

مقدمه
در دنیای واقعی، تصمیمهای مهم بهندرت توسط یک نفر گرفته میشوند؛ معمولاً یک تیم از افراد با تخصصهای مختلف کنار هم مینشینند تا خطا کمتر و دقت بیشتر شود. یادگیری گروهی (Ensemble Learning) دقیقاً از همین منطق انسانی الهام گرفته است. بهجای تکیه بر یک مدل یادگیری ماشین، چندین مدل با هم همکاری میکنند تا به نتیجهای دقیقتر و قابلاعتمادتر برسند.
در بسیاری از مسائل یادگیری ماشین، مدلهای تکی یا بیشازحد سادهاند و الگوهای داده را خوب یاد نمیگیرند، یا آنقدر پیچیده میشوند که روی دادههای جدید عملکرد ضعیفی دارند. یادگیری گروهی با ترکیب هوشمندانهی چند مدل—حتی اگر هرکدام بهتنهایی متوسط یا ضعیف باشند—میتواند این ضعفها را پوشش دهد و تعادل بهتری میان دقت و تعمیمپذیری ایجاد کند.
در این مقاله، با مفهوم یادگیری گروهی، اصطلاحات کلیدی آن، دلیل اهمیتش از دید بایاس و واریانس، نحوه عملکرد، انواع روشها مانند Bagging، Boosting و Stacking و همچنین کاربردهای واقعی آن در صنایع مختلف آشنا میشویم تا ببینیم چرا این رویکرد به یکی از ستونهای اصلی یادگیری ماشین مدرن تبدیل شده است.
تعریف
یادگیری گروهی یا Ensemble Learning تکنیکی هوشمندانه در یادگیری ماشین است که بر یک اصل ساده اما قدرتمند استوار است: یک دست صدا ندارد، اما هزاران دست غوغا میکنند!
این روش برای حل مشکلاتی که ناشی از کمبود داده یا ضعف مدلهای تکنفره هستند، به کار گرفته میشود. به زبان ساده، یادگیری گروهی یعنی ترکیب کردن چندین مدل یادگیرنده (مثل رگرسیون یا شبکههای عصبی) برای رسیدن به پیشبینیهایی دقیقتر و قابلاعتمادتر.
در حالی که یک مدلِ تنها ممکن است اشتباه کند، یک گروه از مدلها با همفکری (Aggregating)، خطای یکدیگر را پوشش میدهند. به همین دلیل، در برخی منابع علمی به این روش یادگیری مبتنی بر کمیته (Committee-based Learning) نیز میگویند؛ درست مثل یک کمیته پزشکی که تشخیص جمعی آنها از تشخیص یک پزشکِ تنها دقیقتر است.
اصطلاحات کلیدی
برای درک عمیق این مبحث، باید با سه نقش اصلی در این سناریو آشنا شویم:
۱. یادگیرنده پایه (Base Learner)
به هر کدام از مدلهای تکنفرهای که در ساختار گروهی استفاده میشوند، یادگیرنده پایه، مدل پایه یا تخمینگر پایه میگویند. اینها در واقع اعضای تیم ما هستند.
۲. یادگیرنده ضعیف (Weak Learner)
اینها مدلهایی هستند که عملکردشان کمی بهتر از شانس تصادفی است.
- تعریف فنی: در یک مسئله طبقهبندی دوتایی (مثلاً تشخیص شیر یا خط)، اگر مدلی حدود ۵۰٪ دقت داشته باشد (یعنی شانسی عمل کند)، یک یادگیرنده ضعیف است.
- مثال: فرض کنید مدلی دارید که میخواهد پیشبینی کند فردا باران میآید یا نه. اگر این مدل فقط با پرتاب سکه بگوید بله یا خیر، یک یادگیرنده ضعیف است. اما در یادگیری گروهی، ما با تکنیکهایی (مثل Boosting) همین مدلهای ضعیف را با هم ترکیب میکنیم تا یک مدل قوی بسازیم.
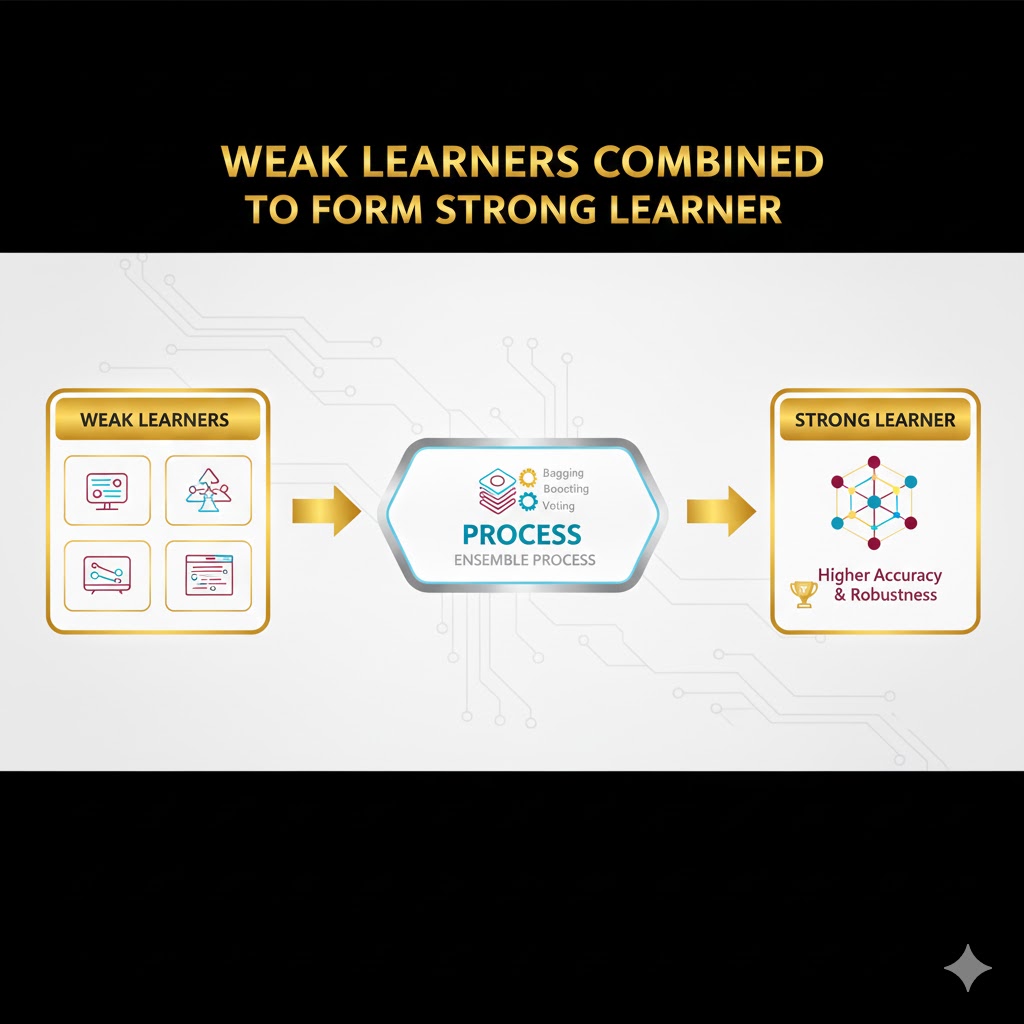
۳. یادگیرنده قوی (Strong Learner)
این مدلها عملکرد پیشبینی فوقالعادهای دارند.
- تعریف فنی: در همان مسئله دوتایی، اگر دقت مدل ۸۰٪ یا بیشتر باشد، یک یادگیرنده قوی محسوب میشود. هدف نهایی یادگیری گروهی این است که مجموعهای از مدلهای ضعیف یا متوسط را به یک یادگیرنده قوی تبدیل کند.
چرا یادگیری گروهی مهم است ؟ معمای بایاس و واریانس
یادگیری گروهی (Ensemble Learning) فقط برای افزایش دقت نیست؛ بلکه راهحلی هوشمندانه برای یکی از قدیمیترین و سختترین چالشهای یادگیری ماشین است: مبادله بایاس و واریانس. (Bias-Variance Tradeoff)
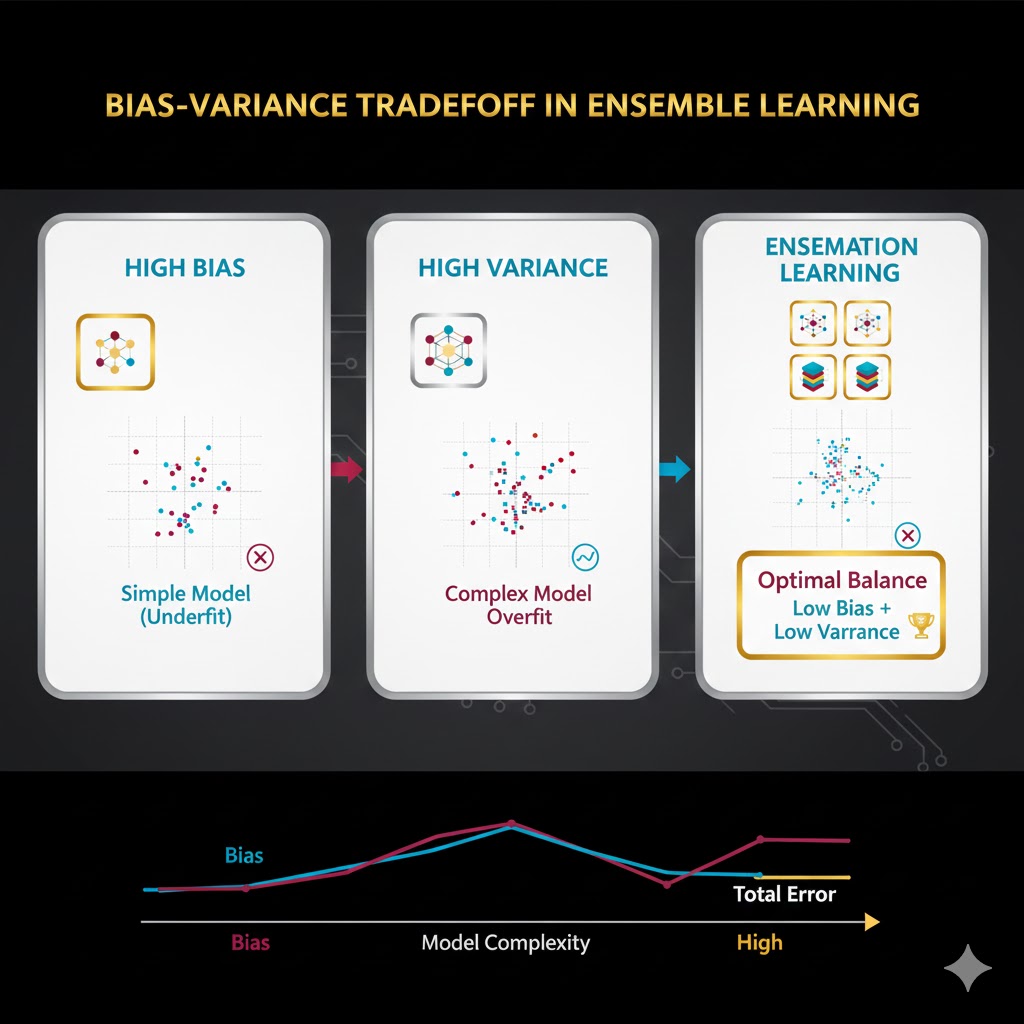
در دنیای مدلسازی، ما همیشه با سه نوع خطا روبرو هستیم که مجموع آنها خطای کل مدل را میسازد . هنر یادگیری گروهی این است که بین این خطاها تعادل ایجاد کند. بیایید آنها را بشناسیم:
۱. بایاس (Bias)؛ مشکلِ پیشداوری
بایاس میانگینِ اختلاف بین پیشبینیهای مدل و مقادیر واقعی است.
- معنی ساده: بایاس یعنی مدل شما چقدر کندذهن یا سادهانگاشته است.
- بایاس بالا: وقتی بایاس زیاد باشد، یعنی مدل الگوهای داده را یاد نگرفته است. در این حالت، دقت مدل روی دادههای آموزشی پایین است.
- هدف: تلاش برای کاهش بایاس را بهینهسازی (Optimization) میگویند.
- مثال: دانشجویی که اصلاً درس نخوانده و سر جلسه امتحان به همه سوالات پاسخ یکسان (مثلاً گزینه “الف”) میدهد. او بایاس دارد و نمرهاش کم میشود.
۲. واریانس (Variance)؛ مشکلِ حساسیت
واریانس میزان تغییرات و پراکندگیِ پیشبینیهای مدل را در شرایط مختلف نشان میدهد.
- معنی ساده: واریانس یعنی مدل شما چقدر حساس و جوگیر است!
- واریانس بالا (High Variance): وقتی واریانس زیاد باشد، یعنی مدل دادههای آموزشی را حفظ کرده . در این حالت، روی دادههای آموزشی عالی عمل میکند، اما روی دادههای جدید (تست) عملکردش افتضاح است.
- هدف: تلاش برای کاهش واریانس را تعمیمپذیری (Generalization) میگویند.
- مثال: دانشجویی که کل کتاب را طوطیوار حفظ کرده است. اگر سوال عین کتاب باشد، عالی جواب میدهد؛ اما اگر استاد سوال را کمی بپیچاند (داده جدید)، دانشجو گیج میشود و غلط مینویسد.
۳. خطای کاهشناپذیر (Irreducible Error)
این بخش سومِ خطای کل است.
- معنی ساده: این خطا ناشی از نویز و تصادفی بودنِ ذاتیِ خودِ دادههاست. هیچ مدلی (حتی بهترین مدل جهان) نمیتواند این خطا را از بین ببرد، چون طبیعتِ دنیا غیرقابلپیشبینی است.
فرمول طلایی خطای مدل
رابطه بین این سه عامل به صورت زیر تعریف میشود:
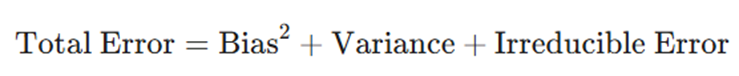
نقش یادگیری گروهی چیست؟
مشکل اصلی در مدلهای تکی این است که معمولاً یا بایاس بالا دارند (سادهاند) یا واریانس بالا (پیچیدهاند). این دو رابطه معکوس دارند. یادگیری گروهی وارد میدان میشود تا این طلسم را بشکند:
- روشهایی مثل Boosting روی کاهش بایاس تمرکز دارند.
- روشهایی مثل Bagging (مثل جنگل تصادفی) روی کاهش واریانس تمرکز دارند.
نتیجه؟ مدلی که هم خوب یاد میگیرد (بایاس کم) و هم خوب امتحان میدهد (واریانس کم).
یادگیری گروهی چگونه کار میکند؟
برای درک عمیق یادگیری گروهی، نباید به آن به چشم یک الگوریتم پیچیده ریاضی نگاه کنید؛ بلکه باید آن را یک استراتژی مدیریتی ببینید.
در دنیای هوش مصنوعی، به جای تلاش بیهوده برای ساختن یک «ابر-الگوریتم» که هیچوقت اشتباه نکند، ما چندین الگوریتم معمولی (و حتی متوسط) را مدیریت میکنیم تا در کنار هم به نتیجهای عالی برسند.
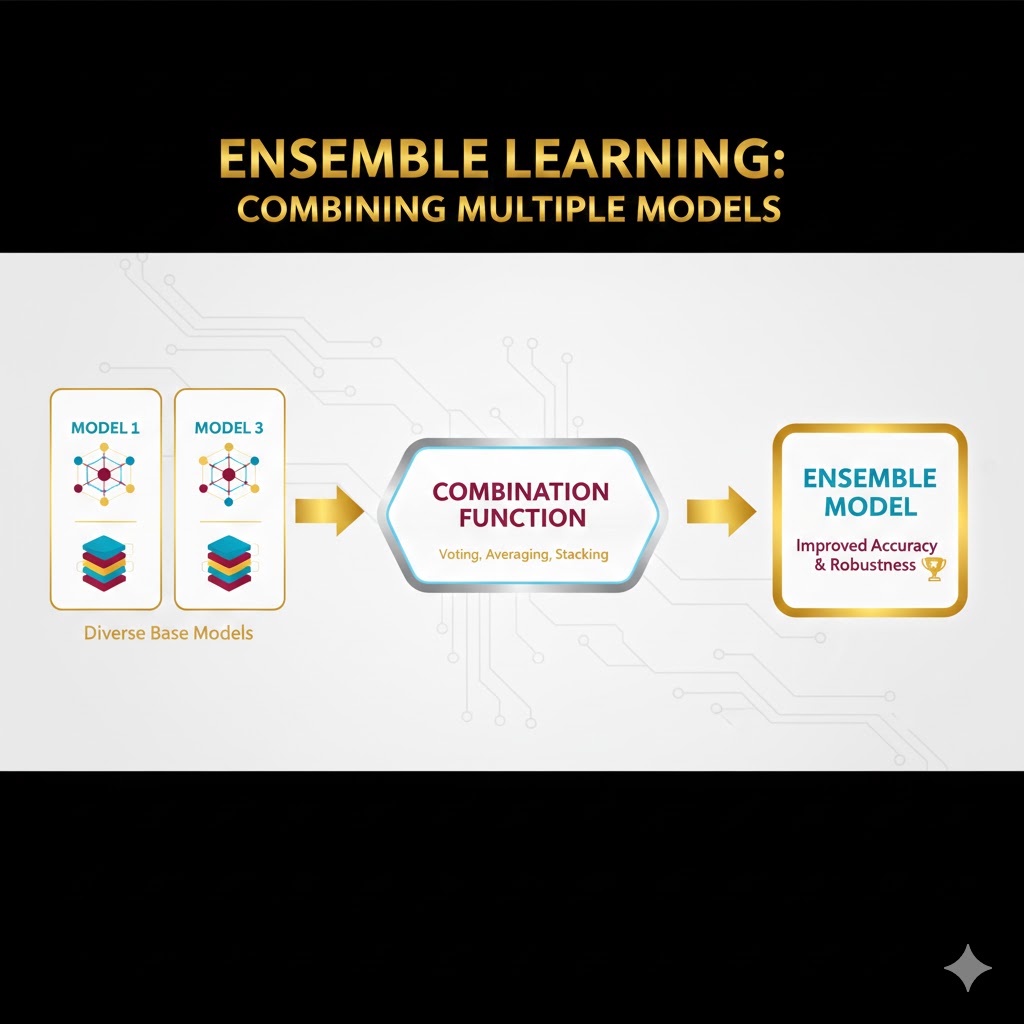
این فرآیند هوشمندانه در ۳ مرحله کلیدی انجام میشود:
مرحله ۱: تیمسازی (انتخاب مدلهای پایه)
همه چیز با استخدام اعضای تیم یا همان یادگیرندههای پایه (Base Learners) شروع میشود. در این مرحله، ما معماری تیم را تعیین میکنیم:
الف) تیم یکدست (Homogenous)
در این حالت، تمام اعضای تیم از یک جنس هستند.
- مثال: استخدام ۱۰۰ عدد «درخت تصمیم» که همگی ساختار مشابهی دارند.
- کاربرد: این روش پایه و اساس تکنیک Bagging (مثل جنگل تصادفی) است.
ب) تیم متنوع (Heterogenous)
در این حالت، اعضای تیم تخصصهای متفاوتی دارند.
- مثال: کنار هم قرار دادن یک «شبکه عصبی» (برای درک پیچیدگی)، یک «SVM» (برای مرزبندی دقیق) و یک «درخت تصمیم» (برای قوانین ساده).
- کاربرد: این روش معمولاً در تکنیک Stacking استفاده میشود.
نکته: راز موفقیت این تیم در تنوع (Diversity) است. اگر همه اعضا یکجور فکر کنند، همگی یک اشتباه را تکرار خواهند کرد. ما به مدلهایی نیاز داریم که نقاط کورِ متفاوتی داشته باشند تا همدیگر را پوشش دهند.
مرحله ۲: فرآیند آموزش (موازی یا متوالی)
حالا که تیم تشکیل شد، نوبت آموزش است. بسته به استراتژی ما، دو روش وجود دارد:
۱. استراتژی موازی (Parallel)- سبکِ Bagging
در این روش، دموکراسی برقرار است و مدلها مستقل از هم کار میکنند.
- روش کار: ما دادهها را با تکنیک بوتاسترپ (Bootstrap) تکهتکه میکنیم و به هر مدل یک بخش متفاوت میدهیم.
- ویژگی: همه مدلها همزمان آموزش میبینند و هیچکس منتظر دیگری نیست.
- هدف نهایی: کاهش حساسیت بیشازحد و کم کردن واریانس مدل.
۲. استراتژی متوالی (Sequential) – سبکِ Boosting
در این روش، سلسلهمراتب وجود دارد و مدلها وابسته به هم هستند.
- روش کار:
- مدل اول آموزش میبیند و اشتباهاتی میکند.
- مدل دوم ساخته میشود تا فقط روی اصلاح اشتباهات مدل اول تمرکز کند.
- این زنجیره ادامه مییابد تا خطا به صفر میل کند.
- هدف نهایی: کاهش خطای سیستماتیک و کم کردن بایاس مدل.
مرحله ۳: شورای تصمیمگیری (ترکیب نتایج)
تیم آموزش دید و حالا هر مدل نظر خودش را دارد. چطور به یک جواب واحد برسیم؟ سیستم رأیگیری (Voting) وارد عمل میشود.
برای مسائل طبقهبندی (مثلاً: آیا این ایمیل اسپم است؟)
- رأیگیری اکثریت (Majority Voting): دموکراسی ساده! هر مدل یک رأی میدهد. گزینهای که بیشترین طرفدار را داشته باشد، برنده است.
- مثال: ۷ مدل میگویند «اسپم» و ۳ مدل میگویند «سالم» ⬅ نتیجه: اسپم.
- رأیگیری وزنی (Weighted Voting): شایستهسالاری! رأی مدلهای باهوشتر (که در دوران آموزش خطای کمتری داشتهاند) ضریب بیشتری میگیرد و حرفشان برو دارد.
برای مسائل رگرسیون (مثلاً: قیمت این خانه چقدر است؟)
- میانگینگیری (Averaging): عدد پیشنهادی تمام مدلها جمع و بر تعداد تقسیم میشود تا به یک قیمت متعادل برسیم.
مثال جامع : خرید خانه هوشمند
برای اینکه قدرت یادگیری گروهی را کاملاً درک کنید، بیایید مثال مسابقه تلویزیونی را کنار بگذاریم و به سراغ یک سناریوی واقعیتر و دقیقتر برویم: تخمین قیمت یک خانه قدیمی برای خرید.
فرض کنید میخواهید یک خانه بخرید و نمیدانید قیمت واقعی آن چقدر است. اگر فقط از “بنگاهدار محله” بپرسید (مدل تکی)، ممکن است اشتباه کند. پس از استراتژی Ensemble استفاده میکنید:
۱. تشکیل تیم (Heterogenous)
شما سه کارشناس مختلف استخدام میکنید:
- کارشناس A (مهندس عمران): فقط به اسکلت و فونداسیون نگاه میکند.
- کارشناس B (طراح دکوراسیون): فقط به زیبایی، نور و نقشه داخلی توجه دارد.
- کارشناس C (تحلیلگر اقتصادی): فقط به قیمت زمین در منطقه و تورم بازار نگاه میکند.
۲. آموزش و تحلیل (Parallel Processing)
هر کدام از این کارشناسان، مستقل از هم (موازی) خانه را بررسی میکنند:
- مهندس عمران میبیند لولهها پوسیدهاند (امتیاز منفی).
- طراح میبیند نقشه عالی است (امتیاز مثبت).
- تحلیلگر میبیند محله رو به رشد است (امتیاز مثبت).
۳. تصمیمگیری نهایی (Weighted Voting)
حالا نوبت شماست که نظرات را ترکیب کنید. اما شما میدانید که در خرید خانه قدیمی، اسکلت ساختمان مهمتر از زیبایی است.
- پس به رأی مهندس عمران ضریب ۲ (وزن بیشتر) میدهید.
- به رأی طراح ضریب ۱ میدهید.
نتیجه: با اینکه طراح و تحلیلگر راضی هستند، اما چون مهندس عمران (با وزن بالا) مخالفت کرده، برآیند نظرات به شما میگوید: نخرید!
این دقیقاً کاری است که یادگیری گروهی انجام میدهد: ترکیب تخصصهای مختلف با وزندهی هوشمند برای رسیدن به کمریسکترین تصمیم.
انواع مدلهای گروهی( موازی یا متوالی)
در دنیای یادگیری ماشین، روشهای گروهی به دو دسته اصلی تقسیم میشوند:
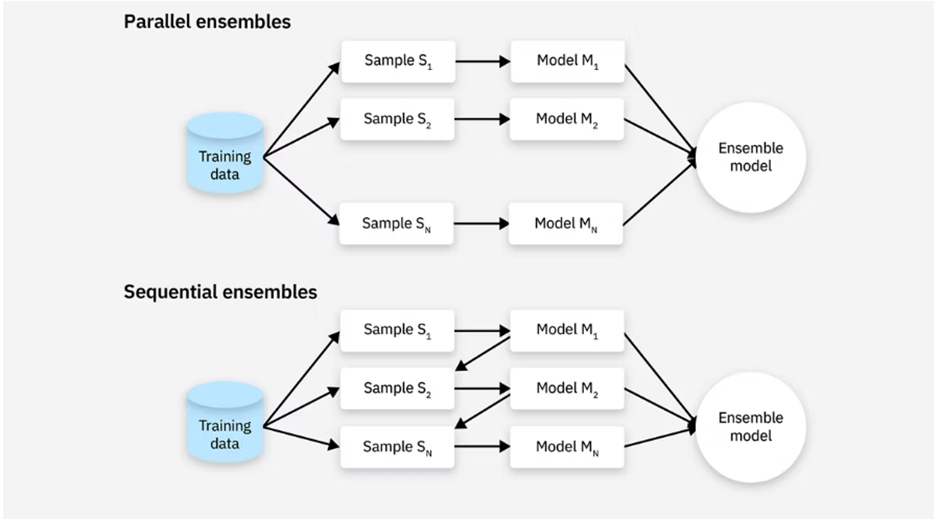
۱. روشهای موازی (Parallel)
همانطور که از نامش پیداست، در این روش مدلهای پایه به صورت مستقل و همزمان آموزش میبینند. چون مدلها کاری به کار هم ندارند، میتوان آنها را موازی اجرا کرد.
- انواع:
- همگن (Homogenous): همه مدلها از یک نوع الگوریتم هستند (مثلاً ۱۰ تا درخت تصمیم).
- ناهمگن (Heterogenous): مدلها از الگوریتمهای مختلفی هستند (مثلاً یکی SVM، یکی شبکه عصبی، یکی درخت تصمیم).
۲. روشهای متوالی (Sequential)
در این روش، مدلها مثل حلقههای زنجیر به هم وصل هستند. هر مدل جدید ساخته میشود تا اشتباهات مدل قبلی را اصلاح کند. این فرآیند مرحلهبهمرحله پیش میرود.
چگونه مدلها با هم تصمیم میگیرند؟
فرض کنید ۵ مدل مختلف دارید. چطور نظرات آنها را یکی میکنید؟ یکی از رایجترین روشها رأیگیری (Voting) است.
رأیگیری اکثریت (Majority Voting):
- در مسائل طبقهبندی (مثلاً تشخیص ایمیل اسپم)، هر مدل نظرش را میگوید. گزینهای که بیشترین رأی را بیاورد، برنده است.
- مثال: اگر ۳ مدل بگویند «اسپم» و ۲ مدل بگویند «سالم»، نتیجه نهایی «اسپم» خواهد بود.
رأیگیری وزنی (Weighted Voting):
- در این روش، نظر همه مدلها ارزش یکسانی ندارد. مدلهای باهوشتر (که در گذشته دقیقتر بودهاند)، رأیشان ضریب بیشتری دارد.
تکنیکهای محبوب یادگیری گروهی (Bagging, Boosting, Stacking)
بیایید سه غولِ دنیای یادگیری گروهی را بشناسیم که تفاوت روشهای موازی، متوالی، همگن و ناهمگن را نشان میدهند.
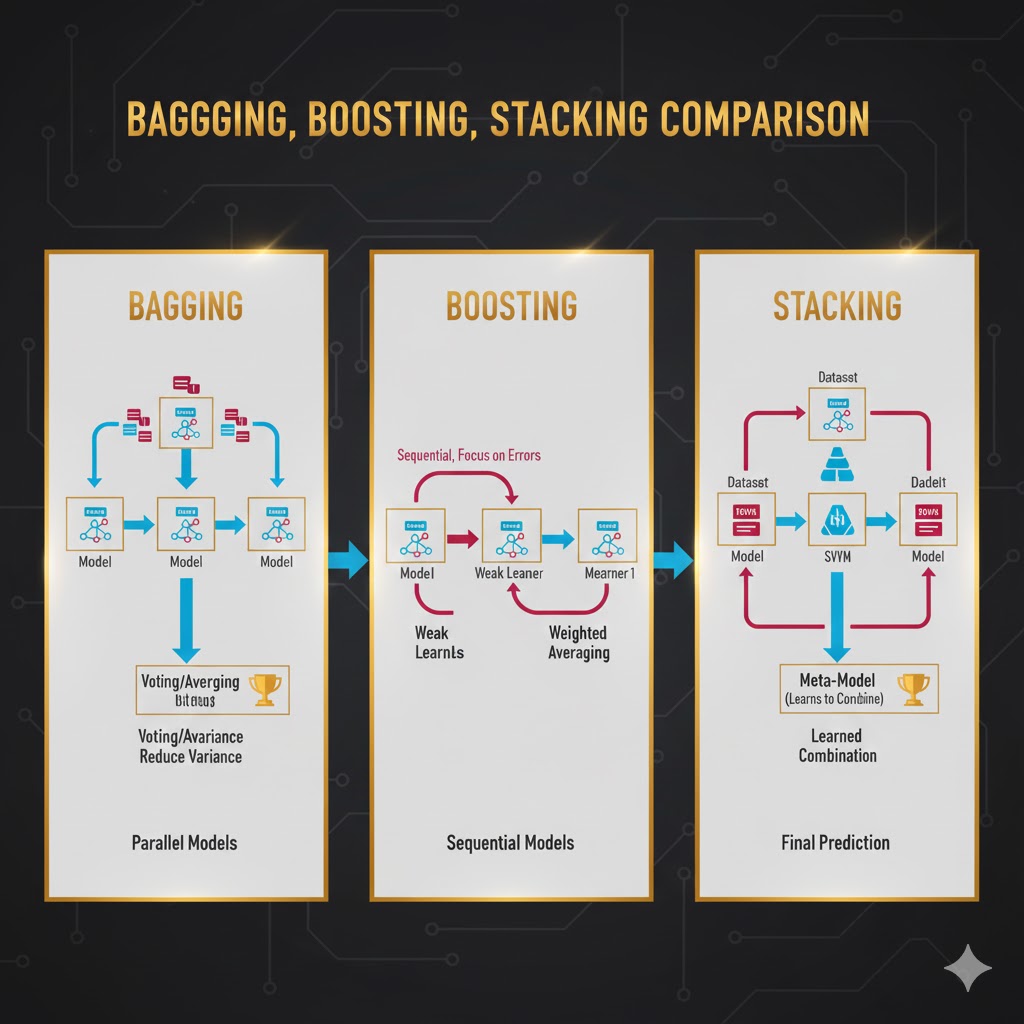
۱. بگینگ (Bagging) -اتحاد در رأیگیری
این یک روش موازی و همگن است. نام آن مخفف Bootstrap Aggregating است.
- چطور کار میکند؟ ما از یک دیتاست اصلی، چندین زیرمجموعه تصادفی (با جایگذاری) میسازیم. سپس روی هر زیرمجموعه، یک مدل مشابه (مثلاً درخت تصمیم) آموزش میدهیم.
- تکنیک بوتاسترپ (Bootstrap): یعنی ساخت نمونههای تکراری از دادهها. مثلاً اگر ۱۰ داده داریم، ۱۰ بار انتخاب تصادفی میکنیم؛ ممکن است داده شماره ۵ سه بار انتخاب شود و داده شماره ۲ اصلاً انتخاب نشود.
- جنگل تصادفی (Random Forest): معروفترین مثال بگینگ است. فرقش با بگینگ معمولی این است که علاوه بر دادهها، ویژگیها (Features) را هم به صورت تصادفی انتخاب میکند تا درختها متنوعتر شوند.
۲. استکینگ -(Stacking) لایهبندی هوشمند
این یک روش موازی و ناهمگن است که به آن فرا-یادگیری (Meta-learning) هم میگویند.
- چطور کار میکند؟
- چندین مدل مختلف (مثلاً KNN، SVM و درخت تصمیم) روی دادهها آموزش میبینند.
- پیشبینیهای این مدلها جمعآوری میشود.
- یک مدل نهایی به نام Meta-learner آموزش میبیند که ورودیاش، پیشبینیهای مدلهای قبلی است.
- نکته حیاتی: برای آموزش مدل نهایی، باید از دادههایی استفاده کرد که مدلهای اولیه آنها را ندیدهاند (جلوگیری از Overfitting). استفاده از روش اعتبارسنجی متقابل (Cross-validation) در اینجا ضروری است.
۳. بوستینگ (Boosting)- یادگیری از اشتباهات
این یک روش متوالی است. هدفش تبدیل مدلهای ضعیف به یک مدل قوی است.
- چطور کار میکند؟
- مدل اول آموزش میبیند (معمولاً با خطای زیاد).
- مدل دوم روی دادههایی تمرکز میکند که مدل اول در آنها اشتباه کرده است.
- این روند تکرار میشود و در نهایت همه مدلها با هم ترکیب میشوند.
- انواع مشهور:
- AdaBoost: به دادههای سخت (که اشتباه پیشبینی شدهاند) وزن بیشتری میدهد تا مدل بعدی مجبور شود آنها را یاد بگیرد.
- Gradient Boosting: به جای وزندهی، سعی میکند خطای باقیمانده (Residual Error) از مدل قبلی را پیشبینی و اصلاح کند.
- XGBoost: نسخه بهینهشده و فوقسریع گرادیان بوستینگ است که در پایتون بسیار محبوب است.
مثال
۱. مثال بگینگ (Bagging): شورای پزشکان عمومی
سناریو: ما نمیخواهیم ریسک کنیم و فقط نظر یک پزشک را بپرسیم.
- روش کار: ما ۱۰ پزشک عمومی (مدلهای همگن/مشابه) استخدام میکنیم.
- تکنیک بوتاسترپ: به جای اینکه کل پرونده بیمار (دیتاست کامل) را به همه بدهیم، به هر پزشک به صورت تصادفی بخشی از پرونده را میدهیم. مثلاً پزشک اول آزمایش خون و فشار را میبیند، پزشک دوم نوار قلب و شرح حال را میبیند.
- نتیجه نهایی (رأیگیری): هر پزشک تشخیص خودش را مینویسد (مثلاً ۶ نفر میگویند آنفولانزا، ۴ نفر میگویند مسمومیت).
- تصمیم: چون اکثریت گفتهاند «آنفولانزا»، تشخیص نهایی آنفولانزا است.
- نکته: این روش واریانس را کم میکند؛ یعنی اگر یک پزشک روی یک آزمایش خاص حساسیت زیادی نشان دهد، رأی بقیه آن را خنثی میکند. (مثال واقعی: Random Forest)
۲. مثال استکینگ (Stacking): تیم متخصصان و رئیس کل
سناریو: پرونده بیمار خیلی پیچیده است و پزشکان عمومی کافی نیستند. ما به تخصصهای مختلف نیاز داریم.
- روش کار: ما سه متخصص کاملاً متفاوت (مدلهای ناهمگن) میآوریم:
- رادیولوژیست (مدل SVM): فقط عکسها را تحلیل میکند.
- متخصص خون (مدل KNN): فقط اعداد آزمایش خون را بررسی میکند.
- پزشک داخلی (درخت تصمیم): علائم ظاهری را چک میکند.
- فرا-یادگیری (Meta-learner): این سه متخصص تشخیص نهایی نمیدهند؛ بلکه گزارش خود را به رئیس بیمارستان میدهند.
- نتیجه نهایی: رئیس بیمارستان (مدل نهایی) یاد گرفته که: هر وقت رادیولوژیست میگوید سرطان و متخصص خون میگوید عفونت، معمولاً حق با رادیولوژیست است. او وزندهی میکند و نظر نهایی را صادر میکند.
- نکته: اینجا هوشمندیِ ترکیب نظرات متفاوت، کلید موفقیت است.
۳. مثال بوستینگ (Boosting): شاگرد و استاد (اصلاح گامبهگام)
سناریو: میخواهیم با اصلاح خطاهایمان، دقیقترین تشخیص را بدهیم.
- گام اول: پزشک اول (یک کارآموز) بیمار را میبیند. او تشخیص میدهد «سرماخوردگی»، اما در تفسیر نوار قلب اشتباه میکند.
- گام دوم: پزشک دوم میآید. او کل پرونده را دوباره نمیخواند، بلکه تمرکز (وزندهی) خود را میگذارد روی همان نوار قلبی که پزشک اول در آن خطا داشت. او خطا را اصلاح میکند اما شاید در تشخیص عفونت ریه ضعیف عمل کند.
- گام سوم: پزشک سوم میآید و تمرکزش را میگذارد روی خطای پزشک دوم (عفونت ریه).
- نتیجه نهایی: تشخیص نهایی حاصل جمعبندی این زنجیره است که هر نفر ضعف نفر قبلی را پوشش داده است.
- نکته: این روش بایاس را کم میکند و یک مدل قوی از دلِ چندین مدل معمولی بیرون میکشد. (مثال واقعی: XGBoost)
مزایا
بر اساس متون تخصصی، استفاده از روش یادگیری گروهی مزایای زیر را به همراه دارد:
- کاهش بیشبرازش (Reduction in Overfitting): با تجمیع پیشبینیهای چندین مدل، آنسامبلها میتوانند بیشبرازشی که مدلهای پیچیده تکی ممکن است از خود نشان دهند، کاهش دهند.
- بهبود تعمیمپذیری (Improved Generalization): این روش با به حداقل رساندن واریانس و بایاس، روی دادههای دیدهنشده (Unseen data) بهتر عمل میکند.
- افزایش دقت (Increased Accuracy): ترکیب چندین مدل، دقت پیشبینی بالاتری نسبت به یک مدل واحد ارائه میدهد.
- مقاومت در برابر نویز (Robustness to Noise): با میانگینگیری از پیشبینیهای مدلهای متنوع، اثر دادههای پرت، نویزی یا نادرست تعدیل میشود.
- انعطافپذیری (Flexibility): این روش میتواند با مدلهای متنوعی از جمله درخت تصمیم، شبکههای عصبی و ماشینهای بردار پشتیبان (SVM) کار کند و آنها را بسیار سازگار نماید.
معایب
با وجود قدرت بالا، این روشها بینقص نیستند:
- پیچیدگی محاسباتی و هزینه بالا: آموزش همزمان ۱۰۰ مدل (مثل جنگل تصادفی) یا آموزش متوالی آنها (مثل Boosting) به قدرت پردازشی، رم و زمان بسیار بیشتری نسبت به یک مدل تکی نیاز دارد.
- کاهش تفسیرپذیری (Black Box): توضیح دادن یک درخت تصمیم آسان است (اگر سن < ۲۰ و درآمد < ۱۰… )، اما توضیح دادن نتیجهای که حاصل رأیگیری ۱۰۰۰ درخت مختلف است، برای انسان و مدیران کسبوکار بسیار دشوار است.
- کندی در زمان اجرا (Inference Time): در سیستمهایی که نیاز به پاسخ در میلیثانیه دارند (مثل ترمز اضطراری خودرو)، پردازش تمام مدلهای گروهی ممکن است کند باشد.
کاربردهای صنعتی یادگیری گروهی
- امور مالی و بانکداری: برای امتیازدهی اعتباری (Credit Scoring) و تشخیص تقلب. بانکها از XGBoost برای ترکیب صدها فاکتور مالی مشتری استفاده میکنند تا احتمال بازپرداخت وام را بسنجند.
- پزشکی و سلامت: تشخیص بیماریهایی مثل سرطان یا دیابت. ترکیب نظرات چندین مدل روی تصاویر MRI یا آزمایش خون، دقت تشخیص را به شدت بالا میبرد و خطای انسانی را کم میکند.
- تجارت الکترونیک: سیستمهای پیشنهاد دهنده (Recommender Systems) در نتفلیکس یا آمازون معمولاً ترکیبی از چندین مدل هستند تا سلیقه شما را دقیقتر حدس بزنند.
- امنیت سایبری: تشخیص حملات DDoS یا بدافزارها با بررسی ترافیک شبکه و شناسایی الگوهای ناهنجار توسط آنسامبلها.
مطالعات موردی
برای درک بهتر، بیایید سه سناریوی واقعی را بررسی کنیم:
۱: مسابقه نتفلیکس (Netflix Prize)
- چالش: نتفلیکس ۱ میلیون دلار جایزه برای کسی تعیین کرد که بتواند الگوریتم پیشنهاد فیلمش را ۱۰٪ بهبود دهد.
- راهکار: تیم برنده از یک مدل تکی استفاده نکرد. آنها از تکنیک Stacking استفاده کردند که ترکیبی از بیش از ۱۰۰ مدل مختلف (شامل ماتریس فاکتوریزاسیون، ماشینهای بولتزمن و…) بود.
- نتیجه: قدرت یادگیری گروهی ثابت کرد که ترکیب مدلهای متنوع، همیشه برنده است.
۲: پیشبینی ریزش مشتری در مخابرات (Customer Churn)
- چالش: یک اپراتور موبایل میخواست بداند کدام مشتریان قصد دارند سیمکارت خود را بسوزانند و به اپراتور رقیب بروند.
- راهکار: استفاده از. XGBoost این مدل توانست الگوهای پیچیده و غیرخطی (مثل رابطه بین تعداد تماسهای قطع شده و نارضایتی مشتری) را بهتر از رگرسیون لجستیک ساده شناسایی کند.
- نتیجه: شناسایی دقیق ۸۵٪ از مشتریان ناراضی و ارائه تخفیف به موقع به آنها.
۳: تشخیص کووید-۱۹ از روی صدای سرفه
- چالش: تشخیص سریع کرونا بدون تست PCR .
- راهکار: محققان چندین مدل یادگیری عمیق (CNN) را آموزش دادند که هر کدام روی ویژگیهای خاصی از صدا (فرکانس، شدت، ریتم) تمرکز داشتند. سپس با روش Majority Voting (رأیگیری اکثریت) خروجیها را ترکیب کردند.
- نتیجه: این سیستم توانست با دقتی بالاتر از هر مدل تکی، بیماران مثبت را از روی فایل صوتی سرفه تشخیص دهد.
نتیجه گیری
یادگیری گروهی نشان میدهد که در یادگیری ماشین، بهترین نتایج معمولاً از همکاری چند مدل به دست میآیند، نه از تکیه بر یک مدل واحد. با ترکیب هوشمندانهی پیشبینیهای چند مدل، میتوان میزان خطا را کاهش داد، پایداری سیستم را افزایش داد و عملکرد مطمئنتری روی دادههای جدید به دست آورد. این رویکرد بهویژه در ایجاد تعادل میان بایاس و واریانس نقشی اساسی دارد.
در این میان، روشهایی مانند Bagging با تمرکز بر کاهش واریانس، Boosting با هدف کاهش بایاس و Stacking با ادغام دیدگاههای متنوع، هرکدام به شیوهای متفاوت کیفیت مدل نهایی را بهبود میدهند. به همین دلیل، بسیاری از سیستمهای موفق هوش مصنوعی در دنیای واقعی—از امتیازدهی اعتباری و تشخیص بیماری گرفته تا سیستمهای توصیهگر و امنیت سایبری—بر پایهی یادگیری گروهی طراحی شدهاند.
البته یادگیری گروهی همیشه بهترین انتخاب نیست. هزینهی محاسباتی بالاتر، کاهش تفسیرپذیری مدل و پیچیدگی در پیادهسازی از چالشهای این رویکرد به شمار میروند. با این حال، هر زمان که دقت بالا، پایداری نتایج و کاهش ریسک خطا اهمیت داشته باشد، یادگیری گروهی یکی از هوشمندانهترین گزینههاست؛ رویکردی که نشان میدهد ترکیب چند تصمیم خوب، اغلب از یک تصمیم بهظاهر عالی، نتیجهای قابلاعتمادتر به همراه دارد.