

مقدمه
در یادگیری عمیق، مدلها با میلیونها پارامتر و حجم عظیمی از دادهها سروکار دارند؛ بنابراین انتخاب الگوریتم بهینهسازی، نقشی تعیینکننده در موفقیت یا شکست فرآیند آموزش دارد. نزول گرادیان تصادفی بهعنوان یکی از قدیمیترین و در عین حال مؤثرترین روشهای بهینهسازی، ستون فقرات آموزش شبکههای عصبی عمیق محسوب میشود.
برخلاف نزول گرادیان کلاسیک که به پردازش کل دادهها در هر مرحله نیاز دارد، SGD با بهروزرسانی تدریجی پارامترها، امکان یادگیری آنلاین، کاهش هزینه محاسباتی و عبور از کمینههای محلی را فراهم میکند. همین ویژگیها باعث شده است که بسیاری از پیشرفتهای مهم در یادگیری عمیق—از شبکههای کانولوشنی گرفته تا مدلهای زبانی بزرگ—بر پایهی SGD و نسخههای توسعهیافتهی آن شکل بگیرند.
در این مقاله، نقش نزول گرادیان تصادفی در آموزش شبکههای عصبی عمیق، منطق عملکرد آن و دلایل محبوبیتش در پروژههای واقعی یادگیری عمیق بررسی میشود.
تعریف
نزول گرادیان تصادفی یا Stochastic Gradient Descent (SGD) یکی از بنیادیترین الگوریتمهای بهینهسازی در یادگیری عمیق است که برای آموزش شبکههای عصبی بهکار میرود. در این روش، بهجای محاسبه گرادیان روی کل دادهها، وزنها و بایاسها با استفاده از یک نمونه یا یک دستهی کوچک از دادهها بهروزرسانی میشوند.
این ویژگی باعث میشود SGD برای دادههای حجیم و مدلهای عمیق، سریعتر، مقیاسپذیرتر و عملیتر از روشهای کلاسیک باشد.
مفاهیم کلیدی
در مسیر بهینهسازی، ما با دو نوع نقطه روبرو هستیم:
- کمینه محلی (Local Minimum): نقطهای که نسبت به اطرافش پایینتر است اما لزوماً کمترین مقدار کل نیست.
- کمینه سراسری (Global Minimum): هدف نهایی ما؛ یعنی پایینترین سطح ممکن خطا در کل تابع.
اگر نرخ یادگیری (Learning Rate) یا همان اندازه گامها به درستی انتخاب نشود، مدل ممکن است در یک کمینه محلی گیر بیفتد یا از روی مقصد (کمینه سراسری) پرش کند.
تفاوت GD و SGDچیست؟
GD برای هر بهروزرسانی پارامترها، کل مجموعهداده را بررسی میکند. این کار برای دادههای بزرگ بسیار کُند و گران است. اما SGD با انتخاب یک نمونه تصادفی در هر تکرار، محاسبات را به شدت سبک و مقیاسپذیر میکند.

درست است که مسیر SGD به دلیل استفاده از تکدادهها “نویزی” و زیگزاگی است، اما همین نویز به مدل قدرت میدهد تا از “نقاط زینی” (Saddle Points) یا چالههای محلی بیرون بپرد و راه خود را به سمت پاسخهای بهتر پیدا کند.
مبانی ریاضی
هدف ما یافتن پارامترهای θ است که تابع زیان L(θ) را مینیمم کند. در رگرسیون خطی، این پارامترها همان w (وزن) و b (بایاس) هستند:
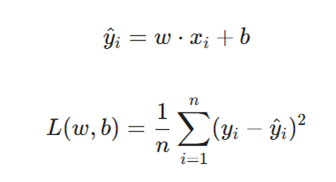
قانون بهروزرسانی کلی برای پارامتر θ:

تشریح متغیرها:
- θ: پارامترهای مدل که باید یاد گرفته شوند.
- η: نرخ یادگیری یا همان طول گام (Alpha).
- L(θ)∇θ: گرادیان تابع زیان نسبت به پارامترها.
در SGD، ما گرادیان کل را با گرادیان یک نمونه تصادفی (xi, yi) تقریب میزنیم:
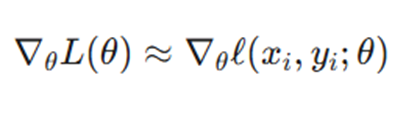
فراتر از SGD کلاسیک: بهینهسازهای پیشرفته
در یادگیری عمیق، الگوریتم SGD کلاسیک به دلیل سادگیِ بیش از حد، اغلب در تلههای هندسی مانند نقاط زینی (Saddle Points) یا درههای تند گیر میافتد. برای حل این بحرانهای محاسباتی، نسخههای تکاملیافتهای ظهور کردهاند که هر کدام با استراتژی خاصی هوشمندی مدل را ارتقا میدهند:

۱. نزول گرادیان مینی-بچ (Mini-Batch Gradient Descent)؛ نقطه تعادل
این روش میانبری هوشمندانه بین دو افراط (Batch GD و SGD) است. به جای دیدن یک داده یا کل دادهها، مدل دستههای کوچکی (مثلاً ۳۲ تا ۵۱۲ نمونه) را پردازش میکند.
- مزیت فنی: این روش اجازه میدهد از قدرت پردازش موازی GPU استفاده کنید. همچنین با کاهش واریانسِ بهروزرسانیها، همگرایی بسیار پایدارتری نسبت به SGD خالص فراهم میکند.
.
۲. بهینهساز مومنتوم (Momentum)؛ غلبه بر اصطکاک
مومنتوم با الهام از فیزیک، مفهومی به نام سرعت را وارد محاسبات میکند. این الگوریتم بخشی از بهروزرسانی قبلی را با گرادیان فعلی ترکیب میکند.
- تحلیل عمیق: مومنتوم در درههایی که شیب یک بعد بسیار تندتر از بعد دیگر است (Ravines)، نوسانات بیهوده را خنثی کرده و مدل را در جهت درست شتاب میدهد. این کار باعث میشود مدل با سرعت بیشتری از سطوح تخت عبور کند.
.
۳. شتابدهنده نِستِروف (NAG)؛ هوشِ پیشبین
Nesterov Accelerated Gradient نسخهای آیندهنگر از مومنتوم است. تفاوت اصلی در این است که NAG ابتدا بر اساس مومنتوم یک پرش خیالی به سمت جلو انجام میدهد و سپس گرادیان را در آن نقطه محاسبه میکند.
- چرا نایاب است؟ این الگوریتم عملاً قبل از رسیدن به پیچهای تند، سرعت را تنظیم میکند و مانع از انحراف مدل از مسیر بهینه میشود.
.
۴. بهینهساز Adagrad؛ متخصص دادههای خلوت (Sparse)
Adagrad نرخ یادگیری را برای هر پارامتر به صورت جداگانه تطبیق میدهد.
- استراتژی: پارامترهایی که به ندرت آپدیت میشوند، گامهای بزرگتری برمیدارند. این ویژگی Adagrad را برای مدلهای NLP و سیستمهای توصیهگر که دادههای آنها اغلب “خلوت” (صفر و یکهای زیاد) هستند، به گزینهای عالی تبدیل میکند.
.
۵. الگوریتم RMSprop؛ مهارِ کاهندگی
این الگوریتم برای حل مشکل بزرگ Adagrad (یعنی کوچک شدن بیش از حد نرخ یادگیری در اواسط آموزش) ابداع شد.
- عملکرد: RMSprop از میانگین متحرکِ مربعات گرادیان استفاده میکند تا نرخ یادگیری را نرمالسازی کند. این روش در محیطهای غیرایستا و آموزش شبکههای عصبی بازگشتی (RNN) بسیار درخشان عمل میکند.
.
۶. بهینهساز Adam؛ پادشاه بلامنازع
Adam (Adaptive Moment Estimation) ترکیبی استراتژیک از Momentum و RMSprop است.
- چرا انتخاب اول است؟ آدام هم جهتِ حرکت را اصلاح میکند (مومنتوم) و هم سرعت را برای هر پارامتر تنظیم میکند (RMSprop). به دلیل کارایی بالا در مواجهه با دادههای نویزی و پارامترهای میلیونی، امروزه به عنوان بهینهساز پیشفرض (Default) در یادگیری عمیق شناخته میشود.
.
جدول جمعبندی استراتژیک
| بهینهساز | مکانیزم کلیدی | نقطه قوت در یادگیری عمیق | سناریوی طلایی |
| Mini-Batch | دستهبندی دادهها | استفاده بهینه از سختافزار (GPU) | تمام پروژههای یادگیری عمیق |
| Momentum | انباشت سرعت | عبور از فلاتهای محاسباتی | شبکههای عصبی عمیق متراکم |
| Adagrad | نرخ یادگیری اختصاصی | مدیریت ویژگیهای کمیاب | پردازش متن (NLP) |
| RMSprop | میانگین متحرک مربعات | پایداری در آموزشهای طولانی | مدلهای RNN و RL |
| Adam | ترکیب هوشمند | همگرایی سریع با حداقل تنظیمات | پیشفرض اکثر معماریهای هوش مصنوعی |
تحلیل موردی (Case Study): بهینهسازی سیستمهای بلادرنگ با استفاده از SGD
در سیستمهای کنترلی مبتنی بر یادگیری عمیق، بهویژه در حوزه هوافضا و خودروهای خودران، سرعتِ تطبیق پارامترها با تغییرات محیطی اولویت اول را دارد. در این بخش، فرآیند بهینهسازی یک سیستم تخمین عمق مبتنی بر سنسور LiDAR را با استفاده از الگوریتم نزول گرادیان تصادفی (SGD) کالبدشکافی میکنیم.
۱. مدلسازی ریاضی و شرایط اولیه
فرض کنید یک شبکه عصبی تکلایه وظیفه تخمین فاصله (y) را بر اساس زمان بازگشت پالس لیزر (x) بر عهده دارد. مدل خطی زیر را در نظر بگیرید:

در یک لحظه بحرانی، دادههای دریافتی از سنسور به شرح زیر است:
- ورودی(xi): 3(واحد زمان استاندارد)
- خروجی مرجع: 10(Ground Truth) (فاصله واقعی تا مانع)
- وضعیت پارامترها در لحظه wt = 1.0: t و bt = 0.0
- نرخ یادگیری :0.05
.
۲. محاسبات انتشار رو به جلو (Forward Propagation)
مدل با پارامترهای فعلی، تخمین اولیه خود را ارائه میدهد:
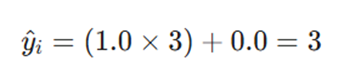
این خروجی نشاندهنده یک خطای عملیاتی فاحش است. سنسور فاصله را ۳ واحد تخمین زده، در حالی که فاصله ایمن ۱۰ واحد است. این اختلاف فاحش منجر به تولید یک سیگنال خطای قوی در لایههای شبکه میشود.
۳. ارزیابی تابع زیان (Loss Evaluation)
برای اندازهگیری میزان انحراف، از تابع زیان میانگین مربعات خطا (MSE) برای یک نمونه واحد استفاده میکنیم:
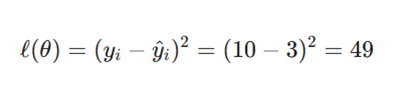
عدد ۴۹ نشاندهنده چگالی خطایی است که باید از طریق اصلاح پارامترها تخلیه شود.
۴. استخراج گرادیان و انتشار رو به عقب (Backpropagation)
در این مرحله، بردار شیب (Gradient Vector) برای تعیین جهت و شدت تغییرات w و b محاسبه میشود. با استفاده از مشتقات جزئی:
- گرادیان نسبت به وزن (w):
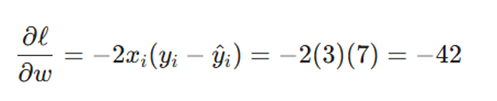
- گرادیان نسبت به بایاس (b):

تحلیل فنی: مقدار منفی گرادیانها نشان میدهد که برای کاهش تابع زیان، باید مقادیر پارامترها را افزایش داد. همچنین، بزرگتر بودن مطلق گرادیان w (42 در مقابل 14) نشان میدهد که تابع هزینه نسبت به تغییرات وزن حساسیت بیشتری دارد.
۵. قانون بهروزرسانی SGD (Update Rule)
الگوریتم SGD در کسری از ثانیه، پارامترهای جدید را جایگزین میکند:
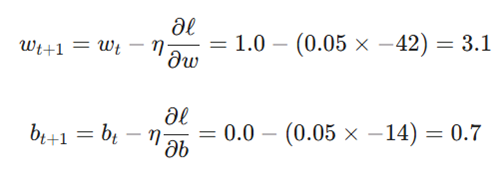
نتیجهگیری و تحلیل استراتژیک
این مثال عملی، سه ویژگی حیاتی SGD را در یادگیری عمیق برجسته میکند:
- کارایی در همگرایی اولیه: تنها با یک تکرار (Iteration)، پیشبینی مدل از ۳ به ۱۰ (دقت ۱۰۰٪ برای این نمونه خاص) جهش کرد. این سرعت در اصلاح خطا، ویژگی بارز SGD در مراحل اولیه آموزش است.
- تخصیص بهینه منابع: SGD به طور خودکار تشخیص داد که متغیر w تاثیرگذاری بیشتری بر خطا دارد، بنابراین تغییرات بزرگتری را روی آن اعمال کرد ( 210% رشد در مقابل رشد عددی بایاس).
- تطبیقپذیری بلادرنگ: برخلاف Batch GD که نیاز به پردازش تمام دادهها دارد، SGD به سیستم اجازه میدهد به صورت رویداد-محور (Event-driven) به هر داده جدید واکنش نشان دهد.
.
کاربردهای SGD: در قلب تپنده تکنولوژی
در دنیای یادگیری عمیق، بهینهساز SGD و مشتقاتش فراتر از یک فرمول ساده، موتور محرک پیچیدهترین معماریهای هوش مصنوعی هستند:
- آموزش مدلهای غولآسا(LLMs): مدلهای زبانی بزرگ مثل GPT برای یادگیری از تریلیونها کلمه، به سرعت SGD نیاز دارند تا پارامترهای میلیاردی خود را در زمان معقول بهروزرسانی کنند.
- بینایی ماشین و CNNها: در شبکههای عصبی کانولوشنال، SGD اجازه میدهد فیلترهای تصویری با دقت بالا روی مجموعهدادههایی مثل ImageNet آموزش ببینند تا کوچکترین جزئیات را در تصاویر پزشکی یا خودروهای خودران تشخیص دهند.
- پردازش صوت و شبکههای بازگشتی(RNN): مدلهای تبدیل گفتار به متن که از ساختارهای زمانی استفاده میکنند، برای اصلاح وزنهای خود در طول زمان (BPTT) به کارایی SGD متکی هستند.
- مدلهای زایشی (GANs): در رقابت بین شبکه سازنده و نقاد در مدلهای GAN، سرعت بهروزرسانی SGD اجازه میدهد تا تصاویر واقعگرایانه با سرعت خیرهکنندهای تولید شوند.
- یادگیری عمیق در لبه (Edge AI): برای اجرای مدلهای هوش مصنوعی روی چیپهای موبایل یا دوربینهای مداربسته که محدودیت توان مصرفی دارند، SGD به دلیل سبک بودن محاسبات، تنها گزینه منطقی است.
.
مزایا
- بهرهوری در مقیاس: یادگیری عمیق یعنی دادههای حجیم. SGD با پردازش بچ به بچ دادهها، اجازه میدهد مدلهایی را آموزش دهیم که مجموعهدادههایشان حتی در رمهای ۵۱۲ گیگابایتی هم جا نمیشوند.
- نویز به مثابه تنظیمکننده: در فضاهای پر از نوسان یادگیری عمیق، نویز SGD مثل یک لرزش هوشمند عمل میکند. این لرزش باعث میشود مدل به جای حفظ کردن دادههای آموزشی (Overfitting)، الگوهای کلی را یاد بگیرد و به تعمیمپذیری (Generalization) بالایی برسد.
- فرار از نقاط زینی: توابع هزینه در یادگیری عمیق پر از سطوح تخت (Saddle Points) هستند که مشتق در آنها صفر است. تکانههای SGD باعث میشود مدل در این مناطق متوقف نشود و به سمت درههای عمیقتر حرکت کند.
- انعطافپذیری در یادگیری آنلاین: در اپلیکیشنهای زنده (مثل تشخیص ناهنجاری در شبکه)، مدل میتواند همزمان با ورود دادههای جدید، بدون نیاز به بازآموزی کل شبکه، خودش را با SGD کالیبره کند.
.
چالشها
- نوسان در نزدیکی دره: به دلیل ماهیت تصادفی، SGD ممکن است در نزدیکی نقطه بهینه مدام “تلوتلو” بخورد و هرگز دقیقاً در مرکز دره آرام نگیرد (که با کاهش تدریجی نرخ یادگیری حل میشود).
- کندی در همگرایی نهایی: نسبت به روشهای دستهای، SGD ممکن است برای رسیدن به دقت ۹۹.۹٪ به تکرارهای بیشتری نیاز داشته باشد، زیرا مسیرش مستقیم نیست و مدام در حال تغییر جهت است.
- وابستگی شدید به هایپرپارامترها: یک انتخاب اشتباه در نرخ یادگیری (Learning Rate) میتواند باعث شود وزنهای شبکه عصبی منفجر شوند (Exploding Gradients) یا آموزش به کلی متوقف شود.
- حساسیت به توزیع دادهها: اگر دستههای کوچک داده (Mini-batches) نماینده خوبی برای کل جامعه نباشند، گرادیانها ممکن است مدل را به مسیرهای اشتباه ببرند. به همین دلیل، بُر زدن دادهها (Shuffling) در هر اپوک حیاتی است.
.
آیندهی SGD؛ تکامل در لبهی تکنولوژی
الگوریتم SGD در یادگیری عمیق مدرن، فراتر از یک تابع ریاضی ساده، به یک موتورِ انطباقی تبدیل شده است که نقشی حیاتی در پایداری مدلهای غولآسا ایفا میکند. آیندهی این الگوریتم نه تنها در بهبود سرعت، بلکه در بازتعریفِ نحوه تعامل هوش مصنوعی با دادههای پیچیده نهفته است.
۱. گذار به بهینهسازی خود-تنظیم
در معماریهای عمیق، تنظیم دستی ابرپارامترها (مانند Learning Rate) گلوگاه اصلی است. نسل جدید SGD به سمت بهینهسازهای فوقپارامتریک حرکت میکند که با استفاده از گرادیانهای مرتبه دوم و تخمین لحظهای واریانس، بهترین نرخ یادگیری را در هر لایه به صورت مستقل تنظیم میکنند. این یعنی پایان دوران آزمون و خطاهای طولانی برای پیدا کردن نرخ یادگیری ایدهآل.
۲. بهینهسازی برای مدلهای مقیاس تریلیونی (LLMs)
با ظهور ترنسفورمرها و مدلهای زبانی عظیم، چالش اصلی SGD مدیریت حافظه و پایداری عددی است. نسخههای آتی SGD مانند نسخه های بهینه شدهی AdamW و Adafactor با هدف کاهش ردپای حافظه (Memory Footprint) طراحی میشوند تا امکان آموزش مدلهایی با صدها تریلیون پارامتر را روی سختافزارهای محدودتر فراهم کنند.
۳. ناوبری در سطوح زیان غیرمحدب و پرنویز
در شبکههای عصبی بسیار عمیق، تابع زیان شبیه به یک هزارتوی پر از نقاط زینی و درههای باریک است. تحقیقات جدید بر روی تکنیکهای هموارسازی گرادیان تمرکز دارند که به SGD اجازه میدهد بدون گیر افتادن در کمینههای محلی بیکیفیت، به سمت نقاطی با قابلیت تعمیمپذیری (Generalization) بالا حرکت کند.
۴. یادگیری فدرال و SGD توزیعشده
آیندهی یادگیری عمیق در گروِ دادههای توزیعشده است. Federated SGD به مدلها اجازه میدهد روی گوشیهای موبایل یا سرورهای محلی بدون انتقال دادههای خام آموزش ببینند. این یعنی آموزش مدلهای تشخیص بیماری یا رفتارهای مالی با حفظ ۱۰۰ درصدی حریم خصوصی کاربران.
۵. محاسبات کوانتومی و جهش در بهینهسازی
ورود به عصر Quantum SGD، محاسباتِ سنگینِ انتشار رو به عقب (Backpropagation) را که بر روی پردازندههای گرافیکی فعلی هفتهها زمان میبرد، به فرآیندهایی آنی تبدیل میکند. این جهش، امکان آموزش مدلهایی با پیچیدگی غیرقابل تصور را فراهم خواهد کرد.
پیادهسازی گامبهگام SGD در پایتون: مهندسی بهینهسازی انرژی
در این راهنما، الگوریتم نزول گرادیان تصادفی (SGD) را بدون تکیه بر کتابخانههای سنگین و صرفاً با استفاده از NumPy پیادهسازی میکنیم تا منطقِ حاکم بر لایههای زیرین هوش مصنوعی را درک کنیم.
مرحله ۱: آمادهسازی دادهها
ابتدا مجموعهداده (Dataset) خود را تعریف میکنیم. در یادگیری عمیق، استفاده از نوع داده float برای پایداری محاسبات ضروری است.
import numpy as np
# X: تعداد کاربران (ورودی) | y: پهنای باند مصرفی (هدف)
X = np.array([1.0, 2.0, 3.0, 4.0, 5.0])
y = np.array([10.0, 25.0, 32.0, 48.0, 61.0])
مرحله ۲: مقداردهی اولیه پارامترها
قبل از شروع، باید وزن (w) و بایاس (b) را مقداردهی کنیم. همچنین نرخ یادگیری را تعیین میکنیم.
w = 0.0 # وزن اولیه
b = 0.0 # بایاس اولیه
learning_rate = 0.01
epochs = 200 # تعداد کل دفعات مرور دادهها
print("--- آغاز فرآیند یادگیری ---")
۳. حلقه اصلی و مخلوطسازی
ویژگی اصلی SGD این است که در هر مرحله (Epoch)، ترتیب دادهها را به صورت تصادفی تغییر میدهد تا از حفظ کردن ترتیب توسط مدل جلوگیری کند.
for epoch in range(epochs):
indices = np.arange(len(X))
np.random.shuffle(indices) # تصادفیسازی ترتیب دادهها
for i in indices:
xi = X[i]
yi = y[i]۴. انتشار رو به جلو (Forward Pass)
در این گام، مدل با پارامترهای فعلی خود یک پیشبینی انجام میدهد.
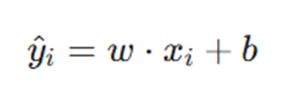
# محاسبه پیشبینی لحظهای
y_pred = w * xi + b
۵. محاسبه تفاضل و زیان (Residual & Loss)
تفاضل بین پیشبینی و واقعیت را محاسبه میکنیم. این تفاضل، سوختِ موتور بهینهسازی ماست.
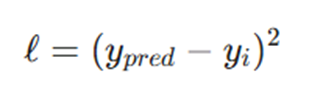
# محاسبه میزان انحراف
diff = y_pred - yi۶. محاسبه گرادیان (Backpropagation)
با استفاده از مشتق، جهت و شدتِ اشتباه مدل را نسبت به پارامترها پیدا میکنیم.

# محاسبه شیب خطا (گرادیان)
grad_w = 2 * xi * diff
grad_b = 2 * diff۷. بهروزرسانی پارامترها
در مرحله آخر، پارامترها را در خلاف جهت گرادیان (سراشیبی دره خطا) اصلاح میکنیم.
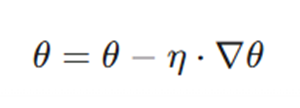
# اصلاح نهایی پارامترها
w = w - learning_rate * grad_w
b = b - learning_rate * grad_b
if epoch % 10 == 0:
print(f"مرحله {epoch}: میانگین خطا = {total_loss/len(X):.4f}")
print("-" * 25)
print(f"آموزش تمام شد!")
print(f"وزن نهایی (w): {w:.2f}")
print(f"بایاس نهایی (b): {b:.2f}")تحلیل خروجی:
این اعداد فقط عدد نیستند؛ آنها فرمول نهایی شما برای حل مسئله هستند.
- وزن نهایی :(w = 12.51)
- این عدد نشاندهنده شدت اثر یا ضریب همبستگی بین ورودی و هدف است.
- تفسیر مهندسی: به ازای هر ۱ واحد افزایش در ورودی (x)، خروجی ما به طور متوسط ۱۲.۵۱ واحد افزایش مییابد. این یعنی مدل فهمیده است که متغیر ورودی تأثیر بسیار قوی و مثبتی روی نتیجه دارد.
- بایاس نهایی :(b = -2.22)
- این عدد نقطه شروع یا مقدار پایه است؛ زمانی که ورودی صفر باشد.
- تفسیر مهندسی: بایاس منفی به این معناست که خط رگرسیون مدل شما، محور عمودی را در نقطه ۲.۲۲ – قطع میکند. این عدد به مدل کمک میکند تا پیشبینیهای خود را به سمت بالا یا پایین جابهجا کند تا با واقعیت منطبق شود.
مدل نهایی
حالا اگر بخواهید از این مدل برای پیشبینی یک دادهی جدید استفاده کنید، فرمول شما این خواهد بود:

چرا این خروجی ارزشمند است؟
- پایداری: رسیدن به این اعداد ثابت یعنی الگوریتم SGD با موفقیت در کف دره تابع زیان آرام گرفته است.
- سادگی در عین قدرت: مدل شما حالا تمام حافظهی مربوط به دادههای آموزشی را رها کرده و فقط این دو عدد را به یاد میسپارد. این یعنی مدل شما بهینه شده است.
جمع بندی
نزول گرادیان تصادفی یکی از مهمترین ابزارهای بهینهسازی در یادگیری عمیق است که امکان آموزش مدلهای بزرگ و پیچیده را در مقیاس واقعی فراهم میکند. اضافه شدن نویز کنترلشده به فرآیند یادگیری، نهتنها سرعت آموزش را افزایش میدهد، بلکه به مدل کمک میکند از کمینههای نامناسب عبور کرده و تعمیم بهتری روی دادههای جدید داشته باشد.
اگرچه SGD بهتنهایی ممکن است نوساندار باشد، اما ترکیب آن با مفاهیمی مانند Mini-Batch، Momentum و تنظیم نرخ یادگیری، آن را به یکی از قدرتمندترین گزینهها برای آموزش شبکههای عصبی عمیق تبدیل کرده است. بسیاری از بهینهسازهای پیشرفتهی امروزی نیز در واقع توسعهیافتهی همین ایدهی پایه هستند.
در نهایت، درک عمیق SGD به ما کمک میکند فرآیند آموزش شبکههای عصبی را نه بهصورت یک جعبهسیاه، بلکه بهعنوان یک سیستم قابلکنترل، تحلیلپذیر و مهندسیشده ببینیم؛ گامی اساسی برای طراحی مدلهای دقیق، پایدار و قابلاعتماد در یادگیری عمیق.



