

1.مقدمه
در عصر دیجیتال، کسبوکارها در اقیانوسی از دادهها غرق شدهاند. هر کلیک، هر خرید، هر تعامل مشتری و هر فرآیند عملیاتی، ردی از خود به جا میگذارد که به تولید حجم بیسابقهای از اطلاعات منجر میشود. اما چالش اصلی اینجاست: چگونه میتوان از این سیلاب دادههای خام به «دانش» قابل اقدام و بینشهای استراتژیک دست یافت؟ پاسخ در دادهکاوی (Data Mining) نهفته است؛ فرآیندی قدرتمند که این امکان را فراهم میکند.
اگر در مقالات پیشین (مانند [علم داده چیست؟] یا [یادگیری ماشین چگونه کار میکند؟] )به اهمیت دادهها اشاره کردهایم، دادهکاوی در واقع هنر و علم استخراج مرواریدهای ارزشمند از اعماق این اقیانوس است. این مقاله برای دانشجویان و متخصصان کسبوکار که تا حدودی با مباحث هوش مصنوعی و تحلیل داده آشنا هستند، نوشته شده است. ما با استناد به تحقیقات پیشگامانه دانشگاه هاروارد، چارچوبهای عملیاتی IBM و گزارشهای تحلیلی مککنزی و BCG، به رمزگشایی از چیستی، چرایی و چگونگی دادهکاوی میپردازیم.
در دنیای امروز، داده تنها یک منبع اطلاعاتی نیست—بلکه سرمایهای استراتژیک است. اما داشتن داده به تنهایی کافی نیست. آنچه واقعاً ارزشآفرین است، توانایی استخراج دانش از این دادههای خام است. اینجاست که دادهکاوی (Data Mining) بهعنوان یکی از ستونهای اصلی علم داده و هوش مصنوعی، نقشی کلیدی دارد.
اما آیا دادهکاوی همان یادگیری ماشین است؟ آیا فقط برای شرکتهای بزرگ کاربرد دارد؟ و مهمتر از همه: چرا یک استارتاپ یا یک سازمان دولتی باید به دادهکاوی توجه کند؟
2.دادهکاوی چیست؟
در سادهترین تعریف، دادهکاوی فرآیند کشف الگوهای معنیدار، روندها (Trends) و اطلاعات پنهان در مجموعههای بزرگ دادهها است. هدف نهایی آن، تبدیل دادههای خام به دانش قابل فهم و قابل استفاده برای تصمیمگیریهای استراتژیک است.
در سطح انتزاعی، دادهکاوی فرآیند کشف الگوهای معنادار، روابط پنهان و بینشهای ارزشمند در مجموعهدادههای بزرگ است. این فرآیند ترکیبی از آمار، یادگیری ماشین، پایگاه داده و تجسم داده است.
از منظر آکادمیک، دادهکاوی را «فرآیند استخراج الگوها و اطلاعات سودمند از مجموعههای بزرگ داده» تعریف میکنیم. کتاب مرجع Data Mining: Concepts and Techniques اثر جیاوی هان، میشلین کمبر و جیان پِی، آن را یک مرحله کلیدی در فرآیند گستردهتر «کشف دانش از پایگاه داده» (KDD) میداند. این فرآیند مراحلی چون پالایش دادهها، یکپارچهسازی، انتخاب، تبدیل، دادهکاوی، ارزیابی الگوها و در نهایت ارائه دانش را در بر میگیرد.
💡 تفاوت کلیدی:
- یادگیری ماشین روی «پیشبینی» تمرکز دارد.
- دادهکاوی روی «کشف» تمرکز دارد.
- یکی از اهداف دادهکاوی میتواند ساخت یک مدل یادگیری ماشین باشد، اما همیشه اینطور نیست.
.
3.تفاوت داده کاوی با تحلیل داده ،علم داده و یادگیری ماشین
برای درک عمیق دادهکاوی، باید آن را از مفاهیم مشابهی مانند علم داده (Data Science)، تحلیل داده (Data Analysis) و پایگاه داده (Databases) تفکیک کنیم:
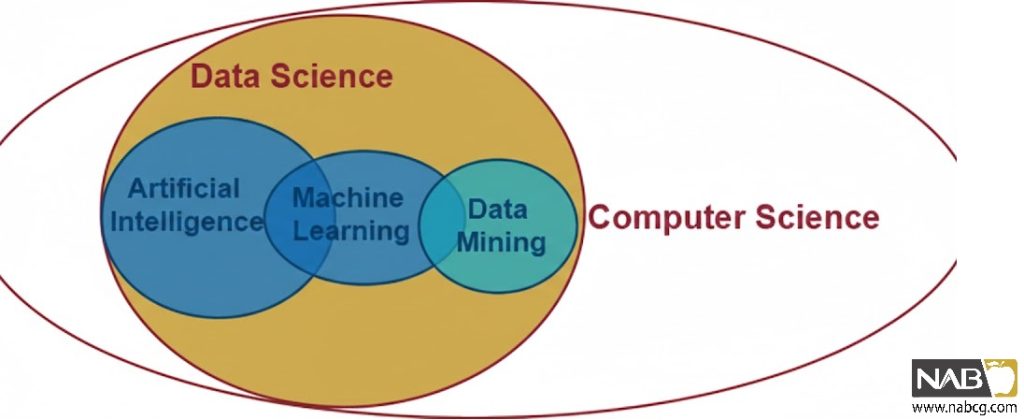
- پایگاه داده(Databases): مخزن ذخیرهسازی دادهها است. دادهکاوی با دادههای موجود در این مخازن کار میکند.
- تحلیل داده(Data Analysis): تحلیل داده، دادهها را بررسی، پاکسازی، تغییر و مدلسازی میکند تا به اطلاعات مفید، نتیجهگیری و پشتیبانی از تصمیمگیری منجر شود. دادهکاوی در واقع زیرمجموعهای پیشرفتهتر از تحلیل داده به شمار میرود.
- علم داده (Data Science): یک حوزه میانرشتهای گسترده است که دادهکاوی یکی از ابزارهای اصلی آن است. علم داده تمامی مراحل، از جمعآوری و پاکسازی تا مدلسازی و تفسیر نتایج را در بر میگیرد. (برای کسب اطلاعات بیشتر به مقاله [علم داده چیست؟] مراجعه کنید.
- یادگیری ماشین (Machine Learning): الگوریتمهای یادگیری ماشین، ابزارهای اصلی و موتورهای پردازشی هستند که در مرحله مدلسازی دادهکاوی برای کشف الگوها به کار میروند. یادگیری ماشین به الگوریتمهایی اشاره دارد که به کامپیوترها توانایی یادگیری از داده بدون برنامهریزی صریح را میدهند. دادهکاوی بهطور گسترده از الگوریتمهای یادگیری ماشین (مانند درخت تصمیم، خوشهبندی) به عنوان “ابزار” خود برای کشف الگو استفاده میکند. رابطه این دو، رابطه ابزار و هدف است.
- آمار (Statistics): آمار علم جمعآوری، تحلیل، تفسیر و ارائه دادههاست. دادهکاوی از مبانی آماری قوی بهره میبرد، اما بر خلاف آمار کلاسیک که اغلب بر آزمون فرضیههای از پیش تعیین شده متمرکز است، دادهکاوی بیشتر بر کشف الگوها و فرضیههای جدید از دل دادهها تأکید دارد (رویکرد اکتشافی).
.
4.مراحل اصلی فرآیند دادهکاوی (CRISP-DM)
یکی از استانداردهای جهانی در دادهکاوی، CRISP-DM (Cross-Industry Standard Process for Data Mining) است که شرکتهایی مانند IBM و SPSS آن را توسعه دادهاند. این چارچوب از شش مرحله تشکیل شده است:
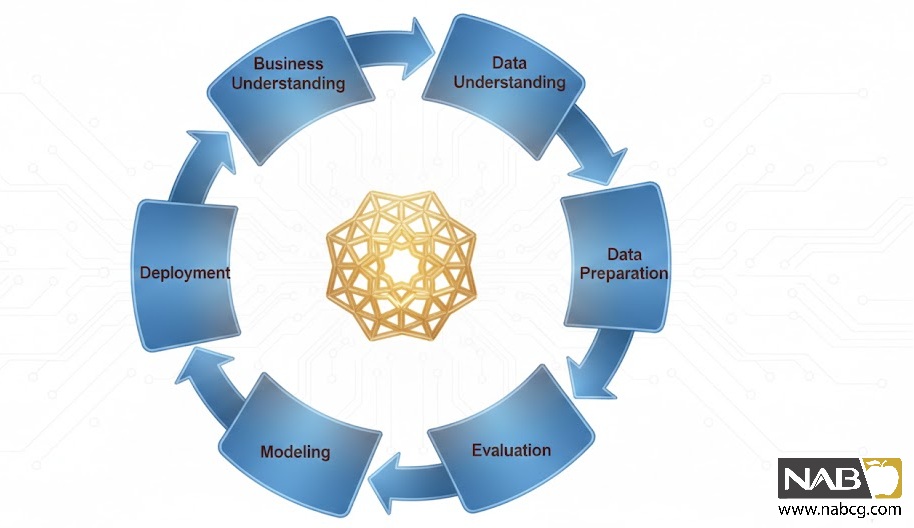
- درک کسبوکار (Business Understanding)
این مرحله حیاتی است! هدف اصلی کسبوکار چیست؟ (مثلاً کاهش ۱۵ درصدی مشتریان فراری). بدون درک واضح از نیاز کسبوکار، پروژه محکوم به شکست است.
در این مرحله، سؤال کلیدی این است: “چه مسئلهای را میخواهیم حل کنیم؟”
مثال: “آیا میتوانیم مشتریانی را شناسایی کنیم که احتمال ترک خدمات را دارند؟”
- درک داده(Data Understanding)
دادههای مورد نیاز از کجا میآیند؟ (فروش، CRM، شبکههای اجتماعی). کیفیت و کمیت آنها چگونه است؟ این مرحله شامل جمعآوری اولیه و شناسایی مشکلات داده است.
- آمادهسازی داده (Data Preparation)
این مرحله، زمانبرترین بخش (حدود ۶۰-۸۰% ) پروژه است. دادهها باید پاکسازی، یکپارچه و تبدیل ، ادغام و انتخاب تا برای مدلسازی آماده گردند.
- مدلسازی (Modeling)
در این مرحله، الگوریتمهای دادهکاوی (مانند رگرسیون، خوشهبندی، شبکههای عصبی) بر روی دادههای آمادهشده اعمال میشوند تا مدلهای پیشبینی یا توصیفی ساخته شوند.
انتخاب و اعمال الگوریتمهای دادهکاوی مانند:
- خوشهبندی (Clustering): کشف گروههای پنهان (مثلاً تقسیمبندی مشتریان)
- قوانین انجمنی (Association Rules): کشف روابط (مثلاً «کسانی که X را میخرند، Y را هم میخرند»)
- طبقهبندی (Classification): پیشبینی دستهبندی
- ارزیابی (Evaluation)
قبل از استقرار، مدل به دقت ارزیابی میشود. آیا نتایج با اهداف کسبوکاری همسو هستند؟ آیا قابل اجرا هستند؟
- استقرار (Deployment)
دانش به دست آمده باید در فرآیندهای تصمیمگیری کسبوکار ادغام شود. این میتواند به صورت یک گزارش خلاصه، یک داشبورد تعاملی یا یک سیستم خودکار (مانند پیشنهاد محصول در Amazon) باشد.
پیادهسازی مدلهای نهایی در فرآیندهای کسبوکار و نظارت بر عملکرد آنها. ادغام یافتهها در فرآیندهای سازمانی — مثلاً در سیستم CRM یا گزارشهای مدیریتی.
5.چرا دادهکاوی برای کسبوکارها حیاتی است؟
در محیط رقابتی امروز، دادهکاوی دیگر یک مزیت نیست، بلکه یک ضرورت است. کسبوکارهایی که از دادهکاوی بهره میبرند، تواناییهای استراتژیک بینظیری به دست میآورند.
تصمیم گیری داده محور(Data-Driven Decision Making)
- جلوگیری از حدس و گمان: مککنزی در گزارشهای خود تأکید میکند که شرکتهای دادهمحور، تا ۲۳ برابر احتمال بیشتری برای جذب مشتری جدید، ۶ برابر احتمال بیشتر برای حفظ مشتری و ۱۹ برابر احتمال بیشتر برای سودآوری دارند. دادهکاوی، تصمیمگیریها را از حدس و گمان به شواهد مستند تبدیل میکند.
- مثال: یک شرکت خردهفروشی میتواند با کاوش در دادههای خرید، ترجیحات مشتریان را شناسایی کرده و تصمیمات بهتری در مورد موجودی کالا یا کمپینهای تبلیغاتی بگیرد.
.
افزایش سودآوری و درآمد
دادهکاوی به روشهای مختلفی به افزایش درآمد کمک میکند:
- هدفگذاری بازاریابی (Targeted Marketing): شناسایی مشتریان با ارزش بالا و طراحی کمپینهای شخصیسازیشده (مانند پیشنهادات محصول در آمازون).
- پیشبینی روندهای بازار(Market Trend Prediction): تحلیل دادههای اجتماعی و اقتصادی برای پیشبینی تغییرات تقاضا و رفتار مصرفکننده.
- قیمتگذاری پویا(Dynamic Pricing): تعیین قیمتهای بهینه بر اساس عوامل متعدد مانند تقاضا، رقابت و زمان.
.
بهبود کارایی عملیاتی
- بهینهسازی زنجیره تأمین : پیشبینی دقیق تقاضا، بهینهسازی مسیرهای حملونقل و مدیریت موجودی کالا برای کاهش هزینهها.
- نگهداری پیشبینانه(Predictive Maintenance): تحلیل دادههای حسگرها از ماشینآلات برای پیشبینی زمان خرابی و انجام تعمیرات پیش از وقوع مشکل.
.
مدیریت ریسک و تشخیص تقلب
- بانکداری و مالی : دادهکاوی امکان شناسایی الگوهای تراکنش مشکوک و غیرعادی را فراهم میکند که به تشخیص تقلب در کارتهای اعتباری، پولشویی و ارزیابی ریسک اعتبار کمک میکند.
- امنیت سایبری: تشخیص نفوذ و حملات سایبری با شناسایی رفتارهای غیرعادی در ترافیک شبکه.
.
کشف فرصتهای نوآورانه
دادهکاوی میتواند نیازهای کشف نشده مشتریان، بخشهای جدید بازار یا ترکیبهای جدید محصول را آشکار کند که قبلاً قابل مشاهده نبودهاند.
مثال واقعی: والمارت با استفاده از قوانین انجمنی کشف کرد که در طوفانها، فروش آبنبات و باتری همزمان افزایش مییابد — و بر این اساس، استراتژی انبارداری خود را تغییر داد.
.
تجربه مشتری شخصیشده
درک عمیق تر از ترجیحات و رفتار هر مشتری، امکان ارائه خدمات و پیشنهادات فوقشخصیشده را فراهم میآورد. طبق گزارش مک کنزی (2023)، شرکتهایی که از دادهکاوی برای شخصیسازی استفاده میکنند، تا 25% وفاداری مشتری بیشتری دارند.
.
6.تکنیکهای دادهکاوی: ابزارهای استخراج دانش
دادهکاوی از طیف وسیعی از الگوریتمها و تکنیکها بهره میبرد که هر یک برای نوع خاصی از وظیفه و کشف الگو طراحی شدهاند.
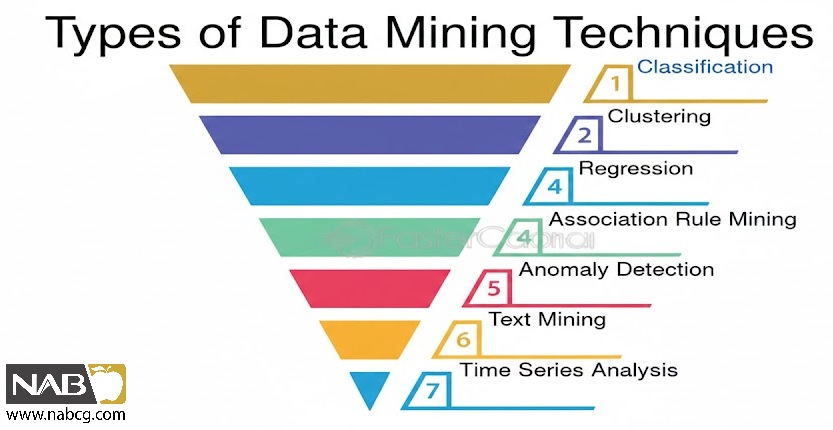
خوشهبندی (Clustering)
- هدف: گروهبندی نقاط داده مشابه به یکدیگر بر اساس ویژگیهای مشترک. این تکنیک یک نوع یادگیری بدون نظارت است.
- کاربرد تجاری : بخشبندی مشتریان (Customer Segmentation) برای بازاریابی هدفمند، شناسایی جوامع در شبکههای اجتماعی، یا گروهبندی اسناد مشابه.
- الگوریتمهای رایج: K-Means، DBSCAN، سلسله مراتبی (Hierarchical Clustering).
.
دستهبندی (Classification)
- هدف: پیشبینی اینکه یک نقطه داده به کدام دسته یا کلاس از پیش تعریفشده تعلق دارد. این تکنیک یک نوع یادگیری تحت نظارت است.
- کاربرد تجاری : تشخیص هرزنامه (Spam Detection)، پیشبینی ورشکستگی شرکتها، تشخیص بیماریها، یا پیشبینی ریزش مشتری (Churn Prediction).
- الگوریتمهای رایج: درخت تصمیم (Decision Trees)، ماشین بردار پشتیبان (SVM)، شبکههای عصبی، رگرسیون لجستیک (Logistic Regression).
.
رگرسیون (Regression)
- هدف: پیشبینی یک مقدار پیوسته (عددی) بر اساس ویژگیهای ورودی. این تکنیک نیز یک نوع یادگیری تحت نظارت است.
- کاربرد تجاری: پیشبینی فروش آینده، پیشبینی قیمت سهام، پیشبینی دما یا تقاضای انرژی.
- الگوریتمهای رایج: رگرسیون خطی (Linear Regression)، رگرسیون چندگانه، رگرسیون در شبکههای عصبی.
.
قوانین انجمنی (Association Rule Mining)
- هدف: کشف روابط “اگر-آنگاه” بین اقلام در مجموعههای داده بزرگ. معروفترین مثال، “تحلیل سبد خرید” (Market Basket Analysis) است.
- کاربرد تجاری: شناسایی محصولاتی که اغلب با هم خریداری میشوند (مثلاً: “اگر یک مشتری پوشک بخرد، به احتمال زیاد دستمال مرطوب هم میخرد”). این دانش به فروشگاهها کمک میکند تا چینش محصولات یا پیشنهادات تخفیف را بهینه کنند.
- الگوریتم رایج. Apriori:
.
تشخیص ناهنجاری (Anomaly Detection)
- هدف: شناسایی نقاط دادهای که به طور قابل توجهی از الگوی کلی دادهها خارج هستند.
- کاربرد تجاری: تشخیص تقلب در تراکنشهای بانکی (رفتار غیرعادی)، تشخیص نفوذ در شبکههای کامپیوتری، یا شناسایی نقص در محصولات تولیدی.
- الگوریتمهای رایج Isolation Forest:،. One-Class SVM
.
7.چالشها و ملاحظات دادهکاوی
با وجود پتانسیل عظیم، دادهکاوی بدون چالش نیست و موفقیت آن مستلزم رویکردی هوشمندانه و اخلاقی است.
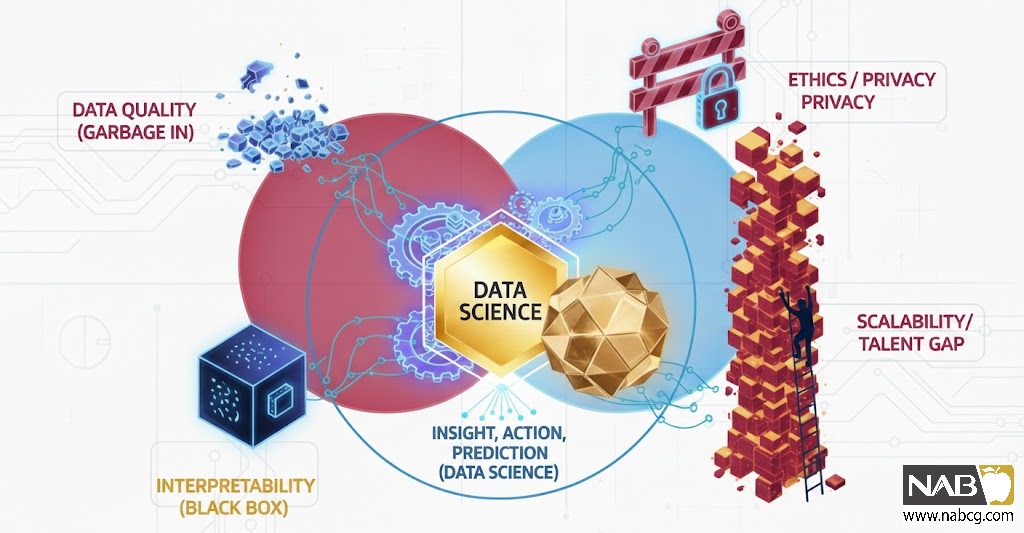
کیفیت دادهها و اهمیت پاکسازی(Garbage In, Garbage Out)
- چالش: دادههای کثیف، ناقص، نویزدار یا دارای ناسازگاری، منجر به نتایج اشتباه و گمراهکننده میشوند.
- راهحل : سرمایهگذاری در حاکمیت داده (Data Governance)، پاکسازی دادهها و تضمین کیفیت داده در تمام مراحل. همانطور که HBR اشاره میکند، دادههای با کیفیت، ستون فقرات هر پروژه تحلیل داده موفق هستند.
.
حریم خصوصی و اخلاق
- چالش: استفاده از دادههای شخصی برای کشف الگوها، نگرانیهای جدی در مورد حریم خصوصی افراد و احتمال سوءاستفاده را به وجود میآورد.
- راهحل: رعایت قوانین حفاظت از دادهها (مانند GDPR)، استفاده از تکنیکهای حفظ حریم خصوصی (Privacy-Preserving Techniques) مانند ناشناسسازی (Anonymization) و در نظر گرفتن ابعاد اخلاقی در طراحی هر پروژه دادهکاوی. BCG در چارچوبهای خود برای هوش مصنوعی مسئولیتپذیر، بر این جنبه تأکید میکند.
.
تفسیرپذیری مدل ها (Interpretability)
- چالش: برخی از مدلهای دادهکاوی (به ویژه شبکههای عصبی عمیق) ممکن است “جعبه سیاه” باشند و توضیح اینکه چرا یک تصمیم خاص گرفته شده، دشوار باشد.
- راهحل: استفاده از تکنیکهای هوش مصنوعی توضیحپذیر (XAI) برای درک بهتر روند تصمیمگیری مدلها، یا انتخاب مدلهای سادهتر و قابل تفسیرتر در مواقعی که شفافیت حیاتی است.
.
کمبود مهارت و مقیاسپذیری
- چالش: نیاز به متخصصان دادهکاوی با مهارتهای تحلیلی، برنامهنویسی و دانش کسبوکار.
- راهحل: سرمایهگذاری در آموزش، استخدام تیمهای متخصص و استفاده از پلتفرمهای ابری مقیاسپذیر برای پردازش حجم عظیمی از دادهها. اکسنچر (Accenture) در گزارشهای خود، کمبود نیروی متخصص را یکی از موانع اصلی در پذیرش AI و دادهکاوی در سازمانها میداند.
.
نتیجهگیری
دادهکاوی نه تنها یک ابزار تحلیل پیشرفته، بلکه یک رویکرد استراتژیک برای استخراج دانش، بهبود تصمیمگیری و ایجاد مزیت رقابتی پایدار است. از کشف الگوهای پنهان در رفتار مشتریان تا پیشبینی روندهای بازار و بهینهسازی عملیات، دادهکاوی به کسبوکارها این امکان را میدهد که از اقیانوس دادهها، به گنجینههایی از بینش دست یابند. درک عمیق از فرآیندها، تکنیکها و چالشهای دادهکاوی، برای هر سازمانی که میخواهد در عصر دیجیتال پیشرو باشد، حیاتی است. این دانش، دانشجویان را برای نقشآفرینی مؤثر در آیندهای که بیش از پیش دادهمحور خواهد بود، آماده میسازد.
دادهکاوی یک جادو نیست — بلکه یک فرآیند منظم، تکرارشونده و چندوجهی است که نیاز به همکاری بین تیمهای فنی، کسبوکار و اخلاقی دارد. موفقیت آن به درک صحیح از مسئله، کیفیت داده و توانایی تبدیل بینش به اقدام بستگی دارد



