

مقدمه
در بسیاری از مسائل دنیای واقعی، سیستمها نهتنها باید تصمیم بگیرند، بلکه باید پیامد تصمیمهای خود را تجربه کنند و از آنها یاد بگیرند. برخلاف روشهای کلاسیک یادگیری ماشین که بر دادههای از پیش آماده تکیه دارند، در این نوع مسائل، یادگیری از طریق تعامل مستقیم با محیط اتفاق میافتد. این دقیقاً همان نقطهای است که یادگیری تقویتی (Reinforcement Learning) معنا پیدا میکند.
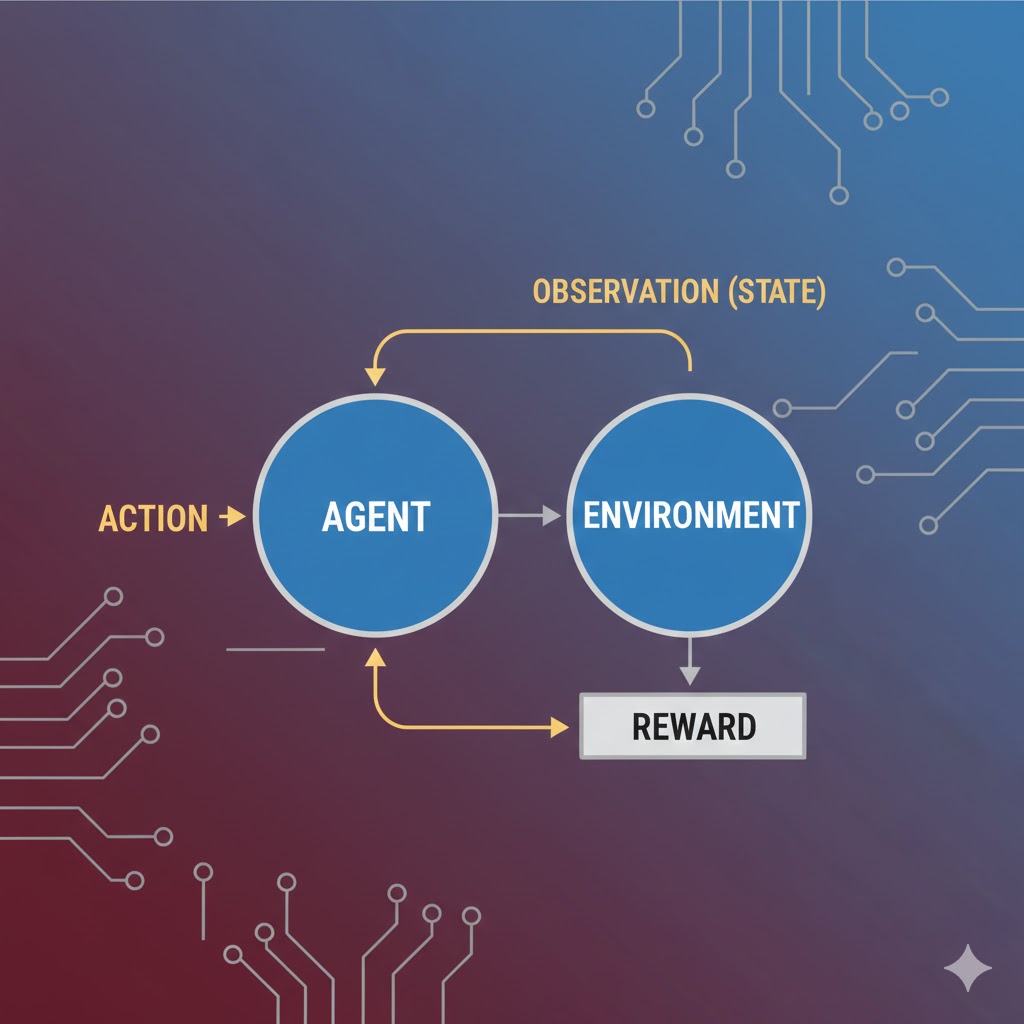
یادگیری تقویتی رویکردی از یادگیری ماشین است که در آن یک عامل (Agent) با انجام عملها (Actions) در یک محیط (Environment) و دریافت پاداش یا جریمه (Reward)، بهتدریج یاد میگیرد چگونه بهترین تصمیمها را برای رسیدن به بیشترین پاداش بلندمدت اتخاذ کند. این نوع یادگیری پایهی بسیاری از پیشرفتهای مهم هوش مصنوعی، از بازیهای هوشمند و رباتیک گرفته تا خودروهای خودران و سیستمهای تصمیمیار پیشرفته است.
در این مقاله، با مفهوم یادگیری تقویتی، اجزای اصلی آن، نحوه عملکرد، الگوریتمهای مهم و کاربردهای واقعی این رویکرد آشنا میشویم تا درک روشنی از نقش آن در حل مسائل تصمیمگیری پیچیده به دست آوریم.
تعریف
یادگیری تقویتی (RL) نوعی فرآیند یادگیری ماشین است که در آن عاملهای خودگردان یاد میگیرند که چگونه با تعامل با محیط اطرافشان، تصمیمگیری کنند.
عامل خودگردان چیست؟
یک عامل خودگردان (Autonomous Agent) به هر سیستمی گفته میشود که میتواند مستقل از دستورات مستقیم انسان، تصمیم بگیرد و در پاسخ به محیط خود عمل کند. رباتها و خودروهای خودران، مثالهای بارزی از این عاملها هستند.
در یادگیری تقویتی، این عاملها یاد میگیرند که یک وظیفه را از طریق آزمون و خطا و بدون هیچگونه راهنمایی از سمت کاربر انسانی انجام دهند. این روش بهویژه برای حل مسائلِ تصمیمگیری متوالی در محیطهای نامشخص طراحی شده و نویدبخش پیشرفتهای بزرگ در توسعه هوش مصنوعی است.
مثال (آموزش حیوان خانگی):
یادگیری تقویتی دقیقاً شبیه آموزش دادن به یک سگ است. شما به سگ نمیگویید چطور بنشیند (دستور مستقیم نمیدهید)؛ بلکه وقتی خودش شانسی نشست، به او تشویقی میدهید (پاداش). اگر گاز گرفت، او را دعوا میکنید (جریمه). سگ با تکرار این چرخه یاد میگیرد چه کاری پاداش دارد.
مقایسه با یادگیری نظارتشده و نظارتنشده
در متون علمی، اغلب یادگیری تقویتی را با دو روش دیگر مقایسه میکنند:
- یادگیری نظارتشده: از دادههای برچسبدار دستی استفاده میکند تا پیشبینی یا طبقهبندی انجام دهد.
- یادگیری نظارتنشده: هدفش کشف و یادگیری الگوهای پنهان از دادههای بدون برچسب است.
در مقابل، یادگیری تقویتی از مثالهای برچسبدارِ رفتار درست یا غلط استفاده نمیکند. تفاوت مهم دیگر این است که یادگیری تقویتی به جای استخراج الگوهای پنهان، از طریق آزمون و خطا و تابع پاداش یاد میگیرد.
تفاوت در ساختار دادهها
- روشهای نظارتشده/نشده: فرض میکنند که هر رکورد داده از بقیه مستقل است (مثل عکسهای جداگانه در یک آلبوم). هدف آنها بهینهسازی دقت پیشبینی است.
- یادگیری تقویتی: یاد میگیرد که عمل کند. این روش فرض میکند که دادهها به صورت تاپلهای وابسته (زنجیرهای از دادهها) هستند که به صورت حالت-اقدام-پاداش (State-Action-Reward) سازماندهی شدهاند.
بسیاری از کاربردهای این الگوریتمها با هدف تقلید از روشهای یادگیری بیولوژیکی در دنیای واقعی (از طریق تقویت مثبت) طراحی شدهاند.
نکته ظریف: تفاوت با یادگیری خودنظارتشده
اگرچه این دو کمتر با هم مقایسه میشوند، اما یادگیری تقویتی با یادگیری خودنظارتشده نیز متفاوت است.
- یادگیری خودنظارتشده: نوعی یادگیری نظارتنشده است که از شبهبرچسبهای مشتق شده از دادههای آموزشی (به عنوان حقیقت مبنا) برای سنجش دقت مدل استفاده میکند.
- یادگیری تقویتی: شبهبرچسب تولید نمیکند و با یک حقیقت مبنا (Ground Truth) سنجیده نمیشود؛ زیرا یک روش طبقهبندی نیست، بلکه یک یادگیرنده عملگرا است.
با این حال، ترکیب این دو روش نتایج امیدوارکنندهای را نشان داده است.
فرآیند یادگیری تقویتی (Reinforcement Learning Process)
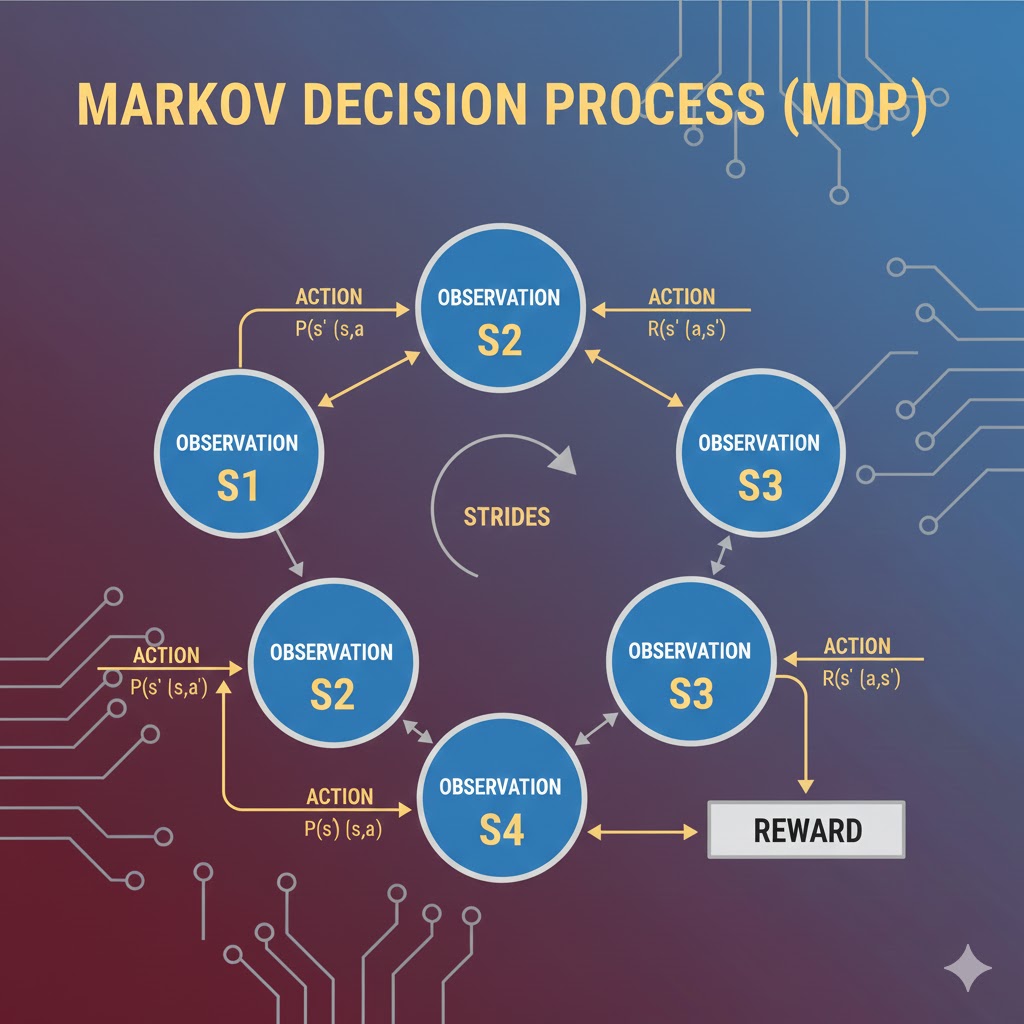
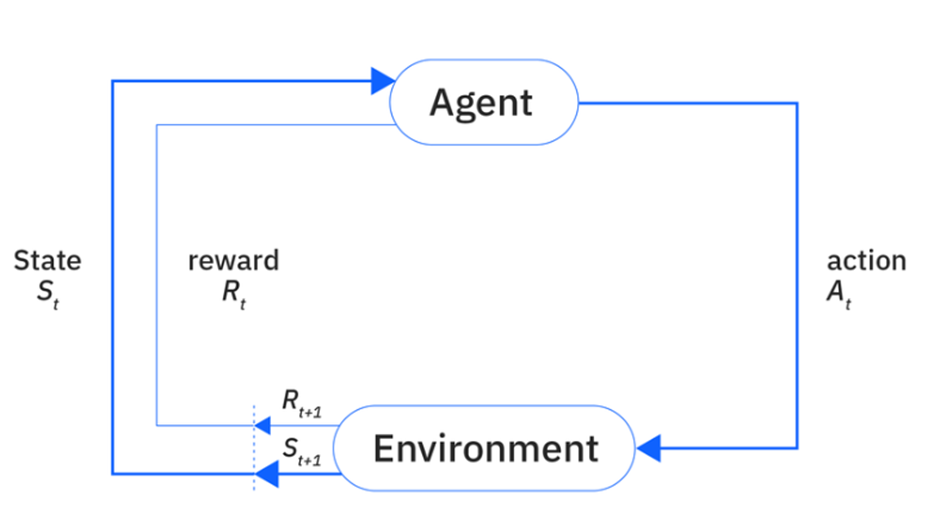
یادگیری تقویتی در اصل از رابطه و تعامل میان سه رکن اصلی تشکیل شده است: عامل (Agent)، محیط (Environment) و هدف. در ادبیات علمی، این رابطه را معمولاً در قالب چارچوبی ریاضی به نام فرآیند تصمیمگیری مارکوف (MDP) فرمولبندی میکنند.
فرآیند تصمیمگیری مارکوف (MDP)
در این فرآیند، عاملِ یادگیری تقویتی با تعامل مستقیم با محیط، درباره یک مسئله یاد میگیرد. این چرخه به صورت زیر عمل میکند:
- مشاهده وضعیت: محیط اطلاعاتی درباره وضعیت فعلی خود را به عامل ارائه میدهد.
- انتخاب اقدام: عامل از آن اطلاعات استفاده میکند تا تصمیم بگیرد چه اقدامی (Action) باید انجام دهد.
- دریافت بازخورد: اگر آن اقدام منجر به دریافت یک سیگنال پاداش (Reward Signal) از محیط شود، عامل تشویق میشود که در آینده وقتی در وضعیت مشابهی قرار گرفت، دوباره همان اقدام را انجام دهد.
- تکرار و یادگیری: این فرآیند برای هر وضعیت جدیدی که پیش میآید، تکرار میشود.
در طول زمان، عامل از طریق این سیستم پاداش و تنبیه یاد میگیرد که اقداماتی را در محیط انجام دهد که او را به هدف مشخصشده برسانند (یعنی پاداش را به حداکثر برسانند).
مطالعه موردی: جاروبرقی هوشمند (Robot Vacuum)
برای اینکه این فرآیند انتزاعی را بهتر درک کنیم، بیایید یک جاروبرقی رباتیک را تصور کنیم که میخواهد یاد بگیرد چگونه خانه را تمیز کند بدون اینکه شارژش تمام شود یا گیر کند.
- عامل (Agent): خودِ جاروبرقی رباتیک.
- محیط (Environment): اتاق پذیرایی با تمام مبلها و دیوارها.
- هدف (Goal): تمیز کردن بیشترین مساحت ممکن.
چرخه یادگیری (MDP) در عمل:
- وضعیت (State): ربات سنسورهایش را چک میکند: “من جلوی دیوار هستم و سمت راستم کثیف است.”
- اقدام (Action): ربات تصمیم میگیرد: “به سمت راست بپیچم.”
- پاداش (Reward): ربات آشغالها را جمع میکند (+۱۰ امتیاز پاداش).
- وضعیت بعدی: حالا ربات جلوی پلههاست.
- اقدام اشتباه: ربات جلو میرود و سقوط میکند.
- تنبیه(Punishment): ربات ضربه میخورد و متوقف میشود (-۵۰ امتیاز جریمه).
نتیجه: دفعه بعد که ربات در وضعیت “جلوی پله” قرار بگیرد، به یاد میآورد که اقدام “جلو رفتن” جریمه سنگینی داشت، پس این بار “توقف و چرخش” را انتخاب میکند. این دقیقاً همان یادگیری از طریق آزمون و خطا است.
مفاهیم کلیدی: فضای حالت و فضای اقدام
در فرآیند تصمیمگیری مارکوف، دو مفهوم پایهای وجود دارد:
- فضای حالت (State Space): به تمام اطلاعاتی اشاره دارد که توسط وضعیتِ فعلی محیط ارائه میشود.
- فضای اقدام (Action Space): نشاندهنده تمام اقدامات ممکنی است که عامل میتواند در آن وضعیت خاص انجام دهد.
چالش تعادل: اکتشاف در برابر بهرهبرداری (Exploration-Exploitation)
از آنجا که یک عامل یادگیری تقویتی (RL) هیچ داده ورودیِ برچسبدار دستی ندارد که رفتارش را هدایت کند، مجبور است محیط خود را کاوش (Explore) کند و اقدامات جدیدی را امتحان نماید تا کشف کند کدامیک پاداش دریافت میکنند.
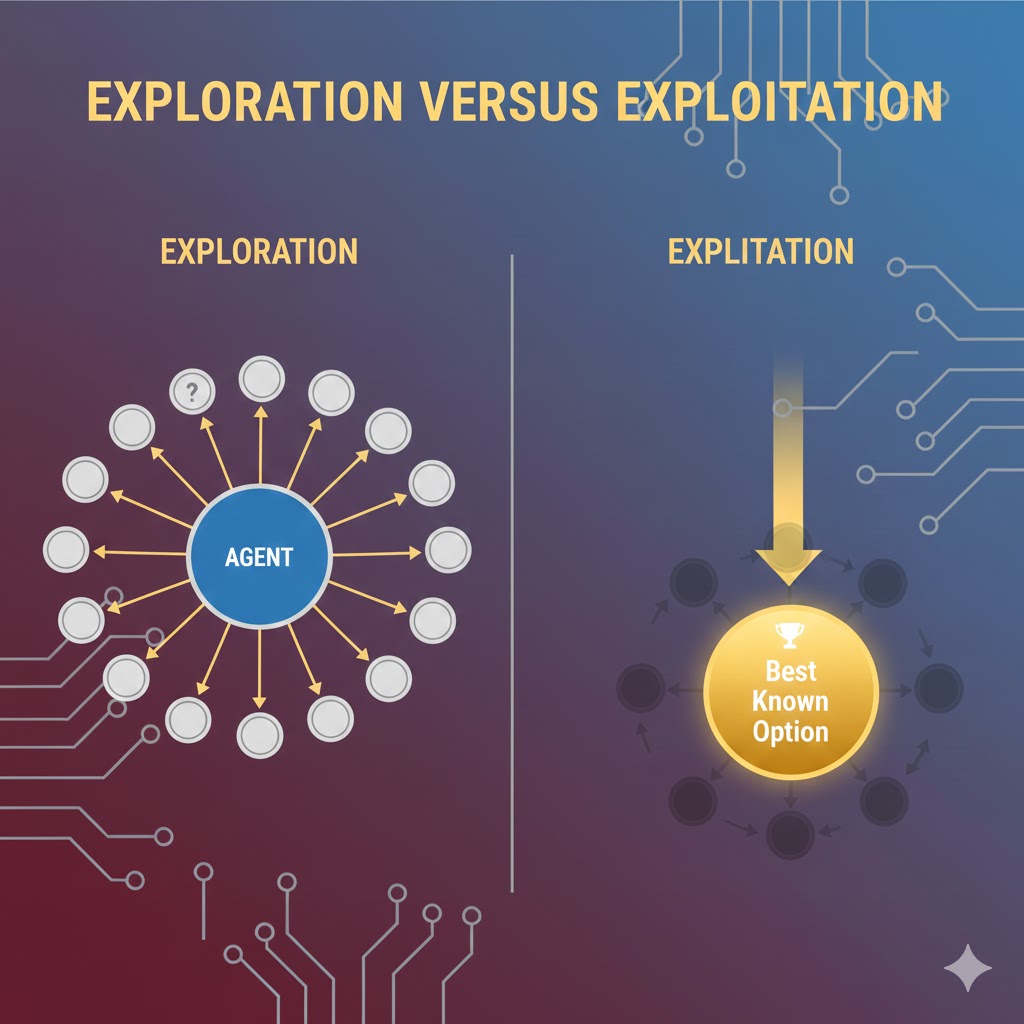
از طریق این سیگنالهای پاداش، عامل یاد میگیرد که اقداماتی را ترجیح دهد که قبلاً بابت آنها پاداش گرفته است تا سود خود را به حداکثر برساند (این یعنی بهرهبرداری). اما عامل باید همزمان به کاوش وضعیتها و اقدامات جدید نیز ادامه دهد. با انجام این کار، عامل میتواند از آن تجربیات جدید برای بهبود تصمیمگیری خود استفاده کند.
بنابراین، الگوریتمهای RL نیازمند عاملی هستند که هم از دانشِ اقداماتِ پاداشدهندهی قبلی بهرهبرداری (Exploit) کند و هم سایر وضعیتها و اقدامات را کاوش (Explore) نماید.
مثال رستوران: این دقیقاً مثل انتخاب رستوران است:
- بهرهبرداری: رفتن به رستوران همیشگی که میدانید غذایش خوب است (پاداش مطمئن).
- اکتشاف: رفتن به یک رستوران جدید که شاید غذایش فوقالعاده باشد یا شاید هم بد باشد (ریسک برای پاداش احتمالی بهتر). عامل نمیتواند منحصراً فقط اکتشاف یا فقط بهرهبرداری کند؛ بلکه باید دائماً اقدامات جدید را امتحان کند و در عین حال اقداماتی (یا زنجیرهای از اقدامات) را ترجیح دهد که بیشترین پاداش تجمعی را تولید میکنند.
چهار رکن اصلی یادگیری تقویتی (Components of RL)
فراتر از مثلثِ عامل-محیط-هدف، چهار زیرمجموعه اصلی وجود دارند که مسائل یادگیری تقویتی را مشخص میکنند:
۱. سیاست (Policy)
این بخش، رفتار عامل RL را تعریف میکند. سیاست، نقشهای است که وضعیتهای درک شده از محیط را به اقدامات خاصی که عامل باید در آن وضعیتها انجام دهد، وصل میکند.
- فرم: میتواند یک تابع ساده و ابتدایی باشد یا یک فرآیند محاسباتی پیچیده.
- مثال: سیاستی که یک خودروی خودران را هدایت میکند، ممکن است تشخیص عابر پیاده (وضعیت) را به اقدام توقف (اقدام) وصل کند.
۲. سیگنال پاداش (Reward Signal)
این عنصر، هدفِ مسئله یادگیری تقویتی را تعیین میکند. هر یک از اقدامات عامل، یا از محیط پاداش میگیرد یا نمیگیرد. تنها هدف عامل این است که مجموع پاداشهای خود از محیط را به حداکثر برساند.
- مثال خودروی خودران: سیگنال پاداش میتواند شامل موارد زیر باشد: کاهش زمان سفر، کاهش تصادفات، ماندن در جاده و خط صحیح، و اجتناب از ترمز یا شتابگیریهای شدید. این مثال نشان میدهد که RL میتواند چندین سیگنال پاداش را برای هدایت یک عامل ترکیب کند.
۳. تابع ارزش (Value Function)
تفاوت پاداش (reward) با تابع ارزش (value function) در این است که پاداش، سود فوریِ دریافتی در یک گذار است، در حالی که تابع ارزش، سودِ بلندمدتِ مورد انتظار را از یک وضعیت (یا جفت وضعیت-عمل) با در نظر گرفتن سیاست عامل و سودهای آتیِ تنزیلشده (discounted future rewards) مشخص میکند.
مثال استراتژیک: یک خودروی خودران ممکن است بتواند با خارج شدن از خط خود، رانندگی در پیادهرو و شتابگیری سریع، زمان سفر را کاهش دهد (پاداش فوری بالا). اما این سه اقدام ممکن است تابع ارزش کلی آن را کاهش دهند (تصادف، جریمه، خطر). بنابراین، خودرو به عنوان یک عامل RL ممکن است زمان سفرِ کمی طولانیتر را بپذیرد تا پاداش خود را در آن سه حوزه دیگر (ایمنی و قانون) افزایش دهد.
۴. مدل (Model)
این یک زیرمجموعه اختیاری در سیستمهای یادگیری تقویتی است. مدلها به عاملها اجازه میدهند تا رفتار محیط را در قبال اقدامات احتمالی پیشبینی کنند. عاملها سپس از پیشبینیهای مدل استفاده میکنند تا مسیرهای احتمالی اقدام را بر اساس نتایج بالقوه تعیین کنند.
- کاربرد: این میتواند مدلی باشد که خودروی خودران را هدایت میکند و به آن کمک میکند تا بهترین مسیرها را پیشبینی کند یا با توجه به موقعیت و سرعت خودروهای اطراف، رفتار آنها را حدس بزند. برخی رویکردهای مبتنی بر مدل (Model-based)، در یادگیری اولیه از بازخورد مستقیم انسانی استفاده میکنند و سپس به یادگیری خودگردان تغییر وضعیت میدهند.
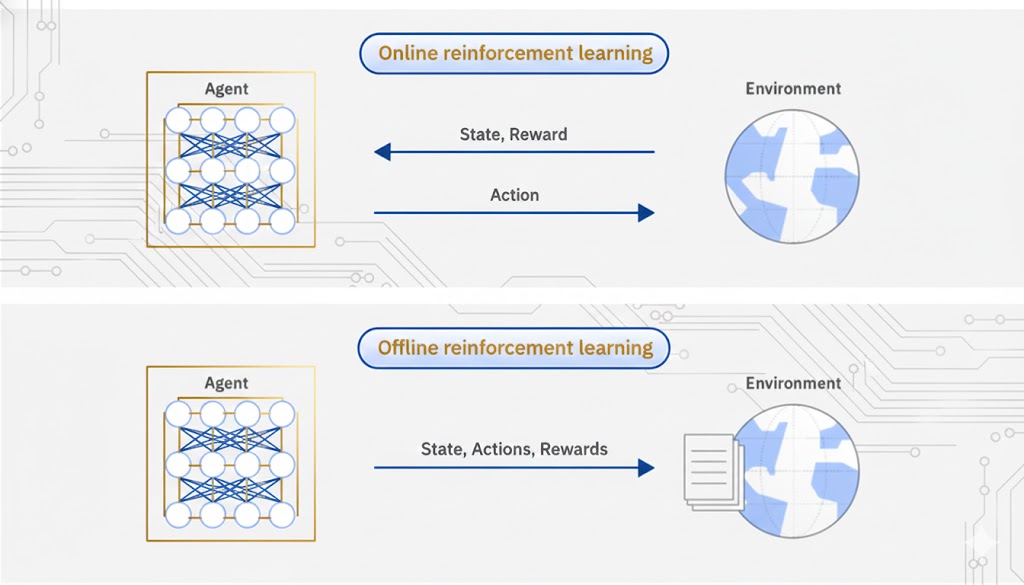
یادگیری آنلاین در برابر یادگیری آفلاین (Online versus offline learning)
دو روش کلی وجود دارد که یک عامل (Agent) از طریق آنها دادههای لازم برای یادگیری سیاستها (Policies) را جمعآوری میکند:
۱. یادگیری آنلاین (Online Learning)
در این روش، عامل دادهها را مستقیماً از طریق تعامل با محیط اطرافش جمعآوری میکند. همزمان که عامل به تعامل با آن محیط ادامه میدهد، این دادهها به صورت تکرارشونده (Iterative) پردازش و جمعآوری میشوند.
مثال (ربات راهرو): تصور کنید یک ربات انساننما را در اتاق رها میکنید تا راه رفتن را یاد بگیرد.
- ربات قدم برمیدارد، تعادلش را از دست میدهد و میافتد.
- در همان لحظه (Real-time) از این شکست درس میگیرد و در قدم بعدی زاویه پایش را اصلاح میکند.
- این یادگیری آنلاین است؛ چون یادگیری در حین “انجام دادن” اتفاق میافتد.
۲. یادگیری آفلاین (Offline Learning)
زمانی که عامل دسترسی مستقیم به محیط ندارد (یا تعامل مستقیم خطرناک/گران است)، میتواند از طریق دادههای ثبتشده (Logged Data) از آن محیط یاد بگیرد. به این روش، یادگیری آفلاین میگویند.
بخش بزرگی از تحقیقات اخیر به سمت یادگیری آفلاین متمایل شده است؛ که دلیل آن، دشواریهای عملیِ آموزش مدلها از طریق تعامل مستقیم با محیطهای واقعی است.
مثال (پزشکی و سلامت): ما نمیتوانیم یک هوش مصنوعی را مستقیماً روی بیماران واقعی تست کنیم تا با روش “آزمون و خطا” یاد بگیرد چه دارویی تجویز کند (چون ممکن است بیمار آسیب ببیند).
- راهکار: ما سوابق پزشکی ۱۰ سال گذشته و نتایج درمانهای قبلی (دادههای لاگ شده) را به مدل میدهیم.
- مدل با مطالعه این پروندههای قدیمی و بدون دسترسی به بیمار زنده، یاد میگیرد که بهترین استراتژی درمان چیست.
انواع روشهای یادگیری تقویتی (Types of Reinforcement Learning)
یادگیری تقویتی (RL) یک حوزه پژوهشی بسیار پویا و در حال تکامل است و به همین دلیل، توسعهدهندگان رویکردهای بیشماری برای آن ابداع کردهاند. با این حال، سه روش بنیادین و پربحث در این حوزه وجود دارد که ستونهای اصلی را تشکیل میدهند: برنامهریزی پویا (Dynamic Programming)، مونت کارلو (Monte Carlo) و یادگیری تفاوت زمانی (Temporal Difference).
در اینجا به بررسی اولین و یکی از ریاضیاتیترین روشها میپردازیم.
۱. برنامهریزی پویا (Dynamic Programming)
برنامهریزی پویا (DP) هنرِ تقسیم و غلبه است. این روش وظایف بزرگ و پیچیده را به وظایف کوچکتر و قابلحل میشکند.
مدلسازی مسئله
در این رویکرد، مسائل به صورت یک جریان کاری (Workflow) از تصمیمات متوالی مدلسازی میشوند که در گامهای زمانی گسسته اتخاذ میگردند. یعنی زمان پیوسته نیست، بلکه لحظه ۱، لحظه ۲ و… داریم.
نکته کلیدی اینجاست که هر تصمیم با در نظر گرفتن حالت احتمالی بعدی گرفته میشود. یعنی عامل فقط به جلوی پایش نگاه نمیکند، بلکه محاسبه میکند که اگر این کار را انجام دهم، دقیقاً به چه وضعیتی خواهم رفت.
معادله پاداش (The Reward Function)
پاداش عامل (r) برای انجام یک اقدام خاص، به عنوان تابعی از سه متغیر تعریف میشود:
- اقدام انجام شده (a): کاری که عامل انجام داده است (مثلاً حرکت به راست).
- حالت فعلی محیط (s): جایی که عامل الان هست (مثلاً خانه شماره ۱).
- حالت بعدی بالقوه (s’): جایی که عامل بعد از اقدام به آنجا میرسد (مثلاً خانه شماره ۲).
فرمول ساده آن به این صورت است:

معادله بلمن و جستجو برای سیاست بهینه
این تابع پاداش (که در بخش قبلی توضیح داده شد) میتواند به عنوان بخشی از سیاست (Policy) یا همان قانونی که اقدامات عامل را کنترل میکند، استفاده شود.
در واقع، قلب تپنده و مولفه اصلی روشهای برنامهریزی پویا (Dynamic Programming) در یادگیری تقویتی، تعیین سیاست بهینه برای رفتار عامل است. یعنی پیدا کردن بهترین نقشه راهی که در هر وضعیتی، بهترین تصمیم ممکن را به عامل دیکته کند.
اینجاست که پای شاهکلیدِ ماجرا به میان میآید: معادله بلمن .
معادله بلمن چیست؟
معادله بلمن یک رابطه بازگشتی (Recursive) قدرتمند است که ارزش یک وضعیت را به ارزش وضعیتهای بعدی پیوند میدهد. فرمول کلی آن به صورت زیر است:

که در آن:
- V(s): ارزش وضعیت فعلی است (چقدر خوب است که الان اینجا باشیم).
- max_a: یعنی انتخاب اقدامی (a) که بیشترین سود را داشته باشد (بهینهسازی).
- R(s,a): پاداش فوری است که همین الان برای انجام اقدام دریافت میکنیم.
- γ (گاما): ضریب تخفیف است (چقدر به آینده اهمیت میدهیم).
- V(s’): ارزش وضعیتی است که بعد از انجام کار به آنجا میرسیم (آینده).
💡 تفسیر انسانی (مثال شطرنج):
معادله بلمن به زبان ساده میگوید:
ارزشِ حرکتِ الانِ من برابر است با:
۱. چیزی که همین لحظه به دست میآورم (مثلاً زدن سرباز حریف) بهعلاوه
۲. بهترین موقعیتی که این حرکت برای من در آینده ایجاد میکند (شانس مات کردن در ۵ حرکت بعد).
این معادله به عامل کمک میکند تا فقط نوک بینیاش را نبیند و با نگاه به آینده، بهترین سیاست را انتخاب کند.
معادله بلمن: نگاهی به آینده (The Bellman Equation)
به طور خلاصه، این معادله v_t(s) را به عنوان مجموع پاداش مورد انتظار تعریف میکند که از زمان t شروع شده و تا پایان یک جریان کاری تصمیمگیری ادامه دارد.
- فرض: عامل در زمان t در حالت s قرار دارد.
- تقسیم پاداش: معادله در نهایت پاداش زمان t را به دو بخش تقسیم میکند:
- پاداش فوری r_t(s,a): همان چیزی که در فرمول پاداش محاسبه میشود.
- پاداش مورد انتظارِ کل: ارزشی که عامل انتظار دارد در آینده کسب کند.
بنابراین، یک عامل با انتخاب مداومِ اقدامی که در هر حالت سیگنال پاداش دریافت میکند، تابع ارزش خود (که همان ارزش کل معادله بلمن است) را به حداکثر میرساند.
۲. روش مونت کارلو (Monte Carlo Method)
در حالی که برنامهریزی پویا (DP) مبتنی بر مدل (Model-based) است—یعنی مدلی از محیط خود میسازد تا پاداشها را درک کند، الگوها را شناسایی کرده و در محیط پیمایش کند—روش مونت کارلو محیط را یک جعبه سیاه فرض میکند و به همین دلیل بدون مدل (Model-free) است.
تفاوتهای کلیدی با برنامهریزی پویا:
- تجربه به جای پیشبینی: برنامهریزی پویا حالتهای آینده و سیگنالهای پاداش را پیشبینی میکند، اما روشهای مونت کارلو منحصراً مبتنی بر تجربه هستند. این یعنی آنها توالیهایی از حالتها، اقدامات و پاداشها را صرفاً از طریق تعامل مستقیم با محیط نمونهبرداری میکنند.
تفسیر: مونت کارلو به جای حل معادلات احتمالی روی کاغذ، از طریق آزمون و خطا یاد میگیرد.
- نحوه محاسبه ارزش: برنامهریزی پویا به دنبال بزرگترین پاداش تجمعی با انتخاب مداوم اقدامات پاداشدهنده در حالتهای پیدرپی است. اما مونت کارلو، بازدهها را برای هر جفتِ حالت-اقدام میانگینگیری میکند.
- زمانبندی بهروزرسانی: این تفاوت میانگینگیری به این معناست که روش مونت کارلو باید صبر کند تا تمام اقدامات در یک اپیزود (یا افق برنامهریزی) تکمیل شود، و تنها پس از پایان بازی است که میتواند تابع ارزش خود را محاسبه کرده و سیاستش را بهروزرسانی کند.
مثال بازی شطرنج:
- برنامهریزی پویا: در هر حرکت، تمام احتمالات حرکتهای بعدی را محاسبه میکند (مثل یک استاد بزرگ).
- مونت کارلو: بازی را تا آخر انجام میدهد. اگر برد، به تمام حرکتهایی که در طول بازی انجام داده بود امتیاز مثبت میدهد. اگر باخت، امتیاز منفی میدهد. او فقط در “پایان بازی” یاد میگیرد.
۳. یادگیری تفاوت زمانی (Temporal Difference – TD)
در ادبیات علمی، یادگیری تفاوت زمانی (TD) اغلب به عنوان ترکیبی هوشمندانه از برنامهریزی پویا و مونت کارلو توصیف میشود.
- شباهت به DP: مانند برنامهریزی پویا، روش TD سیاست خود (و برآوردهایش برای حالتهای آینده) را بعد از هر گام بهروزرسانی میکند و منتظر مقدار نهایی (پایان اپیزود) نمیماند.
- شباهت به MC: مانند مونت کارلو، TD از طریق تعامل خام با محیط یاد میگیرد و نیازی به داشتن مدل از محیط ندارد.
مکانیزم “تفاوت” در TD
همانطور که از نامش پیداست، عامل یادگیری TD سیاست خود را بر اساس تفاوت بین پاداش پیشبینی شده و پاداش واقعی دریافت شده در هر حالت اصلاح میکند.
- در حالی که DP و MC فقط پاداش دریافت شده را در نظر میگیرند، TD تفاوت بین انتظار خود و پاداش دریافتی را وزندهی میکند.
- با استفاده از این تفاوت، عامل تخمینهای خود را برای گام بعدی بهروز میکند، بدون اینکه منتظر پایان افق برنامهریزی (مثل مونت کارلو) بماند.
مثال رانندگی:
روش TD مثل رانندگی است که شما فرمان را لحظه به لحظه اصلاح میکنید. اگر کمی منحرف شدید، بلافاصله (در گام بعد) اصلاح میکنید، نه اینکه صبر کنید تا تصادف کنید (پایان اپیزود) و بعد بگویید “آهان، باید فرمان را میچرخاندم!”
انواع روشهای TD
دو نوع برجسته از این روش عبارتند از:
- سارسا (SARSA) : مخفف . (State–action–reward–state–action) یک روش TD روی سیاست (On-policy) است؛ یعنی سیاستی را ارزیابی میکند و بهبود میبخشد که خودش تصمیمگیرنده است.
- (Q-learning) : یک روش خارج از سیاست (Off-policy) است. روشهای خارج از سیاست از دو سیاست استفاده میکنند: یکی برای بهرهبرداری (سیاست هدف) و دیگری برای اکتشاف جهت تولید رفتار (سیاست رفتاری).
سایر روشهای پیشرفته (Additional Methods)
دنیای یادگیری تقویتی بسیار گسترده است. در اینجا به دو دسته مهم دیگر اشاره میکنیم:
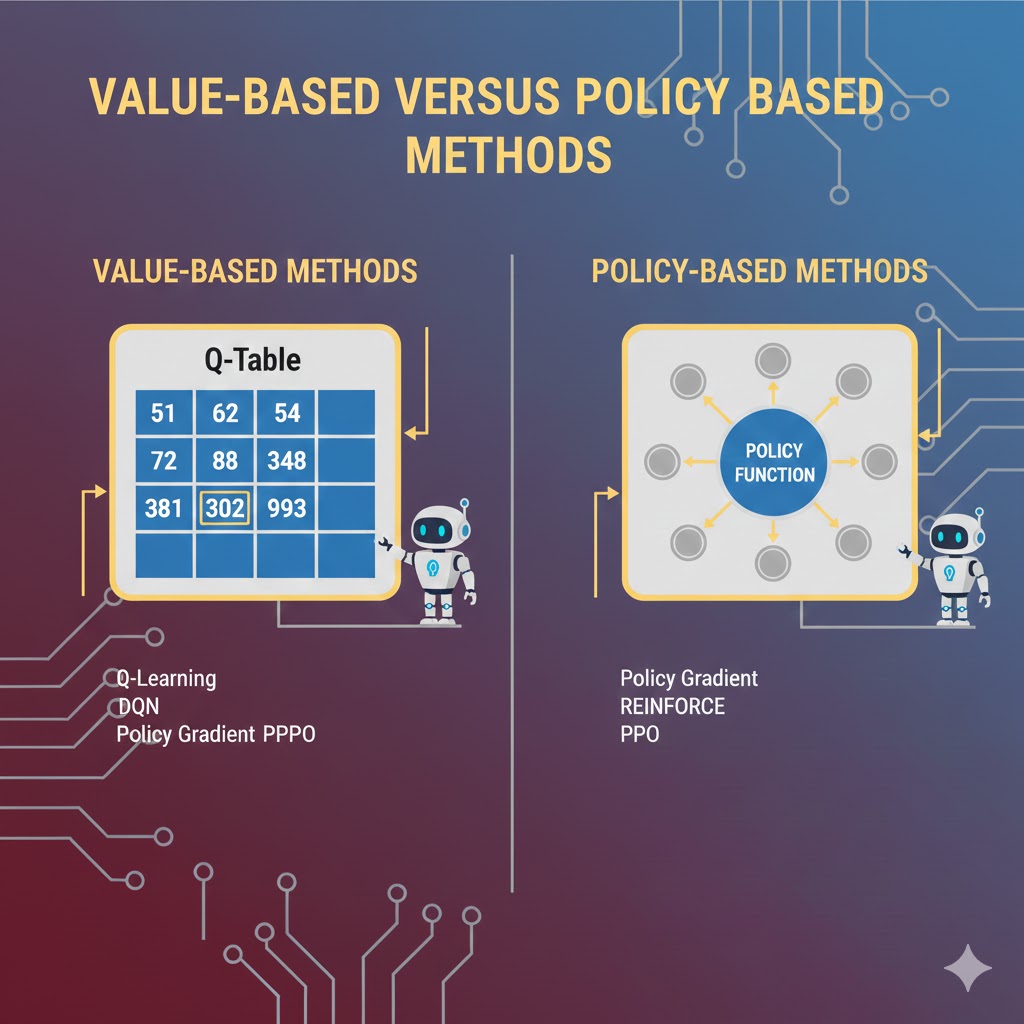
۱. روشهای مبتنی بر گرادیان سیاست (Policy Gradient)
برنامهریزی پویا یک روش مبتنی بر ارزش (Value-based) است (اقدامات را بر اساس ارزش تخمینی انتخاب میکند تا تابع ارزش را ماکزیمم کند).
در مقابل، روشهای گرادیان سیاست، یک سیاستِ پارامتریک را یاد میگیرند که میتواند اقدامات را مستقیماً و بدون مشورت با تابع ارزش انتخاب کند. این روشها مبتنی بر سیاست (Policy-based) نامیده میشوند و در محیطهای با ابعاد بالا (High-dimensional) موثرتر هستند.
۲. روشهای بازیگر-منتقد (Actor-Critic)
این روشها ترکیبی از هر دو رویکرد مبتنی بر ارزش و مبتنی بر سیاست هستند.
- بازیگر(Actor): یک گرادیان سیاست است که تعیین میکند کدام اقدامات باید انجام شوند (عملکننده).
- منتقد(Critic): یک تابع ارزش است که اقدامات انجام شده را ارزیابی میکند (نمره دهنده).
روشهای بازیگر-منتقد در واقع نوعی از TD هستند. به طور دقیقتر، بازیگر-منتقد ارزش یک اقدام خاص را نه تنها بر اساس پاداش خودش، بلکه بر اساس ارزش احتمالیِ حالت بعدی ارزیابی میکند.
- مزیت: به دلیل پیادهسازی همزمان تابع ارزش و سیاست در تصمیمگیری، به طور موثری به تعامل کمتری با محیط نیاز دارد (یادگیری سریعتر).
کاربردهای دنیای واقعی یادگیری تقویتی
یادگیری تقویتی (RL) دیگر فقط یک تئوری دانشگاهی نیست؛ بلکه در حال تغییر چهره صنایع مختلف است:
۱. رباتیک و اتوماسیون (Robotics)
الگوریتمهای RL برای خودکارسازی وظایف در محیطهای ساختاریافته (مانند خطوط تولید و کارخانهها) استفاده میشوند. در اینجا، رباتها یاد میگیرند که حرکات خود را بهینه کنند تا کارایی را افزایش داده و مصرف انرژی را کاهش دهند.
۲. بازیها و استراتژی:
این شاید مشهورترین ویترین RL باشد. الگوریتمهای پیشرفته (مانند AlphaGo) استراتژیهایی را برای بازیهای پیچیدهای مثل شطرنج، Go و بازیهای ویدیویی (مثل Dota 2) توسعه دادهاند که در بسیاری موارد، قهرمانان انسانی را شکست دادهاند.
۳. کنترل صنعتی:
یادگیری تقویتی در تنظیمات بلادرنگ (Real-time) و بهینهسازی عملیات صنعتی نقش حیاتی دارد.
۴. سیستمهای آموزشی شخصیسازیشده :
RLامکان سفارشیسازی محتوای آموزشی را بر اساس الگوهای یادگیری منحصربهفرد هر دانشآموز فراهم میکند. این سیستم با رصد میزان پیشرفت، دروس را سختتر یا آسانتر میکند تا تعامل و اثربخشی آموزش را بالا ببرد.
۵. امور مالی و معاملهگری:
در بازارهای بورس، رباتهای RL یاد میگیرند که چه زمانی بخرند و چه زمانی بفروشند تا سود را در طول زمان به حداکثر برسانند، بدون اینکه تحت تأثیر احساسات انسانی قرار بگیرند.
مزایا
۱. حل مسائل ترتیبی و پیچیده: جایی که سایر روشها شکست میخورند، RL میدرخشد. این روش میتواند زنجیرهای از تصمیمات را مدیریت کند که در آن پاداش نهایی ممکن است صدها حرکت بعد مشخص شود (مثل برنده شدن در شطرنج).
۲. سازگاری با تغییرات: از طریق تعامل بلادرنگ یاد میگیرد. اگر محیط تغییر کند (مثلاً جاده لغزنده شود)، عامل RL میتواند استراتژی خود را تغییر دهد و خود را با شرایط جدید وفق دهد.
۳. بینیاز از دادههای برچسبدار: برخلاف یادگیری نظارتشده، نیازی نیست هزاران انسان بنشینند و به دادهها برچسب بزنند. عامل خودش با کاوش محیط، داده تولید میکند.
۴. نوآوری فراتر از شهود انسانی: این مدلها میتوانند استراتژیهای جدیدی کشف کنند که به ذهن انسان نمیرسد (مثل حرکت ۳۷ معروف در بازی AlphaGo که مفسران ابتدا فکر کردند اشتباه است، اما در واقع نبوغ محض بود).
۵. مدیریت عدم قطعیت : در محیطهای تصادفی (Stochastic) و غیرقابل پیشبینی عملکرد بسیار موثری دارد.
معایب
۱. پرهزینه و سنگین : آموزش این مدلها نیازمند حجم عظیمی از داده و قدرت پردازشی بالاست. عامل ممکن است نیاز داشته باشد میلیونها بار یک بازی را ببازد تا یاد بگیرد چگونه برنده شود (ناکارآمدی نمونه یا Sample Inefficiency).
۲. طراحی حساس تابع پاداش : این پاشنه آشیل RL است. اگر تابع پاداش را بد طراحی کنید، با رفتارهای ناخواسته مواجه میشوید.
۳. نامناسب برای مسائل ساده : استفاده از RL برای مسائلی که با روشهای سنتی (مثل رگرسیون خطی) حل میشوند، مثل استفاده از تانک برای کشتن پشه است؛ ناکارآمد و غیرضروری.
۴. دشواری در خطایابی و تفسیر : تصمیمات این مدلها اغلب غیرقابل توضیح است. اینکه «چرا» ربات در آن لحظه آن تصمیم خاص را گرفت، اغلب مثل یک «جعبه سیاه» باقی میماند.
۵. چالش تعادل اکتشاف-بهرهبرداری: ایجاد تعادل بین «امتحان کردن چیزهای جدید» و «استفاده از آنچه قبلاً یاد گرفتهایم» نیازمند تنظیمات بسیار دقیق و دشوار است.
۶. نگرانیهای ایمنی: در مرحله اکتشاف، عامل ممکن است کارهای خطرناکی انجام دهد (مثلاً رباتی که برای یادگیری راه رفتن، خودش را از پلهها پرت کند). این موضوع استفاده از آن را در دنیای واقعی (قبل از شبیهسازی کامل) محدود میکند.
نتیجه گیری
یادگیری تقویتی یکی از قدرتمندترین و در عین حال چالشبرانگیزترین رویکردهای یادگیری ماشین است که به سیستمها امکان میدهد از طریق تجربه و تعامل با محیط، بهصورت پویا یاد بگیرند. این روش با مدلسازی مسئله به شکل فرآیند تصمیمگیری مارکوف (MDP) و استفاده از مفاهیمی مانند پاداش، سیاست، تابع ارزش و توازن بین اکتشاف و بهرهبرداری، این روش قادر است راهحلهایی برای مسائل پیچیده و چندمرحلهای ارائه دهد.
با وجود مزایای چشمگیر، یادگیری تقویتی با چالشهایی مانند نیاز به دادههای تعاملی زیاد، هزینه محاسباتی بالا و حساسیت به طراحی تابع پاداش روبهرو است. با این حال، پیشرفت الگوریتمها و ترکیب آن با یادگیری عمیق، باعث شده است که این رویکرد در بسیاری از حوزههای پیشرفته بهطور موفق به کار گرفته شود.
در نهایت، هر زمان که مسئله شامل تصمیمگیری پیوسته، بازخورد تدریجی و یادگیری از تجربه باشد، یادگیری تقویتی انتخابی مناسب و آیندهساز خواهد بود؛ رویکردی که مسیر توسعه سیستمهای هوشمند خودآموز را هموار میکند.