

مقدمه
در فرآیند آموزش شبکههای عصبی، یکی از چالشهای مهم گرادیان کاهشی کلاسیک، حساسیت بالا به مقیاس گرادیانها و ناپایداری نرخ یادگیری در طول زمان است. روشهایی مانند SGD یا حتی AdaGrad، اگرچه بهبودهایی نسبت به گرادیان کاهشی ساده ارائه میدهند، اما در عمل میتوانند با مشکلاتی مانند کاهش بیشازحد نرخ یادگیری یا نوسان در مسیر همگرایی مواجه شوند، بهویژه در مسائل غیرمحدب و دادههای نویزی.
بهینهساز RMSprop (Root Mean Square Propagation) بهعنوان پاسخی عملی به این محدودیتها معرفی شد. این روش با استفاده از میانگین متحرک نمایی از مجذور گرادیانها، نرخ یادگیری مؤثری را برای هر پارامتر تنظیم میکند و از کاهش کنترلنشدهی گامهای بهروزرسانی جلوگیری مینماید. نتیجه، الگوریتمی است که در بسیاری از مسائل، آموزش پایدارتر و سازگارتر با تغییرات گرادیان را فراهم میکند.
هدف این مطلب بررسی جامع RMSprop است؛ از انگیزهی طراحی و فرمولبندی ریاضی گرفته تا مثالهای عددی، پیادهسازی عملی و مقایسه با روشهای مرتبط. تمرکز اصلی بر این است که روشن شود RMSprop چه مشکلی را حل میکند، چگونه عمل میکند و در چه شرایطی استفاده از آن منطقیتر است.
.
تعریف
الگوریتم RMSprop (مخففRoot Mean Square Propagation) یک بهینهساز با نرخ یادگیری تطبیقی (Adaptive Learning Rate) است که برای تسریع همگرایی و بهبود عملکرد مدلهای یادگیری عمیق طراحی شده است. این الگوریتم نسخهای پیشرفته از گرادیان کاهشی است که نرخ یادگیری را برای هر پارامتر به صورت مجزا و با در نظر گرفتن بزرگی گرادیانهای اخیر آن پارامتر تنظیم میکند.
هستهی اصلی این بهینهساز بر پایهی محاسبهی میانگین متحرک مجذور گرادیانها (Moving Average of Squared Gradients) بنا شده است که به نرمالسازی آپدیتها کمک کرده و از کاهش شدید نرخ یادگیری (مشکلی که در الگوریتم AdaGrad وجود داشت) جلوگیری میکند.
.
ضرورت بهینهساز RMSProp در آموزش مدلهای عمیق
برای درک اهمیت فنی RMSProp، تحلیل محدودیتهای ساختاری در الگوریتمهای بهینهسازی پیشین ضروری است. این بهینهساز با هدف رفع شکاف میان سرعت همگرایی و تداوم فرآیند یادگیری در مدلهای پیچیده توسعه یافته است.

۱. چالش نرخ یادگیری ثابت در SGD
در الگوریتم گرادیان کاهشی تصادفی (SGD) کلاسیک، از یک نرخ یادگیری ثابت برای تمامی پارامترها استفاده میشود. این رویکرد در فضاهای پارامتری پربُعد و غیرمحدب یادگیری عمیق، کارایی پایینی دارد؛ زیرا ناتوانی در تطبیق اندازه گام با شیبِ نواحی مختلف، مدل را در معرض نوسانات شدید و ناپایداری قرار میدهد.
۲. محدودیتهای AdaGrad در همگرایی بلندمدت
الگوریتم AdaGrad با هدف انطباق نرخ یادگیری، بهویژه برای دادههای پراکنده (Sparse Data)، معرفی شد. با این حال، مکانیسم تجمیع تجمعی مجذور گرادیانها در این روش منجر به کاهش تهاجمی و بازگشتناپذیر نرخ یادگیری میشود.
- توقف بهروزرسانی: در فرآیندهای آموزشی طولانی یا توابع هزینه با سطوح ناهموار، نرخ یادگیری به قدری کوچک میشود که بهروزرسانی پارامترها عملاً متوقف شده و مدل پیش از رسیدن به نقطه بهینه، دچار ایستایی میگردد.
.
۳. مکانیسم انطباقی RMSProp: توازن در پایداری و سرعت
الگوریتم RMSProp برای حل مسئلهی میرایی نرخ یادگیری طراحی شده است. این متد به جای تجمیع کل تاریخچهی گرادیانها، از یک میانگین متحرک نمایی (Exponential Moving Average) از مجذور گرادیانها استفاده میکند.
.
بهینهساز RMSprop چگونه کار میکند؟
الگوریتم RMSprop (مخفف Root Mean Square Propagation) با هدف غلبه بر چالشهای بهینهسازی در فضاهای ناهموار و غیرمحدب، از مفهوم نرمالسازی گرادیان بهره میبرد. برخلاف بهینهسازهای سنتی که بر جهت حرکت تمرکز دارند، RMSprop بر روی ابعاد گام در هر جهت تمرکز میکند تا از نوسانات مخرب جلوگیری کرده و سرعت همگرایی را بهینه کند.
مبانی ریاضی و تحلیل متغیرها
فرآیند بهروزرسانی در RMSprop یک سیستم زنجیرهای و بازخوردی است که در سه مرحلهی اصلی تعریف میشود:
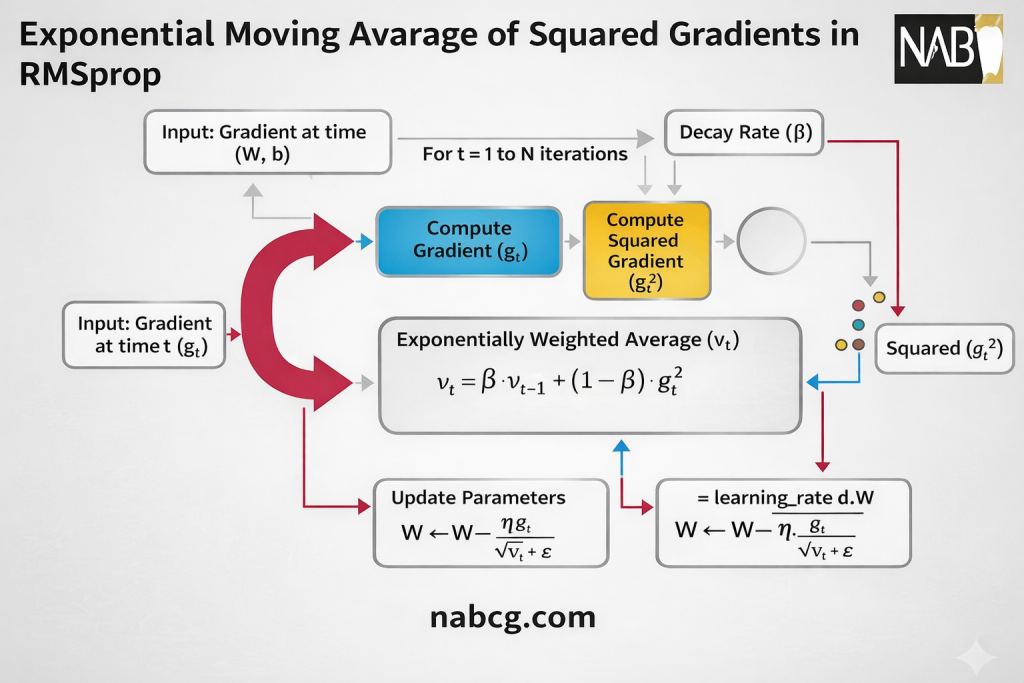
گام اول: محاسبه گرادیان لحظهای (gt)
در هر تکرار، مشتق جزئی تابع هزینه نسبت به پارامترهای مدل محاسبه میشود تا جهت شیب در آن لحظه مشخص گردد. این بردار نشاندهندهی تندترین مسیر صعود است که ما در جهت عکس آن حرکت میکنیم.
گام دوم: بهروزرسانی میانگین متحرک مجذور گرادیانها (E[g^2]t)
در این مرحله، به جای استفاده مستقیم از گرادیان لحظهای، شدت نوسانات پارامتر در یک مخزن حافظه به نام میانگین متحرک نمایی ذخیره میشود:
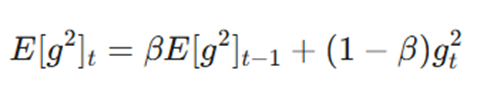
- β (نرخ کاهشی یا ضریب میرایی): این ضریب که معمولاً روی 0.9 تنظیم میشود، نقش فاکتور فراموشی را دارد. اگر β بزرگ باشد، مدل به تاریخچهی طولانیتری از نوسانات وفادار میماند.
- gt^2 (توان دوم گرادیان): این متغیر باعث میشود که جهت گرادیان (مثبت یا منفی) حذف شده و فقط بزرگی (Magnitude) نوسان ملاک عمل قرار گیرد. در واقع، ما به دنبال این هستیم که بدانیم در این جهت خاص، چقدر نوسان داریم.
.
گام سوم: نرمالسازی و بهروزرسانی پارامتر (θ)
در نهایت، پارامتر مدل با استفاده از یک نرخ یادگیری که به صورت پویا مقیاسبندی شده، بهروزرسانی میشود:
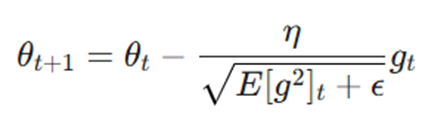
- η (نرخ یادگیری اولیه): طول گام پایه که معمولاً 0.001 در نظر گرفته میشود.
- ϵ (اپسیلون): یک مقدار بسیار کوچک (مثلاً 10^(-8)) برای تضمین پایداری عددی و جلوگیری از تقسیم بر صفر.
- فلسفه مخرج کسر: این بخش قلب تپنده RMSprop است. مخرج کسر باعث میشود پارامترهایی که گرادیانهای بزرگی دارند (نوسان زیاد)، نرخ یادگیری کوچکتری دریافت کنند و پارامترهایی با گرادیان کوچک، با گامهای بلندتری حرکت کنند.
.
مثال: شبیهسازی گامبهگام بهینهسازی
بیایید فرآیند را برای پارامتر x با جزئیات بیشتر تحلیل کنیم.
تنظیمات آزمایش:

تکرار ۱: مواجهه با شیب تند
- فرض: گرادیان g1 = 0.6 است.
- محاسبه حافظه:
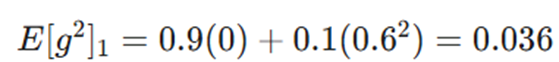
- بهروزرسانی:

- تحلیل: مدل متوجه میشود نوسان شروع شده و گام را بر اساس شدت آن (جذر 0.036) تنظیم میکند.
تکرار ۲: تداوم نوسان
- فرض: گرادیان g2 = 0.5 است.
- محاسبه حافظه:
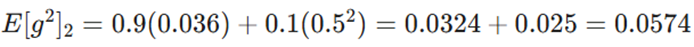
- بهروزرسانی:
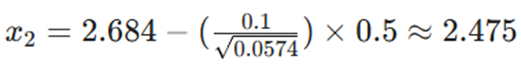
- تکرار ۳: تغییر جهت ناگهانی (نوسان عرضی)
- فرض: گرادیان g3 = -0.4 است (تغییر جهت).
- محاسبه حافظه:
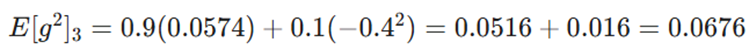
- بهروزرسانی:
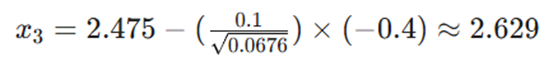
- تحلیل کلیدی: علیرغم منفی شدن گرادیان، مخرج کسر به دلیل توان دوم افزایش یافت. این یعنی RMSprop متوجه شده که در این جهت نوسان وجود دارد و با ترمز گرفتن هوشمند، مانع از پرشهای بزرگ و واگرایی مدل میشود.
.
پیاده سازی در پایتون
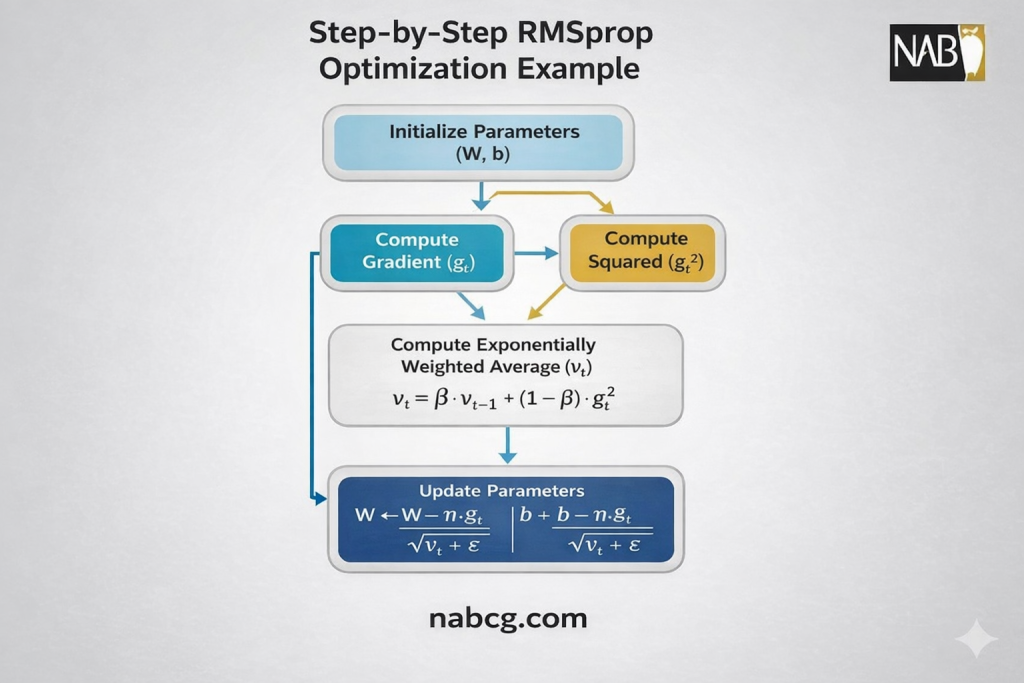
گامهای پیادهسازی RMSprop
برای پیادهسازی این بهینهساز از صفر، این ۵ مرحله را دنبال میکنیم:
- تعریف مخزن حافظه (Cache): برای هر پارامتر مدل، یک متغیر کمکی (برابر با صفر در شروع کار) تعریف میکنیم تا «میانگین متحرک مجذور گرادیانها» در آن ذخیره شود.
- محاسبه گرادیان لحظهای: در هر تکرار، مشتق جزئی تابع هزینه را نسبت به وزن فعلی محاسبه میکنیم.
- بهروزرسانی تاریخچه نوسانات: با استفاده از فرمول E[g^2]t = βE[g^2]t-1 + (1 – β) gt^2، مقدار جدید مخزن حافظه را بر اساس توان دوم گرادیان فعلی و ضریب میرایی (β) آپدیت میکنیم.
- تعدیل نرخ یادگیری (نرمالسازی): نرخ یادگیری پایه را بر جذر مقدار ذخیره شده در حافظه (به اضافهی اپسیلون) تقسیم میکنیم. این کار باعث میشود وزنهای پرنوسان، گامهای کوچکتری بردارند.
- اعمال تغییرات بر پارامتر: در نهایت، وزن مدل را با استفاده از این نرخ یادگیریِ اصلاحشده بهروزرسانی میکنیم.
کد پایتون:
این کد شامل پیادهسازی کلاس بهینهساز و یک محیط شبیهسازی برای مشاهدهی خروجی بصری و عددی است:
import numpy as np
import matplotlib.pyplot as plt
class RMSpropOptimizer:
def __init__(self, learning_rate=0.01, beta=0.9, epsilon=1e-8):
self.lr = learning_rate
self.beta = beta
self.epsilon = epsilon
self.cache = None # مخزن میانگین متحرک مجذور گرادیانها
def update(self, params, grads):
if self.cache is None:
self.cache = [np.zeros_like(p) for p in params]
updated_params = []
for i in range(len(params)):
# گام ۲: بهروزرسانی میانگین متحرک مجذور گرادیان
self.cache[i] = self.beta * self.cache[i] + (1 - self.beta) * (grads[i]**2)
# گام ۳: نرمالسازی نرخ یادگیری و آپدیت پارامتر
rms_step = self.lr / (np.sqrt(self.cache[i]) + self.epsilon)
new_param = params[i] - rms_step * grads[i]
updated_params.append(new_param)
return updated_params
# --- شبیهسازی برای تست الگوریتم ---
def loss_f(w): return w**2
def grad_f(w): return 2*w
optimizer = RMSpropOptimizer(learning_rate=0.1)
w = np.array([10.0]) # شروع از نقطه ۱۰
history = [w[0]]
print(f"{'Step':<5} | {'Weight':<10} | {'Cache (E[g^2])':<15}")
print("-" * 40)
for i in range(1, 11):
g = grad_f(w)
w = optimizer.update([w], [g])[0]
history.append(w[0])
print(f"{i:<5} | {w[0]:<10.4f} | {optimizer.cache[0][0]:<15.4f}")
# خروجی بصری
plt.figure(figsize=(10, 5))
x = np.linspace(-1, 11, 100)
plt.plot(x, loss_f(x), 'k--', alpha=0.3, label='Loss Surface')
plt.plot(history, [loss_f(h) for h in history], 'ro-', label='RMSprop Path')
plt.title('RMSprop Convergence Path')
plt.xlabel('Weight (w)'); plt.ylabel('Loss (L)'); plt.legend(); plt.show()
خروجی:
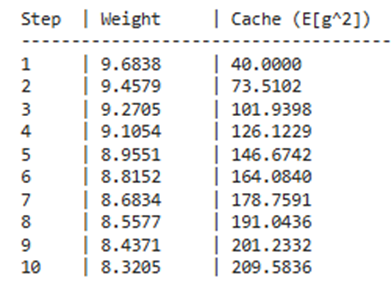

.
مطالعه موردی ۱: مدیریت نوسانات شدید در پیشبینی بازارهای مالی
چالش فنی (Financial Volatility): در بازارهای مالی (مانند بورس یا رمزارزها)، دادهها ماهیتی غیرایستا (Non-stationary) دارند. در لحظاتی که شوکهای خبری یا اقتصادی رخ میدهد، قیمتها دچار جهشهای ناگهانی میشوند. در مدلهای یادگیری عمیق، این نوسانات منجر به تولید گرادیانهای بسیار بزرگ (Exploding Gradients) میشود. بهینهسازهای سنتی مانند SGD در مواجهه با این شوکها، گامهای بسیار بلندی برمیدارند که منجر به واگرایی مدل و از بین رفتن الگوهای یادگرفتهشدهی قبلی میگردد.
نقش استراتژیک RMSprop: الگوریتم RMSprop با بهرهگیری از میانگین متحرک مجذور گرادیانها، در واقع یک «ضربهگیر هوشمند» ایجاد میکند. وقتی یک شوک قیمتی رخ میدهد، مخرج کسر در فرمول RMSprop به سرعت بزرگ شده و نرخ یادگیری را برای آن پارامترهای پرنوسان کاهش میدهد. این مکانیسم اجازه نمیدهد یک نوسان لحظهای و کاذب، کل ساختار وزنهای شبکه را تخریب کند.
دستاورد: مدل پیشبینی بهجای واکنش افراطی به نویزهای کوتاهمدت، بر روی روندهای اصلی (Trends) تمرکز کرده و پایداری خود را در بلندمدت حفظ میکند.
پیادهسازی کد: شبیهسازی RMSprop در پیشبینی دادههای پرنوسان
در این کد، ما یک سری زمانی با نوسانات شدید (شبیه به شوکهای بازار مالی) ایجاد کرده و عملکرد RMSprop را در همگرایی و مقابله با این نوسانات شبیهسازی میکنیم.
import numpy as np
import matplotlib.pyplot as plt
# ۱. شبیهسازی سیگنال بازار مالی (روند اصلی + نویز + شوک ناگهانی)
np.random.seed(42)
time_steps = np.arange(100)
true_trend = 0.5 * time_steps
# ایجاد نویز و یک شوک قیمتی شدید در وسط مسیر
noisy_signal = true_trend + np.random.normal(0, 5, 100)
noisy_signal[50:60] += 50 # وقوع شوک ناگهانی (Shock)
# ۲. پیادهسازی کلاس بهینهساز RMSprop مطابق فرمول ریاضی
class RMSpropOptimizer:
def __init__(self, lr=0.1, beta=0.9):
self.lr = lr
self.beta = beta
self.cache = 0 # ذخیره میانگین متحرک مجذور گرادیانها
self.eps = 1e-8
def update(self, w, grad):
# گام دوم: بهروزرسانی حافظه (E[g^2])
self.cache = self.beta * self.cache + (1 - self.beta) * (grad**2)
# گام سوم: تعدیل هوشمند نرخ یادگیری
adjusted_lr = self.lr / (np.sqrt(self.cache) + self.eps)
return w - adjusted_lr * grad
# ۳. فرآیند آموزش و برازش مدل بر دادهها
w = 0.0 # مقدار اولیه وزن
optimizer = RMSpropOptimizer(lr=0.1, beta=0.9)
weights_history = []
for i in range(len(noisy_signal)):
prediction = w * i
# محاسبه گرادیان (MSE Gradient)
grad = -2 * i * (noisy_signal[i] - prediction)
# کلیپ کردن گرادیان برای پایداری بیشتر محاسبات
grad = np.clip(grad, -10, 10)
w = optimizer.update(w, grad)
weights_history.append(w)
# ۴. رسم نمودار حرفهای و نمایش خروجی
plt.figure(figsize=(12, 6))
# نمودار سیگنال خام و روند اصلی
plt.subplot(1, 2, 1)
plt.plot(time_steps, noisy_signal, color='silver', label='Noisy Market Signal')
plt.plot(time_steps, true_trend, 'k--', alpha=0.6, label='True Trend')
plt.title('Financial Data with Sudden Shocks', fontsize=12)
plt.legend(); plt.grid(True, alpha=0.3)
# نمودار پایداری وزن در طول زمان
plt.subplot(1, 2, 2)
plt.plot(weights_history, color='gold', linewidth=2, label='RMSprop Convergence')
plt.axhline(0.5, color='red', linestyle=':', label='Target Weight (0.5)')
plt.title('Stability of RMSprop during Shocks', fontsize=12)
plt.legend(); plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('rmsprop_financial_analysis.png')
print(f"Final Optimized Weight: {w:.4f}")
خروجی:
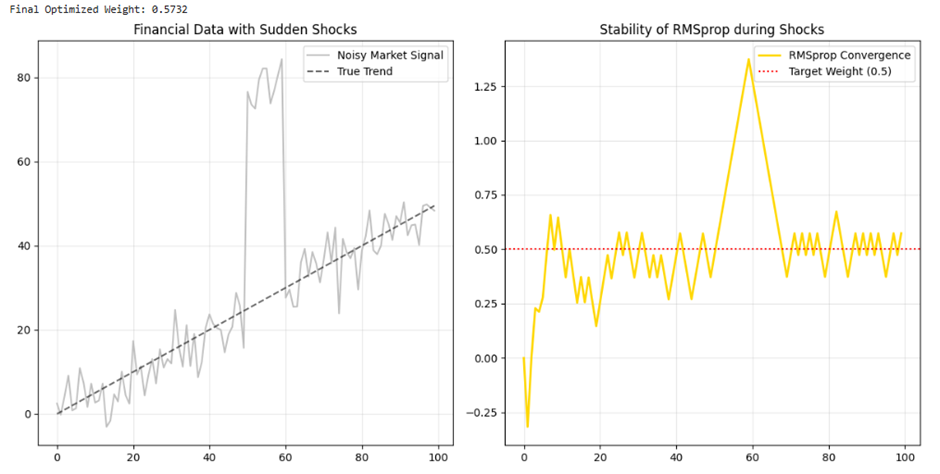
.
مطالعه موردی ۲: پایش دقیق سیگنالهای حیاتی (ECG) در محیطهای نویزی
چالش فنی (Biological Signal Noise): سیگنالهای الکتروکاردیوگرام (ECG) که برای تشخیص بیماریهای قلبی استفاده میشوند، همواره با نویزهای شدیدی همراه هستند؛ از نویز برق شهر گرفته تا نوسانات ناشی از حرکت عضلات بیمار. استخراج الگوهای دقیق (مانند موج P یا کمپلکس QRS) از میان این آشفتگیها برای مدلهای هوش مصنوعی چالشبرانگیز است، زیرا نویزها گرادیانهای ناهماهنگی تولید میکنند که میتواند همگرایی مدل را مختل کند.
نقش استراتژیک RMSprop: در آموزش شبکههای عصبی برای تحلیل سیگنال، RMSprop به عنوان یک «فیلتر تطبیقی» عمل میکند. این بهینهساز نرخ یادگیری را برای پارامترهایی که مدام تحت تأثیر نویزهای فرکانس بالا تغییر میکنند، میرا میکند و در مقابل، نرخ یادگیری را برای بخشهایی از شبکه که الگوهای پایدار و حیاتی قلب را شناسایی میکنند، در سطح بهینه نگه میدارد.
دستاورد: افزایش دقت تشخیص در مدلهای پزشکی، بهویژه در دستگاههای پوشیدنی (Wearables) که بیمار در حین فعالیت از آنها استفاده میکند و سیگنالها دارای نویز حرکتی زیادی هستند.
پیادهسازی کد پایتون: شبیهسازی استخراج سیگنال ECG از نویز
در این کد، ما یک موج ECG فرضی (ضربان قلب) را با نویز شدید ترکیب کرده و نشان میدهیم که RMSprop چگونه با تعدیل نرخ یادگیری، از پرشهای ناگهانی در فرآیند یادگیری جلوگیری میکند.
import numpy as np
import matplotlib.pyplot as plt
# ۱. شبیهسازی سیگنال ECG (ترکیبی از امواج سینوسی برای سادگی الگوی ضربان)
np.random.seed(42)
time = np.linspace(0, 1, 500)
# الگوی پایه ضربان قلب (کمپلکس QRS شبیهسازی شده)
clean_ecg = np.sin(2 * np.pi * 5 * time) + 0.5 * np.sin(2 * np.pi * 10 * time)
# افزودن نویز شدید فرکانس بالا (Muscle Artifacts)
noise = np.random.normal(0, 0.8, 500)
noisy_ecg = clean_ecg + noise
# ۲. کلاس بهینهساز RMSprop
class RMSprop:
def __init__(self, lr=0.01, beta=0.9):
self.lr = lr
self.beta = beta
self.cache = 0
self.eps = 1e-8
def step(self, w, grad):
# بهروزرسانی میانگین متحرک مجذور گرادیان (ذخیره شدت نویز)
self.cache = self.beta * self.cache + (1 - self.beta) * (grad**2)
# تعدیل هوشمند گام بر اساس شدت نوسانات
adjusted_lr = self.lr / (np.sqrt(self.cache) + self.eps)
return w - adjusted_lr * grad
# ۳. شبیهسازی فرآیند برازش (یادگیری الگوی ضربان)
w = 0.0 # وزن اولیه
optimizer = RMSprop(lr=0.05, beta=0.9)
predicted_signal = []
weight_history = []
for i in range(len(noisy_ecg)):
# محاسبه خطا و گرادیان (سادهسازی شده برای نمایش پایداری)
grad = -(noisy_ecg[i] - w)
# کلیپ کردن برای پایداری بیشتر
grad = np.clip(grad, -2, 2)
w = optimizer.step(w, grad)
predicted_signal.append(w)
weight_history.append(w)
# ۴. رسم نمودار مقایسهای
plt.figure(figsize=(12, 6))
# نمایش سیگنال نویزی در مقابل سیگنال پاک
plt.subplot(1, 2, 1)
plt.plot(time, noisy_ecg, color='silver', alpha=0.5, label='Noisy ECG (Sensor Data)')
plt.plot(time, clean_ecg, 'k', linewidth=1.5, label='Clean ECG Pattern')
plt.title('Biological Signal Noise Challenge', fontsize=12)
plt.legend(); plt.grid(True, alpha=0.3)
# نمایش چگونگی همگرایی مدل با RMSprop
plt.subplot(1, 2, 2)
plt.plot(time, predicted_signal, color='gold', linewidth=2, label='RMSprop Learned Signal')
plt.title('RMSprop Adaptive Filtering Result', fontsize=12)
plt.legend(); plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print(f"Final Stability Check: RMSprop efficiently smoothed the signal by adaptive scaling.")
خروجی:
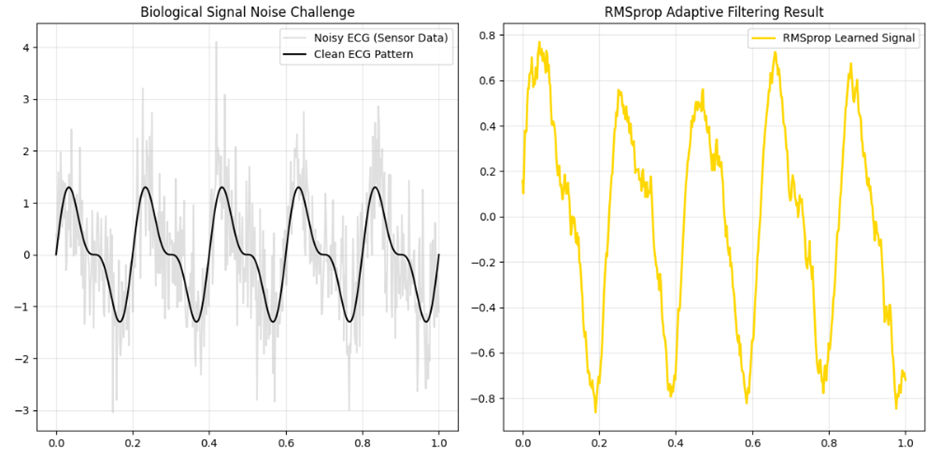
.
مزایا
- نرخ یادگیری تطبیقی و هوشمند (Adaptive Learning Rates): برخلاف SGD سنتی، RMSprop نرخ یادگیری را برای هر پارامتر به صورت مجزا تنظیم میکند. این کار باعث میشود وزنهایی که نوسانات شدیدی دارند با گامهای کوچکتر و وزنهای پایدار با گامهای بلندتر حرکت کنند.
- پایداری در اهداف غیرایستا (Non-Stationary Objectives): این الگوریتم در مواجهه با مسائلی که فضای هزینه آنها در طول زمان تغییر میکند (مثل یادگیری تقویتشونده یا RNNها)، فوقالعاده عمل میکند.
- حل بحران کاهش نرخ یادگیری (Prevents LR Decay): برخلاف الگوریتم AdaGrad که نرخ یادگیری را بیش از حد سریع به صفر نزدیک میکرد، RMSprop با استفاده از ضریب کاهشی(Decay Rate)، نرخ یادگیری را در سطح بهینه حفظ میکند.
- کارایی در مسائل غیرمحدب (Non-Convex Efficiency): این متد در فضای پیچیده و غیرمحدب شبکههای عصبی عمیق، عملکردی بسیار پایدارتر از روشهای کلاسیک دارد.
- تسریع در همگرایی (Faster Convergence): با نرمسازی بهروزرسانیها و جلوگیری از نوسانات عرضی در درههای باریک، مدل را با سرعت بسیار بالایی به نقطه بهینه میرساند.
- عملکرد اثباتشده تجربی (Robust Performance): به دلیل پایداری بالا در معماریهای مختلف، این متد یکی از قابلاعتمادترین گزینهها در صنعت هوش مصنوعی است.
.
محدودیتها
- حساسیت بالا به هایپرپارامترها: عملکرد RMSprop به شدت به تنظیم دقیق ضریب کاهشی (β) و اپسیلون (ε) وابسته است و نیاز به تجربه مهندسی دارد.
- فقدان ممنتوم مستقیم: این الگوریتم به صورت درونی از مفهوم ممنتوم (تکانه) استفاده نمیکند؛ به همین دلیل ممکن است در مقایسه با Adam در برخی مسیرها کندتر عمل کند.
- ضعف در دادههای پراکنده (Sparse Data): در مواجهه با دادههایی که گرادیانهای آنها به ندرت ظاهر میشوند، ممکن است دچار نوسانات ناهماهنگ شود.
- جایگزینی توسط Adam: امروزه الگوریتم Adam با ترکیب ویژگیهای RMSprop و Momentum، جایگاه این بهینهساز را در بسیاری از کاربردها تصاحب کرده است، هرچند RMSprop همچنان هزینه محاسباتی کمتری دارد.
.
کاربردهای واقعی RMSprop
۱. آموزش شبکههای عصبی بازگشتی (RNNs) و LSTM
درخشانترین کاربرد RMSprop در پردازش دادههای متوالی (Sequential Data) است.
- مهار گرادیانهای انفجاری: در مدلهای زبانی یا ترجمه ماشینی، گرادیانها ممکن است در طول زمان به شدت بزرگ شوند. RMSprop با نرمالسازی این مقادیر، مانع از فروپاشی فرآیند آموزش میشود.
- ثبات در تحلیل متن: این الگوریتم به مدل کمک میکند تا بفهمد کدام کلمات در یک جمله اهمیت بیشتری دارند و نرخ یادگیری را برای پارامترهای مربوط به آنها به دقت تنظیم کند.
.
۲. یادگیری تقویتشونده (Reinforcement Learning)
در سناریوهایی که یک عامل هوشمند (Agent) باید از طریق آزمون و خطا در یک محیط پویا یاد بگیرد، RMSprop انتخاب اول است.
- مدیریت پاداشهای متغیر: چون پاداشها در طول زمان تغییر میکنند (Non-stationary)، RMSprop با نرخ یادگیری تطبیقی خود، به عامل هوشمند اجازه میدهد تا به سرعت با استراتژیهای جدید سازگار شود.
- کنترل رباتیک: در آموزش بازوهای رباتیک برای انجام کارهای ظریف، این بهینهساز مانع از حرکات لرزشی و ناگهانی ناشی از نوسانات گرادیان میشود.
.
۳. فشردهسازی و بازسازی تصاویر (Deep Autoencoders)
در پروژههایی که هدف آنها کاهش ابعاد داده یا حذف نویز از تصاویر است، RMSprop نقش فیلتر هوشمند را ایفا میکند.
- دقت در لایهی تنگنا (Bottleneck): در مدلهای Autoencoder، این بهینهساز کمک میکند تا جزئیات حیاتی تصویر (مثل لبهها در عکسهای پزشکی) با دقت بسیار بالایی ذخیره و بازسازی شوند.
- پایداری در همگرایی: RMSprop در مواجهه با توابع هزینه پیچیده و غیرمحدب این مدلها، بسیار پایدارتر از روشهای سنتی عمل میکند.
.
۴. پردازش سیگنال و دادههای صوتی
دستیارهای صوتی مانند Siri یا Google Assistant برای درک صحیح فرکانسهای مختلف صدا به بهینهسازهای تطبیقی نیاز دارند.
- نرمسازی فرکانسها: RMSprop نوسانات شدید در فرکانسهای صوتی را تعدیل کرده و به مدل اجازه میدهد تا ویژگیهای صوتی را بدون توجه به نویز محیطی، به درستی استخراج کند.
.
مقایسهی RMSprop با سایر بهینهسازها
| ویژگی / بهینهساز | SGD | AdaGrad | RMSprop | Adam |
| نرخ یادگیری | ثابت | تطبیقی؛ اما با گذشت زمان کاهش مییابد | تطبیقی؛ بر اساس شدت گرادیانهای اخیر | تطبیقی؛ ترکیبی از ممنتوم و روش مشابه RMSprop |
| ممنتوم | اختیاری | ندارد | ندارد (رفتار شبهممنتوم از طریق میانگین متحرک) | دارد |
| مقیاسبندی گرادیان | یکنواخت برای تمام پارامترها | برای هر پارامتر | برای هر پارامتر (میانگین متحرک مجذور گرادیان) | برای هر پارامتر (میانگین متحرک گشتاور اول و دوم) |
| عملکرد در توابع غیرمحدب | ضعیف؛ احتمال گیر افتادن در کمینههای محلی | دشوار؛ به دلیل کاهش شدید نرخ یادگیری | بسیار موثر؛ بهویژه در مسائل غیرایستا و پیچیده | بسیار عالی؛ به دلیل ترکیب ممنتوم و نرخ تطبیقی |
| سرعت همگرایی | بدون ممنتوم، بسیار کُند است | با گذشت زمان به شدت کُند میشود | سریعتر از SGD و AdaGrad | بسیار سریع؛ |
| هایپرپارامترها | نرخ یادگیری | نرخ یادگیری | نرخ یادگیری، نرخ کاهشی، اپسیلون | نرخ یادگیری، β1 ، β2 ، اپسیلون |
| میزان مصرف حافظه | بسیار پایین | بالا (به دلیل انباشت مجذور گرادیانها) | متوسط (ذخیره میانگین متحرک مجذور گرادیان) | بالاترین (ذخیره میانگین متحرک گشتاورها) |
| موارد کاربرد اصلی | مسائل ساده و توابع محدب | دادههای پراکنده | شبکههای RNN و مسائل غیرایستا | یادگیری عمیق و مدلهای پیچیده (CNN/RNN) |
.
تحلیل نهایی و بینشهای کلیدی
- SGD: همچنان گزینهای مناسب برای مسائل ساده یا محیطهایی با محدودیت شدید حافظه و پردازش است. برای بهبود همگرایی در این متد، استفاده از جملهی ممنتوم توصیه میشود.
- AdaGrad: در مواجهه با دادههای پراکنده عملکرد درخشانی دارد، اما به دلیل میرایی شدید نرخ یادگیری در طول زمان، برای آموزشهای طولانیمدت پیشنهاد نمیشود.
- RMSprop: یک راهکار تخصصی برای بهینهسازی مسائل غیرمحدب است. این الگوریتم با ایجاد توازن در نرخ یادگیریِ پارامترها، فرآیند یادگیری را در محیطهای پویا تثبیت میکند.
- Adam: با ترکیب نقاط قوت ممنتوم و RMSprop، به استانداردی برای آموزش مدلهای بزرگ و پیچیده در یادگیری عمیق تبدیل شده است، هرچند هزینه محاسباتی بیشتری را تحمیل میکند.
.
جمع بندی
RMSprop یکی از بهینهسازهای مهم و تأثیرگذار در تاریخ تکامل الگوریتمهای آموزش شبکههای عصبی است. این روش با کنترل مقیاس گرادیانها و تنظیم تطبیقی نرخ یادگیری، توانست محدودیتهای AdaGrad را تا حد زیادی برطرف کند و آموزش پایدارتر مدلها را ممکن سازد. در این مطلب دیدیم که استفاده از میانگین متحرک نمایی مجذور گرادیانها چگونه به کاهش نوسانات و جلوگیری از افت شدید نرخ یادگیری کمک میکند.
بررسی مثالهای عددی و پیادهسازی عملی نشان داد که RMSprop بهویژه در مسائل دارای گرادیانهای نویزی یا مقیاسهای متفاوت پارامترها عملکرد قابلاعتمادی دارد. با این حال، این روش نیز یک راهحل همهمنظوره نیست و در برخی کاربردها، بهینهسازهای پیشرفتهتری مانند Adam یا نسخههای اصلاحشدهای نظیر AdamW میتوانند گزینههای مناسبتری باشند.
در عمل، RMSprop را میتوان بهعنوان پلی میان روشهای تطبیقی اولیه و بهینهسازهای مدرنتر در نظر گرفت. درک سازوکار RMSprop به مهندس یادگیری ماشین کمک میکند تا منطق تنظیم تطبیقی نرخ یادگیری را بهتر بفهمد و در انتخاب بهینهساز مناسب، تصمیمهایی آگاهانهتر و مبتنی بر ویژگیهای مسئله اتخاذ کند.



