

مقدمه
در آموزش شبکههای عصبی عمیق، گرادیان کاهشی ساده و حتی نسخههای مبتنی بر Momentum میتوانند با نوسان در مسیر بهینهسازی یا عبور از نواحی مناسب بهینه مواجه شوند. این مسئله بهویژه در سطوح خطای ناهموار و مسائل غیرمحدب، باعث کاهش پایداری آموزش و کندی همگرایی میشود. در چنین شرایطی، استفاده از اطلاعات گذشته بهتنهایی کافی نیست و نیاز به اصلاح پیشدستانهی مسیر حرکت احساس میشود.
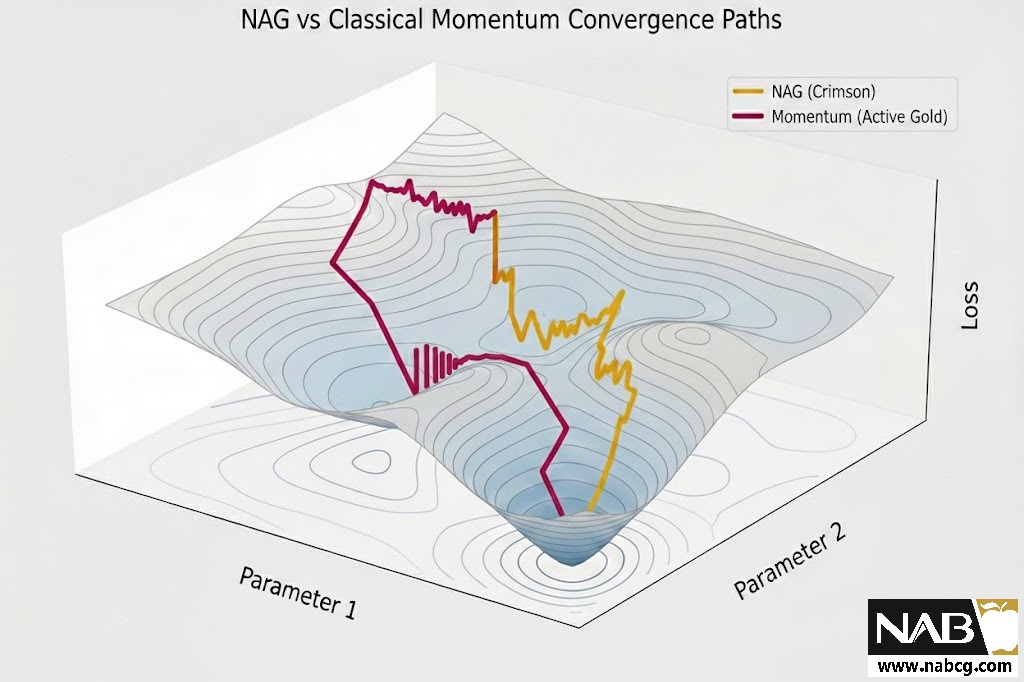
الگوریتم Nesterov Accelerated Gradient یا NAG بهعنوان یک بهبود نظری و عملی بر Momentum کلاسیک معرفی شد. ایدهی اصلی NAG محاسبهی گرادیان در یک موقعیت «پیشبینیشده» از پارامترهاست؛ رویکردی که امکان تصحیح زودهنگام جهت حرکت را فراهم میکند و از نوسان بیشازحد در مسیر بهینهسازی جلوگیری مینماید. این ویژگی باعث میشود NAG در بسیاری از مسائل یادگیری عمیق، همگرایی پایدارتر و کنترلشدهتری نسبت به Momentum ارائه دهد.
در این مطلب، NAG را در چارچوب یادگیری عمیق بهصورت جامع بررسی میکنیم؛ از شهود و فرمولبندی ریاضی گرفته تا مثالهای عددی، پیادهسازی در پایتون و مقایسه با Momentum و سایر بهینهسازها. تمرکز اصلی ما این است که روشن کنیم NAG چگونه عمل میکند، چه مشکلی را حل میکند و جایگاه واقعی آن در آموزش مدلهای عمیق کجاست.
تعریف
الگوریتم NAG یک روش بهینهسازی پیشرفته است که برای غلبه بر کاستیهای روشهای سنتیِ گرادیان کاهشی (Gradient Descent) ابداع شده است. در حالی که ممنتوم معمولی فقط بر اساس سرعت گذشته حرکت میکند، NAG با استفاده از یک مکانیزم نگاه به آینده (Lookahead)، موقعیت بعدی پارامترها را پیشبینی کرده و گرادیان را در آن نقطه محاسبه میکند.
این ویژگی به الگوریتم اجازه میدهد تا پیش از رسیدن به یک نقطه، از وضعیت شیب آن مطلع شود و به طور هوشمندانه سرعت خود را تنظیم کند.
.
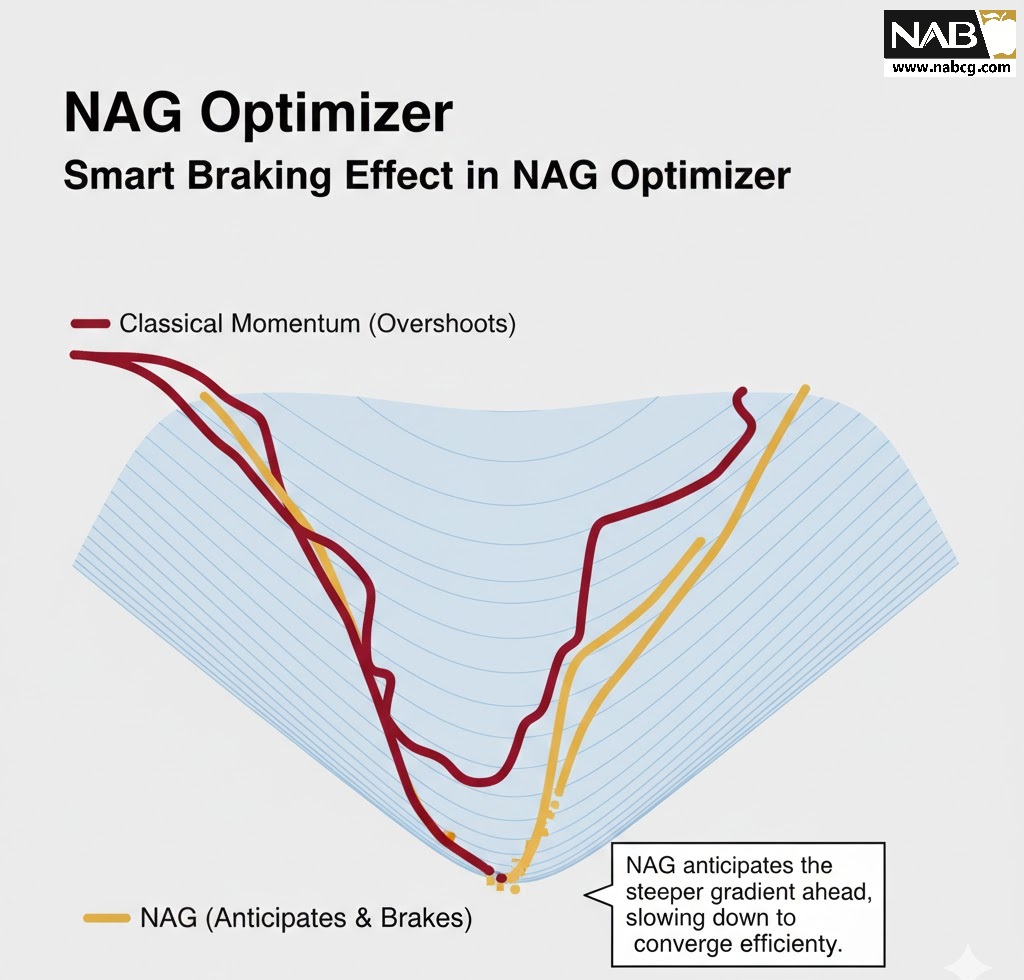
چرا NAG از ممنتوم معمولی برتر است؟
- کاهش خطای پرش (Reduced Overshooting): ممنتوم کلاسیک مانند توپی است که با سرعت زیاد از تپه پایین میآید و ممکن است به دلیل شدت حرکت، از نقطه بهینه (کمینه) رد شود NAG. با نگاه به گرادیانِ آینده، در صورت نزدیک شدن به دره، ترمز میکند و مانع از پرشهای بیهوده میشود.
- ثبات در سطوح پیچیده: NAG در پیمایش سطوح خطای ناهموار و مسائل بهینهسازی غیرمحدب (Non-convex) بسیار موثرتر عمل میکند، زیرا بهتر میتواند از تلههای سطحی عبور کرده و به ثبات برسد.
- دقت در بهروزرسانی: این روش با گنجاندن هوشمندانهتر ممنتوم در بهروزرسانی پارامترها، عملکرد مدلهای عمیق و پیچیده را بهبود میبخشد.
.
NAG چگونه کار میکند؟
الگوریتم NAG با اضافه کردن یک فاکتور اصلاحی به محاسبات ممنتوم، محدودیتهای روشهای سنتی را برطرف میکند. تفاوت اصلی در این است که NAG به جای محاسبه گرادیان در موقعیت فعلی، آن را در موقعیت پیشبینیشدهی بعدی محاسبه میکند. این گامِ نگاه به آینده (Look-ahead) باعث میشود بهروزرسانیها آگاهانهتر انجام شده و نوساناتِ مسیر همگرایی به شدت کاهش یابد.
.
مبانی ریاضی و مراحل اجرای الگوریتم
فرآیند بهینهسازی در NAG طی یک چرخهی هوشمند ۴ مرحلهای انجام میشود:
۱. محاسبه نقطه آینده
در این مرحله، الگوریتم یک پرش فرضی انجام میدهد. ما فرض میکنیم اگر شیب جدیدی وجود نداشت و فقط با تکیه بر سرعت انباشته شده از گامهای قبل حرکت میکردیم، به کجا میرسیدیم.
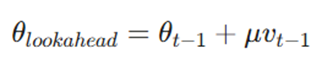
معرفی متغیرها:
- θlookahead: موقعیت تقریبی پارامترها در گام بعدی؛ نقطهای که برای ارزیابی شیب آینده از آن استفاده میشود.
- θt-1: مقادیر فعلی پارامترها (وزنها) قبل از بهروزرسانی در تکرار جاری.
- μ (یا β): ضریب ممنتوم؛ عددی بین 0 تا1 (معمولاً 0.9) که تعیین میکند چه جزیی از سرعت قبلی باید حفظ شود.
- vt-1: بردار سرعت (ممنتوم) انباشته شده از تمامی تکرارهای قبلی.
.
۲. محاسبه گرادیان در نقطه آینده
این مرحله قلب تپندهی هوشمندی NAG است. به جای محاسبه شیب در جایی که هستیم، مشتق تابع را در همان نقطه فرضی که در مرحله قبل به دست آمد، حساب میکنیم.
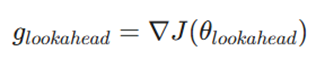
معرفی متغیرها:
- glookahead: بردار گرادیان (شیب) در موقعیت پیشبینی شده.
- (…)J∇: عملگر گرادیان که مشتقات جزئی تابع هزینه (J) را نسبت به تمام پارامترها محاسبه میکند.
.
۳. بهروزرسانی بردار سرعت (Velocity Update)
حالا که میدانیم در نقطه آینده شیب زمین چقدر است، بردار سرعت را اصلاح میکنیم. اگر گرادیان آینده نشان دهد که در حال نزدیک شدن به ته دره هستیم، این فرمول سرعت را کاهش میدهد (ترمز هوشمند).
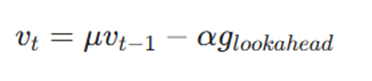
معرفی متغیرها:
- vt: بردار سرعت جدید و اصلاحشده که جهت و شدت حرکت نهایی را تعیین میکند.
- α (یا η): نرخ یادگیری (Learning Rate)؛ ضریبی که تعیین میکند گرادیان جدید با چه وزنی روی تغییرات اعمال شود.
- αglookahead-: بخش اصلاحی که بر اساس شیب آینده، جهتِ سرعت قبلی را تغییر میدهد.
.
۴. بهروزرسانی نهایی پارامترها
در مرحله آخر، پارامترهای مدل با استفاده از سرعت هوشمندی که در مرحله قبل به دست آمد، به مکان جدید منتقل میشوند.
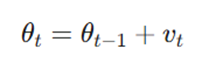
معرفی متغیرها:
- θt: مقادیر جدید و بهینهسازی شدهی پارامترها پس از اتمام این تکرار.
- vt: بردار حرکت نهایی که ترکیبی از ممنتوم اصلاحشده و اطلاعات آینده است.
.
مثال عددی: کمینهسازی تابع هزینه با NAG
فرض کنید میخواهیم تابع هزینه f(x) = x^2 را بهینه کنیم. هدف ما رسیدن به نقطه x = 0 است که در آن هزینه به کمترین مقدار خود میرسد.
تنظیمات اولیه
- نقطه شروع (x0): 10
- سرعت اولیه (v0): 0
- نرخ یادگیری (α): 0.1
- ضریب ممنتوم (μ): 0.9
- مشتق تابع (گرادیان): f'(x) = 2x
.
تکرار اول
در تکرار اول، چون سرعت قبلی صفر است، NAG مشابه ممنتوم معمولی عمل میکند:
- محاسبه نقطه آینده:
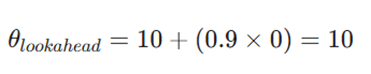
- محاسبه گرادیان در نقطه آینده:
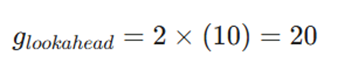
- بهروزرسانی بردار سرعت:
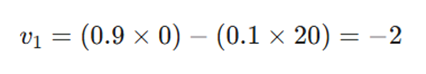
- بهروزرسانی نهایی پارامتر:
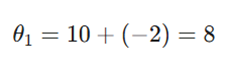
.
تکرار دوم – ظهور قدرت پیشبینی
در این مرحله، سرعت انباشته شده وارد محاسبات میشود:
- محاسبه نقطه آینده:
الگوریتم ابتدا فرض میکند اگر فقط با ممنتوم حرکت کند به کجا میرسد:
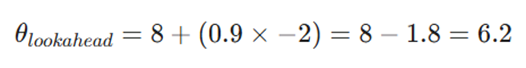
- محاسبه گرادیان در نقطه آینده:
NAG به جای محاسبه شیب در نقطه فعلی (۸)، شیب را در نقطه آینده (۶.۲) میسنجد:
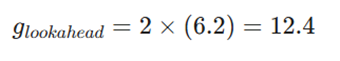
- بهروزرسانی بردار سرعت (Velocity Update):
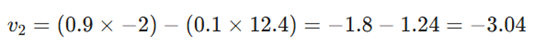
- بهروزرسانی نهایی پارامتر:
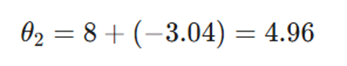
.
تحلیل تفاوت NAG و ممنتوم کلاسیک در این گام
اگر از ممنتوم کلاسیک استفاده میکردیم، محاسبات به این صورت بود:
- گرادیان در نقطه فعلی (۸) محاسبه میشد: g = 2 ✕ 8 = 16
- سرعت جدید: v = (0.9 ✕ -2) – (0.1 ✕ 16) = -1.8 – 1.6 = -3.4
- پارامتر جدید: θ = 8 – 3.4 = 4.6
.
تفاوت کلیدی:
در ممنتوم کلاسیک، سرعت به -3.4 رسید، اما در NAG سرعت به -3.04 محدود شد. چرا؟ چون NAG با نگاه به آینده فهمید که شیب در حال کم شدن است و از قبل شروع به ترمز گرفتن کرد تا با سرعت خیلی زیاد به سمت صفر نرود و دچار نوسان نشود.
.
پیادهسازی گامبهگام NAG در پایتون
- گام اول: پرش فرضی: در هر تکرار، الگوریتم ابتدا پارامترها را صرفاً با تکیه بر سرعت انباشته شده (ممنتوم قبلی) به جلو پرتاب میکند تا موقعیت تقریبی بعدی (θlookahead ) را تخمین بزند.
- گام دوم: سنجش آینده: به جای محاسبه گرادیان در نقطه فعلی، مشتق تابع در همان نقطه فرضی محاسبه میشود. این مرحله قلب هوشمند NAG است که اجازه میدهد مدل قبل از رسیدن به مقصد، از وضعیت شیب مطلع شود.
- گام سوم: ترمز هوشمند : بردار سرعت (vt ) با ترکیب ممنتوم قبلی و گرادیانِ نقطه آینده اصلاح میشود. اگر گرادیان آینده نشان دهد که به ته دره نزدیک شدهایم، این فرمول سرعت را کاهش میدهد تا مانع از پرشهای بیهوده شود.
- گام چهارم: بهروزرسانی نهایی: در نهایت، پارامترهای مدل با استفاده از سرعت اصلاحشده به مکان جدید (θt) منتقل میشوند.
.
کد پایتون
این کد الگوریتم NAG را برای کمینهسازی تابع هزینهf(x) = x^2 پیادهسازی میکند.
import numpy as np
import matplotlib.pyplot as plt
class NAGOptimizer:
def __init__(self, lr=0.1, mu=0.9):
"""
مقداردهی اولیه بهینه ساز NAG
lr: نرخ یادگیری (alpha)
mu: ضریب ممنتوم (beta)
"""
self.lr = lr
self.mu = mu
self.v = 0 # بردار سرعت اولیه (v0)
def step(self, x):
# ۱. محاسبه نقطه آینده (Look-Ahead Point)
# x_lookahead = x + mu * v
x_lookahead = x + self.mu * self.v
# ۲. محاسبه گرادیان در نقطه آینده
# f'(x) = 2x
grad_lookahead = 2 * x_lookahead
# ۳. بهروزرسانی بردار سرعت (Velocity Update)
# v_t = mu * v_{t-1} - lr * grad_lookahead
self.v = self.mu * self.v - self.lr * grad_lookahead
# ۴. بهروزرسانی نهایی پارامترها
# x_t = x_{t-1} + v_t
x_new = x + self.v
return x_new
# --- اجرای شبیهسازی عددی مطابق مثال فایل ---
# تنظیمات اولیه: x0=10, mu=0.9, lr=0.1
nag = NAGOptimizer(lr=0.1, mu=0.9)
x_current = 10.0
history = [x_current]
print(f"{'گام': <5} | {'مقدار x': <10} | {'توضیح'}")
print("-" * 35)
for i in range(1, 11):
x_current = nag.step(x_current)
history.append(x_current)
if i == 1:
# در گام اول x به 8 می رسد
note = "مطابق تکرار اول مثال عددی"
elif i == 2:
# در گام دوم x به 4.96 می رسد
note = "ظهور قدرت ترمز هوشمند"
else:
note = ""
print(f"{i: <5} | {x_current: <10.4f} | {note}")
# نمایش بصری همگرایی
plt.figure(figsize=(10, 5))
plt.plot(history, 'o-', color='#D4AF37', label='NAG Convergence Path')
plt.axhline(0, color='red', linestyle='--', label='Target (x=0)')
plt.title('Nesterov Accelerated Gradient (NAG) Optimization')
plt.xlabel('Iterations')
plt.ylabel('Parameter Value (x)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
خروجی:
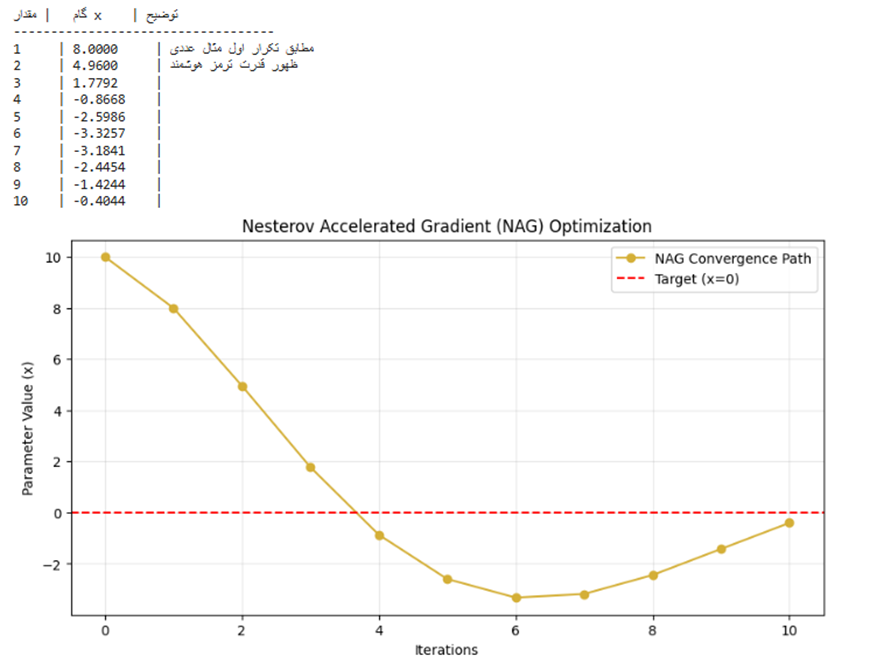
.
کاربردها
.
۱. آموزش شبکههای عصبی بسیار عمیق (Deep CNNs)
در مدلهای بینایی ماشین (مانند ResNet یا VGG) که تعداد لایهها بسیار زیاد است، سطح خطا (Loss Surface) بسیار ناهموار و دارای درههای باریک است. ممنتوم کلاسیک در این درهها دچار نوسانات عرضی شدید میشود، اما NAG با پیشبینی شیبِ چند قدم جلوتر، نوسانات را میرا کرده و با ثبات بیشتری مدل را به سمت کمینه مطلق هدایت میکند.
.
۲. پردازش زبان طبیعی (NLP) و مدلهای توالی
در مدلهای RNN و LSTM که برای ترجمه ماشینی یا تحلیل متن استفاده میشوند، مشکل انفجار یا محو شدگی گرادیان (Exploding/Vanishing Gradients) رایج است.
- پایداری: NAG با اصلاح گامهای حرکت، مانع از تغییرات ناگهانی و مخرب در وزنهای شبکه میشود.
- دقت: در آموزش مدلهای زبانی، این روش راه دقیقتری برای گنجاندن ممنتوم فراهم میکند که منجر به درک بهتر الگوهای پیچیده زبانی میگردد.
.
۳. مسائل بهینهسازی غیرمحدب (Non-convex Optimization)
بیشتر مسائل یادگیری عمیق غیرمحدب هستند، به این معنی که پر از نقاط بهینه محلی (Local Minima) و نقاط زینی (Saddle Points) میباشند.
- عبور از تلهها: NAG به دلیل خاصیت نگاه به آینده، بهتر میتواند از تلههای سطحی عبور کرده و به ثبات برسد.
- سرعت همگرایی: این الگوریتم سرعت همگرایی را نسبت به SGD معمولی به شکل چشمگیری افزایش میدهد که برای پروژههای با محدودیت زمانی و سختافزاری بسیار حیاتی است.
.
۴. یادگیری تقویتی (Reinforcement Learning)
در محیطهای یادگیری تقویتی که پاداشها با تأخیر دریافت میشوند و دادهها نویز زیادی دارند، پایداری بهینهساز کلیدی است.
- کاهش خطای پرش: NAG مانع از پرشهای بیهوده و خروج مدل از مسیر بهینه در اثر نوسانات ناگهانی دادهها میشود.
- تعمیمپذیری: مدلهایی که با NAG آموزش میبینند، اغلب در مواجهه با محیطهای جدید و پیشبینی نشده، عملکرد پایدارتری از خود نشان میدهند.
.
مطالعه موردی ۱: آموزش شبکههای عصبی عمیق (Deep CNNs – ResNet)
چالش فنی: در مدلهای پیشرفته بینایی ماشین مانند ResNet با صدها لایه، تابع هزینه اغلب شامل درههای باریک و طولانی است و فضای پارامتری بسیار پیچیده و پُربعدی ایجاد میکند. ممنتوم کلاسیک در این درهها مانند گلولهای سرگردان عمل میکند: سرعت انباشتهشده مدام آن را به دیوارهها میکوبد و نوسانات عرضی شدیدی بهوجود میآورد. این رفتار همگرایی مدل را بهشدت کند و در موارد پیچیدهتر، غیرممکن میکند.
.
نقش استراتژیکNAG: الگوریتم NAG با استفاده از مکانیزم Look-ahead، نقش یک خلبان هوشمند را ایفا میکند:
- میرا کردن نوسانات : NAG با محاسبه گرادیان در نقطه آینده، پیش از آنکه پارامترها به دیواره دره برخورد کنند، متوجه تغییر شیب شده و با اعمال ترمز هوشمند، نوسانات عرضی را خنثی میکند.
- ثبات در مسیر: این الگوریتم با اصلاح گامهای حرکت بر اساس پیشبینی موقعیت بعدی، مسیر رسیدن به کمینه مطلق را صافتر و مستقیمتر میکند.
- جلوگیری از Overshooting: در شبکههای عمیق، پرش از روی نقاط بهینه (Overshooting) بسیار رایج است. NAG با نگاه به گرادیانِ آینده، از پرشهای بیهوده در نزدیکی مرکز دره جلوگیری کرده و پایداری آموزش را افزایش میدهد.

پیادهسازی پایتون: شبیهسازی ترمز هوشمند NAG در یک دره باریک
این کد نشان میدهد که NAG چگونه در یک محیط با تغییر شیب ناهموار، عملکردی پایدارتر از ممنتوم کلاسیک دارد.
import numpy as np
import matplotlib.pyplot as plt
# تعریف تابعی با شیب متغیر (شبیهسازی دره باریک)
def func(x): return x**2
def grad(x): return 2*x
# تنظیمات مشترک
lr = 0.6 # نرخ یادگیری نسبتا بالا برای مشاهده نوسان
mu = 0.9 # ضریب ممنتوم
iterations = 20
start_x = 10.0
# ۱. شبیهسازی ممنتوم کلاسیک (بدون ترمز هوشمند)
x_mom = start_x
v_mom = 0
history_mom = [x_mom]
for _ in range(iterations):
g = grad(x_mom)
v_mom = mu * v_mom - lr * g
x_mom += v_mom
history_mom.append(x_mom)
# ۲. شبیهسازی NAG (با ترمز هوشمند)
x_nag = start_x
v_nag = 0
history_nag = [x_nag]
for _ in range(iterations):
# گام اول: پرش فرضی به آینده (theta_lookahead)
x_future = x_nag + mu * v_nag
# گام دوم: محاسبه گرادیان در نقطه آینده
g_future = grad(x_future)
# گام سوم: اصلاح سرعت و بهروزرسانی نهایی
v_nag = mu * v_nag - lr * g_future
x_nag += v_nag
history_nag.append(x_nag)
# رسم نمودار مقایسهای
plt.figure(figsize=(10, 6))
plt.plot(history_mom, 'r--o', label='Classical Momentum (Overshoots)')
plt.plot(history_nag, 'g-o', label='NAG (Stable/Look-ahead)')
plt.axhline(0, color='black', linestyle='--')
plt.title('NAG vs Classical Momentum in a Narrow Valley')
plt.xlabel('Steps'); plt.ylabel('Parameter Value')
plt.legend(); plt.grid(True, alpha=0.3); plt.show()
خروجی:
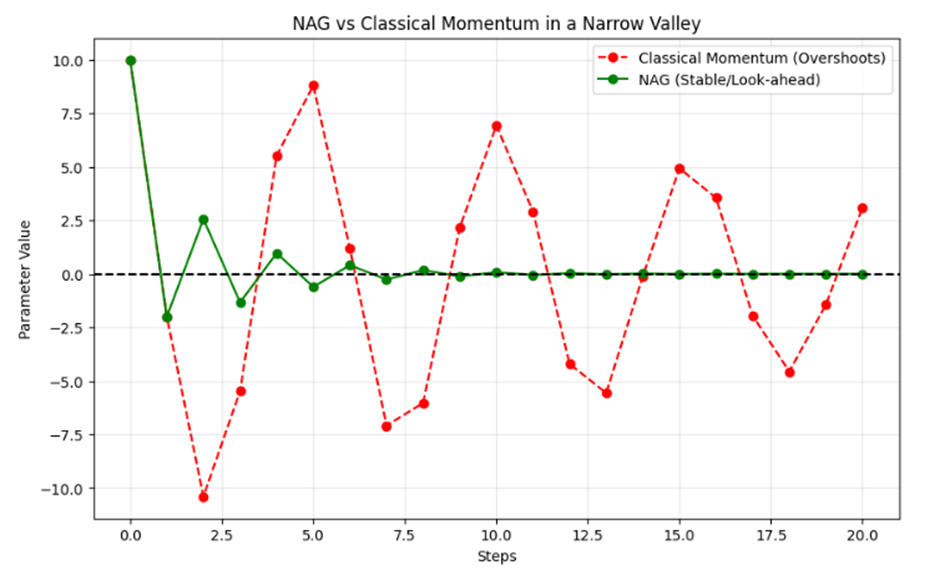
.
تحلیل:
۱. ممنتوم کلاسیک (خطچین قرمز)
این نمودار به خوبی مشکل Overshooting یا پرش از روی هدف را نشان میدهد:
- نوسانات شدید: همانطور که مشاهده میکنید، ممنتوم کلاسیک به دلیل سرعت انباشته شده و عدم آگاهی از شیب آینده، مدام از نقطه صفر رد شده و بین مقادیر مثبت و منفی (حتی تا محدوده ۱۰ و ۱۰-) نوسان میکند.
- بیثباتی: این الگوریتم تا گام ۲۰ هنوز نتوانسته است روی نقطه صفر آرام بگیرد و همچنان با دامنهی زیاد در حال تاب خوردن است.
- علت فنی: این بهینهساز گرادیان را در نقطه فعلی حساب میکند و بدون توجه به اینکه جاده در حال تغییر است، با تمام سرعت به جلو میرود.
۲. بهینهساز NAG (خط سبز)
این منحنی نمایشگر قدرت Look-ahead یا نگاه به آینده است:
- ترمز هوشمند: برخلاف ممنتوم کلاسیک، NAG در همان گامهای اولیه (حدود گام ۵) نوسانات را به شدت میرا (Damp) کرده است.
- همگرایی سریع و پایدار: مشاهده میشود که از گام ۱۰ به بعد، نمودار سبز تقریباً بر روی خط صفر مماس شده و ثبات کامل پیدا کرده است.
- علت فنی: NAG ابتدا یک پرش فرضی به آینده انجام میدهد و چون میبیند شیب در حال معکوس شدن است، پیش از رسیدن به مرکز ترمز میکند تا از هدف رد نشود.
نتیجهگیری
این نمودار نشان می دهد که در شبکههای عصبی عمیق (مانند ResNet) که سطوح خطا شبیه درههای باریک هستند، استفاده از NAG به جای ممنتوم کلاسیک یک ضرورت است:
- پایداری: NAG از حرکات نسنجیده و مخرب جلوگیری میکند.
- دقت: مدل زمان کمتری را صرف نوسانات بیهوده کرده و سریعتر به پاسخ نهایی میرسد.
.
مطالعه موردی 2: پردازش زبان طبیعی (NLP) و مدلهای توالی
چالش فنی: انفجار گرادیان و الگوهای ناگهانی در مدلهای RNN و LSTM که برای ترجمه ماشینی استفاده میشوند، گرادیانها ممکن است به طور ناگهانی مقادیر بسیار بزرگی پیدا کنند (Exploding Gradients) که منجر به تغییرات مخرب در وزنهای شبکه میشود. این موضوع باعث میشود مدل ثبات خود را در یادگیری توالیهای طولانی از دست بدهد.
.
نقش استراتژیک NAG:
- بهروزرسانی دقیق: NAG راه دقیقتری برای ترکیب سرعت گذشته با اطلاعات آینده فراهم میکند که منجر به درک بهتر الگوهای زبانی پیچیده میشود.
- کنترل تغییرات ناگهانی: با استفاده از مکانیزم نگاه به آینده، NAG قبل از اعمال یک بهروزرسانی بزرگ، شدت آن را بر اساس شیبِ مقصد تعدیل میکند.
- پایداری در یادگیری: اصلاح گامهای حرکت در NAG، مسیری پایدارتر برای همگرایی ایجاد کرده و عملکرد مدل را در وظایف سنگین NLP بهبود میبخشد.
.
پیادهسازی پایتون: شبیهسازی ترمز هوشمند NAG در یک دره باریک
این کد نشان میدهد که NAG چگونه در یک محیط با تغییر شیب ناگهانی (مشابه درههای ResNet) عملکردی پایدارتر از ممنتوم کلاسیک دارد.
import numpy as np
import matplotlib.pyplot as plt
# تعریف تابع هزینه (نمایانگر فضای پارامتری یک لایه RNN)
def loss_func(w): return w**2
def get_gradient(w, t):
# ایجاد یک شوک ناگهانی (Exploding Gradient) در تکرار شماره 10
if t == 10:
return 50.0 # مقدار انفجاری
return 2 * w
# تنظیمات هایپرپارامترها
lr = 0.05
mu = 0.9
iterations = 30
start_w = 10.0
# ۱. شبیهسازی ممنتوم کلاسیک
w_mom = start_w
v_mom = 0
history_mom = [w_mom]
for t in range(iterations):
g = get_gradient(w_mom, t)
v_mom = mu * v_mom - lr * g
w_mom += v_mom
history_mom.append(w_mom)
# ۲. شبیهسازی NAG (Nesterov Accelerated Gradient)
w_nag = start_w
v_nag = 0
history_nag = [w_nag]
for t in range(iterations):
# گام اول: نگاه به آینده (Look-ahead)
w_future = w_nag + mu * v_nag
# گام دوم: محاسبه گرادیان در نقطه آینده
g_future = get_gradient(w_future, t)
# گام سوم: اصلاح سرعت و به روزرسانی پایدار
v_nag = mu * v_nag - lr * g_future
w_nag += v_nag
history_nag.append(w_nag)
# رسم نمودار مقایسهای برای تحلیل پایداری
plt.figure(figsize=(12, 6))
plt.plot(history_mom, 'r--o', label='Classical Momentum (Explodes/Instable)')
plt.plot(history_nag, 'g-o', label='NAG (Stable Look-ahead)')
plt.axvline(10, color='blue', linestyle=':', label='Gradient Explosion Point')
plt.axhline(0, color='black', linewidth=1)
plt.title('NAG vs Momentum: Handling Exploding Gradients in NLP Task', fontsize=14)
plt.xlabel('Training Steps (Time Steps)'); plt.ylabel('Weight Value (W)')
plt.legend(); plt.grid(True, alpha=0.3)
plt.show()
خروجی:
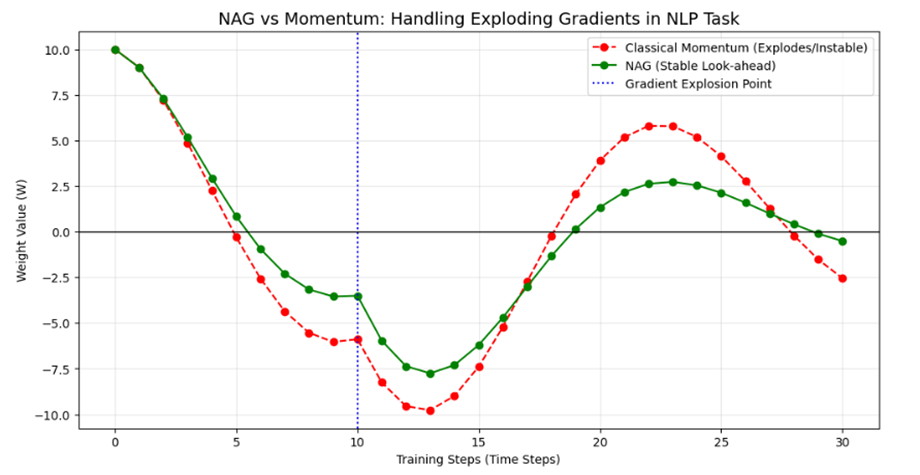
.
مزایا
- همگرایی سریعتر: NAG برخلاف تکنیکهای سنتی، با ترکیب ممنتوم و مکانیزم نگاه به آینده (Lookahead)، مسیر رسیدن به نقطهی بهینه را کوتاهتر میکند. در نتیجه مدل با تکرارهای کمتری به پاسخ نهایی میرسد.
- کاهش چشمگیر نوسانات:یکی از چالشهای اصلی در سطوح خطای پیچیده، نوسانهای بیهوده حول نقطهی کمینه است. NAG با پیشبینی چند گام جلوتر، این نوسانها را در نواحی درهای و پُرفرازونشیب خنثی میکند.
- پایداری و استحکام بالاتر:ممنتوم در فضاهای پُربعد با کاهش پرشهای ناگهانی و جلوگیری از عبور از نقطهی بهینه (Overshooting)، فرایند بهینهسازی را پایدارتر میکند.
- تنظیم سادهتر پارامترها NAG :در مقایسه با بسیاری از بهینهسازهای پیچیده، به هایپرپارامترهای کمتری نیاز دارد. این ویژگی پیادهسازی و آزمایش مدل را سریعتر و آسانتر میکند.
- تعمیمپذیری بهتر: NAG با گریز از کمینههای محلی نامناسب و همگرایی سریع به پاسخ پایدار، مدلهایی را آموزش میدهد که روی دادههای جدید (تست) عملکرد بهتری دارند.
.
محدودیت ها
۱. وابستگی به تنظیم دقیق نرخ یادگیری (α)
برخلاف بهینهسازهای تطبیقی (مانند Adadelta یا Adam)، الگوریتم NAG همچنان از یک نرخ یادگیری ثابت استفاده میکند. اگر این مقدار بیش از حد بزرگ انتخاب شود، حتی مکانیزم ترمز هوشمند NAG نیز نمیتواند مانع از واگرایی و پرشهای مخرب مدل شود. از سوی دیگر، مقدار بسیار کوچک باعث میشود سرعت همگرایی به شدت افت کند.
۲. چالش در دادههای پراکنده (Sparse Data)
NAG برای تمام پارامترها از یک نرخ یادگیری واحد استفاده میکند. در پروژههایی با دادههای پراکنده—مثل پردازش متن و واژگان نادر—بعضی پارامترها به بهروزرسانیهای سریعتر و برخی دیگر به گامهای محتاطانهتری نیاز دارند. در این شرایط، NAG برخلاف Adagrad یا RMSProp نمیتواند برای هر پارامتر نرخ یادگیری جداگانهای تنظیم کند.
۳. حساسیت به ضریب ممنتوم (μ)
کارایی مکانیزم نگاه به آینده به شدت تحت تأثیر انتخاب درست ضریب ممنتوم است. اگر این ضریب را بهدرستی تنظیم نکنیم، پیشبینی نقطه آینده دقیق نخواهد بود و الگوریتم در تشخیص زمان مناسب برای ترمز گرفتن دچار خطا میشود.
۴. پیچیدگی پیادهسازی در مدلهای توزیعشده
به دلیل ماهیت دو مرحلهای (ابتدا محاسبه نقطه آینده و سپس محاسبه گرادیان)، پیادهسازی NAG در سیستمهای محاسبات توزیعشده (Parallel Computing) نسبت به SGD معمولی کمی پیچیدهتر است، زیرا هماهنگی بین گام پرش فرضی و دریافت گرادیان از گرههای مختلف زمانبرتر خواهد بود.
۵. عدم کارایی در محیطهای با نویز بسیار بالا
در شرایطی که گرادیانها به شدت نویزی هستند، نقطه آینده که NAG بر اساس آن تصمیم میگیرد ممکن است یک تخمین کاملاً غلط باشد. در این موارد، نگاه به آینده به جای کمک به ثبات، ممکن است باعث گمراهی بیشتر مدل و نوسانات غیرقابل پیشبینی شود.
.
جمع بندی
Nesterov Accelerated Gradient را میتوان یکی از مهمترین گامها در تکامل روشهای مبتنی بر Momentum دانست. این الگوریتم با افزودن نگاه پیشدستانه به فرآیند بهینهسازی، امکان کاهش نوسانات گرادیان و اصلاح مسیر حرکت قبل از وقوع خطاهای بزرگ را فراهم میکند. در این مطلب دیدیم که این ویژگی چگونه میتواند نسبت به Momentum کلاسیک، همگرایی هموارتر و قابلکنترلتری ایجاد کند.
با این حال، NAG نیز یک راهحل عمومی برای تمام مسائل یادگیری عمیق نیست. در بسیاری از کاربردهای مدرن، بهینهسازهایی مانند Adam یا AdamW بهدلیل تنظیم تطبیقی نرخ یادگیری و سادگی استفاده، گزینههای عملیتری محسوب میشوند. از این منظر، NAG بیشتر بهعنوان یک الگوریتم پایهای و مفهومی اهمیت دارد که ایدههای آن در طراحی بهینهسازهای پیشرفتهتر به کار گرفته شده است.
در عمل، درک دقیق NAG به مهندس یادگیری عمیق کمک میکند تا منطق پشت بهبودهای مبتنی بر Momentum را بهتر بفهمد و رفتار بهینهسازهای مدرن را عمیقتر تحلیل کند. این درک، انتخاب آگاهانهتر بهینهساز و تنظیم دقیقتر فرآیند آموزش را در معماریهای عمیق و مسائل پیچیده ممکن میسازد.



