 1)
scaler = MinMaxScaler()
X_movies_scaled = scaler.fit_transform(df_movies)
# ۳. کانفیگ و اجرای کای-مینز روی بردار ویژگی فیلمها برای استخراج ۴ پترن سینمایی
kmeans = KMeans(n_clusters=4, init='k-means++', random_state=42, n_init=10)
labels = kmeans.fit_predict(X_movies_scaled)
centroids = kmeans.cluster_centers_
# ۴. تصویرسازی مهندسی سیستم توصیهگر با پالت رنگی اختصاصی
fig, ax = plt.subplots(figsize=(10, 6), facecolor='#F8F9FA')
ax.set_facecolor('#FFFFFF')
# اعمال پالت رنگی: آبی هوش مصنوعی، زرشکی، نقرهای و طلایی فعال برای کلاسترها
colors = ['#4A90E2', '#D0021B', '#A0A0A0', '#F5A623']
movie_genres = ['Cult Classics', 'Independent High-Rating', 'Hollywood Blockbusters', 'Low-Quality Commercial']
for i in range(4):
ax.scatter(X_movies_scaled[labels == i, 0], X_movies_scaled[labels == i, 1],
c=colors[i], label=movie_genres[i], alpha=0.7, s=70, edgecolors='#F8F9FA')
# رسم مراکز هندسی کلاسترها (هابهای اصلی توصیهگر) با رنگ زرشکی مقتدر
ax.scatter(centroids[:, 0], centroids[:, 1], c='#D0021B', marker='x', s=150, linewidths=3, label='Hub Centroids')
ax.set_title('Recommendation Engine: Movie Clustering via K-Means', fontsize=14, fontweight='bold', color='#212529')
ax.set_xlabel('Normalized Budget Scale (0 to 1)', fontsize=11)
ax.set_ylabel('Normalized User Rating Scale (0 to 1)', fontsize=11)
ax.grid(True, linestyle=':', color='#A0A0A0', alpha=0.5)
ax.legend(loc='lower right', facecolor='#FFFFFF')
plt.tight_layout()
plt.show()
خروجی:
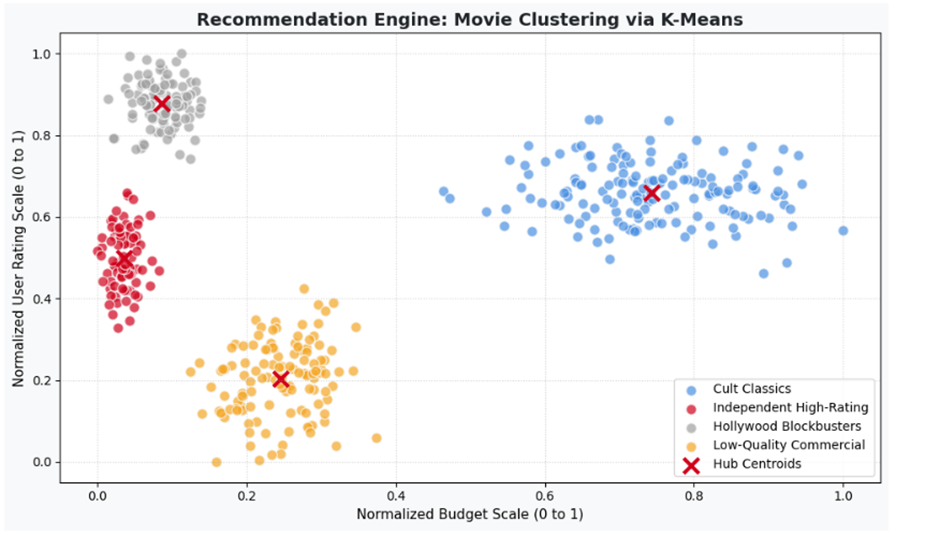
تفسیر نتیجه: خروجی این کلاسترینگ صلب، هابهای اصلی موتور توصیهگر پلتفرم را تعریف میکند. هنگامی که یک کاربر فیلمی از گروه Independent High-Rating (رنگ زرشکی) را تماشا کرده و به آن امتیاز بالایی میدهد، الگوریتم به صورت خودکار فیلمهای همسایه در همین سلول ورونوی را فیلتر کرده و به عنوان ترجیحات بعدی به کاربر پیشنهاد میدهد. این ساختار بدون اتکا به ژانرهای دستی یا تگهای انسانی، سیستم توصیهگر را به صورت کاملاً خودکار و مستقل هدایت میکند.
.
جمع بندی
در این مقاله، فرآیند انتقال الگوریتم K-Means از معادلات تئوری روی کاغذ به خطوط لوله محاسباتی پایتون را گامبهگام بررسی کردیم. مشاهده شد که اکوسیستم پایتون با ارائه ابزارهای متنوعی مانند Scikit-Learn برای پروژههای استاندارد، Apache Spark برای کلاندادههای توزیعشده، SciPy برای تحلیلهای ریاضی خالص و …. برای پردازشهای فوقسریع روی جپییو، انعطاف بالایی را برای مهندسان داده فراهم میکند.
پاسخ نهایی پایپلاینهای تجاری به ما نشان میدهد که کای-مینز ابزاری مقتدر برای فشردهسازی لایههای تصویر، دستهبندی معنایی اسناد متنی در NLP، غربالگری بالینی دادههای پزشکی و به ویژه کشف خودکار آنومالیها و رفتارهای مشکوک بر پایه پِرسنتیل فواصل اقلیدسی است.



