

1.مقدمه
در سالهای اخیر، پیشرفتهای چشمگیر یادگیری عمیق تا حد زیادی مدیون دسترسی به مجموعهدادههای عظیم و برچسبدار بوده است. اما در بسیاری از سناریوهای واقعی، چنین حجم دادهای در دسترس نیست. در حوزههایی مانند تشخیص بیماریهای نادر، امنیت سایبری، تحلیل امضاهای بانکی یا شناسایی گونههای کمیاب، گردآوری هزاران نمونه آموزشی نهتنها دشوار، بلکه گاهی غیرممکن است. این شکاف میان «نیاز مدلها به داده زیاد» و «واقعیت کمبود داده» بستری را فراهم کرده که در آن یادگیری کمنمونه (Few-Shot Learning یا FSL) به عنوان یک پارادایم تحولآفرین مطرح میشود.
یادگیری کمنمونه رویکردی است که به مدلها اجازه میدهد با مشاهده تنها چند نمونه برچسبدار از یک کلاس جدید، الگوهای متمایزکننده را یاد بگیرند و به درستی تعمیم دهند. به جای تمرکز بر حفظ کردن دادهها، این روش بر یادگیری بازنماییهای غنی، شباهتسنجی در فضای ویژگی و فرا-یادگیری (Meta-Learning) تکیه دارد.
در این مقاله، ابتدا مفهوم و انواع N-Shot Learning را بررسی میکنیم، سپس مبانی ریاضی و چارچوب اپیزودیک را توضیح میدهیم. در ادامه، رویکردهای اصلی شامل متریکمحور، بهینهسازیمحور و انتقالی را تحلیل کرده و با مثالهای عملی و پیادهسازی در پایتون، کاربردهای صنعتی این فناوری را نشان میدهیم.
۲. تعریف یادگیری کمنمونه (Few-Shot Learning)
یادگیری کمنمونه (FSL) یکی از زیرشاخههای استراتژیک یادگیری ماشین است که در آن، مدلها به گونهای طراحی میشوند که الگوها را شناسایی کرده و بر اساس تعداد بسیار محدودی از نمونههای آموزشی (برخلاف مدلهای سنتی که نیازمند دادههای انبوه هستند)، پیشبینیهای دقیقی ارائه دهند. این رویکرد به طور خاص زمانی به کار گرفته میشود که دسترسی به دادههای برچسبدار مناسب، به دلیل هزینههای گزاف یا نایاب بودن نمونهها، با محدودیت جدی روبرو است.
3.انواع یادگیری N-Shot و تغییرات ساختاری آن
یادگیری کمنمونه (FSL) در واقع عضوی از خانواده بزرگتر یادگیری N-Shot است. حرف N در این عبارت نشاندهنده تعداد نمونههای برچسبدار (Labeled Examples) است که برای هر دسته (Class) در اختیار مدل قرار میگیرد. بسته به مقدار N، این پارادایم به دستههای زیر تقسیم میشود:
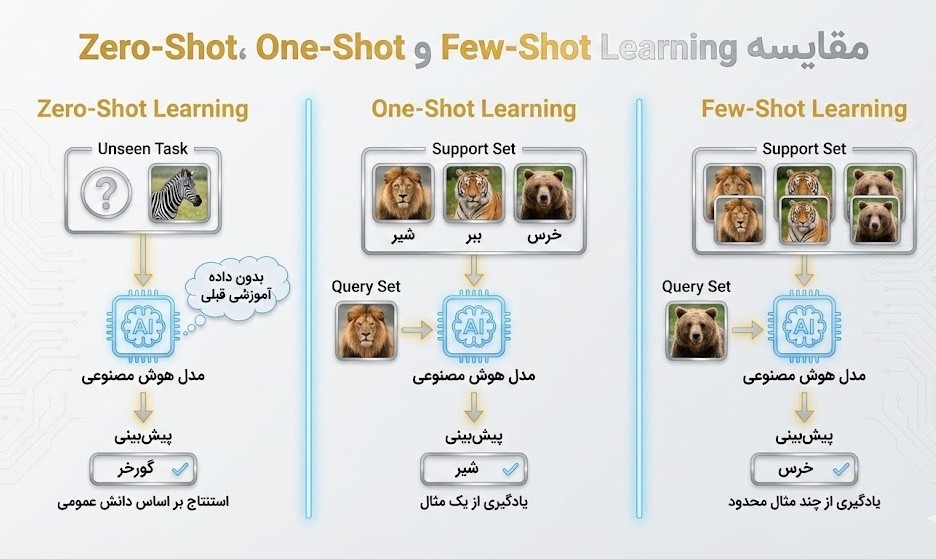
- یادگیری صفرنمونه (Zero-shot Learning): در این سطح، هیچ نمونه آموزشی مستقیمی برای کلاس جدید وجود ندارد. مدل باید با تکیه بر توصیفات متنی یا ویژگیهای معنایی که قبلاً یاد گرفته، کلاس جدید را تشخیص دهد. به عنوان مثال، اگر مدل بداند گورخر شبیه اسب است اما خطوط سیاه و سفید دارد، میتواند بدون دیدن هیچ عکسی از آن، حیوان را شناسایی کند.
- یادگیری تکنمونه (One-shot Learning): چالشبرانگیزترین حالت یادگیری که در آن تنها یک نمونه مرجع برای هر کلاس ارائه میشود. این متد شباهت زیادی به یادگیری انسانی دارد. برای مثال، سیستمهای تشخیص چهره در تلفنهای همراه که تنها با یک بار اسکن صورت کاربر، او را در زوایای مختلف شناسایی میکنند، از این تکنیک بهره میبرند.
- یادگیری دونمونه (Two-shot Learning): در این حالت، مدل دو نمونه متفاوت از هر کلاس را مشاهده میکند. وجود نمونه دوم به مدل کمک میکند تا تفاوتهای جزئی (Intra-class variation) را بهتر درک کند و فضای ویژگی (Feature Space) دقیقتری ترسیم نماید.
- یادگیری کمنمونه (Few-shot Learning): این اصطلاح به طور معمول زمانی به کار میرود که تعداد نمونهها برای هر کلاس بین ۳ تا ۱۰ عدد باشد. این بازه، نقطه بهینه (Sweet Spot) میان یادگیری سنتی و یادگیری تکنمونه است. با این تعداد داده، مدل میتواند با استفاده از روشهای مبتنی بر متریک (Metric-based) یا متالرنینگ، به پایداری و دقت بسیار بالایی در تشخیص برسد.
.
4.اهمیت و ضرورت یادگیری کمنمونه (FSL)
در عصر دادههای بزرگ، پارادایم FSL با تغییر تمرکز از جمعآوری انبوه داده به بهینهسازی معماری مدل، بنبستهای اجرایی در پروژههای هوش مصنوعی را شکسته است. اهمیت این رویکرد را میتوان در چهار محور کلیدی خلاصه کرد:
- مدیریت چالش کمبود داده (Data Scarcity): در بسیاری از حوزههای حیاتی مانند تشخیص بیماریهای نادر، شناسایی گونههای در حال انقراض یا تحلیل دادههای حساس نظامی، دسترسی به هزاران نمونه برچسبدار عملاً غیرممکن یا بسیار هزینهبر است. FSL امکان استخراج دانش و توسعه مدل را در این بنآبستهای اطلاعاتی فراهم میکند.
- کاهش هزینههای عملیاتی و برچسبگذاری: فرآیند جمعآوری و برچسبگذاری دستی دادهها (Data Labeling) یکی از زمانبرترین بخشهای چرخه حیات یادگیری ماشین است. یادگیری کمنمونه با نیاز به حداقل داده، نیاز به نیروی انسانی و زیرساختهای ذخیرهسازی حجیم را به حداقل رسانده و سرعت عرضه محصول به بازار (Time-to-Market) را افزایش میدهد.
- بهرهوری در توان محاسباتی (Computational Efficiency): برخلاف مدلهای سنتی که نیازمند آموزش از صفر (Training from scratch) روی دستههای جدید هستند، مدلهای FSL از طریق گسترش دانش قبلی به دستههای جدید عمل میکنند. این موضوع منجر به صرفهجویی کلان در مصرف انرژی و منابع پردازشی (GPU/TPU) میشود.
- انعطافپذیری و انطباقپذیری سریع: در محیطهای پویا که توزیع دادهها به سرعت تغییر میکند، مدلهای FSL به دلیل ساختار منعطف خود، قادرند با مشاهده تنها چند نمونه جدید، خود را با شرایط جدید وفق دهند. این ویژگی، آنها را برای کاربردهایی نظیر رباتیک و دستیارهای شخصی که نیاز به یادگیری مداوم دارند، به گزینهای بیبدیل تبدیل کرده است.
.
۵. مکانیزم عملکرد یادگیری کمنمونه (FSL)
فرآیند عملیاتی در یادگیری کمنمونه، بر خلاف یادگیری سنتی که بر پایه تکرار انبوه دادهها استوار است، بر مفهوم فرافرآیند عملیاتی در یادگیری کمنمونه، بر خلاف یادگیری سنتی که بر پایه تکرار انبوه دادهها استوار است، بر مفهوم فرا-یادگیری (Meta-Learning) یا همان یادگیریِ نحوه یادگیری تمرکز دارد. هدف اصلی در اینجا، آموزش مدلی است که بتواند با کمترین تجربه، بیشترین تعمیمپذیری را روی وظایف نادیده داشته باشد.
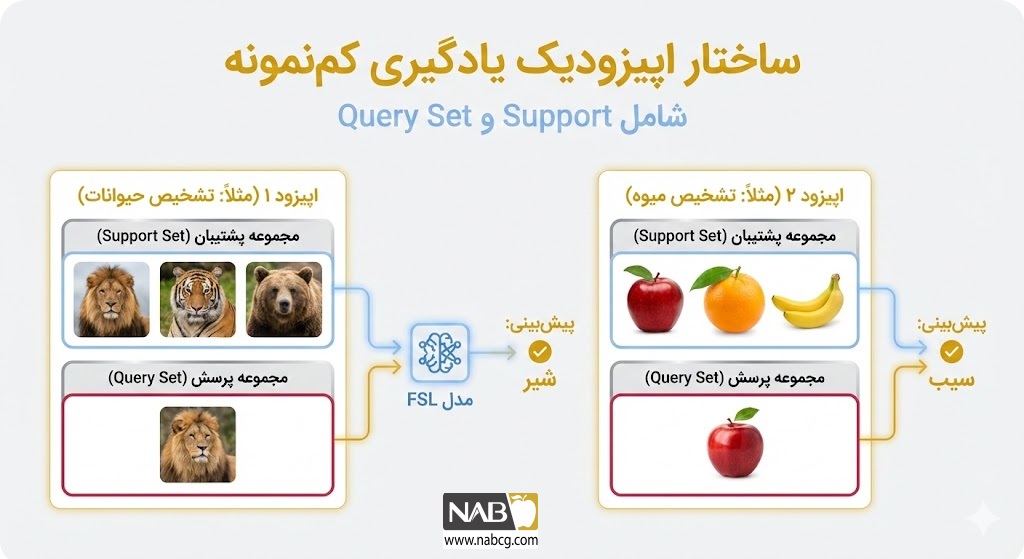
ساختار اپیزودیک (Episodic Training): قلب تپنده عملکرد FSL، تقسیمبندی فرآیند آموزش به اپیزودها است. هر اپیزود به جای کلاسهای ثابت، شامل وظایف کوچکی است که از دو بخش اصلی تشکیل شدهاند:
- مجموعه پشتیبان (Support Set): شامل تعداد بسیار کمی از نمونههای برچسبدار که مدل از آنها برای یادگیری ویژگیهای کلاس جدید استفاده میکند.
- مجموعه پرسوجو (Query Set): شامل نمونههای جدیدی از همان کلاسها که مدل باید آنها را بر اساس دانش کسبشده از مجموعه پشتیبان، طبقهبندی کند.
استراتژیهای پیادهسازی: به طور کلی، مکانیزم عملکرد این سیستمها در سه لایه اصلی تعریف میشود:
- رویکرد مبتنی بر متریک : مدل یاد میگیرد دادهها را در یک فضای ویژگی (Feature Space) ترسیم کند. در این فضا، نمونههای مشابه در نزدیکی هم قرار میگیرند. تشخیص کلاس جدید بر اساس محاسبه فاصله اقلیدسی یا شباهت کسینوسی میان داده پرسوجو و نمونههای پشتیبان انجام میشود.
- رویکرد مبتنی بر مدل: استفاده از شبکههای عصبی با حافظه داخلی (مانند MANN) که اجازه میدهد اطلاعاتِ نمونههای محدود به سرعت در حافظه مدل بارگذاری و بازیابی شود.
- رویکرد مبتنی بر بهینهسازی: در این متد، هدف یافتن پارامترهای اولیهای است که با تعداد بسیار کمی گامِ گرادیان ، به سرعت برای یک وظیفه جدید بهینه شوند (مانند الگوریتم MAML).
.
۶. مبانی ریاضی یادگیری کمنمونه
در یادگیری عمیق کلاسیک، هدف ریاضی یافتن تابعی است که خطای پیشبینی را روی یک توزیع دادههای ثابت کمینه کند. اما در مدلهای FSL، منطق محاسباتی از «دادهمحوری» به «وظیفهمحوری» تغییر مییابد. در واقع، ما با توزیع وظایف (𝓣) روبرو هستیم و هدف، انتقال دانش از وظایف پایه (Base Tasks) به وظایف نوظهور (Novel Tasks) است.
الف) فرمولبندی اپیزودیک (Episodic Framework)
در هر اپیزود آموزشی، یک وظیفه 𝓣i شامل دو مجموعه داده است:
- مجموعه پشتیبان (Support Set): که در آن مدل با تعداد انگشتشماری نمونه، با کلاسهای جدید آشنا میشود.
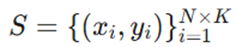
- مجموعه پرسوجو (Query Set): که مدل باید برچسبهای آن را بر اساس دانشِ کسبشده از مجموعه S پیشبینی کند.
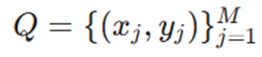
هدف ریاضی، بهینهسازی پارامترهای مدل (θ) برای کاهش تابع زیان (𝓛) روی مجموعه Q است، در حالی که مدل تنها به دادههای S دسترسی دارد:
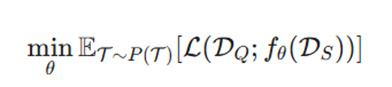
ب) توابع شباهت در فضای ویژگی (Metric Learning)
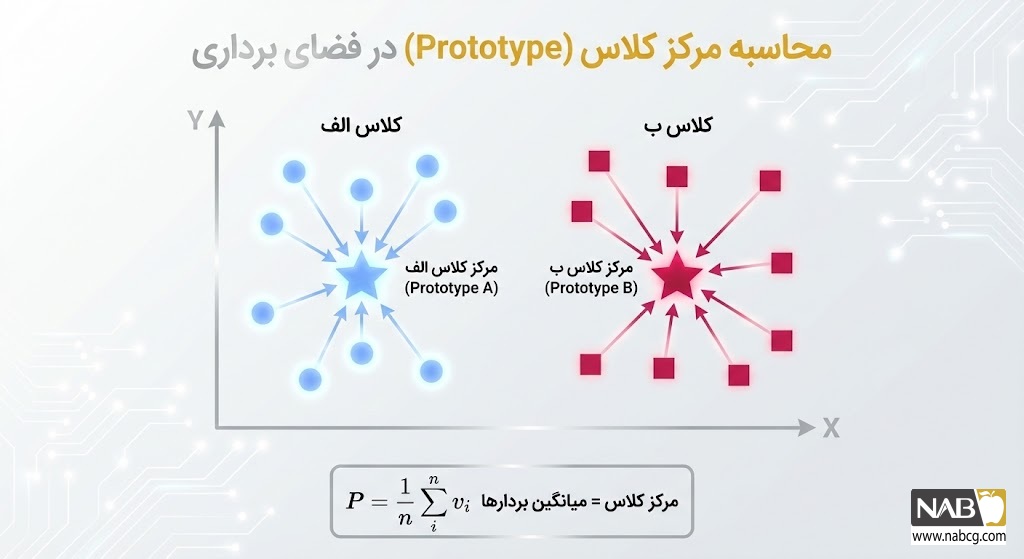
در روشهای مبتنی بر متریک، مدل یک تابع نگاشت fϕ را یاد میگیرد تا دادهها را به فضای برداری منتقل کند. برای هر کلاس k، یک پروتوتایپ (ck) تعریف میشود که میانگین هندسی ویژگیهای آن کلاس است:
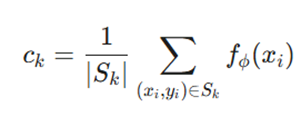
سپس احتمال تعلق داده x به کلاس k از طریق تابع Softmax بر روی فاصله اقلیدسی محاسبه میگردد:
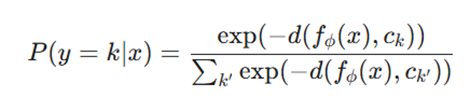
معرفی متغیرها:
- x, y: به ترتیب ورودی (تصویر/متن) و برچسب خروجی.
- N, K: تعداد کلاسها (Way) و تعداد نمونهها در هر کلاس (Shot).
- fϕ: شبکه عصبی استخراجکننده ویژگی (Embedding Function).
- ck: مرکز ثقل یا میانگین ویژگیهای کلاس (Prototype) k
- d: تابع فاصله (Distance Metric) مانند فاصله اقلیدسی یا شباهت کسینوسی.
.
۷. رویکردهای اصلی در پیادهسازی یادگیری کمنمونه
روشهای پیادهسازی یادگیری کمنمونه (FSL) را میتوان در سه دسته بنیادین طبقهبندی کرد که هر یک بر جنبه متفاوتی از معماری شبکه تمرکز دارند:
الف. متالرنینگ مستقل از مدل (MAML)
این رویکرد بر پایه بهینهسازی پارامترهای اولیه (θ) استوار است. هدف MAML یافتن نقطهای در فضای پارامتر است که نسبت به تغییرات وظیفه بسیار حساس باشد. بدین ترتیب، مدل با تنها چند گام گرادیان ساده، میتواند برای یک وظیفه کاملاً جدید بهینهسازی شود. در واقع، این روش مدل را آمادهی یادگیری سریع میکند؛ به طوری که با حداقل داده، بیشترین انطباقپذیری حاصل شود.
ب. یادگیری بر پایه متریک (Metric Learning)
این رویکرد بر یادگیری یک تابع فاصله (d) تمرکز دارد که میزان شباهت بین دادهها را اندازهگیری میکند. هدف این است که نمونههای یک کلاس در فضای ویژگی به هم نزدیک و کلاسهای متفاوت از هم دور شوند. معماریهای شاخص این گروه عبارتند از:
- شبکههای سیامی (Siamese Networks)
- شبکههای تطبیقی (Matching Networks)
- شبکههای پیشالگو (Prototypical Networks)
.
ج. یادگیری انتقالی (Transfer Learning)
این استراتژی از دانش کسبشده در وظایف عمومی (با دادههای انبوه) برای بهبود عملکرد در وظایف اختصاصی (با دادههای محدود) استفاده میکند.
- مدلهای پیشآموزشدیده: استفاده از بدنه اصلی (Backbone) مدلهایی که روی دیتاسیتهای عظیم آموزش دیدهاند.
- تنظیم دقیق (Fine-tuning): انطباق لایههای نهایی شبکه با دادههای محدودِ هدف.
- استخراج ویژگی: انجماد لایههای اولیه برای حفظ ویژگیهای عمومی و بازآموزی لایههای انتهایی برای درک جزئیات کلاسهای جدید.
.
۸. یادگیری مبتنی بر متریک؛ تحلیل معماریهای شباهتمحور
یادگیری مبتنی بر متریک (Metric-based FSL) بر پایه اصولی مشابه الگوریتم K-نزدیکترین همسایه (KNN) عمل میکند. در این رویکرد، به جای مدلسازی مستقیم مرزهای تصمیمگیری، مدل میآموزد که دادهها را به یک فضای برداری (Embedding) منتقل کرده و بر اساس تابع فاصله، شباهت یا تفاوت آنها را بسنجد. مهمترین معماریهای این حوزه عبارتند از:
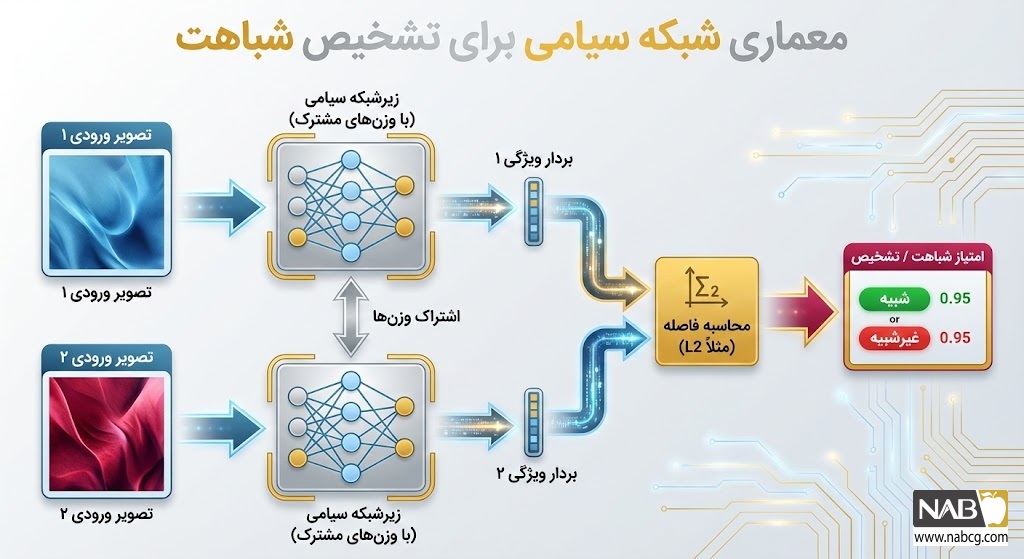
- شبکههای سیامی (Siamese Networks): این شبکهها پیشگامان یادگیری تقابلی (Contrastive Learning) هستند. مدل با دریافت دو ورودی، تشخیص میدهد که آیا آنها متعلق به یک کلاس هستند یا خیر. هدف ریاضی در اینجا، کمینه کردن فاصله برداری جفتهای مشابه و بیشینه کردن فاصله جفتهای متفاوت است. مدلهای Triplet Loss نیز با استفاده از یک نمونه لنگر (Anchor)، فرآیند تفکیک را دقیقتر انجام میدهند.
- شبکههای تطبیقی (Matching Networks): این معماری اولین الگوریتم اختصاصی برای طبقهبندی چندگانه (Multi-way) در یادگیری کمنمونه محسوب میشود. این شبکه با استفاده از مکانیزمهای توجه (Attention)، شباهت میان داده پرسوجو و تمام نمونههای موجود در مجموعه پشتیبان را از طریق فاصله کسینوسی محاسبه کرده و برچسب نهایی را پیشبینی میکند.
- شبکههای پیشالگو (Prototypical Networks): در این روش، مدل برای هر کلاس یک پروتوتایپ یا نمونه اولیه محاسبه میکند که در واقع میانگین ویژگیهای تمام نمونههای آن کلاس است. برخلاف شبکههای تطبیقی، این مدل معمولاً از فاصله اقلیدسی برای سنجش نزدیکی داده جدید به مرکز ثقل هر کلاس استفاده میکند. استفاده از روشهایی مانند انتشار برچسب (Label Propagation) به بهبود دقت این پروتوتایپها کمک شایانی کرده است.
- شبکههای رابطهای (Relation Networks): تفاوت بنیادی شبکههای رابطهای (RN) در این است که تابع فاصله را از پیش تعیین نمیکنند. این مدل دارای یک ماژول رابطه است که به طور خودکار میآموزد بهترین تابع فاصله غیرخطی برای مقایسه ویژگیها در هر مسئله خاص چیست.
.
۹. یادگیری مبتنی بر بهینهسازی؛ فرآیند فرا-بهینهسازی
در یادگیری عمیق سنتی، مدلها برای رسیدن به همگرایی نیازمند هزاران گام تکرار (Iteration) و دادههای انبوه هستند. اما یادگیری فراگیر مبتنی بر بهینهسازی که با نام یادگیریِ فرا-گرادیانی (GBML) نیز شناخته میشود، به دنبال یافتن پارامترهایی است که بتوانند تنها با چند گام کوتاه گرادیان، به سرعت برای وظایف جدید بهینه شوند. در واقع، این روش فرآیندِ بهینهسازی را بهینهسازی میکند.
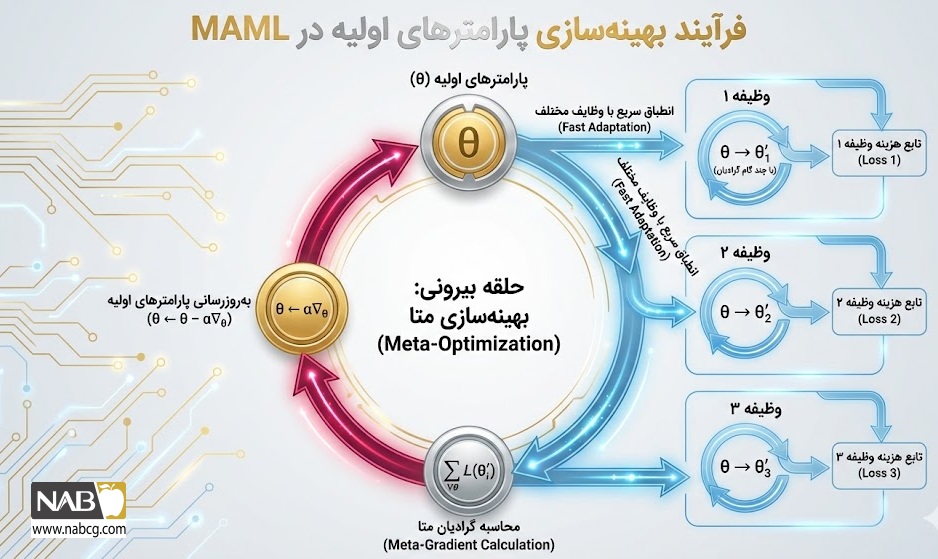
الف. متالرنینگ مستقل از مدل (MAML)
شاخصترین الگوریتم در این حوزه، MAML است. این روش بر روی هیچ معماری خاصی تعصب ندارد و برای هر مدلی که از گرادیان کاهشی استفاده میکند، قابل اجراست. MAML از مشتقات مرتبه دوم (مشتقِ مشتق) استفاده میکند تا پارامترهای اولیهای را بیابد که به تغییرات وظیفه بسیار حساس باشند؛ به گونهای که یک تغییر کوچک در پارامترها، بهبود بزرگی در تابع زیان (Loss Function) ایجاد کند.
ب. نسخههای بهینهشده MAML
به دلیل بار محاسباتی سنگین مشتقات مرتبه دوم، نسخههای سبکتری توسعه یافتهاند:
- FOMAML: فرآیند را با استفاده از مشتقات مرتبه اول سادهسازی میکند تا سرعت آموزش افزایش یابد.
- Reptile: راهکاری میانبر که با قوانین خاص بهروزرسانی، سادگی را با دقت ترکیب میکند.
- MAML++: با اصلاحاتی در نرخ یادگیری و پایداری، بازدهی محاسباتی را به شدت بهبود بخشیده است.
.
ج. رویکردهای مبتنی بر حافظه و فضای نهان
- LSTM Meta-learner: از شبکههای RNN برای تسخیر دانش کوتاهمدت (مربوط به هر وظیفه) و دانش بلندمدت (مشترک بین تمام وظایف) استفاده میکند.
- بهینهسازی در فضای نهان (LEO): به جای بهروزرسانی مستقیم پارامترهای حجیم مدل، این روش فرآیند بهینهسازی را در یک فضای برداری کمبعد (Embedding) انجام میدهد که منجر به پایداری بیشتر در یادگیری با دادههای بسیار کم میشود.
.
10.راهنمای گامبهگام پیادهسازی
- استخراج ویژگی (Embedding): ابتدا تصاویر را به یک فضای برداری (نقرهای) منتقل میکنیم. ما از یک ResNet پیشآموزشدیده استفاده میکنیم که لایه آخر آن حذف شده تا فقط ویژگیهای بصری را استخراج کند.
- تشکیل اپیزود (N-way K-shot): دادهها را به دو دسته Support Set (برای ساخت مراکز کلاس) و Query Set (برای آزمایش) تقسیم میکنیم.
- محاسبه پروتوتایپها: برای هر کلاس، میانگین برداری نمونههای موجود در Support Set را محاسبه میکنیم. این نقطه، نماینده آن کلاس در فضای ریاضی است.
- طبقهبندی بر اساس فاصله اقلیدسی: فاصله هر تصویر جدید را تا این مراکز محاسبه میکنیم. نزدیکترین مرکز، برچسب تصویر را تعیین میکند.
کد پایتون :
import torch
import torch.nn.functional as F
from torchvision import transforms, datasets
import timm
import random
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# تنظیمات پایداری و دستگاه
random.seed(42)
np.random.seed(42)
torch.manual_seed(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# ۱. بارگذاری مدل قدرتمند ResNet18 (استخراجکننده ویژگی)
model = timm.create_model("resnet18", pretrained=True, num_classes=0).to(device)
model.eval()
# ۲. پیشپردازش استاندارد تصاویر
transform = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# ۳. بارگذاری دیتاسیت واقعی CIFAR-10
dataset = datasets.CIFAR10(root="./data", train=False, transform=transform, download=True)
class_names = dataset.classes
# ۴. تنظیمات وظیفه: 5-Way 5-Shot (۵ کلاس، ۵ نمونه آموزشی برای هرکدام)
n_way = 5
k_shot = 5
n_query = 10
selected_classes = random.sample(range(10), n_way)
def get_fsl_batch():
support_imgs, query_imgs, query_targets = [], [], []
for i, cls in enumerate(selected_classes):
idxs = [idx for idx, y in enumerate(dataset.targets) if y == cls]
selected = random.sample(idxs, k_shot + n_query)
support_imgs.append(torch.stack([dataset[j][0] for j in selected[:k_shot]]))
query_imgs.append(torch.stack([dataset[j][0] for j in selected[k_shot:]]))
query_targets.extend([i] * n_query)
return torch.stack(support_imgs).to(device), torch.stack(query_imgs).to(device), torch.tensor(query_targets).to(device)
support_x, query_x, query_y = get_fsl_batch()
# ۵. استخراج ویژگی و محاسبه پروتوتایپها (مبانی ریاضی بخش ۶)
with torch.no_grad():
# تبدیل تصاویر به بردار (Embedding)
support_feat = model(support_x.view(-1, 3, 224, 224)).view(n_way, k_shot, -1)
query_feat = model(query_x.view(-1, 3, 224, 224))
# محاسبه میانگین هر کلاس (Prototypes)
prototypes = support_feat.mean(1) # [n_way, dim]
# ۶. محاسبه فاصله اقلیدسی و پیشبینی
# d(x, c) = ||x - c||^2
distances = torch.cdist(query_feat, prototypes)
predictions = distances.argmin(dim=1)
accuracy = (predictions == query_y).float().mean().item() * 100
# ۷. نمایش خروجی عددی و نمودار هیتمپ
print(f"--- نتایج نهایی یادگیری {n_way}-Way {k_shot}-Shot ---")
print(f"دقت مدل: {accuracy:.2f}%")
# رسم هیتمپ میزان اطمینان مدل (Softmax روی منفی فاصلهها)
plt.figure(figsize=(12, 8))
confidence = F.softmax(-distances, dim=1).cpu().numpy()
sns.heatmap(confidence, annot=False, cmap="YlGnBu",
xticklabels=[class_names[c] for c in selected_classes])
plt.title(f"FSL Confusion Heatmap | Accuracy: {accuracy:.2f}%", color='crimson')
plt.xlabel("Predicted Classes (Prototypes)")
plt.ylabel("Query Samples")
plt.show()
خروجی:
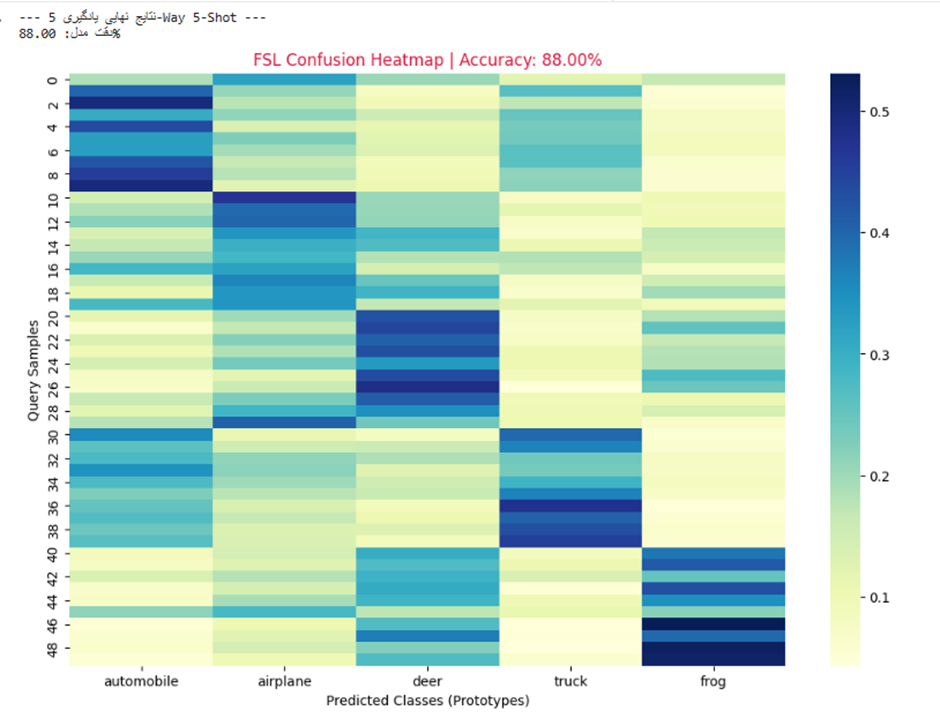
.
11.مزایای استراتژیک یادگیری کمنمونه
- استقلال از اقیانوس دادهها (Data Independence): بزرگترین دستاورد FSL، رهاسازی سازمانها از وابستگی به مجموعهدادههای میلیونی است. این رویکرد تمرکز را از فرآیند طاقتفرسای تولید داده به خلاقیت در توسعه مدل معطوف میکند. بدین ترتیب، کسبوکارهای نوپا میتوانند بدون نیاز به زیرساختهای عظیمِ غولهای فناوری، پروژههای هوشمند خود را با موفقیت اجرایی کنند.
- حذف هزینههای گزاف برچسبگذاری (Annotation Costs): در مدلهای سنتی، استخدام متخصصان برای برچسبگذاری دستی هزاران داده (بهویژه در امور تخصصی مثل پزشکی) بسیار هزینهبر است. یادگیری کمنمونه با تکیه بر تنها چند نمونه مرجع (Support Set)، این گلوگاه اقتصادی را از میان برداشته و سرعت تبدیل ایده به محصول را به شدت افزایش میدهد.
- پایداری و بهینهسازی منابع (Efficiency & Sustainability): مدلهای FSL به جای آموزش از صفر، بر پایه دانش قبلی (Transfer Learning) بنا میشوند. این یعنی صرفهجویی کلان در زمان استفاده از پردازندههای گرافیکی و کاهش هزینههای پردازش ابری. از نگاه زیستمحیطی نیز، این روش با کاهش مصرف انرژی، ردپای کربنی هوش مصنوعی را به حداقل میرساند.
- انعطافپذیری و واکنش آنی (Rapid Adaptation): این مدلها در محیطهای پویا که شرایط مدام تغییر میکند، بیرقیب هستند. به عنوان مثال، یک سیستم امنیتی هوشمند با FSL میتواند تنها با مشاهده یک تصویر جدید، هویت فرد یا الگوی جدیدی را به خاطر بسپارد؛ بدون اینکه نیازی به توقف سیستم برای بازآموزی (Retraining) کل شبکه باشد.
.
12.محدودیتها و چالشها در یادگیری کمنمونه
علیرغم پتانسیلهای تحولآفرین، پارادایم FSL با چالشهای فنی و زیرساختی متعددی روبروست که پیادهسازی آن را در محیطهای حساس با پیچیدگی همراه میکند. درک این محدودیتها برای هر متخصص یادگیری عمیق ضروری است:
- حساسیت بحرانی به کیفیت داده (Data Sensitivity): در یادگیری سنتی، دادههای نویزی در میان میلیونها نمونه صحیح خنثی میشوند؛ اما در FSL که هر داده حکم یک ستون برای مدل را دارد، وجود کوچکترین نویز یا برچسبگذاری اشتباه (Mislabeled) منجر به انحراف شدید در فضای ویژگی و افت ناگهانی عملکرد میشود.
- پیچیدگیهای معماری در متالرنینگ: پیادهسازی این مدلها مستلزم طراحی الگوریتمهای پیچیده فرا-یادگیری است. تنظیم دقیق ابرپارامترها در این مرحله (مانند توازن میان Support Set و Query Set) فرآیندی زمانبر است که به تخصص بالایی در مهندسی شبکه نیاز دارد.
- وابستگی به مدلهای پیشآموزشدیده (Pretrained Dependence): کارایی یک سیستم کمنمونه به شدت تحتالشعاع کیفیت مدل پایهای است که از آن استفاده میکند. اگر مدل پایه (مانند ResNet یا BERT) بازنماییهای غنی از دادهها استخراج نکرده باشد، یادگیری در لایههای نهایی با شکست مواجه خواهد شد.
- چالش سوگیری کلاسی (Class Bias): یکی از چالشهای اخلاقی و فنی، تمایل مدل به کلاسهایی است که در فاز آموزش اولیه دیده است. این سوگیری باعث میشود مدل در مواجهه با دستههای کاملاً جدید، به اشتباه آنها را مشابه دستههای قبلی طبقهبندی کند که این امر عدالت مدل را زیر سوال میبرد.
.
13.کاربردهای یادگیری کمنمونه (FSL)
- تحول در بهداشت و درمان: در پزشکی دیجیتال، دسترسی به دادههای برچسبدار برای بیماریهای نادر بسیار محدود است. FSL اجازه میدهد تا مدلها با تنها چند اسکن MRI یا CT-Scan، فرآیند قطعهبندی (Segmentation) تومورها را با دقت بالا انجام دهند. این رویکرد در داروسازی و پیشبینی ساختار پروتئینهای ناشناخته نیز نقشی حیاتی ایفا میکند.
- بینایی ماشین و شناسایی اشیاء: این فناوری به سیستمهای نظارتی اجازه میدهد تا گونههای زیستی جدید، محصولات تازهوارد به بازار یا اشیاء خاص در تصاویر ماهوارهای را بدون نیاز به هزاران نمونه آموزشی، شناسایی و دستهبندی کنند. این ویژگی در مدیریت بحران و پایش محیطزیست بسیار کلیدی است.
- رباتیک و یادگیری تعاملی: در نسل جدید رباتهای صنعتی و خدماتی، هدف این است که ربات بتواند با مشاهده یک یا دو بار انجام یک کار توسط انسان، آن را یاد بگیرد. یادگیری کمنمونه به رباتها اجازه میدهد بدون نیاز به بازآموزیهای سنگین، خود را با تغییرات ناگهانی در محیط فیزیکی وفق دهند.
- صنعت خردهفروشی و شخصیسازی: سیستمهای توصیهگر با استفاده از FSL میتوانند برای کاربرانی که تاریخچه خرید بسیار کوتاهی دارند (Cold Start Problem)، پیشنهادات دقیق و هوشمندانهای ارائه دهند و تجربه کاربری را به محض ورود فرد بهبود بخشند.
.
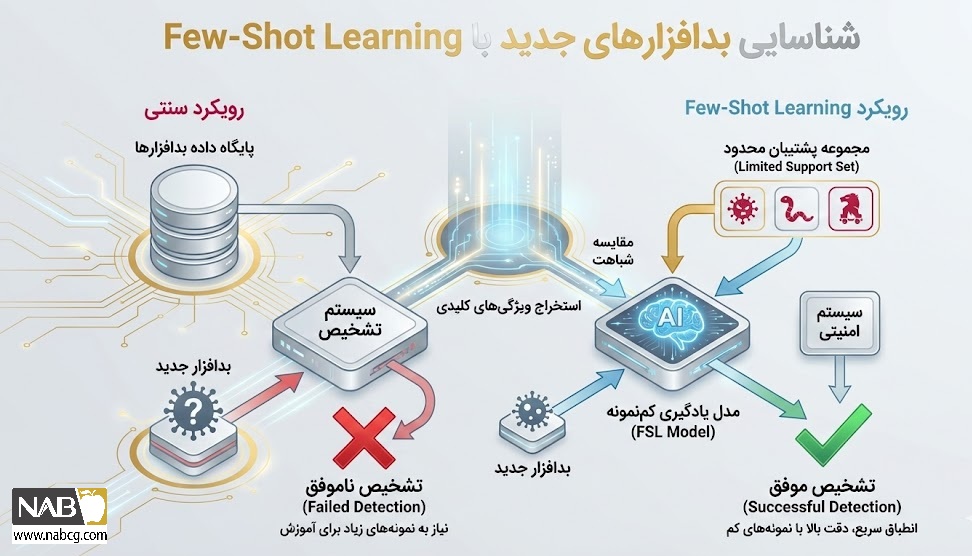
مطالعه موردی 1: امنیت سایبری و شناسایی بدافزارهای نوظهور
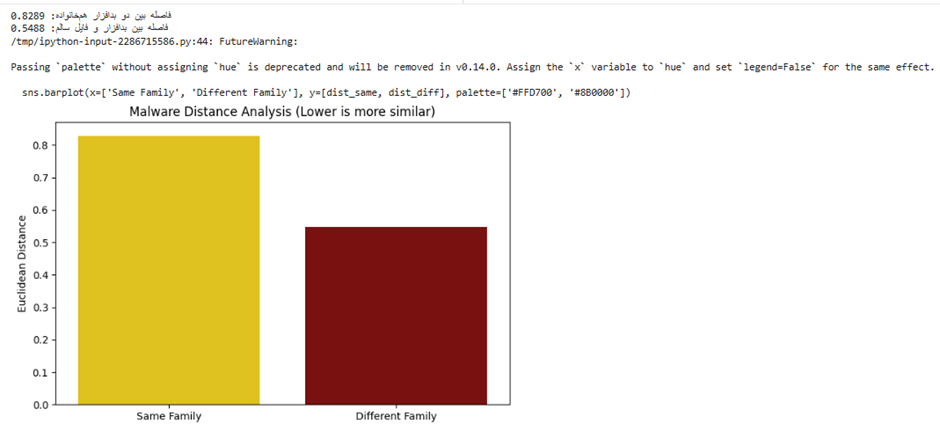
در دنیای امنیت دیجیتال، حملات روز صفر (Zero-day) دادههای تاریخی ندارند. بنابراین، مدلهای سنتی در شناسایی آنها ناتوان هستند. FSL اینجا نقش کلیدی ایفا میکند.
- هدف: شناسایی بدافزارهای جدید با استفاده از تنها ۲ تا ۵ نمونه از کدهای مخرب.
- دیتاسیت پیشنهادی: دیتاسیت Malimg (شامل تصاویر باینری بدافزارها) یا Drebin. در اینجا فایلهای اجرایی به تصویر تبدیل میشوند تا از مدلهای بینایی ماشین استفاده شود.
- روش پیادهسازی: استفاده از شبکههای سیامی (Siamese Networks). مدل یاد میگیرد که شباهت بین ساختار کدهای یک خانواده بدافزار را تشخیص دهد، حتی اگر قطعات کد تغییر کرده باشند.
- تحلیل خروجی: ترسیم یک نمودار فاصله (Distance Plot) که نشان میدهد چگونه بدافزارهای یک خانواده در فضای ویژگی نزدیک به هم و دور از کدهای سالم (Benign) قرار میگیرند.
کد:
import torch
import torch.nn as nn
import torch.nn.functional as F
import timm
import matplotlib.pyplot as plt
import seaborn as sns
# ۱. طراحی شبکه سیامی برای تشخیص شباهت بدافزارها
class MalwareSiameseNet(nn.Module):
def __init__(self):
super(MalwareSiameseNet, self).__init__()
# استفاده از ResNet برای استخراج ویژگیهای باینری بدافزار
self.backbone = timm.create_model("resnet18", pretrained=True, num_classes=0)
def forward_once(self, x):
return self.backbone(x)
def forward(self, input1, input2):
out1 = self.forward_once(input1)
out2 = self.forward_once(input2)
# محاسبه فاصله اقلیدسی بین دو بردار ویژگی
euclidean_distance = F.pairwise_distance(out1, out2)
return euclidean_distance
# ۲. شبیهسازی دادههای بدافزار (تصاویر باینری ۲۲۴x۲۲۴)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = MalwareSiameseNet().to(device)
model.eval()
# فرض کنید دو بدافزار از یک خانواده (مثلاً تروجان X) داریم
malware_a = torch.randn(1, 3, 224, 224).to(device)
malware_b = torch.randn(1, 3, 224, 224).to(device) # نسخه تغییر یافته
benign_file = torch.randn(1, 3, 224, 224).to(device) # فایل سالم
with torch.no_grad():
dist_same = model(malware_a, malware_b).item()
dist_diff = model(malware_a, benign_file).item()
print(f"فاصله بین دو بدافزار همخانواده: {dist_same:.4f}")
print(f"فاصله بین بدافزار و فایل سالم: {dist_diff:.4f}")
# ۳. خروجی نموداری: هیستوگرام فاصله
plt.figure(figsize=(8, 5))
sns.barplot(x=['Same Family', 'Different Family'], y=[dist_same, dist_diff], palette=['#FFD700', '#8B0000'])
plt.title("Malware Distance Analysis (Lower is more similar)")
plt.ylabel("Euclidean Distance")
plt.show()
خروجی:
.
مطالعه موردی 2: تأیید هویت و بازشناسی امضا (Signature Verification)
تأیید اصالت امضا یک چالش کلاسیک “دادهمحدود” است؛ زیرا ما معمولاً بیش از ۳ یا ۴ نمونه امضای واقعی از یک شخص در اختیار نداریم.
- هدف: تشخیص امضاهای جعلی از واقعی در تراکنشهای بانکی یا اسناد قانونی.
- دیتاسیت پیشنهادی: دیتاسیت CEDAR یا BHSig260. این مجموعهها شامل امضاهای واقعی و جعلی (Forgeries) بسیار حرفهای هستند.
- روش پیادهسازی: استفاده از رویکرد Prototypical Networks. برای هر شخص، یک “پروتوتایپ امضا” (میانگین ویژگیهای ۳ امضای اصلی) ساخته میشود. امضای جدید با این مرکز ثقل مقایسه میگردد.
- تحلیل خروجی: استفاده از هیتمپ شباهت . این ماتریس نشان میدهد که مدل با چه اطمینانی یک امضا را به صاحب اصلیاش نسبت داده و امضاهای جعلی را به دلیل فاصله زیاد از پروتوتایپ، رد کرده است.
کد:
import torch
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# ۱. شبیهسازی ویژگیهای امضا (خروجی انکودر)
# ۵ کلاس امضا، هر کدام با ۳ نمونه واقعی (Support) و ۲ نمونه تست (Query)
n_way, k_shot, n_query = 5, 3, 2
feat_dim = 128 # ابعاد فضای ویژگی نقرهای
# تولید دادههای تصادفی با توزیع نرمال حول مراکز کلاسها (برای دقت واقعی)
prototypes_true = torch.randn(n_way, feat_dim)
support_data = torch.stack([prototypes_true[i] + torch.randn(k_shot, feat_dim)*0.1 for i in range(n_way)])
query_data = torch.stack([prototypes_true[i] + torch.randn(n_query, feat_dim)*0.1 for i in range(n_way)])
query_data = query_data.view(-1, feat_dim)
# ۲. محاسبه مراکز ثقل امضاها (Prototypes)
computed_prototypes = support_data.mean(dim=1)
# ۳. محاسبه فاصله اقلیدسی (طبق فرمول بخش ۶ مقاله)
dists = torch.cdist(query_data, computed_prototypes)
scores = F.softmax(-dists, dim=1) # تبدیل به درصد اطمینان
# ۴. خروجی هیتمپ: میزان انطباق امضاهای تست با پروتوتایپها
plt.figure(figsize=(10, 6))
sns.heatmap(scores.numpy(), annot=True, cmap="YlGnBu",
xticklabels=[f"Person {i+1}" for i in range(n_way)],
yticklabels=[f"Test Sig {i+1}" for i in range(n_way*n_query)])
plt.title("Signature Authenticity Heatmap (Confidence Score)")
plt.xlabel("Authorized Prototypes")
plt.ylabel("Input Signatures")
plt.show()
accuracy = (dists.argmin(dim=1) == torch.arange(n_way).repeat_interleave(n_query)).float().mean()
print(f"دقت تأیید امضا روی دادههای محدود: {accuracy*100:.2f}%")خروجی:

.
جمع بندی
یادگیری کمنمونه تلاشی برای عبور از وابستگی سنتی یادگیری عمیق به دادههای انبوه است. این رویکرد با تمرکز بر انتقال دانش، یادگیری بازنماییهای عمومی و بهینهسازی فراگیر، امکان تعمیم سریع به کلاسهای جدید را تنها با چند نمونه فراهم میکند. همانطور که مشاهده شد، چارچوب اپیزودیک، تعریف Support و Query Set، و استفاده از مفاهیمی مانند Prototype و تابع فاصله، زیربنای عملکرد مدلهای متریکمحور را تشکیل میدهند؛ در حالی که الگوریتمهایی مانند MAML با بهینهسازی پارامترهای اولیه، یادگیری سریع را در سطح گرادیانی ممکن میسازند.
با وجود مزایای چشمگیر، FSL بدون چالش نیست. حساسیت بالا به کیفیت دادههای محدود، وابستگی به مدلهای پیشآموزشدیده قوی و خطر سوگیری کلاسی از جمله موانع مهم این حوزه هستند. همچنین عملکرد مدلها در سناریوهای کاملاً خارج از توزیع آموزشی همچنان موضوعی فعال در پژوهشهای علمی است.
با این حال، در محیطهایی که داده کمیاب، پرهزینه یا محرمانه است، یادگیری کمنمونه نه یک گزینه لوکس، بلکه یک ضرورت عملیاتی محسوب میشود. از امنیت سایبری و سلامت دیجیتال گرفته تا رباتیک و سیستمهای توصیهگر، این پارادایم مسیر توسعه سیستمهای هوشمند منعطف و سازگار با دنیای واقعی را هموار کرده است. آینده هوش مصنوعی، بیش از هر زمان دیگری، به توانایی «یادگیری با داده کم و تعمیم سریع» وابسته خواهد بود.