

مقدمه
پرسپترون چندلایه یا Multilayer Perceptron (MLP) یکی از پایهایترین و در عین حال مهمترین مدلها در یادگیری ماشین و یادگیری عمیق است. بسیاری از مفاهیم کلیدی شبکههای عصبی—از لایهها و وزنها گرفته تا توابع فعالسازی و الگوریتم پسانتشار—برای نخستین بار در قالب MLP معنا پیدا میکنند. به همین دلیل، درک درست این مدل نقش مهمی در فهم عمیقتر معماریهای پیشرفتهتر مانند شبکههای کانولوشنی و بازگشتی دارد.
MLP معمولاً بهعنوان نقطه شروع یادگیری شبکههای عصبی شناخته میشود، اما این به معنی ساده یا کماهمیت بودن آن نیست. این مدل توانایی یادگیری روابط غیرخطی را دارد و در بسیاری از مسائل طبقهبندی و پیشبینی همچنان کاربردی است. درک این موضوع که MLP چگونه کار میکند، چه زمانی انتخاب مناسبی است و چه محدودیتهایی دارد، برای هر فردی که وارد دنیای یادگیری عمیق میشود ضروری است.
در این مقاله، بهصورت گامبهگام با پرسپترون چندلایه آشنا میشویم؛ از آمادهسازی دادهها و ساخت مدل گرفته تا آموزش، ارزیابی و بررسی چالشهایی مانند بیشبرازش. هدف این است که MLP را نه صرفاً بهعنوان یک مفهوم تئوریک، بلکه بهعنوان مدلی قابل استفاده در پروژههای واقعی بشناسیم.
تعریف
پرسپترون چندلایه (Multilayer Perceptron یا MLP) نوعی شبکه عصبی پیشخور است که از یک لایه ورودی، یک یا چند لایه پنهان و یک لایه خروجی تشکیل میشود. در این مدل، هر نورون به نورونهای لایه بعدی متصل است و با استفاده از توابع فعالسازی غیرخطی، امکان یادگیری روابط پیچیده میان دادهها فراهم میشود.
MLP با بهرهگیری از الگوریتم پسانتشار (Backpropagation) وزنها و بایاسها را بهصورت تدریجی بهروزرسانی میکند تا اختلاف بین خروجی پیشبینیشده و مقدار واقعی کاهش یابد. به دلیل ساختار ساده اما قدرتمند، پرسپترون چندلایه یکی از پایهایترین مدلها در یادگیری ماشین و نقطه شروع درک بسیاری از معماریهای پیشرفته شبکههای عصبی به شمار میرود.
چرا MLP برای همه چیز مناسب نیست؟
مدلهای MLP تلاش میکنند الگوهای موجود در دادهها را به خاطر بسپارند. به همین دلیل، برای پردازش دادههای چندبعدی (مثل تصاویر با وضوح بالا)، این شبکه به تعداد بسیار زیادی پارامتر نیاز دارد که میتواند منجر به سنگینی بیش از حد مدل شود.
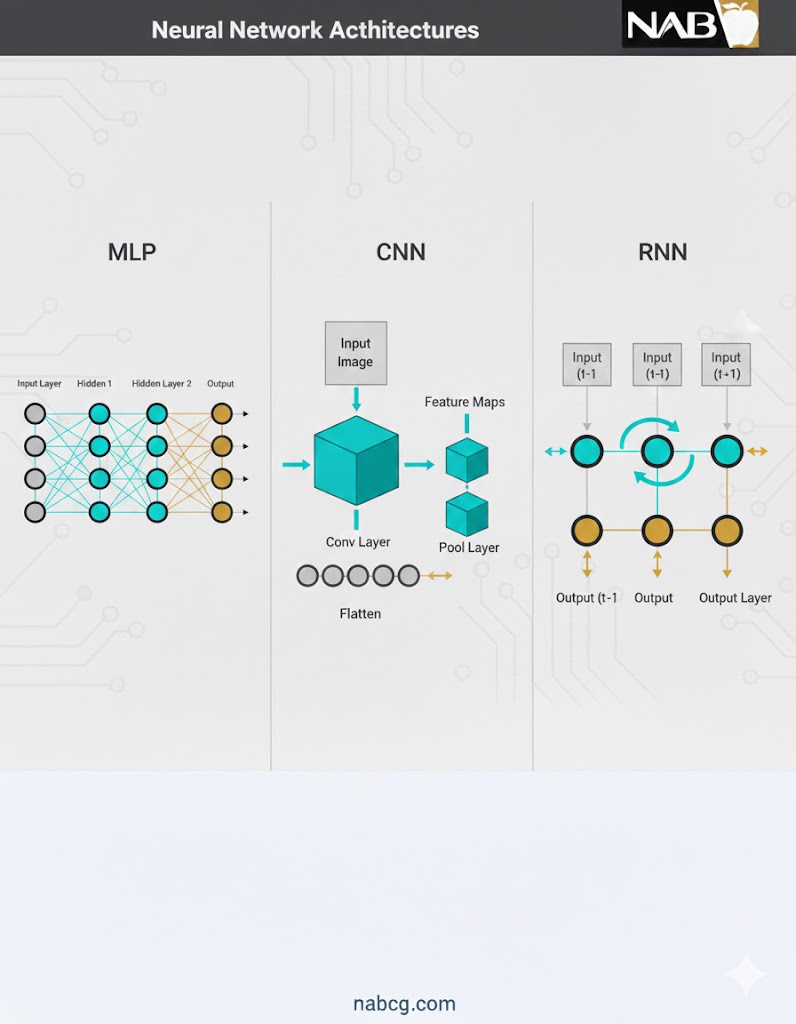
بیایید ببینیم برای دادههای خاص، چه جایگزینهایی وجود دارد:
- دادههای توالیمحور: برای دادههایی که ترتیب در آنها مهم است (مثل متن یا قیمت سهام)، شبکههای عصبی بازگشتی (RNNs) محبوبترین گزینه هستند. این شبکهها به دلیل ساختار خاص خود، وابستگی به دادههای تاریخی را کشف میکنند که برای پیشبینی بسیار حیاتی است.
- دادههای تصویری و ویدئویی: در این حوزه، شبکههای عصبی پیچشی (CNNs) پادشاهی میکنند. آنها در استخراج نقشههای ویژگی (Feature Maps) برای وظایفی مثل دستهبندی و قطعهبندی (Segmentation) تصاویر بینظیرند.
.
ترکیب برنده در یادگیری عمیق
در اکثر مدلهای مدرن یادگیری عمیق، متخصصان به جای استفاده از تنها یک نوع شبکه، ترکیبی از MLP، CNN و RNN را به کار میگیرند تا از نقاط قوت هر کدام بیشترین بهره را ببرند. برای مثال، ممکن است از یک CNN برای استخراج ویژگیهای تصویر استفاده شود و در لایههای نهایی، یک MLP برای تصمیمگیری و دستهبندی قرار گیرد.
فراتر از ساختار شبکه: پارامترهای حیاتی
موفقیت یک مدل هوش مصنوعی فقط به نوع شبکه آن بستگی ندارد. انتخاب درست این سه پارامتر نقش تعیینکنندهای دارد:
- تابع زیان (Loss function): برای اندازهگیری میزان خطای پیشبینی.
- بهینهساز (Optimizer): برای تنظیم وزنها و کاهش خطا (مثل روش پسانتشار که قبلاً بررسی کردیم).
- تنظیمکننده (Regularizer): این بخش بسیار مهم است! وظیفه Regularizer این است که اطمینان حاصل کند مدل به جای حفظ کردن دادههای آموزشی، الگوها را یاد میگیرد تا بتواند روی دادههای جدید (خارج از محیط آموزش) نیز عملکرد خوبی داشته باشد.
.
اجزای سازنده یک شبکه MLP
یک شبکه MLP از سه بخش اصلی یا لایه تشکیل شده است که هر کدام وظیفه خاصی دارند:
- لایه ورودی(Input Layer): هر گره در این لایه متناظر با یک ویژگی (Feature) از دادههای ورودی است1. برای مثال، اگر ۳ ویژگی ورودی داشته باشید، لایه ورودی شما ۳ نورون خواهد داشت.
- لایههای پنهان (Hidden Layers): جادوی اصلی اینجا اتفاق میافتد MLP. میتواند شامل هر تعداد لایه پنهان و هر تعداد نورون در هر لایه باشد. این لایهها اطلاعات دریافتی از لایه ورودی را پردازش و تحلیل میکنند.
- لایه خروجی(Output Layer): این لایه پیشبینی نهایی مدل را تولید میکند. تعداد نورونهای این لایه بستگی به تعداد خروجیهای مدنظر ما دارد.
ویژگی کلیدی: در MLP، هر گره در یک لایه به تمام گرههای لایه بعدی متصل است. این یعنی دادهها در حین عبور از لایهها، به صورت مداوم تغییر شکل مییابند تا به خروجی نهایی برسند.
مکانیسم داخلی MLP؛ هوش مصنوعی چگونه فکر میکند؟
پس از آشنایی با ساختار کلی، نوبت به درک “فرآیند کار” میرسد. یادگیری در یک شبکه عصبی MLP شبیه به یادگیری یک انسان در طول سالیان زندگی است: تجربه کردن، خطا کردن و سپس اصلاح مسیر. این فرآیند از چهار رکن اصلی تشکیل شده است: انتشار رو به جلو، محاسبه زیان، انتشار بازگشتی و بهینهسازی.
۱. انتشار رو به جلو (Forward Propagation)
در این مرحله، دادهها سفر خود را از لایه ورودی آغاز کرده و پس از عبور از “فیلترهای” لایههای پنهان، به لایه خروجی میرسند. هر نورون در لایههای پنهان، مانند یک ایستگاه پردازش عمل کرده و دو عملیات حیاتی را انجام میدهد:
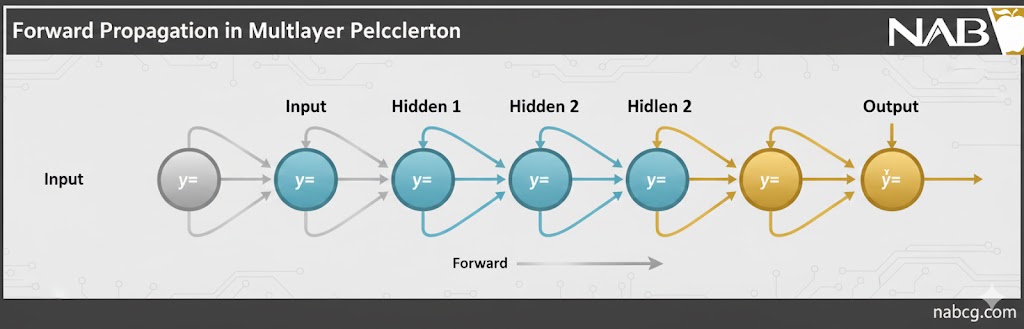
الف) مجموع وزنی (Weighted Sum)
نورون ابتدا تمام ورودیهایی که به آن میرسد را با هم ترکیب میکند. اما هر ورودی اهمیت یکسانی ندارد؛ برخی ورودیها با “وزن” بیشتر (تاثیرگذارتر) و برخی با وزن کمتر (بیاهمیتتر) در نظر گرفته میشوند. همچنین یک مقدار به نام بایاس (Bias) به این مجموع اضافه میشود تا مدل انعطافپذیری بیشتری برای جابهجایی خط تصمیمگیری داشته باشد.
فرمول ریاضی در لایهها به این صورت است:

در این فرمول:
- x_i: ویژگی ورودی.
- w_i: وزن مربوط به آن ورودی.
- b: مقدار بایاس .
ب) تابع فعالساز (Activation Function)
اگر فقط از مجموع وزنی استفاده کنیم، مدل ما فقط میتواند روابط خطی ساده را بفهمد. برای درک پیچیدگیهای جهان (مثل تشخیص چهره یا زبان)، نیاز به غیرخطی بودن داریم. تابع فعالساز این جادو را انجام میدهد.
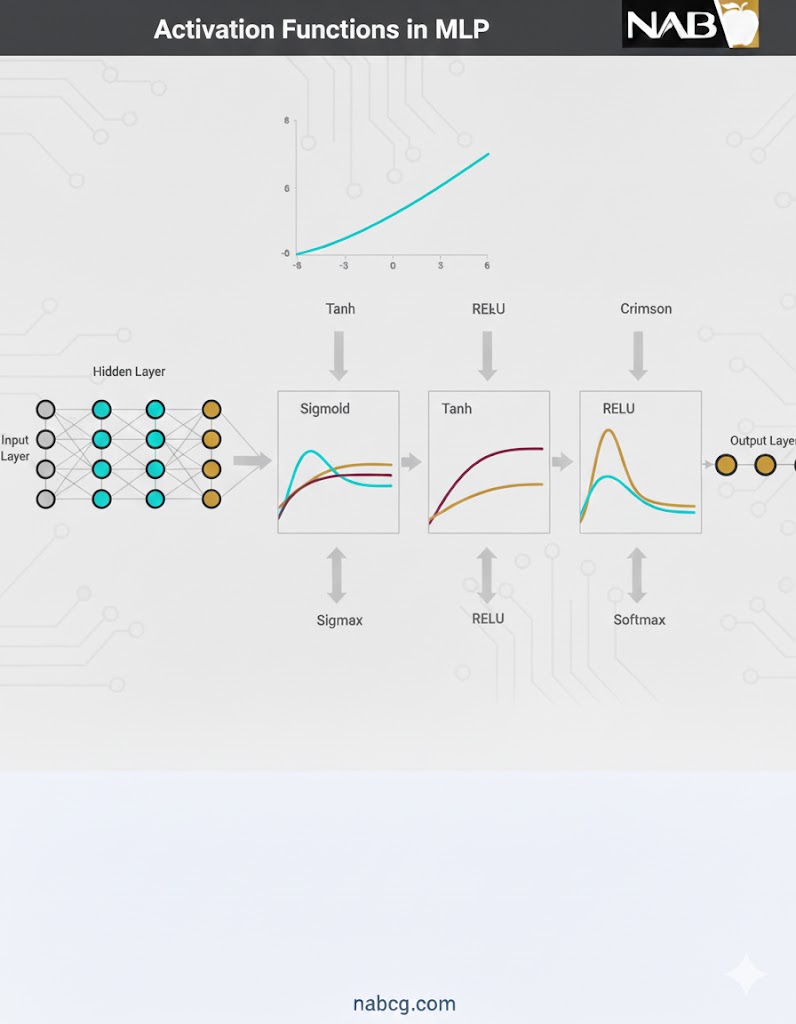
رایجترین آنها عبارتند از:
- Sigmoid (سیگموئید): خروجی را به بازهای بین 0 تا 1 محدود میکند. این تابع برای پیشبینی احتمالات عالی است:
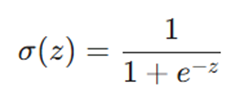
- ReLU (واحد خطی اصلاح شده): محبوبترین تابع در لایههای پنهان! اگر مقدار ورودی مثبت باشد همان را برمیگرداند و اگر منفی باشد، صفر میدهد. این کار باعث سرعت بخشیدن به محاسبات میشود:
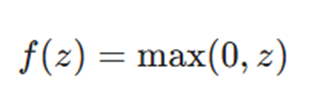
- Tanh (تانژانت هایپربولیک): خروجی را بین 1- تا 1 تنظیم میکند و معمولاً عملکردی بهتر از سیگموئید در لایههای پنهان دارد:

۲. تابع زیان (Loss Function)
وقتی شبکه حدس خود را زد، باید بفهمد چقدر به واقعیت نزدیک است. تابع زیان مانند یک معلم سختگیر، تفاوت بین “پیشبینی” و “واقعیت” را اندازه میگیرد.
- برای مسائل دستهبندی: معمولاً از Binary Cross-Entropy استفاده میشود که بر اساس احتمالات، پیشبینیهای غلط را به شدت جریمه میکند:

که در آن yi مقدار واقعی و ^yi مقدار پیشبینی شده است.
- برای مسائل رگرسیون: از میانگین مربعات خطا (MSE) استفاده میشود تا فاصله پیشبینی عددی از مقدار واقعی سنجیده شود:
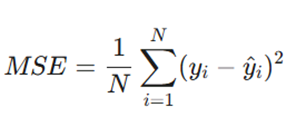
۳. انتشار بازگشتی (Backpropagation)
این مرحله “مغز” اصلی یادگیری است. هدف این است که بفهمیم هر وزن (w) و هر بایاس (b) چقدر در خطای نهایی سهم داشتهاند.
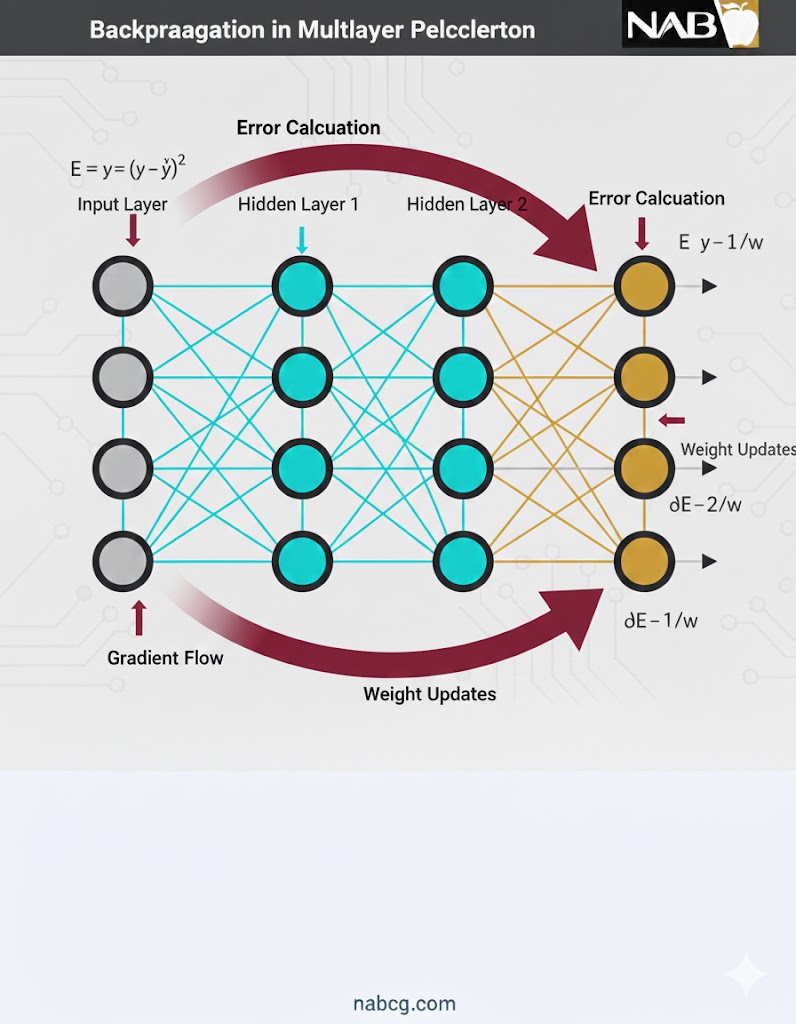
- محاسبه گرادیان: با استفاده از قانون زنجیرهای ریاضی، گرادیان (مشتق) تابع زیان نسبت به تکتک پارامترها حساب میشود.
- انتشار خطا: خطا لایه به لایه به عقب برمیگردد (از لایه خروجی به لایه ورودی).
- آپدیت پارامترها: برای کاهش خطا، پارامترها را در جهت مخالف گرادیان تغییر میدهیم:
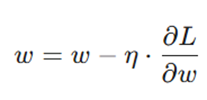
در اینجا η همان نرخ یادگیری (Learning Rate) است که تعیین میکند قدمهای ما برای اصلاح خطا چقدر بزرگ یا کوچک باشد.
۴. بهینهسازی (Optimization)
برای اینکه فرآیند یادگیری بهینهتر شود، از الگوریتمهای هوشمندی برای بهروزرسانی وزنها استفاده میکنیم:
- Stochastic Gradient Descent (SGD): وزنها را بر اساس یک نمونه یا دستهای کوچک از دادهها آپدیت میکند تا فرآیند سریعتر شود.
- Adam Optimizer: پادشاهِ بهینهسازها! این الگوریتم ترکیبی از سرعت و دقت است و نرخ یادگیری را برای هر پارامتر به صورت تطبیقی تنظیم میکند تا مدل سریعتر به بهترین نتیجه برسد:
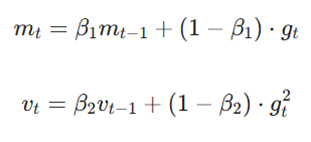
پیادهسازی عملی پرسپترون چندلایه (MLP)
در این بخش، به صورت گامبهگام(8مرحله) فرآیند ساخت یک شبکه عصبی واقعی را با استفاده از کتابخانه قدرتمند TensorFlow دنبال خواهیم کرد.
۱. فراخوانی کتابخانهها و بارگذاری مجموعهداده
در اولین قدم، کتابخانههای مورد نیاز را وارد محیط برنامهنویسی خود میکنیم. ما به TensorFlow برای ساخت مدل، NumPy برای محاسبات عددی و Matplotlib جهت مصورسازی و نمایش دادهها نیاز داریم. همچنین، از مجموعهداده مشهور MNIST (که شامل هزاران تصویر از اعداد دستنویس است) برای آموزش مدل استفاده خواهیم کرد.
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
۲. بارگذاری و نرمالسازی دادههای تصویری
در این مرحله، مقادیر پیکسلهای تصاویر را نرمالسازی میکنیم. از آنجایی که شدت روشنایی هر پیکسل در تصاویر سیاه و سفید عددی بین ۰ تا ۲۵۵ است، تمام مقادیر را بر ۲۵۵ تقسیم میکنیم تا مقیاس آنها به بازهی [ ۱,۰ ] تغییر یابد.
gray_scale = 255
x_train = x_train.astype('float32') / gray_scale
x_test = x_test.astype('float32') / gray_scale
print("Feature matrix (x_train):", x_train.shape)
print("Target matrix (y_train):", y_train.shape)
print("Feature matrix (x_test):", x_test.shape)
print("Target matrix (y_test):", y_test.shape)
خروجی:

.
۳. مصورسازی دادهها
برای درک بهتر دادهها و اطمینان از اینکه تصاویر به درستی بارگذاری شدهاند، ۱۰۰ نمونه اول از دادههای آموزشی را که هر کدام نشاندهنده یک عدد دستنویس هستند، رسم میکنیم.
این کار به ما کمک میکند تا تنوع دستخطها را در مجموعه داده MNIST ببینیم و متوجه شویم که مدل ما با چه نوع چالشهای بصری روبرو خواهد بود.
fig, ax = plt.subplots(10, 10)
k = 0
for i in range(10):
for j in range(10):
ax[i][j].imshow(x_train[k].reshape(28, 28), aspect='auto')
k += 1
plt.show()
خروجی:

.
۴. ساخت مدل شبکه عصبی
در این مرحله، ما یک مدل شبکه عصبی ترتیبی میسازیم. این مدل از لایههای زیر تشکیل شده است:
- لایه Flatten: این لایه ورودیهای دوبعدی ما را (تصاویر ۲۸ در ۲۸ پیکسل) تغییر شکل داده و آنها را به یک آرایه یکبعدی شامل ۷۸۴ عنصر تبدیل میکند.
- لایههای Dense (متراکم): این لایهها کاملاً متصل هستند. ما از دو لایه پنهان با ۲۵۶ و ۱۲۸ نورون استفاده میکنیم که هر دو از تابع فعالساز ReLU برای معرفی ویژگیهای غیرخطی بهره میبرند.
- لایه خروجی: لایه نهایی دارای ۱۰ نورون است که نشاندهنده ۱۰ کلاس از اعداد (۰ تا ۹) میباشد و از تابع فعالساز Sigmoid استفاده میکند.
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(256, activation='sigmoid'),
Dense(128, activation='sigmoid'),
Dense(10, activation='softmax'),
])
۵. کامپایل کردن مدل
پس از تعریف معماری شبکه، نوبت به کامپایل کردن آن میرسد. در این مرحله، ما سه مؤلفه کلیدی را مشخص میکنیم:
- بهینهساز: استفاده از Adam برای بهروزرسانی کارآمد وزنها بر اساس گرادیانها.
- تابع زیان: استفاده از Sparse Categorical Cross-Entropy که برای مسائل دستهبندی چندکلاسه بسیار مناسب است.
- معیار ارزیابی: استفاده از شاخص Accuracy برای سنجش و ارزیابی عملکرد مدل در طول فرآیند آموزش.
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
۶. آموزش مدل
در این مرحله، ما فرآیند آموزش را روی دادههای آموزشی با تنظیم ۱۰ اپوک (Epoch) و اندازه دسته ۲۰۰۰ آغاز میکنیم. همچنین، ۲۰ درصد از دادههای آموزشی را به عنوان دادههای اعتبارسنجی در نظر میگیریم تا عملکرد مدل را روی دادههای دیده نشده در طول فرآیند آموزش نظاره کنیم.
mod = model.fit(x_train, y_train, epochs=10,
batch_size=2000,
validation_split=0.2)
print(mod)
خروجی:

.
۷. ارزیابی مدل
پس از اتمام فرآیند آموزش، ما مدل را روی مجموعهداده تست ارزیابی میکنیم تا میزان عملکرد و دقت نهایی آن را در دنیای واقعی بسنجیم. این مرحله به ما نشان میدهد که مدل تا چه حد در یادگیری الگوها موفق بوده و چقدر میتواند روی دادههای کاملاً جدید، پیشبینیهای درستی انجام دهد.
results = model.evaluate(x_test, y_test, verbose=0)
print('Test loss, Test accuracy:', results)
خروجی:
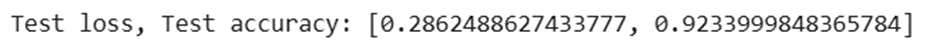
.
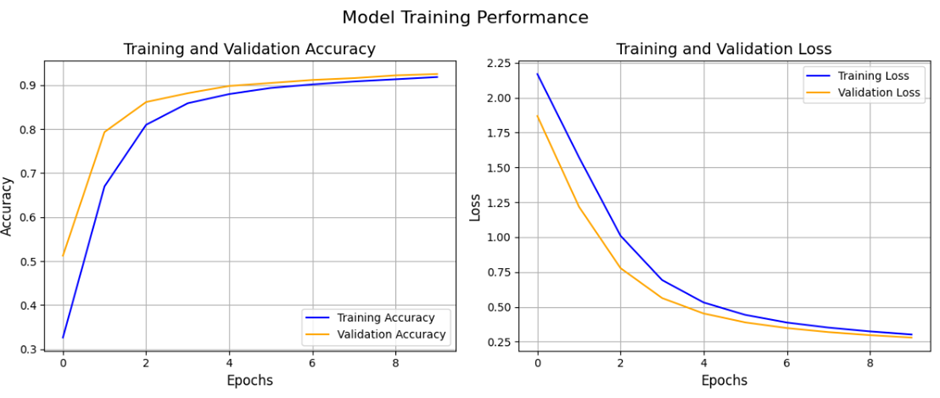
۸. مصورسازی نمودارهای زیان و دقت
در آخرین مرحله از کدنویسی، نمودارهای مربوط به میزان (Loss) و (Accuracy) را برای هر دو مجموعهدادهی آموزش و اعتبارسنجی رسم میکنیم. این کار به ما کمک میکند تا روند یادگیری مدل را تحلیل کرده و متوجه شویم که آیا مدل به درستی آموزش دیده است یا دچار مشکلاتی مثل بیشبرازش شده است.
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(mod.history['accuracy'], label='Training Accuracy', color='blue')
plt.plot(mod.history['val_accuracy'],
label='Validation Accuracy', color='orange')
plt.title('Training and Validation Accuracy', fontsize=14)
plt.xlabel('Epochs', fontsize=12)
plt.ylabel('Accuracy', fontsize=12)
plt.legend()
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(mod.history['loss'], label='Training Loss', color='blue')
plt.plot(mod.history['val_loss'], label='Validation Loss', color='orange')
plt.title('Training and Validation Loss', fontsize=14)
plt.xlabel('Epochs', fontsize=12)
plt.ylabel('Loss', fontsize=12)
plt.legend()
plt.grid(True)
plt.suptitle("Model Training Performance", fontsize=16)
plt.tight_layout()
plt.show()
خروجی:
مزایا
- انعطافپذیری و تطبیقپذیری: یکی از بزرگترین نقاط قوت MLP این است که محدود به یک نوع خاص از مسئله نیست و میتواند در هر دو حوزه دستهبندی (Classification) و رگرسیون (Regression) با دقت بالا عمل کند.
- مدلسازی روابط غیرخطی: به لطف استفاده از توابع فعالساز (مثل ReLU یا Sigmoid)، این شبکهها برخلاف مدلهای کلاسیک، قادرند روابط بسیار پیچیده و غیرخطی موجود در دادههای واقعی را شناسایی و مدلسازی کنند.
- قابلیت پردازش موازی: ساختار MLP به گونهای است که محاسبات آن به راحتی روی GPUها توزیع میشود. این قابلیت باعث میشود که آموزش مدل روی دادههای حجیم با سرعت بسیار بالایی انجام شود.
- یادگیری ویژگیها: برخلاف مدلهای سنتی که نیاز به مهندسی ویژگی دستی دارند، MLP در لایههای پنهان خود میتواند به مرور ویژگیهای مهم را از دادههای خام استخراج کند.
.
معایب
- هزینه محاسباتی بالا: با افزایش تعداد لایهها و نورونها، تعداد پارامترها به شدت بالا میرود که این امر آموزش مدل را، به ویژه روی مجموعهدادههای بسیار بزرگ، زمانبر و سنگین میکند.
- ریسک بیشبرازش: اگر تعداد لایهها بیش از حد زیاد باشد یا دادههای آموزشی کافی نباشند، مدل به جای یادگیری، دادهها را “حفظ” میکند. در این صورت، دقت مدل روی دادههای جدید به شدت افت خواهد کرد.
- حساسیت زیاد به مقیاس دادهها: همانطور که در بخش کدنویسی دیدیم، اگر دادهها نرمالسازی نشوند، الگوریتم گرادیان کاهشی به سختی همگرا میشود و عملکرد مدل به شدت افت میکند.
- ماهیت جعبه سیاه: تفسیر اینکه شبکه دقیقاً بر چه اساسی یک تصمیم را گرفته، بسیار دشوار است. برخلاف درخت تصمیم، فرآیند رسیدن به پاسخ در MLP شفاف نیست.
- حساسیت به هایپرپارامترها: عملکرد MLP به شدت به انتخاب درست نرخ یادگیری (α)، تعداد لایهها و نوع تابع فعالساز بستگی دارد.
.
جمع بندی
پرسپترون چندلایه (MLP) یکی از بنیادیترین مدلها در یادگیری ماشین و یادگیری عمیق است که بسیاری از مفاهیم کلیدی شبکههای عصبی برای نخستین بار در آن معنا پیدا میکنند. این مدل با استفاده از لایههای متصلبههم، توابع فعالسازی غیرخطی و الگوریتم پسانتشار، توانایی یادگیری الگوهای پیچیده را از دادهها به دست میآورد و بهعنوان نقطه شروع درک معماریهای پیشرفتهتر شناخته میشود.
در این مقاله دیدیم که MLP چگونه از مرحله ورود دادهها تا تولید خروجی نهایی عمل میکند و چگونه مفاهیمی مانند انتشار رو به جلو، تابع زیان، گرادیان کاهشی و بهینهسازی در کنار هم فرآیند یادگیری را شکل میدهند. همچنین با بررسی پیادهسازی عملی، مشخص شد که انتخاب درست پارامترهایی مانند تعداد لایهها، نورونها، تابع فعالسازی و بهینهساز، نقش تعیینکنندهای در عملکرد نهایی مدل دارد.
در عین حال، محدودیتهای MLP—مانند هزینه محاسباتی بالا، ریسک بیشبرازش و دشواری تفسیر—نشان میدهد که این مدل برای همه مسائل بهترین انتخاب نیست. به همین دلیل، در سیستمهای مدرن اغلب از ترکیب MLP با معماریهایی مانند CNN و RNN استفاده میشود تا از مزایای هر رویکرد بهره گرفته شود.
در نهایت، درک عمیق پرسپترون چندلایه به شما کمک میکند شبکههای عصبی را نه بهعنوان یک جعبه سیاه، بلکه بهعنوان سیستمی قابل تحلیل و طراحی ببینید. این شناخت، پایهای محکم برای ورود به مباحث پیشرفتهتر یادگیری عمیق و ساخت مدلهای هوشمندتر در پروژههای واقعی فراهم میکند.