

1.مقدمه
در دنیای هوش مصنوعی، یادگیری نظارتشده (Supervised Learning) همان «موتور احتراق داخلی» است که بیشتر سیستمهای هوشمند امروزی را به حرکت درمیآورد. از تشخیص چهره در گوشیهای هوشمند گرفته تا پیشبینی ریسک وام در بانکها، از تشخیص تومور در تصاویر پزشکی تا شخصیسازی پیشنهادات فیلم در استریمینگ — همه و همه بر پایه همین اصل ساده ولی قدرتمند ساخته شدهاند.
اما سؤال اصلی این است: یادگیری نظارتشده واقعاً چگونه کار میکند؟ چرا این روش نسبت به سایر انواع یادگیری ماشین چنان گستردهتر استفاده میشود؟ و مهمتر از همه: چه زمانی باید از آن استفاده کرد و چه زمانی نه؟
در قلب موفقیتهای بزرگ یادگیری ماشین (Machine Learning – ML) در دهههای اخیر، رویکردی قدرتمند و شهودی به نام یادگیری نظارتشده (Supervised Learning) قرار دارد. اگر یادگیری ماشین، فرایند کلی آموزش کامپیوترهاست (همانطور که در مقاله [یادگیری ماشین چگونه کار میکند؟]بررسی کردیم)، یادگیری نظارتشده، روش “آموزش با مثال” آن است.
تصور کنید یک کودک (مدل) را آموزش میدهید. به او چندین عکس از سیب و پرتقال نشان داده و هر بار با دقت به او میگویید که کدام سیب است و کدام پرتقال (برچسب). این فرآیند دقیق، اساساً همان کاری است که در یادگیری نظارتشده رخ میدهد. ماشین از دادههای ورودی برچسبگذاریشده برای استنتاج یک تابع نگاشت (Mapping Function) استفاده میکند که بتواند ورودیهای جدید را با دقت پیشبینی کند.
2.تعریف یادگیری نظارتشده
در سادهترین حالت، یادگیری نظارتشده فرآیندی است که در آن یک الگوریتم از دادههای برچسبدار یاد میگیرد تا بتواند برای دادههای جدید پیشبینی انجام دهد.
“یادگیری نظارتشده، جستوجوی یک تابع بهینه است که بتواند نگاشتی بین فضای ورودی و فضای خروجی ایجاد کند — با حداقل خطای ممکن.”
این «تابع» میتواند یک خط ساده (در رگرسیون خطی) یا یک شبکه عصبی با میلیونها پارامتر باشد. آنچه مهم است، وجود جفتهای (ورودی، خروجی صحیح) در دادههای آموزشی است.
مثال :
- ورودی: دادهها (مثلا ویژگیهای بیماران مانند سن، فشار خون، سابقه بیماری)
- خروجی یا برچسب: نتیجه مورد انتظار (مثلا ابتلا یا عدم ابتلا به بیماری قلبی)
- هدف مدل: یادگیری رابطه بین ورودی و خروجی
.
3.مبانی و مکانیسمهای ریاضی در یادگیری نظارتشده
یادگیری نظارتشده، با تعریف یک رابطه ریاضی بین متغیرهای ورودی (X) و متغیر خروجی (Y) عمل میکند. هدف نهایی، یافتن یک تابع (f) است که بهترین تخمین را از Y=f(X) ارائه دهد.
4.اجزای کلیدی یادگیری نظارت شده
هر سیستم یادگیری نظارتشده حول سه مؤلفه اصلی ساخته میشود:
- مجموعه داده آموزشی (Training Data): مجموعهای از جفتهای ورودی-خروجی برچسبدار
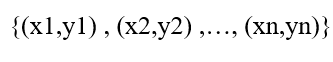
- X (ورودی):مجموعه ویژگیها (Features) یا متغیرهای مستقل.
- Y (خروجی): برچسب (Label) یا متغیر وابسته.
- تابع فرضیه (Hypothesis Function – h) : مدل یا الگوریتمی که برای نگاشت X به Y استفاده میشود. هدف یادگیری، یافتن بهترین پارامترها برای این تابع است.
- تابع هزینه (Cost Function – J) : معیاری که میزان خطای تابع فرضیه (h) را روی دادههای آموزشی اندازهگیری میکند. (برای جزئیات بیشتر در مورد نقش این تابع در بهینهسازی، مقاله (یادگیری ماشین چگونه کار میکند؟) را ببینید.
.
5.فرآیند بهینهسازی: کاهش خطا
یادگیری نظارتشده اساساً یک فرآیند بهینهسازی است. الگوریتمها با استفاده از تکنیکهایی مانند گرادیان کاهشی (Gradient Descent)، پارامترهای مدل را به طور مکرر تنظیم میکنند تا مقدار تابع هزینه (J) به حداقل برسد.
- نقش گرادیان: گرادیان کاهشی، جهتی را نشان میدهد که در آن خطا با بیشترین سرعت کاهش مییابد. مدل در هر مرحله در جهت منفی گرادیان حرکت میکند. این فرآیند تا رسیدن به یک حداقل محلی (Local Minimum) یا سراسری (Global Minimum) ادامه مییابد.
- استناد آکادمیک: در متون آکادمیک دانشگاه استنفورد بر اهمیت درک ابعاد ریاضی و آماری گرادیان کاهشی برای توسعه مدلهای یادگیری عمیق (که نوع پیشرفته یادگیری نظارتشده هستند) تأکید میشود.
.
6.اجزای کلیدی یادگیری نظارتشده
دادههای برچسبدار
پایه و اساس این روش دادههای برچسبدار است. کیفیت و کمیت دادهها نقش مستقیم در عملکرد مدل دارد.
مجموعه آموزشی و آزمایشی
برای جلوگیری از خطا، دادهها معمولاً به دو بخش تقسیم میشوند:
- مجموعه آموزشی(Training Set) برای یادگیری مدل.
- مجموعه آزمایشی(Test Set) برای ارزیابی عملکرد مدل روی دادههای جدید.

الگوریتم ها
الگوریتمها شامل روشهای کلاسیک مانند رگرسیون خطی و لجستیک تا مدلهای پیچیدهتر مانند شبکههای عصبی هستند.
.
معیارهای ارزیابی
- دقت(Accuracy)
- دقت پیشبینی(Precision)
- بازخوانی(Recall)
- امتیاز F1
.
7.دو ستون اصلی یادگیری نظارتشده
وظایف یادگیری نظارتشده به دو طبقه اصلی تقسیم میشوند که بر اساس نوع خروجی (Y) تعریف میگردند:
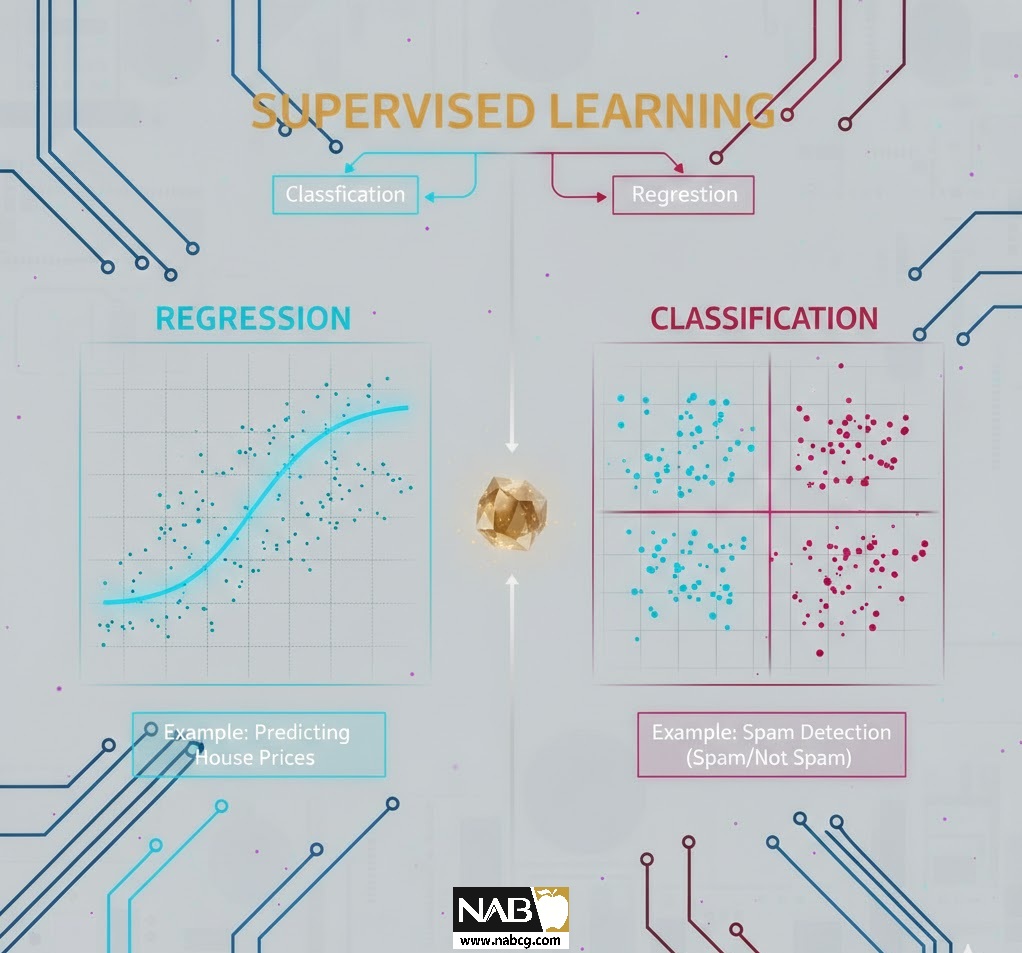
8.طبقهبندی (Classification)
هدف این دسته از مسائل، تخصیص یک برچسب گسسته (Discrete Label) به یک نمونه ورودی است. به عبارت دیگر، مدل ورودی را در یکی از چندین دسته یا کلاس از پیش تعریف شده قرار میدهد.
انواع کلاسیک:
- طبقهبندی دودویی (Binary Classification): تشخیص اسپم بودن یا نبودن یک ایمیل (دو کلاس: spam, not spam).
- طبقهبندی چندکلاسه (Multi-class Classification): تشخیص رقم دستنویس (۱۰ کلاس: اعداد ۰ تا ۹).
- طبقهبندی چندبرچسبی (Multi-label Classification): تخصیص چندین برچسب به یک تصویر (مثلاً یک تصویر میتواند همزمان شامل برچسبهای “دریا”، “غروب آفتاب” و “کشتی” باشد).
.
ویژگیها:
- هدف: پیشبینی اینکه یک ورودی به کدام یک از طبقهها یا کلاسهای گسسته تعلق دارد.
- مثال: تشخیص اینکه یک تصویر سیب است یا پرتقال (طبقهبندی دودویی) یا تشخیص اینکه یک مشتری به کدام یک از سه بخش درآمدی تعلق دارد (طبقهبندی چندکلاسه).
- کاربرد تجاری: سیستمهای تشخیص تقلب، فیلتر هرزنامه و تشخیص بیماری ..
.
الگوریتمهای کلیدی طبقهبندی:
- رگرسیون لجستیک (Logistic Regression): با وجود نامش، یک الگوریتم طبقهبندی است که احتمال تعلق یک ورودی به یک کلاس خاص را محاسبه میکند. این مدل پایه، به دلیل سادگی و قابلیت تفسیرپذیری بالا، به ویژه در علوم اجتماعی و مالی پرکاربرد است.
- ماشین بردار پشتیبان (Support Vector Machines – SVM): هدف SVM، یافتن یک ابرصفحه (Hyperplane) است که کلاسها را با بیشترین حاشیه (Margin) ممکن از یکدیگر جدا کند. این مدل برای مجموعه دادههای کوچک تا متوسط که دارای مرزهای تصمیمگیری پیچیدهای نیستند، بسیار مؤثر است.
- درخت تصمیم و جنگل تصادفی (Decision Trees & Random Forest):
o درخت تصمیم: یک مدل بصری که از ساختار درختی برای تصمیمگیری بر اساس مجموعهای از قوانین “اگر-آنگاه” استفاده میکند.
o جنگل تصادفی: مجموعهای (Ensemble) از تعداد زیادی درخت تصمیم مستقل که هر یک رأی خود را برای طبقهبندی نهایی میدهند. این تجمیع آرا، به شدت دقت مدل را افزایش داده و خطر بیشبرازش (Overfitting) را کاهش میدهد. (این روش در گزارشهای BCG برای تحلیل ریسک مشتریان بسیار توصیه شده است.)
.
9.رگرسیون (Regression)
- هدف: پیشبینی یک مقدار عددی پیوسته (مانند قیمت، دما، فروش یا زمان).
- مثال: پیشبینی قیمت مسکن بر اساس متراژ و موقعیت، یا پیشبینی میزان تقاضا برای یک محصول در هفته آینده.
- کاربرد تجاری (PwC): تیمهای مشاورهای PwC از رگرسیون برای پیشبینی فروش، مدلسازی ریسک و بهینهسازی قیمتگذاری پویا استفاده میکنند.
.
الگوریتمهای کلیدی رگرسیون:
- رگرسیون خطی (Linear Regression): مدل پایه که یک رابطه خطی بین متغیرهای ورودی و خروجی فرض میکند. این مدل به دلیل سادگی و قابلیت تفسیرپذیری، نقطه شروع بسیاری از تحلیلهای آماری است.
- رگرسیون چندجملهای (Polynomial Regression): برای مدلسازی روابط غیرخطی با استفاده از درجات بالاتر متغیرهای ورودی.
- رگرسیون لاسو و ریج (Lasso and Ridge Regression): اینها اشکالی از رگرسیون هستند که برای مدیریت چالش بیشبرازش (Overfitting) از طریق رگولاریزاسیون (Regularization) استفاده میشوند. رگولاریزاسیون به مدل جریمههایی را برای پارامترهای بیش از حد بزرگ اعمال میکند، و مدل را مجبور به سادهسازی مینماید.
.
10.الگوریتمهای Ensemble (ترکیبی)
این الگوریتمها با ترکیب چندین مدل ضعیفتر، یک مدل قوی و Robust میسازند. گزارشهای شرکتهایی مانند مک کینزی بر برتری این دسته از الگوریتمها در بسیاری از مسائل واقعی تأکید دارند.
- Random Forest: ترکیبی از دهها یا صدها درخت تصمیم که نتیجه نهایی بر اساس رأی اکثریت آنها تعیین میشود. این کار از overfitting جلوگیری میکند.
- Gradient Boosting(مثل XGBoost, LightGBM): این الگوریتمها به صورت ترتیبی مدلهای جدید میسازند که هر کدام سعی در اصلاح خطاهای مدل قبلی دارند.
.
11.مراحل اجرای پروژه یادگیری نظارتشده
اجرای یک پروژه یادگیری نظارتشده از یک گردش کار مشخص پیروی میکند:
- جمعآوری و برچسبزنی داده: این مرحله معمولاً پرهزینه و زمانبر است. دادهها باید توسط متخصصان انسانی برچسبزنی شوند.
- پیشپردازش داده: شامل مدیریت مقادیر گمشده، مقیاسبندی ویژگیها (Feature Scaling) .
- تفکیک دادهها: دادهها به طور تصادفی به سه بخش تقسیم میشوند:
- مجموعه آموزش (Training Set): برای آموزش مستقیم مدل استفاده میشود .
- مجموعه اعتبارسنجی (Validation Set): برای تنظیم ابرپارامترهای مدل و انتخاب بهترین مدل استفاده میشود .
- مجموعه آزمون (Test Set): برای ارزیابی نهایی عملکرد مدل روی دادههای کاملاً دیدهنشده به کار میرود .
- انتخاب و آموزش مدل: یک الگوریتم (مثلاً درخت تصمیم) بر روی مجموعه آموزش اجرا میشود.
- ارزیابی مدل: عملکرد مدل بر روی مجموعه اعتبارسنجی و آزمون با معیارهای مناسب (مانند دقت برای طبقهبندی یا خطای مربع میانگین برای رگرسیون) سنجیده میشود.
- تنظیم مدل (Hyperparameter Tuning): ابرپارامترهای مدل برای بهبود عملکرد تنظیم میشوند.
- استقرار و نظارت: مدل نهایی در محیط واقعی قرار گرفته و عملکرد آن به طور مستمر نظارت میشود.
.
12.کاربردهای یادگیری نظارتشده در صنایع مختلف
- پزشکی: تشخیص تومور از تصاویر MRI.
- مالی: ارزیابی ریسک اعتباری مشتریان.
- بازاریابی: پیشبینی نرخ ترک مشتری (Churn Prediction).
- حملونقل: تشخیص اشیاء در خودروهای خودران.
- منابع انسانی: تحلیل رزومهها برای انتخاب بهترین داوطلب.
.
13.چالشهاو ارزیابی عملکرد مدل ها
موفقیت در یادگیری نظارتشده تنها به انتخاب الگوریتم مناسب نیست؛ بلکه به مدیریت چالشهای آماری و ارزیابی دقیق نتایج بستگی دارد.
بیشبرازش و کمبرازش(Overfitting and Underfitting)
این دو مفهوم، بزرگترین دشمنان تعمیمپذیری مدل هستند:
- بیشبرازش (Overfitting): مدل دادههای آموزشی را آنقدر خوب یاد میگیرد که حتی نویز و خطاهای موجود در دادهها را حفظ میکند. نتیجه، عملکرد ضعیف روی دادههای جدید (دادههای آزمون) است.
- راهحل : هاروارد در دورههای خود بر اهمیت تکنیکهایی مانند اعتبارسنجی متقابل (Cross-Validation) و رگولاریزاسیون برای مقابله با این پدیده تأکید میکند.
- کمبرازش (Underfitting): مدل بیش از حد ساده است و قادر به گرفتن الگوهای اساسی و روابط در دادهها نیست.(اغلب نیاز به مدل پیچیدهتر یا ویژگیهای بیشتر دارد.)
.
ارزیابی دقیق (Evaluation Metrics)
برای اطمینان از کیفیت مدل، ارزیابی باید از طریق معیارهای دقیق انجام شود:
طبقهبندی:
- دقت (Accuracy): نسبت کل پیشبینیهای درست )مناسب زمانی که کلاسها متوازن هستند.(
- دقت (Precision) و فراخوانی (Recall): این معیارها زمانی حیاتی هستند که کلاسها نامتوازن باشند (مثلاً تشخیص تقلب که تعداد موارد تقلب بسیار کم است).
- Precision: از میان موارد پیشبینیشده مثبت، چه تعداد واقعاً مثبت بودهاند؟
- Recall : از میان کل موارد مثبت واقعی، چه تعداد توسط مدل تشخیص داده شدهاند؟
- F1-Score و AUC-ROC: ترکیب پیچیدهتر Precision و Recall و منحنیهای ارزیابی برای سنجش عملکرد مدل در آستانههای مختلف.
.
رگرسیون:
- میانگین مربعات خطا(MSE) و ریشه میانگین مربعات خطا (RMSE): میانگین مربع تفاضل بین مقادیر پیشبینیشده و واقعی.
- ضریب تعیین (R2): درصدی از تغییرات متغیر وابسته که توسط متغیرهای مستقل توضیح داده میشود.
.
تعصب و انصاف الگوریتمی (Bias and Fairness)
یادگیری نظارتشده وابسته به دادههای آموزشی است. اگر دادهها دارای تعصبات اجتماعی یا تاریخی باشند، مدل آن تعصبات را آموخته و تقویت میکند.
- چالش: محققان MIT بر این امر تأکید دارند که این تعصب میتواند به تصمیمگیریهای ناعادلانه در حوزههایی مانند استخدام، وامدهی یا عدالت منجر شود.
- راهحل: ممیزی دادهها برای تعصب، استفاده از دادههای متوازن و به کارگیری چارچوبهای هوش مصنوعی مسئولانه (Responsible AI). برای بحثهای عمیقتر، [هوش مصنوعی توضیحپذیر] را مطالعه کنید.
.
14.مزایا
- دقت بالا:در صورت وجود داده برچسبدار باکیفیت و کافی، میتواند به دقت بسیار بالایی دست یابد.
- قابلیت تفسیرپذیری (در برخی مدلها): مدلهایی مانند درخت تصمیم و رگرسیون خطی به راحتی قابل درک و تفسیر هستند.
- پیشبینی سریع: پس از آموزش، پیشبینی برای دادههای جدید بسیار سریع است.دقت بالا در پیشبینی تنوع الگوریتمها
.
15.محدودیتها
- سوگیری (Bias): اگر دادههای آموزشی دارای سوگیری باشند، مدل نیز این سوگیری را یاد گرفته و تقویت میکند.
- عدم تعمیمپذیری (Overfitting): خطر یادگیری جزئیات و نویزهای موجود در داده آموزش به جای یادگیری الگوی کلی وجود دارد، در نتیجه مدل روی دادههای جدید ضعیف عمل میکند.
.
16.ML نظارتشده در استراتژیهای سازمانی
شرکتهای مشاوره جهانی از یادگیری نظارتشده به عنوان ابزاری برای ایجاد مزیت رقابتی در سه حوزه کلیدی استفاده میکنند:

پیشبینی رفتار مشتری (McKinsey)
- کاربرد: مدلهای طبقهبندی (مانند رگرسیون لجستیک یا شبکههای عصبی) برای پیشبینی ریزش مشتری (Churn Prediction) یا پیشبینی ارزش طول عمر مشتری (Customer Lifetime Value – CLV) استفاده میشوند.
- ارزش تجاری: مککنزی تأکید میکند که با پیشبینی مشتریانی که در آستانه ترک شرکت هستند، میتوان مداخلات هدفمندی را برای حفظ آنها طراحی کرد و سودآوری را به طور قابل توجهی افزایش داد.
.
اتوماسیون فرآیندها (Accenture)
- کاربرد: مدلهای طبقهبندی برای اتوماسیون وظایف اداری مانند مسیریابی خودکار اسناد یا طبقهبندی شکایات مشتریان.
- ارزش تجاری: Accenture گزارش میدهد که استفاده از ML نظارتشده در پردازش زبان طبیعی (NLP) میتواند حجم عظیمی از دادههای بدون ساختار (ایمیلها، گزارشها) را طبقهبندی کرده و کارایی عملیاتی را تا دهها درصد بهبود بخشد.
.
نتیجهگیری
یادگیری نظارتشده یکی از ستونهای اصلی هوش مصنوعی و علم داده است. این روش با استفاده از دادههای برچسبدار، امکان پیشبینی دقیق و تصمیمگیری هوشمند را فراهم میکند. از پزشکی و مالی گرفته تا بازاریابی و حملونقل، صنایع مختلف به کمک این رویکرد در حال تحولاند.
با وجود محدودیتهایی همچون نیاز به دادههای برچسبدار، آینده یادگیری نظارتشده روشن است؛ بهویژه در ترکیب با سایر روشها مانند یادگیری نیمهنظارتی و خودنظارتی. برای دانشجویان و پژوهشگران، یادگیری این مبحث بهمنزله آشنایی با یکی از مهمترین ابزارهای قرن بیستویکم است.



