

1.چکیده
خوشهبندی یکی از مهمترین مسائل در دادهکاوی است که هدف آن گروهبندی دادهها بر اساس شباهت میان نمونهها است. بسیاری از الگوریتمهای کلاسیک خوشهبندی مانند K-Means برای دادههای عددی طراحی شدهاند و در مواجهه با دادههای طبقهای (Categorical Data) عملکرد مناسبی ندارند. الگوریتم K-Modes بهعنوان توسعهای از K-Means برای تحلیل دادههای طبقهای ارائه شده است. این الگوریتم با جایگزینی مفهوم میانگین با مد (Mode) و استفاده از معیار عدمتشابه مبتنی بر تطابق صفات، امکان خوشهبندی کارآمد دادههای غیرعددی را فراهم میکند.
در این مقاله، ابتدا مفاهیم پایه و ضرورت استفاده از K-Modes بررسی میشود، سپس مبانی نظری و ریاضی آن ارائه میگردد. در ادامه، فرآیند گامبهگام الگوریتم همراه با شبهکد توضیح داده شده و چند مثال عددی برای درک بهتر عملکرد الگوریتم ارائه میشود. همچنین کاربردهای عملی، مزایا و محدودیتهای روش مورد بررسی قرار میگیرد و مقایسهای میان K-Modes و برخی روشهای مشابه انجام میشود. در پایان، روندهای پژوهشی جدید و مسیرهای توسعه آینده این الگوریتم بیان میگردد. نتایج نشان میدهد K-Modes یکی از روشهای مؤثر برای خوشهبندی دادههای طبقهای در مسائل واقعی دادهکاوی است.
2. مقدمه
خوشهبندی (Clustering) یکی از روشهای بنیادی در یادگیری بدون نظارت است که هدف آن تقسیم مجموعهای از دادهها به گروههایی است که در آن دادههای هر گروه شباهت بیشتری به یکدیگر نسبت به دادههای گروههای دیگر دارند. در بسیاری از مسائل واقعی، دادهها بهصورت طبقهای ذخیره میشوند؛ مانند جنسیت، نوع شغل، نوع محصول یا دستهبندی مشتریان.
الگوریتم K-Means یکی از پرکاربردترین روشهای خوشهبندی است. این الگوریتم بر اساس محاسبه میانگین و فاصله اقلیدسی طراحی شده و بنابراین برای دادههای عددی مناسب است. زمانی که دادهها طبقهای باشند، محاسبه میانگین معنا ندارد و استفاده از فاصله اقلیدسی نیز قابل توجیه نیست.
برای حل این مسئله، الگوریتم K-Modes توسط Huang (1997) معرفی شد. این الگوریتم با جایگزینی میانگین با مد و تعریف معیار عدمتشابه مناسب برای دادههای طبقهای، امکان خوشهبندی چنین دادههایی را فراهم میکند.
هدف این مقاله معرفی جامع الگوریتم K-Modes، مبانی نظری آن، نحوه عملکرد و کاربردهای عملی آن در دادهکاوی است. در ادامه ابتدا مفاهیم پایه معرفی میشود، سپس مبانی نظری و مراحل الگوریتم توضیح داده شده و با ارائه مثالهای عددی، عملکرد الگوریتم روشن میشود.

3. اهمیت و ضرورت الگوریتم K-Modes
بسیاری از دادههای واقعی در حوزههایی مانند:
- تحلیل مشتریان
- سیستمهای توصیهگر
- تحلیل بازار
- دادههای اجتماعی
ماهیت طبقهای دارند.
الگوریتمهای رایج مانند:
- K-Means
- Gaussian Mixture
برای چنین دادههایی مناسب نیستند زیرا:
- میانگین برای دادههای طبقهای تعریف نمیشود.
- فاصله اقلیدسی قابل استفاده نیست.
بنابراین نیاز به روشی وجود دارد که:
- بتواند دادههای غیرعددی را خوشهبندی کند
- از معیار شباهت مناسب برای دادههای طبقهای استفاده کند
- از نظر محاسباتی مقیاسپذیر باشد
الگوریتم K-Modes دقیقاً برای پاسخ به این نیاز طراحی شده است.
.
4.تعاریف و مفاهیم پایه الگوریتم K-Modes
.
4.1. دادههای طبقهای یا Categorical Data
تعریف
دادهی طبقهای به دادهای گفته میشود که مقدار آن از میان مجموعهای محدود از برچسبها، گروهها یا دستهها انتخاب میشود و معمولاً عملیات عددی مانند جمع، میانگین یا تفاضل روی آن معنا ندارد.
مثال
ویژگی «رنگ خودرو» میتواند یکی از مقادیر زیر را داشته باشد:
{قرمز،آبی،سفید،مشکی}
یا ویژگی «نوع سیستمعامل» میتواند شامل موارد زیر باشد:
{Android , iOS , Windows , Linux}
در این دادهها نمیتوان گفت:
Android+iOS
یا
میانگین(قرمز، آبی)
بنابراین روشهایی مانند K-Means که بر پایهی میانگین عددی هستند، برای این نوع دادهها مناسب نیستند.
4.2. انواع دادههای طبقهای
دادههای طبقهای معمولاً به دو دستهی اصلی تقسیم میشوند:
الف. دادههای اسمی یا Nominal
در دادههای اسمی، بین مقادیر هیچ ترتیب ذاتی وجود ندارد.
مثال
ویژگی «رنگ» شامل:
{قرمز،سبز،آبی} {قرمز، سبز، آبی} {قرمز،سبز،آبی}
در اینجا نمیتوان گفت قرمز از سبز بزرگتر است یا آبی از قرمز کمتر است.
مثالهای دیگر
- جنسیت
- شهر محل سکونت
- نوع شغل
- برند محصول
- نوع بیماری
در K-Modes، بیشتر تمرکز روی دادههای اسمی است.
ب.دادههای ترتیبی یا Ordinal
در دادههای ترتیبی، بین مقادیر نوعی ترتیب وجود دارد، اما فاصلهی دقیق بین سطوح الزاماً مشخص نیست.
مثال
سطح رضایت مشتری:
{کم،متوسط،زیاد}
یا سطح تحصیلات:
{دیپلم ، کارشناسی ، کارشناسی ارشد ، دکتری{
در اینجا ترتیب وجود دارد، اما نمیتوان بهسادگی گفت فاصلهی بین «دیپلم» و «کارشناسی» دقیقاً برابر فاصلهی بین «کارشناسی ارشد» و «دکتری» است.
نکته مهم
K-Modes در نسخهی پایه، معمولاً ترتیب را در نظر نمیگیرد و فقط مساوی یا نامساوی بودن مقادیر را بررسی میکند. بنابراین اگر دادهها ترتیبی باشند، گاهی باید معیار فاصله اصلاح شود.
4.3. خوشهبندی یا Clustering
تعریف
خوشهبندی یکی از روشهای یادگیری بدون نظارت است که هدف آن تقسیم دادهها به چند گروه یا خوشه است، بهگونهای که:
- دادههای داخل هر خوشه به یکدیگر شبیهتر باشند؛
- دادههای خوشههای مختلف از یکدیگر متفاوتتر باشند.
اگر مجموعه داده را به صورت زیر داشته باشیم:
X={x1 , x2 ,…, xn}
هدف خوشهبندی، تقسیم آن به K خوشه است:
C={C1 , C2 ,…, CK}
بهگونهای که:
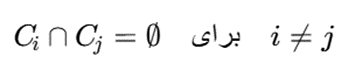
و:
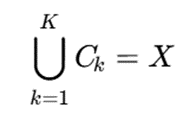
یعنی هر داده دقیقاً در یک خوشه قرار گیرد و هیچ دادهای خارج از خوشهها باقی نماند.
4.4 یادگیری بدون نظارت
تعریف
در یادگیری بدون نظارت، دادهها برچسب خروجی ندارند. یعنی مدل نمیداند هر نمونه متعلق به چه گروهی است و باید الگوهای پنهان را خودش کشف کند.
مثال
فرض کنید دادههایی از مشتریان یک فروشگاه داریم:
| مشتری | جنسیت | نوع خرید | روش پرداخت |
| 1 | زن | پوشاک | آنلاین |
| 2 | مرد | دیجیتال | حضوری |
| 3 | زن | پوشاک | آنلاین |
| 4 | مرد | دیجیتال | حضوری |
هیچ ستونی به نام «گروه مشتری» وجود ندارد. الگوریتم باید خودش مشتریان مشابه را در یک خوشه قرار دهد.
5. مفهوم Mode یا مد
تعریف:مد، مقداری است که بیشترین تکرار را در یک مجموعه دارد.
مثال:برای ویژگی «رنگ» در یک خوشه داریم:
{قرمز،آبی،قرمز،سبز،قرمز}
تعداد تکرارها:
| مقدار | تعداد |
| قرمز | 3 |
| آبی | 1 |
| سبز | 1 |
پس مد برابر است با:
Mode=قرمز
در K-Modes، برای هر ویژگی از هر خوشه، مد جداگانه محاسبه میشود.
مثال چندویژگی
فرض کنید یک خوشه شامل دادههای زیر باشد:
| نمونه | جنسیت | خرید | پرداخت |
| 1 | زن | کتاب | آنلاین |
| 2 | زن | کتاب | آنلاین |
| 3 | مرد | کتاب | حضوری |
| 4 | زن | پوشاک | آنلاین |
مد هر ویژگی:
- جنسیت: زن
- خرید: کتاب
- پرداخت: آنلاین
پس نماینده خوشه:
z=(زن،کتاب،آنلاین)
.
6. مبانی نظری و ریاضی الگوریتم K-Modes
فرض کنید مجموعه داده شامل n نمونه و m ویژگی طبقهای باشد.
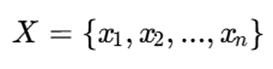
که در آن:
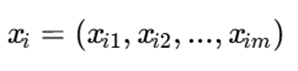
تابع عدم تشابه
برای دو بردار طبقهای xi و xj:
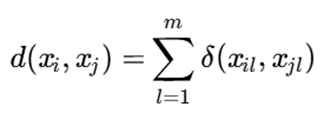
که در آن:
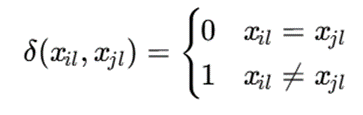
این معیار Simple Matching Dissimilarity نام دارد.
تابع هدف
هدف الگوریتم کمینه کردن مجموع عدمتشابهها درون خوشهها است:
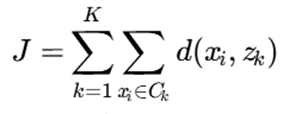
که در آن:
- K تعداد خوشهها
- Ck خوشه k
- zk مد خوشه k
- d تابع عدمتشابه
هدف الگوریتم:minJ
.
7.فرآیند گام به گام الگوریتم
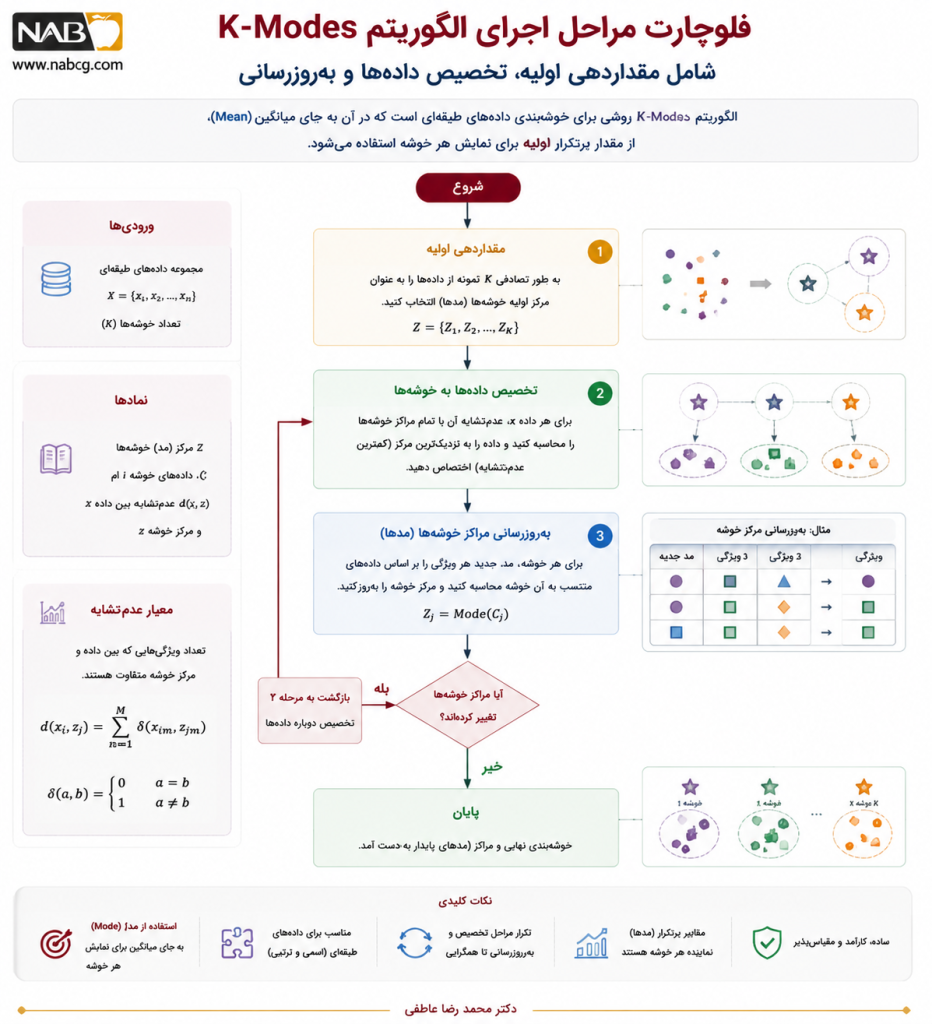
ورودی
- مجموعه داده طبقهای
- تعداد خوشهها K
خروجی
- خوشهبندی دادهها
- مد هر خوشه
مراحل الگوریتم
- مقداردهی اولیه K مد تصادفی از دادهها
- تخصیص هر نمونه به نزدیکترین مد
- بهروزرسانی مد هر خوشه
- تکرار مراحل 2 و 3 تا همگرایی
معیار توقف
- عدم تغییر در تخصیص خوشهها
یا
- رسیدن به تعداد تکرار مشخص
.
8.Prototype یا نماینده خوشه
تعریف
- در الگوریتمهای خوشهبندی، هر خوشه معمولاً یک نماینده دارد. این نماینده برای مقایسه دادههای جدید یا بهروزرسانی خوشهها استفاده میشود.
- در K-Means، نماینده خوشه همان میانگین است.
- در K-Modes، نماینده خوشه همان مد ویژگیها است.
نکته مهم
در K-Modes، prototype ممکن است دقیقاً یکی از نمونههای واقعی داده نباشد، بلکه ترکیبی از مقادیر پرتکرار ویژگیها باشد.
مثال
اگر مد ویژگیها برابر باشد با:z=(زن،کتاب،آنلاین)
ممکن است چنین نمونهای در داده اصلی وجود داشته باشد یا نداشته باشد.
این نکته K-Modes را از K-Medoids متمایز میکند؛ چون در K-Medoids مرکز خوشه حتماً یکی از دادههای واقعی است.
9.تابع عدمتشابه Simple Matching Dissimilarity
تعریف
در دادههای طبقهای، معمولاً نمیتوان فاصلهی عددی معمول محاسبه کرد. بنابراین از معیار عدمتشابه بر اساس تطابق یا عدمتطابق استفاده میشود.
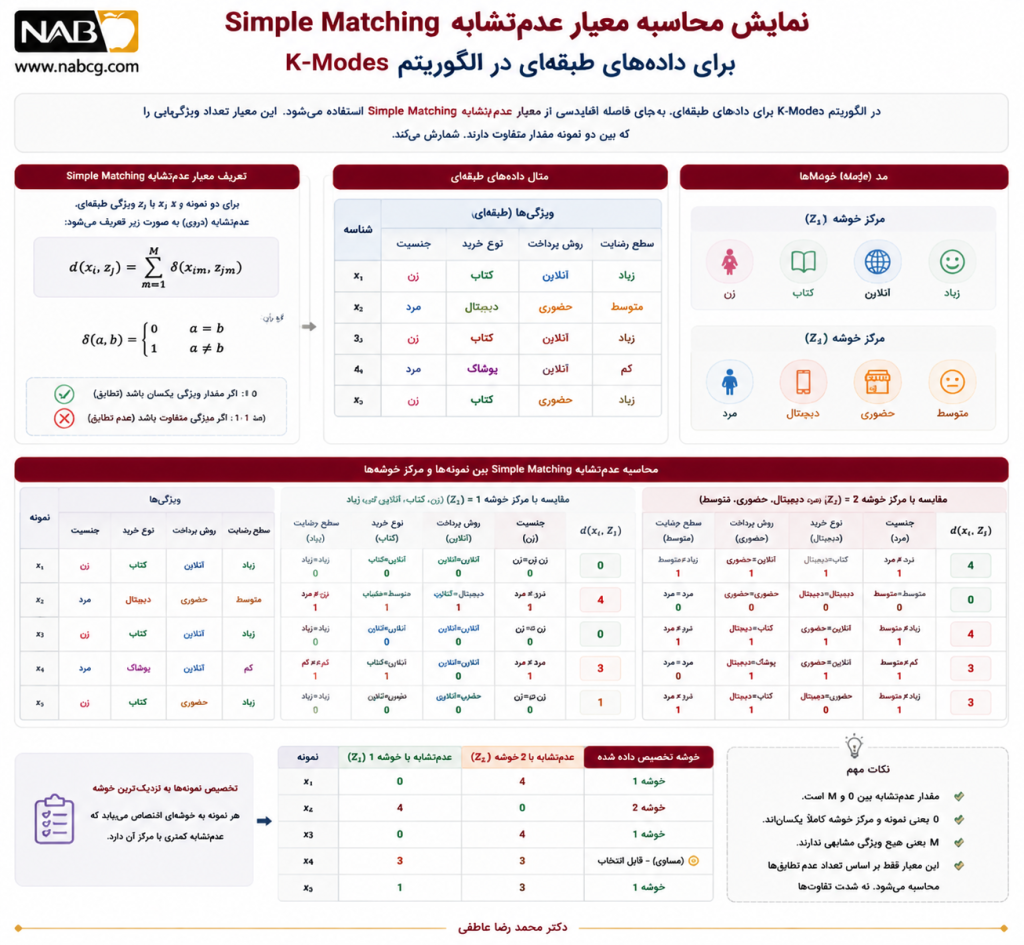
برای دو نمونه:
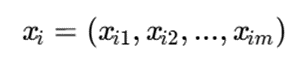
و:
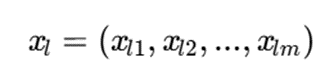
تابع عدمتشابه به صورت زیر تعریف میشود:
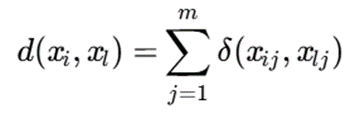
که:
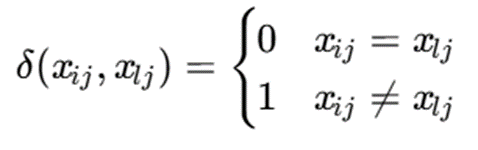
تفسیر
- اگر مقدار دو نمونه در یک ویژگی برابر باشد، هزینه صفر است.
- اگر متفاوت باشد، هزینه یک است.
مثال
دو نمونه زیر را در نظر بگیرید:
- x1=(زن،کتاب،آنلاین)
- x2=(زن،پوشاک،آنلاین)
مقایسه ویژگی به ویژگی:
| ویژگی | مقدار x1 | مقدار x2 | نتیجه |
| جنسیت | زن | زن | برابر، هزینه 0 |
| خرید | کتاب | پوشاک | متفاوت، هزینه 1 |
| پرداخت | آنلاین | آنلاین | برابر، هزینه 0 |
پس:d(x1,x2)=0+1+0=1
.
10. تابع هدف K-Modes
تعریف
هدف K-Modes این است که مجموع عدمتشابه دادهها نسبت به مرکز خوشههای خود حداقل شود.
تابع هدف:
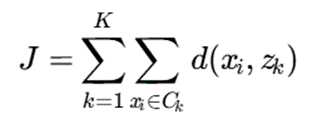
که در آن:
- J: مقدار تابع هدف یا هزینه کل خوشهبندی
- K: تعداد خوشهها
- Ck: خوشهی k-ام
- xi: نمونهی داده
- zk: مد یا prototype خوشهی k-ام
- (xi,zk) d: عدمتشابه بین نمونه و مد خوشه
هدف:
minJ
تفسیر
الگوریتم تلاش میکند دادهها را طوری گروهبندی کند که تعداد اختلافهای بین دادهها و مد خوشههایشان کمترین مقدار ممکن باشد.
11. مقداردهی اولیه
تعریف
- مقداردهی اولیه یعنی انتخاب مراکز اولیه خوشهها در ابتدای اجرای الگوریتم.
- در K-Modes، معمولاً K prototype اولیه انتخاب میشود.
اهمیت K-Mode: مانند K-Means به مقداردهی اولیه حساس است. انتخاب مراکز اولیه ضعیف ممکن است باعث شود الگوریتم در یک جواب محلی نامناسب متوقف شود.
روشهای رایج مقداردهی اولیه
- انتخاب تصادفی نمونهها
- انتخاب نمونههای پرتکرار
- انتخاب نمونههای دور از هم
- روشهای مبتنی بر چگالی
- مقداردهی اولیه هوشمند مشابه K-Means++
.
12. تخصیص دادهها به خوشهها
تعریف
- در هر تکرار، هر داده به خوشهای اختصاص مییابد که کمترین عدمتشابه را با مد آن دارد.
- برای نمونه xi، خوشه مناسب بهصورت زیر تعیین میشود:
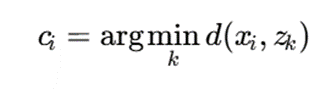
که در آن:
- ci: برچسب خوشه نمونه i
- (xi,zk) d : فاصله یا عدمتشابه نمونه xi با مد خوشه k
مثال
اگر برای یک داده داشته باشیم:
- d(xi,z1)=2
- d(xi,z2)=1
- d(xi,z3)=3
پس داده به خوشه دوم تخصیص مییابد:ci=2
.
13.بهروزرسانی مد خوشه
تعریف:پس از تخصیص دادهها به خوشهها، مد هر ویژگی در هر خوشه دوباره محاسبه میشود.
برای ویژگی j در خوشه k:
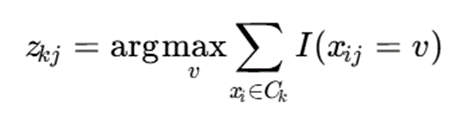
که در آن:
- zk: مقدار ویژگی j در مد خوشه k
- v: یکی از مقادیر ممکن ویژگی j
- I: تابع شاخص
- Ck: خوشه k
تابع شاخص:
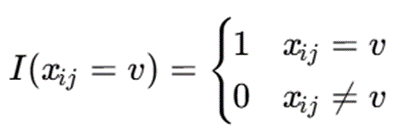
تفسیر:مد هر ویژگی، مقداری است که در آن خوشه بیشترین تکرار را دارد.
.
14. همگرایی الگوریتم
تعریف:همگرایی یعنی الگوریتم پس از چند تکرار به وضعیتی برسد که دیگر تغییر قابلتوجهی در خوشهها ایجاد نشود.
معیارهای توقف رایج
الگوریتم معمولاً زمانی متوقف میشود که یکی از شرایط زیر برقرار شود:
- برچسب خوشه دادهها تغییر نکند؛
- مد خوشهها ثابت بماند؛
- مقدار تابع هدف دیگر کاهش محسوسی نداشته باشد؛
- تعداد تکرارها به حد تعیینشده برسد.
بیان ریاضی
اگر مقدار تابع هدف در تکرار t برابر J^(t) باشد، توقف میتواند با شرط زیر انجام شود:
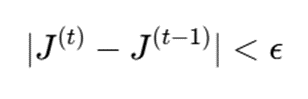
که در آن:
- ϵ: آستانهی کوچک برای توقف
- J^{(t)}: مقدار تابع هدف در تکرار فعلی
- J^{(t-1)}: مقدار تابع هدف در تکرار قبلی
.
15.انتخاب تعداد خوشهها (K)
تعریف
- در K-Modes، تعداد خوشهها K باید از قبل مشخص شود. انتخاب مقدار مناسب برای K یکی از چالشهای مهم است.
- اگر K خیلی کوچک باشد، خوشهها بیش از حد کلی میشوند.
- اگر K خیلی بزرگ باشد، خوشهها بیش از حد خرد و غیرقابلتفسیر میشوند.
روشهای انتخاب K
1. روش Elbow
در این روش مقدار تابع هدف برای مقادیر مختلف K محاسبه میشود. نقطهای که پس از آن کاهش تابع هدف کند میشود، بهعنوان مقدار مناسب K انتخاب میشود.
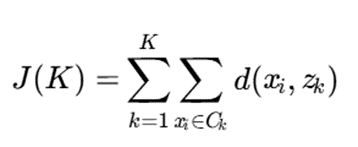
2. شاخص Silhouette
برای دادههای طبقهای نیز میتوان نسخهای از Silhouette را با معیار عدمتشابه مناسب محاسبه کرد.
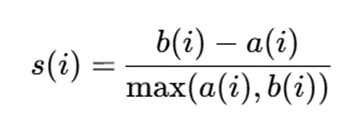
که در آن:
- a(i): میانگین عدمتشابه نمونه iii با دادههای خوشه خودش
- b(i): کمترین میانگین عدمتشابه نمونه iii با خوشههای دیگر
مقدار (i) sبین 1− و 1 است. مقدار بالاتر نشاندهنده خوشهبندی بهتر است.
.
16.مفاهیم پیشرفته در K-Modes
.
16.1.ویژگیهای پرتکرار و غالب
- در K-Modes، هر خوشه توسط مقادیر پرتکرار ویژگیها نمایش داده میشود. بنابراین شناخت مفهوم dominant category مهم است.
- تعریف:مقدار غالب یک ویژگی در یک خوشه، همان مقداری است که بیشترین تعداد تکرار را دارد.
مثال
در خوشهای از مشتریان، برای ویژگی «روش خرید» داریم:
| روش خرید | تعداد |
| آنلاین | 40 |
| حضوری | 10 |
| تلفنی | 5 |
مقدار غالب: آنلاین خواهد بود.
16.2.برخورد با تساوی در مد
ممکن است دو یا چند مقدار در یک ویژگی تعداد تکرار برابر داشته باشند.
مثالدر یک خوشه، ویژگی «رنگ» شامل مقادیر زیر است:
{قرمز،آبی،قرمز،آبی}
تعداد قرمز و آبی هر دو برابر 2 است. در این حالت مد یکتا نیست.
راهحلهای رایج
- انتخاب تصادفی یکی از مقادیر پرتکرار
- حفظ مقدار قبلی مد
- انتخاب مقداری که باعث کاهش بیشتر تابع هدف شود
- انتخاب بر اساس فراوانی کلی در کل دادهها
این موضوع در پیادهسازی الگوریتم اهمیت زیادی دارد.
16.3.دادههای گمشده یا Missing Values
در دادههای واقعی، ممکن است برخی مقادیر ویژگیها نامشخص باشند.
مثال
| مشتری | جنسیت | خرید | پرداخت |
| 1 | زن | کتاب | آنلاین |
| 2 | مرد | ؟ | حضوری |
| 3 | زن | پوشاک | آنلاین |
راهکارهای رایج
- حذف نمونههای دارای مقدار گمشده
- جایگزینی با مد همان ویژگی
- در نظر گرفتن مقدار «نامشخص» بهعنوان یک طبقه مستقل
- محاسبه عدمتشابه بدون ویژگیهای گمشده
فرمول تعدیلشده:اگر Mi مجموعه ویژگیهای مشاهدهشده برای نمونه xi باشد:
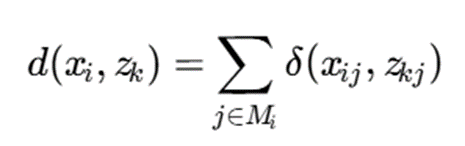
16.4.دادههای پرت و نویز
تعریف
- داده پرت نمونهای است که با بیشتر دادههای دیگر تفاوت زیادی دارد.
- در K-Modes، داده پرت ممکن است دارای ترکیبی از مقادیر نادر باشد.
مثال:اگر در دادههای مشتریان، بیشتر روشهای پرداخت «آنلاین» و «حضوری» باشند، اما مقدار بسیار نادر «رمزارز» وجود داشته باشد، ممکن است این مقدار باعث ایجاد نویز شود.
نکته K-Modes: نسبت به K-Means در دادههای طبقهای مناسبتر است، اما همچنان میتواند تحت تأثیر مقادیر بسیار نادر یا نویزی قرار گیرد.
16.5.وزندهی به ویژگیها
در K-Modes کلاسیک، همه ویژگیها اهمیت یکسانی دارند. اما در دادههای واقعی، این فرض همیشه درست نیست.
مثال:در خوشهبندی مشتریان، ممکن است ویژگی «الگوی خرید» مهمتر از ویژگی «جنسیت» باشد.
در حالت وزندار:
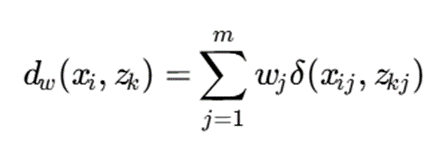
که در آن:
- wj: وزن ویژگیjj
اگر:
wخرید=3
و:
wجنسیت=1
یعنی اختلاف در نوع خرید سه برابر اختلاف در جنسیت اهمیت دارد.
.
17.مقیاسپذیری و پیچیدگی محاسباتی
تعریف:مقیاسپذیری یعنی الگوریتم بتواند با افزایش تعداد دادهها و ویژگیها همچنان قابل اجرا باقی بماند.
اگر داشته باشیم:
- n: تعداد نمونهها
- m: تعداد ویژگیها
- K: تعداد خوشهها
- T: تعداد تکرارها
پیچیدگی تقریبی K-Modes برابر است با:
O(T×n×K×m)
تفسیر:هرچه تعداد نمونهها، ویژگیها یا خوشهها بیشتر شود، زمان اجرای الگوریتم افزایش مییابد.
.
18.ارزیابی کیفیت خوشهبندی
چون K-Modes بدون نظارت است، معمولاً برچسب واقعی وجود ندارد. بنابراین باید از معیارهای ارزیابی داخلی یا خارجی استفاده کرد.
18.1.معیارهای داخلی
این معیارها فقط از داده و ساختار خوشهها استفاده میکنند.
نمونهها:
- تابع هدف K-Modes
- Silhouette مبتنی بر عدمتشابه
- Dunn Index
- Davies-Bouldin Index تعدیلشده
18.2.معیارهای خارجی
اگر برچسب واقعی وجود داشته باشد، میتوان نتیجه خوشهبندی را با برچسبها مقایسه کرد.
نمونهها:
- Accuracy با نگاشت خوشهها به کلاسها
- Adjusted Rand Index
- Normalized Mutual Information
- Purity
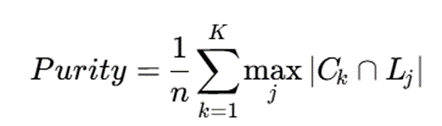
که در آن:
- Ck: خوشه k
- Lj: کلاس واقعی j
- n: تعداد کل دادهها
.
19.مثالهای عددی
.
مثال 1
دادهها:
| شخص | جنسیت | خودرو |
| 1 | مرد | SUV |
| 2 | زن | Sedan |
| 3 | مرد | SUV |
| 4 | زن | SUV |
فرض کنید:
K=2
مد اولیه:
خوشه1: (مرد, SUV)
خوشه2: (زن, Sedan)
مرحله تخصیص
شخص1 → خوشه1
شخص2 → خوشه2
شخص3 → خوشه1
شخص4 → فاصله برابر → انتخاب خوشه نزدیکتر
مد جدید
خوشه1:
- جنسیت: مرد
- خودرو: SUV
مثال 2
ویژگی: نوع دستگاه
| کاربر | دستگاه |
| 1 | Android |
| 2 | iOS |
| 3 | Android |
| 4 | Android |
مد:Android
مثال 3
داده مشتریان:
| مشتری | جنسیت | خرید |
| 1 | مرد | کتاب |
| 2 | زن | کتاب |
| 3 | مرد | لباس |
| 4 | مرد | کتاب |
مد خوشه:
(مرد، کتاب)
.
20.کاربردهای واقعی
- بخشبندی مشتریان در بازاریابی
- تحلیل رفتار کاربران وب
- سیستمهای توصیهگر
- تحلیل دادههای پزشکی طبقهای
- تحلیل دادههای نظرسنجی
- دستهبندی محصولات در تجارت الکترونیک
.
21. مزایا
- مناسب برای دادههای طبقهای
- پیچیدگی محاسباتی نسبتاً پایین
- مقیاسپذیر برای دادههای بزرگ
- سادگی پیادهسازی
- تفسیرپذیری مناسب نتایج
.
22. محدودیتها و معایب
- نیاز به تعیین تعداد خوشهها K
- حساسیت به مقداردهی اولیه
- احتمال گیر افتادن در بهینه محلی
- کاهش کارایی در دادههای بسیار پراکنده
- در نظر نگرفتن وزن ویژگیها در نسخه پایه
.
23.تفاوت K-Means و K-Modes
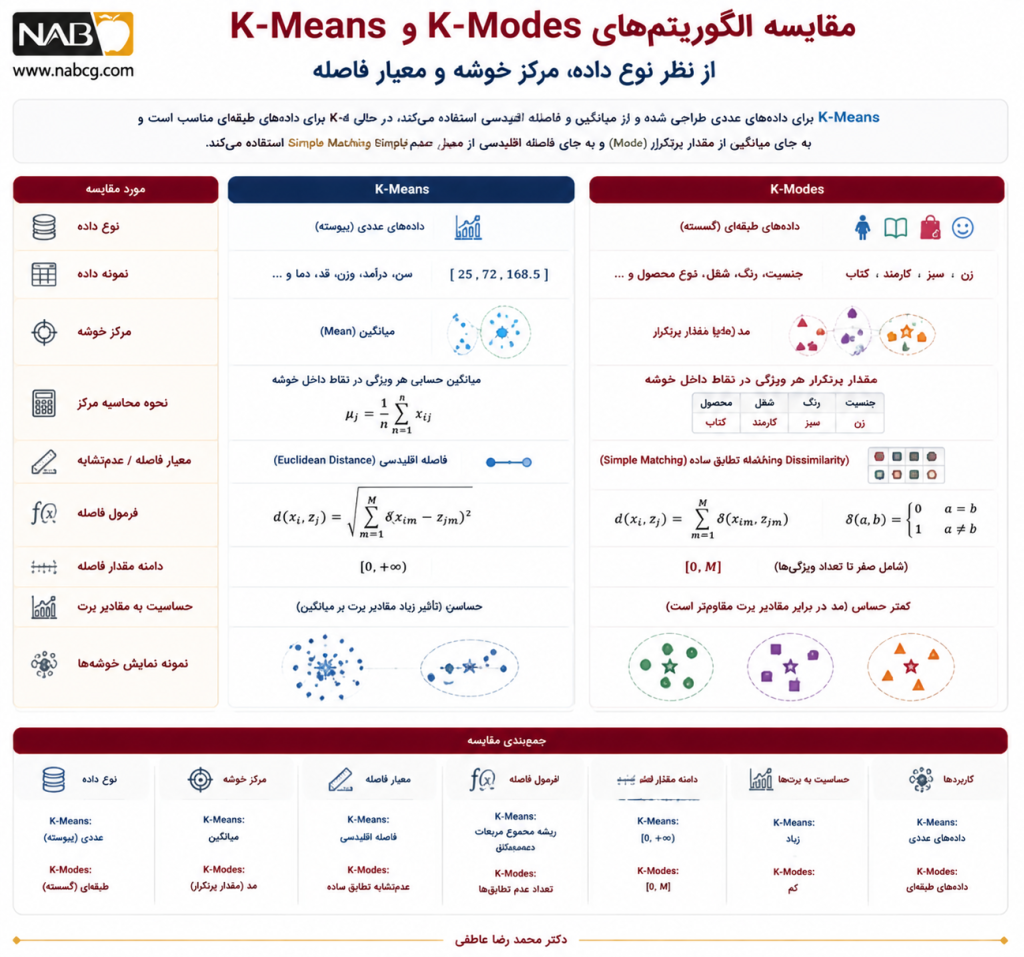
یکی از بهترین راهها برای فهم K-Modes، مقایسهی آن با K-Means است.
| ویژگی | K-Means | K-Modes |
| نوع داده | عددی | طبقهای |
| نماینده خوشه | میانگین | مد |
| معیار فاصله | فاصله اقلیدسی | عدمتشابه تطبیقی |
| نوع مقدار مرکز خوشه | ممکن است داده واقعی نباشد | معمولاً ترکیبی از مقادیر پرتکرار است |
| مناسب برای | دادههای پیوسته | دادههای اسمی و گسسته |
| مسئله اصلی | کمینهسازی مجموع مربعات فاصله | کمینهسازی تعداد عدمتطابقها |
در K-Means مرکز خوشه از رابطه زیر به دست میآید:
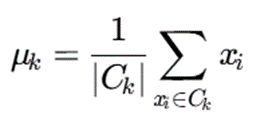
اما در K-Modes مرکز خوشه برای هر ویژگی برابر مقدار پرتکرار آن ویژگی است:
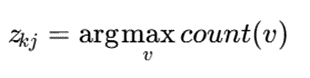
.
24.نوآوریها و روندهای پژوهشی جدید در الگوریتم K-Modes
الگوریتم K-Modes بهعنوان نسخهای مناسب برای خوشهبندی دادههای طبقهای، در سالهای اخیر توسعههای متعددی یافته است. هدف این توسعهها معمولاً افزایش دقت خوشهبندی، کاهش حساسیت به مقداردهی اولیه، افزایش مقیاسپذیری، پشتیبانی از دادههای جریانی و ترکیب با روشهای هوشمند جدید مانند یادگیری عمیق و الگوریتمهای تکاملی است.
در ادامه، مهمترین روندهای پژوهشی جدید در این حوزه بررسی میشوند.

24.1. Weighted K-Modes
- ایده اصلی:در K-Modes کلاسیک، همهی ویژگیها اهمیت یکسانی دارند. اما در بسیاری از دادههای واقعی، برخی ویژگیهای طبقهای نقش بیشتری در تشکیل خوشهها دارند.
- در Weighted K-Modes برای هر ویژگی یک وزن در نظر گرفته میشود تا ویژگیهای مهمتر تأثیر بیشتری در محاسبه عدمتشابه داشته باشند.
فرمول اصلی:در K-Modes کلاسیک، عدمتشابه بهصورت زیر است:
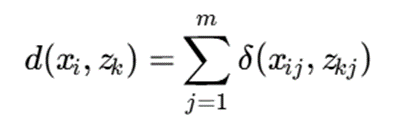
در Weighted K-Modes، این رابطه به شکل زیر تغییر میکند:
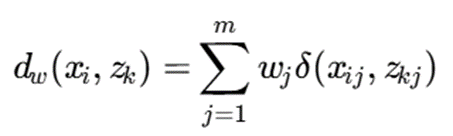
که در آن:
- xi: نمونهی i-ام
- zk: مد خوشهی k-ام
- m: تعداد ویژگیها
- wj: وزن ویژگی j-ام
- δ: تابع عدمتطابق
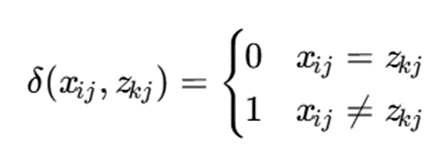
تابع هدف
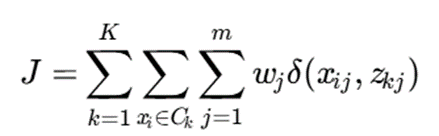
هدف، کمینهسازی J است.
کاربرد پژوهشی:این روش برای دادههایی مناسب است که در آنها ویژگیها اهمیت یکسان ندارند؛ مانند دادههای پزشکی، تحلیل مشتریان و دادههای اجتماعی.
.
24.2. Fuzzy K-Modes
- ایده اصلیدر K-Modes معمولی، هر نمونه فقط به یک خوشه تعلق دارد. اما در بسیاری از مسائل واقعی، یک داده ممکن است تا حدی به چند خوشه وابسته باشد.
- Fuzzy K-Modes عضویت نرم را وارد خوشهبندی میکند.
- در این روش، هر نمونه دارای درجه عضویت نسبت به هر خوشه است.
فرمول اصلی
تابع هدف Fuzzy K-Modes معمولاً بهصورت زیر تعریف میشود:
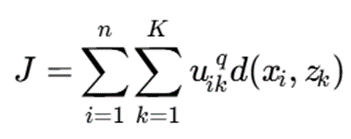
که در آن:
- uik: درجه عضویت نمونه xi در خوشه k
- q: پارامتر فازیسازی، معمولاً q >1
- d(xi,zk) : عدمتشابه بین نمونه و مد خوشه
- zk: مد خوشه k
شرط عضویت:
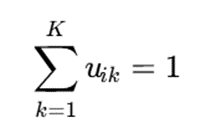
برای هر نمونه xi.
تفسیر:اگر:
ui1=0.7 , ui2=0.3
یعنی نمونهی xi بیشتر به خوشهی 1 تعلق دارد، اما تا حدی نیز به خوشهی 2 وابسته است.
کاربرد پژوهشی:برای دادههایی که مرز خوشهها مبهم است؛ مانند دادههای رفتاری کاربران، دادههای پزشکی و تحلیل نظرسنجیها.
.
24.3. Kernel K-Modes
ایده اصلی
- K-Modes کلاسیک معمولاً روابط سادهی عدمتطابق بین مقادیر طبقهای را در نظر میگیرد. در برخی دادهها، روابط غیرخطی یا ساختارهای پیچیدهتری وجود دارد.
- Kernel K-Modes با استفاده از تابع کرنل تلاش میکند دادهها را به فضای ویژگی بالاتر منتقل کند تا خوشهها بهتر از هم جدا شوند.
ایده ریاضی
فرض کنید نگاشت غیرخطی زیر وجود داشته باشد:
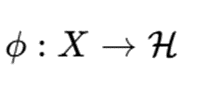
که دادهها را به فضای ویژگی H منتقل میکند.
فاصله در فضای کرنل:
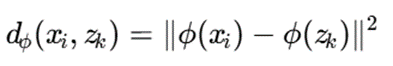
با استفاده از کرنل:
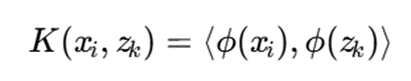
میتوان نوشت:
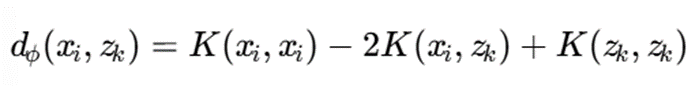
کاربرد پژوهشی
Kernel K-Modes برای دادههایی مناسب است که ساختار خوشهها بهصورت خطی یا ساده قابل تشخیص نیست، بهویژه در دادههای پیچیدهی طبقهای و دادههای زیستی.
.
24.4. Genetic K-Modes
ایده اصلی
- K-Modes به مقداردهی اولیه حساس است و ممکن است در بهینه محلی متوقف شود.
- در Genetic K-Modes از الگوریتم ژنتیک برای جستوجوی بهتر medes یا مراکز خوشه استفاده میشود.
- در این روش، هر کروموزوم میتواند مجموعهای از مدهای اولیه را نمایش دهد.
نمایش کروموزوم
فرض کنید K=3، هر کروموزوم میتواند بهصورت زیر باشد:
Chromosome=[z1 , z2 , z3]
که در آن:
- z1 , z2 , z3 : مدهای پیشنهادی برای سه خوشه
تابع برازندگی
معمولاً تابع برازندگی بر اساس معکوس تابع هدف K-Modes تعریف میشود:
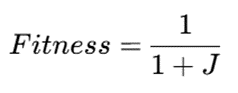
که:
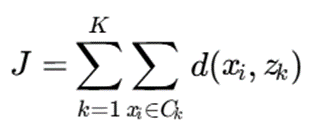
هرچه J کمتر باشد، مقدار Fitness بیشتر است.
کاربرد پژوهشی:برای کاهش وابستگی به مقداردهی اولیه و افزایش احتمال رسیدن به جواب بهتر در دادههای پیچیده.
.
24.5.Ensemble Clustering مبتنی بر K-Modes
ایده اصلی
- در Ensemble Clustering چندین خوشهبندی مختلف با هم ترکیب میشوند تا یک خوشهبندی نهایی پایدارتر و دقیقتر به دست آید.
- در زمینه K-Modes، میتوان الگوریتم را چندین بار با مقداردهیهای اولیه متفاوت اجرا کرد و سپس نتایج را ترکیب نمود.
ماتریس هموابستگی
یکی از رویکردهای رایج، ساخت ماتریس همخوشهای یا Co-association Matrix است:
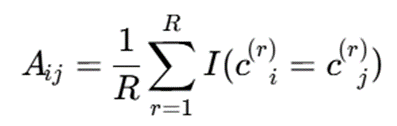
که در آن:
- R: تعداد اجرای الگوریتم
- : cir برچسب خوشه نمونه iii در اجرای rrr-ام
- I: تابع شاخص
- Aij: نسبت دفعاتی که دو نمونه i و j در یک خوشه قرار گرفتهاند
تفسیر
اگر:Aij=0.9
یعنی دو نمونه در 90 درصد اجراها در یک خوشه قرار گرفتهاند.
کاربرد پژوهشی:برای افزایش پایداری نتایج و کاهش اثر تصادفی بودن مقداردهی اولیه.
.
24.6.Deep Clustering مبتنی بر K-Modes
ایده اصلی
- در دادههای پیچیده، ویژگیهای خام ممکن است برای خوشهبندی مناسب نباشند.
- در Deep Clustering ابتدا با استفاده از شبکههای عصبی، نمایش مناسبی از دادهها یاد گرفته میشود، سپس خوشهبندی انجام میگیرد.
- در دادههای طبقهای، معمولاً دادهها ابتدا به embedding تبدیل میشوند.
ساختار کلی
xi→hi=fθ(xi)
که در آن:
- xi: دادهی خام
- fθ: شبکه عصبی با پارامترهای θ
- hi: نمایش نهفته یا embedding
سپس خوشهبندی روی hi انجام میشود:
Cluster(hi)
تابع هدف ترکیبی
در برخی مدلها تابع هدف شامل دو بخش است:
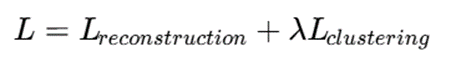
که در آن:
- Lreconstruction: خطای بازسازی در autoencoder
- Lclustering: خطای خوشهبندی
- λ: ضریب تنظیم اهمیت بخش خوشهبندی
کاربرد پژوهشی:برای خوشهبندی دادههای پیچیده مانند دادههای کاربری، متون، رفتار وب، دادههای پزشکی و دادههای اینترنت اشیا.
24.7.Incremental K-Modes
ایده اصلی
- در K-Modes کلاسیک فرض میشود کل دادهها از ابتدا در دسترس هستند.
- اما در بسیاری از سامانههای واقعی، دادهها بهتدریج وارد میشوند.
- Incremental K-Modes خوشهها را با ورود دادههای جدید بهروزرسانی میکند، بدون اینکه نیاز باشد الگوریتم از ابتدا روی کل دادهها اجرا شود.
بهروزرسانی شمارش مقادیر
برای هر خوشه و هر ویژگی، تعداد تکرار مقادیر نگهداری میشود:

که نشان میدهد در خوشه k، ویژگی j، مقدار v چند بار مشاهده شده است.
مد جدید:
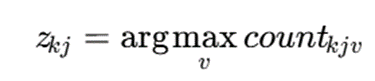
کاربرد پژوهشی:برای پایگاههای دادهای که دائماً بهروزرسانی میشوند، مانند دادههای مشتریان، لاگهای وب و سامانههای توصیهگر.
.
24.8.Streaming K-Modes
ایده اصلی
در Streaming K-Modes دادهها بهصورت جریان پیوسته و سریع وارد میشوند. تفاوت آن با Incremental K-Modes این است که در دادههای جریانی، معمولاً امکان ذخیره کل دادهها وجود ندارد.
بنابراین الگوریتم باید:
- با حافظه محدود کار کند،
- سریع تصمیم بگیرد،
- با تغییر توزیع دادهها سازگار شود.
تابع بهروزرسانی با فراموشی زمانی
برای دادههای جریانی، میتوان از ضریب فراموشی استفاده کرد:
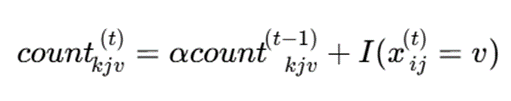
که در آن:
- t: زمان
- α: ضریب فراموشی، 0 < α <1
- I: تابع شاخص
- Count kjv: شمارش مقدار v در زمان t
مد در زمان t:
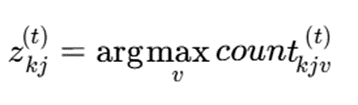
کاربرد پژوهشی
برای تحلیل جریان داده در شبکههای اجتماعی، اینترنت اشیا، پایش بلادرنگ و سامانههای هشدار.
.
24.9.ترکیب K-Modes با یادگیری عمیق
ایده اصلی
- این روند تا حدی با Deep Clustering همپوشانی دارد، اما تمرکز آن بیشتر بر استفاده از یادگیری عمیق برای بهبود نمایش دادههای طبقهای است.
- دادههای طبقهای میتوانند از طریق embedding layer به بردارهای پیوسته تبدیل شوند:
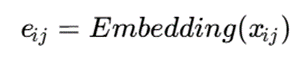
سپس نمایش کل نمونه ساخته میشود:
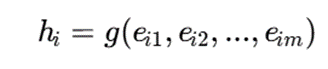
و خوشهبندی روی نمایش آموختهشده انجام میشود.
تابع هدف نمونه
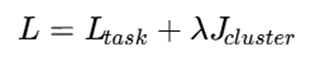
در حالت بدون نظارت کامل:
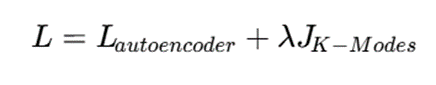
کاربرد پژوهشی
برای دادههای با ابعاد زیاد و مقادیر طبقهای زیاد؛ مانند:
- دادههای تراکنشی
- دادههای سلامت
- دادههای تجارت الکترونیک
- دادههای رفتاری کاربران
24.10.استفاده از K-Modes در کلاندادهها
ایده اصلی
در محیطهای Big Data، چالش اصلی K-Modes هزینه محاسباتی و حافظه است.
بنابراین نسخههای جدید تلاش میکنند K-Modes را روی چارچوبهایی مانند:
- Hadoop
- Spark
- MapReduce
- سیستمهای توزیعشده
پیادهسازی کنند.
تابع هدف
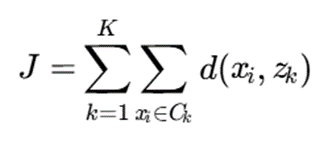
اما محاسبه آن بهصورت توزیعشده انجام میشود:
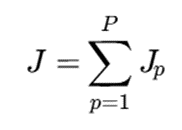
که در آن:
- P: تعداد گرهها یا پارتیشنها
- Jp: هزینه محلی در پارتیشن p
کاربرد پژوهشی
برای خوشهبندی پایگاههای عظیم مشتریان، دادههای وب، دادههای تراکنشی و دادههای شبکهای.
.
24.11.استفاده در سامانههای بلادرنگ
ایده اصلی
در سامانههای بلادرنگ، الگوریتم باید در زمان بسیار کوتاه پاسخ دهد. K-Modes کلاسیک برای چنین محیطهایی نیاز به بهینهسازی دارد.
در این کاربردها معمولاً از نسخههای زیر استفاده میشود:
- Incremental K-Modes
- Streaming K-Modes
- Approximate K-Modes
- Distributed K-Modes
معیار زمان پاسخ
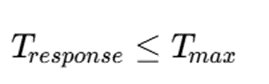
که در آن:
- Tresponse: زمان پاسخ الگوریتم
- Tmax: حداکثر زمان مجاز در سامانه بلادرنگ
کاربرد پژوهشی
- تشخیص الگوی رفتاری در لحظه
- پایش امنیت شبکه
- تشخیص ناهنجاری بلادرنگ
- سیستمهای توصیهگر آنلاین
.
24.12.خوشهبندی دادههای اینترنت اشیا با K-Modes
ایده اصلی
دادههای اینترنت اشیا یا IoT معمولاً شامل ترکیبی از دادههای عددی، طبقهای، زمانی و گسسته هستند.
در بسیاری از کاربردها، وضعیت دستگاهها بهصورت طبقهای بیان میشود؛ مانند:
- روشن / خاموش
- عادی / هشدار
- فعال / غیرفعال
- نوع رخداد
- وضعیت حسگر
برای چنین دادههایی، K-Modes یا نسخههای ترکیبی آن میتواند مفید باشد.
مدل عدمتشابه نمونه برای IoT
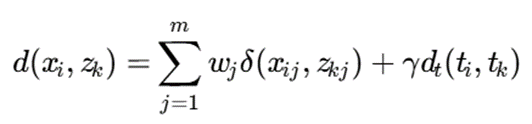
که در آن:
- بخش اول: عدمتشابه ویژگیهای طبقهای
- dt: فاصله زمانی
- γ: وزن اهمیت زمان
- wj: وزن ویژگی طبقهای
کاربرد پژوهشی
- خوشهبندی وضعیت دستگاهها
- تشخیص رفتار غیرعادی حسگرها
- مدیریت انرژی
- پایش سلامت تجهیزات
- تحلیل رخدادهای شبکههای هوشمند
.
24.13.ترکیب K-Modes با الگوریتمهای تکاملی
ایده اصلی
این مورد از نظر مفهومی با Genetic K-Modes مرتبط است، اما گستردهتر است. در اینجا K-Modes میتواند با طیف وسیعی از الگوریتمهای تکاملی و جمعیتمحور ترکیب شود.
نمونهها:
- Genetic Algorithm
- Differential Evolution
- Particle Swarm Optimization
- Ant Colony Optimization
- Artificial Bee Colony
- Whale Optimization Algorithm
چارچوب کلی
در این روشها، هر راهحل کاندیدا مجموعهای از مدهاست:
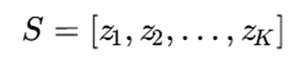
تابع هدف:
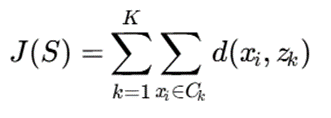
هدف:
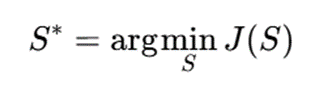
جمعبندی نهایی
روندهای پژوهشی جدید نشان میدهند که K-Modes از یک الگوریتم ساده برای خوشهبندی دادههای طبقهای به یک چارچوب منعطف و قابلگسترش تبدیل شده است. مهمترین مسیرهای آینده عبارتاند از:
- افزایش مقیاسپذیری برای کلاندادهها
- کاهش حساسیت به مقداردهی اولیه
- پشتیبانی از دادههای جریانی و بلادرنگ
- ترکیب با یادگیری عمیق برای یادگیری نمایش بهتر
- استفاده از الگوریتمهای تکاملی برای جستوجوی بهینهتر
- توسعه نسخههای فازی، وزندار و کرنلی برای دادههای پیچیدهتر
بنابراین میتوان گفت:
منابع
Huang, Z. (1997). Clustering large data sets with mixed numeric and categorical values. Proceedings of the First Pacific-Asia Conference on Knowledge Discovery and Data Mining, 21–34.
Huang, Z. (1998). Extensions to the k-means algorithm for clustering large data sets with categorical values. Data Mining and Knowledge Discovery, 2(3), 283–304.
Han, J., Kamber, M., & Pei, J. (2012). Data Mining: Concepts and Techniques. Morgan Kaufmann.
Tan, P. N., Steinbach, M., & Kumar, V. (2019). Introduction to Data Mining. Pearson.· Categorical data clustering: 25 years beyond K-modes (2024/2025)
A Scalable k-Medoids Clustering via Whale Optimization Algorithm (2025)
Fast k-medoids and q-Fold Fast k-medoids: New distance-based clustering algorithms for large mixed-type data (2025)
Global Optimal K-Medoids Clustering of One Million Samples (2022)



