

مقدمه
شبکه عصبی پیشخور (FNN) که گاهی به آن پرسپترون چندلایه (MLP) نیز میگویند، یکی از پایهایترین و در عین حال کاربردیترین مدلها در دنیای هوش مصنوعی است. در این شبکه، اطلاعات دقیقاً مانند یک رودخانه، فقط در یک جهت جریان دارند؛ یعنی دادهها از لایهی ورودی وارد شده، از لایههای پنهان عبور میکنند و در نهایت به لایهی خروجی میرسند.
نکتهی کلیدی در FNN این است که ما هیچگونه حلقه (Loop) یا بازگشت اطلاعات (Feedback) به لایههای قبلی نداریم. اطلاعات مسیر خود را مستقیم طی میکنند تا به مقصد برسند.
تعریف
شبکه عصبی پیشخور (Feedforward Neural Network یا FNN) سادهترین و بنیادیترین نوع شبکه عصبی مصنوعی است که در آن جریان داده تنها در یک جهت، یعنی از لایه ورودی به سمت لایه خروجی، حرکت میکند. این شبکه از یک لایه ورودی، یک یا چند لایه پنهان و یک لایه خروجی تشکیل شده است و هیچ حلقه بازخورد یا اتصال بازگشتی در ساختار آن وجود ندارد.
در شبکههای پیشخور، هر نورون با دریافت ورودیها، اعمال وزنها و عبور دادن نتیجه از یک تابع فعالسازی، خروجی تولید میکند. آموزش این شبکه معمولاً با استفاده از الگوریتم پسانتشار (Backpropagation) انجام میشود تا وزنها بهگونهای تنظیم شوند که خطای پیشبینی مدل به حداقل برسد. به دلیل ساختار ساده و قابلدرک، FNN پایهی بسیاری از مفاهیم یادگیری ماشین و نقطه شروع آموزش شبکههای عصبی محسوب میشود.
کالبدشکافی ساختار یک شبکه عصبی پیشخور
یک شبکه FNN دارای طراحی لایهبندی شده و منظمی است که دادهها در آن به صورت متوالی (پشت سر هم) حرکت میکنند:
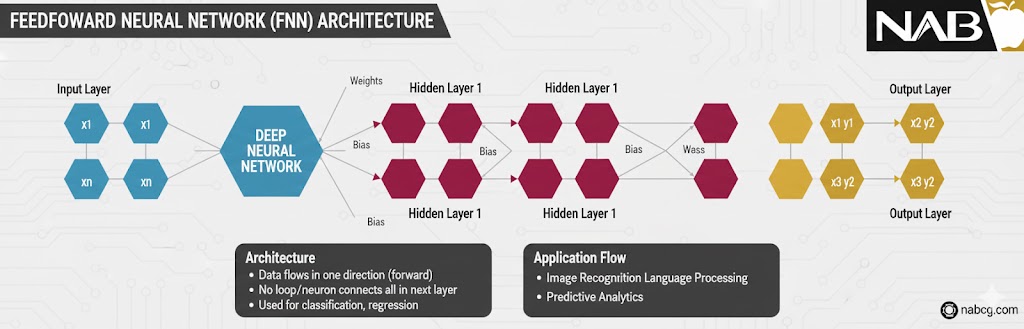
۱. لایه ورودی (Input Layer)
این لایه شامل نورونهایی است که دادههای خام را دریافت میکنند. هر نورون در این لایه، نشاندهندهی یک ویژگی (Feature) خاص از دادههای شماست.
- مثال :در سیستم بانک، یک نورون مختص «درآمد ماهانه» و نورون دیگر مختص «میزان بدهی» است.
.
۲. لایههای پنهان (Hidden Layers)
یک یا چند لایه پنهان بین ورودی و خروجی قرار میگیرند. وظیفه اصلی این لایهها، یادگیری الگوهای پیچیده در دادههاست. در اینجا هر نورون دو کار مهم انجام میدهد:
- مجموع وزندار ورودیها را محاسبه میکند.
- یک تابع فعالسازی غیرخطی (مثل ReLU یا Sigmoid) را روی نتیجه اعمال میکند تا شبکه بتواند مسائل پیچیده را درک کند.
.
۳. لایه خروجی (Output Layer)
این لایه خروجی نهایی شبکه را ارائه میدهد. تعداد نورونهای این لایه بستگی به نوع مسئله دارد:
- در مسائل دستهبندی: تعداد نورونها برابر با تعداد کلاسهاست (مثلاً ۳ نورون برای دستههای جوان، میانسال و پیر).
- در مسائل رگرسیون: معمولاً یک نورون برای نمایش یک عدد پیوسته (مثل قیمت خانه یا امتیاز اعتباری) وجود دارد.
.
جادوی وزنها (Weights) در آموزش ️
هر اتصالی که بین نورونهای لایههای مختلف میبینید، دارای یک وزن (Weight) مخصوص است. در طول فرآیند آموزش، این وزنها مدام تغییر میکنند و اصلاح میشوند تا خطای پیشبینی (Error) به حداقل برسد.
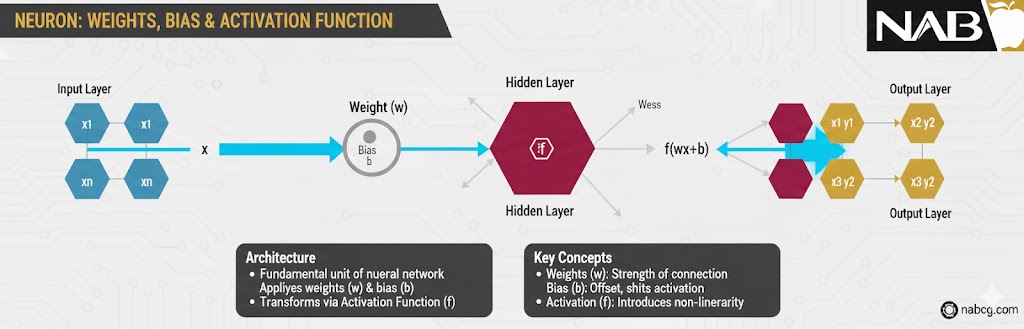
در واقع، یادگیری در هوش مصنوعی یعنی همین تنظیم دقیقِ وزنها؛ به طوری که شبکه یاد بگیرد به کدام ویژگی ورودی اهمیت بیشتری بدهد تا به دقیقترین پاسخ ممکن برسد.
توابع فعالسازی و فرآیند آموزش شبکههای پیشخور
در این بخش به قلب تپنده و موتور محرک شبکههای عصبی میپردازیم؛ یعنی جایی که محاسبات ریاضی ساده به «هوش» تبدیل میشوند.
۱. توابع فعالسازی: جادوی غیرخطی بودن ✨
اگر توابع فعالسازی وجود نداشتند، شبکه عصبی چیزی جز یک معادله ریاضی ساده و خطی نبود که فقط میتوانست الگوهای بسیار ابتدایی را درک کند. این توابع به شبکه اجازه میدهند تا الگوهای پیچیده و غیرخطی را مدلسازی کند.

رایجترین توابع فعالسازی عبارتند از:
- تابع سیگموید (Sigmoid): خروجی را به بازهای بین ۰ و ۱ محدود میکند. این تابع برای مسائلی که خروجی آنها احتمال است، بسیار کاربرد دارد.
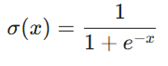
- تابع تانژانت هیپربولیک (Tanh): مشابه سیگموید است اما خروجی را بین ۱- و ۱ میبرد که باعث میشود دادهها حول صفر متمرکز شوند.
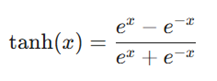
- تابع ReLU: محبوبترین تابع در یادگیری عمیق است. اگر ورودی منفی باشد، آن را صفر میکند و اگر مثبت باشد، خودِ عدد را برمیگرداند. این تابع سرعت آموزش را به شدت بالا میبرد.
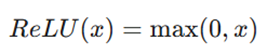
.
۲.آموزش شبکه عصبی: سفر رفت و برگشت دادهها
آموزش یک شبکه FNN در واقع فرآیند تنظیم دقیق وزنها است تا اختلاف بین خروجی پیشبینی شده و خروجی واقعی (هدف) به حداقل برسد. این فرآیند شامل سه مرحلهی کلیدی است:
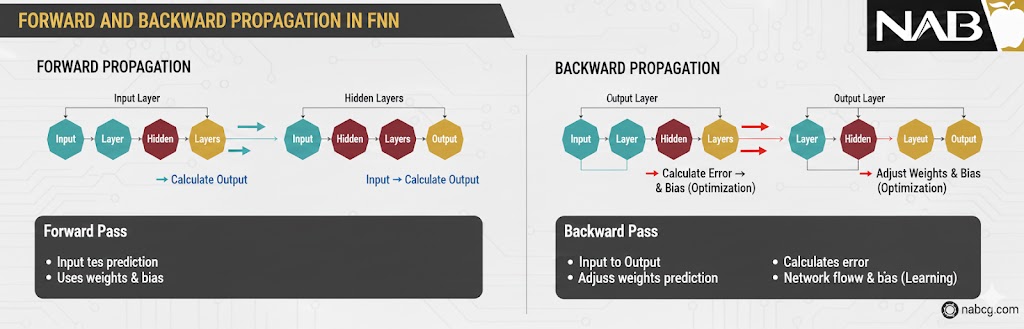
الف) انتشار رو به جلو (Forward Propagation)
در این مرحله، دادههای ورودی وارد شبکه شده، لایه به لایه حرکت میکنند و در نهایت خروجی مدل محاسبه میشود. در این فاز، هیچ تغییری در وزنها ایجاد نمیشود؛ فقط یک «حدس» توسط مدل زده میشود.
ب) محاسبه تابع زیان (Loss Calculation)
حالا باید بفهمیم حدس مدل چقدر با واقعیت فاصله دارد.
- برای مسائل رگرسیون (مثل پیشبینی قیمت)، معمولاً از Mean Squared Error (MSE) استفاده میکنیم.
- برای مسائل دستهبندی (مثل تشخیص چهره)، از Cross-Entropy Loss استفاده میشود.
.
ج) انتشار بازگشتی (Backpropagation) و گرادیان کاهشی
اینجاست که یادگیری واقعی رخ میدهد! خطا از انتهای شبکه به سمت ابتدا بازگردانده میشود. با استفاده از الگوریتم گرادیان کاهشی (Gradient Descent)، سهم هر وزن در ایجاد خطا مشخص شده و وزنها طوری تغییر میکنند که در مرحلهی بعد، خطا کمتر شود.
یک نکتهی کلیدی
به یاد داشته باشید که در زمان آموزش (Training)، هر دو مرحلهی «رفت» (انتشار رو به جلو) و «برگشت» (انتشار بازگشتی برای آپدیت وزنها) انجام میشود. اما در زمان پیشبینی (Prediction) یا استفاده نهایی از مدل، ما فقط از مرحلهی «رفت» یا همان Forward Pass استفاده میکنیم تا به سرعت به جواب برسیم.
بهینهسازی و ارزیابی شبکه عصبی پیش خور
پس از اینکه فرآیند رفت و برگشت دادهها را درک کردیم، نوبت به هوشمندترین بخش کار میرسد؛ یعنی چگونه خطا را به حداقل برسانیم و از کجا بفهمیم مدل ما واقعاً چقدر خوب عمل میکند؟
۱. الگوریتم گرادیان کاهشی (Gradient Descent): هنرِ یافتنِ کمترین خطا
گرادیان کاهشی یک الگوریتم بهینهسازی است که وظیفه دارد با تغییر دادن مداوم وزنها، مقدار تابع زیان (Loss) را به حداقل برساند. تصور کنید در بالای کوهی در مه غلیظ هستید و میخواهید به پایینترین نقطه دره برسید؛ شما هر بار یک قدم در جهتی برمیدارید که بیشترین شیب را به سمت پایین دارد.
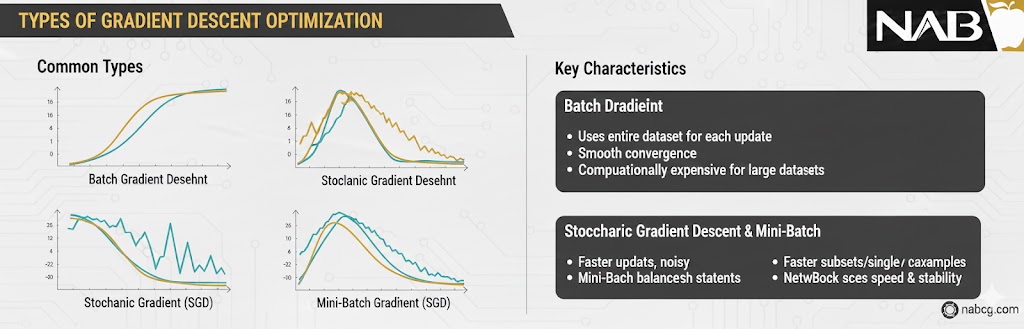
رایجترین روشهای اجرای این الگوریتم عبارتند از:
- گرادیان کاهشی دستهای (Batch Gradient Descent): در این روش، کل دادههای موجود یکجا بررسی شده و بعد وزنها آپدیت میشوند. این روش دقیق اما برای دادههای حجیم بسیار کند است.
- گرادیان کاهشی تصادفی (SGD): در اینجا برای تکتک نمونهها وزنها آپدیت میشوند. این روش بسیار سریع است اما مسیر رسیدن به جواب ممکن است پر از نوسان باشد.
- گرادیان کاهشی دستهای کوچک (Mini-batch Gradient Descent): این روش محبوبترین است! دادهها به دستههای کوچک (مثلاً ۳۲تایی) تقسیم میشوند. این کار تعادلی میان سرعت و پایداری یادگیری ایجاد میکند.
.
۲. معیار های ارزیابی عملکرد
وقتی آموزش تمام شد، نباید فقط به اعداد اعتماد کنیم. ما از معیارهای مختلفی برای سنجش «هوش» مدل استفاده میکنیم:
- دقت: سادهترین معیار؛ یعنی چه نسبتی از کل نمونهها را درست تشخیص دادهایم؟ (مثلاً ۹۰٪ تشخیص درست).
- دقت مثبت (Precision): از تمام مواردی که مدل ما «مثبت» پیشبینی کرده، چند درصد واقعاً مثبت بودهاند؟ (تمرکز روی کیفیت پیشبینی مثبت).
- فراخوانی (Recall): از تمام موارد مثبتی که در واقعیت وجود داشت، مدل ما چند درصد را توانست پیدا کند؟ (تمرکز روی گم نکردن موارد واقعی).
- امتیاز F1 (F1 Score): میانگین هارمونیک بین Precision و Recall است. زمانی که میخواهیم تعادلی میان این دو ایجاد کنیم، بهترین معیار است.
.
ماتریس اغتشاش (Confusion Matrix)
این ماتریس مانند یک جدول نمرات عمل میکند که به ما نشان میدهد مدل کجاها گیج شده است. این جدول شامل چهار بخش حیاتی است:
- مثبتِ درست (TP): درست حدس زدید، مثبت بود.
- منفیِ درست (TN): درست حدس زدید، منفی بود.
- مثبتِ کاذب (FP): اشتباهاً گفتید مثبت است (خطای نوع اول).
- منفیِ کاذب (FN): اشتباهاً گفتید منفی است (خطای نوع دوم).

نتیجه
شبکههای عصبی پیشخور با ترکیب ساختار لایهبندی شده، توابع فعالسازی هوشمند و الگوریتمهای بهینهسازی قدرتمند، ابزاری بینظیر برای حل مسائل پیچیده هستند. اما یادتان باشد، حتی بهترین معماریها هم بدون دادههای نرمالسازی شده و ارزیابی دقیق، ممکن است ما را به بیراهه ببرند.
کاربردهای شبکه عصبی پیشخور (FNN)
شبکههای عصبی پیشخور به دلیل توانایی در یادگیری نگاشتهای پیچیده بین ورودی و خروجی، در صنایع مختلفی نفوذ کردهاند. در اینجا دستهبندی کاربردهای اصلی این مدل آورده شده است:
۱. دستهبندی و تشخیص الگو
این رایجترین کاربرد FNN است. هر جا که نیاز باشد دادهای در گروههای خاصی قرار بگیرد، این شبکه وارد عمل میشود.
- تشخیص دستخط: تبدیل اعداد و حروف نوشته شده روی کاغذ به متون دیجیتال (مثل مجموعهداده MNIST).
- تشخیص بیماری: تحلیل علائم حیاتی و نتایج آزمایشگاه برای تشخیص زودهنگام بیماریهایی مثل دیابت یا نارساییهای قلبی.
.
۲. رگرسیون و پیشبینی عددی
زمانی که هدف پیشبینی یک مقدار عددی پیوسته است.
- تخمین قیمت :پیشبینی قیمت مسکن بر اساس ویژگیهایی مثل متراژ، محله و قدمت بنا.
- مهندسی: پیشبینی میزان مقاومت مصالح تحت فشارهای مختلف در سازههای عمرانی.
.
۳. پردازش سیگنال و گفتار
- کاهش نویز: حذف صداهای مزاحم محیط از سیگنال اصلی صدا.
- فشردهسازی دادهها: کاهش حجم اطلاعات بدون از دست رفتن ویژگیهای کلیدی.
.
۴. سیستمهای توصیهگر
بسیاری از پلتفرمهای فروشگاهی یا استریم ویدیو، در لایههای نهایی خود از FNN برای رتبهبندی پیشنهادات استفاده میکنند.
- مثال: یوتیوب یا نتفلیکس ویژگیهای شما (سن، ویدیوهای قبلی، زمان بازدید) را به عنوان ورودی میگیرند و احتمال کلیک شما روی یک ویدیوی خاص را پیشبینی میکنند.
.
۵. تحلیل بازارهای مالی و بورس
اگرچه برای دادههای زمانی طولانی از مدلهای دیگر استفاده میشود، اما FNN در تحلیلهای نقطهای عالی است.
- رتبهبندی اعتباری :همانطور که قبلاً اشاره شد، برای تعیین صلاحیت وامگیرنده.
- پیشبینی ورشکستگی: تحلیل شاخصهای مالی یک شرکت برای پیشبینی احتمال شکست تجاری آن در آینده نزدیک.
.
۶. کنترل فرآیندهای صنعتی و رباتیک 🤖
- کنترل خودکار: در کارخانهها برای تنظیم دقیق پارامترهای دستگاه (مثل دما یا فشار) به صورت لحظهای بر اساس سنسورهای ورودی.
- ناوبری ساده رباتها: تشخیص موانع از روی دادههای سنسور التراسونیک و صدور فرمان حرکت به چپ یا راست.
.
۷. بیوانفورماتیک و پزشکی پیشرفته 🧬🔬
- توالییابی پروتئین :پیشبینی ساختار سوم پروتئینها بر اساس اسیدهای آمینه.
- غربالگری دارویی: پیشبینی اینکه یک ترکیب شیمیایی خاص چه تأثیری روی یک سلول سرطانی خواهد داشت (بدون نیاز به تست آزمایشگاهی گرانقیمت).
.
پیادهسازی عملی شبکه عصبی پیشخور (FNN) با TensorFlow و Keras
در این بخش، به سراغ کُد میرویم تا ببینیم چگونه میتوانیم یک شبکه عصبی را برای تشخیص اعداد دستنویس (مجموعهداده مشهور MNIST) از صفر بسازیم، آموزش دهیم و ارزیابی کنیم.
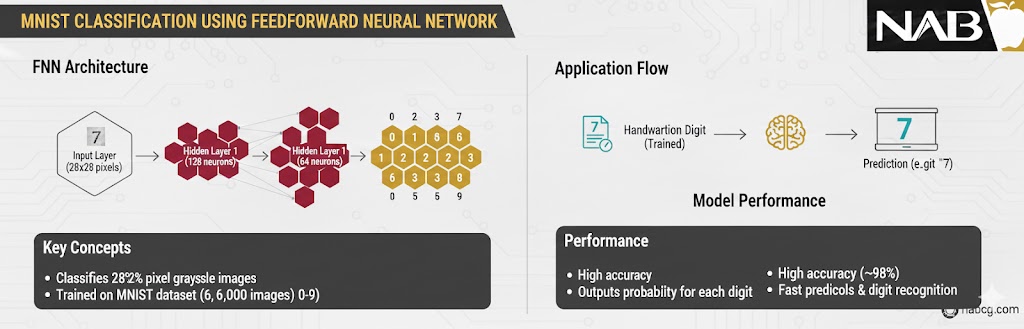
تعریف معماری مدل
ما از مدل Sequential استفاده میکنیم که به ما اجازه میدهد لایهها را به ترتیب پشت سر هم بچینیم. ساختار شبکه ما به این صورت است:
- لایه Flatten: تصاویر MNIST ابعاد 28 ✕ 28 پیکسل دارند. این لایه، تصویر دوبعدی را به یک آرایه یکبعدی (۷۸۴ نورون) تبدیل میکند تا برای لایههای بعدی قابل فهم باشد.
- لایه Dense (پنهان): یک لایه کاملاً متصل با ۱۲۸ نورون و تابع فعالسازی. ReLU این لایه مسئول یادگیری ویژگیهای اصلی اعداد است.
- لایه Dense (خروجی): لایه نهایی با ۱۰ نورون (متناسب با اعداد ۰ تا ۹). ما از تابع Softmax استفاده میکنیم تا خروجی به صورت «احتمال» بیان شود (مثلاً ۹۰٪ احتمال دارد این تصویر عدد ۵ باشد).
پیکربندی و آموزش مدل
پس از تعریف ساختار، باید مدل را کامپایل و سپس با دادهها تغذیه کنیم:
- بهینهساز: از Adam استفاده میکنیم که نسخهای هوشمند و تطبیقی از گرادیان کاهشی است و سرعت همگرایی بالایی دارد.
- تابع زیان: از Sparse Categorical Crossentropy استفاده میکنیم؛ چون برچسبهای ما اعداد صحیح (۰ تا ۹) هستند و میخواهیم اختلاف پیشبینی با واقعیت را محاسبه کنیم.
- معیار ارزیابی: دقت مدل بر اساس Sparse Categorical Accuracy سنجیده میشود.
- تعداد دورههای آموزش (Epochs): مدل را برای ۵ دور روی دادهها آموزش میدهیم.
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import SparseCategoricalCrossentropy
from tensorflow.keras.metrics import SparseCategoricalAccuracy
# Load and prepare the MNIST dataset
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# Build the model
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])
# Compile the model
model.compile(optimizer=Adam(),
loss=SparseCategoricalCrossentropy(),
metrics=[SparseCategoricalAccuracy()])
# Train the model
model.fit(x_train, y_train, epochs=5)
# Evaluate the model
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f'\nTest accuracy: {test_acc}')
خروجی:
Test accuracy: 0.9761000275611877.
مزایا
- سادگی در طراحی: ساختار لایهای و مستقیم آن، درک و پیادهسازی مدل را بسیار آسان میکند.
- سرعت بالای پیشبینی: به دلیل نبود حلقه یا بازگشت اطلاعات، مرحلهی پیشبینی با سرعت بسیار بالایی انجام میشود.
- کارایی در دادههای مستقل: برای مسائلی که دادهها به هم وابسته نیستند (مثل ویژگیهای یک مشتری برای وام)، بسیار عالی عمل میکند.
- پایداری بیشتر: نسبت به شبکههای پیچیدهتر(مثل RNNها)، در طول آموزش ثبات بیشتری دارد و کمتر دچار مشکلاتی مثل انفجار گرادیان میشود.
معایب
- عدم وجود حافظه: این شبکهها گذشته را به خاطر نمیآورند؛ بنابراین برای دادههای سری زمانی (مثل بورس) یا متنهای طولانی مناسب نیستند.
- ناتوانی در درک توالی :FNN نمیتواند ترتیب قرارگیری دادهها را درک کند (مثلاً جابهجا شدن کلمات در یک جمله).
- محدودیت در دادههای پیچیده تصویری :برای تصاویر حجیم و پیچیده، به دلیل تعداد بسیار زیاد پارامترها در لایههای Dense، نسبت به شبکههای کانولوشنی (CNN) ضعیفتر و سنگینتر عمل میکند.
- خطر بیشبرازش: اگر تعداد لایههای پنهان یا نورونها خیلی زیاد باشد، مدل به جای یادگیری الگو، دادهها را حفظ میکند.
.
مطالعه موردی: بهینهسازی زنجیره تأمین در خردهفروشی با استفاده از FNN
برای درک کامل قدرت شبکه عصبی پیشخور، بیایید نگاهی به یک چالش واقعی در دنیای تجارت بیندازیم: پیشبینی موجودی انبار برای یک فروشگاه زنجیرهای بزرگ.
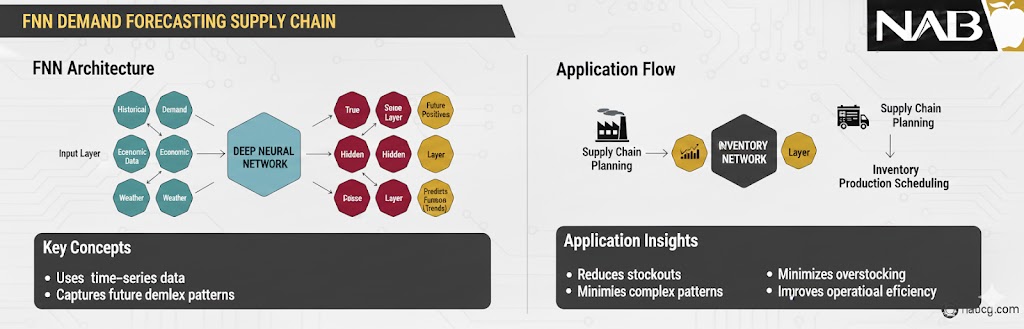
۱. بیان مسئله
یک فروشگاه زنجیرهای با هزاران قلم کالا، با دو مشکل اساسی روبروست:
- بیشازحد بودن موجودی: سرمایه شرکت در انبار قفل میشود و محصولات تاریخمصرفگذشته روی دستشان میماند.
- کمبود موجودی: مشتریان ناراضی فروشگاه را ترک میکنند و سود خالص کاهش مییابد.
هدف: ساخت مدلی که بتواند مقدار دقیق تقاضا برای هر کالا در هفته آینده را پیشبینی کند.
۲. طراحی شبکه عصبی پیشخور (FNN Design)
برای حل این مسئله، یک شبکه FNN با ساختار زیر طراحی میشود:
الف) لایه ورودی (Input Features):
در این مرحله، ویژگیهای اثرگذار بر خرید مشتری به نورونها داده میشود:
- قیمت فعلی کالا
- میزان تخفیف (کمپینهای تبلیغاتی)
- روز هفته و مناسبتهای خاص (مثل عید یا بلکفرایدی)
- میانگین دمای هوا (بسیار مهم برای نوشیدنیها یا لباس)
- میزان فروش در ۷ روز گذشته
.
ب) لایههای پنهان (Hidden Layers):
دو لایه پنهان با توابع فعالسازی ReLU طراحی میکنیم. این لایهها وظیفه دارند رابطهی غیرخطی بین «دما» و «میزان فروش بستنی» یا «تخفیف» و «هجوم مشتریان» را کشف کنند.
ج) لایه خروجی (Output Layer):
یک نورون واحد که یک عدد پیوسته را برمیگرداند: «تعداد فروش پیشبینی شده».
۳. فرآیند آموزش و عملیات
- نرمالسازی: قیمتها (مثلاً از ۱۰ هزار تا ۱ میلیون تومان) و تعداد فروش به بازهی ۰ تا ۱ برده میشوند تا شبکه لجبازی نکند.
- کُدگذاری: روزهای هفته (شنبه تا جمعه) با استفاده از کُدگذاری تک-فعال (One-Hot) به بردارهای عددی تبدیل میشوند.
- بهینهسازی: از بهینهساز Adam برای یافتن سریعترین راه کاهش خطا استفاده میشود.
.
۴. نتیجه و ارزش افزوده
پس از پیادهسازی این مطالعه موردی، نتایج زیر حاصل شد:
- کاهش ۱۵ درصدی ضایعات: به دلیل پیشبینی دقیقتر محصولات فاسدشدنی.
- افزایش ۱۰ درصدی رضایت مشتری: کالاها همیشه در قفسه موجود بودند.
- تصمیمگیری خودکار: سیستم به طور خودکار وقتی موجودی به عدد خاصی میرسید، سفارش خرید جدید صادر میکرد.
.
کد پایتون:
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers, models
# ۱. ایجاد دادههای فرضی (برای نمایش کارکرد)
# ورودیها: [قیمت، دما، درصد تخفیف]
X_train = np.array([
[100, 30, 0.1], [120, 28, 0.0], [90, 35, 0.2],
[110, 25, 0.05], [95, 32, 0.15], [130, 20, 0.0]
], dtype='float32')
# خروجی: [تعداد فروش واقعی]
y_train = np.array([50, 35, 75, 40, 65, 20], dtype='float32')
# ۲. پیشپردازش: نرمالسازی دادهها (بسیار حیاتی!)
# تقسیم بر حداکثر مقدار برای آوردن اعداد به بازه ۰ تا ۱
X_train_norm = X_train / np.max(X_train, axis=0)
y_train_norm = y_train / 100.0 # فرض میکنیم حداکثر فروش ۱۰۰ است
# ۳. طراحی معماری شبکه عصبی پیشخور
model = models.Sequential([
# لایه ورودی با ۳ ویژگی
layers.Input(shape=(3,)),
# لایه پنهان اول با ۱۶ نورون
layers.Dense(16, activation='relu'),
# لایه پنهان دوم با ۸ نورون
layers.Dense(8, activation='relu'),
# لایه خروجی برای پیشبینی یک عدد (تعداد فروش)
layers.Dense(1, activation='linear')
])
# ۴. کامپایل مدل
model.compile(optimizer='adam', loss='mse', metrics=['mae'])
# ۵. آموزش مدل
print("در حال آموزش مدل...")
model.fit(X_train_norm, y_train_norm, epochs=100, verbose=0)
# ۶. تست مدل با یک داده جدید
new_data = np.array([[105, 33, 0.1]], dtype='float32')
new_data_norm = new_data / np.max(X_train, axis=0)
prediction = model.predict(new_data_norm)
print(f"تعداد فروش پیشبینی شده: {prediction[0][0] * 100:.2f}")
جمع بندی
شبکه عصبی پیشخور یکی از پایهایترین معماریهای شبکههای عصبی است که درک آن نقش مهمی در فهم کلی یادگیری عمیق دارد. این شبکه با ساختار ساده و جریان یکطرفه داده، برای مسائل طبقهبندی و رگرسیون روی دادههای ساختیافته عملکرد قابل قبولی ارائه میدهد و همچنان در بسیاری از کاربردهای واقعی مورد استفاده قرار میگیرد.
با این حال، شبکههای پیشخور محدودیتهایی نیز دارند. ناتوانی در مدلسازی وابستگیهای مکانی و زمانی باعث میشود این معماری برای دادههای تصویری یا ترتیبی، نسبت به مدلهایی مانند CNN و RNN انتخاب ایدهآلی نباشد. به همین دلیل، شناخت زمان مناسب استفاده از FNN بهاندازه یادگیری نحوه پیادهسازی آن اهمیت دارد.
در نهایت، تسلط بر شبکه عصبی پیشخور پایهای محکم برای ورود به معماریهای پیشرفتهتر شبکههای عصبی فراهم میکند. اگر بتوانید FNN را بهدرستی درک و پیادهسازی کنید، یادگیری مدلهای پیچیدهتر نهتنها سادهتر، بلکه منطقیتر و هدفمندتر خواهد شد—و این همان نقطهای است که مسیر حرفهای در یادگیری عمیق شکل میگیرد.