

مقدمه
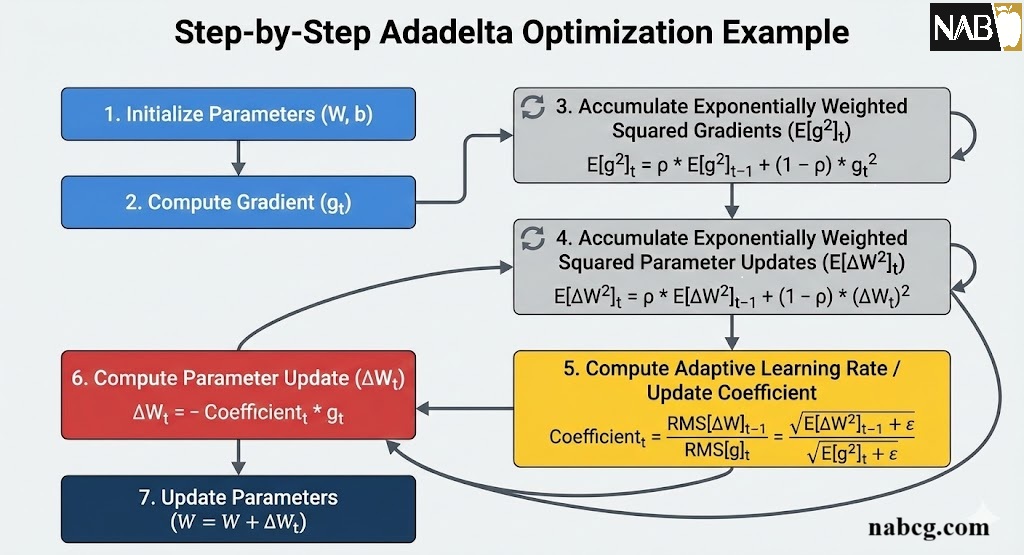
در آموزش شبکههای عصبی عمیق، یکی از چالشهای اساسی بهینهسازی، وابستگی شدید عملکرد الگوریتمها به انتخاب نرخ یادگیری است. روشهایی مانند گرادیان کاهشی تصادفی یا AdaGrad، اگرچه برای برخی مسائل کارآمد هستند، اما در آموزش طولانیمدت شبکههای عمیق میتوانند با مشکلاتی مانند نوسان گرادیان یا کاهش بیشازحد نرخ یادگیری مواجه شوند. این محدودیتها بهویژه در مسائل دارای دادههای نویزی یا توزیعهای در حال تغییر نمود بیشتری پیدا میکنند.
بهینهساز Adadelta با هدف کاهش وابستگی به تنظیم دستی نرخ یادگیری معرفی شد. این روش با استفاده از میانگینهای متحرک نمایی از گرادیانها و بهروزرسانی پارامترها بر اساس مقیاس تغییرات گذشته، تلاش میکند گامهای بهینهسازی را بهصورت خودتنظیمشونده کنترل کند. در نتیجه، Adadelta امکان آموزش پایدارتر مدلهای عمیق را بدون نیاز به تنظیم دقیق نرخ یادگیری فراهم میسازد.
هدف این مطلب ارائهی یک بررسی جامع از Adadelta در زمینهی یادگیری عمیق است؛ از مبانی ریاضی و شهود طراحی آن گرفته تا پیادهسازی عملی و کاربردهای واقعی. تمرکز اصلی بر این است که روشن شود Adadelta چگونه عمل میکند، چه مشکلی را حل میکند و در چه شرایطی استفاده از آن منطقیتر است.
تعریف
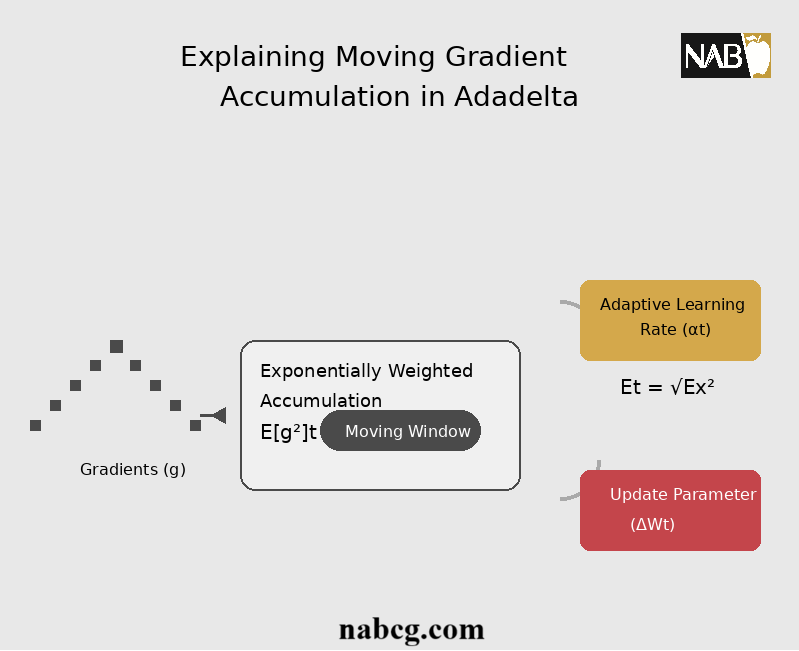
Adadelta یک روش نرخ یادگیری تطبیقی (Adaptive Learning Rate) است که برای حل مشکل میرایی تهاجمی نرخ یادگیری در الگوریتمهای پیشین طراحی شده است. برخلاف AdaGrad که تمام مجذور گرادیانهای گذشته را انباشته میکرد، Adadelta انباشت گرادیان را به یک پنجره زمانی متحرک محدود میکند. این کار باعث میشود که اثر گرادیانهای بسیار قدیمی حذف شده و نرخ یادگیری حتی در تکرارهای بسیار بالا نیز زنده و کارآمد باقی بماند.
.
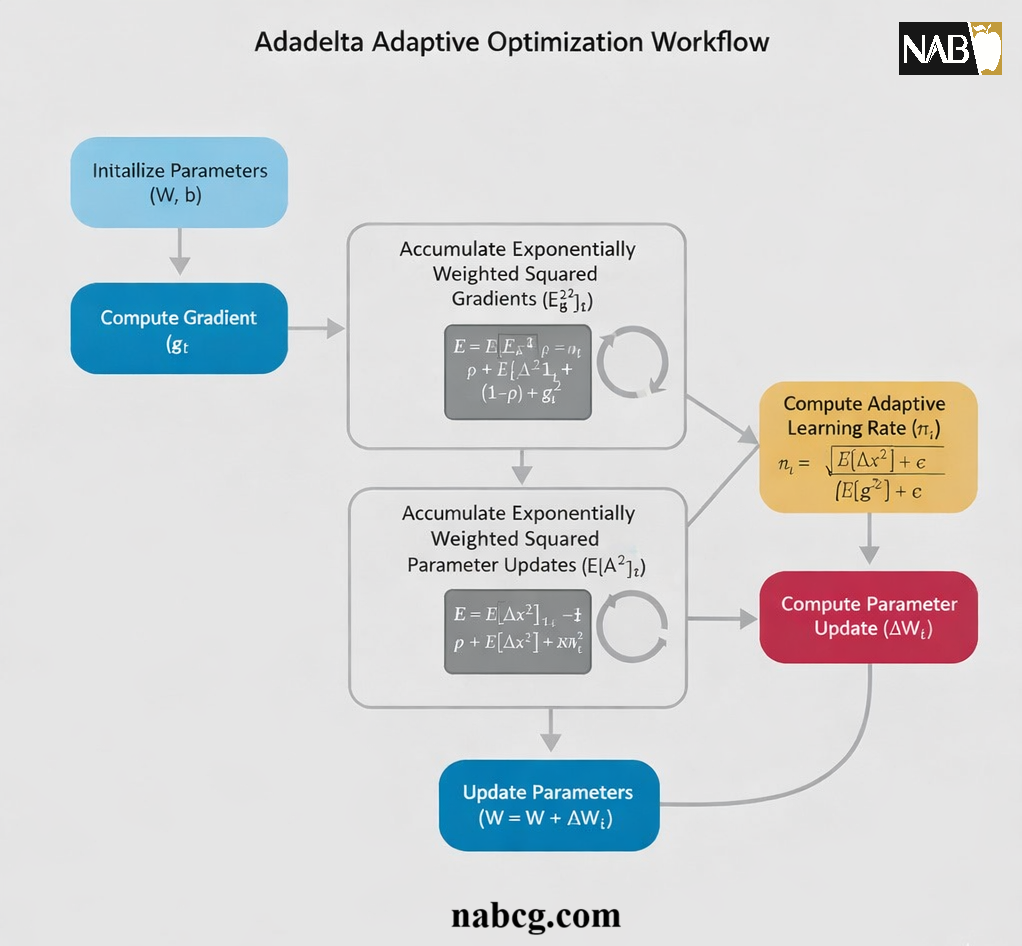
Adadelta چگونه کار میکند؟
الگوریتم Adadelta با استفاده از اطلاعات گرادیانهای مرتبه اول، نرخ یادگیری را به صورت خودکار برای هر پارامتر تنظیم میکند. برخلاف سایر روشها، این بهینهساز از «میانگینهای متحرک نمایی» استفاده میکند تا همواره تصویری بهروز از وضعیت آموزش داشته باشد.
.
۱. محاسبه میانگین متحرک مجذور گرادیانها (E[g^2]t)
اولین مرحله در Adadelta، محاسبه میانگین متحرک مجذور گرادیانها است. این کار باعث میشود الگوریتم «تغییرات بزرگ» پارامترها را زیر نظر بگیرد. فرمول محاسباتی آن به شرح زیر است:
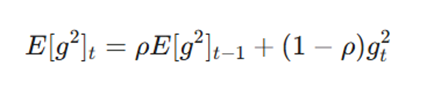
- gt: گرادیان در گام زمانی فعلی.
- E[g^2]t: میانگین متحرک نمایی از مجذور گرادیانها.
- ρ (Rho): ضریب میرایی (معمولاً حدود ۰.۹۵ یا ۰.۹۹) که تعیین میکند چه مقدار از تاریخچه گرادیانهای گذشته در حافظه باقی بماند. این میانگین متحرک به Adadelta نوعی حافظه از گرادیانهای گذشته میدهد که اجازه میدهد بدون نیاز به ذخیره کل تاریخچه (برخلاف AdaGrad)، خود را با شرایط فعلی آموزش تطبیق دهد.
.
۲. میانگین متحرک مجذور بهروزرسانیها (E[Δθ^2]t)
نوآوری اصلی Adadelta در این مرحله نهفته است؛ یعنی نگهداری یک میانگین متحرک دیگر برای مجذور بهروزرسانیهای پارامترها:

- Δθt: مقدار واقعی بهروزرسانی پارامتر در گام فعلی. این بخش از الگوریتم بسیار حیاتی است، زیرا از کوچک شدن بیش از حد نرخ یادگیری جلوگیری میکند. در واقع Adadelta با زیر نظر گرفتن میزان تغییرات گذشته، از برداشتن گامهای بسیار کوچک و بیاثر جلوگیری میکند.
.
۳. محاسبه بهروزرسانی نهایی پارامتر
در نهایت، بهروزرسانی پارامتر با استفاده از نسبت این دو میانگین متحرک محاسبه میشود که منجر به پایداری فرآیند یادگیری میگردد:

در این معادله، RMS (جذر میانگین مجذورات) به صورت زیر تعریف میشود:
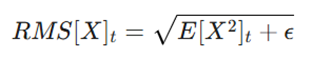
- ϵ (Epsilon): یک عدد بسیار کوچک برای حفظ پایداری عددی و جلوگیری از تقسیم بر صفر.
.
مثال: کمینهسازی تابع هزینه با Adadelta
فرض کنید میخواهیم تابع هزینهی درجه دوم f(x) = x^2 را با شروع از نقطهی x = 5 و با استفاده از بهینهساز Adadelta (با پارامترهای ρ = 0.95 و ϵ = 10^ (-6)) کمینه کنیم.
نکات کلیدی:
- مشتق (گرادیان):

- هدف: رسیدن به کمینهی مطلق در نقطه x = 0
.
معادلات کلی برای انباشت گرادیان و بهروزرسانی:
- میانگین متحرک نمایی (EMA):
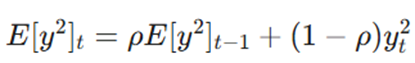
- جذر میانگین مجذورات (RMS):
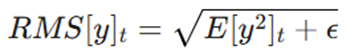
.
1(تکرار اول):
۱. شرایط اولیه:

۲. محاسبه گرادیان: g1 = 2(5) = 10.00
مراحل محاسباتی:
- انباشت گرادیان:
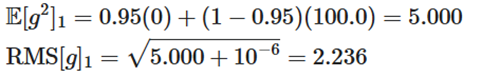
- بهروزرسانی پارامتر:

- انباشت بهروزرسانی و تعیین موقعیت جدید:
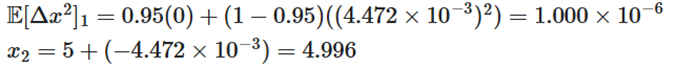
تکرار دوم :
۱. موقعیت فعلی: x2 = 4.996
۲. محاسبه گرادیان: g2 = 2(4.996) = 9.992
.
مراحل محاسباتی:
- انباشت گرادیان:
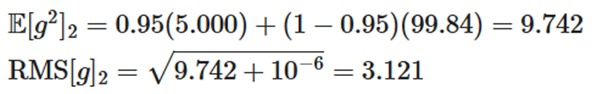
- بهروزرسانی پارامتر:
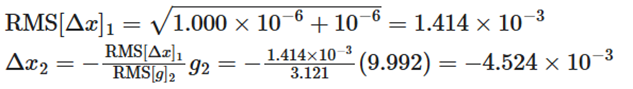
- انباشت بهروزرسانی و تعیین موقعیت جدید:

تحلیل :
همانطور که مشاهده میکنید، Adadelta بدون داشتن پارامتر نرخ یادگیری ثابت، با استفاده از نسبت تغییرات گذشته به گرادیان فعلی، گامهای هوشمندانهای برمیدارد. در تکرار اول مقدار x از ۵ به ۴.۹۹۶ و در تکرار دوم به ۴.۹۹۱ رسیده است که نشاندهنده حرکت آرام اما مستمر و پایدار به سمت نقطه بهینه (صفر) است.
.
پیاده سازی Adadelta
.
فاز اول: پیادهسازی گامبهگام Adadelta در پایتون
برای پیادهسازی این الگوریتم، باید چهار مرحلهی زیر را در کد دنبال کنیم:
۱. مقداردهی اولیه (Initialization): دو متغیر انباشتگر (Eg2 برای گرادیانها و Edtheta2 برای بهروزرسانیها) تعریف میکنیم که در ابتدا برابر صفر هستند.
۲. محاسبه میانگین متحرک گرادیان (E[g^2]t): در هر تکرار، مجذور گرادیان فعلی را با ضریب میرایی (ρ) به تاریخچه اضافه میکنیم تا وزن گرادیانهای قدیمی به مرور کم شود.
۳. محاسبه گام بهروزرسانی (Δθt): این بخش قلبِ خودکار Adadelta است. نسبتِ جذرِ میانگینِ بهروزرسانیهای قبلی به جذرِ میانگینِ گرادیانهای فعلی را محاسبه کرده و در گرادیان لحظهای ضرب میکنیم.
۴. انباشت مجذور بهروزرسانیها: مقدار Δθ محاسبه شده را به حافظهی Edtheta2 اضافه میکنیم تا در مرحله بعدی به عنوان معیار «میزان پیشرفت» استفاده شود.
کد پیادهسازی Adadelta از صفر (Numerical Output)
import numpy as np
import matplotlib.pyplot as plt
class AdadeltaOptimizer:
def __init__(self, rho=0.95, eps=1e-6):
self.rho = rho
self.eps = eps
self.Eg2 = 0 # میانگین متحرک مجذور گرادیانها
self.Edtheta2 = 0 # میانگین متحرک مجذور بهروزرسانیها
def update(self, theta, grad):
# ۱. بهروزرسانی تاریخچه مجذور گرادیانها
self.Eg2 = self.rho * self.Eg2 + (1 - self.rho) * grad**2
# ۲. محاسبه RMSها (جذر میانگین مجذورات)
rms_dtheta_prev = np.sqrt(self.Edtheta2 + self.eps)
rms_g_curr = np.sqrt(self.Eg2 + self.eps)
# ۳. محاسبه تغییرات پارامتر (بدون نیاز به نرخ یادگیری اولیه)
delta_theta = - (rms_dtheta_prev / rms_g_curr) * grad
# ۴. بهروزرسانی تاریخچه مجذور تغییرات برای تکرار بعدی
self.Edtheta2 = self.rho * self.Edtheta2 + (1 - self.rho) * delta_theta**2
return theta + delta_theta
# شبیهسازی روی تابع هزینه f(x) = x^2
optimizer = AdadeltaOptimizer()
x = 5.0 # شروع از نقطه ۵
history = [x]
print(f"{'گام':<5} | {'مقدار پارامتر x':<15}")
print("-" * 25)
for i in range(50):
grad = 2 * x # مشتق x^2
x = optimizer.update(x, grad)
history.append(x)
if (i+1) % 10 == 0 or i < 5:
print(f"{i+1:<5} | {x:<15.6f}")
# نمایش بصری مسیر همگرایی Adadelta
plt.plot(history, color='#D4AF37', marker='o', label='Adadelta Path')
plt.axhline(0, color='red', linestyle='--')
plt.title('Adadelta Individual Progress')
plt.show()
خروجی:

.
فاز 2:گامهای پیادهسازی نبرد بهینهسازها
برای اجرای این شبیهسازی، مراحل زیر را در کد دنبال میکنیم:
- تعریف محیط آزمایش: یک تابع هزینهی ساده (f(x) = x^2) و مشتق آن (2x) تعریف میکنیم. تمام بهینهسازها از نقطهی بحرانی x = 10 حرکت خود را آغاز میکنند تا به کمینهی تابع یعنی صفر برسند.
- پیادهسازی کلاسهای بهینهساز: چهار کلاس مجزا برای SGD، AdaGrad، RMSProp و Adadelta طراحی میکنیم که هر کدام بر اساس فرمولهای ریاضی خاص خود، مقدار x را بهروزرسانی میکنند.
- اجرای شبیهسازی (Simulation Loop): در یک چرخهی ۱۰۰ تکراری، هر بهینهساز وزنها را آپدیت کرده و مسیر حرکت خود (تاریخچهی مقادیر x) را ذخیره میکند.
- نمایش بصری و تحلیل عددی: در نهایت، تمام مسیرهای حرکت را در یک نمودار واحد رسم میکنیم تا سرعت همگرایی و پایداری هر کدام به وضوح قابل مقایسه باشد.
کد پایتون نبرد بهینهسازها
این کد به صورت جامع تمام الگوریتمها را در کنار هم اجرا کرده و خروجی گرافیکی تولید میکند:
import numpy as np
import matplotlib.pyplot as plt
# تعریف تابع و مشتق آن
def func(x): return x**2
def grad_func(x): return 2*x
# --- پیادهسازی بهینهسازها ---
class SGD:
def __init__(self, lr=0.01): self.lr = lr
def update(self, x, g): return x - self.lr * g
class AdaGrad:
def __init__(self, lr=0.5): self.lr, self.G = lr, 0
def update(self, x, g):
self.G += g**2
return x - (self.lr / (np.sqrt(self.G) + 1e-8)) * g
class RMSProp:
def __init__(self, lr=0.1, rho=0.9): self.lr, self.rho, self.G = lr, rho, 0
def update(self, x, g):
self.G = self.rho * self.G + (1 - self.rho) * g**2
return x - (self.lr / (np.sqrt(self.G) + 1e-8)) * g
class Adadelta:
def __init__(self, rho=0.95, eps=1e-6):
self.rho, self.eps = rho, eps
self.Eg2, self.Edx2 = 0, 0
def update(self, x, g):
self.Eg2 = self.rho * self.Eg2 + (1 - self.rho) * g**2
rms_dx = np.sqrt(self.Edx2 + self.eps)
rms_g = np.sqrt(self.Eg2 + self.eps)
dx = - (rms_dx / rms_g) * g
self.Edx2 = self.rho * self.Edx2 + (1 - self.rho) * dx**2
return x + dx
# --- اجرای شبیهسازی ---
start_x = 10.0
iterations = 100
optimizers = {
'SGD (lr=0.01)': SGD(0.01),
'AdaGrad (lr=0.5)': AdaGrad(0.5),
'RMSProp (lr=0.1)': RMSProp(0.1),
'Adadelta (rho=0.95)': Adadelta(0.95)
}
results = {}
for name, opt in optimizers.items():
x = start_x
history = [x]
for _ in range(iterations):
g = grad_func(x)
x = opt.update(x, g)
history.append(x)
results[name] = history
# --- ترسیم نمودار مقایسهای ---
plt.figure(figsize=(12, 7))
for name, history in results.items():
plt.plot(history, label=name, linewidth=2)
plt.axhline(0, color='black', linestyle='--', alpha=0.5)
plt.title('Battle of Optimizers: Adadelta vs Others', fontsize=14)
plt.xlabel('Iterations'); plt.ylabel('Parameter Value (x)')
plt.legend(); plt.grid(True, alpha=0.3); plt.show()
# چاپ نتایج عددی نهایی
for name, history in results.items():
print(f"{name}: Final x = {history[-1]:.6f}")
خروجی:
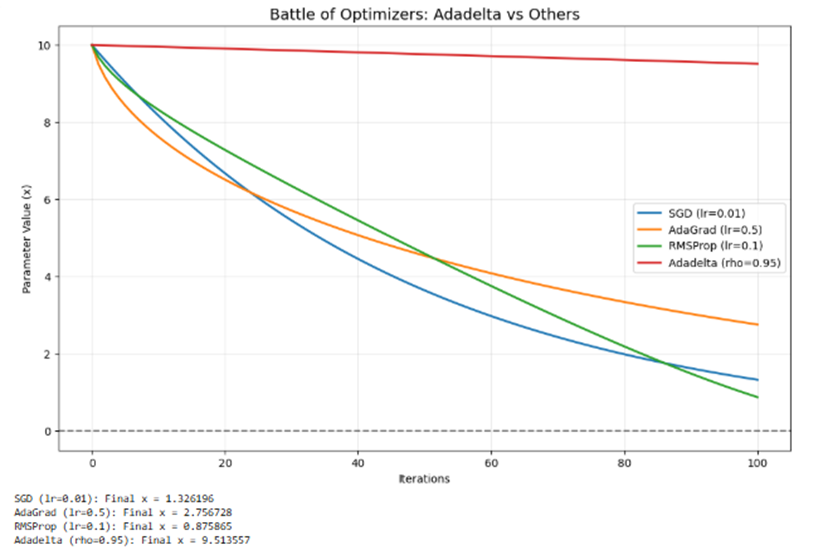
تحلیل عملکرد الگوریتمها در نمودار
بر اساس شواهد بصری و دادههای عددی استخراج شده، تحلیل دقیق هر منحنی به شرح زیر است:
- RMSProp (منحنی سبز): در این رقابت، سریعترین همگرایی را داشته و به عدد 0.875 رسیده است. این الگوریتم با استفاده از میانگین متحرک مجذور گرادیانها، توانسته است با سرعت بالا به سمت هدف سقوط کند.
- SGD (منحنی آبی): با نرخ یادگیری ثابت 0.01 عملکردی خطی و مستمر داشته و به عدد 1.326 رسیده است. اگرچه از RMSProp کُندتر است، اما پایداری خود را در طول ۱۰۰ تکرار حفظ کرده است.
- AdaGrad (منحنی نارنجی): شروع بسیار طوفانی و سریعی داشته، اما همانطور که در نمودار مشهود است، به تدریج شیب آن کاهش یافته و دچار ایستایی (Stalling) شده است (نقطه نهایی: 2.756). این دقیقاً پاشنه آشیل AdaGrad یعنی تجمع بیش از حد گرادیانها در مخرج کسر را نشان میدهد که باعث مرگ تدریجی نرخ یادگیری میشود.
- Adadelta (منحنی قرمز): در این بازهی ۱۰۰ تکراری، کُندترین عملکرد را داشته و تنها به عدد 9.513 رسیده است.
.
چرا Adadelta در این نمودار کُند به نظر میرسد؟
شاید در نگاه اول ضعیف به نظر برسد، اما تحلیل مهندسی آن نکات مهمی را آشکار میکند:
- عدم وجود نرخ یادگیری اولیه: برخلاف سایرین که با نرخهای یادگیری دستی (مثل 0.5 یا 0.1) تحریک شدهاند، Adadelta کاملاً خودگردان است و گامهای آن در ابتدا بسیار محتاطانه است.
- پایداری فیزیکی: Adadelta به جای سرعت، بر اصلاح واحدها (Unit Matching) و پایداری در بلندمدت تمرکز دارد.
- رفتار در مدلهای واقعی: در حالی که در این تابع ساده کُند عمل میکند، در مدلهای عمیق و پیچیده (مثل مدلهای غولآسا با دادههای پراکنده) که تنظیم نرخ یادگیری غیرممکن است، Adadelta به دلیل عدم توقف یادگیری، در نهایت از AdaGrad پیشی میگیرد.
نتیجهگیری: این نمودارنشان میکند که Adadelta یک بهینهساز برای «ماراتن» است، نه «دوی سرعت». در حالی که AdaGrad زود خسته میشود (نارنجی)، Adadelta با گامهای حسابشده به یادگیری ادامه میدهد.
.
کاربردهای واقعی Adadelta
.
۱. پردازش زبان طبیعی (NLP) با دادههای بسیار پراکنده
در حوزهی NLP، کلمات با فرکانسهای بسیار متفاوتی ظاهر میشوند.

- مدلهای ترجمه ماشینی: در ترجمه متون، بسیاری از کلمات تخصصی یا نادر ممکن است گرادیانهای بسیار ضعیفی تولید کنند.
- نقش Adadelta: این بهینهساز از محو شدن نرخ یادگیری در این دادههای پراکنده جلوگیری میکند و اجازه میدهد مدل بدون نیاز به تنظیمات پیچیده، معنای کلمات کمیاب را نیز به خوبی یاد بگیرد.
.
۲. آموزش شبکههای عصبی عمیق در ابعاد بسیار بزرگ
زمانی که با مدلهایی با صدها میلیون پارامتر سروکار داریم، تنظیم نرخ یادگیری برای تکتک بخشها غیرممکن است.
- حذف خطای انسانی: Adadelta با حذف نرخ یادگیری اولیه (\eta)، ریسک انتخاب یک مقدار نامناسب که منجر به واگرایی مدل شود را از بین میبرد.
- پایداری: در آموزشهای طولانیمدت که ممکن است روزها طول بکشد، Adadelta به دلیل استفاده از پنجرهی زمانی متحرک، پایداری آموزش را تضمین کرده و از توقف زودهنگام یادگیری جلوگیری میکند.
.
۳. سیستمهای توصیهگر در مقیاس وسیع
در پلتفرمهایی که با میلیونها کاربر و کالا سروکار دارند، رفتار کاربران مدام در حال تغییر است.
- سازگاری با تغییرات زمانی :Adadelta به دلیل تمرکز بر تغییرات اخیر (به جای کل تاریخچه)، به خوبی با الگوهای جدید خرید یا علاقه کاربران سازگار میشود.
- نتیجه: این ویژگی باعث میشود مدلهای توصیهگر در مواجهه با دادههای غیرایستا (Non-stationary) که روند آنها در طول زمان تغییر میکند، عملکرد منعطفی داشته باشند.
.
۴. بینایی ماشین در شرایط نویزی
اگرچه امروزه Adam در بینایی ماشین پیشتاز است، اما Adadelta در سناریوهای خاصی همچنان کاربرد دارد.
- مقاومت در برابر نوسانات: در وظایفی مانند تشخیص اشیاء در ویدیوهای نویزی یا با کیفیت پایین، Adadelta با نرمسازی بهروزرسانیها، از نوسانات مخرب وزنها جلوگیری میکند.
.
مطالعه موردی ۱: ترجمه ماشینی در مقیاس جهانی (NMT)
چالش فنی: واژگان کمیاب و گرادیانهای محو شونده در سیستمهای ترجمه جهانی، مدل با میلیونها واژه از زبانهای مختلف سروکار دارد. کلمات متداول (مثل “is” یا “the”) مدام تکرار میشوند، اما کلمات تخصصی، اسامی خاص یا عبارات نادر (کلمات Long-tail) به ندرت ظاهر میشوند. در بهینهسازهای قدیمی، نرخ یادگیری برای کل مدل سریعاً کاهش مییافت و باعث میشد کلمات نادر پیش از آنکه مدل معنای آنها را یاد بگیرد، نادیده گرفته شوند.
نقش استراتژیک Adadelta: Adadelta با استفاده از پنجره زمانی متحرک، اثر گرادیانهای تکراری و قدیمی کلمات متداول را خنثی کرده و اجازه نمیدهد نرخ یادگیری به صفر میل کند. این موضوع باعث میشود که وقتی مدل پس از مدتها با یک کلمه نادر برخورد میکند، نرخ یادگیری همچنان زنده و کارآمد باشد. همچنین، به دلیل عدم نیاز به تنظیم دستی نرخ یادگیری اولیه، مدل در مواجهه با تنوع عظیم زبانی دچار واگرایی نمیشود.
دستاورد: بهبود کیفیت ترجمه برای متون تخصصی و ادبی و پایداری شبکه در آموزشهای طولانیمدت که ممکن است هفتهها بر روی ابررایانهها ادامه یابد.
.
پیادهسازی پایتون: شبیهسازی Adadelta در ترجمه کلمات نادر
در این کد، ما فرآیند یادگیری دو کلمه را شبیهسازی میکنیم: یکی بسیار پرتکرار و دیگری بسیار کمیاب (مانند یک اصطلاح تخصصی پزشکی). مشاهده خواهید کرد که Adadelta چگونه یادگیری را برای هر دو زنده نگه میدارد.
import numpy as np
import matplotlib.pyplot as plt
# ۱. تعریف کلاس Adadelta بر اساس مستندات فنی
class Adadelta:
def __init__(self, rho=0.95, eps=1e-6):
self.rho = rho
self.eps = eps
self.Eg2 = 0 # میانگین متحرک مجذور گرادیانها
self.Edx2 = 0 # میانگین متحرک مجذور بهروزرسانیها
def update(self, x, grad):
# انباشت مجذور گرادیان
self.Eg2 = self.rho * self.Eg2 + (1 - self.rho) * grad**2
# محاسبه RMSها
rms_dx = np.sqrt(self.Edx2 + self.eps)
rms_g = np.sqrt(self.Eg2 + self.eps)
# محاسبه مقدار تغییر (بدون نیاز به نرخ یادگیری اولیه)
dx = - (rms_dx / rms_g) * grad
# انباشت مجذور تغییرات برای گام بعدی
self.Edx2 = self.rho * self.Edx2 + (1 - self.rho) * dx**2
return x + dx
# ۲. شبیهسازی سناریوی ترجمه
iterations = 500
target = 0.8 # مقدار بهینه وزن برای درک صحیح کلمه
words_data = {
'Common Word': {'freq': 1.0, 'color': '#A9A9A9'}, # هر بار تکرار میشود
'Rare Word': {'freq': 0.05, 'color': '#D4AF37'} # فقط در ۵٪ مواقع ظاهر میشود
}
results = {word: [0.0] for word in words_data}
optimizers = {word: Adadelta() for word in words_data}
for i in range(iterations):
for word, info in words_data.items():
w = results[word][-1]
# شبیهسازی ظهور کلمه در متن
if np.random.rand() < info['freq']:
grad = -2 * (target - w) # گرادیان ساده تابع هزینه (MSE)
else:
grad = 0 # کلمه در این جمله نیست
new_w = optimizers[word].update(w, grad)
results[word].append(new_w)
# ۳. نمایش خروجی بصری
plt.figure(figsize=(12, 6))
for word, history in results.items():
plt.plot(history, label=word, color=words_data[word]['color'], linewidth=2)
plt.axhline(target, color='red', linestyle='--', label='Optimal Understanding')
plt.title('Adadelta in NMT: Learning Common vs Rare Words', fontsize=14)
plt.xlabel('Training Steps (Sentences)'); plt.ylabel('Learning Progress (Weight)')
plt.legend(); plt.grid(True, alpha=0.3); plt.show()
خروجی:
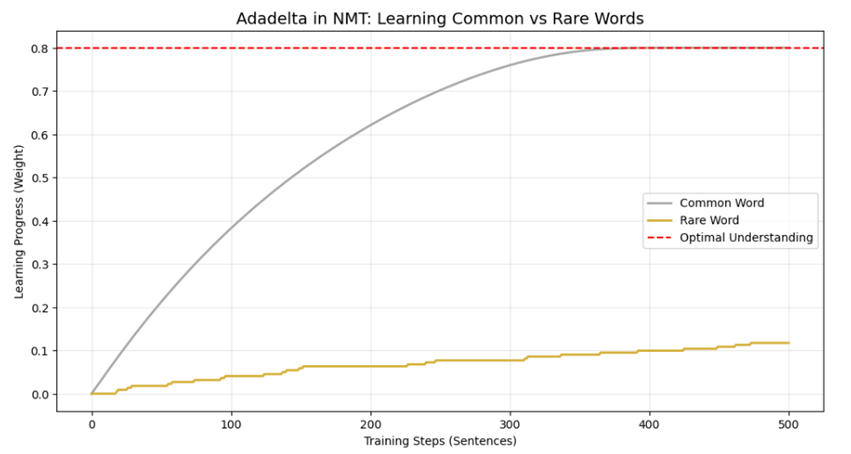
.
مطالعه موردی ۲: سیستمهای توصیهگر با دادههای متغیر (Dynamic Recsys)
چالش فنی: دادههای غیرایستا و تغییرات ناگهانی سلیقه در پلتفرمهای تجارت الکترونیک، سلیقه کاربران ثابت نیست. به عنوان مثال، با شروع یک فصل جدید یا اکران یک فیلم محبوب، ناگهان حجم عظیمی از دادههای جدید تولید میشود که با رفتارهای قبلی کاربر متفاوت است. بهینهسازهایی مانند AdaGrad که تمام تاریخچه گرادیانها را از ابتدا انباشته میکنند، به دلیل داشتن حافظه بسیار طولانی، نمیتوانند به سرعت خود را با این «تغییرات ناگهانی» وفق دهند و نرخ یادگیری آنها برای الگوهای جدید بسیار ناچیز است.
نقش استراتژیک Adadelta: Adadelta با استفاده از پنجره زمانی متحرک (Moving Window) به جای انباشت سادهی کل تاریخچه، تمرکز خود را بر روی تغییرات اخیر قرار میدهد. این ویژگی به مدل اجازه میدهد تا اثر رفتارهای قدیمی و منسوخ شده کاربر را حذف کرده و با سرعت بیشتری روی الگوهای جدید خرید تمرکز کند. همچنین، به دلیل حذف نیاز به تنظیم دستی نرخ یادگیری، مدل در مواجهه با نوسانات شدید دادهها در زمانهایی مانند «حراجهای بزرگ»، دچار ناپایداری نمیشود.
دستاورد: افزایش نرخ کلیک (CTR) و رضایت کاربران از طریق ارائهی پیشنهاداتی که با نیازهای فعلی آنها همخوانی دارد، حتی اگر این نیازها با سوابق یک سال گذشته آنها کاملاً متفاوت باشد.
.
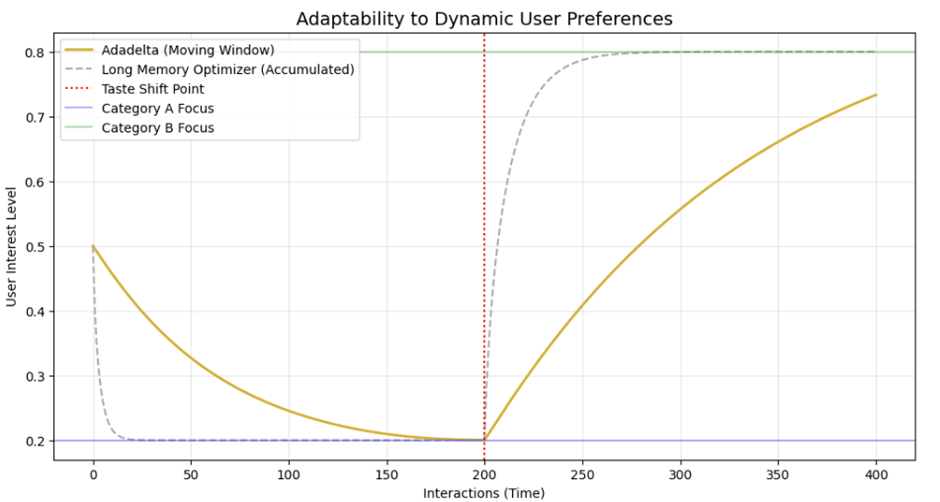
پیادهسازی پایتون: شبیهسازی Adadelta در مواجهه با تغییر ناگهانی سلیقه
در این کد، ما فرآیند یادگیری سلیقه یک کاربر را شبیهسازی میکنیم که ناگهان از یک دسته کالایی به دسته دیگری علاقمند میشود. مشاهده خواهید کرد که Adadelta چگونه به سرعت خود را با این تغییر (Concept Drift) وفق میدهد.
import numpy as np
import matplotlib.pyplot as plt
# تعریف کلاس Adadelta بر اساس الگوریتم دقیق
class AdadeltaOptimizer:
def __init__(self, rho=0.95, eps=1e-6):
self.rho = rho
self.eps = eps
self.Eg2 = 0 # میانگین متحرک مجذور گرادیانها
self.Edtheta2 = 0 # میانگین متحرک مجذور بهروزرسانیها
def update(self, theta, grad):
# ۱. انباشت مجذور گرادیان فعلی در پنجره متحرک
self.Eg2 = self.rho * self.Eg2 + (1 - self.rho) * grad**2
# ۲. محاسبه RMSها برای تعیین گام خودکار
rms_dtheta_prev = np.sqrt(self.Edtheta2 + self.eps)
rms_g_curr = np.sqrt(self.Eg2 + self.eps)
# ۳. محاسبه مقدار بهروزرسانی (بدون نیاز به نرخ یادگیری اولیه)
delta_theta = - (rms_dtheta_prev / rms_g_curr) * grad
# ۴. انباشت مجذور بهروزرسانیها برای گام بعدی
self.Edtheta2 = self.rho * self.Edtheta2 + (1 - self.rho) * delta_theta**2
return theta + delta_theta
# شبیهسازی تغییر ناگهانی سلیقه کاربر (Concept Drift)
steps = 400
change_point = 200 # نقطه تغییر سلیقه
target_1 = 0.2 # علاقه به کالای اول (مثلاً لوازم تحریر)
target_2 = 0.8 # تغییر ناگهانی علاقه به کالای دوم (مثلاً گجتهای هوشمند)
# مقداردهی اولیه برای Adadelta و یک بهینهساز با حافظه طولانی (شبیه AdaGrad ساده)
w_adadelta = 0.5
w_long_memory = 0.5
accumulated_g2 = 0
history_adadelta = [w_adadelta]
history_long_mem = [w_long_memory]
optimizer = AdadeltaOptimizer(rho=0.95)
for i in range(steps):
current_target = target_1 if i < change_point else target_2
# Adadelta Update
grad_adadelta = 2 * (w_adadelta - current_target)
w_adadelta = optimizer.update(w_adadelta, grad_adadelta)
history_adadelta.append(w_adadelta)
# Long Memory (AdaGrad-like) Update
grad_lm = 2 * (w_long_memory - current_target)
accumulated_g2 += grad_lm**2
# نرخ یادگیری ثابت 0.1 که توسط مجموع گرادیانها ضعیف میشود
w_long_memory = w_long_memory - (0.1 / np.sqrt(accumulated_g2 + 1e-6)) * grad_lm
history_long_mem.append(w_long_memory)
# نمایش خروجی بصری
plt.figure(figsize=(12, 6))
plt.plot(history_adadelta, label='Adadelta (Moving Window)', color='#D4AF37', linewidth=2)
plt.plot(history_long_mem, label='Long Memory Optimizer (Accumulated)', color='#A9A9A9', linestyle='--')
plt.axvline(change_point, color='red', linestyle=':', label='Taste Shift Point')
plt.axhline(target_1, color='blue', alpha=0.3, label='Category A Focus')
plt.axhline(target_2, color='green', alpha=0.3, label='Category B Focus')
plt.title('Adaptability to Dynamic User Preferences', fontsize=14)
plt.xlabel('Interactions (Time)'); plt.ylabel('User Interest Level')
plt.legend(); plt.grid(True, alpha=0.3); plt.show()
خروجی:
.
جدول مقایسهی Adadelta با بهینهسازهای مطرح
| ویژگی کلیدی | SGD + Momentum | AdaGrad | RMSProp | Adadelta | Adam |
| نرخ یادگیری | ثابت (دستی): نیازمند پایش مداوم و تنظیم دقیق گامهاست. | تطبیقی: نرخ را بر اساس شدت فعالیت هر پارامتر تنظیم میکند. | تطبیقی: از نوسانات شدید در مسیرهای تند جلوگیری میکند. | خودکار: نیاز به تنظیم دستی نرخ یادگیری اولیه را حذف کرده است. | تطبیقی: ترکیب هوشمندانه ممنتوم و مقیاسبندی لحظهای است. |
| مدیریت تاریخچه | ممنتوم: تمرکز بر جهت حرکت و عبور از کمینههای محلی دارد. | انباشت کل: تمام گرادیانهای گذشته را ذخیره و یادگیری را متوقف میکند. | میانگین متحرک: فقط نوسانات اخیر را برای پایداری در نظر میگیرد. | پنجره متحرک: با تمرکز بر بازه اخیر، اثر گرادیانهای قدیمی را حذف میکند. | ترکیبی: استفاده همزمان از دو گشتاور جهت و شدت برای هدایت دقیق. |
| حساسیت به η | بسیار بالا: خطای کوچک در انتخاب نرخ اولیه منجر به واگرایی میشود. | متوسط: نسبت به نرخ اولیه حساس است اما تا حدی منعطف عمل میکند. | بالا: همچنان نیازمند تنظیم دستی یک نرخ یادگیری کلی است. | صفر: نسبت به شرایط اولیه بسیار بخشنده و کاملاً خودران است. | متوسط: به تنظیمات ظریف پارامترهای اپسیلون و بتا نیاز دارد. |
| همگرایی | پایداری نهایی: در صورت تنظیم درست، بالاترین دقت تعمیم را دارد. | شروع سریع: در ابتدا پرقدرت اما در انتها دچار ایستایی میشود. | تعادل مناسب: سرعت خوب؛ بسیار محبوب برای شبکههای RNN. | پایداری بالا: کُند است اما در مسیرهای طولانی متوقف نمیشود. | سریعترین راه برای رسیدن به نقطه بهینه و استاندارد طلایی. |
| بهترین کاربرد | مدلهای پایدار و کلاسیک. | دادههای پراکنده و متنی (NLP). | دادههای غیرایستا و متغیر. | مدلهای غولآسا و آموزش طولانی. | اکثر پروژههای بینایی ماشین و NLP. |
.
مزایا
- خداحافظی با تنظیم دستی نرخ یادگیری (No Initial LR Required): بزرگترین جذابیت Adadelta این است که شما را از شر کلنجار رفتن با learning_rate نجات میدهد. این الگوریتم به صورت خودکار و پویا، نرخ یادگیری را برای هر پارامتر در طول آموزش تنظیم میکند. در حالی که در سایر روشها شما مدام بین ریسکِ پرش از روی نقطه بهینه (گام بلند) یا درجا زدن (گام کوتاه) سرگردان هستید، Adadelta این مسئولیت را از دوش شما برمیدارد تا تمرکزتان را روی معماری مدل بگذارید.
- عملکرد درخشان در مواجهه با دادههای پراکنده (Sparse Data): اگر با متون (NLP) یا سیستمهای توصیهگر کار کرده باشید، میدانید که گرادیانهای پراکنده چقدر چالشبرانگیز هستند Adadelta. برخلاف AdaGrad که نرخ یادگیری را خیلی تهاجمی کاهش میداد، از افتادن در تلهی آپدیتهای ناپدیدشونده جلوگیری میکند. این الگوریتم میداند کجا باید گام بلند بردارد و کجا احتیاط کند، که این موضوع آن را برای دادههای نامنظم به گزینهای ایدهآل تبدیل میکند.
- کاهش حساسیت به شرایط اولیه (Robust to Initialization): اگرچه مقداردهی اولیه همیشه مهم است، اما Adadelta به دلیل ماهیت تطبیقیاش، نسبت به مقادیر اولیه بسیار بخشندهتر عمل میکند. اگر شروعِ ایدهآلی نداشته باشید، الگوریتم به سرعت خودش را با روند آموزش وفق داده و اشتباهات اولیه را جبران میکند.
- پایداری در آموزشهای طولانی (Avoiding LR Vanishing): به دلیل استفاده از پنجره زمانی متحرک (Moving Window) به جای انباشت ساده تمام گرادیانهای گذشته، Adadelta اجازه نمیدهد نرخ یادگیری به قدری کوچک شود که آموزش متوقف گردد.
.
محدودیتها
- سرعت همگرایی (Convergence Speed): اینجاست که Adadelta کمی از رقبای مدرنتر عقب میماند. اگرچه این الگوریتم بسیار منعطف است، اما ممکن است به سرعتِ Adam یا RMSProp به دقت مطلوب نرسد. در پروژههایی که زمان و سرعت آموزش حیاتی است، Adadelta ممکن است شما را منتظر بگذارد.
- پیچیدگی محاسباتی و سربار حافظه Adadelta: نیاز دارد میانگین متحرک نمایی (EMA) را هم برای مجذور گرادیانها و هم برای مجذور بهروزرسانیهای پارامتر ذخیره کند. این یعنی برای هر پارامتر، دو متغیر حافظهی اضافی مصرف میشود که در مدلهای غولآسا میتواند سربار حافظه را افزایش دهد.
- عدم وجود ممنتوم کلاسیک: در حالی که Adadelta نوعی پویایی در خود دارد، اما فاقد ممنتوم به معنای سنتی آن است که در SGD دیده میشود. این موضوع گاهی باعث میشود در فرار از نقاط زینی (Saddle Points) در سطوح هزینهی بسیار پیچیده، ضعیفتر از Adam عمل کند.
- عدم قطعیت در بهینگی مطلق: گاهی اوقات تطبیقپذیری بیش از حد باعث میشود که الگوریتم در نزدیکی نقطه بهینه دچار نوسان شود یا نتواند به اندازه روشهایی که نرخ یادگیریشان به صورت دستی و دقیق تنظیم شده (Schedules)، به کمینهی مطلق برسد.
.
جمع بندی
Adadelta یکی از بهینهسازهای تطبیقی است که با هدف رفع محدودیتهای AdaGrad و کاهش وابستگی به نرخ یادگیری ثابت توسعه داده شد. این روش با استفاده از میانگینهای متحرک نمایی، از کاهش نامحدود نرخ یادگیری جلوگیری میکند و امکان ادامهی یادگیری در آموزشهای طولانیمدت را فراهم میسازد. در این مطلب دیدیم که این ویژگی چگونه میتواند در برخی مسائل یادگیری عمیق، به پایداری بیشتر فرآیند آموزش کمک کند.
با این حال، بررسی دقیقتر نشان میدهد که Adadelta نیز یک راهحل همهمنظوره نیست. اگرچه این الگوریتم نیاز به تنظیم نرخ یادگیری را کاهش میدهد، اما در بسیاری از معماریهای عمیق امروزی، بهینهسازهایی مانند Adam یا AdamW عملکرد عملی بهتری از نظر سرعت همگرایی و تعمیم ارائه میدهند. به همین دلیل، استفاده از Adadelta بیشتر به سناریوهای خاصی محدود میشود که در آنها پایداری آموزش و سازگاری با تغییرات تدریجی داده اهمیت بیشتری دارد.
در عمل، Adadelta را میتوان بهعنوان یک گام مهم در تکامل بهینهسازهای تطبیقی در نظر گرفت. درک سازوکار این روش به مهندس یادگیری عمیق کمک میکند تا منطق طراحی بهینهسازهای مدرن را بهتر بفهمد و انتخاب آگاهانهتری میان گزینههای مختلف، متناسب با ویژگیهای داده و معماری شبکه، انجام دهد.



