

1.مقدمه
تا حالا برایتان پیش آمده که انبوهی از دادههای بدون برچسب داشته باشید – مثلاً فهرست مشتریان یک فروشگاه، تصاویر پزشکی، یا رفتار کاربران یک اپلیکیشن – و ندانید از کجا شروع کنید؟ در چنین شرایطی، یکی از قدرتمندترین ابزارهای علم داده به کمک شما میآید: خوشهبندی .(Clustering).
خوشهبندی یک روش یادگیری بدون ناظر است؛ یعنی بدون نیاز به دادههای آموزشی از پیش برچسبخورده، میتواند گروههای طبیعی و پنهان را در میان دادهها پیدا کند. فرض کنید هزاران مشتری دارید، اما نمیدانید آنها به چند دسته رفتاری تقسیم میشوند. خوشهبندی خودکار این کار را برای شما انجام میدهد: افرادی که الگوی خرید مشابهی دارند، در یک خوشه قرار میگیرند و آنها که متفاوتاند، در خوشهای دیگر.
اهمیت این روش به روزهایی برمیگردد که حجم دادهها آنقدر زیاد شده که تحلیل خطی و دستی دیگر ممکن نیست. از بخشبندی مشتریان در بازاریابی، تا تشخیص تومور در تصاویر پزشکی، از کشف تقلبات بانکی تا بهینهسازی زنجیره تأمین – خوشهبندی در همهی این حوزهها نقشی کلیدی ایفا میکند.
در این مقاله، قصد داریم به زبانی ساده اما دقیق، مفهوم خوشهبندی را شرح دهیم، تفاوت آن با طبقهبندی را بررسی کنیم، انواع الگوریتمها را معرفی کنیم و مهمترین کاربردهای واقعی آن را مرور کنیم. اگر به یادگیری ماشین و تحلیل داده علاقه دارید، این مطلب نقطهی شروع بسیار خوبی برای شماست.
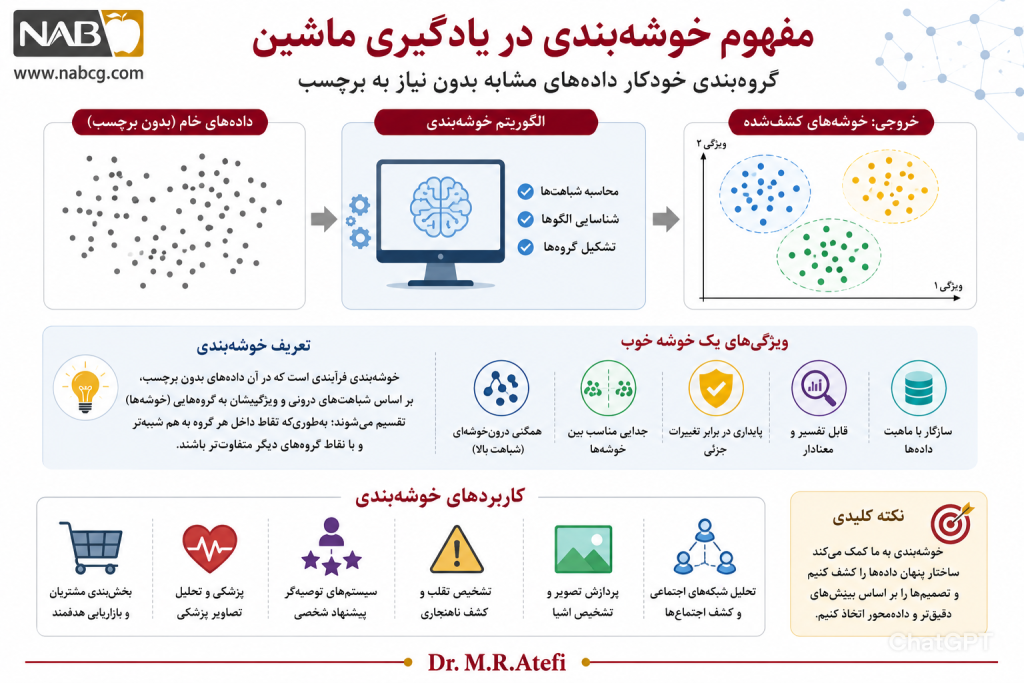
2.تعریف خوشه بندی
خوشهبندی (Clustering) یکی از مهمترین روشهای یادگیری بدونناظر در یادگیری ماشین است. در این روش، هدف آن است که دادههای بدون برچسب به گروههایی به نام خوشه تقسیم شوند؛ بهگونهای که نمونههای داخل هر خوشه از نظر ویژگیهای موردنظر تا حد امکان شبیه به هم باشند و نمونههای متعلق به خوشههای مختلف کمتر به هم شباهت داشته باشند .
به بیان ساده، خوشهبندی یعنی گروهبندی خودکار دادهها بر اساس شباهت؛ بدون آنکه کلاس یا برچسب از پیش تعریفشدهای وجود داشته باشد. این ویژگی، خوشهبندی را از روشهای نظارتشده مانند طبقهبندی متمایز میکند، زیرا در طبقهبندی، برچسبهای آموزشی از قبل معلوماند، اما در خوشهبندی ساختار گروهها باید از خود داده استخراج شود (Hastie et al., 2009; Jain, 2010).
از منظر مفهومی، اگر مجموعه داده را به صورت زیر بنویسیم:
X={x1,x2,…,xn}
هدف خوشهبندی یافتن یک افراز یا تقسیم مناسب از این مجموعه به K زیرمجموعه است:
C={C1,C2,…,CK}
بهنحوی که درون هر خوشه، شباهت درونی بیشینه و جدایی میان خوشهها بیشینه باشد (Xu & Wunsch, 2005). با این حال، باید توجه داشت که مفهوم «شباهت» در خوشهبندی مطلق نیست و به نوع داده، نمایش ویژگیها و معیار فاصله یا شباهت انتخابشده وابسته است (Aggarwal & Reddy, 2014).

در عمل، خوشهبندی صرفاً یک ابزار گروهبندی نیست، بلکه روشی برای کشف الگوهای پنهان، خلاصهسازی دادههای پیچیده و آمادهسازی داده برای تحلیلهای بعدی نیز بهشمار میرود. به همین دلیل، این روش در حوزههایی مانند تحلیل مشتری، زیستاطلاعاتی، پردازش تصویر، تحلیل متن و کشف ناهنجاری کاربرد گسترده دارد (Everitt et al., 2011; Jain, 2010).
3.تعریف خوشه
خوشه مجموعهای از اشیاء یا نمونههاست که بر اساس یک معیار مشخص، نسبت به سایر نمونهها شباهت بیشتری به یکدیگر دارند. در ادبیات دادهکاوی و یادگیری ماشین، خوشه معمولاً بهعنوان ناحیهای از فضای ویژگیها در نظر گرفته میشود که در آن، دادهها از نظر آماری، هندسی یا معنایی به هم نزدیکاند (Xu & Wunsch, 2005).
در ادبیات خوشهبندی، خوشه به مجموعهای از نمونهها گفته میشود که نسبت به سایر نمونههای داده، شباهت درونگروهی بالاتر و تمایز بینگروهی بیشتری دارند. به بیان دقیقتر، اگر مجموعه داده را X={x1,x2,…,xn} در نظر بگیریم، خوشهها زیرمجموعههایی از این فضا هستند که بر اساس یک معیار شباهت یا فاصله، ساختار طبیعی داده را آشکار میکنند (Jain, 2010; Everitt et al., 2011).
از دیدگاه عملی، خوشه صرفاً «یک گروه» نیست؛ بلکه ناحیهای از فضای داده است که در آن، نمونهها از نظر ویژگیهای مورد بررسی به هم نزدیکترند. همین نزدیکی میتواند بر پایه فاصله هندسی، تراکم محلی، شباهت آماری، یا حتی ساختار گرافی تعریف شود. به همین دلیل، خوشه در خوشهبندی یک مفهوم وابسته به مدل و داده است، نه یک مفهوم مطلق و یکتا (Aggarwal & Reddy, 2014).
4.ویژگیهای یک خوشه خوب
یک خوشه خوب، خوشهای است که هم از نظر آماری منسجم باشد و هم از نظر کاربردی قابل تفسیر. مهمترین ویژگیهای آن عبارتاند از:
الف.همگنی درونخوشهای:در یک خوشه مناسب، نقاط داده باید تا حد زیادی به هم نزدیک باشند. اگر پراکندگی داخل خوشه زیاد باشد، آن خوشه احتمالاً چند ساختار متفاوت را در خود جای داده است و از نظر مفهومی ضعیف محسوب میشود (Xu & Wunsch, 2005).
ب.جدایی مناسب از خوشههای دیگر:خوشهها باید تا جای ممکن مرزهای مشخصی با یکدیگر داشته باشند. هرچه همپوشانی میان خوشهها بیشتر باشد، تفسیر آنها دشوارتر میشود و اعتماد به خوشهبندی کاهش مییابد (Handl et al., 2005).
ج. پایداری:یک خوشه خوب باید در برابر تغییرات جزئی در داده یا مقداردهی اولیه تا حدی پایدار باشد. اگر با یک تغییر کوچک، ساختار خوشهها بهکلی دگرگون شود، آن خوشهبندی از نظر تحلیلی قابل اتکا نیست.
د. تفسیرپذیری:خوشهها باید بتوانند به یک مفهوم معنادار در دامنه مسئله اشاره کنند؛ برای مثال، گروهی از مشتریان با رفتار خرید مشابه یا گروهی از بیماران با ویژگیهای بالینی نزدیک.
ه. سازگاری با ماهیت داده:شکل و ساختار خوشه باید با الگوی واقعی داده سازگار باشد. در برخی مسائل، خوشهها فشرده و تقریباً کرویاند؛ در برخی دیگر، کشیده، بیضوی یا کاملاً نامنظماند .
5.مفهوم تراکم، شباهت و همگنی در خوشه
سه مفهوم تراکم، شباهت و همگنی، با هم مرتبط هستند اما یکی نیستند:
تراکم
تراکم به این معناست که تعداد زیادی از نقاط در یک ناحیه محدود از فضا قرار گرفتهاند. در روشهای تراکممحور مانند DBSCAN، خوشه ناحیهای است که تراکم نقاط در آن از یک آستانه مشخص بیشتر باشد و توسط نواحی کمتراکم از سایر نواحی جدا شود (Ester et al., 1996).
شباهت
شباهت به میزان نزدیکی نمونهها از نظر ویژگیها اشاره دارد. این نزدیکی میتواند با فاصله، زاویه، همبستگی یا معیارهای دیگر سنجیده شود. در خوشهبندی مبتنی بر مرکز، شباهت غالباً به نزدیکی به centroid معنا میشود.
همگنی
یعنی اعضای خوشه از نظر ویژگیهای کلیدی، الگوی نسبتاً یکنواختی داشته باشند. همگنی معمولاً نتیجه تراکم بالا یا شباهت زیاد است، اما از آنها متمایز است؛ زیرا ممکن است خوشهای متراکم باشد اما از نظر معنایی کاملاً همگن نباشد، اگر معیار فاصله نامناسب انتخاب شده باشد.
6.تفاوت خوشههای فشرده، کشیده، کروی، بیضوی و نامنظم
شکل خوشهها یکی از مهمترین نکات در تحلیل خوشهبندی است، زیرا همه الگوریتمها قادر به کشف همه انواع شکلها نیستند.

خوشههای کروی
خوشههای کروی تقریباً در اطراف یک مرکز قرار میگیرند و پراکندگی آنها در همه جهتها مشابه است. K-Means معمولاً برای این نوع خوشهها مناسبتر است، چون بر میانگین و فاصله اقلیدسی تکیه دارد (Jain, 2010).
خوشههای بیضوی
در خوشههای بیضوی، پراکندگی در برخی جهتها بیشتر از جهتهای دیگر است. مدلهای آمیخته گاوسی و برخی روشهای مبتنی بر کواریانس، برای این نوع خوشهها مناسبترند، زیرا میتوانند ناهمسانی و جهتداری داده را بهتر مدل کنند (Bishop, 2006).
خوشههای کشیده
خوشههای کشیده، در یک امتداد خاص ادامه پیدا میکنند؛ برای مثال، دادههایی که روی یک منحنی یا مسیر توزیع شدهاند. الگوریتمهای مبتنی بر فاصله اقلیدسی ممکن است در این حالت عملکرد ضعیفی داشته باشند، چون فاصله مستقیم لزوماً بیانگر ساختار واقعی خوشه نیست.
خوشههای نامنظم
این خوشهها شکل هندسی سادهای ندارند و ممکن است حلقهای، موجدار یا چندشاخه باشند. روشهایی مانند DBSCAN و OPTICS معمولاً برای چنین ساختارهایی مناسبترند، چون بر تراکم محلی متکیاند نه بر فرض کروی بودن خوشه (Ester et al., 1996; Ankerst et al., 1999).
7. خوشههای جدا از هم در برابر خوشههای همپوشان
خوشههای جدا از هم
در این حالت، مرز میان خوشهها روشنتر است و هر نمونه بهطور غالب به یک خوشه تعلق دارد. این وضعیت برای بسیاری از روشهای سخت خوشهبندی ایدهآل است.
خوشههای همپوشان
در بسیاری از دادههای واقعی، مرز خوشهها شفاف نیست و برخی نمونهها میتوانند به بیش از یک ناحیه تعلق مفهومی داشته باشند. برای چنین مسائلی، مدلهای احتمالاتی و خوشهبندی نرم مناسبترند، زیرا درجه تعلق نمونهها را به هر خوشه بهصورت پیوسته بیان میکنند (Hastie et al., 2009).
وجود همپوشانی الزاماً نشانه ضعف خوشهبندی نیست؛ بلکه ممکن است بازتاب واقعیت پیچیده داده باشد. برای مثال، در دادههای زیستی یا رفتاری، افراد یا نمونهها میتوانند ویژگیهای مشترک چند گروه را همزمان داشته باشند.
8. خوشههای سخت و خوشههای نرم
الگوریتمها بر اساس نوع خروجی و میزان قطعیتی که به مرزها تخصیص میدهند، فضا را به دو روش کاملاً متفاوت مدلسازی میکنند:
- خوشهبندی سخت (Hard Clustering):
در این نگاه، مرزبندیها کاملاً صلب، قاطع و باینری هستند. یک نقطه داده یا ۱۰۰٪ متعلق به یک خوشه است یا اصلاً به آن تعلق ندارد (۰ یا ۱). هیچ مرز مشترک یا ناحیه خاکستری وجود ندارد؛ مانند اینکه یک مشتری را قطعاً فقط در گروه “خریداران کممصرف” قرار دهیم.
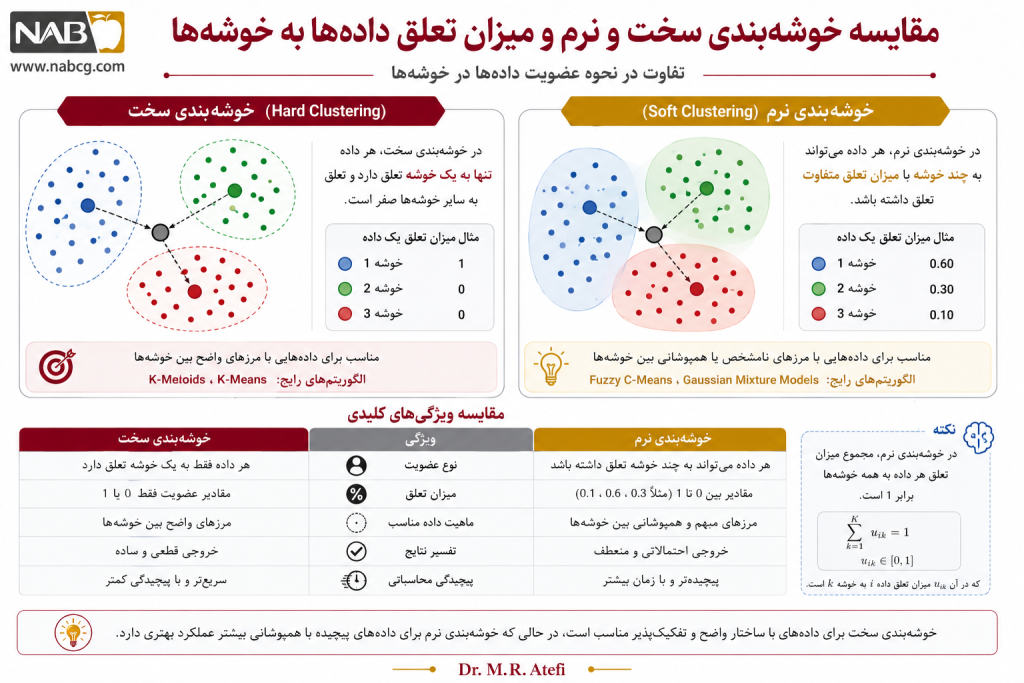
در خوشهبندی سخت، هر نمونه فقط به یک خوشه تعلق میگیرد. بهعبارت دیگر، عضویت نمونهها دودویی است:
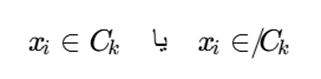
روشهایی مانند K-Means از این نوعاند.
- خوشهبندی نرم (Soft Clustering):
این رویکرد نگاهی واقعبینانه و احتمالی دارد. به جای تایید صلب، یک درجه عضویت بین ۰ تا ۱ به داده تخصیص داده میشود. برای مثال، یک داده میتواند ۷۰٪ به خوشه اول و ۳۰٪ به خوشه دوم تعلق داشته باشد که نشاندهنده رفتارهای چندگانه آن نمونه در دنیای واقعی است.
در خوشهبندی نرم، یک نمونه میتواند با درجات مختلف به چند خوشه وابسته باشد. این وابستگی معمولاً بهصورت احتمال یا درجه عضویت بیان میشود:
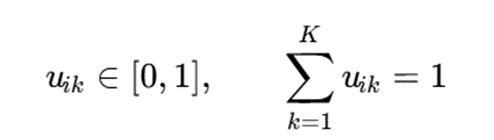
این رویکرد برای دادههایی مناسب است که مرزهای قطعی ندارند یا از نظر مفهومی بهصورت پیوسته توزیع شدهاند؛ مانند مدلهای آمیخته گاوسی و Fuzzy C-Means (Bezdek, 1981).
9.دلایل اهمیت الگوریتم خوشه بندی
اهمیت خوشهبندی از این واقعیت ناشی میشود که در بسیاری از مسائل واقعی، دادهها برچسب آماده ندارند، اما درون خود دارای نظم، شباهتها و الگوهایی هستند که میتوان آنها را کشف کرد. خوشهبندی به ما اجازه میدهد این نظم پنهان را بدون نیاز به پاسخهای از پیش تعیینشده شناسایی کنیم و دادههای خام را به گروههایی قابلتحلیل تبدیل نماییم. به همین دلیل، خوشهبندی یکی از پایهایترین ابزارها در یادگیری بدونناظر، دادهکاوی و تحلیل اکتشافی داده است (Jain, 2010; Xu & Wunsch, 2005).
9.1. کشف ساختارهای ناشناخته در دادهها
بسیاری از مجموعهدادهها در ظاهر مجموعهای نامنظم از نمونهها هستند، اما در سطح عمیقتر ممکن است شامل گروههایی با ویژگیهای مشترک باشند. خوشهبندی این امکان را فراهم میکند که چنین ساختارهایی بدون نیاز به برچسبهای قبلی شناسایی شوند.
اهمیت این ویژگی در آن است که تحلیلگر میتواند از دادهها فرضیههای جدید استخراج کند. برای مثال، در دادههای پژوهشی ممکن است زیرگروههایی از نمونهها وجود داشته باشند که پیشتر شناخته نشدهاند. خوشهبندی میتواند این زیرگروهها را آشکار کند و مسیر تحلیلهای بعدی را روشنتر سازد (Everitt et al., 2011).
9.2 سادهسازی تحلیل دادههای پیچیده
وقتی تعداد نمونهها، ویژگیها یا روابط میان دادهها زیاد باشد، تحلیل مستقیم داده دشوار میشود. خوشهبندی با تبدیل مجموعه بزرگی از نمونهها به چند گروه معنادار، بار شناختی و محاسباتی تحلیل را کاهش میدهد.
در این حالت، بهجای بررسی تکتک دادهها، میتوان هر خوشه را بهعنوان یک واحد تحلیلی در نظر گرفت. این کار بهویژه در دادههای بزرگ، دادههای چندبعدی و سامانههایی که نیاز به تفسیر سریع دارند، اهمیت زیادی دارد (Han et al., 2012).
9.3. آشکارسازی الگوهای طبیعی و روابط درونی
خوشهبندی فقط دادهها را به چند گروه تقسیم نمیکند، بلکه نشان میدهد چه نوع شباهتها یا روابطی در داده غالب است. این روابط ممکن است بر اساس نزدیکی هندسی، شباهت رفتاری، الگوی زمانی، ساختار شبکهای یا ویژگیهای آماری شکل گرفته باشند.
از این منظر، خوشهبندی ابزاری برای فهم سازمان درونی داده است. تحلیلگر با بررسی خوشهها میتواند تشخیص دهد که دادهها بیشتر حول چه ویژگیهایی سامان یافتهاند و کدام متغیرها در شکلگیری گروهها نقش پررنگتری دارند (Aggarwal & Reddy, 2014).
9.4. آمادهسازی داده برای مدلهای پیشرفتهتر
خوشهبندی میتواند بهعنوان مرحلهای مقدماتی در فرایندهای پیچیدهتر یادگیری ماشین استفاده شود. برای مثال، خروجی خوشهبندی میتواند بهصورت یک ویژگی جدید به مدلهای دیگر اضافه شود، دادهها را به زیرمجموعههای همگنتر تقسیم کند یا نمونههای نماینده را برای آموزش انتخاب نماید.
این نقش پیشپردازشی باعث میشود مدلهای بعدی با دادههایی منظمتر و قابلتفکیکتر روبهرو شوند. در برخی کاربردها، ابتدا دادهها خوشهبندی میشوند و سپس برای هر خوشه، مدل جداگانهای ساخته میشود؛ زیرا الگوهای حاکم بر هر گروه ممکن است متفاوت باشد (Hastie et al., 2009).
9.5. پشتیبانی از تصمیمگیری دادهمحور
خوشهبندی زمانی ارزش عملی پیدا میکند که نتایج آن به تصمیمهای بهتر منجر شود. هنگامی که دادهها به گروههای معنادار تقسیم میشوند، میتوان برای هر گروه راهبردی متناسب با ویژگیهای همان گروه طراحی کرد.
این موضوع در مدیریت، بازاریابی، خدمات سلامت، آموزش، بانکداری و بسیاری از حوزههای دیگر کاربرد دارد. تصمیمگیرنده بهجای اتکا به میانگینهای کلی یا برداشتهای شهودی، میتواند تفاوتهای درونی داده را ببیند و بر اساس آن تصمیمهای دقیقتر اتخاذ کند .
9.6 شناسایی نمونههای غیرعادی
یکی از کاربردهای مهم خوشهبندی، کمک به تشخیص نمونههایی است که به الگوهای غالب داده تعلق ندارند. اگر یک نمونه از همه خوشههای اصلی فاصله زیادی داشته باشد یا در هیچ گروهی بهخوبی جای نگیرد، میتواند نشانهای از رفتار غیرعادی، خطای ثبت داده یا پدیدهای نادر باشد.
البته باید توجه داشت که خوشهبندی بهتنهایی همیشه ابزار کامل تشخیص ناهنجاری نیست، اما میتواند مبنایی قوی برای شناسایی موارد مشکوک و هدایت تحلیلهای دقیقتر فراهم کند (Chandola et al., 2009).
9.7. فشردهسازی و نمایش خلاصهای از دادهها
در بسیاری از کاربردها، هدف فقط یافتن گروهها نیست، بلکه نیاز داریم تصویری خلاصه و قابلفهم از دادههای بزرگ داشته باشیم. خوشهبندی میتواند با انتخاب نمایندههایی برای هر خوشه، مانند مرکز خوشه یا نمونه شاخص، حجم اطلاعات را کاهش دهد و ساختار کلی داده را حفظ کند.
این ویژگی در تصویرسازی داده، گزارشسازی مدیریتی، طراحی داشبوردهای تحلیلی و پردازش مجموعهدادههای بزرگ اهمیت دارد. بهجای نمایش همه نمونهها، میتوان نمایندگان خوشهها یا توزیع گروهها را نشان داد و تصویری فشرده اما معنادار از داده ارائه کرد (Han et al., 2012).
9.8. تحلیل دادههای فاقد برچسب
در بسیاری از حوزهها، برچسبگذاری دادهها پرهزینه، زمانبر یا وابسته به نظر متخصصان است. خوشهبندی در چنین شرایطی امکان شروع تحلیل را بدون نیاز به دادههای برچسبدار فراهم میکند.
این ویژگی بهویژه در مراحل اولیه پژوهش، تحلیل اکتشافی، کشف دانش و طراحی سامانههای هوشمند اهمیت دارد. خوشهبندی میتواند تصویری اولیه از ساختار داده ارائه دهد و حتی به تعریف برچسبها یا طبقات بعدی کمک کند (Jain, 2010).
10.تفاوت خوشهبندی با طبقهبندی
خوشهبندی (Clustering) و طبقهبندی (Classification) هر دو از روشهای مهم یادگیری ماشین هستند و هر دو بهنوعی با گروهبندی دادهها سروکار دارند. با این حال، تفاوت بنیادین آنها در این است که طبقهبندی بر اساس برچسبهای از پیش تعریفشده انجام میشود، اما خوشهبندی برای کشف گروههایی به کار میرود که از قبل مشخص نیستند.
به بیان ساده، در طبقهبندی، میدانیم چه کلاسهایی وجود دارند و مدل باید یاد بگیرد نمونههای جدید را به یکی از این کلاسها نسبت دهد. اما در خوشهبندی، کلاس یا برچسبی از قبل وجود ندارد و هدف این است که الگوریتم، بر اساس شباهت میان نمونهها، ساختار طبیعی داده را کشف کند (Hastie et al., 2009; Jain, 2010).
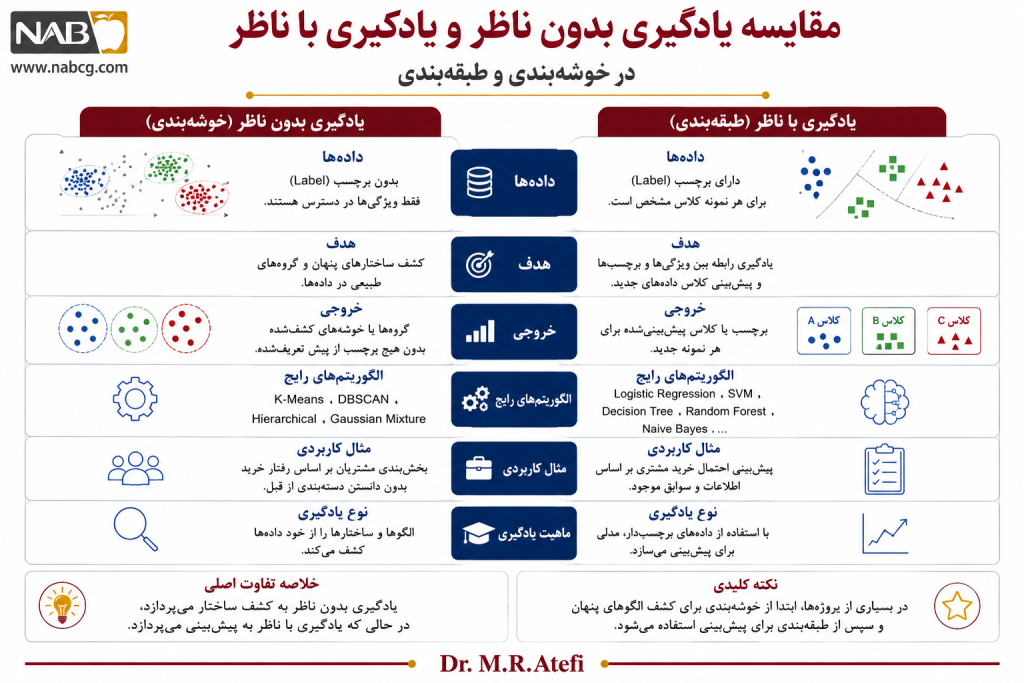
طبقهبندی چیست؟
یکی از روشهای یادگیری باناظر است. در این روش، مدل با دادههایی آموزش میبیند که برای هر نمونه، برچسب یا کلاس مشخصی وجود دارد. هدف مدل این است که رابطه میان ویژگیهای ورودی و برچسب خروجی را یاد بگیرد و سپس بتواند برچسب نمونههای جدید را پیشبینی کند.
برای مثال، فرض کنید مجموعهای از ایمیلها در اختیار داریم که هر کدام از قبل با برچسب «اسپم» یا «غیراسپم» مشخص شدهاند. یک مدل طبقهبندی با استفاده از این دادههای برچسبدار آموزش میبیند و یاد میگیرد که ایمیلهای جدید را در یکی از این دو کلاس قرار دهد.
اگر داده آموزشی به صورت زیر باشد:
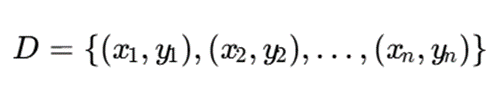
در اینجا xi نشاندهنده ویژگیهای نمونه و yi نشاندهنده برچسب آن نمونه است. هدف طبقهبندی یادگیری تابعی مانند زیر است:
f:X→Y
بهطوری که برای هر نمونه جدید x، کلاس مناسب y پیشبینی شود.
خوشهبندی چیست؟
در مقابل، خوشهبندی یکی از روشهای یادگیری بدونناظر است. دادهها فاقد برچسب هستند و الگوریتم باید بدون دانستن کلاسهای واقعی، نمونهها را بر اساس شباهت یا نزدیکی در گروههایی به نام خوشه قرار دهد.
در خوشهبندی، داده معمولاً به شکل زیر در نظر گرفته میشود:
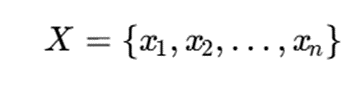
با این حالت، هیچ yi یا برچسب از پیش تعیینشدهای وجود ندارد. هدف این است که مجموعه داده به چند زیرمجموعه یا خوشه تقسیم شود:
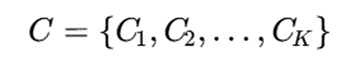
بهگونهای که نمونههای درون هر خوشه به یکدیگر شبیهتر باشند و نمونههای متعلق به خوشههای مختلف تفاوت بیشتری داشته باشند (Xu & Wunsch, 2005).
تفاوت اصلی از نظر هدف تحلیل
مهمترین تفاوت خوشهبندی و طبقهبندی در هدف تحلیل است. در طبقهبندی، هدف پیشبینی یک برچسب مشخص برای دادههای جدید است. یعنی کلاسها از قبل معلوماند و مدل فقط باید مرز تصمیم میان آنها را یاد بگیرد.
اما در خوشهبندی، هدف پیشبینی برچسب از پیش تعریفشده نیست؛ بلکه هدف، کشف گروههای ناشناخته در داده است. به همین دلیل، خوشهبندی بیشتر در تحلیل اکتشافی داده به کار میرود، در حالی که طبقهبندی بیشتر برای پیشبینی و تصمیمگیری خودکار استفاده میشود.
برای مثال، اگر بخواهیم بدانیم یک ایمیل جدید «اسپم» است یا «غیراسپم»، با مسئله طبقهبندی روبهرو هستیم. اما اگر مجموعهای از کاربران را داشته باشیم و بخواهیم بدون دانستن گروههای قبلی، آنها را بر اساس رفتارشان دستهبندی کنیم، مسئله از نوع خوشهبندی است.
تفاوت در نقش برچسبها
در طبقهبندی، برچسبها نقش مرکزی دارند. مدل از دادههای برچسبدار یاد میگیرد که هر نوع نمونه به چه کلاسی تعلق دارد. بنابراین کیفیت برچسبها، تعداد نمونههای برچسبدار و توازن کلاسها بر عملکرد مدل اثر مستقیم دارد.
اما در خوشهبندی، هیچ برچسبی برای آموزش وجود ندارد. الگوریتم فقط به ویژگیهای داده و معیار شباهت یا فاصله میان نمونهها تکیه میکند. در نتیجه، خروجی خوشهبندی الزاماً همان کلاسهای انسانی یا مفهومی نیست؛ بلکه گروههایی است که الگوریتم بر اساس ساختار داده کشف کرده است.
این نکته بسیار مهم است: خوشهها همیشه معادل کلاسها نیستند. ممکن است یک کلاس واقعی به چند خوشه تقسیم شود یا چند کلاس متفاوت در یک خوشه قرار گیرند، زیرا خوشهبندی بر اساس شباهت عددی یا آماری عمل میکند، نه بر اساس تعریف انسانی کلاسها (Jain, 2010).
تفاوت در خروجی مدل
خروجی طبقهبندی، یک برچسب از مجموعهای از کلاسهای مشخص است. برای مثال، مدل ممکن است برای یک پیام ایمیل خروجی «اسپم» یا «غیراسپم» تولید کند.
اما خروجی خوشهبندی، معمولاً شماره یا نام یک خوشه است؛ مانند خوشه ۱، خوشه ۲ یا خوشه ۳. این خوشهها در ابتدا معنای از پیش تعیینشده ندارند و تحلیلگر باید پس از مشاهده ویژگیهای اعضای هر خوشه، برای آنها تفسیر مناسب ارائه کند.
برای نمونه، پس از خوشهبندی مشتریان، ممکن است سه خوشه به دست آید. سپس تحلیلگر با بررسی ویژگیهای هر خوشه تشخیص دهد که یک خوشه شامل مشتریان وفادار، خوشه دیگر شامل مشتریان حساس به قیمت و خوشه سوم شامل مشتریان کمتعامل است. این نامگذاری پس از اجرای الگوریتم انجام میشود، نه قبل از آن.
تفاوت در ارزیابی عملکرد
ارزیابی طبقهبندی معمولاً روشنتر است، زیرا برچسب واقعی دادهها در اختیار است. بنابراین میتوان از معیارهایی مانند دقت، بازخوانی، امتیاز F1 ، ماتریس آشفتگی و AUC استفاده کرد.
اما در خوشهبندی، چون برچسب واقعی معمولاً وجود ندارد، ارزیابی دشوارتر است. در اینجا از معیارهایی مانند ضریب سیلوئت، شاخص دیویس–بولدین، شاخص کالینسکی–هاراباس یا ارزیابی تفسیری توسط متخصص استفاده میشود. اگر برچسبهای واقعی برای مقایسه موجود باشند، میتوان از معیارهای خارجی مانند ARI یا NMI نیز استفاده کرد؛ اما این وضعیت همیشه در مسائل واقعی رخ نمیدهد .
مثال ساده برای درک تفاوت
فرض کنید دادههایی درباره کاربران یک فروشگاه اینترنتی داریم.
اگر برای هر کاربر از قبل مشخص باشد که او به کدام گروه تعلق دارد، مثلاً «مشتری وفادار»، «مشتری جدید» یا «مشتری ازدسترفته»، و بخواهیم مدلی بسازیم که گروه کاربران جدید را پیشبینی کند، مسئله از نوع طبقهبندی است.
اما اگر هیچ گروهی از قبل تعریف نشده باشد و بخواهیم خود دادهها نشان دهند که کاربران بر اساس رفتار خرید، میزان بازدید، مبلغ سفارش و تعداد خرید به چه گروههایی تقسیم میشوند، مسئله از نوع خوشهبندی است.
بنابراین، تفاوت اصلی این است که در طبقهبندی، گروهها از قبل شناخته شدهاند؛ اما در خوشهبندی، گروهها باید کشف شوند.
جدول مقایسه ای خوشهبندی و طبقهبندی
| ویژگی | خوشهبندی | طبقهبندی |
| نوع یادگیری | یادگیری بدونناظر | یادگیری باناظر |
| وجود برچسب در داده آموزشی | ندارد | دارد |
| هدف اصلی | کشف گروههای پنهان در داده | پیشبینی کلاس نمونههای جدید |
| ماهیت خروجی | خوشههای کشفشده بر اساس شباهت | کلاسهای از پیش تعریفشده |
| نقش الگوریتم | یافتن ساختار طبیعی داده | یادگیری رابطه میان ویژگیها و برچسبها |
| معیار اصلی | شباهت یا فاصله میان نمونهها | دقت پیشبینی کلاسها |
| نمونه کاربرد | گروهبندی مشتریان ناشناخته | تشخیص ایمیل اسپم و غیراسپم |
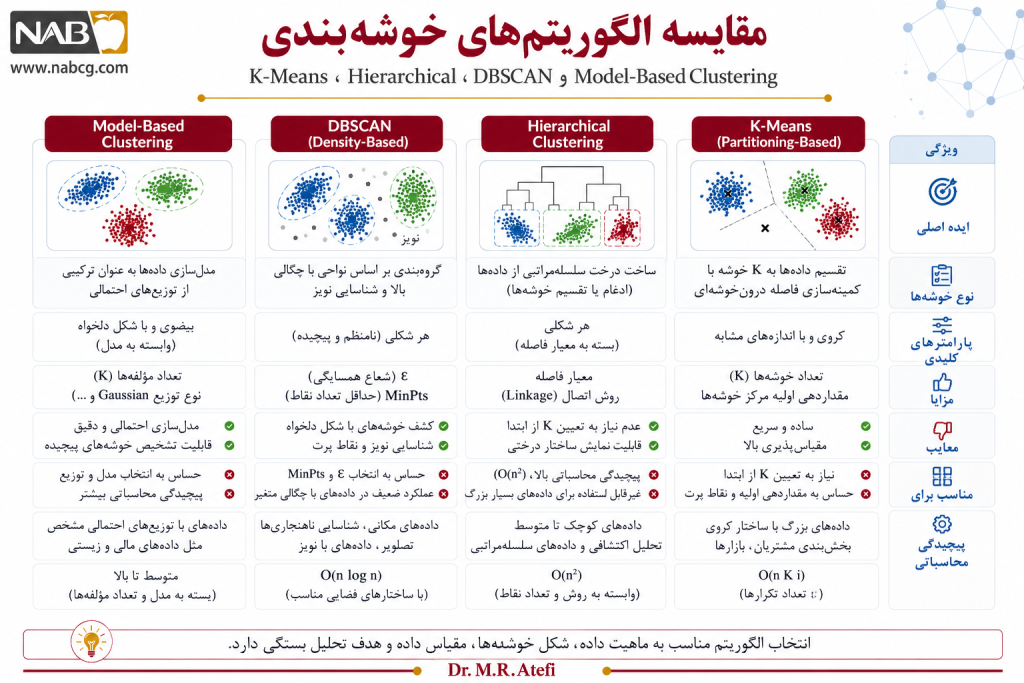
11.دستهبندی و رویکردهای اصلی الگوریتمها
با توجه به تنوع بالای دادهها در دنیای واقعی و نیازمندیهای مختلفی که بررسی کردیم، دانشمندان علم داده الگوریتمهای خوشهبندی را بر اساس «منطق محاسباتی» و «نحوه نگاه آنها به فضا» به ۵ گروه اصلی تقسیم میکنند تا بتوانند هر نوع چالش ساختاری را مهار کنند:
- رویکرد افرازی (Partitioning Methods): این رویکرد دادهها را حول چند مرکز مشخص سازماندهی میکند. هدف آن فشردهسازی فضا و یافتن نزدیکترین فواصل هندسی میان نقاط و مرکز هر گروه است (مانند الگوریتم معروف K-Means).
- رویکرد سلسلهمراتب (Hierarchical Methods): دادهها را به صورت گامبهگام، لایهای و درختی به هم متصل میکند یا آنها را از بالا به پایین از هم تفکیک مینماید تا یک نقشه درختی از کل روابط فضا به دست آید.
- رویکرد چگالیمحور (Density-Based Methods): این روش کاری به فواصل خطی مستقیم ندارد؛ بلکه نواحی شلوغ و پرجمعیت فضا را به عنوان خوشه شناسایی کرده و نواحی خلوت و کمتراکم را به عنوان نویز به طور کامل فیلتر و حذف میکند (مانند الگوریتم DBSCAN).
- رویکرد مبتنی بر شبکه (Grid-Based Methods): فضا را به جای اسکن نقطه به نقطه، به سلولهای متناهی یک جدول یا شبکه تقسیم میکند. محاسبات در این روش روی سلولها انجام میشود تا سرعت پردازش را مستقل از تعداد نقاط، مافوق تصور بالا ببرد.
- رویکرد مدلمحور (Model-Based Methods): فرض میکند دادهها بر اساس یک سری قوانین احتمالی و الگوهای ریاضی پنهان پدید آمدهاند و به دنبال کشف ویژگیها و پارامترهای آماری آن مدلهاست (مثل روشهای احتمالی فازی یا شبکههای عصبی).
12. کاربردهای واقعی و کلان خوشهبندی
- بخشبندی بازار و پرسونای مشتریان (Market Segmentation): گروهبندی خریداران بر اساس رفتارهای خرید، میزان وفاداری و علایق مشترک برای طراحی استراتژیهای بازاریابی هدفمند.
- سیستمهای توصیهگر پیشرفته (Recommendation Systems): گروهبندی کاربران یا محصولات همگام (مانند فیلمها، موسیقیها یا کالاهای مشابه) برای ارائه دقیقترین پیشنهادهای بعدی به مخاطبان.
- کشف ناهنجاری و تشخیص تقلب (Anomaly Detection): شناسایی تراکنشهای مشکوک بانکی، نفوذهای امنیتی در شبکه و رفتارهای خارج از عرف با رهگیری دادههای منزوی.
- پردازش تصویر و بینایی ماشین (Image Segmentation): تفکیک پیکسلهای یک تصویر به خوشههای رنگی و ساختاری مجزا جهت تشخیص اشیاء و مرزبندی محیط در خودروهای خودران.
- گروهبندی مقالات علمی:در تحلیل متون علمی، خوشهبندی برای سازماندهی مقالات بر اساس شباهت موضوعی به کار میرود. شباهت میتواند از طریق عنوان، چکیده، کلیدواژهها، ارجاعات یا نمایش برداری متن محاسبه شود.این کاربرد به پژوهشگران کمک میکند حوزههای تحقیقاتی، جریانهای علمی و ارتباط میان موضوعات را بهتر شناسایی کنند. همچنین در موتورهای جستوجوی علمی و سامانههای پیشنهاد مقاله اهمیت دارد (Manning et al., 2008).
- تحلیل شبکههای اجتماعی:در شبکههای اجتماعی، خوشهبندی برای شناسایی اجتماعها و گروههای کاربران به کار میرود. این گروهها ممکن است بر اساس ارتباطات، تعاملات، علایق یا الگوهای انتشار محتوا شکل بگیرند.با این روش میتوان ساختار اجتماعی پنهان در شبکه را تحلیل کرد، گروههای اثرگذار را شناخت و الگوهای انتشار اطلاعات را بهتر فهمید (Newman, 2010).
13. مزایا خوشه بندی
- بینیازی مطلق از برچسبگذاری دادهها: کار بر روی دادههای خام و ساختارنیافته بدون نیاز به فرآیند پرهزینه، زمانبر و انسانیِ برچسبگذاری دستی.
- تفسیرپذیری و ارتقای درک شهودی: خلاصه کردن روابط هزاران سطر داده در چند گروه متمایز و چابکسازی فرآیند تصویرسازی دیتابیس برای مدیران کسبوکار.
- سرعت محاسباتی و مقیاسپذیری بالا: وجود الگوریتمهای کلاسیک با پیچیدگی زمانی خطی که امکان پردازش کلاندادهها را در کسر کوچکی از ثانیه فراهم میکنند.
- انعطافپذیری هندسی و ساختاری: تنوع بالا در متدها (چگالی، شبکه و سلسلهمراتب) که تفکیک انواع فرمهای توپولوژیکی و اشکال نامنظم را ممکن میسازد.
- سازگاری بالا در نقش هماهنگکننده پیشپردازش: امکان استفاده از برچسبهای تولیدشده توسط مدل به عنوان یک ویژگی جدید برای افزایش کیفیت الگوریتمهای نظارتشده بعدی.
- قابلیت تنظیم سطح قطعیت: ارائه ابزارهای منعطف فازی و احتمالی برای سنجش حضور یک داده در خوشههای مختلف به جای مرزبندیهای صلب صفر و یکی.
14. محدودیتها و معایب
اگرچه خوشهبندی ابزاری فوقالعاده برای کشف ساختارهای پنهان است، اما در فاز عملیاتی با چالشهای جدی روبرو است:
- دشواری در تعیین تعداد بهینه خوشهها: نیاز مبرم برخی الگوریتمهای مرجع به تعیین پیشفرض تعداد دستهها از سوی کاربر و عدم قطعیت کامل روشهای کمکی.
- حساسیت شدید به مقیاس متغیرها (Scaling Sensitivity): اتکای محاسبات بر توابع هندسی و کج شدن مرز خوشهها به نفع متغیرهایی با دامنههای اعدادی بزرگتر.
- آسیبپذیری شدید در برابر نویز و دادههای پرت: جابهجا شدن مرکز ثقل خوشهها و افت دقت کل سیستم به دلیل اجبار برخی متدها به تخصیص تمام نقاط مخدوش به گروهها.
- ضعف محاسباتی در مواجهه با نفرین ابعاد (Curse of Dimensionality): برابر شدن تقریبی فواصل هندسی نقاط با افزایش تعداد ویژگیها و از بین رفتن معنای واقعی شباهت در فضا.
- محدودیتهای ناشی از فرضهای هندسی صلب: تمایل ذاتی الگوریتمهای مبتنی بر مرکز به ایجاد خوشههای کروی و شکست کامل در مواجهه با توپولوژیهای مارپیچ و حلقوی.
- گرفتار شدن در تله مقداردهی اولیه (Initialization Trap): وابستگی شدید خروجی متدهای تکرارشونده به نقطه شروع تصادفی و تولید نتایج کاملاً متفاوت در هر بار اجرا.
- نبود متریک ارزیابی عینی و مطلق (Subjective Evaluation): نبود برچسب واقعی برای تایید صددرصدی درست بودن خوشهها و وابستگی زیاد نتایج به شهود و قضاوت تحلیلگر.
جمع بندی
خوشهبندی یکی از آن روشهای جادویی علم داده است که وقتی هیچ چیز نمیدانید، شروع به کشف ساختار میکند. بدون نیاز به برچسب، بدون نیاز به آموزش قبلی، صرفاً با تکیه بر «شباهت» میان دادهها، گروههایی را پیدا میکند که اغلب با نگاه انسانی هم همخوانی دارد.
در این مقاله دیدیم که خوشهبندی با طبقهبندی چه تفاوت بنیادی دارد: اولی کشف میکند، دومی پیشبینی میکند. همچنین فهمیدیم که خوشهها میتوانند کروی، بیضوی، کشیده یا حتی کاملاً نامنظم باشند و هر شکلی الگوریتم خاص خود را میطلبد.
از مزایای شگفتانگیز خوشهبندی میتوان به بینیازی از برچسبزنی پرهزینه، مقیاسپذیری بالا، و انعطاف در برابر اشکال مختلف داده اشاره کرد. اما در کنار این قوتها، محدودیتهایی هم وجود دارد: حساسیت به مقیاس متغیرها، دشواری تعیین تعداد خوشهها، آسیبپذیری در برابر دادههای پرت، و مسئلهی نفرین ابعاد که دقت را کاهش میدهد.
نکتهی کلیدی این است که خوشهبندی یک راهحل آماده و همیشهجواب نیست، بلکه یک ابزار اکتشافی است که باید با درک درستی از داده و مسئله به کار گرفته شود. انتخاب الگوریتم مناسب، تنظیم پارامترها، و ارزیابی خروجی معمولاً نیازمند تخصص و تجربه است.
اگر شما هم با دادههای بدون برچسب سر و کار دارید، خوشهبندی میتواند اولین و مهمترین گام شما برای کشف الگوها، سادهسازی تحلیل، و اتخاذ تصمیمهای هوشمندانه باشد. در مقالات بعدی، هر یک از الگوریتمهای معروف (K-Means، خوشهبندی سلسلهمراتبی، DBSCAN و …) را به طور عمیقتر بررسی خواهیم کرد.
منابع
Aggarwal, C. C. (2017). Outlier analysis (2nd ed.). Springer.
Aggarwal, C. C., & Reddy, C. K. (Eds.). (2014). Data clustering: Algorithms and applications. CRC Press.
Ankerst, M., Breunig, M. M., Kriegel, H.-P., & Sander, J. (1999). OPTICS: Ordering points to identify the clustering structure. Proceedings of the 1999 ACM SIGMOD International Conference on Management of Data, 49–60. https://doi.org/10.1145/304181.304187
Bezdek, J. C. (1981). Pattern recognition with fuzzy objective function algorithms. Plenum Press.
Bishop, C. M. (2006). Pattern recognition and machine learning. Springer.
Everitt, B. S., Landau, S., Leese, M., & Stahl, D. (2011). Cluster analysis (5th ed.). Wiley.
Handl, J., Knowles, J., & Kell, D. B. (2005). Computational cluster validation in post-genomic data analysis. Bioinformatics, 21(15), 3201–3212. https://doi.org/10.1093/bioinformatics/bti517
Han, J., Kamber, M., & Pei, J. (2012). Data mining: Concepts and techniques (3rd ed.). Morgan Kaufmann.
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The elements of statistical learning: Data mining, inference, and prediction (2nd ed.). Springer.
Jain, A. K. (2010). Data clustering: 50 years beyond K-means. Pattern Recognition Letters, 31(8), 651–666. https://doi.org/10.1016/j.patrec.2009.09.011
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., & Duchesnay, E. (2011). Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12(85), 2825–2830.
Xu, R., & Wunsch, D. (2005). Survey of clustering algorithms. IEEE Transactions on Neural Networks, 16(3), 645–678. https://doi.org/10.1109/TNN.2005.845141



