

1. چکیده
الگوریتم PAM یا Partitioning Around Medoids یکی از روشهای مهم خوشهبندی افرازی در دادهکاوی است که معمولاً با نام K-Medoids نیز شناخته میشود. هدف این الگوریتم، تقسیم دادهها به چند خوشه است؛ بهگونهای که هر خوشه توسط یک نمونه واقعی از دادهها، یعنی میدوید، نمایندگی شود. برخلاف K-Means که مرکز خوشه را با میانگین محاسبه میکند، PAM از نقاط واقعی داده بهعنوان مرکز خوشه استفاده میکند؛ به همین دلیل در برابر دادههای پرت و نویز معمولاً مقاومتر است. این مقاله مفهوم PAM، مبانی ریاضی، سازوکار عملکرد، مثالهای عددی، کاربردهای واقعی، مزایا، محدودیتها و پیادهسازی عملی آن در پایتون را بررسی میکند. همچنین PAM با روشهای مشابه مانند K-Means، CLARA و خوشهبندی سلسلهمراتبی مقایسه میشود. نتیجه اصلی این است که PAM برای دادههای کوچک تا متوسط، دادههای دارای نویز و سناریوهایی که تفسیرپذیری مرکز خوشه اهمیت دارد، گزینهای دقیق و قابل اعتماد است.
.
2. مقدمه
خوشهبندی یکی از مهمترین وظایف یادگیری بدون ناظر در دادهکاوی و یادگیری ماشین است. در خوشهبندی، هدف این است که دادهها بدون داشتن برچسب از پیش تعیینشده، بر اساس شباهت یا فاصله به چند گروه معنادار تقسیم شوند. این گروهها میتوانند الگوهای پنهان، رفتارهای مشابه کاربران، ساختارهای طبیعی داده یا بخشبندیهای کاربردی را آشکار کنند.
یکی از شناختهشدهترین روشهای خوشهبندی، K-Means است؛ اما این الگوریتم به دادههای پرت حساس است، زیرا مرکز هر خوشه را با میانگین نقاط محاسبه میکند. در بسیاری از مسائل واقعی، مانند تحلیل مشتریان، دادههای پزشکی یا کشف ناهنجاری، وجود نقاط پرت اجتنابناپذیر است. با چنین شرایطی، استفاده از الگوریتم PAM میتواند انتخاب مناسبتری باشد.
در این مقاله، ابتدا مفهوم پایه PAM و مسئلهای را که حل میکند توضیح میدهیم. سپس مبانی ریاضی، مراحل اجرای الگوریتم، مثالهای عددی، کاربردها، ابزارهای مرتبط و پیادهسازی پایتون را بررسی میکنیم. در ادامه نیز مزایا، محدودیتها، مقایسه با روشهای مشابه و چشماندازهای آینده این الگوریتم مطرح میشود.
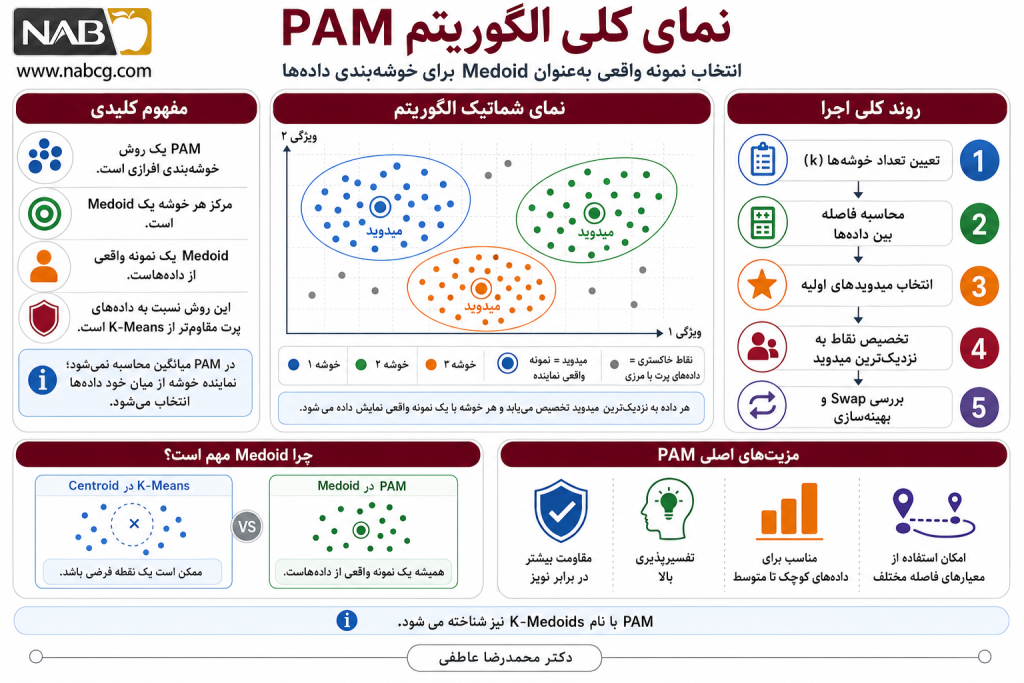
3. تعریف و مفهوم پایه
PAM مخفف Partitioning Around Medoids به معنای «افراز حول میدویدها» است. این الگوریتم یکی از روشهای خوشهبندی افرازی است که دادهها را به تعداد مشخصی خوشه، یعنی k خوشه، تقسیم میکند. در هر خوشه، یک نقطه واقعی از مجموعه داده بهعنوان نماینده خوشه انتخاب میشود. به این نقطه نماینده، میدوید یا Medoid گفته میشود.
میدوید نقطهای از داده است که مجموع فاصله آن با سایر نقاط همان خوشه کمینه باشد. بنابراین، برخلاف مرکز در K-Means که ممکن است یک نقطه فرضی و خارج از مجموعه داده باشد، میدوید همیشه یکی از نمونههای واقعی داده است.
برای مثال، اگر دادههای یک خوشه شامل سن مشتریان زیر باشد:
22, 23, 24, 25, 80
میانگین برابر است با: 34.8
اما مقدار 34.8 در دادهها وجود ندارد و تحت تأثیر مقدار پرت 80 قرار گرفته است. در مقابل، میدوید احتمالاً یکی از مقادیر 23، 24 یا 25 خواهد بود؛ یعنی نقطهای واقعیتر و مقاومتر نسبت به داده پرت.
تمایز مهم:
- K-Means از centroid یا مرکز میانگینی استفاده میکند.
- PAM از medoid یا نمونه واقعی نماینده استفاده میکند.
- K-Means معمولاً سریعتر است.
- PAM معمولاً در برابر نویز و دادههای پرت مقاومتر است.
.
4. مسئلهای که الگوریتم PAM حل میکند
PAM برای حل مسئله خوشهبندی دادههایی طراحی شده است که در آنها انتخاب یک نماینده واقعی برای هر خوشه اهمیت دارد. در بسیاری از مسائل دادهکاوی، صرفاً تقسیم دادهها به چند گروه کافی نیست؛ بلکه لازم است هر گروه با یک نمونه واقعی، قابل مشاهده و قابل تفسیر نمایش داده شود.
برای مثال، در بخشبندی مشتریان، ممکن است مدیر بازاریابی بخواهد برای هر گروه از مشتریان یک «مشتری نمونه» داشته باشد. در دادههای پزشکی، پزشک ممکن است بخواهد برای هر گروه از بیماران یک بیمار واقعی را بهعنوان نماینده بررسی کند، نه یک نقطه میانگینی که در عمل وجود خارجی ندارد.
ضرورت اصلی PAM از اینجا ناشی میشود که بسیاری از دادههای واقعی دارای نویز، مقادیر پرت یا توزیعهای نامتقارن هستند. روشهایی مانند K-Means در چنین شرایطی ممکن است مراکز خوشه را به سمت نقاط پرت منحرف کنند. PAM با انتخاب میدوید از میان نقاط واقعی، این مشکل را تا حد زیادی کاهش میدهد.
همچنین PAM محدود به فاصله اقلیدسی نیست و میتواند با معیارهای فاصله مختلف مانند فاصله منهتن، فاصله اقلیدسی، فاصله کسینوسی یا حتی ماتریس فاصله سفارشی کار کند. این ویژگی باعث میشود برای دادههای عددی، متنی، زیستی و رفتاری کاربردپذیر باشد.
.
5.مبانی نظری و ریاضی الگوریتم PAM
در این بخش، پیش از ورود به مراحل اجرایی الگوریتم PAM، مفاهیم پایه و مبانی ریاضی آن توضیح داده میشود. هدف این است که خواننده ابتدا بداند الگوریتم با چه نوع مرکزی کار میکند، چگونه فاصله را محاسبه میکند، تابع هزینه چه معنایی دارد، Build و Swap چه نقشی دارند، نقاط چگونه به خوشهها اختصاص داده میشوند و مقدار k چرا مهم است. پس از فهم این مفاهیم، مراحل اجرای الگوریتم در بخش بعدی بسیار روشنتر خواهد شد.
۵.۱. تفاوت نقطه مرکزی و نمونه نماینده
- در بسیاری از الگوریتمهای خوشهبندی، هدف این است که برای هر خوشه یک مرکز پیدا شود. اما نوع این مرکز در الگوریتمهای مختلف فرق دارد.
- در K-Means مرکز خوشه یک Centroid است؛ یعنی میانگین عددی نقاط آن خوشه. این مرکز ممکن است اصلاً یکی از نمونههای واقعی داده نباشد.
- اما در PAM مرکز خوشه یک Medoid است؛ یعنی یکی از نمونههای واقعی همان مجموعه داده که کمترین فاصله کلی را با سایر اعضای خوشه دارد.
به زبان ساده:
- Centroid: نقطه میانگین، ممکن است واقعی نباشد.
- Medoid: نمونه واقعی از دادههاست.
- K-Means: با میانگین کار میکند.
- PAM: با نماینده واقعی کار میکند.
این تفاوت باعث میشود PAM برای دادههایی که نیاز به تفسیر انسانی دارند، مناسبتر باشد.
.
۵.۲. مفهوم Medoid در الگوریتم PAM
در PAM، نماینده هر خوشه Medoid نام دارد. Medoid نقطهای از داخل دادههاست که بهترین نماینده برای اعضای همان خوشه محسوب میشود. به بیان ساده، Medoid عضوی از خوشه است که مجموع فاصله آن تا سایر اعضای خوشه کمترین مقدار باشد.
برای مثال، اگر در یک خوشه چند مشتری داشته باشیم، Medoid مشتریای است که از نظر رفتار خرید، بیشترین شباهت کلی را به سایر مشتریان همان گروه دارد. بنابراین Medoid فقط یک عدد محاسباتی نیست، بلکه یک نمونه واقعی از داده است.
این ویژگی اهمیت زیادی دارد. در مسائل واقعی، گاهی لازم است نماینده هر گروه بررسی شود. برای نمونه، پزشک ممکن است بخواهد بیمار نماینده یک گروه را ببیند، یا تیم بازاریابی بخواهد رفتار مشتری نماینده را تحلیل کند. در چنین شرایطی، Medoid بسیار کاربردیتر از Centroid است؛ زیرا Centroid ممکن است اصلاً در داده واقعی وجود نداشته باشد.
۵.۳. تعریف مجموعه دادهها و مجموعه Medoidها
برای بیان ریاضی PAM، ابتدا مجموعه دادهها را تعریف میکنیم. فرض کنید مجموعه داده شامل n نمونه باشد:
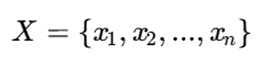
در اینجا هر xi یک نمونه از داده است. این نمونه میتواند مشتری، بیمار، کاربر، سند، تصویر یا هر داده دیگری باشد که قرار است خوشهبندی شود.
در الگوریتم PAM، تعداد خوشهها با k نشان داده میشود. بنابراین الگوریتم باید k نمونه واقعی از دادهها را بهعنوان Medoid انتخاب کند. مجموعه Medoidها را میتوان اینگونه نمایش داد:
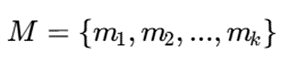
- هر mj یکی از نمونههای واقعی مجموعه داده است. یعنی برخلاف K-Means، مرکز خوشه از بیرون داده ساخته نمیشود، بلکه از میان خود دادهها انتخاب میشود.
- هدف PAM این است که این مجموعه Medoidها را طوری انتخاب کند که دادهها تا حد امکان به نزدیکترین Medoid خود نزدیک باشند و هزینه کلی خوشهبندی کاهش یابد.
5.4.مفهوم تابع هزینه در PAM
PAM تلاش میکند مجموعهای از medoidها را انتخاب کند که مجموع فاصله همه نقاط تا نزدیکترین medoid حداقل شود.
تابع هزینه کلی معمولاً به شکل زیر نوشته میشود:
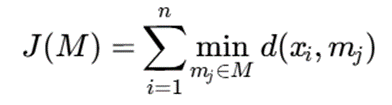
در این فرمول:
- X: مجموعه کل دادهها است.
- xi: نمونه شماره i از دادهها است.
- n: تعداد کل نمونهها است.
- M: مجموعه میدویدهای انتخابشده است.
- mj: میدوید شماره j است.
- k: تعداد خوشهها یا تعداد میدویدها است.
- d(xi,mj) : فاصله یا نابرابری بین نمونه xi و میدوید mj است.
- Min mj∈M d(xi,mj): کمترین فاصله نمونه xi تا نزدیکترین میدوید است.
- J(M): هزینه کل خوشهبندی است.
هدف اصلی الگوریتم این است که مقدار J(M) را تا حد امکان کاهش دهد.
اگر از فاصله اقلیدسی استفاده شود، فاصله دو نقطه x و y در فضای p-بعدی بهصورت زیر است:
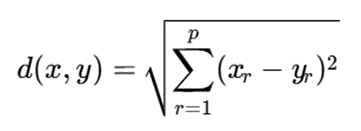
در این فرمول:
- x و y: دو نمونه داده هستند.
- p: تعداد ویژگیها یا ابعاد داده است.
- xr: مقدار ویژگی شماره r برای نمونهx است.
- yr: مقدار ویژگی شماره r برای نمونه y است.
- d(x,y) : فاصله اقلیدسی بین دو نمونه است.
برای برخی کاربردها، فاصله منهتن مناسبتر است:
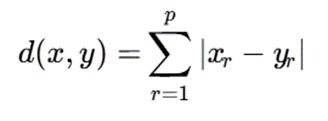
در این فرمول، فاصله بر اساس مجموع قدرمطلق اختلاف ویژگیها محاسبه میشود.
فرضهای پایه PAM:
- تعداد خوشهها، یعنی k، از قبل مشخص است.
- معیار فاصله یا نابرابری باید تعریف شده باشد.
- هر خوشه دقیقاً یک میدوید دارد.
- هر نمونه به نزدیکترین میدوید اختصاص داده میشود.
- هدف، کمینهسازی مجموع فاصله نقاط تا میدویدهای متناظر است.
.
5.5. مفهوم Build و Swap
PAM معمولاً دو مرحله اصلی دارد.
مرحله Build
در این مرحله، الگوریتم medoidهای اولیه را انتخاب میکند. هدف این است که از همان ابتدا چند نمونه نسبتاً مناسب بهعنوان نماینده خوشهها انتخاب شوند.
مرحله Swap
در این مرحله، الگوریتم بررسی میکند آیا جایگزین کردن یک medoid فعلی با یک نقطه غیرmedoid باعث کاهش هزینه کل میشود یا نه.
اگر جابهجایی باعث کاهش هزینه شود، انجام میشود. این روند ادامه پیدا میکند تا دیگر هیچ swap مفیدی پیدا نشود.
به زبان ساده:
- Build یعنی انتخاب اولیه نمایندهها.
- Swap یعنی بهتر کردن نمایندهها با آزمون جابهجایی.
- الگوریتم زمانی متوقف میشود که هزینه دیگر کاهش پیدا نکند.
.
5.6.مفهوم تخصیص نقاط به خوشهها
بعد از انتخاب medoidها، هر نقطه به نزدیکترین medoid اختصاص داده میشود. این کار باعث تشکیل خوشهها میشود.
اگر medoidها را m1,m2,…,mk mk بنامیم، نقطه xi به خوشهای میرود که فاصله آن تا medoid مربوطه کمترین باشد:
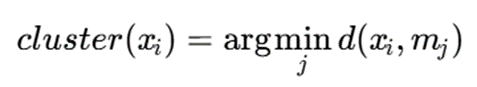
یعنی برای هر نقطه بررسی میکنیم کدام medoid به آن نزدیکتر است.
.
5.7.مفهوم مقدار k
در PAM باید تعداد خوشهها، یعنی k، از قبل مشخص شود. انتخاب مقدار مناسب k بسیار مهم است.
اگر k خیلی کوچک باشد:
- خوشهها بیش از حد کلی میشوند.
- گروههای متفاوت در یک خوشه ادغام میشوند.
- جزئیات داده از بین میرود.
اگر k خیلی بزرگ باشد:
- خوشهها بیش از حد خرد میشوند.
- الگوهای تصادفی ممکن است بهعنوان خوشه واقعی دیده شوند.
- تفسیر نتایج دشوارتر میشود.
روشهای رایج برای انتخاب k:
- روش Elbow
- شاخص Silhouette
- شاخص Davies-Bouldin
- شاخص Calinski-Harabasz
- دانش دامنهای متخصص
.
5.8.مفهوم همگرایی در PAM
همگرایی یعنی الگوریتم به نقطهای برسد که دیگر با جابهجایی medoidها، هزینه کاهش پیدا نکند.
در PAM، همگرایی معمولاً به یک بهینه محلی است، نه لزوماً بهترین جواب جهانی. یعنی ممکن است ترکیب دیگری از medoidها وجود داشته باشد که هزینه کمتری داشته باشد، اما الگوریتم به آن نرسد.
برای کاهش این مشکل میتوان:
- چند بار الگوریتم را با شروعهای متفاوت اجرا کرد.
- از مقداردهی اولیه بهتر استفاده کرد.
- از نسخههای تصادفی یا جستوجوی گستردهتر استفاده کرد.
- نتایج را با شاخصهایی مانند Silhouette ارزیابی کرد.
.
۶. ملاحظات داده، ارزیابی و شرایط اجرای الگوریتم PAM
پیش از اجرای الگوریتم PAM، باید چند نکته مهم درباره دادهها و کیفیت خوشهبندی بررسی شود. چون PAM بر پایه فاصله کار میکند، عواملی مانند مقیاس ویژگیها، وجود دادههای نویزی، تعداد ابعاد داده، معیار ارزیابی خوشهها و حجم دادهها میتوانند مستقیماً بر نتیجه اثر بگذارند.
اگر دادهها درست آماده نشده باشند، حتی انتخاب درست Medoidها نیز ممکن است به خوشهبندی قابل اعتماد منجر نشود. برای مثال، اگر یک ویژگی عددی دامنه بسیار بزرگی داشته باشد، میتواند محاسبه فاصله را تحت تأثیر قرار دهد. همچنین اگر دادهها بسیار پُربعد باشند، فاصلهها ممکن است قدرت تفکیک خود را از دست بدهند.
در این بخش، مهمترین نکاتی که باید قبل از اجرای عملی PAM شناخته شوند توضیح داده میشوند. این نکات شامل مقیاسبندی دادهها، مقاومت PAM در برابر نویز، اثر دادههای پُربعد، شاخص Silhouette، پیچیدگی محاسباتی و تفاوت PAM با K-Means از نظر نوع داده است.
۶.۱. مفهوم مقیاسبندی دادهها در PAM
در الگوریتم PAM، فاصله بین نمونهها نقش اصلی را دارد. بنابراین اگر ویژگیهای عددی در مقیاسهای متفاوت باشند، فاصلهها ممکن است گمراهکننده شوند. برای مثال، فرض کنید دو ویژگی داریم: سن و درآمد. سن ممکن است بین ۱۸ تا ۸۰ باشد، اما درآمد میتواند از چند میلیون تا چندصد میلیون تغییر کند.
اگر فاصله اقلیدسی یا منهتن را مستقیماً روی چنین دادههایی محاسبه کنیم، ویژگی درآمد به دلیل دامنه عددی بزرگتر اثر بسیار بیشتری روی نتیجه میگذارد. در نتیجه، الگوریتم ممکن است خوشهها را بیشتر بر اساس درآمد بسازد و اثر سن را نادیده بگیرد.
برای جلوگیری از این مشکل، قبل از اجرای PAM باید دادهها مقیاسبندی شوند. روشهای رایج مقیاسبندی شامل Standardization، Min-Max Scaling و Robust Scaling هستند. اگر دادهها دارای مقدار پرت باشند، Robust Scaling معمولاً مناسبتر است.
پس در PAM نیز مانند K-Means، قبل از محاسبه فاصله باید مطمئن شویم که مقیاس ویژگیها متعادل است.
.
۶.۲. مفهوم مقاومت PAM در برابر نویز
نویز به دادههایی گفته میشود که الگوی اصلی دادهها را مبهم یا مخدوش میکنند. این دادهها ممکن است به دلیل خطای ثبت، رفتارهای غیرعادی، دادههای ناقص یا رخدادهای نادر ایجاد شده باشند.
الگوریتم PAM نسبت به بسیاری از روشهای مبتنی بر میانگین، مانند K-Means، در برابر نویز مقاومتر است. دلیل آن این است که PAM از Medoid استفاده میکند، نه Centroid. چون Medoid یک نمونه واقعی از دادههاست و بر اساس مجموع فاصلهها انتخاب میشود، معمولاً کمتر از میانگین تحت تأثیر مقدارهای پرت قرار میگیرد.
با این حال، PAM کاملاً ضدنویز نیست. اگر تعداد دادههای نویزی زیاد باشد یا نویزها خودشان ساختاری شبیه خوشه بسازند، ممکن است الگوریتم یکی از Medoidها را به آن ناحیه اختصاص دهد.
برای کاهش اثر نویز، بهتر است قبل از اجرای PAM از روشهایی مانند حذف دادههای پرت شدید، استانداردسازی دادهها، کاهش بُعد، انتخاب ویژگی و انتخاب معیار فاصله مناسب استفاده شود.
.
۶.۳. اثر دادههای پُربعد بر PAM
در دادههای پُربعد، محاسبه فاصله میتواند با مشکل مواجه شود. هرچه تعداد ویژگیها یا ابعاد داده بیشتر شود، فاصلهها ممکن است خاصیت تفکیککنندگی خود را از دست بدهند. این مسئله معمولاً با عنوان Curse of Dimensionality شناخته میشود.
در چنین شرایطی، فاصله نزدیکترین و دورترین نقاط ممکن است خیلی متفاوت نباشد. وقتی فاصلهها دیگر تفاوت معناداری ایجاد نکنند، الگوریتم PAM نیز نمیتواند خوشهها را بهخوبی تشخیص دهد، چون تمام تصمیمهای آن بر اساس فاصله انجام میشود.
برای کنترل این مسئله، میتوان پیش از اجرای PAM از روشهای انتخاب ویژگی یا کاهش بُعد استفاده کرد. روشهایی مانند PCA و UMAP میتوانند دادهها را به فضای کمبعدتر منتقل کنند. برای بردارهای embedding نیز استفاده از فاصله کسینوسی و نرمالسازی بردارها میتواند مفید باشد.
بنابراین در دادههای پُربعد، اجرای مستقیم PAM همیشه بهترین انتخاب نیست. ابتدا باید بررسی شود که فاصلهها هنوز معنای تحلیلی دارند یا نه.
.
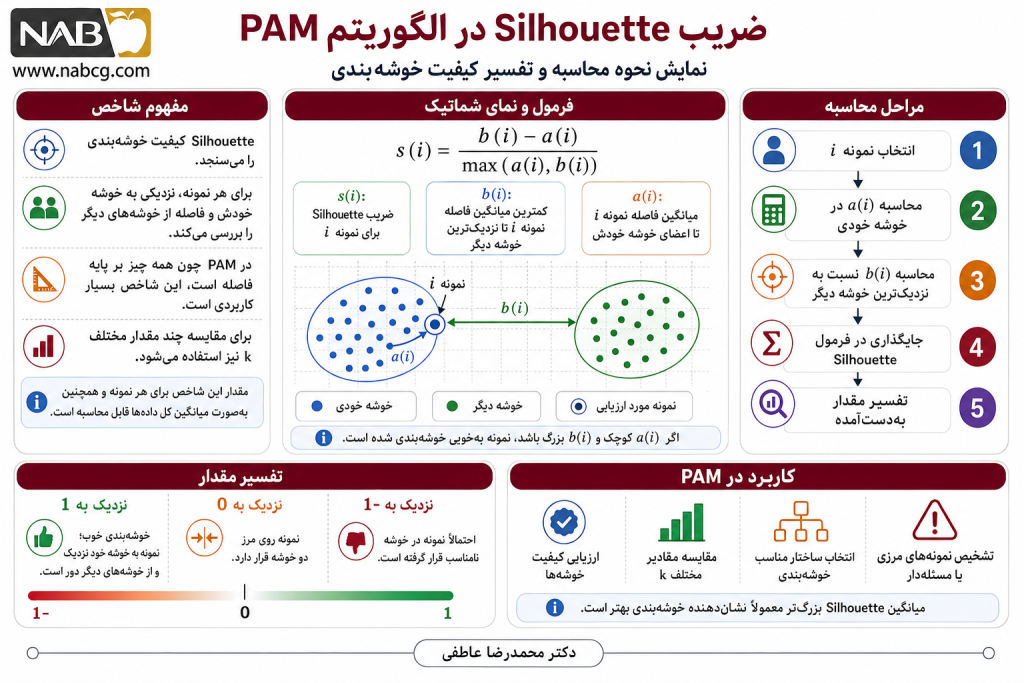
۶.۴. شاخص Silhouette برای ارزیابی خوشهها
شاخص Silhouette یکی از معروفترین معیارها برای ارزیابی کیفیت خوشهبندی است. این شاخص بررسی میکند هر نمونه چقدر به خوشه خودش نزدیک و از خوشههای دیگر دور است.
برای هر نمونه i، مقدار Silhouette بهصورت زیر تعریف میشود:
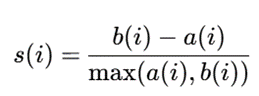
در این فرمول، a(i) میانگین فاصله نمونه i تا اعضای خوشه خودش است. این مقدار b(i) کمترین میانگین فاصله نمونه i تا نزدیکترین خوشه دیگر است. مقدار s(i) نیز ضریب Silhouette برای همان نمونه است.
مقدار Silhouette بین ۱- و ۱ قرار دارد. اگر مقدار آن به ۱ نزدیک باشد، خوشهبندی خوب است. حالا اگر نزدیک به صفر باشد، نمونه روی مرز دو خوشه قرار دارد. اگر به ۱- نزدیک باشد، احتمالاً نمونه در خوشه اشتباه قرار گرفته است.
برای PAM، شاخص Silhouette بسیار کاربردی است، زیرا هر دو بر پایه فاصله کار میکنند. همچنین میتوان از آن برای مقایسه چند مقدار مختلف k استفاده کرد.
.
۶.۵. مفهوم پیچیدگی محاسباتی در PAM
الگوریتم PAM معمولاً از K-Means کندتر است. دلیل اصلی این موضوع آن است که PAM برای انتخاب و بهبود Medoidها باید فاصلههای زیادی را محاسبه و بررسی کند.
در نسخه کلاسیک PAM، مرحله Swap میتواند بسیار پرهزینه باشد. در این مرحله، الگوریتم بررسی میکند که آیا جایگزین کردن یک Medoid فعلی با یک نقطه غیرMedoid باعث کاهش هزینه میشود یا نه. وقتی تعداد دادهها زیاد باشد، تعداد این جابهجاییهای احتمالی نیز بسیار زیاد میشود.
بهطور مفهومی، هرچه تعداد نمونهها، یعنی n، بیشتر شود، تعداد فاصلههای قابل محاسبه بیشتر میشود. همچنین هرچه مقدار k بیشتر شود، تعداد Medoidها و گزینههای جابهجایی افزایش پیدا میکند. بنابراین مرحله Swap معمولاً گرانترین بخش PAM است.
به همین دلیل، برای دادههای بزرگ از نسخههای سریعتر یا تقریبی مانند FastPAM، FasterPAM، CLARA، CLARANS یا BanditPAM استفاده میشود.
.
۶.۶. تفاوت PAM با K-Means از نظر نوع داده
K-Means برای دادههای عددی پیوسته و خوشههای تقریباً کروی مناسبتر است، زیرا مرکز هر خوشه را با میانگین نقاط محاسبه میکند. بنابراین وقتی دادهها عددی، بزرگ و نسبتاً منظم باشند، K-Means معمولاً سریعتر و اقتصادیتر است.
اما PAM انعطاف بیشتری دارد، زیرا فقط به یک معیار فاصله نیاز دارد. در PAM لازم نیست مرکز خوشه یک نقطه میانگینی باشد. مرکز خوشه، یعنی Medoid، از میان نمونههای واقعی انتخاب میشود. به همین دلیل، PAM برای دادههایی مناسب است که میانگینگیری در آنها معنای روشنی ندارد.
PAM میتواند برای دادههای عددی دارای مقدار پرت، دادههای ترکیبی، دادههای ترتیبی، دادههای متنی با فاصله کسینوسی، دادههای زیستی با فاصلههای تخصصی و دادههایی که در آنها نمونه نماینده اهمیت دارد مناسبتر باشد.
البته اگر داده بسیار بزرگ باشد و خوشهها شکل ساده و تقریباً کروی داشته باشند، K-Means معمولاً گزینه سریعتری است. بنابراین انتخاب بین PAM و K-Means باید بر اساس نوع داده، حساسیت به نویز، نیاز به تفسیرپذیری و حجم داده انجام شود.
.
۶.۷. جمعبندی ملاحظات اجرای PAM
پیش از اجرای PAM، باید مطمئن شویم دادهها برای محاسبه فاصله آماده هستند. مقیاس ویژگیها باید متعادل باشد، دادههای نویزی باید تا حد امکان کنترل شوند و در دادههای پُربعد باید بررسی شود که فاصلهها هنوز معنای تحلیلی دارند یا نه.
همچنین باید از معیارهایی مانند Silhouette برای ارزیابی کیفیت خوشهبندی استفاده کرد. این شاخص کمک میکند بفهمیم خوشهها چقدر از هم جدا هستند و اعضای هر خوشه چقدر به یکدیگر نزدیکاند.
از نظر محاسباتی نیز باید توجه داشت که PAM نسبت به K-Means سنگینتر است، بهویژه در مرحله Swap. بنابراین برای دادههای بزرگ، استفاده از نسخههای بهینهشده مانند CLARA، CLARANS، FastPAM، FasterPAM یا BanditPAM منطقیتر است.
با رعایت این ملاحظات، اجرای PAM دقیقتر، قابل اعتمادتر و قابل تفسیرتر خواهد بود.
.
7. مراحل گامبهگام الگوریتم PAM
الگوریتم PAM یا Partitioning Around Medoids برای خوشهبندی دادهها بهکار میرود. هدف آن انتخاب چند نمونه واقعی از دادهها بهعنوان مرکز خوشههاست. به این نمونههای واقعی، Medoid گفته میشود.
برخلاف K-Means که مرکز خوشه را با میانگین محاسبه میکند، PAM مرکز هر خوشه را از میان خود دادهها انتخاب میکند؛ بنابراین برای دادههای پرت، دادههای غیرعددی و مسائل قابل تفسیر مناسبتر است.
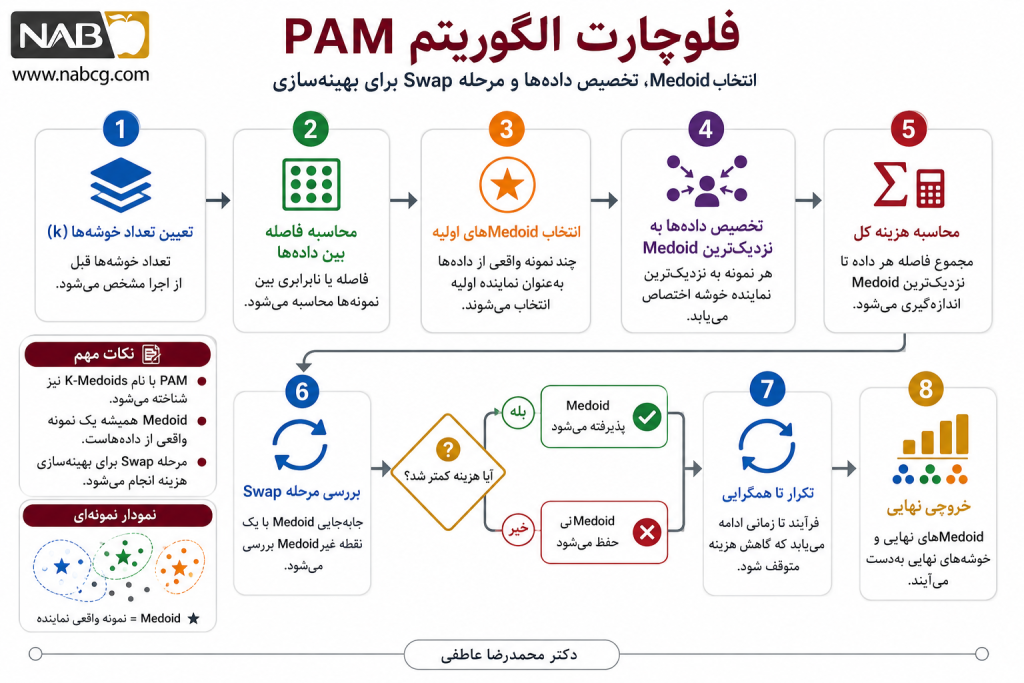
7.1.گام 1: تعیین تعداد خوشهها
اولین گام در الگوریتم PAM، تعیین تعداد خوشههاست. این تعداد با نماد k نشان داده میشود. اگر k برابر ۲ باشد، الگوریتم باید دو Medoid انتخاب کند و دادهها را به دو خوشه تقسیم کند. اگر k برابر ۳ باشد، سه Medoid و سه خوشه خواهیم داشت.
انتخاب k باید قبل از اجرای الگوریتم انجام شود. PAM خودش بهصورت خودکار تعداد خوشهها را تعیین نمیکند. بنابراین تحلیلگر باید بر اساس هدف مسئله، شناخت دادهها یا معیارهای ارزیابی، مقدار مناسبی برای k انتخاب کند.
برای مثال، اگر بخواهیم مشتریان یک فروشگاه را به دو گروه «کمخرید» و «پرخرید» تقسیم کنیم، میتوانیم k را برابر ۲ قرار دهیم. اما اگر بخواهیم مشتریان را به گروههای «کمارزش»، «میانارزش» و «پرارزش» تقسیم کنیم، مقدار k برابر ۳ مناسبتر است.
.
7.2.گام 2: محاسبه فاصله بین دادهها
در این مرحله، فاصله بین همه نمونهها محاسبه میشود. نوع فاصله به مسئله بستگی دارد.
برای دادههای عددی میتوان از فاصله اقلیدسی استفاده کرد:
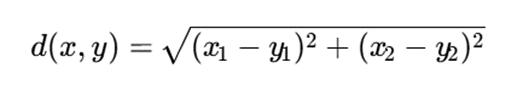
یا از فاصله منهتن:
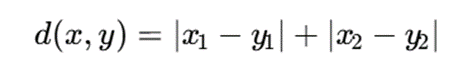
در مسائل واقعی:
- برای مشتریان: فاصله بر اساس رفتار خرید
- برای بیماران: فاصله بر اساس شباهت علائم
- برای کاربران اپلیکیشن: فاصله بر اساس رفتار استفاده
.
7.3.گام 3: انتخاب medoidهای اولیه
PAM ابتدا چند نمونه واقعی را بهعنوان medoid اولیه انتخاب میکند.
این انتخاب میتواند:
- تصادفی باشد.
- با روش Build انجام شود.
- براساس کمترین مجموع فاصلهها انجام شود.
برای مثال اگر k=2، دو نمونه از دادهها بهعنوان medoid اولیه انتخاب میشوند.
.
7.4.گام 4: تخصیص هر داده به نزدیکترین medoid
پس از انتخاب medoidها، هر نمونه به نزدیکترین medoid اختصاص داده میشود.
فرمول تخصیص:
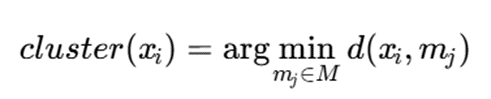
یعنی هر داده وارد خوشهای میشود که medoid آن نزدیکتر است.
.
7.5.گام 5: محاسبه هزینه کل خوشهبندی
هزینه کل برابر است با مجموع فاصله هر داده تا نزدیکترین medoid.
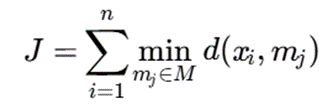
هرچه مقدار J کمتر باشد، خوشهبندی بهتر است.
.
7.6.گام 6: اجرای مرحله Swap
در این مرحله، PAM بررسی میکند که آیا با جابهجا کردن یک medoid با یک نقطه غیرmedoid، هزینه کل کمتر میشود یا نه.
اگر هزینه کمتر شود، جابهجایی انجام میشود.
مثلاً:
{A,D}→{B,D}
اگر هزینه جدید کمتر باشد، medoid قبلی با medoid جدید جایگزین میشود.
.
7.7.گام 7: توقف الگوریتم
الگوریتم زمانی متوقف میشود که هیچ جابهجایی جدیدی باعث کاهش هزینه نشود.
در این حالت، medoidهای نهایی و خوشههای نهایی بهدست میآیند.
.
8.مثال
مثال 1: خوشهبندی ساده یکبعدی
صورت مسئله:
دادههای زیر را با PAM و k = 2 خوشهبندی کنید.
داده ورودی:X={1,2,10,11}
فرض کنید میدویدهای اولیه برابر باشند با:M={1,10}
حل گامبهگام:
فاصله هر نقطه تا نزدیکترین میدوید:
| نقطه | فاصله تا 1 | فاصله تا 10 | نزدیکترین میدوید | هزینه |
| 1 | 0 | 9 | 1 | 0 |
| 2 | 1 | 8 | 1 | 1 |
| 10 | 9 | 0 | 10 | 0 |
| 11 | 10 | 1 | 10 | 1 |
هزینه کل:J=0+1+0+1=2
پاسخ نهایی:
- خوشه اول: {1,2}
- خوشه دوم: {10,11}
- میدویدها: 11 و 10
- هزینه کل: 222
تفسیر نتیجه:
دادهها بهطور طبیعی به دو گروه کوچک و بزرگ تقسیم شدهاند. هر گروه با یکی از نقاط واقعی داده نمایش داده میشود.
مثال 2: بخشبندی مشتریان فروشگاه آنلاین
صورت مسئله
فرض کنید یک فروشگاه آنلاین میخواهد مشتریان خود را براساس دو ویژگی خوشهبندی کند:
- تعداد خرید در ماه
- میانگین مبلغ خرید، برحسب میلیون تومان
دادهها به شکل زیر هستند:
| مشتری | تعداد خرید | مبلغ میانگین خرید |
| A | 1 | 2 |
| B | 2 | 2 |
| C | 2 | 3 |
| D | 8 | 9 |
| E | 9 | 9 |
میخواهیم مشتریان را به دو گروه تقسیم کنیم: k=2
1: محاسبه فاصلهها
برای سادهسازی، از فاصله منهتن استفاده میکنیم:
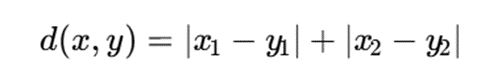
ماتریس فاصله:
| فاصله | A | B | C | D | E |
| A | 0 | 1 | 2 | 14 | 15 |
| B | 1 | 0 | 1 | 13 | 14 |
| C | 2 | 1 | 0 | 12 | 13 |
| D | 14 | 13 | 12 | 0 | 1 |
| E | 15 | 14 | 13 | 1 | 0 |
2: انتخاب medoidهای اولیه
فرض کنیم medoidهای اولیه این دو مشتری باشند:M={A,D}
یعنی A نماینده خوشه اول و D نماینده خوشه دوم است.
3: تخصیص مشتریان به نزدیکترین medoid
| مشتری | فاصله تا A | فاصله تا D | خوشه |
| A | 0 | 14 | A |
| B | 1 | 13 | A |
| C | 2 | 12 | A |
| D | 14 | 0 | D |
| E | 15 | 1 | D |
پس خوشهها:
C1={A,B,C}
C2={D,E}
4: محاسبه هزینه کل
J=0+1+2+0+1=4
پس هزینه فعلی برابر است با:J=4
5: بررسی Swap
حالا بررسی میکنیم آیا اگر A را با B جایگزین کنیم، هزینه کمتر میشود یا نه.
medoidهای جدید: M={B,D}
| مشتری | فاصله تا B | فاصله تا D | نزدیکترین فاصله |
| A | 1 | 14 | 1 |
| B | 0 | 13 | 0 |
| C | 1 | 12 | 1 |
| D | 13 | 0 | 0 |
| E | 14 | 1 | 1 |
هزینه جدید: J=1+0+1+0+1=3
چون: 3<4
پس جابهجایی انجام میشود.
medoidهای جدید:
M={B,D}
6: بررسی جابهجاییهای بعدی
اگر D را با E جایگزین کنیم:
M={B,E}
| مشتری | فاصله تا B | فاصله تا E | نزدیکترین فاصله |
| A | 1 | 15 | 1 |
| B | 0 | 14 | 0 |
| C | 1 | 13 | 1 |
| D | 13 | 1 | 1 |
| E | 14 | 0 | 0 |
هزینه:J=1+0+1+1+0=3
هزینه کمتر نشد؛ فقط برابر شد. بنابراین نیازی به جابهجایی نیست.
نتیجه مثال 2
medoidهای نهایی:
B,D
خوشههای نهایی:
| خوشه | Medoid | اعضا | تفسیر |
| خوشه 1 | B | A, B, C | مشتریان کمخرید یا کمهزینه |
| خوشه 2 | D | D, E | مشتریان پرخرید و ارزشمند |
مثال 3: محاسبه ساده کیفیت خوشه با Silhouette
صورت مسئله:
دو خوشه زیر را در نظر بگیرید:
content_copy
خوشه 1: A = (1,1), B = (1,2)
خوشه 2: C = (8,8), D = (9,8)
برای نقطه A، ضریب Silhouette را تقریب بزنید.
فرمول:
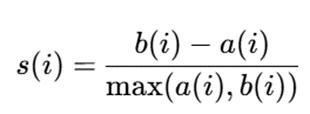
در این فرمول:
- s(i) : ضریب Silhouette برای نقطه i است.
- a(i) : میانگین فاصله نقطه i تا نقاط خوشه خودش است.
- b(i) : کمترین میانگین فاصله نقطه i تا نقاط خوشههای دیگر است.
برای نقطه A:
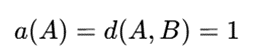
فاصله اقلیدسی A تا C:
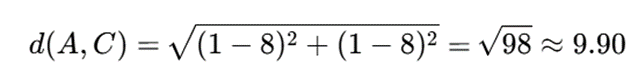
فاصله اقلیدسی A تا D:
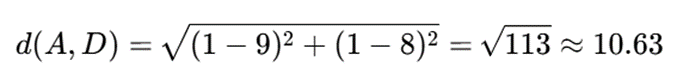
پس:
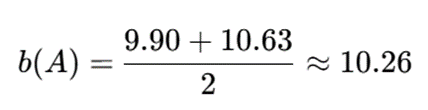
ضریب Silhouette:
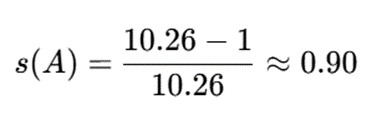
پاسخ نهایی:
s(A)≈0.90
تفسیر نتیجه:
مقدار نزدیک به 1 نشان میدهد نقطه A در خوشه خود قرار گرفته و از خوشه دیگر فاصله زیادی دارد.
.
9. کاربردهای واقعی الگوریتم PAM

- بخشبندی مشتریان بر اساس رفتار خرید، ارزش طول عمر مشتری یا الگوی تعامل با محصول.
- خوشهبندی بیماران بر اساس ویژگیهای بالینی، نتایج آزمایشگاهی یا علائم مشابه.
- تحلیل متون و اسناد با استفاده از فاصله کسینوسی یا ماتریس شباهت.
- کشف الگوهای رفتاری کاربران در وبسایتها، اپلیکیشنها و سامانههای توصیهگر.
- گروهبندی مناطق جغرافیایی بر اساس شاخصهای اقتصادی، جمعیتی یا زیستمحیطی.
- خوشهبندی ژنها یا نمونههای زیستی در بیوانفورماتیک.
- انتخاب نمونههای نماینده برای خلاصهسازی دادهها یا کاهش پیچیدگی تحلیل.
- شناسایی گروههای مشابه در دادههای مالی و اعتباری.
.
10.مطالعه موردی
سناریوهای واقعی مرتبط با PAM:
- بخشبندی مشتریان فروشگاه آنلاین
- گروهبندی بیماران بر اساس الگوی علائم
- خوشهبندی کاربران اپلیکیشن موبایل
- شناسایی مناطق مشابه شهری بر اساس شاخصهای ترافیکی
- انتخاب نمونههای نماینده از مجموعه دادههای بزرگ
سناریوی منتخب: بخشبندی مشتریان فروشگاه آنلاین
فرض کنید یک فروشگاه اینترنتی میخواهد مشتریان خود را بر اساس دو ویژگی زیر خوشهبندی کند:
- تعداد خرید در ماه
- میانگین مبلغ هر خرید
هدف این است که مشتریان مشابه در یک گروه قرار گیرند و برای هر گروه، یک مشتری واقعی بهعنوان نماینده انتخاب شود. انتخاب نماینده واقعی مهم است، زیرا تیم بازاریابی میتواند رفتار واقعی آن مشتری را بررسی کند و بر اساس آن کمپین طراحی کند.
تحلیل مسئله:
اگر از K-Means استفاده شود، مرکز هر خوشه ممکن است یک مشتری فرضی باشد؛ مثلاً مشتریای با 3.7 خرید در ماه و مبلغ میانگین 615 هزار تومان. چنین نقطهای الزاماً در داده واقعی وجود ندارد. اما PAM یک مشتری واقعی را بهعنوان میدوید انتخاب میکند.
کاربرد PAM در سناریو:
- دادههای مشتریان پاکسازی و نرمالسازی میشود.
- مقدار k با روشهایی مانند Silhouette انتخاب میشود.
- PAM اجرا میشود و برای هر خوشه یک میدوید تعیین میگردد.
- تیم بازاریابی، مشتریان نماینده را تحلیل میکند.
- برای هر خوشه، پیشنهادها و پیامهای تبلیغاتی متفاوت طراحی میشود.
تفسیر نتایج:
ممکن است سه خوشه اصلی به دست آید:
- مشتریان کمخرید و کمهزینه
- مشتریان میانرده با خرید منظم
- مشتریان ارزشمند با خرید زیاد و مبلغ بالا
درسآموختهها:
- PAM برای تحلیلهای قابل تفسیر بسیار مناسب است.
- میدویدها میتوانند بهعنوان نمونههای واقعی برای تصمیمگیری استفاده شوند.
- وجود مشتریان پرت، مانند خریدهای بسیار بزرگ و غیرمعمول، کمتر باعث انحراف مرکز خوشه میشود.
.
11. مزایا الگوریتم PAM
- مقاومت بیشتر نسبت به دادههای پرت در مقایسه با K-Means.
- انتخاب مرکز خوشه از میان نمونههای واقعی داده.
- تفسیرپذیری بالا، بهویژه در مسائل کسبوکار و پزشکی.
- امکان استفاده از معیارهای فاصله مختلف، نه فقط فاصله اقلیدسی.
- مناسب برای دادههایی که میانگین در آنها معنای مناسبی ندارد.
- عملکرد قابل اعتماد در دادههای کوچک تا متوسط.
.
12. محدودیتها و معایب
- پیچیدگی محاسباتی بالاتر نسبت به K-Means.
- مناسب نبودن برای دادههای بسیار بزرگ، مگر با نسخههای بهینهشده مانند CLARA.
- نیاز به تعیین تعداد خوشهها k قبل از اجرا.
- حساسیت به انتخاب میدویدهای اولیه در برخی پیادهسازیها.
- احتمال گیرکردن در بهینه محلی، زیرا الگوریتم مبتنی بر جستوجوی جابهجایی است.
- نیاز به محاسبه فاصلههای متعدد، که در دادههای بزرگ هزینهبر است.
- وابستگی کیفیت نتیجه به انتخاب معیار فاصله مناسب.
.
13. مقایسه PAM با روشهای مشابه
| روش | مرکز خوشه | مقاومت به داده پرت | سرعت | تفسیرپذیری | مناسب برای |
| K-Means | میانگین نقاط | کم | زیاد | متوسط | دادههای بزرگ و تقریباً کروی |
| PAM / K-Medoids | نقطه واقعی داده | زیاد | متوسط تا کم | زیاد | دادههای کوچک تا متوسط و نویزی |
| CLARA | میدوید روی نمونهگیری | متوسط تا زیاد | بیشتر از PAM | خوب | دادههای بزرگتر |
| خوشهبندی سلسلهمراتبی | وابسته به روش اتصال | متغیر | معمولاً کم | زیاد | تحلیل ساختار سلسلهای |
| DBSCAN | مرکز صریح ندارد | زیاد | متوسط | متوسط | خوشههای با شکل نامنظم و نویزدار |

مقایسه تحلیلی:
اگر سرعت و مقیاسپذیری مهمترین معیار باشند، K-Means معمولاً انتخاب سریعتری است. اما اگر دادهها دارای نقاط پرت باشند یا لازم باشد مرکز خوشه یک نمونه واقعی باشد، PAM انتخاب مناسبتری است. در دادههای بزرگ، نسخههایی مانند CLARA میتوانند جایگزین عملیتری برای PAM باشند. اگر شکل خوشهها نامنظم باشد و تعداد خوشهها از قبل مشخص نباشد، DBSCAN ممکن است گزینه بهتری باشد.
.
14. نوآوریها و چشمانداز آینده الگوریتم PAM
الگوریتم PAM یا Partitioning Around Medoids از نظر تاریخی یک روش کلاسیک برای خوشهبندی K-Medoids است، اما در سالهای اخیر دوباره مورد توجه قرار گرفته است؛ دلیل اصلی این توجه، نیاز روزافزون به خوشهبندی مقاوم، تفسیرپذیر و قابل استفاده روی دادههای غیرکروی، نویزی، متنی، زیستی و embeddingمحور است. برخلاف K-Means، در PAM هر خوشه با یک نمونه واقعی داده نمایش داده میشود؛ همین ویژگی باعث شده است در کاربردهای جدیدی مانند انتخاب نمونه نماینده، خلاصهسازی داده، خوشهبندی اسناد و تحلیل دادههای حساس به داده پرت همچنان ارزشمند باشد.
با این حال، چالش اصلی PAM سنتی، هزینه محاسباتی بالای آن است. به همین دلیل، نوآوریهای جدید عمدتاً روی افزایش سرعت، مقیاسپذیری، کاهش مصرف حافظه، ترکیب با یادگیری عمیق و بهبود انتخاب میدویدها متمرکز شدهاند.

14.1. بهینهسازی سرعت: از PAM کلاسیک به FastPAM و FasterPAM
در نسخه کلاسیک PAM، الگوریتم تمام جابهجاییهای ممکن میان میدویدها و نقاط غیرمیدوید را بررسی میکند. اگر تعداد دادهها زیاد باشد، این فرایند بسیار پرهزینه میشود. به همین دلیل، یکی از مهمترین مسیرهای نوآوری، کاهش هزینه محاسبه مرحله Swap بوده است.
در پژوهشهای جدید، بهویژه کارهای Schubert و Rousseeuw، نسخههایی مانند FastPAM و FasterPAM معرفی شدهاند که همان ایده اصلی PAM را حفظ میکنند، اما محاسبات غیرضروری را کاهش میدهند. این روشها با ذخیره و بهروزرسانی هوشمند فاصله هر نقطه تا نزدیکترین و دومین میدوید، سرعت اجرای جابهجاییها را بهبود میدهند (Schubert & Rousseeuw, 2019).
ایده اصلی این نوآوری ساده اما مؤثر است:
بهجای محاسبه مجدد فاصله همه نقاط در هر جابهجایی، الگوریتم از اطلاعات قبلی استفاده میکند و فقط تغییرات لازم را ارزیابی میکند.
نتیجه عملی این است که PAM میتواند روی مجموعهدادههای بزرگتر از گذشته اجرا شود، بدون آنکه ماهیت تفسیرپذیر و مقاوم خود را از دست بدهد.
.
14.2. BanditPAM: استفاده از یادگیری تقویتی و مسئله چندبازویی
یکی از نوآوریهای مهم جدید، الگوریتم BanditPAM است. این روش از ایده مسئله چندبازویی یا Multi-Armed Bandit برای کاهش تعداد ارزیابیهای لازم در انتخاب میدویدها استفاده میکند.
در PAM کلاسیک، برای انتخاب بهترین جابهجایی، بسیاری از گزینهها بهطور کامل بررسی میشوند. اما BanditPAM تلاش میکند با نمونهگیری هوشمند، گزینههای ضعیف را زودتر حذف کند و منابع محاسباتی را روی گزینههای امیدوارکننده متمرکز سازد. این رویکرد باعث میشود هزینه اجرا بهطور چشمگیری کاهش یابد، بهخصوص زمانی که تعداد نمونهها زیاد است (Tiwari et al., 2020).
اهمیت BanditPAM در این است که PAM را از یک الگوریتم دقیق اما کند، به روشی نزدیکتر به مقیاسپذیری مدرن تبدیل میکند. این مسیر میتواند برای دادههای بزرگ، دادههای زیستی، دادههای رفتاری کاربران و تحلیل embeddingها بسیار مهم باشد.
.
14.3. مقیاسپذیری برای کلاندادهها: CLARA، CLARANS و نسخههای مدرنتر
یکی از محدودیتهای قدیمی PAM، ضعف آن در دادههای بسیار بزرگ است. برای حل این مسئله، روشهایی مانند CLARA و CLARANS پیشنهاد شدهاند. CLARA بهجای اجرای PAM روی کل داده، چند نمونه از دادهها را انتخاب میکند و PAM را روی این نمونهها اجرا میکند. CLARANS نیز از جستوجوی تصادفی در فضای همسایگی استفاده میکند.
اگرچه این روشها قدیمیتر هستند، اما در پژوهشهای جدید همچنان بهعنوان پایهای برای طراحی نسخههای مقیاسپذیر K-Medoids مطرحاند. در واقع، ایده نمونهگیری، جستوجوی تصادفی و ارزیابی تقریبی همچنان در نسخههای جدید PAM و K-Medoids استفاده میشود.
چشمانداز آینده در این بخش شامل موارد زیر است:
- نمونهگیری هوشمند بهجای نمونهگیری تصادفی ساده
- اجرای موازی روی CPU و GPU
- استفاده از پردازش توزیعشده برای دادههای بسیار بزرگ
- ترکیب PAM با الگوریتمهای approximate nearest neighbor
- کاهش حافظه لازم برای ذخیره ماتریس فاصله
.
14.4.ترکیب PAM با embeddingها و مدلهای زبانی
یکی از کاربردهای آیندهدار PAM، خوشهبندی بردارهای embedding است. امروزه دادههای متنی، تصویری، صوتی و گرافی معمولاً ابتدا با مدلهای یادگیری عمیق به بردارهای عددی تبدیل میشوند. برای مثال:
- متنها با مدلهای زبانی مانند BERT یا Sentence-BERT به embedding تبدیل میشوند.
- تصاویر با شبکههای عصبی کانولوشنی یا مدلهای vision transformer به بردار ویژگی تبدیل میشوند.
- کاربران یا آیتمها در سامانههای توصیهگر به embedding رفتاری تبدیل میشوند.
پس از تولید embedding، میتوان از PAM برای خوشهبندی این بردارها استفاده کرد. مزیت PAM در اینجا این است که برای هر خوشه، یک نمونه واقعی را بهعنوان نماینده انتخاب میکند. این ویژگی در تحلیل متون، انتخاب سند نماینده، خلاصهسازی مجموعه اسناد و کشف موضوعات بسیار ارزشمند است.
برای مثال، اگر هزاران نظر کاربران درباره یک محصول را خوشهبندی کنیم، PAM میتواند برای هر خوشه یک نظر واقعی و نماینده انتخاب کند. این خروجی از نظر انسانی بسیار قابل فهمتر از یک مرکز میانگینی در فضای embedding است.
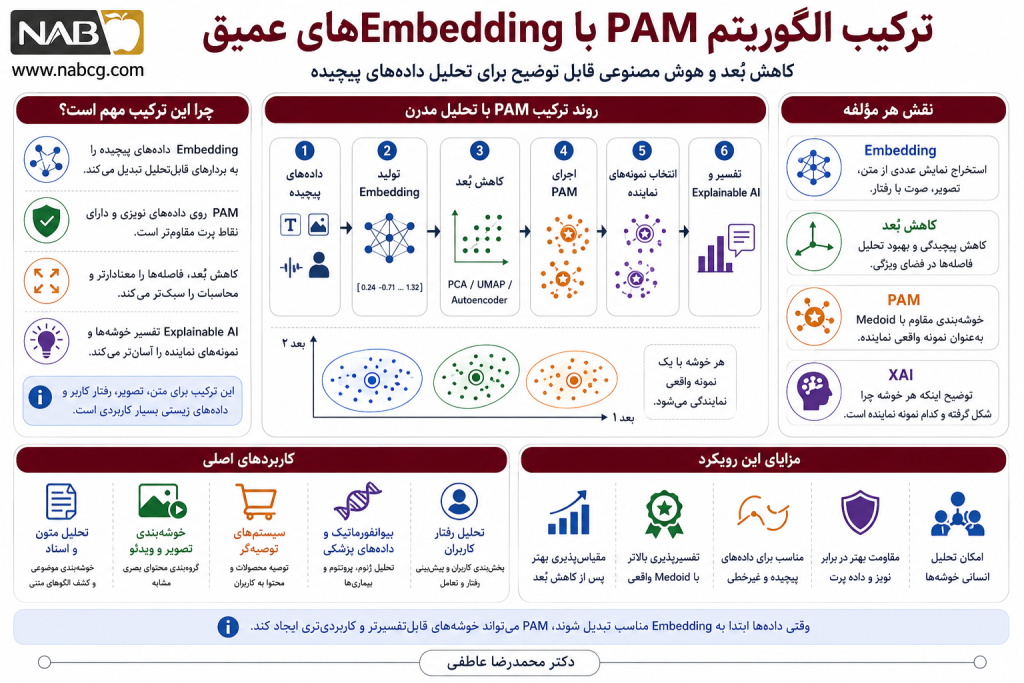
14.5. نقش PAM در خوشهبندی قابل تفسیر
در سالهای اخیر، تفسیرپذیری در هوش مصنوعی اهمیت زیادی پیدا کرده است. بسیاری از مدلهای یادگیری ماشین، بهویژه مدلهای عمیق، خروجیهایی تولید میکنند که توضیح آنها برای انسان دشوار است. در چنین شرایطی، PAM مزیت مهمی دارد: مرکز هر خوشه یک نمونه واقعی است.
این ویژگی باعث میشود PAM برای کاربردهای حساس مناسب باشد؛ مانند:
- پزشکی و سلامت
- اعتبارسنجی مالی
- تحلیل رفتار مشتری
- تحلیل دادههای آموزشی
- دادهکاوی اجتماعی
- زیستدادهها و بیوانفورماتیک
در این کاربردها، پژوهشگر یا متخصص دامنه میتواند میدوید هر خوشه را مشاهده کند و بپرسد: «این نمونه چرا نماینده این گروه است؟» این سطح از تفسیرپذیری در روشهایی مانند K-Means کمتر وجود دارد، زیرا centroid الزاماً نمونهای واقعی نیست.
از این دیدگاه، آینده PAM فقط در سرعت بیشتر نیست؛ بلکه در تبدیلشدن به ابزاری برای خوشهبندی قابل توضیح یا Explainable Clustering نیز هست.
.
14.6. استفاده از فاصلههای سفارشی و دامنهمحور
یکی دیگر از مسیرهای مهم نوآوری، استفاده از معیارهای فاصله تخصصی است. PAM بهطور طبیعی به فاصله اقلیدسی محدود نیست. این ویژگی باعث میشود بتوان آن را با انواع دادهها سازگار کرد.
برای مثال:
- در دادههای متنی: فاصله کسینوسی
- در دادههای ترتیبی: فاصلههای مبتنی بر رتبه
- در دادههای ژنتیکی: فاصلههای زیستی و توالیمحور
- در دادههای زمانی: Dynamic Time Warping یا DTW
- در دادههای ترکیبی: فاصله Gower
این انعطاف باعث شده است PAM در پژوهشهای جدید برای دادههایی استفاده شود که میانگینگیری در آنها بیمعنا یا نادرست است. برای نمونه، در دادههای categorical یا mixed-type، محاسبه centroid مشابه K-Means همیشه تعریف روشنی ندارد، اما میدوید همچنان میتواند یک نمونه واقعی از داده باشد.
.
14.7. PAM در کنار کاهش بُعد: PCA، UMAP و Autoencoder
یکی از راههای عملی برای بهبود PAM، اجرای آن پس از کاهش بُعد است. چون محاسبه فاصلهها در فضای بُعد بالا دشوار، پرهزینه و گاهی گمراهکننده است، پژوهشگران معمولاً ابتدا دادهها را به فضای کمبعدتر منتقل میکنند و سپس خوشهبندی را انجام میدهند.
روشهای رایج عبارتاند از:
- PCA برای کاهش بُعد خطی
- t-SNE برای نمایش دوبعدی و تحلیل بصری
- Autoencoder برای کاهش بُعد غیرخطی
- embeddingهای یادگیری عمیق برای استخراج ویژگی
در آینده، ترکیب PAM با representation learning اهمیت بیشتری پیدا خواهد کرد. یعنی ابتدا یک مدل عمیق، نمایش مناسب داده را یاد میگیرد و سپس PAM روی آن نمایش اجرا میشود. این ترکیب میتواند هم کیفیت خوشهبندی را افزایش دهد و هم خروجی را قابل تفسیرتر کند.
.
14.8. PAM برای انتخاب نمونه نماینده و خلاصهسازی داده
یکی از کاربردهای رو به رشد PAM، انتخاب نمونههای نماینده از دادههای بزرگ است. چون میدویدها نمونههای واقعی هستند، میتوان از آنها برای خلاصهسازی مجموعه داده استفاده کرد.
برای مثال:
- انتخاب چند تصویر نماینده از یک مجموعه تصویر بزرگ
- انتخاب چند متن نمونه از هزاران سند
- انتخاب چند تراکنش نمونه برای تحلیل تقلب
- انتخاب چند کاربر نماینده برای تحلیل رفتار
در این نوع کاربردها، هدف فقط خوشهبندی نیست؛ بلکه کاهش حجم داده و حفظ تنوع اطلاعاتی است. PAM میتواند بهعنوان یک روش نمونهگزینی هوشمند عمل کند.
این مسیر در آینده میتواند با active learning نیز ترکیب شود؛ یعنی بهجای برچسبگذاری تصادفی دادهها، میدویدهای خوشهها برای برچسبگذاری انتخاب شوند، چون نماینده بخشهای مهمی از داده هستند.
.
14.9.ترکیب PAM با یادگیری نیمهنظارتی و قیود انسانی
در کاربردهای واقعی، گاهی متخصص دامنه میداند که بعضی نمونهها باید در یک خوشه باشند یا نباید در یک خوشه قرار بگیرند. این اطلاعات را میتوان بهصورت قیود زیر بیان کرد:
- Must-link: دو نمونه باید در یک خوشه باشند.
- Cannot-link: دو نمونه نباید در یک خوشه باشند.
یکی از چشماندازهای آینده PAM، ترکیب آن با خوشهبندی قیددار یا Constrained Clustering است. در چنین حالتی، الگوریتم علاوه بر کمینهسازی فاصله تا میدویدها، باید قیود انسانی را نیز رعایت کند.
این ایده برای کاربردهایی مانند پزشکی، آموزش، حقوق، امنیت و تحلیل اجتماعی اهمیت زیادی دارد؛ زیرا در این حوزهها دانش انسانی میتواند کیفیت خوشهبندی را بهبود دهد.
.
14.10.جایگاه PAM در هوش مصنوعی قابل اعتماد
پژوهشهای جدید در هوش مصنوعی فقط به دقت مدل توجه نمیکنند؛ بلکه معیارهایی مانند شفافیت، پایداری، عدالت، مقاومت در برابر نویز و قابلیت توضیح نیز مهم شدهاند. PAM از این نظر چند ویژگی ارزشمند دارد:
- خروجی آن با نمونههای واقعی قابل توضیح است.
- نسبت به دادههای پرت مقاومتر از K-Means است.
- میتواند با معیارهای فاصله متناسب با دامنه مسئله کار کند.
- برای تحلیل انسانی خوشهها مناسب است.
- در دادههای حساس، خروجی آن قابل بررسی و ممیزی است.
به همین دلیل، میتوان انتظار داشت PAM و نسخههای مدرن K-Medoids در آینده در سیستمهای تصمیمیار، تحلیل دادههای پزشکی، تحلیل ریسک و سامانههای شفافتر هوش مصنوعی نقش بیشتری پیدا کنند.
.
14.11.چالشهای باز پژوهشی
با وجود پیشرفتها، PAM هنوز چند چالش مهم دارد:
- مقیاسپذیری آن در دادههای بسیار بزرگ همچنان مسئلهساز است.
- کیفیت نتیجه به انتخاب معیار فاصله وابسته است.
- تعیین مقدار مناسب k همیشه ساده نیست.
- در دادههای بسیار پُربعد، فاصلهها ممکن است معنای خود را از دست بدهند.
- نسخههای تقریبی ممکن است دقت PAM کلاسیک را کاملاً حفظ نکنند.
مسیرهای پژوهشی آینده احتمالاً روی این موضوعات متمرکز خواهند بود:
- PAM آنلاین برای دادههای جریانی
- PAM توزیعشده برای کلاندادهها
- K-Medoids مبتنی بر GPU
- انتخاب خودکار k
- ترکیب با مدلهای زبانی و embeddingهای عمیق
- خوشهبندی قیددار و تعاملی
- ارزیابی پایداری خوشهها در دادههای نویزی
نوآوریهای جدید PAM عمدتاً در سه مسیر اصلی قرار میگیرند: افزایش سرعت، افزایش مقیاسپذیری و افزایش تفسیرپذیری. نسخههایی مانند FastPAM، FasterPAM و BanditPAM نشان دادهاند که میتوان ضعف محاسباتی PAM سنتی را تا حد زیادی کاهش داد. از سوی دیگر، ظهور embeddingها، مدلهای زبانی، دادههای پیچیده و نیاز به هوش مصنوعی قابل توضیح باعث شده است PAM دوباره اهمیت پیدا کند.
آینده PAM احتمالاً در اجرای صرف آن روی داده خام نیست، بلکه در ترکیب آن با روشهای مدرن خواهد بود؛ مانند کاهش بُعد، یادگیری نمایش، نمونهگیری هوشمند، active learning، خوشهبندی قیددار و پردازش توزیعشده. بنابراین PAM را میتوان الگوریتمی کلاسیک اما همچنان زنده دانست؛ الگوریتمی که اگر با تکنیکهای جدید ترکیب شود، میتواند در دادهکاوی مدرن نقش مهمی ایفا کند.
.
جمعبندی
PAM یکی از روشهای مهم خوشهبندی در دادهکاوی است که بهجای استفاده از مرکز میانگینی، از نقاط واقعی داده بهعنوان نماینده خوشه استفاده میکند. این ویژگی باعث میشود الگوریتم نسبت به دادههای پرت مقاومتر و از نظر تفسیری قابل فهمتر باشد.
در این مقاله، مفهوم PAM، تابع هدف، فرمولهای فاصله، سازوکار اجرای الگوریتم، مثالهای عددی، کاربردهای واقعی و پیادهسازی پایتون بررسی شد. همچنین دیدیم که PAM برای دادههای کوچک تا متوسط، مسائل نیازمند تفسیرپذیری و دادههای دارای نویز گزینهای مناسب است؛ هرچند در دادههای بسیار بزرگ ممکن است از نظر محاسباتی سنگین باشد.
برای مطالعه و استفاده عملی، پیشنهاد میشود ابتدا PAM را روی دادههای کوچک پیادهسازی کنید، سپس معیارهای ارزیابی مانند Silhouette را برای انتخاب تعداد خوشهها بهکار ببرید و در نهایت، در صورت افزایش حجم داده، سراغ روشهای مقیاسپذیرتر مانند CLARA بروید.
منابع
Aggarwal, C. C. (2015). Data mining: The textbook. Springer.
Han, J., Pei, J., & Tong, H. (2022). Data mining: Concepts and techniques (4th ed.). Morgan Kaufmann.
Kaufman, L., & Rousseeuw, P. J. (1990). Finding groups in data: An introduction to cluster analysis. Wiley.
Schubert, E., & Rousseeuw, P. J. (2019). Faster k-medoids clustering: Improving the PAM, CLARA, and CLARANS algorithms. In Similarity Search and Applications (SISAP 2019). Springer.
Tiwari, M., Zhang, M. J., Mayclin, J., Thrun, S., Piech, C., & Shomorony, I. (2020). BanditPAM: Almost linear time k-medoids clustering via multi-armed bandits. Advances in Neural Information Processing Systems, 33.



