

مقدمه
محققان برای مدلسازی الگوهای پیچیده و پیشبینی مسائل دشوار، به سراغ الگوریتمهایی رفتهاند که مستقیماً از عملکرد مغز انسان الهام گرفته شدهاند: شبکههای عصبی مصنوعی (ANN).
این تکنولوژی که یکی از ستونهای اصلی یادگیری عمیق (Deep Learning) است، از مفهوم شبکههای عصبی بیولوژیکی نشأت گرفته است. امروزه، این شبکهها جزو قدرتمندترین الگوریتمهای یادگیری ماشین در جهان محسوب میشوند. در واقع، توسعه ANN تلاشی بود برای کپیبرداری از طرز کار مغز انسان. اگرچه عملکرد آنها کاملاً با هم یکسان نیست، اما شباهتهای بسیار زیادی دارند. البته یک نکته فنی وجود دارد: الگوریتمهای پایه ANN معمولاً فقط دادههای عددی و ساختاریافته را قبول میکنند.
.
در این مقاله چه میخوانیم؟
این مقاله سفری است به دنیای شبکههای عصبی در یادگیری ماشین.
- ما بررسی میکنیم که چگونه نسخههای پیشرفتهتر مثل CNN (کانولوشنال) و RNN (بازگشتی) میتوانند دادههای بدون ساختار مثل تصاویر، متن و صدا را پردازش کنند.
- شما با الفبای شبکههای عصبی، معماری آنها و انواع مختلفشان آشنا خواهید شد.
- همچنین کاربردهای آنها در هوش مصنوعی را مرور خواهیم کرد.
اهداف یادگیری :
- درک عمیق: فهمیدن مفهوم و معماری شبکههای عصبی مصنوعی .(ANN)
- شناخت انواع: آشنایی با انواع مختلف شبکهها مثل پیشخور (Feedforward)، کانولوشنال (Convolutional) و بازگشتی (Recurrent).
- تجربه عملی: دستبهکد شدن و ساختن یک مدل ANN ساده با استفاده از Python و کتابخانه Keras.
تعریف
بیایید ساده شروع کنیم: شبکههای عصبی مصنوعی (ANNs) در واقع تلاشی هستند برای اینکه به سیستمهای کامپیوتری یاد بدهیم دقیقاً مثل مغز انسان فکر کنند و دادهها را پردازش نمایند.
در این سیستمها، واحدهایی به نام نورون وجود دارند که مثل یک تیم هماهنگ به هم متصلاند. آنها با همکاری یکدیگر الگوها را شناسایی میکنند، از دادهها دانش استخراج میکنند و در نهایت پیشبینی انجام میدهند. امروزه ردپای ANNها را همه جا میبینید؛ از تشخیص تصاویر (مثل باز شدن قفل گوشی با چهره) تا پردازش زبان و تصمیمگیریهای هوشمند.
درست مانند مغز ما، این شبکهها هم از نورونهایی تشکیل شدهاند که به هم متصل هستند. هر نورون اطلاعات را از همسایهاش میگیرد، آن را پردازش میکند و نتیجه را به نورون بعدی پاس میدهد.
.
ریاضیات پشت پرده: داخل یک نورون چه میگذرد؟
شاید بپرسید این پردازش دقیقاً چطور انجام میشود؟

به زبان ریاضی، هر نورون مصنوعی از فرمول زیر پیروی میکند:
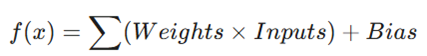
در اینجا:
- ورودیها (Inputs): دادههای خام هستند.
- وزنها (Weights): نشاندهنده اهمیت هر ورودی هستند.
- بایاس (Bias): مثل عرض از مبدأ در معادله خط عمل میکند. بایاس به مدل اجازه میدهد حتی وقتی تمام ورودیها صفر هستند، فعال شود یا نمودار پاسخ را جابجا کند تا تطبیق بهتری با دادهها داشته باشد.
- نهایتاً مجموع اینها وارد یک تابع فعالسازی میشود تا خروجی نهایی تولید شود.
معماری شبکه عصبی مصنوعی
اگر بخواهیم نقشه ساختمانی یک شبکه عصبی را بکشیم، با سه طبقه (لایه) اصلی روبرو میشویم:
- لایه ورودی (Input Layer):دروازه ورود اطلاعات.
- لایه(های) پنهان(Hidden Layer): موتورخانه شبکه که پردازشهای اصلی آنجا انجام میشود (معمولاً بیش از یک لایه است).
- لایه خروجی(Output Layer): جایی که نتیجه نهایی تحویل داده میشود.
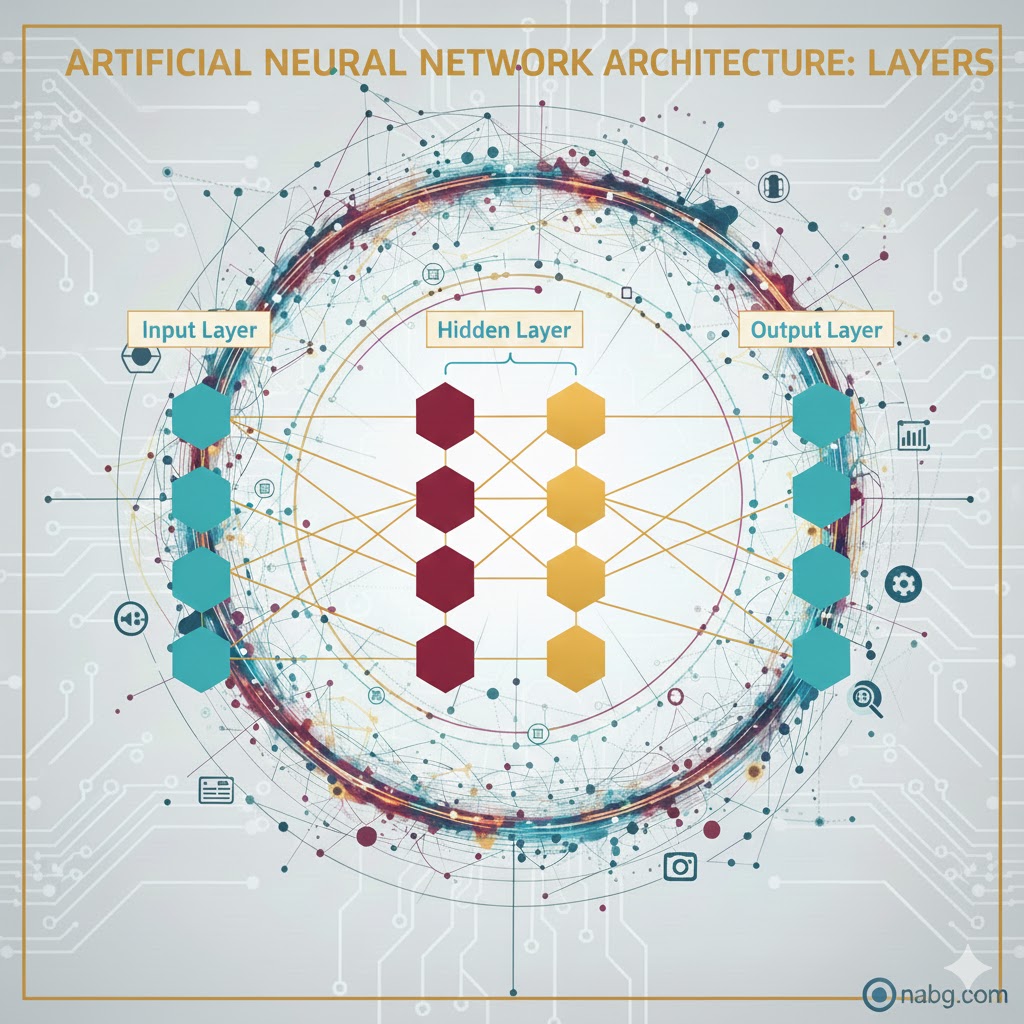
در یک شبکه معمولی که به آن پیشخور (Feedforward) میگویند، اطلاعات فقط در یک مسیر حرکت میکند: از ورودی به سمت خروجی (بدون برگشت به عقب). به دلیل وجود لایههای متعدد در این ساختار، گاهی به آن پرسپترون چندلایه (MLP) هم گفته میشود.
.
لایه پنهان: دستگاه تقطیر اطلاعات
بیایید لایه پنهان (Hidden Layer) را مثل یک دستگاه تقطیر یا یک صافی هوشمند تصور کنیم. وظیفه این لایه چیست؟ این است که مهمترین و مرتبطترین الگوها را از میان انبوه ورودیها بیرون بکشد و آنها را برای تحلیلهای بعدی به لایه بعد بفرستد.
این فرآیند باعث میشود شبکه ما سریعتر و کارآمدتر شود؛ چرا؟ چون یاد میگیرد که فقط روی اطلاعات ارزشمند تمرکز کند و اطلاعات اضافی و بهدردنخور (Redundant) را دور بریزد.
.
نقش کلیدی تابع فعالسازی
حالا نوبت به تابع فعالسازی میرسد. این تابع به دو دلیل بسیار حیاتی است:
- روشن کردن نورونها: این تابع تصمیم میگیرد که آیا یک نورون باید فعال (روشن) شود یا نه. در واقع به تبدیل ورودی خام به یک خروجی نهایی و قابلاستفاده کمک میکند.
- درک پیچیدگیها (روابط غیرخطی): این مدل به شبکه اجازه میدهد تا روابط پیچیده و غیرخطی بین ورودیها را درک کند. (بدون این تابع، شبکه عصبی فقط یک خط صاف و ساده را میفهمد و نمیتواند مسائل واقعی و پیچیده دنیا را حل کند).
.
توابع فعالسازی رایج: کلیدهای تصمیمگیری شبکه
(Activation Functions) قهرمانان خاموش شبکههای عصبی هستند. چرا؟ چون آنها خاصیت غیرخطی (Non-linearity) را به شبکه تزریق میکنند. بدون آنها، شبکه فقط خطهای صاف را میفهمد، اما با وجود آنها، میتواند الگوهای پیچیده و منحنیهای دشوار را یاد بگیرد.

بیایید با معروفترین این توابع آشنا شویم:
۱. تابع سیگموید (Sigmoid)
- رفتار: خروجی را بین ۰ و ۱ فشرده میکند.
- کاربرد: عالی برای دستهبندی دودویی. (Binary Classification) مثلاً وقتی میخواهید مدل فقط بگوید: آیا این عکس گربه هست یا نه؟ (بله/خیر).
.
۲. تابع ReLU (واحد خطی اصلاحشده)
- رفتار: اگر ورودی مثبت باشد، خودِ عدد را عبور میدهد؛ اگر منفی باشد، خروجی صفر میشود.
- ویژگی: محبوبترین انتخاب برای لایههای پنهان. این تابع به حل مشکل معروف محو شدن گرادیان (Vanishing Gradient) کمک میکند و سرعت آموزش را بالا میبرد.
.
۳. تابع Tanh (تانژانت هیپربولیک)
- رفتار: شبیه سیگموید است، اما خروجی را بین ۱– و ۱ تنظیم میکند.
- کاربرد: در لایههای پنهان استفاده میشود؛ بهویژه زمانی که به طیف وسیعتری از خروجی (شامل اعداد منفی) نیاز داریم.
.
۴. تابع سافتمکس (Softmax)
- رفتار: خروجیهای خام را به احتمالات تبدیل میکند (مجموع خروجیها برابر با ۱ میشود).
- کاربرد: معمولاً در لایه آخر (خروجی) شبکههایی استفاده میشود که باید بین چند کلاس مختلف انتخاب کنند (مثلاً: این عکس گربه است، یا سگ، یا پرنده؟).
.
۵. تابع Leaky ReLU
- رفتار: نوعی از ReLU است که کمی مهربانتر رفتار میکند! به جای اینکه ورودیهای منفی را کاملاً صفر کند، اجازه میدهد یک مقدار منفی بسیار کوچک عبور کند.
- ویژگی: این کار باعث جلوگیری از مشکل نورونهای مرده (Dead Neurons) در طول آموزش میشود (یعنی نورونها را زنده نگه میدارد).
.
یادگیری در شبکه عصبی:وزن ها چگونه تنظیم میشوند؟
.
پیدا کردن مقادیر بهینه برای W (وزنها)، کلید طلاییِ ساخت یک مدل موفق است. هدف اصلی چیست؟ به حداقل رساندن خطای پیشبینی. یعنی مدل ما کمترین اشتباه را داشته باشد.
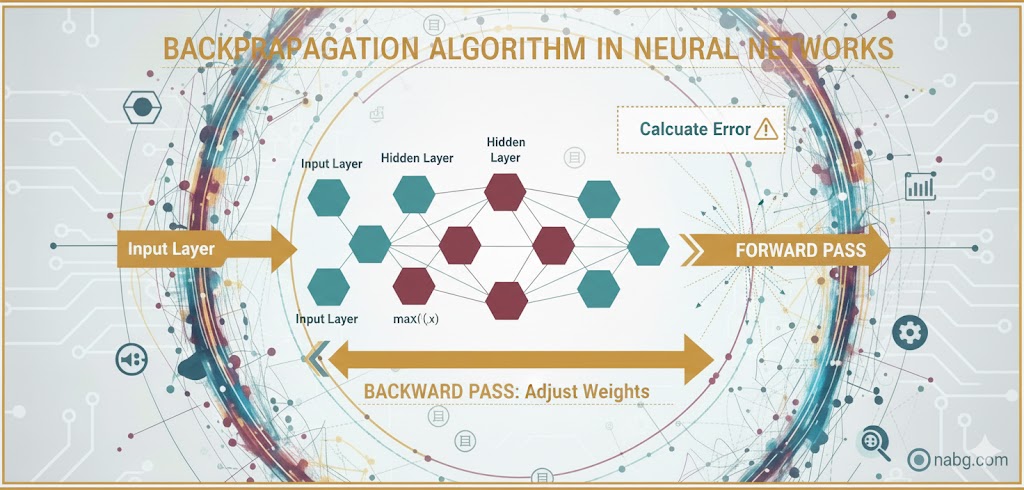
در اینجا با دو مفهوم قهرمان روبرو میشویم:
۱. الگوریتم پسانتشار(Backpropagation):
این همان روشی است که شبکههای عصبی با آن کار میکنند. این الگوریتم، یک شبکه عصبی معمولی را به یک شبکه یادگیرنده تبدیل میکند. چطور؟ با یادگیری از اشتباهات. تصور کنید شبکه یک پیشبینی غلط انجام میدهد؛ الگوریتم پسانتشار به عقب برمیگردد تا ببیند کجای کار اشتباه بوده و آن را اصلاح کند.
۲. گرادیان نزولی(Gradient Descent):
برای اینکه بفهمیم چقدر خطا داریم و چطور باید آن را کم کنیم، از تکنیک گرادیان نزولی استفاده میکنیم. این روش، سنگ بنای یادگیری نظارتشده (Supervised Learning) است.
این تغییرات کوچک و هوشمندانه با فرمول زیر انجام میشود:
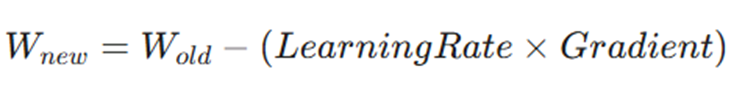
یعنی وزن جدید برابر است با وزن قبلی، منهایِ (نرخ یادگیری ضربدر شیب خطا). این فرمول تضمین میکند که ما همیشه در جهت کاهش خطا حرکت میکنیم (مثل پایین آمدن از کوه).
این روش چطور کار میکند؟ گرادیان نزولی مدام وزنها را دستکاری و تنظیم میکند تا خطا کمتر و کمتر شود.
- ما تغییرات بسیار کوچکی در مقدار W (وزن) ایجاد میکنیم.
- بررسی میکنیم که این تغییر کوچک چه تاثیری روی خطای پیشبینی گذاشت.
- این کار را آنقدر تکرار میکنیم تا به نقطهای برسیم که دیگر تغییر دادنِ W باعث کاهش خطا نشود.
- آن لحظه، ما مقدار ایدهآل W را پیدا کردهایم!
انواع اصلی شبکههای عصبی مصنوعی
دنیای شبکههای عصبی وسیع است، اما اگر بخواهیم مهمترین بازیکنان این زمین را بشناسیم، باید به سراغ این ۵ مورد برویم:
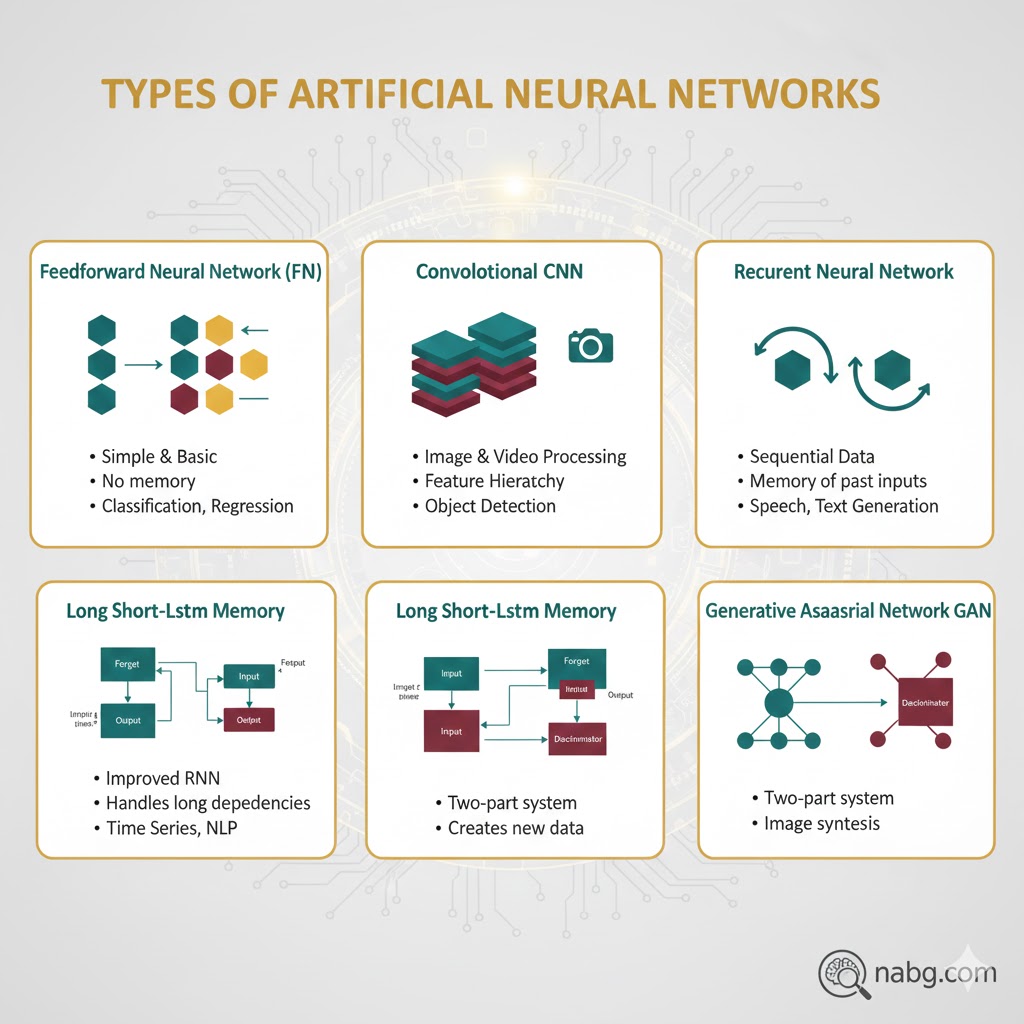
۱. شبکههای عصبی پیشخور(FNNs):
اینها سادهترین نوع شبکهها هستند. اطلاعات در آنها مثل یک خیابان یکطرفه جریان دارد: فقط از ورودی به خروجی.
- کاربرد: عالی برای شناسایی الگوهای ساده در دادهها یا پیشبینیهای مستقیم.
.
۲. شبکههای عصبی کانولوشنال(CNNs):
هر وقت اسم تصویر یا ویدیو آمد، یاد CNN بیفتید. این شبکهها دقیقاً برای درک تصاویر طراحی شدهاند.
- کاربرد: شناسایی الگوها در عکسها، تشخیص چهره و اشیاء در ویدیوها.
.
۳. شبکههای عصبی بازگشتی (RNNs):
این شبکهها حافظه دارند! آنها در پردازش دنبالهها (مثل کلمات در یک جمله) استاد هستند. RNN اطلاعات قبلی را به خاطر میسپارد تا دادههای فعلی را بهتر بفهمد.
- کاربرد: پیشبینی کلمه بعدی در تایپ، درک مفهوم متن.
.
۴. شبکههای حافظه کوتاه-مدتِ طولانی (LSTMs):
اینها نوع پیشرفتهتری از RNN هستند که برای به خاطر سپردن دنبالههای خیلی طولانی ساخته شدهاند. برخلاف RNN معمولی، اینها موضوع اصلی را در طول زمان فراموش نمیکنند.
- کاربرد: ترجمه زبانها (مثل گوگل ترنسلیت) یا تحلیل دادههای سری زمانی (مثل بورس).
.
۵. شبکههای مولد تخاصمی (GANs):
اینها جذابترین نوع هستند. مثل یک دوئل هنری میمانند: یک بخش تولید میکند (مثلاً موسیقی یا نقاشی) و بخش دیگر نقد میکند تا مطمئن شود نتیجه واقعی به نظر میرسد.
- کاربرد: خلق محتوای جدید (Generative AI)، افزایش کیفیت عکسها و ساخت دیپفیک (Deepfake).
.
شبکههای عصبی چطور یاد میگیرند؟ 🎓🧠
شاید بپرسید این تودههای کد و ریاضی چطور باهوش میشوند؟ بیایید مراحل یادگیری یک هوش مصنوعی را با مثال ربات و گربه مرور کنیم:
۱. نقطه شروع (مغز خالی): فرض کنید میخواهید مغز یک ربات را بسازید. در ابتدا، این ربات هیچ چیزی نمیداند. ما اتصالات بین نورونهایش را با مقادیر کاملاً تصادفی تنظیم میکنیم. (مثل نوزادی که تازه متولد شده).
۲. دیدن دادهها (کلاس درس): حالا وقت آموزش است. مثالهایی از چیزی که میخواهیم یاد بگیرد را نشانش میدهیم. مثلاً هزاران عکس گربه را جلوی چشمانش میگذاریم.
۳. حدس و خطا (تلاش اول): ربات با توجه به همان اتصالات تصادفی اولیهاش سعی میکند حدس بزند که چه میبیند. طبیعتاً اوایل کار اکثر حدسهایش غلط است (مثلاً به گربه میگوید سگ!).
۴. دریافت بازخورد (تصحیح معلم): شما به عنوان ناظر به او میگویید چقدر اشتباه کرده است. مثلاً: نه! این گربه نیست، سگ است. این بازخورد به ربات کمک میکند بفهمد کجای کارش ایراد داشته (این همان حلقههای بازخورد یا Feedback Loops است).
۵. تنظیم قدرتها (سیمکشی مجدد): این مهمترین بخش است. ربات بر اساس بازخوردی که گرفته، قدرت اتصالات مغزش را کمی تغییر میدهد (وزنها را کم و زیاد میکند). اگر اشتباه کرده بود، اتصالات را طوری تغییر میدهد که دفعه بعد شانس درست گفتنش بیشتر شود.
۶. تمرین، تمرین، تمرین (تکرار): ربات این چرخه را بارها تکرار میکند: دیدن مثالهای بیشتر، حدس زدن، بازخورد گرفتن و تنظیم کردن. آنقدر ادامه میدهد تا در شناسایی گربهها استاد شود.
۷. امتحان نهایی (تست): وقتی حس کردیم ربات آماده است، یک عکس جدید به او نشان میدهیم که قبلاً ندیده است. اگر بتواند درست تشخیص دهد که این گربه است یا نه، یعنی یادگیری با موفقیت انجام شده است!
مزایا و معایب شبکههای عصبی مصنوعی (ANN)
.
هیچ تکنولوژیای کامل نیست. شبکههای عصبی هم مثل هر ابزار دیگری، نقاط قوت درخشان و نقاط ضعف خاص خودشان را دارند. بیایید کفه ترازو را بسنجیم.
مزایای شبکههای عصبی
.
۱. انعطافپذیری در دادهها: الگوریتمهای ANN برای نمایش مسائل از جفتهای ویژگی-مقدار (Attribute-value) استفاده میکنند. این یعنی دستمان باز است! خروجی شبکه میتواند هر چیزی باشد: یک عدد گسسته (مثل دستهبندی)، یک عدد واقعی (مثل قیمت)، یا حتی برداری از چندین ویژگی مختلف.
۲. پوستکلفت در برابر نویز (Noise Tolerance): این یکی از جذابترین ویژگیهاست. نویز یا خطا در دادههای آموزشی برای ANN مشکل بزرگی نیست. حتی اگر در نمونههای آموزشی اشتباهاتی وجود داشته باشد، شبکه معمولاً میتواند آنها را نادیده بگیرد و روی نتیجه نهایی تاثیر منفی نگذارد.
۳. سرعت بالا در اجرا (پس از آموزش): وقتی شبکه آموزش دید، استفاده از آن بسیار سریع است. اگر نیاز به ارزیابی سریع تابع هدف دارید، ANN گزینه عالیای است.
نکته ظریف: اگرچه استفاده از مدل سریع است، اما توجه داشته باشید که تعداد زیاد وزنها و نمونههای آموزشی میتواند زمان آموزش (Training Period) را طولانی کند. اما پس از پایان آموزش، سرعت پاسخگویی بالاست.
.
معایب شبکههای عصبی
۱. وابستگی شدید به سختافزار (Hardware Dependence) شبکههای عصبی برای اجرا شدن نیاز به محاسبات سنگین و موازی دارند.
- نتیجه: ساخت و اجرای آنها نیازمند پردازندههای موازی (مثل GPUهای قدرتمند) است و بدون تجهیزات مناسب، کار لنگ میماند.
۲. مشکل جعبه سیاه (عدم درک عملکرد شبکه) این جدیترین نقد به ANN است. وقتی شبکه یک جواب به شما میدهد، نمیگوید چرا و چگونه به این نتیجه رسیده است.
- نتیجه: این عدم شفافیت باعث میشود اعتماد کردن به شبکه در مسائل حیاتی سخت شود (چون توضیحی برای تصمیمش ندارد).
۳. ساختار نامشخص (نبود قانون ثابت): هیچ فرمول دقیقی وجود ندارد که بگوید ساختار شبکه (تعداد لایهها و نورونها) باید دقیقاً چطور باشد.
- راه حل فعلی: مهندسان مجبورند از تجربه شخصی و روش آزمون و خطا استفاده کنند تا به ساختار مناسب برسند.
۴. مشکل تبدیل دادهها به عدد: شبکههای عصبی فقط زبان اعداد را میفهمند. قبل از هر کاری، شما باید مسائل دنیای واقعی را به مقادیر عددی تبدیل کنید.
- چالش: روشی که برای نمایش دادهها انتخاب میکنید، مستقیماً روی عملکرد شبکه تاثیر میگذارد و این کار نیاز به مهارت بالای کاربر دارد.
۵. عمر نامشخص شبکه (کی تمام میشود؟): معمولاً آموزش زمانی متوقف میشود که خطای شبکه به یک حد خاص کاهش یابد.
- چالش: اما این لزوماً به این معنی نیست که شبکه به بهترین حالت ممکن رسیده است. ما دقیقاً نمیدانیم نقطه ایدهآل کجاست و ممکن است در یک نقطه بهینه محلی گیر کرده باشیم.
کاربردهای شبکه عصبی مصنوعی
.
شاید ندانید، اما شبکههای عصبی (ANN) همین حالا هم در تار و پود زندگی روزمره ما تنیده شدهاند. بیایید ببینیم این مغزهای مصنوعی دقیقاً کجا مشغول به کارند:
۱. رسانههای اجتماعی
تا حالا فکر کردهاید اینستاگرام یا توییتر چطور دقیقاً میدانند چه دوستی را به شما پیشنهاد دهند یا چه محتوایی را دوست دارید؟
- جادوی ANN: شبکههای عصبی با تحلیل پروفایل، علایق و تعاملات شما، محتوای مرتبط و دوستان احتمالی را پیشنهاد میدهند.
- تبلیغات: همچنین در تبلیغات هدفمند نقش کلیدی دارند تا مطمئن شوند شما فقط تبلیغاتی را میبینید که واقعاً به سلیقهتان میخورد.
۲. بازاریابی و فروش
سایتهای بزرگی مثل آمازون (و دیجیکالا) از ANN استفاده میکنند تا وقتی یک کالا را میبینید، بگویند: شاید این را هم دوست داشته باشید!
- کارکرد: آنها تاریخچه جستجوی شما را شخم میزنند، رفتار مشتریان را پیشبینی میکنند و پیشنهادات را کاملاً شخصیسازی میکنند تا کمپینهای فروش موثرتر باشند.
۳. مراقبتهای بهداشتی و پزشکی
اینجا جایی است که ANN جان انسانها را نجات میدهد.
- تشخیص بیماری: آنها در پردازش تصاویر پزشکی (مثل MRI یا X-Ray) برای تشخیص بیماریهایی مثل سرطان استفاده میشوند و دقتی مشابه (و گاهی بهتر از) پزشکان دارند.
- پیشبینی: همچنین ریسکهای سلامتی را پیشبینی کرده و برنامههای درمانی شخصیسازی شده پیشنهاد میدهند.
۴. دستیارهای شخصی
سیری (Siri)، الکسا (Alexa) و گوگل اسیستنت مغزشان را از شبکههای عصبی قرض گرفتهاند.
- کارکرد: آنها زبان طبیعی ما را پردازش میکنند، دستورات صوتی را میفهمند و پاسخ میدهند. از تنظیم زنگ ساعت گرفته تا تماس گرفتن و پاسخ به سوالات عجیب و غریب ما!
۵. پشتیبانی مشتری
بخش زیادی از چتباتها و سیستمهای پاسخگویی خودکار توسط ANN مدیریت میشوند.
- مزیت: آنها سوالات مشتری را تحلیل میکنند و پاسخ دقیق میدهند. این کار باعث میشود صفهای انتظار کوتاهتر شود و کارایی سیستم بالا برود (خستگی هم برایشان معنا ندارد!).
۶. امور مالی (Finance) در دنیای پول، امنیت حرف اول را میزند.
- کارکرد: بانکها از ANN برای تشخیص کلاهبرداری (Fraud Detection)، امتیازدهی اعتباری (Credit Scoring) و پیشبینی روندهای بازار بورس استفاده میکنند. آنها حجم عظیمی از تراکنشها را زیر نظر دارند تا هرگونه ناهنجاری یا الگوی مشکوک را در لحظه شکار کنند.
پروژه عملی: ساخت یک شبکه عصبی ساده برای دیتاست تایتانیک 🚢🧠
در این آموزش، ما با هم یک مدل ANN میسازیم تا روی یکی از معروفترین دیتاستهای دنیا کار کنیم: دیتاست تایتانیک.
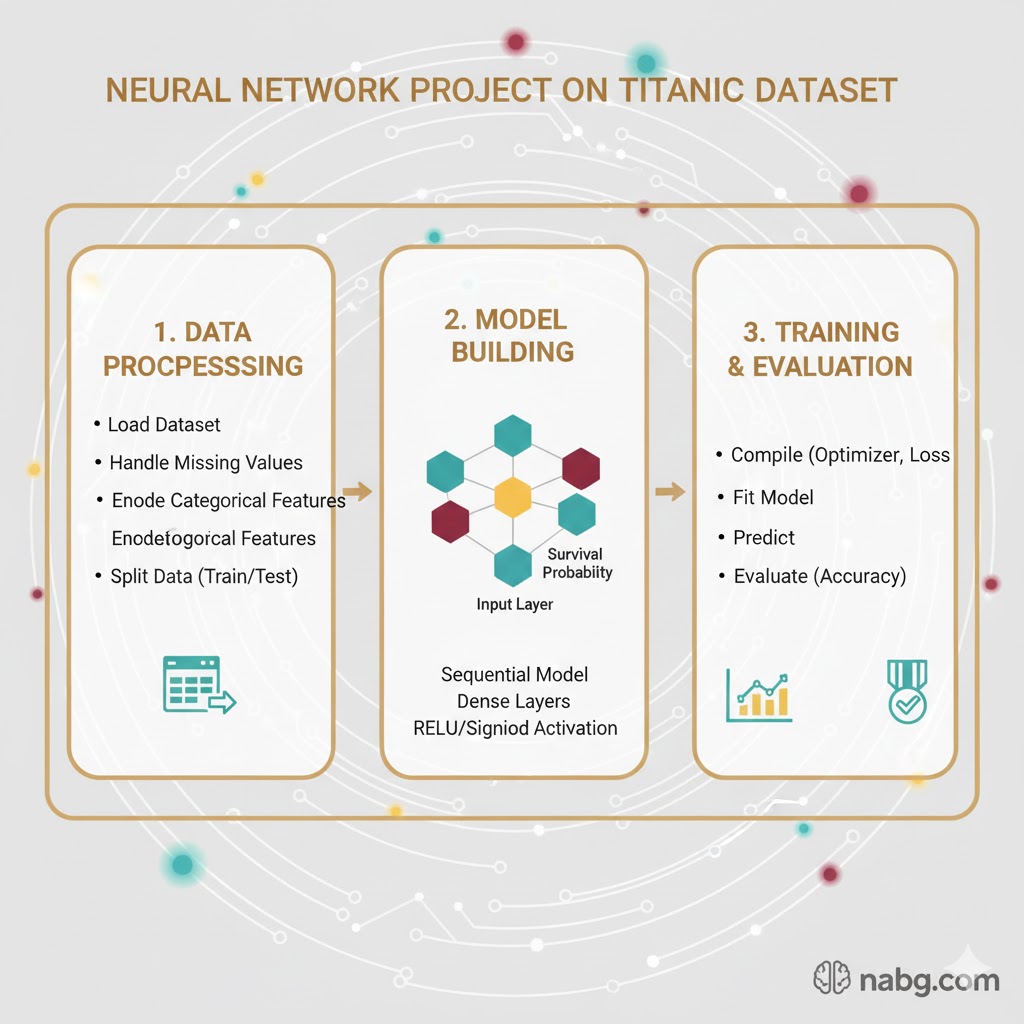
هدف چیست؟
برای درک عمیق الگوریتمهای ANN، ما از مسئله مشهور پیشبینی بقا در تایتانیک استفاده میکنیم. ما میخواهیم یک طبقهبند (Classifier) بسازیم که با بررسی ویژگیهای مسافران (مثل سن، جنسیت، کلاس بلیط و…) پیشبینی کند که آیا آنها از آن فاجعه جان سالم به در بردهاند یا خیر.
دسترسی به دادهها: میتوانید دیتاست تمیز شده و آماده را از لینک زیر در کگل (Kaggle) دانلود کنید
https://www.kaggle.com/jamesleslie/titanic-neural-network-for beginners/data?select=train_clean.csv
قدم اول: وارد کردن ابزارها
هر پروژه خوبی با چیدن ابزارها روی میز کار شروع میشود. بیایید کتابخانههای مورد نیاز را فراخوانی کنیم:
## import dependencies
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib.pyplot import rcParams
%matplotlib inline
rcParams['figure.figsize'] = 10,8
sns.set(style='whitegrid', palette='muted',
rc={'figure.figsize': (15,10)})
import os
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from keras.wrappers.scikit_learn import KerasClassifier
from keras.models import Sequential
from keras.layers import Dense, Activation, Dropout
from numpy.random import seed
from tensorflow import set_random_seed
.
مرحله بعدی: بارگذاری دادهها
حالا که تمام کتابخانههای لازم برای پیشپردازش و مدلسازی را وارد (Import) کردیم، وقت آن است که دادههای آموزشی (Training) و آزمایشی (Testing) را بخوانیم و وارد محیط برنامه کنیم.
# Load data as Pandas dataframe train = pd.read_csv('./train_clean.csv', ) test = pd.read_csv('./test_clean.csv') df = pd.concat([train, test], axis=0, sort=True) df.head()
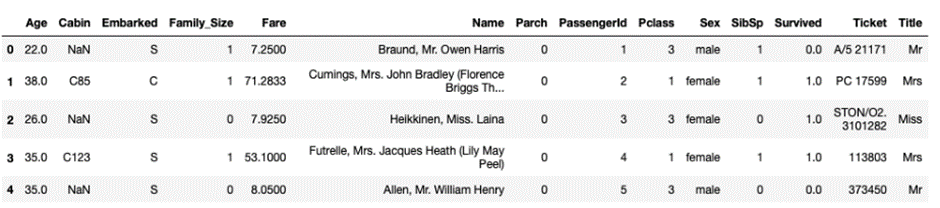
.
ادغام و پیشپردازش: تبدیل کلمات به اعداد
ما در اینجا فایلهای آموزش (Training) و تست (Testing) را به هم چسباندیم. چرا این کار را کردیم؟ برای اینکه میخواهیم مطمئن شویم هر عملیات پیشپردازشی که انجام میدهیم، دقیقاً به یک شکل و با یک استاندارد روی هر دو دسته داده اعمال میشود.
وقتی این دیتاست یکپارچه ساخته شد، نوبت به پیشپردازش (Preprocessing) میرسد. چرا؟ چون این دیتاست پر از ستونهایی است که عدد نیستند (مثلاً متن هستند) و همانطور که میدانید، شبکههای عصبی فقط زبان ریاضی و اعداد را میفهمند.
کار را با ستون جنسیت (Sex) شروع میکنیم. از آنجایی که این ستون متنی است (Male/Female)، ما آن را به متغیرهای باینری (صفر و یک) تبدیل خواهیم کرد تا برای مدل قابلفهم باشد.
# convert to cateogry dtype
df['Sex'] = df['Sex'].astype('category')
# convert to category codes
df['Sex'] = df['Sex'].cat.codes
.
تبدیل سایر متغیرها
بعد از اینکه تکلیف ستون جنسیت مشخص شد، حالا باید سراغ بقیه متغیرها برویم و آنها را هم تبدیل کنیم:
# subset all categorical variables which need to be encoded
categorical = ['Embarked', 'Title']
for var in categorical:
df = pd.concat([df,
pd.get_dummies(df[var], prefix=var)], axis=1)
del df[var]
# drop the variables we won't be using
df.drop(['Cabin', 'Name', 'Ticket', 'PassengerId'], axis=1, inplace=True)
df.head()

## scale continuous variable
continuous = ['Age', 'Fare', 'Parch', 'Pclass', 'SibSp', 'Family_Size']
scaler = StandardScaler()
for var in continuous:
df[var] = df[var].astype('float64')
df[var] = scaler.fit_transform(df[var].values.reshape(-1, 1))
پس از اینکه کار پیشپردازش و تمیزکاری دادهها تمام شد، باید دوباره آن دادههایی را که با هم ادغام کرده بودیم، از هم جدا کنیم. یعنی دوباره آنها را به دو دسته آموزش (Train) و تست (Test) تقسیم کنیم.
برای انجام این جداسازی، میتوانید از کد زیر استفاده کنید:
X_train = df[pd.notnull(df['Survived'])].drop(['Survived'], axis=1)
y_train = df[pd.notnull(df['Survived'])]['Survived']
X_test = df[pd.isnull(df['Survived'])].drop(['Survived'], axis=1)
.
تعریف معماری و هایپرپارامترها: نقشهکشی مغز مدل
حالا نوبت لحظه حساس است: زمان آن رسیده که هایپرپارامترها (Hyperparameters) را مشخص کنیم و معماری کلی مدل شبکه عصبی (ANN) خودمان را طراحی کنیم.
به زبان ساده، الان میخواهیم تصمیم بگیریم که این مغز مصنوعی چند لایه داشته باشد، هر لایه چقدر ظرفیت داشته باشد و با چه سرعتی یاد بگیرد.
layrs=[8]
act='linear'
opt='Adam'
dr=0.0
# set random seed for reproducibility
seed(42)
set_random_seed(42)
model = Sequential()
# create first hidden layer
model.add(Dense(lyrs[0], input_dim=X_train.shape[1], activation=act))
# create additional hidden layers
for i in range(1,len(lyrs)):
model.add(Dense(lyrs[i], activation=act))
# add dropout, default is none
model.add(Dropout(dr))
# create output layer
model.add(Dense(1, activation='sigmoid')) # output layer
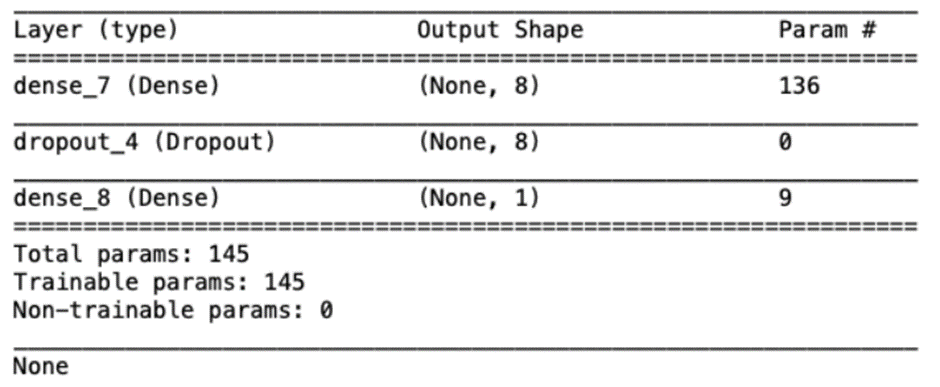
model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy'])
model = create_model()
print(model.summary())
.
آموزش و دریافت بینش (Fit & Insight)
بعد از اینکه تعریف مدل تمام شد، نوبت به مرحله اصلی میرسد: فیت کردن (Fit) یا همان برازش مدل روی دادههای آموزشی.
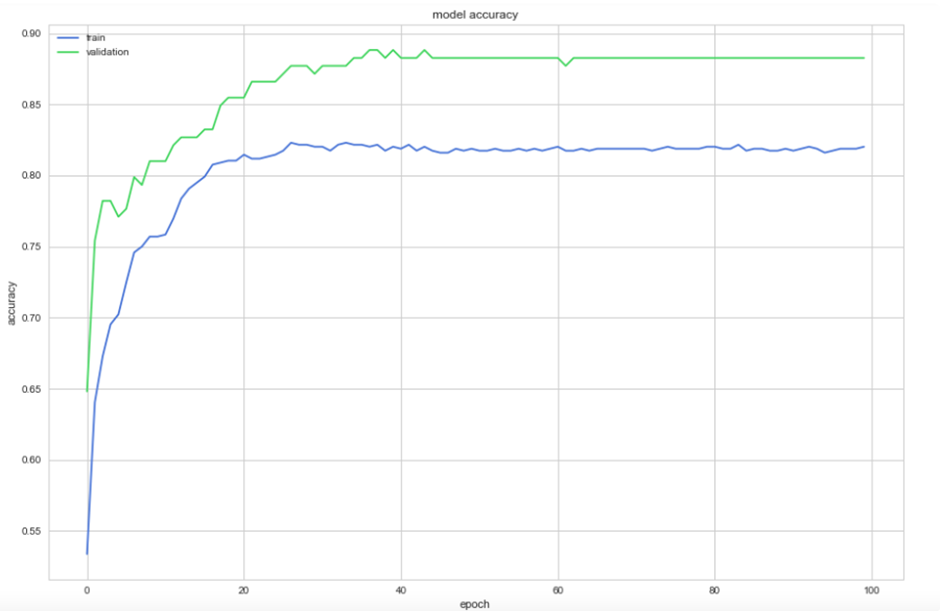
در این مرحله، ما دادهها را به خورد مدل میدهیم تا یاد بگیرد. پس از پایان آموزش، میتوانیم خروجیها و بینشهای (Insights) مدل را بررسی کنیم تا ببینیم چقدر خوب عمل کرده است و آیا توانسته الگوهای پنهان در دادهها را کشف کند یا خیر.
# train model on full train set, with 80/20 CV split
training = model.fit(X_train, y_train, epochs=100, batch_size=32, validation_split=0.2, verbose=0)
val_acc = np.mean(training.history['val_acc'])
print("n%s: %.2f%%" % ('val_acc', val_acc*100))
# summarize history for accuracy
plt.plot(training.history['acc'])
plt.plot(training.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()
.
پیشبینی نهایی: لحظه حقیقت
حالا که مدل آموزش دید و آماده شد، وقت آن است که آن را به میدان بفرستیم! با استفاده از تکه کد زیر، میتوانید از مدل بخواهید که روی دادههای تست (Test Data) پیشبینی انجام دهد و ببینیم برای مسافران جدید چه سرنوشتی را حدس میزند.
# calculate predictions
test['Survived'] = model.predict(X_test)
test['Survived'] = test['Survived'].apply(lambda x: round(x,0)).astype('int')
solution = test[['PassengerId', 'Survived']]

.
جمع بندی
شبکههای عصبی مصنوعی یکی از پایهایترین و در عین حال قدرتمندترین ابزارهای هوش مصنوعی هستند که امکان یادگیری از دادههای پیچیده و حجیم را فراهم میکنند. با استفاده از ساختار لایهای و تنظیم تدریجی وزنها، این مدلها قادرند الگوهایی را کشف کنند که با روشهای سنتی بهسختی قابل شناساییاند.
با وجود مزایای چشمگیر، شبکههای عصبی بدون چالش نیستند. نیاز به داده زیاد، هزینه محاسباتی بالا و کاهش تفسیرپذیری از جمله محدودیتهای آنهاست. بنابراین انتخاب این مدل باید متناسب با نوع مسئله، حجم داده و هدف پروژه انجام شود.
در نهایت، هر زمان که با روابط غیرخطی، دادههای بزرگ و مسائل پیچیده روبهرو باشیم، شبکه عصبی مصنوعی یکی از بهترین انتخابهاست. این مدلها نهتنها پایهی یادگیری عمیق محسوب میشوند، بلکه نقش کلیدی در توسعه سیستمهای هوشمند امروز و آینده ایفا میکنند.