

مقدمه
در آموزش شبکههای عصبی عمیق، یکی از چالشهای اساسی، تنظیم مناسب نرخ یادگیری برای پارامترهایی است که رفتار گرادیان آنها در طول زمان یکسان نیست. در بسیاری از معماریهای عمیق—بهویژه در مسائل دارای دادههای پُربعد یا ویژگیهای کمتکرار—استفاده از یک نرخ یادگیری ثابت میتواند باعث آموزش ناپایدار یا یادگیری ناکارآمد برخی پارامترها شود.
بهینهساز (Adaptive Gradient Algorithm) AdaGrad با هدف حل این مسئله معرفی شد. ایدهی اصلی AdaGrad تنظیم تطبیقی نرخ یادگیری برای هر پارامتر بر اساس تاریخچهی گرادیانهای آن است. در این روش، پارامترهایی که گرادیانهای بزرگی دریافت کردهاند بهتدریج با گامهای کوچکتری بهروزرسانی میشوند، در حالی که پارامترهای مرتبط با ویژگیهای نادر یا کمتکرار همچنان نرخ یادگیری بالاتری حفظ میکنند.
در زمینهی یادگیری عمیق، AdaGrad از نخستین تلاشها برای تطبیق خودکار نرخ یادگیری در مقیاس پارامترهای بسیار زیاد محسوب میشود و نقش مهمی در شکلگیری بهینهسازهای پیشرفتهتر ایفا کرده است. هدف این مطلب بررسی دقیق AdaGrad از منظر یادگیری عمیق است؛ از سازوکار ریاضی و رفتار آن در شبکههای عمیق گرفته تا مزایا، محدودیتها و جایگاه امروزی آن در مقایسه با بهینهسازهای مدرنتر.
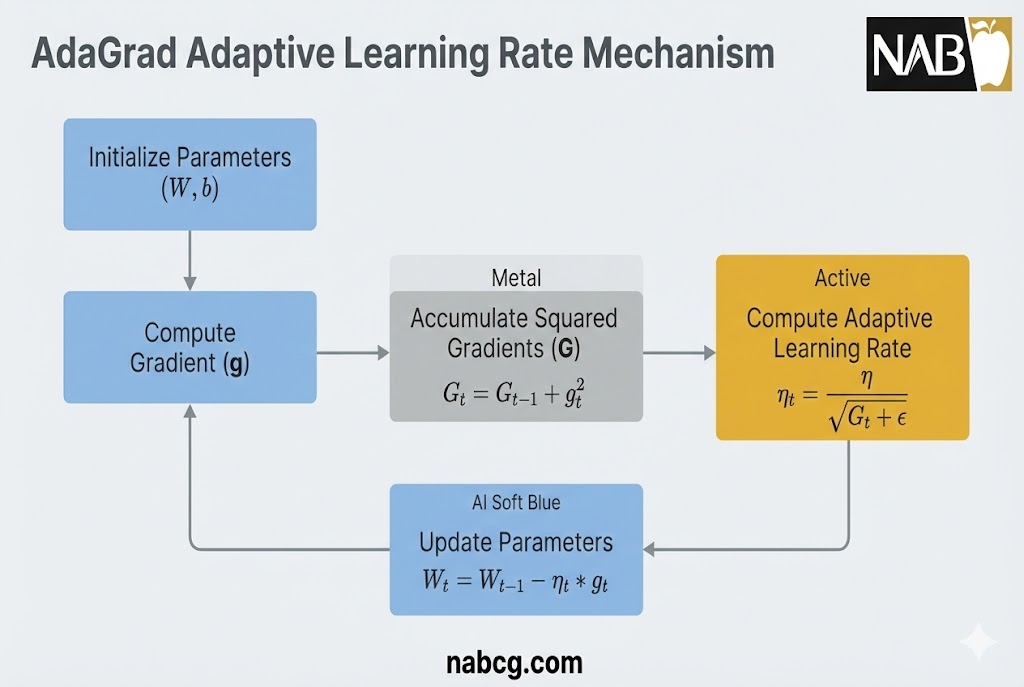
تعریف
AdaGrad که مخفف عبارت Adaptive Gradient (گرادیان تطبیقی) است، یک الگوریتم بهینهسازی پیشرفته برای آموزش مدلهای یادگیری ماشین، بهویژه شبکههای عصبی عمیق است. این متد برخلاف روشهای سنتیِ گرادیان کاهشی که از یک نرخ یادگیری ثابت (Fixed) برای تمامی پارامترها استفاده میکنند ، نرخ یادگیری را بهصورت پویا و مجزا برای هر پارامتر بر اساس تاریخچهی گرادیانهای آن تنظیم میکند.
.
چرا AdaGrad یک تحول بود؟
الگوریتم AdaGrad با هدف رفع چالشهای موجود در دادههای ناهمگون و بهینهسازی فرآیند یادگیری در فضاهای پارامتری پیچیده توسعه یافته است. ویژگیهای کلیدی این الگوریتم عبارتند از:
۱. مدیریت هوشمند دادههای پراکنده (Sparse Data)
دادههای پراکنده به ویژگیهایی اطلاق میشود که اکثر مقادیر آنها صفر است (مانند دادههای متنی یا مجموعهدادههایی با ویژگیهای غیرفعال فراوان).
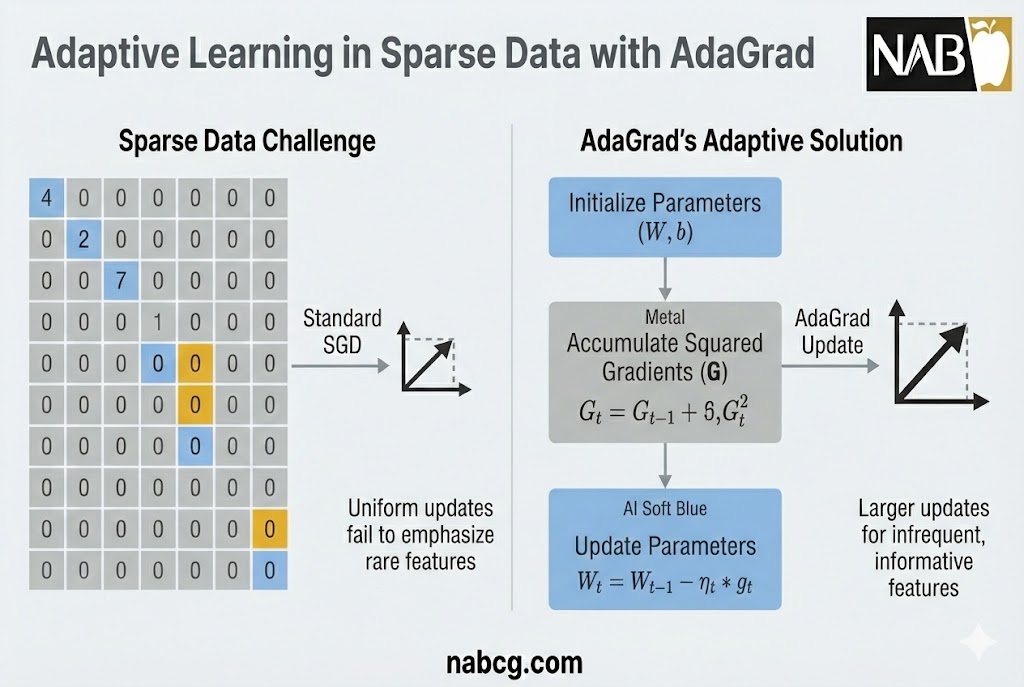
- تبعیض مثبت برای ویژگیهای کمیاب: AdaGrad به ویژگیهایی که به ندرت در دادهها ظاهر میشوند اما اهمیت بالایی دارند، نرخ یادگیری بالاتری اختصاص میدهد.
- تعدیل برای ویژگیهای رایج: در مقابل، برای پارامترهایی که مدام بهروزرسانی میشوند، نرخ یادگیری را کاهش میدهد تا پایداری مدل حفظ شود.
.
۲. مقیاسبندی بر اساس تاریخچهی گرادیان
این الگوریتم از گرادیانهای گذشته برای مقیاسبندی آپدیتهای فعلی استفاده میکند. این رویکرد اجازه میدهد تا پارامترهایی که نرخ همگرایی متفاوتی دارند، هر کدام با سرعت بهینهی خود به سمت هدف حرکت کنند.
۳. حذف نیاز به تنظیمات دستی (Auto-Tuning)
یکی از بزرگترین مزایای AdaGrad، کاهش چشمگیر نیاز به تنظیم دستی نرخ یادگیری (Manual Rate Tuning) است. با خودکارسازی این فرآیند، پیچیدگیهای مرحلهی آموزش کاهش یافته و کارایی مدل در مواجهه با بردارهای ویژگی با مقیاسهای متفاوت افزایش مییابد.
۴. افزایش بهرهوری در مدلهای عمیق
با تخصیص هوشمندانهی نرخ یادگیری به هر پارامتر، AdaGrad همگرایی در شبکههای عصبی عمیق را تسهیل کرده و فرآیند آموزش را در سناریوهایی که پارامترها با سرعتهای متفاوتی به بهینه میرسند، بسیار کارآمدتر میکند
.
بهینهساز AdaGrad چگونه کار میکند؟
الگوریتم AdaGrad برخلاف روشهای سنتی که از یک نرخ یادگیری ثابت برای تمام پارامترها استفاده میکنند، نرخ یادگیری را برای هر وزن به صورت مجزا و بر اساس تاریخچه فعالیت آن تنظیم میکند. این فرآیند در چهار مرحله اصلی اجرا میشود:
۱. مقداردهی اولیه (Initialization)
در شروع کار، مؤلفههای زیر تنظیم میشوند:
- پارامترها (θ): مقادیر اولیه وزنها (معمولاً به صورت تصادفی یا صفر).
- نرخ یادگیری اولیه (η): گام نخستین که سرعت شروع آموزش را تعیین میکند.
- اپسیلون (ϵ): یک عدد بسیار کوچک (مثلاً 10^(-8)) برای جلوگیری از خطای تقسیم بر صفر در محاسبات بعدی.
- مجموع مجذور گرادیانها (G): متغیری که در ابتدا برابر صفر است و وظیفه ذخیره تاریخچه نوسانات هر پارامتر را بر عهده دارد.
.
۲. محاسبه گرادیان لحظهای (gt)
در هر مرحله از آموزش (زمان t)، مشتق جزئی تابع هزینه نسبت به هر پارامتر محاسبه میشود:
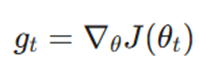
- gt: بردار گرادیان در زمان فعلی.
- θ∇: عملگر مشتق جزئی نسبت به پارامترها.
- J(θt): تابع هزینه (Loss Function) که میزان خطای مدل را نشان میدهد.
این گرادیان نشاندهنده شیب تابع هزینه است و به ما میگوید برای کاهش خطا، پارامترها باید در چه جهتی و با چه شدتی تغییر کنند.
.
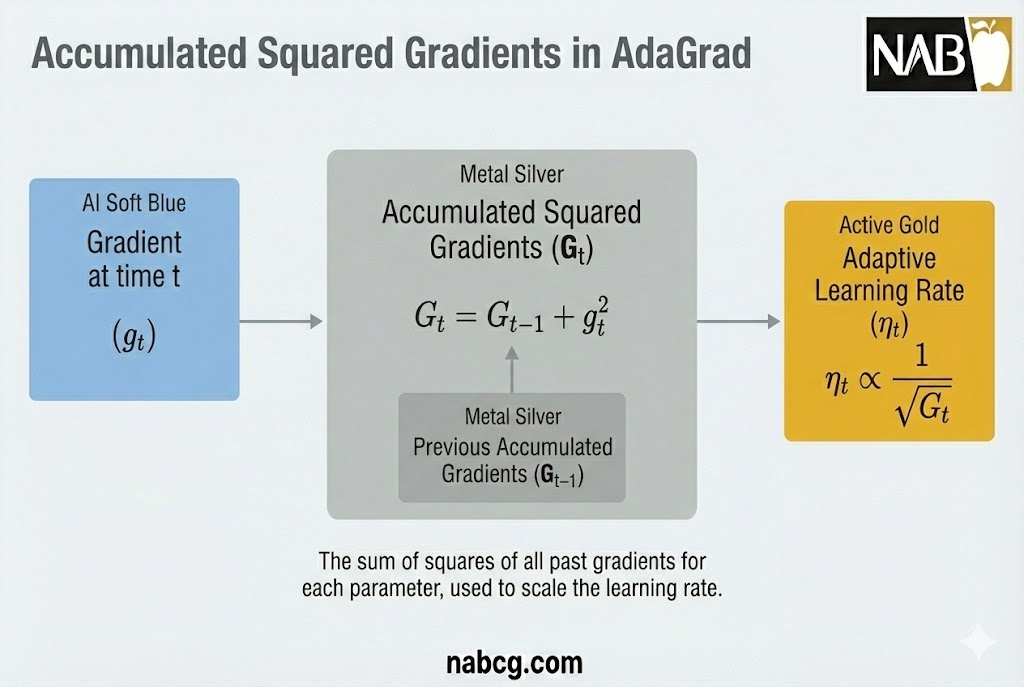
۳. انباشت مجذور گرادیانها (Gt)
این مرحله قلب تپنده AdaGrad است. به جای استفاده مستقیم از گرادیان، الگوریتم توان دوم گرادیان فعلی را به مجموع گرادیانهای قبلی اضافه میکند:
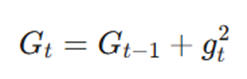
- Gt: مجموع انباشتهشدهی مجذور گرادیانها تا زمان فعلی.
- Gt-1: مجموع مجذور گرادیانها در مرحلهی قبلی.
- gt^2: توان دوم گرادیان فعلی (بزرگی نوسان بدون در نظر گرفتن جهت).
این متغیر (Gt) در واقع یک تاریخچه فعالیت برای هر پارامتر ایجاد میکند. پارامترهایی که مدام در حال تغییر هستند، G بزرگتری خواهند داشت و پارامترهایی که به ندرت فعال میشوند، G کوچکی دارند.
.
۴. بهروزرسانی پارامترها با نرخ یادگیری تطبیقی
در نهایت، وزنهای مدل با استفاده از فرمول زیر اصلاح میشوند:
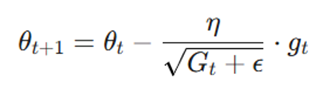
تحلیل متغیرهای فرمول:
- مخرج کسر (√Gt + ϵ): وظیفه مقیاسبندی نرخ یادگیری را بر عهده دارد.
- تعدیل هوشمند: هرچه مجموع مجذور گرادیانها (Gt) بزرگتر شود، مخرج بزرگتر شده و در نتیجه نرخ یادگیری برای آن پارامتر کاهش مییابد.
.
مثال عددی واقعی: آموزش مدل تحلیل نظرات (NLP)
فرض کنید در حال آموزش یک مدل برای تشخیص احساسات نظرات هستیم. دو ویژگی (کلمه) کلیدی داریم:
- کلمهی “the” (w1): بسیار پرتکرار (در هر جمله هست).
- کلمهی “excellent” (w2): کمیاب اما بسیار حیاتی برای تشخیص حس مثبت.
تنظیمات اولیه:

تکرار ۱: هر دو کلمه در جمله هستند
- گرادیانهای فرضی: g1 = 0.8 و g2 = 0.7
محاسبات:
- آپدیت حافظه:
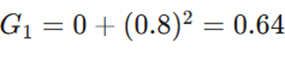
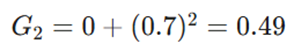
- آپدیت وزنها:
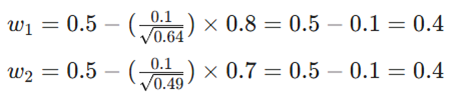
تکرار ۲: فقط کلمه پرتکرار (“the”) ظاهر میشود
- گرادیانها: g1 = 0.6 (پرتکرار) و g2 = 0.01 (کلمه عالی وجود ندارد)
محاسبات:
- آپدیت حافظه:
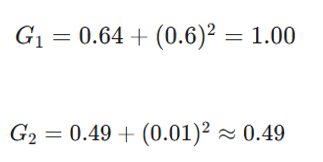
- آپدیت وزنها:
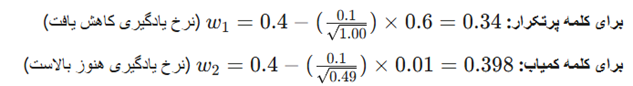
تکرار ۳: ظهور دوباره کلمه کمیاب (“excellent”)
- گرادیانها: g1 = 0.5 و g2 = 0.6
محاسبات نهایی:
- آپدیت حافظه:
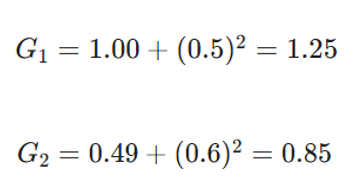
- آپدیت وزنها:
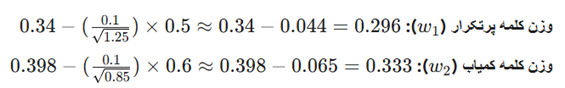
تحلیل نهایی: چرا AdaGrad برندهی این میدان است؟
در پایان تکرار سوم، ببینید مخرج کسر برای هر کدام چقدر است:

نتیجه: AdaGrad متوجه شد که کلمهی “the” نویز زیادی دارد، پس یادگیریاش را کُند کرد. اما برای کلمهی “excellent” که کمیاب است، نرخ یادگیری را بالا نگه داشت تا مدل به محض دیدن آن، بیشترین یادگیری را داشته باشد. این همان عدالت در یادگیری است که AdaGrad به ارمغان آورد.
.
پیادهسازی AdaGrad
گامهای پیادهسازی AdaGrad
برای پیادهسازی این الگوریتم از صفر، چهار مرحلهی اصلی زیر را در کد دنبال میکنیم:
- مقداردهی اولیه (Initialization): علاوه بر پارامترهای مدل و نرخ یادگیری پایه ، یک متغیر انباشتگر (G) تعریف میکنیم که در ابتدا برابر صفر است و وظیفه دارد تاریخچهی نوسانات هر وزن را در خود ذخیره کند.
- محاسبه گرادیان (gt): در هر تکرار، میزان خطای مدل نسبت به هر پارامتر محاسبه میشود تا جهت حرکت مشخص گردد.
- انباشت مجذور گرادیانها (Gt): این مرحله قلب تپنده الگوریتم است؛ توان دوم گرادیان فعلی را به مقدار قبلی در انباشتگر اضافه میکنیم (Gt = Gt-1 + gt^2). این کار باعث میشود وزنهای پرتکرار، عدد بزرگتری در انباشتگر داشته باشند.
- بهروزرسانی با نرخ یادگیری اصلاحشده: در نهایت، نرخ یادگیری پایه را بر جذر مقدار انباشتهشده (به اضافهی اپسیلون) تقسیم میکنیم تا گام نهایی برای هر پارامتر بهصورت اختصاصی محاسبه و اعمال شود.
.
کد پایتون:
در ادامه، کد کامل این بهینهساز به همراه یک مثال شبیهسازی برای مشاهدهی نحوهی همگرایی ارائه شده است:
import numpy as np
import matplotlib.pyplot as plt
class AdaGradOptimizer:
def __init__(self, learning_rate=0.1, epsilon=1e-8):
self.lr = learning_rate
self.epsilon = epsilon
# انباشتگر مجموع مجذور گرادیانها (G)
self.G = None
def update(self, params, grads):
# در اولین اجرا، انباشتگر با ابعاد پارامترها و مقدار صفر ساخته میشود
if self.G is None:
self.G = [np.zeros_like(p) for p in params]
new_params = []
for i in range(len(params)):
# گام ۳: انباشت مجذور گرادیان فعلی در تاریخچه
self.G[i] += grads[i]**2
# گام ۴: محاسبه نرخ یادگیری تطبیقی و بهروزرسانی پارامتر
# تقسیم نرخ یادگیری پایه بر جذر تاریخچه نوسانات
adaptive_lr = self.lr / (np.sqrt(self.G[i]) + self.epsilon)
p_new = params[i] - adaptive_lr * grads[i]
new_params.append(p_new)
return new_params
# --- شبیهسازی عملکرد بر روی یک تابع هزینه ساده (f(w) = w^2) ---
def loss_function(w): return w**2
def gradient_function(w): return 2*w
optimizer = AdaGradOptimizer(learning_rate=0.5)
w = np.array([10.0]) # شروع از نقطه 10
history = [w[0]]
print(f"{'Step':<5} | {'Weight (w)':<12} | {'Accumulator (G)':<15}")
print("-" * 45)
for i in range(1, 11):
grad = gradient_function(w)
w = optimizer.update([w], [grad])[0]
history.append(w[0])
print(f"{i:<5} | {w[0]:<12.4f} | {optimizer.G[0][0]:<15.4f}")
# نمایش بصری مسیر همگرایی
plt.figure(figsize=(10, 5))
x_range = np.linspace(-2, 11, 100)
plt.plot(x_range, loss_function(x_range), 'k--', alpha=0.3, label='Loss Surface')
plt.plot(history, [loss_function(h) for h in history], 'go-', label='AdaGrad Path')
plt.title('AdaGrad Convergence simulation')
plt.xlabel('Weight (w)'); plt.ylabel('Loss (L)'); plt.legend(); plt.show()
خروجی:
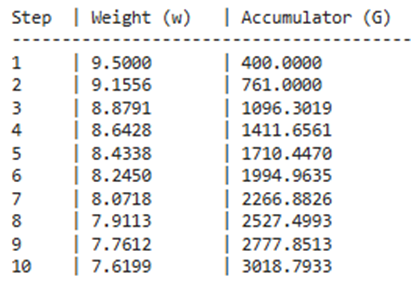
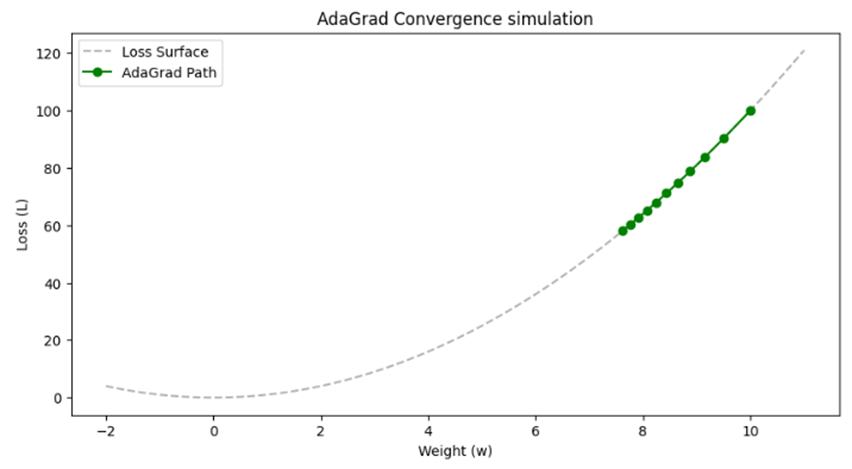
.
انواع نسخههای تکاملیافتهی AdaGrad
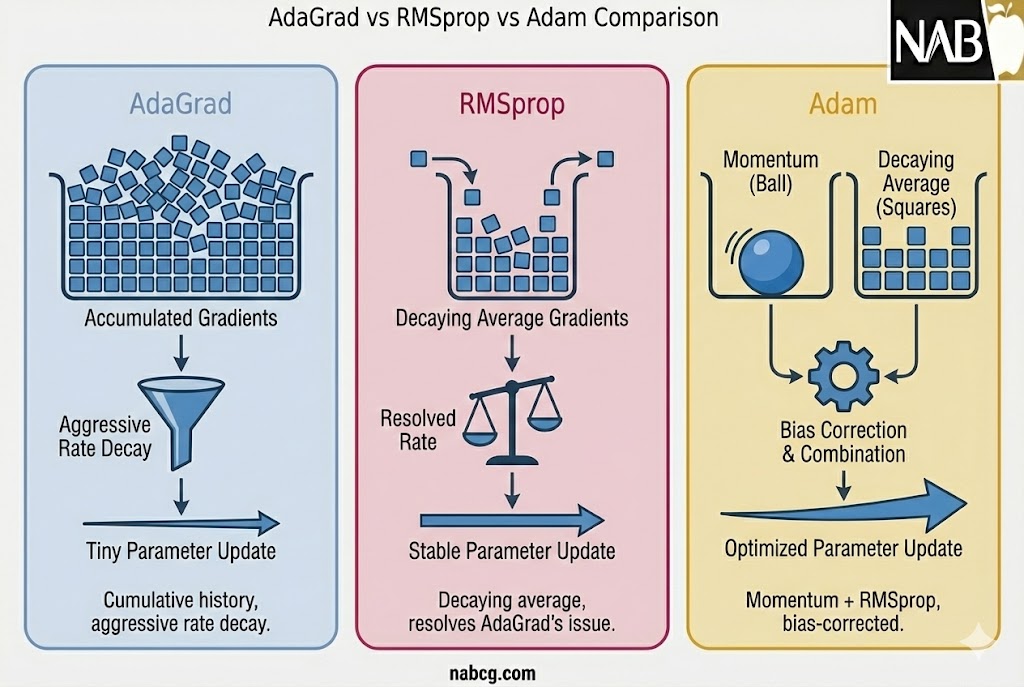
۱. الگوریتم RMSProp (نرمسازی تلاطمها)
الگوریتم RMSProp (مخفف Root Mean Square Propagation) با هدف مستقیم رفع مشکل «کاهش شدید نرخ یادگیری» در AdaGrad معرفی شد.
- مکانیسم تغییر: برخلاف AdaGrad که تمام گرادیانهای گذشته را با هم جمع میکرد، RMSProp از میانگین متحرک نمایی مجذور گرادیانها استفاده میکند.
- فرمول کلیدی: در این روش، متغیر انباشت (Gt) با استفاده از یک ضریب میرایی (γ) بهروزرسانی میشود:
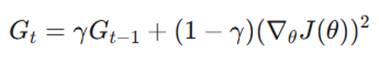
- مزیت اصلی: این ضریب میرایی (که معمولاً روی ۰.۹ تنظیم میشود) مانع از بزرگ شدن بیرویهی مخرج کسر و توقف زودهنگام یادگیری میشود که آن را برای آموزش شبکههای عصبی عمیق بسیار کارآمدتر میکند.
.
۲. الگوریتم AdaDelta (تکامل بدون نرخ یادگیری)
AdaDelta نسخهی هوشمندانهتری از AdaGrad است که تمرکز خود را بر محدود کردن انباشت گرادیانهای گذشته در یک «پنجره زمانی» مشخص قرار داده است.
- مکانیسم تغییر: این الگوریتم با استفاده از میانگین متحرک مجذور بهروزرسانیها، تلاش میکند پایداری بیشتری در گامها ایجاد کند.
- حذف نیاز به نرخ یادگیری اولیه: یکی از بزرگترین نوآوریهای AdaDelta این است که نیاز به تعیین نرخ یادگیری اولیه را حذف میکند.
- فرمول بهروزرسانی: در این روش، اندازه گام بر اساس نسبت میانگین متحرک تغییرات پارامتر به میانگین متحرک گرادیانها تنظیم میشود:
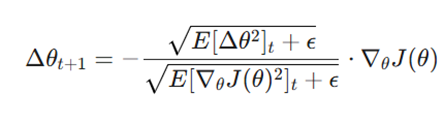
۳. الگوریتم Adam (ترکیب قدرت و هوشمندی)
الگوریتم Adam (مخفف Adaptive Moment Estimation) محبوبترین بهینهساز در یادگیری عمیق امروزی است که بهترین ویژگیهای AdaGrad و روشهای مبتنی بر ممنتوم را با هم ترکیب کرده است.
- مکانیسم تغییر: Adam همزمان از میانگین متحرک گرادیانها (گشتاور اول برای جهتدهی) و مجذور گرادیانها (گشتاور دوم برای تنظیم نرخ یادگیری) استفاده میکند.
- اصلاح سوگیری (Bias Correction): این الگوریتم شامل یک مرحلهی هوشمند برای اصلاح سوگیری در گامهای اولیه آموزش است تا از پایداری شروع اطمینان حاصل کند.
- فرمولهای اصلی:
- تخمین گشتاور اول (ممنتوم):
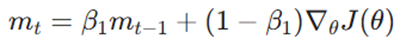
- تخمین گشتاور دوم (تطبیق):

- نتیجه: این ترکیب باعث شده Adam در اکثر وظایف یادگیری ماشین، عملکردی بسیار پایدارتر و سریعتر از سایر رقبا داشته باشد.
.
جدول مقایسهای
| ویژگی | RMSProp | AdaDelta | Adam |
| هدف اصلی | حل میرایی شدید نرخ یادگیری | کاهش انباشت گرادیان و حذف نرخ یادگیری اولیه | ترکیب ممنتوم و نرخ یادگیری تطبیقی |
| نوآوری کلیدی | میانگین متحرک نمایی | نرخ یادگیری خودکار بر اساس تغییرات پارامتر | اصلاح سوگیری و استفاده از دو گشتاور |
| محبوبیت فعلی | بالا (بهویژه در RNNها) | متوسط | بسیار بالا (استاندارد یادگیری عمیق) |
.
مطالعه موردی 1: بهینهسازی سیستمهای توصیهگر در فروشگاههای بزرگ
چالش فنی (Long-tail Recommendation): در فروشگاههای بزرگی مانند آمازون، با میلیونها کالا روبرو هستیم. محصولاتی مانند «نان» یا «شیر» مدام توسط کاربران دیده و خریداری میشوند، در حالی که محصولات تخصصی (مانند یک قطعه یدکی کمیاب) ممکن است در ماه فقط توسط دو نفر جستجو شوند. در مدلهای یادگیری عمیق، پارامترهای مربوط به محصولات پرفروش مدام بهروزرسانی میشوند، اما پارامترهای محصولات خاص به دلیل کمبود داده (Sparsity)، به ندرت فرصت یادگیری پیدا میکنند.
نقش استراتژیک AdaGrad: این بهینهساز برای محصولات پرفروش که گرادیانهای مکرر تولید میکنند، مخرج کسر را بزرگ کرده و نرخ یادگیری را کاهش میدهد تا پایداری مدل حفظ شود. اما برای محصولات کمیاب، مخرج کسر کوچک باقی میماند. این یعنی وقتی یک کاربر بالاخره آن قطعه یدکی خاص را جستجو میکند، AdaGrad با یک نرخ یادگیری بالا وارد عمل شده و به سرعت وزنهای مربوط به آن محصول را بهروزرسانی میکند.
دستاورد: سیستم توصیهگر دیگر فقط محصولات پرفروش را پیشنهاد نمیدهد؛ بلکه میتواند با دقت بسیار بالا، محصولات خاص و کمیاب را نیز به کاربرانِ هدف پیشنهاد دهد و تجربه شخصیسازی را به کمال برساند.
کد پایتون: شبیهسازی یادگیری در دادههای پراکنده
در این کد، ما یک سناریوی «سیستم توصیهگر» را شبیهسازی میکنیم که در آن یک ویژگی بسیار پرتکرار (محصول عمومی) و یک ویژگی بسیار کمیاب (محصول خاص) وجود دارد. مشاهده خواهید کرد که AdaGrad چگونه برای هر دو تعادل برقرار میکند.
import numpy as np
import matplotlib.pyplot as plt
# ۱. شبیهسازی دادههای پراکنده (مانند محصولات کمیاب یا تراکنشهای کلاهبرداری)
np.random.seed(42)
iterations = 200
target_weights = np.array([0.5, 0.5]) # هدف نهایی مدل برای هر دو ویژگی
# ۲. کلاس بهینهساز AdaGrad مطابق فرمول ریاضی
class AdaGrad:
def __init__(self, lr=0.2):
self.lr = lr
self.G = np.zeros(2) # انباشتگر مجذور گرادیانها برای ۲ پارامتر
self.eps = 1e-8
def step(self, w, grad):
# گام ۳: انباشت مجذور گرادیانها
self.G += grad**2
# گام ۴: محاسبه نرخ یادگیری تطبیقی برای هر پارامتر به صورت مجزا
adaptive_lr = self.lr / (np.sqrt(self.G) + self.eps)
return w - adaptive_lr * grad
# ۳. فرآیند آموزش (یادگیری وزنها)
w = np.array([0.0, 0.0]) # شروع از وزن صفر
optimizer = AdaGrad(lr=0.5) # نرخ یادگیری اولیه
history = []
for i in range(iterations):
grad = np.zeros(2)
# ویژگی پرتکرار (مثل نان یا تراکنش عادی): در هر مرحله گرادیان دارد
grad[0] = -2 * (target_weights[0] - w[0]) + np.random.normal(0, 0.1)
# ویژگی کمیاب (مثل قطعه یدکی خاص یا کلاهبرداری): فقط در ۵٪ مواقع ظاهر میشود
if i % 20 == 0:
# وقتی ظاهر میشود، گرادیان آن بسیار مهم و تاثیرگذار است
grad[1] = -2 * (target_weights[1] - w[1]) * 15
w = optimizer.step(w, grad)
history.append(w.copy())
history = np.array(history)
# ۴. نمایش بصری با کدهای رنگی استاندارد (نقرهای و طلایی متالیک)
plt.figure(figsize=(12, 6))
# رسم روند یادگیری محصول پرتکرار
plt.plot(history[:, 0], color='#A9A9A9', label='Frequent Feature (High Frequency)', alpha=0.8)
# رسم روند یادگیری محصول کمیاب (با تاکید بصری بیشتر)
plt.plot(history[:, 1], color='#D4AF37', linewidth=2.5, label='Rare/Sparse Feature (High Importance)')
# خط هدف
plt.axhline(0.5, color='red', linestyle=':', label='Target Weight')
plt.title('AdaGrad: Adaptive Learning in Sparse vs Dense Data', fontsize=14)
plt.xlabel('Iterations'); plt.ylabel('Learned Weight (w)')
plt.legend(); plt.grid(True, alpha=0.3)
plt.show()
print(f"Final Weights -> Frequent: {w[0]:.4f}, Rare: {w[1]:.4f}")
خروجی:
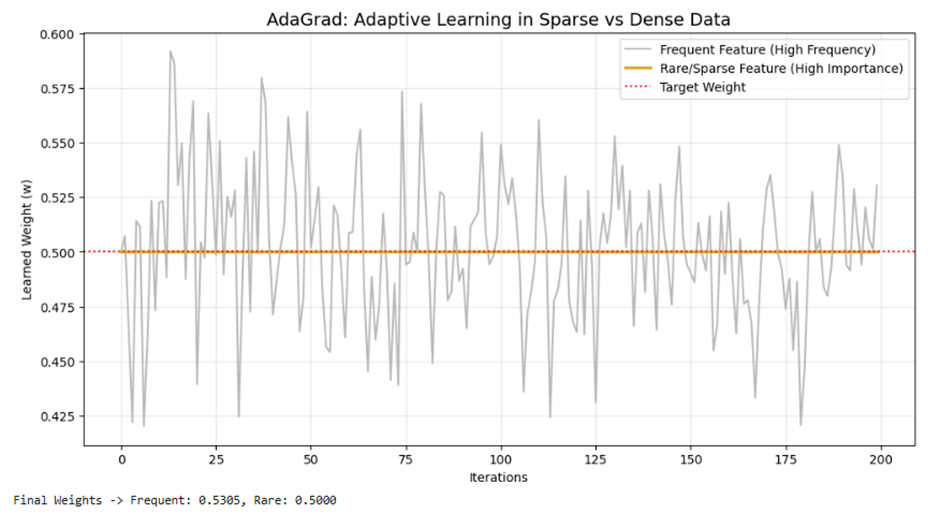
.
مطالعه موردی 2: تشخیص ناهنجاری (Fraud Detection) در تراکنشهای بانکی
چالش فنی (Imbalanced Sparse Data): در سیستمهای بانکی، ۹۹.۹٪ تراکنشها کاملاً عادی هستند و تنها درصد بسیار ناچیزی به فعالیتهای مشکوک اختصاص دارد. ویژگیهای معرف کلاهبرداری (مانند موقعیت مکانی غیرعادی یا الگوی خرید ناگهانی) بسیار «پراکنده» هستند و در حجم عظیم دادههای عادی غرق میشوند.
نقش استراتژیک AdaGrad: بهینهسازهای معمولی ممکن است نرخ یادگیری را برای کل مدل سریعاً کاهش دهند، که باعث میشود الگوهای نادرِ کلاهبرداری هرگز یاد گرفته نشوند. اما AdaGrad اجازه نمیدهد نرخ یادگیری پارامترهای مربوط به این الگوهای کمیاب میرا شود. این الگوریتم با بالا نگه داشتن حساسیت مدل نسبت به گرادیانهای ضعیف و نادر، تضمین میکند که پارامترهای امنیتی به اندازه کافی بهروزرسانی شوند.
دستاورد: شناسایی سریعتر و دقیقتر الگوهای مشکوک کلاهبرداری که در میان میلیاردها تراکنش عادی پنهان شدهاند، منجر به افزایش امنیت سیستمهای مالی و کاهش خسارات میشود.
پیادهسازی کد پایتون: شبیهسازی تشخیص کلاهبرداری با AdaGrad
در این کد، ما دو ویژگی را شبیهسازی میکنیم: یکی مربوط به «تراکنشهای عادی» (پرتکرار) و دیگری مربوط به «امضای کلاهبرداری» (بسیار کمیاب). مشاهده خواهید کرد که AdaGrad چطور نرخ یادگیری را برای امضای کلاهبرداری بالا نگه میدارد.
import numpy as np
import matplotlib.pyplot as plt
# ۱. شبیهسازی محیط بانکی
# ویژگی ۱: تراکنش عادی (همیشه وجود دارد)
# ویژگی ۲: الگوی کلاهبرداری (فقط در تکرارهای بسیار خاص ظاهر میشود)
np.random.seed(42)
iterations = 300
target_pattern = np.array([0.4, 0.9]) # هدف نهایی مدل برای شناسایی الگوها
# ۲. کلاس بهینهساز AdaGrad (پیادهسازی گامبهگام مطابق فرمول)
class AdaGradOptimizer:
def __init__(self, lr=0.5):
self.lr = lr
self.G = np.zeros(2) # انباشتگر مجذور گرادیانها
self.eps = 1e-8
def update(self, w, grad):
# [cite_start]گام ۳: انباشت مجذور گرادیان فعلی در تاریخچه
self.G += grad**2
# [cite_start]گام ۴: بهروزرسانی با نرخ یادگیری تطبیقی
adaptive_lr = self.lr / (np.sqrt(self.G) + self.eps)
return w - adaptive_lr * grad
# ۳. فرآیند آموزش مدل امنیتی
w = np.array([0.0, 0.0]) # شروع از وزن صفر
optimizer = AdaGradOptimizer(lr=0.3)
history = []
for i in range(iterations):
grad = np.zeros(2)
# گرادیان تراکنش عادی (پرتکرار)
grad[0] = -2 * (target_pattern[0] - w[0]) + np.random.normal(0, 0.05)
# گرادیان الگوی کلاهبرداری (کمیاب - فقط هر ۵۰ تکرار یکبار ظاهر میشود)
if (i + 1) % 50 == 0:
grad[1] = -2 * (target_pattern[1] - w[1]) * 20 # وزندهی به اهمیت ناهنجاری
w = optimizer.update(w, grad)
history.append(w.copy())
history = np.array(history)
# ۴. نمایش بصری با تم رنگی اختصاصی (سرمهای و طلایی)
plt.figure(figsize=(12, 6))
# نمایش روند یادگیری تراکنش عادی
plt.plot(history[:, 0], color='#C0C0C0', label='Normal Transaction Pattern', alpha=0.7)
# نمایش روند یادگیری الگوی کلاهبرداری (با تاکید بصری)
plt.plot(history[:, 1], color='#FFD700', linewidth=2.5, label='Fraud Signature (Sparse)')
# خطوط هدف
plt.axhline(0.4, color='red', linestyle='--', alpha=0.5)
plt.axhline(0.9, color='red', linestyle='--', alpha=0.5, label='Fraud Detection Target')
plt.title('AdaGrad: Detecting Rare Fraud Patterns in Sparse Data', fontsize=14)
plt.xlabel('Training Steps'); plt.ylabel('Detection Confidence (Weight)')
plt.legend(); plt.grid(True, alpha=0.2)
plt.show()
print(f"Final Weights -> Normal: {w[0]:.4f}, Fraud Pattern: {w[1]:.4f}")
خروجی:

تحلیل خروجی:
همانطور که در نمودار مشخص است، خط نقرهای (تراکنش عادی) به دلیل تکرار زیاد، نرخ یادگیریاش به سرعت تعدیل شده و به ثبات میرسد. اما خط طلایی (الگوی کلاهبرداری) با وجود فاصلههای زمانی طولانی بین هر ظهور، به دلیل اینکه AdaGrad نرخ یادگیری آن را میرا نکرده است، با جهشهای بلند و قدرتمند خود را به هدف میرساند. این یعنی سیستم شما حتی با کمترین داده، نسبت به ناهنجاریها بسیار حساس باقی مانده است.
.
کاربردهای استراتژیک بهینهساز AdaGrad
۱. پردازش زبان طبیعی (NLP) و تحلیل متن
یکی از برجستهترین و گستردهترین کاربردهای AdaGrad در حوزه NLP است.
- بهینهسازی تعبیه کلمات: این الگوریتم برای بهینهسازی بردارهای تعبیه کلمات حیاتی است؛ زیرا کلمات کمیاب اما مهم را با نرخ یادگیری مناسبی آپدیت میکند.
- تنوع وظایف: AdaGrad در تحلیل احساسات ، دستهبندی متن، مدلسازی زبانی و ترجمه ماشینی به طور گسترده استفاده میشود.
- مدیریت دادههای پراکنده: از آنجایی که در متون، بسیاری از کلمات به ندرت ظاهر میشوند، نرخ یادگیری تطبیقی AdaGrad در کار با این دادههای پراکنده بسیار مؤثر عمل میکند.
.
۲. سیستمهای توصیهگر
- پیشبینی علایق کاربر: این بهینهساز وزنهای مدل توصیه را بهینهسازی میکند تا احتمال علاقهمندی یک کاربر به یک محصول خاص را با دقت بیشتری پیشبینی کند.
- انعطاف در برابر دادههای نامنظم: توانایی تنظیم پویای نرخ یادگیری به مدلها کمک میکند تا با مجموعه دادههای پراکنده که در سناریوهای توصیه کالا معمول هستند، به خوبی کنار بیایند.
.
۳. تشخیص تصویر و بینایی ماشین
اگرچه امروزه بهینهسازهایی مثل Adam محبوبتر هستند، اما AdaGrad همچنان جایگاه خود را در آموزش شبکههای عصبی عمیق برای بینایی ماشین حفظ کرده است.
- تنظیم دقیق وزنها: با تطبیق نرخ یادگیری برای هر پارامتر، AdaGrad اطمینان حاصل میکند که وزنهای شبکه متناسب با وظیفه مورد نظر (مانند شناسایی لبهها یا اشیاء خاص) بهروزرسانی میشوند.
- بهرهوری در آموزش: در وظایف بینایی ماشین که برخی ویژگیها نیاز به نرخ یادگیری بالاتری دارند، AdaGrad فرآیند آموزش را بهینه میکند.
.
۴. تحلیل سریهای زمانی
- مدیریت الگوهای غیریکنواخت: در پیشبینی قیمت سهام، که الگوهای داده ممکن است نامنظم باشند، تنظیمات انطباقی نرخ یادگیری به مدل کمک میکند تا با تغییرات ناگهانی سازگار شود.
.
۵. پردازش گفتار و صوت
- تشخیص گفتار: AdaGrad برای بهینهسازی مدلهای تشخیص گفتار و طبقهبندی فایلهای صوتی، بهویژه زمانی که بازنمایی ویژگیها به صورت پراکنده است، بسیار کارآمد عمل میکند.
.
مزایا
- کارایی بینظیر در دادههای پراکنده :AdaGrad برای ویژگیهایی که به ندرت فعال میشوند اما اطلاعات مهمی دارند، فوقالعاده عمل میکند. این الگوریتم با انباشت تاریخچه گرادیان، نرخ یادگیری را برای ویژگیهای کمیاب تقویت کرده و آپدیتهای مناسبی به آنها اختصاص میدهد.
- نرخ یادگیری تطبیقی و خودکار: بزرگترین مزیت این است که نرخ یادگیری برای هر پارامتر بهصورت مجزا تنظیم میشود. این ویژگی نیاز به تنظیم دستی نرخ یادگیری (Manual Tuning) را برای هر پارامتر از بین میبرد.
- ناوبری در سطوح پیچیده هزینه: با تنظیم نرخ یادگیری بر اساس بزرگی گرادیانها، AdaGrad میتواند سطوح پیچیدهی هزینه را با بازدهی بیشتری نسبت به متدهای نرخ یادگیری ثابت طی کند.
- قدرت و پایداری: این الگوریتم نسبت به انتخاب نرخ یادگیری اولیه حساسیت کمتری دارد و در عمل استفاده از آن سادهتر است. همچنین در مواجهه با دادههای نویزی، پایداری خوبی از خود نشان میدهد.
.
محدودیتها
- میرایی تهاجمی نرخ یادگیری (Learning Rate Decay): پاشنه آشیل AdaGrad، انباشت مداوم مجذور گرادیانها در طول تمام تکرارهاست. این تجمع باعث میشود مخرج کسر به طور مداوم بزرگ شده و نرخ یادگیری به شدت منقبض شود.
- توقف زودرس یادگیری (Early Stopping): در مراحل پایانی آموزش یا در مدلهای عمیق با جلسات آموزشی طولانی، نرخ یادگیری به قدری کوچک میشود که مدل عملاً یادگیری را متوقف کرده و پیش از رسیدن به نقطه بهینه دچار ایستایی میشود.
- مصرف بالای حافظه: AdaGrad برای هر پارامتر نیاز به ذخیره مجموع مجذور گرادیانهای تاریخی دارد. این موضوع در مدلهای بزرگمقیاس یادگیری عمیق، سربار محاسباتی و مصرف حافظه را به شدت افزایش میدهد.
- عملکرد ضعیف در مسائل غیرمحدب (Non-Convex): در فضاهای پیچیده و غیرمحدب، نرخ یادگیریِ همیشه کاهشیِ AdaGrad مانع از فرار مدل از نقاط زینی (Saddle Points) یا کمینههای محلی کمعمق میشود.
- عدم وجود ممنتوم: این الگوریتم فاقد جملات ممنتوم است، که عبور از نواحی تخت و رسیدن به همگرایی سریع در مسائل پیچیده را دشوارتر میکند.
.
جمع بندی
AdaGrad یکی از نخستین بهینهسازهای تطبیقی است که بهطور جدی مسئلهی ناهمگونی گرادیانها در مدلهای پُربعد را هدف قرار داد. این روش با انباشت مجذور گرادیانها و کاهش تدریجی نرخ یادگیری مؤثر، امکان یادگیری پایدارتر پارامترهایی را فراهم میکند که بهندرت بهروزرسانی میشوند؛ ویژگیای که در برخی مسائل یادگیری عمیق، مانند پردازش زبان طبیعی یا سیستمهای توصیهگر، اهمیت ویژهای دارد.
با این حال، بررسی دقیقتر نشان میدهد که همین کاهش تجمعی نرخ یادگیری میتواند در شبکههای عصبی عمیق به یک محدودیت جدی تبدیل شود. در طول آموزش طولانیمدت، نرخ یادگیری بهقدری کوچک میشود که مدل عملاً توان ادامهی یادگیری را از دست میدهد. به همین دلیل، AdaGrad بهتنهایی گزینهی مناسبی برای بسیاری از معماریهای عمیق امروزی نیست و معمولاً با روشهایی مانند RMSprop، AdaDelta یا Adam جایگزین شده است که این مشکل را برطرف میکنند.
در عمل، AdaGrad بیش از آنکه یک انتخاب پیشفرض برای آموزش شبکههای عمیق باشد، یک نقطهی مرجع مفهومی محسوب میشود. درک دقیق سازوکار AdaGrad به مهندس یادگیری عمیق کمک میکند تا منطق بهینهسازهای تطبیقی مدرن را بهتر بفهمد و انتخاب آگاهانهتری میان روشهای مختلف بهینهسازی، متناسب با معماری شبکه و ویژگیهای داده، انجام دهد.



