

1. چکیده
الگوریتم CLARA، مخفف Clustering Large Applications، یکی از روشهای کلاسیک و مهم در خوشهبندی دادههای بزرگ است که بر پایه الگوریتم k-Medoids و بهطور مشخص PAM توسعه یافته است. مسئله اصلی این است که PAM با وجود تفسیرپذیری مناسب و مقاومت بهتر در برابر دادههای پرت، برای مجموعهدادههای بزرگ از نظر زمانی و محاسباتی پرهزینه است. CLARA این محدودیت را با استفاده از نمونهگیری تصادفی برطرف میکند: بهجای اجرای مستقیم PAM روی کل داده، چند زیرنمونه از داده انتخاب میشود، روی هر زیرنمونه خوشهبندی انجام میگیرد و سپس کیفیت نتیجه روی کل مجموعهداده ارزیابی میشود.
در این مقاله، ما CLARA را از منظر مفهومی، ریاضی و اجرایی بررسی میکنیم و نشان میدهیم که این الگوریتم چگونه میان کیفیت خوشهبندی و مقیاسپذیری تعادل برقرار میکند. همچنین، مثالهای عددی، کاربردهای واقعی، مزایا، محدودیتها و تفاوت آن با روشهایی مانند k-Means، PAM و CLARANS بهصورت آموزشی و آکادمیک ارائه میشود (Kaufman & Rousseeuw, 1990; Schubert & Rousseeuw, 2021).
2. مقدمه
در بسیاری از درسها و پروژههای یادگیری ماشین، وقتی از خوشهبندی صحبت میکنیم، معمولاً نخستین الگوریتمی که مطرح میشود k-Means است. با این حال، در عمل همیشه نمیتوان فرض کرد که میانگین، نماینده مناسبی برای یک خوشه است. در برخی مسائل، وجود دادههای پرت، دادههای غیرعددی، یا نیاز به استفاده از معیارهای فاصله متنوع، ما را به سمت روشهای مبتنی بر medoid هدایت میکند.
در اینجا الگوریتم CLARA اهمیت پیدا میکند. این روش برای شرایطی طراحی شده است که دادهها زیادند و در عین حال میخواهیم مزیتهای خوشهبندی مبتنی بر medoid را حفظ کنیم. CLARA در اصل پاسخی است به یک مسئله عملی: چگونه میتوان از ایدههای قوی k-Medoids برای دادههای بزرگ استفاده کرد، بدون آنکه هزینه محاسباتی روشهای دقیقتر بیش از حد بالا برود؟
در این مقاله، ابتدا مفاهیم پایه مانند medoid، dissimilarity و PAM را مرور میکنیم. سپس به مسئلهای که CLARA حل میکند، مبانی نظری و ریاضی، مراحل اجرای الگوریتم، مثالهای عددی، کاربردهای واقعی، مزایا، محدودیتها و مقایسه با روشهای نزدیک میپردازیم.
.
3.تعاریف و مفاهیم پایه
خوشهبندی چیست؟
خوشهبندی (Clustering) یکی از شاخههای اصلی یادگیری بدوننظارت (Unsupervised Learning) است. در خوشهبندی، هدف این است که مجموعهای از نمونهها را به گروههایی تقسیم کنیم که اعضای هر گروه از نظر معیار شباهت یا فاصله، به یکدیگر نزدیکتر باشند و با اعضای گروههای دیگر تفاوت بیشتری داشته باشند .
Medoid چیست؟
medoid یک نمونه واقعی از دادههاست که بهعنوان نماینده یک خوشه انتخاب میشود. اگر در یک خوشه، نقطهای را پیدا کنیم که مجموع فاصلهاش تا سایر نقاط آن خوشه کمینه باشد، آن نقطه medoid آن خوشه است.
این مفهوم را نباید با centroid اشتباه گرفت:
- centroid معمولاً میانگین مختصات اعضای خوشه است و ممکن است اصلاً یکی از دادههای واقعی نباشد.
- medoid حتماً یکی از نمونههای موجود در داده است.

این تفاوت، از نظر تفسیرپذیری و مقاومت در برابر دادههای پرت اهمیت زیادی دارد.
عدمشباهت یا Dissimilarity
در بسیاری از روشهای خوشهبندی، بهویژه روشهای مبتنی بر medoid، آنچه اهمیت دارد یک معیار برای سنجش فاصله یا عدمشباهت میان دو نمونه است. بسته به نوع داده، این معیار میتواند متفاوت باشد:
- فاصله اقلیدسی برای دادههای عددی پیوسته
- فاصله منهتن برای دادههای جدولی و بعضی کاربردهای مکانی
- فاصله همینگ برای دادههای دودویی
- معیارهای سفارشی برای دادههای متنی، ردهای یا ترکیبی
بنابراین CLARA به یک نوع داده خاص محدود نیست؛ بلکه تا حد زیادی به مناسببودن معیار فاصله بستگی دارد.
الگوریتم PAM
PAM یا Partitioning Around Medoids یکی از الگوریتمهای کلاسیک برای حل مسئله k-Medoids است. این الگوریتم با انتخاب اولیه چند medoid شروع میکند و سپس با جابهجایی میان medoidها و نقاط دیگر، سعی میکند هزینه خوشهبندی را کاهش دهد. PAM معمولاً کیفیت خوبی دارد، اما برای دادههای بزرگ بسیار کند میشود (Kaufman & Rousseeuw, 1990).
الگوریتم CLARA
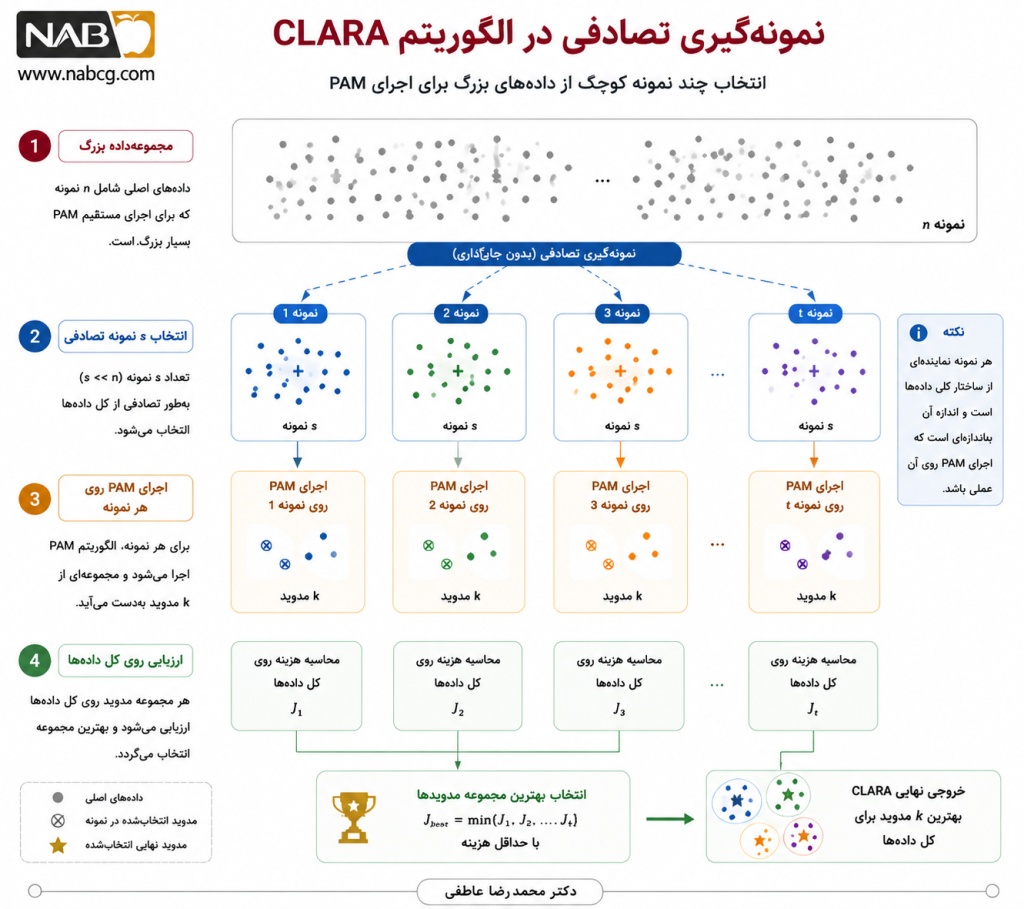
CLARA نسخهای مقیاسپذیرتر از ایده PAM است. در این روش، بهجای آنکه PAM روی کل داده اجرا شود، چند نمونه نسبتاً کوچک از داده اصلی انتخاب میشود. سپس PAM روی هر نمونه اجرا میشود و کیفیت medoidهای حاصل روی کل داده سنجیده میشود. بهترین مجموعه medoid در نهایت انتخاب میشود.
به زبان ساده، CLARA تلاش میکند ساختار خوشهای دادههای بزرگ را از طریق چند نماینده کوچکتر تقریب بزند.
4. مسئلهای که این روش حل میکند؛ اهمیت و ضرورت
الگوریتم CLARA برای حل یک مسئله کاملاً مشخص طراحی شده است: اجرای خوشهبندی مبتنی بر medoid روی مجموعهدادههای بزرگ، بدون تحمل هزینه محاسباتی بسیار زیاد.
روش PAM از نظر مفهومی دقیق و از نظر مقاومت در برابر دادههای پرت، روش قابلاعتمادی است؛ اما وقتی تعداد نمونهها زیاد میشود، بررسی جابهجاییهای ممکن میان medoidها و سایر نقاط بسیار پرهزینه خواهد بود. به همین دلیل، استفاده مستقیم از PAM در بسیاری از مسائل واقعی مقیاسپذیر نیست.
CLARA این ضرورت را از دل یک مصالحه عملی پاسخ میدهد. بهجای جستوجو در کل داده، این الگوریتم چند زیرنمونه از داده اصلی برمیدارد، روی آنها PAM را اجرا میکند و سپس بهترین راهحل را با ارزیابی روی کل داده برمیگزیند. بنابراین CLARA نه صرفاً یک الگوریتم سریعتر، بلکه راهی برای عملیکردن ایده k-Medoids در دادههای بزرگ است.
اهمیت این مسئله در کاربردهایی روشن میشود که در آنها:
- دادهها بزرگاند،
- میانگینگیری نماینده مناسبی برای خوشه نیست،
- دادههای پرت وجود دارند،
- یا معیار فاصلهای غیر از فاصله اقلیدسی لازم است.
در چنین شرایطی، CLARA یک راهحل میانی و مهندسیشده ارائه میدهد که میان کیفیت و کارایی تعادل برقرار میکند (Schubert & Rousseeuw, 2021).
.
5.مبانی نظری و ریاضی
تابع هدف در k-Medoids و CLARA
پایه نظری CLARA همان تابع هدف k-Medoids است. فرض کنید مجموعه داده شامل n نمونه باشد:
X={x1,x2,…,xn}
و بخواهیم k medoid انتخاب کنیم. اگر مجموعه medoidها را با M نشان دهیم، تابع هزینه بهصورت زیر تعریف میشود:
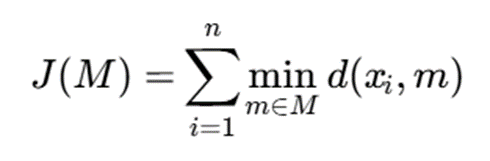
توضیح نمادها:
- J(M): هزینه کل خوشهبندی
- X: مجموعه کل دادهها
- xi: نمونه شماره i
- M: مجموعه medoidهای انتخابشده
- m: یک medoid از مجموعه M
- d(xi,m) : فاصله یا عدمشباهت بین نمونه xix_ixi و medoid mmm
- Min m∈M d(xi,m) )فاصله نمونه xi تا نزدیکترین medoid
هدف این است که مجموعهای از k medoid پیدا شود که مقدار (M)J کمینه کند.
فرض پایه این تابع
این فرمول فرض میکند که:
- برای هر جفت نمونه، یک معیار فاصله معتبر قابل تعریف است.
- تعداد خوشهها، یعنی k، از پیش مشخص شده است.
- هر نمونه به نزدیکترین medoid نسبت داده میشود.
نمونهای از معیار فاصله
برای دادههای عددی، یکی از معیارهای متداول فاصله اقلیدسی است:
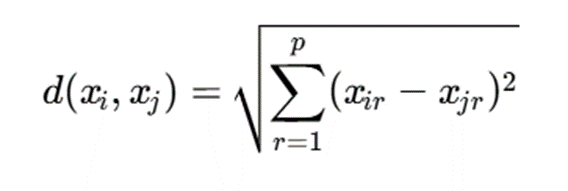
توضیح نمادها:
- (xj,xi) d: فاصله بین نمونههای xi و xj
- p: تعداد ویژگیها
- xir: مقدار ویژگی rام در نمونه i
- xjr: مقدار ویژگی rام در نمونه j
برای دادههای دودویی یا ردهای، ممکن است از فاصله همینگ یا معیارهای دیگر استفاده شود.
ایده نظری CLARA
CLARA مستقیماً تابع هدف را روی کل داده کمینه نمیکند. در عوض، با انتخاب یک زیرنمونه S⊂X با اندازه s، ابتدا medoidها را روی S پیدا میکند. سپس کیفیت آن medoidها روی کل مجموعه X سنجیده میشود.
اگر medoidهای حاصل از نمونه را با Mt نشان دهیم، هزینه ارزیابی روی کل داده چنین است:
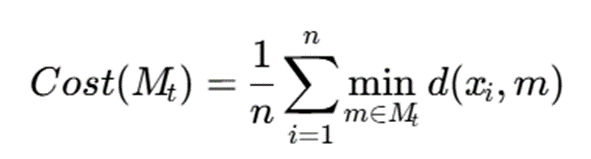
توضیح نمادها:
- (Mt) Cost: میانگین هزینه خوشهبندی برای medoidهای حاصل از نمونه t
- n: تعداد کل نمونهها
- Mt: مجموعه medoidهای بهدستآمده از زیرنمونه t
- (xi,m) d: فاصله نمونه xi تا medoid m
CLARA این فرایند را چند بار تکرار میکند و در نهایت مجموعه medoidهایی را انتخاب میکند که کمترین (Mt)Cost را روی کل داده داشته باشند.
نکته تحلیلی
بنابراین CLARA یک روش تقریبی است، نه یک حل دقیق برای مسئله k-Medoids روی کل داده. کیفیت نهایی آن به این بستگی دارد که زیرنمونههای انتخابشده تا چه حد ساختار واقعی داده را نمایندگی کنند (Kaufman & Rousseeuw, 1990).
.
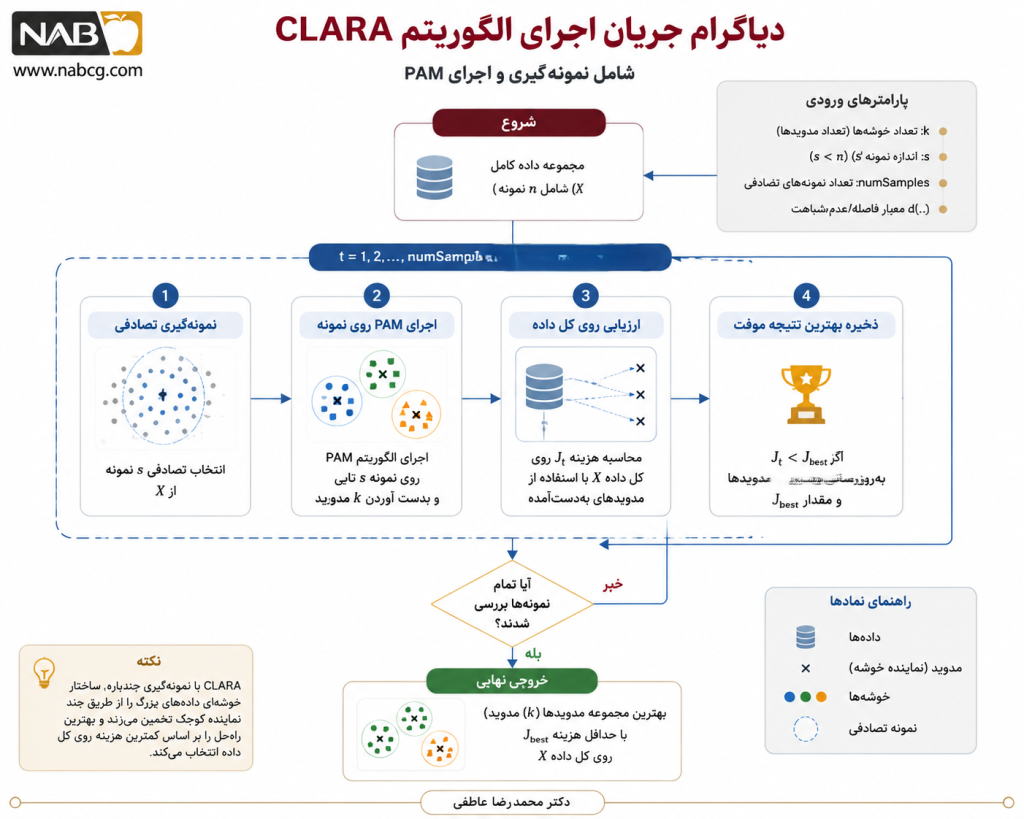
6. مراحل گام به گام اجرای الگوریتم
ورودیهای الگوریتم
برای اجرای CLARA معمولاً این ورودیها را در نظر میگیریم:
- مجموعهداده X
- تعداد خوشهها k
- اندازه نمونه s
- تعداد دفعات نمونهگیری q
- معیار فاصله d
خروجی الگوریتم
خروجی شامل سه جزء اصلی است:
- medoidهای نهایی
- برچسب خوشه هر نمونه
- هزینه نهایی خوشهبندی
فرایند اجرای CLARA
- گام 1: انتخاب یک زیرنمونه از داده
از مجموعهداده اصلی، یک نمونه تصادفی با اندازه s انتخاب میشود. این نمونه باید تا حد ممکن نمایندهای از ساختار داده باشد.
- گام 2: اجرای PAM روی زیرنمونه
الگوریتم PAM روی این زیرنمونه اجرا میشود تا k medoid اولیه یا بهینه برای آن زیرنمونه بهدست آید.
- گام 3: تعمیم medoidها به کل داده
هر نمونه از کل مجموعهداده به نزدیکترین medoid منتسب میشود. در این مرحله، خوشهبندی صرفاً بر اساس medoidهای حاصل از زیرنمونه انجام میشود.
- گام 4: محاسبه هزینه روی کل داده
برای تمام نقاط داده، فاصله تا نزدیکترین medoid محاسبه میشود و میانگین یا مجموع این فاصلهها بهعنوان کیفیت راهحل ثبت میشود.
- گام 5: تکرار نمونهگیری
مراحل 1 تا 4 به تعداد q بار تکرار میشود. در هر تکرار، ممکن است زیرنمونه متفاوتی انتخاب شود و در نتیجه medoidهای متفاوتی بهدست آید.
- گام 6: انتخاب بهترین راهحل
در پایان، مجموعه medoidهایی انتخاب میشود که کمترین هزینه را روی کل داده ایجاد کرده باشد.
معیار توقف
CLARA معمولاً با رسیدن به تعداد از پیش تعیینشدهای از نمونهگیریها متوقف میشود. درون هر اجرای PAM نیز توقف زمانی اتفاق میافتد که هیچ جابهجایی جدیدی باعث کاهش تابع هزینه نشود.
شبهکد الگوریتم
Input: X, k, s, q, d
Output: Best medoids and cluster assignments
best_cost = infinity
best_medoids = null
for t = 1 to q:
S = random_sample(X, size = s)
M = PAM(S, k)
cost = 0
for each point x in X:
cost += min distance from x to medoids in M
cost = cost / |X|
if cost < best_cost:
best_cost = cost
best_medoids = M
Assign each point in X to nearest medoid in best_medoids
Return best_medoids and final assignments
منطق تصمیمگیری
منطق اصلی CLARA این است که اگر چند زیرنمونه مناسب از داده انتخاب کنیم، دستکم یکی از آنها میتواند ساختار خوشهای کل داده را بهخوبی بازتاب دهد. بنابراین بهجای جستوجوی کامل و پرهزینه، از چند جستوجوی کوچکتر و ارزیابی نهایی روی کل داده استفاده میشود.
.
7.مثالهای عددی
مثال 1: خوشهبندی یکبعدی ساده
صورت مسئله
میخواهیم دادههای زیر را با دو خوشه دستهبندی کنیم:
X={1,2,3,10,11,12} , k=2
فرض کنید CLARA یک زیرنمونه زیر را انتخاب کرده است:
S={1,2,10,11}
معیار فاصله، فاصله مطلق است:
d(xi,xj)=∣xi−xj∣
توضیح نمادها:
- xi , xj: دو نمونه عددی
- ∣xi−xj∣: قدر مطلق اختلاف آنها
داده ورودی
- داده اصلی: {1,2,3,10,11,12}
- نمونه: {1,2,10,11}
- تعداد خوشهها: 2
حل گامبهگام
فرض کنید PAM روی نمونه، medoidهای 2 و 10 را انتخاب کند.
اکنون هر نقطه را به نزدیکترین medoid اختصاص میدهیم:
- 1 به 2 نزدیکتر است، فاصله 1
- 2 به 2، فاصله 0
- 3 به 2، فاصله 1
- 10 به 10، فاصله 0
- 11 به 10، فاصله 1
- 12 به 10، فاصله 2
پس هزینه کل برابر است با:
J=1+0+1+0+1+2=5
و میانگین هزینه:
Cost=5 / 6≈0.83
پاسخ نهایی
- خوشه اول: {1,2,3}
- خوشه دوم: {10,11,12}
- medoidها: 2 و 10
تفسیر نتیجه
در این مثال، حتی با یک نمونه کوچک، ساختار دو خوشهای داده بهخوبی حفظ شده است.
.
مثال 2: داده دوبعدی با فاصله منهتن
صورت مسئله
دادهها بهصورت زیر هستند:
A(1,1),B(1,2),C(2,1) ,D(8,8),E(9,8) ,F(8,9)
و میخواهیم آنها را در دو خوشه قرار دهیم.
فرض کنید CLARA نمونه زیر را انتخاب میکند:
S={A,B,D,E}
فاصله مورد استفاده، فاصله منهتن است:
d(xi,xj)=∣xi1−xj1∣+∣xi2−xj2∣
توضیح نمادها:
- xi1 , xi2: مختصات نمونه i
- xj1 , xj2: مختصات نمونه j
داده ورودی
- نقاط:A, B, C, D, E, F
- تعداد خوشهها: 2
حل گامبهگام
فرض کنید PAM medoidهای B(1,2) و D(8,8) را برمیگزیند.
فاصله نقاط تا medoidها:
- A: تا B برابر 1، تا D برابر 14
- B: تا B برابر 0، تا D برابر 13
- C: تا B برابر 2، تا D برابر 13
- D: تا D برابر 0
- E: تا D برابر 1
- F: تا D برابر 1
هزینه کل:
J=1+0+2+0+1+1=5
میانگین هزینه:
Cost=5 /6≈0.83
پاسخ نهایی
- خوشه اول: {A,B,C}
- خوشه دوم: {D,E,F}
تفسیر نتیجه
چون دو گروه نقطهای بهصورت فضایی از هم جدا هستند، CLARA با medoidهای واقعی، نمایندههای قابلتفسیر و مناسبی تولید کرده است.
.
مثال 3: داده دودویی با فاصله همینگ
صورت مسئله
دادههای زیر را در نظر بگیرید:
A(1,1,0) ,B(1,0,0) ,C(0,0,1),D(0,1,1),E(1,1,1)
میخواهیم آنها را در دو خوشه قرار دهیم. فرض کنید نمونه انتخابی CLARA چنین باشد:
S={A,B,C,D}
فاصله همینگ:
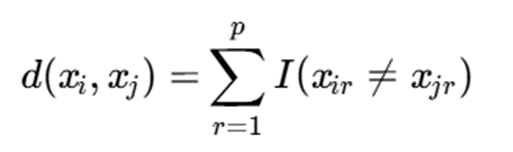
توضیح نمادها:
- p: تعداد ویژگیها
- (⋅)I: تابع شاخص
- xir: مقدار ویژگی rام برای نمونه i
داده ورودی
- پنج بردار دودویی
- تعداد خوشهها: 2
حل گامبهگام
فرض کنید PAM medoidهای A و C را انتخاب کند.
فاصلهها:
- A3 : C تا A: 0 ، تا
- B2: C تا A: 1 تا
- C0 :C تا A: 3 تا
- D1 : C تا A: 2 تا
- E2 : C تا A: 1
پس انتساب خوشهها چنین میشود:
- A,B,E در خوشه medoid A
- C,D در خوشه medoid C
هزینه کل:
J=0+1+0+1+1=3
میانگین هزینه:
Cost=3 / 5=0.6
پاسخ نهایی
- خوشه اول: {A,B,E}
- خوشه دوم: {C,D}
تفسیر نتیجه
این مثال نشان میدهد CLARA فقط برای دادههای عددی پیوسته نیست و در صورت تعریف فاصله مناسب، برای دادههای دودویی نیز کاربرد دارد.
.
مثال 4: اثر نمونهگیری بر نتیجه نهایی
صورت مسئله
فرض کنید دادهها بهصورت زیر باشند:
X={1,2,3,20,21,22,50} , k=2
دو زیرنمونه مختلف داریم:
S1={1,2,20,21}
S2={2,3,22,50}
داده ورودی
- داده اصلی: {1,2,3,20,21,22,50}
- تعداد خوشهها: 2
- فاصله: قدر مطلق
حل گامبهگام
برای S1، فرض کنید medoidها برابر 2 و 21 باشند.
هزینه روی کل داده:
J1=1+0+1+1+0+1+29=33
Cost1=337≈4.71
برای S2، فرض کنید medoidها برابر 3 و 22 باشند.
J2=2+1+0+2+1+0+28=34
Cost2=34 / 7≈4.86
پاسخ نهایی
چون Cost1 < Cost2 ، راهحل اول انتخاب میشود؛ یعنی medoidهای 2 و 21.
تفسیر نتیجه
این مثال نشان میدهد CLARA به یک نمونه واحد متکی نیست. همین تکرار نمونهگیری، احتمال انتخاب راهحل بهتر را بیشتر میکند؛ هرچند همچنان تضمینی برای جواب بهینه جهانی وجود ندارد.
.
8.کاربردهای واقعی
- بخشبندی مشتریان در بازاریابی و CRM بر اساس رفتار خرید، مراجعات و الگوهای مصرف
- خوشهبندی کاربران وبسایت یا اپلیکیشن بر اساس کلیک، مسیر پیمایش و نوع تعامل
- تحلیل دادههای پزشکی و زیستی، بهویژه زمانی که دادهها ترکیبی یا دارای فاصلههای تخصصی باشند
- خوشهبندی دادههای مکانی در حملونقل، مکانیابی خدمات و تحلیل شهری
- گروهبندی اسناد، پروفایلها یا اشیایی که میانگینگیری روی آنها معنای روشنی ندارد
- استفاده در دادهکاوی صنعتی، جایی که PAM برای کل داده بیش از حد پرهزینه است
.
9.مزایا
- نسبت به PAM برای مجموعهدادههای بزرگ مقیاسپذیرتر است
- از medoid واقعی استفاده میکند و بنابراین تفسیرپذیری خوبی دارد
- نسبت به روشهای میانگینمحور، در برابر دادههای پرت مقاومتر است
- با معیارهای فاصله متنوع سازگار است
- برای دادههای غیرعددی، دودویی یا ترکیبی نیز قابل استفاده است
- ارزیابی نهایی را روی کل داده انجام میدهد، نه فقط روی نمونه
.
10.محدودیتها و معایب
- کیفیت خروجی به کیفیت نمونهگیری وابسته است
- ممکن است خوشههای کوچک یا کمتراکم در نمونهها دیده نشوند
- باید تعداد خوشهها k از قبل تعیین شود
- انتخاب معیار فاصله نامناسب میتواند کل خوشهبندی را منحرف کند
- یک روش تقریبی است و لزوماً بهترین جواب ممکن را پیدا نمیکند
- در دادههای بسیار پیچیده یا با ساختار خوشهای غیرمعمول، ممکن است عملکرد آن محدود باشد
.
11.مقایسه با روشهای مشابه
جدول مقایسهای
| روش | مرکز خوشه | مرکز واقعی است؟ | مناسب برای دادههای بزرگ | مقاومت در برابر داده پرت | تفسیرپذیری | هزینه محاسباتی |
| k-Means | Centroid | خیر | بله | پایینتر | متوسط | کم |
| PAM | Medoid | بله | معمولاً خیر | بالا | بالا | زیاد |
| CLARA | Medoid | بله | بله | بالا | بالا | متوسط |
| CLARANS | Medoid | بله | نسبتاً بله | بالا | بالا | متوسط تا زیاد |
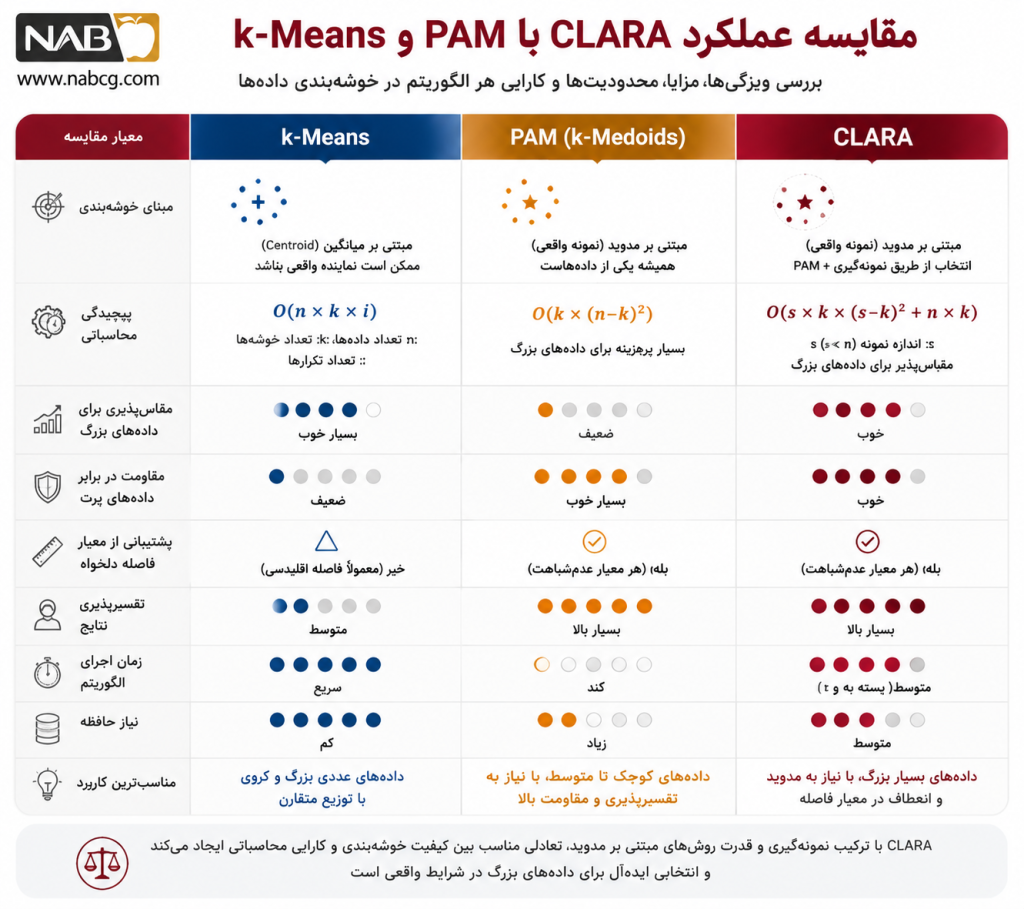
تحلیل مقایسه
ما معمولاً این تفاوت را بهصورت زیر جمعبندی میکنیم:
- اگر دادهها عددی، نسبتاً تمیز و بزرگ باشند و سرعت مهمتر از تفسیرپذیری باشد، k-Means اغلب گزینه مناسبی است.
- اگر کیفیت medoidمحور و دقت روی کل داده مهم باشد و اندازه داده کوچک یا متوسط باشد، PAM انتخاب خوبی است.
- اگر بخواهیم از مزایای medoid استفاده کنیم، اما با دادههای بزرگ سروکار داشته باشیم، CLARA معمولاً گزینه متعادلی است.
- اگر بخواهیم جستوجوی تصادفیتری در فضای راهحلها داشته باشیم، CLARANS میتواند جایگزین قابل بررسی باشد (Schubert & Rousseeuw, 2021).
.
12.نوآوریها و چشمانداز آینده
اگرچه CLARA الگوریتمی کلاسیک است، اما ایده اصلی آن هنوز در بسیاری از روشهای مدرن زنده است: حل تقریبی یک مسئله بزرگ از طریق زیرنمونههای نماینده.
چند مسیر مهم برای توسعه آینده این روش عبارتاند از:
- استفاده از نمونهگیری هوشمند بهجای نمونهگیری کاملاً تصادفی
- ترکیب CLARA با روشهای کاهش بُعد مانند PCA یا UMAP برای دادههای پُربعد
- اجرای توزیعشده و موازی در محیطهای کلانداده
- استفاده از معیارهای فاصله یادگرفتهشده از embeddingها در مسائل جدید
- ترکیب با معیارهای ارزیابی پایداری خوشهها برای افزایش اعتمادپذیری
- بهرهگیری از نسخههای سریعتر k-Medoids که در پژوهشهای جدید پیشنهاد شدهاند (Schubert & Rousseeuw, 2021)
به همین دلیل، CLARA فقط یک الگوریتم آموزشی نیست؛ بلکه بخشی از یک خانواده مهم از روشهای مقیاسپذیر خوشهبندی است.
.
13.جمعبندی
در این مقاله، ما الگوریتم CLARA را بهعنوان یک روش خوشهبندی مناسب برای دادههای بزرگ بررسی کردیم. این الگوریتم بر پایه k-Medoids و PAM ساخته شده، اما با استفاده از نمونهگیری، هزینه محاسباتی را کاهش میدهد و در عین حال تلاش میکند کیفیت خوشهبندی را حفظ کند.
نکته کلیدی این است که CLARA برای مسائلی مناسب است که در آنها استفاده از medoid بر centroid ترجیح دارد؛ بهویژه زمانی که دادههای پرت وجود دارند، دادهها صرفاً عددی نیستند، یا میخواهیم از یک معیار فاصله اختصاصی استفاده کنیم. در مقابل، باید توجه داشت که کیفیت آن به نمایندهبودن نمونهها وابسته است و مانند هر روش تقریبی، تضمین بهینگی جهانی ندارد.
اگر بخواهم یک توصیه آموزشی و عملی ارائه کنیم، آن این است که CLARA را نه صرفاً بهعنوان نسخهای سریعتر از PAM، بلکه بهعنوان راهکاری برای ایجاد تعادل میان کیفیت، تفسیرپذیری و مقیاسپذیری در خوشهبندی در نظر بگیریم.
.
14.منابع
Kaufman, L., & Rousseeuw, P. J. (1990). Finding groups in data: An introduction to cluster analysis. John Wiley & Sons.
Rousseeuw, P. J. (1987). Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. Journal of Computational and Applied Mathematics, 20, 53-65. https://doi.org/10.1016/0377-0427(87)90125-7
Schubert, E., & Rousseeuw, P. J. (2021). Fast and eager k-medoids clustering: O(k) runtime improvement of the PAM, CLARA, and CLARANS algorithms. Information Systems, 101, 101804. https://doi.org/10.1016/j.is.2021.101804
scikit-learn-extra developers. (n.d.). KMedoids: scikit-learn-extra documentation. https://scikit-learn-extra.readthedocs.io



