

1.مقدمه
در کالبدشکافی یادگیری ماشین (ML)، دو رویکرد بنیادی وجود دارد که تقریباً تمام الگوریتمها و کاربردهای دنیای واقعی را شکل میدهند: یادگیری نظارتشده و یادگیری بدون نظارت. درک تفاوتهای ظریف و کاربردهای منحصر به فرد این دو رویکرد، برای هر کسی که قصد ورود به حوزه هوش مصنوعی (AI) و علم داده (Data Science) را دارد، حیاتی است.
اگر در مقالات پیشین (مانند [یادگیری ماشین چگونه کار میکند؟]) به سازوکار کلی ML پرداختیم، در این مقاله، عمیقاً به ماهیت دادهها و نحوه هدایت فرآیند یادگیری توسط این دو پارادایم خواهیم پرداخت. این دانش، دانشجویان را قادر میسازد تا هنگام مواجهه با یک مسئله تجاری یا علمی، تشخیص دهند که کدام ابزار برای استخراج دانش از دادهها مناسبتر است. با تکیه بر تحقیقات دانشگاه استنفورد و گزارشهای استراتژیک مککنزی و BCG، به واکاوی این دو رویکرد اصلی میپردازیم.
2.یادگیری نظارتشده
یادگیری نظارتشده، رایجترین و شناختهشدهترین پارادایم در ML است که بر اساس دادههای از پیش برچسبگذاری شده (Labeled Data) آموزش میبیند. در این مدل، یک مدل با استفاده از جفتهای ورودی-خروجی مشخص شده (Input-Output Pairs) آموزش داده میشود تا بتواند یک تابع نگاشت (Mapping Function) را یاد بگیرد که به بهترین شکل، دادههای ورودی را به خروجیهای مورد انتظار متصل کند.
مکانیسم کار و نقش دادههای برچسبدار
فرآیند در این رویکرد، کاملاً به حضور معلم یا ناظر متکی است:
- ورودی برچسبدار: مجموعه داده شامل نمونههایی است که هر نمونه (x) دارای یک خروجی یا برچسب صحیح (y) است مانند: (عکس سیب، “سیب”)، (تراکنش مشکوک، “تقلب”).
- فرآیند خطا و بازخورد: مدل پیشبینی (y′) خود را تولید میکند. سپس تابع زیان (Loss Function)، خطای مدل (تفاوت بین y و y′) را محاسبه میکند.
- بهینهسازی: الگوریتمهای بهینهساز (مانند گرادیان کاهشی که در مقاله [یادگیری ماشین چگونه کار میکند؟] توضیح داده شد)، از این خطا برای تنظیم وزنها و پارامترهای مدل استفاده میکنند. این فرآیند تا زمانی که مدل به حداقل خطای ممکن برسد، ادامه مییابد.
.
3.انواع مسائل در یادگیری نظارتشده
یادگیری نظارتشده عموماً دو نوع مسئله اصلی را حل میکند:
الف. دستهبندی (Classification) :پیشبینی یک دسته گسسته
- تعریف: مدل، یک خروجی گسسته یا دستهای را پیشبینی میکند (مثلاً “بله” یا “خیر”، “سگ”، “گربه” یا “پرنده”).
- مثال کاربردی (Deloitte) تشخیص تقلب بانکی :مدل با دادههای تراکنشهای گذشته (برچسبدار به عنوان “عادی” یا “تقلب”) آموزش داده میشود و یاد میگیرد یک تراکنش جدید را به یکی از این دو دسته اختصاص دهد.
- الگوریتمهای رایج: رگرسیون لجستیک (Logistic Regression)، ماشینهای بردار پشتیبان (SVM)، درختهای تصمیم (Decision Trees)، و شبکههای عصبی عمیق (Deep Neural Networks).
.
ب. رگرسیون (Regression):پیشبینی یک مقدار پیوسته
- تعریف: مدل، یک خروجی پیوسته یا عددی را پیشبینی میکند (مانند دما، قیمت، یا احتمال).
- مثال کاربردی (PwC) پیشبینی قیمت مسکن :مدل با استفاده از ویژگیهایی مانند متراژ، موقعیت و سن ملک، یک قیمت دقیق را به عنوان خروجی عددی پیشبینی میکند.
- الگوریتمهای رایج: رگرسیون خطی (Linear Regression)، رگرسیون چندگانه، و الگوریتمهای مبتنی بر تقویتکننده (Boosting) مانند XGBoost.
.
مزایا و چالشهای یادگیری نظارت شده
| مزایا (Advantage) | چالشها (Challenge) |
|---|---|
| دقت بالا: عملکرد بسیار دقیق در مسائلی که دادههای برچسبدار کافی دارند. | هزینه برچسبگذاری: فرآیند برچسبگذاری دادهها، زمانبر، پرهزینه و مستعد خطای انسانی است. |
| ارزیابی ساده: عملکرد مدل به راحتی با معیارهای استاندارد (مانند دقت یا F1-Score) قابل ارزیابی است. | بیشبرازش (Overfitting):مدل به دلیل تکیه زیاد بر دادههای آموزشی، ممکن است جزئیات بیش از حد را حفظ کرده و بر روی دادههای جدید عملکرد ضعیفی داشته باشد. |
| کاربردهای تجاری اثبات شده: ستون اصلی در صنایع پزشکی، مالی و تولید. | نیاز به دادههای تمیز: عملکرد مدل به شدت به کیفیت و صحت برچسبها وابسته است. |
4.یادگیری بدون نظارت
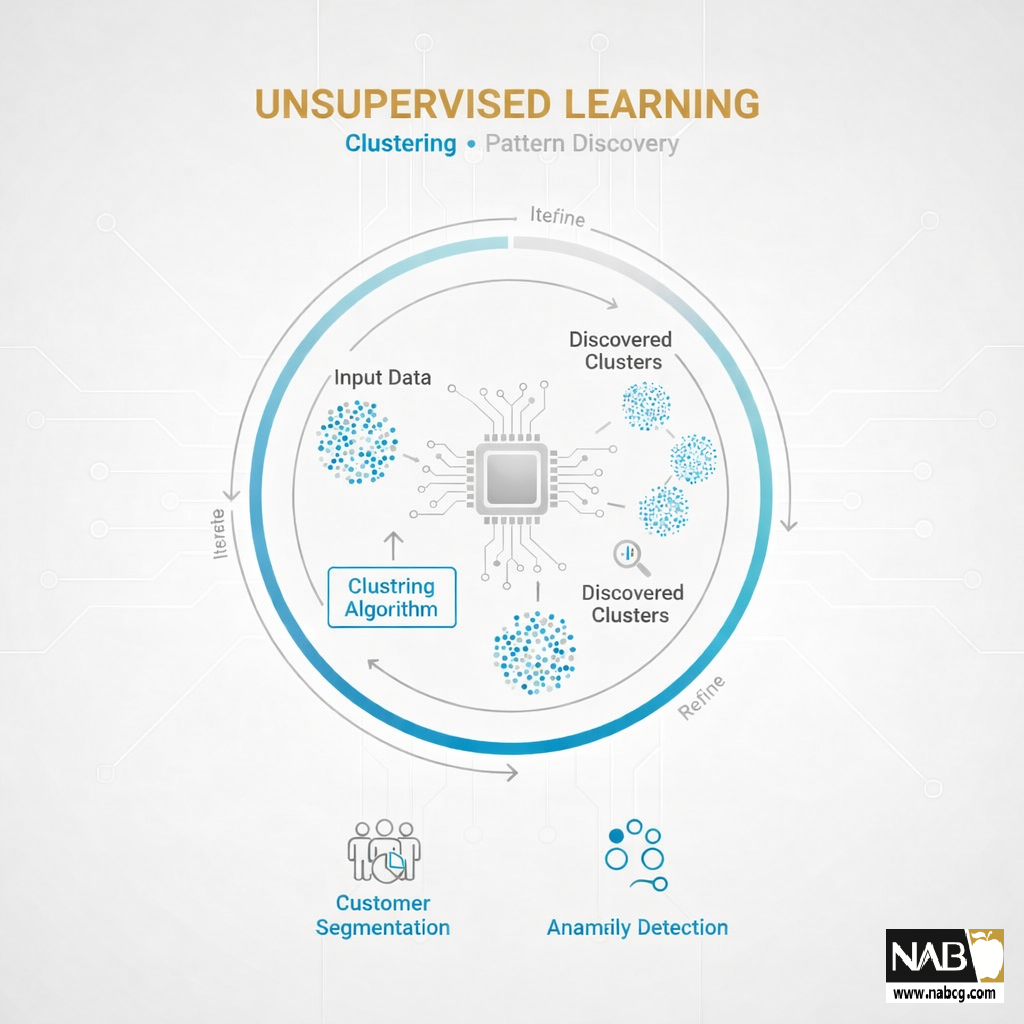
یادگیری بدون نظارت، پارادایم مخالف است. در این رویکرد، مدل با دادههای بدون برچسب (Unlabeled Data) آموزش میبیند و وظیفه دارد به صورت مستقل، ساختارها، روابط و الگوهای ذاتی دادهها را کشف کند.
مکانیسم کار و نقش کاوش داده ها
در غیاب معلم، مدل باید خود به یک کاشف تبدیل شود:
- ورودی بدون برچسب: مجموعه داده شامل نمونههای ورودی (x) است، اما خروجی یا برچسب مشخصی (y) وجود ندارد.
- هدف الگوریتم: الگوریتم تلاش میکند تا با اندازهگیری شباهتها یا فاصلهها بین نمونهها، آنها را گروهبندی کند یا ویژگیهای زیربنایی مشترک را استخراج نماید.
- تفسیر انسانی: نتایج حاصل (مانند گروهبندیها یا ابعاد جدید) باید توسط تحلیلگر داده (که در مقاله [علم داده چیست؟])به نقش او اشاره شد) برای کسبوکار تفسیر شوند.
.
5.انواع مسائل در یادگیری بدون نظارت
یادگیری بدون نظارت دو نوع مسئله اصلی را حل میکند که بر ساختار داده تمرکز دارند:
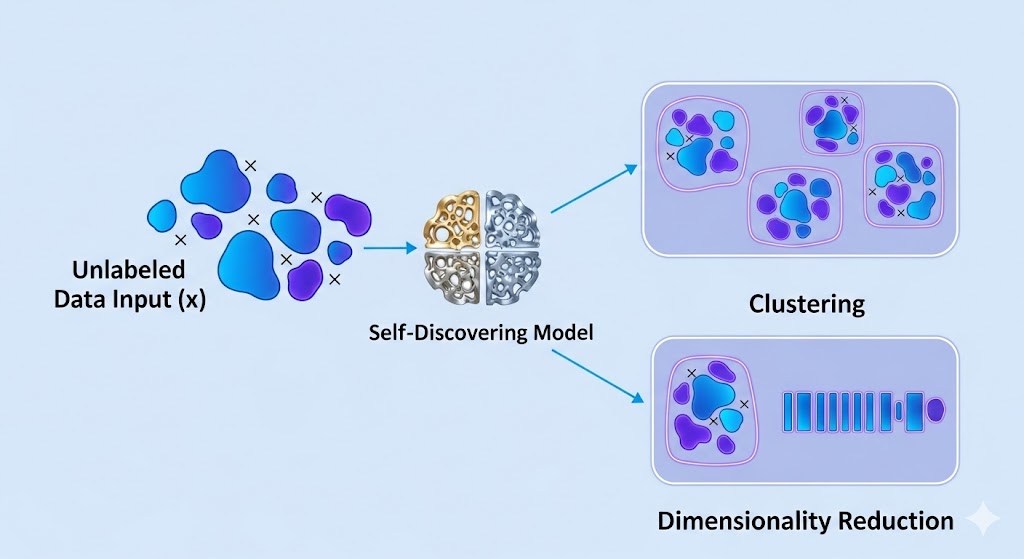
الف. خوشهبندی (Clustering):کشف گروههای طبیعی
- تعریف: فرآیند سازماندهی نقاط داده مشابه در گروههایی به نام خوشه (Cluster)، به طوری که نمونههای درون هر خوشه بیشترین شباهت و نمونههای بین خوشهها کمترین شباهت را داشته باشند.
- مثال کاربردی (McKinsey) بخشبندی مشتریان : یک شرکت میتواند مشتریان خود را بر اساس عادات خرید و دموگرافی (بدون اطلاع قبلی از گروهها) خوشهبندی کرده و برای هر خوشه، استراتژی بازاریابی متفاوتی تعریف کند. این امر سودآوری و هدفگذاری را به شدت افزایش میدهد.
- الگوریتمهای رایج: K-Means، DBSCAN، و خوشهبندی سلسله مراتبی. (Hierarchical Clustering)
.
ب. کاهش ابعاد (Dimensionality Reduction):سادهسازی دادهها
- تعریف: فرآیند کاهش تعداد متغیرهای تصادفی (ویژگیها) در نظر گرفته شده با به دست آوردن مجموعهای از متغیرهای اصلی. این کار به منظور مبارزه با “نفرین ابعاد” (Curse of Dimensionality) است.
- مثال کاربردی (BCG) فشردهسازی ویژگیها :در مجموعههای داده با هزاران ویژگی، کاهش ابعاد میتواند نویز را حذف کرده و زمان آموزش مدلهای شبکه عصبی را به شدت کاهش دهد.
- الگوریتمهای رایج: تحلیل مؤلفههای اصلی (Principal Component Analysis – PCA) و t-SNE برای بصریسازی.
.
6.مزایا و چالشهای یادگیری بدون نظارت
| مزایا (Advantage) | چالشها (Challenge) |
|---|---|
| کشف دانش جدید: قابلیت کشف الگوها و روابطی که انسان به آنها فکر نکرده است. | ارزیابی دشوار: هیچ برچسبی برای مقایسه وجود ندارد؛ بنابراین ارزیابی عملکرد و صحت مدل، پیچیدهتر و ذهنیتر است. |
| کار با دادههای خام: عدم نیاز به برچسبگذاری پرهزینه و زمانبر. | تفسیر پذیری چالشبرانگیز: گروههای کشفشده توسط مدل، اغلب نیاز به تحلیل عمیق انسانی دارند تا به بینش تجاری تبدیل شوند. |
| ایدهآل برای کاوش اولیه: ابزاری عالی برای کاوش دادههای اولیه (EDA) و شناخت ساختار مجموعه داده. | غیرقطعی بودن: نتایج خوشهبندی اغلب تحت تأثیر پارامترهای اولیه الگوریتم قرار میگیرند و ممکن است به طور جهانی ثابت نباشند. |
7.مقایسه عمیق و کاربردهای همزمان
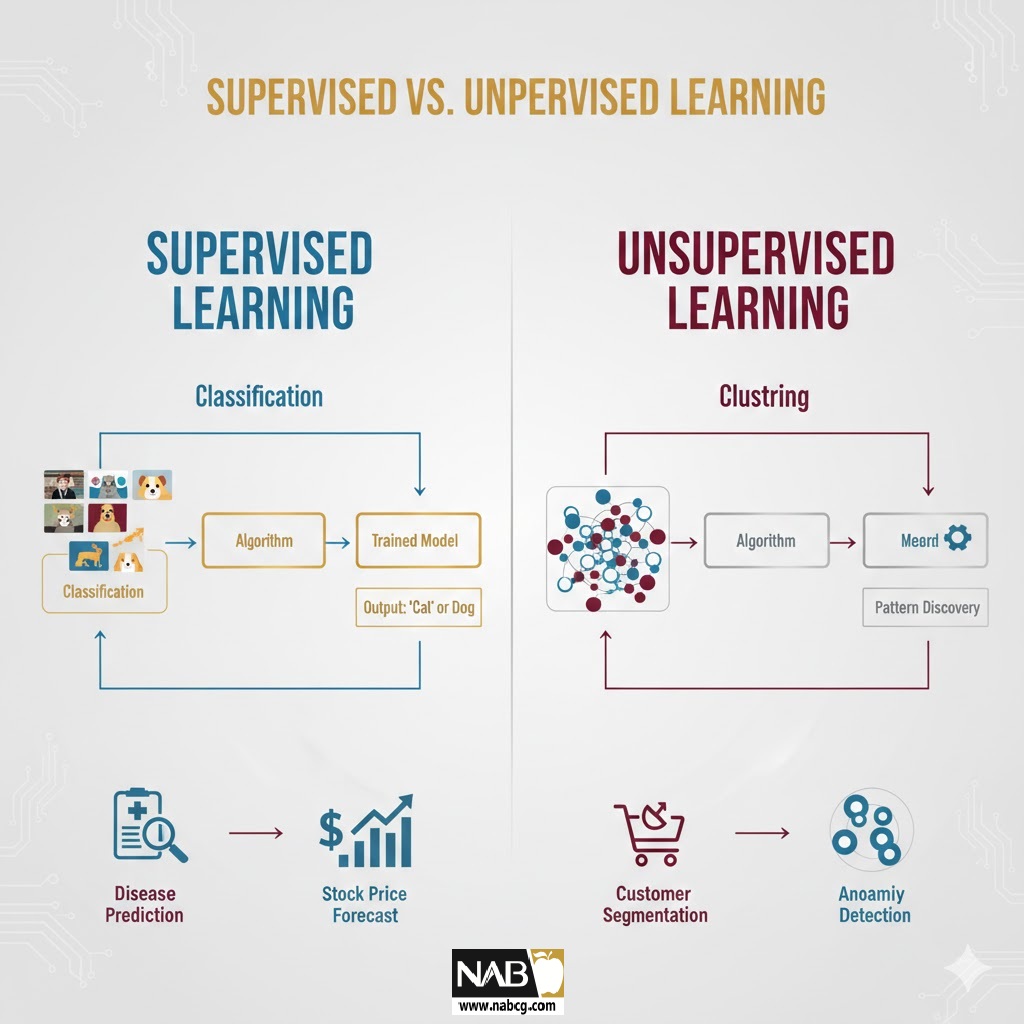
جدول مقایسه ویژگی ها
| ویژگی | یادگیری نظارتشده (Supervised) | یادگیری بدون نظارت (Unsupervised) |
|---|---|---|
| ماهیت داده | برچسبگذاری شده (ورودی + خروجی هدف) | بدون برچسب (فقط ورودی) |
| هدف اصلی | پیشبینی خروجی بر اساس ورودیهای جدید | کشف ساختار و الگوهای پنهان |
| انواع وظایف | دستهبندی و رگرسیون | خوشهبندی، کاهش ابعاد، قوانین انجمنی |
| بازخورد | بله (خطا در برابر برچسب صحیح) | خیر (یادگیری خودکار) |
| کاربردهای محوری | تشخیص بیماری، پیشبینی قیمت، فیلتر اسپم | بخشبندی مشتریان، تشخیص ناهنجاری، کاهش نویز |
8.یادگیری نیمهنظارتشده (Semi-Supervised Learning)
این رویکرد ترکیبی، تلاشی برای پل زدن میان دو پارادایم است. در یادگیری نیمهنظارتشده، مدل با حجم کمی از دادههای برچسبدار و حجم زیادی از دادههای بدون برچسب آموزش داده میشود.
- اهمیت: در بسیاری از حوزهها (مانند پردازش زبان طبیعی یا بینایی کامپیوتر) برچسبگذاری تمام دادهها غیرممکن است. این رویکرد به مدل اجازه میدهد که ابتدا با دادههای برچسبدار آموزشهای اولیه را ببیند و سپس از دادههای بدون برچسب برای اصلاح و بهبود نمایش ویژگیهای خود استفاده کند.
.
9.چه زمانی از کدام رویکرد استفاده کنیم؟
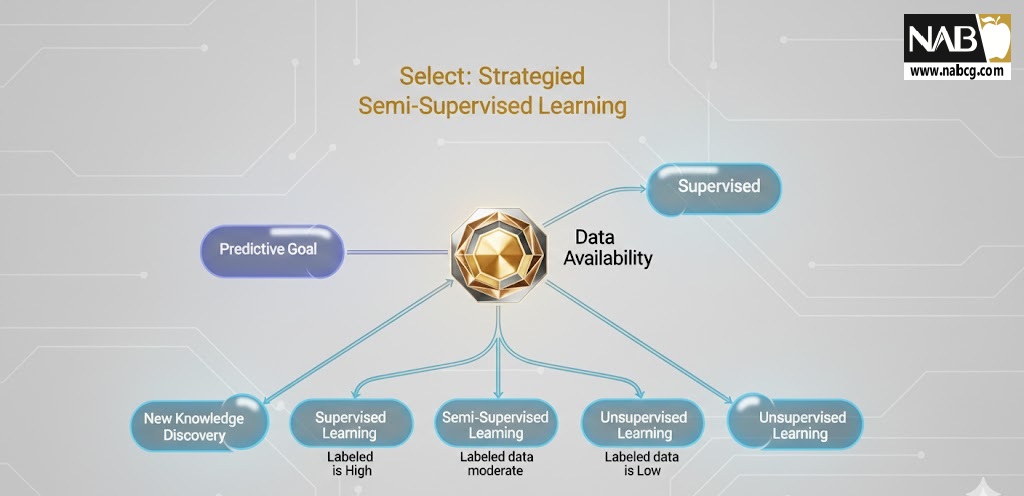
- آیا هدف یک پیشبینی مستقیم است؟ اگر هدف، پیشبینی یک خروجی مشخص (قیمت، کلاس، وضعیت) باشد، یادگیری نظارتشده مناسب است.
- آیا دادههای برچسبدار کافی در دسترس هستند؟ اگر دادههای با کیفیت برچسبدار وجود نداشته باشند یا هزینه برچسبگذاری بالا باشد، یادگیری بدون نظارت برای کاوش اولیه یا نیمهنظارتشده برای ساخت مدل نهایی، بهترین انتخاب است.
- آیا میخواهید کشف دانش جدید کنید؟ اگر هدف کشف الگوهای ناشناخته در دادهها باشد (مثلاً گروههای مشتریان جدید)، یادگیری بدون نظارت تنها راه است.
نکته استراتژیک: (Harvard Business Review) در پروژههای نوآورانه، اغلب از یادگیری بدون نظارت برای کشف سؤال درست و سپس از یادگیری نظارتشده برای پاسخ دقیق به آن سؤال استفاده میشود. این رویکرد انعطافپذیر، لازمه پروژههای بزرگ تحول دیجیتال است.
.
نتیجهگیری
یادگیری نظارتشده و یادگیری بدون نظارت، دو نیروی محوری هستند که هوش ماشینها را شکل میدهند. نظارتشده، با تکیه بر هدایت دقیق دادههای برچسبدار، به دقت در پیشبینیهای هدفمند دست مییابد؛ در حالی که بدون نظارت، با کاوش مستقل در اعماق دادههای خام، به کشف الگوها و ساختارهای زیربنایی میپردازد. تسلط بر مکانیسمهای کار و نقاط قوت هر یک از این رویکردها، دانشجویان شما را قادر میسازد تا در پروژههای واقعی علم داده و هوش مصنوعی، با هوشمندی کامل، میان دادهها، الگوریتمها و اهداف تجاری، تعادل برقرار کنند.



