

مقدمه
در دنیایی که دادهها هر روز بیشتر و پیچیدهتر میشوند، روشهای سنتی تحلیل داده دیگر پاسخگوی بسیاری از مسائل نیستند. ما به سیستمهایی نیاز داریم که بتوانند الگوهای پنهان را کشف کنند، از تجربه یاد بگیرند و با دادههای جدید سازگار شوند. شبکههای عصبی (Neural Networks) دقیقاً با همین هدف وارد دنیای هوش مصنوعی شدند و به یکی از مهمترین ابزارهای یادگیری ماشین تبدیل شدند.
شبکههای عصبی الهامگرفته از مغز انسان هستند و تلاش میکنند نحوه پردازش اطلاعات در ذهن انسان را شبیهسازی کنند. این رویکرد باعث شده است کامپیوترها بتوانند کارهایی انجام دهند که تا چند سال پیش غیرممکن به نظر میرسید؛ از تشخیص چهره و گفتار گرفته تا ترجمه زبان، رانندگی خودکار و سیستمهای توصیهگر هوشمند.
در این مقاله، ابتدا شبکه عصبی را بهصورت ساده و دقیق تعریف میکنیم، سپس سازوکار یادگیری آن را بررسی کرده و در پایان، جایگاه و اهمیت آن را در هوش مصنوعی مدرن جمعبندی میکنیم.

تعریف
شبکه عصبی یک مدل پیشرفته در هوش مصنوعی (AI) و یادگیری ماشین (ML) است که به کامپیوترها امکان میدهد دادهها را به شیوهای الهامگرفته از مغز انسان پردازش کنند. این مدل که پایهی بسیاری از روشهای یادگیری عمیق (Deep Learning) محسوب میشود، از مجموعهای از نورونهای مصنوعی متصلبههم در قالب لایههای مختلف تشکیل شده است.
همانطور که مغز انسان با تجربه و بازخورد یاد میگیرد، شبکه عصبی نیز با تنظیم وزنها و یادگیری از خطاها، بهتدریج عملکرد خود را بهبود میدهد. هدف این فرآیند، حل مسائل پیچیدهای مانند تشخیص چهره، تحلیل متن یا خلاصهسازی اسناد با دقت و کارایی بالا است.
چرا شبکههای عصبی مهم هستند؟
۱. شناسایی الگوهای پیچیده: این سیستمها استادِ پیدا کردن سوزن در انبار کاه هستند! آنها میتوانند ساختارهای ظریف و روابط پنهان در دادهها را تشخیص دهند و خودشان را با محیطهای پویا و در حال تغییر سازگار کنند.
۲. یادگیری از دادهها: شبکههای عصبی از حجم انبوه دادهها نمیترسند؛ برعکس، از آن تغذیه میکنند. آنها میتوانند کلاندادهها را به راحتی مدیریت کنند و با کسب تجربه و بازآموزی، عملکردشان روزبهروز بهتر میشود.
۳. موتور محرک تکنولوژیهای کلیدی: این تکنولوژی، سوخت اصلی نوآوریهای مدرن است. از قدرت بخشیدن به پردازش زبان طبیعی (NLP) گرفته تا فعالسازی خودروهای خودران و پشتیبانی از سیستمهای تصمیمگیری خودکار، همه مدیون شبکههای عصبی هستند.
۴. جهش در بهرهوری: شبکههای عصبی با روانسازی جریانهای کاری و خودکارسازی فرآیندها، بازدهی و بهرهوری را در صنایع مختلف به طرز چشمگیری افزایش میدهند.
۵. ستون فقرات هوش مصنوعی: بدون شک، شبکههای عصبی هسته اصلی و پیشران پیشرفتهای هوش مصنوعی هستند و نقشی حیاتی در شکلدهی آینده تکنولوژی و نوآوری ایفا میکنند.
شبکههای عصبی چطور کار میکنند؟ از آناتومی تا اجرا
معماری شبکههای عصبی مستقیماً از مغز انسان الهام گرفته شده است. در مغز ما، سلولهایی به نام نورون وجود دارند که شبکهای پیچیده و درهمتنیده را تشکیل میدهند و با ارسال سیگنالهای الکتریکی به یکدیگر، اطلاعات را پردازش میکنند.
یک شبکه عصبی مصنوعی (Artificial Neural Network) هم دقیقاً همین کار را شبیهسازی میکند:
- نورونهای مصنوعی: ماژولهای نرمافزاری هستند که به آنها گره (Node) میگوییم.
- شبکه عصبی: الگوریتمها یا برنامههایی هستند که از این گرهها برای حل محاسبات ریاضی پیچیده استفاده میکنند.
معماری ساده یک شبکه عصبی
یک شبکه عصبی پایه، از سه لایه اصلی تشکیل شده که گرههای آن به هم متصل هستند:
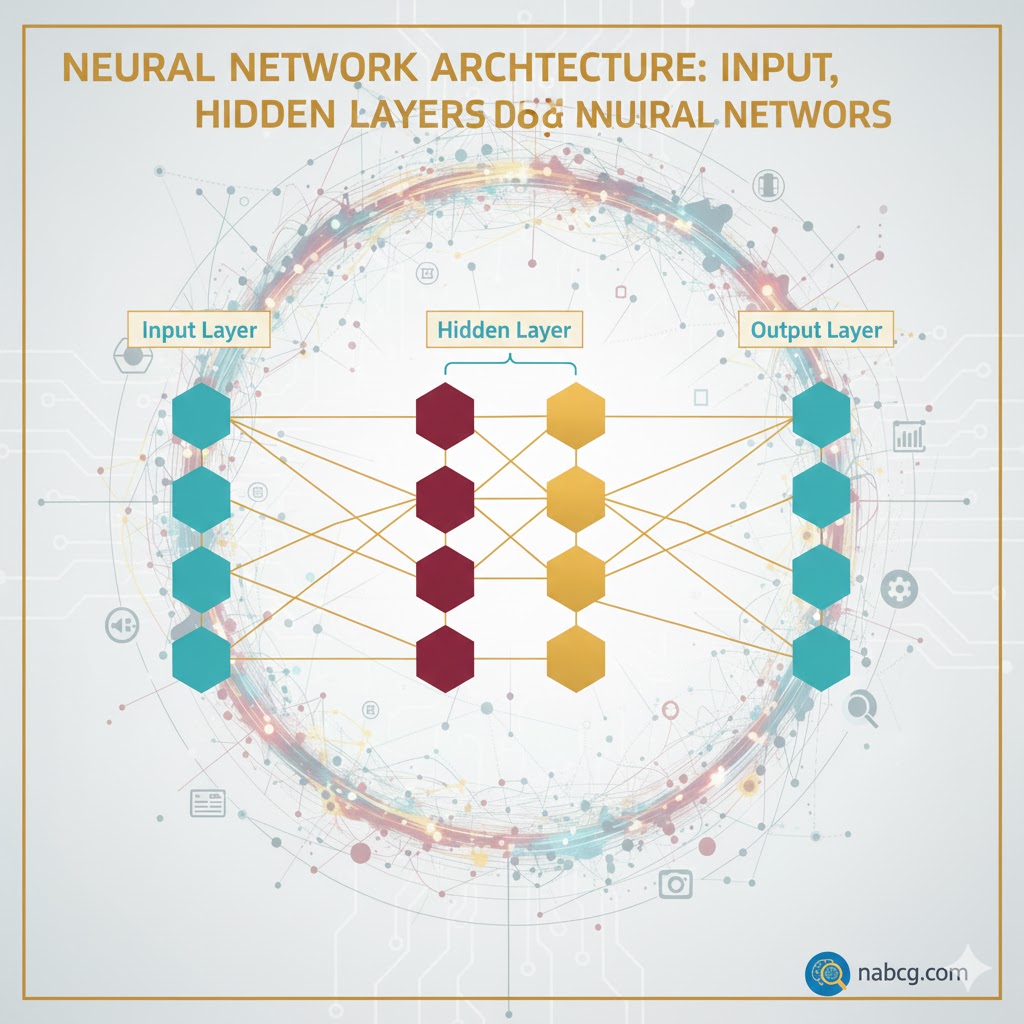
۱. لایه ورودی (Input Layer)؛ دروازه ورود
اطلاعات دنیای بیرون از طریق این لایه وارد شبکه میشود. گرههای ورودی دادهها را پردازش، تحلیل یا دستهبندی کرده و به لایه بعدی پاس میدهند.
۲. لایه پنهان (Hidden Layer)؛ اتاق پردازش
این لایه ورودی خود را از لایه قبلی میگیرد. یک شبکه عصبی میتواند تعداد زیادی لایه پنهان داشته باشد. هر لایه پنهان، خروجی لایه قبل را میگیرد، روی آن محاسبات انجام میدهد و نتیجه را به لایه بعد میفرستد.
۳. لایه خروجی (Output Layer)؛ نتیجه نهایی
این لایه حاصل تمام پردازشها را نشان میدهد.
- مثال: اگر مسئله ما یک جواب بله/خیر داشته باشد (مثل تشخیص اسپم)، لایه خروجی یک گره دارد (۱ یا ۰).
- اگر مسئله چندگزینهای باشد (مثل تشخیص نوع حیوان)، لایه خروجی میتواند چند گره داشته باشد.
عملکرد دقیق شبکههای عصبی
حالا که اجزا را شناختیم، بیایید ببینیم وقتی دکمه “Start” را میزنیم، دقیقاً چه اتفاقی داخل شبکه میافتد. فرآیند یادگیری در سه مرحله اصلی انجام میشود:
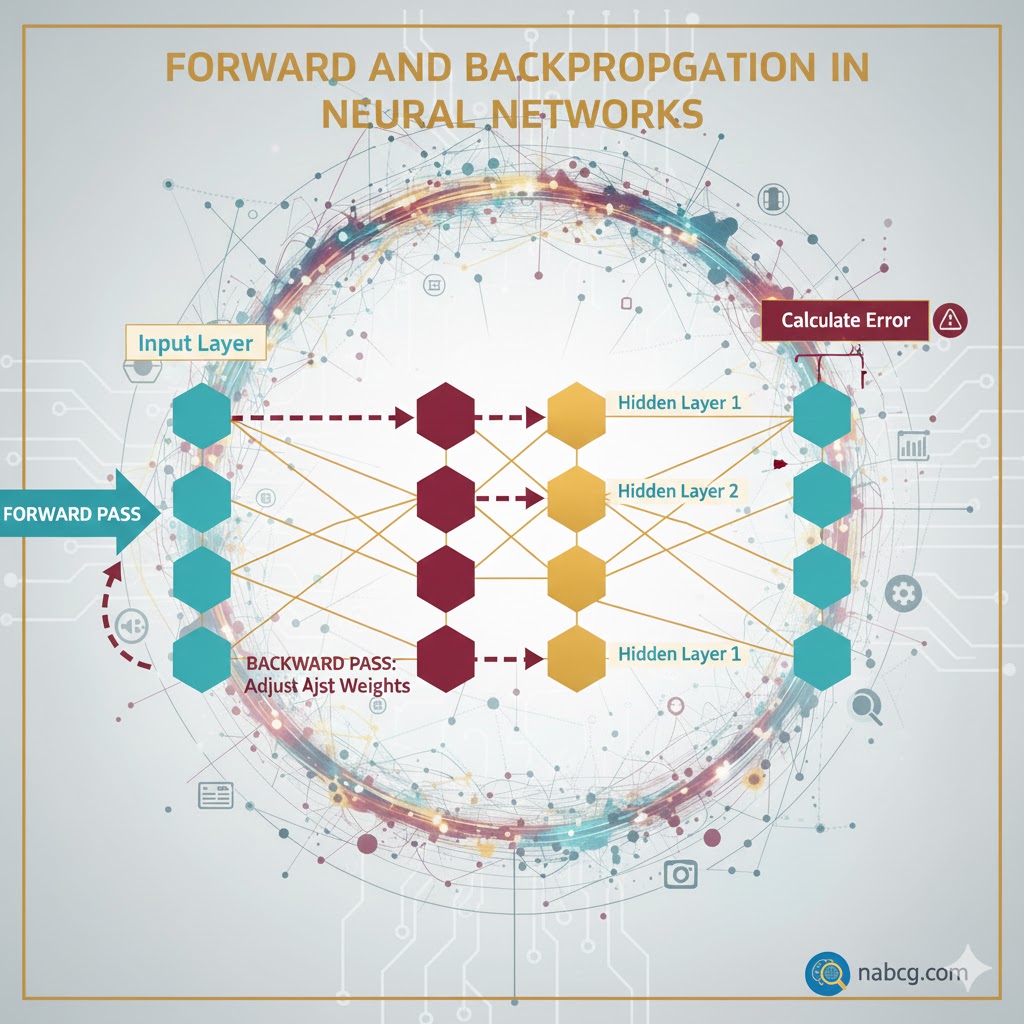
۱. انتشار رو به جلو (Forward Propagation)؛ سفر دادهها
وقتی دادهها وارد شبکه میشوند، در یک مسیر مستقیم از لایه ورودی به سمت لایههای پنهان و در نهایت به لایه خروجی حرکت میکنند. به این حرکت، «انتشار رو به جلو» میگویند.
در این مرحله دو اتفاق مهم میافتد:
الف) تبدیل خطی (Linear Transformation)
هر نورون مثل یک ایستگاه بازرسی است. دادهها (Input) وارد میشوند و در میزان اهمیتشان (Weight) ضرب میشوند. سپس همه با هم جمع شده و با یک عدد ثابت به نام بایاس (Bias) ترکیب میشوند.
به زبان ریاضی، این اتفاق میافتد:
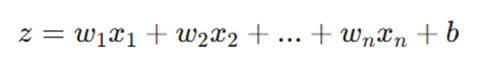
- w (وزنها): نشان میدهد هر داده چقدر مهم است.
- x (ورودیها): دادههای خام ما هستند.
- b (بایاس): مثل یک آستانه عمل میکند تا مطمئن شویم نورون در زمان مناسب فعال میشود.
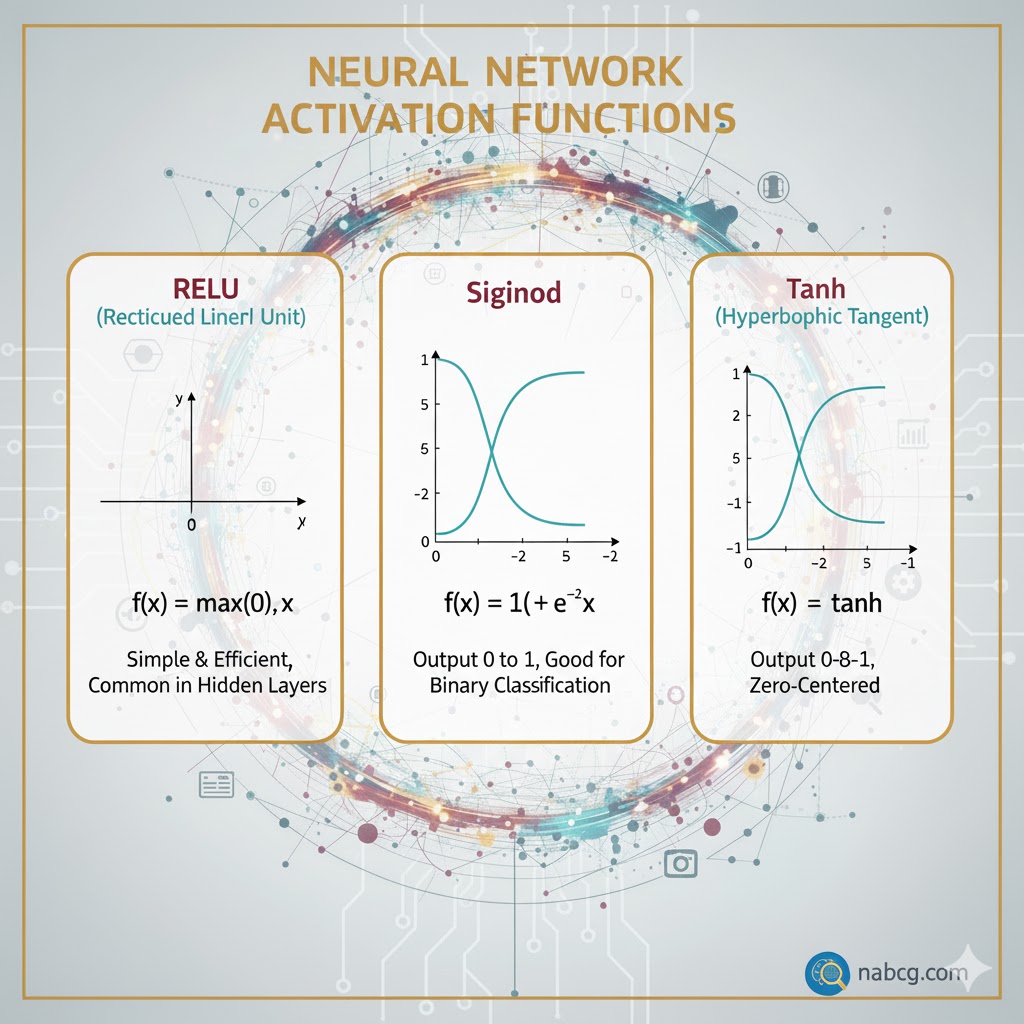
ب) فعالسازی (Activation)
نتیجه فرمول بالا (z) هنوز خام و خطی است. حالا نوبت تابع فعالساز است که وارد عمل شود.
- نقش: این تابع مثل ReLU یا Sigmoid به شبکه «غیرخطی بودن» را اضافه میکند.
- چرا مهم است؟ بدون این مرحله، شبکه عصبی فقط یک ماشین حساب ساده خطی بود و نمیتوانست الگوهای پیچیده را یاد بگیرد.
۲. پسانتشار (Backpropagation)؛ یادگیری از اشتباهات
این مهمترین بخش ماجراست! بعد از اینکه دادهها به آخر خط رسیدند و شبکه یک پیشبینی انجام داد، حالا باید عملکردش را بسنجد.
هدف آموزش این است که خطا را به حداقل برسانیم. اینجاست که پسانتشار وارد میدان میشود:
الف)محاسبه خطا (Loss Calculation)
شبکه خروجی خود را با واقعیت مقایسه میکند.
- مثال: شبکه گفته “تصویر سگ است” (پیشبینی) اما تصویر واقعی “گربه” بوده.
- فاصله بین این دو، توسط تابع هزینه (Loss Function) محاسبه میشود. (مثل Mean Squared Error در مسائل رگرسیون).
ب)محاسبه گرادیان (Gradient Calculation)
حالا شبکه باید بفهمد “تقصیر کدام نورون بود؟”
شبکه با استفاده از ریاضیات (قانون زنجیرهای در مشتق)، محاسبه میکند که هر وزن (w) و بایاس (b) چقدر در ایجاد این خطا نقش داشتهاند. به این کار محاسبه گرادیان میگویند.
ج)بهروزرسانی وزنها (Weight Update)
وقتی مقصرها پیدا شدند، نوبت اصلاح است. با استفاده از یک الگوریتم بهینهساز (مثل SGD)، وزنها تغییر میکنند.
- وزنها در خلاف جهت خطا تنظیم میشوند تا در دور بعدی، خطا کمتر شود.
- نرخ یادگیری(Learning Rate): تعیین میکند که این تغییرات چقدر بزرگ باشند (قدمهای کوچک و مطمئن، یا قدمهای بزرگ و سریع).
۳. تکرار (Iteration)
یک بار انجام دادن این کار کافی نیست.
چرخه «انتشار جلو ⬅️ محاسبه خطا ⬅️ پسانتشار» هزاران یا میلیونها بار روی دادهها تکرار میشود.
- در هر تکرار، خطا کمی کمتر میشود.
- به مرور زمان، شبکه از یک سیستم که شانسی حدس میزد، به یک مدل هوشمند تبدیل میشود که الگوها را دقیقاً درک میکند.
خلاصه: شبکه عصبی پارامترهای خود را (وزنها و بایاسها) آنقدر تغییر میدهد تا در نهایت بتواند بهترین رابطه را بین ورودی و خروجی پیدا کند. این یعنی “یادگیری”.
روشهای یادگیری شبکه عصبی
یک شبکه عصبی به خودی خود هوشمند نیست؛ باید به آن آموزش داد. اما چگونه؟ به طور کلی، سه روش اصلی برای آموزش دادن به این مغزهای دیجیتالی وجود دارد:
۱. یادگیری نظارتشده (Supervised Learning)؛ مثل کلاس درس
در این روش، شبکه عصبی درست مثل یک دانشآموز عمل میکند که معلمی بالای سرش دارد.
- نحوه کار: معلم (دادهدانشمند) جفتهای «ورودی و خروجی» برچسبدار را به شبکه میدهد. یعنی هم سوال را میدهد و هم جواب درست را.
- اصلاح خطا: شبکه یک خروجی تولید میکند و آن را با «جواب درست» مقایسه میکند. اگر اشتباه کرده باشد، یک سیگنال خطا ایجاد میشود.
- تکرار: شبکه بارها و بارها پارامترهایش را تنظیم میکند تا خطا را به حداقل برساند و به سطح قابل قبولی از عملکرد برسد.
۲. یادگیری نظارتنشده (Unsupervised Learning)؛ کشف در تاریکی
در اینجا خبری از معلم و پاسخنامه نیست. دادهها هیچ برچسبی ندارند.
- هدف: هدف اصلی درک ساختار زیربنایی دادههای ورودی است. شبکه باید خودش الگوها را پیدا کند.
- نحوه کار: از آنجا که مربی راهنمایی وجود ندارد، تمرکز روی مدلسازی الگوها و روابط است.
- ابزارها: تکنیکهایی مثل خوشهبندی (Clustering) (دستهبندی دادههای مشابه) و قواعد انجمنی (Association) در این روش رایج هستند.
۳. یادگیری تقویتی (Reinforcement Learning)؛ روش آزمون و خطا
این روش شبیه آموزش حیوانات خانگی یا بازی کردن است.
- نحوه کار: شبکه عصبی از طریق تعامل مستقیم با محیط یاد میگیرد.
- پاداش و تنبیه: شبکه بازخوردهایی به شکل «پاداش» (برای کار درست) یا «جریمه» (برای کار غلط) دریافت میکند.
- هدف: پیدا کردن یک استراتژی یا سیاست بهینه که بتواند مجموع پاداشها را در طول زمان به حداکثر برساند. این روش در بازیهای کامپیوتری و تصمیمگیریهای رباتیک بسیار کاربرد دارد.
انواع شبکههای عصبی؛ کدام مدل برای چه کاری؟
مهندسان هوش مصنوعی برای هر مسئله، معماری خاصی طراحی کردهاند. در اینجا با مهمترین انواع آن آشنا میشویم:
۱. شبکههای پیشخور (Feedforward Networks)
این سادهترین معماری شبکه عصبی مصنوعی است.
- ویژگی: همانطور که از نامش پیداست، دادهها فقط در یک جهت حرکت میکنند: از ورودی به سمت خروجی. هیچ بازگشتی در کار نیست.
۲. پرسپترون تکلایه (Single-layer Perceptron)
سلول بنیادی شبکههای عصبی!
- ویژگی: فقط یک لایه دارد. این مدل وزنها را اعمال میکند، ورودیها را جمع میزند و با استفاده از یک تابع فعالساز، خروجی را تولید میکند.
۳. پرسپترون چندلایه (MLP)
نسخه قدرتمندتر مدل قبلی.
- ساختار: نوعی از شبکه پیشخور است که حداقل سه لایه دارد: ورودی، یک یا چند لایه پنهان، و خروجی.
- قدرت: این مدل از توابع فعالساز غیرخطی استفاده میکند که به آن اجازه میدهد مسائل پیچیده را حل کند.
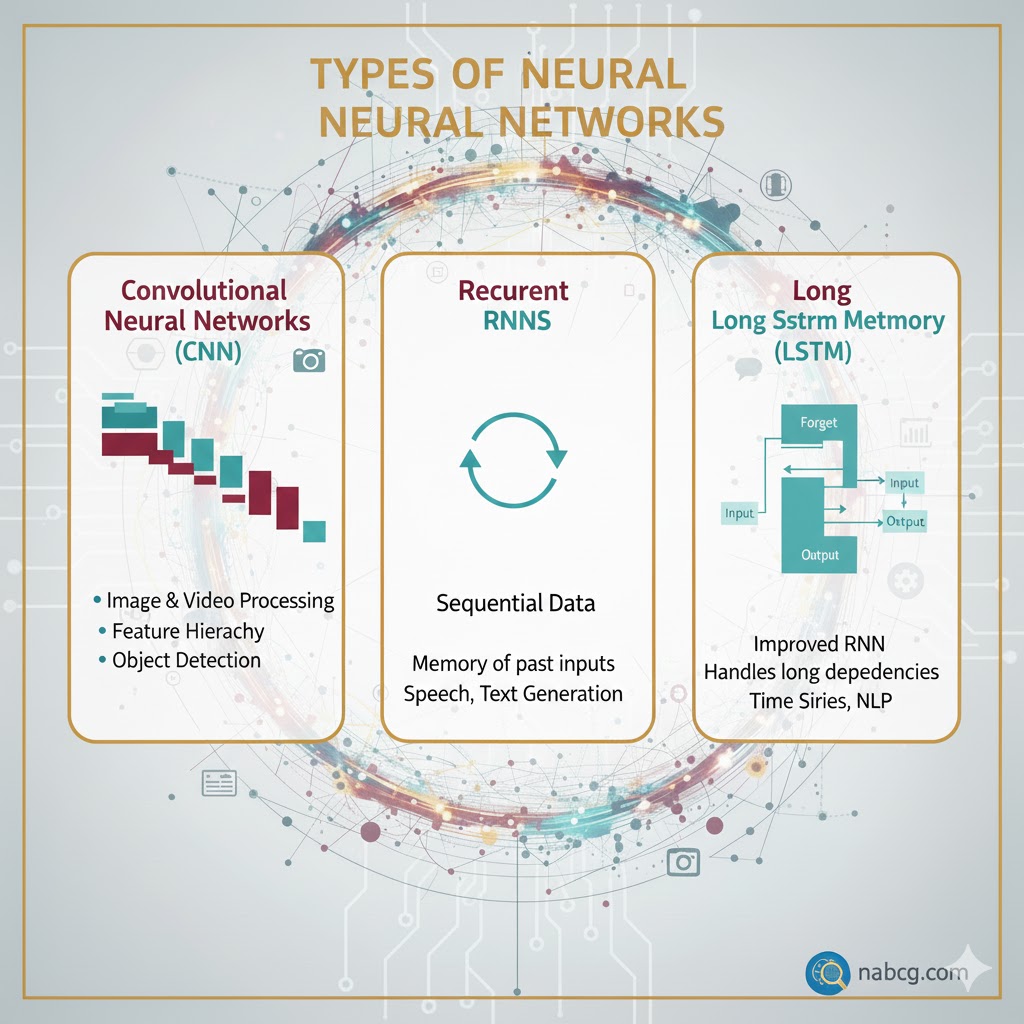
۴. شبکه عصبی کانولوشنال (CNN)؛ متخصص تصاویر
اگر با عکس و ویدیو سر و کار دارید، این بهترین گزینه است.
- کاربرد: مخصوص پردازش تصویر طراحی شده است.
- نحوه کار: از لایههای کانولوشن استفاده میکند تا ویژگیهای تصویر (مثل لبهها و بافتها) را بهطور خودکار یاد بگیرد و شناسایی و طبقهبندی تصویر را ممکن کند.
۵. شبکه عصبی بازگشتی (RNN)؛ دارای حافظه کوتاه
- کاربرد: برای دادههای ترتیبی (مثل متن یا صدا) عالی است.
- نحوه کار: از حلقههای بازخورد (Feedback Loops) استفاده میکند تا اطلاعات را در طول زمان حفظ کند و زمینه (Context) را نگه دارد.
۶. حافظه طولانی کوتاهمدت (LSTM)؛ حافظه بلند
یک نسخه پیشرفته از RNN است.
- ویژگی: دارای سلولهای حافظه و دروازههایی است که میتوانند وابستگیهای طولانیمدت را مدیریت کنند.
- مزیت: مشکل معروف «محو شدن گرادیان» (که باعث میشود شبکههای معمولی چیزهای قدیمی را فراموش کنند) را حل کرده است.
پیادهسازی شبکه عصبی با تنسورفلو
وقت آن است که تئوریها را کنار بگذاریم و دست به کد شویم! در این بخش، ما یک شبکه عصبی پیشخور (Feedforward) ساده را پیادهسازی میکنیم. هدف این است که شبکه روی یک مجموعه داده نمونه آموزش ببیند و یاد بگیرد که پیشبینی انجام دهد.
این کار را قدمبهقدم با هم انجام میدهیم.
مرحله ۱: وارد کردن کتابخانههای ضروری
اولین قدم در هر پروژه دادهکاوی، فراخوانی ابزارهاست. ما باید کتابخانههای قدرتمندی را که غولهای تکنولوژی ساختهاند، به پروژه خود اضافه کنیم.
- TensorFlow وKeras: برای ساخت و آموزش شبکه عصبی (مغز متفکر پروژه).
- NumPy وPandas: برای مدیریت، تمیزکاری و آمادهسازی دادهها.
import numpy as np
import pandas as pd
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
مرحله ۲: ساخت و بارگذاری دادهها
شبکه عصبی بدون داده، مثل ماشین بدون بنزین است. در این مرحله، ما باید دادههایمان را ایجاد یا بارگذاری کنیم و آنها را به فرمتی تبدیل کنیم که تنسورفلو عاشق آن است: آرایههای نامپای (NumPy Arrays).
برای آموزش شبکه، ما دادهها را به دو دسته اصلی تقسیم میکنیم:
- ویژگیها (Features) یاX: سوالاتی که به مدل میدهیم (دادههای ورودی).
- برچسبها (Labels) یاy: جوابهای درستی که انتظار داریم مدل یاد بگیرد (دادههای خروجی).
بیایید یک مجموعه داده نمونه (مثلاً برای یک مسئله طبقهبندی ساده) بسازیم:
data = {
'feature1': [0.1, 0.2, 0.3, 0.4, 0.5],
'feature2': [0.5, 0.4, 0.3, 0.2, 0.1],
'label': [0, 0, 1, 1, 1]
}
df = pd.DataFrame(data)
X = df[['feature1', 'feature2']].values
y = df['label'].values
مرحله ۳: ساخت بدنه شبکه عصبی
یک مدل Sequential (ترتیبی) ایجاد کنید و لایهها را به آن اضافه نمایید. لایه ورودی و لایههای پنهان معمولاً با استفاده از لایههای Dense (متراکم) ساخته میشوند؛ در این لایهها باید تعداد نورونها و نوع توابع فعالساز را مشخص کنید.
model = Sequential()
model.add(Dense(8, input_dim=2, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
مرحله ۴: کامپایل کردن مدل
مدل را با مشخص کردن تابع هزینه (Loss Function)، بهینهساز (Optimizer) و معیارهایی که باید در حین آموزش ارزیابی شوند، کامپایل کنید. در اینجا، ما از تابع هزینه آنتروپی متقاطع باینری (Binary Crossentropy) و بهینهساز Adam استفاده خواهیم کرد.
model.compile(loss='binary_crossentropy',
optimizer='adam', metrics=['accuracy'])
مرحله ۵: آموزش مدل
مدل را روی دادههای آموزشی برازش (Fit) دهید؛ برای این کار باید تعداد ایپاکها (Epochs) و اندازه دسته (Batch Size) را مشخص کنید. این مرحله دقیقاً همان جایی است که شبکه عصبی آموزش میبیند تا از دادههای ورودی یاد بگیرد.
model.fit(X, y, epochs=100, batch_size=1, verbose=1)مرحله ۶: انجام پیشبینیها
از مدل آموزشدیده برای انجام پیشبینی روی دادههای جدید استفاده کنید. سپس خروجی را پردازش کنید تا بتوانید نتیجه را تفسیر نمایید؛ برای مثال، تبدیل احتمالات به نتایج باینری (مثلاً تبدیل احتمال ۹۰٪ به کلاس ۱).
test_data = np.array([[0.2, 0.4]])
prediction = model.predict(test_data)
predicted_label = (prediction > 0.5).astype(int)
خروجی:

یادگیری عمیق در مقابل یادگیری ماشین؛ تفاوت کجاست؟
هوش مصنوعی (AI) علم ساخت ماشینهای هوشمند است. یادگیری ماشین (ML) تکنیکی است که به کامپیوتر اجازه میدهد از دادهها یاد بگیرد. یادگیری عمیق (Deep Learning) زیرمجموعهای از یادگیری ماشین است که از شبکههای عصبی عمیق استفاده میکند.
مقایسه عملکرد (مثال شناسایی حیوان خانگی 🐶🐱)
۱. روش یادگیری ماشین (سنتی): نیاز به دخالت انسان دارد. شما باید دستی ویژگیها را به نرمافزار بدهید.
- باید هزاران عکس گربه، سگ و… را دستی برچسب بزنید.
- باید به نرمافزار بگویید دنبال چه باشد (مثلاً: تعداد پاها، شکل گوش، دم).
- اگر عکس “گربه سفید” را به مدلی که فقط “گربه سیاه” دیده بدهید، احتمالا اشتباه میکند و شما باید دستی اصلاح کنید.
۲. روش یادگیری عمیق (مدرن): دادهدانشمند فقط دادههای خام را به سیستم میدهد.
- شبکه عصبی خودش عکسها را پردازش میکند.
- خودش تشخیص میدهد که اول باید “تعداد پاها” را بشمارد، بعد “شکل صورت” را ببیند و در آخر به “دم” نگاه کند.
- این روش مستقلتر، هوشمندتر و برای حل مسائل پیچیده و بدون ساختار (مثل متن و تصویر) بسیار قدرتمندتر است.
کاربردهای شبکه عصبی؛ از پزشکی تا انرژی 🌍
شبکههای عصبی در صنایع مختلف کاربردهای حیاتی دارند، از جمله:
- پزشکی: تشخیص بیماریها از طریق طبقهبندی تصاویر پزشکی (مثل رادیولوژی).
- بازاریابی هدفمند: تحلیل رفتار کاربران در شبکههای اجتماعی برای تبلیغات موثر.
- پیشبینی مالی: پردازش دادههای تاریخی بورس و ابزارهای مالی برای پیشبینی آینده.
- انرژی: پیشبینی میزان تقاضای برق و بار انرژی.
- کنترل کیفیت: نظارت بر فرآیندهای تولید.
- شیمی: شناسایی ترکیبات شیمیایی جدید.
در ادامه، ۴ مورد از مهمترین کاربردهای تخصصی را بررسی میکنیم.
۱. بینایی ماشین (Computer Vision)
بینایی ماشین یعنی توانایی کامپیوتر در استخراج اطلاعات از تصاویر و ویدیوها. با کمک شبکههای عصبی، کامپیوترها میتوانند مثل انسانها تصاویر را تشخیص دهند و متمایز کنند.
کاربردها:
- خودروهای خودران: تشخیص علائم راهنمایی و رانندگی و سایر خودروها در جاده.
- مدیریت محتوا: حذف خودکار محتوای نامناسب یا خطرناک از آرشیو عکسها و ویدیوها.
- تشخیص چهره: شناسایی افراد و حتی ویژگیهایی مثل باز بودن چشمها، داشتن عینک یا ریش.
- برچسبگذاری تصاویر: شناسایی لوگوی برندها، نوع لباس یا تجهیزات ایمنی در عکسها.
۲. تشخیص گفتار (Speech Recognition)
شبکههای عصبی میتوانند گفتار انسان را با وجود تفاوت در الگوهای بیان، لجه، تن صدا و زبان تحلیل کنند. دستیارهای صوتی مثل الکسا (Amazon Alexa) از این فناوری استفاده میکنند.
کاربردها:
- مراکز تماس: کمک به اپراتورها و دستهبندی خودکار تماسها.
- مستندسازی پزشکی: تبدیل مکالمات پزشک و بیمار به اسناد متنی در لحظه (Real-time).
- زیرنویس خودکار: تولید دقیق زیرنویس برای ویدیوها و جلسات آنلاین برای دسترسی بیشتر مخاطبان.
۳. پردازش زبان طبیعی (NLP)؛ درک کلام انسان
پردازش زبان طبیعی (NLP) توانایی درک متونی است که توسط انسان نوشته شده است. شبکههای عصبی به کامپیوتر کمک میکنند تا از دل متنها و اسناد، معنا و بینش استخراج کند.
کاربردها:
- چتباتها: پاسخگویی خودکار و هوشمند به مشتریان.
- سازماندهی دادهها: طبقهبندی خودکار متون و نامههای اداری.
- هوش تجاری: تحلیل اسناد طولانی مثل ایمیلها و فرمها.
- تحلیل احساسات: پیدا کردن عبارات کلیدی که نشاندهنده حس کاربر هستند (مثل کامنتهای مثبت یا منفی در اینستاگرام).
- تولید محتوا: خلاصهسازی اسناد یا نوشتن مقاله درباره یک موضوع خاص.
۴. موتورهای توصیه گر (Recommendation Engines)؛ پیشبینی خواستهها
شبکههای عصبی میتوانند فعالیت کاربر را ردیابی کنند تا پیشنهادهای شخصیسازی شده ارائه دهند
. مثال واقعی(استارتاپ Curalate): یک استارتاپ به نام Curalate به برندها کمک میکند تا پستهای شبکههای اجتماعی را به فروش تبدیل کنند. آنها از سرویسی به نام برچسبگذاری هوشمند محصول (IPT) استفاده میکنند.
- نحوه کار: IPT با استفاده از شبکههای عصبی، بهصورت خودکار محصولاتی را که با فعالیتهای اجتماعی کاربر مرتبط هستند، پیدا و پیشنهاد میکند.
- نتیجه: مشتری دیگر لازم نیست برای پیدا کردن لباسی که در یک عکس اینستاگرامی دیده، کل کاتالوگ سایت را بگردد؛ بلکه سیستم خودش آن محصول را برای خرید آسان به او نشان میدهد.
مزایا
شبکههای عصبی بیدلیل در صدر اخبار تکنولوژی نیستند. آنها ویژگیهایی دارند که روشهای قدیمی آرزوی آن را داشتند:
۱. سازگاری فوقالعاده (Adaptability)
این شبکهها مثل آب روان هستند و شکل ظرف را به خود میگیرند!
- چرا مفید است؟ در موقعیتهایی که رابطه بین ورودی و خروجی پیچیده است یا قوانین مشخصی ندارد، شبکههای عصبی عالی عمل میکنند. آنها خودشان را با شرایط جدید وفق میدهند و مستقیماً از دادهها یاد میگیرند.
۲. استاد تشخیص الگو (Pattern Recognition)
اگر دنبال سوزن در انبار کاه هستید، این کار را به شبکه عصبی بسپارید.
- کاربرد: مهارت آنها در تشخیص الگو باعث شده تا در کارهای پیچیدهای مثل شناسایی صدا و تصویر یا پردازش زبان طبیعی (NLP) بیرقیب باشند.
۳. سرعت در پردازش موازی (Parallel Processing)
برخلاف کامپیوترهای قدیمی که کارها را نوبتبهنوبت انجام میدادند، شبکههای عصبی ذاتاً توانایی پردازش موازی دارند.
- نتیجه: آنها میتوانند چندین وظیفه را همزمان انجام دهند. این ویژگی سرعت محاسبات را به شدت بالا میبرد و کارایی را بهبود میبخشد.
۴. درک دنیای غیرخطی (Non-Linearity)
دنیای واقعی خطکشی شده و صاف نیست.
- مزیت: به لطف توابع فعالساز غیرخطی، این شبکهها میتوانند روابط پیچیده و درهمتنیده دادهها را درک کنند. این همان جایی است که مدلهای خطی قدیمی شکست میخورند.
محدودیت ها
با تمام این قدرتها، شبکههای عصبی بدون اشکال نیستند و استفاده از آنها هزینههایی دارد:
۱. هزینههای سنگین محاسباتی (Computational Intensity)
آموزش دادن به این شبکهها کار هر کسی نیست!
- مشکل: آموزش شبکههای بزرگ فرآیندی زمانبر و طاقتفرساست که به قدرت پردازشی بسیار بالا (سختافزارهای گرانقیمت مثل GPU) نیاز دارد.
۲. معمای جعبه سیاه (Black box Nature)
بزرگترین ترس متخصصان از شبکههای عصبی، ماهیت مرموز آنهاست.
- مشکل: ما ورودی و خروجی را میبینیم، اما فهمیدن اینکه مدل دقیقاً چگونه و چرا تصمیم گرفته، بسیار دشوار است. این “جعبه سیاه” بودن در کارهای حساس (مثل پزشکی یا قضاوت) یک چالش بزرگ است.
۳. پدیده بیشبرازش (Overfitting)؛ حفظ کردن به جای یادگیری
گاهی شبکه عصبی مثل دانشآموزی عمل میکند که شب امتحان کتاب را حفظ کرده اما چیزی نفهمیده است!
- توضیح: در این حالت، شبکه دادههای آموزشی را حفظ میکند و الگوهای کلی را یاد نمیگیرد. اگرچه روشهایی برای جلوگیری از این مشکل وجود دارد (مثل Regularization)، اما همچنان یک چالش رایج است.
۴. عطش سیریناپذیر برای داده (Need for Large datasets)
شبکه عصبی بدون داده، مثل ماشین بدون بنزین است.
- نیاز: برای آموزش مؤثر، این شبکهها اغلب به مجموعههای عظیم و برچسبگذاری شده از داده نیاز دارند. اگر دادهها ناقص یا جهتدار باشند، عملکرد مدل به شدت افت میکند.
جمع بندی
شبکههای عصبی یکی از بنیادیترین و قدرتمندترین ابزارهای هوش مصنوعی هستند که امکان یادگیری از دادههای پیچیده و حجیم را فراهم میکنند. با الهام از ساختار مغز انسان و استفاده از لایههای متصل به هم، این مدلها میتوانند الگوهایی را کشف کنند که با روشهای کلاسیک بهسختی قابل شناساییاند.
با وجود توانمندیهای چشمگیر، شبکههای عصبی بدون چالش نیستند؛ نیاز به دادههای زیاد، هزینه محاسباتی بالا و کاهش تفسیرپذیری از جمله محدودیتهای آنهاست. بنابراین استفاده از این مدلها باید آگاهانه و متناسب با نوع مسئله انجام شود.
در نهایت، هر زمان که مسئلهای شامل الگوهای پیچیده، دادههای بزرگ و روابط غیرخطی باشد، شبکههای عصبی یکی از بهترین انتخابها محسوب میشوند. این فناوری نهتنها مسیر پیشرفت هوش مصنوعی را هموار کرده، بلکه آینده سیستمهای هوشمند را نیز شکل میدهد.



