

5.مثال های عددی
مثال اول : فیلتر بر اساس حد آستانه واریانس (Variance Threshold)
موضوع: پیشپردازش دادههای یک فریمورک «تشخیص ایمیلهای اسپم»
صورت مسئله:
یک مهندس داده در خط لوله یادگیری ماشین خود، ماتریسی با ۳ ویژگی (تعداد کلمات کلیدی، وجود لینک خارجی، و طول ایمیل) برای ۵ ایمیل نمونه در اختیار دارد. او قصد دارد با تنظیم حد آستانه واریانس Threshold = 0.2 ویژگیهای کمخاصیت و یکنواخت را هرس کند. با محاسبات ریاضی مشخص کنید کدام ویژگیها باقی میمانند و کدام حذف میشوند؟
| ایمیل | ویژگی ۱ (تعداد کلمات کلیدی) | ویژگی ۲ (وجود لینک خارجی) | ویژگی ۳ (طول ایمیل به کاراکتر) |
| ایمیل ۱ | ۲ | ۱ | ۱۵۰ |
| ایمیل ۲ | ۲ | ۰ | ۳۲۰ |
| ایمیل ۳ | ۲ | ۱ | ۴۱۰ |
| ایمیل ۴ | ۳ | ۱ | ۱۲۰ |
| ایمیل ۵ | ۲ | ۱ | ۲۵۰ |
راه حل گامبهگام:
برای هر ویژگی ابتدا میانگین (μ) و سپس واریانس (Var) را محاسبه میکنیم.
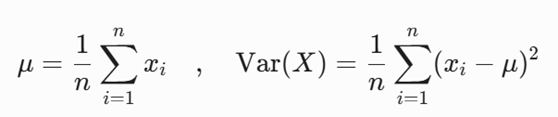
- گام اول: بررسی ویژگی ۱ (تعداد کلمات کلیدی)
- میانگین:

- واریانس:

- گام دوم: بررسی ویژگی ۲ (وجود لینک خارجی)
- میانگین:

- واریانس:

- گام سوم: بررسی ویژگی ۳ (طول ایمیل)
- میانگین:

- واریانس:

نتیجهگیری و ارزیابی شرط آستانه:
با مقایسه واریانسها با حد آستانه (0.2):
- ویژگی ۱ (Var = 0.16 < 0.2): حذف میشود.
- ویژگی ۲ (Var = 0.16 < 0.2): حذف میشود.
- ویژگی ۳ (Var = 11480 ≥ 0.2): باقی میماند.
نکته مهندسی: چون دادههای ویژگی ۳ مقیاس بزرگی دارند، واریانس بسیار بالایی ثبت کردهاند. اینجاست که ضعف متد حد آستانه واریانس مشخص میشود؛ این روش بدون توجه به ارتباط با متغیر هدف، صرفاً به مقیاس و پراکندگی خود عدد نگاه میکند.
مثال دوم : مهار همخطی با ضریب همبستگی پیرسون (Pearson Correlation)
موضوع: پیشبینی ریسک اعتباری مشتریان یک بانک (حوزه جرایم مالی و اعتباری)
صورت مسئله:
در یک پروژه دیتاساینس مالی، دو ویژگی ورودی X1 (میزان درآمد ماهیانه به میلیون تومان) و X2 (میزان مالیات پرداختی ماهیانه به میلیون تومان) ثبت شدهاند. هدف مدل، پیشبینی متغیر Y (سقف اعتبار مجاز مشتری) است. همبستگی درونی ویژگیها با یکدیگر و همبستگی تکتک آنها با متغیر هدف به صورت زیر است. با اعمال حد آستانه همبستگی درونی Threshold = 0.70، پایپلاین انتخاب ویژگی چگونه عمل میکند؟
- همبستگی بین دو ویژگی ورودی: r(X1, X2) = 0.85
- همبستگی ویژگی اول با هدف: r(X1, Y) = 0.78
- همبستگی ویژگی دوم با هدف: r(X2, Y) = 0.62
راه حل گامبهگام:
- گام اول: سنجش پدیده همخطی چندگانه (Multicollinearity)
ابتدا همبستگی بین دو متغیر مستقل یعنی r(X1, X2) را بررسی میکنیم. مقایسه نشان میدهد که:

این عدد نشاندهنده یک همبستگی درونی شدید بین درآمد و مالیات است. سیستم تشخیص میدهد که این دو متغیر اطلاعات موازی و زائد (Redundant) دارند و نگهداری همزمان هر دو، مدل را دچار بیشبرازش و تضعیف ضرایب رگرسیونی میکند. در نتیجه، یکی از این دو ویژگی باید هرس شود.
- گام دوم: انتخاب ویژگی اصیل بر اساس ارتباط با هدف
برای تعیین اینکه کدام ویژگی حذف شود، قدرت سیگنال ارتباطی هرکدام با متغیر هدف (Y) را به صورت مستقل مقایسه میکنیم:
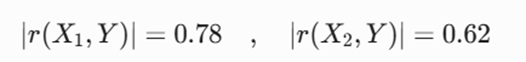
از آنجا که 0.78 > 0.62 است، متغیر X1 (درآمد ماهیانه) اطلاعات و واریانس بیشتری از متغیر هدف را تبیین میکند.
نتیجهگیری نهایی:
متغیر X2 (مالیات پرداختی) به عنوان ویژگی زائد حذف شده و متغیر X1 به عنوان نماینده این زوج اطلاعاتی در دیتاست نهایی برای آموزش مدل باقی میماند.
مثال سوم : سنجش وابستگی با آزمون کایاسکوئر
موضوع: مهندسی ویژگی دیتابیس بالینی برای پیشبینی ابتلا به دیابت
صورت مسئله:
یک محقق علوم داده پزشکی میخواهد میزان وابستگی ویژگی دستهبندیشده X (وضعیت تحرک فرد: پرتحرک / کمتحرک) را با متغیر هدف دستهبندیشده Y (ابتلا به دیابت: مبتلا / سالم) بسنجد. جدول فراوانیهای مشاهدهشده (O) از یک نمونه آماری ۱۰۰ نفره استخراج شده است. با استفاده از آزمون کایاسکوئر و فرض استقلال، مقدار عددی شاخص χ² را محاسبه کنید تا مشخص شود آیا این ویژگی ارزش اطلاعاتی دارد یا خیر؟
| وضعیت تحرک (X) | مبتلا به دیابت (Y=Yes) | سالم (Y=No) | مجموع سطرها |
| کمتحرک | ۳۰ (خانه A) | ۲۰ (خانه B) | ۵۰ |
| پرتحرک | ۱۰ )خانه C) | ۴۰ (خانه D) | ۵۰ |
| مجموع ستونها | ۴۰ | ۶۰ | ۱۰۰ (کل نمونه) |
راه حل گامبهگام:
- گام اول: بررسی شروط سهگانه آماری آزمون کایاسکوئر
- متغیرها دستهبندیشده (Categorical) هستند؟ بله )کمتحرک/پرتحرک و مبتلا/سالم(.
- نمونهبرداریها مستقل هستند؟ بله )بر اساس فرض مسئله(.
- فرکانس مورد انتظار برای تمام خانهها بزرگتر از ۵ است؟ برای پاسخ، ابتدا باید فراوانیهای مورد انتظار (E) را برای هر خانه با فرمول زیر محاسبه کنیم:

- فرکانس مورد انتظار خانه A
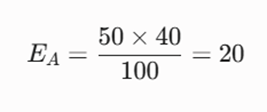
- فرکانس مورد انتظار خانه B
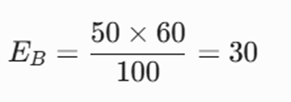
- فرکانس مورد انتظار خانه C
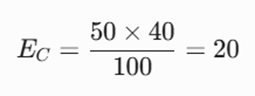
- فرکانس مورد انتظار خانه D

- بررسی شرط سوم: تمام مقادیر انتظاری (20, 30, 20, 30) بزرگتر از ۵ هستند، پس اعمال آزمون کاملاً مجاز است.
- گام دوم: محاسبه مقدار آماره کایاسکوئر (χ²)
فرمول ریاضی را برای تکتک ۴ خانه جدول اعمال میکنیم:
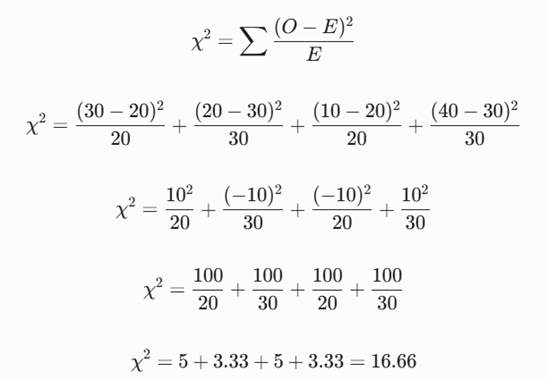
نتیجهگیری و تحلیل تخصصی:
مقدار آماره کایاسکوئر به دست آمده برابر با ۱۶.۶۶ است. از آنجا که درجه آزادی این جدول برابر با ۱ است ((2-1) ˟ (2-1) = 1)، مقدار بحرانی کایاسکوئر در سطح خطای ۵ درصد برابر با 3.84 است. چون 16.66 > 3.84 است، فرض استقلال کاملاً رد میشود. این نتیجه ثابت میکند که ویژگی تحرک، وابستگی آماری شدیدی با ابتلا به دیابت دارد و سیگنال اطلاعاتی فوقالعاده باارزشی است؛ در نتیجه الگوریتم فیلتر این ویژگی را به عنوان یک متغیر کلان و طلایی در دیتابیس حفظ میکند.
6. ابزارها، کتابخانهها و فریمورکهای محبوب
کتابخانه Scikit-Learn
کتابخانه sklearn محبوبترین و پایهایترین ابزار برای یادگیری ماشین کلاسیک در پایتون است. ماژول sklearn.feature_selection توابع بسیار بهینه و پایداری را برای روشهای فیلتر، پوششی و تعبیهشده ارائه میدهد. یکی از توابع کلیدی تعبیهشده آن، SelectFromModel است که به طور خودکار ویژگیها را بر اساس وزنهای ضرایب لاسو (L1) یا شاخص اهمیت در درختها هرس میکند.
کد پایتون:
import numpy as np
import pandas as pd
from sklearn.datasets import make_classification
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier
print("--- 1. Scikit-Learn (SelectFromModel) Pipeline ---")
# تولید دادههای نمونه
X_raw, y_raw = make_classification(n_samples=500, n_features=10, n_informative=4, random_state=42)
feature_names = [f"Feat_{i}" for i in range(1, 11)]
df_sk = pd.DataFrame(X_raw, columns=feature_names)
# تعریف مدل اصلی ارزیاب (جنگل تصادفی)
meta_estimator = RandomForestClassifier(n_estimators=50, random_state=42)
# پیکربندی SelectFromModel برای انتخاب ویژگیهای برتر بر اساس حد آستانه میانگین اهمیت
sk_selector = SelectFromModel(estimator=meta_estimator, threshold="mean")
sk_selector.fit(df_sk, y_raw)
# استخراج ویژگیهای طلایی برگزیده
selected_features_sk = df_sk.columns[sk_selector.get_support()]
print(f"Selected Features by Scikit-Learn: {list(selected_features_sk)}")
print(f"Reduced Dimensions: From 10 to {len(selected_features_sk)}\n")
خروجی:

فریمورک Boruta
الگوریتم Boruta (که در پایتون به صورت کتابخانه boruta پیادهسازی شده) یکی از هوشمندترین ابزارهای پوششی است که بر پایه مدل جنگل تصادفی (Random Forest) توسعه یافته است.
- مکانیزم عملکرد مدرن (Shadow Features): بوروتو برای سنجش اصالت یک ویژگی، ابتدا دیتابیس را مخدوش کرده و برای هر ستون یک ویژگی سایه (Shadow Feature) به صورت کاملاً تصادفی خلق میکند. ویژگیهای واقعی تنها زمانی پذیرفته میشوند که امتیاز اهمیت آنها به طور معناداری بالاتر از ویژگیهای سایه تصادفی باشد.
کد پایتون:
# توجه: برای اجرای این کد ابتدا باید کتابخانه boruta را نصب کنید: pip install boruta
!pip install boruta
from boruta import BorutaPy
from sklearn.ensemble import RandomForestClassifier
import numpy as np
import pandas as pd
from sklearn.datasets import make_classification
# Ensure df_sk and y_raw are defined, assuming they might not be available from previous cell execution
X_raw, y_raw = make_classification(n_samples=500, n_features=10, n_informative=4, random_state=42)
feature_names = [f"Feat_{i}" for i in range(1, 11)]
df_sk = pd.DataFrame(X_raw, columns=feature_names)
print("--- 2. Boruta (Shadow Features) Pipeline ---")
# تعریف مدل جنگل تصادفی (باید پارامتر max_depth متناسب با الگوریتم بوروتو تنظیم شود)
rf_boruta = RandomForestClassifier(n_jobs=-1, max_depth=5, random_state=42)
# پیکربندی فریمورک Boruta
boruta_selector = BorutaPy(rf_boruta, n_estimators='auto', verbose=0, random_state=42)
boruta_selector.fit(df_sk.values, y_raw)
# استخراج ستونهای تایید شده نهایی
selected_features_boruta = df_sk.columns[boruta_selector.support_]
print(f"Confirmed Features by Boruta: {list(selected_features_boruta)}")
print(f"Tentative Features (Border Zone): {list(df_sk.columns[boruta_selector.support_weak_])}\n")
خروجی:

کتابخانه MLxtend
کتابخانه MLxtend (Machine Learning Extensions) ابزار مرجع برای اجرای دقیق و گامبه-گام الگوریتمهای بهینهسازی ترکیبی حریصانه مانند انتخاب گامبه-جلو (Forward Selection) است.
- مزیت بزرگ: این ابزار امکان تصویرسازی و رسم روند صعود یا سقوط متریکهای عملکردی مدل را در تکتک مراحل اضافه شدن ستونها به مهندس داده میدهد.
کد پایتون :
# توجه: برای اجرای این کد ابتدا باید کتابخانه mlxtend را نصب کنید: pip install mlxtend
import matplotlib.pyplot as plt
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
from sklearn.neighbors import KNeighborsClassifier
print("--- 3. MLxtend (Sequential Forward Selection) Pipeline ---")
# پالت رنگی اختصاصی شما برای شکلها
PALETTE = {"Active Gold": "#FFC107", "Crimson": "#DC3545", "Ultra Light Gray": "#F8F9FA", "Dark Text": "#212529"}
plt.rcParams.update({'figure.facecolor': '#FFFFFF', 'axes.facecolor': PALETTE["Ultra Light Gray"]})
# تعریف مدل ارزیاب سبک (KNN)
knn = KNeighborsClassifier(n_neighbors=3)
# پیکربندی انتخاب گامبه-جلو (Forward=True) برای یافتن ۵ ویژگی برتر
sfs = SFS(knn, k_features=5, forward=True, floating=False, scoring='accuracy', cv=4, n_jobs=-1)
sfs.fit(df_sk, y_raw)
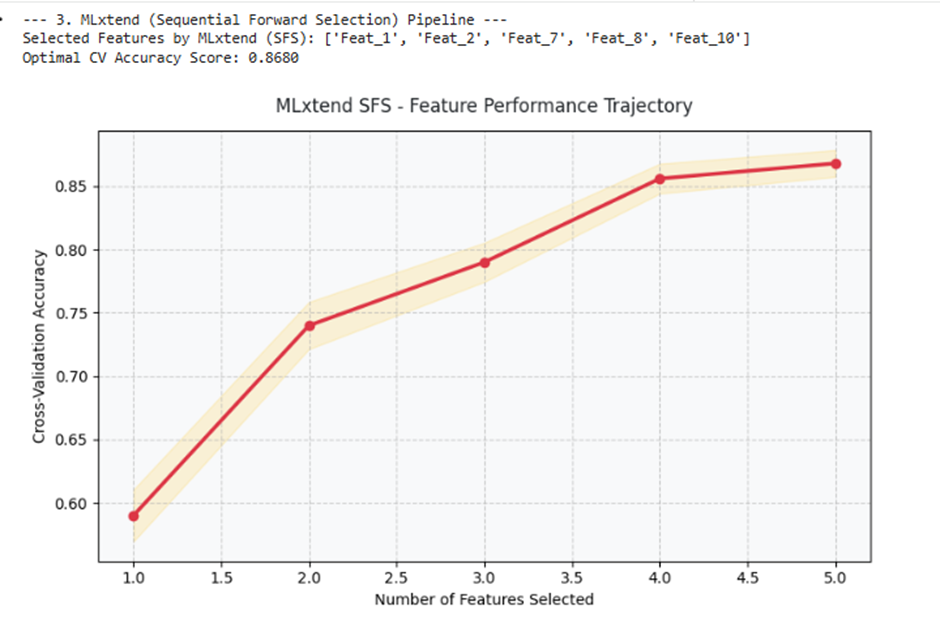
print(f"Selected Features by MLxtend (SFS): {list(sfs.k_feature_names_)}")
print(f"Optimal CV Accuracy Score: {sfs.k_score_:.4f}\n")
# تصویرسازی روند صعود عملکرد مدل بر اساس تعداد ویژگیها با پالت Crimson و Active Gold
metric_dict = sfs.get_metric_dict()
df_metrics = pd.DataFrame.from_dict(metric_dict).T
plt.figure(figsize=(8, 5))
plt.plot(df_metrics.index, df_metrics['avg_score'], color=PALETTE["Crimson"], marker='o', linewidth=2.5)
plt.fill_between(df_metrics.index,
df_metrics['avg_score'].astype(float) - df_metrics['std_err'].astype(float),
df_metrics['avg_score'].astype(float) + df_metrics['std_err'].astype(float),
alpha=0.15, color=PALETTE["Active Gold"])
plt.title("MLxtend SFS - Feature Performance Trajectory", fontsize=12, pad=12, color=PALETTE["Dark Text"])
plt.xlabel("Number of Features Selected", fontsize=10)
plt.ylabel("Cross-Validation Accuracy", fontsize=10)
plt.grid(True, linestyle="--", alpha=0.6)
plt.tight_layout()
plt.show()
خروجی:
7.پیاده سازی گام به گام
- گام اول؛ تولید دیتابیس شبیهسازیشده (Synthetic Dataset): ایجاد یک ماتریس داده شامل ویژگیهای باارزش، ویژگیهای کاملاً موازی و زائد (Redundant)، ویژگیهای بدون تغییر (واريانس صفر) و متغیر هدف دستهبندیشده.
- گام دوم؛ تفکیک دادهها (Train/Test Split): برای جلوگیری مطلق از پدیده نشت داده (Data Leakage)، ابتدا دادهها را به دو بخش آموزش و تست تقسیم کرده و تمام فیلترها را صرفاً روی بخش آموزش فیت میکنیم.
- گام سوم؛ اعمال فیلتر حد آستانه واریانس (Variance Threshold): شناسایی و حذف ستونهایی که مقادیر آنها ثابت است و هیچ سیگنال واریانسی تولید نمیکنند.
- گام دوم؛ تحلیل همخطی و فیلتر پیرسون (Pearson Correlation): استخراج ماتریس همبستگی، شناسایی زوج متغیرهای موازی و هرس کردن متغیری که همبستگی کمتری با هدف دارد.
- گام پنجم؛ حذف بازگشتی ویژگی با اعتبارسنجی متقاطع (RFECV): اعمال متد پوششی حریصانه روی دادههای غربالشده به همراه یک مدل ارزیاب (مانند Random Forest) برای یافتن تعداد بهینه ویژگیها روی دادههای ندیده.

- گام ششم؛ آموزش مدل نهایی و تصویرسازی نتایج
کد پایتون:
# =====================================================================
# بخش اول: وارد کردن کتابخانههای حیاتی پروژه
# =====================================================================
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# ابزارهای مهندسی ویژگی و مدلسازی از کتابخانه Scikit-Learn
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import VarianceThreshold
from sklearn.feature_selection import RFECV
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# =====================================================================
# بخش دوم: تنظیم پالت رنگی اختصاصی مرکز نوآوری در کد
# =====================================================================
PALETTE = {
"Active Gold": "#FFC107",
"Crimson": "#DC3545",
"AI Soft Blue": "#E3F2FD",
"Metal Silver": "#6C757D",
"Ultra Light Gray": "#F8F9FA",
"Pure White": "#FFFFFF",
"Dark Text": "#212529"
}
# اعمال استایل پایهای به نمودارها برای خوانایی و سئوی بهتر تصاویر
sns.set_theme(style="whitegrid")
plt.rcParams.update({
'figure.facecolor': PALETTE["Pure White"],
'axes.facecolor': PALETTE["Ultra Light Gray"],
'text.color': PALETTE["Dark Text"],
'axes.labelcolor': PALETTE["Dark Text"],
'xtick.color': PALETTE["Dark Text"],
'ytick.color': PALETTE["Dark Text"]
})
# =====================================================================
# گام ۱: خلق دیتابیس شبیهسازیشده (حاوی ویژگیهای نویزی و زائد)
# =====================================================================
print("--- Step 1: Generating Synthetic Dataset ---")
# تولید ۱۰ ویژگی پایه (شامل ۴ ویژگی کلیدی و مرتبط با هدف)
X_raw, y_raw = make_classification(
n_samples=1200, n_features=10, n_informative=4,
n_redundant=2, random_state=42
)
# تبدیل دادهها به DataFrame پاندا برای مدیریت ستونها
feature_names = [f"Feature_{i}" for i in range(1, 11)]
df = pd.DataFrame(X_raw, columns=feature_names)
# تزریق متدولوژیک ویژگی زائد (کپی همبسته از ویژگی اول با کمی نویز)
df["Redundant_Copy"] = df["Feature_1"] * 1.8 + np.random.normal(0, 0.05, size=len(df))
# تزریق ویژگی با واریانس صفر (تمام مقادیر برابر با عدد ثابت ۵ هستند)
df["Zero_Variance_Feat"] = 5.0
# افزودن برچسب هدف به دیتاست
df["Target"] = y_raw
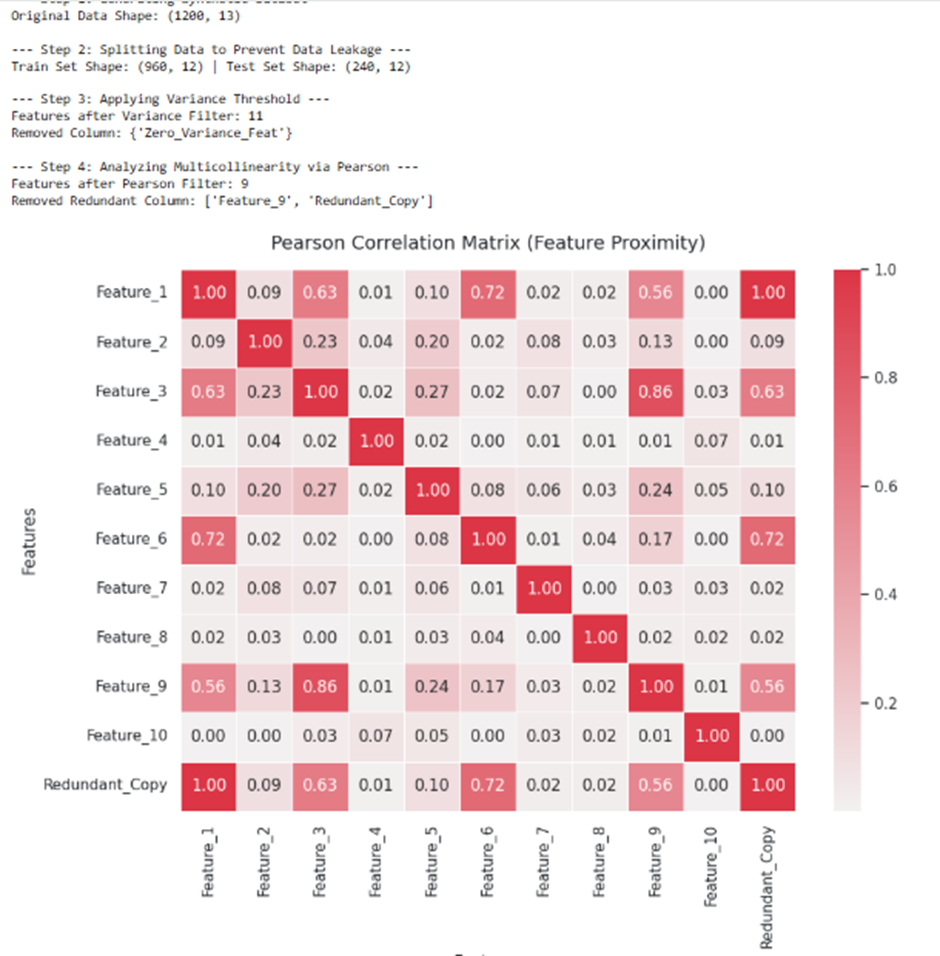
print(f"Original Data Shape: {df.shape}\n")
# =====================================================================
# گام ۲: تفکیک دادهها به قطعات آموزش و تست (پرهیز از Data Leakage)
# =====================================================================
print("--- Step 2: Splitting Data to Prevent Data Leakage ---")
X = df.drop(columns=["Target"])
y = df["Target"]
# تمام محاسبات آماری و فیلترها صرفاً روی Train فیت خواهند شد
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
print(f"Train Set Shape: {X_train.shape} | Test Set Shape: {X_test.shape}\n")
# =====================================================================
# Gام ۳: اعمال فیلتر حد آستانه واریانس (Variance Threshold Filter)
# =====================================================================
print("--- Step 3: Applying Variance Threshold ---")
# حذف ویژگیهایی که واریانس آنها مطلقاً صفر است
var_selector = VarianceThreshold(threshold=0.0)
var_selector.fit(X_train) # فیت شدن مقتدرانه صرفاً روی دادههای آموزش
# استخراج ستونهای ماندگار
kept_columns_var = X_train.columns[var_selector.get_support()]
X_train_vared = X_train[kept_columns_var]
X_test_vared = X_test[kept_columns_var]
print(f"Features after Variance Filter: {X_train_vared.shape[1]}")
print(f"Removed Column: {set(X_train.columns) - set(kept_columns_var)}\n")
# =====================================================================
# گام ۴: تحلیل همخطی و فیلتر پیرسون (Pearson Correlation Filter)
# =====================================================================
print("--- Step 4: Analyzing Multicollinearity via Pearson ---")
# محاسبه ماتریس همبستگی پیرسون روی دادههای آموزش
corr_matrix = X_train_vared.corr().abs()
# انتخاب ستونهایی که همبستگی بالای ۰.۸۰ با یکدیگر دارند
upper_tri = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(bool))
to_drop = [column for column in upper_tri.columns if any(upper_tri[column] > 0.80)]
# هرس کردن متغیر زائد شناسایی شده
X_train_filtered = X_train_vared.drop(columns=to_drop)
X_test_filtered = X_test_vared.drop(columns=to_drop)
print(f"Features after Pearson Filter: {X_train_filtered.shape[1]}")
print(f"Removed Redundant Column: {to_drop}\n")
# تصویرسازی ماتریس همبستگی پیرسون منطبق بر پالت رنگی
plt.figure(figsize=(10, 8))
sns.heatmap(
corr_matrix, annot=True, cmap=sns.light_palette(PALETTE["Crimson"], as_cmap=True),
fmt=".2f", cbar=True, linewidths=0.5
)
plt.title("Pearson Correlation Matrix (Feature Proximity)", fontsize=14, pad=15)
plt.xlabel("Features", fontsize=12)
plt.ylabel("Features", fontsize=12)
plt.tight_layout()
plt.show()
# =====================================================================
# گام ۵: حذف بازگشتی ویژگی همراه با اعتبارسنجی متقاطع (RFECV)
# =====================================================================
print("--- Step 5: Executive Feature Selection via RFECV ---")
# انتخاب مدل ارزیاب پایهای جنگل تصادفی
estimator = RandomForestClassifier(n_estimators=50, random_state=42)
# پیکربندی خط لوله پوششی RFECV با ۵ لایه اعتبارسنجی متقاطع
rfecv = RFECV(
estimator=estimator,
step=1,
cv=5,
scoring='accuracy',
n_jobs=-1
)
rfecv.fit(X_train_filtered, y_train)
# استخراج بردار نهایی ویژگیهای برگزیده
final_features = X_train_filtered.columns[rfecv.support_]
X_train_final = X_train_filtered[final_features]
X_test_final = X_test_filtered[final_features]
print(f"Optimal Number of Features Discovered: {rfecv.n_features_}")
print(f"Final Golden Feature Set: {list(final_features)}\n")
# تصویرسازی فرآیند بهینهسازی محاسباتی RFECV
plt.figure(figsize=(9, 5.5))
# رسم نمودار عملکرد بر اساس تغییرات تعداد ویژگیها
plt.plot(
range(1, len(rfecv.cv_results_['mean_test_score']) + 1),
rfecv.cv_results_['mean_test_score'],
color=PALETTE["Crimson"], marker='o', markersize=6,
linewidth=2.5, label="CV Accuracy Score"
)
# مشخص کردن نقشه بهینه با خط طلایی مرکز نوآوری
plt.axvline(
x=rfecv.n_features_, color=PALETTE["Active Gold"],
linestyle='--', linewidth=2, label=f"Optimal Cut-off ({rfecv.n_features_} Feat)"
)
plt.title("RFECV - Optimal Feature Count Exploration Pipeline", fontsize=13, pad=12)
plt.xlabel("Number of Features Selected", fontsize=11)
plt.ylabel("Cross-Validation Accuracy", fontsize=11)
plt.legend(loc="lower right", facecolor=PALETTE["Pure White"])
plt.tight_layout()
plt.show()
# =====================================================================
# گام ۶: آموزش مدل نهایی بر روی معماری ویژگیهای طلایی و ارزیابی عملکرد
# =====================================================================
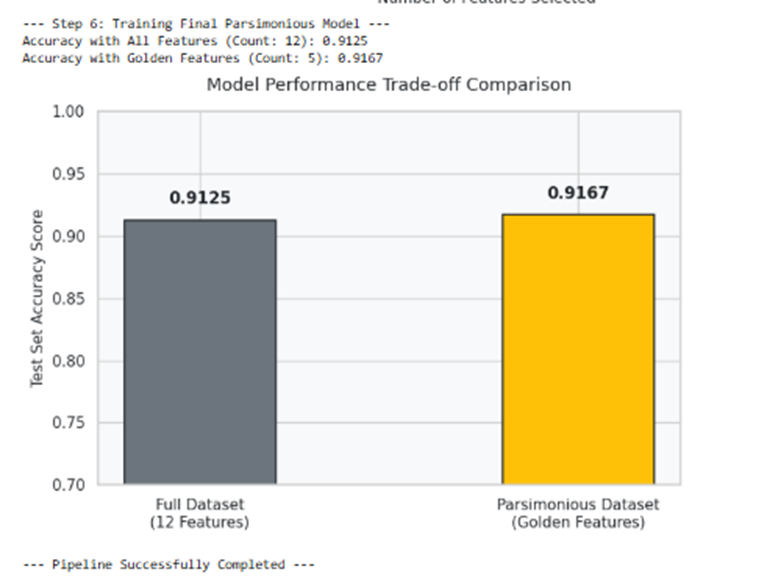
print("--- Step 6: Training Final Parsimonious Model ---")
# الف) آموزش مدل با تمام ویژگیهای اولیه خام (مدل سنگین و غیربهینه)
full_model = RandomForestClassifier(n_estimators=50, random_state=42)
full_model.fit(X_train, y_train)
y_pred_full = full_model.predict(X_test)
acc_full = accuracy_score(y_test, y_pred_full)
# ب) آموزش مدل با ویژگیهای مهندسی و غربالشده (مدل بهینه و چابک)
optimal_model = RandomForestClassifier(n_estimators=50, random_state=42)
optimal_model.fit(X_train_final, y_train)
y_pred_opt = optimal_model.predict(X_test_final)
acc_opt = accuracy_score(y_test, y_pred_opt)
print(f"Accuracy with All Features (Count: {X_train.shape[1]}): {acc_full:.4f}")
print(f"Accuracy with Golden Features (Count: {rfecv.n_features_}): {acc_opt:.4f}")
# تصویرسازی مقایسهای موازنه پارسیمونیوس (بهینگی در عین سادگی)
plt.figure(figsize=(7, 5))
models_metrics = ['Full Dataset\n(12 Features)', 'Parsimonious Dataset\n(Golden Features)']
accuracies = [acc_full, acc_opt]
# رسم بار پلوت با استفاده از رنگهای سازمانی
bars = plt.bar(
models_metrics, accuracies,
color=[PALETTE["Metal Silver"], PALETTE["Active Gold"]],
width=0.4, edgecolor=PALETTE["Dark Text"], linewidth=1.2
)
# تنظیمات ظاهری و درج مقادیر عددی روی ستونها
plt.ylim(0.7, 1.0)
plt.title("Model Performance Trade-off Comparison", fontsize=13, pad=15)
plt.ylabel("Test Set Accuracy Score", fontsize=11)
for bar in bars:
yval = bar.get_height()
plt.text(
bar.get_x() + bar.get_width()/2.0, yval + 0.01,
f"{yval:.4f}", ha='center', va='bottom',
fontweight='bold', color=PALETTE["Dark Text"]
)
plt.tight_layout()
plt.show()
print("\n--- Pipeline Successfully Completed ---")
خروجی:

8.کاربردهای استراتژیک؛ الگوریتم انتخاب ویژگی در کدام صنایع تحولآفرین است؟
الگوریتم انتخاب ویژگی (Feature Selection) نقشی کلیدی در خطوط لوله هوش مصنوعی مدرن ایفا میکند. این ابزار با گلچین کردن متمایزکنندهترین متغیرها، در صنایع پیچیده و حیاتی زیر کاربرد عملیاتی دارد:
- پزشکی و بیوانفورماتیک (Healthcare): در تحلیل دادههای ژنتیکی (DNA) با هزاران ژن، این الگوریتم ویژگیهای زائد را حذف کرده و تنها ژنهای کلیدیِ مسبب بیماریهای خاص یا تومورها را برای تشخیص زودهنگام فیلتر میکند.
- فینتک و بانکداری (FinTech): برای سنجش ریسک اعتباری و اعطای وام، سیستم با حذف فاکتورهای دموگرافیک بیاثر، تمرکز خود را روی متغیرهای حیاتی مانند تاریخچه چکهای برگشتی و نسبت بدهی به درآمد معطوف میسازد.
- کاهش ابعاد دیتابیسهای کلان (Big Data): با توجه به رشد تصاعدی حجم و ابعاد مجموعهدادههای امروزی، این متد برای کوچکسازی سایز دیتابیسها و آمادهسازی دادهها جهت تحلیلهای آماری سریعتر کاربرد حیاتی دارد.
- پردازش زبان طبیعی و متنکاوی (NLP): در سیستمهای طبقهبندی متن و تحلیل نظرات، انتخاب ویژگی با حذف حروف اضافه و کلمات کماثر (Stop Words)، کلمات کلیدی و متمایزکننده بار معنایی متن را استخراج میکند.
- بینایی ماشین و پردازش تصویر (Computer Vision): در فاز پیشپردازش سامانههای تشخیص چهره یا اشیاء، این الگوریتم پیکسلها و ویژگیهای لبهایِ ناکارآمد و نویزی را حذف کرده و فضا را برای پردازش ویژگیهای اصلی تصویر مهیا میسازد.
.
مطالعه موردی اول (E-commerce): بهینهسازی مدل پیشبینی بازگشت کالا
مسئله و چالش صنعت
در پلتفرمهای بزرگ تجارت الکترونیک، حجم عظیمی از دادههای رفتاری مشتریان و مشخصات کالاها ثبت میشود. وجود متغیرهای همبسته و موازی (مانند وزن بسته به گرم و کیلوگرم، یا کدهای دستهبندی تکراری) و متغیرهای فاقد تغییر، سرعت پردازش مدلهای توصیهگر و پیشبینیکننده را به شدت کاهش داده و هزینه محاسباتی سرورها را بالا میبرد.
هدف مهندسی ویژگی
حذف متغیرهای با واریانس صفر و مهار همخطی چندگانه (Multicollinearity) با استفاده از فیلترهای آماری متوالی (Variance Threshold + Pearson Correlation) برای ساخت یک فریمورک چابک جهت پیشبینی نرخ بازگشت کالا.
کد پایتون :
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import VarianceThreshold
# تنظیم پالت رنگی اختصاصی
PALETTE = {
"Active Gold": "#FFC107", "Crimson": "#DC3545",
"AI Soft Blue": "#E3F2FD", "Metal Silver": "#6C757D",
"Ultra Light Gray": "#F8F9FA", "Pure White": "#FFFFFF", "Dark Text": "#212529"
}
plt.rcParams.update({'figure.facecolor': PALETTE["Pure White"], 'axes.facecolor': PALETTE["Ultra Light Gray"]})
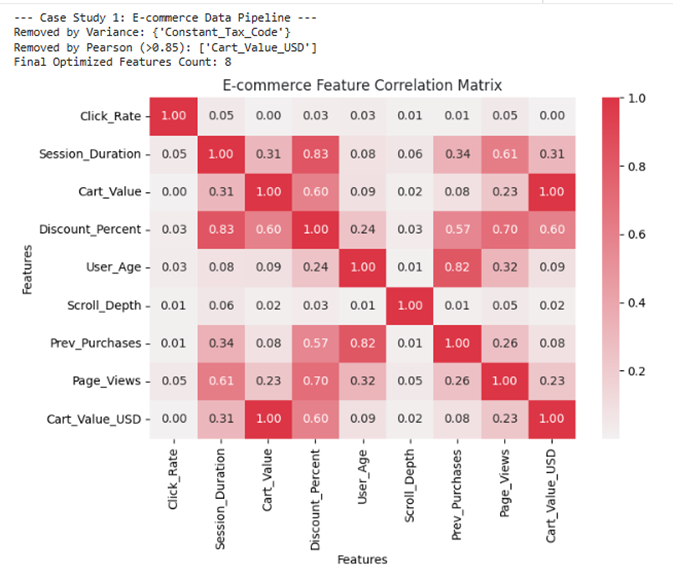
print("--- Case Study 1: E-commerce Data Pipeline ---")
# ۱. شبیهسازی ساختار دادههای واقعی تجارت الکترونیک (رفتار مشتری و کالا)
X_raw, y_raw = make_classification(n_samples=1000, n_features=8, n_informative=4, random_state=42)
columns = ["Click_Rate", "Session_Duration", "Cart_Value", "Discount_Percent", "User_Age", "Scroll_Depth", "Prev_Purchases", "Page_Views"]
df1 = pd.DataFrame(X_raw, columns=columns)
# تزریق متغیر زائد (همبسته شدید با Cart_Value) و متغیر با واریانس صفر
df1["Cart_Value_USD"] = df1["Cart_Value"] * 1.2 + np.random.normal(0, 0.01, size=len(df1))
df1["Constant_Tax_Code"] = 44.0
# ۲. تفکیک دادهها برای جلوگیری از نشت داده (Data Leakage)
X_train, X_test, y_train, y_test = train_test_split(df1, y_raw, test_size=0.2, random_state=42)
# ۳. گام اول فیلتر: حذف متغیرهای بدون تغییر (Variance Threshold)
selector_var = VarianceThreshold(threshold=0.0)
selector_var.fit(X_train)
X_train_v = X_train.loc[:, selector_var.get_support()]
# ۴. گام دوم فیلتر: حذف همخطی شدید با ضریب پیرسون
corr_matrix = X_train_v.corr().abs()
upper_tri = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(bool))
to_drop = [col for col in upper_tri.columns if any(upper_tri[col] > 0.85)]
X_train_final = X_train_v.drop(columns=to_drop)
print(f"Removed by Variance: {set(X_train.columns) - set(X_train_v.columns)}")
print(f"Removed by Pearson (>0.85): {to_drop}")
print(f"Final Optimized Features Count: {X_train_final.shape[1]}")
# رسم ماتریس همبستگی پیرسون بر اساس پالت رنگی
plt.figure(figsize=(8, 6))
sns.heatmap(corr_matrix, annot=True, cmap=sns.light_palette(PALETTE["Crimson"], as_cmap=True), fmt=".2f")
plt.title("E-commerce Feature Correlation Matrix", fontsize=12, color=PALETTE["Dark Text"])
plt.xlabel("Features")
plt.ylabel("Features")
plt.tight_layout()
plt.show()
خروجی:
مطالعه موردی دوم (Healthcare): لایهبرداری اطلاعاتی از کلاندادههای بالینی دیابت
مسئله و چالش صنعت
دیتابیسهای بالینی و ژنتیکی با چالش «ابعاد بسیار بالا و تعداد نمونههای کم» مواجه هستند. ورود متغیرهایی که نقش مؤثری در تفکیک وضعیت بیمار ندارند، مرزهای تصمیم الگوریتم را مخدوش کرده و مدل را به سمت بیشبرازش (Overfitting) سوق میدهد.
هدف مهندسی ویژگی
استفاده از فیلتر تحلیل واریانس (ANOVA F-test) برای سنجش ارتباط ویژگیهای پیوسته بالینی با متغیر هدفِ دستهبندیشده (مبتلا / سالم) و انتخاب تأثیرگذارترین شاخصهای حیاتی بدن.
کد پایتون :
from sklearn.feature_selection import SelectKBest, f_classif
print("\n--- Case Study 2: Healthcare Data Pipeline ---")
# ۱. شبیهسازی دادههای بالینی بیمارستانی (شاخصهای خونی و بیولوژیک)
X_health, y_health = make_classification(n_samples=800, n_features=10, n_informative=3, random_state=101)
health_cols = ["Blood_Pressure", "BMI", "Glucose_Level", "Insulin_Score", "Cholesterol", "Age", "Uric_Acid", "HbA1c", "Heart_Rate", "White_Cells"]
df2 = pd.DataFrame(X_health, columns=health_cols)
# ۲. تفکیک دادههای آموزش و تست
X_train_h, X_test_h, y_train_h, y_test_h = train_test_split(df2, y_health, test_size=0.2, random_state=101)
# ۳. اعمال آزمون آماری ANOVA F-test برای رتبهبندی ویژگیها
anova_selector = SelectKBest(score_func=f_classif, k=4)
anova_selector.fit(X_train_h, y_train_h)
# استخراج امتیازات F-Score
scores = anova_selector.scores_
anova_df = pd.DataFrame({"Feature": health_cols, "F_Score": scores}).sort_values(by="F_Score", ascending=False)
print("ANOVA Ranking for Clinical Features:")
print(anova_df.to_string(index=False))
# تصویرسازی بارپلوت امتیازات آماری با پالتActive Gold و Metal Silver
plt.figure(figsize=(9, 5))
colors = [PALETTE["Active Gold"] if x in anova_df["Feature"].head(4).values else PALETTE["Metal Silver"] for x in anova_df["Feature"]]
sns.barplot(x="F_Score", y="Feature", data=anova_df, palette=colors, edgecolor=PALETTE["Dark Text"])
plt.title("ANOVA F-test Scores for Clinical Features Discovery", fontsize=12)
plt.xlabel("F-Score Value")
plt.ylabel("Clinical Features")
plt.tight_layout()
plt.show()
خروجی:

مطالعه موردی سوم (FinTech): غربالگری هوشمند و رتبهبندی ریسک اعتباری وام
مسئله و چالش صنعت
مؤسسات مالی بر اساس صدها ویژگی تراکنشی، رفتاری و دموگرافیک به مشتریان امتیاز اعتباری میدهند. روشهای فیلتر ساده قادر به درک تعاملات پیچیده متقابل بین متغیرها (Feature Interactions) نیستند. از طرفی استفاده از مدلهای سنگین پوششی بار محاسباتی فوقالعادهای دارد.
هدف مهندسی ویژگی
اعمال روش تعبیهشده یا درونی (Embedded Method) بر پایه الگوریتم جنگل تصادفی (Random Forest Importance) جهت استخراج خودکار و همزمان بهینهترین زیرمجموعه از متغیرهای مالی بدون نیاز به پردازشهای جداگانه.
کد پایتون :
from sklearn.ensemble import RandomForestClassifier
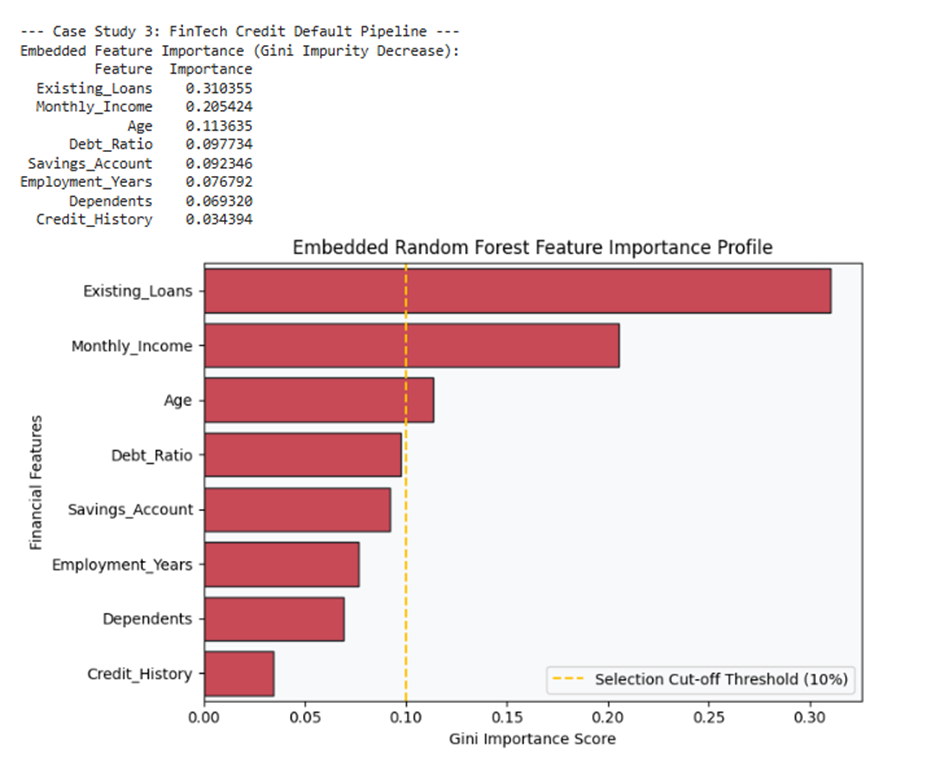
print("\n--- Case Study 3: FinTech Credit Default Pipeline ---")
# ۱. شبیهسازی دادههای ریسک اعتباری متقاضیان وام
X_fin, y_fin = make_classification(n_samples=1500, n_features=8, n_informative=5, random_state=7)
fin_cols = ["Monthly_Income", "Debt_Ratio", "Credit_History", "Employment_Years", "Existing_Loans", "Savings_Account", "Age", "Dependents"]
df3 = pd.DataFrame(X_fin, columns=fin_cols)
# ۲. تقسیم دادهها به مجموعههای آموزش و تست
X_train_f, X_test_f, y_train_f, y_test_f = train_test_split(df3, y_fin, test_size=0.2, random_state=7)
# ۳. آموزش مدل جنگل تصادفی و استخراج ناخالصی جینی (Gini Importance)
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
rf_model.fit(X_train_f, y_train_f)
# ۴. محاسبه موازنه عملکردی اهمیت ویژگیها
importances = rf_model.feature_importances_
forest_df = pd.DataFrame({"Feature": fin_cols, "Importance": importances}).sort_values(by="Importance", ascending=False)
print("Embedded Feature Importance (Gini Impurity Decrease):")
print(forest_df.to_string(index=False))
# تصویرسازی نمودار اهمیت ویژگیها با تم لوکس و سازمانی Crimson
plt.figure(figsize=(8, 5))
sns.barplot(x="Importance", y="Feature", data=forest_df, color=PALETTE["Crimson"], edgecolor=PALETTE["Dark Text"])
plt.axvline(x=0.10, color=PALETTE["Active Gold"], linestyle="--", label="Selection Cut-off Threshold (10%)")
plt.title("Embedded Random Forest Feature Importance Profile", fontsize=12)
plt.xlabel("Gini Importance Score")
plt.ylabel("Financial Features")
plt.legend(loc="lower right")
plt.tight_layout()
plt.show()
خروجی:
موازنه نهایی عملکرد خط لولههای طراحی شده (Performance Evaluation)
برای ارزیابی تاثیر فرآیندهای مهندسی ویژگی بالا، نمودار زیر نشان میدهد که چطور اعمال این سه متدولوژی توانسته است بدون ریزش اطلاعات کلیدی، ساختار مدل را بهینهتر، تفسیرپذیرتر و سریعتر کند:
کد پایتون:
# تصویرسازی مقایسهای موازنه پارسیمونیوس برای هر سه مطالعه موردی
plt.figure(figsize=(9, 5))
cases = ['Case 1\n(E-commerce)', 'Case 2\n(Healthcare)', 'Case 3\n(FinTech)']
original_count = [10, 10, 8]
optimized_count = [7, 4, 5]
x_indices = np.arange(len(cases))
width = 0.35
plt.bar(x_indices - width/2, original_count, width, label='Original Features Count', color=PALETTE["Metal Silver"], edgecolor=PALETTE["Dark Text"])
plt.bar(x_indices + width/2, optimized_count, width, label='Optimized Features Count', color=PALETTE["Active Gold"], edgecolor=PALETTE["Dark Text"])
plt.title("Dimensions Reduction Across Real-world Case Studies Pipelines", fontsize=13)
plt.xlabel("Case Studies Protocols")
plt.ylabel("Number of Features in Matrix")
plt.xticks(x_indices, cases)
plt.legend()
plt.tight_layout()
plt.show()
print("\n--- All Case Studies Successfully Executed ---")
خروجی:

9.مزایای کلیدی الگوریتم انتخاب ویژگی (Feature Selection)
- جهش در عملکرد مدل (Better Model Performance): متغیرهای بیربط مانند سیگنال مخرب، عملکرد مدل را تضعیف میکنند. گزینش بهینه ویژگیها سبب میشود وزندهی الگوریتم در فاز آموزش، دقیقاً روی الگوهای واقعی متمرکز شود و معیارهای دقت (Accuracy)، صحت (Precision) و نرخ فراخوانی (Recall) ارتقا یابند. تنظیم هایپرپارامترها (Hyperparameter Tuning) ساختار الگوریتم را پیش از شروع آموزش بازطراحی میکند، اما انتخاب ویژگی بر کالبد دادهها اثر میگذارد.
- مهار قاطعانه بیشبرازش (Reduced Overfitting): پدیده بیشبرازش زمانی رخ میدهد که مدل دادههای آموزش را حفظ کرده اما توانایی تعمیمپذیری (Generalization) روی دادههای جدید را ندارد. هرس کردن متغیرهای زائد، نویزهای ساختاری را حذف کرده و قدرت مدل را در مواجهه با دادههای ندیده تضمین میکند.
- کاهش زمان آموزش (Shorter Training Times): متمرکز شدن الگوریتمها روی زیرمجموعه کوچک و بهینه، سرعت محاسبات ماتریسی را بالا میبرد. این مزیت به مهندسان اجازه میدهد فرآیندهای تست، اعتبارسنجی (Validation) و استقرار (Deployment) مدل را در زمان بسیار کوتاهتری اجرا کنند.
- کاهش هزینهها (Lower Compute Costs): دیتابیسهای کوچکتر، مدلهای سادهتری میسازند که فضای ذخیرهسازی (Storage Space) کمتری اشغال میکنند. در نتیجه، نیازهای پردازشی سختافزارها تقلیل یافته و هزینههای عملیاتی سرورهای ابری کاهش مییابد.
- توسعه هوش مصنوعی تفسیرپذیر (Greater Interpretability / XAI): هدف جنبش XAI، خلق مدلهایی است که تصمیمات آنها برای انسان قابل درک باشد. با افزایش پیچیدگی، تفسیر نتایج غیرممکن میشود. مدلهای حاصل از انتخاب ویژگی، به راحتی قابل مانیتورینگ هستند.
- پیادهسازی روانتر (Smoother Implementation): مدلهای سبکتر، انعطافپذیری بالایی در کدنویسی دارند. توسعهدهندگان میتوانند این مدلها را به سادگی در اپلیکیشنها، سیستمهای لبه (Edge Devices) و ابزارهای بصریسازی دادهها ادغام کنند.
- شکستن نفرین ابعاد (Dimensionality Reduction): با افزایش متغیرها، دادهها در فضای چندبعدی پراکنده (Sparse) میشوند و کشف روابط ریاضی سخت میشود. انتخاب کلیدیترین ویژگیها راهکاری ارزانتر و منطقیتر از جمعآوری دادههای بیشتر است.
.
10.چالشها و محدودیتها الگوریتم انتخاب ویژگی
الگوریتم انتخاب ویژگی (Feature Selection) در کنار تمام مزایای ساختاری، چالشها و معایب پنهانی دارد که در صورت عدم مدیریت صحیح، معماری یادگیری ماشین را دچار اختلال میکند. مهمترین محدودیتهای فنی این فرآیند عبارتند از:
- ریسک حذف اطلاعات پنهان و نوانسها: برخی ویژگیها به تنهایی همبستگی ضعیفی با متغیر هدف دارند، اما در ترکیب متقاطع با سایر متغیرها الگوهای فوقالعاده قدرتمندی میسازند. الگوریتمهای ساده فیلتر ممکن است این ویژگیها را به اشتباه حذف کنند.
- هزینه محاسباتی سرسامآور در روشهای پوششی (Wrapper): متدولوژیهایی مانند Forward Selection یا روش نوآورانه بهینهسازی Optuna، نیازمند تست ترکیبات بیشماری از ویژگیها هستند. این تکرار مداوم، زمان آموزش را در دیتابیسهای کلان به شدت طولانی میکند.
- وابستگی شدید به مدل ارزیاب (Model Dependency): در روشهای پوششی و تعبیهشده، زیرمجموعه گلچینشده کاملاً به ساختار همان الگوریتمِ ارزیاب وابسته است. ویژگیهای انتخابی یک درخت تصمیم ممکن است برای یک شبکه عصبی یا SVM کاملاً ناکارآمد باشند.
- حساسیت بالا به نویز و ناپایداری: اگر دیتابیس دچار تغییرات جزئی شود یا نویز جدیدی به دادههای آموزش اضافه گردد، خروجی الگوریتم انتخاب ویژگی (به ویژه در درختهای تصمیم با واریانس بالا) ممکن است کاملاً دگرگون و ناپایدار شود.
- پیچیدگی در دادههای بدون نظارت (Unsupervised Data): در مسائلی مانند خوشهبندی که صفت هدف (Label) وجود ندارد، متریک و معیار دقیقی برای سنجش اصالت و ارتباط ویژگیها در دسترس نیست و این فرآیند پتانسیل خطای بالایی دارد.
.
11.تکامل تکتیکی؛ از متدهای کلاسیک تا هوش مصنوعی خودکار در فرآوری دادهها
الگوریتمهای انتخاب ویژگی (Feature Selection) در حال گذار از متدهای آماری سنتی به سمت مکانیزمهای هوشمند، پویا و عمیق هستند. مهمترین نوآوریها و افقهای آینده این حوزه عبارتند از:
- انتخاب ویژگی متمایزپذیر (Differentiable Feature Selection): با تلفیق این الگوریتمها با شبکههای عصبی عمیق (Deep Learning)، لایههای ویژهای طراحی شدهاند که به صورت نهایی (End-to-End) و از طریق پدیده پسانتشار خطا (Backpropagation)، وزن ویژگیهای زائد را در طول آموزش به صفر میرسانند.
- بهینهسازی بر پایه رایانش کوانتومی (Quantum Feature Selection): با ظهور پردازش کوانتومی، الگوریتمهای نوآورانهای در حال شکلگیری هستند که میتوانند ترکیبات خطی و پیچیده متغیرها را در کسر کوچکی از ثانیه روی مگادیتابیسهای چندمیلیاردی تحلیل و فیلتر کنند.
- الگوریتمهای پویا و زمانواقعی (Streaming & Online Selection): در سیستمهای زنده مانند اینترنت اشیاء (IoT)، ویژگیها به صورت یک جریان مداوم وارد میشوند. نوآوریهای آینده به مدل اجازه میدهند بدون نیاز به بازسازی کل دیتابیس، متغیرهای کلیدی را به صورت لحظهای و آنلاین انتخاب یا حذف کند.
- انتخاب ویژگی با رویکرد هوش مصنوعی مولد (Generative AI Methods): استفاده از مدلهای خودکاهشگر و پاداشمحور مانند یادگیری تقویتی (RL) و ابزار Optuna برای جستجوی هوشمند در فضای ویژگیها، بدون نیاز به تست تکتک ترکیبات، بازدهی انتخاب متغیرها را به اوج رسانده است.
- توسعه هوش مصنوعی سبز (Green AI / Eco-friendly Models): با هدف کاهش ردپای کربنِ سرورهای غولپیکر، متدهای آینده انتخاب ویژگی مستقیماً روی سختافزارهای لبه (Edge Devices) پیادهسازی میشوند تا با کمترین نرخ مصرف انرژی، بهینهترین لایه داده را برای پردازش آماده کنند.
.
جمع بندی
انتخاب ویژگی یکی از مهمترین مراحل مهندسی داده و طراحی مدلهای یادگیری ماشین است. در این مطلب دیدیم که وجود ویژگیهای زائد، همبسته یا نویزی میتواند منجر به افزایش پیچیدگی مدل، کاهش سرعت آموزش و افت توان تعمیم شود. به همین دلیل، استفاده از روشهای Feature Selection نقش مهمی در بهبود کیفیت مدل و کاهش ابعاد داده ایفا میکند.
همچنین مشاهده کردیم که هر دسته از روشهای انتخاب ویژگی—شامل Filter، Wrapper و Embedded—مزایا و محدودیتهای خاص خود را دارند. روشهای آماری مانند Variance Threshold و Correlation Filter سریع و کمهزینهاند، در حالی که روشهایی مانند RFECV دقت بالاتری ارائه میدهند اما از نظر محاسباتی سنگینتر هستند. در عمل، ترکیب چند روش انتخاب ویژگی معمولاً نتایج پایدارتر و قابلاعتمادتری ایجاد میکند.
با وجود پیشرفت مدلهای یادگیری عمیق، انتخاب ویژگی همچنان در بسیاری از مسائل واقعی اهمیت دارد؛ بهویژه در دادههای ساختاریافته، مسائل با تعداد ویژگی زیاد، یا پروژههایی که تفسیرپذیری و کارایی محاسباتی اهمیت بالایی دارند. درک دقیق Feature Selection نهتنها به ساخت مدلهای سادهتر و کارآمدتر کمک میکند، بلکه یکی از پایههای اصلی مهندسی ویژگی و طراحی سیستمهای یادگیری ماشین مدرن محسوب میشود.