

مقدمه
در بسیاری از پروژههای یادگیری ماشین، مشکل اصلی کمبود داده نیست؛ بلکه برچسبگذاری دادهها هزینهبر و دشوار است. برچسبگذاری دستی — بهویژه در پردازش زبان طبیعی، بینایی ماشین و پزشکی — زمانبر، پرهزینه و نیازمند نیروی انسانی متخصص است. در چنین شرایطی، استفاده از تمام دادههای موجود نهتنها بهینه نیست، بلکه منابع زیادی را هدر میدهد. دقیقاً در این نقطه، یادگیری فعال (Active Learning) بهعنوان راهکاری هوشمندانه وارد میدان میشود.
یادگیری فعال رویکردی از یادگیری ماشین است که در آن مدل بهصورت تعاملی تصمیم میگیرد کدام دادهها ارزش برچسبگذاری دارند. بهجای اینکه انسان بهصورت تصادفی دادهها را انتخاب کند، الگوریتم نمونههایی را پیشنهاد میدهد که بیشترین اطلاعات را برای بهبود مدل فراهم میکنند—معمولاً دادههایی که مدل درباره آنها بیشترین عدم قطعیت را دارد یا در نزدیکی مرز تصمیمگیری قرار گرفتهاند.
در این مقاله با مفهوم، منطق، عملکرد، استراتژیهای انتخاب داده، کاربردها در صنعت و پژوهش، ابزارها و چالشهای یادگیری فعال آشنا میشویم تا بفهمیم چگونه با دادهٔ کمتر، مدلهای دقیقتر بسازیم.
تعریف
در دنیای یادگیری ماشین، دادهٔ بیشتر همیشه به معنای نتایج بهتر نیست — بهویژه وقتی برچسبگذاری هزینهبر باشد. دقیقاً در این شرایط، یادگیری فعال (Active Learning) وارد میدان میشود.
یادگیری فعال یک حالت خاص و پیشرفته از یادگیری ماشین است که در آن الگوریتم فقط شنونده نیست؛ بلکه میتواند سوال بپرسد! در این روش، الگوریتم بهصورت تعاملی از کاربر (یا یک منبع اطلاعاتی دیگر) میخواهد تا دادههای جدید را برچسبگذاری کند. در متون آماری، به این روش طراحی آزمایش بهینه (Optimal Experimental Design) نیز میگویند.
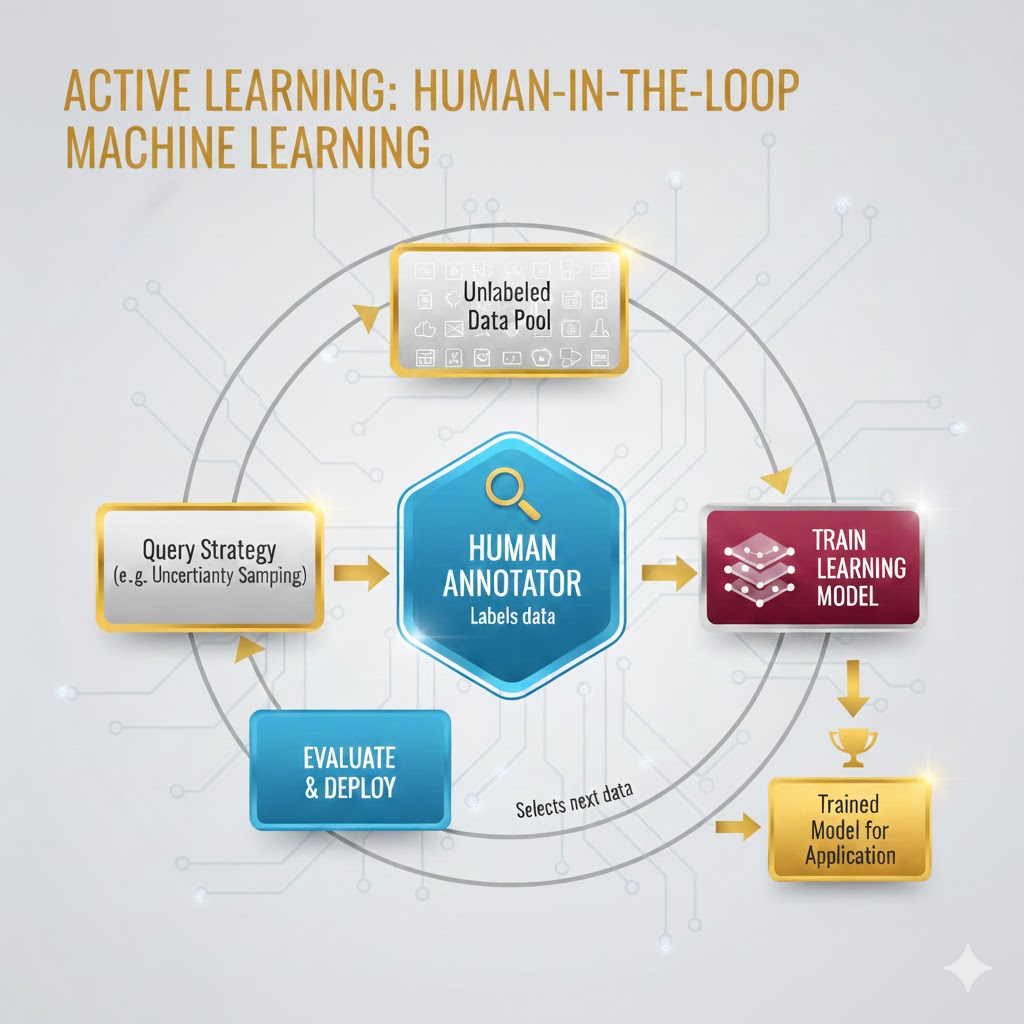
چرا یادگیری فعال مهم است؟
هدف اصلی این تکنیک، ساخت یک مدل یادگیری ماشین دقیق با حداقل مقدار دادههای برچسبدار است. الگوریتم این کار را با انتخاب هوشمندانه و گلچین کردنِ مهمترین دادهها انجام میدهد.
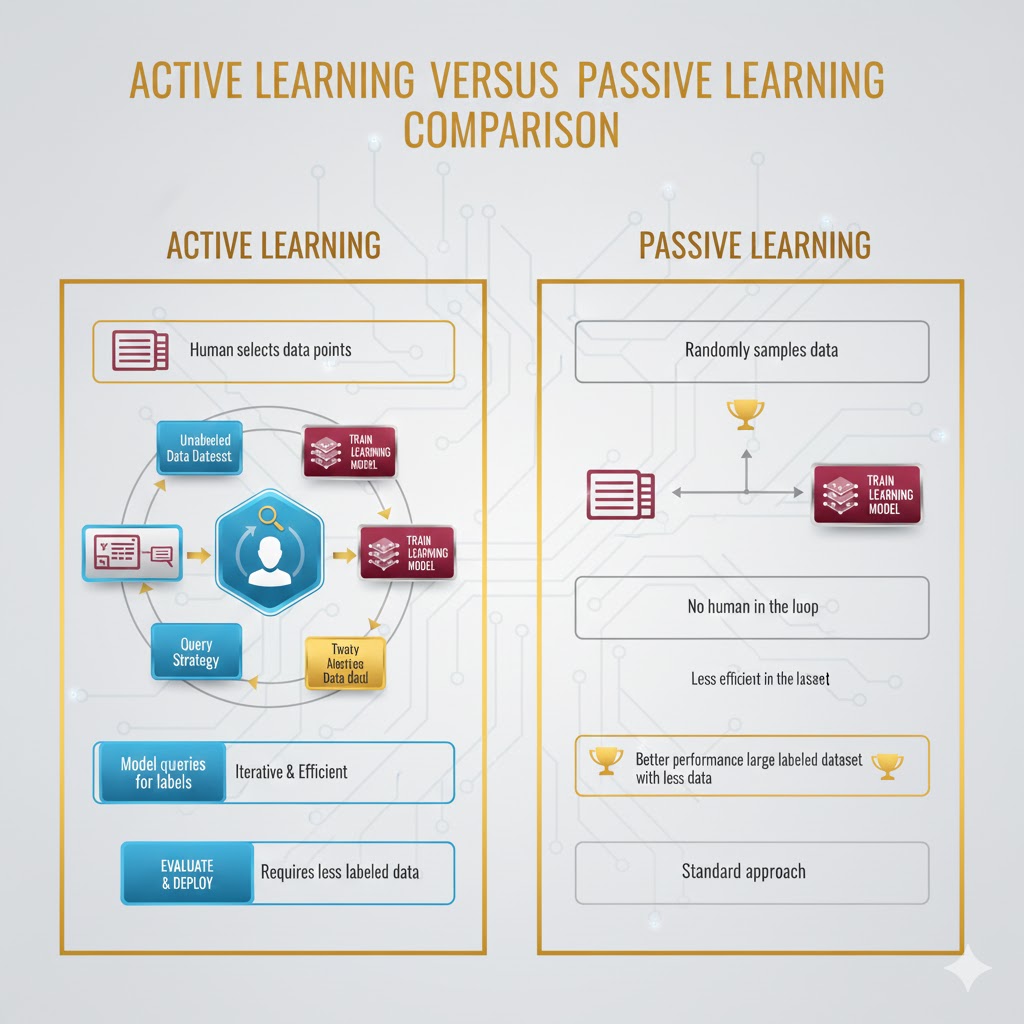
مقایسه یادگیری فعال و یادگیری غیرفعال (Passive Learning)
- یادگیری غیرفعال (روش سنتی): در این روش، حجم عظیمی از دادهها توسط انسانها (Human Oracle) برچسبگذاری میشود. این کار نیازمند تلاش انسانی فوقالعاده و صرف زمان بسیار زیاد است.
- یادگیری فعال (روش هوشمند): الگوریتم خودش تشخیص میدهد کدام دادهها حاوی اطلاعات ارزشمندتری هستند. سپس فقط همان دادههای خاص را به انسان میدهد تا برچسب بزند و آنها را به مجموعه آموزشی اضافه میکند.
منطق پشت پرده: چرا همه دادهها برابر نیستند؟
ایده یادگیری فعال از این واقعیت سرچشمه میگیرد که ارزش تمام دادهها برای آموزش مدل یکسان نیست.
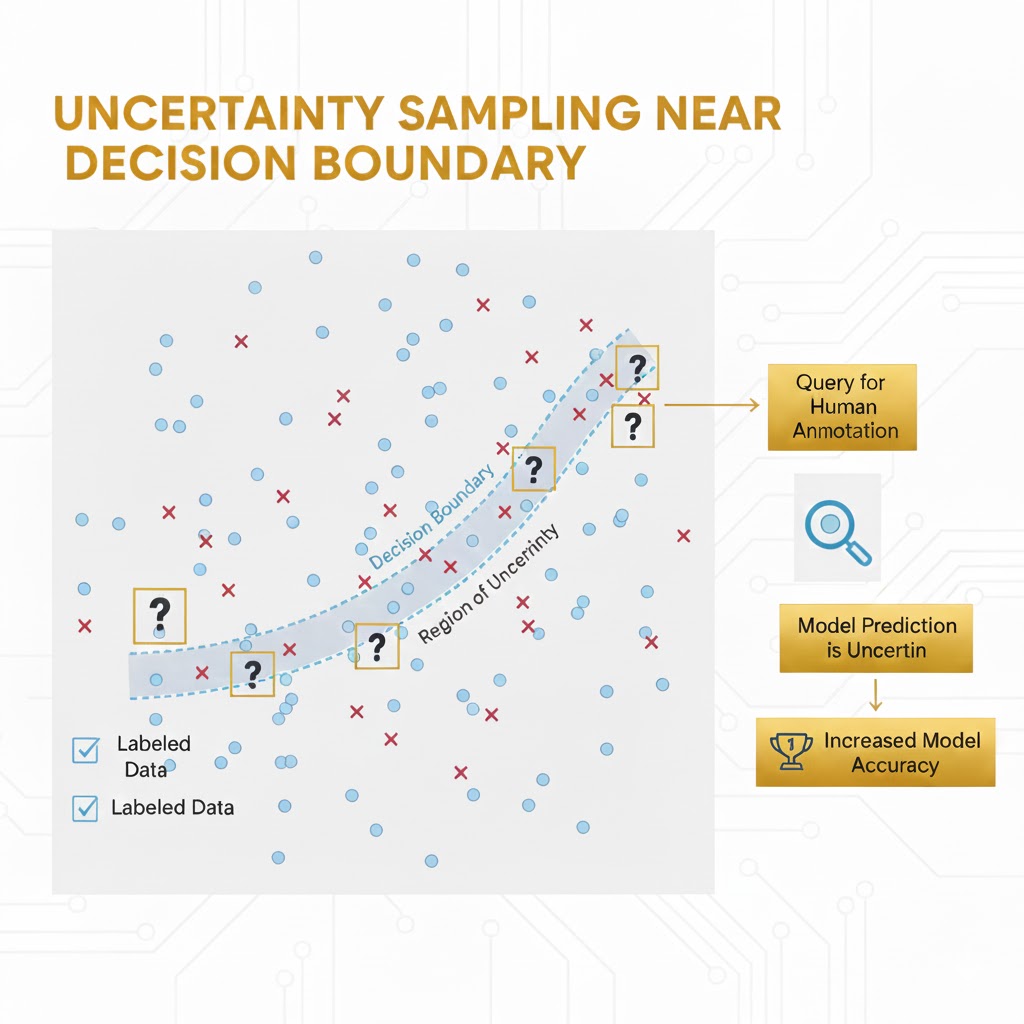
بیایید مثالی بزنیم: فرض کنید دو کلاس دارید که یک مرز تصمیمگیری (Decision Boundary) بین آنها قرار دارد.
- اگر دهها هزار نمونه داشته باشید و بخواهید همه را برچسبگذاری کنید، هزینهای سرسامآور میشود.
- اگر به صورت تصادفی بخشی از دادهها را انتخاب کنید، ممکن است مدل شما عملکرد ضعیفی داشته باشد و مرز بین دستهها را اشتباه تشخیص دهد.
جادوی یادگیری فعال اینجاست: اگر بتوانیم دادههایی را انتخاب کنیم که دقیقاً نزدیک به مرز تصمیمگیری هستند (جایی که مدل بیشترین شک را دارد)، مدل با سرعت و دقت بسیار بالاتری یاد میگیرد. این سناریو بهویژه در پردازش زبان طبیعی (NLP) مثل تشخیص اجزای کلام (POS Tagging) بسیار حیاتی است، زیرا پیدا کردن دادههای برچسبدار مرتبط در این حوزه دشوار است.
هزینه واقعی برچسبگذاری دادهها (چرا پولتان هدر میرود؟)
ایجاد دادههای برچسبدار برای آموزش مدلهای بزرگ، هم گران است و هم زمانبر. بیایید نگاهی به تعرفههای واقعی (مثلاً در Google Cloud Platform) بیندازیم:
برای اطمینان از کیفیت، معمولاً ۲ تا ۳ نفر هر داده را بررسی میکنند.
- مثال ۱ (بینایی ماشین): فرض کنید میخواهید ۱۰۰,۰۰۰ تصویر را برای یک مدل تخصصی با کادربندی (Bounding Box) برچسب بزنید. اگر هر تصویر ۵ کادر داشته باشد و ۲ نفر آن را چک کنند، هزینه ممکن است به ۱۱۲,۰۰۰ دلار برسد!.
- مثال ۲ (پزشکی): در حوزه سلامت، اگر بخواهید ۱۰,۰۰۰ تصویر پزشکی را با دقت بالا (Segmentation) برچسبگذاری کنید، هزینه میتواند تا ۳۹۱,۵۰۰ دلار افزایش یابد!.
این ارقام برای مدلهای زبانی بزرگ (LLMs) یا سیستمهای بینایی ماشین عظیم، حتی ترسناکتر هم میشود. چه از نیروهای داخلی استفاده کنید و چه برونسپاری کنید، زمان و هزینه قابل توجهی صرف میشود؛ مخصوصاً که گاهی برچسبزننده باید متخصص آن حوزه باشد (مثلاً پزشک).
مثال: خودروهای خودران NVIDIA
یک محاسبه سرانگشتی نشان میدهد که اگر ناوگانی شامل ۱۰۰ خودروی خودران داشته باشیم که روزی ۸ ساعت رانندگی کنند، برای برچسبگذاری تمام فریمهای دوربینها (برای تشخیص اشیاء)، به بیش از ۱ میلیون نیروی انسانی نیاز است! این کار عملاً غیرممکن است. یادگیری فعال اینجاست تا با دور زدن این حجم از دادههای تکراری، در زمان، پول و حتی ردپای کربنی صرفهجویی کند.
یادگیری فعال چگونه کار میکند؟ بررسی سناریوها و استراتژیها
بیایید از کلیات بگذریم و یک شیرجه عمیق به نحوه کارکرد یادگیری فعال (Active Learning) بزنیم.
در یک چرخهٔ کلاسیک یادگیری فعال، الگوریتم هوشمندانه نمونههای باارزشتر را انتخاب میکند — بهویژه موارد مرزی (Edge Cases) — و از انسان میخواهد آنها را برچسبگذاری کند. سپس این نمونههای جدید به مجموعهٔ آموزشی میپیوندند و مدل دوباره آموزش میبیند. الگوریتم این انتخاب را از طریق فرآیندی انجام میدهد که پژوهشگران آن را پرسشگری (Querying) مینامند.
بهطور کلی، دو سناریوی اصلی برای یادگیری فعال در متون علمی وجود دارد:
- مبتنی بر ترکیب پرسش (Query Synthesis)
- مبتنی بر نمونهبرداری (Sampling-based).
۱. سناریوی ترکیب پرسش (Query Synthesis)
این روش بر این فرض استوار است که نمونههای نزدیک به مرز تصمیمگیری (Classification Boundary) مبهمتر هستند و برچسبگذاری آنها بیشترین اطلاعات را به مدل میدهد.
الگوریتم چگونه کار میکند؟
فرض کنید یک طبقهبندی دوتایی داریم. الگوریتم نقاطی را در نزدیکی مرز تصمیمگیری انتخاب میکند. این کار میتواند با ایجاد نقاط جدید یا انتخاب نزدیکترین نقاط موجود با استفاده از تکنیکهای فاصله اقلیدسی انجام شود.
- روش جستجوی باینری: تصور کنید دو نقطه X1 و X2 متعلق به دو کلاس متفاوت هستند. الگوریتم نقطه میانی اقلیدسی آنها را پیدا میکند. اگر برچسب این نقطه میانی را بپرسیم، میفهمیم برای رسیدن به مرز تصمیمگیری باید به کدام سمت برویم.
- توقف پرسشگری: برای اینکه بدانیم کی به مرز تصمیم رسیدهایم، اختلاف امتیاز احتمال بین کلاسهای متضاد را میسنجیم؛ اگر این اختلاف از حد خاصی کمتر شد، یعنی به منطقه ابهام رسیدهایم.
چالش دادههای عجیب و غریب
این روشهای ریاضی در تئوری عالی هستند، اما در بینایی ماشین (Computer Vision) یا پردازش زبان (NLP) ممکن است نقطهای که الگوریتم تولید میکند (مثلاً ترکیب پیکسلهای دو عکس)، برای انسان بیمعنی باشد. راه حل چیست؟ به جای تولید نقطه مصنوعی، الگوریتم نزدیکترین همسایه (Nearest Neighbor) را از بین دادههای واقعیِ بدون برچسب پیدا کرده و در مورد آن سوال میکند.
مثال واقعی (دیتاست MNIST): اگر به اعداد دستنویس انتخاب شده توسط یادگیری فعال نگاه کنید (مثلاً اعداد ۳، ۵، ۷)، متوجه میشوید که نسبت به نمونههای تصادفی، ظاهر عجیبتر و بدخطتری دارند. دقیقاً هدف همین است! الگوریتم دنبال موارد عجیب یا همان Edge Caseها میگردد تا آنها را یاد بگیرد.
۲. سناریوی مبتنی بر نمونهبرداری (Sampling Techniques)
این روش رایجتر است و میتوان آن را در ۶ مرحله خلاصه کرد:
- برچسبگذاری یک زیرمجموعه کوچک توسط انسان.
- آموزش یک مدل نسبتاً سبک روی این دادهها.
- پیشبینی کلاس برای تمام دادههای بدون برچسب باقیمانده توسط مدل.
- امتیازدهی به دادههای بدون برچسب بر اساس خروجی مدل.
- انتخاب یک زیرمجموعه بر اساس این امتیازها و ارسال برای برچسبگذاری انسانی.
- آموزش مجدد مدل با دادههای جدید و تکرار چرخه تا رسیدن به عملکرد مطلوب.
این روش خود به دو دسته تقسیم میشود:
- نمونهبرداری جریانی(Stream-based): دادهها به صورت مداوم وارد میشوند (مثلاً در محیط واقعی) و مدل تصمیم میگیرد آیا این داده خاص ارزش برچسبگذاری دارد یا خیر.
- نمونهبرداری مبتنی بر استخر(Pool-based): مدل از یک استخر بزرگ دادههای بدون برچسب، بهترین نمونهها را گلچین میکند.
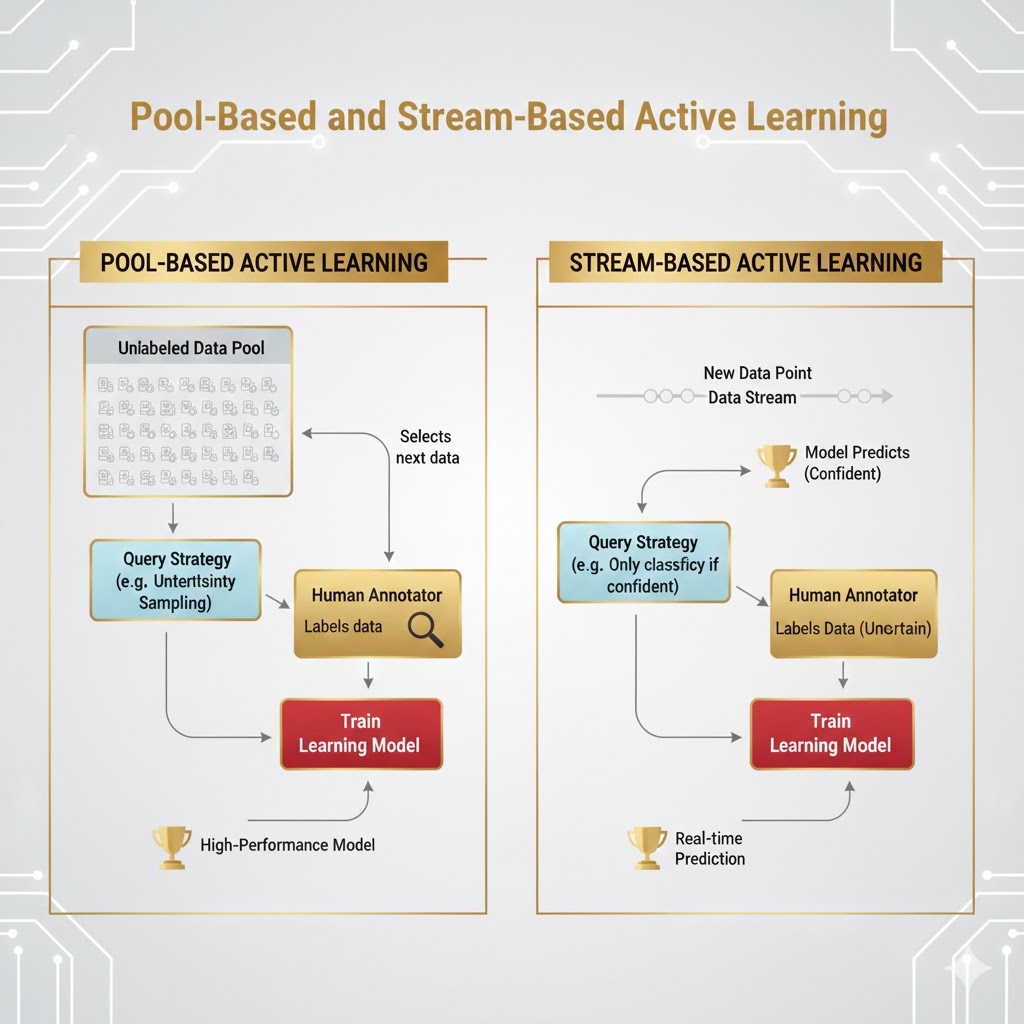
استراتژیهای انتخاب داده
الگوریتم چگونه میفهمد کدام داده مهم است؟ از استراتژیهای زیر استفاده میشود:
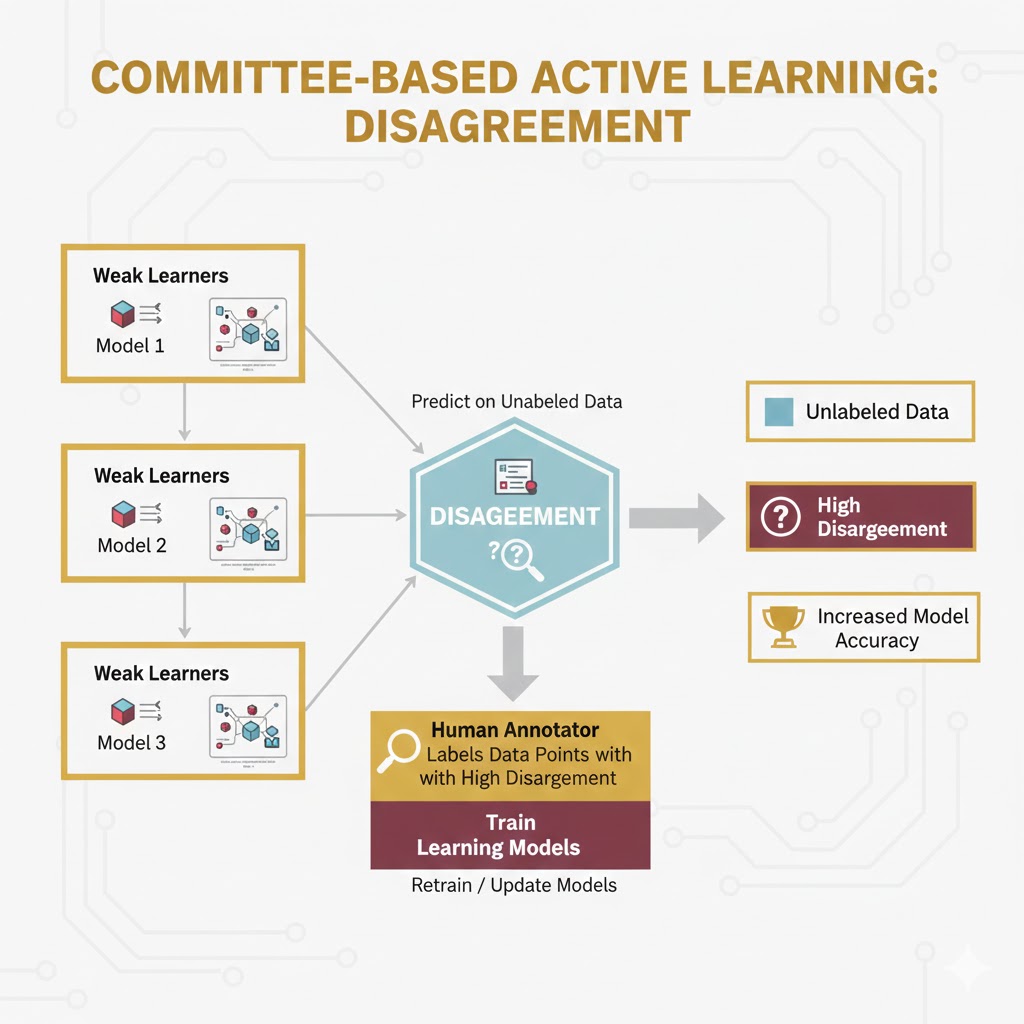
الف) استراتژیهای مبتنی بر کمیته (Committee based)
چندین مدل مختلف (یک کمیته) ساخته میشود. اگر این مدلها در مورد یک داده اختلاف نظر داشته باشند، آن داده ارزشمند است. برای اندازهگیری این اختلاف از معیارهایی مثل آنتروپی (Entropy) یا واگرایی KL استفاده میشود.
- آنتروپی: معیاری برای سنجش عدم قطعیت است. اگر احتمالات پیشبینی شده برای کلاسها نزدیک به هم باشند (مثلاً ۴۵٪ کلاس ۱ و ۴۰٪ کلاس ۲)، آنتروپی بالاست و مدل گیج شده است؛ پس این داده باید برچسبگذاری شود.
ب) استراتژیهای مبتنی بر حاشیه بزرگ (Large-margin)
این روش مخصوص مدلهایی مثل SVM است. دادههایی که روی حاشیه یا نزدیک به ابرصفحه جداکننده (Decision Boundary) قرار میگیرند، بیشترین اطلاعات را دارند.
- نمونهبرداری حاشیه: انتخاب دادهای که کمترین فاصله را با مرز تصمیمگیری دارد.
ج) استراتژیهای مبتنی بر احتمال (Probability-based)
این روش برای هر مدلی که خروجی احتمالات دارد مناسب است.
- کمترین حاشیه: اختلاف احتمال بین بهترین کلاس و دومین بهترین کلاس محاسبه میشود. هرچه این اختلاف کمتر باشد، یعنی مدل در انتخاب بین دو گزینه مردد است و نیاز به کمک دارد.
- کمترین اطمینان: دادههایی انتخاب میشوند که مدل کمترین اطمینان را به پیشبینی خود برای آنها دارد (مثلاً بالاترین احتمالی که داده، فقط ۵۰٪ است).
د) کاهش خطا و تغییر مدل
- تغییر مورد انتظار مدل: انتخاب نمونهای که باعث بیشترین تغییر در مدل (مثلاً گرادیانها) میشود.
- کاهش خطای مورد انتظار: انتخاب نمونههایی که بیشترین پتانسیل را برای کاهش خطای کلی آموزش دارند.
یادگیری فعال در دنیای واقعی؛ از چتباتها تا خودروهای خودران 🚗🤖
یادگیری فعال (Active Learning) در حال حاضر ستارهی درخشان دنیای پردازش زبان طبیعی (NLP) و بینایی ماشین (Computer Vision) است. چرا؟ چون مدلهای پیشرفته یادگیری عمیق تشنهی داده هستند، اما هزینه سیراب کردن آنها با دادههای برچسبدار بسیار سنگین است.
اگر دادههای شما کم باشد، قدرت یادگیری عمیق عملاً هدر میرود. یادگیری فعال دقیقاً همان راهحلی است که باعث میشود یادگیری عمیق حتی با دادههای محدود هم کاربردی و مقرونبهصرفه باشد. بیایید سه کاربرد واقعی و جذاب آن را بررسی کنیم.

۱. کاربرد در پردازش زبان طبیعی (NLP)؛ شکارِ کلمات 📝
یکی از سختترین کارها در NLP، کارهایی مثل تشخیص موجودیتهای نامدار (NER) یا برچسبگذاری اجزای کلام است.
- چالش: برای اینکه مدل بفهمد “اپل” در یک جمله، نام میوه است یا نام شرکت، نیاز به هزاران مثال برچسبدار دارد.
- راهحل یادگیری فعال: در یک تحقیق معتبر (روی دیتاست OntoNotes 5.0)، استراتژیهای یادگیری فعال با روش سنتی (انتخاب تصادفی دادهها) مقایسه شدند.
- نتایج: نمودارها به وضوح نشان دادند که تمام استراتژیهای یادگیری فعال با اختلاف زیادی از روش نمونهبرداری تصادفی (Random Sampling) بهتر عمل کردند. این یعنی مدل با دیدن نمونههای کمتر، سریعتر و دقیقتر یاد گرفت.
۲. کاربرد در بینایی ماشین (خودروهای خودران) 🚘
شاید بتوان گفت حیاتیترین و پولسازترین کاربرد یادگیری فعال در حال حاضر، صنعت خودروهای خودران است. اینجا بحث جان انسانهاست و دقت مدل باید نزدیک به ۱۰۰٪ باشد.
چالش اصلی: دادههای بیپایان
مدلهای بینایی ماشین برای رسیدن به دقت بالا، به اقیانوسی از داده نیاز دارند. اما انتخاب داده درست از میان میلیونها فریم ویدیو، کار حضرت فیل است!
- مشکل مقیاس: یک محاسبه ساده نشان میدهد که اگر ناوگانی شامل ۱۰۰ خودرو داشته باشیم که روزی ۸ ساعت رانندگی کنند، برای برچسبگذاری تمام فریمهای دوربینها (برای تشخیص اشیاء)، به بیش از ۱ میلیون نیروی انسانی نیاز داریم! این کار عملاً غیرممکن و بهشدت پرهزینه است.
راهحل NVIDIA: یادگیری فعال با کمیته اختلافنظر
شرکت انویدیا (NVIDIA) در مقالهای توضیح داده که چطور از بین ۲ میلیون فریم ویدیو، بهترینها را انتخاب میکند. آنها از روش اختلافنظر در مدلهای گروهی (Ensemble Disagreement) استفاده میکنند.
این روش چطور کار میکند؟ (یک مثال ساده ریاضی) فرض کنید دو مدل مختلف (مدل ۱ و مدل ۲) داریم که به تصاویر نگاه میکنند:
- تصویر اول (X1): مدل اول با احتمال ۷۸٪ و مدل دوم با احتمال ۹۱٪ یک کلاس را پیشبینی میکنند. (اختلاف نظر = ۰.۱۳)
- تصویر دوم (X2): مدل اول ۷۶٪ و مدل دوم ۸۲٪ اطمینان دارند. (اختلاف نظر = ۰.۰۶)
نتیجه: اختلاف نظر در تصویر اول (X1) بیشتر است. این یعنی تصویر اول مبهمتر و چالشبرانگیزتر است. پس سیستم یادگیری فعال، تصویر X1 را انتخاب میکند و به انسان میدهد تا برچسب بزند.
چرخه جادویی انویدیا:
- چندین مدل را با پارامترهای تصادفی آموزش میدهند.
- تصاویری را پیدا میکنند که مدلها بیشترین اختلاف نظر را روی آنها دارند.
- این تصاویر خاص را به انسان میدهند تا برچسب بزند.
- دادههای جدید به مدل اضافه شده و آموزش تکرار میشود.
دستاورد: این روش نه تنها هزینهها را کاهش داد، بلکه دقت مدل (mAP) را در تشخیص اشیاء، هم برای اشیاء بزرگ و هم متوسط، به طرز چشمگیری بالا برد. نقشههای حرارتی (Heat Maps) نشان دادند که مدل دقیقاً روی نقاط مبهم و گیجکننده تمرکز کرده است.
۳. کاربرد در حوزه پزشکی؛ مهندسی ژنتیک 🧬
در پزشکی، انجام آزمایشهای بیولوژیکی بسیار گران و زمانبر است.
- مثال: بهینهسازی شبکههای ژنتیکی و متابولیک.
- کارکرد: محققان از یادگیری فعال استفاده کردند تا با کمترین تعداد آزمایش، تابعی را پیدا کنند که تولید پروتئین را به حداکثر برساند. نمودارها نشان دادند که با استفاده از استراتژی نمونهبرداری هوشمند، بازده تولید پروتئین با سرعت بسیار بیشتری نسبت به روشهای عادی بهبود یافته است.
ابزارها و فریمورکهای محبوب یادگیری فعال
برای پیادهسازی یادگیری فعال، نیازی نیست چرخ را از اول اختراع کنید! کتابخانههای قدرتمندی در زبان پایتون وجود دارند که فرآیند پرسشگری (Querying) و انتخاب داده را برای شما مدیریت میکنند. در اینجا با بهترینهای آنها آشنا میشویم:
۱. فریمورک modAL؛ ماژولار و قدرتمند برای پایتون
modAL یک فریمورک اختصاصی برای یادگیری فعال در پایتون ۳ است که با تمرکز بر سه اصل کلیدی طراحی شده است: ماژولار بودن، انعطافپذیری و قابلیت توسعه.
این ابزار قدرتمند دقیقاً بر پایه کتابخانه مشهور scikit-learn ساخته شده است. این یعنی اگر شما با scikit-learn آشنا باشید، در modal احساس غریبی نخواهید کرد و میتوانید با آزادی عمل تقریباً کامل، جریانهای کاری (Workflows) یادگیری فعال را به سرعت ایجاد کنید.
چرا modAL انتخاب اول است؟
این فریمورک فقط یک ابزار ساده نیست؛ بلکه جعبهابزاری کامل است که بسیاری از استراتژیهای پیشرفته یادگیری فعال را پوشش میدهد:
- الگوریتمهای مبتنی بر احتمال/عدم قطع (Uncertainty-based):انتخاب دادههایی که مدل در مورد آنها گیج شده است.
- الگوریتمهای مبتنی بر کمیته (Committee-based): استفاده از چند مدل برای تصمیمگیری بهتر.
- کاهش خطا (Error Reduction): تمرکز بر دادههایی که خطای مدل را کم میکنند.
سادگی در اجرا
کار با modAL بسیار ساده است. برای مثال، اگر بخواهید یادگیری فعال را با یک طبقهبندِ جنگل تصادفی (Random Forest) از کتابخانه scikit-learn پیادهسازی کنید، کدنویسی آن بسیار کوتاه و روان خواهد بود.
from modAL.models import ActiveLearner
from sklearn.ensemble import RandomForestClassifier
# initializing the learner, X_training refers to the initial labeled dataset
learner = ActiveLearner(
estimator=RandomForestClassifier(),
X_training=X_training, y_training=y_training
)
# query for labels X_pool refers to unlabeled dataset
query_idx, query_inst = learner.query(X_pool)
# ...obtaining new labels from the Oracle…
# supply label for queried instance
learner.teach(X_pool[query_idx], y_new)
۲. پکیج libact؛ یادگیری فعال مبتنی بر استخر (Pool-based)
دومین ابزار قدرتمند در لیست ما، libact است. این پکیج پایتون با یک هدف مشخص طراحی شده است: سادهسازی یادگیری فعال برای کاربران دنیای واقعی.
اگر با چالش انتخاب استراتژی مناسب روبرو هستید، libact میتواند نجاتدهنده باشد. این پکیج نه تنها اکثر استراتژیهای محبوب یادگیری فعال را در خود دارد، بلکه یک ویژگی انقلابی و هوشمند به نام یادگیریِ یادگیری فعال (Active Learning by Learning) را ارائه میدهد.
ویژگی منحصربهفرد: متا-استراتژی (Meta-strategy)
شاید بپرسید این ویژگی چیست؟ به زبان ساده، libact دارای یک متا-استراتژی است که به ماشین اجازه میدهد بهصورت خودکار و در لحظه (On the fly)، بهترین استراتژی یادگیری را برای دادههای خاصِ شما یاد بگیرد و انتخاب کند. یعنی به جای اینکه شما حدس بزنید کدام روش بهتر است، خودِ ابزار آن را کشف میکند.
این ابزار برای سناریوهای مبتنی بر استخر (Pool-based) که در آن شما یک مخزن بزرگ از دادههای بدون برچسب دارید، بسیار ایدهآل است.
# declare Dataset instance, X is the feature, y is the label (None if unlabeled)
dataset = Dataset(X, y)
query_strategy = QueryStrategy(dataset) # declare a QueryStrategy instance
labler = Labeler() # declare Labeler instance
model = Model() # declare model instance
for _ in range(quota): # loop through the number of queries
query_id = query_strategy.make_query() # let the specified QueryStrategy suggest a data to query
lbl = labeler.label(dataset.data[query_id][0]) # query the label of the example at query_id
dataset.update(query_id, lbl) # update the dataset with newly-labeled example
model.train(dataset) # train model with newly-updated Dataset
۳. فریمورک AlpacaTag؛ متخصص برچسبگذاری متون
اگر پروژه شما روی برچسبگذاری توالی (Sequence Tagging) مثل تشخیص موجودیتهای نامدار (NER) متمرکز است، AlpacaTag دقیقاً برای شما ساخته شده است.
این فریمورک یک ابزار برچسبگذاری جمعی (Crowd Annotation) مبتنی بر یادگیری فعال است. یعنی نه تنها از هوش مصنوعی استفاده میکند، بلکه برای مدیریت تیمهای انسانی که همزمان روی یک دیتاست کار میکنند، بهینهسازی شده است.
چرا AlpacaTag متمایز است؟
طبق مستندات رسمی این ابزار، سه ویژگی کلیدی آن را از رقبا جدا میکند:
- توصیههای فعال و هوشمند: این ابزار فقط یک صفحه خالی به شما نشان نمیدهد؛ بلکه به صورت پویا برچسبهای احتمالی را پیشنهاد میدهد و همزمان، آموزندهترین نمونههای بدون برچسب را برای شما گلچین (Sample) میکند تا اولویتبندی شوند.
- ادغام خودکار کار گروهی: وقتی چند نفر روی یک متن کار میکنند، اختلاف نظر پیش میآید (مثلاً یکی تهران را “شهر” میگیرد و دیگری “مکان”) AlpacaTag. به صورت خودکار برچسبهای متناقض را از چندین کاربر میگیرد و ادغام میکند تا توافق و دقت نهایی (Inter-annotator agreement) در لحظه بالا برود.
- استقرار مدل در لحظه: لازم نیست صبر کنید تا برچسبگذاری تمام شود! کاربران میتوانند همزمان که دادههای جدید در حال برچسبگذاری هستند، نسخه فعلی مدل را در سیستمهای نهایی خود مستقر و استفاده کنند.
چالشهای فنی و محدودیتها؛ نیمه تاریک یادگیری فعال
هرچند یادگیری فعال در کاهش هزینهها معجزه میکند، اما پیادهسازی آن بدون چالش نیست. قبل از شروع، باید از موانع زیر آگاه باشید:
۱. مشکل شروع سرد (Cold Start Problem)
یادگیری فعال برای تشخیص نمونههای «مهم» نیازمند یک مدل اولیه است؛ اما در آغاز پروژه، معمولاً هیچ دادهٔ برچسبداری در دسترس نیست.
- چالش: الگوریتم در ابتدا «کور» است و نمیداند چه سوالی بپرسد.
- راهکار: معمولاً در ابتدا یک زیرمجموعه کوچک به صورت تصادفی توسط انسان برچسبگذاری میشود تا مدل اولیه شکل بگیرد.
۲. هزینه محاسباتی و تأخیر (Computational Cost)
یادگیری فعال یک فرآیند تکرارشونده است. در هر چرخه، مدل باید دوباره آموزش ببیند و روی تمام دادههای بدون برچسب پیشبینی انجام دهد.
- چالش: آموزش همزمان چندین مدل (در روشهای کمیتهای) یا آموزشهای متوالی مکرر، به قدرت پردازشی و زمان زیادی نیاز دارد.
- نکته: در سیستمهایی که نیاز به پاسخ در لحظه دارند (مثل ترمز اضطراری خودرو)، این تأخیر میتواند مشکلساز شود.
۳. خطای انسانی و اوراکلهای خسته (Noisy Oracles)
ما فرض میکنیم انسانی که برچسب میزند (Oracle)، همیشه درست میگوید. اما انسانها خسته میشوند یا ممکن است تخصص کافی نداشته باشند.
- چالش: اگر الگوریتم موارد سخت و مبهم (Edge Cases) را پیدا کند و انسان آنها را اشتباه برچسبگذاری کند، مدل با اعتمادبهنفس بالا روی دادهٔ نادرست آموزش میبیند — که خطرناکتر از نبود داده است.
- نکته: گاهی برچسبزننده باید حتماً متخصص (مثلاً پزشک) باشد که هزینه را بالا میبرد.
۴. سوگیری نمونهبرداری (Sampling Bias)
الگوریتمهای یادگیری فعال معمولاً روی دادههای «مبهم» و «مرزی» تمرکز دارند.
- چالش: اگر مدل فقط دادههای سخت و عجیب را ببیند، ممکن است توزیع واقعی و نرمال دادهها را فراموش کند و روی دادههای آسان عملکردش افت کند.
معیارهای ارزیابی؛ چطور بفهمیم موفق شدیم؟
در یادگیری ماشین معمولی، ما فقط دقت (Accuracy) را میسنجیم. اما در یادگیری فعال، هدف ما رسیدن به دقت بالا با دادهی کم است. پس معیارهای ما متفاوت است:
۱. منحنی یادگیری (Learning Curve)
این مهمترین نمودار در یادگیری فعال است.
- محور افقی: تعداد نمونههای برچسبخورده.
- محور عمودی: دقت مدل (Accuracy/F1-Score).
- تفسیر: ما منحنی یادگیری فعال را با منحنی نمونهبرداری تصادفی (Random Sampling) مقایسه میکنیم. اگر منحنی یادگیری فعال بالاتر باشد و سریعتر صعود کند، یعنی استراتژی ما موفق بوده است.
۲. نرخ صرفهجویی در داده (Data Savings Ratio)
این معیار به زبان پول صحبت میکند!
- تعریف: محاسبه میکنیم که برای رسیدن به دقت هدف (مثلاً ۹۰٪)، یادگیری فعال به چند نمونه نیاز دارد و نمونهبرداری تصادفی به چند نمونه؟
- مثال: اگر روش تصادفی با ۱۰۰۰ عکس به دقت ۹۰٪ برسد و یادگیری فعال با ۴۰۰ عکس، ما ۶۰٪ صرفهجویی در داده (و هزینه برچسبگذاری) داشتهایم.
۳. مساحت زیر منحنی یادگیری (AULC)
به جای اینکه فقط نقطه پایان را ببینیم، کل مسیر یادگیری را بررسی میکنیم. هرچه مساحت زیر منحنی یادگیری بیشتر باشد، یعنی مدل در تمام مراحل (حتی وقتی داده خیلی کم بوده) عملکرد پایدارتری داشته است.
نتیجهگیری
یادگیری فعال نشان میدهد که در یادگیری ماشین، همیشه داده بیشتربه معنای یادگیری بهتر نیست. آنچه اهمیت دارد، انتخاب هوشمندانه دادههای درست است. با تمرکز بر نمونههای مبهم، مرزی و اطلاعاتی، یادگیری فعال میتواند هزینه برچسبگذاری را بهطور چشمگیری کاهش دهد و در عین حال دقت و پایداری مدل را افزایش دهد.
کاربردهای موفق یادگیری فعال در حوزههایی مانند پردازش زبان طبیعی، بینایی ماشین، خودروهای خودران و پزشکی نشان میدهد که این رویکرد صرفاً یک ایده تئوریک نیست، بلکه ابزاری عملی و اثباتشده برای حل مسائل واقعی است. البته پیادهسازی آن بدون چالش نیست؛ مسائلی مانند هزینه محاسباتی، خطای انسانی در برچسبگذاری و سوگیری نمونهبرداری نیازمند طراحی دقیق و آگاهانه هستند.
در نهایت، هر زمان دادهٔ بدون برچسب فراوان اما منابع برچسبگذاری محدود باشد، یادگیری فعال انتخابی هوشمندانه و اقتصادی است. این رویکرد یادآور میشود که در دنیای دادهمحور امروز، پرسیدن سؤالهای درست گاهی از داشتن پاسخهای زیاد مهمتر است.



