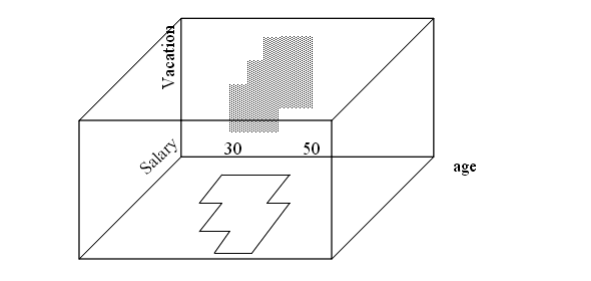
شناساییخودکارزیرفضاهاییکفضایدادهباابعادبالاکهامکانخوشهبندیبهترازفضایاصلیرافراهممیکند . CLIQUE (Clustering in QUEst) اولینالگوریتمپیشنهادی بود برای خوشه بندیزیرفضای رشد ابعاد در فضایبا ابعاد بالااز زیرفضاهایتکبعدی شروع کنیدو به سمت فضاهایبا ابعاد بالاتر رشد کنید . CLIQUE هر بعد را مانندیکساختارشبکهایپارتیشنبندیمیکند و چگالییک سلول را بر اساس تعداد نقاط آن تعیینمیکند . CLIQUE ادغام روش هایمبتنی بر شبکه و مبتنی بر چگالی است
فضایداده d بعدیرابهواحدهایمستطیلیغیرهمپوشانیتقسیمکنید (برایهرپارتیشنبهصورت 1-D انجاممیشود)واحدهایمتراکمراشناساییکنید . یکواحدمتراکماستاگرکسریازکلنقاطدادهموجوددرآنازپارامترمدلورودیبیشترشود.
from pyclustering.cluster.clique import clique, clique_visualizer
from pyclustering.utils import read_sample
from pyclustering.samples.definitions import FCPS_SAMPLES
# read two-dimensional input data 'Target'
data = read_sample(FCPS_SAMPLES.SAMPLE_TARGET)
# create CLIQUE algorithm for processing
intervals = 10 # defines amount of cells in grid in each dimension
threshold = 0 # lets consider each point as non-outlier
clique_instance = clique(data, intervals, threshold)
# start clustering process and obtain results
clique_instance.process()
clusters = clique_instance.get_clusters() # allocated clusters
noise = clique_instance.get_noise() # points that are considered as outliers (in this example should be empty)
cells = clique_instance.get_cells() # CLIQUE blocks that forms grid
print("Amount of clusters:", len(clusters))
# visualize clustering results
clique_visualizer.show_grid(cells, data) # show grid that has been formed by the algorithm
clique_visualizer.show_clusters(data, clusters, noise) # show clustering results
intervals = 10
threshold = 3 # block that contains 3 or less points is considered as a outlier as well as its points
clique_instance = clique(data, intervals, threshold)