

مقدمه
در بسیاری از مسائل یادگیری ماشین، هدف اصلی ما پیشبینی یا تبیین یک کمیت عددی بر اساس مجموعهای از ویژگیهای قابلاندازهگیری است. زمانی که انتظار داریم تغییرات خروجی بهصورت نسبتاً یکنواخت و قابلتفسیر به تغییرات ورودی وابسته باشد، مدلهای خطی یکی از اولین و مهمترین گزینههایی هستند که برای مدلسازی در نظر میگیریم.
مدلهای خطی با فرض وجود یک رابطهی خطی میان ویژگیها و متغیر هدف، چارچوبی ساده اما قدرتمند برای تحلیل داده ایجاد میکنند. این سادگی فرآیند آموزش را سریع، نتایج را شفاف و تفسیر ضرایب را ممکن میسازد؛ ویژگیهایی که در بسیاری از کاربردهای عملی—بهویژه حوزههایی با الزام توضیحپذیری—اهمیت حیاتی دارند.
این مطلب با هدف ارائهی یک بررسی ساختیافته از مدلهای خطی نوشته شده است؛ از تعریف و سازوکار یادگیری گرفته تا انواع متداول، کاربردهای واقعی، مزایا و محدودیتها. تمرکز اصلی ما بر این است که روشن کنیم چه زمانی مدلهای خطی انتخاب مناسبی هستند و در چه شرایطی باید به سراغ گزینههای پیچیدهتر رفت.
تعریف
مدلهای خطی زیرمجموعهای از روشهای یادگیری نظارتشده هستند که عمدتاً برای حل مسائل رگرسیون – یعنی پیشبینی مقادیر عددی پیوسته – به کار میروند.
فرض بنیادی در این مدلها این است که خروجی هدف (Target)، حاصل یک ترکیب خطی از ویژگیهای ورودی (Features) است. به زبان ساده، ما معتقدیم که تغییر در ورودی، با یک نسبت مشخص و ثابت، باعث تغییر در خروجی میشود. این یعنی ما به دنبال کشف یک جاده مستقیم میان سوال (ورودی) و جواب (خروجی) هستیم.
ساختار داخلی مدلهای خطی
هر مدل خطی چهار جزء حیاتی دارد که درک آنها برای هر متخصص هوش مصنوعی ضروری است.
- متغیر وابسته(Target – y): همان نتیجهای که تشنهی پیشبینی آن هستیم (مثلاً قیمت نهایی یک سهم یا میزان فروش).
- متغیرهای مستقل(Features – x): فاکتورهایی که فکر میکنیم بر خروجی اثر میگذارند (مثلاً متراژ خانه یا بودجه تبلیغات).
- ضرایب یا وزنها (Weights – w یا β): قلب تپنده مدل. این اعداد نشان میدهند که هر ویژگی چقدر “قدرت” دارد و تغییر یک واحدی در آن، خروجی را چقدر جابجا میکند. در کتابخانههای برنامهنویسی مثل Scikit-Learn، این بردار با نام _coef شناخته میشود.
- جمله خطا(Error Term – ε): این بخش نشاندهنده نویزهای دنیای واقعی و عواملی است که در مدل ما لحاظ نشدهاند.

منطق عملکرد و فرآیند یادگیری
عملکرد مدلهای خطی بر پایه یک معادله هندسی بنا شده است که سعی میکند بهترین “خط” یا “صفحه” را از میان ابری از دادهها عبور دهد.
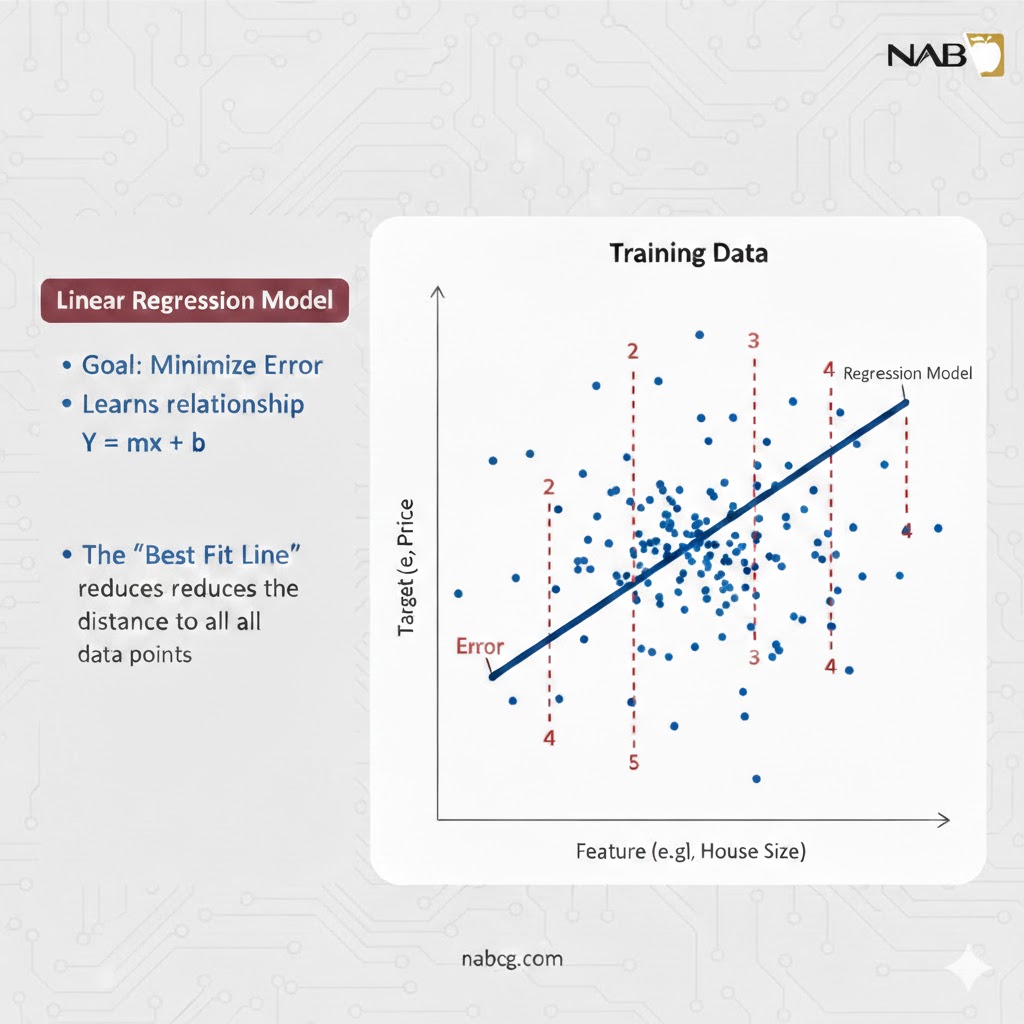
تحلیل فرمول پیشبینی
فرمول زیر، زبان مشترک ریاضیات و داده است:
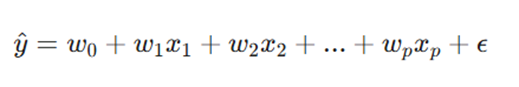
- ^y (مقدار پیشبینی شده): خروجی نهایی مدل. چتری که تمام محاسبات زیر آن جمع میشوند.
- x1, x2, …, xp (Predictors/ ویژگیها): مواد اولیه ما؛ متغیرهایی که حدس میزنیم بر خروجی اثر دارند (مثل میزان آلودگی هوا، سن بیمار، یا بودجه بازاریابی).
- w1, w2, …, wp (Weights/ وزنها): عیارِ هر ویژگی. ماشین در طول آموزش میفهمد که کدام ویژگی “وزن” یا اهمیت بیشتری دارد.
- w0 (Intercept /بایاس): نقطه تلاقی خط با محور عمودی. مقداری که اگر تمام ورودیها صفر باشند، خروجی به آن تمایل دارد.
- ε (خطا ): تفاوت بین آنچه مدل پیشبینی کرده و آنچه در واقعیت رخ داده است.
.
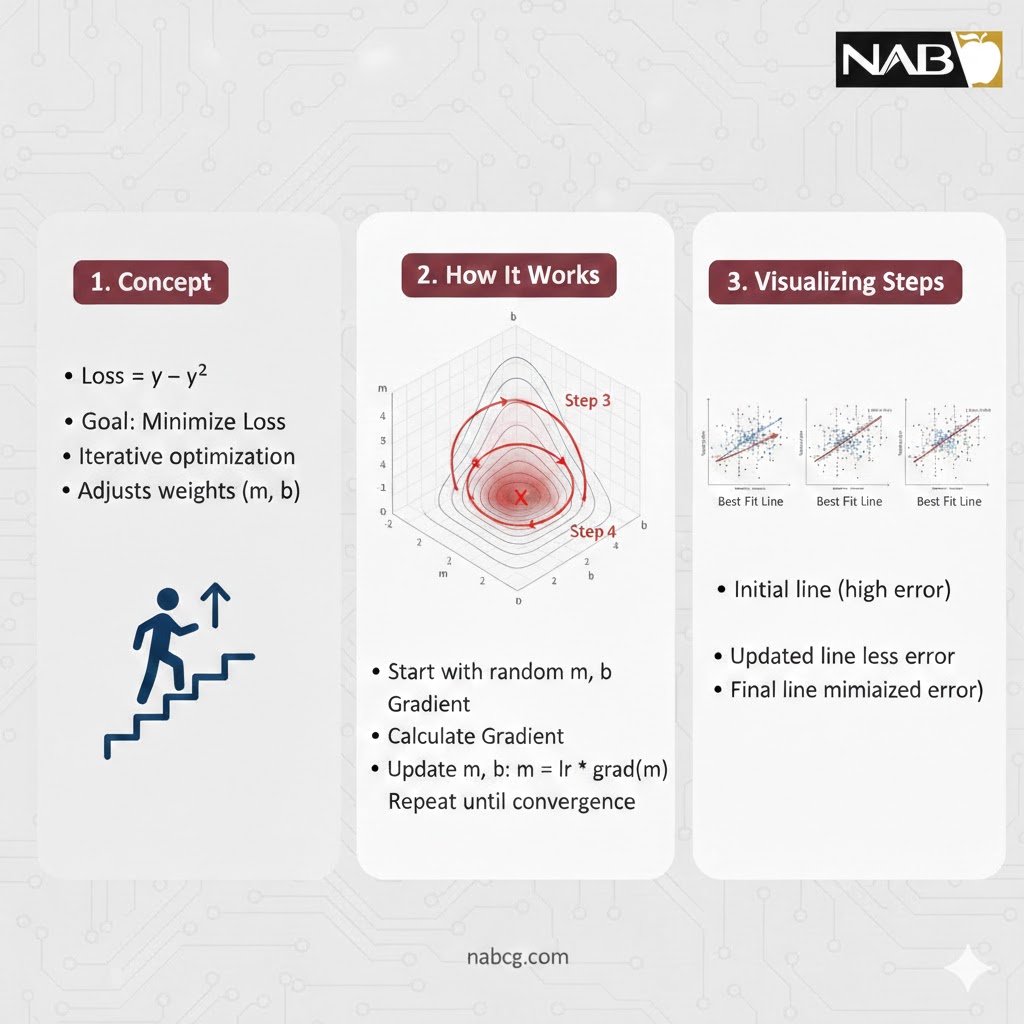
فرآیند آموزش: سفر از حدس تصادفی تا پیشبینی دقیق
آموزش در مدل خطی صرفاً یک محاسبه ساده نیست؛ بلکه یک چرخه بهینهسازی تکرارشونده است که ماشین طی آن تلاش میکند «زبان دادهها» را یاد بگیرد. این فرآیند شامل سه گام استراتژیک است:
۱. گام پیشبینی و ایجاد فرضیه:
در شروع کار، ماشین هیچ تصوری از روابط ندارد. پس وزنها (w) را به صورت تصادفی انتخاب میکند. با جایگذاری دادههای ورودی در فرمول، یک خروجی فرضی (پیشبینی) تولید میشود.
۲. تابع زیان و ارزیابی خطا:
اینجاست که ماشین متوجه اشتباهاتش میشود. مدل تفاوت بین پیشبینی خود و واقعیت (Ground Truth) را محاسبه میکند. در رگرسیون خطی، ما معمولاً از میانگین مربعات خطا (MSE) استفاده میکنیم. چرا توان دو؟ چون میخواهیم خطاهای بزرگ را با شدت بیشتری جریمه کنیم و منفی یا مثبت بودن خطا تأثیری در اصلِ جریمه نداشته باشد.
۳. بهینهسازی با OLS و گرادیان کاهشی:
هدف نهایی، یافتن وزنهایی است که مجموع مربعات خطا را به حداقل برساند.
- در روش OLS (کمترین توانهای دوم)، ماشین از طریق یک فرمول ریاضی مستقیم، کوتاهترین مسیر به سمت “بهترین برازش” را پیدا میکند.
- در روش SGD (گرادیان کاهشی)، ماشین مانند کوهنوردی که در مه به دنبال پایینترین نقطه دره است، ذرهذره وزنها را تغییر میدهد تا به کمترین میزان خطا برسد.
مثال: استراتژی حفظ سرمایههای انسانی
به عنوان یک دانشمند داده، فرض کنید مأموریت شما مدلسازی نرخ رضایت شغلی (Job Satisfaction) در یک شرکت تکنولوژی است. پس از آموزش مدل روی دادههای ۱۰۰۰ پرسنل، فرمول نهایی مدل به شرح زیر خواهد بود:
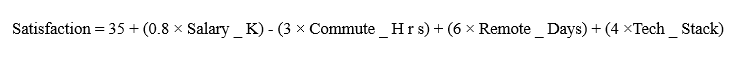
تفسیر استراتژیک:
- نقطه شروع(w0 = 35): این عدد «رضایت پایه» است. یعنی حتی اگر تمام عوامل رفاهی در کمترین سطح باشد، فرهنگ سازمانی و برند شرکت، رضایتی معادل ۳۵ واحد برای کارمند ایجاد میکند.
- اثر پاداش(w1 = 0.8): به ازای هر ۱ میلیون تومان افزایش حقوق، رضایت ۰.۸ واحد رشد میکند. رابطه مستقیم است، اما جالب است که قدرت آن از عوامل دیگر کمتر است!
- قاتل انگیزه(w2 = -3): این ضریب منفی نشاندهنده یک رابطه معکوس شدید است. هر یک ساعت اضافه در ترافیک مسیر شرکت، ۳ واحد از رضایت کارمند را به شدت تخریب میکند.
- برگ برنده (w3 = 6): بزرگترین ضریب مثبت متعلق به «دورکاری» است. این یعنی در این شرکت، آزادی عمل و کار در منزل، ۷.۵ برابر بیشتر از افزایش حقوق (۶ تقسیم بر ۰.۸) در خوشحالی کارمندان نقش دارد.
- فاکتور تخصص(w4 = 4): استفاده از تکنولوژیهای روز (Tech Stack) رضایت را ۴ واحد بالا میبرد. این نشان میدهد کارمندان شما به رشد علمی خود اهمیت زیادی میدهند.
.
انواع مدلهای خطی
مدلهای خطی طیف گستردهای از روشها را شامل میشوند که هر کدام برای حل چالش خاصی (مثل دادههای پرت، تعداد زیاد ویژگیها یا پیچیدگیهای غیرخطی) طراحی شدهاند:
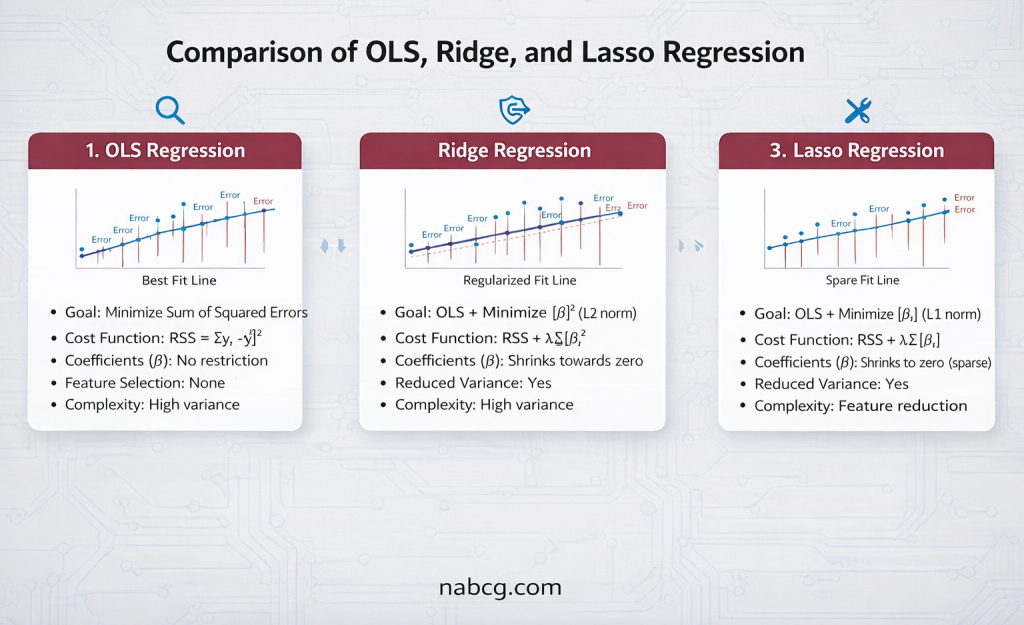
- کمترین توانهای دوم معمولی(OLS): سنگبنای مدلهای خطی که به دنبال یافتن خطی با کمترین مجموع مربعات خطا است.
- رگرسیون و طبقهبندی ریج(Ridge): مدلی که با اضافه کردن یک جریمه (L2)، از بزرگ شدن بیش از حد ضرایب و بیشبرازش جلوگیری میکند.
- لاسو(Lasso): متخصص در حذف ویژگیهای بیاهمیت؛ این مدل ضرایب برخی ویژگیها را دقیقاً صفر میکند.
- لاسوی چندوظیفهای: زمانی استفاده میشود که بخواهیم چندین مسئله رگرسیون مرتبط را به طور همزمان حل کنیم.
- شبکه الاستیک(Elastic-Net): ترکیبی هوشمندانه از لاسو و ریج برای بهرهگیری از مزایای هر دو روش.
- شبکه الاستیک چندوظیفهای: نسخه چندوظیفهای برای مسائل پیچیده با خروجیهای متعدد.
- رگرسیون کمترین زاویه(LARS): الگوریتمی کارآمد برای دادههای پُربعد (تعداد ویژگیهای بسیار زیاد).
- لاسویِ لارز(LARS Lasso): پیادهسازی مدل لاسو با استفاده از الگوریتم بهینه LARS.
- تعقیب تطبیقی متعامد(OMP): روشی برای تقریب مدلهای خطی با تمرکز بر ویژگیهای کلیدی.
- رگرسیون بیزی(Bayesian Regression): وارد کردن احتمالات و پیشفرضها در مدلسازی خطی برای مدیریت بهتر عدم قطعیت.
- رگرسیون لجستیک(Logistic Regression): استفاده از ساختار خطی برای حل مسائل طبقهبندی (مثل بله/خیر).
- مدلهای خطی تعمیمیافته(GLM): گسترش مدلهای خطی برای دادههایی که توزیع نرمال ندارند (مثل دادههای شمارشی).
- گرادیان کاهشی تصادفی(SGD): روشی فوقسریع برای آموزش مدلهای خطی روی مجموعهدادههای عظیم.
- رگرسیون مقاوم(Robustness) مدلهایی که در برابر نقاط پرت (Outliers) و خطاهای مدلسازی تحت تأثیر قرار نمیگیرند.
- رگرسیون چندکی(Quantile): به جای پیشبینی میانگین، چندکهای مختلف (مثل میانه) را پیشبینی میکند.
- رگرسیون چندجملهای: با استفاده از توابع پایه، به مدل خطی اجازه میدهد الگوهای منحنیوار و غیرخطی را یاد بگیرد.
.
جدول مقایسهای انواع مدلهای خطی (Linear Models)
| نام الگوریتم | ویژگی کلیدی و تخصص | بهترین زمان استفاده |
| OLS (پایه) | به حداقل رساندن مجموع مربعات خطا | دادههای تمیز با روابط خطی ساده |
| Ridge (ریج) | استفاده از جریمه L2 برای کنترل ضرایب | جلوگیری از بیشبرازش (Overfitting) |
| Lasso (لاسو) | صفر کردن ضرایب ویژگیهای بیاهمیت | گزینش ویژگی (Feature Selection) |
| Elastic-Net | ترکیب جریمههای لاسو و ریج | دادههایی با ویژگیهای همبسته |
| LARS | کارایی بالا در محاسبات پُربعد | زمانی که تعداد ویژگیها > تعداد نمونههاست |
| OMP | تقریب سریع با انتخاب ویژگیهای کلیدی | مدلسازی فشرده و بازسازی سیگنال |
| Bayesian | ورود احتمالات به ضرایب مدل | مدیریت عدم قطعیت در دادهها |
| Logistic | تبدیل خروجی خطی به احتمال (۰ تا ۱) | مسائل طبقهبندی (مثلاً تشخیص اسپم) |
| GLM (تعمیمیافته) | پذیرش توزیعهای غیرنرمال | دادههای شمارشی یا احتمالاتی خاص |
| SGD | آموزش سریع و تکرارشونده | مواجهه با کلاندادهها (Big Data) |
| Robust (مقاوم) | بیاثر کردن نویزهای شدید | وجود نقاط پرت (Outliers) زیاد |
| Quantile | پیشبینی میانه یا چندکهای خاص | تحلیل توزیع خروجی (نه فقط میانگین) |
| Polynomial | تبدیل روابط خطی به منحنی | الگوهای پیچیده و غیرخطی |
| Multi-task | حل همزمان چندین خروجی مرتبط | رگرسیونهای چندگانه و وابسته به هم |
کاربردهای واقعی مدلهای خطی
۱. علوم پایه و قلب طبیعت
- نقطه جوش: در فیزیک، رابطه مستقیمی بین کاهش فشار هوا در ارتفاعات و پایین آمدن نقطه جوش آب وجود دارد. این یکی از کلاسیکترین نمونههای رگرسیون خطی برای درک رفتارهای جوی است.
- کشاورزی دقیق: کشاورزان مدرن با استفاده از مدلهای خطی پیشبینی میکنند که دقیقاً به ازای هر کیلوگرم کود اضافه، بازدهی محصول چند درصد افزایش مییابد تا از هدررفت منابع جلوگیری کنند.
.
۲. کسبوکار، اقتصاد و مدیریت سرمایه
در دنیای بیزینس، مدلهای خطی ابزاری برای بهینهسازی سود و کاهش هزینهها هستند:
- مهندسی فروش و تبلیغات: یکی از حیاتیترین کاربردها، سنجش اثربخشی بودجه تبلیغاتی است. سازمانها محاسبه میکنند که هر ریال هزینه در رسانهها، دقیقاً چقدر به درآمد کل (Revenue) اضافه میکند.
- تخمین هزینههای مقیاس: مدیران کارخانهها پیشبینی میکنند که با افزایش تیراژ تولید، هزینههای جاری عملیاتی با چه نرخی رشد خواهد کرد تا قیمتگذاری دقیقتری داشته باشند.
.
۳. ورزش حرفهای و مهندسی سلامت
- فرمول قهرمانی: مربیان حرفهای از رگرسیون خطی برای تحلیل “برنامه تمرینی” استفاده میکنند تا بفهمند افزایش شدت تمرینات تا چه حد بر بهبود رکوردهای جهانی ورزشکار اثرگذار است.
- داروسازی و دوزبندی: در پزشکی، رابطهی بین مقدار مصرف یک دارو (Dosage) و میزان کاهش علائم بیماری، اغلب از طریق این مدلها سنجیده میشود تا ایمنترین دوز برای هر بیمار تجویز شود.
۴. گامهای حرفهای در دنیای مدرن
- هوشمندسازی انرژی: مهندسان با بررسی متراژ بنا و دمای محیط، میزان مصرف برق یا گاز را پیشبینی میکنند. این پایه و اساس سیستمهای مدیریت انرژی هوشمند است.
- روانسنجی و آموزش: محققان آموزشی با بررسی رابطهی بین “ساعات مطالعه مستمر” و “نمره نهایی”، الگوهای موفقیت تحصیلی را استخراج میکنند.
.
مزایا
تفسیرپذیری خیرهکننده:
مدلهای خطی مثل یک جعبه شیشهای هستند. برخلاف شبکههای عصبی که شبیه جعبه سیاه عمل میکنند، در اینجا شما دقیقاً میدانید هر متغیر چقدر در نتیجه نهایی سهم دارد. شما میتوانید با اطمینان بگویید که مثلاً به ازای هر متر مربع افزایش متراژ، قیمت خانه دقیقاً wi مقدار افزایش مییابد. این شفافیت در حوزههایی مثل پزشکی، حقوق و بانکداری که نیاز به توضیح علتِ تصمیمگیری ماشین دارند، حیاتی است.
سرعت و کارایی در مقیاس بزرگ:
آموزش این مدلها بسیار سریع است و به منابع محاسباتی سنگین (مثل GPUهای گرانقیمت) نیاز ندارد. به دلیل وجود راهحلهای ریاضی مستقیم ، این مدلها میتوانند میلیونها رکورد داده را در چند ثانیه پردازش کنند. این ویژگی آنها را برای سیستمهایی که نیاز به پاسخدهی آنی (Real-time) دارند، ایدهآل میکند.
پایداری و قابلیت اطمینان:
اگر ویژگیهای ورودی به درستی انتخاب شوند، مدلهای خطی بسیار پایدار هستند. یعنی تغییرات کوچک در دادههای ورودی، باعث تغییرات ناگهانی و عجیب در خروجی نمیشود. همچنین این مدلها به دلیل سادگی، کمتر در معرض خطاهای تصادفی قرار میگیرند.
استاندارد طلایی برای بنچمارک (Baseline Modeling):
مدل خطی بهترین نقطه شروع برای هر پروژه است. اگر یک مدل خطی ساده بتواند ۸۰٪ دقت را ارائه دهد، صرف زمان و هزینه برای یک مدل پیچیده عمیق که فقط ۲٪ دقت بیشتری دارد، منطقی نباشد.
معایب
محدودیت خطیبودن روابط (Underfitting)
مدلهای خطی بر این فرض پایهگذاری شدهاند که رابطهی میان ورودی و خروجی خطی است. اگر الگوی واقعی دادهها غیرخطی، چندمرحلهای یا دارای برهمکنشهای پیچیده باشد، یک مدل خطی نمیتواند آن را بازنمایی کند و در نتیجه دچار کمبرازش (Underfitting) میشود. در چنین شرایطی، حتی با وجود دادهی فراوان نیز دقت مدل به سطح قابلقبولی نمیرسد و لازم است از مدلهای غیرخطی یا تبدیل ویژگیها استفاده کنیم.
حساسیت به نقاط پرت (Outliers)
در بسیاری از روشهای خطی کلاسیک، بهویژه OLS، وجود نقاط پرت میتواند بهطور قابلتوجهی ضرایب مدل را منحرف کند. نقاط پرت خطاهای بزرگی ایجاد میکنند، تابع هزینه به آنها وزن زیادی میدهد و خط برازششده به سمت آنها کشیده میشود. برای کاهش این اثر، میتوان از رگرسیونهای مقاوم (Robust Regression) یا روشهایی مانند Huber Loss استفاده کرد.
مشکل همخطی میان ویژگیها (Multicollinearity)
همخطی زمانی رخ میدهد که دو یا چند ویژگی ورودی بهشدت با یکدیگر همبسته باشند؛ برای مثال، «قد» و «وزن» یا «هزینه تبلیغات تلویزیونی» و «کل بودجه تبلیغات». در این حالت، مدل خطی در تفکیک اثر مستقل هر ویژگی دچار مشکل میشود و ضرایب ناپایدار و حساس به تغییرات کوچک داده خواهند شد.
جمع بندی
مدلهای خطی یکی از بنیادیترین ابزارهای یادگیری ماشین به شمار میروند و همچنان کاربرد مهمی در تحلیل دادهها و سیستمهای پیشبینی دارند. سادگی ساختار، سرعت آموزش و تفسیرپذیری بالا باعث شده است که بسیاری از پروژهها از این مدلها بهعنوان نقطه شروع استاندارد (Baseline) استفاده کنند.
در این مطلب دیدیم که اگرچه مدلهای خطی در مواجهه با روابط غیرخطی پیچیده یا دادههای پرت محدودیت دارند، اما با شناخت صحیح فرضها و بهکارگیری تکنیکهایی مانند منظمسازی و انتخاب ویژگی، میتوانیم دامنهی کاربرد آنها را بهطور قابلتوجهی گسترش دهیم. نکتهی کلیدی این است که باید مدل را بر اساس ماهیت داده و هدف مسئله انتخاب کنیم، نه صرفاً پیچیدگی یا محبوبیت یک روش.
در عمل، تسلط بر مدلهای خطی نهتنها برای حل مسائل ساده ضروری است، بلکه پایهای محکم برای درک مدلهای پیشرفتهتر میسازد. بسیاری از روشهای غیرخطی و عمیق، از نظر مفهومی گسترشی از همین ایدههای ساده هستند؛ ایدههایی که مدلهای خطی آنها را به شفافترین شکل ممکن نمایش میدهند.



