

مقدمه
در فرآیند آموزش مدلهای یادگیری ماشین و یادگیری عمیق، انتخاب روش بهروزرسانی پارامترها تأثیر مستقیمی بر سرعت همگرایی، پایداری آموزش و مصرف منابع محاسباتی دارد. گرادیان کاهشی بهعنوان الگوریتم پایهی بهینهسازی، در عمل به سه رویکرد اصلی تقسیم میشود: بچ گرادیان کاهشی (Batch Gradient Descent)، گرادیان کاهشی تصادفی (SGD) و مینیبچ گرادیان کاهشی (Mini-Batch Gradient Descent).
هر یک از این روشها شیوهی متفاوتی برای استفاده از دادهها در محاسبهی گرادیان دارند . همین تفاوت، رفتار کاملاً متمایزی در آموزش مدل ایجاد میکند. در برخی مسائل، پایداری و دقت اهمیت بیشتری دارد و در برخی دیگر، سرعت و مقیاسپذیری اولویت اصلی است. انتخاب نادرست میان این روشها میتواند منجر به آموزش کند، ناپایدار یا حتی شکست در همگرایی مدل شود.
در این مقاله، تفاوتهای SGD، Batch GD و Mini-Batch GD را از جنبههای مفهومی، ریاضی و عملی بررسی میکنیم. هدف این مقایسه آن است که روشن شود هر روش دقیقاً در چه شرایطی مناسبتر است .
گرادیان کاهشی تصادفی (SGD)چیست؟
تعریف
گرادیان کاهشی تصادفی (SGD) با بهرهگیری از ماهیت احتمالی، بهجای محاسبه گرادیان دقیق بر روی کل مجموعهداده (Full Batch)، در هر تکرار تنها از یک نمونه تصادفی برای تولید یک تخمین نااریب (Unbiased Estimate) از گرادیان واقعی استفاده میکند. این استراتژی، هزینه محاسباتی (Computational Cost) هر گام را از وابستگی به کل دادهها جدا کرده و پیچیدگی زمانی را به شدت کاهش میدهد. ، SGD به جای پیمایش کل اقیانوس دادهها برای یافتن جهت حرکت، با تحلیل هوشمندانه تکنمونهها، مدل را در فضاهای پارامتری پُربعد با سرعتی در بسیاری از کاربردها رایج به سمت نقطه بهینه هدایت میکند.
بخش ریاضی
SGD با هدف حذف محاسبات تکراری و سنگین، تنها بر پایه یک نمونه تصادفی در هر تکرار عمل میکند.
فرمول بهروزرسانی:
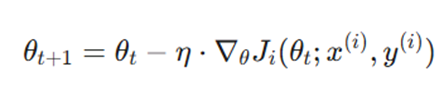
متغیرها:
- (x^ (i), y^ (i)) : نشاندهنده یک نمونه آموزشی تصادفی است که در تکرار فعلی انتخاب شده است.
- حذف مخرج n و عملگر مجموع: برخلاف Batch GD، در اینجا هیچ جمعبندی کلی وجود ندارد. مدل بلافاصله پس از محاسبه خطای یک نمونه، وزنها را اصلاح میکند.
- منطق محاسباتی این فرمول باعث میشود هزینه محاسباتی هر گام مستقل از حجم کل مجموعهداده باشد. اگرچه این کار سرعت را به شدت بالا میبرد، اما به دلیل وابستگی به تنها یک نمونه، “نویز” زیادی وارد محاسبات شده و مسیر همگرایی را پرنوسان میکند.
.
چه زمانی باید از گرادیان کاهشی تصادفی (SGD) استفاده کرد؟
انتخاب الگوریتم SGD فراتر از یک انتخاب ساده، یک ضرورت فنی در مواجهه با چالشهای یادگیری عمیق مدرن است. در شرایط زیر، استفاده از این روش بر بچ گرادیان کاهشی ارجحیت دارد:
۱. مدیریت مجموعهدادههای عظیم (Big Data)
در پروژههای یادگیری عمیق که با میلیونها یا میلیاردها نمونه داده سروکار داریم، محاسبه گرادیان روی کل مجموعهداده (Batch GD) به دلیل محدودیتهای حافظه RAM و توان پردازشی غیرممکن است SGD. با پردازش تنها یک نمونه در هر تکرار، این بنبست محاسباتی را شکسته و سرعت آموزش را به شدت افزایش میدهد.
۲. فرار از کمینههای محلی (Local Minima)
توابع هزینه در شبکههای عصبی عمیق معمولاً غیرمحدب (Non-convex) و بسیار پیچیده هستند. ماهیت نویزی و پرنوسان بهروزرسانیها در SGD به عنوان یک مزیت عمل کرده و به مدل اجازه میدهد تا از تلههای کمینه محلی یا نقاط زینی (Saddle Points) جهش کرده و به سمت بهینه مطلق حرکت کند.
۳. یادگیری آنلاین و دادههای جریانی (Online Learning)
در سیستمهایی که دادهها به صورت مداوم و جریانی (Stream) وارد میشوند (مانند سیستمهای پیشنهاد دهنده یا تحلیل رفتار لحظهای کاربران)، نمیتوان منتظر جمعآوری کل دادهها ماند. SGD به دلیل آپدیتهای لحظهای، بهترین گزینه برای این نوع یادگیری است.
۴. محدودیت در منابع سختافزاری
هنگامی که دسترسی به پردازندههای گرافیکی (GPU) فوقپیشرفته محدود است، SGD به دلیل اشغال فضای بسیار کم در حافظه، امکان آموزش مدلهای عمیق را روی سختافزارهای معمولی فراهم میکند.
.
کاربردهای واقعی گرادیان کاهشی تصادفی
۱. بینایی ماشین
- تشخیص اشیا: در مدلهای مشهوری مانند YOLO و Res Net برای شناسایی و رهگیری بلادرنگ اشیا در ویدئوها استفاده میشود.
- تصویربرداری پزشکی: برای افزایش دقت در تشخیص بیماریهایی مانند سرطان از طریق تحلیل تصاویر هیستوپاتولوژی.
.
۲. پردازش زبان طبیعی (NLP)
- ترجمه ماشینی و درک متن: مدلهای قدرتمندی مانند BERT که درک عمیقی از زبان انسان دارند، در مراحل آموزش خود از بهینهسازهای مبتنی بر گرادیان تصادفی بهره میبرند.
- تحلیل احساسات: برای تشخیص مثبت یا منفی بودن نظرات کاربران در شبکههای اجتماعی.
.
۳. پردازش صوت و گفتار
- بهبود کیفیت صدا: در شبکههایی مانند DCCRN برای حذف نویز از سیگنالهای صوتی در تماسهای تلفنی.
.
۴. مدیریت بحران و تحلیل شبکههای اجتماعی
- شناسایی بلایا: تحلیل لحظهای توییتها برای شناسایی سریع نوع فاجعه (سیل، زلزله و غیره) و پاسخگویی سریع نیروهای امدادی.
.
مزایا
- نیاز به حافظه کمتر: به دلیل پردازش تنها یک نقطه داده در هر لحظه، حافظه بسیار کمی اشغال میشود که آن را برای مجموعهدادههای حجیم مناسب میسازد.
- فرار از کمینههای محلی: به دلیل ماهیت تصادفی (Stochastic)، SGD میتواند از کمینههای محلی (Local Minima) جهش کرده و بهویژه در توابع غیرمحدب، به سمت کمینه مطلق حرکت کند.
- قابلیت یادگیری آنلاین: یکی از بزرگترین مزایای SGD این است که برای بهروزرسانی مدل، نیازی به داشتن کل مجموعهداده در ابتدا ندارد. در سیستمهای واقعی که دادهها به صورت جریانی (Stream) وارد میشوند، SGD میتواند به محض دریافت یک داده جدید، خود را اصلاح کند.
- استقلال از حجم مجموعهداده: برخلاف بچ گرادیان که هزینه محاسباتی آن با بزرگ شدن دیتاست به شدت بالا میرود، در SGD هزینه هر تکرار کاملاً مستقل از کل حجم دادههاست. این یعنی چه ۱ میلیون داده داشته باشید چه ۱ میلیارد، سرعت هر گام تغییر نمیکند.
- سادگی در پیادهسازی و انعطاف پذیری: ساختار ریاضی SGD بسیار ساده است و به همین دلیل به راحتی در معماریهای پیچیدهای مثل شبکههای عصبی عمیق (Deep Neural Networks) ادغام میشود و با متدهای مختلف منظمسازی سازگار است.
.
معایب
- حساسیت شدید به نرخ یادگیری: SGD به شدت به هایپرپارامتر نرخ یادگیری وابسته است. اگر این نرخ کمی بزرگ انتخاب شود، مدل هرگز همگرا نشده و ناپایدار میشود؛ و اگر بیش از حد کوچک باشد، فرآیند آموزش به قدری طولانی میشود که عملاً غیرممکن خواهد بود.
- واریانس بالا در بهروزرسانیها: از آنجا که هر آپدیت فقط بر اساس یک نمونه است، واریانس گرادیان بسیار بالاست. این موضوع باعث میشود مسیر حرکت مدل به سمت بهینه، به جای یک خط مستقیم، شبیه به یک نوسان تصادفی در مسیر همگرایی و زیگزاگی باشد که همگرایی را در مراحل نهایی دشوار میکند.
- چالش در موازیسازی(Parallelization): برخلاف Batch GD که میتوان محاسبات را به راحتی بین چندین GPU تقسیم کرد، SGD استاندارد به دلیل ماهیت ترتیبی (Sequential) در موازیسازی با محدودیت روبرو است. (اگرچه نسخههایی مثل Hogwild برای حل این مشکل ایجاد شدهاند).
.
بچ گرادیان کاهشی (Batch GD)چیست؟
تعریف
بچ گرادیان کاهشی یک الگوریتم بهینهسازی قطعی (Deterministic) است که در هر تکرار، گرادیان تابع هزینه را نسبت به تمامی نمونههای موجود در مجموعهداده آموزشی محاسبه میکند. در این روش، مدل تا زمانی که یک اپوک (Epoch) کامل – یعنی پردازش کل دادهها – به پایان نرسد، هیچ اقدامی برای بهروزرسانی وزنها انجام نمیدهد. این رویکرد باعث میشود که بردار گرادیان حاصل، میانگین دقیقی از خطای کل سیستم باشد و مدل را در مسیری مستقیم و بدون نوسان به سمت هدف هدایت کند.
بخش ریاضی:
در این روش، بهروزرسانی پارامترها تنها پس از پردازش تمام نمونههای موجود در مجموعهداده انجام میشود. این رویکرد به معنای محاسبه میانگین دقیق گرادیان برای کل سیستم است.
فرمول بهروزرسانی:
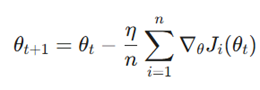
متغیرها:
- θ (پارامترها): نشاندهنده وزنهای مدل است که باید بهینه شوند.
- η (نرخ یادگیری): ضریبی که اندازه هر گام بهروزرسانی را تعیین میکند.
- Σi=1^n (عملگر مجموع): این نماد کلیدیترین بخش فرمول است؛ زیرا نشان میدهد مدل باید گرادیان تکتک n نمونه را محاسبه و با هم جمع کند تا بتواند یک گام به جلو بردارد.
- منطق محاسباتی: به دلیل وجود علامت مجموع روی کل دادهها، این روش از نظر ریاضی بسیار دقیق است اما در مجموعهدادههای حجیم، بار محاسباتی سنگینی ایجاد کرده و سرعت را به شدت کاهش میدهد.
.
چه زمانی باید از بچ گرادیان کاهشی استفاده کرد؟
استفاده از این روش در سناریوهای استراتژیک زیر توصیه میشود:
- پروژههای با دقت میلیمتری: زمانی که نیاز دارید به دقیقترین نقطه بهینه ممکن برسید و محدودیت زمانی ندارید.
- دادههای کوچک و متوسط: اگر مجموعهداده شما به راحتی در حافظه گرافیکی (VRAM) یا رم سیستم جا میشود، بچ گرادیان کاهشی انتخابی مطمئن است.
- توابع هدف صاف و محدب: برای مسائلی مانند رگرسیون لجستیک (Logistic Regression) یا ریج (Ridge Regression) که سطح خطای همواری دارند.
- مراحل پایانی آموزش (Fine-tuning): گاهی پس از اینکه با روشهای سریعتر به نزدیکی بهینه رسیدید، برای تثبیت مدل روی نقطه نهایی از این روش استفاده میشود.
.
مزایا
- همگرایی پایدار: به دلیل استفاده از کل دادهها، فرکانس بهروزرسانیها کاهش یافته و مدل به سمت یک راه حل پایدار حرکت میکند.
- تضمین ریاضی برای توابع محدب: اگر تابع هدف مدل از نوع محدب (Convex) باشد، رسیدن به بهینه مطلق (Global Optimum) از نظر ریاضی تضمین شده است.
- نرخ همگرایی خطی: در مسائل محدب، این روش دارای نرخ همگرایی خطی است که در مقایسه با روشهای تصادفی در مراحل پایانی، پایداری بیشتری دارد.
- بهرهوری از محاسبات برداری: با پردازش کل دسته (Batch)، میتوان به طور بهینه از توان محاسباتی کتابخانههای جبر خطی و موازیسازی در سطح سختافزار استفاده کرد.
- کاهش نوسانات گرادیان: برخلاف روشهای دیگر، در اینجا خبری از نوسانات زیگزاگی نیست و مدل با پایداری بالاتر در شرایط مشخص در جهت شیب حرکت میکند.
.
معایب
در کنار دقت، محدودیتهای عملیاتی جدی نیز وجود دارد:
- کندی در مقیاس بزرگ: در مجموعهدادههای عظیم، زمان مورد نیاز برای یک بار بهروزرسانی پارامترها به شدت افزایش مییابد.
- تنگنای حافظه: کل مجموعهداده باید در حافظه (RAM) جا شود، که این موضوع برای دادههای حجیم (Big Data) غیرممکن است.
- تکرار محاسبات زائد: در مسائل بزرگ، این روش قبل از هر آپدیت، گرادیان نمونههای مشابه را چندین بار محاسبه میکند که باعث اتلاف زمان میشود.
- تلهی نقاط زینی: به دلیل حرکت کاملاً صاف، احتمال اینکه مدل در نقاط زینی (Saddle Points) متوقف شود و نتواند به مسیر خود ادامه دهد، بیشتر از روشهای تصادفی است.
- ناپایداری در لایههای عمیق: در شبکههای عصبی بسیار عمیق، استفاده از بچهای کامل ممکن است باعث ناپایداری در گرادیان (انفجار یا محو شدن گرادیان) شود.
.
کاربردهای واقعی
بر اساس مستندات فنی، کاربردهای صنعتی این متد عبارتند از:
- تحلیل دادههای علمی و پزشکی محدود: در مواردی که تعداد نمونههای آزمایشی بسیار ارزشمند و محدود هستند (مثل تحلیل دادههای یک بیماری نادر)، دقت Batch GD حیاتی است.
- مدلسازی اقتصادی و فینتک: برای برازش مدلهای پیشبینی بازار که بر پایه رگرسیونهای کلاسیک هستند و نیاز به پایداری ریاضی بالا دارند.
- بهینهسازی سیستمهای کنترل: در مهندسی کنترل، جایی که کوچکترین نوسان در پارامترها ممکن است باعث ناپایداری کل سیستم شود.
- پردازش تصویر در مقیاس کوچک: استفاده در مدلهای اولیهای مانند LeNet-5 برای شناسایی الگوها در دیتاستهای با ابعاد محدود.
.
مینی-بچ گرادیان کاهشی (Mini-Batch Gradient Descent) چیست؟
تعریف
در این روش، مجموعهداده به گروههای کوچکی به نام بچ (Batch) تقسیم میشود (معمولاً با اندازهای بین ۲ تا ۳۲ یا مضاربی از توان ۲ مانند ۶۴ و ۱۲۸). در هر تکرار، مدل به جای دیدن کل دادهها یا فقط یک نمونه، گرادیان را بر اساس میانگین خطای یک دسته کوچک محاسبه کرده و وزنها را بهروزرسانی میکند. این کار باعث میشود فرآیند آموزش همزمان دارای سرعت بالا و پایداری قابل قبولی باشد.
بخش ریاضی:
این روش به عنوان استاندارد طلایی، سعی میکند دقت Batch GD و سرعت SGD را با هم ترکیب کند.
فرمول بهروزرسانی:
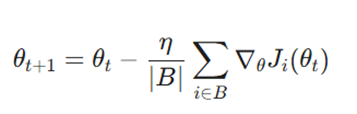
متغیرها:
- B (بچ): زیرمجموعهای کوچک از دادهها (مثلاً ۳۲ یا ۶۴ نمونه) است.
- |B| (اندازه دسته): تعداد نمونههای موجود در هر مینی-بچ را نشان میدهد.
- عملگر مجموع رویB:گرادیانها فقط برای نمونههای موجود در دسته فعلی جمع زده میشوند.
- منطق محاسباتی: این فرمول نویز SGD را با میانگینگیری روی چندین نمونه کاهش میدهد و در عین حال، بسیار سریعتر از Batch GD عمل میکند. همچنین این ساختار ریاضی اجازه میدهد تا محاسبات برداری به طور بهینه روی GPU انجام شود.
.
چه زمانی باید از مینی-بچ استفاده کرد؟
- آموزش شبکههای عصبی عمیق (CNN, RNN, Transformers): تقریباً در ۹۹٪ مواقعی که با کتابخانههایی مثل PyTorch یا TensorFlow کار میکنید، این متد انتخاب اصلی شماست.
- محدودیت حافظه گرافیکی (VRAM): زمانی که دیتاست در رم جا نمیشود اما میخواهید از قدرت GPU استفاده کنید، دستهبندی دادهها تنها راه است.
- دستاورد موازیسازی: هنگامی که میخواهید فرآیند آموزش را روی چندین کارت گرافیک همزمان توزیع کنید.
.
مزایا
- تعادل میان سرعت و دقت: این روش بسیار سریعتر از بچ گرادیان است و در عین حال، تخمینهای بسیار دقیقتری نسبت به SGD خالص ارائه میدهد.
- بهرهوری از توان GPU: پردازندههای گرافیکی مدرن برای محاسبات موازی روی دستههای کوچک داده (Mini-batches) طراحی شدهاند؛ لذا این روش بالاترین بهرهوری سختافزاری را دارد.
- قابلیت تعمیمیافتگی بهتر: حفظ مقدار کمی نویز (کمتر از SGD) به مدل کمک میکند تا از بیشبرازش جلوگیری کرده و در عین حال از تلههای کمینه محلی جهش کند.
.
معایب
- اضافه شدن هایپرپارامتر Batch Size: انتخاب اندازه بهینه برای هر دسته (Batch Size) خود یک چالش جدید است که نیاز به آزمایش و خطا دارد.
- نیاز به تنظیم نرخ یادگیری: به دلیل تغییر در اندازه دستهها، نرخ یادگیری (Learning Rate) نیز باید متناسب با آن کالیبره شود تا پایداری حفظ شود.
.
کاربردهای واقعی
- پردازش زبان طبیعی (NLP): در آموزش مدلهای خودرمزگذار بازگشتی (RAEs) برای شناسایی پارافریزها از مینی-بچ استفاده میشود.
- تشخیص احساسات در گفتار: در مدلهای ELM برای طبقهبندی احساسات در سطوح مختلف گفتار از این الگوریتم بهره میبرند.
- بینایی ماشین پیشرفته: در آموزش لایههای عمیق مدلهای Res Net و Alex Net برای حفظ پایداری گرادیان در طول اپوکها.
.
تنظیم نرخ یادگیری (Learning Rate Scheduling) در گرادیان کاهشی
یکی از عوامل تعیینکننده در عملکرد گرادیان کاهشی، نحوهی تنظیم نرخ یادگیری در طول فرآیند آموزش است. در عمل، استفاده از یک نرخ یادگیری ثابت در تمام مراحل آموزش اغلب به همگرایی کند یا ناپایدار منجر میشود. به همین دلیل، از راهکارهایی تحت عنوان Learning Rate Schedulers استفاده میشود که مقدار نرخ یادگیری را بهصورت تدریجی و برنامهریزیشده کاهش میدهند.
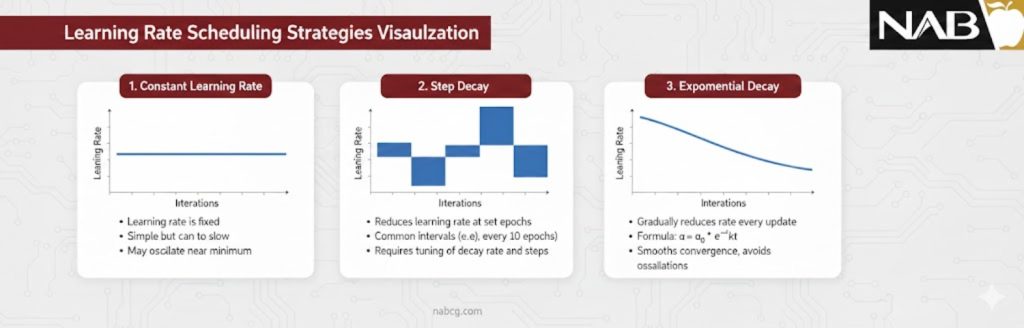
- در Step Decay، نرخ یادگیری در بازههای زمانی مشخص بهصورت پلهای کاهش مییابد و به مدل اجازه میدهد پس از عبور از نواحی پرنوسان، با گامهای کوچکتر به همگرایی نزدیک شود.
- در Exponential Decay، نرخ یادگیری بهصورت نمایی کاهش پیدا میکند که معمولاً همگرایی نرمتر و یکنواختتری ایجاد میکند.
- در Cosine Annealing، نرخ یادگیری بهصورت تناوبی و بر اساس تابع کسینوسی تغییر میکند تا مدل بتواند از بهینههای محلی عبور کرده و به نواحی مناسبتری در فضای پارامترها برسد.
- در عمل، استفاده از SGD بدون یک راهبرد مناسب برای تنظیم نرخ یادگیری، در بسیاری از مسائل به آموزش ناکارآمد منجر میشود. به همین دلیل، ترکیب SGD + Scheduler بهعنوان یک رویکرد استاندارد در آموزش مدلهای یادگیری عمیق در نظر گرفته میشود.
.
مقایسه جامع Batch GD، SGD و Mini-Batch GD
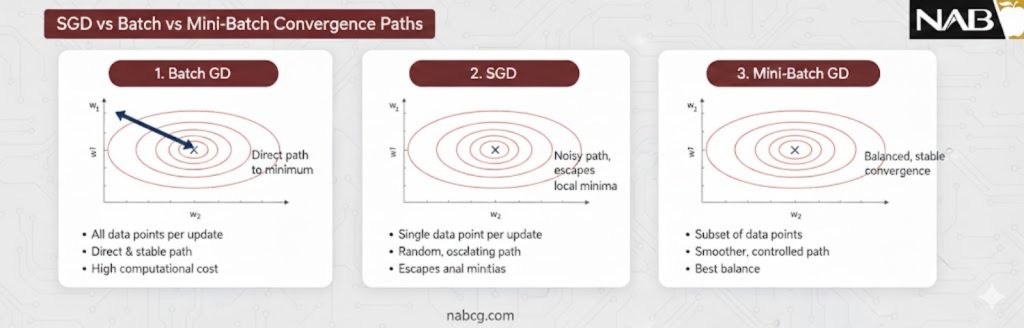
۱. پردازش دادهها
- Batch GD: از تمام مجموعهداده برای یک آپدیت استفاده میکند.
- SGD: تنها از یک نمونه تصادفی استفاده میکند.
- Mini-Batch GD: مجموعهداده را به دستههای کوچکی (مثلاً ۳۲ یا ۶۴ تایی) تقسیم کرده و هر دسته را مبنای آپدیت قرار میدهد.
.
۲. سرعت همگرایی
- Batch GD: بسیار کند؛ زمان زیادی صرف پردازش کل دادهها میشود.
- SGD: بسیار سریع؛ به دلیل آپدیتهای مکرر بلافاصله حرکت میکند.
- Mini-Batch GD: سرعت بهینه؛ سریعتر از Batch و با ثباتتر از SGD همگرا میشود.
.
۳. دقت تخمین گرادیان
- Batch GD: دقیقترین تخمین (میانگین واقعی خطا).
- SGD: نویزیترین تخمین (تقریب آماری ضعیف).
- Mini-Batch GD: تخمین میانرده؛ میانگینگیری روی دسته، نویز را نسبت به SGD کاهش میدهد.
.
۴. نیاز به حافظه
- Batch GD: بسیار بالا؛ کل دیتاست باید در رم باشد.
- SGD: بسیار ناچیز؛ فقط یک نمونه در رم پردازش میشود.
- Mini-Batch GD: متوسط و مدیریتشده؛ تنها یک دسته (Batch) در رم بارگذاری میشود.

۵. هزینه محاسباتی
- Batch GD: سنگین در هر تکرار.
- SGD: سبکترین حالت در هر تکرار.
- Mini-Batch GD: بسیار بهینه؛ از توان محاسبات موازی GPU به بهترین شکل استفاده میکند.
.
۶. ماهیت الگوریتم
- Batch GD: قطعی (Deterministic)؛ مسیر همیشه یکسان است.
- SGD: کاملاً احتمالی (Stochastic)؛ مسیر به شدت نوسانی است.
- Mini-Batch GD: احتمالی معتدل؛ به دلیل نمونهبرداری تصادفی دستهها.
.
۷. فرار از کمینههای محلی
- Batch GD: احتمال گرفتار شدن در تلهها زیاد است.
- SGD: قدرت فرار بسیار بالا به دلیل نویز زیاد.
- Mini-Batch GD: عملکرد عالی؛ نویز کنترلشده به فرار از تلهها کمک میکند.
.
۸. تناسب با دادههای بزرگ
- Batch GD: غیرقابل استفاده در مقیاس عظیم.
- SGD: بسیار ایدهآل برای کلاندادهها.
- Mini-Batch GD: استاندارد طلایی و انتخاب اول برای پروژههای بزرگ یادگیری عمیق.
.
9. تنظیم نرخ یادگیری (Learning Rate)
- Batch GD: معمولاً ثابت.
- SGD: حتماً باید پویا و کاهشی باشد.
- Mini-Batch GD: به سایز دسته وابسته است و معمولاً با استراتژیهای کاهشی تنظیم میشود.
جدول مقایسه استراتژیک سه بهینهساز
| جنبه مقایسه | (Batch GD) | (SGD) | (Mini-Batch) |
| پردازش داده | کل مجموعهداده در هر گام | یک نمونه تصادفی در هر گام | یک دسته کوچک (بچ) |
| سرعت همگرایی | کند و زمانبر | بسیار سریع و چابک | متعادل و بهینه |
| دقت گرادیان | عالی و دقیق | نویزی و تقریبی | متوسط متمایل به خوب |
| مصرف حافظه | بسیار بالا (کل دیتاست) | بسیار پایین و ناچیز | متوسط و مدیریتشده |
| بهرهوری GPU | پایین (تنگنای حافظه) | پایین (ترتیبی بودن) | بسیار بالا (موازیسازی) |
| فرار از تلهها | ضعیف در نقاط زینی | عالی در فرار از تلهها | بسیار خوب و کاوشگر |
| ماهیت | قطعی (Deterministic) | احتمالی (Stochastic) | احتمالی معتدل |
| بیشبرازش | مستعد Overfitting | کاهش ریسک با نوسان | تعمیمیافتگی فوقالعاده |
| ثبات نهایی | پایدار و ساکن | پرنوسان حول هدف | نوسان ملایم و کنترلشده |
| نرخ یادگیری | معمولاً ثابت | پویا و کاهشی | پویا (وابسته به بچ) |
نقش این روش ها در بهینه ساز های مدرن
گرچه در این مقاله گرادیان کاهشی تصادفی، بچ و مینیبچ بهصورت مستقل بررسی شدند، اما این روشها در عمل پایهی تمامی بهینهسازهای مدرن یادگیری عمیق محسوب میشوند. الگوریتمهایی مانند Momentum، RMSprop و Adam همگی بر مبنای گرادیان کاهشی مینیبچ طراحی شدهاند و با افزودن مکانیزمهایی برای هموارسازی گرادیان، تطبیق نرخ یادگیری و کاهش نوسان، کارایی آن را بهبود میبخشند.

به بیان دیگر، تفاوت اصلی این بهینهسازها در «نوع گرادیان» نیست، بلکه در نحوهی پردازش و بهروزرسانی گرادیان مینیبچ است. به همین دلیل، درک تفاوت میان SGD، Batch GD و Mini-Batch GD پیشنیاز فهم صحیح عملکرد بهینهسازهای پیشرفته و انتخاب آگاهانهی آنها در مسائل واقعی محسوب میشود.
.
جمع بندی
گرادیان کاهشی تصادفی، بچ گرادیان کاهشی و مینیبچ گرادیان کاهشی بر پایهی یک ایدهی مشترک ساخته شدهاند، اما تفاوت آنها در نحوهی استفاده از دادهها باعث تفاوت چشمگیر در رفتار آموزشی مدل میشود. بچ گرادیان کاهشی با وجود پایداری بالا، در مقیاسهای بزرگ عملاً ناکارآمد است، در حالی که SGD با سرعت بالا، نوسان بیشتری در مسیر همگرایی ایجاد میکند.
در عمل، مینیبچ گرادیان کاهشی توازنی مناسب میان این دو رویکرد برقرار میکند. این روش با استفاده از دستههای کوچک داده، هم از مزایای محاسبات موازی روی GPU بهره میبرد و هم پایداری آموزش را در سطح قابلقبولی حفظ میکند. به همین دلیل، تقریباً تمام مدلهای مدرن یادگیری عمیق، از شبکههای کانولوشنی تا مدلهای زبانی بزرگ، بر پایهی مینیبچ آموزش داده میشوند.
نکتهی مهم این است که انتخاب روش گرادیان کاهشی یک تصمیم مطلق نیست، بلکه به عواملی مانند اندازه داده، محدودیت سختافزاری، نوع مسئله و حساسیت مدل به نوسان گرادیان بستگی دارد. درک تفاوت این سه رویکرد به مهندس یادگیری ماشین کمک میکند تا فراتر از تنظیمات پیشفرض فریمورکها، تصمیمهای آگاهانهتر و بهینهتری در طراحی فرآیند آموزش مدل اتخاذ کند.



