الگوریتمیبرایگروهبندی n مشاهدهدرk خوشه استکهازکوانتیزاسیونبرداریاستفادهمیکند. این الگوریتم یکروشبرایخوشهبندیدادههادریادگیریبدوننظارتاست. اینالگوریتمبهطورمکررنقاطدادهرابابهحداقلرساندنواریانسدرهرخوشهبه k خوشهتقسیممیکند
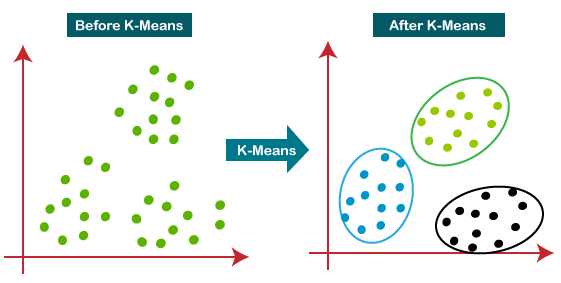
خوشه بندی k-means یکالگوریتم خوشه بندیانحصاری است. هر شی دقیقاً به یکی از خوشهها اختصاص داده شده است. (روشهایدیگری وجود دارد که به اشیا اجازه میدهد در بیش از یک خوشه قرار بگیرند). برایاین روش خوشهبندی، ما باتصمیمگیری در مورد تعداد خوشه شروع میکنیم که میخواهم دادههای ما را شامل شود. ما این مقدار را k مینامیم. مقدار k به طور کلی یک عدد صحیحکوچک، مانند 2، 3، 4 یا 5 است، اما ممکن است بزرگتر باشد. بعدابه این سؤال که تعداد مناسب K چقدر باید باشد صحبت میکنیم.
راههایزیادی وجود دارد که در آنها k خوشه به طور بالقوهممکن است، تشکیلشوند. مامیتوانیمکیفیت مجموعه ای از خوشهها را بااستفاده از مقدار یک هدف اندازهگیریکنیم. این تابع هدف میتواند مجموع مجذور فواصل باشد. فاصله عبارت است از فاصله هر نقطه از مرکز خوشه ایکه به آن اختصاص داده شده است. ما میخواهیممقدار این تابع تا حد امکانکوچک باشد. حال k نقطه اول را به صورت تصادفی انتخاب میکنیم. اینها به عنوان مرکز K خوشه، در نظر گرفتهمیشوند. مرکزهای k خوشه بالقوه در ابتدا هیچعضویندارند. مامیتوانیماین نقاط را به هر شکلیکهمیخواهیم انتخاب کنیم، اما شاید بهتر باشد k نقطه اولیه را به گونه ای انتخاب کنیمکه نسبتاً از هم فاصله داشته باشند.اکنون هر یک از نقاط را یکییکی به خوشه ایکهدارای کمترین فاصله است اختصاص میدهیم یعنینزدیکترینمرکزهنگامیکه تمام اشیاء اختصاص داده شدند، k خوشه بر اساس آن خواهیم داشتk مرکزاصلی اما «مرکزیت ها» دیگرمرکزواقعی آن نخواهند بود.سپسمرکزهایخوشهها را مجدداً محاسبه میکنیم و سپس آن را تکرارمیکنیم
📌 کاربرد الگوریتم K-Means
بازاریابی: میتوان از آن برای شناسایی و کشف بخش های مشتری برای اهداف بازاریابی استفاده کرد.
زیست شناسی: میتوان از آن برای طبقهبندی در میان گونههای مختلف گیاهی و جانوری استفاده کرد.
کتابخانهها: در خوشهبندی کتابهای مختلف بر اساس موضوعات و اطلاعات استفاده میشود.
بیمه: برای شناسایی مشتریان، سیاستهای آنها و شناسایی تقلب ها استفاده میشود.
برنامهریزی شهری: برای گروهبندی خانهها و بررسی ارزش آنها بر اساس موقعیت جغرافیایی و سایر عوامل موجود استفاده میشود.
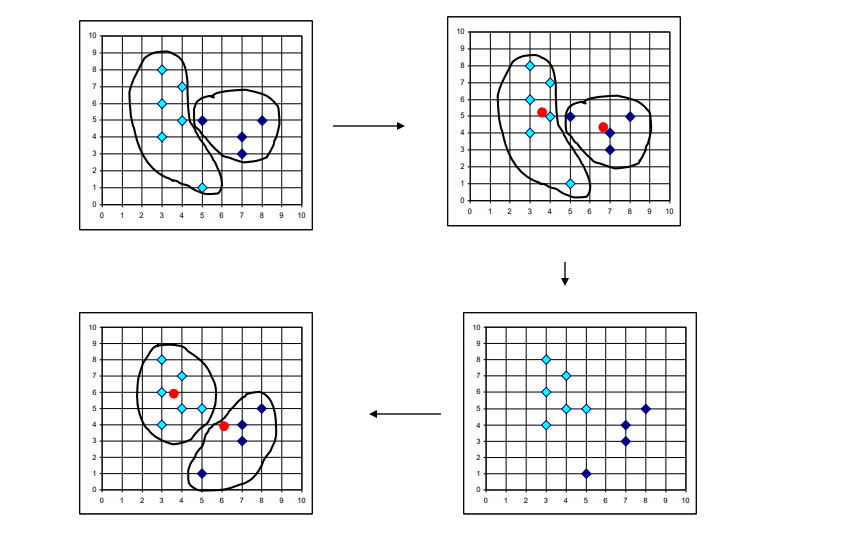
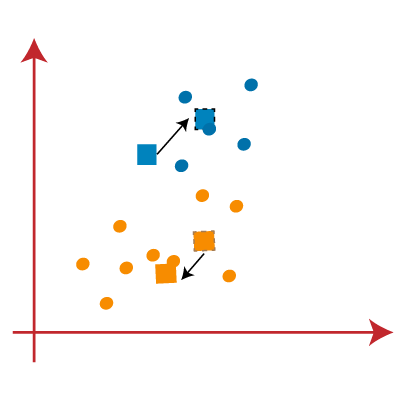
دراینمرحلهفاصلههرنقطهراباتکتکخوشههامحاسبهمیکنیمبااستفادهازفاصلهاقلیدوسیو نقطهایکهفاصلهکمتریبا مرکز خوشههاداردواردآنخوشهمیشود. اینکاررابرایتمامنقاطانجاممیدهیم
پسازاتماممرحله سوممجددبایدیکمرکزجدیدبرایخوشههامحاسبهکنیم.برایاینکاربایدمیانگیننقاطداخلهرخوشهرامحاسبهکنیم. این میانگین نشان دهنده مختصات مرکز جدید خوشه است((x1+x2+…+xn/ n),(y1+y2+…+yn/ n))
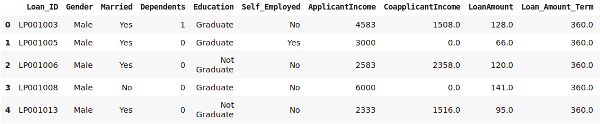
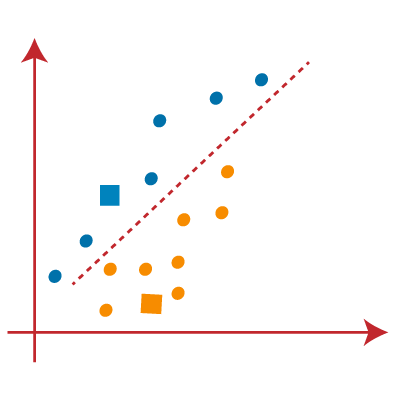
فرض کنید دو متغیر M1 و M2 داریم. نمودار پراکندگی محور x-y این دو متغیر در زیر آورده شده است:
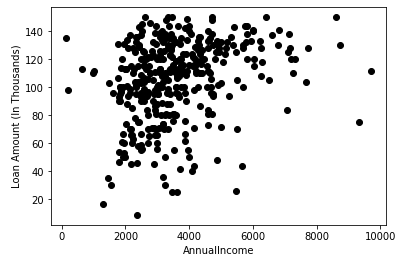
برای شناسایی مجموعه داده ها و قرار دادن آنها در خوشه های مختلف، عدد k از خوشه ها را در نظر می گیریم، یعنی K=2. یعنی در اینجا سعی خواهیم کرد این مجموعه داده ها را در دو خوشه مختلف گروه بندی کنیم.
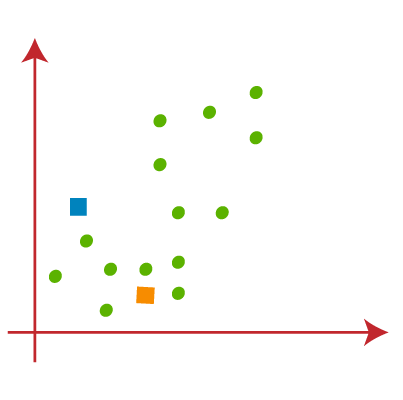
برای تشکیل خوشه باید k نقطه یا مرکز تصادفی را انتخاب کنیم. این نقاط می توانند نقاطی از مجموعه داده یا هر نقطه دیگری باشند. بنابراین، در اینجا ما دو نقطه زیر را به عنوان K نقطه انتخاب میکنیم که بخشی از مجموعه داده ما نیستند. تصویر روبرو را در نظر بگیرید:
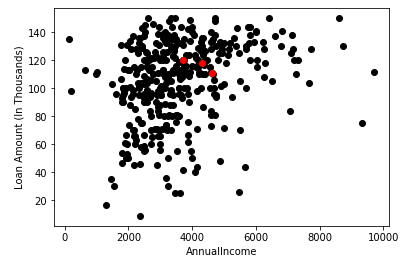
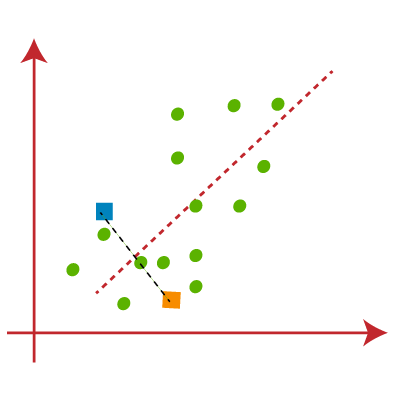
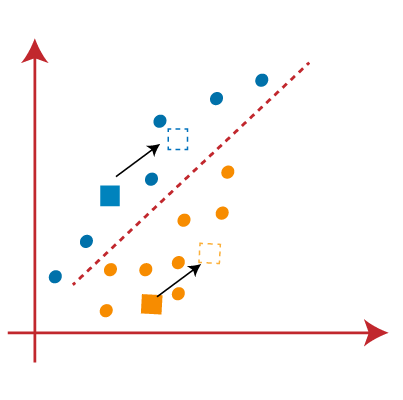
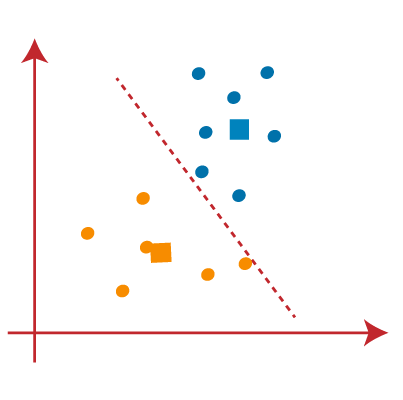
اکنون هر نقطه داده نمودار پراکندگی را به نزدیکترین نقطه K یا مرکز آن اختصاص میدهیم. ما آن را با استفاده از ریاضیاتی که برای محاسبه فاصله بین دو نقطه مطالعه کردهایم محاسبه خواهیم کرد. بنابراین، ما یک میانه بین هر دو مرکز ترسیم میکنیم. تصویر روبرو را در نظر بگیرید:
از تصویر بالا مشخص است که نقاط سمت چپ خط نزدیک به مرکز K1 یا آبی است و نقاط سمت راست خط نزدیک به مرکز زرد است. برای تجسم واضح، آنها را به رنگ آبی و زرد رنگ تبدیل میکنیم.
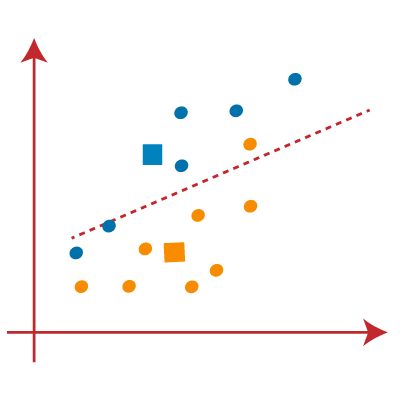
حال باید نزدیکترین خوشه را پیدا کنیم، با انتخاب یک مرکز جدید، این فرآیند را تکرار خواهیم کرد. برای انتخاب مرکزهای جدید، مرکز ثقل یا میانگین دادههای هر خوشه را محاسبه کرده و مرکزهای جدید را به صورت روبرو پیدا خواهیم کرد:
در مرحله بعد، هر نقطه داده را به مرکز جدید اختصاص می دهیم. برای این کار، همان فرآیند یافتن خط میانه را تکرار میکنیم. میانگین مانند تصویر زیر خواهد بود:
از تصویر بالا میبینیم که یک نقطه زرد در سمت چپ خط و دو نقطه آبی رنگ درست به خط قرار دارند. بنابراین، این سه نقطه به مرکزهای جدید اختصاص داده میشود.
همانطور که تخصیص مجدد انجام میشود، ما دوباره به مرحله 4 خواهیم رفت، که یافتن مرکزها یا نقاط K جدید است.
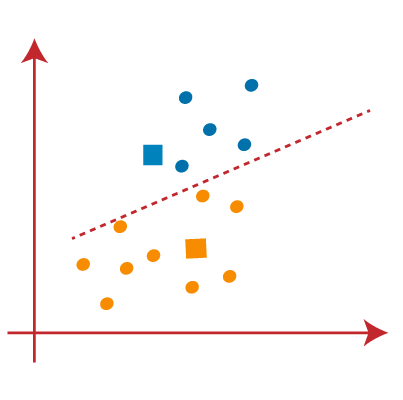
ما این فرآیند را با یافتن مرکز ثقل تکرار می کنیم، بنابراین مرکزهای جدید مانند تصویر روبرو خواهند بود:
همانطور که ما مرکز جدید را یافتهایم، دوباره خط میانه را رسم می کنیم و نقاط داده را دوباره اختصاص می دهیم. بنابراین، تصویر به صورت زیر خواهد بود:
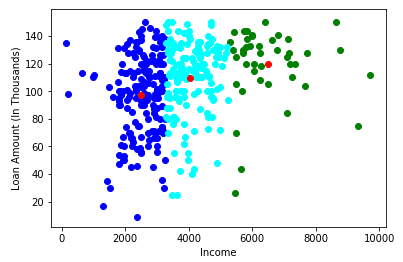
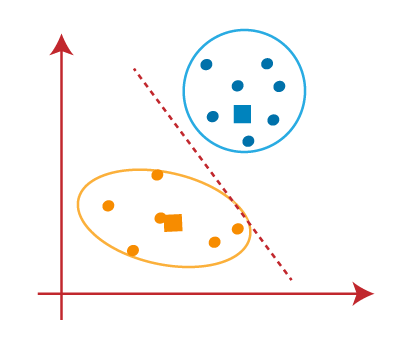
در تصویر بالا می بینیم؛ هیچ نقطه داده متفاوتی در دو طرف خط وجود ندارد، به این معنی که مدل ما شکل یافته است. تصویر روبرو را در نظر بگیرید:
همانطور که مدل ما آماده است، اکنون می توانیم مرکزهای فرضی را حذف کنیم و دو خوشه نهایی مانند تصویر روبرو خواهند بود:
محاسبه کیفیت خوشهها
مجموعتواندومفواصلنقاطتامرکزخوشه
E = Σk I=1 Σ dist(p.ci)2
محاسبه ی k
عملکرد الگوریتم خوشه بندی K-means به خوشههای بسیار کارآمدی که تشکیل میدهد بستگی دارد. اما انتخاب تعداد بهینه خوشهها کار بزرگی است. روشهای مختلفی برای یافتن تعداد بهینه خوشهها وجود دارد، اما در اینجا ما مناسبترین روش برای یافتن تعداد خوشهها یا مقدار K را مورد بحث قرار میدهیم. این روش در زیر آورده شده است:
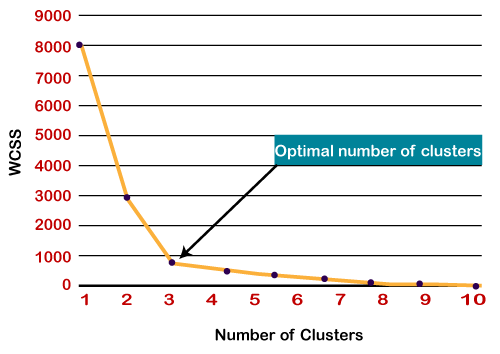
Elbow Method
روش زانو یکی از محبوبترین روشها برای یافتن تعداد بهینه خوشهها است. این روش از مفهوم مقدار WCSS استفاده میکند. WCSS مخفف عبارت Within Cluster Sum of Squares است که کل تغییرات را در یک خوشه تعریف میکند. فرمول محاسبه مقدار WCSS (برای 3 خوشه) در زیر آمده است:
WCSS= ∑Pi in Cluster1distance(Pi C1)2 +∑Pi in Cluster2distance(Pi C2)2+∑Pi in CLuster3distance(Pi C3)2
برای یافتن مقدار بهینه خوشه ها، روش زانویی مراحل زیر را دنبال می کند:
خوشه بندی K-means را بر روی یک مجموعه داده معین برای مقادیر مختلف K (محدوده 1-10) اجرا می کند.
برای هر مقدار K، مقدار WCSS را محاسبه می کند.
منحنی بین مقادیر محاسبهشده WCSS و تعداد خوشههای K ترسیم میکند.
نقطه تیز خم یا یک نقطه از طرح شبیه یک بازو است، سپس آن نقطه به عنوان بهترین مقدار K در نظر گرفته می شود.
از آنجایی که نمودار خم تیز را نشان میدهد که شبیه یک آرنج است، از این رو به روش آرنج معروف است. نمودار روش آرنج مانند تصویر زیر است:
مثالهای کاربردی
📌 مثال عددی-1
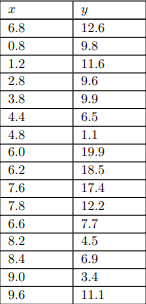
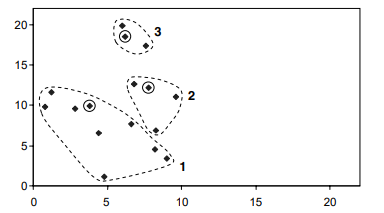
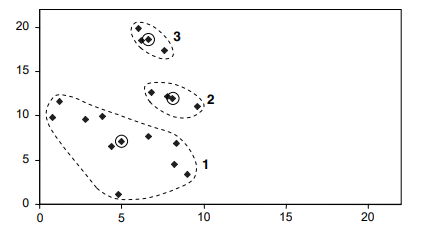
ماالگوریتم k-means رابرایخوشهبندی 16 شیءنشانخواهیمداد.بادوویژگی x و y کهدر شکل زیر فهرست شدهاند. 16 نقطهمربوطبهایناشیابهصورتنمودارینشاندادهشدهاست. محورهایافقی و عمودیباویژگیهای x و مطابقتدارند y بهترتیب.
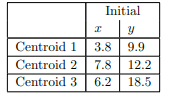
سهتاازنقاطنشاندادهشدهدرشکلبالابا دایرههای کوچکیاحاطهشدهاند.فرضمیکنیم k = 3 و اینسهنقطهراانتخابکردهایمبهعنوانمکانسهمرکزاولیهانتخابشدهاند. ایناولیهانتخاب (نسبتادلخواه) درشکلزیرنشاندادهشدهاست
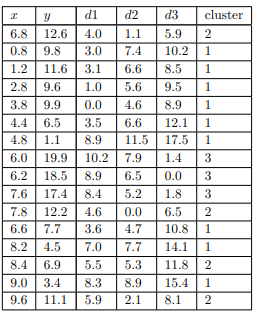
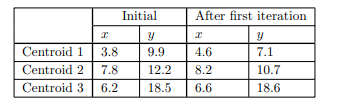
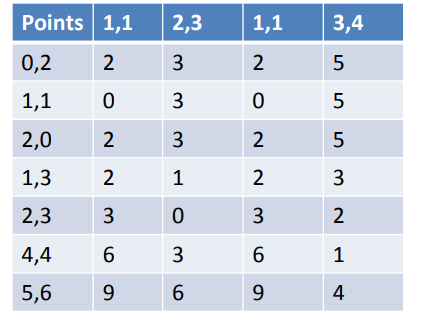
نقاط d1، d2 و d3 درشکلزیرفاصلهاقلیدسیهریکاز 16 نقطهراازسهمرکز نشانمیدهند. برایاهدافدراینمثال، ماهیچیکازویژگیهارانرمالیا موزون نمیکنیم، بنابراینفاصلهاولیننقطه (6.8، 12.6) ازمرکزاول (3.8، 9.9) بهسادگیاست.
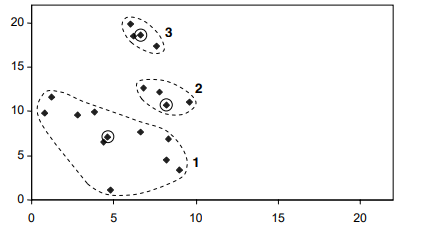
مرکزهابادایرههایکوچکنشاندادهمیشوند. برایایناولینتکرارآنهاهستند. همچنیننقاطواقعیدرونخوشهها. مرکزهاآنهاییهستندکهمورداستفادهقرارگرفتند. برایساختنسهخوشهامامرکزواقعیخوشههاپسازایجادآنهانیستند.سپسمرکزهایسهخوشهرابااستفادهازمقادیر x و y محاسبهمیکنیم. ازاشیاییکهدرحالحاضربههریکاختصاصدادهشدهاست. نتایجدرشکلنشاندادهشدهاست
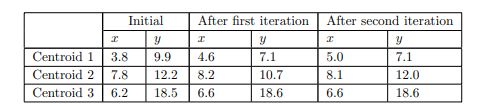
سهمرکزهمگیبافرآیندتخصیصجابهجاشدهاند، اماحرکتمرکزسومبهطورقابلتوجهیکمترازدومرکزدیگراست.سپسباتعییناینکه فاصله هریک از نقاط از مراکز جدید، 16 شیرابهسهخوشهاختصاصمیدهیم .


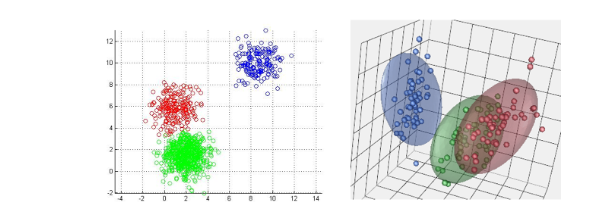
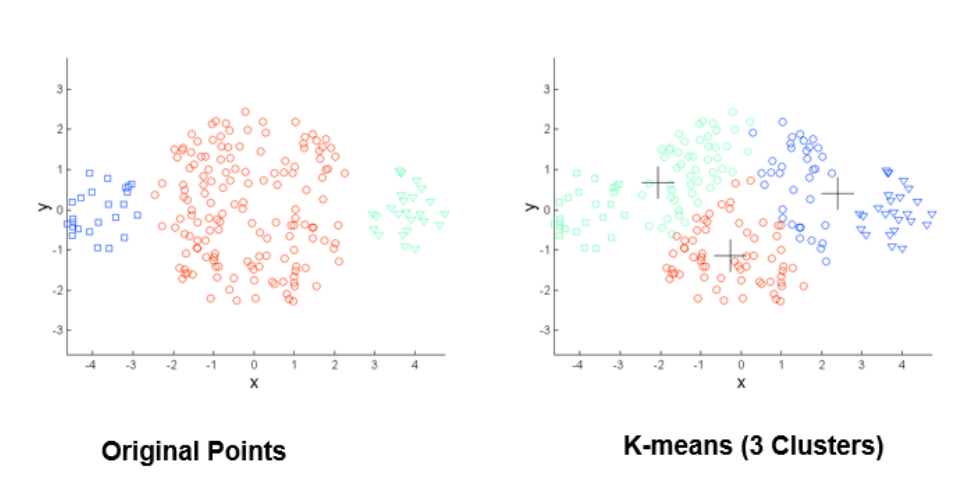
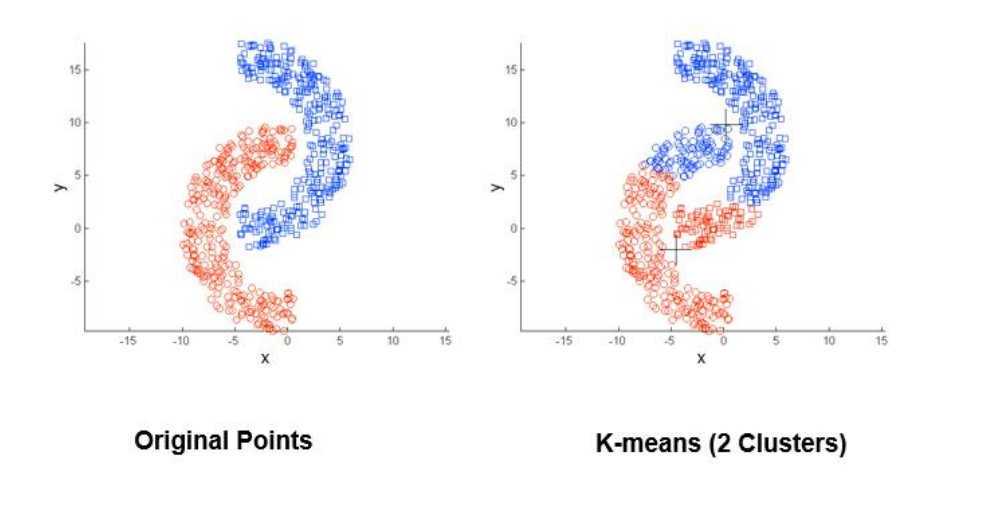
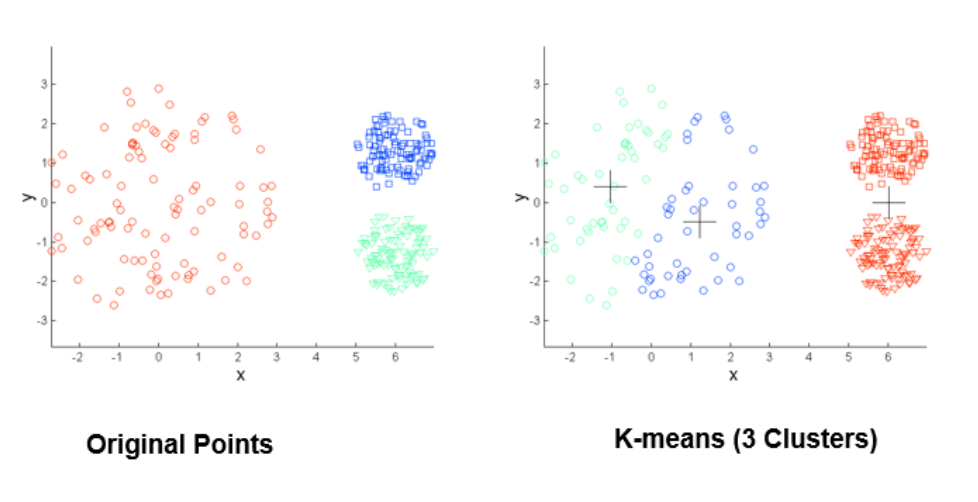




 محاسبه کیفیت خوشهها
محاسبه کیفیت خوشهها  محاسبه کیفیت خوشهها
محاسبه کیفیت خوشهها