

مقدمه
در یک شبکه عصبی مصنوعی، دادهها مانند جریانی از اطلاعات از لایهی ورودی آغاز شده و پس از عبور از یک یا چند لایهی پنهان، در نهایت به لایهی خروجی میرسند. هر لایه از واحدهای کوچکی به نام نورون تشکیل شده است که وظیفه دارند ورودی را دریافت، پردازش و نتیجه را به لایهی بعدی منتقل کنند.
این لایهها در کنار هم کار میکنند تا ویژگیهای کلیدی دادهها را استخراج کرده، آنها را تغییر شکل دهند و در نهایت یک پیشبینی دقیق انجام دهند.
انواع اصلی لایهها در ANN
به طور کلی، هر شبکه عصبی مصنوعی از سه نوع لایهی اصلی تشکیل شده است:
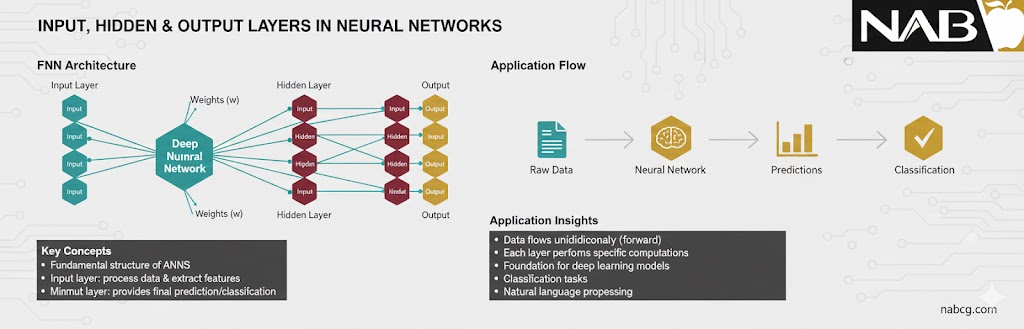
۱. لایهی ورودی (Input Layer)
این لایه دروازهی ورود دادهها به دنیای شبکه عصبی است. نورونهای این لایه هیچ پردازش پیچیدهای انجام نمیدهند؛ آنها فقط ویژگیهای دادههای خام (مثل مقادیر پیکسلهای یک تصویر یا مشخصات مالی یک فرد) را دریافت کرده و به لایههای بعدی میفرستند.
۲. لایههای پنهان (Hidden Layers)
اینجا دقیقاً همان جایی است که هوش مدل شکل میگیرد. لایههای پنهان بین ورودی و خروجی قرار دارند و وظیفهی آنها انجام محاسبات ریاضی سنگین برای یافتن الگوهای پنهان در دادههاست. هرچه تعداد این لایهها بیشتر باشد، شبکه عمیقتر میشود و میتواند مسائل پیچیدهتری را حل کند.
۳. لایهی خروجی (Output Layer)
این لایه نتیجهی نهایی تمام پردازشها را به ما نشان میدهد. خروجی این لایه میتواند یک مقدار عددی (در مسائل رگرسیون) یا دستهای از احتمالات (در مسائل طبقهبندی) باشد.
نورونها: اجزای سازنده لایهها
هر لایه مجموعهای از گرهها (Nodes) یا همان نورونهاست که با پیوندهایی به یکدیگر متصل شدهاند. قدرت هر یک از این پیوندها با عددی به نام وزن (Weight) مشخص میشود. لایهها با همکاری هم، دادهها را از طریق یک سری تغییرات ریاضی (تبدیلات) به خروجی نهایی تبدیل میکنند.
لایههای پایه در شبکه عصبی مصنوعی (ANN)
۱. لایه ورودی (Input Layer)
۲. لایههای پنهان (Hidden Layers)
۳. لایهی خروجی (Output Layer)
۱. لایه ورودی (Input Layer)
لایه ورودی، اولین ایستگاه در یک شبکه عصبی مصنوعی است که وظیفه دریافت دادههای خام را بر عهده دارد. تعداد نورونهای این لایه دقیقاً با تعداد ویژگیهای (Features) موجود در دادههای ورودی شما برابر است.
به عنوان مثال، در پردازش تصویر، اگر یک تصویر کوچک سیاه و سفید داشته باشید، هر نورون در لایه ورودی ممکن است مقدار عددی یک پیکسل (شدت روشنایی) را نمایندگی کند. نکته مهم اینجاست که لایه ورودی هیچگونه محاسبات ریاضی یا پردازشی روی دادهها انجام نمیدهد؛ وظیفه آن صرفاً انتقال امانتدارانهی دادهها به لایه بعدی است.
نکات کلیدی:
- نقش: دریافتکننده دادههای خام از دنیای بیرون.
- عملکرد: انتقال دادهها به لایههای پنهان بدون تغییر در مقادیر آنها.
- مثال: برای یک تصویر با ابعاد 28 ✕ 28 پیکسل، لایه ورودی دارای ۷۸۴ نورون خواهد بود (هر نورون برای یک پیکسل).
.
چرا لایه ورودی در مدلها اهمیت حیاتی دارد؟
همانطور که در تجربههای قبلی دیدیم، لایه ورودی جایی است که ما باید مطمئن شویم دادهها نرمالسازی شدهاند. اگر دادهها در این مرحله با مقیاسهای متفاوتی وارد شوند (مثلاً یکی بین ۰ تا ۱ و دیگری بین ۰ تا ۲۵۵)، نورونهای لایه ورودی این تفاوت فاحش را به لایههای بعدی منتقل میکنند و کل فرآیند یادگیری مختل میشود.
۲. لایههای پنهان (Hidden Layers)
لایههای پنهان، لایههای واسطهای هستند که بین ورودی و خروجی قرار میگیرند. این لایهها در واقع موتورخانه شبکه هستند و بخش اعظم محاسبات شبکه در اینجا انجام میشود. تعداد و اندازه (تعداد نورونهای) این لایهها کاملاً به پیچیدگی مسئلهای که میخواهید حل کنید بستگی دارد.
در هر لایه پنهان، مجموعهای از وزنها (Weights) و بایاسها (Biases) روی دادههای ورودی اعمال شده و سپس نتیجه از یک تابع فعالسازی عبور داده میشود تا شبکه بتواند الگوهای غیرخطی و پیچیده را درک کند.
۳. لایهی خروجی (Output Layer)
لایه خروجی، آخرین بخش از یک شبکه عصبی مصنوعی است که پیشبینی نهایی را تولید میکند. تعداد نورونهای این لایه بر اساس نوع مسئله تعیین میشود:
- در مسائل دستهبندی: تعداد نورونها برابر با تعداد کلاسهاست.
- در مسائل رگرسیون: تعداد نورونها برابر با تعداد خروجیهای مورد انتظار (معمولاً یک عدد) است.
.
نوع تابع فعالسازی در لایه خروجی به شدت به نوع هدف شما بستگی دارد:
- Softmax: برای دستهبندیهای چندگانه (مثلاً تشخیص بین سگ، گربه و اسب).
- Sigmoid: برای دستهبندیهای دوگانی (بله/خیر، اسپم/غیر اسپم).
- Linear: برای مسائل رگرسیون (مثلاً پیشبینی قیمت خانه).
.
انواع لایههای پنهان در شبکههای عصبی مصنوعی
تا اینجا لایههای اصلی را شناختیم. حالا بیایید کمی عمیقتر شویم و با پرکاربردترین انواع لایههای پنهان آشنا شویم:
- لایه متراکم
- لایه کانولوشنی
- لایهی بازگشتی
- لایهی تجمیع
- لایهی تسطیح
- لایهی دراپاوت
- لایهی نرمالسازی دستهای
- لایههای پیشرفتهتر
.
۱. لایه متراکم یا تماممتصل (Dense / Fully Connected Layer)
لایه Dense رایجترین نوع لایه پنهان در شبکههای عصبی است. در این لایه، هر نورون به تکتک نورونهای لایه قبلی و لایه بعدی متصل است. این لایه مجموع وزندار ورودیها را محاسبه کرده و با استفاده از توابع فعالسازی )مثل ReLU یا Tanh)، به شبکه کمک میکند تا الگوهای پیچیده را از دادههای ورودی استخراج کند.
- نقش: یادگیری نمایشهای مختلف از دادههای ورودی.
- عملکرد: انجام محاسبات ریاضی (مجموع وزندار) و اعمال تابع فعالسازی.
.
۲. لایه کانولوشنی (Convolutional Layer)
لایه کانولوشنی قلب تپنده شبکههای عصبی کانولوشنی (CNN) است و مخصوصاً برای کارهایی مثل پردازش تصویر و ویدیو طراحی شده است. بر خلاف لایههای Dense که به کل تصویر به صورت یکجا نگاه میکنند، لایههای کانولوشنی با استفاده از عملیات ریاضیِ کانولوشن، الگوهای محلی و سلسلهمراتب فضایی دادهها را استخراج میکنند.
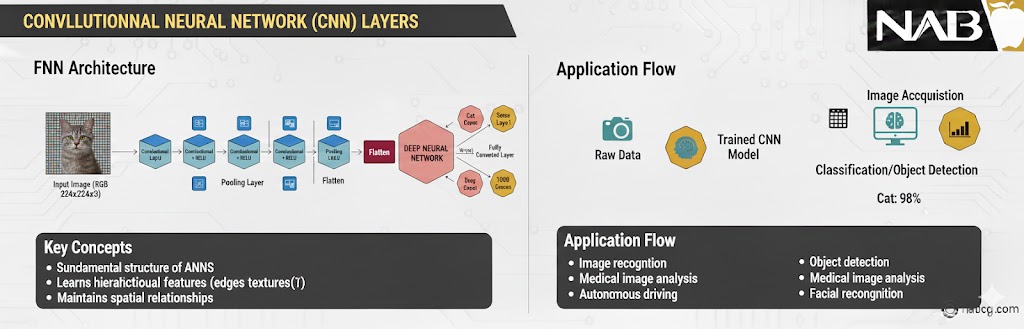
در این لایه، از تعدادی فیلتر (Filter) یا هسته (Kernel) استفاده میشود که روی تصویر میلغزند (اسکن میکنند) تا نقشههای ویژگی (Feature Maps) را ایجاد کنند. این فرآیند به شبکه کمک میکند تا از سادهترین ویژگیها مثل لبهها و خطوط شروع کرده و در لایههای عمیقتر به بافتها، اشکال و در نهایت اشیاء کامل برسد.
- نقش: استخراج ویژگیهای فضایی (Spatial Features) از تصاویر.
- عملکرد: اعمال عملیات ضرب نقطهای فیلترها روی ورودی برای شناسایی الگوهای بصری.
.
۳. لایهی بازگشتی (Recurrent Layer)
لایههای بازگشتی قطعات اصلی در شبکههای عصبی بازگشتی (RNN) هستند و مخصوصاً برای دادههایی طراحی شدهاند که به صورت توالی (Sequence) هستند؛ مثل دادههای سری زمانی بورس، سیگنالهای صوتی یا متون زبان طبیعی (Natural Language).
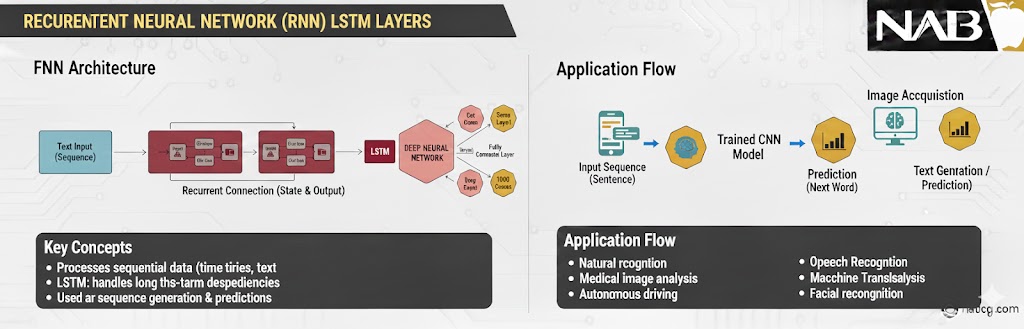
تفاوت بزرگ این لایه با لایههای قبلی در این است که لایههای بازگشتی دارای اتصالات حلقوی (Loop) هستند. این حلقهها به اطلاعات اجازه میدهند تا از گامهای زمانی قبلی عبور کرده و به گامهای بعدی برسند. به عبارت سادهتر، این لایه نوعی حافظه دارد که باعث میشود شبکه بفهمد هر داده در چه بستری (Context) قرار گرفته است.
- نقش: پردازش دادههای توالیمحور با وابستگیهای زمانی (Temporal Dependencies).
- عملکرد: حفظ وضعیت (State) یا حافظه در طول گامهای زمانی مختلف.
مثال:
تصور کنید میخواهید کلمهی بعدی یک جمله را پیشبینی کنید: من امروز به نانوایی رفتم تا … بخرم. یک لایه معمولی (Dense) فقط کلمات آخر را میبیند، اما لایه بازگشتی کلمهی نانوایی را که در ابتدای جمله آمده به خاطر میسپارد و به احتمال زیاد کلمهی نان را پیشنهاد میدهد.
۴. لایهی دراپاوت (Dropout Layer)
لایه Dropout در واقع یک لایه پردازشی نیست، بلکه یک تکنیک منظمسازی (Regularization) برای جلوگیری از یک مشکل بزرگ به نام بیشبرازش است.
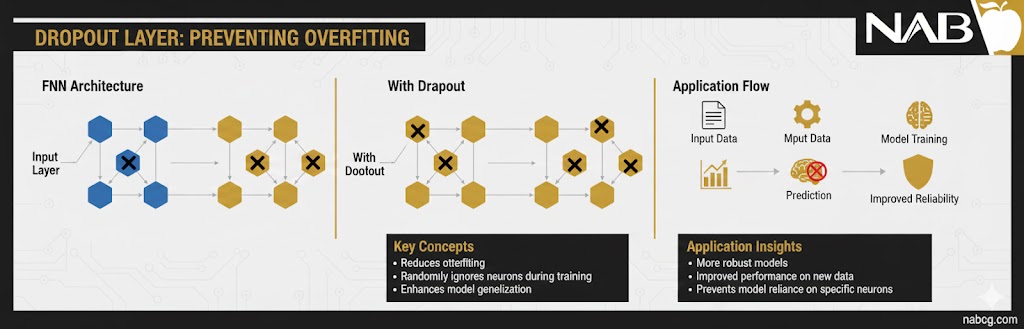
تصور کنید یک تیم ورزشی دارید که فقط به یک بازیکن ستاره وابسته است؛ اگر آن بازیکن مصدوم شود، تیم از هم میپاشد. در شبکه عصبی هم گاهی چند نورون تمام وزن کار را بر عهده میگیرند و بقیه نورونها عملاً تنبل میشوند. لایه Dropout در طول فرآیند آموزش، به صورت تصادفی بخشی از نورونها را غیرفعال یا حذف میکند. این کار شبکه را مجبور میکند تا یاد بگیرد به جای وابستگی به چند نورون خاص، ویژگیهای مقاومتر و توزیعشدهتری را در کل شبکه یاد بگیرد.
- نقش: جلوگیری از بیشبرازش و افزایش قدرت تعمیم مدل.
- عملکرد: حذف تصادفی درصدی از نورونها در هر مرحله از آموزش با احتمال p (مثلاً ۲۰٪ یا ۵۰٪).
نکتهی مهم:
فراموش نکنید که لایه Dropout فقط و فقط در زمان آموزش (Training) فعال است. وقتی مدل شما آماده شد و میخواهید از آن برای پیشبینی واقعی استفاده کنید، تمام نورونها دوباره فعال میشوند تا مدل با تمام توان خود پاسخ دهد.
۵. لایهی تجمیع (Pooling Layer)
لایه Pooling که معمولاً بلافاصله بعد از لایههای کانولوشنی (CNN) قرار میگیرد، وظیفه دارد ابعاد فضایی (عرض و ارتفاع) دادهها را کاهش دهد. تصور کنید یک عکس با کیفیت بسیار بالا دارید؛ لایه Pooling بدون اینکه ویژگیهای مهم (مثل لبهها) را از بین ببرد، حجم پیکسلها را کم میکند تا محاسبات سریعتر انجام شود و شبکه روی جزئیات بیاهمیت حساس نشود (جلوگیری از بیشبرازش).
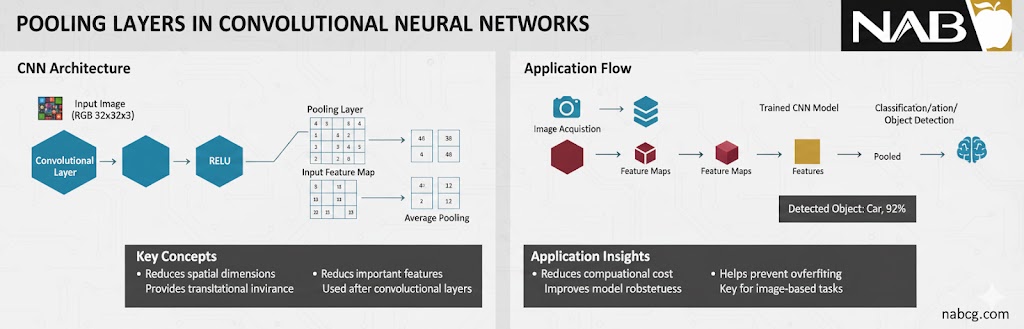
رایجترین انواع لایههای تجمیع عبارتند از:
- Max Pooling (بیشینهگیری): از میان یک پنجره مشخص (مثلاً 2 ✕ 2 پیکسل)، فقط بزرگترین مقدار را انتخاب میکند. این روش در استخراج برجستهترین ویژگیها مثل لبههای تیز بسیار عالی عمل میکند.
- Average Pooling (میانگینگیری): میانگین تمام مقادیر موجود در پنجره را محاسبه میکند. این روش باعث نرمتر شدن ویژگیها میشود.
موارد استفاده: کاهش ابعاد (Dimensionality Reduction) در شبکههای CNN.
- کاهش بار محاسباتی و حافظه مصرفی.
- ایجاد مقاومت در برابر جابهجاییهای کوچک در تصویر (مثلاً اگر سوژه کمی به چپ یا راست متمایل شود، خروجی Pooling تغییر زیادی نمیکند).
.
6. لایهی تسطیح (Flatten Layer)
لایه Flatten یکی از لایههای کلیدی و در واقع پل ارتباطی در شبکههای عصبی ترکیبی است. زمانی که ما در لایههای قبلی (مثل لایههای کانولوشنی و Pooling) با دادههای چندبعدی یا ماتریسی سر و کار داریم، نمیتوانیم آنها را مستقیماً به لایههای متراکم (Dense) بفرستیم. لایه Flatten بدون اینکه تغییری در مقادیر دادهها ایجاد کند، تمام پیکسلها یا ویژگیهای موجود در یک ماتریس چندبعدی را برداشته و آنها را پشت سر هم در یک بردار یکبعدی میچیند.
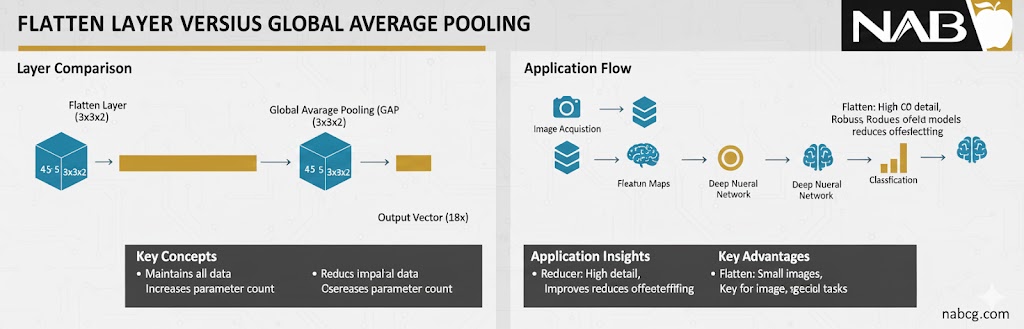
- نقش: آمادهسازی دادههای چندبعدی برای ورود به لایههای تماممتصل .(Dense)
- عملکرد: تبدیل ماتریسهای داده به یک صف طولانی از اعداد (بردار) بدون تغییر در محتوا.
- مثال: اگر خروجی لایه Pooling یک ماتریس 5 ✕ 5 باشد، لایه Flatten آن را به یک بردار با ۲۵ نورون تبدیل میکند.
.
7. لایهی نرمالسازی دستهای
لایه Batch Normalization یا به اختصار Batch Norm، یکی از تکنیکهای انقلابی در یادگیری عمیق است که برای پایدارسازی و سرعت بخشیدن به آموزش شبکههای عصبی استفاده میشود.
همانطور که در گامهای ابتدایی یاد گرفتیم که نرمالسازی دادههای ورودی چقدر حیاتی است، لایه Batch Norm همین کار را درونِ خودِ شبکه و بین لایهها انجام میدهد. این لایه خروجی لایهی قبلی را میگیرد و با کم کردن میانگین دسته و تقسیم بر انحراف معیار دسته، مقادیر را دوباره استاندارد میکند.
مزایای اصلی این لایه:
- افزایش سرعت آموزش: به شما اجازه میدهد از نرخ یادگیری (Learning Rate) بالاتری استفاده کنید بدون اینکه شبکه ناپایدار شود.
- کاهش وابستگی به مقداردهی اولیه: دیگر لازم نیست خیلی نگران مقادیر اولیه وزنها باشید.
- نوعی منظمسازی: این لایه تأثیر کمی شبیه به Dropout دارد و به جلوگیری از بیشبرازش کمک میکند.
موارد استفاده: پایدارسازی و شتابدهی به فرآیند آموزش در شبکههای عمیق.
چرا Batch Normalization مهم است؟
یادتان هست که در ابتدای مسیر، مدل ما به خاطر مقادیر ۰ تا ۲۵۵ آموزش نمیدید؟ لایه Batch Norm تضمین میکند که حتی اگر لایههای میانی شبکه بخواهند اعداد را خیلی بزرگ یا خیلی کوچک کنند، دوباره همهچیز به یک نظم استاندارد برگردد. این کار باعث میشود سیگنالهای یادگیری (گرادیانها) خیلی راحتتر در اعماق شبکه جریان پیدا کنند.
8. لایههای پیشرفتهتر
اگر بخواهیم نگاهی به تکنولوژیهای مدرنتر در شبکههای عصبی عمیق بیندازیم، دو نوع لایه زیر نقشی انقلابی ایفا میکنند:
- Global Average Pooling (GAP): این لایه یک جایگزین هوشمند و مدرن برای لایه Flatten در شبکههای تصویری عمیق است. به جای اینکه تمام مقادیر را به یک بردار طولانی تبدیل کند، میانگین کل هر نقشه ویژگی را محاسبه میکند. این کار علاوه بر کاهش شدید بار محاسباتی، مقاومت مدل را در برابر بیشبرازش (Overfitting) به شدت بالا میبرد.
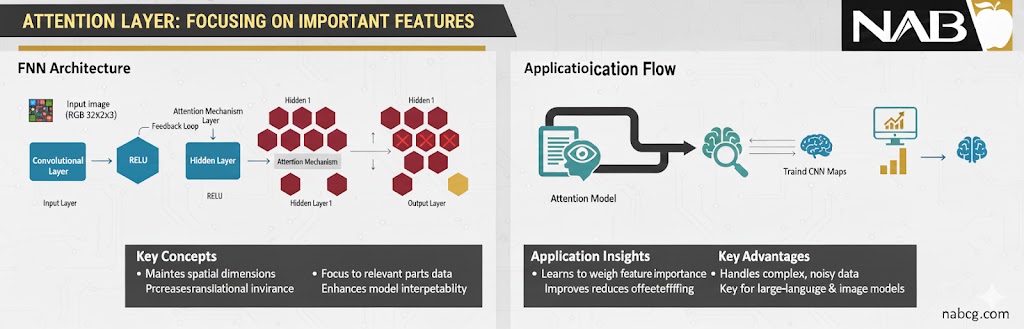
- لایههای توجه (Attention Layers): این لایهها قلب تپنده مدلهای ترنسفورمر (مثل ChatGPT) هستند. لایه Attention به شبکه اجازه میدهد تا به جای پردازش یکسان تمام ورودیها، روی بخشهای مهمتر تمرکز کند. به زبان ساده، این لایه به مدل میگوید که در یک جمله طولانی، کدام کلمات ارتباط معنایی قویتری با هم دارند
جدول راهنمای جامع لایههای شبکه عصبی مصنوعی
| نوع لایه | نام تخصصی | وظیفه اصلی و عملکرد | بهترین مورد استفاده |
| ورودی | Input | دریافت دادههای خام (ویژگیها) و انتقال بدون تغییر آنها به لایههای بعدی. | نقطه شروع تمام مدلهای یادگیری عمیق. |
| متراکم | Dense | یادگیری الگوهای کلی از طریق اتصال تمام نورونهای لایه قبل به بعد. | دستهبندی دادههای عددی و رتبهبندی اعتباری. |
| کانولوشنی | Convolutional | استخراج ویژگیهای فضایی (لبه، بافت) با استفاده از فیلترهای لغزنده. | پردازش تصویر و بینایی ماشین. |
| بازگشتی | Recurrent | حفظ ترتیب و بستر دادهها با استفاده از حلقههای حافظه داخلی. | پردازش متن، صوت و پیشبینی بورس. |
| تجمیع | Pooling | کاهش ابعاد نقشه ویژگی برای کاهش بار محاسباتی و جلوگیری از بیشبرازش. | کوچکسازی تصاویر در شبکههای CNN. |
| تسطیح | Flatten | تبدیل ماتریسهای چندبعدی به بردار یکبعدی برای ورود به لایههای Dense. | اتصال بخش استخراج ویژگی به بخش تصمیمگیرنده. |
| دراپاوت | Dropout | حذف تصادفی نورونها در زمان آموزش برای جلوگیری از وابستگی مدل به چند گره خاص. | مقابله با بیشبرازش (Overfitting). |
| نرمالسازی | Batch Norm | استانداردسازی خروجی لایههای میانی برای پایداری و سرعت بخشیدن به آموزش. | افزایش پایداری در شبکههای بسیار عمیق. |
| توجه | Attention | وزندهی به بخشهای مهمتر ورودی بر اساس اهمیت آنها در بستر داده. | مدلهای زبانی بزرگ و ترنسفورمرها (مانند ChatGPT). |
| خروجی | Output | ارائه پیشبینی نهایی (احتمال کلاسها یا مقدار عددی). | آخرین لایه در تمام معماریهای عصبی. |
مطالعات موردی
در ادامه 2 مطالعه موردی که مکمل یکدیگرند، با جزئیات کامل، تحلیل استراتژیک لایهها و سناریوی گامبهگام توضیح میدهیم.
1. سیستم تشخیص هویت بصری (بینایی ماشین)
2. سیستم تحلیل هوشمند نظرات (پردازش متن و زبان)
.
مطالعه موردی اول: سیستم تشخیص هویت بصری (بینایی ماشین)
هدف: تشخیص نوع اشیاء (مثلاً تفاوت بین خودرو، عابر پیاده و علائم راهنمایی) در سیستمهای رانندگی خودکار.
۱. تحلیل لایهها و نقش آنها:
- لایه ورودی: تصاویر دوربین با کیفیت بالا وارد میشوند. اینجا اولین چالش نرمالسازی است؛ چون نور محیط همیشه یکسان نیست، مقادیر پیکسلها را بین ۰ و ۱ قرار میدهیم تا مدل در شب و روز به یک اندازه دقیق باشد.
- لایههای کانولوشنی: این لایهها مانند ذرهبین عمل میکنند. لایههای اول لبهها و خطوط را میبینند، و لایههای عمیقتر شکل چرخ خودرو یا چراغ راهنما را تشخیص میدهند.
- لایه :Batch Normalization این لایه در این پروژه حیاتی است. چون تصاویر ورودی ممکن است بسیار متنوع باشند، این لایه خروجی لایههای قبلی را تراز میکند تا شبکه دچار سردرگمی نشود و آموزش سریعتر پیش برود.
- لایه تجمیع: به جای پردازش تمام پیکسلها، فقط مهمترینها را نگه میدارد. این کار باعث میشود اگر خودرو کمی در تصویر جابهجا شد، مدل باز هم آن را بشناسد.
- لایه تسطیح: تمام نقشههای ویژگی که توسط فیلترها ساخته شده را به یک صف طولانی تبدیل میکند تا برای بخش تصمیمگیری نهایی آماده شوند.
- لایه متراکم: این لایه مغز متفکر است که تمام ویژگیهای بصری را کنار هم میگذارد و میگوید: چون چرخ و بدنه فلزی داریم، پس این یک خودرو است.
- لایه دراپاوت: مانع از این میشود که مدل فقط عکسهای آموزشی را حفظ کند. این لایه باعث میشود مدل بتواند خودروهایی که تا به حال ندیده را هم تشخیص دهد.
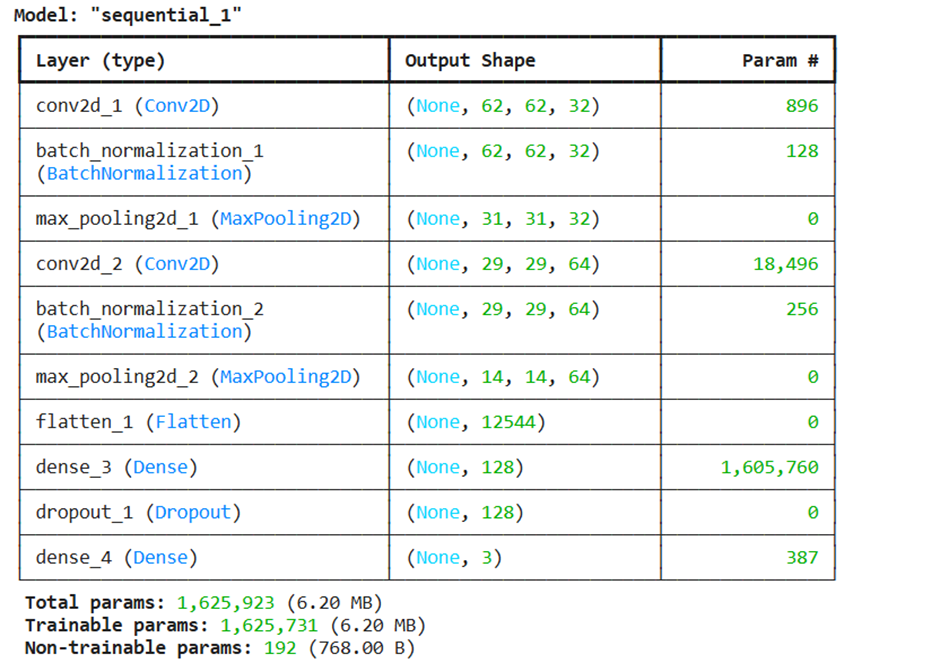
۲. پیادهسازی عملی (Python Code):
import tensorflow as tf
from tensorflow.keras import layers, models
def build_self_driving_vision_model():
# ایجاد یک مدل متوالی (Sequential)
model = models.Sequential([
# ۱. لایه ورودی: تصاویر رنگی ۶۴ در ۶۴ (۳ کانال رنگی)
# مقادیر پیکسلها را از قبل بین ۰ و ۱ نرمالسازی میکنیم
layers.Input(shape=(64, 64, 3)),
# ۲. لایه کانولوشنی اول: استخراج لبهها و خطوط ساده
layers.Conv2D(32, (3, 3), activation='relu'),
# ۳. لایه Batch Normalization: تراز کردن خروجی برای پایداری در شرایط نوری مختلف
layers.BatchNormalization(),
# ۴. لایه تجمیع (MaxPooling): حفظ ویژگیهای مهم و کاهش حساسیت به جابهجایی خودرو
layers.MaxPooling2D((2, 2)),
# ۵. لایه کانولوشنی دوم: تشخیص اشکال پیچیدهتر مثل چرخ یا چراغ
layers.Conv2D(64, (3, 3), activation='relu'),
layers.BatchNormalization(),
layers.MaxPooling2D((2, 2)),
# ۶. لایه تسطیح (Flatten): تبدیل ماتریس تصویر به یک بردار عددی طولانی
layers.Flatten(),
# ۷. لایه متراکم (Dense): مغز متفکر برای تحلیل ویژگیها و تصمیمگیری
layers.Dense(128, activation='relu'),
# ۸. لایه دراپاوت (Dropout): خاموش کردن ۵۰٪ نورونها برای جلوگیری از حفظ کردن دادهها
layers.Dropout(0.5),
# ۹. لایه خروجی: تشخیص ۳ کلاس (خودرو، عابر پیاده، علائم راهنمایی)
# استفاده از Softmax برای گرفتن احتمال هر کلاس
layers.Dense(3, activation='softmax')
])
# تنظیمات نهایی مدل (بهینهساز و تابع خطا)
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
return model
# ایجاد و نمایش ساختار مدل
vision_model = build_self_driving_vision_model()
vision_model.summary()
خروجی:
.
مطالعه موردی دوم: سیستم تحلیل هوشمند نظرات (پردازش متن و زبان)
هدف: تشخیص رضایت یا نارضایتی مشتری از روی متن کامنتها در یک سایت فروشگاهی.
۱. تحلیل لایهها و نقش آنها:
- لایه ورودی: جملات به صورت رشتهای از کلمات وارد میشوند.
- لایه جایگذاری: کامپیوتر کلمات را نمیفهمد. این لایه کلمات را به فضایی میبرد که کلمات خوب و عالی در آن فضا به هم نزدیک باشند و کلمه بد دورتر قرار بگیرد. این یعنی درک معنای کلمات.
- لایه بازگشتی (LSTM/GRU): برخلاف عکس، در متن ترتیب مهم است. جمله من از این محصول راضی نیستم با من از این محصول ناراضی نیستم کاملاً متفاوت است. لایه بازگشتی با داشتن حافظه، کلمات قبلی را به خاطر میسپارد تا بستر (Context) جمله حفظ شود.
- لایه توجه: در یک کامنت طولانی، ممکن است مشتری کلی مقدمهچینی کند اما اصل حرفش در سه کلمه آخر باشد. لایه Attention به شبکه میگوید: بیشتر روی کلمات “خراب بود” تمرکز کن و به کلمات “سلام و خسته نباشید” وزن کمتری بده.
- لایه خروجی: در نهایت یک عدد بین ۰ تا ۱ میدهد. مثلاً ۰.۹ یعنی با احتمال ۹۰ درصد مشتری راضی است.
۲. پیادهسازی عملی (Python Code):
import tensorflow as tf
from tensorflow.keras import layers, models
def build_customer_sentiment_model(vocab_size, max_length):
# ۱. لایه ورودی: [cite: 8, 26]
inputs = layers.Input(shape=(max_length,))
# ۲. لایه جایگذاری (Embedding): درک معنای کلمات
x = layers.Embedding(input_dim=vocab_size, output_dim=32)(inputs)
# ۳. لایه بازگشتی (LSTM): حفظ بستر و ترتیب کلمات [cite: 77, 81]
lstm_out = layers.LSTM(64, return_sequences=True)(x)
# ۴. لایه توجه (Attention): تمرکز بر بخشهای مهمتر
# اصلاح شده: استفاده از خروجی LSTM برای محاسبه توجه
attention_out = layers.Attention()([lstm_out, lstm_out])
# ۵. لایه تجمیع جهانی (Global Pooling):
# جایگزین هوشمند برای Flatten جهت کاهش بار محاسباتی [cite: 132]
x = layers.GlobalAveragePooling1D()(attention_out)
# ۶. لایه متراکم (Dense): پردازش نهایی [cite: 63, 67]
x = layers.Dense(32, activation='relu')(x)
# ۷. لایه دراپاوت (Dropout): جلوگیری از بیشبرازش در زمان آموزش [cite: 88, 93]
x = layers.Dropout(0.2)(x)
# ۸. لایه خروجی: تولید احتمال با Sigmoid [cite: 44, 51]
outputs = layers.Dense(1, activation='sigmoid')(x)
# ساخت مدل نهایی
model = tf.keras.Model(inputs=inputs, outputs=outputs)
# تنظیمات آموزش
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
return model
# تست مدل با پارامترهای فرضی
model = build_customer_sentiment_model(vocab_size=10000, max_length=100)
model.summary()
خروجی:
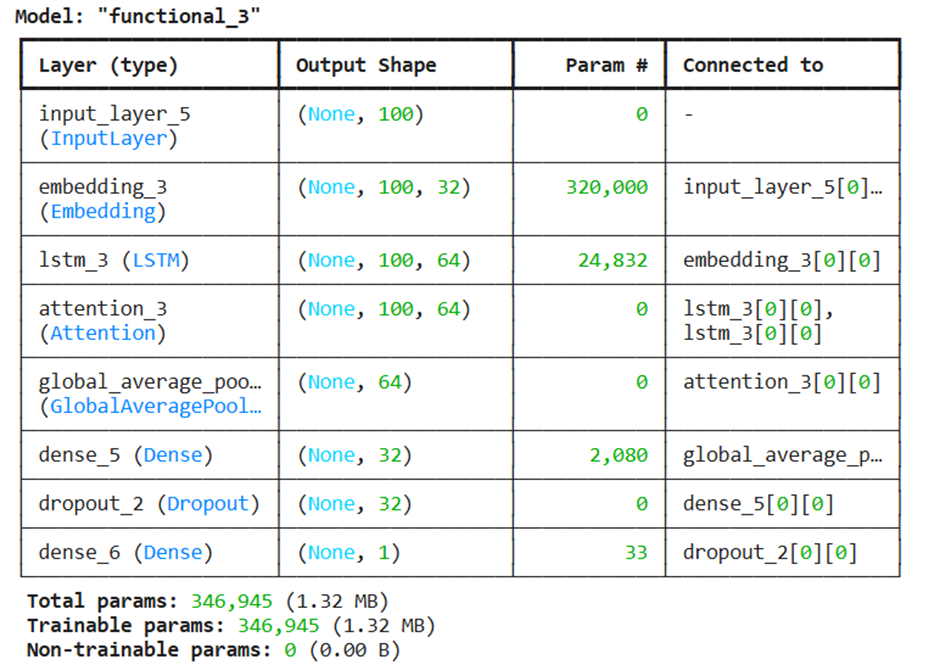
نکات مهم:
- اگر دادههای شما ماتریسی و تصویری است: از ترکیب Conv + Pooling + Flatten استفاده کنید.
- اگر دادههای شما متوالی و متنی است: از ترکیب Embedding + LSTM + Attention استفاده کنید.
- در هر دو حالت: لایههای Dense (برای تصمیم)، Dropout (برای جلوگیری از خطا) و Batch Norm (برای سرعت) را فراموش نکنید.
جمع بندی
ساختار لایهها در شبکههای عصبی مصنوعی، چارچوب اصلی یادگیری و پردازش اطلاعات را شکل میدهد. هر لایه نقش مشخصی در تبدیل دادههای خام به نمایشهای معنادار دارد و انتخاب درست آنها تأثیر مستقیمی بر عملکرد نهایی مدل میگذارد. از لایههای ورودی و کاملاً متصل گرفته تا لایههای تخصصی مانند کانولوشن، بازگشتی و توجه، هرکدام برای نوع خاصی از داده و مسئله طراحی شدهاند.
در این مقاله دیدیم که هیچ لایهای بهتنهایی «بهترین» انتخاب نیست. موفقیت یک شبکه عصبی به درک درست نقش لایهها، ترتیب استفاده از آنها و هماهنگیشان با نوع داده بستگی دارد. گاهی یک معماری ساده با لایههای مناسب، عملکردی بهتر از یک شبکه پیچیده اما نادرست طراحیشده ارائه میدهد.
در نهایت، شناخت ساختار لایهها به شما کمک میکند شبکههای عصبی را نه بهعنوان یک جعبه سیاه، بلکه بهعنوان سیستمی قابل تحلیل و طراحی ببینید. این درک، پایهای محکم برای ساخت مدلهای کارآمدتر، عیبیابی دقیقتر و ورود حرفهایتر به دنیای یادگیری عمیق فراهم میکند—و دقیقاً همین نگاه ساختاری است که یک یادگیرنده را به یک طراح واقعی شبکههای عصبی تبدیل میکند.