

1.چکیده
الگوریتم CLARANS که مخفف ِClustering Large Applications based on Randomized Search است، یکی از روشهای مهم خوشهبندی مبتنی بر medoid به شمار میرود که برای بهبود مقیاسپذیری و کیفیت جستوجو در دادههای نسبتاً بزرگ طراحی شده است. این روش را میتوان حلقهای میان PAM و CLARA دانست: از یک سو مانند PAM در چارچوب k-medoids عمل میکند و از سوی دیگر، برای اجتناب از جستوجوی پرهزینه کامل، از راهبرد جستوجوی تصادفی در همسایگی راهحلها بهره میگیرد. ایده اصلی CLARANS این است که بهجای بررسی همه جابهجاییهای ممکن میان medoidها و نقاط غیرmedoid، تنها بخشی از همسایهها را بهصورت تصادفی ارزیابی کند و در صورت مشاهده بهبود، به راهحل جدید منتقل شود. این ویژگی باعث میشود الگوریتم بتواند در بسیاری از مسائل، توازنی عملی میان کیفیت خوشهبندی و هزینه محاسباتی برقرار کند.
در این مقاله، ما CLARANS را از منظر مفهومی، ریاضی و اجرایی بررسی میکنیم، سپس با مثالهای عددی، مزایا، محدودیتها، کاربردهای واقعی و مقایسه آن با روشهای نزدیک، جایگاه این الگوریتم را در خوشهبندی دادههای بزرگ روشن میسازیم (Ng & Han, 1994; Kaufman & Rousseeuw, 1990).
2.مقدمه
خوشهبندی یکی از بنیادیترین مسائل در یادگیری بدوننظارت (Unsupervised Learning) است. در این مسئله، هدف آن است که دادههای فاقد برچسب را بر اساس شباهت یا فاصله، به گروههایی معنادار تقسیم کنیم. اگر اعضای هر گروه تا حد امکان به یکدیگر شبیه باشند و در عین حال از اعضای گروههای دیگر فاصله بیشتری داشته باشند، میتوان گفت خوشهبندی بهخوبی انجام شده است.
در میان خانواده الگوریتمهای خوشهبندی، روشهای مبتنی بر medoid جایگاه ویژهای دارند. برخلاف centroid در الگوریتم k-Means که معمولاً یک میانگین انتزاعی است، medoid یک نقطه واقعی از خود دادههاست. همین ویژگی باعث میشود این دسته از روشها تفسیرپذیری بیشتری داشته باشند و در مواجهه با نقاط پرت یا فاصلههای غیراقلیدسی، عملکرد قابلقبولتری نشان دهند.
الگوریتم PAM یکی از کلاسیکترین روشهای k-medoids است، اما هزینه محاسباتی آن در دادههای بزرگ بهسرعت افزایش مییابد. CLARA برای کاهش این هزینه از نمونهگیری استفاده کرد، اما این راهحل نیز وابستگی بالایی به کیفیت نمونهها دارد. CLARANS برای پاسخ به همین چالش مطرح شد: روشی که بهجای نمونهگیری صرف، از جستوجوی تصادفی در فضای راهحلها استفاده میکند تا بدون بررسی کامل همه حالتها، به پاسخهای خوب برسد.
3.تعاریف و مفاهیم پایه
3.1. همسایگی (Neighborhood) در CLARANS
در CLARANS، هر راهحل را میتوان مجموعهای از k medoid در نظر گرفت. همسایه یک راهحل، راهحلی است که در آن یکی از medoidها با یک نقطه غیرmedoid جایگزین شده باشد.
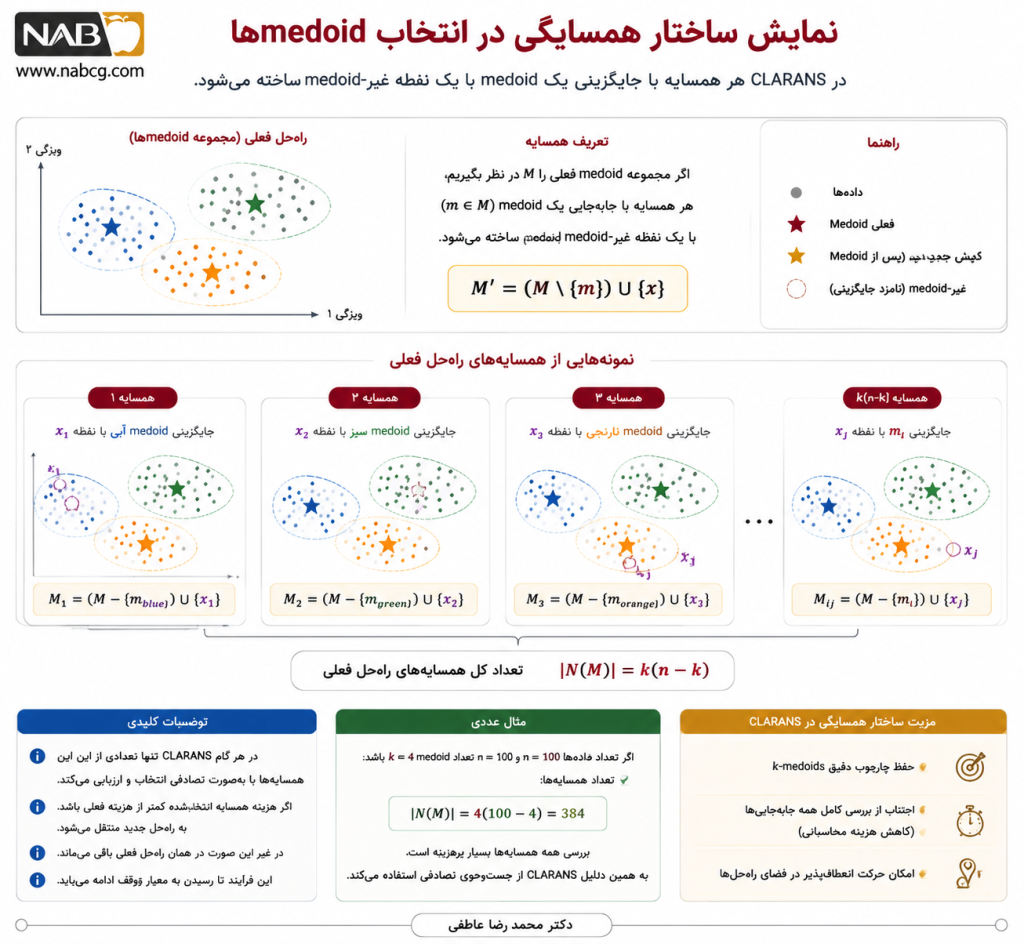
اگر راهحل فعلی را M بنامیم، هر همسایه از شکل زیر به دست میآید:
M′ = (M∖{m}) ∪ {x}
که در آن:
- M: مجموعه medoidهای فعلی
- ′M: یک راهحل همسایه
- m: یکی از medoidهای فعلی
- x: یک نقطه غیرmedoid
- \: عملگر حذف از مجموعه
- ∪: اجتماع مجموعهها
ایده CLARANS این است که بهجای بررسی همه این همسایهها، فقط تعداد محدودی از آنها را بهصورت تصادفی بررسی کند.
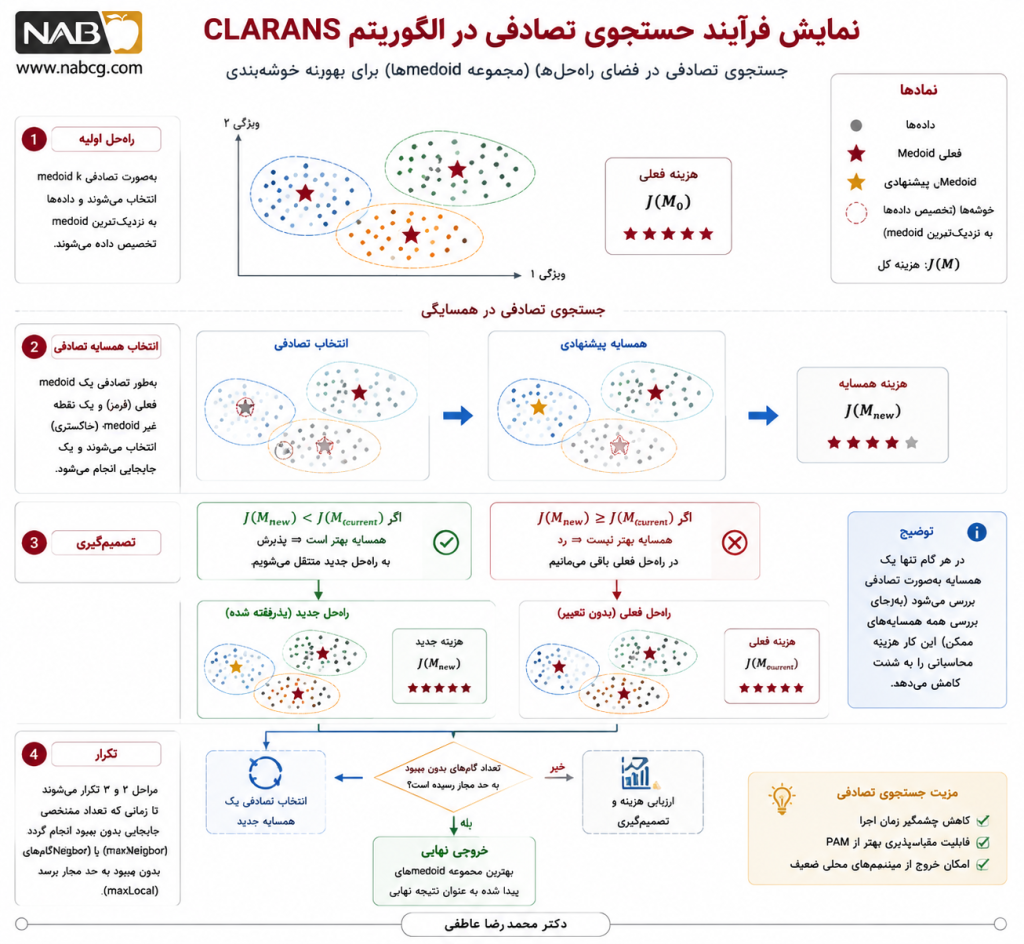
3.2.جستوجوی تصادفی (Randomized Search)
جستوجوی تصادفی در اینجا به این معناست که الگوریتم بهجای پیمایش نظاممند کل فضای همسایهها، تعدادی از جابهجاییهای ممکن را بهطور تصادفی انتخاب و ارزیابی میکند. این کار باعث میشود هزینه محاسباتی کاهش یابد و الگوریتم بتواند در فضای راهحلها با انعطاف بیشتری حرکت کند.
4.مسئلهای که این روش حل میکند؛ اهمیت و ضرورت
CLARANS برای حل یک مسئله مشخص طراحی شده است: یافتن خوشههای medoidمحور در دادههایی که آنقدر بزرگ یا پیچیده هستند که جستوجوی کامل در فضای راهحلها از نظر زمانی بسیار پرهزینه میشود.
در الگوریتم PAM، برای بهبود راهحل باید جابهجاییهای فراوانی میان medoidها و نقاط غیرmedoid بررسی شود. این فرایند در دادههای کوچک قابلمدیریت است، اما با افزایش تعداد نمونهها، تعداد همسایههای ممکن بهسرعت رشد میکند. در نتیجه، اجرای PAM در مقیاس بزرگ کند و گاهی غیرعملی میشود. CLARA این مشکل را با نمونهگیری کاهش میدهد، اما اگر نمونهها نماینده خوبی از ساختار داده نباشند، کیفیت راهحل افت میکند.
CLARANS در پاسخ به همین شکاف مطرح شد. این الگوریتم تلاش میکند بدون اتکا به یک زیرنمونه ثابت و بدون جستوجوی کامل همه همسایهها، در فضای راهحلها حرکت کند و راهحلهای بهتری پیدا کند. اهمیت این رویکرد در آن است که میان کیفیت و هزینه محاسباتی تعادل برقرار میکند. بهبیان دیگر، CLARANS برای موقعیتهایی مناسب است که PAM بیش از حد سنگین و CLARA بیش از حد وابسته به نمونهگیری باشد.
ضرورت این روش بهویژه در مسائل دادهکاوی، تحلیل مشتریان، دادههای مکانی و کاربردهای بزرگمقیاس دیده میشود؛ جایی که هم تفسیرپذیری medoid اهمیت دارد و هم سرعت اجرای الگوریتم یک محدودیت واقعی است (Ng & Han, 1994; Han et al., 2011).
.
5.مبانی نظری و ریاضی
5.1. تابع هدف در k-Medoids
فرض کنید مجموعه داده بهصورت زیر باشد:
X={x1,x2,…,xn}
و بخواهیم k medoid انتخاب کنیم. اگر مجموعه medoidها را با M نشان دهیم، تابع هدف کلاسیک k-medoids چنین است:
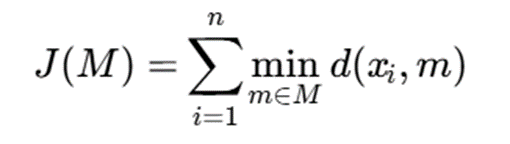
توضیح نمادها:
- X: مجموعه کل دادهها
- xi: نمونه شماره i
- n: تعداد کل نمونهها
- M: مجموعه medoidهای انتخابشده
- m: یک medoid از مجموعه M
- d(xi,m): فاصله میان نمونه xix_ixi و medoid mmm
- J(M): هزینه کل خوشهبندی
تفسیر فرمول:
برای هر نقطه، فاصله آن تا نزدیکترین medoid محاسبه میشود و مجموع این فاصلهها بهعنوان هزینه کل در نظر گرفته میشود. هدف، کمینه کردن این هزینه است.
.
5.2. تابع هزینه میانگین
در برخی پیادهسازیها یا تحلیلهای مقایسهای، بهجای مجموع فاصلهها از میانگین آن استفاده میشود:
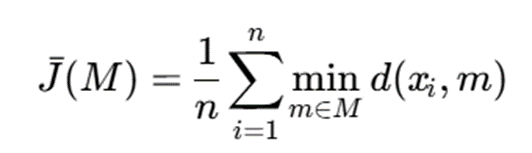
که در آن:
- (M)ˉJ: میانگین هزینه
- سایر نمادها همان معانی قبلی را دارند
این فرم برای مقایسه نتایج روی مجموعهدادههای با اندازه متفاوت مفید است.
.
5.3. فضای همسایگی در CLARANS
اگر راهحل فعلی M شامل k medoid باشد، هر همسایه با جایگزینی یک medoid و یک non-medoid ساخته میشود. در نتیجه، تعداد کل همسایههای مستقیم راهحل فعلی برابر است با:
∣N(M)∣=k(n−k)
که در آن:
- ∣N(M)|: تعداد همسایههای راهحل M
- k: تعداد medoidها
- n-k: تعداد نقاط غیرmedoid
این مقدار نشان میدهد چرا بررسی کامل همه همسایهها در دادههای بزرگ پرهزینه میشود.
.
5.4. منطق جستوجو در CLARANS
CLARANS از یک فرایند جستوجوی محلی تصادفی استفاده میکند. در هر مرحله، یک همسایه تصادفی از راهحل فعلی انتخاب میشود. اگر هزینه همسایه کمتر از هزینه راهحل فعلی باشد، الگوریتم به آن همسایه منتقل میشود. در غیر این صورت، جستوجو ادامه پیدا میکند تا تعداد مشخصی همسایه بدون بهبود بررسی شوند.
اگر هزینه راهحل فعلی را با J(M) و هزینه همسایه را با J(M’)نشان دهیم، قاعده تصمیم بهصورت زیر است:
if J(M′) < J(M) then M←M′
این رابطه بیان میکند:
- M: راهحل فعلی
- ′M: راهحل همسایه
- (M) J: هزینه راهحل فعلی
- J(M’) : هزینه همسایه
- ‘M←M : جایگزینی راهحل فعلی با همسایه بهتر
.
5.5.پارامترهای کلیدی CLARANS
دو پارامتر مهم در CLARANS عبارتاند از:
الف) numlocal
تعداد دفعاتی که جستوجوی محلی از یک نقطه شروع تصادفی آغاز میشود. هرچه این مقدار بیشتر باشد، احتمال رسیدن به راهحل بهتر بیشتر میشود، اما زمان اجرا نیز افزایش مییابد.
ب) maxneighbor
حداکثر تعداد همسایههایی که در یک جستوجوی محلی، بدون یافتن بهبود بررسی میشوند. اگر این حد پر شود، الگوریتم فرض میکند در یک کمینه محلی مناسب قرار گرفته و آن جستوجوی محلی را خاتمه میدهد.
.
5.6. فرضهای پایه
برای استفاده معنادار از CLARANS معمولاً چند فرض ضمنی وجود دارد:
- دادهها را بتوان با یک معیار فاصله مناسب مقایسه کرد.
- تعداد خوشهها k از قبل مشخص یا قابلتخمین باشد.
- ساختار خوشهها تا حدی با چارچوب k-medoids سازگار باشد.
- راهحل تقریبی اما سریع، از نظر عملی قابلقبول باشد.
.
6.مراحل گام به گام اجرای الگوریتم
6.1. ورودیها
ورودیهای اصلی CLARANS عبارتاند از:
- مجموعه داده X
- تعداد خوشهها k
- تعداد جستوجوهای محلی numlocaln
- حداکثر همسایههای بدون بهبود maxneighbor
- معیار فاصله d
.
6.2. خروجیها
خروجی الگوریتم شامل موارد زیر است:
- مجموعه نهایی medoidها
- تخصیص هر داده به نزدیکترین medoid
- هزینه نهایی خوشهبندی
.
6.3. مراحل اجرایی
گام 1: انتخاب راهحل اولیه
در آغاز هر جستوجوی محلی، k نقطه از دادهها بهصورت تصادفی بهعنوان medoid اولیه انتخاب میشوند.
گام 2: محاسبه هزینه راهحل اولیه
برای هر نقطه از داده، نزدیکترین medoid پیدا میشود و مجموع فاصلهها محاسبه میگردد.
گام 3: تولید همسایه تصادفی
یک medoid فعلی و یک non-medoid بهصورت تصادفی انتخاب میشوند. سپس با جایگزینی آنها، یک راهحل همسایه ساخته میشود.
گام 4: ارزیابی همسایه
هزینه راهحل همسایه محاسبه میشود.
گام 5: تصمیمگیری
اگر همسایه جدید بهتر باشد، راهحل فعلی با آن جایگزین میشود و شمارنده همسایههای ناموفق به صفر برمیگردد. اگر بهتر نباشد، فقط شمارنده یک واحد افزایش مییابد.
گام 6: پایان جستوجوی محلی
اگر تعداد همسایههای بررسیشده بدون بهبود به maxneighbo برسد، جستوجوی محلی متوقف میشود و بهترین راهحل همین جستوجو ثبت میگردد.
گام 7: تکرار جستوجوی محلی
فرایند از یک شروع تصادفی جدید، numlocal بار تکرار میشود.
گام 8: انتخاب بهترین پاسخ نهایی
از میان همه جوابهای محلی بهدستآمده، راهحلی انتخاب میشود که کمترین هزینه را دارد.
.
6.4. معیار توقف
CLARANS دو معیار توقف اصلی دارد:
- در سطح جستوجوی محلی: وقتی maxneighbor همسایه متوالی بدون بهبود بررسی شود.
- در سطح کلی الگوریتم: وقتی تعداد جستوجوهای محلی به numlocal برسد.
6.5. شبهکد
Input: X, k, numlocal, maxneighbor
Output: best medoids
bestnode = null
bestcost = infinity
for i = 1 to numlocal:
current = random solution with k medoids
currentcost = cost(current)
j = 0
while j < maxneighbor:
neighbor = random neighbor of current
neighborcost = cost(neighbor)
if neighborcost < currentcost:
current = neighbor
currentcost = neighborcost
j = 0
else:
j = j + 1
if currentcost < bestcost:
bestnode = current
bestcost = currentcost
return bestnode
6.6. نکته اجرایی مهم
CLARANS برخلاف CLARA بر یک زیرنمونه ثابت متکی نیست. همچنین برخلاف PAM همه همسایهها را exhaustively بررسی نمیکند. همین تفاوت، منطق اصلی این الگوریتم را شکل میدهد.
.
7.مثالهای عددی
مثال 1: خوشهبندی یکبعدی ساده
صورت مسئله
مجموعه داده زیر را با k=2 خوشهبندی کنید:
X={1,2,3,10,11,12}
فاصله را بهصورت قدرمطلق در نظر بگیرید:
d(xi,xj) = ∣xi−xj∣
داده ورودی
- دادهها: {1,2,3,10,11,12}
- تعداد خوشهها: 2
حل گامبهگام
فرض کنید راهحل اولیه بهصورت زیر باشد:
M={1,10}
هزینه راهحل اولیه:
- برای 1: فاصله تا 1 برابر 0
- برای 2: کمینه فاصله =1
- برای 3: کمینه فاصله =2
- برای 10: فاصله تا 10 برابر 0
- برای 11: کمینه فاصله =1
- برای 12: کمینه فاصله =2
پس:
J(M)=0+1+2+0+1+2=6
اکنون یک همسایه تصادفی بسازید. مثلاً medoid برابر 1 را با 2 جایگزین میکنیم:
M′={2,10}
هزینه جدید:
- 1 → 1
- 2 → 0
- 3 → 1
- 10 → 0
- 11 → 1
- 12 → 2
پس:
J(M′)=1+0+1+0+1+2=5
چون:
J(M′) < J(M)
راهحل جدید پذیرفته میشود.
پاسخ نهایی
در این مرحله، medoidهای بهتر برابرند با:
{2,10}
تفسیر نتیجه
این مثال نشان میدهد CLARANS با بررسی یک همسایه تصادفی میتواند از یک راهحل ضعیفتر به یک راهحل بهتر حرکت کند.
.
مثال 2: ادامه جستوجوی محلی روی همان داده
صورت مسئله
از راهحل {2,10} شروع کنید و بررسی کنید آیا یک همسایه بهتر وجود دارد یا نه.
داده ورودی
- راهحل فعلی: {2,10}
حل گامبهگام
فرض کنید همسایه تصادفی بعدی چنین باشد:
M′′={2,11}
هزینه این راهحل:
- 1 → فاصله تا 2 برابر 1
- 2 → 0
- 3 → 1
- 10 → فاصله تا 11 برابر 1
- 11 → 0
- 12 → 1
در نتیجه:
J(M′′)=1+0+1+1+0+1=4
از آنجا که:
4<5
راهحل جدید پذیرفته میشود.
پاسخ نهایی
medoidهای جدید برابرند با:
{2,11}
تفسیر نتیجه
CLARANS الزاماً در اولین بهبود متوقف نمیشود؛ بلکه تا زمانی که بتواند با همسایههای بهتر حرکت کند، جستوجوی محلی را ادامه میدهد.
.
مثال 3: داده دوبعدی با فاصله منهتن
صورت مسئله
نقاط زیر را با k=2 خوشهبندی کنید:
A(1,1),B(1,2),C(2,1),D(8,8),E(9,8),F(8,9)
از فاصله منهتن استفاده کنید:
d(xi,xj) = ∣xi1−xj1∣ + ∣xi2−xj2∣
داده ورودی
- شش نقطه دوبعدی
- دو خوشه
حل گامبهگام
فرض کنید راهحل اولیه:
M={A,D}
فاصلهها تا نزدیکترین medoid:
- A→0
- B→1
- C→1
- D→0
- E→1
- F→1
پس:
J(M)=0+1+1+0+1+1=4
اکنون یک همسایه تصادفی تولید شود، مثلاً:
M′={B,D}
فاصلهها:
- A→1
- B→0
- C→2
- D→0
- E→1
- F→1
پس:
J(M′)=1+0+2+0+1+1=5
چون هزینه افزایش یافته است، این همسایه رد میشود.
پاسخ نهایی
راهحل فعلی{A,D} حفظ میشود.
تفسیر نتیجه
در CLARANS هر همسایه جدید لزوماً بهتر نیست. الگوریتم فقط در صورت کاهش هزینه، راهحل همسایه را میپذیرد.
.
مثال 4: اثر پارامتر maxneighbor
صورت مسئله
فرض کنید در یک جستوجوی محلی، راهحل فعلی { 2,11} باشد و maxneighbor=3 سه همسایه متوالی بررسی میشوند و هیچکدام بهبودی ایجاد نمیکنند.
داده ورودی
- راهحل فعلی: {2,11}
- 3maxneighbor=
حل گامبهگام
فرض کنید سه همسایه تصادفی بررسی شوند:
{3,11},{2,12},{1,11}
و هزینههای آنها بهترتیب برابر 5، 5 و 6 باشد. چون هیچکدام از این مقادیر از هزینه فعلی یعنی 4 کمتر نیستند، شمارنده همسایههای ناموفق به 3 میرسد.
در این لحظه:
unsuccessful neighbors=maxneighbor
پس جستوجوی محلی خاتمه مییابد.
پاسخ نهایی
راهحل {2,11} بهعنوان پاسخ این جستوجوی محلی ثبت میشود.
تفسیر نتیجه
این مثال نشان میدهد CLARANS برای جلوگیری از جستوجوی بیپایان، پس از تعداد مشخصی عدمبهبود، جستوجوی محلی را متوقف میکند.
.
8.کاربردهای واقعی
- بخشبندی مشتریان در بازاریابی و تحلیل رفتار خرید
- خوشهبندی مکانها و نقاط جغرافیایی در سامانههای مکانی
- تحلیل گروههای کاربری در وبسایتها و اپلیکیشنها
- گروهبندی اسناد یا بردارهای متنی پس از embedding
- خوشهبندی دادههای پزشکی و بالینی با نیاز به نماینده واقعی
- تحلیل دادههای بیولوژیکی و ژنومی با معیارهای فاصله سفارشی
- پیشپردازش داده برای کاهش پیچیدگی در سیستمهای توصیهگر
- دادهکاوی در مجموعهدادههای بزرگ که PAM روی آنها سنگین است
.
9.مزایا
- نسبت به PAM مقیاسپذیرتر است و همه همسایهها را بررسی نمیکند
- نسبت به CLARA کمتر به کیفیت یک نمونه ثابت وابسته است
- medoidهای واقعی و تفسیرپذیر تولید میکند
- در برابر نقاط پرت معمولاً مقاومتر از k-Means است
- با معیارهای فاصله متنوع قابل استفاده است
- در عمل میتواند با هزینه معقول به پاسخهای خوب برسد
- از طریق چند جستوجوی محلی، احتمال خروج از برخی راهحلهای ضعیف را افزایش میدهد
.
10.محدودیتها و معایب
- بهینه جهانی را تضمین نمیکند
- به پارامترهای numlocal و maxneighbor حساس است
- در دادههای بسیار بزرگ، محاسبه مکرر هزینه همسایهها هنوز میتواند سنگین باشد
- اگر شروعهای تصادفی ضعیف باشند، ممکن است در کمینههای محلی نامطلوب گرفتار شود
- مانند سایر روشهای k-medoids نیازمند تعیین قبلی k است
- در دادههای با خوشههای بسیار نامنظم یا با چگالیهای متفاوت، ممکن است بهترین انتخاب نباشد
- نتیجه میتواند بین اجراهای مختلف تا حدی تغییر کند، مگر اینکه بذر تصادفی ثابت شود
.
11.مقایسه با روشهای مشابه
جدول مقایسه
| الگوریتم | نوع مرکز | مرکز واقعی است؟ | راهبرد جستوجو | مناسب برای داده بزرگ | مقاومت به پرت | وابستگی به نمونهگیری |
| k-Means | centroid | خیر | بهروزرسانی میانگین | بالا | کمتر | ندارد |
| PAM | medoid | بله | جستوجوی کامل همسایهها | پایینتر | بالا | ندارد |
| CLARA | medoid | بله | نمونهگیری + PAM | بالا | بالا | زیاد |
| CLARANS | medoid | بله | جستوجوی تصادفی همسایهها | نسبتاً بالا | بالا | کمتر از CLARA |
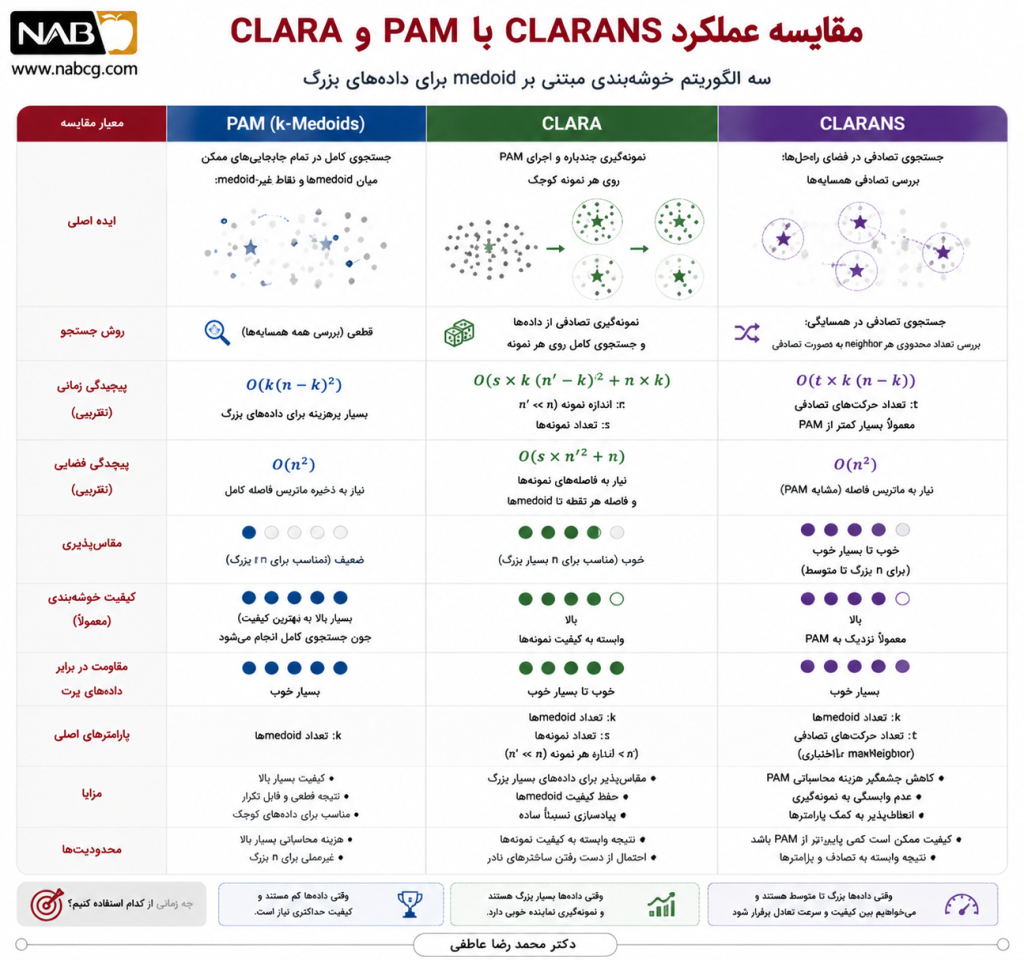
تحلیل مقایسهای
CLARANS را میتوان نوعی مصالحه میان PAM و CLARA دانست. PAM از نظر کیفیت جستوجو دقیقتر است، اما برای دادههای بزرگ هزینه بالایی دارد. CLARA سریعتر است، اما اگر نمونههای انتخابی ضعیف باشند، نتیجه افت میکند. CLARANS بهجای تکیه بر یک زیرمجموعه محدود، در خود فضای راهحلها حرکت میکند و با جستوجوی تصادفی، تعادل مناسبی میان کیفیت و کارایی برقرار میسازد (Ng & Han, 1994).
در مقایسه با k-Means نیز باید توجه داشت که CLARANS گرچه معمولاً کندتر است، اما medoidهای واقعی ارائه میدهد و در حضور نقاط پرت یا فاصلههای غیراستاندارد، مزیت مفهومی و عملی بیشتری دارد.
.
12.نوآوریها و چشمانداز آینده
الگوریتم CLARANS در اصل برای کاهش هزینه محاسباتی روشهای medoidمحور و افزایش مقیاسپذیری خوشهبندی نسبت به PAM و تا حدی CLARA معرفی شد. با این حال، اهمیت CLARANS فقط به نسخه اولیه آن محدود نمیشود. در پژوهشهای جدید، بهویژه پس از سال 2015، توجه اصلی کمتر بر تغییر ایده بنیادی الگوریتم و بیشتر بر بهینهسازی محاسباتی، بهبود راهبرد جستوجو، افزایش مقیاسپذیری و سازگارکردن آن با دادههای مدرن متمرکز بوده است.
از این منظر، CLARANS را میتوان بخشی از خانواده گستردهتر الگوریتمهای k-Medoids دانست؛ خانوادهای که همچنان بهدلیل تفسیرپذیری، انعطاف در انتخاب معیار فاصله و توانایی کار با دادههای غیرعددی یا ناهمگن، در بسیاری از کاربردهای علمی و صنعتی ارزشمند است (Kaufman & Rousseeuw, 1990; Xu & Wunsch, 2009).
.
12.1. شتابدهی محاسباتی در خانواده k-Medoids
یکی از مهمترین جریانهای نوآوری در سالهای اخیر، بازنگری در نحوه محاسبه هزینه جابهجاییها در الگوریتمهای medoidمحور است. در نسخه کلاسیک CLARANS، هر بار که یک همسایه جدید بررسی میشود، الگوریتم باید اثر جایگزینی یک medoid با یک non-medoid را بر کل هزینه خوشهبندی ارزیابی کند. این فرایند، بهویژه در دادههای بزرگ، میتواند بسیار زمانبر باشد.
پژوهشهای جدید نشان دادهاند که با نگهداری اطلاعات کمکی، مانند نزدیکترین و دومین medoid نزدیک برای هر نقطه، میتوان هزینه بسیاری از جابهجاییها را سریعتر محاسبه کرد. Schubert و Rousseeuw نشان دادند که الگوریتمهای PAM، CLARA و CLARANS را میتوان با طراحی محاسباتی دقیقتر، بدون تغییر در هدف اصلی خوشهبندی، به شکل قابلتوجهی سریعتر اجرا کرد (Schubert & Rousseeuw, 2019, 2021).
اهمیت این بهبود برای CLARANS بسیار زیاد است؛ زیرا این الگوریتم بر پایه بررسی مکرر همسایههای تصادفی کار میکند. بنابراین، هر کاهش در هزینه ارزیابی یک همسایه، مستقیماً موجب افزایش کارایی کل الگوریتم میشود.
.
12.2. حرکت بهسوی جستوجوی تصادفی هوشمندتر
در طراحی اولیه CLARANS، انتخاب همسایهها عمدتاً بهصورت تصادفی انجام میشود. این ویژگی باعث میشود الگوریتم بتواند از محدودیتهای جستوجوی کاملاً قطعی فاصله بگیرد و بخشهای متفاوتی از فضای پاسخ را بررسی کند. با این حال، تصادفیبودن کامل همیشه بهترین راهبرد نیست؛ زیرا بخشی از زمان الگوریتم ممکن است صرف ارزیابی جابهجاییهایی شود که احتمال بهبود اندکی دارند.
یکی از مسیرهای نوآورانه در توسعههای جدید، حرکت از جستوجوی تصادفی خام به سمت جستوجوی تصادفی هدایتشده است. در چنین رویکردی، الگوریتم میتواند برای انتخاب همسایهها از اطلاعاتی مانند تراکم نقاط، سهم هر نقطه در هزینه کل، فاصله نقاط از medoidهای فعلی یا کیفیت اولیه خوشهها استفاده کند. این ایده با منطق کلی جستوجوی محلی سازگار است و میتواند احتمال رسیدن به پاسخ بهتر را در زمان کمتر افزایش دهد (Han et al., 2011; Xu & Wunsch, 2009).
.
12.3. استفاده از هرس محاسباتی برای کاهش ارزیابیهای غیرضروری
یکی دیگر از مسیرهای مهم بهبود CLARANS، استفاده از هرس محاسباتی یا pruning است. در این روش، الگوریتم تلاش میکند پیش از محاسبه کامل هزینه یک جابهجایی، تشخیص دهد که آیا آن جابهجایی اساساً امکان بهبود معنادار دارد یا خیر.
برای مثال، اگر با استفاده از کرانهای محاسباتی مشخص شود که جایگزینی یک medoid با یک نقطه دیگر نمیتواند هزینه کل را کاهش دهد، نیازی به بررسی کامل آن همسایه نیست. این ایده بهویژه زمانی اهمیت دارد که تعداد دادهها زیاد باشد و محاسبه فاصلهها بخش اصلی زمان اجرا را مصرف کند.
در نسخههای بهینهتر خانواده k-Medoids، کاهش تعداد محاسبات فاصله و اجتناب از ارزیابیهای غیرضروری، یکی از عوامل اصلی بهبود عملکرد است (Schubert & Rousseeuw, 2019). از این نظر، CLARANS میتواند از یک الگوریتم جستوجوی تصادفی ساده به روشی کارآمدتر و مناسبتر برای محیطهای دادهمحور جدید تبدیل شود.
.
12.4. افزایش مقیاسپذیری برای دادههای بزرگ
CLARANS از ابتدا با هدف بهبود مقیاسپذیری نسبت به روشهای دقیقتر medoidمحور طراحی شد. با این حال، رشد حجم دادهها در سالهای اخیر باعث شده است که نسخه کلاسیک الگوریتم برای بسیاری از کاربردهای بزرگمقیاس کافی نباشد. امروزه مسئله فقط این نیست که الگوریتم از نظر نظری قابل اجرا باشد؛ بلکه باید در زمان و حافظه قابلقبول نیز عمل کند.
برای افزایش مقیاسپذیری CLARANS، چند مسیر مهم قابلتوجه است:
- کاهش تعداد محاسبات فاصله؛
- استفاده از حافظه نهان برای ذخیره نتایج پرتکرار؛
- اجرای موازی ارزیابی همسایهها؛
- تقسیم دادهها به دستههای کوچکتر؛
- استفاده از ساختارهای داده کارآمد برای جستوجوی نزدیکترین نقاط.
این جهتگیریها باعث میشوند CLARANS در کاربردهایی مانند تحلیل مشتریان، دادهکاوی وب، دادههای مکانی، دادههای زیستی و خوشهبندی اسناد همچنان قابل استفاده باشد؛ بهویژه در موقعیتهایی که medoid واقعی، از centroid انتزاعی قابلتفسیرتر است (Kaufman & Rousseeuw, 1990; Han et al., 2011).
.
12.5. ادغام CLARANS با embeddingها و بازنماییهای جدید داده
یکی از تحولات مهم یادگیری ماشین در سالهای اخیر، گسترش استفاده از embeddingهاست. embedding یک نمایش برداری فشرده و یادگرفتهشده از داده است که میتواند برای متن، تصویر، کاربر، کالا، گراف یا حتی توالیهای زیستی ساخته شود. در چنین فضایی، CLARANS میتواند نه روی داده خام، بلکه روی بازنماییهای عددی و معنادارتر اجرا شود.
برای نمونه، در پردازش زبان طبیعی، ابتدا میتوان اسناد یا جملهها را به بردارهای embedding تبدیل کرد و سپس با CLARANS آنها را خوشهبندی نمود. در سیستمهای توصیهگر نیز کاربران یا آیتمها میتوانند در یک فضای نهفته نمایش داده شوند و سپس خوشههای medoidمحور از آنها استخراج شود.
مزیت CLARANS در این کاربردها آن است که نماینده هر خوشه یک نمونه واقعی از دادههاست، نه یک میانگین مصنوعی. این ویژگی برای تحلیل انسانی، تفسیر خوشهها و انتخاب نمونههای شاخص اهمیت زیادی دارد.
.
12.6. کاربرد در چارچوبهای ترکیبی با یادگیری عمیق
CLARANS ذاتاً یک الگوریتم یادگیری عمیق نیست، اما میتواند در کنار مدلهای عمیق بهعنوان بخشی از یک فرایند ترکیبی استفاده شود. در چنین چارچوبی، مدل عمیق وظیفه استخراج ویژگی یا ساخت embedding را بر عهده دارد و CLARANS مرحله خوشهبندی نهایی را انجام میدهد.
این ترکیب در چند موقعیت مفید است:
- زمانی که داده خام پیچیده است، اما embedding ساختار خوشهای بهتری ایجاد میکند؛
- زمانی که نیاز به انتخاب نمونه واقعی نماینده برای هر خوشه وجود دارد؛
- زمانی که خروجی خوشهبندی باید برای تحلیلگر انسانی قابلفهم باشد؛
- زمانی که دادهها غیرخطی، پرُبعد یا ناهمگن هستند.
از این نظر، آینده CLARANS الزاماً در رقابت مستقیم با روشهای عمیق نیست؛ بلکه بیشتر در نقش مکمل آن در زنجیره تحلیل داده معنا پیدا میکند.
.
12.7. توسعه نسخههای موازی و توزیعشده
بخش بزرگی از عملیات CLARANS، بهویژه محاسبه فاصله نقاط تا medoidها و ارزیابی همسایههای مختلف، قابلیت موازیسازی دارد. این ویژگی مسیر مهمی برای توسعه نسخههای مدرنتر الگوریتم فراهم میکند.
در پیادهسازیهای پیشرفته، میتوان چند همسایه را بهصورت همزمان ارزیابی کرد یا محاسبات فاصله را میان چند پردازنده، چند هسته یا چند گره محاسباتی تقسیم نمود. همچنین در برخی مسائل، استفاده از GPU میتواند محاسبه فاصلهها را شتاب دهد؛ هرچند کارایی نهایی به نوع داده، معیار فاصله و نحوه پیادهسازی بستگی دارد.
این مسیر توسعه برای کاربردهای دادهبزرگ اهمیت دارد، زیرا اجرای ترتیبی CLARANS روی مجموعههای بسیار بزرگ ممکن است زمانبر باشد. نسخههای موازی و توزیعشده میتوانند این محدودیت را تا حدی کاهش دهند.
.
12.8. بهبود مقداردهی اولیه
یکی از چالشهای CLARANS، وابستگی نسبی آن به medoidهای اولیه است. اگر مقداردهی اولیه نامناسب باشد، الگوریتم ممکن است زمان بیشتری برای رسیدن به پاسخ خوب صرف کند یا در ناحیهای نهچندان مطلوب از فضای جستوجو متوقف شود.
به همین دلیل، یکی از جهتگیریهای مهم در توسعههای جدید، استفاده از راهبردهای هوشمندتر برای انتخاب medoidهای اولیه است. این راهبردها میتوانند شامل انتخاب نقاط پراکندهتر، نمونهگیری وزندار، شروع از خروجی الگوریتمهای سریعتر یا استفاده از ایدههایی مشابه k-means++ باشند. هدف اصلی این روشها، فراهمکردن نقطه شروعی بهتر برای جستوجوی محلی است.
بهبود مقداردهی اولیه نهتنها کیفیت پاسخ را افزایش میدهد، بلکه میتواند تعداد تلاشهای لازم و زمان اجرای الگوریتم را نیز کاهش دهد.
.
12.9. تنظیم دادهمحور پارامترها
در CLARANS، پارامترهایی مانند تعداد خوشهها، تعداد جستوجوهای محلی و تعداد همسایههای بررسیشده نقش مهمی در کیفیت و زمان اجرای الگوریتم دارند. در نسخههای ساده، این پارامترها معمولاً با آزمون و خطا انتخاب میشوند. اما در رویکردهای جدید، تلاش میشود انتخاب آنها با معیارهای ارزیابی خوشهبندی همراه شود.
برای نمونه، معیارهایی مانند Silhouette Score، Davies–Bouldin Index و Calinski–Harabasz Index میتوانند برای مقایسه نتایج مختلف و انتخاب تنظیمات مناسبتر به کار روند. چنین رویکردی CLARANS را از یک الگوریتم منفرد به بخشی از یک فرایند کاملتر تحلیل خوشهای تبدیل میکند.
این نکته بهویژه در کاربردهای واقعی مهم است، زیرا در بسیاری از مسائل، مقدار مناسب kkk از قبل مشخص نیست و باید با تحلیل داده و اعتبارسنجی تجربی تعیین شود.
.
12.10. سازگاری با دادههای غیرعددی و معیارهای فاصله سفارشی
یکی از مزیتهای پایدار CLARANS و سایر روشهای medoidمحور، وابسته نبودن آنها به مفهوم میانگین عددی است. برخلاف k-Means که معمولاً بر دادههای عددی و فاصله اقلیدسی تکیه دارد، CLARANS میتواند با معیارهای فاصله متنوعتری کار کند.
برای مثال، بسته به نوع داده میتوان از معیارهای زیر استفاده کرد:
- فاصله منهتن برای دادههای عددی با حساسیت کمتر به مقادیر بسیار بزرگ؛
- فاصله همینگ برای دادههای دودویی یا اسمی؛
- عدم شباهت کسینوسی برای دادههای متنی و بردارهای پراکنده؛
- فاصله Gower برای دادههای ترکیبی؛
- معیارهای فاصله دامنهمحور در پزشکی، زیستاطلاعات، متنکاوی یا تحلیل رفتار کاربر.
این انعطاف باعث میشود CLARANS در بسیاری از موقعیتهایی که k-Means مناسب نیست، گزینهای قابلتوجه باقی بماند (Kaufman & Rousseeuw, 1990; Xu & Wunsch, 2009).
.
12.11. نقش CLARANS در تفسیرپذیری و انتخاب نمونههای نماینده
در سالهای اخیر، تفسیرپذیری به یکی از دغدغههای اصلی در علم داده و یادگیری ماشین تبدیل شده است. برای بسیاری از کاربردها، فقط خوشهبندی دادهها کافی نیست؛ بلکه تحلیلگر باید بتواند بفهمد هر خوشه با چه نمونههایی نمایندگی میشود و چرا اعضای آن خوشه به هم شباهت دارند.
در این زمینه، CLARANS یک مزیت طبیعی دارد: هر medoid یک نمونه واقعی از دادههاست. بنابراین، خروجی الگوریتم میتواند برای انتخاب نمونههای شاخص، خلاصهسازی مجموعه داده، تحلیل نمایندههای خوشه و توضیح نتایج به کاربران غیرمتخصص استفاده شود.
این ویژگی در حوزههایی مانند تحلیل مشتری، آموزش، پزشکی، بازیابی اطلاعات و تحلیل اسناد اهمیت زیادی دارد؛ زیرا تصمیمگیرنده میتواند به جای مشاهده یک مرکز محاسباتی انتزاعی، یک نمونه واقعی و قابل بررسی را بهعنوان نماینده خوشه مشاهده کند.
.
12.12. جمعبندی چشمانداز آینده
چشمانداز آینده CLARANS را میتوان در چند محور اصلی خلاصه کرد. نخست، بهینهسازیهای محاسباتی باعث میشوند این الگوریتم در دادههای بزرگتر و پیچیدهتر کاربردپذیرتر شود. دوم، ترکیب آن با embeddingها و مدلهای یادگیری عمیق میتواند کیفیت خوشهبندی را در دادههای متنی، تصویری و رفتاری افزایش دهد. سوم، توسعه نسخههای موازی و توزیعشده امکان استفاده از CLARANS را در محیطهای دادهبزرگ تقویت میکند. چهارم، تفسیرپذیری medoidها باعث میشود این الگوریتم در کاربردهایی که انتخاب نمونه نماینده اهمیت دارد، همچنان جایگاه خود را حفظ کند.
بنابراین، CLARANS را نباید صرفاً یک الگوریتم کلاسیک متعلق به گذشته دانست. این روش، در صورت پیادهسازی بهینه و ترکیب با ابزارهای جدید یادگیری ماشین، همچنان میتواند در خوشهبندی دادههای مدرن، انتخاب نمونههای نماینده و تحلیل قابلتفسیر دادهها نقش مؤثری داشته باشد.
.
13.جمعبندی
الگوریتم CLARANS یکی از روشهای مهم در خانواده k-medoids است که برای خوشهبندی دادههای نسبتاً بزرگ و کاهش هزینه جستوجوی کامل طراحی شده است. این الگوریتم بهجای بررسی همه همسایههای ممکن مانند PAM، تنها بخشی از آنها را بهصورت تصادفی ارزیابی میکند و در صورت مشاهده بهبود، به راهحل جدید منتقل میشود. به همین دلیل، CLARANS در عمل میتواند میان کیفیت راهحل و هزینه محاسباتی توازن مناسبی برقرار کند.
نکته اصلی در فهم CLARANS این است که این روش نه مانند CLARA صرفاً بر نمونهگیری از داده تکیه دارد و نه مانند PAM به جستوجوی کامل وابسته است. جوهره آن، جستوجوی محلی تصادفی در فضای medoidهاست. اگر مسئلهای داشته باشیم که در آن تفسیرپذیری مرکز خوشه مهم باشد، دادهها دارای نقاط پرت باشند و اجرای PAM بیش از حد سنگین شود، CLARANS میتواند گزینهای جدی و قابلدفاع باشد.
برای مطالعه بیشتر، پیشنهاد ما این است که CLARANS را در کنار PAM، CLARA و k-Means بررسی کنید؛ زیرا درک تفاوت این چهار روش، دید بسیار خوبی نسبت به خوشهبندی افرازی و medoidمحور به خواننده میدهد.
.
14.منابع
Ester, M., Kriegel, H.-P., Sander, J., & Xu, X. (1996). A density-based algorithm for discovering clusters in large spatial databases with noise. In E. Simoudis, J. Han, & U. Fayyad (Eds.), Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (pp. 226-231). AAAI Press.
Han, J., Kamber, M., & Pei, J. (2011). Data mining: Concepts and techniques (3rd ed.). Morgan Kaufmann.
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The elements of statistical learning: Data mining, inference, and prediction (2nd ed.). Springer.
Jain, A. K., Murty, M. N., & Flynn, P. J. (1999). Data clustering: A review. ACM Computing Surveys, 31(3), 264-323. https://doi.org/10.1145/331499.331504
Kaufman, L., & Rousseeuw, P. J. (1990). Finding groups in data: An introduction to cluster analysis. John Wiley & Sons.
Ng, R. T., & Han, J. (1994). Efficient and effective clustering methods for spatial data mining. In Proceedings of the 20th International Conference on Very Large Data Bases (pp. 144-155).
Rousseeuw, P. J. (1987). Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. Journal of Computational and Applied Mathematics, 20, 53-65. https://doi.org/10.1016/0377-0427(87)90125-7
Schubert, E., & Rousseeuw, P. J. (2019). Faster k-medoids clustering: Improving the PAM, CLARA, and CLARANS algorithms. In G. Amato, C. Gennaro, V. Oria, & M. Radovanovic (Eds.), Similarity Search and Applications (pp. 171-187). Springer. https://doi.org/10.1007/978-3-030-32047-8_16
Schubert, E., & Rousseeuw, P. J. (2021). Fast and eager k-medoids clustering: O(k) runtime improvement of the PAM, CLARA, and CLARANS algorithms. Information Systems, 101, 101804. https://doi.org/10.1016/j.is.2021.101804
Tan, P.-N., Steinbach, M., & Kumar, V. (2019). Introduction to data mining (2nd ed.). Pearson.
Xu, R., & Wunsch, D. C. (2009). Clustering. Wiley-IEEE Press.



