

مقدمه:داده به عنوان سرمایه استراتژیک در عصر دیجیتال
در دنیایی که هر روز 463 اکسابایت داده تولید میشود (منبع IDC, :2023 )، داده دیگر فقط یک منبع نیست — بلکه سرمایهای استراتژیک محسوب میشود. اما داده خام، مانند نفت خام است: تا زمانی که پالایش نشود، ارزشی برای کسبوکار یا جامعه ندارد. و اینجاست که علم داده (Data Science) وارد میدان میشود.
اما سؤال اصلی این است: علم داده واقعاً چیست؟ آیا فقط یک نام جدید برای آمار است؟ آیا همان دادهکاوی است؟ و مهمتر از همه: چه کسانی در این حوزه کار میکنند و چه مهارتهایی نیاز دارند؟
این مقاله با هدف پاسخ به این پرسشهای بنیادین نوشته شده است. من بهعنوان یک استاد دانشگاه در حوزه هوش مصنوعی، سعی کردهام این مفاهیم را نه تنها از دیدگاه فنی، بلکه از منظر کاربرد آکادمیک، صنعتی و آینده شغلی تبیین کنم — با استناد به منابع معتبر جهانی و تجربههای واقعی از دنیای صنعت.در عصر حاضر، داده به یکی از داراییهای کلیدی سازمانها و جوامع بدل شده است. سازمانهای پیشرو کسانی هستند که نه صرفاً داده تولید میکنند، بلکه توانایی استخراج معنا، الگو، و بینش از داده را دارند و آن را به تصمیمی مؤثر تبدیل میکنند. علم داده (Data Science) دقیقاً در این نقطه وارد میدان میشود: پلی میان داده خام و تصمیم هوشمندانه.
در دنیای مدرن که هر تعامل دیجیتال به تولید دادههای حجیم (Big Data) میانجامد، دیگر صرفاً ذخیره یا حتی تحلیل ساده این دادهها کافی نیست. سازمانها برای بقا و رقابت، به توانایی تبدیل این دارایی خام به بینشهای قابل اقدام (Actionable Insights) نیازمندند. اینجا است که علم داده (Data Science) به عنوان یک حوزه میانرشتهای حیاتی، وارد عمل میشود.
علم داده یک فرآیند کلنگر است که از همان آغاز جمعآوری داده تا مرحله نهایی استقرار یک مدل یا تأثیرگذاری بر یک تصمیم تجاری را در بر میگیرد. این مقاله برای دانشجویان، متخصصان و مدیرانی نوشته شده است که میخواهند بدانند علم داده دقیقاً چه چیزی را شامل میشود و نخبگان این حوزه (دانشمندان داده) چگونه با ترکیب مهارتهای آمار، برنامهنویسی و دانش کسبوکار، سازمانها را متحول میکنند.
علم داده چیست؟ تعریفی میانرشتهای از یک حوزه نوین
تعریف عمومی
تعاریف متعددی برای علم داده ارائه شده است، اما یک تعریف مهم از دیدگاه دانشگاه هاروارد به این شرح است: “علم داده زمینهای است که از روشها، فرایندها و سیستمهای علمی برای استخراج دانش و بینش از داده استفاده میکند”
شرکت IBM علم داده را بهصورت ترکیبی از ریاضیات و آمار، برنامهنویسی پیشرفته، هوش مصنوعی و تخصص دامنه تعریف میکند که به سازمانها کمک میکند تا بینشهای عملی از داده استخراج کنند.
اما اگر بخواهیم دقیقتر باشیم، باید بگوییم علم داده حوزهای میانرشتهای است که ابزارها و مفاهیمی از آمار، یادگیری ماشین، مهندسی نرمافزار، مدیریت داده و تفسیر حوزه (Domain) را ترکیب میکند.
علم داده چیست؟ تعریفی فراتر از دادهکاوی
بسیاری علم داده را با دادهکاوی (Data Mining) یکی میدانند. این یک سوءتفاهم رایج است. در واقع:
- دادهکاوی فقط یکی از ابزارهای علم داده است — فرآیندی برای کشف الگوهای پنهان در دادههای بزرگ.
- علم داده یک حوزه چندرشتهای است که ترکیبی از آمار، علوم رایانه، تخصص دامنهای (Domain Knowledge) و مهارتهای ارتباطی است تا بتواند از داده، بینش (Insight) و ارزش عملیاتی استخراج کند.
همانطور که در کتاب مرجع The Elements of Statistical Learning نوشته Hastie, Tibshirani و Friedman آمده است، علم داده هنر تبدیل داده به دانش است.
و طبق تعریف دانشگاه استنفورد:
“علم داده فرآیندی است که شامل جمعآوری، پاکسازی، تحلیل، مدلسازی و ارائه داده برای پاسخ به سؤالات پیچیده است”.
تفاوت با دادهکاوی و تحلیل داده

یکی از دغدغههای رایج این است که آیا علم داده همان دادهکاوی است یا چگونه با تحلیل داده تفاوت دارد. در واقع، دادهکاوی (Data Mining) یکی از زیرمجموعههای علم داده است؛ تمرکز آن بیشتر بر کشف الگوها و ساخت مدلهای پیشبینی است. علم داده علاوه بر آن، شامل طراحی فرایندها، مهندسی داده، استقرار مدلها، نگهداری و تفسیر نتایج در بُعد کسبوکاری نیز هست.
تحلیل داده (Data Analytics) معمولاً معطوف به تحلیل توصیفی دادههای گذشته و استخراج گزارشات و الگوهاست؛ در مقابل علم داده به جنبه پیشبینی (پیشبینی آینده) و اقدام (Action) متکی است.
همچنین، یک بحث نظری مهم در ادبیات تحقیق، دیدگاه “وظیفههای علم داده: توصیف، پیشبینی، پیشبینی علی (causal inference) ” است. مثلاً Hernán و همکاران معتقدند که یکی از تفاوتهای علمی علم داده نسبت به آمار، نگاه علّی به داده است.
💡 تفاوت کلیدی:
- دادهکاوی: “چه الگوهایی در داده وجود دارد؟”
- علم داده: “این الگوها چه معنایی دارند و چگونه میتوان از آنها برای تصمیمگیری بهتر استفاده کرد؟”
- اگر میخواهید بدانید چگونه دادهکاوی در عمل بهکار میرود، مقاله دادهکاوی چیست و چرا برای کسبوکارها مهم است؟ را مطالعه کنید — اما توجه داشته باشید که آن مقاله فقط یکی از ابزارهای اینجا را پوشش میدهد.
تاریخچه و تکامل علم داده
اگرچه اصطلاح علم داده جدید به نظر میرسد، ریشههای آن به دهههای گذشته بازمیگردد. مثلاً دانشمندان آمار از دههها پیش به تحلیل داده پرداختهاند، اما ترکیب با محاسبات دیجیتال و گستردگی دادهها (Big Data) باعث شد مفهوم جدیدی به وجود آید.
در سال ۲۰۱۲ مقالهای در Harvard Business Review عنوان کرد که دانشمند داده (Data Scientist) شغل جذاب قرن بیستویکم است، که این نقطه عطف باعث شد علاقه گستردهتری به این حوزه شکل بگیرد.
سه ستون اصلی علم داده
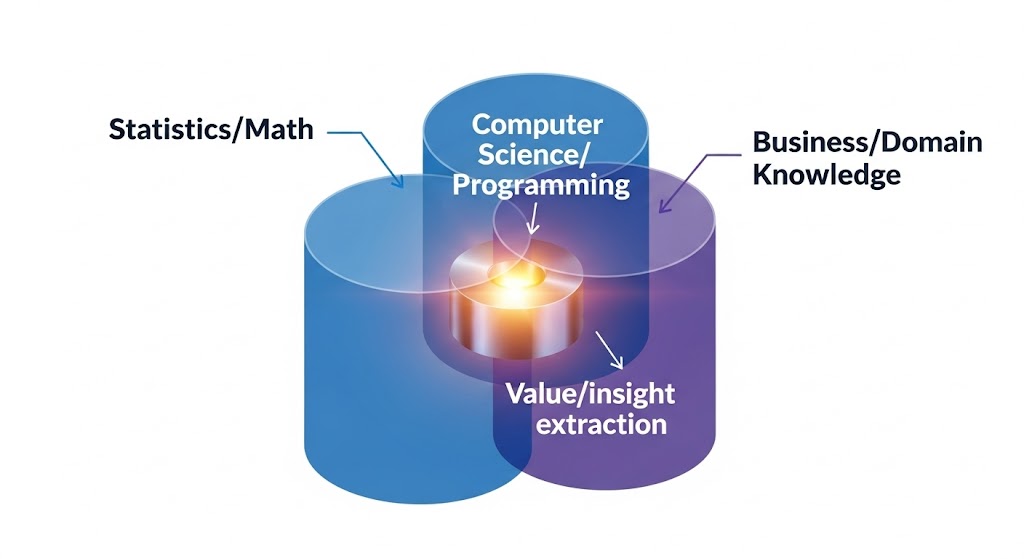
برخلاف تحلیلهای سنتی که اغلب تکبعدی هستند، علم داده بر پایه همپوشانی و ترکیب سه حوزه کلیدی استوار است. این سه ستون، به خوبی در مدلهای آموزشی دانشگاههای پیشرو مانند هاروارد و واشنگتن نمودار شدهاند:
آمار و ریاضیات (Statistics & Math):
این ستون، درک عمیق از مدلسازی، استنباط، احتمالات و مفاهیم الگوریتمی (مانند رگرسیون و دستهبندی) را فراهم میکند. آمار پایه و اساس یادگیری ماشین (ML) است.
علوم کامپیوتر و برنامهنویسی (Computer Science & Programming):
شامل مهارت در زبانهایی مانند پایتون و R، توانایی کار با پایگاههای داده (SQL، NoSQL) و تسلط بر معماریهای ابری برای مقیاسپذیری (مانند Google Cloud یا Microsoft Azure).
دانش تخصصی کسبوکار (Domain Expertise):
توانایی درک مسئله اصلی سازمان (مانند مالی، سلامت یا بازاریابی)، ترجمه آن به یک مسئله قابل حل با داده، و تفسیر نتایج در چارچوب عملیاتی.
مککنزی در گزارشهای خود تأکید میکند که بزرگترین چالش در پروژههای داده، نه فناوری، بلکه شکاف مهارتی (Talent Gap) در نقطه تقاطع این سه حوزه است.
این چرخه ممکن است چند بار تکرار شود و هر بار با اصلاح فرضیات، ویژگیها یا انتخاب مدل بهتر، به بهبود عملکرد منجر شود.
نقشها و تخصصها در تیم علم داده
یک نکته اساسی در پروژههای موفق داده این است که وظایف مختلف در یک تیم داده به افراد مختلف واگذار شود؛ به عبارت دیگر، فرد واحدِ همهفنحریف به ندرت کافی است. در ادامه به مهمترین نقشها اشاره میکنم، همراه با توضیح وظایف و مهارتهای هر کدام:
دانشمند داده (Data Scientist)
- تعریف نقش: دانشمند داده، یک تحلیلگر فراتر از سطح است. او فردی است که در تقاطع سه ستون اصلی علم داده قرار دارد. او قادر است یک مسئله مبهم تجاری را گرفته، فرضیههای آماری را مطرح کند، مدلهای پیچیده ML بسازد و نتایج را به صورت استراتژیک گزارش دهد.
- مهارتهای کلیدی (Stanford) : تسلط بر آمار پیشرفته، مهارت برنامهنویسی سطح بالا، و تفکر انتقادی برای طراحی آزمایشهای علمی. پایتون/R، یادگیری ماشین.
- وظیفه: طراحی مدلهای پیشبینیکننده، آزمایش فرضیهها، تبدیل داده به بینش.
- تفاوت با تحلیلگر داده: تحلیلگر داده معمولاً به دادههای گذشته نگاه میکند (“چه اتفاقی افتاده است؟”)، در حالی که دانشمند داده بر پیشبینی و ایجاد مدلها تمرکز دارد (“چه اتفاقی خواهد افتاد؟ و چرا؟”).
- مثال: ساخت مدلی برای پیشبینی تقاضای محصول در فصل آینده.
مهندس داده (Data Engineer)
- تعریف نقش: مهندس داده، معمار و سازنده زیرساختهایی است که دادهها را قابل دسترس و قابل استفاده میسازند. او مسئول خطوط لوله داده (Data Pipelines)، انبار داده (Data Warehouse) و اطمینان از کیفیت و مقیاسپذیری جریان داده است.
- مهارتهای کلیدی: (IBM) تسلط بر ETL (استخراج، تبدیل، بارگذاری)، معماریهای ابری، و مدیریت پایگاههای داده توزیعشده اطلاعات داشته باشد. او باید در زمینههای سیستم بانکاطلاعاتیSQL، مهندسی نرمافزار، پردازش داده بزرگ (Big Data)، و ابزارهایی مانند Apache Spark،Kafka، Hadoop، دیتالِیک (Data Lake) ، معماری ابری (AWS, GCP) و غیره تسلط داشته باشد.
- وظیفه: ساخت و نگهداری زیرساختهای داده (مثل Data Pipelines، Data Lakes).
- اهمیت استراتژیک: Accenture در گزارشهای خود تأکید میکند که ۹۰٪ از شکستهای پروژه ML، ناشی از ضعف در زیرساخت داده و مهندسی ناکارآمد داده است. مهندسان داده تضمین میکنند که دانشمندان داده با دادههای تمیز و در دسترس کار میکنند.
- مثال: طراحی سیستمی که دادههای بلادرنگ از 10,000 فروشگاه را جمعآوری کند.
تحلیلگر داده ومتخصص (BI)
- تعریف نقش: اولین حلقه در زنجیره تحلیل داده. او دادهها را جمعآوری، پاکسازی و از طریق داشبوردهای بصریسازیشده، الگوهای گذشته را به مدیران گزارش میدهد. تمرکز او روی تحلیل دادههای توصیفی، ایجاد داشبورد، گزارشدهی و پشتیبانی تصمیمگیری است.
- مهارتهای کلیدی: تسلط بر ابزارهای BI (مانند Tableau)، SQL و توانایی قوی در داستانسرایی با دادهها (Data Storytelling). ابزارهایی مانند SQL، Tableau، Power BI، و Excel برای او کاربردی هستند.
- اگرچه نقش او ممکن است با دانشمندان داده همپوشانی داشته باشد، اما غالباً با تمرکز بر تعامل با مدیران تجاری و تفسیر گزارشها فعالیت میکند.
- وظیفه: گزارشدهی، تجسم داده، پاسخ به سؤالات توصیفی.
- مثال: تحلیل فصلی روند فروش و شناسایی نقاط ضعف.
طبق گزارش دیلویت (2024)، سازمانهایی که این سه نقش را بهخوبی تفکیک و هماهنگ میکنند، 3.5 برابر بیشتر از رقبای خود از سرمایهگذاریهای دادهمحور بازگشت دارند.
نقشهای فرعی تر که در بعضی از مراجع به آن اشاره شده است عبارتند از:
مهندس یادگیری ماشین (Machine Learning Engineer / MLE)
- تعریف نقش: MLE یک مهندس نرمافزار است که در ML تخصص دارد. وظیفه اصلی او، انتقال مدلهای ساختهشده توسط دانشمند داده از محیط آزمایشی به محیط عملیاتی (Production) و نگهداری آنها است.
- مهارتهای کلیدی : تسلط بر اصول مهندسی نرمافزار، DevOps، و پلتفرمهای MLOps (عملیات یادگیری ماشین) برای استقرار مدلها در مقیاس وسیع. مهارتهای نرمافزاری قوی، طراحی سیستم، پایش عملکرد مدل و مقیاسپذیری از الزامات اوست
- ارتباط با سئو: مدلهای MLE در شرکتهایی مانند Google برای بهینهسازی موتورهای جستجو و تحلیل رفتار کاربران بسیار حیاتی هستند.
مدیر پروژه یا مدیر تیم داده (Data Science Program / Project Manager)
- وظیفه هماهنگی بین تیمهای فنی و ذینفعان، برنامهریزی پروژه، تخصیص منابع، تضمین کیفیت و زمانبندی پروژه بر عهده اوست.
- باید با مفاهیم چابک (Agile)، اسکرام، مدیریت ریسک و فرآیندهای دادهای آشنا باشد. DataCamp+1
متخصص تبیین مدل و اخلاق داده (Model Explainability / Ethics Specialist)
با توجه به اهمیت اخلاق، شفافیت و تبیینپذیری (Explainability) در علم داده و هوش مصنوعی، در بسیاری از پروژهها یک نقش تخصصی برای بررسی انصاف (Fairness)، آسیبپذیری (Bias)، و شفافیت در مدلها مورد نیاز است.
معمار داده (Data Architect)
- مسئول طراحی کلان ساختار دادهای سازمان، استانداردسازی، مدیریت اطلاعات مرکزی، و تعیین نحوه تعامل بین سیستمهای دادهای است. Data Science PM
در بسیاری از سازمانها، بعضی افراد ممکن است چند نقش را به هم ترکیب کنند، مخصوصاً در تیمهای کوچک؛ اما در پروژههای پیچیده و مقیاس بزرگ، تفکیک نقشها عامل موفقیت است. همچنین در مقالهای در Forbes آمده است که یک تیم موفق علم داده باید ترکیبی از این نقشها داشته باشد تا ارزش واقعی از داده استخراج شود.
مهارتهای کلیدی برای موفقیت در علم داده
برای فعالیت موفق در علم داده، ترکیبی از مهارتهای فنی، تحلیلی و نرمافزاری ضروری است. در ادامه فهرستی از مهمترین مهارتها را میآورم:
مهارتهای فنی
- آمار و احتمال پیشرفته : فرضیات آماری، آزمون فرض، تحلیل واریانس، متغیرهای تصادفی
- یادگیری ماشین و الگوریتمها: رگرسیون خطی و لجستیک، درخت تصمیم، جنگلهای تصادفی، تقویت تدریجی (Boosting)، شبکه عصبی، خوشهبندی
- برنامهنویسی: بهویژه Python کتابخانههایی مانند pandas, scikit-learn, TensorFlow, PyTorch) و R)
- مهارت در کار با پایگاه دادهها و SQL
- بصریسازی داده و داستانسرایی داده (Data Storytelling)
- پردازش داده بزرگ (Big Data) : کار با Hadoop، Spark، دیتالیکها
- مهندسی نرمافزار و مهارت استقرار مدل: طراحی API، ساخت میکروسرویس، DevOps
مهارتهای نرم
- تفکر انتقادی و حل مسئله: توانایی شکستن مسائل پیچیده کسبوکار به سوالات قابل پاسخ با داده.
- کنجکاوی فکری: میل ذاتی به پرسش “چرا” و کاوش برای یافتن پاسخ.
- مهارتهای ارتباطی و داستانسرایی: توانایی ترجمه یافتههای فنی به insights قابل درک برای مدیران بازاریابی یا مالی.
- درک کسبوکار (Business Acumen): یک دانشمند داده بدون درک از صنعت و مدل کسبوکار مشتری، نمیتواند ارزش آفرینی کند.
شرکت مککینزی در آگهیهای شغلی خود تاکید دارد که متخصصان داده باید بتوانند بین تیمهای محصول، کسبوکار و فنی پل بزنند و بینش فنیشان را به راهحلهای تجاری مبدل کنند. همچنین در سازمانهایی مانند IBM، علم داده و مهندسی داده بهصورت مشترک دیده میشود و متخصصان باید نسبت به زیرساخت و عملیات در کنار مدلسازی تسلط داشته باشند
بر اساس بررسی 50,000 آگهی شغلی در سال 2024 منبع: LinkedIn Workforce Report ، مهارتهای پرطرفدار عبارتند از:
فنی:
- زبانهای برنامهنویسی: Python (92%) ، SQL (88%)، R (45%)
- ابزارهای تجسم : Tableau، Power BI، Matplotlib
- پلتفرمهای ابری: AWS، Google Cloud، Azure
- چارچوبهای یادگیری ماشین: Scikit-learn، TensorFlow، PyTorch
غیرفنی:
- تفکر انتقادی
- ارتباط مؤثر با ذینفعان غیرفنی
- درک عمیق از صنعت هدف (مثلاً بانکداری یا سلامت)
کاربردهای علم داده در صنایع مختلف

یکی از دلایل محبوبیت علم داده، تأثیر مستقیم آن بر نتایج کسبوکاری است. در این بخش به برخی از کاربردهای برجسته در صنایع مختلف اشاره میشود:
· بازاریابی و پیشبینی رفتار مشتری
· کشف تقلب در بانکداری و بیمه
· نگهداری پیشبینانه در صنعت
· بهینهسازی زنجیره تأمین و لجستیک
· تحلیل سلامت و تشخیص بیماریها
· پرداخت اعتبار و رتبهبندی ریسک در حوزه مالی
· سیستم های پیشنهادگر و تحلیل احساسات
گزارشهایی نشان دادهاند که شرکتهایی که از تحلیل پیشرفته و هوش مصنوعی بهره میبرند، عملکرد مالی بهتری دارند و نسبت به رقبا برتری رقابتی کسب میکنند. مثلاً یکی از گزارشهای McKinsey ادعا میکند که سازمانهایی که تحلیل پیشرفته به کار میگیرند میتوانند تا ۱۲۶٪ افزایش عملکرد تجربه کنند. https://www.usdsi.org/
IBM نیز در مستندات خود به مواردی اشاره میکند که شرکتها از علم داده برای بهینهسازی فرآیندهای داخلی، پیشبینی تقاضا و بهبود تجربه کاربری استفاده کردهاند. IBM
در شرکتهای مشاوره بزرگ، تیم داده-مهندسی وظیفه دارد که راهکارهای تحلیلی را در پروژههای مشتریان ادغام کند، به مدیران ارشد کمک کند تا تصمیمات مبتنی بر داده بگیرند، و ابزارهایی (داشبورد، پلتفرمها) برای بهکارگیری مدلها ارائه دهد. McKinsey & Company+1
ارزش و نقش استراتژیک علم داده کسبوکار
علم داده، تنها یک دپارتمان هزینهبر نیست؛ بلکه موتور رشد و نوآوری است. شرکتهای مشاوره بینالمللی، سودآوری حاصل از آن را در سه محور اصلی تعریف میکنند:
شخصیسازی در مقیاس (Hyper-Personalization)
- مکانیسم: علم داده از الگوریتمهای پیشرفته برای تحلیل رفتار تکتک مشتریان استفاده میکند. با خوشهبندی دقیق (Clustering) و تحلیل شبکهای (Network Analysis)، مدلهایی ساخته میشود که نه تنها پیشنهاد محصول، بلکه زمان و کانال ارائه آن را نیز بهینهسازی میکنند.
- ارزش تجاری: PwC تأکید میکند که شخصیسازی موفق منجر به افزایش ۵ تا ۱۵ درصدی درآمد و کاهش تا ۵۰ درصدی هزینههای جذب مشتری (CAC) میشود.
بهینه سازی ریسک و کاهش هزینه ها
- مکانیسم: دانشمندان داده در حوزه مالی، مدلهایی را بر اساس رگرسیون و دستهبندی میسازند که الگوهای تقلب یا نکول وام را پیشبینی میکنند. این مدلها هزاران متغیر را در کسری از ثانیه پردازش میکنند.
- ارزش تجاری: Deloitte اشاره میکند که این ابزارها در بخشهای مالی و بیمه، نه تنها از ضررهای هنگفت جلوگیری میکنند، بلکه با ارزیابی دقیقتر ریسک، امکان ارائه خدمات به گروههای جدید مشتریان را فراهم میسازند.
نوآوری در محصول و مزیت رقابتی
- مکانیسم: علم داده با تحلیل دادههای بدون ساختار (مانند نظرات مشتریان در شبکههای اجتماعی یا دادههای سنسورهای محصول)، نیازهای پنهان مشتریان را کشف کرده و به تیمهای R&D در طراحی محصولات نسل بعد کمک میکند.
- ارزش تجاری: BCG این توانایی را بهعنوان “هوش بومی” (Indigenous Intelligence) توصیف میکند که مزیت رقابتی پایداری را برای شرکت در بازار به ارمغان میآورد.
چشمانداز آینده علم داده

با توجه به روندهای فعلی در هوش مصنوعی، رایانش ابری، محاسبات لبه (Edge Computing)، مدلهای بنیادین (Foundation Models) و پیشرفت در تحلیل علّی، آینده علم داده بسیار پرامید است. در ادامه برخی روندهای مهم را مرور میکنیم:
در سالهای آینده، تمرکز علم داده از ساخت مدل به سمت ادغام مدل در تصمیمگیری منتقل میشود. برخی از روندهای کلیدی:
- علم داده توضیحپذیر (Explainable Data Science) : مدلهایی که بتوانند چرایی تصمیم خود را توضیح دهند.
- علم داده خودکار (AutoML) : ابزارهایی که بخشهای فنی را خودکار میکنند — اما نیاز به درک مفهومی را از بین نمیبرند.
- علم داده در لبه (Edge Data Science): پردازش داده در دستگاههای کوچک (مثل گوشی یا سنسور).
- هوش مصنوعی ترکیبی (Hybrid AI) : که بخشهایی از دانش انسانی/دامنه را در مدل میآورد، اهمیت بیشتری مییابد.
- اتوماسیون در علم داده (AutoML, AutoMLops) : فرآیند تولید مدل را سرعت میبخشد و به دانشجویان امکان میدهد در سطوح بالاتری کار کنند.
- علم داده سبز (Green Data Science) : و اهمیت انرژی محاسباتی کمتر، بهینهسازی مصرف منابع در مدلها اهمیت دارد.
- ترکیب داده و مدلهای زبانی بزرگ (Large Language Models, LLMs) : و نقش آنها در پیشبینی، تفسیر متن، تولید دانش جدید.
جمعبندی:علم داده ،پلی میان داده و تصمیمات هوشمند
علم داده پلی است بین داده خام و تصمیمات هوشمند. این حوزه نه فقط تکنیکهای پیشبینی و مدلسازی را در بر میگیرد، بلکه نیازمند مهندسی داده، تبیین نتایج، تعامل با مدیران کسبوکاری، و رعایت اخلاق و شفافیت است. تیمهای موفق داده توأمان شامل دانشمندان داده، مهندسین داده، مهندسین یادگیری ماشین، تحلیلگران کسبوکار و مدیران پروژه هستند.