

مقدمه
در یادگیری عمیق، مسئلهی اصلی تنها ساختن یک مدل پیچیده نیست، بلکه یاد دادنِ مؤثر به آن مدل است. شبکههای عصبی با میلیونها یا حتی میلیاردها پارامتر، بدون یک سازوکار منظم برای اصلاح خطا، صرفاً مجموعهای از محاسبات تصادفی باقی میمانند. آنچه این پارامترها را به سمت یادگیری هدایت میکند، الگوریتمی است که بتواند مسیر کاهش خطا را در فضای بسیار پرابعاد مدل پیدا کند.
گرادیان کاهشی (Gradient Descent) دقیقاً همین نقش را ایفا میکند. این الگوریتم با استفاده از اطلاعات مشتق تابع خطا، جهت و مقدار تغییر لازم برای هر پارامتر را مشخص میکند تا مدل، گامبهگام به سمت بهینهترین وضعیت ممکن حرکت کند. اهمیت گرادیان کاهشی در یادگیری عمیق به حدی است که تقریباً تمام الگوریتمهای آموزش شبکههای عصبی—از سادهترین مدلها تا پیشرفتهترین معماریها—بر پایهی آن یا نسخههای توسعهیافتهاش بنا شدهاند.
درک صحیح گرادیان کاهشی، نهتنها فهم فرآیند یادگیری شبکههای عصبی را سادهتر میکند، بلکه امکان انتخاب آگاهانهی نرخ یادگیری، نوع بهینهساز و استراتژی آموزش را نیز فراهم میسازد.
تعریف
گرادیان کاهشی (Gradient Descent) یک الگوریتم بهینهسازی تکرارشونده (Iterative Optimization Algorithm) است که هدف آن کمینهسازی تابع هزینه (Cost Function) از طریق بهروزرسانی تدریجی پارامترهای مدل است. این الگوریتم با محاسبهی گرادیان تابع هزینه نسبت به هر پارامتر، مشخص میکند که برای کاهش خطا، هر پارامتر باید در چه جهتی و به چه میزانی تغییر کند.
در هر تکرار، پارامترها در جهت مخالف گرادیان (جهت بیشترین کاهش تابع هزینه) بهروزرسانی میشوند. اندازهی این تغییر توسط پارامتری به نام نرخ یادگیری (Learning Rate) کنترل میشود که تعیین میکند گامهای اصلاح چقدر بزرگ یا کوچک باشند.
بهصورت مفهومی، گرادیان کاهشی را میتوان حرکتی دانست در یک فضای چندبعدی که در آن:
- تابع هزینه، سطحی از پستی و بلندیهاست،
- گرادیان، شیب محلی این سطح را نشان میدهد،
- و الگوریتم، با گامهای پیدرپی تلاش میکند به پایینترین نقطهی این سطح برسد.
در یادگیری عمیق، گرادیان کاهشی بهتنهایی عمل نمیکند، بلکه بهعنوان بخش مکمل الگوریتم انتشار رو به عقب (Backpropagation)، نقش اصلی را در بهروزرسانی وزنها و بایاسهای شبکههای عصبی ایفا میکند.
گرادیان کاهشی(Gradient Descent): موتور محرک یادگیری عمیق
الگوریتم گرادیان کاهشی، قلب تپنده و موتور محرک یادگیری در تمامی شبکههای عصبی است. این الگوریتم یک حلکننده تکرار شونده (Iterative Solver) است که وظیفه دارد پارامترهای مدل (وزنها و بایاسها) را به گونهای تنظیم کند که تابع هدف یا همان میزان خطا به حداقل ممکن برسد. بدون این مکانیسم، یادگیری عمیق چیزی جز یک توده از اعداد تصادفی نخواهد بود.
۱. شهود بصری
برای درک بهتر، تصور کنید در بالای یک کوه (نقطه حداکثر خطا) هستید و میخواهید به پایینترین نقطه دره (حداقل خطا) برسید، اما مه غلیظی مانع دید شماست. در این حالت، شما با پاهای خود شیب زمین را احساس کرده و در جهتی قدم برمیدارید که بیشترین شیب را به سمت پایین دارد.
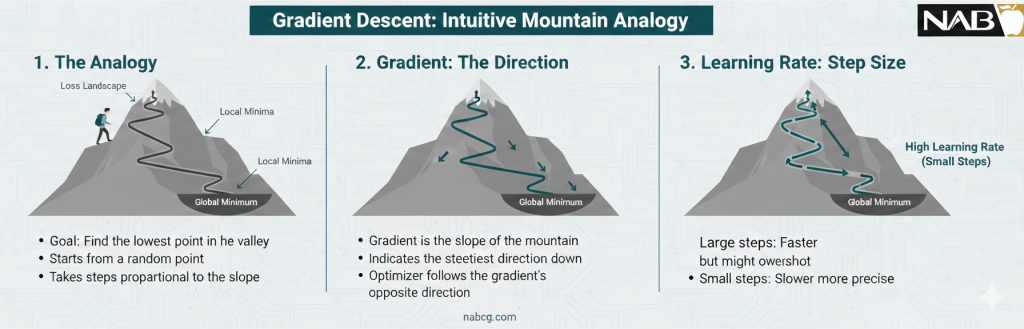
- کوه: همان تابع زیان یا خطا (Loss Function) است.
- قدمها: تغییراتی است که در وزنها (W) ایجاد میکنیم.
- شیب: همان مشتق یا گرادیان تابع نسبت به وزنهاست.
.
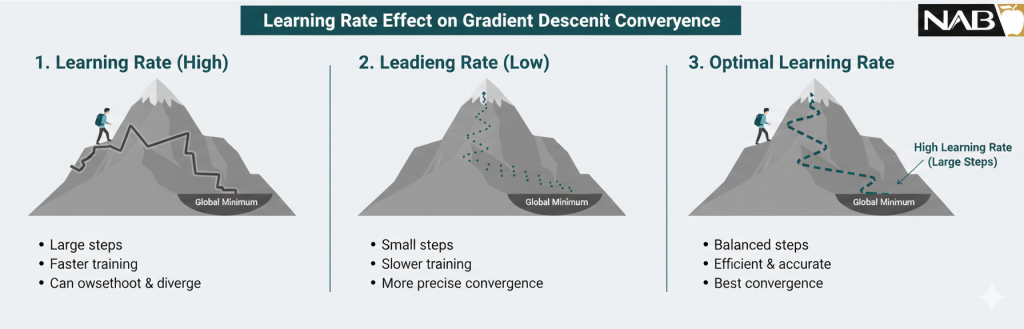
۲. مفاهیم حیاتی در کنترل حرکت
برای رسیدن به نقطه بهینه، دو فاکتور کلیدی وجود دارد:
- جهت حرکت(Direction): مشتق یا گرادیان در هر نقطه، شیب خط مماس را نشان داده و جهت پایین رفتن را مشخص میکند.
- اندازه گام یا نرخ یادگیری(Learning Rate / α): ضریبی که تعیین میکند گامهای ما به سمت پایین چقدر بزرگ یا کوچک باشند.
- α بالا: باعث سرعت میشود اما خطر رد شدن از نقطه بهینه (Overshooting) را دارد.
- α پایین: دقت را بالا میبرد اما به توان محاسباتی و تکرار بیشتری نیاز دارد.
۳. رگرسیون خطی؛ آزمایشگاهی برای درک هزینه
در یک مدل رگرسیون خطی با معادله Y = mX + b، هدف ما تنظیم وزنها (m و b) به گونهای است که مجموع فاصله بین خط پیشبینی و نقاط واقعی به حداقل برسد.
تفاوت فنی Loss و Cost:
- تابع زیان(Loss Function): خطا را فقط برای یک نمونه آموزشی محاسبه میکند.
- تابع هزینه(Cost Function): میانگین یا مجموع خطاها را در کل مجموعه داده میسنجد.
از نظر ریاضی، تابع هزینه در اینجا مشابه یک تابع سهمی (U شکل) است که یک مینیمم مطلق (Global Minimum) دارد و مدل با برداشتن گامهای کوچک سعی میکند به پایینترین نقطه آن برسد.
۴. استخراج ریاضی فرمول بهروزرسانی (Update Rule)
برای اینکه مدل وزنها را اصلاح کند، از دو قاعده اساسی در حساب دیفرانسیل استفاده میکنیم: قاعده توان (برای مشتقگیری از مربع خطا) و قاعده زنجیرهای (برای انتقال خطا از خروجی به لایههای عقبتر(.
فرمول:
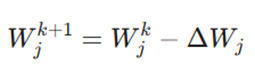
تحلیل اجزای فرمول:
- Wj^(k+1): موقعیت بعدی یا وزن جدید در تکرار k+1.
- Wj^k: موقعیت فعلی یا وزن موجود در تکرار فعلی k.
- ΔWj: مقدار تغییر، که همان شیب یا مشتق تابع نسبت به وزن است.
فرمول:
در برنامهنویسی شبکههای عصبی برای محاسبه مقدار تغییر وزن استفاده میشود:
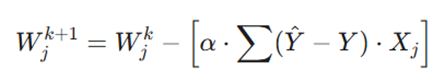
تشریح پارامترهای عملیاتی:
- α (نرخ یادگیری): ضریبی که تعیین میکند قدمهای ما به سمت پایین تپه چقدر بزرگ باشد.
- Y ^- Y (مقدار خطا): تفاوت بین پیشبینی مدل (Y^) و مقدار واقعی هدف (Y).
- Xj: مقدار ورودی مربوط به آن وزن خاص.
- Σ: مجموع خطاها برای تمام نمونههای آموزشی (رکوردهای مشتریان).
این فرمول قلب تپنده بخش انتشار رو به عقب (Backward Propagation) است. شبکه با محاسبه تفاوت پیشبینی (Y^) و واقعیت (Y)، متوجه میشود که هر وزن چقدر در ایجاد خطا نقش داشته است و آن را اصلاح میکند.
۵. استانداردسازی و مراحل نهایی
در دنیای شبکههای عصبی، پارامتر b (بایاس) را به عنوان θ0 و m (وزن) را به عنوان θ1 میشناسیم. فرآیند اصلاح به صورت گامبهگام انجام میشود:
- تغییر در شیب Error . X . Learning Rate: (Δm)
- تغییر در عرض از مبدأ Error . Learning Rate:(Δb)
- بهروزرسانی نهایی:
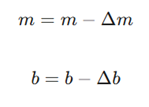
تعریف متغیرها:
- Δm: تغییرات کوچک در مقدار m (مشتق تابع هزینه نسبت به شیب).
- Δb: تغییرات کوچک در مقدار b (مشتق تابع هزینه نسبت به عرض از مبدأ).
این فرآیند تا زمان همگرایی (Convergence) ادامه مییابد؛ یعنی زمانی که تغییرات در تابع زیان بسیار ناچیز شده و مدل به بهینهترین حالت خود برسد.
انواع گرادیان کاهشی
در یادگیری عمیق، انتخاب نوع روشِ اجرای گرادیان کاهشی، مرز میان بهینگی سختافزاری و دقت مدل را تعیین میکند. این تصمیم مشخص میکند که آیا مدل شما در حافظه محدود GPU جا میشود یا خیر، و با چه سرعتی به نقطه بهینه همگرا میشود.
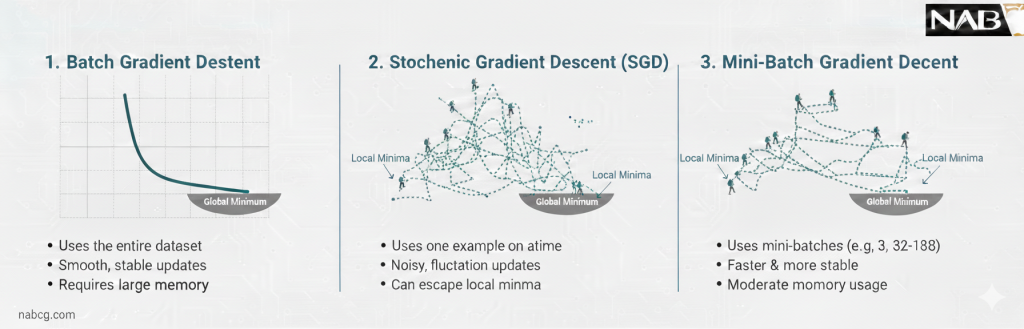
۱. گرادیان کاهشی دستهای (Batch Gradient Descent)
در این رویکرد، برای هر یک گام بهروزرسانی پارامترها، مدل باید کل مجموعهداده را پیمایش کند.
فرمول:
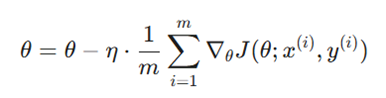
- دینامیک محاسباتی: گرادیان محاسبهشده، میانگین دقیقی از تمام نمونههاست. در نتیجه، بردار بهروزرسانی بدون انحراف و مستقیماً به سمت کمینه حرکت میکند.
- چالش حافظه: در پروژههای یادگیری عمیق با دادههای عظیم (Big Data)، بارگذاری کل دادهها در حافظه RAM یا VRAM غیرممکن است.
- تلههای هندسی: به دلیل حرکت کاملاً پایدار، این روش قدرت عبور از نقاط زینی (Saddle Points) را ندارد و به راحتی در کمینههای محلی گیر میافتد؛ چرا که هیچ نویز محاسباتی برای پرتاب کردن مدل به بیرون از این تلهها وجود ندارد.
.
۲. گرادیان کاهشی تصادفی (Stochastic Gradient Descent – SGD)
در این سناریو، ما گرادیان کل را با گرادیانِ تنها یک نمونه تصادفی تقریب میزنیم.
فرمول:
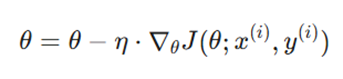
- اثر نویز و تکانه: نوسانات شدید در مسیر همگرایی (Zig-zagging) یک مزیت پنهان دارد؛ این نوسانات به مدل تکانه میدهند تا از نواحی تخت تابع زیان و کمینههای محلی ضعیف عبور کند.
- گلوگاه پردازشی: بزرگترین ضعف SGD، عدم بهرهگیری از قابلیت SIMD در GPUهاست. ارسال دادهها به صورت تکبهتک، توان پردازش موازی کارت گرافیک را هدر میدهد.
- نوسان پایانی: این روش به سختی در یک نقطه آرام میگیرد و معمولاً در اطراف نقطه بهینه رقص (Oscillation) میکند، مگر اینکه از استراتژی کاهش نرخ یادگیری (Learning Rate Decay) استفاده شود.
.
۳. گرادیان کاهشی مینی-بچ (Mini-Batch Gradient Descent)
این روش، استاندارد طلایی صنعت هوش مصنوعی است. دادهها به بلوکهای کوچک (n) تقسیم میشوند.
فرمول:
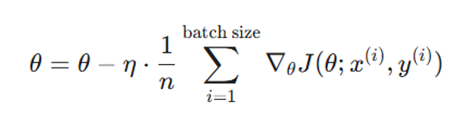
- بهرهوری سختافزاری: مینی-بچها دقیقاً برای معماری پردازش موازی طراحی شدهاند و هستههای GPU را به طور همزمان درگیر میکنند.
- کاهش واریانس: مسیر همگرایی نسبت به SGD پایدارتر است، اما هنوز آنقدر نویز دارد که از تلههای هندسی فرار کند.
- تأثیر اندازه دسته(Batch Size):
- بچهای کوچک: نویز بیشتر، قدرت تعمیمپذیری (Generalization) بالاتر، اما زمان آموزش طولانیتر.
- بچهای بزرگ: سرعت محاسباتی بسیار بالا، اما خطر همگرایی به کمینههای تیز (Sharp Minima) که منجر به کاهش دقت روی دادههای تست میشود.
.
جدول مقایسهای
| ویژگی | Batch GD | SGD | Mini-Batch GD |
| دقت گرادیان | بسیار بالا (دقیق) | پایین (تقریبی) | متوسط (متعادل) |
| سرعت هر آپدیت | بسیار کند | بسیار سریع | سریع |
| استفاده از GPU | ضعیف (حجم زیاد) | ضعیف (عدم موازیسازی) | عالی (ایدهآل) |
| مسیر همگرایی | مستقیم و نرم | پرنوسان و آشوبناک | نوسانات کنترلشده |
| ظرفیت فرار از تله | ندارد | بسیار زیاد | مناسب |
تکامل بهینهسازها در شبکههای عصبی عمیق
در معماریهای عمیق، ما با دو چالش بزرگ روبرو هستیم: ۱. سرعت آموزش و ۲. فرار از تلههای ریاضی. الگوریتمهای زیر راهکارهای هوشمندانه برای این چالشها هستند:

۱. گرادیان کاهشی مبتنی بر تکانه (Momentum)
در شبکههای عمیق، گرادیان ممکن است در جهتهای غیرضروری نوسان کند Momentum. مانند یک توپ سنگین عمل میکند که از تپه پایین میآید؛ این توپ اینرسی یا تکانه دارد.
- نقش در یادگیری عمیق: با جمع کردن گرادیانهای قبلی، سرعت حرکت در جهتهای صحیح را افزایش و نوسانات در جهتهای غلط را کاهش میدهد. این کار باعث میشود مدل سریعتر از نواحی تخت تابع زیان عبور کند.
.
۲. الگوریتم Adagrad (Adaptive Gradient)
در یادگیری عمیق، برخی پارامترها (وزنها) ممکن است به ندرت آپدیت شوند و برخی دیگر مدام در حال تغییر باشند.
- نقش در یادگیری عمیق: این الگوریتم برای هر پارامتر یک نرخ یادگیری اختصاصی در نظر میگیرد. برای وزنهایی که گرادیان بزرگی دارند، نرخ یادگیری را کم میکند تا از مسیر خارج نشوند.
.
۳. الگوریتم RMSprop
این بهینهساز توسط “جفری هینتون” معرفی شد تا مشکل کاهش شدید نرخ یادگیری در Adagrad را حل کند.
- نقش در یادگیری عمیق: به جای جمع کردن تمام گرادیانهای گذشته، از یک میانگین متحرک مجذور گرادیانها استفاده میکند. این کار مانع از آن میشود که نرخ یادگیری خیلی سریع به صفر برسد؛ در نتیجه برای شبکههای عصبی بازگشتی (RNN) ایدهآل است.
.
۴. الگوریتم (Adaptive Moment Estimation) Adam
این محبوبترین و قدرتمندترین بهینهساز در دنیای یادگیری عمیق است Adam. ترکیبی هوشمند از Momentum (برای جهتدهی) و RMSprop (برای تنظیم سرعت) است.
فرمول :
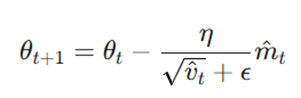
- mt: تخمین گشتاور اول (میانگین گرادیانها برای جهتدهی).
- v ̂ t: تخمین گشتاور دوم (میانگین مجذور گرادیانها برای تنظیم نرخ یادگیری).
- ε: یک عدد بسیار کوچک برای جلوگیری از تقسیم بر صفر.
.
مثال عددی:
در یادگیری عمیق، ما با جریان دادهها در قالب ماتریسها سروکار داریم. برای درک بهتر، بیایید آموزش یک فیلتر تشخیص ویژگی را در یک شبکه عصبی کانوولوشنال به صورت دستی بررسی کنیم:
سناریو: تشخیص شدت لبه در یک تصویر کوچک.
- ورودی(Input): دو پیکسل مجاور با مقادیر x1=1 و. x2=2
- هدف واقعی:(Target) ما میدانیم خروجی ایدهآل باید y=15 باشد.
- پارامترهای اولیه: وزنها w1=0.5 و w2=0.5 و بایاس. b=0
- نرخ یادگیری: برابر با. 0.1
.
گام اول: انتشار رو به جلو (Forward Pass)
ابتدا تخمین فعلی شبکه را محاسبه میکنیم:
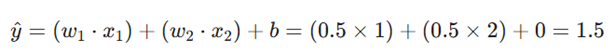
گام دوم: محاسبه تابع زیان (Loss Function)
میزان خطای مدل را با استفاده از تابع زیان نیم-مربعات محاسبه میکنیم:
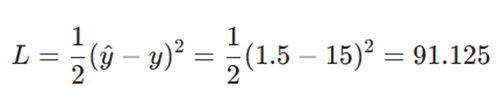
گام سوم: انتشار رو به عقب و محاسبه گرادیان (Backpropagation)
حالا طبق قاعده زنجیرهای، سهم هر پارامتر در ایجاد این خطا را پیدا میکنیم (تفاضل خطا = 13.5-):

گام چهارم: بهروزرسانی پارامترها (Update Rule)
پارامترها را در جهت مخالف گرادیان (سراشیبی خطا) اصلاح میکنیم:
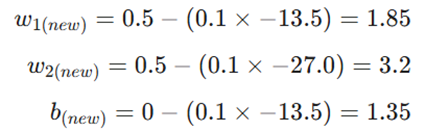
تحلیل نتیجه: تنها با یک تکرار، پیشبینی مدل از ۱.۵ به ۹.۶ رسید. این یعنی شبکه با موفقیت شروع به دیدن الگو کرده است.
کاربردهای گرادیان کاهشی در یادگیری عمیق
گرادیان کاهشی در لایه زیرین پیچیدهترین معماریهای عصبی جهان قرار دارد و به عنوان نیروی محرکهی یادگیری در حوزههای زیر عمل میکند:
۱. تصویربرداری پزشکی و تشخیص تومور: در شبکههای عصبی کانولوشنال ، گرادیان کاهشی وظیفه تنظیم فیلترهایی را دارد که ویژگیهای میکروسکوپی تصاویر MRI یا CT را شناسایی میکنند. این الگوریتم با به حداقل رساندن تابع زیان ، به شبکه میآموزد که مرز دقیق بین بافتهای سرطانی و سالم را در سطح پیکسل تشخیص دهد.
۲. ناوبری و بینایی در خودروهای خودران: خودروهای هوشمند از مدلهای یادگیری عمیق برای درک محیط استفاده میکنند. گرادیان کاهشی در اینجا پارامترهای مدلهای تشخیص اشیاء را بهینهسازی میکند تا خودرو بتواند در کسری از ثانیه، عابران پیاده، علائم راهنمایی و موانع را با کمترین ضریب خطا شناسایی کرده و مسیر حرکتی ایمن را طراحی کند.
۳. انقلاب در پردازش زبان طبیعی: مدلهای غولآسایی مثل GPT یا BERT دارای میلیاردها پارامتر هستند. نسخههای پیشرفته گرادیان کاهشی این پارامترها را طوری تنظیم میکنند که مدل بتواند بستر معنایی جملات را درک کند. هدف در اینجا، به حداقل رساندن خطای پیشبینی کلمهی بعدی و تولید متنی است که از نظر منطق انسانی بینقص باشد.
۴. هواشناسی و مدلسازی اقلیمی عمیق: در پیشبینیهای جوی، مدلهای RNN یا LSTM از گرادیان کاهشی برای تحلیل دادههای زمانی استفاده میکنند. این الگوریتم به مدل کمک میکند تا الگوهای پیچیده و غیرخطی جریانات هوایی را از میان تریلیونها دادهی سنسورهای جهانی استخراج کرده و دقیقترین پیشبینی بارندگی یا طوفان را ارائه دهد.
۵. سیستمهای توصیهگر و قیمتگذاری پویا: غولهای تجارت الکترونیک از شبکههای عصبی عمیق برای تحلیل رفتار کاربران استفاده میکنند. گرادیان کاهشی در اینجا به بهینهسازی توابع مطلوبیت کمک میکند تا سیستم بتواند دقیقاً در لحظهی مناسب، کالایی را پیشنهاد دهد یا قیمتی را تعیین کند که احتمال تبدیلِ بازدیدکننده به خریدار به حداکثر برسد.
مزایا
- انعطافپذیری عملیاتی : این الگوریتم با انواع توابع زیان (Loss Functions) سازگار است. در یادگیری عمیق، چه با Cross-Entropy برای طبقهبندی تصویر کار کنید و چه با MSE برای رگرسیون، گرادیان کاهشی ستون فقراتِ بهروزرسانی پارامترها باقی میماند. این الگوریتم به راحتی از پس پیچیدگیهای غیرخطی در شبکههای عصبی برمیآید.
- مقیاسپذیری در دادههای کلان : به خصوص در نسخه SGD، این الگوریتم برای مجموعهدادههای عظیم (Big Data) ایدهآل است. به جای اشغال تمام حافظه GPU برای کل دادهها، با پردازش نمونهبهنمونه یا دستهای (Mini-batch)، امکان آموزش مدلهای غولآسا فراهم میشود.
- همگرایی به بهینهی جهانی: اگر نرخ یادگیری (Learning Rate) به درستی تنظیم شود و تابع هزینه محدب باشد، این الگوریتم تضمین میکند که مدل به کمترین خطای ممکن برسد. در یادگیری عمیق، این به معنای رسیدن به دقیقترین وزنها برای پیشبینی است.
.
محدودیت
- حساسیت شدید به نرخ یادگیری : این پارامتر، حیاتیترین تنظیم در یادگیری عمیق است. اگر نرخ یادگیری خیلی بزرگ باشد، مدل دچار انفجار گرادیان (Exploding Gradient) شده و واگرا میشود. اگر خیلی کوچک باشد، دچار محو شدگی گرادیان (Vanishing Gradient) شده و آموزش عملاً متوقف میشود.
- وابستگی به مقداردهی اولیه : در شبکههای عمیق، اینکه وزنها را از چه عددی شروع کنید، سرنوشت مدل را تعیین میکند. مقداردهی ضعیف میتواند باعث شود مدل از همان ابتدا در مسیر غلط حرکت کند و هرگز به دقت مطلوب نرسد.
- تلهی کمینههای محلی : در توابع پیچیده یادگیری عمیق، هزاران چاله یا کمینه محلی وجود دارد. گرادیان کاهشی ساده ممکن است در یکی از این چالهها گیر کند و فکر کند به بهترین نتیجه رسیده است، در حالی که نقطه بهتری (Global Minimum) وجود دارد. همچنین در فضاهای پر ابعاد، نقاط زینی (Saddle Points) چالش بزرگتری هستند که سرعت آموزش را به صفر نزدیک میکنند.
- هزینه زمانی و محاسباتی : در مدلهایی با تریلیونها پارامتر، تکیه بر گرادیان کاهشی ساده میتواند آموزش را ماهها به طول بیندازد. به همین دلیل در یادگیری عمیق مدرن، از نسخههای بهبود یافته مثل Adam یا RMSprop استفاده میشود تا این نقص زمانی جبران شود.
.
پیادهسازی در پایتون
در این سناریو، هدف ما این است که رابطهی بین تعداد درخواستهای ورودی به سرور (X) و میزان اشغال پردازنده (y) را پیدا کنیم. این یک مسئلهی کلاسیک در زیرساختهای یادگیری عمیق برای مدیریت خودکار منابع (Auto-scaling) است.
۱. آمادهسازی محیط
ابتدا ابزارهای اصلی را وارد میکنیم NumPy. برای محاسبات برداری سنگین و Matplotlib برای مصورسازی رفتار مدل.
۲. تولید دادههای مصنوعی
ما ۱۰۰ نمونه داده تولید میکنیم که در آن تعداد درخواستها با نویزی تصادفی، بر میزان مصرف CPU اثر میگذارند.
۳. نرمالسازی
در یادگیری عمیق، اگر مقیاس ورودیها (مثلاً هزاران درخواست) با خروجی (درصد مصرف) هماهنگ نباشد، گرادیان کاهشی دچار سردرگمی میشود. ما دادهها را استاندارد میکنیم (میانگین ۰ و انحراف معیار ۱).
۴. موتور محرک گرادیان کاهشی
ما پارامترهای m (وزن) و c (بایاس) را به صورت خودکار و در طی ۱۰۰۰ تکرار بهروزرسانی میکنیم تا کمترین میزان خطا (Loss) حاصل شود.
import numpy as np
import matplotlib.pyplot as plt
# 1. Simulate Data: Server Requests (X) vs CPU Usage (y)
np.random.seed(42)
requests = 2 * np.random.rand(100, 1) + 5 # Number of requests
cpu_usage = 4 + 3 * requests + np.random.randn(100, 1) # CPU percentage
# 2. Feature Scaling (Z-score Normalization)
x_mean, x_std = np.mean(requests), np.std(requests)
X_scaled = (requests - x_mean) / x_std
# 3. Initialize Hyperparameters
m, c = 0.0, 0.0 # Initial weight and bias
learning_rate = 0.1
iterations = 1000
loss_history = []
# 4. Gradient Descent Loop
n = len(X_scaled)
for i in range(iterations):
# Forward Pass: Predict y
y_pred = m * X_scaled + c
# Calculate Mean Squared Error (Loss)
error = y_pred - cpu_usage
loss = np.mean(error ** 2)
loss_history.append(loss)
# Backpropagation: Compute Gradients
dm = (2 / n) * np.sum(error * X_scaled)
dc = (2 / n) * np.sum(error)
# Update Parameters
m -= learning_rate * dm
c -= learning_rate * dc
if i % 100 == 0:
print(f"Iteration {i}: Loss = {loss:.4f}, Weight = {m:.4f}, Bias = {c:.4f}")
# 5. Visualization with English Labels
plt.figure(figsize=(14, 5))
# Plot 1: Model Fitting
plt.subplot(1, 2, 1)
plt.scatter(X_scaled, cpu_usage, color='cyan', alpha=0.6, label="Actual Data")
plt.plot(X_scaled, m * X_scaled + c, color='red', linewidth=2, label="Regression Line")
plt.title("Server Load Prediction (Fitted Model)")
plt.xlabel("Requests (Scaled)")
plt.ylabel("CPU Usage (%)")
plt.legend()
plt.grid(True, linestyle='--', alpha=0.5)
# Plot 2: Convergence (Loss Curve)
plt.subplot(1, 2, 2)
plt.plot(loss_history, color='lime', linewidth=2)
plt.title("Model Training Convergence")
plt.xlabel("Number of Iterations")
plt.ylabel("Loss (MSE)")
plt.grid(True, linestyle='--', alpha=0.5)
plt.tight_layout()
plt.show()
print(f"\nOptimization Finished!")
print(f"Final Parameters -> Weight: {m:.2f}, Intercept: {c:.2f}")
خروجی:

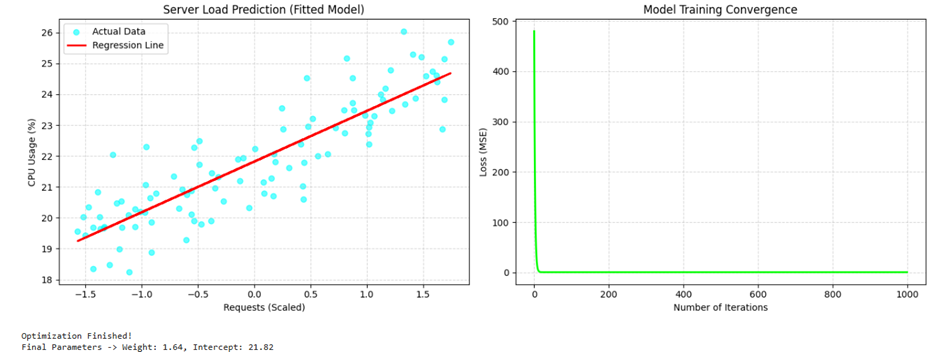
تفسیر خروجی مدل
در نمودار اول، برازش مدل بر روی دادههای واقعی ترافیک سرور به خوبی دیده میشود (خط قرمز). نمودار دوم (Model Training Convergence) نشاندهنده موفقیت کامل فرآیند بهینهسازی است؛ جایی که میزان خطا (Loss) در تکرارهای اولیه با سرعت بسیار زیاد سقوط کرده و سپس در نزدیکی صفر پایدار شده است.
- وزن نهایی (Weight): 1.64
- بایاس نهایی (Intercept): 21.82
.
جمع بندی
گرادیان کاهشی، هستهی اصلی فرآیند یادگیری در شبکههای عصبی است و بدون آن، مفهومی به نام «آموزش مدل» عملاً وجود نخواهد داشت. این الگوریتم با تبدیل خطای خروجی به اصلاحات هدفمند در پارامترهای داخلی، امکان یادگیری تدریجی و پایدار را فراهم میکند.
در این مسیر، عواملی مانند نرخ یادگیری، نوع دادهها، مقداردهی اولیه و انتخاب نسخهی مناسب گرادیان کاهشی (Batch، SGD، Mini-batch یا بهینهسازهای پیشرفتهتر مانند Adam) نقش تعیینکنندهای در سرعت همگرایی و کیفیت نهایی مدل دارند. به همین دلیل، تسلط بر منطق گرادیان کاهشی صرفاً یک دانش نظری نیست، بلکه یک مهارت عملی کلیدی برای طراحی و آموزش مؤثر مدلهای یادگیری عمیق محسوب میشود.
با وجود ظهور بهینهسازهای پیشرفته و خودتنظیم، گرادیان کاهشی همچنان زیربنای تمامی آنها باقی مانده است. درک این الگوریتم به مهندس یادگیری عمیق کمک میکند تا فراتر از اجرای صرف کد، رفتار مدل را تحلیل کند، مشکلات آموزش را تشخیص دهد و تصمیمهای مهندسی آگاهانهتری در ساخت سیستمهای هوشمند اتخاذ کند.



