

1.چکیده
الگوریتم K-Means (کای-مینز) کاربردیترین و اصیلترین روش خوشهبندی افرازی در حوزه یادگیری بدون نظارت است. مسئله اصلی در مواجهه با حجم دادههای خام و انبوه صنعتی، عدم وجود کلاسها یا برچسبهای پیشفرض برای تفکیک لایههای اطلاعاتی است. این الگوریتم با بهکارگیری یک رویه تکرارشونده، مجموعهدادهها را به K خوشه مجزا تقسیم میکند؛ به طوری که مجموع فواصل هر نقطه داده تا مرکز خوشه خودش به حداقل ممکن برسد. نتیجه این فرآیند، سازماندهی فضا به مناطق محدب و بهینهای است که رفتار دیتابیس را بر پایه مختصات چند میانگین آماری خلاصه میکند
2.مقدمه
با افزایش حجم دادهها در حوزههای مختلف مانند تجارت الکترونیک، شبکههای اجتماعی و علوم زیستی، استخراج ساختارهای پنهان در دادهها اهمیت ویژهای پیدا کرده است. یکی از مهمترین تکنیکهای یادگیری بدون نظارت برای کشف ساختار دادهها، خوشهبندی (Clustering) است.
خوشهبندی فرآیندی است که در آن دادههای مشابه در یک گروه قرار میگیرند و دادههای غیرمشابه در گروههای متفاوت قرار داده میشوند. در میان الگوریتمهای مختلف خوشهبندی، الگوریتم K-Means به دلیل سادگی، کارایی محاسباتی بالا و قابلیت مقیاسپذیری، یکی از پرکاربردترین روشها در دادهکاوی محسوب میشود.
با این حال، استفاده مؤثر از این الگوریتم نیازمند درک دقیق مبانی نظری، نحوه عملکرد، محدودیتها و شرایط کاربرد آن است.هدف این مقاله ارائه یک بررسی نظاممند از الگوریتم K-Means شامل مبانی نظری، فرآیند الگوریتمی، مثالهای عددی و کاربردهای واقعی است.
ساختار مقاله به این صورت است: ابتدا مفاهیم پایه معرفی میشوند، سپس مسئلهای که الگوریتم حل میکند بررسی میشود. در ادامه مبانی ریاضی و فرآیند الگوریتمی ارائه شده و پس از آن مثالهای عددی، کاربردها، مزایا و محدودیتها بررسی میگردند.
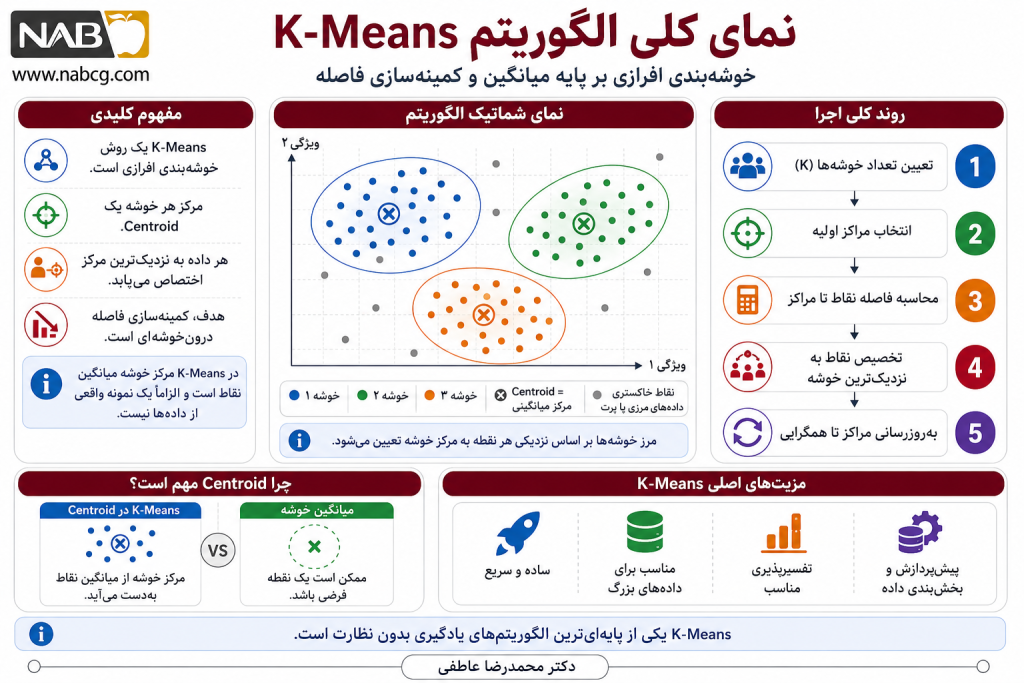
3. تعریف الگوریتم K-Means به زبان ساده
3.1.خوشه بندی چیست؟
خوشهبندی (Clustering) فرآیند تقسیم مجموعهای از دادهها به چند گروه بهگونهای است که:
- دادههای درون یک خوشه بیشترین شباهت را با یکدیگر داشته باشند.
- دادههای متعلق به خوشههای مختلف بیشترین تفاوت را داشته باشند.
۳.۲. الگوریتم K-Means چیست؟
الگوریتم K-Means یک روش خوشهبندی مبتنی بر مرکز (Centroid-based Clustering) است که مجموعه داده را به K خوشه تقسیم میکند بهطوری که هر خوشه توسط میانگین نقاط آن خوشه نمایش داده میشود.
به بیان ساده:
هر داده به نزدیکترین مرکز خوشه (Centroid) اختصاص داده میشود.
3.3.مثال :
فرض کنید دادههای زیر نشاندهنده سن مشتریان هستند:
18، 20، 22، 45، 48، 50
اگر K=2 باشد، الگوریتم میتواند دادهها را به دو خوشه تقسیم کند:
خوشه 1: {18، 20، 22}
خوشه 2: {45، 48، 50}
۳.۴. خوشهبندی سخت یا Hard Clustering چیست؟
الگوریتم K-Means یک متد خوشهبندی قطعی و سخت (Hard Clustering) است که فضا را به گروههای کاملاً مجزا تفکیک میکند. در این چارچوب، هر شیء داده تنها و منحصراً به یک گروه تعلق میگیرد و هیچگونه همپوشانی، مرز مشترک یا وزن احتمالی مابین خوشهها مجاز نیست.
برای درک شهودی، میتوان این فرآیند را به استقرار ایستگاههای آتشنشانی در سطح یک منطقه تشبیه کرد؛ مدل تلاش میکند ایستگاهها را در نقاطی قرار دهد که مجموع مسافت شهروندان تا نزدیکترین ایستگاه به حداقل برسد.
۳.۵. تفاوت K-Means با K-NN
بسیاری از تحلیلگران تازه کار، این روش بدون نظارت را با الگوریتم K-NN (کای-نزدیکترین همسایه) اشتباه میگیرند، در حالی که تمایز ساختاری عمیقی مابین آنها برقرار است:
- الگوریتم K-NN: یک تکنیک “با نظارت” برای مسائل دستهبندی است که بر پایه کلاسهای از پیش تعریفشده، هویت یک داده جدید را بر اساس چیدمان همسایگان نزدیکش حدس میزند.
- الگوریتم K-Means: یک تکنیک “بدون نظارت” برای مسائل خوشهبندی است که هیچ دسته پیشفرضی ندارد و خود وظیفه دارد فضا را بر پایه محاسبات میانگین مرزبندی کند.
.
4.چرا الگوریتم K-Means مهم است؟
هنگامی که با دیتابیسهای چندبعدی مواجه هستیم، ذهن انسان توانایی تشخیص همجواری و خوشگی نقاط را ندارد. الگوریتم K-Means دقیقاً مسئله«پیچیدگی زمان پردازش و عدم همگرایی در دادههای انبوه عددی» را حل میکند.
ضرورت وجودی این روش در خط لوله دادهها از این جهت است که فضا را به صورت محیطهای محدب (Convex Shapes) تقسیم میکند که در هندسه به سلولهای ورونوی معروف است. این ابزار برای فاز پیشپردازش و کاهش بعد ضرورت دارد؛ زیرا به جای مهار و ذخیرهسازی تکتک مشاهدات پراکنده در سرورها، مجموعهداده را به چند میانگین و نماینده آماری خلاصه میکند. این فشردهسازی هوشمند، دیتابیس را برای تحلیلهای بعدی چابک میسازد.
.
5. مبانی نظری و ریاضی
۵.۱. نمایش مجموعه داده
فرض کنید مجموعه داده شامل n نمونه باشد:
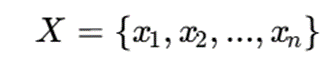
که در آن:
- n یعنی تعداد دادهها
d یعنی تعداد ویژگیها
K یعنی تعداد خوشهها
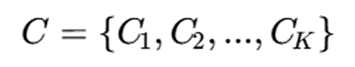
5.2.مرکز خوشه
مرکز خوشه Ck:
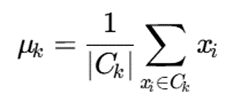
که در آن:
- μk مرکز خوشه k
- Ck : مجموعه نقاط خوشه k
- ∣Ck∣ تعداد نقاط در خوشه k
تفسیر
مرکز خوشه لزوماً یکی از نقاط واقعی داده نیست، بلکه یک نقطه میانگین در فضای ویژگی است. به همین دلیل K-Means با K-Medoids تفاوت دارد؛ در K-Medoids مرکز حتماً یکی از دادههای واقعی است.
.
5.3 واریانس درونخوشهای (Within-Cluster Variance)
هدف K-Means کمینهسازی پراکندگی درون هر خوشه است. هرچه نقاط یک خوشه به مرکز آن نزدیکتر باشند، آن خوشه فشردهتر و بهتر است.
این مفهوم با تابع هدف زیر بیان میشود:
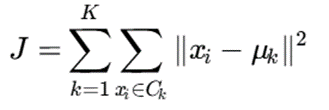
تفسیر
الگوریتم سعی میکند مجموع مربعات فاصله نقاط از مراکز خوشهها را کمینه کند. بنابراین K-Means در اصل یک مسئله بهینهسازی را حل میکند.
.
5.4.تابع هدف K-Means
الگوریتم تلاش میکند تابع زیر را کمینه کند:
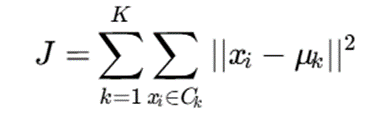
که در آن:
- J تابع هزینه
- فاصله اقلیدسی مربع بین نقطه و مرکز خوشه:
این تابع بیانگر مجموع مربعات فاصله نقاط از مرکز خوشهها است
.
6. همگرایی (Convergence)
الگوریتم K-Means یک الگوریتم تکراری است. در هر تکرار:
- نقاط به نزدیکترین مرکز نسبت داده میشوند
- مراکز جدید محاسبه میشوند
این فرایند تا زمانی ادامه مییابد که:
- مراکز تغییر نکنند
- یا تخصیص نقاط ثابت شود
- یا تغییرات از یک آستانه کمتر شود
نکته مهم
K-Means معمولاً همگرا میشود، اما همگرایی آن الزاماً به بهترین جواب سراسری نیست؛ بلکه ممکن است به یک کمینه محلی برسد.
.
6.1. کمینه محلی و حساسیت به مقداردهی اولیه
یکی از مهمترین مفاهیم در تحلیل K-Means، مینیمم محلی است. از آنجا که تابع هدف الگوریتم غیرمحدب است، نتیجه نهایی به انتخاب مراکز اولیه وابسته است.
پیامد
اگر مراکز اولیه نامناسب انتخاب شوند:
- همگرایی ممکن است کند شود
- کیفیت خوشهبندی پایین بیاید
- یا ساختار واقعی دادهها درست کشف نشود
راهحل
برای کاهش این مشکل از روشهایی مانند:
- اجرای چندباره الگوریتم
- K-Means++
- انتخاب هوشمند مراکز اولیه
استفاده میشود.
.
7.پیش پردازش داده ها قبل از اجرای K-Means
.
7.1.مقیاسبندی ویژگیها (Feature Scaling)
از آنجا که K-Means بر مبنای فاصله عمل میکند، اگر ویژگیها در مقیاسهای متفاوت باشند، ویژگیهای بزرگتر تأثیر بیشتری در خوشهبندی خواهند داشت.
مثال
فرض کنید دو ویژگی داریم:
- سن: بین 20 تا 60
- درآمد: بین 1,000 تا 1,000,000
در این حالت، بدون نرمالسازی، درآمد تقریباً تمام ساختار فاصله را کنترل میکند.
7.2.روشهای رایج
- Standardization
- Min-Max Normalization
نتیجه
پیشپردازش و مقیاسبندی دادهها در K-Means غالباً یک مرحله ضروری است، نه اختیاری.
.
8. شکل خوشهها و مرز تصمیم در K-Means
.
8.1. K-Meansبرای چه شکل خوشه هایی مناسب است؟
در بهترین حالت برای خوشههایی مناسب است که:
- تقریباً کروی
- فشرده
- و با اندازههای نسبتاً مشابه باشند
چرا؟
زیرا مرزهای تصمیمگیری K-Means بر اساس فاصله تا مرکز تعیین میشوند. بنابراین اگر خوشهها:
- کشیده باشند
- چگالی متفاوت داشته باشند
- یا شکل پیچیده و غیرخطی داشته باشند
ممکن است K-Means عملکرد مناسبی نداشته باشد.
.
8.2. نواحی Voronoi در K-Means
از دید هندسی، فضای داده توسط مراکز خوشهها به نواحی مختلف تقسیم میشود. هر ناحیه شامل نقاطی است که به یک مرکز خاص نزدیکترند. این تقسیمبندی را میتوان با مفهوم نواحی Voronoi توضیح داد.
اهمیت
این دید هندسی کمک میکند بفهمیم چرا:
- مرز خوشهها در K-Means خطی یا نیمصفحهای است
- و چرا این الگوریتم برای ساختارهای پیچیده محدودیت دارد
.
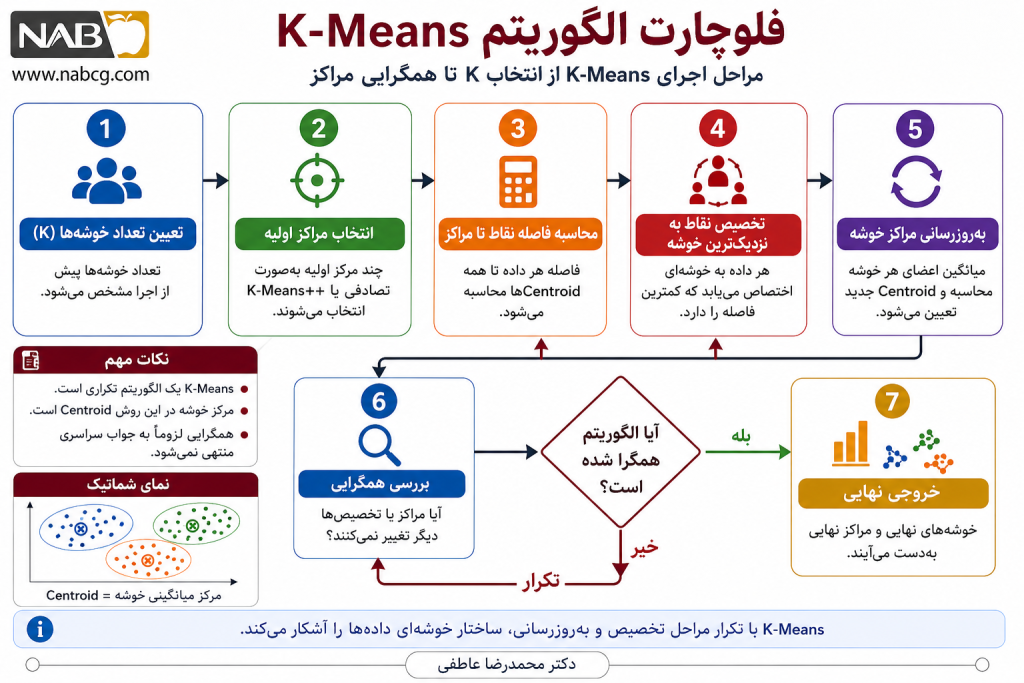
9. مراحل اجرای گامبهگام
الگوریتم K-Means یک روش بهینهسازی تکراری (Iterative Optimization) است که با هدف کمینهسازی مجموع مربعات فاصله نقاط از مراکز خوشهها اجرا میشود. در هر تکرار دو عمل اصلی انجام میشود:
- تخصیص نقاط به نزدیکترین مرکز خوشه (Assignment Step)
- بهروزرسانی مرکز خوشهها (Update Step)
این دو مرحله تا زمانی ادامه پیدا میکنند که الگوریتم به همگرایی (Convergence) برسد.
9.1.ورودی الگوریتم
- مجموعه دادهها
- تعداد خوشهها:
.
9.2.خروجی الگوریتم
- برچسب خوشه هر داده
- مراکز نهایی خوشهها
.
9.3.گام ۱: مقداردهی اولیه مراکز خوشهها
در ابتدا، تعداد کلاسترها (K) توسط کاربر تعیین میشود. سپس الگوریتم به صورت دلخواه و تصادفی، K نقطه را در فضای دادهها به عنوان مراکز آغازین یا میانگینهای اولیه خوشهها انتخاب میکند که با نماد μ(Cj) یا cj نمایش داده میشوند.
روشهای رایج:
- انتخاب تصادفی از میان دادهها
- انتخاب تصادفی در فضای ویژگی
- روش K-Means++
.
9.4.گام ۲: محاسبه فاصله هر داده تا مراکز خوشهها
در این مرحله، فاصله تکتک اشیاء موجود تا مراکز K گانه محاسبه میشود. این فاصله معمولاً بر پایه معیار اقلیدسی سنجیده میشود. اگر فاصله یک شیء از میانگین خوشه خود زیاد و به خوشه دیگری نزدیکتر باشد، این شیء به خوشهای که کمترین فاصله را با آن دارد اختصاص مییابد.
فرمول ریاضی سنجش فاصله اقلیدسی مابین یک داده (X) تا مرکز خوشه (μ(Cj)):
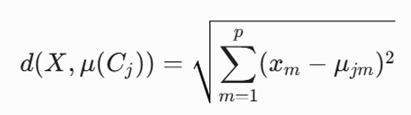
9.5.گام 3: تخصیص دادهها به نزدیکترین خوشه
هر داده به خوشهای تخصیص داده میشود که فاصله آن با مرکز خوشه کمینه باشد:
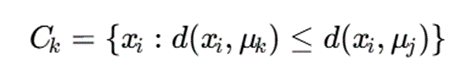
در این فاز، وضعیت تخصیص با یک متغیر باینری پنهان به نام وزن عضویت صلب (wij) مدیریت میشود تا تضمین شود هر شیء تنها در یک گروه قرار میگیرد:

9.6.گام 4: بهروزرسانی مراکز خوشه
مرکز هر خوشه برابر میانگین نقاط آن خوشه محاسبه میشود:
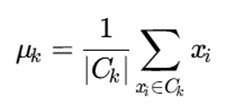
پس از اینکه تمام دادهها به نزدیکترین مرکز خود واگذار شدند، میانگین یا مرکز هندسی جدید هر خوشه بر اساس اعضای جدید آن دوباره محاسبه میشود. این کار باعث جابهجایی مراکز فرضی به سمت هسته چگالی واقعی تودهها میگردد.
فرمول ریاضی نوسازی میانگین خوشه j-ام:
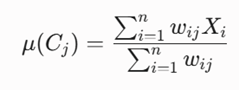
9.7.گام 5: بررسی شرط توقف
الگوریتم تا زمانی ادامه مییابد که یکی از شرایط زیر برقرار شود:
- مراکز خوشهها تغییر نکنند
- تغییرات بسیار کوچک شود
- حداکثر تعداد تکرارها انجام شود
9.8.ارزیابی تابع هدف و دستور توقف
الگوریتم چرخه تخصیص و بهروزرسانی را مرتباً تکرار میکند تا تابع هدف نهایی مدل کمینه شود. این تابع هدف که میزان خطای کل فضا را ارزیابی میکند، تحت عنوان تابع خطا (EF) یا مجموع مجذور خطاهای درونخوشهای (SSE) شناخته میشود.
تابع هدف ریاضی الگوریتم K-Means :
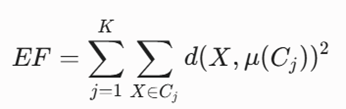
معرفی متغیرها :
- n: تعداد کل اشیاء موجود در مجموعه داده D.
- p: تعداد شاخصها یا ویژگیهای ابعادی هر شیء.
- X: بردار ویژگیهای یک شیء داده.
- μ(Cj): بردار میانگین یا مرکز ثقل خوشه j-ام.
- EF: مقدار کل تابع خطای سیستم که مدل به دنبال حداقل کردن آن است.
دستور توقف الگوریتم:
این فرآیند تکراری تا زمانی ادامه مییابد که یکی از شرایط زیر برقرار شود:
- اعضای خوشهها در دو تکرار متوالی هیچ تغییری نکنند (تغییر نیافتن اعضای خوشهها).
- مقدار تابع خطا (EF) دیگر کاهش نیابد و فضا به همگرایی مطلق یا موضعی برسد.
.
10.مثال عددی
.
مثال اول (یکبعدی بر پایه یک متغیر)
صورت مسئله: چنین تصور کنید ۹ نفر داریم که سن آنها بر حسب سال به این صورت است:{ .{2,4,10,12,3,20,30,11,25 میخواهیم با به کارگیری روش میانگین آنها را به دو خوشه (k=2) افراز کنیم.
حل گامبهگام:
- گام آغازین: به صورت تصادفی دو مرکز خوشه μ1=3 و μ2=4 را انتخاب میکنیم. اشیاء دیگر را بر پایه نزدیکی به یکی از این دو مرکز واگذار میکنیم. برای نمونه عدد ۲ به ۳ نزدیک تر است تا به ۴ بنابراین آن را به خوشه اول واگذار میکنیم. همچنین عدد ۱۰ به مرکز خوشه دوم یعنی عدد ۴ نزدیک تر است، بنابراین آن را در خوشه دوم قرار میدهیم این کار را تا جایی ادامه میدهیم که همه اشیاء در یکی از این دو خوشه جای گیرند. نتیجه این گام دو خوشه به این صورت خواهد بود
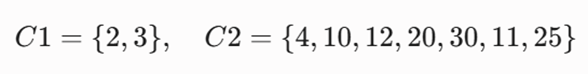
گام تکراری (تکرار اول): در این گام مراکز جدید هر خوشه را حساب میکنیم و بر پایه مراکز جدید واگذاری را انجام میدهیم. مرکز (میانگین) خوشه اول μ1=2.5 و μ2=16 خواهد شد. اکنون اعضای ۲، ۳ و ۴ به مرکز 5/2 نزدیک ترند تا به ۱۶ بنابراین این سه عضو در خوشه اول و اعضای دیگر در خوشه دوم قرار میگیرند:
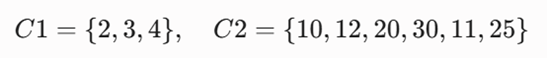
تکرارهای بعدی: این کار تا جایی تکرار میشود که تغییری در اعضای خوشه ها ایجاد نشود. روند حل به این صورت خواهد شد:

پاسخ نهایی و دستور ایست: به دلیل تغییر نکردن اعضای خوشه ها توقف میکنیم. بنابراین اعضای هر خوشه به این صورت خواهند شد:
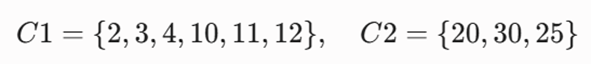
تفسیر نتیجه: الگوریتم توانست مرز مابین افراد کمسن (کودکان و نوجوانان زیر ۱۲ سال) را از افراد بزرگسال (جوانان و میانسالان بالای ۲۰ سال) بدون داشتن برچسب و صرفاً بر اساس تجمیع فواصل عددی سن تفکیک کند.
.
مثال دوم K-Means با چند تکرار و جدول فاصلهها
صورت مسئله
مجموعه داده زیر در فضای دوبعدی داده شده است:
| نقطه | مختصات |
| A | (2,10) |
| B | (2,5) |
| C | (8,4) |
| D | (5,8) |
| E | (7,5) |
| F | (6,4) |
تعداد خوشهها:K = 2
معیار فاصله: فاصله اقلیدسی
تکرار اول
مرحله 1: انتخاب مراکز اولیه
فرض میکنیم:
μ₁ = A (2,10)
μ₂ = C (8,4)
مرحله 2: محاسبه فاصله نقاط تا مراکز
فرمول فاصله:
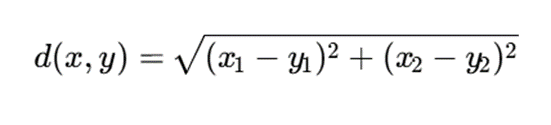
جدول فاصلهها
| نقطه | فاصله تا μ₁(2,10) | فاصله تا μ₂(8,4) | خوشه |
| A | 0 | 8.49 | C1 |
| B | 5 | 6.08 | C1 |
| C | 8.49 | 0 | C2 |
| D | 3.61 | 5 | C1 |
| E | 7.07 | 1.41 | C2 |
| F | 7.21 | 2 | C2 |
مرحله 3: تشکیل خوشهها
خوشه 1:
A , B , D
خوشه 2:
C , E , F
مرحله 4: محاسبه مراکز جدید
مرکز خوشه 1
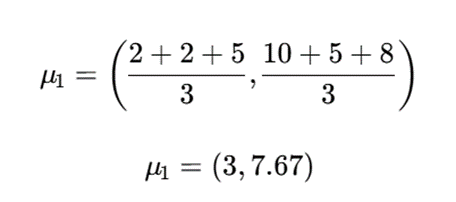
مرکز خوشه 2
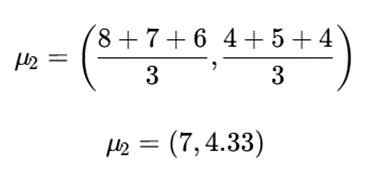
تکرار دوم
محاسبه فاصلهها با مراکز جدید
| نقطه | فاصله تا μ₁(3,7.67) | فاصله تا μ₂(7,4.33) | خوشه |
| A | 2.54 | 7.34 | C1 |
| B | 2.85 | 5.02 | C1 |
| C | 5.38 | 1.05 | C2 |
| D | 2.54 | 4.01 | C1 |
| E | 4.69 | 0.75 | C2 |
| F | 4.47 | 1.20 | C2 |
خوشهها
خوشه 1:
A , B , D
خوشه 2:
C , E , F
تخصیصها تغییر نکردهاند، الگوریتم همگرا شده است.
نتیجه نهایی
خوشه 1
A (2,10)
B (2,5)
D (5,8)
مرکز:
(3,7.67) (3 , 7.67) (3,7.67)
خوشه 2
C (8,4)
E (7,5)
F (6,4)
مرکز:
(7,4.33) (7 , 4.33) (7,4.33)
مثال سوم (دوبعدی بر پایه دو متغیر)
صورت مسئله: در جدول زیر مقادیر استاندارد شده هزینه غذا و پوشاک ،۵ نفر در سال گذشته آورده شده است. میخواهیم با روش میانگین این اشیاء را در دو خوشه گروه بندی کنیم (k=2).
| افراد | هزینه غذا (x) | هزینه پوشاک (y) |
| A | 2 | 4 |
| B | 8 | 2 |
| C | 9 | 3 |
| D | 1 | 5 |
| E | 8.5 | 1 |
توضیح پیشفرض: با استفاده از فاصله اقلیدسی ماتریس مجاورت (فاصله) را به دست میآوریم.
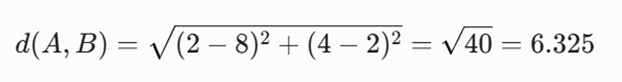
حل گامبهگام:
- گام آغازین: فرض کنیم در آغاز خوشه بندی اشیاء A، B و C در خوشه ۱ و D و E در خوشه ۲ قرار داشته باشند.
- تکرار صفر: اکنون میانگین مختصات اشیاء هر دو خوشه را حساب میکنیم.
- برای خوشه ۱ یعنی :{A,B,C}
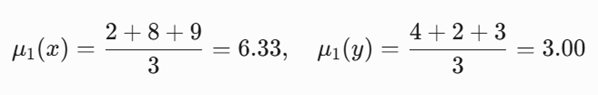
- برای خوشه ۲ یعنی {D,E}:
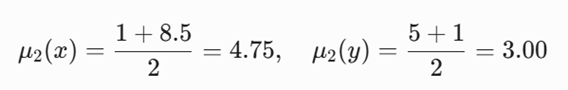
سپس فاصله اقلیدسی هر شیء تا میانگین خوشه خود را به دست میآوریم:
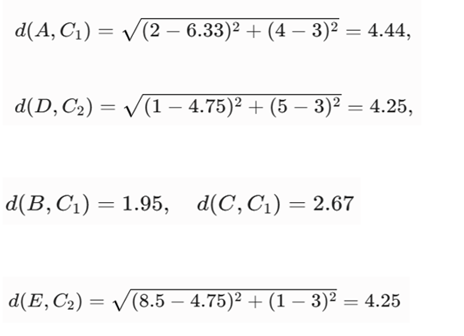
اکنون تابع خطا (EF) را محاسبه میکنیم:
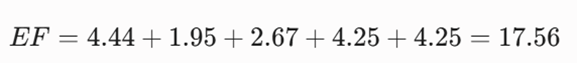
- تکرار ۱: بیشترین فاصله را شیء A با خوشه اول دارد بنابراین شیء A را به خوشه دوم منتقل میکنیم و مرکز خوشه ها (میانگین) را دوباره حساب میکنیم.
- برای خوشه ۱ یعنی {B,C} :
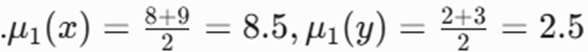
- برای خوشه ۲ یعنی{A,D,E} :
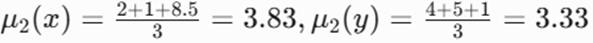
- فاصله اقلیدسی جدید هر شیء تا میانگین خوشه خود
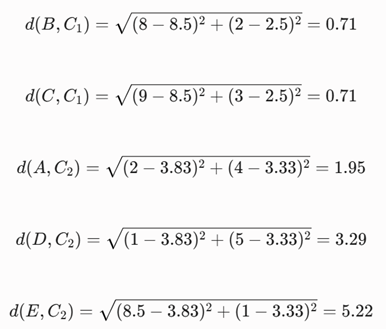
مقدار تابع خطا:

پاسخ نهایی و تفسیر: مقدار خطا (۱۱/۳۸) نسبت به تکرار پیش بیشتر شده است بنابراین ادامه نمیدهیم. بهترین خوشه بندی مربوط به تکرار ۲ میباشد که مقدار خطای آن کمتر است؛ که در آن یکی از خوشه ها {A,D} و دیگری {B,C,E} است. این خروجی نشان میدهد کسانی که الگوی مخارج آنها مشابه است (مثلاً افراد A و D که هزینه کمتری در غذا دارند) به درستی در یک کلاستر اقتصادی قرار گرفتهاند.
.
11.روشهای انتخاب تعداد خوشهها (K)
K-Means نیاز دارد مقدار K از قبل مشخص شود. این ویژگی هم یک مزیت کنترلی و هم یک محدودیت عملی است.
11.1.چرا K مهم است؟
- اگر K خیلی کوچک باشد، خوشههای متفاوت با هم ادغام میشوند
- اگر K خیلی بزرگ باشد، یک ساختار واحد بیجهت به چند بخش شکسته میشود

11.2.روش Elbow (روش آرنج)
یکی از رایجترین روشها برای تعیین مقدار K است.
ایده اصلی
در این روش مقدار تابع خطای درون خوشهای برای مقادیر مختلف K محاسبه میشود.
تابع خطا همان مجموع مربعات فاصله نقاط از مرکز خوشهها است:
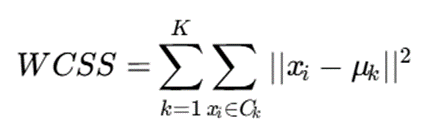
که در آن:
- WCSS مجموع مربعات فاصله درون خوشهها
- xi یک داده
- μk مرکز خوشه
- Ck مجموعه نقاط خوشه k
روند اجرا
- الگوریتم K-Means برای مقادیر مختلف K اجرا میشود (مثلاً 1 تا 10).
- مقدار WCSS برای هر K محاسبه میشود.
- نمودار K در برابر WCSS رسم میشود.
- نقطهای که در آن کاهش خطا ناگهان کند میشود (شکل آرنج)، مقدار مناسب K در نظر گرفته میشود.
تفسیر
افزایش K همیشه باعث کاهش خطا میشود، اما پس از یک نقطه، بهبود بسیار کم میشود. آن نقطه همان Elbow است.
.
11.3.شاخص Silhouette
یکی از دقیقترین معیارهای ارزیابی کیفیت خوشهبندی است.
ایده اصلی
این شاخص میزان شباهت هر داده به خوشه خودش در مقایسه با خوشههای دیگر را اندازهگیری میکند.
برای هر نقطه مقدار زیر محاسبه میشود:
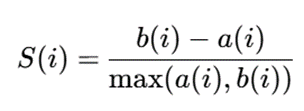
که در آن:
- (i)a میانگین فاصله نقطه i از سایر نقاط خوشه خودش
- (i)b کمترین میانگین فاصله نقطه i تا نقاط نزدیکترین خوشه دیگر
مقدار Silhouette بین:
−1 ≤ S(i) ≤ 1
.
تفسیر مقدار شاخص
- نزدیک به 1 → خوشهبندی بسیار خوب
- نزدیک به 0 → مرز بین دو خوشه
- نزدیک به -1 → تخصیص اشتباه
روش انتخاب K
- الگوریتم برای چند مقدار K اجرا میشود.
- میانگین شاخص Silhouette برای همه نقاط محاسبه میشود.
- مقداری از K که بیشترین مقدار Silhouette را دارد انتخاب میشود.
.
11.4.روش Gap Statistic
این روش برای مقایسه خوشهبندی داده واقعی با داده تصادفی استفاده میشود.
ایده اصلی
اگر دادهها واقعاً دارای ساختار خوشهای باشند، مقدار خطای درون خوشهای آنها باید بسیار کمتر از دادههای تصادفی باشد.
فرمول Gap:
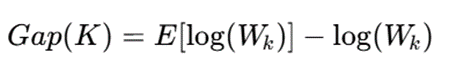
که در آن:
- Wk خطای درون خوشهای برای داده واقعی
- [ (Wk)log]Eمقدار مورد انتظار برای داده تصادفی
انتخاب K
مقداری از K انتخاب میشود که Gap Statistic بیشینه شود.
.
11.5.روش Cross Validation
در این روش دادهها به چند بخش تقسیم میشوند و الگوریتم برای مقادیر مختلف K اجرا میشود. سپس کیفیت خوشهبندی روی دادههای آزمون ارزیابی میشود.
این روش بیشتر در مدلهای ترکیبی یا probabilistic clustering استفاده میشود.
.
11.6.معیار اطلاعاتی (AIC و BIC)
در برخی مدلهای خوشهبندی آماری مانند Gaussian Mixture Models از معیارهای اطلاعاتی استفاده میشود.
دو معیار رایج:
- AIC (Akaike Information Criterion)
- BIC (Bayesian Information Criterion)
این معیارها بین دقت مدل و پیچیدگی آن تعادل برقرار میکنند.
مقداری از K انتخاب میشود که مقدار معیار کمینه شود.
.
12.تحلیل پیچیدگی زمانی و حافظه الگوریتم K-Means
پیچیدگی زمانی الگوریتم K-Means به چند عامل بستگی دارد:
- تعداد دادهها
- تعداد خوشهها
- تعداد ویژگیها
- تعداد تکرارهای الگوریتم
.
12.1.پارامترهای موثر بر پیچیدگی زمانی
فرض کنید:
n = تعداد دادهها
K = تعداد خوشهها
d = تعداد ویژگیها
t = تعداد تکرارها
.
12.2.هزینه مرحله تخصیص نقاط (Assignment Step)
برای هر داده فاصله آن تا همه مراکز محاسبه میشود.
تعداد محاسبات فاصله:
n × K
هر محاسبه فاصله در فضای d بعدی:
O(d)
پس هزینه این مرحله:
O(nKd)
.
12.3.مرحله بهروزرسانی مراکز (Update Step)
برای هر خوشه میانگین نقاط محاسبه میشود.
هزینه تقریبی:
O(nd)
زیرا باید تمام نقاط بررسی شوند.
12.4.پیچیدگی کل الگوریتم
اگر الگوریتم در t تکرار همگرا شود:
O(nKdt)
تحلیل عملی
در کاربردهای واقعی معمولاً:
- t بین 10 تا 100 است
- K کوچک است
- n ممکن است بسیار بزرگ باشد
بنابراین K-Means برای دادههای بزرگ بسیار مقیاسپذیر است.
12.5.پیچیدگی حافظه
حافظه مورد نیاز:
O(n+K)
زیرا باید:
- دادهها ذخیره شوند
- مراکز خوشهها ذخیره شوند
نکته مهم :الگوریتم K-Means در حالت کلی میتواند به مینیمم محلی همگرا شود. بنابراین نتیجه نهایی به موارد زیر وابسته است:
- مقداردهی اولیه مراکز
- ترتیب دادهها
- مقدار K
به همین دلیل در عمل معمولاً الگوریتم چند بار با مقداردهی اولیه مختلف اجرا میشود.
.
13.کاربرد
الگوریتم K-Means به عنوان یک متد چابک و سریع محاسباتی، نقشی کلیدی در حل مسائل کاربردی صنعت، پژوهش و کسبوکارهای مدرن ایفا میکند. این روش به دلیل معماری غیرسلسلهمراتب و توابع فاصله مستقیم، امکان مدیریت حجم بزرگی از دادههای عددی خام را فراهم میسازد. مهمترین کاربردهای عملیاتی این الگوریتم در حوزههای مختلف هوش تجاری و پردازش داده به شرح زیر است:

- بخشبندی هوشمند مشتریان (Customer Segmentation): سازمانها با استفاده از این تکنیک، خریداران و کاربران خود را بر اساس الگوهای مخارج، میزان درآمد، فواصل خرید و رفتارهای مالی تعاملی به گروههای همگن تقسیم میکنند. این کلاسترینگ به مدیران بازاریابی اجازه میدهد تا پرسونای دقیق مخاطبان را استخراج کرده و کمپینهای تبلیغاتی شخصیسازیشده و پربازده طراحی کنند.
- فشردهسازی تصویر و دادهها (Data Compression): در کلاندادهها، ذخیرهسازی تکتک مشاهدات پراکنده بار محاسباتی سنگینی دارد. K-Means با فشردهسازی هوشمند فضا، مجموعهدادههای عظیم را از طریق نگاشت هزاران نمونه به چند مرکز ثقل میانگین خلاصه میکند. این کار ابعاد دیتابیس را بدون از دست رفتن روندهای آماری کلان، برای سرورها چابک میسازد.
- بینایی ماشین و پردازش تصویر (Image Segmentation): در این حوزه، الگوریتم با تفکیک لایهها، رنگها و پارتهای مختلف یک تصویر به خوشههای فرکانسی متمایز، فرآیند قطعهبندی پیکسلی را انجام میدهد. این ویژگی یکی از ابزارهای بنیادین برای ردیابی دقیق اشیاء، عابران پیاده و علائم راهنمایی در سیستمهای ناوبری خودروهای خودران است.
- مهندسی سیستمهای توصیهگر (Recommendation Systems): پلتفرمهای پخش محتوا و فروشگاههای اینترنتی بزرگ، محصولات، مقالات یا کاربران را بر اساس شباهتهای ساختاری و ترجیحات همگام آماری گروهبندی میکنند. با این روش، سیستم میتواند آیتمهای موجود در یک کلاستر را به عنوان پیشنهادهای دقیق به کاربران همگروه معرفی کند و نرخ تعامل سایت را ارتقا دهد.
.
14.مزایای الگوریتم K-Means
الگوریتم K-Means به عنوان یکی از محبوبترین سنگبناهای یادگیری بدون نظارت، ویژگیهای شاخصی دارد که آن را به گزینهای ایدهآل برای شروع بسیاری از پروژههای علم داده در سازمانها تبدیل کرده است. این نقاط قوت ترکیبی از سادگی منطقی و کارایی عملیاتی هستند که مزایای زیر را برای سیستمهای محاسباتی به همراه میآورند:
- سادگی مفرط در مکانیزم اجرایی: فرآیند و پایههای ریاضی این الگوریتم بسیار واضح و به دور از پیچیدگیهای توابع احتمالی سنگین است. این سادگی ساختاری باعث میشود که مهندسان داده و تحلیلگران تازه کار بتوانند منطق آن را به سرعت درک کرده و بدون چالش پایداری، مدل را در خطوط لوله پیش-پردازش پیادهسازی کنند.
- سرعت محاسباتی و چابکی بالا: بزرگترین مزیت فنی K-Means ، پیچیدگی زمانی خطی آن است که با نماد O (tKn) نمایش داده میشود. از آنجا که تعداد تکرارها (t) و تعداد خوشهها (K) معمولاً بسیار کوچکتر از تعداد کل دادهها (n) هستند، این الگوریتم میتواند دیتابیسهای مگا-سایز صنعتی را در کسر کوچکی از ثانیه پردازش کند.
- تفسیرپذیری عالی و شهودی خروجیها: برخلاف مدلهای جعبه سیاه، خروجی این روش کاملاً شفاف است. از آنجا که مرزها بر اساس میانگین هندسی دادههای درون هر گروه تعیین میشوند، مختصات مراکز نهایی ویژگیهای دقیق و ملموسی از رفتار هر کلاستر ارائه میدهند که برای مدیران کسبوکار به راحتی قابل تحلیل است.
- قابلیت تعمیم و انعطاف بالا: این الگوریتم پایه به راحتی میتواند با متریکهای مختلف فواصل خطی یکپارچه شود. همچنین برچسبهای سخت و باینری خروجی آن به عنوان ویژگیهای ساختاری جدید برای غنیسازی مدلهای یادگیری با نظارت بعدی (مانند درخت تصمیم یا رگرسیون) کارایی بالایی در فرآیند مهندسی ویژگی دارند.
.
15.معایب الگوریتم K-Means
با وجود سرعت و سادگی، الگوریتم K-Means دارای فرضهای محدودکننده و ضعفهای ذاتی ساختاری است که عدم توجه به آنها در لایههای عملیاتی میتواند منجر به تولید نتایج مخدوش و تحلیلهای نادرست شود. شناخت واقعبینانه این محدودیتها برای انتخاب بهینه مدل ضرورت دارد:
- نیاز به تنظیم پارامتر صلب اولیه (K): بزرگترین چالش عملیاتی این است که کاربر باید تعداد کلاسترها را از قبل به مدل دیکته کند. در دیتابیسهای بزرگ، چندبعدی و کاملاً ناشناخته، حدس زدن تعداد واقعی گروهها بدون دانش قبلی بسیار دشوار است و تحلیلگر را وارد چرخههای خستهکننده آزمون و خطا میکند.
- حساسیت شدید به مقداردهی اولیه: فرآیند انتخاب تصادفی مراکز آغازین یک تله بزرگ است. اگر نقاط شروع به طور نامناسب انتخاب شوند، الگوریتم ممکن است در اولین بهینه موضعی (Local Minima) متوقف شود و همگرایی به سمت مرکز چگالی واقعی فضا رخ ندهد. این امر باعث تولید خروجیهای کاملاً متفاوت در هر بار اجرای مجدد میشود.
- ضعف شدید در برابر نویز و دادههای پرت (Outliers): از آنجا که مبنای نوسازی مراکز بر پایه میانگین ریاضی استوار است، ورود حتی یک داده پرت شدید با ارزش عددی بزرگ میتواند مختصات مرکز ثقل خوشه را به شدت به سمت خود بکشد. این حساسیت مرزهای طبیعی کلاسترها را مخدوش کرده و کیفیت تفکیک را کاهش میدهد.
- محدودیت هندسی در شکل خوشهها: این الگوریتم به دلیل فرضیات خطی، فضا را به صورت محیطهای محدب و کروی شکل تفکیک میکند. در نتیجه، در مواجهه با دیتابیسهایی که الگوهای واقعی آنها به صورت اشکال نامنظم، کشیده، مارپیچ یا تو در تو شکل گرفتهاند، کاملاً شکست خورده و دادهها را به شکل نادرستی برش میزند.
.
16. مقایسه K-Means با روشهای مشابه
برای درک استراتژیک جایگاه الگوریتم K-Means در لایه طراحی ابزارها، مقایسه ساختاری زیر مابین این متد و دو روش شاخص افرازی و چگالیمحور انجام شده است تا تفاوتهای عملکردی آنها در مواجهه با چالشهای مختلف داده آشکار شود:
| شاخص ارزیابی | الگوریتم K-Means | الگوریتم K-Medoids | الگوریتم DBSCAN |
| سرعت محاسباتی | بسیار بالا و دارای پیچیدگی خطی؛ ایده آل برای دیتابیسهای حجیم. | متوسط و نسبتاً کند؛ محاسبات سنگین در تکرار دادههای بزرگ. | متوسط؛ سرعت مدل به تراکم نقاط و شعاع همسایگی وابسته است. |
| مقاومت در برابر نویز | ضعیف؛ میانگین هندسی تحت تاثیر شدید دادههای پرت جابهجا میشود. | عالی؛ استفاده از اشیاء واقعی دیتابیس به عنوان مرجع به جای میانگین. | فوقالعاده؛ شناسایی و حذف خودکار نقاط خلوت و منزوی فضا. |
| شکل هندسی خوشهها | انحصارا محدب، متقارن و کروی شکل (سلولهای خطی ورونوی). | تودههای کروی شکل پیرامون شیء مرجع. | اشکال کاملاً اختیاری، آزاد، نامنظم و تو در تو. |
| نیاز به تعیین اولیه K | بله؛ تعداد خوشهها باید توسط کاربر از پیش تعیین شود. | بله؛ تعداد بخشها پیش از شروع پردازش مشخص میشود. | خیر؛ تعداد خوشهها را بر اساس تراکم فضا خودکار کشف میکند. |
.
17.نوآوریها و آینده الگوریتم K-Means
الگوریتم K-Means با وجود قدمت زیاد، همچنان یکی از ستونهای اصلی خوشهبندی در یادگیری ماشین است. دلیل ماندگاری آن، سادگی محاسباتی، تفسیرپذیری و قابلیت توسعه به سناریوهای متنوع است. با این حال، پژوهشهای جدید نشان میدهند که تمرکز اصلی دیگر صرفاً بر خودِ نسخه کلاسیک الگوریتم نیست، بلکه بر بهبود مقداردهی اولیه، افزایش مقیاسپذیری، مقاومسازی در برابر نویز، تعمیم به فضاهای غیرخطی، و ترکیب با یادگیری عمیق و حریم خصوصی است.
در ادامه، مهمترین روندهای نوآورانه و مسیر آینده K-Means را بهصورت ساختیافته بررسی میکنیم.
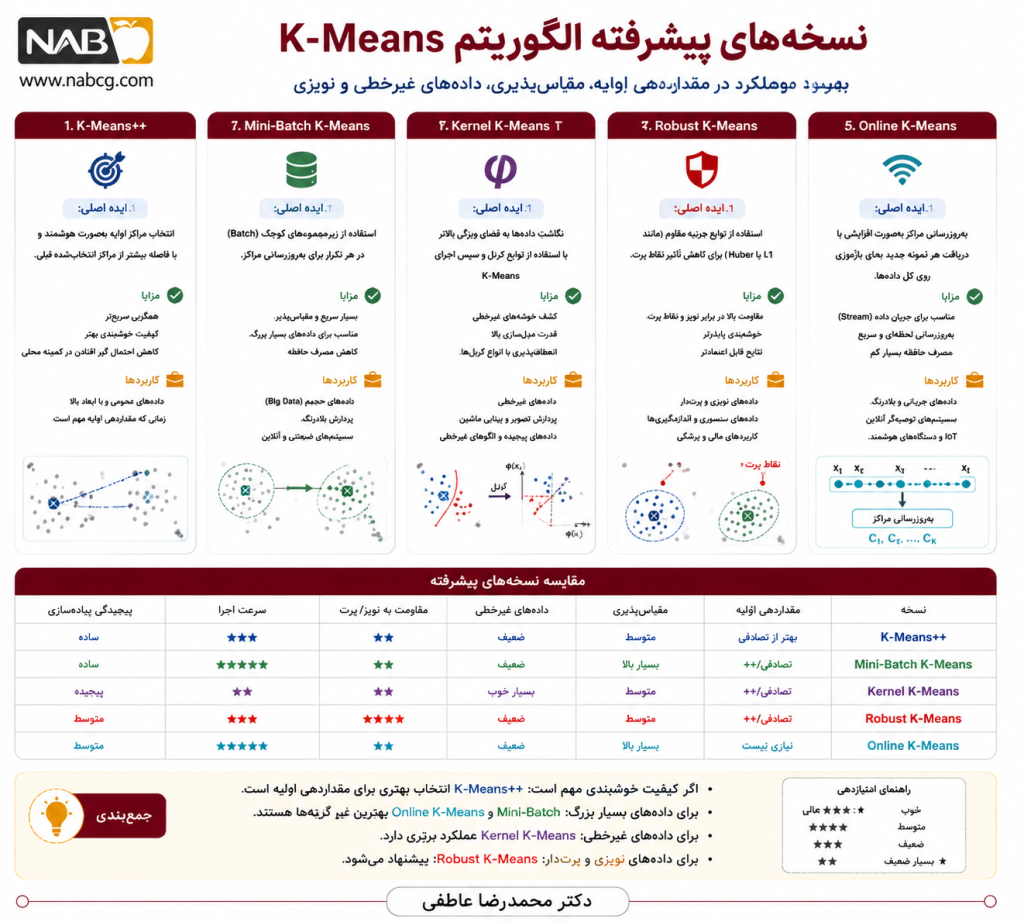
17.1. بهبود مقداردهی اولیه: ++ K-Means
یکی از مهمترین نقاط ضعف K-Means کلاسیک، وابستگی شدید به مراکز اولیه است. انتخاب تصادفی مراکز میتواند به همگرایی در مینیمم محلی نامطلوب منجر شود. در پاسخ به این مسئله، ++ K-Means معرفی شد که مراکز اولیه را بهصورت هوشمندتر انتخاب میکند.
ایده اصلی
در K-Means++، مرکز اول تصادفی انتخاب میشود و سپس هر مرکز بعدی با احتمالی متناسب با مجذور فاصله از نزدیکترین مرکز موجود انتخاب میشود. این کار باعث میشود مراکز اولیه از هم فاصله مناسبی داشته باشند.
اهمیت پژوهشی
در مقالات جدید، ++ K-Means هنوز بهعنوان استاندارد پایه برای مقداردهی اولیه استفاده میشود. بسیاری از بهبودهای جدید، در عمل بر این ایده استوارند که:
- مقداردهی اولیه بهتر از شروع تصادفی،
- کاهش تعداد تکرارها،
- و افزایش پایداری نتایج را به همراه دارد.
چشمانداز
پژوهشهای آینده به سمت:
- نسخههای توزیعشده و موازی K-Means++
- مقداردهی اولیه برای دادههای بسیار بزرگ و جریانی
- و نسخههای مبتنی بر embedding
حرکت میکنند.
.
17.2.مقیاسپذیری در دادههای عظیم: Mini-Batch K-Means
با رشد دادههای حجیم، اجرای کامل K-Means روی کل داده در هر تکرار، از نظر زمانی پرهزینه میشود. در اینجا Mini-Batch K-Means بهعنوان یکی از مهمترین نوآوریها مطرح شده است.
ایده اصلی
بهجای استفاده از کل دادهها در هر تکرار، تنها یک بسته کوچک تصادفی (mini-batch) از دادهها انتخاب و برای بهروزرسانی مراکز استفاده میشود.
اهمیت
این روش:
- هزینه محاسباتی را کاهش میدهد
- برای دادههای بزرگ و جریاندار مناسب است
- امکان اجرای سریعتر روی سیستمهای توزیعشده را فراهم میکند
روند آینده
در ادبیات جدید، Mini-Batch K-Means در ترکیب با:
- GPU acceleration
- پردازش توزیعشده
- دادههای streaming
- و learning-at-scale
بسیار برجسته شده است.
.
17.3.تعمیم به فضاهای غیرخطی: Kernel K-Means
K-Means کلاسیک فرض میکند خوشهها در فضای ویژگی تقریباً کروی و قابل جداسازی با فاصله اقلیدسی هستند. اما در بسیاری از دادههای واقعی، ساختار خوشهها غیرخطی است.
ایده اصلی
در Kernel K-Means دادهها با استفاده از یک تابع کرنل به فضای ویژگی با بُعد بالاتر نگاشت میشوند، بدون آنکه این نگاشت بهصورت صریح محاسبه شود.
اهمیت
این رویکرد اجازه میدهد:
- مرزهای خوشهبندی غیرخطی مدل شوند
- ساختارهای پیچیدهتر داده کشف شوند
- در مسائل تصویری، زیستی و متنی عملکرد بهتری حاصل شود
مسیر آینده
پژوهشهای اخیر بیشتر بر:
- انتخاب خودکار کرنل مناسب
- کاهش پیچیدگی محاسباتی
- و ترکیب kernel methods با representation learning
متمرکز شدهاند.
.
17.4.خوشهبندی مقاوم: Robust K-Means
یکی از مشکلات مهم K-Means کلاسیک، حساسیت به دادههای پرت (outliers) است. چون مرکز هر خوشه بر اساس میانگین محاسبه میشود، دادههای غیرعادی میتوانند آن را بهطور جدی جابهجا کنند.
ایده نوآورانه
نسخههای Robust K-Means با تغییر تابع هزینه یا استفاده از فاصلهها و برآوردگرهای مقاوم، اثر نقاط پرت را کاهش میدهند.
نمونههای رویکردی
- استفاده از L1 بهجای L2
- استفاده از trimming
- استفاده از median-based centers
- مدلهای مقاوم آماری
چشمانداز
با توجه به رشد دادههای noisy در دنیای واقعی، خوشهبندی مقاوم یکی از مهمترین مسیرهای آینده K-Means است.
.
17.5.خوشهبندی در مقیاس صنعتی: Distributed و Parallel K-Means
در سالهای اخیر، یکی از مسیرهای اصلی نوآوری، اجرای K-Means روی سامانههای:
- چندپردازندهای
- خوشهای
- ابری
- و GPU-based
بوده است.
ایده
دادهها بین چند گره تقسیم میشوند و هر گره بخشی از محاسبات تخصیص و بهروزرسانی را انجام میدهد. سپس نتایج تجمیع میشوند.
اهمیت
این موضوع برای:
- دادههای اینترنتی
- لاگهای بزرگ
- سیستمهای توصیهگر
- و دادههای sensor-based
حیاتی است.
آینده
مسیر آینده شامل:
- الگوریتمهای communication-efficient
- نسخههای fault-tolerant
- و asynchronous distributed clustering
است.
.
17.6.خوشهبندی در فضای تعبیهشده: Integration with Deep Learning
یکی از مهمترین روندهای جدید، ترکیب K-Means با یادگیری عمیق است. در اینجا K-Means معمولاً روی نمایشهای نهفته (latent representations) اجرا میشود، نه روی داده خام.
ایده اصلی
یک شبکه عصبی، نمایش فشرده و معناداری از داده یاد میگیرد و سپس K-Means در آن فضای نهفته خوشهبندی انجام میدهد.
اهمیت
این ترکیب باعث میشود:
- ویژگیها بهصورت خودکار استخراج شوند
- خوشهها در فضایی معناییتر شکل بگیرند
- دادههای پیچیده مانند تصویر، متن و صوت بهتر خوشهبندی شوند
چشمانداز
روند آینده به سمت:
- Deep Embedded Clustering
- Self-supervised clustering
- Contrastive learning + K-Means
حرکت میکند.
.
17.7. خوشهبندی جریان داده و آنلاین: Online K-Means
در بسیاری از کاربردها، دادهها بهصورت پیوسته وارد میشوند و امکان اجرای الگوریتم روی کل داده از ابتدا وجود ندارد.
ایده
در Online K-Means، مراکز خوشهها با ورود هر داده یا هر mini-batch بهروزرسانی میشوند.
اهمیت
این رویکرد برای:
- پایش بلادرنگ
- تشخیص رفتار کاربر
- شبکههای حسگر
- سیستمهای مالی
بسیار مهم است.
آینده
نسخههای آینده احتمالاً با:
- adaptive learning rates
- concept drift detection
- و memory-aware updates
توسعه خواهند یافت.
.
17.8.حریم خصوصی و خوشهبندی امن: Privacy-Preserving K-Means
با گسترش مقررات حفاظت از داده، یکی از روندهای مهم، اجرای K-Means بدون افشای داده خام است.
ایده
خوشهبندی میتواند با:
- differential privacy
- secure multi-party computation
- federated clustering
- encrypted computation
انجام شود.
اهمیت
این موضوع در:
- دادههای پزشکی
- دادههای مالی
- دادههای سازمانی حساس
بسیار حیاتی است.
چشمانداز
آینده این حوزه به سمت خوشهبندی فدره، خصوصی و قابل اعتماد حرکت میکند.
.
17.9.انتخاب خودکار K و نسخههای خودتنظیم
یکی از چالشهای بنیادین K-Means نیاز به تعیین K پیش از اجراست. پژوهشهای جدید به سمت self-tuning clustering و روشهای خودکار برای تخمین K رفتهاند.
ایده
ترکیب K-Means با:
- معیارهای اعتبارسنجی داخلی
- مدلهای بیزی
- روشهای elbow و silhouette خودکار
- و optimization-based model selection
اهمیت
در مسائل واقعی، انتخاب دستی K همیشه ممکن یا قابل اعتماد نیست.
آینده
انتظار میرود نسخههای آینده K-Means بیشتر:
- adaptive
- data-driven
- و criterion-aware
باشند.
.
17.10.استفاده از معیارهای فاصله پیشرفته و هندسه داده
K-Means کلاسیک عمدتاً بر فاصله اقلیدسی متکی است، اما در دادههای پیچیده این فرض همیشه مناسب نیست.
روندهای نوآورانه
- استفاده از فاصله Mahalanobis
- فاصله cosine برای دادههای متنی
- فاصلههای مبتنی بر گراف
- فضاهای متریک یادگرفتنی
اهمیت
این توسعهها K-Means را از یک روش صرفاً هندسی به یک چارچوب انعطافپذیرتر تبدیل میکنند.
جمعبندی روندهای پژوهشی جدید
بهطور خلاصه، نوآوریهای مهم K-Means در سالهای اخیر را میتوان در شش محور اصلی خلاصه کرد:
- مقداردهی اولیه هوشمند مانند K-Means++
- مقیاسپذیری بالا با Mini-Batch و نسخههای موازی
- تعامل با دادههای غیرخطی از طریق kernel methods
- مقاومت در برابر نویز و outlier
- ترکیب با یادگیری عمیق و نمایشهای نهفته
- حریم خصوصی، آنلاین بودن و خودتنظیمی
.
18.چشمانداز آینده K-Means

آینده K-Means احتمالاً در این مسیرها شکل خواهد گرفت:
- خوشهبندی در فضای یادگرفتهشده بهجای فضای خام
- خوشهبندی فدره و خصوصی
- خوشهبندی مقیاسپذیر روی جریان داده
- نسخههای مقاوم و adaptive
- ترکیب با self-supervised learning
- مدلهای ترکیبی آماری-عمیق
- خوشهبندی روی دادههای چندوجهی و گرافی
به بیان دیگر، K-Means احتمالاً بهجای یک الگوریتم مستقل و ساده، بهعنوان هستهای پایه در معماریهای خوشهبندی پیشرفته باقی خواهد ماند.



